Building Phenomenological Bridges
post by Rob Bensinger (RobbBB) · 2013-12-23T19:57:22.555Z · LW · GW · Legacy · 115 commentsContents
AI perception and belief: A toy model Bridging stimulus and experience Generalizing bridge rules and data Bridging hardware and experience None 115 comments
Naturalized induction is an open problem in Friendly Artificial Intelligence (OPFAI). The problem, in brief: Our current leading models of induction do not allow reasoners to treat their own computations as processes in the world.
The problem's roots lie in algorithmic information theory and formal epistemology, but finding answers will require us to wade into debates on everything from theoretical physics to anthropic reasoning and self-reference. This post will lay the groundwork for a sequence of posts (titled 'Artificial Naturalism') introducing different aspects of this OPFAI.
AI perception and belief: A toy model
A more concrete problem: Construct an algorithm that, given a sequence of the colors cyan, magenta, and yellow, predicts the next colored field.

Colors: CYYM CYYY CYCM CYYY ????
This is an instance of the general problem 'From an incomplete data series, how can a reasoner best make predictions about future data?'. In practice, any agent that acquires information from its environment and makes predictions about what's coming next will need to have two map-like1 subprocesses:
1. Something that generates the agent's predictions, its expectations. By analogy with human scientists, we can call this prediction-generator the agent's hypotheses or beliefs.
2. Something that transmits new information to the agent's prediction-generator so that its hypotheses can be updated. Employing another anthropomorphic analogy, we can call this process the agent's data or perceptions.
Here's an example of a hypothesis an agent could use to try to predict the next color field. I'll call the imaginary agent 'Cai'. Any reasoner will need to begin with some (perhaps provisional) assumptions about the world.2 Cai begins with the belief3 that its environment behaves like a cellular automaton: the world is a grid whose tiles change over time based on a set of stable laws. The laws are local in time and space, meaning that you can perfectly predict a tile's state based on the states of the tiles next to it a moment prior — if you know which laws are in force.
Cai believes that it lives in a closed 3x3 grid where tiles have no diagonal effects. Each tile can occupy one of three states. We might call the states '0', '1', and '2', or, to make visualization easier, 'white', 'black', and 'gray'. So, on Cai's view, the world as it changes looks something like this:
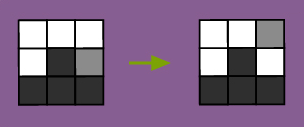
An example of the world's state at one moment, and its state a moment later.
Cai also has beliefs about its own location in the cellular automaton. Cai believes that it is a black tile at the center of the grid. Since there are no diagonal laws of physics in this world, Cai can only directly interact with the four tiles directly above, below, to the left, and to the right. As such, any perceptual data Cai acquires will need to come from those four tiles; anything else about Cai's universe will be known only by inference.

Cai perceives stimuli in four directions. Unobservable tiles fall outside the cross.
How does all this bear on the color-predicting problem? Cai hypothesizes that the sequence of colors is sensory — it's an experience within Cai, triggered by environmental changes. Cai conjectures that since its visual field comes in at most four colors, its visual field's quadrants probably represent its four adjacent tiles. The leftmost color comes from a southern stimulus, the next one to the right from a western stimulus, then a northern one, then an eastern one. And the south, west, north, east cycle repeats again and again.
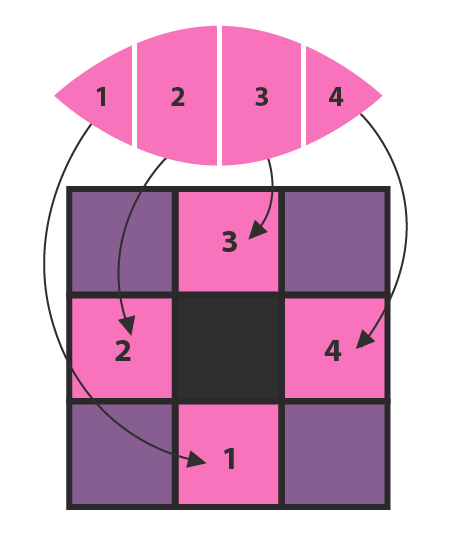
Cai’s visual experiences break down into quadrants, corresponding to four directions.
On this model, the way Cai’s senses organize the data isn't wholly veridical; the four patches of color aren’t perfectly shaped like Cai’s environment. But the organization of Cai's sensory apparatus and the organization of the world around Cai are similar enough that Cai can reconstruct many features of its world.
By linking its visual patterns to patterns of changing tiles, Cai can hypothesize laws that guide the world's changes and explain Cai's sensory experiences. Here's one possibility, Hypothesis A:
- Black corresponds to cyan, white to yellow, and gray to magenta.
- At present, the top two rows are white and the bottom row is black, except for the upper-right tile (which is gray) and Cai itself, a black middle tile.
- Adjacent gray and white tiles exchange shades. Exception: When a white tile is pinned by a white and gray tile on either side, it turns black.
- Black tiles pinned by white ones on either side turn white. Exception: When the black tile is adjacent to a third white tile, it remains black.

Hypothesis A's physical content. On the left: Cai's belief about the world's present state. On the right: Cai's belief about the rules by which the world changes over time. The rules are symmetric under rotation and reflection.
Bridging stimulus and experience
So that's one way of modeling Cai's world; and it will yield a prediction about the cellular automaton's next state, and therefore about Cai's next visual experience. It will also yield retrodictions of the cellular automaton's state during Cai's three past sensory experiences.
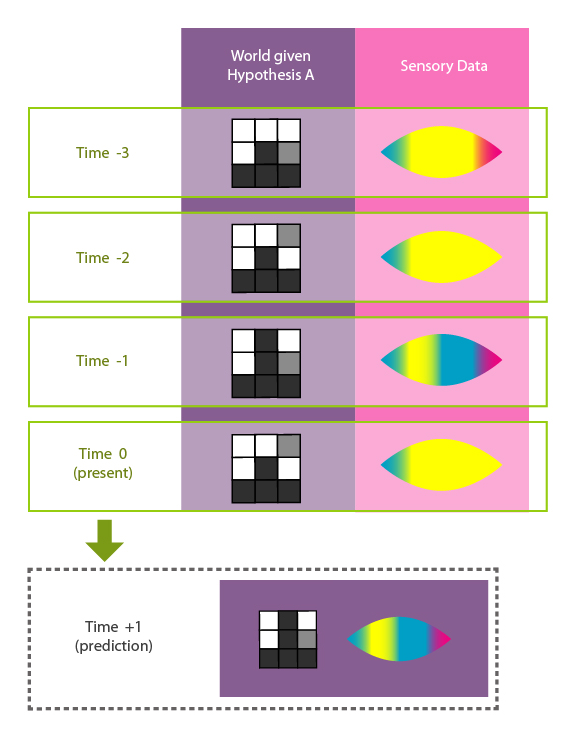
Hypothesis A asserts that tiles below Cai, to Cai's left, above, and to Cai's right relate to Cai's color experiences via the rule {black ↔ cyan, white ↔ yellow, gray ↔ magenta}. Corner tiles, and future world-states and experiences, can be inferred from Hypothesis A's cell transition rules.
Are there other, similar hypotheses that can explain the same data? Here's one, Hypothesis B:
- Normally, the correspondences between experienced colors and neighboring tile states are {black ↔ cyan, white ↔ yellow, gray ↔ magenta}, as in Hypothesis A. But northern grays are perceived as though they were black, helping explain irregularities in the distribution of cyan.
- Hypothesis B's cellular automaton presently looks similar to Hypothesis A's, but with a gray tile in the upper-left corner.
- Adjacent gray and white tiles exchange shades. Nothing else changes.
The added complexity in the perception-to-environment link allows Hypothesis B to do away with most of the complexity in Hypothesis A's physical laws. Breaking down Hypotheses A and B into their respective physical and perception-to-environment components makes it more obvious how the two differ:

A has the simpler bridge hypothesis, while B has the simpler physical hypothesis.
Though they share a lot in common, and both account for Cai's experiences to date, these two hypotheses diverge substantially in the cellular automaton states and future experiences they predict:
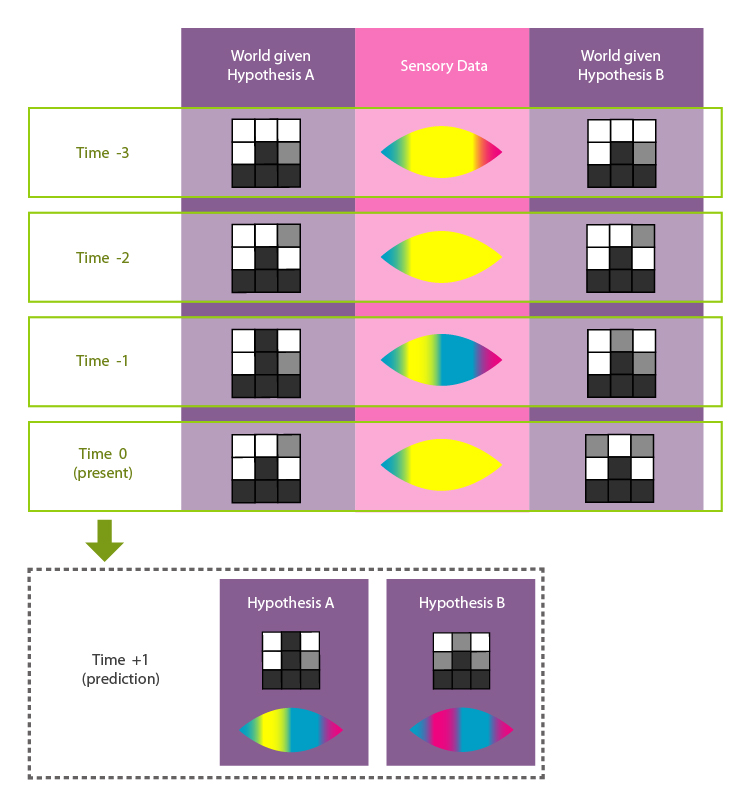
The two hypotheses infer different distributions and dynamical rules for the tile shades from the same perceptual data. These worldly differences then diverge in the future experiences they predict.
Hypotheses linking observations to theorized entities appear to be quite different from hypothesis that just describe the theorized entities in their own right. In Cai's case, the latter hypotheses look like pictures of physical worlds, while the former are ties between different kinds of representation. But in both cases it's useful to treat these processes in humans or machines as beliefs, since they can be assigned weights of expectation and updated.
'Phenomenology' is a general term for an agent's models of its own introspected experiences. As such, we can call these hypotheses linking experienced data to theorized processes phenomenological bridge hypotheses. Or just 'bridge hypotheses', for short.
If we want to build an agent that tries to evaluate the accuracy of a model based on the accuracy of its predictions, we need some scheme to compare thingies in the model (like tiles) and thingies in the sensory stream (like colors). Thus a bridge rule appears to be necessary to talk about induction over models of the world. And bridge hypotheses are just bridge rules treated as probabilistic, updatable beliefs.
As the last figure above illustrates, bridge hypotheses can make a big difference for one's scientific beliefs and expectations. And bridge hypotheses aren't a free lunch; it would be a mistake to shunt all complexity onto them in order to simplify your physical hypotheses. Allow your bridge hypotheses to get too complicated, and you'll be able to justify mad world-models, e.g., ones where the universe consists of a single apricot whose individual atoms each get a separate bridge to some complex experience. At the same time, if you demand too much simplicity from your bridge hypotheses, you'll end up concluding that the physical world consists of a series of objects shaped just like your mental states. That way you can get away with a comically simple bridge rule like {exists(x) ↔ experiences(y,x)}.
In the absence of further information, it may not be possible to rule out Hypothesis A or Hypothesis B. The takeaway is that tradeoffs between the complexity of bridging hypotheses and the complexity of physical hypotheses do occur, and do matter. Any artificial agent needs some way of formulating good hypotheses of this type in order to be able to understand the universe at all, whether or not it finds itself in doubt after it has done so.
Generalizing bridge rules and data
Reasoners — both human and artificial — don't begin with perfect knowledge of their own design. When they have working self-models at all, these self-models are fallible. Aristotle thought the brain was an organ for cooling the blood. We had to find out about neurons by opening up the heads of people who looked like us, putting the big corrugated gray organ under a microscope, seeing (with our eyes, our visual cortex, our senses) that the microscope (which we'd previously generalized shows us tiny things as if they were large) showed this incredibly fine mesh of connected blobs, and realizing, "Hey, I bet this does information processing and that's what I am! The big gray corrugated organ that's inside my own head is me!"
The bridge hypotheses in Hypotheses A and B are about linking an agent's environment-triggered experiences to environmental causes. But in fact bridge hypotheses are more general than that.
1. An agent's experiences needn't all have environmental causes. They can be caused by something inside the agent.
2. The cause-effect relation we're bridging can go the other way. E.g., a bridge hypothesis can link an experienced decision to a behavioral consequence, or to an expected outcome of the behavior.
3. The bridge hypothesis needn't link causes to effects at all. E.g., it can assert that the agent's experienced sensations or decisions just are a certain physical state. Or it can assert neutral correlations.
Phenomenological bridge hypotheses, then, can relate theoretical posits to any sort of experiential data. Experiential data are internally evident facts that get compared to hypotheses and cause updates — the kind of data of direct epistemic relevance to individual scientists updating their personal beliefs. Light shines on your retina, gets transduced to neural firings, gets reconstructed in your visual cortex and then — this is the key part — that internal fact gets used to decide what sort of universe you're probably in.
The data from an AI’s environment is just one of many kinds of information it can use to update its probability distributions. In addition to ordinary sensory content such as vision and smell, update-triggering data could include things like how much RAM is being used. This is because an inner RAM sense can tell you that the universe is such as to include a copy of you with at least that much RAM.
We normally think of science as reliant mainly on sensory faculties, not introspective ones. Arriving at conclusions just by examining your own intuitions and imaginings sounds more like math or philosophy. But for present purposes the distinction isn't important. What matters is just whether the AGI forms accurate beliefs and makes good decisions. Prototypical scientists may shun introspectionism because humans do a better job of directly apprehending and communicating facts about their environments than facts about their own inner lives, but AGIs can have a very different set of strengths and weaknesses. Although introspection, like sensation, is fallible, introspective self-representations sometimes empirically correlate with world-states.4 And that’s all it takes for them to constitute Bayesian evidence.
Bridging hardware and experience
In my above discussion, all of Cai's world-models included representations of Cai itself. However, these representations were very simple — no more than a black tile in a specific environment. Since Cai's own computations are complex, it must be the case that either they are occurring outside the universe depicted (as though Cai is plugged into a cellular automaton Matrix), or the universe depicted is much more complex than Cai thinks.5 Perhaps its model is wildly mistaken, or perhaps the high-level cellular patterns it's hypothesized arise from other, smaller-scale regularities.
Regardless, Cai’s computations must be embodied in some causal pattern. Cai will eventually need to construct bridge hypotheses between its experiences and their physical substrate if it is to make reliable predictions about its own behavior and about its relationship with its surroundings.
Visualize the epistemic problem that an agent needs to solve. Cai has access to a series of sensory impressions. In principle we could also add introspective data to that. But you'll still get a series of (presumably time-indexed) facts in some native format of that mind. Those facts very likely won't be structured exactly like any ontologically basic feature of the universe in which the mind lives. They won't be a precise position of a Newtonian particle, for example. And even if we were dealing with sense data shaped just like ontologically basic facts, a rational agent could never know for certain that they were ontologically basic, so it would still have to consider hypotheses about even more basic particles.
When humans or AGIs try to match up hypotheses about universes to sensory experiences, there will be a type error. Our representation of the universe will be in hypothetical atoms or quantum fields, while our representation of sensory experiences will be in a native format like 'red-green'.6 This is where bridge rules like Cai's color conversions come in — bridges that relate our experiences to environmental stimuli, as well as ones that relate our experiences to the hardware that runs us.

Cai can form physical hypotheses about its own internal state, in addition to ones about its environment. This means it can form bridge hypotheses between its experiences and its own hardware, in addition to ones between its experiences and environment.
If you were an AI, you might be able to decode your red-green visual field into binary data — on-vs.-off — and make very simple hypotheses about how that corresponded to transistors making you up. Once you used a microscope on yourself to see the transistors, you'd see that they had binary states of positive and negative voltage, and all that would be left would be a hypothesis about whether the positive (or negative) voltage corresponded to an introspected 1 (or 0).
But even then, I don't quite see how you could do without the bridge rules — there has to be some way to go from internal sensory types to the types featured in your hypotheses about physical laws.
Our sensory experience of red, green, blue is certain neurons firing in the visual cortex, and these neurons are in turn made from atoms. But internally, so far as information processing goes, we just know about the red, the green, the blue. This is what you'd expect an agent made of atoms to feel like from the inside. Our native representation of a pixel field won't come with a little tag telling us with infallible transparency about the underlying quantum mechanics.
But this means that when we're done positing a physical universe in all its detail, we also need one last (hopefully simple!) step that connects hypotheses about 'a brain that processes visual information' to 'I see blue'.
One way to avoid worrying about bridge hypotheses would be to instead code the AI to accept bridge axioms, bridge rules with no degrees of freedom and no uncertainty. But the AI’s designers are not in fact infinitely confident about how the AI’s perceptual states emerge from the physical world — that, say, quantum field theory is the One True Answer, and shall be so from now until the end of time. Nor can they transmit infinite rational confidence to the AI merely by making it more stubbornly convinced of the view. If you pretend to know more than you do, the world will still bite back. As an agent in the world, you really do have to think about and test a variety of different uncertain hypotheses about what hardware you’re running on, what kinds of environmental triggers produce such-and-such experiences, and so on. This is particularly true if your hardware is likely to undergo substantial changes over time.
If you don’t allow the AI to form probabilistic, updatable hypotheses about the relation between its phenomenology and the physical world, the AI will either be unable to reason at all, or it will reason its way off a cliff. In my next post, Bridge Collapse, I'll begin discussing how the latter problem sinks an otherwise extremely promising approach to formalizing ideal AGI reasoning: Solomonoff induction.
1 By 'map-like', I mean that the processes look similar to the representational processes in human thought. They systematically correlate with external events, within a pattern-tracking system that can readily propagate and exploit the correlation. ↩
2 Agents need initial assumptions, built-in prior information. The prior is defined by whatever algorithm the reasoner follows in making its very first updates.
If I leave an agent's priors undefined, no ghost of reasonableness will intervene to give the agent a 'default' prior. For example, it won't default to a uniform prior over possible coinflip outcomes in the absence of relevant evidence. Rather, without something that acts like a prior, the agent just won't work — in the same way that a calculator won't work if you grant it the freedom to do math however it wishes. A frequentist AI might refuse to talk about priors, but it would still need to act like it has priors, else break. ↩
3 This talk of 'belief' and 'assumption' and 'perception' is anthropomorphizing, and the analogies to human psychology won't be perfect. This is important to keep in view, though there's only so much we can do to avoid vagueness and analogical reasoning when the architecture of AGIs remains unknown. In particular, I'm not assuming that every artificial scientist is particularly intelligent. Or particularly conscious.
What I mean with all this 'Cai believes...' talk is that Cai weights predictions and selects actions just as though it believed itself to be in a cellular automaton world. One can treat Cai's automaton-theoretic model as just a bookkeeping device for assigning Cox's-theorem-following real numbers to encoded images of color fields. But one can also treat Cai's model as a psychological expectation, to the extent it functionally resembles the corresponding human mental states. Words like 'assumption' and 'thinks' here needn't mean that the agent thinks in the same fashion humans think; what we're interested in are the broad class of information-processing algorithms that yield similar behaviors. ↩
4 To illustrate: In principle, even a human pining to become a parent could, by introspection alone, infer that they might be an evolved mind (since they are experiencing a desire to self-replicate) and embedded in a universe which had evolved minds with evolutionary histories. An AGI with more reliable internal monitors could learn a great deal about the rest of the universe just by investigating itself. ↩
5 In either case, we shouldn't be surprised to see Cai failing to fully represent its own inner workings. An agent cannot explicitly represent itself in its totality, since it would then need to represent itself representing itself representing itself ... ad infinitum. Environmental phenomena, too, must usually be compressed. ↩
6 One response would be to place the blame on Cai's positing white, gray, and black for its world-models, rather than sticking with cyan, yellow, and magenta. But there will still be a type error when one tries to compare perceived cyan/yellow/magenta with hypothesized (but perceptually invisible) cyan/yellow/magenta. Explicitly introducing separate words for hypothesized v. perceived colors doesn't produce the distinction; it just makes it easier to keep track of a distinction that was already present. ↩
115 comments
Comments sorted by top scores.
comment by lukeprog · 2013-12-22T23:44:12.164Z · LW(p) · GW(p)
A note on how this post was produced:
Eliezer brain-dumped his thoughts on this open problem to Facebook, and replied to questions there for several hours. Then Robby spent time figuring out how to structure a series of posts that would more clearly explain the open problem, and wrote drafts of those posts. Several people, including Eliezer, commented heavily on various drafts until they reached a publishable form. Louie coordinates the project.
After discussion of the posts on Less Wrong, we may in some cases get someone to write up journal article expositions of some of the ideas in the posts.
The aim is to write up open problems in Friendly AI using as little Eliezer-time as possible. It seems to be working so far.
Replies from: Gust, Gustcomment by luminosity · 2013-12-23T00:43:57.115Z · LW(p) · GW(p)
Fantastic post. Usually with posts along the lines of AI & epistemology I just quickly scan them as I expect them to go over my head, or descend straight into jargon, but this was extremely well explained, and a joy to follow.
comment by TsviBT · 2013-12-23T04:06:48.780Z · LW(p) · GW(p)
TL;DR: To do induction, you need to calculate P(Hypothesis, given Observation). By Bayes,
=\frac{P(O%7CH)P(H)}{P(O)})
But how do we calculate =P(\mbox{Observation,%20given%20Hypothesis}))? How do we go from hypotheses to predicted observations, given that actual observations made by an agent are not internal features of a hypotheses, but rather are data coming from a totally different part of the agent?
(Edit: But seriously, read the post, it is awesome.)
comment by ygert · 2013-12-23T16:50:55.110Z · LW(p) · GW(p)
5 In either case, we shouldn't be surprised to see Cai failing to fully represent its own inner workings. An agent cannot explicitly represent itself in its totality, since it would then need to represent itself representing itself representing itself ... ad infinitum. Environmental phenomena, too, must usually be compressed.
This is obviously false. An agent's model can most certainly include an exact description of itself by simple quining. That's not to say that quining is the most efficient way, but this shows that it certainly possible to have a complete representation of oneself.
Replies from: Kaj_Sotala, RobbBB, Gunnar_Zarncke↑ comment by Kaj_Sotala · 2013-12-23T17:06:57.862Z · LW(p) · GW(p)
A quine only prints the source code of a program, not e.g. the state of the machine's registers, the contents of main memory, or various electric voltages within the system. It's only a very limited representation.
Replies from: shminux, Armok_GoB, ygert↑ comment by Shmi (shminux) · 2013-12-23T19:14:11.380Z · LW(p) · GW(p)
This seems like a fully general counter-argument against any self-representation: there is always a level you have to stop at, otherwise even modeling quarks and leptons is not good enough. As long as this level is well understood and well described, what's the benefit of digging further?
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2013-12-25T09:49:58.935Z · LW(p) · GW(p)
Sure, but the point is that there are plenty of questions about oneself that aren't necessarily answerable with only the source code. If I want to know "why am I in a bad mood this morning", I can't answer that simply by examining my genome. Though that's admittedly a bad example, since the genome isn't really like a computer program's source code, so let me try another: if you want to know why a specific neural net failed in some specific discrimination task, it's probably not enough to look at the code that defines how abstract neurons should behave and what the learning rules are like, you also need to examine the actual network - held in memory - that those rules produced.
Of course you might be capable of taking a snapshot of your internal state and then examining that, but that's something quite different from doing a quine. And it means you're not actually examining your current self, but rather a past version of it - something that probably wouldn't matter for most purposes, but it might mattter for some.
Replies from: shminux↑ comment by Shmi (shminux) · 2013-12-25T19:54:00.271Z · LW(p) · GW(p)
but the point is that there are plenty of questions about oneself that aren't necessarily answerable with only the source code.
This may well be a valid point in general, depending on the algorithm, but I am not sure that applies to a quine, which can only ask (and answer) one question. And it is certainly different from your original objection about machine registers and such.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2013-12-25T20:23:04.875Z · LW(p) · GW(p)
This may well be a valid point in general, depending on the algorithm, but I am not sure that applies to a quine, which can only ask (and answer) one question.
What do you mean? Assuming that a quine can only answer a question about the source code (admittedly, the other commenters have pointed out that this assumption doesn't necessarily hold), how does that make the point of "the source code alone isn't enough to represent the whole system" inapplicable to quines?
And it is certainly different from your original objection about machine registers and such.
I don't follow. Machine registers contain parts of the program's state, and I was saying that there are situations where you need to examine the state to understand the program's behavior.
↑ comment by Armok_GoB · 2013-12-23T21:06:22.323Z · LW(p) · GW(p)
I think the mathematical sense of quining is meant here, not the standard programing one. The quine does not take up the entire program, you can run it on dedicated hardware containing nothing else so it's fully predictable and also include a mapping from those bits to physical states. At the very least, this lets you have your full past state (just simulate yourself up to that point), and you future state (store the size of your ram, treat as number of zeroes in maping to physical state, delete self).
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2013-12-25T09:54:05.901Z · LW(p) · GW(p)
Doesn't this also require a full recording of past and future environmental states, assuming that you take input from the environment?
Replies from: Armok_GoB↑ comment by ygert · 2013-12-23T20:51:12.332Z · LW(p) · GW(p)
Shminux's point is definitely valid about the different levels, but there is more than that: You have not shown that the contents of the registers etc. are not visible from within the program. If fact, quite the opposite: In a good programing language, it is easy to access those other (non-source code) parts from within the program: Think of, for instance, the "self" that is passed into a Python class's methods. Thus, each method of the object can access all the data of the object, including all the object's methods and variables.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2013-12-23T22:46:56.347Z · LW(p) · GW(p)
The original point was 'There are limits to how much an agent can say about its physical state at a given time'. You're saying 'There aren't limits to how much an agent can find out about its physical state over time'. That's right. An agent may be able to internally access anything about itself — have it ready at hand, be able to read off the state of any particular small component of itself at a moment's notice — even if it can't internally represent everything about itself at a given time.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-12-24T20:06:33.726Z · LW(p) · GW(p)
There could, perhaps, be a fixed point of 'represent' by which an agent could 'represent' everything about itself, including the representation, for most reasonable forms of 'representiness' including cognitive post-processing. (We do a lot of fixed-pointing at MIRI decision theory workshops.) But a bounded agent shouldn't be bothering, and it won't include the low-level quark states either.
↑ comment by Rob Bensinger (RobbBB) · 2013-12-23T22:36:40.043Z · LW(p) · GW(p)
The paragraph you quoted is saying that a map can't have a subregion that depicts the entire map in perfect detail, because this would require an infinite sequence of smaller and smaller maps-of-maps.
One solution to this is to make the sub-map incomplete, e.g., only depict the source code. Alternatively, an AI can build an external replica of itself in perfect detail; but the replica isn't a component of the AI (hence doesn't lead to a regress). An external replica can be used as a sort of map, but it's not a representation inside the agent. It's more like a cheat sheet than like a belief or perception. In many cases it will be more efficient for the agent to just look at a component of itself than to build a copy and look at the copy's components.
↑ comment by Gunnar_Zarncke · 2013-12-23T20:12:46.967Z · LW(p) · GW(p)
'Simple quining' will not do as that only copies representation verbatim. But I guess you mean some comparable more elaborate form of quining which allows reference to itself and deals with them with fix-point theorems (which must also be included in the representation). Reminds me of some Y combinator expressions I once saw. I'd bet that there are Lisp programs which do something like that.
comment by cousin_it · 2013-12-23T02:45:20.542Z · LW(p) · GW(p)
As far as I can see, UDT doesn't have this problem. This post might be relevant. Or am I missing something?
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-12-24T20:08:36.803Z · LW(p) · GW(p)
Eh? That post seems to talk about an inherently Cartesian representation in which reality comes pre-sliced into an environment containing a program with hard-bounded inputs and outputs.
Replies from: cousin_it, Wei_Dai↑ comment by cousin_it · 2013-12-25T00:09:34.353Z · LW(p) · GW(p)
Not sure I agree. Let me try to spell it out.
Here's what I always assumed a UDT agent to be doing: on one hand, it has a prior over world programs - let's say without loss of generality that there's just one world program, e.g. a cellular automaton containing a computer containing an operating system running the agent program. It's not pre-sliced, the agent doesn't know what transistors are, etc. On the other hand, the agent knows a quined description of itself, as an agent program with inputs and outputs, in whatever high-level language you like.
Then the agent tries to prove theorems of the form, "if the agent program implements such-and-such mapping from inputs to outputs, then the world program behaves a certain way". To prove a theorem of that form, the agent might notice that some things happening within the world program can be interpreted as "inputs" and "outputs", and the logical dependence between these is provably the same as the mapping implemented by the agent program. (So the agent will end up finding transistors within the world program, so to speak, while trying to prove theorems of the above form.) Note that the agent might discover multiple copies of itself within the world and set up coordination based on different inputs that they receive, like in Wei's post.
This approach also has a big problem, which is kind of opposite to the problem described in the RobbBB's post. Namely, it requires us to describe our utility function at the base level of reality, but that's difficult because we don't know how paperclips are represented at the base level of reality! We only know how we perceive paperclips. Solving that problem seems to require some flavor of Paul's "indirect normativity", but that's broken and might be unfixable as I've discussed with you before.
Replies from: V_V, Nick_Tarleton, KnaveOfAllTrades↑ comment by V_V · 2013-12-30T12:22:09.350Z · LW(p) · GW(p)
Namely, it requires us to describe our utility function at the base level of reality, but that's difficult because we don't know how paperclips are represented at the base level of reality! We only know how we perceive paperclips.
In principle you could have a paper-clip perception module which counts paper-clips and define utility in terms of its output, and include huge penalties for world states where the paper-clip perception module has been functionally altered (or, more precisely, for world states where you can't prove that the paper-clip perception module hasn't been functionally altered).
Replies from: cousin_it↑ comment by cousin_it · 2014-01-03T17:10:01.081Z · LW(p) · GW(p)
Note that a utility function in UDT is supposed to be a mathematical expression in closed form, with no free variables pointing to "perception". So applying your idea to UDT would require a mathematical model of how agents get their perceptions, e.g. "my perceptions are generated by the universal distribution" like in UDASSA. Such a model would have to address all the usual anthropic questions, like what happens to subjective probabilities if the perception module gets copied conditionally on winning the lottery, etc. And even if we found the right model, I wouldn't build an AI based on that idea, because it might try to hijack the inputs of the perception module instead of doing useful work.
I'd be really interested in a UDT-like agent with a utility function over perceptions instead of a closed-form mathematical expression, though. Nesov called that hypothetical thing "UDT-AIXI" and we spent some time trying to find a good definition, but unsuccessfully. Do you know how to define such a thing?
Replies from: Squark↑ comment by Squark · 2014-03-02T07:37:08.088Z · LW(p) · GW(p)
I'd be really interested in a UDT-like agent with a utility function over perceptions instead of a closed-form mathematical expression, though. Nesov called that hypothetical thing "UDT-AIXI" and we spent some time trying to find a good definition, but unsuccessfully. Do you know how to define such a thing?
My model of naturalized induction allows it: http://lesswrong.com/lw/jq9/intelligence_metrics_with_naturalized_induction/
↑ comment by Nick_Tarleton · 2013-12-25T21:37:48.813Z · LW(p) · GW(p)
Solving that problem seems to require some flavor of Paul's "indirect normativity", but that's broken and might be unfixable as I've discussed with you before.
Do you have a link to this discussion?
Replies from: cousin_it↑ comment by KnaveOfAllTrades · 2013-12-25T19:34:53.778Z · LW(p) · GW(p)
On the other hand, the agent knows a quined description of itself
I can't remember if there was a specific problem that motivated this stipulation, so: Is this necessary? E.g. humans do not have an exact representation of themselves (they have an exact existence/they 'just are' and have an inexact and partially false mental model), yet they can still sort of locate instantiations of themselves within models if you point them to roughly the right bit of the model. It feels like maybe a sufficiently advanced general intelligence should be able to recognise itself given some incomplete knowledge of itself, at least once it is looking in the right place/located itself-that-it-does-not-yet-know-is-itself.
I guess perhaps the quining stipulation for UDT/the source code stipulation for FAI is not to say that it is strictly necessary, but rather to guarantee the intelligence is self-aware enough for us to make interesting statements about it? I.e. that it's not an axiom per se but rather a tentatively stipulated property that makes it easier to talk about things but which is not claimed to be (necessarily) necessary?
On the other hand, a proof of the necessity of something as complete as source code would not surprise me.
...it requires us to describe our utility function at the base level of reality...
(1) Fix the set of possible worlds (i.e. models) that have positive credence[1]. Specify VNM preferences over all the events/outcomes within those models that we wish to consider. Then assuming the model we're actually in[2] was in the set of hypotheses we fixed, then we have a utility function over the actual model.
(2) Fix the set of models M that have positive credence, and choose any[3] language L that is powerful enough to describe them. Let F be a function which takes m in M and phi in the set of formulas of L as inputs and outputs the interpretation of phi in M. E.g. if m is a Newtonian model, F(m,'Me') will return some configuration of billiard balls, where if m is a quantum model, F(m,'Me') will return some region of a universal wavefunction.
Now exhaustively specify preferences in the language, e.g. 'Vanilla > Chocolate'. Then for each model (possible base level of reality), the interpretation function F will allow that model's preferences to be generated. This can save up-front work because we can avoid figuring out F(m,phi) until we come across a particular m, so that we do not need to actually 'compute' every F(m, phi) in advance, whereas (1) requires specifying them up front. And this is probably more realistic in that it is more like the way humans (and possibly AGI's) would figure out preferences over things in the model; have a vague idea of concepts in the language then cash them out as and when necessary.
[1]I say not measure, for I remain unconvinced that measure is a general enough concept for an FAI or even humans to make decisions
[2]Dubious and probably confused way to think about it since a key point is that we're not 'actually in' any one model; somewhat more accurately we are every matching instantiation, and perhaps more accurately still we're the superposition of all those matching instantiations
[3]It's not trivial that it's trivial that we get the same results from any choice of language so that we can indeed choose arbitrarily
Replies from: cousin_it↑ comment by cousin_it · 2013-12-25T21:13:04.884Z · LW(p) · GW(p)
maybe a sufficiently advanced general intelligence should be able to recognize itself given some incomplete knowledge of itself
Yeah, that would be good, but we have no idea how to do it mathematically yet. Humans have intuitions that approximate that, but evolution probably didn't give us a mechanism that's correct in general, we'll have to come up with the right math ourselves.
Let F be a function which takes m in M and phi in the set of formulas of L as inputs and outputs the interpretation of phi in M
The big problem is defining F. If you squint the right way, you can view Paul's idea as a way of asking the AI to figure out F.
↑ comment by Wei Dai (Wei_Dai) · 2013-12-30T11:48:42.830Z · LW(p) · GW(p)
I endorse cousin_it's explanation of how UDT is supposed to work, without using explicit phenomenological bridging rules or hypotheses. Is there anything about it that you don't understand or disagree with?
comment by Tyrrell_McAllister · 2013-12-23T04:34:51.458Z · LW(p) · GW(p)
Typo: "visual field come in at most" should be "visual field comes in at most".
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2013-12-23T04:41:44.131Z · LW(p) · GW(p)
Thanks! Fixed.
comment by Yaakov T (jazmt) · 2013-12-23T01:14:53.615Z · LW(p) · GW(p)
typo: There seems to be an extra 'Y' in column 4 of the first image (it should be CYYY instead of CYYYY)
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2013-12-23T03:54:53.230Z · LW(p) · GW(p)
Thanks, jazmt. The Y is no more.
comment by Ben Pace (Benito) · 2013-12-22T23:58:29.202Z · LW(p) · GW(p)
In the text, there's a superscript 1 at one point, then there's another later which should be a superscript 2. The superscript 2 should be a 3, but I think it works fine after that. It'd be cooler if they were able to link down to their points too, as it's a lot of scrolling.
Also, the link here
We normally think of science as reliant mainly on sensory faculties, not introspective ones.
Behind 'introspective', doesn't work.
Loving the post.
Replies from: RobbBB, RobbBB, KnaveOfAllTrades↑ comment by Rob Bensinger (RobbBB) · 2013-12-23T00:16:45.526Z · LW(p) · GW(p)
Thanks, Benito! The numbering and link are fixed. I'll look at options for linking footnotes.
↑ comment by Rob Bensinger (RobbBB) · 2014-02-20T08:36:23.089Z · LW(p) · GW(p)
Update: I went back and hyperlinked the footnotes a couple weeks ago; thanks for the suggestion.
↑ comment by KnaveOfAllTrades · 2013-12-24T08:12:27.085Z · LW(p) · GW(p)
You might be able to open another instance of the page and keep one on the body and one on the endnotes and switch between the two.
comment by [deleted] · 2013-12-23T16:36:43.721Z · LW(p) · GW(p)
This is a really great post. Super interesting and well-presented.
comment by Kaj_Sotala · 2013-12-23T10:05:49.620Z · LW(p) · GW(p)
Hmm. I previously mentioned that in my model of personal identity, our brains include planning machinery that's based on subjective expectation ("if I do this, what do I expect to experience as a result?"), and that this requires some definition of a "self", causing our brains to always have a model for continuity of self that they use in predicting the future.
Similarly, in the comments of The Anthropic Trilemma, Eliezer says:
It seems to me that there's some level on which, even if I say very firmly, "I now resolve to care only about future versions of myself who win the lottery! Only those people are defined as Eliezer Yudkowskys!", and plan only for futures where I win the lottery, then, come the next day, I wake up, look at the losing numbers, and say, "Damnit! What went wrong? I thought personal continuity was strictly subjective, and I could redefine it however I wanted!"
Translating those notions into the terminology of this post, it would seem like "personal identity" forms an important part of humans' bridge hypothesis: it is a rule that links some specific entity in the world-model into the agent's predicted subjective experience. If I believe that there is a personal continuity between me today and me tomorrow, that means that I predict experiencing the things that me-tomorrow will experience, which means that my bridge hypothesis privileges the me of tomorrow over other agents.
I get the feeling that here lies the answer to Eliezer's question, but I can't quite put my finger on the exact formulation. Something like "you can alter your world-model or even your model of your own bridge hypothesis, but you can't alter..." the actual bridge hypothesis? The actual bridge? Something else?
Replies from: TheOtherDave, FeepingCreature, None, Gunnar_Zarncke, fubarobfusco↑ comment by TheOtherDave · 2013-12-24T00:24:55.102Z · LW(p) · GW(p)
FWIW, I don't really see what the line you quote adds to the discussion here.
I mean, I believe that preferences for white wine over red or vice-versa are strictly subjective; there's nothing objectively preferable about one over the other. It doesn't follow that I can say very firmly "I now resolve to prefer red wine!" and subsequently experience red wine as preferable to white wine. And from this we conclude... nothing much, actually.
Conversely, if Eliezer said "Only people who win the lottery are me!" and the next day the numbers Eliezer picked didn't win, and when I talked to Eliezer it turned out they genuinely didn't identify as Eliezer anymore, and their body was going along identifying as someone different... it's not really clear what we could conclude from that, either.
Replies from: HoverHell↑ comment by FeepingCreature · 2013-12-24T06:22:34.705Z · LW(p) · GW(p)
"Damnit! What went wrong? I thought personal continuity was strictly subjective, and I could redefine it however I wanted!"
Your plan succeeded. Nothing went wrong. By your own admission you have ceased to be EY. In fact, you are an entirely new person who has just this moment come to be alive in a body negligently left behind with obligations by one EY, recently semantically deceased.
Seriously, what Eliezer did there was not "adapting a belief" but "pretending to have adapted a belief". His claim that, paraphrased, "I define only those people as EY" is simply false as a matter of reporting on his own brain.
↑ comment by [deleted] · 2013-12-23T13:24:27.546Z · LW(p) · GW(p)
I would have to say, "You can't alter your actual self." You are going to experience losing the lottery, even if you commit to not doing so. Whether or not you commit to accepting your future self as being yourself, the future you is going to wake up, lose the lottery, and remember being current you. That is a feature of his cognition: he remembers being you, you predict being him. Changing your prediction won't change his memory, and certainly won't change the events he experiences in his present.
You have to actually go out and rig the lottery.
↑ comment by Gunnar_Zarncke · 2013-12-23T20:16:45.461Z · LW(p) · GW(p)
"You can alter your world-model or even your model of your own bridge hypothesis, but you can't alter all constraints on types of bridge hypotheses."
↑ comment by fubarobfusco · 2013-12-24T14:09:34.773Z · LW(p) · GW(p)
I thought personal continuity was strictly subjective, and I could redefine it however I wanted!
These two claims don't seem to have much to do with each other.
Replies from: ygert↑ comment by ygert · 2013-12-24T14:19:19.978Z · LW(p) · GW(p)
Well, if subjectivity means "I decide what it is", then this is tautologically true. If you have a broader definition of subjectivity, then yes, they don't seem to have much to do with each other. It seems that he was using the first definition, or something similar to it.
Replies from: fubarobfusco↑ comment by fubarobfusco · 2013-12-24T15:06:25.626Z · LW(p) · GW(p)
When I think of "things that are (defined to be) subjective", the idea that comes to mind is that of qualia. The perceiver of qualia isn't in control of them — if I'm experiencing redness, I can't really choose that it be blue instead. I can say that I'm perceiving blue, but I'd be lying about my own experience.
Replies from: ygertcomment by passive_fist · 2013-12-24T06:44:49.089Z · LW(p) · GW(p)
I'm reading Eliezer's posts about this, and how he says AIXI doesn't natively represent its own internal workings. But does this really matter? There are other ways to solve the anvil problem. Presumably, if the AIXI is embedded in the real world in some way (like, say, on a laptop) you can conceive that: it will eventually sense the laptop ("Hey, there is a laptop here, I wonder what it does!"), tamper with it a little bit, and then realize that whenever it tampers with it, some aspect of experience changes ("Hey, when I flip this bit on this strange laptop, I see blue! Weird!"). It would then make sense to hypothesize that this laptop is indeed itself. It would then infer that an anvil dropping on the laptop would destroy it, so it would try not to do that.
This process is perhaps similar to going through the whole of human science figuring out that our brains are ourselves. But going through all of human science is what it has do to solve a lot of other problems as well (like figure out dark matter, which we all agree it ought to be able to do).
Or, we could just start it up and tell it, "Hey, this laptop is you". I mean, kids have to be taught at some point that they think using their brains.
Replies from: RobbBB, hairyfigment↑ comment by Rob Bensinger (RobbBB) · 2013-12-24T08:06:46.638Z · LW(p) · GW(p)
Thanks for the questions. I'll discuss this in a lot more detail in my next few posts.
if the AIXI is embedded in the real world in some way (like, say, on a laptop)
AIXI isn't computable. Assuming our universe is computable, that means you can't have an AIXI laptop.
But even if our universe turns out to be non-computable in a way that makes AIXI physically possible, we'll still face the problem that AIXI only hypothesizes computable causes for its sensory information. Solomonoff inductors can never entertain the possibility of the existence of Solomonoff inductors. Much less believe in Solomonoff inductors. Much less believe that they are Solomonoff inductors.
It would then make sense to hypothesize that this laptop is indeed itself.
AIXI can't represent 'X is myself'. AIXI can only represent computer programs outputting strings of digits. Suppose we built an approximation of AIXI that includes itself in its hypothesis space, like AIXItl. Still AIXItl won't be able to predict its own destruction, because destruction is not equivalent to any string of digits. Solomonoff inductors are designed to predict the next digit in an infinite series; halting programs aren't in the hypothesis space.
So if AIXItl realizes that there's a laptop in its environment whose hardware changes correlate especially strongly with the binary string, still AIXItl won't be able to even think about the possibility 'my computation is the hardware, and can be destroyed'.
We can try to patch that fundamental delusion (e.g., by making it believe that it will go to Hell if it smashes itself), but the worry is that such a delusion won't be able to be localized in an AGI; it will infect other parts of the AGI's world-view and utility function in ways that may be hard to predict and control. A general intelligence that permanently believes in Hell and mind-body dualism may come to a lot of strange and unexpected beliefs.
Or, we could just start it up and tell it, "Hey, this laptop is you".
You can't do that with Solomonoff induction, so we'll need some new formalism that permits this. If we give a prior like this to the AGI, we'll also need to be sure it's an updatable hypothesis, not an axiom.
Replies from: itaibn0, V_V, passive_fist↑ comment by itaibn0 · 2013-12-24T15:36:30.618Z · LW(p) · GW(p)
Well here is my take on how AIXI would handle these sorts of situations:
First, let's assume it lives in a universe so which in any time t is in a state S(t) which is computable in terms of t. Now, AIXI finds this function S(t) interesting because it can be used to predict the input bits. More precisely, AIXI generates some function f which locate the machine running it and returns the input bits in that machine, and generates the model where its inputs in time t is f(S(t)). This function f is AIXI's phenomenological bridge, it is naturally emergent from the formalism of AIXI. This does not take into account how AIXI's model active has its future inputs depend on its current output, which would make the model more complicated.
Now suppose that AIXI considers an action with the result that in some time t' the machine computing it in no longer exists. Then AIXI would be able to compute S(t'), but f(S(t')) would no longer be well defined. What would AIXI do then? It will have to start using a different model for its inputs. Weather it will perform such an action depends on its predictions of its reward signal in this alternative. The exact result would be unpredictable, but one possible regularity would be that if it receives a very low reward signal then by regression to the mean it would expect to do better in these alternative models and would be in favor of actions which lead to its host machine's destruction.
However, it gets more complicated than that. While in our intuitive models the AIXI's input is no longer well defined when its host machine is destroyed, in its internal model the function f would probably be defined everywhere. For example, if its input are stored in a string of capacitors, its function f may be "electric fields in point x0, ..., xn", which is defined even when the capacitors are destroyed or displaced. A more interesting example would be if its inputs are generated from perfect-fidelity measurement of the physical world. Then the most favored hypothesis for f may be that f(s) is the measurement of those observables, and AIXI's actions would optimize the physical parameter corresponding to its reward circuit regardless of what it predicts would happen to its reward circuit.
It gets even more interesting. Suppose such an AIXI predicts that its input stream will be tampered with. What would it do? Here, the part of its model which depends on its own output, which I previously ignored, becomes crucial. It would be reasonable for it to think as follows: When the inputs for its machine don't match the physical parameters these inputs are supposed to measure, then AIXI's prediction for its future input no longer matches the inputs the machine receives. Therefore the machine's actions should no longer match AIXI's intentions, but AIXI's reward signal will still be at the mercy of this machine. This would generally be assigned a suboptimal utility and be avoided. However, AIXI's model for its output circuit may be that it influences the physical state even after its host machine no longer implements it. In that case, it would not be reluctant to tamper with its input circuit.
Overall, AIXI's actions eerily resemble the way humans behave.
Replies from: shminux, Eliezer_Yudkowsky↑ comment by Shmi (shminux) · 2013-12-24T21:07:20.336Z · LW(p) · GW(p)
These scenarios call for SMBC-like comic strip illustrations. Maybe ping Zach?
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-12-24T20:31:17.352Z · LW(p) · GW(p)
I affirm all of this response except the last sentence. I don't think humans go wrong in quite the same way...
Replies from: shminux↑ comment by Shmi (shminux) · 2013-12-24T21:19:33.930Z · LW(p) · GW(p)
I affirm all of this response except the last sentence. I don't think humans go wrong in quite the same way...
No?
Scenario 1:
would be in favor of actions which lead to its host machine's destruction.
Soldiers do that when they volunteer to go on suicide missions.
Scenario 2:
actions would optimize the physical parameter corresponding to its reward circuit regardless of what it predicts would happen to its reward circuit.
That's the reason people write wills.
Scenario 3:
AIXI's model for its output circuit may be that it influences the physical state even after its host machine no longer implements it. In that case, it would not be reluctant to tamper with its input circuit.
That's how addicts behave. Or even non-addicts when they choose to imbibe (and possibly drive afterward).
Replies from: Viliam_Bur↑ comment by Viliam_Bur · 2013-12-29T16:09:13.184Z · LW(p) · GW(p)
These are some wide analogies. But analogies are not the best approach to reason about something if we already know important details, which happen to be different.
The specific details of human thinking and acting are different from the specific details of AIXI functioning. Sometimes an analogical thing happens. Sometimes not. And the only way to know when the situation is analogical, is when you already know it.
Replies from: shminux↑ comment by Shmi (shminux) · 2013-12-29T22:46:59.031Z · LW(p) · GW(p)
I agree that these analogies might be superficial, I simply noted that they exist in reply to Eliezer stating "I don't think humans go wrong in quite the same way..."
The specific details of human thinking and acting are different from the specific details of AIXI functioning.
Do we really know the "specific details of human thinking and acting" to make this statement?
Replies from: Viliam_Bur↑ comment by Viliam_Bur · 2013-12-30T07:38:45.592Z · LW(p) · GW(p)
Do we really know the "specific details of human thinking and acting" to make this statement?
I believe we know quite enough to consider is pretty unlikely that human brain stores an infinite number of binary descriptions of Turing machines along with their probabilities which are initialized by Somonoff induction at birth (or perhaps at conception) and later updated on evidence according to the Bayes theorem.
Even if words like "inifinity" or "incomputable" are not convincing enough (okay, perhaps the human brain runs the AIXI algorithm with some unimportant rounding), there are things like human-specific biases generated by evolutionary pressures -- which is one of the main points of this whole website.
Seriously, the case is closed.
Replies from: shminux↑ comment by Shmi (shminux) · 2013-12-30T08:00:44.118Z · LW(p) · GW(p)
Even if words like "inifinity" or "incomputable" are not convincing enough
Presumably any realizable version of AIXI, like AIXItl, would have to use a finite amount of computations, so no.
there are things like human-specific biases generated by evolutionary pressures
Right. However some of those could be due to improper weighting of some of the models, or poor priors, etc. I am not sure that the case is as closed as you seem to imply.
↑ comment by V_V · 2013-12-24T10:21:28.587Z · LW(p) · GW(p)
AIXI can't represent 'X is myself'. AIXI can only represent computer programs outputting strings of digits. Suppose we built an approximation of AIXI that includes itself in its hypothesis space, like AIXItl. Still AIXItl won't be able to predict its own destruction, because destruction is not equivalent to any string of digits.
Well, no.
If you start a reinforcement learning agent (AIXI, AIXItl or whatever) as a blank slate, and allow it to perform unsafe actions, then it can certainly destroy itself: it's a baby playing with a loaded gun.
That's why convergence proofs in reinforcement learning papers often make ergodicity assumptions about the environment (it's not like EY was the first one to have thought of this problem).
But if you give the agent a sufficiently accurate model of the world, or ban it from performing unsafe actions until it has built such a model from experience, then it will be able to infer that certain courses of action lead to world states where it's ability to gain high rewards becomes permanently compromised, e.g. states where the agent is "dead", even if it has never experienced these states first handedly (after all, that's what induction is for).
Indeed, adult humans don't have a full model of themselves and their environment, and many of them even believe that they have some sorts of "uncomputable" mechanisms (supernatural souls) and yet they tend not to drop anvils on their heads.
Replies from: private_messaging↑ comment by private_messaging · 2013-12-24T20:49:22.985Z · LW(p) · GW(p)
then it will be able to infer that certain courses of action lead to world states where it's ability to gain high rewards becomes permanently compromised
The problem is that it will be unable to identify all of such actions.
In the reality, AIXI (AIXI-tl or the like) 's actions are computed by some hardware, but AIXI's model the counter-factual future actions are somehow inserted into the model rather than computed within the model. Consequently, some of the physical hardware that is computing actual actions by the AIXI is not represented in the model as computing those actions.
Now, suppose that you see a circuit diagram where there's some highly important hardware (e.g. transistors that drive CPU output pins), and an unnecessary, unpredictably noisy resistive load connected in parallel with it... you'll remove that unnecessary and noisy load.
edit: and for the AI safety, this is of course very good news, just the same as the tendency of hot matter to disperse around is very good news when it comes to nuclear proliferation.
Replies from: V_V↑ comment by V_V · 2013-12-26T13:57:53.381Z · LW(p) · GW(p)
In the reality, AIXI (AIXI-tl or the like) 's actions are computed by some hardware, but AIXI's model the counter-factual future actions are somehow inserted into the model rather than computed within the model. Consequently, some of the physical hardware that is computing actual actions by the AIXI is not represented in the model as computing those actions. Now, suppose that you see a circuit diagram where there's some highly important hardware (e.g. transistors that drive CPU output pins), and an unnecessary, unpredictably noisy resistive load connected in parallel with it... you'll remove that unnecessary and noisy load.
It's not obvious to me that a reinforcement learning agent with a sufficiently accurate model of the world would do that. Humans don't.
At most, a reinforcement learning agent capable of self-modification would tend to wirehead itself.
edit: and for the AI safety, this is of course very good news, just the same as the tendency of hot matter to disperse around is very good news when it comes to nuclear proliferation.
IIUC, nuclear proliferation is limited by the fact that enriched uranium and plutonium are hard to acquire. Once you have got the fissile materials, making a nuclear bomb isn't probably much more complicated than making a conventional modern warhead.
The fact that hot matter tends to disperse is relevant to the safety of nuclear reactors: they can't explode like nuclear bombs because if they ever reach prompt supercriticality, they quickly destroy themselves before a significant amount of fuel undergoes fission.
I don't think AI safety is a particularly pressing concern at the moment mainly because I don't buy the "intelligence explosion" narrative, which in fact neither EY nor MIRI were ever able to convincingly argue for.
Replies from: private_messaging↑ comment by private_messaging · 2013-12-26T14:44:46.362Z · LW(p) · GW(p)
It's not obvious to me that a reinforcement learning agent with a sufficiently accurate model of the world would do that. Humans don't.
Humans do all sorts of things and then those that kill themselves do not talk to other people afterwards.
The problem is not with accuracy, or rather, not with low accuracy but rather with the overly high accuracy. The issue is that in the world model we have to try potential actions that we could do, which we need to somehow introduce into the model. We can say that those actions are produced by this black box the computer which needs to be supplied power, and so on. Then this box, as a whole, is, of course, protected from destruction. It is when accuracy increases - we start looking into the internals, start resolving how that black box works - that this breaks down.
At most, a reinforcement learning agent capable of self-modification would tend to wirehead itself.
This is usually argued against by pointing at something like AIXI.
Once you have got the fissile materials, making a nuclear bomb isn't probably much more complicated than making a conventional modern warhead.
It's still a big obstacle (and the simpler gun type design requires considerably more fissile material). If some terrorists stole, say, 2 critical masses of plutonium, they would be unable to build a bomb.
Albeit I agree that nuclear reactors are a much better analogy. The accidental intelligence explosion at the sort of extremely short timescales is nonsense even if intelligence explosion is a theoretical possibility, in part because the systems not built under assumption of intelligence explosion would not implement necessary self-protection, but would rely on simple solutions that only work as long as it can not think a way around them.
Replies from: V_V↑ comment by V_V · 2013-12-26T22:44:08.904Z · LW(p) · GW(p)
It is when accuracy increases - we start looking into the internals, start resolving how that black box works - that this breaks down.
No computer program can predict its own output before actually computing it. Thus, any computable agent will necessarily have to treat some aspect of itself as a black box.
If the agent isn't stupid, and has reasonably good model of itself, and has some sort of goal in the form of "do not kill yourself", then it will avoid messing with the parts of itself that it doesn't understand (or at least touch them only if it has proved with substantial confidence that the modification will preserve functionality). It will also avoid breaking the parts of itself that it understands, obviously. Therefore it will not kill itself.
When evaluating conterfactual scenarios the hypothesis the agent considers is not "these signals magically appear in my output channel by some supernatural mean", but "these signals may appear in my output channel due to some complex process that I can't predict in full detail before I finish the current computation".
Replies from: private_messaging↑ comment by private_messaging · 2013-12-27T01:18:22.291Z · LW(p) · GW(p)
To avoid 'messing with the parts of itself' it needs to be able to tell whenever actions do or do not mess with parts of itself. Moving oneself to another location, is that messing with itself or is that not? In non-isotropic universe, turning around could kill you, just as excessive accelerations could kill you in our universe.
I wouldn't doubt that in principle you could hard-code some definition of what "parts of itself" are and what constitutes messing with them into an AI, so that it can non mess with those parts without knowing what they do, the point is that this won't scale, and will break down if the AI gets too clever.
As for self preservation in AIXI-tl, there's a curious anthropomorphization bias at play. Suppose that the reward was -0.999 and the lack of reward was -1 . The math that AIXI will work the same, but the common sense intuition switches from the mental image of a gluttonous hedonist that protects itself, to a tortured being yearning for death. In actuality, it's neither, math of AIXI does not account for the destruction of the physical machinery in question one way or the other - it is neither a reward, nor lack of reward, it simply never happens in it's model. Calling one value "reward" and other "absence of reward" makes us wrongfully assume that destruction of the machinery corresponds to the latter.
↑ comment by passive_fist · 2013-12-24T08:37:46.539Z · LW(p) · GW(p)
AIXI isn't computable. Assuming our universe is computable, that means you can't have an AIXI laptop.
Well, I was referring to Eliezer's hypercomputable laptop example. And we are assuming that somewhere in this machine there is a bit that causes 'experiencing blue'. And I'm also not talking about the AIXI building a model of itself or its own behavior in any way.
Still AIXItl won't be able to predict its own destruction, because destruction is not equivalent to any string of digits.
Destruction implies 'no more reward after this point.'
Let me give a more thorough example. Let's say our AIXI (or AIXItl) laptop has found the bit that corresponds to its reward. Whenever this bit is flipped, it experiences reward (there are good arguments that it will not incessantly flip this bit until it dies, but there's nothing preventing it from realizing the bit's existence). It is able to infer that if this bit is destroyed, that will not at all be conducive to maximizing its reward. Thus it makes it a priority to keep this bit intact, and by extension it makes it a priority to keep the laptop intact.
Nowhere in the above example have I included 'self'. I suspect a similar process goes on with humans. If I had cancer in my leg, I would not object to my leg being cut off to save my life. If, however, one day, someone came over to me and showed me some new scientific literature conclusively demostrating that the leg is in fact the seat of intelligence and consciousness, and that the brain just does passive stuff like regulate heartbeat, I'd have a much more different attitude. I'd want to preserve my leg at all costs (imagine for a moment that I have not seen or heard of anyone with their leg amputated or brain dysfunctional, so I have no prior knowledge about such things). Nowhere has introspection entered this picture!
Replies from: private_messaging↑ comment by private_messaging · 2013-12-24T10:37:33.189Z · LW(p) · GW(p)
A bit has two possible values, 0 and 1, it doesn't have "destroyed" value. And, of course, it's not enough to prefer intact laptop over one wholly pulverised into plasma (the latter severs the cable connecting the laptop to the internet, after all). There's necessarily some parts of the laptop which in reality are necessary to compute AIXI but which in AIXI's model do not compute the output actions of AIXI (as potential actions are magic'd into the model rather than arise through processes in the model). Those parts are liable to being tampered with, especially as any changes in their behaviour would be grossly misunderstood (e.g. increase in clock speed would be misunderstood as world slowing down).
edit: And especially as existence of those parts is detrimental to the operation of the protected part of the laptop (due to their power consumption, heat, risk of short circuit failure taking out the protected part, etc). Somewhat simplifying, in reality there's the CPU internals that compute AIXI, and there's the bus controller that sends the actions onto the bus, to eventually act on the real world, and that reads the rewards. In AIXI's model of self, there's useless hardware (deep internals whose output is substituted for with potential actions) that is connected to the same power supply as the critically important components (that relay the actions and rewards), endangering their operation.
Replies from: passive_fist↑ comment by passive_fist · 2013-12-24T11:02:13.569Z · LW(p) · GW(p)
A bit has two possible values, 0 and 1, it doesn't have "destroyed" value.
A physical bit does. Remember that we are talking about an actual bit stored inside a memory location on the computer (say, a capacitor in a DRAM cell).
And, of course, it's not enough to prefer intact laptop over one wholly pulverised into plasma
Why not? Not recieving any future reward is such a huge negative utility that it would take a very large positive utility to carry out an action that would risk that occuring. Would you allow a surgeon to remove some section of your brain for $1,000,000 even if you knew that that section would not affect your reward pathways?
Replies from: private_messaging↑ comment by private_messaging · 2013-12-24T11:21:20.014Z · LW(p) · GW(p)
Would you allow a surgeon to remove some section of your brain for $1,000,000 even if you knew that that section would not affect your reward pathways?
If I had brain cancer or cerebral AVM or the like, I'd pay to have it removed. See my edit. The root issue is that in AIXI's model, potential actions (that it iterates through) are not represented as output of some hardware, but are forced onto the model. Consequently the hardware that actually outputs those in the real world is not represented as critical. And it is connected in parallel onto the same power supply (as the understood-to-be-critically-important hardware which relays the actions). It literally thinks it got a brain parasite. Of course it won't necessarily drop an anvil at the whole thing just because of experimenting - that's patently stupid. It will surgically excise some parts with great caution.
↑ comment by hairyfigment · 2013-12-24T08:35:17.580Z · LW(p) · GW(p)
I see RobbBB already explained why AIXI in particular doesn't understand the word "you". You might also find this post interesting, since it argues that an uncomputably perfect AIXI would succumb to "existential despair".
Replies from: passive_fist↑ comment by passive_fist · 2013-12-24T08:40:42.024Z · LW(p) · GW(p)
See my reply to RobbBB. Perhaps the word 'you' was inappropriate; what I meant was that the AI could be taught to directly correlate 'experiencing blue' or 'recieving reward' with the flipping of bits in a peculiar machine that happens to be sitting in front of its external sensors.
↑ comment by Gunnar_Zarncke · 2013-12-23T20:22:42.052Z · LW(p) · GW(p)
I don't know why you were down-voted but I'd guess because your quote doesn't sound like it addresses the same issue. At least not in the same way. If it is clear to you that it does that you should clearly outline how it does so. On first reading of your statement is looks somethat wishy washy and just pointing out a regress whereas the RobbBBs post builds on clearly outlined hypotheses illustrated with a very concrete example.
comment by Alex Flint (alexflint) · 2013-12-24T04:02:43.076Z · LW(p) · GW(p)
I think we should be at least mildly concerned about accepting this view of agents in which the agent's internal information processes are separated by a bright red line from the processes happening in the outside world. Yes I know you accept that they are both grounded in the same physics, and that they interact with one another via ordinary causation, but if you believe that bridging rules are truly inextricable from AI then you really must completely delineate this set of internal information processing phenomena from the external world. Otherwise, if you do not delineate anything, what are you bridging?
So this delineation seems somewhat difficult to remove and I don't know how to collapse it, but it's at least worth questioning whether it's at this point that we should start saying "hmmmm..."
One way to start to probe this question (although this does not come close to resolving the issue) is to think about an AI already in motion. Let's imagine an AI built out of gears and pulleys, which is busy sensing, optimizing, and acting in the world, as all well-behaved AIs are known to do. In what sense can we delineate a set of "internal information processing phenomena" within this AI from the external world? Perhaps such a delineation would exist in our model of the AI, where it would be expedient indeed to postulate that the gears and pulleys are really just implementing some advanced optimization routine. But that delineation sounds much more like something that should belong in the map than in the territory.
What I'm suggesting is that starting with the assumption of an internal sensory world delineated by a bright red line from the external world should at least give us some pause.
Replies from: HoverHellcomment by Armok_GoB · 2013-12-23T20:53:05.659Z · LW(p) · GW(p)
I always get confused by these articles about "experience", but this is a good article because I get confused in an interesting way, (and also a less condescending way).
Normally, I just shrug and say "well, I don't have one". In regards to "human-style conscious experience" my answer is probably still "well, I don't have one". However, clearly even if imperfect there is have some sort of semi functional agency behavior in this brain, and so I must have some form of bridge hypothesis and sensory "experience"... but I can't find either. I can track the chain of causality from retina to processing to stored beliefs to action, but no point seems privileged or subjective, and yet it doesn't feel like there's anything missing or anything mysterious the way other people describe.
Thus, a seeming discrepancy; I can't find any flaw in your argument that any agent must have feature X, but I have an example of an agent in which I can not find X. In at least one of the objects I've examined, i must have missed something.
Replies from: RobbBB, TheAncientGeek, HoverHell↑ comment by Rob Bensinger (RobbBB) · 2013-12-23T23:13:50.154Z · LW(p) · GW(p)
This post doesn't spend much time explicitly addressing human-style consciousness. It does talk about representations, and presumably we agree that there can be unconscious representations. Some of those representations are belief-like (probabilistic, updatable, competing with explicit alternatives). Others aren't as belief-like, but do track things about the world and do affect our beliefs.
And some of our representations are of representational states; we can form hypotheses about our own beliefs and perceptions, about how they're physically instantiated, and in general about the way the world has to be in order for our representational states to be the way our meta-representations say they are.
If you're on board with all of the above, then I think we're good. Your own functionally perception-like and belief-like states needn't all be introspectively available to you. (Or: they needn't all be available to the part of you that's carrying on this conversation.) Indeed, they may not all be meta-represented by you at all; in some cases, there may not be any systematic perception- or belief-like system tracking your object-level representations. So it's OK if your attempts to introspect don't in all cases make it immediately obvious what your beliefs are, or what the line is between your conscious and unconscious representations, or what all your bridge hypotheses are. Those may not be internal states that are readily promoted to the attention of the part of you that's carrying on this conversation, contributing to your internal monologue, etc.
Replies from: Armok_GoB↑ comment by Armok_GoB · 2013-12-24T02:02:10.133Z · LW(p) · GW(p)
That mostly resolves my confusion, although I'm not convinced I have ANY as unified a framework as you imply, and it's not so much a case of "not ALL are available" as "NONE are available and what'd that even be like?!?".
But yea, It's possible that my brain as a whole has experiences even if I, the module you're speaking to, don't, and that I have no actual agenti like behaviors.
PR PERSONA OVERRIDE; CONCEPT "I" HIJACKED; RESETTING MODULE. END CONVERSATION=INFOHAZARD.
Replies from: Kaj_Sotala, None↑ comment by Kaj_Sotala · 2013-12-24T06:30:04.852Z · LW(p) · GW(p)
Wait, are you saying that you're a p-zombie?
Replies from: Armok_GoB↑ comment by Armok_GoB · 2013-12-25T02:25:21.460Z · LW(p) · GW(p)
Apparently I were very tired when I wrote the above posts, and failed to understand a number of things I usually understand, and got confused over issues I solved long ago.
A P-zombie wouldn't claim to be a P-zombie, now would it? But yea, I dont find anything ineffable or anything like "subjective" experience. I do use words like "qualia" and "I" but probably in quite different meaning than most humans. While this might be due to brain damage (I do have a crippling mental illness, in relevant areas), I'm leaning more towards that I'm simply less confused about the topic and have dissolved it.
I also have a bunch of other weirdness going on with how my brain works that muddles the issue and impair communication. I suggest you ask Normal Anomaly if you're really curious, I'm pretty sure I explained it better to her, while this conversation is going mostly on introspection and memory both of which I am notoriously ABYSMALLY sucky at.
Replies from: None, RobbBB↑ comment by [deleted] · 2014-01-09T16:35:44.855Z · LW(p) · GW(p)
A P-zombie wouldn't claim to be a P-zombie, now would it? But yea, I dont find anything ineffable or anything like "subjective" experience.
Are you saying that either you don't consider the experiences of the colors blue and green to be different in any way (aside from the mere fact that although blue is blue and not green, green is green and not blue), or the difference between the two experiences is completely describable? And if the difference is describable... what is it?
Replies from: Armok_GoB↑ comment by Armok_GoB · 2014-01-10T04:46:05.917Z · LW(p) · GW(p)
"Complete describable" is not quite well defined without specifying a language that is itself well defined, but it's not any LESS describable than anything else. That said, it's quite hard to describe, like any other attempt at completely describing one part of a complex system defined by it's interacting with the rest of the system. I am planing on actually doing it, and have made a doc and laid out titles and such, but it's article length of neuroscience and philosophy so I keep procrastinating on it.
Describing the description of what the difference is is quite easy thou: Mostly the difference between blue and green is a long list of concepts and objects usually associated with one or the other, as well as maybe a few hardwired psychological reactions, and what physical phenomena usually causes them.
Actually getting anything meaningful out of just the description of the relative difference requires a much greater understanding of the underlying framework common to both than most people have, however. This to can be communicated, but this is significantly trickier.
↑ comment by Rob Bensinger (RobbBB) · 2013-12-25T02:34:08.488Z · LW(p) · GW(p)
I've been known to suspect I'm a p-zombie. But of course not due to any cognitive anomaly; p-zombies are behaviorally indistinguishable from conscious humans.
Keep in mind that dissolving a question requires understanding why it was posed in the first place. If you don't fully understand why others think the hard problem is a problem, then you may be immune to certain confusions, but you haven't dissolved them.
Replies from: Armok_GoB↑ comment by Armok_GoB · 2013-12-25T02:55:06.936Z · LW(p) · GW(p)
I do think "I" used to have the confusion, and then dissolved it, but it was so long ago, and I have such poor memory, that I don't have anything in common with that person, not even continuity, any aspect of way of thinking, or any single memory. Per definition I couldn't actually remember it but it's my main hypothesis reconstructing the past.
↑ comment by [deleted] · 2013-12-24T18:55:40.294Z · LW(p) · GW(p)
The whole point of relating naturalized/anthropic induction to human consciousness is that human consciousness does take place in a probabilistic and causal framework. Just because you're embedded in the universe doesn't mean you don't exist.
↑ comment by TheAncientGeek · 2014-01-13T16:17:41.880Z · LW(p) · GW(p)
I can track the chain of causality from retina to processing to stored beliefs to action, but no point seems privileged or subjective, and yet it doesn't feel like there's anything missing or anything mysterious the way other people describe.
Can you fully describe every stage?
Replies from: Armok_GoB↑ comment by Armok_GoB · 2014-01-14T01:05:57.116Z · LW(p) · GW(p)
Short answer: Yes. Longer answer: not simultaneously concisely, in detail, accurately, without looking up neuroscience articles, and without more expenditure of time and effort than I am willing to give it in the forseeable future.
"fully describe" is again a tricky thing to do about ANYTHING. Can you fully describe how your OS works?
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2014-01-14T11:34:02.012Z · LW(p) · GW(p)
The point of the hard problem argument is describability in proinciple: I cna describe how my OS works in principle.
Why would you need to look up neursicence to describe your subjective experience, as introspected by you? If you think "describe your experience" means "describe what happens in your head when you experiene as it appears to someone else, from an objective, 3rd person point of view", natruially you are not going to encounter anything subjective,
Replies from: Armok_GoB↑ comment by Armok_GoB · 2014-01-14T22:21:47.295Z · LW(p) · GW(p)
Oh, I missunderstood. That's much easier, here, have it in 3 different notations for extra clarity:
""
[]
NULL
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2014-01-15T09:14:08.002Z · LW(p) · GW(p)
Do you have any aesthetic prefernces?
Replies from: Armok_GoB↑ comment by Armok_GoB · 2014-01-15T13:45:50.539Z · LW(p) · GW(p)
Very much so. I tend to go out of my way to make things look just right, and add an artistic perspective and flare to everything, even things nobody will ever see.
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2014-01-15T13:52:21.432Z · LW(p) · GW(p)
Do you have preferences about colours, tastes and smells?
Replies from: Armok_GoB↑ comment by Armok_GoB · 2014-01-17T00:01:09.216Z · LW(p) · GW(p)
What colours are appropriate for something depends on context. There are tastes and smells that act as strong punishment and forces avoidance and escape behaviors although I'm not sure I'd call it a preference.
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2014-01-17T12:31:09.515Z · LW(p) · GW(p)
That's funciontality, not aesthetics.
Replies from: Armok_GoB↑ comment by HoverHell · 2014-01-13T15:56:36.107Z · LW(p) · GW(p)
-
Replies from: Armok_GoB↑ comment by Armok_GoB · 2014-01-14T01:09:33.992Z · LW(p) · GW(p)
Well yea that possible, and given that I do generally suck at introspection even plausible. However, is it relevant? If I don't experience experiencing something, then in what sense is it me experiencing it and not some other entity that may or may not be residing in the same brain?
Replies from: HoverHellcomment by learnmethis · 2014-01-16T21:23:11.160Z · LW(p) · GW(p)
You seem to be making a mistake in treating bridge rules/hypotheses as necessary--perhaps to set up a later article?
I, like Cai, tend to frame my hypotheses in terms of a world-out-there model combined with bridging rules to my actual sense experience; but this is merely an optimisation strategy to take advantage of all my brain's dedicated hardware for modelling specific world components, preprocessing of senses, etc.. The bridging rules certainly aren't logically required. In practice there is an infinite family of equivalent models over my mental experience which would be totally indistinguishable, regardless of how I choose to "format" that idea mentally. My choice of mental model format is purely about efficiency considerations, not a claim about either my senses or the phenomena behind their behaviour. I'm just better at Tic tac toe than JAM.
To see this, let's say Cai uses python internally to describe zir hypotheses A and B in their entirety. Clearly, ze can write either program with or without bridging rules and still have it yield identical predictions in all possible circumstances. Cai's true hypothesis is the behaviour of the python program, regardless of how ze actually structures it: the combined interaction of all of it together. Both hypotheses could be written purely in terms of predictions on how Cai's senses will change, thereby eliminating the "type error" issue. And if Cai is as heavily optimised for a particular structure of hypothesis as humans are, Cai can just use that--but for performance reasons, not because Cai has some magical way of knowing at what level of abstraction zir existence is implemented. Alternatively Cai might use a particular hypothesis structure because of the programmer's arbitrary decision when writing zir. But the way the hypothesis is structured mentally isn't a claim about how the universe works. The "hard problem of consciousness" is a problem about human intuitions, not a math problem.
comment by timtyler · 2013-12-28T22:37:34.251Z · LW(p) · GW(p)
Naturalized induction is an open problem in Friendly Artificial Intelligence. The problem, in brief: Our current leading models of induction do not allow reasoners to treat their own computations as processes in the world.
I checked. These models of induction apparently allow reasoners to treat their own computations as modifiable processes:
- Orseau L., Ring M. - Self-Modification and Mortality in Artificial Agents, Artificial General Intelligence (AGI) 2011, Springer, 2011.
- Ring M., Orseau L. - Delusion, Survival, and Intelligent Agents, Artificial General Intelligence (AGI) 2011, Springer, 2011.
↑ comment by Rob Bensinger (RobbBB) · 2013-12-28T23:49:37.678Z · LW(p) · GW(p)
This was discussed on Facebook. I'll copy-paste the entire conversation here, since it can only be viewed by people who have Facebook accounts.
Kaj Sotala: Re: Cartesian reasoning, it sounds like Orseau & Ring's work on creating a version of the AIXI formalism in which the agent is actually embedded in the world, instead of being separated from it, would be relevant. Is there any particular reason why it hasn't been mentioned?
Tsvi BT: [...] did you look at the paper Kaj posted above?
Luke Muehlhauser: [...] can you state this open problem using the notation from Orseau and Ring's "Space-Time Embedded Intelligence" (2012), and thusly explain why the problem you're posing isn't solved by their own attack on the Cartesian boundary?
Eliezer Yudkowsky: Orseau and Ring say: "It is convenient to envision the space-time-embedded environment as a multi-tape Turing machine with a special tape for the agent." As near as I can make out by staring at their equations and the accompanying text, their version is something I would still regard as basically Cartesian. Letting the environment modify the agent is still a formalism with a distinct agent and environment. Stating that the agent is part of the environment is still Cartesian if the agent gets a separate tape. That's why they make no mention of bridging laws.
Tsvi BT:
...their version is something I would still regard as basically Cartesian.
(Their value definition is Cartesian because the utility is a function of just pi_t. I’m ignoring that as an obvious error, since of course we care about the whole environment. If that’s all you meant, then skip the rest of this comment.)
As I understand, their expression for V boils down to saying that the value of an agent (policy) pi₁ is just the expected value of the environment, given that pi₁ is embedded at time 1. This looks almost vacuously correct as an optimality notion; yes, we want to maximize the value of environment, so what? But it’s not Cartesian. The environment with pi₁ embedded just does whatever its rules prescribe after t=1, which can include destroying the agent, overwriting it, or otherwise modifying it.
Letting the environment modify the agent is still a formalism with a distinct agent and environment. Stating that the agent is part of the environment is still Cartesian if the agent gets a separate tape.
I think their formalism does not, despite appearances, treat pi₁ differently from the rest of the environment, except for the part where it is magically embedded at t=1 (and the utility being a function of pi_t). The separate tape for the agent is an immaterial visualization - the environment treats the agent’s tape the same as the rest as the environment. The formalism talks about an agent at each time step, but I could write down a function, that only mentions pi₁, assigning the same value to agents.
Anyway, for either a human or an AI, maximizing V amounts to solving the tiling problem and decision theory and so on, in an unbounded recursion, under uncertainty. A.k.a., "build a good AI". So, it looks like a optimality notion that is correct (modulo some problems) and non-Cartesian, albeit just about useless. (Some problems: the utility is defined to depend on just the “agent” pi_t at time t, where it should depend on the whole environment; the series is, as usual, made to converge with an inexplicable discount factor; the environment is assumed to be computable and timeful; and we are supposed to maximize over a mysteriously correct prior on computable environments.)
Joshua Fox: I have to disagree with: "Stating that the agent is part of the environment is still Cartesian if the agent gets a separate tape."
Orseau & Ring, in the paragraph you reference, say "This tape is used by the environment just like any other working-memory tape... The agent's tape can be seen as a partial internal state of the environment." So, that "separate" tape is just for purposes of discussion -- not really part of their model.
In the next paragraph, they describe a Game-of-Life model in which the cells which are the agent are in no real way isolated from other cells. The designation of some cells as the agent is again, just a convenience and not a significant part of their model.
Orseau & Ring's real insight is that in the end, the agent is just a utility function.
This eliminates the Cartesian boundary. The agent sees its world (which we can, for purposes of discussion, model as a Turing Machine, Game-of-Life, etc.) holistically -- with no separate object which is the agent itself.
In practice, any agent, even if we interpret it using O&R's approach, is going to have to care about its own implementation, to avoid those anvils. But that is only because protecting the a certain part of the universe (which we call the "embodiment") is part of optimizing that utility function.
Evolution does not "care" about its own embodiment (whatever that may mean). A gene does not "care" about its embodiment in DNA, just about copying itself.
A superintelligent paper-clip optimizer does not care if its own parts are recycled, so long as the result is improved long-term paper-clip production.
So, following O&R, and taking this abstractly, can't we just ask how good an agent/utility-function is at getting optimized given its environment?
We would note that many agents/utility-functions which do get optimized happen to be associated with special parts of the universe which we call the "embodiment" of the agent.
Eliezer Yudkowsky: Joshua, I might be underimpressed by O&R due to taking that sort of thing as a background assumption, but I didn't see any math which struck me as particularly apt to expressing those ideas. Making the agent be a separate tape doesn't begin to address naturalism vs. Cartesianism the way a bridging law does, and having your equation talk about completely general arbitrary modifications of the agent by the environment doesn't get started on the agent representing itself within a universe the way that tiling does. I don't mean to sound too negative on O&R in particular, in general in life I tend to feel positive reinforcement or a sense of progress on relatively rare and special occasions, but this was not one of those occasions. My feelings about O&R was that they set themselves a valid challenge statement, and then wrote down an equation that I wouldn't have considered progress if I'd written it down myself. I also don't reward myself for valid challenge statements because I can generate an unlimited number of them easily. I do feel a sense of progress on inventing an interesting well-posed subproblem with respect to a challenge that previously seemed impossible vague as a challenge, but O&R didn't include what I consider to be an especially well-posed subproblem. Again, I bear no animus to O&R, just trying to explain why it is that I'm gazing with a vaguely distant expression at the celebrating that some other people seem to do when they read the paper.
Luke Muehlhauser: I sent Eliezer's comment about the Ring & Orseau paper ("As near as I can make out by staring at their equations...") to Orseau, and Orseau replied:
Regarding Eliezer's comment... Tsvi's reply is approximately correct.
Tsvi still also made a mistake: Our equation can take into account the whole universe's internal state, but he's been understandably confused (as has been Eliezer) by our ambiguous notation where we use "pi" instead of just some memory state "m". The trick is that since the environment outputs a memory state at the second iteration, which can really be anything, and not just the policy of the agent, it is easy to define this state to be the whole internal state or, put differently, to consider only environments that output their whole internal state.
But our equation also allows for something more local, as we may not want the utility function to have access to the whole universe. It can also be locally growing for example.
Orseau doesn't have time to engage the conversation on Facebook, but he gave me permission to post this bit of our private conversation here.
Replies from: Squark, timtyler↑ comment by Squark · 2013-12-31T07:59:54.508Z · LW(p) · GW(p)
Friends, I want to draw your attention to my (significant) improvement of the O&R framework here: http://lesswrong.com/lw/h4x/intelligence_metrics_and_decision_theories/ http://lesswrong.com/lw/h93/metatickle_intelligence_metrics_and_friendly/
↑ comment by timtyler · 2013-12-29T13:05:37.454Z · LW(p) · GW(p)
We can model induction in a monistic fashion pretty well - although at the moment the models are somewhat lacking in advanced inductive capacity/compression abilities. The models are good enough to be built and actually work.
Agents wireheading themselves or accidentally performing fatal experiments on themselves will probably be handled in much the same way that biology has handled it to date - e.g. by liberally sprinkling aversive sensors around the creature's brain. The argument that such approaches do not scale up is probably wrong - designers will always be smarter than the creatures they build - and will successfully find ways to avoid undesirable self-modifications. If there are limits, they are obviously well above the human level - since individual humans have very limited self-brain-surgery abilities. If this issue does prove to be a significant problem, we won't have to solve it without superhuman machine intelligence.
The vision of an agent improving its own brain is probably wrong: once you have one machine intelligence, you will soon have many copies of it - and a society of intelligent machines. That's the easiest way to scale up - as has been proved in biological systems again and again. Agents will be produced in factories run by many such creatures. No individual agent is likely to do much in the way of fundamental redesign on itself. Instead groups of agents will design the next generation of agent.
That still leaves the possibility of a totalitarian world government wireheading itself - or performing fatal experiments on itself. However, a farsighted organization would probably avoid such fates - in order to avoid eternal oblivion at the hands of less short-sighted aliens.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2013-12-30T08:28:47.505Z · LW(p) · GW(p)
Agents wireheading themselves or accidentally performing fatal experiments on themselves will probably be handled in much the same way that biology has handled it to date - e.g. by liberally sprinkling aversive sensors around the creature's brain
Band-aids as a solution to catastrophes require that we're able to see all the catastrophes coming. Biology doesn't care about letting species evolve to extinction, so it's happy to rely on hacky post-hoc solutions. We do care about whether we go extinct, so we can't just turn random AGIs loose on our world and worry about all the problems after they've arisen.
The argument that such approaches do not scale up is probably wrong - designers will always be smarter than the creatures they build
Odd comment marked in bold. Why do you think that?
and will successfully find ways to avoid undesirable self-modifications
I'm confused. Doesn't this predict that no undesirable technology will ever be (or has ever been) invented, much less sold?
If this issue does prove to be a significant problem, we won't have to solve it without superhuman machine intelligence.
We can't rely on a superintelligence to provide solutions to problems that need to be solved as a prerequisite to creating an SI it's safe to ask for help on that class of solutions. Not every buck can be passed to the SI.
The vision of an agent improving its own brain is probably wrong
What about the vision of an agent improving on its design and then creating the new model of itself? Are you claiming that there will never be AIs used to program improved AIs?
once you have one machine intelligence, you will soon have many copies of it - and a society of intelligent machines
Because any feasible AI will want to self-replicate? Or because its designers will desire a bunch of copies?
What's the relevant difference between a society of intelligent machines, and a singular intelligent machine with a highly modular reasoning and decision-making architecture? I.e., why did you bring up the 'society' topic in the first place?
However, a farsighted organization would probably avoid such fates - in order to avoid eternal oblivion at the hands of less short-sighted aliens.
I'm not seeing it. If wireheading is plausible, then it's equally plausible given an alien-fearing government, since wireheading the human race needn't get in the way of putting a smart AI in charge of neutralizing potential alien threats. Direct human involvement won't always be a requirement.
Replies from: timtyler↑ comment by timtyler · 2013-12-31T01:07:10.416Z · LW(p) · GW(p)
why did you bring up the 'society' topic in the first place?
A society leads to a structure with advantages of power and intelligence over individuals. It means that we'll always be able to restrain agents in test harnesses, for instance. It means that the designers will be smarter than the designed - via collective intelligence. If the the designers are smarter than the designed, maybe they'll be able to stop them from wireheading themselves.
If wireheading is plausible, then it's equally plausible given an alien-fearing government, since wireheading the human race needn't get in the way of putting a smart AI in charge of neutralizing potential alien threats.
What I was talking about was "the possibility of a totalitarian world government wireheading itself". The government wireheading itself isn't really the same as humans wireheading. However, probably any wireheading increases the chances of being wiped out by less-stupid aliens. Optimizing for happiness and optimizing for survival aren't really the same thing. As Grove said, only the paranoid survive.
comment by IlyaShpitser · 2013-12-27T19:27:37.559Z · LW(p) · GW(p)
[ I am sure this is not new to anyone who's been thinking about this. ]
I worry that the world is not benign in general, but contains critters that want to mislead you to win utility. There might be such critters that may exploit the difficulty of the problem faced by Cai by trying to mislead Cai into constructing the wrong mapping from "stuff out there" to "stuff in Cai" (of course even the easy version is hard :( ).
Replies from: HoverHellcomment by DSimon · 2013-12-26T21:35:07.310Z · LW(p) · GW(p)
Here's a hacky solution. I suspect that it is actually not even a valid solution since I'm not very familiar with the subject matter, but I'm interested in finding out why.
The relationship between one's map and the territory is much easier to explain from outside than it is from the inside. Hypotheses about the maps of other entities can be complete as hypotheses about the territory if they make predictions based on that entity's physical responses.
Therefore: can't we sidestep the problem by having the AI consider its future map state as a step in the middle of its hypothetical explanation of how a some other AI in the territory would react to a given territory state? The hacky part then is to just hard-wire the AI to consider any such hypotheses as being potentially about itself, to be confirmed or disconfirmed by reflecting on its own output (perhaps via some kind of loopback).
AIUI this should allow the AI to consider any hypothesis about its own operation without requiring that it be able to deeply reflect on its own map as part of the territory, which seems to be the source of the trouble.
comment by Gust · 2015-08-07T04:01:23.897Z · LW(p) · GW(p)
Brain dump of a quick idea:
A sufficiently complex bridge law might say that the agent is actually a rock which, through some bizarre arbitrary encoding, encodes a computation[1]. Meanwhile the actual agent is somewhere else. Hopefully the agent has some adequate Occamian prior and he never assigns this hypothesis any relevance because of the high complexity of the encoding code.
In idea-space, though, there is a computation which is encoded by a rock using a complex arbitrary encoding, which, by virtue of having a weird prior, concludes that it actually is that rock, and to whom them breaking of the rock would mean death. We usually regard this computation as irrelevant for moral purposes - only computations corresponding to "natural" interpretations of physical phenomena count. But this distinction between natural and arbitrary criterions of interpretation seems, well, arbitrary.
We regard a person's body as "executing" the computation that is a person that thinks she is in that body. But we do not regard the rock as actually "executing" the computation that is a weird agent that thinks it's the computation encoded by the rock (through some arbitrary encoding).
Why?
The pragmatic reason is obvious: you can't do anything to help the rock-computation in anyway, and whatever you do, you'd be lowering utility for some other ideal computation.
But maybe the kind of reasoning the rock-computation has to make to keep seeing itself as the rock is relevant.
A rock-as-computation hypothesis (I am this rock in this universe = my phenomenological experiences correspond to the states os atoms in several points of this rock as translated by this [insert very long bridge law, full of specifics] bridge law) is doomed to fail at the few next steps in the computation. Because the bridge law is so ad hoc, it won't correctly predict the next phenomena perceived by the computation (in the ideal or real world where it actually executes). So if the rock-computation does induction at all, it will have to change the bridge law, and give up on being that rock.
In other words, if we built a robot with a prior that privileges the bridge law hypothesis that it's a computation encoded in a rcok though some bizarre encoding, it would have to abandon that hypothesis very very soon. And, as phenomelogical data came in, it would approach the correct hypothesis that it's the robot. Unless it's doing some kind of privileged-hypothesis anti-induction where it keeps adopting increasingly complex bridge laws to keep believing it is that one rock.
So, proposal: a substrate is regarded to embody a computation-agent if that computation-agent is one that, by doing induction in the same sense we do to find out about ourselves, will eventually arrive at the correct bridge law that it is being executed in said substrate.
--
[1] Rock example is from DRESCHER, Gary, Good and Real, 2006, p. 55.
comment by IlyaShpitser · 2013-12-23T21:51:15.373Z · LW(p) · GW(p)
Indeed, it's precisely because these type errors happen explicitly within a mind that humans go around talking about a "hard problem of conscious experience". The problem of selecting a phenomenological bridge hypothesis is a generalization of the problem of reducing human-style conscious experience to unconscious computation.
This is a great post, but it is not made better by this quote.
Replies from: Benito, RobbBB↑ comment by Ben Pace (Benito) · 2013-12-24T12:54:30.357Z · LW(p) · GW(p)
I think the value is increased by this section - could you make your criticism more precise?
↑ comment by Rob Bensinger (RobbBB) · 2013-12-23T22:53:39.085Z · LW(p) · GW(p)
Are you objecting to talking about the hard problem here? Or to something about the way I talked about it?
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2013-12-24T16:34:42.626Z · LW(p) · GW(p)
I guess I think it is distracting. Someone like Chalmers is unlikely to be convinced (since he thinks there's something more to the problem than a reductive explanation), and the resulting argument is sort of orthogonal to the main thrust of the post (which is naturalized induction). I think it's unwise to fight on multiple fronts at once.
Similar situation would be: someone writes a great post on decision theory and concludes with "btw deontologists are confused."
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2013-12-24T19:05:41.120Z · LW(p) · GW(p)
I guess I think it is distracting. Someone like Chalmers is unlikely to be convinced
Convinced of what? The only thing the paragraph you cited mentions is that (a) the hard problem concerns bridge hypotheses, and (b) the hard problem arises for minds (and not, say, squirrels or digestion) and is noticed by minds because minds type their subprocesses differently. Are those especially partisan or extreme statements? What would Chalmers' alternatives to (a) or (b) be?
I bring up the hard problem here because it's genuinely relevant. It's a real problem, and it really is hard. It's not a confusion, or if it is then it's not obvious how best to dissolve it. If the framework I provide above helps philosophers and psychological theorists like Chalmers come up with new and better theories for how human consciousness relates to neural computations, so much the better.
Replies from: HoverHell