Attribution-based parameter decomposition
post by Lucius Bushnaq (Lblack), Dan Braun (dan-braun-1), StefanHex (Stefan42), jake_mendel, Lee Sharkey (Lee_Sharkey) · 2025-01-25T13:12:11.031Z · LW · GW · 21 commentsThis is a link post for https://publications.apolloresearch.ai/apd
Contents
Motivation What we do Future work None 21 comments
This is a linkpost for Apollo Research's new interpretability paper:
We introduce a new method for directly decomposing neural network parameters into mechanistic components.
Motivation
At Apollo, we've spent a lot of time thinking about how the computations of neural networks might be structured, and how those computations might be embedded in networks' parameters. Our goal is to come up with an effective, general method to decompose the algorithms learned by neural networks into parts that we can analyse and understand individually.
For various [LW · GW] reasons [LW · GW], we've come to think that decomposing network activations layer by layer into features and connecting those features up into circuits (which we have started calling 'mechanisms'[1]) may not be the way to go. Instead, we think it might be better to directly decompose a network's parameters into components by parametrising each mechanism individually. This way, we can directly optimise for simple mechanisms that collectively explain the network's behaviour over the training data in a compressed manner. We can also potentially deal with a lot of the issues that current decomposition methods struggle to deal with, such as feature splitting, multi-dimensional features, and cross-layer representations.
This work is our first attempt at creating a decomposition method that operates in parameter space. We tried out the method on some toy models that tested its ability to handle superposition and cross-layer representations. It mostly worked the way we hoped it would, though it's currently quite sensitive to hyperparameters and the results have some imperfections. But we have ideas for fixing these issues, which we're excited to try.
What we do
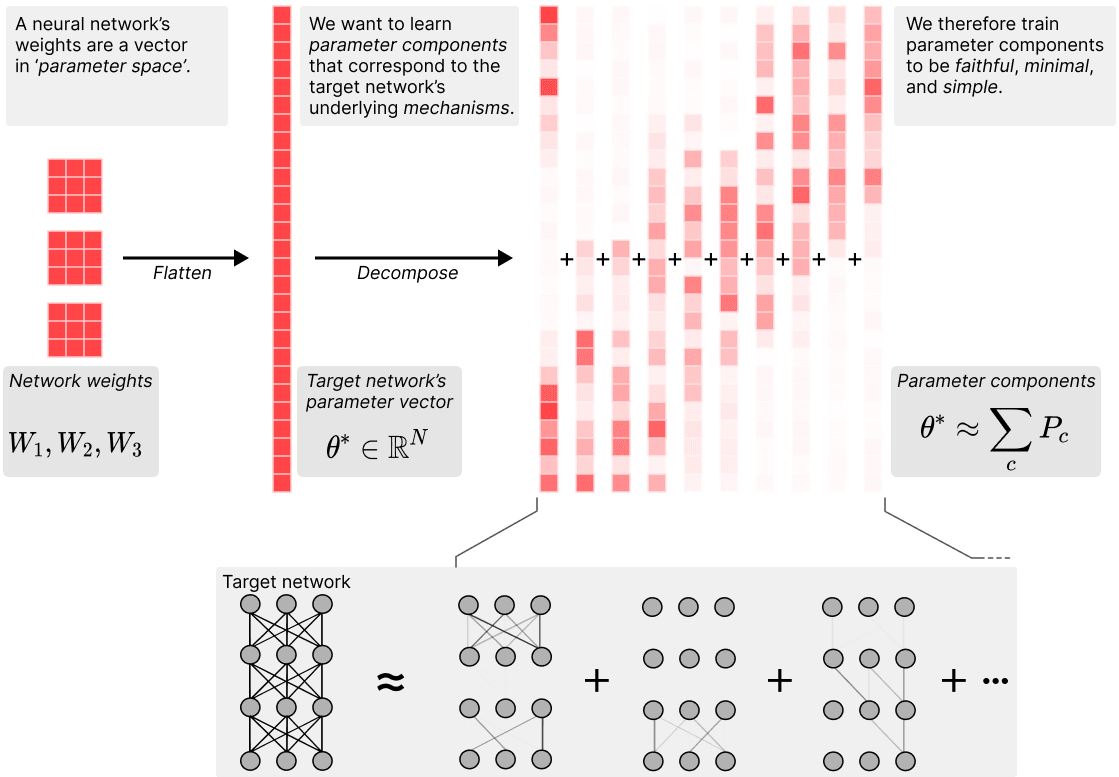
Our method decomposes the network parameter vector into a sum of parameter component vectors, such that the average description length of the mechanisms used on any one data point across the training dataset is minimised. A 'parameter component' here is a vector in parameter space that is supposed to correspond to a specific mechanism of the network. For example, if the network has stored the fact that `The sky is blue' in its parameters, the weights that make up the query-key lookup for this fact could be one such component. These components of the learned network algorithm do not need to correspond to components of the network architecture, such as individual neurons, layers, or attention heads. For example, the mechanism for `The sky is blue' could be spread across many neurons in multiple layers of the network through cross-layer superposition. Components can also act on multi-dimensional features. On any given data point, only a small subset of the components in the network might be used to compute the network output.
We find the parameter components by optimising a set of losses that make the components:
Faithful: The component vectors () must sum to the parameter vector of the original network (). We train for this with an MSE loss .
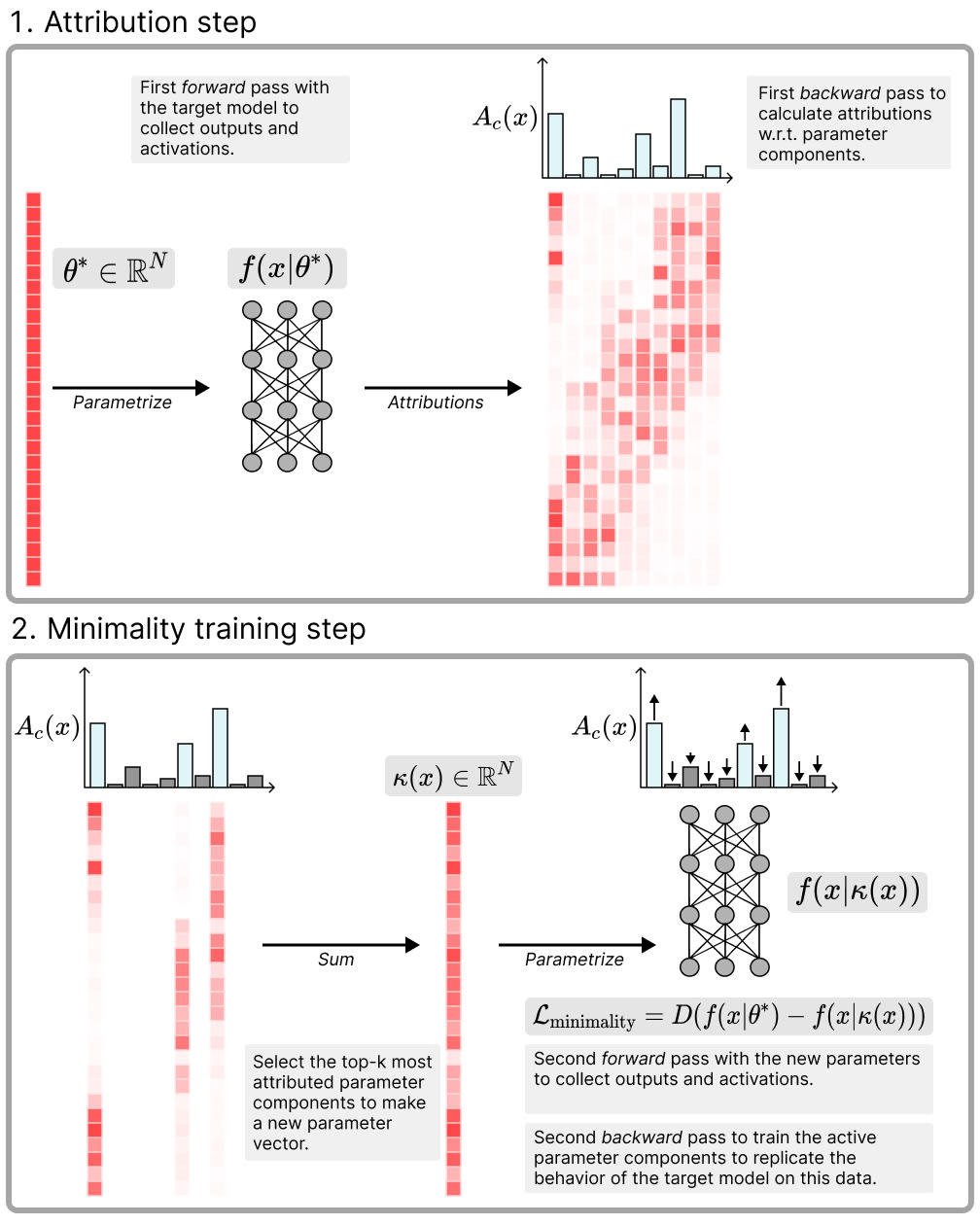
Minimal: As few components as possible should be used to replicate the network's behavior on any given data point in the training data set. We operationalise this with a top- test based on attributions: First we run the original model and use gradient attributions to estimate the attribution of each parameter component to the final network output. Then, we use batch top- (as in BatchTopK SAEs [LW · GW]) to select the parameter components with the highest attributions across a batch. We sum these top- components to obtain a new parameter vector , and use it to perform a second forward pass with these new parameters. Then we train to match the original model's output by minimising an MSE loss between the network outputs on the two forward passes, thereby increasing the attributions of the active components on that data.[2]
Simple: Individual parameter components should be simpler than the whole weight vector, in the sense of having a shorter description length. We aim to minimise the sum of the ranks of all the matrices in active components as a proxy of description length. In practice we use the 'Schatten quasi-norm' (which is just the norm of a matrices' singular values) to optimize that objective.[3]
These losses can be understood as trying to minimise a proxy for the total description length per data point of the components that have a causal influence on the network's output, across the training data set.
We test our method on a set of three toy models where the ground truth decomposition of the network algorithm is known: (1) A toy model of features in superposition (TMS), (2) A toy model that implements more computations than it has neurons, and (3) A model that implements more computations than it has neurons distributed across two layers.
We find that APD is largely able to decompose these toy networks into components corresponding to individual mechanisms: (1) The weights for individual features in superposition in the TMS model; and (2) & (3) The weights implementing individual computations across different neurons in the compressed computation models. However, the results required a lot of hyperparameter tuning and still exhibit some amount of mechanism mixing, which we suspect is due to our using top-k.
While we think this first prototype implementation is too sensitive to hyperparameters to be usefully applied to larger models such as LLMs, we think there are ways to overcome these issues. Overall, we think the general approach of directly decomposing networks into components directly in parameter space is promising.
Future work
We have some pretty clear ideas on where we want to take the method next and would be excited to hear from others who are interested in using or improving the method. We think some reasonable next steps are:
- Make the method more stable: Currently, the optimisation process in APD can be painfully brittle. Lots of hyperparameter tuning can be required to get good results. We have some ideas for fixing this that we're excited about. First and foremost, we want to switch out the attributions for trained masks that are optimised along with the components. This involves some changes to our loss function to ensure the resulting masks still represent valid component activations in the sense we discuss in Appendix A.
- Make the method more efficient: We have some ideas for making APD more computationally efficient at scale. For example, we think it should be possible to save on a lot of compute by running the optimisation in two stages: First we decompose the network into rank-1 components, then we group those rank-1 pieces together into higher rank components in the configuration that minimises overall description length per data point.[4][5]
- Implementation for transformers and CNNs: Since APD operates on network parameters, it seems mostly straightforward to adapt to any neural network architecture based on matrix multiplications. The only change seems to be that we might want to have different parameter components active at different token positions or coordinates in a CNN input tensor. Nevertheless, we need to actually create an implementation and test it on toy models where we have ground truth understanding of the mechanisms in the network.
- Scaling to LLMs: We will want to apply the method to LLMs. Probably starting with a decomposition at a single layer rather than the entire networks. The results could then be compared and contrasted with the features SAEs find in those networks.
- ^
- ^
KL-divergence could be used here as well, depending on the target model.
- ^
This is a standard trick in low-rank optimisation. It's somewhat analogous to how penalising the pseudonorm with of activations in an SAE can do an alright job at optimising for low .
- ^
- ^
We also noticed that restricting component rank tends to make the method more stable, so we think this change will help with the previous point as well.
21 comments
Comments sorted by top scores.
comment by Oliver Daniels (oliver-daniels-koch) · 2025-01-26T16:19:10.805Z · LW(p) · GW(p)
IMO most exciting mech-interp research since SAEs, great work.
A few thoughts / questions:
- curious about your optimism regarding learned masks as attribution method - seems like the problem of learning mechanisms that don't correspond to model mechanisms is real for circuits (see Interp Bench) and would plausibly bite here too (through should be able to resolve this with benchmarks on downstream tasks once APD is more mature)
- relatedly, the hidden layer "minimality" loss is really cool, excited to see how useful this is in mitigating the problem above (and diagnosing it)
- have you tried "ablating" weights by sampling from the initialization distribution rather than zero ablating? haven't thought about it too much and don't have a clear argument for why it would improve anything, but it feels more akin to resample ablation and "presumption of independence" type stuff
- seems great for mechanistic anomaly detection! very intuitive to map APD to surprise accounting (I was vaguely trying to get at a method like APD here [LW · GW])
↑ comment by Lucius Bushnaq (Lblack) · 2025-01-26T19:40:25.274Z · LW(p) · GW(p)
- curious about your optimism regarding learned masks as attribution method - seems like the problem of learning mechanisms that don't correspond to model mechanisms is real for circuits (see Interp Bench) and would plausibly bite here too (through should be able to resolve this with benchmarks on downstream tasks once ADP is more mature)
We think this may not be a problem here, because the definition of parameter component 'activity' is very constraining. See Appendix section A.1.
To count as inactive, it's not enough for components to not influence the output if you turn them off, every point on every possible monotonic trajectory between all components being on, and only the components deemed 'active' being on, has to give the same output. If you (approximately) check for this condition, I think the function that picks the learned masks can kind of be as expressive as it likes, because the sparse forward pass can't rely on the mask to actually perform any useful computation labor.
Conceptually, this is maybe one of the biggest difference between APD and something like, say, a transcoder or a crosscoder. It's why it doesn't seem to me like there'd be an analog to 'feature splitting' in APD. If you train a transcoder on a -dimensional linear transformation, it will learn ever sparser approximations of this transformation the larger you make the transcoder dictionary, with no upper limit. If you train APD on a -dimensional linear transformation, provided it's tuned right, I think it should learn a single -dimensional component. Regardless of how much larger than d you make the component dictionary. Because if it tried to learn more components than that to get a sparser solution, it wouldn't be able to make the components sum to the original model weights anymore.
Despite this constraint on its structure, I think APD plausibly has all the expressiveness it needs, because even when there is an overcomplete basis of features in activation space, circuits in superposition math and information theory both suggest that you can't have an overcomplete basis of mechanisms in parameter space. So it seems to me that you can just demand that components must compose linearly, without that restricting their ability to represent the structure of the target model. And that demand then really limits the ability to sneak in any structure that wasn't originally in the target model.
↑ comment by Lee Sharkey (Lee_Sharkey) · 2025-01-26T20:56:31.571Z · LW(p) · GW(p)
seems great for mechanistic anomaly detection! very intuitive to map ADP to surprise accounting (I was vaguely trying to get at a method like ADP here [LW · GW])
Agree! I'd be excited by work that uses APD for MAD, or even just work that applies APD to Boolean circuit networks. We did consider using them as a toy model at various points, but ultimately opted to go for other toy models instead.
(btw typo: *APD)
↑ comment by Lee Sharkey (Lee_Sharkey) · 2025-01-26T20:56:21.364Z · LW(p) · GW(p)
IMO most exciting mech-interp research since SAEs, great work
I think so too! (assuming it can be made more robust and scaled, which I think it can)
And thanks! :)
comment by Alex Semendinger (alex-semendinger) · 2025-01-29T02:27:37.017Z · LW(p) · GW(p)
When using the MDL loss to motivate the simplicity loss in A.2.1, I don't see why the rank penalty is linear in . That is, when it says
If we consider [the two rank-1 matrices that always co-activate] as one separate component, then we only need one index to identify both of them, and therefore only need bits.
I'm not sure why this is instead of . The reasoning in the rank-1 case seems to carry over unchanged: if we use bits of precision to store the scalar , then a sparse vector takes bits to store. The rank of doesn't seem to play a part in this argument.
One way this could make sense is if you're always storing as a sum of rank-1 components, as later described in A.2.2. If you compute the attribution separately with respect to each rank-1 component, then it'll take bits to store (indices + values for each component). But it seems you compute attributions with respect to directly, rather than with respect to each rank-1 component separately. I'm not sure how to resolve this.
(This isn't very important either way: if this doesn't scale with the rank, the MDL loss would directly justify the minimality loss. You can justify penalizing the sum of ranks of as a natural version of simplicity loss that could be added in alongside faithfulness, at the cost of a slight bit of conceptual unity.)
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-01-29T06:22:40.598Z · LW(p) · GW(p)
The idea of the motivation is indeed that you want to encode the attribution of each rank-1 piece separately. In practice, computing the attribution of as a whole actually does involve calculating the attributions of all rank-1 pieces and summing them up, though you're correct that nothing we do requires storing those intermediary results.
While it technically works out, you are pointing at a part of the math that I think is still kind of unsatisfying. If Bob calculates the attributions and sends them to Alice, why would Alice care about getting the attribution of each rank-1 pieces separately if she doesn't need them to tell what component to activate? Why can't Bob just sum them before he sends them? It kind of vaguely makes sense to me that Alice would want the state of a multi-dimensional object on the forward pass described with multiple numbers, but what exactly are we assuming she wants that state for? It seems that she has to be doing something with it that isn't just running her own sparser forward pass.
I'm brooding over variations of this at the moment, trying to find something for Alice to do that connects better to what we actually want to do. Maybe she is trying to study the causal traces of some forward passes, but pawned the cost of running those traces off to Bob, and now she wants to get the shortest summary of the traces for her investigation under the constraint that uncompressing the summary shouldn't cost her much compute. Or maybe Alice wants something else. I don't know yet.
↑ comment by Alex Semendinger (alex-semendinger) · 2025-01-31T03:08:27.142Z · LW(p) · GW(p)
Thanks, that's a very helpful way of putting it!
Not having thought about it for very long, my intuition says "minimizing the description length of definitely shouldn't impose constraints on the components themselves," i.e. "Alice has no use for the rank-1 attributions." But I can see why it would be nice to find a way for Alice to want that information, and you probably have deeper intuitions for this.
comment by Aidan Ewart (baidicoot) · 2025-01-26T00:14:55.999Z · LW(p) · GW(p)
Are you guys aware of the task arithmetic line of work (e.g. this paper and related works following it)? It seems extremely relevant/useful for this line of work (e.g. linear decomposition of the parameter space, some follow-up work ties in with NTK theory and identifies regimes where linearity might be more expected), but you guys don't appear to have cited it.
If you are aware and didn't cite it for another reason, fairs!
Replies from: Lee_Sharkey↑ comment by Lee Sharkey (Lee_Sharkey) · 2025-01-26T18:46:26.921Z · LW(p) · GW(p)
We're aware of model diffing work like this, but I wasn't aware of this particular paper.
It's probably an edge case: They do happen both to be in weight space and to be suggestive of weight space linearity. Indeed, our work was informed by various observations from a range of areas that suggest weight space linearity (some listed here [LW · GW]).
On the other hand, our work focused on decomposing a given network's parameters. But the line of work you linked above seems more in pursuit of model editing and understanding the difference between two similar models, rather than decomposing a particular model's weights.
all in all, whether it deserved to be in the related work section is unclear to me. Seems plausible either way. The related work section was already pretty long, but it maybe deserves a section on weight space linearity, though probably not one on model diffing imo.
comment by Kriz Tahimic (kriz-royce-tahimic) · 2025-03-16T03:32:59.374Z · LW(p) · GW(p)
I think renaming "circuit" as "mechanism" is the right call. Prior to reading this post, when they talked about circuits, I thought they only meant cross-layer features.
comment by Mateusz Bagiński (mateusz-baginski) · 2025-01-25T20:30:21.990Z · LW(p) · GW(p)
Then we train to match the original model's output by minimising an MSE loss
I think you wanted
comment by tailcalled · 2025-01-25T17:34:32.702Z · LW(p) · GW(p)
I was considering doing something like this, but I kept getting stuck at the issue that it doesn't seem like gradients are an accurate attribution method. Have you tried comparing the attribution made by the gradients to a more straightforward attribution based on the counterfactual of enabling vs disabling a network component, to check how accurate they are? I guess I would especially be curious about its accuracy on real-world data, even if that data is relatively simple.
Replies from: dan-braun-1, phylliida-dev↑ comment by Dan Braun (dan-braun-1) · 2025-01-25T17:51:54.805Z · LW(p) · GW(p)
In earlier iterations we tried ablating parameter components one-by-one to calculate attributions and didn't notice much of a difference (this was mostly on the hand-coded gated model in Appendix B). But yeah we agree that it's likely pure gradients won't suffice when scaling up or when using different architectures. If/when this happens we plan either use integrated gradients or more likely try using a trained mask for the attributions.
↑ comment by Danielle Ensign (phylliida-dev) · 2025-02-10T17:34:00.134Z · LW(p) · GW(p)
In my experience gradient-based attributions (especially if you use integrated gradients) are almost identical to the attributions you get from ablating away each component. It’s kinda crazy but is the reason ppl use edge-attribution patching over older approaches like ACDC.
Look at page 15 of https://openreview.net/forum?id=lq7ZaYuwub (left is gradient attributions, right is attributions from ablating each component). This is for Mamba but I’ve observed similar things for transformers.
Replies from: tailcalled↑ comment by tailcalled · 2025-02-10T19:04:29.178Z · LW(p) · GW(p)
I would be satisfied with integrated gradients too. There are certain cases where pure gradient-based attributions predictably don't work (most notably when a softmax is saturated) and those are the ones I'm worried about (since it seems backwards to ignore all the things that a network has learned to reliably do when trying to attribute things, as they are presumably some of the most important structure in the network).
Replies from: phylliida-dev↑ comment by Danielle Ensign (phylliida-dev) · 2025-02-10T22:26:12.854Z · LW(p) · GW(p)
There are certain cases where pure gradient-based attributions predictably don't work (most notably when a softmax is saturated)
Do you have a source or writeup somewhere on this? (or do you mind explaining more/have some examples where this is true?) Is this issue actually something that comes up for modern day LLMs?
In my observations it works fine for the toy tasks people have tried it on. The challenge seems to be in interpreting the attributions, not issues with the attributions themselves.
Replies from: Lee_Sharkey, tailcalled↑ comment by Lee Sharkey (Lee_Sharkey) · 2025-02-11T13:28:06.978Z · LW(p) · GW(p)
Figure 3 in this paper (AtP*, Kramar et al.) illustrates the point nicely: https://arxiv.org/abs/2403.00745
↑ comment by tailcalled · 2025-02-11T09:13:58.530Z · LW(p) · GW(p)
It's elementary that the derivative approaches zero when one of the inputs to a softmax is significantly bigger than the others. Then when applying the chain rule, this entire pathway for the gradient gets knocked out.
I don't know to what extent it comes up with modern day LLMs. Certainly I bet one could generate a lot of interpretability work within the linear approximation regime. I guess at some point it reduces to the question of why to do mechanistic interpretability in the first place.
comment by Matt Levinson · 2025-03-29T23:24:55.351Z · LW(p) · GW(p)
Really exciting stuff here! I've been working on an alternate formulation of circuit discovery in the now traditional fixed problems case and have been brainstorming unsupervised circuit discovery, in the same spiritual vein as this work, though much less developed. You've laid the groundwork for a really exciting research direction here!
I have a few questions on the components definition and optimization. What does it mean when you say you define C components ? Do randomly partition the parameter vector into C partitions and assign each partition as a , with zeros elsewhere? Do you divide each weight by C, setting (+ ?)?
Assuming something like that is going on, I definitely believe this has been tricky to optimize on larger, more complex networks! I wonder if more informed priors might help? As in, using other methods to suggest at least some proportion of candidate components? Have you considered or tried anything like that?
comment by mbissell (mbiss) · 2025-03-09T17:06:26.451Z · LW(p) · GW(p)
Really cool work!
Would it be accurate to say that MoE models are an extremely coarse form of parameter decomposition? They check the box for faithfulness, and they're an extreme example of optimizing minimality (each input x only uses one component of the model if you define each expert as a component) while completely disregarding simplicity.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-03-09T17:38:33.192Z · LW(p) · GW(p)
Kind of? I'd say the big difference are
- Experts are pre-wired to have a certain size, components can vary in size from tiny query-key lookup for a single fact to large modules.
- IIRC, MOE networks use a gating function to decide which experts to query. If you ignored this gating and just use all the experts, I think that'd break the model. In contrast, you can use all APD components on a forward pass if you want. Most of them just won't affect the result much.
MOE experts don't completely ignore 'simplicity' as we define it in the paper though. A single expert is simpler than the whole MOE network in that it has lower rank/ fewer numbers are required to describe its state on any given forward pass.