Towards a Less Bullshit Model of Semantics
post by johnswentworth, David Lorell · 2024-06-17T15:51:06.060Z · LW · GW · 44 commentsContents
But Why Though?
Overview
What’s The Problem?
Central Problem 1: How To Model The Magic Box?
Subproblem: What’s The Range Of Box Outputs?
SubSubProblem: What Can Children Attach Words To?
Summary So Far
Central Problem 2: How Do Alice and Bob “Agree” On Semantics?
Summary: Interoperable Semantics
First (Toy) Model: Clustering + Naturality
Equivalence Via Naturality
A Quick Empirical Check
Strengths and Shortcomings of This Toy Model
Aside: What Does “Grounding In Spacetime Locality” Mean?
Second (Toy) Model Sketch: Rigid Body Objects
The Teacup
Geometry and Trajectory Clusters
Strengths and Shortcomings of This Toy Model
Summary and Call To Action
Call To Action
None
44 comments
Or: Towards Bayesian Natural Language Semantics In Terms Of Interoperable Mental Content
Or: Towards a Theory of Interoperable Semantics
You know how natural language “semantics” as studied in e.g. linguistics is kinda bullshit? Like, there’s some fine math there, it just ignores most of the thing which people intuitively mean by “semantics”.
When I think about what natural language “semantics” means, intuitively, the core picture in my head is:
- I hear/read some words, and my brain translates those words into some kind of internal mental content.
- The mental content in my head somehow “matches” the mental content typically evoked in other peoples’ heads by the same words, thereby allowing us to communicate at all; the mental content is “interoperable” in some sense.
That interoperable mental content is “the semantics of” the words. That’s the stuff we’re going to try to model.
The main goal of this post is to convey what it might look like to “model semantics for real”, mathematically, within a Bayesian framework.
But Why Though?
There’s lots of reasons to want a real model of semantics, but here’s the reason we expect readers here to find most compelling:
The central challenge of ML interpretability is to faithfully and robustly translate the internal concepts of neural nets into human concepts (or vice versa). But today, we don’t have a precise understanding of what “human concepts” are. Semantics gives us an angle on that question: it’s centrally about what kind of mental content (i.e. concepts) can be interoperable (i.e. translatable) across minds.
Later in this post, we give a toy model for the semantics of nouns and verbs of rigid body objects. If that model were basically correct, it would give us a damn strong starting point on what to look for inside nets if we want to check whether they’re using the concept of a teacup or free-fall or free-falling teacups. This potentially gets us much of the way to calculating quantitative bounds on how well the net’s internal concepts match humans’, under conceptually simple (though substantive) mathematical assumptions.
Then compare that to today: Today, when working on interpretability, we’re throwing darts in the dark, don’t really understand what we’re aiming for, and it’s not clear when the darts hit something or what, exactly, they’ve hit. We can do better.
Overview
In the first section, we will establish the two central challenges of the problem we call Interoperable Semantics. The first is to characterize the stuff within a Bayesian world model (i.e. mental content) to which natural-language statements resolve; that’s the “semantics” part of the problem. The second aim is to characterize when, how, and to what extent two separate models can come to agree on the mental content to which natural language resolves, despite their respective mental content living in two different minds; that’s the “interoperability” part of the problem.
After establishing the goals of Interoperable Semantics, we give a first toy model of interoperable semantics based on the “words point to clusters in thingspace [LW · GW]” mental model. As a concrete example, we quantify the model’s approximation errors under an off-the-shelf gaussian clustering algorithm on a small-but-real dataset. This example emphasizes the sort of theorems we want as part of the Interoperable Semantics project, and the sorts of tools which might be used to prove those theorems. However, the example is very toy.
Our second toy model sketch illustrates how to construct higher level Interoperable Semantics models using the same tools from the first model. This one is marginally less toy; it gives a simple semantic model for rigid body nouns and their verbs. However, this second model is more handwavy and has some big gaps; its purpose is more illustration than rigor.
Finally, we have a call to action: we’re writing this up in the hopes that other people (maybe you!) can build useful Interoperable Semantics models and advance our understanding. There’s lots of potential places to contribute.
What’s The Problem?
Central Problem 1: How To Model The Magic Box?
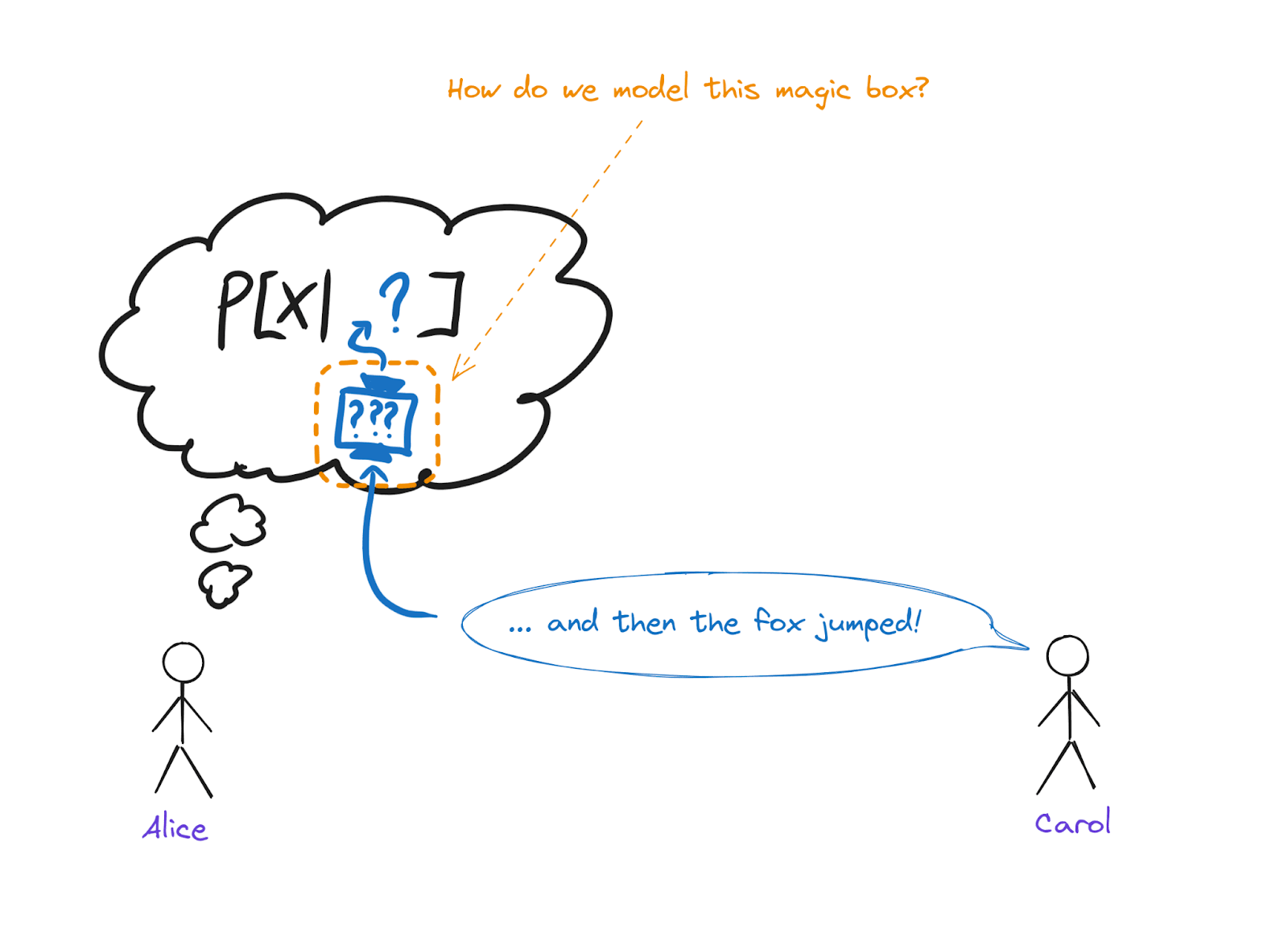
So we have two agents, Alice and Carol. (Yes, Bob is also hanging around, we’ll get to him shortly). We’re in a Bayesian framework, so they each have a probabilistic world model. Carol is telling a story and says “... and then the fox jumped!”. Alice hears these words, and updates her internal world model to include the fox jumping.[1]
Somewhere in the middle there, some magic box in Alice’s brain needed to turn the words “and then the fox jumped” into some stuff which she can condition on - e.g. things like , where is some random variable in Alice's world model. That magic box is the semantics box: words go in, mental content comes out. The first central problem of Interoperable Semantics, in a Bayesian frame, is how to model the box. The semantics of ‘and then the fox jumped’ is the stuff which Alice conditions on, like : i.e. the Bayesian “mental content” into which natural language is translated by the box.
Subproblem: What’s The Range Of Box Outputs?

A full Bayesian model of semantics would probably involve a full human-like world model. After all, the model would need to tell us exactly which interoperable-variable values are spit out by a magic semantics box for any natural language text.
A shorter-term intermediate question is: what even is the input set (i.e. domain) and output set (i.e. range) of the semantics box? Its inputs are natural language, but what about the outputs?
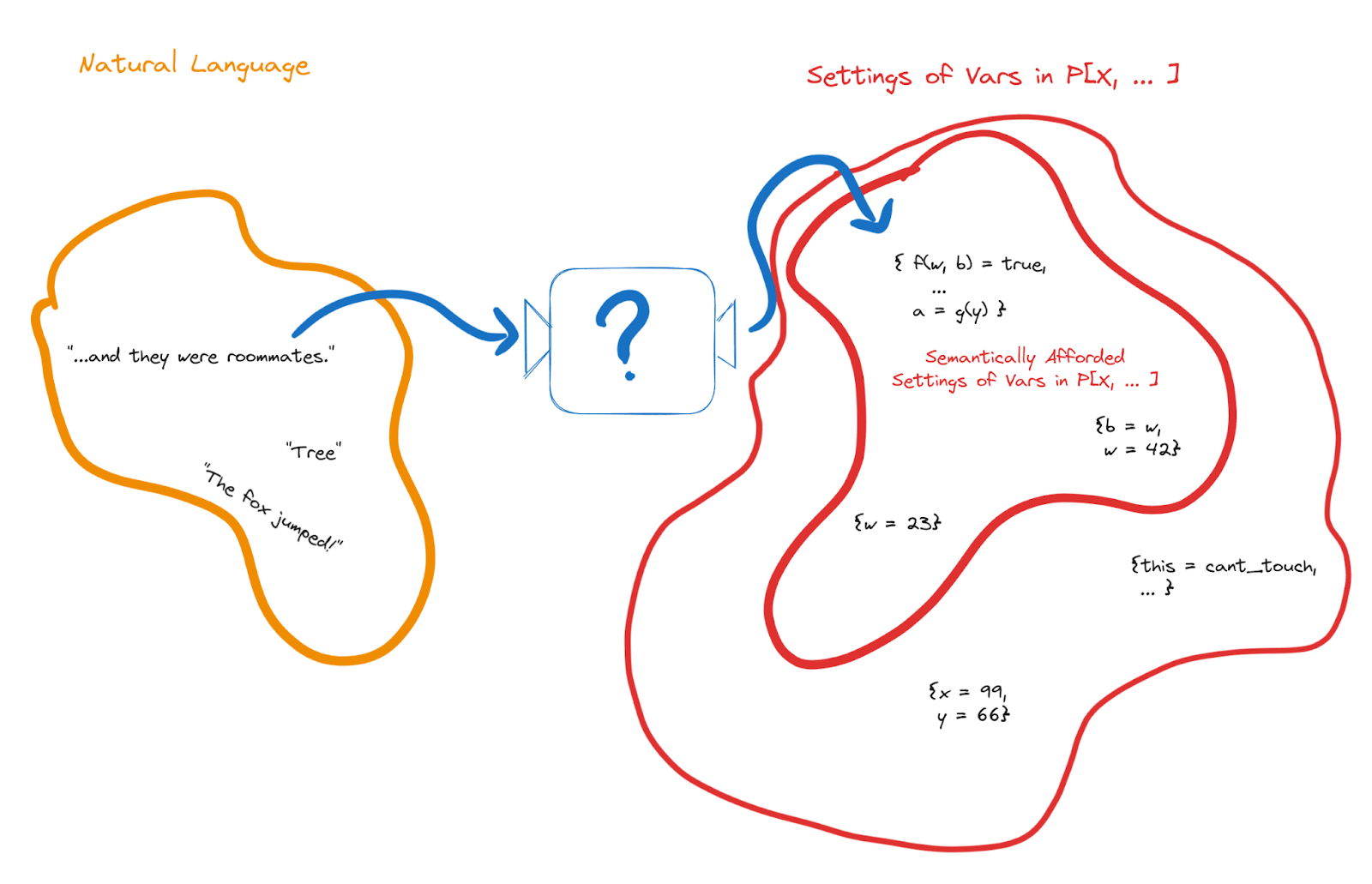
We can already give a partial answer: because we’re working in a Bayesian frame, the outputs of the semantics box need to be assignments of values to random variables in the world model, like . (Note that functions of random variables and data structures over random variables are themselves random variables, so the semantics box could e.g. output assignments of values to a whole list of functions of random variables.)
… but that’s only a partial answer, because the set of semantic outputs must be far smaller than the set of assignments of values to random variables. We must think of the children.
SubSubProblem: What Can Children Attach Words To?
Key observation: children need only a handful of examples - sometimes even just one - in order to basically-correctly learn the meaning of a new word (or short phrase[2].) So there can’t be that many possible semantic targets for a word.
For instance, we noted earlier that any function of random variables in Alice’s model is itself a random variable in Alice’s model - e.g. if is a (real-valued) random variable, then so is . Now imagine that a child’s model includes their visual input as a 1 megabit random variable, and any function of that visual input is a candidate semantic target. Well, there are functions of 1 million bits, so the child would need bits in order to pick out one of them. In other words: the number of examples that hypothetical child would need in order to learn a new word would be quite dramatically larger than the number of atoms in the known universe.
Takeaway: there can’t be that many possible semantic targets for words. The set of semantic targets for words (in humans) is at least exponentially smaller than the set of random variables in an agent’s world model.
That’s the main problem of interest to us, for purposes of this post: what’s the set of possible semantic targets for a word?[3]
Summary So Far
Roughly speaking, we want to characterize the set of things which children can attach words to, in a Bayesian frame. Put differently, we want to characterize the set of possible semantic targets for words. Some constraints on possible answers:
- Since we’re in a Bayesian frame, any semantic targets should be assignments of values (e.g. ) to random variables in an agent’s model. (Note that this includes functions of random variables in the agent’s model, and data structures of random variables in the agent’s model.)
- … but the set of possible semantic targets for words must be exponentially smaller than the full set of possible assignments of values to random variables.
So we know the set we’re looking for is a relatively-small subset of the whole set of assignments to random variables, but we haven’t said much yet about which subset it is. In order to narrow down the possibilities, we’ll need (at least) one more criterion… which brings us to Central Problem 2.
Central Problem 2: How Do Alice and Bob “Agree” On Semantics?
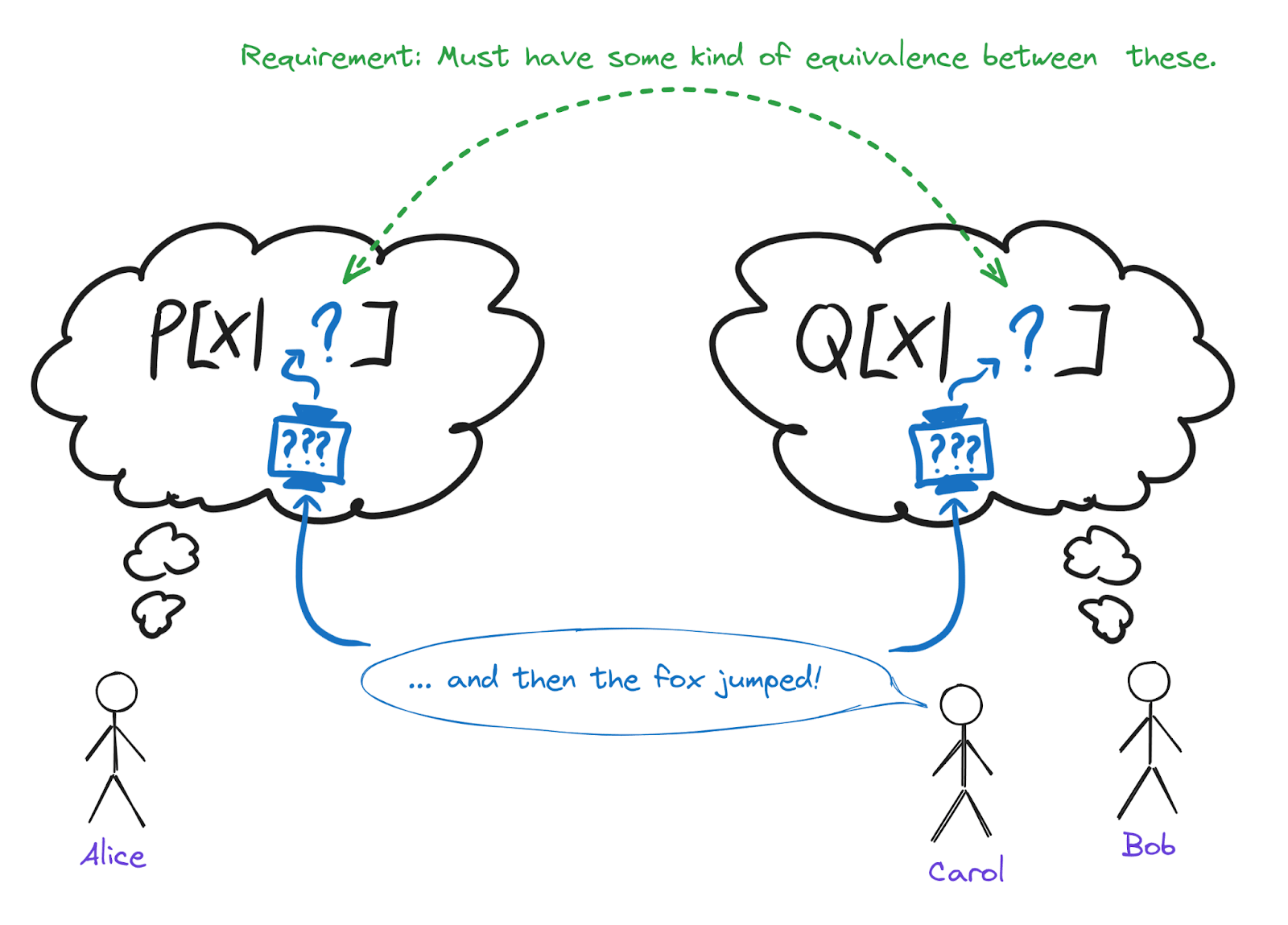
Let’s bring Bob into the picture.
Bob is also listening to Carol’s story. He also hears “... and then the fox jumped!”, and a magic semantics box in his brain also takes in those words and spits out some stuff which Bob can condition on - e.g. things like , where is some random variable in Bob’s world model.
Now for the key observation which will constrain our semantic model: in day-to-day practice, Alice and Bob mostly agree, in some sense, on what sentences mean. Otherwise, language couldn’t work at all.
Notice that in our picture so far, the output of Alice’s semantics-box consists of values of some random variables in Alice’s model, and the output of Bob’s semantics-box consists of values of some random variables in Bob’s model. With that picture in mind, it’s unclear what it would even mean for Alice and Bob to “agree” on the semantics of sentences. For instance, imagine that Alice and Bob are both Solomonoff inductors with a special module for natural language. They both find some shortest program to model the world, but the programs they find may not be exactly identical; maybe Alice and Bob are running slightly different Turing machines, so their shortest programs have somewhat different functions and variables internally. Their semantics-boxes then output values of variables in those programs. If those are totally different programs, what does it even mean for Alice and Bob to “agree” on the values of variables in these totally different programs?
The second central problem of Interoperable Semantics is to account for Alice and Bob’s agreement. In the Bayesian frame, this means that we should be able to establish some kind of (approximate) equivalence between at least some of the variables in the two agents’ world models, and the outputs of the magic semantics box should only involve those variables for which we can establish equivalence.
In other words: not only must our model express the semantics of language in terms of mental content (i.e. values of random variables, in a Bayesian frame), it must express the semantics of language in terms of interoperable mental content - mental content which has some kind of (approximate) equivalence to other agents’ mental content.
Summary: Interoperable Semantics
In technical terms: we’d ultimately like a model of (interoperable mental content)-valued semantics, for Bayesian agents. The immediate challenge which David and I call Interoperable Semantics is to figure out a class of random variables suitable for the “interoperable mental content” in such a model, especially for individual words. Specifically, we want a class of random variables which
- is rich enough to reasonably represent the semantics of most words used day-to-day in natural language, but
- small enough for each (word -> semantics) mapping to be plausibly learnable with only a few examples, and
- allows us to establish some kind of equivalence of variables across Bayesian agents in the same environment.
Beyond that, we of course want our class of random variables to be reasonably general and cognitively plausible as an approximation - e.g. we shouldn’t assume some specific parametric form.
At this point, we’re not even necessarily looking for “the right” class of random variables, just any class which satisfies the above criteria and seems approximately plausible.
The rest of this post will walk through a couple initial stabs at the problem. They’re pretty toy, but will hopefully illustrate what a solution could even look like in principle, and what sort of theorems might be involved.
First (Toy) Model: Clustering + Naturality
As a conceptual starting point, let’s assume that words point to clusters in thingspace [LW · GW] in some useful sense. As a semantic model, the “clusters in thingspace” conceptual picture is both underspecified and nowhere near rich enough to support most semantics - or even the semantics of any single everyday word. But it will serve well as a toy model to illustrate some foundational constraints and theorems involved in Interoperable Semantics. Later on, we’ll use the “clusters in thingspace” model as a building block for a richer class of variables.
With that in mind: suppose Alice runs a bog-standard Bayesian clustering algorithm on some data. (Concrete example: below we’ll use an off-the-shelf expectation-maximization algorithm for a mixture of Gaussians with diagonal covariance, on ye olde iris dataset.) Out pop some latents: estimated cluster labels and cluster parameters. Then Bob runs his Bayesian clustering algorithm on the data - but maybe he runs a different Bayesian clustering algorithm than Alice, or maybe he runs the same algorithm with different initial conditions, or maybe he uses a different random subset of the data for training. (In the example below, it’s the ‘different-initial-conditions’ option.)
Insofar as words point to clusters in thingspace and the project of Interoperable Semantics is possible at all, we should be able to establish some sort of equivalence between the clusters found by Alice and Bob, at least under some reasonably-permissive conditions which Alice and Bob can verify. In other words, we should be able to take the cluster labels and/or parameters as the “set of random variables” representing interoperable mental content.
Equivalence Via Naturality
We want a set of random variables which allows for some kind of equivalence between variables in Alice’s model and variables in Bob’s model. For that, we’ll use the machinery of natural [LW · GW] latents [LW · GW].
Here are the preconditions we need:
- Predictive Agreement: once Alice and Bob have both trained their clustering algorithms on the data, they must agree on the distribution of new data points. (This assumption does not require that they train on the same data, or that they use the same clusters to model the distribution of new data points.)
- Mediation: under both Alice and Bob’s trained models, (some subset of) the “features” must be independent within each cluster, i.e. the cluster label mediates between features.
- Redundancy: under both Alice and Bob’s trained models, the cluster label must be estimable to high confidence while ignoring any one feature.
The second two conditions (mediation and redundancy) allow for approximation via KL-divergence; see Natural Latents: The Math [LW · GW] for the details. Below, we’ll calculate the relevant approximation errors for an example system.[4] We do not currently know how to handle approximation gracefully for the first condition; the first thing we tried didn’t work [LW · GW] for that part.
So long as those conditions hold (approximately, where relevant), the cluster label is a(n approximate) natural latent, and therefore Alice’s cluster label is (approximately) isomorphic to Bob’s cluster label. (Quantitatively: each agent’s cluster label has bounded entropy given the other agent’s cluster label, with the bound going to zero linearly as the approximation error for the preconditions goes to zero.)
So, when the preconditions hold, we can use assignments of values to the cluster label (like e.g. “cluster_label = 2”) as semantic targets for words, and have an equivalence between the mental content which Alice and Bob assign to the relevant words. Or, in English: words can point to clusters.
A Quick Empirical Check
In order for cluster equivalence to apply, we needed three preconditions:
- Predictive Agreement: Alice and Bob must agree on the distribution of new data points.
- Mediation: under both Alice and Bob’s trained models, (some subset of) the “features” must be independent within each cluster, i.e. the cluster label mediates between features.
- Redundancy: under both Alice and Bob’s trained models, the cluster label must be estimable to high confidence while ignoring any one feature.
We don’t yet know how to usefully quantify approximation error for the first precondition. But we can quantify the approximation error for the mediation and redundancy conditions under a small-but-real model. So let’s try that for a simple clustering model: mixture of gaussians, with diagonal covariance, trained on ye olde iris dataset.
The iris dataset contains roughly 150 points in a 4 dimensional space of flower-attributes[5]. For the mixture of gaussians clustering, we David used the scikit implementation. Github repo here, which consists mainly of the methods to estimate the approximation errors for the mediation and redundancy conditions.
How do we estimate those approximation errors? (Notation: is one sample, is the cluster label for that sample.)
- Mediation: under this model, mediation holds exactly. The covariance is diagonal, so (under the model) the features are exactly independent within each cluster. Approximation error is 0.
- Redundancy: as somewhat-sneakily stated, our redundancy condition includes two pieces
- Actual Redundancy Condition: How many bits of information about are lost when dropping variable : , which can be rewritten as . Since the number of values of is the number of clusters, that last expression is easy to estimate by sampling a bunch of -values and averaging the for each of them.
- Determinism: Entropy of given [6]. Again, we sample a bunch of -values, and average the entropy of conditional on each -value.
Here are the redundancy approximation errors, in bits, under dropping each of the four components of , after two different training runs of the model:
| Redundancy Error (bits) | Drop (0,) | Drop (1,) | Drop (2,) | Drop (3,) |
| First run (“Alice”) | 0.0211 | 0.011 | 0.048 | 0.089 |
| Second run (“Bob”) | 0.034 | 0.004 | 0.031 | 0.177 |
Recall that we use these approximation errors to bound the approximation error of isomorphism between the two agents’ cluster labels. Specifically, if we track the ’s through the proofs in Natural Latents: The Math, we’ll find that:
- Alice’s natural latent is a deterministic function of Bob’s to within (sum of Alice’s redundancy errors) + (entropy of Alice’s label given ) + (entropy of Bob’s label given )
- Bob’s natural latent is a deterministic function of Alice’s to within (sum of Bob’s redundancy errors) + (entropy of Alice’s label given ) + (entropy of Bob’s label given )
(Note: the proofs as-written in Natural Latents: The Math assume that the redundancy error for each component of is the same; dropping that assumption is straightforward and turns into ; thus the sum of redundancy errors.) In the two runs of our clustering algorithm above, we find:
- Sum of redundancy errors in the first run is 0.168 bits
- Sum of redundancy errors in the second run is 0.246 bits
- Entropy of label given in the first run is 0.099 bits
- Entropy of label given in the second run is 0.099 bits
So, ignoring the differing distribution over new data points under the two models, we should find:
- The first model’s cluster label is a deterministic function of the second to within 0.366 bits (i.e. entropy of first label given second is at most 0.366 bits)
- The second model’s cluster label is a deterministic function of the first to within 0.444 bits.
Though the differing distribution over new data points is still totally unaccounted-for, we can estimate those conditional entropies by averaging over the data, and we actually find:
- Entropy of first model’s cluster label given second model’s: 0.222 bits
- Entropy of second model’s cluster label given first model’s, is also: 0.222 bits
The entropies of the cluster labels under the two models are 1.570 and 1.571 bits, respectively, so indeed each model’s cluster label is approximately a deterministic function of the other, to within reasonable error (~0.22 bits of entropy out of ~1.57 bits).
Strengths and Shortcomings of This Toy Model
First, let’s walk through our stated goals for Interoperable Semantics. We want a class of (assignments of values to) random variables which:
- is rich enough to reasonably represent the semantics of most words used day-to-day in natural language, but
- small enough for each (word -> semantics) mapping to be plausibly learnable with only a few examples, and
- allows us to establish some kind of equivalence of variables across Bayesian agents in the same environment.
When the preconditions hold, how well does the cluster label variable fit these requirements?
We already discussed the equivalence requirement; that one works (as demonstrated numerically above), insofar as the preconditions hold to within reasonable approximation. The main weakness is that we don’t yet know how to handle approximation in the requirement that our two agents have the same distribution over new data points.
Can the (word -> semantics) mapping plausibly be learned with only a few examples? Yes! Since each agent already calculated the clusters from the data (much like a child), all that’s left to learn is which cluster gets attached to which word. So long as the clusters don’t overlap much (which turns out to be implied by the mediation and redundancy conditions), that’s easy: we just need ~1 example from each cluster with the corresponding word attached to it.
Is the cluster label rich enough to reasonably represent the semantics of most words used day-to-day in natural language? Lol no. What’s missing?
Well, we implicitly assumed that the two agents are clustering data in the same (i.e. isomorphic) space, with the same (i.e. isomorphic) choice of features (axes.) In order to “do semantics right”, we’d need to recurse: find some choice of features which comes with some kind of equivalence between the two agents.
Would equivalence between choice of features require yet another assumption of equivalence, on which we also need to recurse? Probably. Where does it ground out? Usually, I (John) am willing to assume that agents converge on a shared notion of spacetime locality, i.e. what stuff is “nearby” other stuff in the giant causal web of our universe. So insofar as the equivalence grounds out in a shared notion of which variables are local in space and time, I’m happy with that. Our second toy model will ground out at that level, though admittedly with some big gaps in the middle.
Aside: What Does “Grounding In Spacetime Locality” Mean?
The sort of machinery we’re using (i..e natural latents) needs to start from some random variable which is broken into components . The machinery of natural latents doesn’t care about how each component is represented; replacing with something isomorphic to doesn’t change the natural latents at all. But it does matter which components we break into.
I’m generally willing to assume that different agents converge on a shared notion of spacetime locality, i.e. which stuff is “near” which other stuff in space and time. With that assumption, we can break any random variable into spacetime-local components - i.e. each component represents the state of the world at one point in space and time. Thanks to the assumed convergent notion of spacetime locality, different agents agree on that decomposition into components (though they may have different representations of each component).
So when we talk about “grounding in spacetime locality”, we mean that our argument for equivalence of random variables between the two agents should start, at the lowest level, from the two agents having equivalent notions of how to break up their variables into components each representing state of the world at a particular place and time.
Second (Toy) Model Sketch: Rigid Body Objects
Our first model was very toy, but we walked through the math relatively thoroughly (including highlighting the “gaps” which our theorems don’t yet cover, like divergence of the agents’ predictive distributions). In this section we’ll be less rigorous, but aim to sketch a more ambitious model. In particular, we’ll sketch an Interoperable Semantic model for words referring to rigid-body objects - think “teacup” or “pebble”. We still don’t expect this model to be fully correct, even for rigid-body objects, but it will illustrate how to build higher-level semantic structures using building blocks similar to the clustering model.
First we’ll sketch out the model and argument for interoperability (i.e. naturality of the latents) for just one rigid-body object - e.g. a teacup. We’ll see that the model naturally involves both a “geometry” and a “trajectory” of the object. Then, we’ll introduce clusters of object-geometries as a model of (rigid body) noun semantics, and clusters of object-trajectories as a model of verb semantics.
Note that there will be lots of handwaving and some outright gaps in the arguments in this model sketch. We’re not aiming for rigor here, or even trying to be very convincing; we’re just illustrating how one might build up higher-level semantic structures.
The Teacup
Imagine a simple relatively low-level simulation of a teacup moving around. The teacup is represented as a bunch of particles. In terms of data structures, the code tracks the position and orientation of each particle at each time.
There’s a lot of redundancy in that representation; an agent can compress it a lot while still maintaining reasonable accuracy. For instance, if we approximate away vibrations/bending (i.e. a rigid body approximation), then we can represent the whole set of particle-trajectories using only:
- The trajectory of one reference particle’s position and orientation
- The initial position and orientation of each particle, relative to the reference particle
We’ll call these two pieces “trajectory” and “geometry”. Because the teacup’s shape stays the same, all the particles are always in the same relative positions, so this lower-dimensional factorization allows an agent to compress the full set of particle-trajectories.
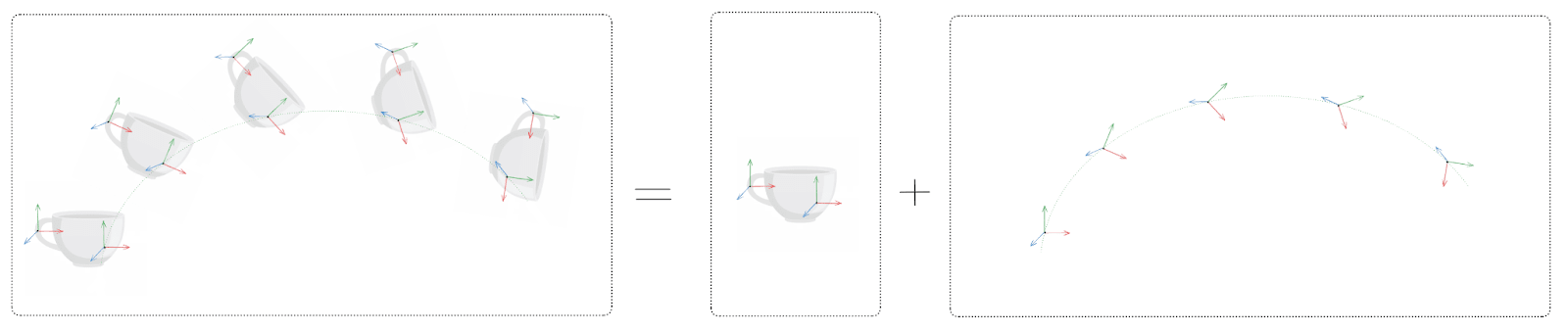
Can we establish naturality (i.e. mediation + redundancy) for the geometry and trajectory, much like we did for clusters earlier?
Here’s the argument sketch for the geometry:
- Under the rigid body approximation, the geometry is conserved over time. So, if we take to be the state of all the particles at time , the geometry is redundantly represented over ; it should approximately satisfy the redundancy condition.
- If the teacup moves around randomly enough for long enough, the geometry will be the only information about the cup at an early time which is relevant to much later times. In that case, the geometry mediates between and for times and sufficiently far apart; it approximately satisfies the mediation condition.
So, intuitively, the geometry should be natural over the time-slices of our simulation.
Next, let’s sketch the argument for the trajectory:
- Under the rigid body approximation, if I know the trajectory of any one particle, that tells me the trajectory of the whole teacup, since the particles always maintain the same relative positions and orientations. So, the trajectory should approximately satisfy the redundancy condition over individual particle-trajectories.
- If I know the trajectory of the teacup overall, then under the rigid body approximation I can calculate the trajectory of any one particle, so the particle trajectories are technically all independent given the teacup trajectory. So, the trajectory should approximately satisfy the mediation condition over individual particle-trajectories.
That means the trajectory should be natural over individual particle trajectories.
Now, there’s definitely some subtlety here. For instance: our argument for naturality of the trajectory implicitly assumes that the geometry was also known; otherwise I don’t know where the reference particle is relative to the particle of interest. We could tweak it a little to avoid that assumption, or we could just accept that the trajectory is natural conditional on the geometry. That’s the sort of detail which would need to be nailed down in order to turn this whole thing into a proper Interoperable Semantics model.
… but we’re not aiming to be that careful in this section, so instead we’ll just imagine that there’s some way to fill in all the math such that it works.
Assuming there’s some way to make the math work behind the hand-wavy descriptions above, what would that tell us?
We get a class of random variables in our low-level simulation: “geometry” (natural latent over time-slices), and “trajectory” (natural latent over individual particle-trajectories). Let’s say that the simulation is Alice’s model. Then for the teacup’s geometry, naturality says:
- If two Alice and Bob both make the same predictions about the low-level particles constituting the teacup…
- and those predictions match a rigid body approximation reasonably well, but have lots of uncertainty over long-term motion…
- and there’s some variable in Alice’s model which both mediates between the particle-states at far-apart times and can be reconstructed from particle-states at any one time…
- and there’s some variable in Bob’s model which also both mediates between the particle-states at far-apart times and can be reconstructed from particle-states at any one time…
- … then Alice’s variable and Bob’s variable give the same information about the particles. Furthermore, if the two variables’ values can both be approximated reasonably well from the full particle-trajectories, then they’re approximately isomorphic.
In other words: we get an argument for some kind of equivalence between “geometry” in Alice’s model and “geometry” in Bob’s model, insofar as their models match predictively. Similarly, we get an argument for some kind of equivalence between “trajectory” in Alice’s model and “trajectory” in Bob’s model.
So:
- We have a class of random variables in Alice’s model and Bob’s model…
- … which isn’t too big (roughly speaking, natural latents are approximately unique, so there’s approximately just the two variables)
- … and for which we have some kind of equivalence between Alice and Bob’s variables.
What we don’t have, yet, is enough expressivity for realistic semantics. Conceptually, we have a class of interoperable random variables which includes e.g. any single instance of a teacup, and the trajectory of that teacup. But our class of interoperable random variables doesn’t contain a single variable representing the whole category of teacups (or any other category of rigid body objects), and it’s that category which the word “teacup” itself intuitively points to.
So let’s add a bit more to the model.
Geometry and Trajectory Clusters
Now we imagine that Alice’s model involves lots of little local models running simulations like the teacup, for different rigid-body objects around her. So there’s a whole bunch of geometries and trajectories which are natural over different chunks of the world.
Perhaps Alice notices that there’s some cluster-structure to the geometries, and some cluster-structure to the trajectories. For instance, perhaps there’s one cluster of similarly-shaped rigid-body geometries which one might call “teacups”. Perhaps there’s also one cluster of similar trajectories which one might call “free fall”. Perhaps this particular geometry-cluster and trajectory-cluster are particularly fun when combined.
Hopefully you can guess the next move: we have clusters, so let’s apply the naturality conditions for clusters from the first toy model. For both the geometry-clusters and the trajectory-clusters, we ask:
- Are (some subset of) the “features” approximately independent within each single cluster?
- Can the cluster-label of a point be estimated to high confidence ignoring any one of (the same subset of) the “features”?
If yes to both of these, then we have naturality, just like in the first toy model. Just like the first toy model, we then have an argument for approximate equivalence between Alice and Bob’s clusters, assuming they both satisfy the naturality conditions and make the same predictions.
(Note that we’ve said nothing at all about what the “features” are; that’s one of the outright gaps which we’re handwaving past.)
With all that machinery in place, we make the guess:
- (rigid body) nouns typically refer to geometry clusters; example: “teacup”
- (rigid body) verbs typically refer to trajectory clusters; example: “free fall”
With that, we have (hand-wavily)
- a class of random variables in each agent’s world model…
- which we expect to typically be small enough for each (word -> semantics) mapping to be learnable with only a handful of examples (i.e. a word plus one data point in a cluster is enough to label the cluster with the word)...
- and we have a story for equivalence of these random variables across two agents’ models…
- and we have an intuitive story on how this class of random variables is rich enough to capture the semantics of many typical rigid body nouns and verbs, like “teacup” or “free fall”.
Modulo handwaving and (admittedly large) gaps, we have hit all the core requirements of an Interoperable Semantics model.
Strengths and Shortcomings of This Toy Model
The first big strength of this toy model is that it starts from spacetime locality: the lowest-level natural latents are over time-slices of a simulation and trajectories of particles. (The trajectory part is not quite fully grounded, since “particles” sure are an ontological choice, but you could imagine converting the formulation from Lagrangian to Eulerian; that’s an already-reasonably-common move in mathematical modeling. In the Eulerian formulation, the ontological choices would all be grounded in spacetime locality.)
The second big strength is expressivity. We have a clear notion of individual (rigid body) objects and their geometries and trajectories, nouns and verbs point to clusters of geometries and trajectories, this all intuitively matches our day-to-day rigid-body models relatively nicely.
The shortcomings are many.
First, we reused the clustering machinery from the first toy model, so all the shortcomings of that model (other than limited expressivity) are inherited. Notably, that includes the “what features?” question. We did ground geometries in spacetime locality and trajectories in particles (which are a relatively easy step up from spacetime locality), so the “what features” question is handled for geometries and trajectories. But then we cluster geometries, and cluster trajectories. What are the “features” of a rigid body object’s geometry, for clustering purposes? What are the “features” of a rigid body object’s trajectory, for clustering purposes? We didn’t answer either of those questions. The underdetermination of feature choice at the clustering stage is probably the biggest “gap” which we’ve ignored in this model.
Second, when defining geometries and trajectories, note that we defined the geometry to be a random variable which “both mediates between the particle-states at far-apart times and can be reconstructed from particle-states at any one time”. That works fine if there’s only one rigid body object, but if there’s multiple rigid body objects in the same environment, then the “geometry” under that definition would be a single variable summarizing the geometry of all the rigid body objects. That’s not what we want; we want distinct variables for the geometry (and trajectory) of each object. So the model needs to be tweaked to handle multiple rigid bodies in the same environment.
Third, obviously we were very handwavy and didn’t prove anything in this section.
Fourth, obviously the model is still quite limited in expressivity. It doesn’t handle adjectives or adverbs or non-rigid-body nouns or …
Summary and Call To Action
The problem we call Interoperable Semantics is to find some class of random variables (in a Bayesian agent’s world model) which
- is rich enough to reasonably represent the semantics of most words used day-to-day in natural language, but
- small enough for each (word -> semantics) mapping to be plausibly learnable with only a few examples, and
- allows us to establish some kind of equivalence of variables across Bayesian agents in the same environment.
Beyond that, we of course want our class of random variables to be reasonably general and cognitively plausible as an approximation - e.g. we shouldn’t assume some specific parametric form.
At this point, we’re not even necessarily looking for “the right” class of random variables, just any class which satisfies the above criteria and seems approximately plausible.
That, we claim, is roughly what it looks like to “do semantics for real” - or at least to start the project.
Call To Action
We’re writing up this post now because it’s maybe, just barely, legible enough that other people could pick up the project and make useful progress on it. There’s lots of potential entry points:
- Extend the methods used in our toy models to handle more kinds of words and phrases:
- other kinds of nouns/verbs
- adjectives and adverbs
- subject/object constructions
- etc.
- Fill some of the gaps in the arguments
- Find some other arguments to establish equivalence across agents
- Take the toy models from this post, or some other Interoperable Semantics models, and go look for the relevant structures in real models and/or datasets (either small scale or large scale)
- Whatever other crazy stuff you come up with!
We think this sort of project, if it goes well, could pretty dramatically accelerate AI interpretability, and probably advance humanity’s understanding of lots of other things as well. It would give a substantive, quantitative, and non-ad-hoc [LW · GW] idea of what stuff interpretability researchers should look for. Rather than just shooting in the dark, it would provide some actual quantitative models to test.
Thank you to Garret Baker, Jeremy Gillen, and Alexander Gietelink-Oldenziel for feedback on a draft of this post.
- ^
In this post, we’ll ignore Gricean implicature; our agents just take everything literally. Justification for ignoring it: first, the cluster-based model in this post is nowhere near the level of sophistication where lack of Gricean implicature is the biggest problem. Second, when it does come time to handle Gricean implicature, we do not expect that the high-level framework used here - i.e. Bayesian agents, isomorphism between latents - will have any fundamental trouble with it.
- ^
When we say “word” or “short phrase”, what we really mean is “atom of natural language.”
- ^
A full characterization of interoperable mental content / semantics requires specifying the possible mappings of larger constructions, like sentences, into interoperable mental content, not just words. But once we characterize the mental content which individual words can map to (i.e. their ‘semantic targets’,) we are hopeful that the mental content mapped to by larger constructions (e.g. sentences,) will usually be straightforwardly constructable from those smaller pieces. So if we can characterize “what children can attach words to”, then we’d probably be most of the way to characterizing the whole range of outputs of the magic semantics box.
Notably, going from words to sentences and larger constructs is the focus of the existing academic field of “semantics”. What linguists call “semantics” is mostly focused on constructing semantics of sentences and larger constructs from the semantics of individual words (“atoms”). From their standpoint, this post is mostly about characterizing the set of semantic values of atoms, assuming Bayesian agents.
- ^
For those who read Natural Latents: The Math before this post, note that we added an addendum [LW · GW] shortly before this post went up. It contains a minor-but-load-bearing step for establishing approximate isomorphism between two agents’ natural latents.
- ^
Sepal length, sepal width, petal length, and petal width in case you were wondering, presumably collected from a survey of actual flowers last century.
- ^
Remember that addendum we mentioned in an earlier footnote? The determinism condition is for that part.
44 comments
Comments sorted by top scores.
comment by Paradiddle (barnaby-crook) · 2024-06-19T12:13:47.813Z · LW(p) · GW(p)
I enjoyed the content of this post, it was nicely written, informative, and interesting. I also realise that the "less bullshit" framing is just a bit of fun that shouldn't be taken too seriously. Those caveats aside, I really dislike your framing and want to explain why! Reasons below.
First, the volume of work on "semantics" in linguistics is enormous and very diverse. The suggestion that all of it is bullshit comes across as juvenile, especially without providing further indication as to what kind of work you are talking about (the absence of a signal that you are familiar with the work you think is bullshit is a bit galling).
Second, this work might interest people who work on similar things. Indeed, this seems like something you are explicitly after. However, your casual dismissal of prior work on semantics as bullshit combined with a failure to specify the nature of the project you are pursuing in terms a linguist would recognise (i.e., your project is far more specific than "semantics") could prevent engagement and useful feedback from the very people who are best-placed to provide it.
Third, on the object level, I think there is a gulf in numerosity (from more to less numerous) separating 1) human concepts (these might roughly be the "latent variables in probabilistic generative models" in your and Steven Byrnes comment chain), 2) communicable human concepts (where communicability is some kind of equivalence, as in your model), and 3) human concepts with stable word meanings in the current lexicon (like common nouns). I think your framing in this post conflates the three (even if you yourself do not). The reason I include this object level worry here is that, if my worry is indicative of how others might react, then it could be more of a turn off for potential collaborators to see these notions conflated in the same post as deriding other work as not capturing what semantics is really about (if you think my distinctions are reasonable, which of them do you think semantics is really about and what exactly do you worry linguists have been erroneously working on all this time?).
Again, interesting work, hope this didn't come off too combative!
Replies from: johnswentworth↑ comment by johnswentworth · 2024-06-19T16:12:02.246Z · LW(p) · GW(p)
Again, interesting work, hope this didn't come off too combative!
Not at all, you are correctly critiquing the downsides of a trade-off which we consciously made.
There was a moment during writing when David suggested we soften the title/opening to avoid alienating classical semantics researchers. I replied that I expected useful work on the project to mostly come, not from people with a background in classical semantics, but from people who had bounced off of classical semantics because they intuited that it "wasn't addressing the real problem". Those are the people who've already felt, on a gut level, a need for the sort of models the post outlines. (Also, as one person who reviewed the post put it: "Although semantics would suggest that this post would be interesting to logicians, linguists and their brethren [...] I think they would not find it interesting because it is a seemingly nonsymbolic attempt to approach semantics. Symbolical methods are their bread and butter, without them they would be lost.")
To that end, the title and opening are optimized to be a costly signal to those people who bounced off classical semantics, signalling that they might be interested in this post even though they've been unsatisfied before with lots of work on semantics. The cost of that costly signal is alienating classical semantics researchers. And having made that trade-off upfront, naturally we didn't spend much time trying to express this project in terms more familiar to people in the field.
If we were writing a version more optimized for people already in the field, I might have started by saying that the core problem is the use of model theory as the primary foundation for semantics (i.e. Montague semantics and its descendants as the central example). That foundation explicitly ignores the real world, and is therefore only capable of answering questions which don't require any notion of the real world - e.g. Montague nominally focused on how truth values interact with syntax. Obviously that is a rather narrow and impoverished subset of the interesting questions about natural language semantics, and I would have then gone through some standard alternate approaches (and critiques) which do allow a role for the real world, before introducing our framework.
Replies from: barnaby-crook↑ comment by Paradiddle (barnaby-crook) · 2024-06-19T17:08:08.468Z · LW(p) · GW(p)
Thanks for the response. Personally, I think your opening sentence as written is much, much too broad to do the job you want it to do. For example, I would consider "natural language semantics as studied in linguistics" to include computational approaches, including some Bayesian approaches which are similar to your own. If I were a computational linguist reading your opening sentence, I would be pretty put off (presumably, these are the kind of people you are hoping not to put off). Perhaps including a qualification that it is classical semantics you are talking about (with optional explanatory footnote) would be a happy medium.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-06-19T17:24:19.161Z · LW(p) · GW(p)
I would make a similar critique of basically-all the computational approaches I've seen to date. They generally try to back out "semantics" from a text corpus, which means their "semantics" grounds out in relations between words; neither the real world nor mental content make any appearance. They may use Bayes' rule and latents like this post does, but such models can't address the kinds of questions this post is asking at all.
(I suppose my complaints are more about structuralism than about model-theoretic foundations per se. Internally I'd been thinking of it more as an issue with model-theoretic foundations, since model theory is the main route through which structuralism has anything at all to say about the stuff which I would consider semantics.)
Of course you might have in mind some body of work on computational linguistics/semantics with which I am unfamiliar, in which case I would be quite grateful for my ignorance to be corrected!
Replies from: barnaby-crook↑ comment by Paradiddle (barnaby-crook) · 2024-06-19T18:07:37.327Z · LW(p) · GW(p)
I see. I'm afraid I don't have much great literature to recommend on computational semantics (though Josh Tenenbaum's PhD dissertation seems relevant). I still wonder whether, even if you disagree with the approaches you have seen in that domain, those might be the kind of people well-placed to help with your project. But that's your call of course.
Depending on your goals with this project, you might get something out of reading work by relevance theorists like Sperber, Wilson, and Carston (if you haven't before). I find Carston's reasoning about how various aspects of language works quite compelling. You won't find much to help solve your mathematical problems there, but you might find considerations that help you disambiguate between possible things you want your model of semantics to do (e.g., do you really care about semantics, per se, or rather concept formation?).
comment by Steven Byrnes (steve2152) · 2024-06-18T03:15:39.361Z · LW(p) · GW(p)
I think Alice’s & Bob’s brains have learning algorithms that turn sensory inputs into nice probabilistic generative models that predict and explain those sensory inputs. For example, if a kid sees a bunch of teddy bears, they’ll form a concept (latent variable) of teddy bears, even if they don’t yet know any word for it.
And then language gets associated with latent nodes in those generative models. E.g. I point to a teddy bear and say “that’s called a teddy bear”, and now the kid associates “teddy bear” with that preexisting latent variable, i.e. the teddy bear concept variable which was active in their minds while you were talking.
So I see basically two stages:
- Stage 1: Sensory inputs → Probabilistic generative model with latent variables,
- Stage 2: Latent variables ↔ Language
…where you seem to see just one stage, if I understand this post correctly.
And likewise, for the “rich enough… small enough… equivalence of variables across Bayesian agents…” problems, you seem to see it as a language problem, whereas I see it as mostly solved by Stage 1 before anyone even opens their mouth to speak a word. (“Rich enough” and “small enough” because the learning algorithm is really good at finding awesome latents and the inference algorithm is really good at activating them at contextually-appropriate times, and “equivalence” because all humans have almost the same learning algorithm and are by assumption in a similar environment.)
Also, I think Stage 1 (i.e. sensory input → generative model) is basically the hard part of AGI capabilities. (That’s why the probabilistic programming people usually have to put in the structure of their generative models by hand.) So I have strong misgivings about a call-to-arms encouraging people to sort that out.
(If you can solve Stage 1, then Stage 2 basically happens automatically as a special case, given that language is sensory input too.)
Sorry if I’m misunderstanding.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-06-18T03:50:15.425Z · LW(p) · GW(p)
…where you seem to see just one stage, if I understand this post correctly.
Oh, I totally agree with your mental model here. It's implicit in the clustering toy model, for example: the agents fit the clusters to some data (stage 1), and only after that can they match words to clusters with just a handful of examples of each word (stage 2).
In that frame, the overarching idea of the post is:
- We'd like to characterize what the (convergent/interoperable) latents are.
- ... and because stage 2 exists, we can use language (and our use thereof) as one source of information about those latents, and work backwards. Working forwards through stage 1 isn't the only option.
Also, I think Stage 1 (i.e. sensory input → generative model) is basically the hard part of AGI capabilities. [...] So I have strong misgivings about a call-to-arms encouraging people to sort that out.
Note that understanding what the relevant latents are does not necessarily imply the ability to learn them efficiently. Indeed, the toy models in the post are good examples: both involve recognizing "naturality" conditions over some stuff, but they're pretty agnostic about the learning stage.
I admit that there's potential for capability externalities here, but insofar as results look like more sophisticated versions of the toy models in the post, I expect this work to be multiple large steps away from application to capabilities.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-06-18T13:27:14.100Z · LW(p) · GW(p)
I think I’m much more skeptical than you that the latents can really be well characterized in any other way besides saying that “the latents are whatever latents get produced by such-and-such learning algorithm as run by a human brain”. As examples:
- the word “behind” implies a person viewing a scene from a certain perspective;
- the word “contaminate” implies a person with preferences (more specifically, valence assessents [? · GW]);
- the word “salient” implies a person with an attentional spotlight;
- visual words (“edge”, “jagged”, “dappled”, etc.) depend on the visual-perception priors, i.e. the neural architecture involved in analyzing incoming visual data. For example, I think the fact that humans factor images into textures versus edges, unlike ImageNet-trained CNNs, is baked into the neural architecture of the visual cortex (see discussion of “blobs” & “interblobs” here);
- “I’m feeling down” implies that the speaker and listener can invoke spatial analogies (cf Lakoff & Johnson).
- the verb “climb” as in “climbing the corporate ladder”, and the insult “butterfingers”, imply that the speaker and listener can invoke more colorful situational analogies
- the word “much” (e.g. “too much”, “so much”) tends to imply a background context of norms and propriety (see Hofstadter p67)
- conjunctions like “and” and “but” tend to characterize patterns in the unfurling process of how the listener is parsing the incoming word stream, moment-by-moment through time (see Hofstadter p72)
↑ comment by johnswentworth · 2024-06-18T17:31:22.407Z · LW(p) · GW(p)
Great examples! I buy them to varying extents:
- Features like "edge" or "dappled" were IIRC among the first discoveries when people first started doing interp on CNNs back around 2016 or so. So they might be specific to a data modality (i.e. vision), but they're not specific to the human brain's learning algorithm.
- "Behind" seems similar to "edge" and "dappled", but at a higher level of abstraction; it's something which might require a specific data modality but probably isn't learning algorithm specific.
- I buy your claim a lot more for value-loaded words, like "I'm feeling down", the connotations of "contaminate", and "much". (Note that an alien mind might still reify human-value-loaded concepts in order to model humans, but that still probably involves modeling a lot of the human learning algorithm, so your point stands.)
- I buy that "salient" implies an attentional spotlight, but I would guess that an attentional spotlight can be characterized without modeling the bulk of the human learning algorithm.
- I buy that the semantics of "and" or "but" are pretty specific to humans' language-structure, but I don't actually care that much about the semantics of connectives like that. What I care about is the semantics of e.g. sentences containing "and" or "but".
- I definitely buy that analogies like "butterfingers" are a pretty large chunk of language in practice, and it sure seems hard to handle semantics of those without generally understanding analogy, and analogy sure seems like a big central piece of the human learning algorithm.
At the meta-level: I've been working on this natural abstraction business for four years now, and your list of examples in that comment is one of the most substantive and useful pieces of pushback I've gotten in that time. So the semantics frame is definitely proving useful!
One mini-project in this vein which would potentially be high-value would be for someone to go through a whole crapton of natural language examples and map out some guesses at which semantics would/wouldn't be convergent across minds in our environment.
Replies from: tailcalled↑ comment by tailcalled · 2024-06-19T10:38:30.531Z · LW(p) · GW(p)
I think a big aspect of salience arises from dealing with commensurate variables that have a natural zero-point (e.g. physical size), because then one can rank the variables by their distance from zero, and the ones that are furthest from zero are inherently more salient. Attentional spotlights are also probably mainly useful in cases where the variables have high skewness so there are relevant places to put the spotlight.
I don't expect this model to capture all of salience, but I expect it to capture a big chunk, and to be relevant in many other contexts too. E.g. an important aspect of "misleading" communication is to talk about the variables of smaller magnitude while staying silent about the variables of bigger magnitude.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-06-19T10:55:33.829Z · LW(p) · GW(p)
For example, if I got attacked by a squirrel ten years ago, and it was a very traumatic experience for me, then the possibility-of-getting-attacked-by-a-squirrel will be very salient in my mind whenever I’m making decisions, even if it’s not salient to anyone else. (Squirrels are normally shy and harmless.)
Replies from: tailcalled↑ comment by tailcalled · 2024-06-19T11:42:52.758Z · LW(p) · GW(p)
In this case, under my model of salience as the biggest deviating variables, the variable I'd consider would be something like "likelihood of attacking". It is salient to you in the presence of squirrels because all other things nearby (e.g. computers or trees) are (according to your probabilistic model) much less likely to attack, and because the risk of getting attacked by something is much more important than many other things (e.g. seeing something).
In a sense, there's a subjectivity because different people might have different traumas, but this subjectivity isn't such a big problem because there is a "correct" frequency with which squirrels attack under various conditions, and we'd expect the main disagreement with a superintelligence to be that it has a better estimate than we do.
A deeper subjectivity is that we care about whether we get attacked by squirrels, and we're not powerful enough that it is completely trivial and ignorable whether squirrels attack us and our allies, so squirrel attacks are less likely to be of negligible magnitude relative to our activities.
comment by abramdemski · 2024-07-02T16:39:42.489Z · LW(p) · GW(p)
Notice that in our picture so far, the output of Alice’s semantics-box consists of values of some random variables in Alice’s model, and the output of Bob’s semantics-box consists of values of some random variables in Bob’s model. With that picture in mind, it’s unclear what it would even mean for Alice and Bob to “agree” on the semantics of sentences. For instance, imagine that Alice and Bob are both Solomonoff inductors with a special module for natural language. They both find some shortest program to model the world, but the programs they find may not be exactly identical; maybe Alice and Bob are running slightly different Turing machines, so their shortest programs have somewhat different functions and variables internally. Their semantics-boxes then output values of variables in those programs. If those are totally different programs, what does it even mean for Alice and Bob to “agree” on the values of variables in these totally different programs?
This importantly understates the problem. (You did say "for instance" -- I don't think you are necessarily ignoring the following point, but I think it is a point worth making.)
Even if Alice and Bob share the same universal prior, Solomonoff induction comes up with agent-centric models of the world, because it is trying to predict perceptions. Alice and Bob may live in the same world, but they will perceive different things. Even if they stay in the same room and look at the same objects, they will see different angles.
If we're lucky, Alice and Bob will both land on two-part representations which (1) model the world from a 3rd person perspective, and (2) then identify the specific agent whose perceptions are being predicted, providing a 'phenomonological bridge [LW · GW]' to translate the 3rd-person view of reality into a 1st person view [LW · GW]. Then we're left with the problem which you mention: Alice and Bob could have slightly different 3rd-person understandings of the universe.
If we could get there, great. However, I think we imagine Solomonoff induction arriving at such a two-part model largely because we think it is smart, and we think smart people understand the world in terms of physics and other 3rd-person-valid concepts. We think the physicalist/objective conception of the world is true, and therefore, Solomonoff induction will figure out that it is the best way.
Maybe so. But it seems pretty plausible that a major reason why humans arrive at these 'objective' 3rd-person world-models is because humans have a strong incentive to think about the world in ways that make communication possible. We come up with 3rd-person descriptions of the words because they are incredibly useful for communicating. Solomonoff induction is not particularly designed to respect this incentive, so it seems plausible that it could arrange its ontology in an entirely 1st-person manner instead.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-07-02T19:59:47.835Z · LW(p) · GW(p)
But it seems pretty plausible that a major reason why humans arrive at these 'objective' 3rd-person world-models is because humans have a strong incentive to think about the world in ways that make communication possible.
This is an interesting point which I had not thought about before, thank you. Insofar as I have a response already, it's basically the same as this thread [LW(p) · GW(p)]: it seems like understanding of interoperable concepts falls upstream of understanding non-interoperable concepts on the tech tree, and also there's nontrivial probability that non-interoperable concepts just aren't used much even by Solomonoff inductors (in a realistic environment).
Replies from: abramdemski↑ comment by abramdemski · 2024-07-02T20:09:03.568Z · LW(p) · GW(p)
Ah, don't get me wrong: I agree that understanding interoperability is the thing to focus on. Indeed, I think perhaps "understanding" itself has something to do with interoperability.
The difference, I think, is that in my view the whole game of interoperability has to do with translating between 1st person and 3rd person perspectives.
Your magic box takes utterances and turns them into interoperable mental content.
My magic box takes non-interoperable-by-default[1] mental content and turns them into interoperable utterances.
The language is the interoperable thing. The nature of the interoperable thing is that it has been optimized so as to easily translate between many not-so-easily-interoperable (1st person, subjective, idiosyncratic) perspectives.
- ^
"Default" is the wrong concept here, since we are raised from little babies to be highly interoperable, and would die without society. What I mean here is something like, it is relatively easy to spell out non-interoperable theories of learning / mental content, EG solomonoff's theory, or neural nets.
comment by abramdemski · 2024-07-02T16:11:12.386Z · LW(p) · GW(p)
Takeaway: there can’t be that many possible semantic targets for words. The set of semantic targets for words (in humans) is at least exponentially smaller than the set of random variables in an agent’s world model.
I don't think this follows. The set of semantic targets could be immense, but children and adults could share sufficiently similar priors, such that children land on adequately similar concepts to those that adults are trying to communicate with very little data.
Think of it like a modified Schelling-point game, where some communication is possible, but sending information is expensive. Alice is trying to find Bob in the galaxy, and Bob has been able to communicate only a little information for Alice to go on. However, Alice and Bob are both from Earth, so they share a lot of context. Bob can say "the moon" and Alice knows which moon Bob is probably talking about, and also knows that there is only one habitable moon-base on the moon to check.
Bob could find a way to point Alice to any point in the galaxy, but Bob probably won't need to. So the set of possibilities appears to be small, from the perspective of someone who only sees a few rounds of this game.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-07-02T18:13:52.339Z · LW(p) · GW(p)
So really, rather than "the set of semantic targets is small", I should say something like "the set of semantic targets with significant prior probability is small", or something like that. Unclear exactly what the right operationalization is there, but I think I buy the basic point.
comment by Bill Benzon (bill-benzon) · 2024-06-20T15:43:50.145Z · LW(p) · GW(p)
Yes, the matching of "mental content" between one mind and another is perhaps the central issue in semantics. You might want to take a look at Warglien and Gärdenfors, Semantics, conceptual spaces, and the meeting of minds:
Abstract: We present an account of semantics that is not construed as a mapping of language to the world but rather as a mapping between individual meaning spaces. The meanings of linguistic entities are established via a “meeting of minds.” The concepts in the minds of communicating individuals are modeled as convex regions in conceptual spaces. We outline a mathematical framework, based on fixpoints in continuous mappings between conceptual spaces, that can be used to model such a semantics. If concepts are convex, it will in general be possible for interactors to agree on joint meaning even if they start out from different representational spaces. Language is discrete, while mental representations tend to be continuous—posing a seeming paradox. We show that the convexity assumption allows us to address this problem. Using examples, we further show that our approach helps explain the semantic processes involved in the composition of expressions.
You can find those ideas further developed in Gärdenfors' 2014 book, Geometry of Meaning, chapters 4 and 5, "Pointing as Meeting of Minds" and "Meetings of Minds as Fixpoints," respectively. In chapter 5 he develops four levels of communication.
comment by tailcalled · 2024-08-14T08:37:33.448Z · LW(p) · GW(p)
Not sure where to post this so I might as well post it here:
I think the current natural abstractions theory lacks a concept of magnitude [? · GW] that applies across inhomogenous, qualitatively distinct things. You might think it's no big deal to not have it inherent in the theory, because it can be derived empirically, so since you make better predictions when you assume energy etc. is conserved, you will learn the concept anyway.
The issue is, there's a shitton of things that give you better predictions [? · GW], so if you are not explicitly biased towards magnitude, you might learn it very "late" in the ordering of things you learn.
Conversely, for alignment and interpretability purposes, we want to learn it very early and treat it quite fundamentally because it gives meaning to root cause analyses [? · GW], which is what allows us to slice the world into a smallish number of discrete objects [? · GW].
Replies from: johnswentworth, tailcalled↑ comment by johnswentworth · 2024-08-14T16:48:18.796Z · LW(p) · GW(p)
Yeah, this is an open problem that's on my radar. I currently have two main potential threads on it.
First thread: treat each bit in the representation of quantities as distinct random variables, so that e.g. the higher-order and lower-order bits are separate. Then presumably there will often be good approximate natural latents (and higher-level abstract structures) over the higher-order bits, moreso than the lower-order bits. I would say this is the most obvious starting point, but it also has a major drawback: "bits" of a binary number representation are an extremely artificial ontological choice for purposes of this problem. I'd strongly prefer an approach in which magnitudes drop out more naturally.
Thus the second thread: maxent. It continues to seem like there's probably a natural way to view natural latents in a maxent form, which would involve numerically-valued natural "features" that get added together. That would provide a much less artificial notion of magnitude. However, it requires figuring out the maxent thing for natural latents, which I've tried and failed at several times now (though with progress each time).
Replies from: tailcalled↑ comment by tailcalled · 2024-08-14T18:46:14.112Z · LW(p) · GW(p)
First thread: treat each bit in the representation of quantities as distinct random variables, so that e.g. the higher-order and lower-order bits are separate. Then presumably there will often be good approximate natural latents (and higher-level abstract structures) over the higher-order bits, moreso than the lower-order bits. I would say this is the most obvious starting point, but it also has a major drawback: "bits" of a binary number representation are an extremely artificial ontological choice for purposes of this problem. I'd strongly prefer an approach in which magnitudes drop out more naturally.
Is the idea here to try to find a way to bias the representation towards higher-order bits than lower-order bits in a variable? I don't think this is necessary, because it seems like you would get it "for free" due to the fact that lower-order bits usually aren't predictable without the higher-order bits.
The issue I'm talking about is that we don't want a bias towards higher-order bits, we want a bias towards magnitude. As in, if there's 100s of dynamics that can be predicted about something that's going on at the scale of 1 kJ or 1 gram or 1 cm, that's about 1/10th as important as if there's 1 dynamic that can be predicted about something that's going on at the scale of 1000 MJ or 1 kg or 10 m.
(Obviously on the agency side of things, we have a lot of concepts that allow us to make sense of this, but they all require a representation of the magnitudes, so if the epistemics don't contain some bias towards magnitudes, the agents might mostly "miss" this.)
Thus the second thread: maxent. It continues to seem like there's probably a natural way to view natural latents in a maxent form, which would involve numerically-valued natural "features" that get added together. That would provide a much less artificial notion of magnitude. However, it requires figuring out the maxent thing for natural latents, which I've tried and failed at several times now (though with progress each time).
Hmmm maybe.
You mean like, the macrostate is defined by an equation like, the highest-entropy distribution of microstates that satisfies ? My immediate skepticism would be that this is still defining the magnitudes epistemically (based on the probabilities in the expectation), whereas I suspect they would have to be based on something like a conservation law or diffusion process, but let's take some more careful thought:
It seems like we'd generally not expect to be able to directly observe a microstate. So we'd really use something like ; for instance the classical case is putting a thermometer to an object, or putting an object on a scale.
But for most natural features , your uncertainty about the macrostates would (according to the central thesis of my sequence) be ~lognormally distributed. Since a lognormal distribution is maxent based on and , this means that a maximally-informative would be something like .
And, because the scaling of is decided by the probabilities, its scaling is only defined up to a multiplicative factor , which means is only defined up to a power, such that would be as natural as .
Which undermines the possibility of addition, because .
As a side-note, a slogan I've found which communicates the relevant intuition is "information is logarithmic". I like to imagine that the "ideal" information-theoretic encoder is a function such that (converting tensor products to direct sums). Of course, this is kind of underdefined, doesn't even typecheck, and can easily be used to derive contradictions; but I find it gives the right intuition in a lot of places, so I expect to eventually find a cleaner way to express it.
↑ comment by tailcalled · 2024-08-14T09:22:05.880Z · LW(p) · GW(p)
In particular I think this would yield the possibility of talking about "fuzzier" concepts which lack the determinism/predictability that physical objects have. In order for the fuzzier concepts to matter, they still need to have a commensurate amount of "magnitude" to the physical objects.
comment by abramdemski · 2024-07-02T16:19:02.854Z · LW(p) · GW(p)
That’s the main problem of interest to us, for purposes of this post: what’s the set of possible semantic targets for a word?
From the way you've defined things so far, it seems relatively clear what it would mean to solve this problem for sentences; translating from "X" to X has been operationalized as what you condition on if you take "X" literally.
However, the jump you are making to the meaning of a word seems surprising and unclear. If Carol shouts "Ball!" it is unclear what it would mean to condition on the literal content; it seems to be all pragmatics. Since Carol didn't bother to form a valid sentence, she is not making a claim which can be true or false. It could mean "there is a ball coming at your head" or it could mean "We forgot the basketball at the court" or any number of other things, depending on context.
So, while it does indeed seem meaningful to talk about the semantics of words, the picture you have drawn so far of the "magic box" does not seem to fit the case of individual words. We do not condition on the literal meaning of individual words; those meanings have the wrong type signature to condition on.
comment by abramdemski · 2024-07-02T16:01:29.238Z · LW(p) · GW(p)
We can already give a partial answer: because we’re working in a Bayesian frame, the outputs of the semantics box need to be assignments of values to random variables in the world model, like
Why random variables, rather than events? In terms of your sketched formalism so far, it seems like events are the obvious choice -- events are the sort of thing we can condition on. Assigning a random variable to a value is just an indirect way to point out an event; and, this indirect method creates a lot of redundancy, since there are many many assignments-of-random-variables-to-values which would point out the same event.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-07-02T18:24:25.161Z · LW(p) · GW(p)
First: if the random variables include latents which extend some distribution, then values of those latents are not necessarily representable as events over the underlying distribution. Events are less general. (Related: updates allowed under radical probabilism can be represented by assignments of values to latents.)
Second: I want formulations which feel like they track what's actually going on in my head (or other peoples' heads) relatively well. Insofar as a Bayesian model makes sense for the stuff going on in my head at all, it feels like there's a whole structure of latent variables, and semantics involves assignments of values to those variables. Events don't seem to match my mental structure as well. (See How We Picture Bayesian Agents [LW · GW] for the picture in my head here.)
Replies from: abramdemski↑ comment by abramdemski · 2024-07-02T19:12:07.345Z · LW(p) · GW(p)
The two perspectives are easily interchangeable, so I don't think this is a big disagreement. But the argument about extending a distribution seems... awful? I could just as well say that I can extend my event algebra to include some new events which cannot be represented as values of random variables over the original event algebra, "so random variables are less general".
comment by tailcalled · 2024-06-18T09:41:05.087Z · LW(p) · GW(p)
Kind of tangential, but:
For clustering, one frame I've sometimes found useful is that if you don't break stuff up into individual objects, you've got an extended space where for each location you've got the features that are present in that location. If you marginalize over location, you end up with a variable that is highly skewed, representing the fact that most locations are empty.
You could then condition on the variable being nonzero to return to something similar to your original clustering problem, but what I sometimes find useful is to think in the original highly skewed distribution.
If you do something like an SVD, you characterize the directions one can deviate from 0, which gives you something like a clustering, but in contrast to traditional clusterings it contains a built-in scale invariance element, since the magnitude of deviation from 0 is allowed to vary.
Thinking about the skewness is also neat for other reasons, e.g. it is part of what gives us the causal sparsity. ("Large" objects are harder to affect, and have more effect on other objects.)
comment by abramdemski · 2024-07-02T16:45:59.211Z · LW(p) · GW(p)
The second central problem of Interoperable Semantics is to account for Alice and Bob’s agreement. In the Bayesian frame, this means that we should be able to establish some kind of (approximate) equivalence between at least some of the variables in the two agents’ world models, and the outputs of the magic semantics box should only involve those variables for which we can establish equivalence.
To me, this seems like a strange way to go about it, if your hope is to address AI safety concerns. If Alice is trying to understand Bob, and Alice sees that Bob uses a weird blob of incomprehensible gibberish as a key step in his reasoning, then Alice should think she has failed, rather than thinking she should ignore that part.
In some sense, agents come equipped with a 1st-person perspective (a set of cognitive tools which is useful for predicting their own sense-data and managing their own actions), and the challenge we face is one of translating that 1st-person perspective to a 3rd-person perspective (an interoperable language which can readily be translated into many different 1st person perspectives, ie, understood by many different agents).
Replies from: johnswentworth↑ comment by johnswentworth · 2024-07-02T18:27:49.530Z · LW(p) · GW(p)
That particular paragraph was intended to be about two humans. The application to AI safety is less direct than "take Alice to be a human, and Bob to be an AI" or something like that.
Replies from: abramdemski↑ comment by abramdemski · 2024-07-02T19:00:32.983Z · LW(p) · GW(p)
That makes sense. But, effectively, you are deferring the question of how it relates to AI safety. If I have my intuition (roughly, that the most important part of the problem is how to understand alien concepts which AIs might have) and you have your intuition (roughly, that the most important part of the problem is how to understand human concepts) then presumably we can try and articulate some reasons.
I've said something about why I think it seems important not to give up on mental content that seems hard to translate. Perhaps you could say a bit more about why you are interested in a thingy that only looks for easily translatable content and ignores hard-to-translate content?
Replies from: johnswentworth↑ comment by johnswentworth · 2024-07-02T19:26:14.842Z · LW(p) · GW(p)
I definitely have substantial probability on the possibility that AIs will use a bunch of alien (i.e. non-interoperable or hard-to-interoperate) concepts. And in worlds where that's true, I largely agree that those are the most important (i.e. hardest/rate-limiting) part of the technical problems of AI safety.
That said:
- I have substantial probability that AIs basically don't use a bunch of non-interoperable concepts (or converge to more interoperable concepts as capabilities grow, or ...). In those worlds, I expect that "how to understand human concepts" is the rate-limiting part of the problem.
- Even in worlds where AIs do use lots of alien concepts, it feels like understanding human concepts is "earlier on the tech tree" than figuring out what to do with those alien concepts. Like, it is a hell of a lot easier to understand those alien concepts by first understanding human concepts and then building on that understanding, than by trying to jump straight to alien concepts.
↑ comment by abramdemski · 2024-07-02T20:00:05.676Z · LW(p) · GW(p)
What would constitute "understanding human concepts" in the relevant sense?
In another comment [LW(p) · GW(p)], I suggested that human concepts can be represented in human language. This might miss out on some important human mental content, but it would not miss out on anything that the magic box spits out, since the magic box is specifically dealing with language.
This trivializes the magic box; it becomes the identity function, or at best, a paraphrasing function. But what, exactly, is wrong with such a trivial understanding of the magic box? Where does it fall short of the sort of understanding you seek to achieve?
It frames things in terms of events (each event labeled with a natural-language sentence) rather than random variables, like you want, but I can trivially reframe it in terms of random variables by considering the truth value of the sentences as 0,1 instead of true,false.
Yes, I intuitively feel that this is a dumb trivial proposal that contributes nothing to our understanding of concepts. But, I quote:
Replies from: johnswentworthAt this point, we’re not even necessarily looking for “the right” class of random variables, just any class which satisfies the above criteria and seems approximately plausible.
↑ comment by johnswentworth · 2024-07-02T20:20:13.333Z · LW(p) · GW(p)
One example: you know that thing where I point at a cow and say "cow", and then the toddler next to me points at another cow and is like "cow?", and I nod and smile? That's the thing we want to understand. How the heck does the toddler manage to correctly point at a second cow, on their first try, with only one example of me saying "cow"? (Note that same question still applies if they take a few tries, or have heard me use the word a few times.)
The post basically says that the toddler does a bunch of unsupervised structure learning, and then has a relatively small set of candidate targets, so when they hear the word once they can assign the word to the appropriate structure. And then we're interested in questions like "what are those structures?", and interoperability helps narrow down the possibilities for what those structures could be.
... and I don't think I've yet fully articulated the general version of the problem here, but the cow example is at least one case where "just take the magic box to be the identity function" fails to answer our question.
comment by abramdemski · 2024-07-02T16:22:43.111Z · LW(p) · GW(p)
- Since we’re in a Bayesian frame, any semantic targets should be assignments of values (e.g. ) to random variables in an agent’s model. (Note that this includes functions of random variables in the agent’s model, and data structures of random variables in the agent’s model.)
- … but the set of possible semantic targets for words must be exponentially smaller than the full set of possible assignments of values to random variables.
I commented about why I disagree with the first bullet point here [LW(p) · GW(p)], and the second bullet point here [LW(p) · GW(p)].
comment by abramdemski · 2024-07-02T15:58:51.315Z · LW(p) · GW(p)
A shorter-term intermediate question is: what even is the input set (i.e. domain) and output set (i.e. range) of the semantics box? Its inputs are natural language, but what about the outputs?
Because you are making the assumption that the important semantic content is inter-operable, and you're assuming this interoperable content is mediated entirely through language (Carol doesn't get to EG demonstrate how to tie shoelaces visually), It seems like Alice should be able to tell people what she understood Carol to mean.
In other words, it seems like your framework implies that you can use language itself as the representation without losing anything. Yes, an utterance will have many equivalent paraphrasings; IE the magic box is not a 1-1 function. It can be very lossy. However, the magic box should not add information. So the semantic content Y can be represented by one of the utterances X which would land on it.
If the magic box does add information (EG, if Carol says 'apple', Alice always imagines a specific color of apple, and does so randomly so that information is really added in an infotheoretic sense) ... well, I suppose that can happen, but we've violated the assumption that the magic box is a function, and also I think something has gone wrong in terms of Alice trying to understand Carol (Alice should understand that the apple could be any color).
Replies from: johnswentworth↑ comment by johnswentworth · 2024-07-02T16:25:31.878Z · LW(p) · GW(p)
I don't think this is quite right? Most of the complexity of the box is supposed to be learned in an unsupervised way from non-language data (like e.g. visual data). If someone hasn't already done all that unsupervised learning, then they don't "know what's in the box", so they don't know how to extract semantics from words.
Replies from: abramdemski↑ comment by abramdemski · 2024-07-02T17:26:29.454Z · LW(p) · GW(p)
I don't disagree with this point. I don't see how it undermines the idea that all of the semantic content of language can be represented via language. (I'm not sure what you understood me to be saying, such that this objection of yours felt relevant.)
I'm not claiming that our mental representations of semantic content "are" linguistic, or that they "come from" language. I'm just saying that we can use language to represent them.
Importantly, it is also possible that there are forms of mental content which are very difficult or even impossible to communicate with language alone, like perhaps thoughts about knot-tying. I am only claiming that the output of the magic box described here can necessarily be represented linguistically.
comment by abramdemski · 2024-07-02T15:44:15.143Z · LW(p) · GW(p)
The central challenge of ML interpretability is to faithfully and robustly translate the internal concepts of neural nets into human concepts (or vice versa). But today, we don’t have a precise understanding of what “human concepts” are. Semantics gives us an angle on that question: it’s centrally about what kind of mental content (i.e. concepts) can be interoperable (i.e. translatable) across minds.
It seems to me like there's an important omission here: we also don't understand what we really want to point at whet we say "the internal concepts of neural nets".
One might say that understanding "human concepts" is more the central difficulty here, because the human concepts are what we're trying to translate into.
However, we also need to understand what we're translating out of. For example, we might find a translation from NN activations to human concepts which is highly satisfying by some metric, but, which fails to uncover deceptive cognition within the NN. One idea for how to avoid this: ignoring content which we do not know how to translate into human concepts needs to count as a failure, rather than a success. Notice how this requires a notion of 'content' which we are trying to translate.
We can perhaps understand this as a 'strategy-stealing' requirement: to fully understand the content of an NN means to be able to replicate all of its capabilities using the translated content (importantly, including hidden capabilities which we don't see on our test data).
comment by abramdemski · 2024-07-02T15:36:01.845Z · LW(p) · GW(p)
In this post, we’ll ignore Gricean implicature; our agents just take everything literally. Justification for ignoring it: first, the cluster-based model in this post is nowhere near the level of sophistication where lack of Gricean implicature is the biggest problem. Second, when it does come time to handle Gricean implicature, we do not expect that the high-level framework used here - i.e. Bayesian agents, isomorphism between latents - will have any fundamental trouble with it.
A naive reader may think that "ignoring Gricean implicature" means pretending that it doesn't exist; to be more precise: pretending that the semantics and pragmatics of an utterance are equal.
(I will use 'pragmatics' to mean all implications a listener can draw from an utterance, including Gricean implicature, and 'semantics' to mean only the literal implications. For example, if I say "you left the door open" then (depending on context) I probably am implying that you should close it; this is pragmatics and gricean implicature, but is not a literal implication of what I said. This is also a near-synonym of a connotation/denotation distinction, where connotationpragmatics, denotationsemantics.)
However, the way you frame the problem actually critically relies on a semantics/pragmatics distinction. You define "the magic box" to be what translates from the utterance to what you would condition on if you took the sentence literally: the difference between vs .
IE, when Alice hears Carol say something, she conditions on the full sensory experience, and reaches the full range of pragmatic conclusions: . But, for the purpose of sussing out semantics, what you want to do in the post is pretend that Alice takes Carol literally, and conditions only on the semantic content of what Carol says: .
Hence, the magic box is a function relating pragmatics to semantics; it takes the event which we would condition on to get the pragmatics (namely: the full sensory experience) and maps it to the semantics (the literal meaning of what was said).
Replies from: abramdemski↑ comment by abramdemski · 2024-07-02T21:15:32.921Z · LW(p) · GW(p)
I suppose I didn't draw out the critical implication I'm trying to point to:
If you buy my argument that, far from ignoring semantics vs pragmatics, your way of framing the problem relies critically on the distinction...
...then you should be more curious about what is going on with the distinction, rather than writing it off as a less important detail to be figured out later.
I take pragmatics to be easy to understand (so long as we take it to include semantics, rather than be exclusive): the pragmatics of an utterance is just what a Bayesian listener would infer from it. (We can, if we like, also point to the pragmatic intent: what the speaker was trying to get the listener to infer.)
What seems hard is, how do we point out only the semantic content, when in conversation we always need to think about the full pragmatics?
Why do we even believe that utterances have literal content, rather than only a cloud of probabilistic implications? How could such a belief be grounded in linguistic behavior, aside from the brute fact that people talk about this distinction as if it is a thing? What singles out some inferences as semantic? What makes those inferences different from other pragmatic inferences?
It seems like it has something to do with always-valid inferences vs context-sensitive inferences, for one thing.
comment by Htarlov (htarlov) · 2024-06-20T16:25:14.402Z · LW(p) · GW(p)
I think there is a general misconception that we humans without training can learn some features, classes, and semantics based on one or few examples. It seems so in observation and it seems nearly magical, but really it is that way just because we don't see the whole picture, and we assume that a human is a "carte blanche" at first.
In reality, we are not a blank page when we are born - our brain is an effect of training that took millions of years based on evolution. We have already trained and very similar pattern recognition (aka complex features detection), similar basic senses including basic features in spaces of each sense (like cold or yellow), and image segmentation (aka object clustering) with multilevel capabilities (see the object as a whole and see parts) and pose detection (aka division between object geometry and pose in space).
For example, if you enter a kind of store that you never entered and you see some stuff - you might not know names for the things, maybe don't know and can't even guess the purpose for some. Still, you can easily differentiate each object from the background, you are able to take it into hand properly and ask the cashier what is that tool for. Even you can take a small baby, put some things around for which he/she does not know name or purpose, and observe it will rather grab at those things than at random in the background - he/she already can see features and can make that clustering in the same way other humans do (maybe with more errors as brain still develops - but it is very guided development, not training from zero).
What was astonishing to me is that so much about semantics, features, relations, etc. can be learned without having any human-like way to relate words to real objects and features and observations. Transformer-based LLM can grasp it only by reinforced learning on a huge amount of text.
I have some intuition as to why this might be the case. If you take a 2D map with points e.g. cities and measure approximate distances f.ex. by radio signal power loss between points and plug that information into a force-directed graph algorithm with forces based on a measure that approximated distance, then with enough measurements it will recreate something very resembling the original map - even when the original positions are not known and measures are not exact and by proxy. Learning word embeddings is similar to this in an abstract sense. From a lot of text, we measure relations between words in a multidimensional space and the algorithm learns similar structure, even if not anchored to reality. Transformed-based LLMs go one step further - they are learned how to emulate the kind of processing that we do in minds based on "applying additional forces" in that graph (not exactly that, but similar - focus based on weights and transforming positions in embedding space).
comment by Elliot Callender (javanotmocha) · 2024-06-18T02:09:39.780Z · LW(p) · GW(p)
I agree that this seems like a very promising direction.
Beyond that, we of course want our class of random variables to be reasonably general and cognitively plausible as an approximation - e.g. we shouldn’t assume some specific parametric form.
Could you elaborate on this; "reasonably general" sounds to me like the redundancy axiom, so I'm unclear about whether this sentence is an intuition pump.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-06-18T03:51:48.490Z · LW(p) · GW(p)
That sentence was mostly just hedging. The intended point was that the criteria which we focused on in the post aren't necessarily the be-all end-all.
comment by Valerio · 2024-06-21T16:21:23.840Z · LW(p) · GW(p)
I am skeptical about your theory of impact for investigating the question of which concepts would be convergent across minds, specifically your expectation that concepts validated through linguistic conventions may assist in non-ad-hoc interpretability of deep learning networks. Yet, I am interested in investigating semantics for the purpose of alignment. Let me try to explain how my model differs from yours.
First, for productively studying semantics, I recommend keeping a distinction between a semantics for vision (as the prototypical sensory input) and one for symbolic reasoning. I have the impression that your project can be described as curriculum learning for a visual reasoner. In the space of minds or programs, we have diffusion models and multi-modal LLMs, but there is space for programs (say a probabilistic computer vision program) learning to make visual predictions from visual data more efficiently than deep learning. It is a legitimate research question how to design a curriculum enabling a visual reasoner to successfully form concepts of increasing complexity or whether an algorithm exists enabling the visual reasoner to navigate in autonomy through a mass of visual data to successfully reach the same objective (in this paper, I described the visual reasoner as "visual AGI").
Early milestones could be learning concepts of edges, tridimensional space, rigid-body motion (very much in the direction of your toy example). Other milestones would be natural latents for shadows, textures, shapes, leaves, trees, laws of physics. I do not see any fundamental reasons why to stop here, instead you can indeed project learning concepts for animals, concepts for various actions, concepts for the sense of sights such as eyes as the organ of vision and attention focus of an animal, concepts related to animal behavior. Humans are a special case of animal, this can be proven also through ethology.
I have two comments:
- you say you want to use language as one source of information about latents. There are two possibilities. The first possibility involves the use of labels and even knowledge bases, but still requires a visual reasoner, only assuming its operation on an augmented reality. This modality does not exist in nature and is available only to programs, but there certainly exist programs successfully navigating linguistic conventions (see also Bill Benzon's comment [LW · GW]). It seems to me that you plan to use language in this way. The alternative is postulating a symbolic reasoner which somehow got to master “language”, but then a different kind of semantics need to be accounted for and I could not find any discussion of it in your post.
- a visual reasoner does not seem an existential risk for humanity. Thanks to deep learning, we already have visual reasoners (it was easy to turn visual predictors into visual reasoners, even if adversarial attacks are still possible against AI). The naturality of laws of physics or patterns of human individual/social behavior is scientific inquiry which may however not be central to AI safety. The study of semantics of visual reasoning would support an interpretation of our AI as a naturalist, or even a human ethologist. On the contrary, I see risks connected to a possible development of an AI scientist (or computer scientist), but this development is subordinate to developing symbolic reasoning. I consider LLMs symbolic predictors whose internals are difficult to interpret. Can LLMs be turned into (potentially deadly) symbolic reasoners? I am not an expert; such a possibility cannot be safely excluded. My intuitions below about a semantics for symbolic reasoning would not provide much hint to those looking to integrate this reasoning capabilities in LLMs, but would not assist in advancing their interpretability either. However, I think they can help with AI safety.
In the space of minds or programs, there is space for programs learning symbolic reasoning in a way differing from human brains and in a way that is transparent to their programmer. A symbolic reasoner can be a program exposed to words and other symbols solely, for example does not need to have any sense of sight, can be very data-efficient, does not need to have any equivalent in nature. A symbolic reasoner would start from a concept that someone used words to say something and create increasingly complex reflective concepts about words, about the inventors of the words and their other inventions such as mathematics and computer programming. I pioneered investigation into symbolic reasoning some years ago. A early milestone is understanding reported saying [LW · GW] (such as in “Augrh!” said Father Wolf. “It is time to hunt again.”). Other milestones are learning concepts of being an element of a class, of truth, of negation, of conjunction, of believing, of wanting, of functional application. You can see that the curriculum is completely different from that for a visual reasoner. The resulting semantics is less about the real world, but involves rather reflection about a “mental” internal world.
Now: can a semantics for symbolic reasoning help with AI safety? My intuition is that a symbolic reasoner with the property of transparency can be made to reason about the goals of its programmer such that there is at least a technical possibility of alignment (as opposed to language models whose internals we do not know how to interpret). The bonus point is the possibility to experiment with alignment at an early stage of the curriculum and to decide how far go with the curriculum (when it is safe to pursue distant milestones such as geometry, algebra, physics, biology).