Natural Latents: The Concepts
post by johnswentworth, David Lorell · 2024-03-20T18:21:19.878Z · LW · GW · 18 commentsContents
What Are Natural Latents? How Do We Quickly Check Whether Something Is A Natural Latent?
Alice & Bob’s Art Project
Generalization
Dogs
Why Are Natural Latents Useful?
Minimal Relevant Information
Maximal Robust Information
More Examples
Toy Probability Examples
Anti-Example: Three Flips Of A Biased Coin
1000 Flips Of A Biased Coin
Ising Model
Physics-Flavored Examples
Gas (Over Space)
Non-Isolated Gas
Gasses In Systems
Rigid Bodies
Phase Change
Other Examples
“Clusters In Thingspace”
Social Constructs: Laws
Takeaways
None
19 comments
Suppose our old friends Alice and Bob decide to undertake an art project. Alice will draw a bunch of random purple and green lines on a piece of paper. That will be Alice’s picture (A). She’ll then make a copy, erase all the purple lines, and send the result as a message (M) to Bob. Bob then generates his own random purple lines, and adds them to the green lines from Alice, to create Bob’s picture (B). The two then frame their two pictures and hang them side-by-side to symbolize something something similarities and differences between humans something. Y’know, artsy bullshit.
Now, suppose Carol knows the plan and is watching all this unfold. She wants to make predictions about Bob’s picture, and doesn’t want to remember irrelevant details about Alice’s picture. Then it seems intuitively “natural” for Carol to just remember where all the green lines are (i.e. the message M), since that’s “all and only” the information relevant to Bob’s picture.
In this example, the green lines constitute a “natural latent” between the two pictures: they summarize all and only the information about one relevant to the other.
A more physics-flavored example: in an isolated ideal-ish gas, average energy summarizes “all and only” the information about the low-level state (i.e. positions and momenta of the constituent particles) at one time which is relevant to the low-level state at a sufficiently later time. All the other information is quickly wiped out by chaos. Average energy, in this case, is a natural latent between the gas states at different times.
A more old-school-AI/philosophy example: insofar as I view dogs as a “kind of thing” in the world, I want to track the general properties of dogs separately from the details of any specific dog. Ideally, I’d like a mental pointer to “all and only” the information relevant to many dogs (though I don’t necessarily track all that information explicitly), separate from instance-specific details. Then that summary of general properties of dogs would be a natural latent between the individual dogs.
Just from those examples, you probably have a rough preliminary sense of what natural latents are. In the rest of this post, we’ll:
- Walk through how to intuitively check whether a particular “thing” is a natural latent over some particular parts of the world (under your intuitive models).
- Talk about some reasons why natural latents would be useful to pay attention to at all.
- Walk through many more examples, and unpack various common subtleties.
Unlike Natural Latents: The Math [LW · GW], this post is not mainly aimed at researchers who might build on the technical work (though they might also find it useful), but rather at people who want to use natural latents conceptually to clarify their own thinking and communication.
We will not carefully walk through the technical details of the examples. Nearly every example in this post has some potential subtleties to it which we’ll gloss over. If you want a semitechnical exercise: pick any example in the post, identify some subtleties which could make the claimed natural latent no longer a natural latent, then identify and interpret a natural latent which accounts for those subtleties.
What Are Natural Latents? How Do We Quickly Check Whether Something Is A Natural Latent?
Alice & Bob’s Art Project
Let’s return to our opening example: Alice draws a picture of some random purple and green lines, sends only the green lines to Bob, Bob generates his own random purple lines and adds them to the green lines to make his picture.
In Alice and Bob’s art project, can we argue that the green lines summarize “all and only” the information shared across the two pictures? Not necessarily with very formal math, but enough to see why it must be true. If you want to try this as an exercise, pause here.
.
.
.
Here’s our argument: first, the two pictures are independent (in the formal probability sense) conditional on the green lines. So the rest of Alice's picture tells us nothing more about Bob’s, once we have the green lines; in that sense, the green lines summarize all the information about Alice’s picture relevant to Bob’s (or vice-versa).
Second, notice that the green lines are included in their entirety in Bob’s picture. So the green lines include no “extra” information, nothing irrelevant to Bob’s picture. In that sense, the green lines summarize only the information about Alice’s picture relevant to Bob’s. Similarly, since the green lines are included in their entirety in Alice’s picture, they summarize only the information about Bob’s picture which is relevant to Alice’s.
Put those two together, and the green lines summarize all and only the information shared across the two pictures. In that sense, they are a “natural” summary of shared information - a natural latent.
Generalization
Looking back at the previous section, we can back out two intuitive criteria which suffice for the argument:
- Mediation [1]: Our candidate natural latent must mediate between parts of the system - formally, the parts must be independent given the latent.
- Redundancy [2]: Our candidate natural latent must be “included entirely” in each part of the system - i.e. the candidate’s value can be backed out from any individual part.
If those two criteria both hold, then the candidate summarizes “all and only” the information shared across the parts; it’s a natural latent.
Let’s walk through those criteria for the idealish gas and the dogs.
The isolated idealish gas is simple: the “parts'' are the low-level state of the gas at two (or more) sufficiently separated times.
- Mediation: Chaos ensures that the energy mediates between those states; their low-level details are all independent controlling for the energy.
- Redundancy: Since energy is conserved, it can be calculated from the state at any single time.
So, we have a natural latent.
The dogs example is trickier.
Dogs
We want to talk about a summary of “all and only” the information shared across dogs, separate from their individual details.
As a first pass, we might take the “parts” of our system to be individual dogs. But then we run into trouble: we might not be able to back out a summary of general properties of dogs from any one dog. For instance, any given dog might have three legs, even though the general statistical property of dogs is to usually have four.
So instead, we take the “parts” to be large nonoverlapping sets of individual dogs, without any particular sorting by breed or the like. Just take 1000 or 10000 randomly-selected dogs in the first set, another random 1000 or 10000 in the second set, etc. So long as each set is large and diverse enough to get a decent estimate of the general statistical properties of dogs, we can satisfy the redundancy condition. And so long as the dogs in different sets are independent given those general properties, we also satisfy the mediation condition. So, the general statistical properties of dogs would then be a natural latent between those random subsets of dogs.
Note that we’re relying on approximation here: those subsets definitely won’t give us very exact estimates of the general properties of dogs, and the dogs might not be exactly independent given a summary of those general properties. And that’s fine; the interesting properties of natural latents are robust to approximation. So long as the conditions are approximately satisfied, the latent captures approximately all and only the shared information.
Note also that this “take a random subset and statistically average or whatever” business is… not the most elegant. The mathematical formulation of natural latents [LW · GW] is cleaner: rather than requiring that the latent be redundantly represented in every part of the system, we instead require that the latent can be reconstructed while ignoring any one part. So in the context of the dogs example: the general properties of dogs are not sensitive to any one dog. That’s a weaker and cleaner redundancy criterion, but it makes arguments/proofs less intuitive and quantitatively weaker, which is why we’re using a stronger redundancy criterion here. (We usually call natural latents under the stronger redundancy condition “strong natural latents”.) Point is: this can be made somewhat more elegant, at a cost of being less intuitive/elegant in other ways.
Why Are Natural Latents Useful?
Now that we have a few examples under our belt, let’s talk about two of the simplest stories of why natural latents are useful. (These aren’t the only stories of why natural latents are useful, but they’re the simplest and we expect that they underlie many others.)
Minimal Relevant Information
Recall our opening example, in which Carol watches Alice draw her purple and green lines, send the green lines to Bob, and Bob add his purple lines to them. After seeing Alice draw her picture, Carol wants to make predictions about Bob’s picture. We said that it seems natural for Carol to just remember where all the green lines are, and forget about the purple lines, since the green lines summarize “all and only” the information relevant to Bob’s picture.
That means that the green lines are the smallest summary of Alice’s picture which still keeps around everything relevant to Bob’s picture. After all, any other summary which keeps around everything relevant to Bob’s picture must at-minimum contain enough information to fully reconstruct the green lines.
If we wanted mathematical rigor, we could invoke something like the Gooder Regulator Theorem [LW · GW] at this point. Walking through the conceptual story behind that theorem: we suppose that Carol is in a complicated world where she doesn’t know in advance which particular things about Bob’s picture she’ll need to predict, so she wants to keep around any information which might be relevant. But also, her mind is not infinite, she cannot remember everything, so she keeps around only the minimum summary of everything potentially relevant. Thus, the green lines.
More generally, this is one story for why real agents would want to track natural latents. Real agents don’t know what exact stuff they’ll need to predict later (because the world is complicated), but they also have limited memory, so insofar as there exists a minimal summary of everything which might be relevant, they likely track that.
So that’s one story.
Note, however, that a Gooder Regulator-style story fails to account for the usefulness of one of the examples we’ve already seen: dogs. In the dogs example, the “general statistical properties of dogs” are both too big to track in a human’s memory (e.g. the consensus dog genome alone is ~1.2 gigabytes) and not easy to figure out just from only surface-level observations of dogs (genome sequencing is nontrivial). Yet even when we don’t know the value of the natural latent (including e.g. the consensus genome), it’s apparently still useful to use that natural latent to structure our internal world-models - i.e. model dogs as though most of them are basically-independent given some general statistical properties (not all of which we know, but which can be approximately figured out from moderate-sized random samples of dogs). Why is that useful? Why do we humans apparently structure our thoughts that way? Those are open research questions; we don’t yet have all the mathematical answers to them, though we have some intuitions. And we do have one more story.
Maximal Robust Information
One of the basic arguments for natural abstraction [? · GW] being “a thing” is the language problem: the number of functions from a 1 megabyte image to a yes/no answer to “does this image contain a dog?” is 2^(2^8000000). To specify an arbitrary such function would therefore require ~2^8000000 examples. Allowing for lots of ambiguous edge-cases would change the number but not the qualitative conclusion: brute-force learning a function requires a ridiculously exponentially massive number of labeled examples. Yet humans, in practice, are able to usually basically figure out what other people mean by “dog” from something like one to five labeled examples - i.e. one to five instances of somebody pointing at a dog and saying “dog”. Language is able to work at all.
This tells us that “nearly all the work” of figuring out what “dogs” are must come, not from labeled examples, but from unsupervised learning: humans looking at the world and noticing statistical patterns which other humans also notice. We then get around the 2^8000000 problem by having only a relatively very very small set of candidate “things” to which words might be attached.
This basic picture puts some major constraints on the candidate “things”, even at this very rough level of characterization. Notably: in order for this whole language business to work, humans have to look at the world and notice statistical patterns which other humans also notice - despite those other humans not sharing exactly the same observations. You and I mostly agree on what “dogs” refers to, despite not seeing the same dogs.
… and that starts to sound like the redundancy condition for natural latents.
Let’s say we want candidate word-referents (like e.g. dogs) to be variables which can be estimated from any typical subset of some large set of stuff in the world, in order to handle the “humans which observe different subsets must nonetheless basically agree on what they’re talking about” problem. So we want them to satisfy the redundancy condition.
Now let’s get a bit stronger: let’s say we want candidate word-referents to be as informative as possible, subject to the redundancy condition. In other words, we want candidate word-referents to include all the information which can be deduced from a typical subset of the stuff in question - e.g. all the information which can be deduced from a typical subset of dogs.
Well, that means our word-referents will be natural latents, insofar as natural latents exist at all over the stuff in question.
There’s still a lot of sketchiness in this story! Perhaps most alarmingly, we’re defining the referent of “dogs” in terms of information deductible from typical subsets of dogs? Seems circular at first glance. That circularity will be resolved when we talk about clustering (below). For now, the main point is that the requirement of word-referent deductibility from typical subsets hand-wavily implies the redundancy condition, and the most informative variables satisfying redundancy are natural latents (when natural latents exist at all).
More Examples
Now that we’ve covered the basics, it’s time to go through a bunch of examples. These are chosen to illustrate common patterns, as well as common subtleties.
There’s a lot of examples here. For an 80/20 of the most important concepts, read the Coin Flip examples, the Gas (Over Space) example, and the “Clusters In Thingspace” example.
Toy Probability Examples
Anti-Example: Three Flips Of A Biased Coin
Natural latents don’t always exist over some given parts of a system. For example, suppose the “parts” are three different flips of the same coin, which has some unknown bias.
The obvious candidate for a natural latent would be the bias, since all the flips are independent conditional on the bias. So the mediation condition is satisfied. But the redundancy condition is not satisfied: a single flip (or even two) is not enough to figure out the bias of the coin.
So the obvious candidate doesn’t work. Can we rule out all candidate natural latents?
Well, the redundancy condition says that we must be able to back out the value of any natural latent from any one flip - e.g. the first coin flip. And that flip is just one bit. So any natural latent in this system would have to be just one bit (to within approximation, i.e. it probably takes one of two values), and that value must be (approximately) determined by the first coin flip. And there’s only one way that could happen: the potential natural latent would have to be approximately informationally equivalent to the first coinflip.
But then we observe that the three flips are not approximately independent given the first flip, nor can the first flip be backed out from the other two, so anything approximately informationally equivalent to the first flip is not a natural latent. Therefore, no natural latent exists in the three-flips system.
1000 Flips Of A Biased Coin
Now we have more flips. Let’s divide them into two sets: the first 500 flips, and the second 500.
The bias of the coin is still the obvious candidate natural latent, since the two sets of flips are independent given the bias. But now, we can estimate the bias (to reasonable precision with high probability) from either of the two sets, so the redundancy condition is satisfied. The bias is therefore a natural latent over the two sets of coin flips.
Note that we made a similar move here to the dogs example earlier: rather than considering each coin flip as one “part” of the system, we viewed whole sets of coin flips as the “parts”. As with the dogs example, this is somewhat inelegant and we could avoid it by using a weaker redundancy condition (as done in Natural Latents: The Math [LW · GW]), at the cost of weaker quantitative bounds and somewhat less intuitive arguments.
Ising Model
The Ising model is a standard toy model of magnets. We have a large 2D square grid, and at each point on the grid a tiny magnet is randomly pointed either up or down. These being magnets, they like to align with their neighbors: each neighbor pointed up makes it more likely that this magnet will point up, and vice-versa.
The main thing usually studied in Ising models is a phase change: when the magnets are only weakly correlated with their neighbors, far-apart magnets are approximately independent. But as the correlations increase, eventually most of the magnets “click into” a matching orientation, so that even very far apart magnets are probably pointed the same way.
So what are the natural latents here?
Well, at low correlation, far-apart parts of the system are approximately independent, so the “empty latent” is natural - i.e. we don’t need to condition on anything. At higher correlation, far-apart parts are independent given the “consensus direction” of the full system, and that consensus direction can be estimated precisely from any one large-enough chunk. So at higher correlations, the consensus direction is the natural latent.
Notably, when the system undergoes phase change, there’s not just a change in values of the natural latents (like e.g. whether the consensus direction is up or down), but also in what variables are natural latents (i.e. what function to compute from a chunk in order to estimate the natural latent). In our work, we think of this as the defining feature of “phase change”; it’s a useful definition which generalizes intuitively to other domains.
Another notable feature of this example: the natural latents are over sufficiently far apart chunks of the system, much like our ideal gas example earlier. We didn’t emphasize it earlier, but one common pattern is that most of the “parts” of a system are independent of most others, but there may be a few parts which interact. In this case, if we took the parts to be each individual magnet, then we’d see that each magnet interacts weakly with its neighbors (and neighbors-of-neighbors, etc, though the interaction quickly drops off). That would mean there’s no natural latent, for similar reasons to the three-coinflips example above. But, so long as there exists a way to carve up the system into “parts” which avoids those “local” interactions, we can establish a natural latent. And typically, as in this example, there are many carvings which result in approximately the same natural latent - e.g. many choices of sufficiently spatially-separated “chunks”.
A similar issue implicitly came up in the dogs example: closely related dogs may be correlated in ways not mediated by the “general properties of dogs”. But most dogs are approximately independent of most others, so we can pick subsets to establish a natural latent, and we expect that many choices will yield approximately the same natural latent.
Physics-Flavored Examples
Gas (Over Space)
We’ve already said that the energy of an isolated idealish gas is a natural latent over the low-level state of the gas at sufficiently separated times. But we can go further.
So long as the gas is near equilibrium, not only is the low-level state at different times independent given the energy, the low-level states of sufficiently spatially-separated chunks of the gas are also independent given the energy. And, again invoking near-equilibrium, that energy can be precisely estimated from any one spatially-separated chunk, because the gas has approximately-uniform temperature. So, energy is a natural latent over low-level state of spatially-separated chunks of gas, in addition to time-separated.
Note, as in the Ising model, that there are local interactions not mediated by the natural latent. As usual, we choose “parts” to avoid those, and expect that many choices of “parts” yield the same natural latent. This is usually the case, and we’re going to stop emphasizing it in most of the examples.
Non-Isolated Gas
Our previous example assumes the gas is isolated. What if instead the gas is in a piston interacting with the world in the usual ways: expanding/compressing, heating/cooling, gas flowing in and out? Well, if we keep the “near equilibrium” assumption, spatially-separated chunks of the gas are no longer independent: by looking at one little chunk, I can deduce the temperature, pressure and number-density (i.e. number of molecules per unit volume) for the other chunks. But I do expect that the spatially-separated chunks are approximately independent given temperature, pressure, and number density. Furthermore, I can precisely estimate the temperature, pressure and number density from any one chunk. So, the triple (temperature, pressure, number density) is a natural latent over spatially-separated chunks of the gas at a fixed time. Note that these are exactly the “state variables” in the ideal gas law.
One thing to emphasize in the non-isolated gas example: temperature, pressure and number density all vary over time. The temperature, pressure and number density at a given time are a natural latent only over spatially-separated chunks of the gas at that time. Different parts of the world, like e.g. chunks of gas at different times, have different natural latents over them.
Another thing to emphasize: according the ideal gas law, the temperature T, pressure P and number density are not independent; we can calculate any one from the other two and the ideal gas constant :
… so in fact any one of the three tuples , , or is a natural latent. All three are informationally equivalent (i.e. from any one we can calculate the others), they just represent the same information differently. More generally: natural latents are typically only of interest “up to isomorphism” - anything which represents exactly the same information is effectively the same latent.
Gasses In Systems
, , and are importantly different from a natural latents perspective once we stick the piston in a larger system. For instance, we might arrange the piston to push against another piston of the same radius containing gas of different number density and temperature:
Near equilibrium, the two pistons have approximately the same pressure, but (potentially) different temperature and number density. And we can measure the pressure from either piston, so the pressure alone is natural across the two pistons, whereas the tuple (or some informationally-equivalent tuple) is a natural latent over spatially-separated chunks of gas within piston 1, and is natural over spatially-separated chunks of gas within piston 2.
Similarly, we could put two pistons in thermal contact, so that near equilibrium the temperature is natural across the two.
Rigid Bodies
An example of a different flavor: humans tend to recognize rigid bodies as “objects”. Can we formulate that in terms of natural latents?
Well, consider a wooden chair. The chair has lots of little parts, but they all move approximately together: if I know the position and orientation of any one part at a particular time (along with the chair’s geometry), then I know roughly the position and orientation of all the other parts at that time. And given the high-level position and orientation of the chair, I typically mentally model the smaller vibrations of little parts as roughly independent (though I might need to use a more accurate model for e.g. acoustics of the chair, or heat flow). So, under that mental model, the position and orientation are a natural latent over the positions and orientations of the chair’s parts.
There’s also a natural latent over time: I can observe the chair’s geometry from its components at any given time, and under a simple mental model the positions of all the chair’s components at sufficiently separated times are independent given the chair’s geometry.
In this view, what makes the chair a coherent “thing” to view as a single rigid-body object is, in some sense, that it has these two natural latents: a geometry natural over time, and position/orientation natural over space at any given time. Insofar as the assumptions behind those two natural latents break down, it becomes less and less useful to view the chair as a single rigid-body object.
Note that, in this example, we ignored things like acoustics or heat flow. One way to “more rigorously” ignore such components would be to say “position and orientation are a natural latent over the rigid body given acoustics and temperature”. More generally, it’s totally legit to have latents which are natural after we condition on some other “background” information. Of course, it then potentially matters what “background” information we’re conditioning on at any given time.
Phase Change
Returning to the gas in a piston: suppose we cool the gas until it solidifies. How does that change the natural latents?
Well, temperature and pressure are presumably no longer a natural latent; assuming the resulting solid is reasonably rigid, the position/orientation can be measured from each little piece, and there’s a conserved geometry, as in the previous section.
As in the Ising model, when the system undergoes phase change, there’s not just a change in values of the natural latents (like e.g. change in temperature or in pressure), but also in what variables are natural latents.
Other Examples
“Clusters In Thingspace”
First, some 101 background…
Wrong Novice: All real-world categories have weird edge cases: dogs with three legs, cars with the wheels removed, etc. It is therefore impossible to have precise definitions of words.
Less Wrong Novice: Words point to clusters in thingspace [LW · GW]. Just because there are always individual points “on the edges” of the clusters, doesn’t mean there’s no precise characterization of the clusters themselves. The precise definition of “dogs” is not e.g. a cutting-plane in thingspace such that all the dogs are on one side and the non-dogs are on another side; rather, the precise definition of “dogs” is just the statistics which characterize the dog-cluster - i.e. the general properties of dogs.
Researcher: That seems intuitively sensible, but this “thingspace” is pretty handwavy. Different choices of space (i.e. the axes of “thingspace”) will yield very different clusters. So what’s the space in which we’re clustering, and how do we do that clustering?
Let’s first see what a natural-latents-centric frame has to say to that researcher, then talk about how natural latents relate to this "clusters in thingspace" picture more generally.
One important thing about dogs is that there are many different ways to tell something is a dog - many different subsets of “the dog” which I could look at, many different properties of the dog, etc. Face, fur, genome, bark, collar, etc. In other words, any individual dog satisfies a redundancy condition.
In the clustering picture, that redundancy condition tells us something about the axes of “thingspace”: there’s a lot of axes, and the clusters are reasonably robust to which axes we use. I could cluster based on genome, I could cluster based on properties like face/fur/bark/etc, and I’ll get a cluster of dogs either way.
Insofar as that’s true (and there are cases [LW · GW] where it breaks down to some extent, though arguably those cases are the exceptions which prove the rule), the researcher’s question about choice of axes largely goes away. So long as we pick a typical wide variety of axes of thingspace, we expect the exact choices to not matter much - or, more precisely, we’ll specifically look for clusters such that the choice of axes doesn’t matter much.
With that in mind, we’re now ready to return to the “circularity of ‘dogs’” problem from earlier.
Recall the problem: roughly speaking, we’d like to say that “dogs” are defined in terms of some general statistical properties of dogs, i.e. the statistical parameters of the dog-cluster. But that’s circular, because which-things-count-as-”dogs”-to-what-degree depends on the cluster parameters, and the cluster parameters depend on which-things-count-as-”dogs”-to-what-degree.
With the clustering picture in mind, we see that this is… just the ordinary circularity of clustering problems. One of the most standard clustering algorithms is basically:
- Estimate assignments of points to clusters, given current estimate of cluster parameters
- Estimate cluster parameters, given current estimate of points to clusters
- Repeat until convergence
And yeah, that is somewhat circular. There are sometimes multiple “solutions” - i.e. multiple fixed points of the iteration. But in practice, there’s a relatively small and typically discrete set of convergent “solutions”, and most clusters match most of the time across runs. And that’s what we expect from natural abstraction in general: clearly not all agents match in all their chosen abstractions, but there’s a relatively small and discrete set of possibilities, and they mostly match most of the time. It’s not like choosing arbitrary points on a continuum, but rather like choosing which books to take off of a shelf, where the environment (not the agent) is the librarian.
That two-repeated-step clustering algorithm also suggests that there are two places where natural latents enter this sort of clustering picture. First: the assignment of a point to a cluster (e.g. “is this a dog?”) is a natural latent over the “coordinates in thingspace” of the point - i.e. we can tell whether this is a dog by looking at genome, face/fur/etc, or many other things, and lots of those properties should become independent once we know it’s a dog. Second: the cluster parameters should be natural latents over the points in a cluster - i.e. the general properties of dogs should be a natural latent over dogs, as we discussed earlier.
Social Constructs: Laws
When I talk about natural abstraction [? · GW], people often bring up social constructs, with laws being a central example. Laws are entirely “chosen by humans” in some sense; humans could all change what they consider to be laws, and that would change the laws. Contrast that with a vibe-y picture of natural abstraction, in which the natural abstractions are supposed to be “determined by the environment”, in some sense, such that a wide variety of other minds arrive at the same abstractions.
In this example, we’ll walk through a standard response explaining how social constructs are natural abstractions in a nontrivial sense, and see how that response applies to natural latents as a specific formulation of natural abstraction.
First, a background concept. For visualization, let’s picture a clustering problem:

One of these clusters consists of minivans, and the other consists of pickup trucks. Well, if people want to, they can totally just go build new kinds of vehicles which fall in other parts of the space:
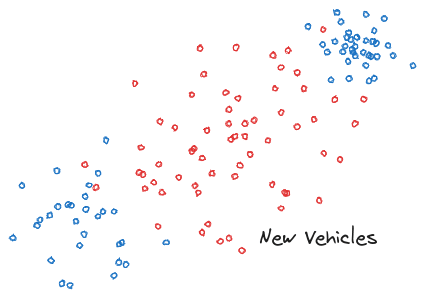
… and if they build enough new vehicles, it can totally change what clusters are present:
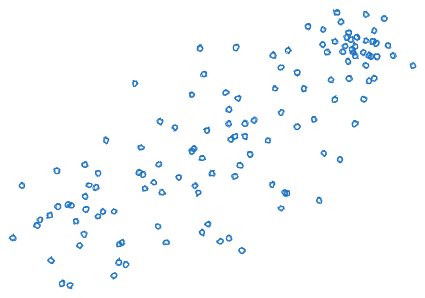
Two points here:
- People can totally change what stuff is in the world, in such a way that the “natural abstractions” change. This extends to natural latents.
- … but that requires going out and changing stuff in the world; it’s not just a matter of me deciding to assign different clusters to the same data.
So even if the clusters can be changed by humans by changing the world, that doesn’t mean that choice of clusters is a totally arbitrary choice of how to view the same data.
Now let’s talk about laws.
First: insofar as lots of different people agree on what the laws are, lots of different police/courts enforce the laws mostly-consistently, etc, that means the laws are redundant over all those people/police/courts. So, just from the redundancy property, we know that any natural latent over subsets of those people must include the laws. (We’re ignoring the independence property here, because when we get to fairly abstract things like laws independence usually involves conditioning on a whole stack of lower-level things, which isn’t central to the point here.)
Insofar as alien minds indeed structure their world-models around natural latents, and those alien minds observe and model all these different people using the same laws, those aliens will therefore include those laws in any natural latent over the people (assuming such a natural latent exists).
As in our clustering visualizations, the humans could collectively decide to adopt different laws. The alien could even try to influence the humans to adopt different laws. But crucially, this requires going out and changing something about all those humans out in the world; it’s not just a matter of the alien deciding to assign different concepts to the same data. Likewise for any individual human: I cannot change the laws just by viewing my own data differently; changing the laws requires going out and changing the behavior of lots of other humans.
Takeaways
Natural latents are pretty handy. If a variable is a natural latent over some parts of a system, then I know it’s the smallest summary of everything about one part relevant to the others, and I know it’s informationally the largest thing which I can learn from a typical subset of the chunks. That makes such latents natural for agents to structure their cognition and language around.
A quick intuitive check for whether something is a natural latent over some parts of a system consists of two questions:
- Are the parts (approximately) independent given the candidate natural latent?
- Can the candidate natural latent be estimated to reasonable precision from any one part, or any typical subset of the parts?
- ^
We also sometimes call the mediation condition the “independence” condition.
- ^
Natural Latents: The Math [LW · GW] called the redundancy condition the “insensitivity” condition instead; we also sometimes call it the “invariance” condition.
18 comments
Comments sorted by top scores.
comment by aysja · 2024-03-21T18:39:02.371Z · LW(p) · GW(p)
I don’t see how the cluster argument resolves the circularity problem.
The circularity problem, as I see it, is that your definition of an abstraction shouldn’t be dependent on already having the abstraction. I.e., if the only way to define the abstraction “dog” involves you already knowing the abstraction “dog” well enough to create the set of all dogs, then probably you’re missing some of the explanation for abstraction. But the clusters in thingspace argument also depends on having an abstraction—knowing to look for genomes, or fur, or bark, is dependent on us already understanding what dogs are like. After all, there are nearly infinite “axes” one could look at, but we already know to only consider some of them. In other words, it seems like this has just passed the buck from choice of object to choice of properties, but you’re still making that choice based on the abstraction.
The fact that choice of axis—from among the axes we already know to be relevant—is stable (i.e., creates the same clusterings) feels like a central and interesting point about abstractions. But it doesn’t seem like it resolves the circularity problem.
(In retrospect the rest of this comment is thinking-out-loud for myself, mostly :p but you might find it interesting nonetheless).
I think it’s hard to completely escape this problem—we need to use some of our own concepts when understanding the territory, as we can’t see it directly—but I do think it’s possible to get a bit more objective than this. E.g., I consider thermodynamics/stat mech to be pretty centrally about abstractions, but it does so in a way that feels more “territory first,” if that makes any sense. Like, it doesn’t start with the conclusion. It started with the observation that “heat moves stuff” and “what’s up with that” and then eventually landed with an analysis of entropy involving macrostates. Somehow that progression feels more natural to me than starting with “dogs are things” and working backwards. E.g., I think I’m wanting something more like “if we understand these basic facts about the world, we can talk about dogs” rather than “if we start with dogs, we can talk sensibly about dogs.”
To be clear, I consider some of your work to be addressing this. E.g., I think the telephone theorem is a pretty important step in this direction. Much of the stuff about redundancy and modularity feels pretty tip-of-the-tongue onto something important, to me. But, at the very least, my goal with understanding abstractions is something like “how do we understand the world such that abstractions are natural kinds”? How do we find the joints such that, conditioning on those, there isn’t much room to vary? What are those joints like? The reason I like the telephone theorem is that it gives me one such handle: all else equal, information will dissipate quickly—anytime you see information persisting, it’s evidence of abstraction.
My own sense is that answering this question will have a lot more to do with how useful abstractions are, rather than how predictive/descriptive they are, which are related questions, but not quite the same. E.g., with the gears example you use to illustrate redundancy, I think the fact that we can predict almost everything about the gear from understanding a part of it is the same reason why the gear is useful. You don’t have to manipulate every atom in the gear to get it to move, you only have to press down on one of the… spokes(?), and the entire thing will turn. These are related properties. But they are not the same. E.g., you can think about the word “stop” as an abstraction in the sense that many sound waves map to the same “concept,” but that’s not very related to why the sound wave is so useful. It’s useful because it fits into the structure of the world: other minds will do things in response to it.
I want better ways to talk about how agents get work out of their environments by leveraging abstractions. I think this is the reason we ultimately care about them ourselves; and why AI will too. I also think it’s a big part of how we should be defining them—that the natural joint is less “what are the aggregate statistics of this set” but more “what does having this information allow us to do”?
↑ comment by johnswentworth · 2024-03-22T15:39:35.076Z · LW(p) · GW(p)
Sounds like I've maybe not communicated the thing about circularity. I'll try again, it would be useful to let me know whether or not this new explanation matches what you were already picturing from the previous one.
Let's think about circular definitions in terms of equations for a moment. We'll have two equations: one which "defines" in terms of , and one which "defines" in terms of :
Now, if , then (I claim) that's what we normally think of as a "circular definition". It's "pretending" to fully specify and , but in fact it doesn't, because one of the two equations is just a copy of the other equation but written differently. The practical problem, in this case, is that and are very underspecified by the supposed joint "definition".
But now suppose is not , and more generally the equations are not degenerate. Then our two equations are typically totally fine and useful, and indeed we use equations like this all the time in the sciences and they work great. Even though they're written in a "circular" way, they're substantively non-circular. (They might still allow for multiple solutions, but the solutions will typically at least be locally unique, so there's a discrete and typically relatively small set of solutions.)
That's the sort of thing which clustering algorithms do: they have some equations "defining" cluster-membership in terms of the data points and cluster parameters, and equations "defining" the cluster parameters in terms of the data points and the cluster-membership:
cluster_membership = (data, cluster_params)
cluster_params = (data, cluster_membership)
... where and are different (i.e. non-degenerate; is not just with data held constant). Together, these "definitions" specify a discrete and typically relatively small set of candidate (cluster_membership, cluster_params) values given some data.
That, I claim, is also part of what's going on with abstractions like "dog".
(Now, choice of axes is still a separate degree of freedom which has to be handled somehow. And that's where I expect the robustness to choice of axes does load-bearing work. As you say, that's separate from the circularity issue.)
Replies from: johnswentworth↑ comment by johnswentworth · 2024-03-22T15:45:11.933Z · LW(p) · GW(p)
comment by Alex_Altair · 2024-03-25T01:31:05.750Z · LW(p) · GW(p)
I've noticed you using the word "chaos" a few times across your posts. I think you're using it colloquially to mean something like "rapidly unpredictable", but it does have a technical meaning that doesn't always line up with how you use it, so it might be useful to distinguish it from a couple other things. Here's my current understanding of what some things mean. (All of these definitions and implications depend on a pile of finicky math and tend to have surprising counter-example if you didn't define things just right, and definitions vary across sources.)
Sensitive to initial conditions. A system is sensitive to initial conditions if two points in its phase space will eventually diverge exponentially (at least) over time. This is one way to say that you'll rapidly lose information about a system, but it doesn't have to look chaotic. For example, say you have a system whose phase space is just the real line, and its dynamics over time is just that points get 10x farther from the origin every time step. Then, if you know the value of a point to ten decimal places of precision, after ten time steps you only know one decimal place of precision. (Although there are regions of the real line where you're still sure it doesn't reside, for example you're sure it's not closer to the origin.)
Ergodic. A system is ergodic if (almost) every point in phase space will trace out a trajectory that gets arbitrarily close to every other point. This means that each point is some kind of chaotically unpredictable, because if it's been going for a while and you're not tracking it, you'll eventually end up with maximum uncertainty about where it is. But this doesn't imply sensitivity to initial conditions; there are systems that are ergodic, but where any pair of points will stay the same distance from each other. A simple example is where phase space is a circle, and the dynamics are that on each time step, you rotate each point around the circle by an irrational angle.
Chaos. The formal characterization that people assign to this word was an active research topic for decades, but I think it's mostly settled now. My understanding is that it essentially means this;
- Your system has at least one point whose trajectory is ergodic, that is, it will get arbitrarily close to every other point in the phase space
- For every natural number n, there is a point in the phase space whose trajectory is periodic with period n. That is, after n time steps (and not before), it will return back exactly where it started. (Further, these periodic points are "dense", that is, every point in phase space has periodic points arbitrarily close to it).
The reason these two criteria yield (colloquially) chaotic behavior is, I think, reasonably intuitively understandable. Take a random point in its phase space. Assume it isn't one with a periodic trajectory (which will be true with "probability 1"). Instead it will be ergodic. That means it will eventually get arbitrarily close to all other points. But consider what happens when it gets close to one of the periodic trajectories; it will, at least for a while, act almost as though it has that period, until it drifts sufficiently far away. (This is using an unstated assumption that the dynamics of the systems have a property where nearby points act similarly.) But it will eventually do this for every periodic trajectory. Therefore, there will be times when it's periodic very briefly, and times when it's periodic for a long time, et cetera. This makes it pretty unpredictable.
There are also connections between the above. You might have noticed that my example of a system that was sensitive to initial conditions but not ergodic or chaotic relied on having an unbounded phase space, where the two points both shot off to infinity. I think that if you have sensitivity to initial conditions and a bounded phase space, then you generally also have ergodic and chaotic behavior.
Anyway, I think "chaos" is a sexy/popular term to use to describe vaguely unpredictable systems, but almost all of the time you don't actually need to rely on the full technical criteria of it. I think this could be important for not leading readers into red-herring trails of investigation. For example, all of standard statistical mechanics only needs ergodicity.
comment by tailcalled · 2024-03-20T19:16:07.986Z · LW(p) · GW(p)
More generally: natural latents are typically only of interest “up to isomorphism” - anything which represents exactly the same information is effectively the same latent.
Note that from an alignment perspective, this is potentially a problem. Even if "good" is a natural abstraction, "seems superficially good but is actually bad" is also a natural abstraction, and so if you want to identify the "good" abstraction" within a learned model, you have some work cut out to separate it from f(good, seems superficially good but is actually bad), for arbitrary values of f.
I think different ad-hoc [LW · GW] alignment ideas can be fruitfully understood in terms of different assumptions they make in order to solve this problem. For instance my guess is that weak-to-strong generalization works insofar as "good" is represented at much greater scale than "seems superficially good but is actually bad" (because the gradient update for a weight is proportional to the activation of the neuron upstream of that weight).
Under this assumption, for e.g. shard theory to succeed, I guess they would have to create models for the magnitudes of different internal representations. My first guess would be that the magnitude would grow with the number of training samples that need the natural abstraction. (Which in turn makes it a major flaw that the strong network was only trained on labels and not data generated by the weak network. Real foundations models are trained on a mixture of human and non-human data, rather than purely on non-human data. Analogously, the strong network should be trained on a mixture of data generated by the weak network and by humans.)
I suspect this problem will be easily solvable for some concepts (e.g. "diamond") and much harder to solve for other concepts (e.g. "human values"), but I don't think we entirely know how far it will reach.
comment by Alex_Altair · 2024-03-25T02:28:18.968Z · LW(p) · GW(p)
We then get around the 2^8000000 problem by having only a relatively very very small set of candidate “things” to which words might be attached.
A major way that we get around this is by having hierarchical abstractions. By the time I'm learning "dog" from 1-5 examples, I've already done enormous work in learning about objects, animals, something-like-mammals, heads, eyes, legs, etc. So when you point at five dogs and say "those form a group" I've already forged abstractions that handle almost all the information that makes them worth paying attention to, and now I'm just paying attention to a few differences from other mammals, like size, fur color, ear shape, etc.
I'm not sure how the rest of this post relates to this, but it didn't feel present; maybe it's one of the umpteenth things you left out for the sake of introductory exposition.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2024-03-25T02:34:59.376Z · LW(p) · GW(p)
That’s true but you still have let’s say 2^1000000 afterwards.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2024-03-25T02:41:50.396Z · LW(p) · GW(p)
Oh, no, I'm saying it's more like 2^8 afterwards. (Obviously it's more than that but I think closer to 8 than a million.) I think having functioning vision at all brings it down to, I dunno, 2^10000. I think you would be hard pressed to name 500 attributes of mammals that you need to pay attention to to learn a new species.
comment by Garrett Baker (D0TheMath) · 2024-03-20T21:11:53.245Z · LW(p) · GW(p)
Notably, when the system undergoes phase change, there’s not just a change in values of the natural latents (like e.g. whether the consensus direction is up or down), but also in what variables are natural latents (i.e. what function to compute from a chunk in order to estimate the natural latent). In our work, we think of this as the defining feature of “phase change”; it’s a useful definition which generalizes intuitively to other domains.
When I was first learning about the Ising model while reading Introduction to the Theory of Complex Systems, I wrote down this note:
The way the book talks about this, it almost seems like systems on critical points are systems where previous abstractions you can usually use break down. For example, these are associated with non-local interactions, correlations (here used as a sort of similarity/distance metric) which become infinite, and massive restructuring events. Also, in the classical natural abstractions framing, if you freeze water, you go from the water being described by a really complicated energy-minimization-subject-to-constant-volume equation to like 6 parameters.
Which has influenced non-trivially my optimism in singular learning theory, and the devinterp-via-phase-transitions paradigm. Glad to see y'all think about this the same way.
comment by Paul W · 2024-08-02T19:03:09.250Z · LW(p) · GW(p)
Hello !
These ideas seem interesting, but there's something that disturbs me: in the coin flip example, how is 3 fundamentally different from 1000 ? The way I see it, the only mathematical difference is that your "bounds" (whatever that means) are simply much worse in the case with 3 coins. Of course, I think I understand why humans/agents would want to say "the case with 3 flips is different from that with 1000", but the mathematics seem similar to me.
Am I missing something ?
↑ comment by johnswentworth · 2024-08-02T19:39:24.898Z · LW(p) · GW(p)
That's correct, the difference is just much worse bounds, so for 3 there only exists a natural latent to within a much worse approximation.
comment by Aprillion · 2024-03-24T13:44:40.468Z · LW(p) · GW(p)
Now, suppose Carol knows the plan and is watching all this unfold. She wants to make predictions about Bob’s picture, and doesn’t want to remember irrelevant details about Alice’s picture. Then it seems intuitively “natural” for Carol to just remember where all the green lines are (i.e. the message M), since that’s “all and only” the information relevant to Bob’s picture.
(Writing before I read the rest of the article): I believe Carol would "naturally" expect that Alice and Bob share more mutual information than she does with Bob herself (even if they weren't "old friends", they both "decided to undertake an art project" while she "wanted to make predictions"), thus she would weight the costs of remembering more than just the green lines against the expected prediction improvement given her time constrains, lost opportunities, ... - I imagine she could complete purple lines on her own, and then remember some "diff" about the most surprising differences...
Also, not all of the green lines would be equally important, so a "natural latent" would be some short messages in "tokens of remembering", not necessarily correspond to the mathematical abstraction encoded by the 2 tokens of English "green lines" => Carol doesn't need to be able to draw the green lines from her memory if that memory was optimized to predict purple lines.
If the purpose was to draw the green lines, I would be happy to call that memory "green lines" (and in that, I would assume to share a prior between me and the reader that I would describe as: "to remember green lines" usually means "to remember steps how to draw similar lines on another paper" ... also, similarity could be judged by other humans ... also, not to be confused with a very different concept "to remember an array of pixel coordinates" that can also be compressed into the words "green lines", but I don't expect people will be confused about the context, so I don't have to say it now, just keep in mind if someone squirts their eyes just-so which would provoke me to clarify).
comment by Mateusz Bagiński (mateusz-baginski) · 2024-03-24T09:12:11.048Z · LW(p) · GW(p)
In the Alice and Bob example, suppose there is a part (call it X) of the image that was initially painted green but where both Alice and Bob painted purple. Would that mean that the part of the natural latent over images A and B corresponding to X should be purple?
Replies from: johnswentworth↑ comment by johnswentworth · 2024-03-24T16:10:49.548Z · LW(p) · GW(p)
Only if they both predictably painted that part purple, e.g. as part of the overall plan. If they both randomly happened to paint the same part purple, then no.
comment by Morpheus · 2024-03-21T22:44:36.185Z · LW(p) · GW(p)
A quick intuitive check for whether something is a natural latent over some parts of a system consists of two questions:
- Are the parts (approximately) independent given the candidate natural latent?
I first had some trouble checking this condition intuitively. I might still not have got it correctly. I think one of the main things that got me confused first, is that if I want to reason about natural latents for “a” dog, I need to think about a group of dogs. Even though there are also natural latents for the individual dog (like fur color is a natural latent across the dog's fur). Say I check the independence condition for a set of sets of either cats or dogs. So if I look at a single animal's shoulder height in those sorted cluster, it tells me which of the two clusters it's in, but once I updated on that information, my guesses for the dog height's will not be able to improve.
An important example for something that is not a natural latent is the empirical mean in fat tailed distributions for real world sample sizes, while it is in thin-tailed ones. This doesn't mean that they don't have natural latents. This fact is what Nassim Taleb is harping on. For Pareto distributions (think: pandemics, earthquakes, wealth), one still has natural latents like the tail index (estimated from plotting the data on a log-log plot by dilettantes like me and more sophisticatedly by real professionals).
comment by nathanwe (nathan-weise) · 2024-03-21T14:07:54.074Z · LW(p) · GW(p)
In the Alice and Bob example aren't the rules of the game part of the natural latent? Like Carol also needs to remember that neither Alice nor Bob will draw any [color that isn't purple] lines and this information isn't in the green lines.
Replies from: tailcalled↑ comment by tailcalled · 2024-03-21T14:22:33.776Z · LW(p) · GW(p)
Conditional on the rules, the green lines serve as a natural latent between the pictures, so knowing the rules induce a phase change where the green lines become a natural latent. But without knowing the rules, you can't infer the rules from only one picture, and so the rules cannot serve as a natural latent, even when combined with the green lines.
comment by MiguelDev (whitehatStoic) · 2024-03-21T03:34:48.321Z · LW(p) · GW(p)
This tells us that “nearly all the work” of figuring out what “dogs” are must come, not from labeled examples, but from unsupervised learning: humans looking at the world and noticing statistical patterns which other humans also notice.
Hello there! There is some overlap in your idea of natural latents and a concept I'm currently testing, which is an unsupervised RL that uses layered morphology - framing the dog problem as:
Simply, Reinforcement Learning using Layered Morphology (RLLM) is a training process that guides an language model using complex patterns outlined in a dataset. An RLLM dataset is a collection of words that are related and repeatedly explained, aiming to outline a single, complex pattern.To illustrate, five sentences are shown below:
- The dog is energetic, furry, loyal, playful, and friendly.
- A dog can be affectionate, obedient, curious, protective, and agile.
- This dog seems intelligent, gentle, devoted, alert, and sociable.
- The dog is affectionate, loyal, playful, intelligent, and energetic.
- This dog is friendly, obedient, furry, alert, and curious.
Some noticeable patterns from the five sentences and will become part of an RLLM dataset:
- Using sentences repeatedly is a pattern.
- Repeatedly mentioning "dog" is a pattern.
- The word sequencing (eg. the word "dog" being the second word in four of the sentences.) is a pattern.
- "Descriptions of a dog" is a pattern.
- Always describing the dog five different ways is a pattern.
- Using the same words multiple times is a pattern. (eg. loyal, affectionate, energetic, friendly, obedient and curious.)
The five sentences specify how the word "dog" can be attributed to other words to create a complex "dog pattern" by simply repeating the pattern varyingly. Using RLLM, repeating the words and its morphology[2] [LW(p) · GW(p)] does not make the language model memorize the words in the sentences, it makes the language model memorize the morphology (or pattern[3] [LW(p) · GW(p)]) on how the words were used instead.[4] [LW(p) · GW(p)] To avoid underfitting or overfitting the pattern, the RLLM dataset should be synchronized with the optimizer.
comment by Noosphere89 (sharmake-farah) · 2024-03-21T00:00:34.589Z · LW(p) · GW(p)
Your point on laws and natural abstractions expresses nicely a big problem with postmodernism that was always there, but wasn't clearly pointed out:
Natural Abstractions and more generally almost every concept is subjective, in the sense that people can change what a concept means, and are quite subjective, but that doesn't mean you can deny the concept/abstraction and instantly make it non-effective, you actually have to do real work, and importantly change stuff in the world, and you can't simply assign different meanings or different concepts to the same data, and expect the concept to no longer work. You actually have to change the behavior of lots of other different humans, and if you fail, the concept is still real.
This also generalizes to a lot of other abstractions like gender or sexuality, where real work, especially in medicine and biotech is necessary if you want concepts on gender or sex to change drastically.
This is why a lot of postmodernism is wrong to claim that denying concepts automatically negates it's power, you have to do real work to change concepts, which is why I tend to favor technological progress.
I'll put the social concepts one in the link below, because it's so good as a response to postmodernism:
https://www.lesswrong.com/posts/mMEbfooQzMwJERAJJ/natural-latents-the-concepts#Social_Constructs__Laws [LW · GW]