A Solomonoff Inductor Walks Into a Bar: Schelling Points for Communication
post by johnswentworth, David Lorell · 2024-07-26T00:33:42.000Z · LW · GW · 2 commentsContents
Main Tool: Natural Latents for Minimum Description Length Fundamental Theorem The Intuition Background: Working with Kolmogorov Complexity More Precise Statement of the Fundamental Theorem Implications: Minimality, Maximality, Isomorphism Minimality Maximality Isomorphism Main Takeaway Back to Solomonoff’s Bar Even Simpler Subproblem: Just One Drink Type Multiple Drink Types: Categorizing by Shared Natural Latent Formal Specification Conclusion & Takeaways Appendix: Proof of the Fundamental Theorem Interpretation & Manipulation of Diagrams The Dangly Bit Lemma Re-Rooting of Markov Chains Marginalization in Markov Chains Proof of the Fundamental Theorem Mediation -> Graph Redundancy -> Graph The Graphical Part None 2 comments
A Solomonoff inductor walks into a bar in a foreign land. (Stop me if you’ve heard this one before.) The bartender, who is also a Solomonoff inductor, asks “What’ll it be?”. The customer looks around at what the other patrons are having, points to an unfamiliar drink, and says “One of those, please.”. The bartender points to a drawing of the same drink on a menu, and says “One of those?”. The customer replies “Yes, one of those.”. The bartender then delivers a drink, and it matches what the first inductor expected.
What’s up with that?
The puzzle, here, is that the two Solomonoff inductors seemingly agree on a categorization - i.e. which things count as the Unnamed Kind Of Drink, and which things don’t, with at least enough agreement that the customer’s drink-type matches the customer’s expectations. And the two inductors reach that agreement without learning the category from huge amounts of labeled data - one inductor points at an instance, another inductor points at another instance, and then the first inductor gets the kind of drink it expected. Why (and when) are the two inductors able to coordinate on roughly the same categorization?
Most existing work on Solomonoff inductors, Kolmogorov complexity, or minimum description length can’t say much about this sort of thing. The problem is that the customer/bartender story is all about the internal structure of the minimum description - the (possibly implicit) “categories” which the two inductors use inside of their minimal descriptions in order to compress their raw data. The theory of minimum description length typically treats programs as black boxes, and doesn’t attempt to talk about their internal structure.
In this post, we’ll show one potential way to solve the puzzle - one potential way for two minimum-description-length-based minds to coordinate on a categorization.
Main Tool: Natural Latents for Minimum Description Length
Fundamental Theorem
Here’s the main foundational theorem we’ll use. (Just the statement for now, more later.)
We have a set of n data points (binary strings) , and a Turing machine TM. Suppose we find some programs/strings such that:
- Mediation: is an approximately-shortest string such that (TM() = for all )
- Redundancy: For all , is an approximately-shortest string such that TM() = .[1]
Then: the K-complexity of given , is approximately zero - in other words, is approximately determined by , in a K-complexity sense.
(As a preview: later we’ll assume that both and satisfy both conditions, so both and are approximately zero. In that case, and are “approximately isomorphic” in the sense that either can be computed from the other by a short program. We’ll eventually tackle the customer/bartender puzzle from the start of this post by suggesting that and each encode a summary of things in one category according to one inductor, so the theorem then says that their category summaries are “approximately isomorphic”.)
The Intuition
What does this theorem mean intuitively?
Let’s start with the first condition: is an approximately-shortest string such that (TM() = for all ). Notice that there’s a somewhat-trivial way to satisfy that condition: take to be a minimal description of the whole dataset , take , and then add a little bit of code to to pick out the datapoint at index [2]. So TM() computes all of from , then picks out index . Now, that might not be the only approximately-minimal description (though it does imply that whatever approximately-minimal we do use is approximately a minimal description for all of x). Conceptually, insofar as there’s information in which is irrelevant to all the other ’s, we could “move” that information from into . But any information which is relevant to more than one has to be in .
Now let’s consider the second condition: for all , is an approximately-shortest string such that TM() = . Again, there’s a somewhat-trivial way to satisfy the condition: take to be empty, and to be a minimal description of . Again, that might not be the only approximately-minimal description. Conceptually, insofar as there’s information which is redundantly represented across all the ’s, that information can be “moved” into . But can only contain information which is redundantly represented across all ’s.
Put those two together, and we get a simple intuitive statement of the theorem: if contains all information which is relevant to more than one datapoint, and contains only information which is redundantly represented across all datapoints, then contains all the information in .
Intuitively: imagine that is a pipe between and , and the only way for information to move between and is through that pipe. Then if some information is present in both and , it must have gone through the pipe. It’s the same idea as deterministic natural latents [LW · GW], but now in a minimum description length setting.
So that’s the idea. Now we’re ready for the actual math.
Background: Working with Kolmogorov Complexity
We kicked around the word “approximation” a lot, in stating the theorem. Approximation in what sense?
When working with Kolmogorov complexity, a prototypical theorem looks like:
- Take in the value of some K-complexity, . That means assuming there exists a program of length which outputs on input . Call that program (for “function”).
- Construct some other program which either uses as a subroutine, or relies somehow on the existence of . The length of the new program is either the length of (i.e. ) plus a little bit of new code, or just a little bit of new code. The theorem says the new code is small in a big- sense compared to the length of - i.e. or is typical.
As an example: if is a shortest program to compute , then
log [3]
Here’s a rough sketch of the program of size log which outputs on input . The program will have hardcoded (which takes log bits). It will also have hardcoded a number , such that among inputless programs of size which output , is the to halt. It turns out that there can’t be very many minimal programs (though we won’t prove that part here), so log log . The program itself runs all programs of length until the halts and returns , then returns the program to halt and return ; that code requires only a constant number of bits to specify. So, the total size of the program is log bits.
That’s what the programs involved in prototypical K-complexity theorems tend to look like. The key idea to remember is that, wherever you see O(blah) terms, that usually means there’s some simple wrapper code of the relevant size.
More Precise Statement of the Fundamental Theorem
We have a set of data points (binary strings) , and a Turing machine TM. Suppose we find some programs/strings such that:
- Mediation: len() min len() subject to (TM() = for all )
- Redundancy: For all , len() min len() subject to TM() = .
Then: log ) .
The proof has been relegated to the appendix.
Implications: Minimality, Maximality, Isomorphism
When a string satisfies both the mediation and redundancy conditions over some strings , we call a natural latent over (overloading our terminology for "natural latents" in the probabilistic setting). Equipped with the fundamental theorem, we can now carry over all the standard properties of deterministic natural latents [LW · GW] in the probabilistic setting to natural latents in the minimum description length setting.
Minimality
Suppose the string satisfies both the mediation and redundancy conditions over some strings :
- Mediation: there exists such that has minimal length to within bits subject to (: TM() = ).
- Redundancy: For all , there exists such that () has minimal length to within bits subject to TM() = .
Then satisfies the mediation condition, and for any other string which satisfies the mediation condition to within bits, the Fundamental Theorem tells us
log
i.e. there exists a short program to compute from . So is a “minimal” string which satisfies the mediation condition; it can be computed from any other via a short program.
Maximality
Suppose, again, that the string satisfies both the mediation and redundancy conditions over some strings :
- Mediation: there exists such that has minimal length to within bits subject to (: TM() = ).
- Redundancy: For all , there exists such that has minimal length to within bits subject to TM() = .
Then satisfies the redundancy condition, and for any other string which satisfies the redundancy condition to within bits, the Fundamental Theorem tells us
log
i.e. there exists a short program to compute from . So is a “maximal” string which satisfies the redundancy condition; any other can be computed from via a short program.
Isomorphism
Finally, suppose that both the string and the string satisfy both mediation and redundancy to within and ’ bits, respectively. Then
log
and
log
So either of the strings can be computed from the other via a short program. In that sense, the two are “isomorphic”.
Main Takeaway
The main upshot which we’ll use in the next section is the isomorphism property, so we’ll restate it here in full.
Suppose the string satisfies both the mediation and redundancy conditions over some strings :
- Mediation: there exists such that has minimal length to within bits subject to (: TM() = ).
- Redundancy: For all , there exists such that has minimal length to within bits subject to TM() = .
Assume that also satisfies both conditions:
- Mediation: there exists such that has minimal length to within bits subject to (: TM() = ).
- Redundancy: For all , there exists such that has minimal length to within bits subject to TM() = .
Intuitively, these say that both and capture approximately all the information which is relevant to more than one , and approximately only the information which is redundantly represented across all .
Then:
log
log
In other words: a short program exists to compute from , and a short program exists to compute from .
Back to Solomonoff’s Bar
Let’s talk about the problem faced by our two Solomonoff inductors - the customer and the bartender.
As a (very) simplified model, let’s say that they both start out with matching background models of what generally happens when one places an order in a bar - i.e. certain words are spoken, a liquid shows up in a container, all that jazz. We’ll assume that the two already break up the world into a bunch of individual instances of “drinks” (a pint on the bar over here, a glass on the table over there, …) all of which are observed by both inductors; that will be our most egregious simplification of the problem. We’ll call those individual drink-instances in the world . The (very simplified) problem the two then face is how to categorize various physical instances of liquids-in-containers, such that when the customer asks for a drink in a certain category (i.e. “one of those” + pointing), they end up with the kind of drink they expected.
By contrast, what would be a bad outcome for the two? Well, maybe the bartender just categorizes drinks by booze content, and the customer just categorizes drinks by color, so the customer thinks they’re asking for a blue drink but the bartender thinks they’re asking for a drink with 10% alcohol content, and the customer unexpectedly-to-them ends up with a pink drink. That’s the sort of thing we want to avoid.
So the customer and the bartender face a coordination problem - both want the customer to not be surprised at their drink. And it’s a coordination problem in the Schelling sense [LW · GW], insofar as the two will not be able to exchange anywhere near enough data to brute-force learn each others’ categorizations.
How can the two use the theorems here to coordinate on a choice of categorization, without exponentially huge amounts of communication? We’ll tackle the problem in two steps:
- First, an even simpler problem in which there’s just one drink type, in order to illustrate what parts of the problem are handled by the isomorphism argument.
- Second, the simplified customer/bartender problem itself, with multiple drink types.
Even Simpler Subproblem: Just One Drink Type
Suppose there’s just one drink type - maybe this is soviet Russia, and a shot of vodka is the only option. We still have a version of the customer/bartender problem: they should both roughly agree on what a shot of vodka is. If the bartender prepares a thing which they think of as a shot of vodka, the customer should not receive a thing which they think of as, say, a giraffe.
Well, both inductors see , which are all shot-of-vodka-instances. Suppose they both look for a natural latent over those instances, and both find one: for the customer, for the bartender. Then we know that the two have found approximately-isomorphic strings.
Now, the bartender creates a new thing , which is approximately-optimally compressed as passing a new incompressible string (i.e. noise) to the generator , just like the bartender models all the other ’s as having been generated. is therefore natural over . And since is approximately isomorphic to , is natural over . So, when the customer receives their drink, they see that it’s approximately-optimally compressed by plus some incompressible noise, and it’s also approximately-optimally compressed jointly with by plus some incompressible noise. It is, in other words, basically what the customer expected.
So that’s the basic story. Now let’s kick it up a notch, and handle multiple drink-types.
Multiple Drink Types: Categorizing by Shared Natural Latent
Our two inductors both start out with the “data points” , each of which is one physical instance of a drink. Then one obvious move is to look for a natural latent over these strings, or over various subsets of the strings.
In general, there’s no guarantee that any natural latent exists at all (to within reasonable approximation). And even if natural latents do exist over some subsets of the data points, they might have some complicated structure - e.g. maybe there’s a natural latent between and and another between and but those two have very different stuff in them, or maybe there’s hierarchical structure like e.g. a natural latent over the first half of the data and another over the second half and then a natural latent over those two natural latents, or ???. Most of those possibilities don’t look much like “categories of drinks”, at least not in a simple sense. But perhaps our intuitive notion of simple “categories” maps to a specific kind of natural latent structure?
Here’s a simple structure which seems like a decent fit.
Imagine that we have 8 drink-instances . We find a natural latent between and . On further investigation, we find that the same string is natural over all of , and .[4] Then we find another string which is natural over and , and a third string which is natural over and . Finally, we find that the strings are independent[5] of the strings and all those are independent of the strings .
We can summarize all that with the diagrams:
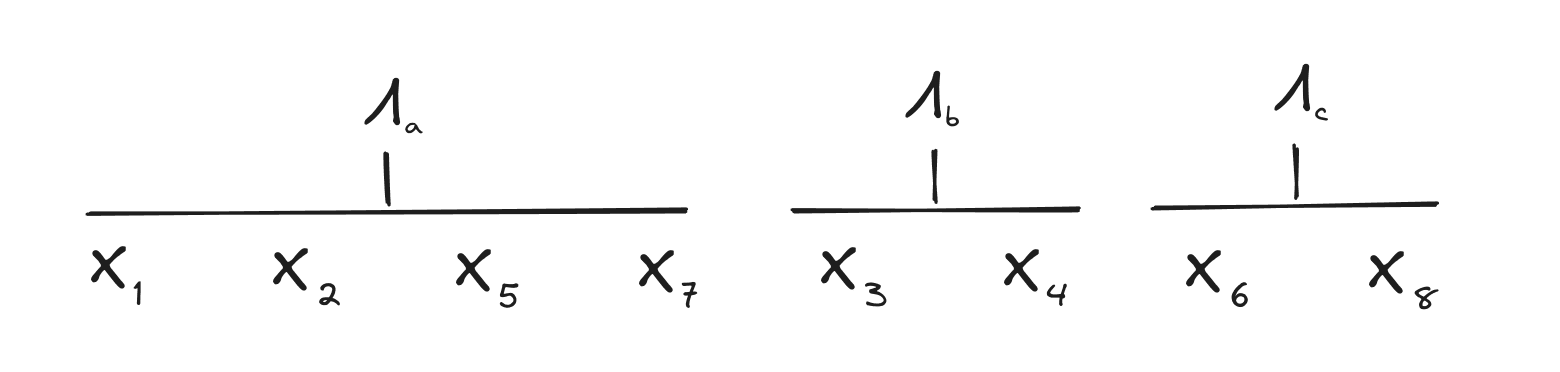
where we use the “” symbol to denote naturality, and unconnected diagrams next to each other indicate independence.
In this case, it makes a lot of intuitive sense to view each of the three latents as a generator or specification for a certain category of drink. There is no compressible shared information across drinks in different categories, and captures all-and-only the information shared across drinks with category , for each category .
If such ’s exist, how can the customer and bartender use them to solve their coordination problem?
Well, assume they’re both looking for ’s with this structure - i.e. they both want to partition the set of drinks such that there exists a nonempty natural latent over each subset, and independence[6] across subsets. If that’s possible at all, then the partition is unique: pairwise independent strings must go in different subsets, and pairwise non-independent strings must go in the same subset. (If we consider a graph in which each node is one of the strings and two nodes are connected iff they are non-independent, then the connected components of that graph must be the subsets of the partition.)[7]
With the partition nailed down, we next invoke uniqueness (up to isomorphism) of natural latents within each subset, i.e. the “isomorphism” result we proved earlier.[8]
As long as the customer and bartender are both looking for this kind of structure in the strings , and the structure exists to be found in the strings, they will find the same partition (modulo approximation) and approximately isomorphic latents characterizing each class of drinks.
So the customer walks into the bar. They point at a drink - let’s say it’s - and say “One of those, please.”. The bartender has in subset , with generator . Just to double check, they point to a picture of a drink also generated by , and the customer confirms that’s the type of drink they want. The bartender generates a drink accordingly. And since the customer and bartender have approximately isomorphic , the customer gets what they expected, to within reasonable approximation.
Formal Specification
Both inductors look for
- some strings (conceptually: encodes a generator for drink type ),
- integers in (conceptually: the category of each drink-instance),
- and bitstrings (conceptually: random noise encoding details of each drink-instance for each of the optimization problems)
such that
- Mediation: is minimal to within subject to ( s.t. : TM() = )
- Redundancy: For all , is minimal to within subject to TM() =
- Independence across categories: is minimal to within subject to (: TM() = ))
Note that all of these might be conditional on other background knowledge of the inductors - i.e. the Turing machine TM has access to a database full of all the other stuff the inductors know. However, they do need to condition only on things which they expect the other inductor to also know, since we’ve assumed the two inductors use the same Turing machine.[9]
If you’ve been wondering why on Earth we would ever expect to find such simple structures in the complicated real world, conditioning on background knowledge is the main answer. Furthermore, our current best guess is that most of that background knowledge is also itself organized via natural latents, so that the customer and bartender can also coordinate on which knowledge to condition on.
Conclusion & Takeaways
First, let’s recap the core theorem of this post.
Suppose that some string satisfies both the following conditions over strings for a Turing machine TM:
- Mediation: there exists such that has minimal length to within bits subject to (: TM() = ).
- Redundancy: For all , there exists such that has minimal length to within bits subject to TM() = .
Further, suppose that some string also satisfies those conditions over the same strings and Turing machine TM. Then:
log
log
In other words: a short program exists to compute from , and a short program exists to compute from .
Conceptually, we imagine two different agents each look for approximately-best compressions in the same form as the mediation and redundancy conditions. One agent finds , one finds . Then the two have found approximately isomorphic compressions.
Crucially, these are approximately isomorphic “parts of” compressions - i.e. they separate out “signal” from “noise” , and the two agents approximately agree on what the “signal” and “noise” each have to say about the data. So, they’ll approximately agree on what it would mean to sample new data points with the same “signal” but different random “noise” - e.g. the new drink-instance which the bartender prepares for the customer.
Conceptually, both the questions we tackle here and the methods used to answer it are similar to our semantics post [LW · GW], with two big differences. First, we’re now working with minimum description length rather than generic Bayesian probability, which means everything is uncomputable but conceptually simpler. Second, our method here for “multiple drink types” was actually totally different and non-analogous to the corresponding method [LW · GW] in the semantics post, even though the two methods used similar low-level tools (i.e. natural latents).[10] One item for potential future work is to transport the method used in the semantics post over to the minimum description length context, and the method used in this post over to the generic Bayesian context. Another potential item is to unify the two; intuitively they seem closely related.
Our main hope is that other people will be able to pick up these methods and use them to characterize other kinds of concepts which different minds are able to converge upon and communicate about. We’ve only just scratched the surface here.
Appendix: Proof of the Fundamental Theorem
We’re going to use essentially the same diagrammatic proof as Deterministic Natural Latents [LW · GW] (don’t worry, we don’t assume you’ve read that). Of course, now we’re working with Kolmogorov complexity, so we have a new interpretation of each diagram, and we’ll need to prove all the diagrammatic rules we need to use.
Interpretation & Manipulation of Diagrams
Let’s start with an example diagram:
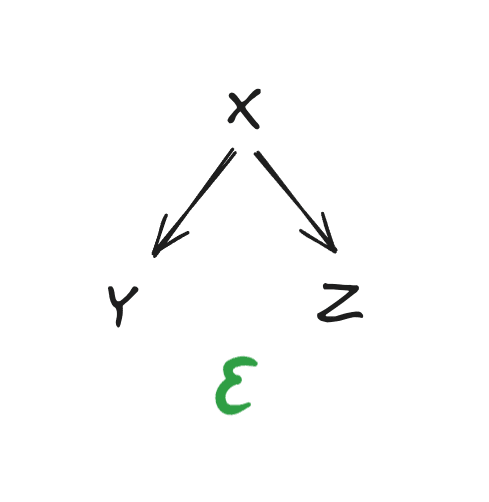
We say that this diagram “holds for” three strings , , and iff
where will often be a big- term.
More generally, a diagram is a directed acyclic graph in which each node is a string , along with an error term . The diagram holds iff
where denotes the parents of node in the graph.
Note that the same string can appear more than once! For instance, the diagram
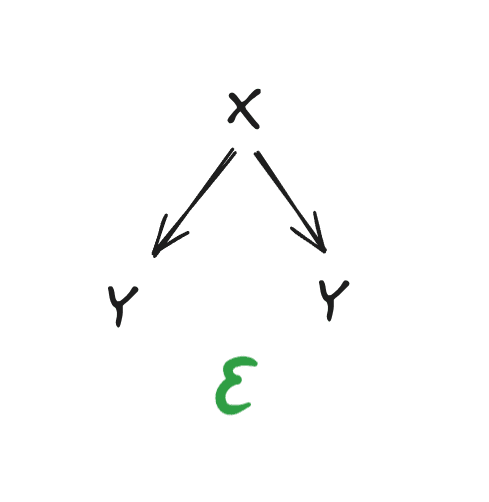
says that . Using the chain rule, that simplifies to
i.e. has only logarithmic complexity given (assuming the log term dominates ). We’ll use diagrams like that one several times below, in order to indicate that one string has quite low complexity given another.
Now for some rules. We’ll need three:
- The Dangly Bit Lemma
- Re-Rooting of Markov Chains
- Marginalization in Markov Chains
The Dangly Bit Lemma
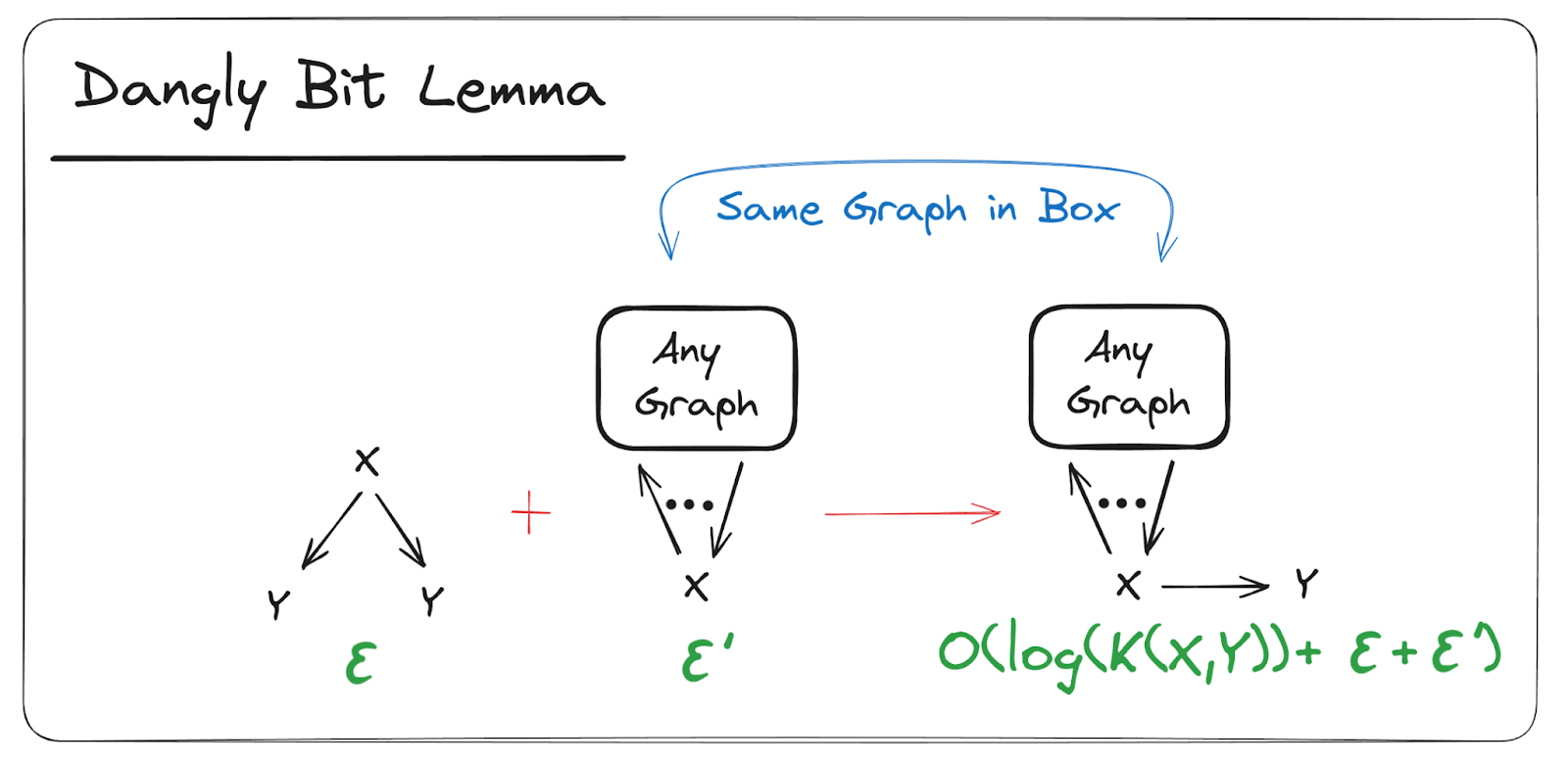
If holds to within bits, and any other diagram involving holds to within bits, then we can create a new diagram which is identical to but has another copy of (the “dangly bit”) as a child of . The new diagram will hold to within bits.
Proof (click to expand):
Assume the diagram is over and some other variables ; it asserts that
Since holds to within bits,
log
(as shown in the previous section). Let’s add those two inequalities:
log
And since , we can replace the term to get
log
which is the inequality asserted by the new diagram D’.
Re-Rooting of Markov Chains
Suppose we have a “Markov chain” diagram to within bits. That diagram asserts
Then we can move the root node right one step to form the diagram to within log bits. Likewise for moving left one step.
Proof (click to expand):
We’ll do the proof for moving right one step, the proof for moving left one step works the same way.
By applying this rule repeatedly, we can arbitrarily re-root a Markov chain diagram.
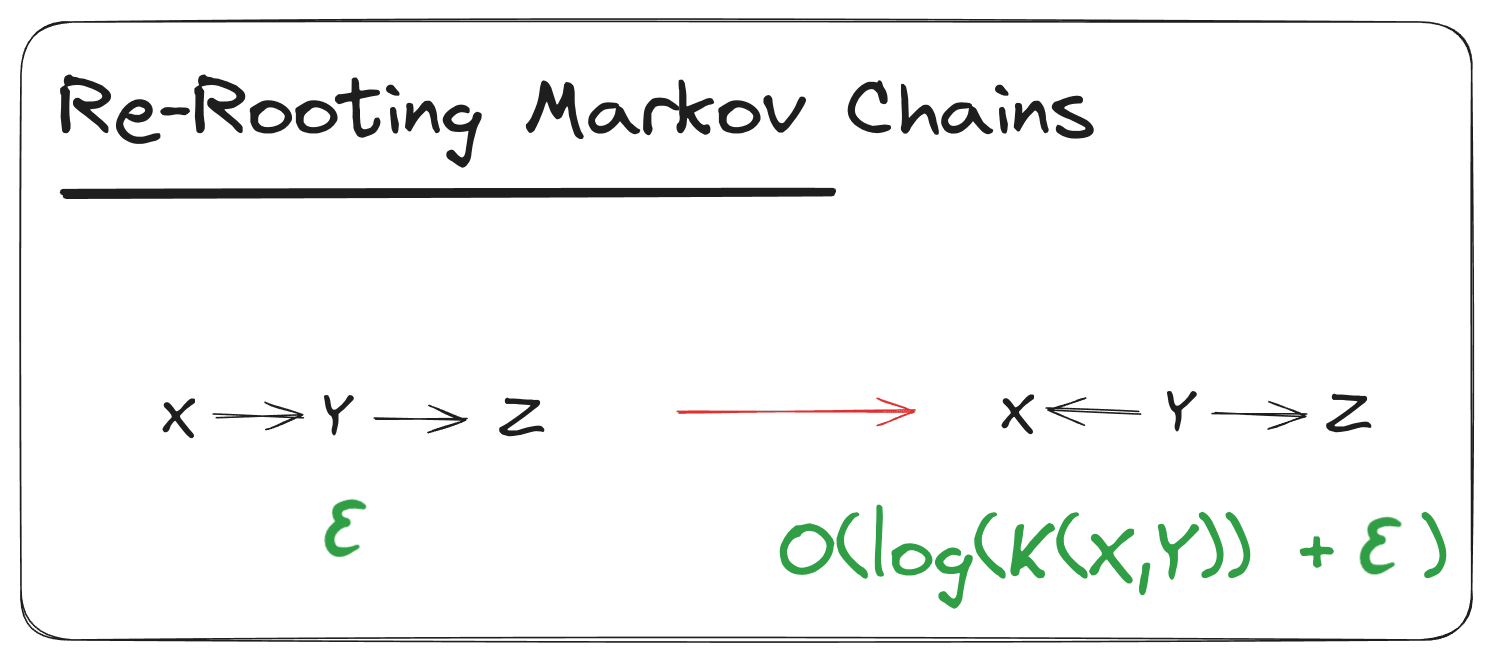
Marginalization in Markov Chains
Suppose the diagram holds to within bits. Then holds to within log bits.
Proof (click to expand):
log
log
log
This proof also extends straightforwardly to longer Markov chains; that’s a good exercise if you’re looking for one.
When working with a longer chain , note that reversing the direction of arrows in the Markov chain and further marginalization both also cost no more than log , so we can marginalize out multiple variables and put the root anywhere for the same big- cost in the bounds.
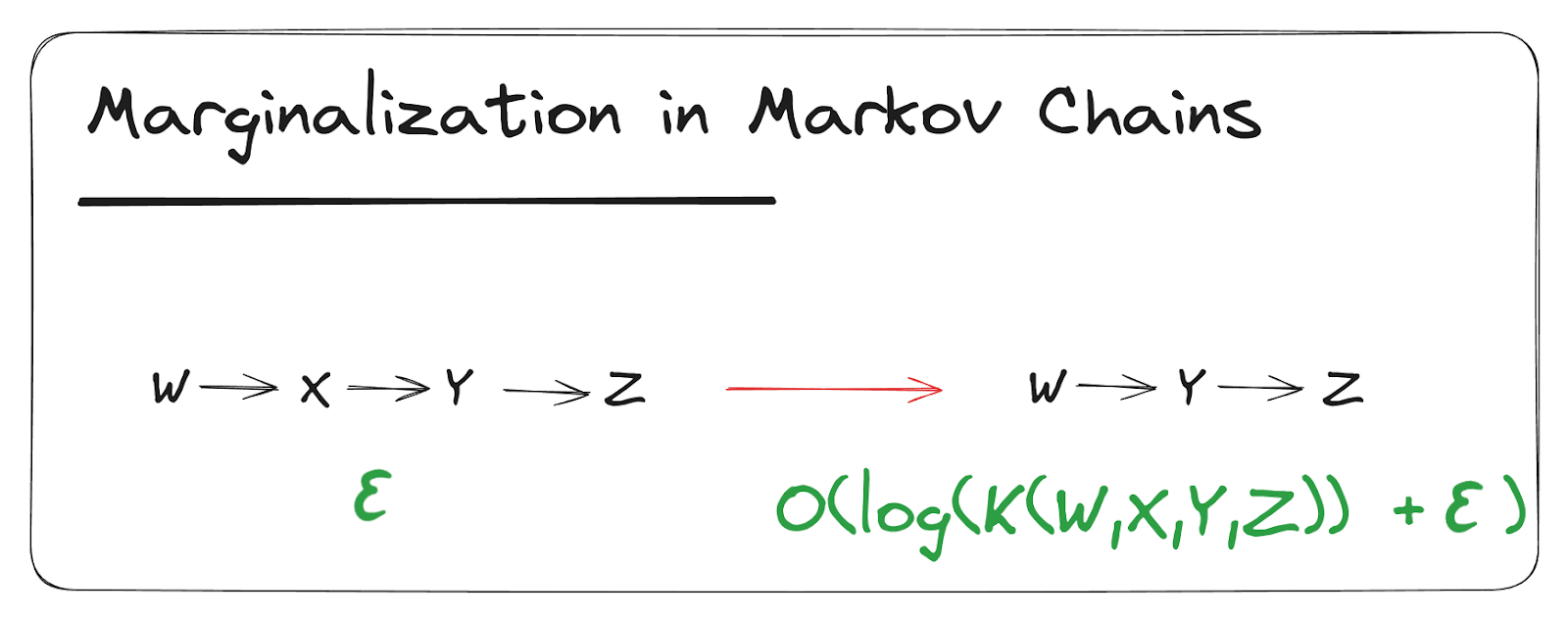
Proof of the Fundamental Theorem
With all the foundations done, we’re now ready for the main proof. Here’s the full statement again:
We have a set of data points (binary strings) , and a Turing machine TM. Suppose we find some programs/strings such that:
- Mediation: len() min len() subject to (TM() = for all )
- Redundancy: For all , min len() subject to TM() = .
Then: log .
First, we’ll show that the mediation condition implies
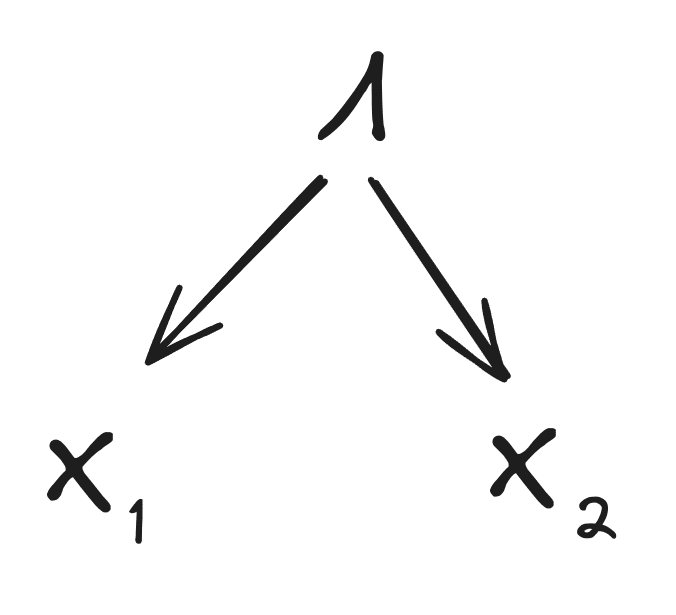
and the redundancy condition implies
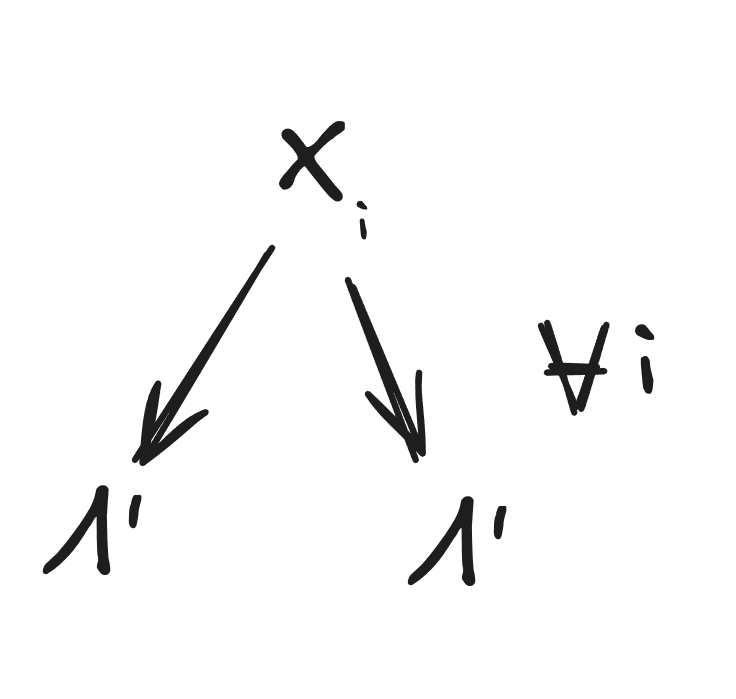
Following those two parts of the proof, the rest will proceed graphically.
Mediation -> Graph
Note that the mediation condition can always be satisfied to within log [11] by taking to be a shortest program for plus code to index into the result at position , and taking . So:
1: If are to be minimal to within , they must satisfy len() log [12]
Furthermore, for to be minimal to within for anything:
2: must themselves be incompressible to within that same : len() log = log . As a corollary, and must individually be incompressible to within that same bound or else together they couldn’t be minimal either.
Additionally note that (plus some constant-size wrapper code) specifies given , so:
3: log len()) = len() log K(X_i | \Lambda))
Now we put all that together. (2) is incompressible to within log and (1) , together are a shortest-to-within log program for :
len() len() log
and:
log
since \Lambda specifies and (3) specifies given .
Redundancy -> Graph
Lemma: suppose is a minimal-to-within log program which outputs . Then by the chain rule
log log
Applying the chain rule in the other order:
log log
Equating and canceling, we find
log
Note that together are a minimal-to-within log program for , so by the previous lemma:
log log
Thus:
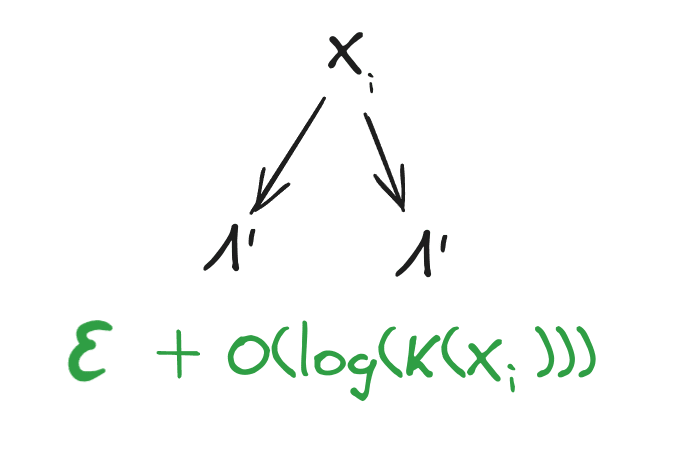
The Graphical Part
From here, we just directly carry over the proof from Deterministic Natural Latents [LW · GW], using the lemmas and bounds proven in this appendix.
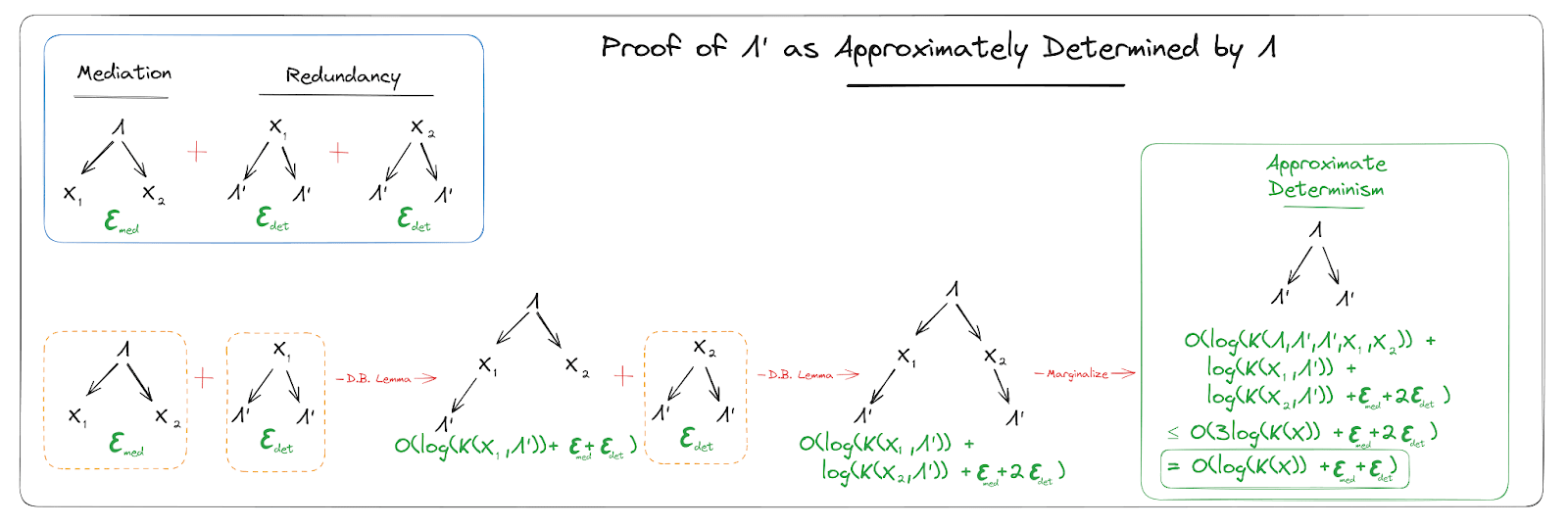
That completes the proof.
- ^
Note that the quantifiers have importantly different scopes between these two conditions.
- ^
Note that we’re mainly interested in the case where individual datapoints are large/rich. The overhead from the indexing is fine, since it doesn’t scale with the complexity of the individual datapoints.
- ^
Read in this exampleas the length of the shortest program which, given as input, returns the shortest program for computing
- ^
Aside: if a string is natural over some strings y_1, …, y_n, then it’s also natural over any subset consisting of two or more of those strings.
- ^
Independent in the minimum description sense, i.e. length of joint shortest description is approximately the sum of lengths of separate shortest descriptions
- ^
Reminder again that this is independence in the minimum description length sense, i.e. length of joint shortest description is approximately the sum of lengths of separate shortest descriptions
- ^
Note that we haven’t talked about how approximation plays with uniqueness of the partition, if there’s ambiguity about how “approximately unique” different strings are.
- ^
We have established that the uniqueness of natural latents in each subset plays well with approximation. Furthermore, note that the uniqueness proof of a natural latent can use any two data points over which the latent is natural, ignoring all others. So the natural latent string itself is in some sense quite robust to classifying a small number of data points differently, as long as there are plenty of points in each class, so we typically expect a little variation in different agents' partitions to be fine.
- ^
We can allow for different Turing machines easily by incorporating into , the bit-cost to simulate one machine using the other. That’s not a focus in this post, though.
- ^
Here we search for a natural latent (in the compression sense) across subsets of data points. In the semantics post, we looked for natural latents (in the bayesian sense) across features of individual data points.
- ^
Note that this has dependence on .
- ^
The log term is to allow for the possibility that the lengths of the strings need to be passed explicitly. This is a whole thing when dealing with K-complexity. Basically we need to include an log error term in everything all the time to allow for passing string-lengths. If you really want all the details on that, go read the K-complexity book.
2 comments
Comments sorted by top scores.
comment by johnswentworth · 2024-09-10T17:55:00.500Z · LW(p) · GW(p)
Note to future self: Li & Vitanyi use for empty string, which makes this post confusing for people who are used to that notation.
comment by Gurkenglas · 2025-01-01T19:50:37.768Z · LW(p) · GW(p)
Can this program that you've shown to exist be explicitly constructed?