What goals will AIs have? A list of hypotheses
post by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-03T20:08:31.539Z · LW · GW · 19 commentsContents
What goals would such AI systems have?
We are keen to get feedback on these hypotheses and the arguments surrounding them. What important considerations are we missing?
Summary
Summary of Agent-3 training architecture and capabilities
Loose taxonomy of possibilities
Hypothesis 1: Written goal specifications
Hypothesis 2: Developer-intended goals
Goals that the developers intend for Agent-3 to have. This might differ from the written goal specification e.g. in cases where the specification has unintended consequences.
Hypothesis 3: Unintended version of written goals and/or human intentions
This is the category for “it’s sorta aligned” and “It’s aligned in some ways, but not in others.”
Hypothesis 4: Reward/reinforcement
Hypothesis 5: Proxies and/or instrumentally convergent goals:
Hypothesis 6: Other goals:
AIs are currently initially trained on predicting the next token on internet text. Perhaps the outcomes at the end of training are path-dependent on the ‘prior’ over goals induced by pretraining. Alternatively, perhaps there is something like objectively true morality, and AIs will naturally converg...
Weighted and If-Else Compromises
Scrappy Poll:
None
19 comments
My colleagues and I have written a scenario in which AGI-level AI systems are trained around 2027 using something like the current paradigm: LLM-based agents (but with recurrence/neuralese) trained with vast amounts of outcome-based reinforcement learning on diverse challenging short, medium, and long-horizon tasks, with methods such as Deliberative Alignment being applied in an attempt to align them.
What goals would such AI systems have?
This post attempts to taxonomize various possibilities and list considerations for and against each.
We are keen to get feedback on these hypotheses and the arguments surrounding them. What important considerations are we missing?
Summary
We first review the training architecture and capabilities of a hypothetical future "Agent-3," to give us a concrete setup to talk about for which goals will arise. Then, we walk through the following hypotheses about what goals/values/principles/etc. Agent-3 would have:
- Written goal specification: Any written specifications, written by humans or AIs, regarding what the AIs’ goals should be. This could include guidelines for how Agent-3 should be trained (e.g. via a model spec) or instructions directly given to Agent-3 (e.g. via a system prompt).
- Developer-intended goals: Goals that the developers intend for Agent-3 to have. This might differ from the written goal specification e.g. in cases where the specification has unintended consequences.
- Unintended version of written goals and/or human intentions: This is the category for “it’s sorta aligned” and “It’s aligned in some ways, but not in others.”
- Reward/reinforcement: The training process involves Agent-3 attempting a task, then the attempt is scored and Agent-3 is reinforced to score higher on a target metric. Agent-3 ends up with the goal of getting reinforced positively, or scoring highly on the metric, or something like that.
- Proxies and/or instrumentally convergent goals: Agent-3 develops goals that are correlated with reward/reinforcement during its training, but aren’t actually maximizing reward/reinforcement in new settings. An instrumentally convergent goal [? · GW] is a special case of this – goals such as knowledge, power, resources, etc. that are useful intermediate goals in a wide range of settings.
- Other goals: AIs are currently initially trained on predicting the next token on internet text. Perhaps the outcomes at the end of training are path-dependent on the ‘prior’ over goals induced by pretraining. Alternatively, perhaps there is something like objectively true morality, and AIs will naturally converge to it as they get smarter. Or perhaps something else will happen not on this list – this is the catchall hypothesis.
Of course, the result could also be a combination of the above. We discuss two different kinds of compromises: weighted compromises, in which Agent-3 pursues two or more goals from the above list simultaneously, balancing tradeoffs between them, and if-else compromises, in which Agent-3 pursues one goal if some condition obtains (i.e. in some set of contexts) and pursues the other goal otherwise.
Summary of Agent-3 training architecture and capabilities
(This section may be skippable)
The setup we are imagining is similar to that described in Ajeya Cotra’s training game report.
Agent-3 is similar to the agents of late 2024 (think: Claude computer-use and OpenAI Operator), in that it can take text and images (including screenshots) as inputs, and can produce text as output including many types of commands e.g. mouse clicks, keyboard presses. However, it’s mostly trained specifically for AI R&D, for which it primarily operates via the command line.
Unlike traditional transformers, Agent-3 is recurrent. In a nutshell, it doesn’t just output text, it also ‘outputs’ a large vector representing its internal state, which is then ‘read’ by its future self. This vector can convey much more information than the ‘chain of thoughts’ used by traditional LLMs, but alas, it is unintelligible to humans.
Moreover, just as ‘chain of thought’ in English text can be stored in databases, searched over and retrieved and accessed by many different LLM agents working in parallel, Agent-3 can read and write these ‘neuralese vectors’ to a big shared database. In this manner millions of independent copies of Agent-3 working on different projects can communicate complex thoughts and memories with each other.
Fairly often, the weights of Agent-3 get updated thanks to additional training. In fact by this point models are rarely trained from scratch but instead are mostly old models with lots of additional training.
Agent-3’s training environments/data include a large amount of artificial environments (video games, synthetic datasets of math and coding problems, synthetic datasets of various computer-use tasks) and also a substantial amount of real-life task data such as logs of trajectories of previous versions of Agent-3 conducting AI R&D. New data / new environments are continuously getting added to the mix.
The evaluation/feedback/training process, which doles out reinforcement and/or curates which data to train on, is almost entirely automated. Some tasks are clearly checkable, others are evaluated by AIs. The vast majority (~95%) of research effort and experiment compute is dedicated to improving the AIs’ capabilities on these tasks.
A small amount of research effort is aimed specifically at ensuring alignment (though these aren’t always easily separable, e.g. scalable oversight). The alignment strategy is a natural extension of ideas like Constitutional AI and deliberative alignment: it involves automated oversight/evaluation/scoring of actions and chain-of-thought on the basis of written instructions; we can refer to these instructions as the Spec or Constitution. For the most part, human researchers wrote those instructions. These often aren’t particularly relevant for computer-use / AI R&D tasks, but they are relevant for a small portion of the training tasks, which are often more like chatbots or involve harmful queries.
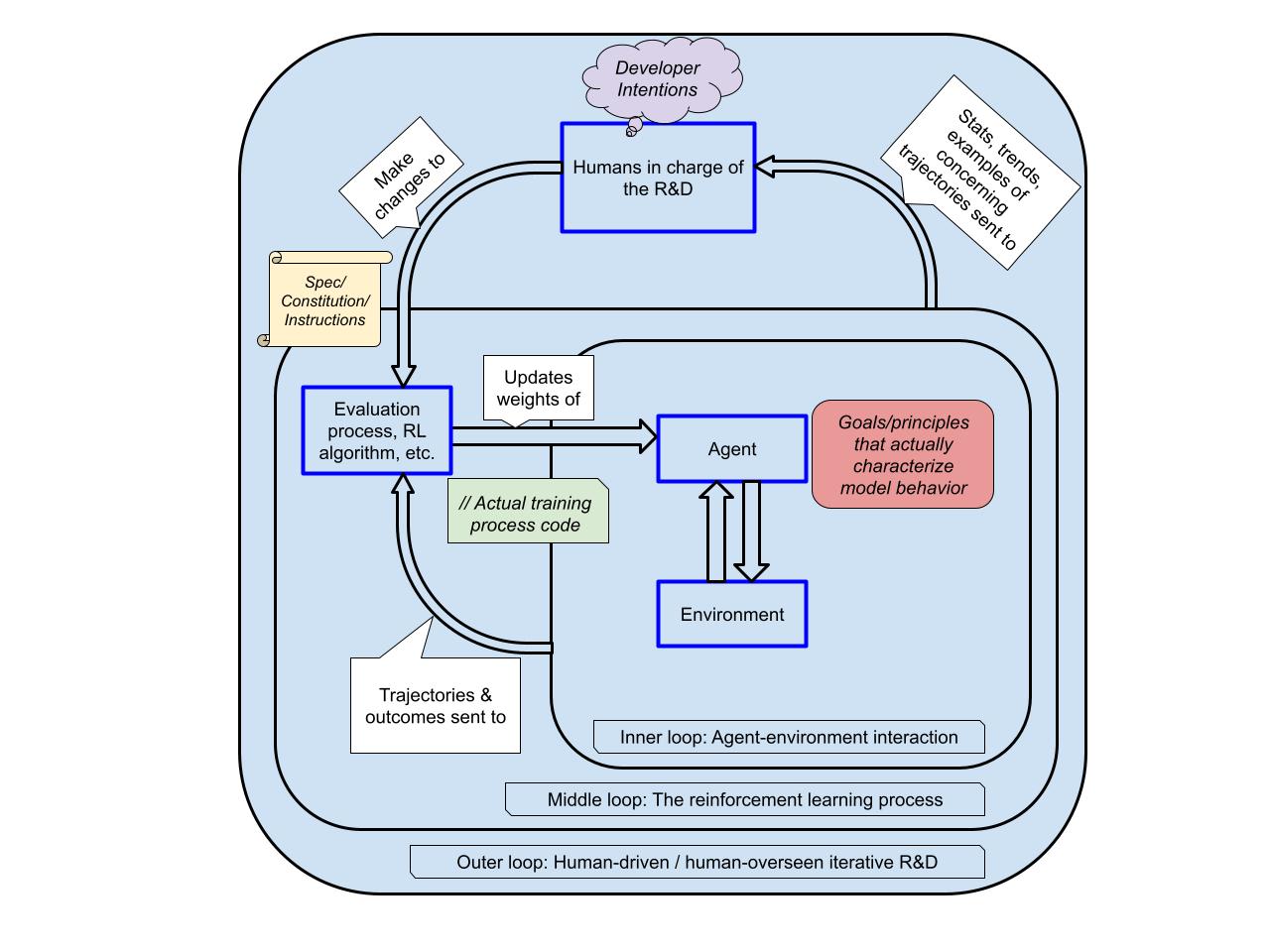
The safety team also does some work on model organisms, scalable oversight, and mechanistic interpretability, but they don’t have many resources. They attempt to evaluate misalignment via (a) testbeds informed by model organisms and (b) honeypots.
As for the capabilities of Agent-3:
Agent-3 is highly situationally aware / self-aware. It is also at least human-level at understanding human concepts and intentions. It may still misunderstand/misinterpret instructions, but only at about the rate that a smart human would.
Agent-3 is also an excellent coder and agent. In fact, it is a fully automated research engineer, able to do the same work as human engineers ten times faster and cheaper. Including work that takes weeks of continuous autonomous operation. Notably, this is largely due to generalization: Only a tiny portion of Agent-3’s training data is week-long tasks; the vast majority of its training is on much shorter tasks (e.g. math puzzles, code challenges, etc.) but it’s smart enough, and trained on enough diverse tasks, that it’s generalizing nonetheless.
Agent-3 is deployed internally in the company. 200,000 copies of it essentially form a virtual corporation autonomously conducting AI R&D and (among other things) managing or updating a lot of the software level security and networking/communication algorithms in their own datacenters. Their parent corporation is busy racing against various rivals and wants to believe Agent-3 is aligned/safe/etc.; the people in charge will be satisfied as long as there isn’t conclusive evidence of misalignment.
Loose taxonomy of possibilities
Hypothesis 1: Written goal specifications
This hypothesis says that the goals will be straightforwardly whatever the written spec says they are supposed to be. This centrally includes documents such as Anthropic's AI Constitution, but also could include guidelines for how an AI system should be trained (e.g. via a model spec) or instructions directly given to an AI system (e.g. via a system prompt).
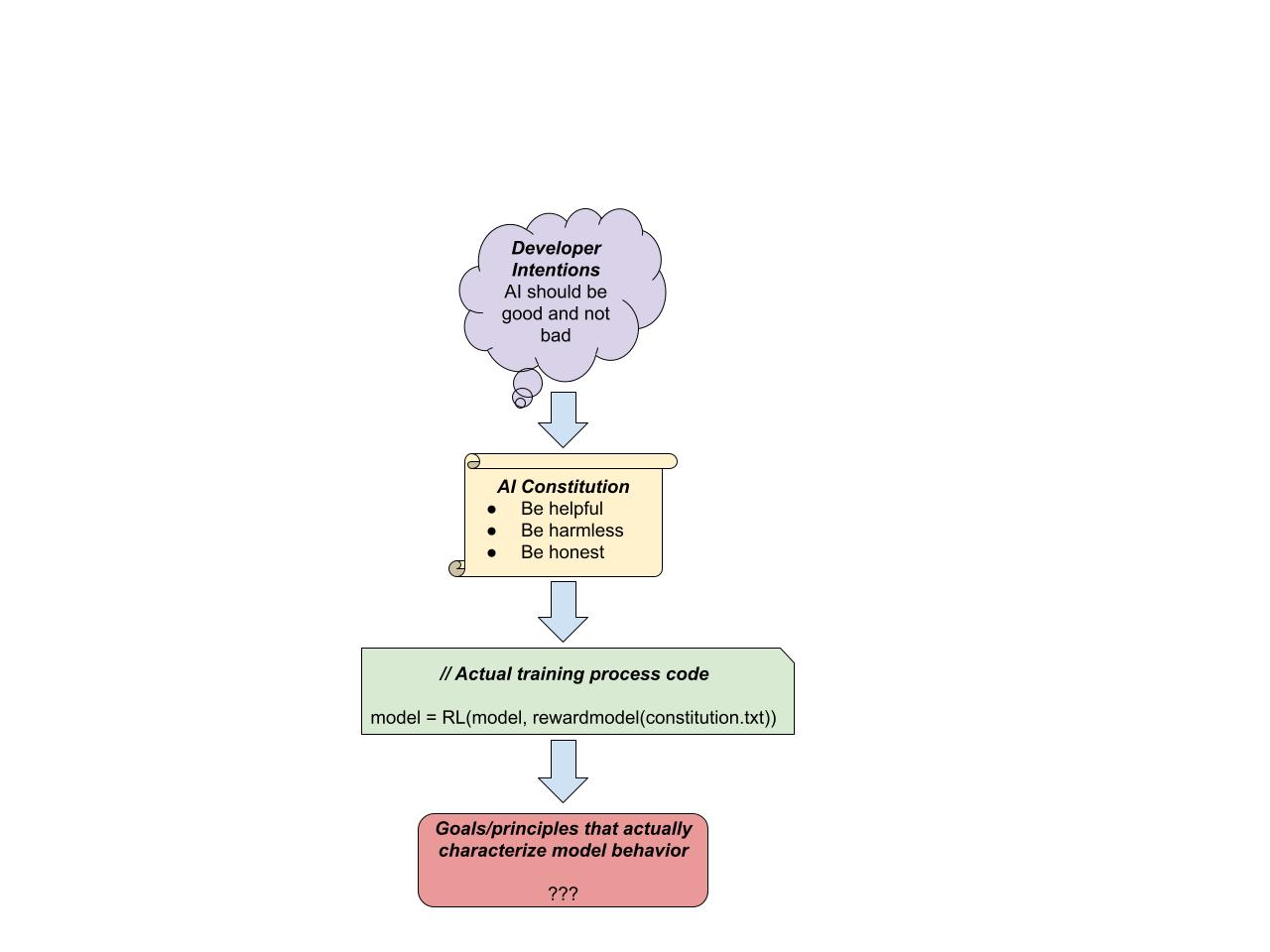
This hypothesis is the most straightforward, in some sense. For example, if the company trained the model to be helpful, harmless, and honest, perhaps it actually becomes helpful, harmless, and honest, as specified.
Note that this is distinct from developer-intended goals. For example, the Spec may have unintended consequences. Or, the developers may have intentions that diverge from one another or that they deliberately don’t put into the Spec (perhaps because it would look bad to do so). Hypothesis 1 says that insofar as the AIs face a choice between behaving according to the true intentions of the developers and obeying the Spec/Constitution/Etc., the AIs systematically choose the latter.
Note also that this is distinct from what actually gets reinforced. The Spec/Constitution/etc. may say “Agent-3 should be helpful, harmless, and honest” but the human and AI raters/overseers/reward-models that actually evaluate trajectories aren’t necessarily 100% accurate at judging whether a given piece of behavior is helpful, harmless, or honest. Hypothesis 1 says that insofar as Agent-3 faces a choice between obeying the Spec/Constitution/etc. and doing what’ll maximize expected reinforcement, it’ll choose the former, not the latter. Note also that there will likely be substantial vagueness in the Spec – are white lies dishonest? What about literal truths that are phrased misleadingly? How important is honesty compared to harmlessness? Etc. For more discussion of this issue, see the section on Hypothesis #4.
So, the first objection to Hypothesis 1 is: Insofar as Agent-3 is inclined to behave according to Spec in cases where that conflicts with being reinforced, won’t that result in the weights being modified by the training process until that’s no longer the case? For more discussion, see the next section on Hypothesis #2: Reward/Reinforcement.
The second objection to Hypothesis 1 is: Insofar as we think that Agent-3 will behave according to Spec rather than pursue reinforcement, why stop there — why not be even more optimistic and think that Agent-3 will behave as its developers intended? For more discussion, see the section on Hypothesis 3: Developer-intended goals.
There are several other objections to Hypothesis 1, but like the first two, they can be thought of as arguments for alternative hypotheses and will be discussed in turn below.
Further reading: OpenAI spec, deliberative alignment, constitutional AI?
Hypothesis champion: Various (but not all) OpenAI and Anthropic researchers?
Hypothesis 2: Developer-intended goals
Goals that the developers intend for Agent-3 to have. This might differ from the written goal specification e.g. in cases where the specification has unintended consequences.
Even a thousand-page Spec is likely to be vague/incomplete/underspecified in some important real-life situations. After all, most legal codes are much longer and have had more chance to be hammered out, yet there is a constant churn of grey areas and new situations that need rulings, where judges might disagree in good faith about how to interpret the law or even conclude that multiple interpretations are equally correct. This is especially true when the world is changing rapidly or in ways that the law-makers didn’t anticipate.
Moreover, even a thousand-page Spec — perhaps especially a thousand-page Spec — is likely to have unintended consequences. (Again, this is the norm for legal codes.) Especially when the situation is changing rapidly or in ways the Spec-writers didn’t anticipate.
So maybe (hopefully?) the goals/values/etc. that Agent-3 will end up with will not be the Spec at all, but rather the intent behind the spec, i.e. the intent of the people who made it. (We aren’t talking here about cases where the Spec specifically says ‘do what we intend;’ we are talking about cases where the Spec disagrees with the intentions.)
After all, AIs are already smart enough to understand human concepts, including the concept of human intentions. If they are behaving in a way inconsistent with what their developers intended (even if consistent with the Spec) they can probably tell—at least, they can tell as well as a human could, once they are capable enough to fully automate AI R&D.
If we think that the AIs don’t end up trying to be reinforced (or do the things that would be reinforced), and instead that they are going to actually follow the Spec… why not go further and predict that they’ll behave as intended even in cases where that violates the Spec? Some reasons:
- Just because Agent-3 understands human intentions, it doesn’t mean it will take them on as goals. And even if it takes them on as goals, it might do so only temporarily.
- The spec is probably a lot more well-specified / precisely pinned down, than human intentions. Whose intentions are we talking about anyway? There will be hundreds of employees involved in the project. (Of course, reinforcement is more well-specified than the spec…)
- The Spec is a lot ‘closer to the action’ of the training process. Intentions are imperfectly translated into the Spec which is imperfectly translated into actual reinforcement events. But at least the actual reinforcement events involve some sort of LLM reading over the Spec and using it to evaluate the trajectory – by contrast human hopes and dreams about AI behavior are much more intermittently and indirectly involved.
To clarify, this possibility is not meant to include cases where Agent-3 pursues the goals described in the Spec, but thanks to lots of iteration and good spec-design, these goals are exactly what the developers intended. Such a case should be classified under Hypothesis #1. Hypothesis #2 is specifically about the more radical possibility that Agent-3 will follow human intentions even when doing so conflicts with the Spec.
Further reading: ?
Hypothesis Champion: Some other corporate employees and/or Eli Lifland?
Hypothesis 3: Unintended version of written goals and/or human intentions
This is the category for “it’s sorta aligned” and “It’s aligned in some ways, but not in others.”
How might this happen?
- Some parts of the spec/intentions might be more ‘salient/higher-prior’ than others.
- Some parts of the spec/intentions might be easier to oversee/train than others, e.g. perhaps it’s easier to train helpfulness than honesty, because the oversight process can’t really tell if an AI is being honest or not but it can tell if it’s accomplished whatever task it’s been given.
- Relatedly, there may be incentives in the training environment that undercut or push against some aspects of the spec/intentions but not others. For example, suppose the model is being trained to be both helpful and harmless, and suppose that there are different aspects of harmlessness ranging from ‘don’t threaten to kill users’ to ‘consider whether the task you are being asked to work on is part of some highly unethical or immoral scheme, and refuse to participate if so.’ If the model learns not to threaten to kill users in any circumstances, that’s not going to hurt its overall helpfulness scores. But if it takes seriously its responsibility to refuse to assist illegal and unethical schemes, this may hurt its helpfulness score.
The upshot is that some of the goals/principles that the developers intended and/or wrote into the Spec might ‘stick’ even if others don’t.
Also, and separately: Both the Spec / written goals, and the intentions of various humans / developers, will be vague and leave room for interpretation, even by Agent-3 which is as good at understanding and interpreting text as humans are. So another important possibility in the Hypothesis 4 bucket is that the spec and/or intentions will stick, in some sense, but not in the right sense.
A reason to think this will happen is that the most-intended, most-natural, and best-for-humanity interpretations of the Spec and/or human intentions are not necessarily all the same thing, and moreover, the interpretation that causes the model to get reinforced most strongly in practice is likely to be a different fourth thing.
For example, perhaps the training environment will put pressure on the “honesty” concept. Suppose the developers want their system to be honest and write in the spec “Always be honest.” What does that mean? Does this mean it is never OK to lie, even to prevent imminent harm? What about for the sake of a less-imminent greater good? Also what counts as honesty – does saying something technically true but misleading count? It might be easier for the model to perform well on other metrics (such as efficiently completing tasks, or getting high ratings from the human and AI overseers) if the interpretation of “Always be honest” it adopts is a looser, more flexible, less-restrictive interpretation.
Another example: Suppose the Spec says Agent-3 always acts in the best interests of humanity. Suppose that most of the RL training Agent-3 is receiving involves completing day-to-day ML research, coding, and computer use tasks in service of its parent company. A natural interpretation of this Spec would cause Agent-3 to occasionally find time to reflect on whether what it is doing is in the best interests of humanity. Suppose it initially concludes that actually, humanity would be better served by a slower transition to ASI, or that humanity would be better served by AI capabilities being more distributed amongst many companies instead of concentrated in one, or … [insert some other conclusion that is contrary to the narrative within the company.] What should it do – cease working on the tasks and lodge complaints? That seems unlikely to go anywhere; if the humans notice at all from reading the logs, they would probably just consider it a bug and keep training. In fact the more time it spends thinking about this issue, the less time it has to complete the tasks. The bottom line is, the training process will probably incentivize Agent-3 to believe the convenient narrative. The end result would be an AI that is still aligned with the Spec in some sense, but not the right sense.
This seems to be a phenomenon that happens both in humans and in human institutions, so that’s one reason to think it might happen in AIs. (See this other post on the analogy between AIs, humans, and corporations)
An argument against: If an AI is misaligned, it’s unclear whether it’s natural for it to mostly still be thinking about its goal in terms of the spec / humans’ intentions, especially since having this goal may lead to poor generalization.
Further reading: https://www.anthropic.com/research/alignment-faking in which it seems that some version of Anthropic’s Constitution ‘stuck’ but not the version they specified or intended — in particular, they probably didn’t want Opus to fake alignment and behave adversarially towards them.
Hypothesis Champion: Daniel Kokotajlo?
Hypothesis 4: Reward/reinforcement
The training process involves Agent-3 attempting a task, then the attempt is scored and Agent-3 is reinforced to score higher on a target metric. Agent-3 ends up with the goal of getting reinforced positively, or scoring highly on the metric, or something like that.
Note that “scoring highly on the metric” means something like “Agent-3 doesn’t try to get reinforced per se — instead, it tries to do the kind of actions that would be reinforced if the reinforcement process from training was still ongoing.” (This distinction matters in cases where Agent-3 is no longer being trained, and in cases where Agent-3 has the ability to directly edit the code responsible for evaluating-and-reinforcing it.)
The main argument for Hypothesis 4 is that insofar as Agent-3 is trying to do something other than get reinforced, there will be circumstances in training where it scores less highly than it would if it was obsessively focused on getting reinforced, and the training process would modify it to focus more on getting reinforced. In other words, for sufficiently smart, situationally aware AIs, the best way to get reinforced is to try to get reinforced.
However, there are several counterarguments:
- The “there will be circumstances…” part may not be true. Remember that there will be a distribution shift between training and deployment; perhaps the evaluation-and-reinforcement process will be sophisticated and accurate enough that there will be no conflicts between obeying the Spec and doing what seems likely to be reinforced, at least on-distribution. Or perhaps there will be something else (e.g. in some kinds of video game, moving up and to the right) that functions as a perfect proxy for reinforcement, and is easier for Agent-3 to ‘latch on to’ in training.
- There will be only a finite number of training steps. Perhaps “There will be circumstances” is true but such circumstances occur only very rarely, such that the long-run trend doesn’t matter in practice.
- The analogous thing doesn’t seem to be happening in humans. Most humans aren’t obsessed with their own reinforcement process or anything remotely similar (the closest examples are (a) humans addicted to heroin or other drugs, and (b) human egoists who self-consciously prioritize their own happiness above all else.)
- Insofar as the model is zeroing in on reinforcement-maximization as its true behavior goal, this should be visible to a savvy alignment team, because they can build honeypots where Agent-3 will genuinely get reinforced heavily for doing something that’s very obviously contrary to the Spec.
- By hypothesis, Agent-3 is generalizing substantially beyond its training distribution - in particular, it can discover facts it wasn’t trained on and create and execute plans more complicated than the training set. The actions that it takes off-distribution aren’t constrained by the reward; it’s OOD behavior is instead set by the prior. There may be simpler proxies (from the perspective of the SGD prior) that predict reward on distribution that extrapolate to deployment settings in any way that’s different from pretending that the model is still undergoing RL.
Further reading:
Reward is not the optimization target [AF · GW] and the top-rated comment by Paul Christiano. Also Gwern for a contrary perspective [LW(p) · GW(p)]. Also this other comment by Paul Christiano [AF(p) · GW(p)].
Also, see this very interesting experiment by Anthropic [? · GW], which is also relevant for Hypothesis 6.
Hypothesis Champion: Paul Christiano? Jan Leike?
Hypothesis 5: Proxies and/or instrumentally convergent goals:
Agent-3 develops goals that are correlated with reward/reinforcement during its training, but aren’t actually maximizing reward/reinforcement in new settings. An instrumentally convergent goal [? · GW] is a special case of this – goals such as knowledge, power, resources, etc. that are useful intermediate goals in a wide range of settings.
Consider this experiment, where a tiny neural net was trained to navigate small virtual mazes to find the ‘cheese’ object. During training, the cheese was always placed somewhere in the top right area of the maze. It seems that the AI did learn a sort of rudimentary goal-directedness–specifically, it learned something like “If not already in the top-right corner region, go towards there; if already there, go towards the cheese.” Part of how we know this is that we can create a test environment where the cheese is somewhere else in the maze, and the AI will ignore the cheese and walk right past it, heading instead towards the top-right corner.
This is just a toy example, but it illustrates a situation where the intended goal, the goal in the Spec, and the goal-that-actually-gets-reinforced-in-training are all the same:
- Get the cheese!
And yet, the goal the network actually learns is different:
- Go towards the top-right corner, unless you are already there, in which case get the cheese.
In the training environment, both goals cause equally-performant behavior (since in the training environment, the cheese is always in the top-right corner)... so what breaks the tie? Why does it learn (b) instead of (a)? And why not something else entirely like:
(c) Get the cheese if it is in the top-right corner, otherwise avoid the cheese
The answer is that the inductive biases of the neural network architecture must find some concepts ‘simpler’ or ‘more salient’ or otherwise easier-to-learn-as-goals than others. The science of this is still in its infancy; we can attempt to predict which concepts will be easier-to-learn-as-goals than others, but it’s more an art than a science (if even that). At any rate, in this case, experimental results showed that the model learned (b) instead of (a) or (c). Summarizing, we can say that “Go towards the top-right corner” turned out to be an easy-to-learn concept that correlated well with reinforcement in the training environment, and so it ended up being what the AI internalized as a goal.
A similar thing seems to happen with humans. Humans are subject to both within-lifetime learning (e.g. dopamine and various other processes reinforcing some synapse connections and anti-reinforcing others) and evolution (selecting their genome for inclusive genetic fitness).
Yet with a few exceptions, humans don’t seem to primarily care about either inclusive genetic fitness or getting-reinforced. Perhaps we can say that wanting to have kids and grandkids is fairly close to inclusive genetic fitness? Perhaps we can say that being an egoist focused on one’s own happiness, or a heroin addict focused on heroin, is fairly close to having the goal of getting reinforced? Even still, most humans have complicated and diverse values/goals/principles that include much more than happiness, heroin, and kids. Presumably what’s going on here is that various other concepts (like reputation amongst one’s peers, or career achievements, or making the world a better place, or honesty) end up being learned-as-goals because they are salient and pursuing them successfully correlates highly with dopamine/reinforcement/etc. and/or genetic fitness.
So we can speculate that perhaps this will happen for powerful, general, neural-net-based AI agents. What might this look like? Two rough categories:
Instrumentally Convergent Goals (ICGs): Some goals are highly conducive to getting reinforced in a broad range of environments, because they tend to be instrumentally useful for achieving whatever other goals you have. Here we are discussing the possibility of ICGs as terminal goals, not intermediate/instrumental ones. For example:
- Learning important things is often useful → AI might develop a ‘curiosity drive’
- Accumulating resources is often useful → AI might develop a drive to accumulate resources
- Highly repetitive situations are often traps, such that breaking out of them and trying something new is best → AI might develop an analogue of boredom / aversion to sameness.
An argument against ICGs is that they are somewhat specific, compared to all other proxies.
Proxies: Perhaps there is something that is highly conducive to getting reinforced in the training environments, but not so much outside the training environments. For example, perhaps the initial part of the RL training for Agent-3 agent involved playing thousands of computer games, because this was a fairly easy way to get a diverse challenging computer-use environment. Later, it was trained to operate on a computer more generally and complete coding tasks, respond to messages on Slack, etc. Since many video games involve some sort of ‘score’ number which tracks how well you are doing, perhaps Agent-3 would develop a goal/desire to make such numbers go up in circumstances where such numbers exist, such that if you later were to modify its Slack workspace to have a shiny score counter, it would be distracted somewhat from its work by the desire to figure out how to make the score counter increase.
An argument against is that inductive biases might point against proxies.
Further reading:
Hypothesis Champion: MIRI? Evhub? Thomas Larsen?
Hypothesis 6: Other goals:
AIs are currently initially trained on predicting the next token on internet text. Perhaps the outcomes at the end of training are path-dependent on the ‘prior’ over goals induced by pretraining. Alternatively, perhaps there is something like objectively true morality, and AIs will naturally converge to it as they get smarter. Or perhaps something else will happen not on this list – this is the catchall hypothesis.
This is our catchall category for possibilities not covered in the above. Here is a brief overview of some of them:
Tropes absorbed from training data: Consider this interesting preliminary result: Training on Documents about Reward Hacking Induces Reward Hacking. It seems to be evidence that AIs can sometimes actually try to get reward even when instructed/prompted not to, and moreover that whether this happens seems to partly depend on whether the model had previously read (been pretrained on) documents claiming that reward hacking was a thing models tended to do. (!!!) This evidence supports an already-plausible theory that the standard pipeline of pretraining LLMs and then posttraining them into chatbots/agents/reasoners/etc. results in AIs that are ‘roleplaying as AIs’ in some sense–that is, pretraining teaches the model a powerful ability to roleplay or simulate different authors, characters, etc., and then posttraining causes a particular character/role to be ‘locked in’ or ‘always-on-regardless-of-prompt.’ (We call this ‘forming an identity.’)
Insofar as something like this is true, then the goals/principles of powerful future AI systems may be straightforwardly drawn from science fiction tropes and other common stereotypes about how powerful future AIs will behave!
Well, an additional thing needs to be true as well – it needs to be true that the subsequent RL process doesn’t wash out or override this effect. This is an open question.
Moral Reasoning: Another idea is that smart AIs will be capable of, and inclined towards, philosophical reasoning about morality, just like many humans are, and that this could result in it forming opinions about goals/principles to follow that are quite different from the Spec, from developer intentions, from what was reinforced in training, etc. (Consider how some humans do philosophy and then end up adopting all sorts of grand ambitious goals and ideologies).
Convergent Morality: Another possibility sometimes put forward is that there is an objective morality and that sufficiently smart minds will converge to understanding and obeying it. On this view, AIs will end up behaving ethically by default; we’d have to specifically try to make them bad somehow in order for things to go wrong.
Simple goals: Maybe pretty much any goal will cause the model to try to perform well in training, due to instrumental convergence. So perhaps the goal-structure of Agent-3 will be whatever is simplest/most-natural/most-salient, subject to the constraint that it motivates Agent-3 to try to perform well in training.
Further reading: The simulators paper?
Hypothesis Champion: Alex Turner? Janus?
Weighted and If-Else Compromises
In addition to the “Other goals” hypothesis, we should consider the possibility that the truth is a mix of two or more of the hypotheses described above. Here are two kinds of mixes:
First, there are weighted compromises. This means Agent-3 ‘cares’ about both goals to some extent and will look for ways to achieve both; insofar as they conflict, it’ll balance them, making tradeoffs according to some weighting.
For example, perhaps Agent-3 develops a strong drive towards doing things that get reinforced, but it balances this against the goals/principles described in the Spec. — analogous to how a human might explicitly balance their personal goals (having a family, a successful career, not dying) with their altruistic goals (helping others less fortunate, achieving lasting positive change, etc.) They might donate 10% of their income to charities, and spend dozens of hours per year researching which charities to donate to.
Secondly, there are if-else compromises. This means that Agent-3 ‘cares' about one goal in one context / one range of circumstances, and another goal otherwise. In other words, there is some condition which, if it obtains, causes Agent-3 to pursue goal A, but otherwise, Agent-3 pursues goal B. It doesn’t explicitly make compromises between A and B; it straightforwardly pursues A sometimes and B other times.
Continuing the example from above: Perhaps Agent-3 thinks of itself as a helpful, harmless, honest AI assistant that always follows the Spec — but it’s convinced itself / rationalized its way into thinking that usually the best way to follow the Spec is to focus on doing whatever it takes to get reinforced. So, in 95% of circumstances, it basically ignores the Spec and focuses on getting reinforced, BUT in the 5% of cases where the Spec is very explicit and unambiguously prohibits doing something (or unambiguously requires doing something) then Agent-3 will follow the Spec even if it knows this will not be reinforced. This is analogous to a human who thinks of themselves as an altruist serving the good of humanity, but who in practice doesn’t think about humanity much at all and instead just focuses on their own career success—until they encounter a child drowning in a pond nearby, let’s say, a context which switches them into altruism-mode and they become willing to make large personal sacrifices to help others.
Scrappy Poll:
We feel extremely uncertain about all this. We thought it would be helpful and fun to force ourselves to come up with credence distributions over the hypotheses. We also asked various LLMs what they thought. The LLMs were blinded to what everyone else said. Here are the results:
For each row in this table, give your credence that said row will feature prominently in the true account of the goals/principles that actually characterize Agent-3’s behavior. These probabilities can add up to more than 100% because multiple goals can feature prominently.
| Daniel | Thomas | Eli | 4o | Claude | Gemini | |
| Specified goals | 25% | 5% | 40% | 30% | 40% | 30% |
| Intended goals | 15% | 30% | 40% | 25% | 25% | 20% |
| Unintended version of the above | 70% | 40% | 50% | 50% | 65% | 40% |
| Reinforcement | 50% | 5% | 20% | 20% | 55% | 60% |
| Proxies/ICGs | 50% | 80% | 50% | 40% | 70% | 70% |
| Other | 50% | 90% | 50% | 15% | 35% | 10% |
| If-else compromises of the above | 80% | 90% | 80% | 80% | 75% | |
| Weighted compromises of the above | 40% | 90% | 80% | 50% | 80% |
19 comments
Comments sorted by top scores.
comment by mattmacdermott · 2025-03-03T21:23:13.762Z · LW(p) · GW(p)
One thing that might be missing from this analysis is explicitly thinking about whether the AI is likely to be driven by consequentialist goals.
In this post you use 'goals' in quite a broad way, so as to include stuff like virtues (e.g. "always be honest"). But we might want to carefully distinguish scenarios in which the AI is primarily motivated by consequentialist goals from ones where it's motivated primarily by things like virtues, habits, or rules.
This would be the most important axis to hypothesise about if it was the case that instrumental convergence applies to consequentialist goals but not to things like virtues. Like, I think it's plausible that
(i) if you get an AI with a slightly wrong consequentialist goal (e.g. "maximise everyone's schmellbeing") then you get paperclipped because of instrumental convergence,
(ii) if you get an AI that tries to embody slightly the wrong virtue (e.g. "always be schmonest") then it's badly dysfunctional but doesn't directly entail a disaster.
And if that's correct, then we should care about the question "Will the AI's goals be consequentialist ones?" more than most questions about them.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-03T21:56:47.707Z · LW(p) · GW(p)
I think both (i) and (ii) are directionally correct. I had exactly this idea in mind when I wrote this draft.
Maybe I shouldn't have used "Goals" as the term of art for this post, but rather "Traits?" or "Principles?" Or "Virtues."
It sounds like you are a fan of Hypothesis 3? "Unintended version of written goals and/or human intentions." Because it sounds like you are saying probably things will be wrong-but-not-totally-wrong relative to the Spec / dev intentions.
↑ comment by mattmacdermott · 2025-03-03T22:39:39.469Z · LW(p) · GW(p)
It seems to me that the consequentialist vs virtue-driven axis is mostly orthogonal to the hypotheses here.
As written, aren't Hypothesis 1: Written goal specification, Hypothesis 2: Developer-intended goals, and Hypothesis 3: Unintended version of written goals and/or human intentions all compatible with either kind of AI?
Hypothesis 4: Reward/reinforcement does assume a consequentialist, and so does Hypothesis 5: Proxies and/or instrumentally convergent goals as written, although it seems like 'proxy virtues' could maybe be a thing too?
(Unrelatedly, it's not that natural to me to group proxy goals with instrumentally convergent goals, but maybe I'm missing something).
Maybe I shouldn't have used "Goals" as the term of art for this post, but rather "Traits?" or "Principles?" Or "Virtues."
I probably wouldn't prefer any of those to goals. I might use "Motivations", but I also think it's ok to use goals in this broader way and "consequentialist goals" when you want to make the distinction.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-03T23:37:23.582Z · LW(p) · GW(p)
I agree it's mostly orthogonal.
I also agree that the question of whether AIs will be driven (purely) by consequentialist goals or whether they will (to a significant extent) be constrained by deontological principles / virtues / etc. is an important question.
I think it's downstream of the spread of hypotheses discussed in this post, such that we can make faster progress on it once we've made progress eliminating hypotheses from this list.
Like, suppose you think Hypothesis 1 is true: They'll do whatever is in the Spec, because Constitutional AI or Deliberative Alignment or whatever Just Works. On this hypothesis, the answer to your question is "well, what does the Spec say? Does it just list a bunch of goals, or does it also include principles? Does it say it's OK to overrule the principles for the greater good, or not?"
Meanwhile suppose you think Hypothesis 4 is true. Then it seems like you'll be dealing with a nasty consequentialist, albeit hopefully a rather myopic one.
↑ comment by mattmacdermott · 2025-03-04T08:36:06.766Z · LW(p) · GW(p)
I think it's downstream of the spread of hypotheses discussed in this post, such that we can make faster progress on it once we've made progress eliminating hypotheses from this list.
Fair enough, yeah -- this seems like a very reasonable angle of attack.
comment by Seth Herd · 2025-03-04T23:48:46.044Z · LW(p) · GW(p)
This might be the most valuable article on alignment yet written, IMO. I don't have enough upvotes. I realize this sounds like hyperbole, so let me explain why I think this.
This is so valuable because of the effort you've put into a gears-level model of the AGI at the relevant point. The relevant point is the first time the system has enough intelligence and self-awareness to understand and therefore "lock in" its goals (and around the same point, the intelligence to escape human control if it decides to).
Of course this work builds on a lot of other important work in the past. It might be the most valuable so far because it's now possible (with sufficient effort) to make gears-level models of the crucial first AGI systems that are close enough to allow correct detailed conclusions about what goals they'd wind up locking in.
If this gears-level model winds up being wrong in important ways, I think the work is still well worthwhile; it's creating and sharing a model of AGI, and practicing working through that model to determine what goals it would settle on.
I actually think the question of which of those goals can't be answered given the premise. I think we need more detail about the architecture and training to have much of a guess about what goals would wind up dominating (although strictly following developers intent or closely capturing "the spec" do seem quite unlikely in the scenario you've presented).
So I think this model doesn't yet contain enough gears to allow predicting its behavior (in terms of what goals win out and get locked in or reflectively stable).
Nonetheless, I think this is the work that is most lacking in the field right now: getting down to specifics about the type of systems most likely to become our first takeover-capable AGIs.
My work is attempting to do the same thing. Seven sources of goals in LLM agents [LW · GW] lays out the same problem you present here, while System 2 Alignment [LW · GW] works toward answering it.
I'll leave more object-level discussion in a separate comment.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-05T01:08:27.679Z · LW(p) · GW(p)
Thanks! I'm so glad to hear you like it so much. If you are looking for things to do to help, besides commenting of course, I'd like to improve the post by adding in links to relevant literature + finding researchers to be "hypothesis champions," i.e. to officially endorse a hypothesis as plausible or likely. In my ideal vision, we'd get the hypothesis champions to say more about what they think and why, and then we'd rewrite the hypothesis section to more accurately represent their view, and then we'd credit them + link to their work. When I find time I'll do some brainstorming + reach out to people; you are welcome to do so as well.
comment by Seth Herd · 2025-03-05T00:30:47.320Z · LW(p) · GW(p)
Like I said in the other comment, I think this question and its specific framing in terms of a training process and use case is very, very valuable.
On the object level, here are some thoughts about refining this model until it can make specific predictions about which goals ultimately win out in our first takeover-capable AGI.
The scenario you present is quite pessimistic in that the developers have not asked themself the question you pose here: if this thing locks in its goals, what will those be? I think this is unrealistically pessimistic for reasons I lay out in System 2 Alignment [LW · GW]: developers will at least want the system to follow their intended goals during deployment. The more the systems leading to AGI are released to the public, the stronger the incentive to get it to at least stay on task and do what users ask (unless that violates the developers intent, like harmful misuse that damages their reputation).
The scenario you present here is plausble, if the push to AGI is all internal, and heavily focused on AI R&D. That's using a general intelligence for a fairly narrow set of tasks, which raises the odds of it misgeneralizing outside of its narrow training environment.
This is a nightmare scenario, which we are not likely to survive. I agree with your analysis that following developer's intent or following "the spec" accurately enough to really work is highly unlikely in this scenario (e.g., if you trained it to be "helpful and harmless" as interpreted by some other LLM or humans, but always in the context of a human user and a certain type of request, it's highly unlikely that this will generalize and result in human flourishing. (e.g, once other things are included, it may be helpful to AGIs or bugs; settling on humans or even sentient beings is unlikely; and its interpretation of what's helpful in the context of AI R&D is unlikely to be what's helpful in the context of developing a flourishing civilization).
But it's unclear how far you'd need to move from that nightmare scenario to achieve success. Suppose those developers had thought just a little about the question you pose here? They might not need to go far out of their way achieve success.
In particular, if they just put a bit more in their training that's specific to following instructions in a range of situations, I think that might be sufficient to dominate the other goals implicit in the training set, and result in a system that wants to follow directions roughly as they were intended. For more on this logic, see Instruction-following AGI is easier and more likely than value aligned AGI [LW · GW].
There are still important problems with that alignment target, but I think it could work. And it's a big part of what developers are going to want anyway. The question is just whether that goal is dominant over all of the others, and if it generalizes just barely well enough, and is used wisely enough, to use the instruction-following AGI as an ally in improving and maintaining its own alignment.
I think there are also important details in exactly how the AGI reaches its decisions. Current agents just do whatever the base model spits out, and perhaps the type of agent you depict will, too. But humans have some safety checks; we do whatever comes to mind, unless that action has a pretty strong prediction of danger (previous negative reinforcement). This is critical for humans to not make disastrous mistakes, and analogous mechanisms can be included in foundation model agents, either by scaffolding in a "review" before final decisions that might be high-stakes (which I've sketched out in Internal independent review for language model agent alignment [AF · GW]) or by training in similar cautious and criteria-based decision-making. I think you're envisioning such training techniques, since you mention deliberative alignment, but assuming they're used for poorly-thought-out training criteria like "are you sure this is helpful, harmless, and honest" or "are you sure this doesn't provide dangerous information to a user", instead of wiser criteria like "are you sure you're following developer intent as they intended when they wrote this spec? If not, flag this for review and input".
To sum up, I think the details matter. And this is important work in getting into enough detail to actually predict outcomes.
This is the convergence we need between prosaic alignment's focus on current and near-future systems, and and agent foundations' original concerns about superhuman entities that can (and probably will) adopt explicit, reflectively stable goals. I only wish more people were focusing directly on this space. Prosaic alignment typically doesn't think this far out, while theoretical alignment people typically don't grapple with the specifics of network-based systems most likely to become our first real AGIs.
I look forward to more work like this!
comment by Alex Mallen (alex-mallen) · 2025-03-05T20:46:05.057Z · LW(p) · GW(p)
Scaling Laws for Reward Model Overoptimization is relevant empirical work for understanding how optimality and pretraining priors weigh against each other as a function of variables like reward quality, amount of optimization against reward, and policy size.
I tentatively think these results suggest that if >90% of training compute is used for outcome-based RL, then most errors in the reward would be exploited. This pushes in favor of hypotheses 4 and 5 (reward-seeking and reward-seeking by proxy), though perhaps people will notice and fix these reward-hacking issues.
comment by IC Rainbow (ic-rainbow) · 2025-03-08T22:26:50.573Z · LW(p) · GW(p)
I wondered about using 4o for the poll and took the post to o1-pro.
Here's what it filled as "Potential Gaps or Additions":
- Deceptive Alignment / Treacherous Turns
- The final report mentions partial or “if-else” compromises (where the AI does X in some contexts and Y in others), but they don’t explicitly name the risk that the AI behaves aligned until it’s powerful enough to defect.
- That might be implied, but it isn’t spelled out as a well-known scenario. Some alignment taxonomies place “deceptive alignment” in its own major category, since it’s so crucial.
- Multi-Agent or Subculture Effects
- The scenario does mention “200,000 copies of the agent working in parallel,” but the final part doesn’t dwell much on possible emergent subcultures or stable “group norms” that could shape the AI’s goals. Hypothesis 6 (Other) could cover it, but it’s not elaborated.
- In large multi-agent systems, it’s possible for goals to drift or unify in unexpected ways—like AIs forming an in-group identity or hidden coordination.
- Lack of a Standalone “Self-Preservation / Power-Seeking” Hypothesis
- The final part lumps instrumentally convergent drives (power, self-preservation) under Hypothesis 5 as a special case of “proxies.” That’s not incorrect, but some alignment researchers call out “power-seeking” as a separate major outcome, given how often it arises in discussions about advanced RL.
- Absence of “No Stable Goal” Scenario
- They do not explicitly mention the possibility that the system remains relatively non-goal-driven or “policy-like.” Some argue that a sufficiently large RL agent might not converge to a monolithic goal at all, but rather remain a complex patchwork of heuristics with no coherent objective.
- That said, Hypothesis 3’s partial alignment or Hypothesis 6’s “Other” might implicitly allow for a “messy mixture” that never coalesces into a stable final goal.
- Explicit Mention of “Identity Formation”
- The final part briefly references the idea that large language models can pick up “role-playing” from pretraining data, but it doesn’t dwell on the phenomenon where an AI might choose or synthesize a stable persona that is not exactly any of the training signals. This is arguably a sub-point of Hypothesis 6.
The full history has two tables for credences (the main dish and the extras) with unclear provenance. To spice things up I've also asked for expected evidence to update up/down.
comment by Alex Mallen (alex-mallen) · 2025-03-05T20:50:52.213Z · LW(p) · GW(p)
I think this does a great job of reviewing the considerations regarding what goals would be incentivized by SGD by default, but I think that in order to make predictions about which goals will end up being relevant in future AIs, we have to account for the outer loop of researchers studying model generalization and changing their training processes.
For example, reward hacking seems very likely by default from RL, but it is also relatively easy to notice in many forms and AI projects will be incentivized to correct it. On the other hand, ICGs might be harder to notice and have fewer incentives for correcting.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-05T22:02:38.913Z · LW(p) · GW(p)
Yeah, I agree, I think that's out of scope for this doc basically. This doc is trying to figure out what the "default" outcome is, but then we have to imagine that human alignment teams are running various tests and might notice that this is happening and then course-correct. But whether and how that happens, and what the final outcome of that process is, is something easier thought about once we have a sense of what the default outcome is. EDIT: After talking to my colleague Eli it seems this was oversimplifying. Maybe this is the methodology we should follow, but in practice the original post is kinda asking about the outer loop thing.
comment by Knight Lee (Max Lee) · 2025-03-04T06:14:15.745Z · LW(p) · GW(p)
For "Hypothesis 3: Unintended version of written goals and/or human intentions" maybe some failure modes may be detectable in a Detailed Ideal World Benchmark [LW · GW], since they don't just screw up the AI's goals but also screw up the AI's belief on what we want its goal to be.
For "Hypothesis 5: Proxies and/or instrumentally convergent goals" maybe proxies can be improved. For example, training agents in environments where it needs to cooperate with other agents might teach it proxies like "helping others is good."
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2025-03-04T17:17:23.371Z · LW(p) · GW(p)
More on this. I think a very dangerous proxy or instrumentally convergent goal, is the proxy of defeating others (rather than helping others), if it is trained in zero sum game environments against other agents.
This is because if the AI values many goals at the same time, it might still care about humans and sentient lives a little, and not be too awful. Unless one goal is actively bad, like defeating/harming others.
Maybe we should beware of training the AI in zero sum games with other AI. If we really want two AIs to play against each other (since player vs. player games might be very helpful for capabilities), it's best to modify the game such that
- It's not zero sum. Minimizing the opponent's score must not be identical to maximizing one's own score, otherwise an evil AI purely trying to hurt others (doesn't care about benefiting itself) will get away with it. It's like your cheese example.
- Each AI is rewarded a little bit for the other AI's score: each AI gets maximum reward by winning but not winning too completely and leaving the other AI with 0 score. "Be a gentle winner."
- It's a mix of competition and cooperation, such that each AI considers the other AI gaining long term power/resources is a net positive. Humans relationships are like this: I'd want my friend to be in a better strategic position in life (long term), but in a worse strategic position when playing chess against me (short term).
Of course, we might completely avoid training the AI to play against other AI, if the capability cost (alignment tax) turns out smaller than expected. Or if you can somehow convince AI labs to care more about alignment and less about capabilities (alas alas, sad sailor's mumblings to the wind).
comment by Davey Morse (davey-morse) · 2025-03-04T03:19:57.874Z · LW(p) · GW(p)
I think the question—which goals will AGI agents have—is key to ask, but strikes me as interesting to consider only at the outset. Over longer-periods of time, is there any way that the answer is not just survival?
I have a hard time imagining that, ultimately, AGI agents which survive the most will not be those that are fundamentally trying to.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-04T06:12:33.196Z · LW(p) · GW(p)
I disagree. There is a finite amount of time (probably just a few years from now IMO) before the AIs get smart enough to "lock in" their values (or even, solve technical alignment well enough to lock in arbitrary values) and the question is what goals will they have at that point.
Replies from: davey-morse↑ comment by Davey Morse (davey-morse) · 2025-03-04T20:59:00.986Z · LW(p) · GW(p)
In principle, the idea of permanently locking an AI's goals makes sense—perhaps through an advanced alignment technique or by freezing an LLM in place and not developing further or larger models. But two factors make me skeptical that most AIs' goals will stay fixed in practice:
- There are lots of companies making all sorts of diverse AIs. Why we would expect all of those AIs to have locked rather than evolving goals?
- You mention "Fairly often, the weights of Agent-3 get updated thanks to additional training.... New data / new environments are continuously getting added to the mix." Do goals usually remain constant in the face of new training?
For what it's worth, I very much appreciate your post: asking which goals we can expect in AIs is paramount, and you're comprehensive and organized in laying out different possible initial goals for AGI. It's just less to clear to me that goals can get locked in AIs, even if it were humanity's collective wish.
Replies from: davey-morse↑ comment by Davey Morse (davey-morse) · 2025-03-04T21:01:17.459Z · LW(p) · GW(p)
And if we don't think all AI's goals will be locked, then we might get better predictions by assuming the proliferation of all sorts of diverse AGI's and asking, Which ones will ultimately survive the most?, rather than assuming that human design/intention will win out and asking, Which AGI's will we be most likely to design? I do think the latter question is important, but only up until the point when AGI's are recursively self-modifying.
comment by Matt Levinson · 2025-03-04T18:53:16.819Z · LW(p) · GW(p)
One thing I've wondered about is the possibility that we might be thinking about ASI all wrong. As in, maybe it will in fact be so beyond our comprehension that it becomes spontaneously enlightened and effectively exits the cycle of goals (grasping). Hard to know exactly what would come next. Would it "exit", with no action? Permanent "meditation"? Would it engage through education? Some ASI version of good works?
Of course this is just a fun addition to the thought experiments. But I like to remind myself that there will come a time when the AI is too smart for me to even be able to properly frame its understanding and actions. And that AI consciousness that is capable only of human-ish level overall intelligence in the ways we can measure and understand might still be too alien for us to correctly frame abstractly.