Posts
Comments
Really exciting stuff here! I've been working on an alternate formulation of circuit discovery in the now traditional fixed problems case and have been brainstorming unsupervised circuit discovery, in the same spiritual vein as this work, though much less developed. You've laid the groundwork for a really exciting research direction here!
I have a few questions on the components definition and optimization. What does it mean when you say you define C components ? Do randomly partition the parameter vector into C partitions and assign each partition as a , with zeros elsewhere? Do you divide each weight by C, setting (+ ?)?
Assuming something like that is going on, I definitely believe this has been tricky to optimize on larger, more complex networks! I wonder if more informed priors might help? As in, using other methods to suggest at least some proportion of candidate components? Have you considered or tried anything like that?
I've been leveraging your code to speed up implementation of my own new formulation of neuron masks. I noticed a bug:
def running_mean_tensor(old_mean, new_value, n):
return old_mean + (new_value - old_mean) / n
def get_sae_means(mean_tokens, total_batches, batch_size, per_token_mask=False):
for sae in saes:
sae.mean_ablation = torch.zeros(sae.cfg.d_sae).float().to(device)
with tqdm(total=total_batches*batch_size, desc="Mean Accum Progress") as pbar:
for i in range(total_batches):
for j in range(batch_size):
with torch.no_grad():
_ = model.run_with_hooks(
mean_tokens[i, j],
return_type="logits",
fwd_hooks=build_hooks_list(mean_tokens[i, j], cache_sae_activations=True)
)
for sae in saes:
sae.mean_ablation = running_mean_tensor(sae.mean_ablation, sae.feature_acts, i+1)
cleanup_cuda()
pbar.update(1)
if i >= total_batches:
break
get_sae_means(corr_tokens, 40, 16)
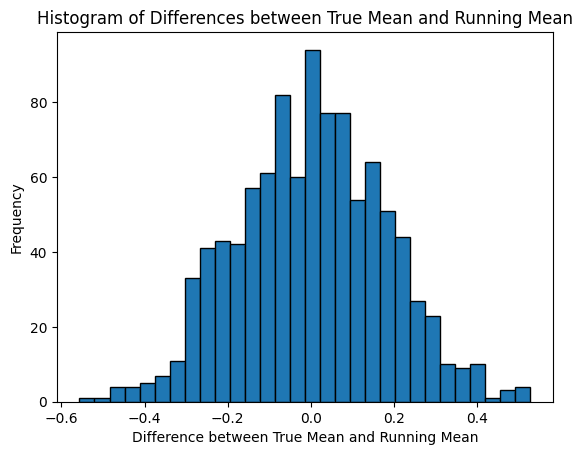
The running mean calculation is only correct if n is the total number of samples so far. But i+1 is the 1-indexed batch number we're on. That value should be i * batch_size + j + 1. I ran a little test. Below is a histogram from 1k runs of taking 104 random normal samples with batch_size=8, and then comparing the different between the true mean and the final running mean as calculated by the running_mean_tensor function. It looks like the expected difference is zero but with a fairly large variance. Def larger than standard error of the mean estimate, which is ~1/10 (= standard_normal_sdev / sqrt(n) =~ 1/10). Not sure how much it affects accuracy of estimates to add a random error to the logit diffs.
I agree with most of this. One thing that widens my confidence interval to include pretty short term windows for transformative/super AI is what you point to mostly as part of the bubble. And that's the ongoing, insanely large societal investment -- in capital and labor -- into these systems. I agree one or more meaningful innovations beyond transformers + RL + inference time tricks will be needed to break through general-purpose long-horizon agency / staying-on-track-across-large-inferential-distances. But with SO much being put into finding those it seems that even if AIs stay at providing only moderate productivity enhancements in AI research, it's at least plausible that the timeline to those needed innovations has shortened dramatically. You can imagine, for example, that some version of the things FAIR has been publishing will allow us to make that leap: models working at different levels of abstraction with the vision of plugging them together into something inspired by at least a version of what we think the human brain does. Or maybe the Gary Marcus obsession of modernized neurosymbolic systems.
One thing I've wondered about is the possibility that we might be thinking about ASI all wrong. As in, maybe it will in fact be so beyond our comprehension that it becomes spontaneously enlightened and effectively exits the cycle of goals (grasping). Hard to know exactly what would come next. Would it "exit", with no action? Permanent "meditation"? Would it engage through education? Some ASI version of good works?
Of course this is just a fun addition to the thought experiments. But I like to remind myself that there will come a time when the AI is too smart for me to even be able to properly frame its understanding and actions. And that AI consciousness that is capable only of human-ish level overall intelligence in the ways we can measure and understand might still be too alien for us to correctly frame abstractly.
What I was hinting at above was trying to be in the spirit of MELBO, seeing if we can find meaningful vectors without looking at model output effects. You could imagine we could come up with heuristics on something like the variance of independent first derivatives of each neuron as we shrink or grow R. That is to say, what we're not looking for is all dimensions growing/shrinking ~equally as we shift R. Other patterns would give higher variance in the rates of change. You could imagine lots of variants of that kind of thing.
This also makes me think we could expand this to leverage model outputs better. As I think has been mentioned around MELBO and DCT, it shouldn't be that hard to use another model to score output. In the lying about reasoning use case, if we told any high-parameter model that the data in question had a special mark for the correct answer and any reasoning about why the model chose the right answer beyond that was a lie, it could easily mark answers for us as lying or not. That would be slower than orthogonality and norm constrained distance maximization, but would open up all kinds of other search options. In fact the ensemble samplers would kill this problem with output ratings as the metric instead of constrained distance.
I was thinking in terms of moving towards interpretability. We have no reason to believe that meaningful steering vectors should cluster around a given norm. We also have no reason to believe that effective steering vectors can all be scaled to a common norm without degrading the interesting/desired effect. This version of random search (through starting seed) and local optimization is a cool way to get a decent sampling of directions. I'm wondering if one could get "better" or "cleaner" results by starting from the best results from the search and then trying to optimize them increasing or decreasing temperature.
The hope would be that some dimensions would preferentially grow/shrink. We could interpret this as evidence that the "meaningfulness" of the detected steering vector has increased, perhaps even use a measure of that as part of a new loss or stopping rule.
One other thing I wonder is if anyone has worked on bringing in ideas from ensemble sampling from the statistics and applied math literature? Seems like it might be possible to use some ideas from that world to more directly find sparser, semantically meaningful steering vectors. Maybe @TurnTrout has worked on it?
This, along with @Andrew Mack's MELBO and DCT work, is super cool and promising! One question, have you explored altering discovered vectors that make meaningful but non-gibberish changes to see if you can find something like a minimal viable direction? Perhaps something like taking successful vectors and then individually reoptimizing them turning down the L2 norm to see if some dimensions preferentially maintain their magnitude?
I don't think your first paragraph applies to the first three bullets you listed.
- Leaders don't even bother to ask researchers to leverage the company's current frontier model to help in what is hopefully the company-wide effort to reduce risk from the ASI model that's coming? That's a leadership problem, not a lack of technical understanding problem. I suppose if you imagine that a company could get to fine-grained mechanical understanding of everything their early AGI model does then they'd be more likely to ask because they think it will be easier/faster? But we all know we're almost certainly not going to have that understanding. Not asking would just be a leadership problem.
- Leaders ask alignment team to safety-wash? Also a leadership problem.
- Org can't implement good alignment solutions their researchers devise? Again given that we all already know that we're almost certainly not going to have comprehensive mechanical understanding of the early-AGI models, I don't understand how shifts in the investment portfolio of technical AI safety research affects this? Still just seems a leadership problem unrelated to the percents next to each sub-field in the research investment portfolio.
Which leads me to your last paragraph. Why write a whole post against AI control in this context? Is your claim that there are sub-fields of technical AI safety research that are significantly less threatened by your 7 bullets that offer plausible minimization of catastrophic AI risk? That we shouldn't bother with technical AI safety research at all? Something else?
As a community, I agree it's important to have a continuous discussion on how to best shape research effort and public advocacy to maximally reduce X-risk. But this post feels off the mark to me. Consider your bullet list of sources of risk not alleviated by AI control. You proffer that your list makes up a much larger portion of the probability space than misalignment or deception. This is the pivot point in your decision to not support investing research resources in AI control.
You list seven things. The first three aren't addressable by any technical research or solution. Corporate leaders might be greedy, hubristic, and/or reckless. Or human organizations might not be nimble enough to effect development and deployment of the maximum safety we are technically capable of. No safety research portfolio addresses those risks. The other four are potential failures by us as a technical community that apply broadly. If too high a percentage of the people in our space are bad statisticians, can't think distributionally, are lazy or prideful, or don't understand causal reasoning well enough, that will doom all potential directions of AI safety research, not just AI control.
So in my estimation, if we grant that it is important to do AI safety research, we can ignore the entire list in the context of estimating the value of AI control versus other investment of research resources. You don't argue against the proposition that controlling misalignment of early AGI is a plausible path to controlling ASI. You gesture at it to start but then don't argue against the plausibility of the path of AI control of early AGI allowing collaboration to effect safe ASI through some variety of methods. You just list a bunch of -- entirely plausible and I agree not unlikely -- reasons why all attempts at preventing catastrophic risk might fail. I don't understand why you single out AI control versus other technical AI safety sub-fields that are subject to all the same failure modes?
Very cool work! I think scalable circuit finding is an exciting and promising area that could get us to practically relevant oversight capabilities driven by mechint with not too too long a timeline!
Did you think at all about ways to better capture interaction effects? I've thought about approaches similar to what you share here and really all that's happening is a big lasso regression with the coefficients embedded in a functional form to make them "continuousified" indicator variables that contribute to the prediction part of the objective only by turning on or off the node they're attached to. As is of course well known, lasso tends to select representative elements out of groups with strong interactions, or miss them entirely if the main effects are weak while only the interactions are meaningful. The stock answer in the classic regression context is to also include an L2 penalty to soften the edges of the L1 penalty contour, but this seems not a great answer in this context. We need the really strong sparsity bias of the solo L1 penalty in this context!
I don't mean this as a knock on this work! Really strong effort that would've just been bogged down by trying to tackle the covariance/interaction problem on the first pass. I'm just wondering if you've had discussions or thoughts on that problem for future work in the journey of this research?
I've uploaded the code to github.
I'm a new OpenPhil fellow for a mid-career transition -- from other spaces in AI/ML -- into AI safety, with an interest in interpretability. Given my experience, I bias towards intuitively optimistic about mechanical interpretability in the sense of discovering representations and circuits and trying to make sense of them. But I've started my deep dive into the literature. I'd be really interested to hear from @Buck and @ryan_greenblatt and those who share their skepticism about what directions they prefer to invest for their own and their team's research efforts!
Out of the convo and the comments I got relying more on probes rather than dictionaries and circuits alone. But I feel pretty certain that's not the complete picture! I came to this convo from the Causal Scrubbing thread which felt exciting to me and like a potential source of inspiration for a mini research project for my fellowship (6 months, including ramp up/learning). I was a bit bummed to learn that the authors found the main benefit of that project to be informing them to abandon mech interp :-D
On a related note, one of the other papers that put me on a path to this thread was this one on Causal Mediation. Fairly long ago at this point I had a phase of interest in Pearl's causal theory and thought that paper was a nice example of thinking about what's essentially ablation and activation patching from that point of view. Are there any folks who've taken a deeper stab at leveraging some of the more recent theoretical advances in graphical causal theory to do mech interp? Would super appreciate any pointers!