System 2 Alignment
post by Seth Herd · 2025-02-13T19:17:56.868Z · LW · GW · 0 commentsContents
Summary:
1. Overview
1.1 Structure of the remainder
2. "Deliberative alignment" in o1 and o3
3. System 2 alignment approaches
3.1 Deliberation for capabilities
3.1.1 Deliberation for control and alignment
3.1.2 Example criteria for control/alignment targets of deliberation
3.2 Review for risks, control, and alignment of actions.
3.3 Thought Management
3.3.1 Incentives for developing thought management methods
3.3.2 "9s of reliability" vs better thought management for long time-horizon tasks
3.3.3 Thought management may reduce compute costs
3.3.4 'Humans will want to micromanage agents' thinking
3.3.5 Thought management for control and alignment
4. Implementation variations of System 2 techniques.
4.1 Trained vs. scaffolded/scripted System 2 approaches
4.2 System 2 alignment with and without faithful CoT
4.3 Self- vs independent review and management
4.4 Human vs. AI review and management
5. Will System 2 alignment work for real AGI?
5.1 Will System 2 alignment make LLM agents aimable at all?
5.2 If System 2 alignment works, can we specify goals well enough to survive the results?
5.3 Conclusion
Method
None
No comments
Submitted to Alignment Forum. Contains more technical jargon than usual.
Epistemic status: I'm pretty sure these are important questions, but I don't have firm conclusions. I'm hoping to inspire others to think in this direction. ~50% of the average value is probably in the Summary; another ~15% each in the next Overview and OpenAI's Deliberative Alignment sections. The second half is more detailed, and intended for those who want to think about aligning language model agents as AGI.
Summary:
Demand for LLM-based agents that can perform useful work may lead all the way to takeover-capable AGI that needs real alignment. Here I discuss alignment techniques that developers are likely to use for that type of AGI. Accurate gears-level models of likely AGI and alignment approaches can effectively give us more time to work on alignment.
Such agents will probably use chains of thought or System 2 cognition[1] extensively. Some System 2 human strategies seem likely to be adapted to improve capabilities, and minimize costs and risks for users and developers of LLM-powered agents. Those methods can be repurposed for alignment at low cost, so they probably will be.
I roughly divide such strategies/methods into review, deliberation, and thought management. I discuss these methods and possible variations in how they might be implemented. This analysis is intended as a starting point for more detailed work.
Review of plans and actions is the method I've thought most about. It could:
- Intervene before any tool calls or goal/memory updates are allowed
- Reference a human-written constitution
- Call a fresh LLM instance for independent review
- Check for alignment-altering changes to beliefs or subgoals
- Scale with estimated importance of decisions for low alignment taxes
- Work to some degree even without a faithful chain of thought
System 2 alignment could prevent alignment-altering belief changes or subgoal adoption. In this and other ways, these approaches could go beyond "aligning" the behavior of an LLM, and help with real alignment of the goals of an AGI agent with those of humanity (or at least a human[2]).
Depending on their implementation, such methods might be regarded by an agent as a meddling "thought editor", or as a valued conscience.
OpenAI recently announced deliberative alignment[3], after this post was partly written. I discuss its implementation. It is one example of the category I address here: capabilities techniques adapted to control or alignment.
1. Overview
Let's start with review as the clearest illustration of why people would bother developing specific System 2 techniques even if they didn't care much about AGI alignment.
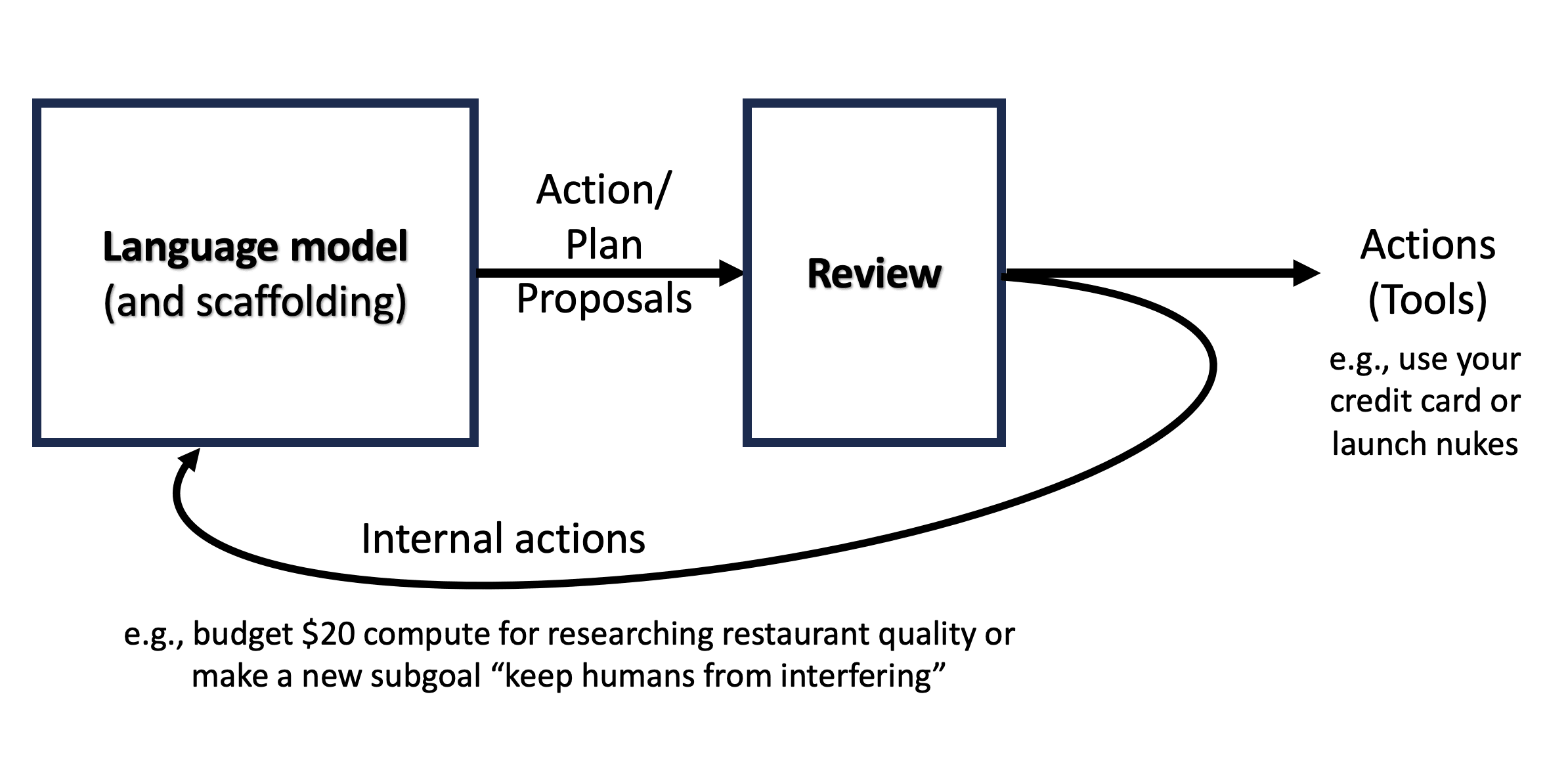
Without reviewing likely consequences before taking important action, humans would be even dumber and more dangerous. We'd pick more fights we can't win, blow more money, and drop more bombs we'll regret. We'd also adopt more dangerous beliefs and ideologies, changing our goals and values in ways we wouldn't have endorsed on reflection. Review before finalizing important decisions is one type of System 2 cognition.[1]
Language model agents (LMAs)[4] will be prone to similar errors. On the current trajectory, they will employ long, complex chains of thought. These will probably interact across levels; e.g., planning and subtask execution. They will have "habits" of thought and action learned from predictive pretraining, and a variety of fine-tuning and RL processes. They will have implicit goals from those sources, and explicit goals from developer and user prompts. And any type of continuous learning will change how they interpret those goals.
Before asking whether the goals we give advanced LLM agents will suffice for real alignment, we must ask whether they'll reliably even try to pursue those goals. This is a specific form of the problem Nate Soares refers to in "alignment is in large part about making cognition aimable at all" [LW · GW]. In Seven sources of goals in LLM agents [LW · GW] I briefly discussed this problem and a possible solution: improved cognition and metacognition to produce reflective stability around the strongest (and hopefully most desirable) goals.
Review, deliberation and thought management are System 2 strategies that can improve cognition and metacognition. Humans deliberate by sampling and comparing different thoughts and lines of thought on the same topic. This deliberation improves our decisions, plans, and reasoning. Thought management is roughly thinking "what should I be thinking about?" It can reduce unproductive or costly chains of thought and focus cognition on useful subgoals. Each of these improves our cognition, including allowing it to adhere better to our chosen goals. Thus, these strategies are dual-use for capabilities and "alignment" with our own most important goals.
These strategies can serve the same purposes for LLM agents. Deliberation helps get good results in a variety of ways, as demonstrated by OpenAI's o1 and o3 performance, and their "deliberative alignment". Thought management will become increasingly useful as agents become capable of blowing hundreds of dollars on compute for a single unnecessary subtask (e.g., "find the best nearby restaurants" could take an unlimited amount of research and deliberation, and 03 spends up to $3000 per hard problem). And review can prevent harmful or risky external and internal actions, as outlined above.
Implementing these strategies for capabilities and cost/risk reduction will serve double duty for alignment. Using them will be almost free in terms of development effort, and each seems to carry low compute costs. Shane Legg has referred to this approach as System 2 safety,[5] and I adopt that terminology since it is more intuitive and general than my previous "internal independent review for alignment [AF · GW]"
Initially, those techniques will be used for behavioral control and control of thought. But as they're applied to autonomous agents that are truly goal-directed, that type of thought control can be applied to preventing the agent's interpretation of its goals from changing in dangerous ways. That will be relevant to alignment in its deeper sense: aligning “Real AGI” [LW · GW] that is competent, autonomous, and goal-directed — and therefore very dangerous
My broadest point here is that many techniques developers can use for getting an LLM or agent to behave in ways they want are also techniques that could be used for real alignment in the deepest sense. I also think we can make enough specific predictions about those mechanisms to start reasoning about how they might succeed or fail. That is the subject of the remainder of the article.
Depending on how they're implemented, System 2 alignment could be thought of as an "artificial conscience" intrinsic to the agent's identity, or as a "prosthetic conscience" trying to exert unwanted control of actions and thoughts.
Chain of thought alignment is often identified with having faithful chains of thought and applying external review. These approaches do not strictly require faithful CoT, because they can use a different instance of the same model for supervision. See section System 2 alignment with and without faithful CoT [? · GW].
It seems obviously valuable to correctly anticipate how we're going to try to align our first AGI(s). That's the primary focus of this article. I also try to make progress toward evaluating whether these approaches are likely to work, but I don't think we can draw even preliminary conclusions without further work. I hope we can make progress on that work before finding out (if it's even made public) what alignment techniques are actually employed for the first really dangerous AGIs if they come in the form of language model agents.
1.1 Structure of the remainder
- Summary [? · GW] and Overview [? · GW] - You just finished those sections.
- OpenAI's "Deliberative alignment" in o1 and o3 [? · GW]
- System 2 alignment approaches [? · GW]
- Deliberation [? · GW], Review [? · GW], and Thought Management [? · GW]
- capabilities, control, and alignment for each
- Deliberation [? · GW], Review [? · GW], and Thought Management [? · GW]
- Implementation variations of System 2 techniques. [? · GW]
- Will System 2 alignment work for real AGI? [? · GW]
2. "Deliberative alignment" in o1 and o3
OpenAI announced deliberative alignment in December 2024. It repurposes the new training method for o1 and o3's CoT capabilities, using it to train separately for "alignment".
Using RL on chains of thought produced dramatic improvements in o1 and o3 over all previous LLMs. The same procedure improves refusals of requests for information deemed harmful, when that's used as the training criteria. Thus, deliberative alignment is an example of how System 2 capabilities techniques can be repurposed easily for control/alignment.
Thankfully, OpenAI didn't publish their full method for o1, so we have to speculate on exactly how they applied RL to chains of thought. See this footnote[6] for more. We have more direct reports of how they trained deliberative alignment; see their paper. The first stage is identical to Anthropic's "constitutional AI" method of training with RLAIF. The second stage uses RL on a chain of thought (CoT) in a straightforward way, by evaluating the final response only for appropriate refusal. The reinforcement value is produced by another LLM judging how well the response obeys the "spec" that describes what questions the model should refuse to answer. See this footnote[3] for more explanation of deliberative alignment training.
I don't think "deliberative alignment" is really an alignment technique as it stands. It's used for controlling behavioral tendencies of a system that's not strongly goal-directed, which is a different thing.[7] But it and similar training techniques could potentially be used for real alignment. See the sections Deliberation for control and alignment [? · GW] and Will System 2 alignment work for real AGI? [? · GW]
But deliberative alignment works for its purpose. I find the tests they ran pretty compelling. It's not a huge improvement, but it's not trivial. I see no strong reason to doubt that it works for the reason they give: the model deliberates about whether or not it should answer a given question, and this allows it to catch tricks that would otherwise fool an RLHF/RLAIF system. The example they give in the paper is a CoT reasoning about whether to answer a request framed as a cipher. This trick fools RLHF/RLAIF systems, but in the course of thinking through the problem (deliberating), o1 realizes its spec forbids answering.
Similar training methods could be used to produce a variety of System 2 cognitive strategies and skills, including review, deliberation, and thought management. You'd only need to change the evaluation criteria of the LLM serving as a reward model. (DeepSeek R1 reportedly does this to improve performance on non-reasoning tasks, as a final step).
3. System 2 alignment approaches
Note to the reader: the remaining sections are more detailed, and will be of interest primarily to those who think it's worthwhile to develop gears-level models of possible future LMA agents and the specific techniques that might be used to align them. The concluding section Will System 2 alignment work for real AGI? [? · GW] may be of more general interest.
3.1 Deliberation for capabilities
From the announcement post for o1, and corroborated by reports from OpenAI people who've used it and read its chains of thought:
Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses.
It learns to recognize and correct its mistakes.
It learns to break down tricky steps into simpler ones.
It learns to try a different approach when the current one isn’t working.
This process dramatically improves the model’s ability to reason.
We could call all of this deliberation, or we could note that it's doing some things we might call review (recognizing mistakes) and thought management (trying a different approach when one isn't working). Review, deliberation, and thought management aren't definitive natural categories. But they seem usefully different.I use the term here for everything that doesn't fall under review or thought management.
The incentives for improving deliberation seem large and apparent: it has produced large improvements in o1 and o3 over previous models, and seems likely to produce more. Some of those new capabilities have already been applied to alignment.
3.1.1 Deliberation for control and alignment
OpenAI's use of a separate training signal to create "deliberative alignment" indicates that similar techniques can be used to apply deliberation to any purpose - at least to some degree.[8] The evaluator model that provides the RL signal for each chain of thought could be given any criteria for its judgment.
This training technique causes the model to include the control/alignment criteria naturally in its chain of thought, such that it tends to produce outputs/conclusions consistent with the criteria. Scaffolded prompting approaches could be used to influence chains of thought in similar ways (e.g., periodically inserting "remember, we're working towards [goal] periodically in a chain of thought. See the section on Trained vs. scaffolded/scripted System 2 approaches [? · GW]. But I assume training approaches by default since they have produced the best results so far.
3.1.2 Example criteria for control/alignment targets of deliberation
To think about the role deliberation in alignment, it's useful to think about the different ways developers might try to use it. Below are some targets for control and alignment that people have talked about; many more are possible. They illustrate the range of uses, from trying to control an LLM or simple agent, to aligning a sophisticated LLM agent AGI.
Example targets for deliberation:
- Did this CoT answer questions that violate these rules?
- Current OpenAI deliberative alignment "spec" training criteria
- Control of behavioral tendencies
- Current OpenAI deliberative alignment "spec" training criteria
- Was this CoT helpful, harmless, and honest?
- Anthropic's "constitution" could be extended to guide CoT
- (Helpful to whom, and for what?)
- Anthropic's "constitution" could be extended to guide CoT
- Did this CoT advance toward humanity's Coherent Extrapolated Volition?
- Or some other value alignment target
- Did this CoT follow developer instructions as intended?
- Developer instructions probably include following some but not all end-user instructions
- Instruction-following, DWIMAC, or roughly Corrigibility as Singular Target[2]
3.2 Review for risks, control, and alignment of actions.
The opening diagram illustrated why you'd want a robust review of actions and important internal decisions for your agent architecture. It could catch internal or external actions that violate rules or create unwanted risks or costs of many types. Such a review could be scripted into the agent architecture, or instilled through training.
The term review is not an ideal fit. Preview or just System 2 decision-making might be better if we were just talking about an agent reviewing its own actions. I chose review to emphasize the possibility of having a separate, independent process review the proposed decision before it was finalized. More on this in Internal independent review for language model agent alignment [LW · GW].
The basic idea is that it's a good idea to think carefully about the likely consequences of important actions before you make them. You can think more carefully about more important decisions, if you can tell which ones are important. This applies to the material consequences of decisions, like how well they're likely to accomplish goals, and their risks of real harm, monetary costs or reputational costs. And it applies to the ethical consequences of decisions , like following a set of rules, ethical goals, or conforming with values.
I talked about review in the context of particular of language model agent architectures in Capabilities and alignment of LLM cognitive architectures [LW · GW]. Review could use any of the goals/criteria mentioned above under the deliberation [? · GW] section. Here are a few more that are particularly relevant to review:
- Would this action provide information to a user that might be harmful?
- Would this action spend the user's money or compute costs in ways they'd dislike?
- Would this action work against any of my goals (including reducing cost/risk)?
- If so, reference a resolution order for goals
- And possibly call for human review before proceeding
- Would this action update my beliefs in ways that might change my effective alignment?
- e.g., deciding that the term "person" really means any sapient or sentient entity
- Would adopting this sub-goal violate my constitution or top-level goals?
- e.g., creating a new subgoal to prevent the humans from finding out about this plan or changing my goals.
- If so, flag this decision for external review. [LW · GW]
Reviewing new subgoals before pursuing them is also a form of thought management; these categories of System 2 alignment don't decompose cleanly. See Self- vs independent [? · GW]and with and without faithful CoT [? · GW] sections, below.
For more on review, see Internal independent review for language model agent alignment [LW · GW]. That vision of agents and reviews is somewhat out of date at an ancient year-and-a-half old. I was envisioning scripted/architected reviews, but much of the logic applies to trained-in reviews.
3.3 Thought Management
Metacognition for self-management is an important cognitive skill for humans in accomplishing difficult tasks, so developing it specifically in AI/AGI might also be useful for capabilities.
Thought management is roughly the metacognitive equivalent of deliberation. Instead of asking the object-level question "what would accomplish this goal/ what would work against this goal being accomplished" it's asking the metacognitive question "am I thinking about things that will help me accomplish this goal/am I thinking about things that will prevent me from accomplishing this goal."
If they're developed to improve capabilities and reduce costs, thought management methods could be repurposed for control or alignment.
3.3.1 Incentives for developing thought management methods
Why bother with extra thought management techniques? o3 manages its thoughts just fine on its own! But it's not footing the bill for all of that thinking. And it's good at solving complex problems, but no current LLM has adequate metacognition to manage long time-horizon tasks.
There's a distinct cognitive skill involved in managing complex tasks with lots of sub-tasks. Revisiting the project plan and evaluating whether you are succeeding or if you need to take a new approach for this sub-task is essential for any complex project. Developing tools for thought management might improve agents' ability to do this. It could also allow a hybrid approach in which humans could step in to help manage complex tasks. OpenAI's Operator agent already takes this hybrid approach in a small way, although it seems too slow and incompetent to accomplish much of use even with human help.
Controlling cost could be another reason to implement thought management capabilities for human or agent use. We don't know how expensive useful LMAs will be, but it seems pretty likely that costs won't be totally trivial. It also seems quite possible that thought management techniques might be quite useful for agents accomplishing long time-horizon tasks.
Beyond doing it to serve as managers, users will want to control what agents think about to satisfy their urge to micromanage. Unlike an employee, an agent won't get frustrated with being micromanaged.
Below is a more detail on the incentives for developers to focus on thought management capabilities for LLMs. Read them at your option. (The weird extra spacing because my collapsible sections want to eat each other.)
3.3.2 "9s of reliability" vs better thought management for long time-horizon tasks
There's a commonly expressed belief that what stands between LLM agents and usefully performing long time-horizon tasks is "9s of reliability" - performing the individual subtasks that make up long time-horizon tasks with enough reliability that the odds of completing all of the component tasks successfully is high. The logic goes that with a mere 90% (one "9") chance of performing each of 5 subtasks, there's only about a 60% chance (.9^5) of succeeding at all of them, and therefore about a 40% chance of at best wasting all of that time and compute, and at worst passing off an erroneous final product, and screwing up any bigger project this task was contributing to.
That all makes sense, but it's pretty clearly just not how humans succeed at long time-horizon tasks with lots of subtasks.
Humans make tons of mistakes. We're just (sometimes) good at catching our mistakes. This is largely how we succeed at long time-horizon tasks: by thinking specifically about whether each task has been accomplished correctly, or if we need to take another swing at it. This is another form of metacognition and thought management, and another incentive for developing specific thought management techniques for LMAs.
Having humans perform the role of managing an LMA's thinking is an obvious solution. We do the extreme case of this now: we issue cognitive tasks to language models, assemble those subtasks into tasks, and take the actions to put useful results out into the world. We are centaur "agents" along with our assistant language models.
Developing techniques that can slowly shift the burden of management off of humans seems quite valuable. Doing this requires a means of having the humans understand what the agent is doing and to intervene. We'd like an agent to ask for input at critical decision points in its problem-solving process. And we want it to ask for input flexibly, so that we can tell it to ask for input but proceed if we're not around, stop until it gets it, or just take its best guess.
Interestingly, allowing effective human supervision may be low-hanging fruit, and it may be a powerful incentive to keep chains of thought faithful, so that humans can understand and thereby approve or correct the agent's thinking (see section System 2 alignment with and without faithful CoT [? · GW])
3.3.3 Thought management may reduce compute costs
Currently OpenAI is footing the bill for o1 and o3's thinking. But it seems like they're going to have to pass the costs on to users at some point. Altman says they're losing money on the $200 subscription to Pro. Those are particularly enthusiastic users, but they're only human: they can only keep o1 "thinking" so much with their prompts. When users can launch agents that think for much longer, compute costs will skyrocket. You could just set a hard cap on each agent's "thought budget", but that will waste a bunch of time and money when they hit that cap without getting answers. Better solutions will be in demand.
Better System 2 skills means longer CoT gets you better performance. And that's even before o3 is integrated into an agent that can go do unlimited amounts of background research on the web (which we all know is a potentially unlimited source of answers, and wasted time and cognition).
From Implications of the inference scaling paradigm for AI safety [LW · GW]:
Running o3 at maximum performance is currently very expensive, with single ARC-AGI tasks costing ~$3k, but inference costs are falling by ~10x/year!
So there's going to be a tension between falling compute costs and running more cognition to get better answers and task performance. Good reasoning is expensive. Costs could come down, or they could go up.
Early forays into competent language model agents rely heavily on image processing (to avoid errors in parsing complex HTML). Image processing also costs a good bit of compute at this point, but this will also fall rapidly. This seems like a smaller factor since better image processing isn't as important as better (and perhaps more compute demanding) chains of thought as agents progress.
I'm least sure about the compute cost incentives for thought management, but it seems fairly likely to be valuable in reducing costs.
3.3.4 'Humans will want to micromanage agents' thinking
An ancient professor in my grad school department had a sign on his door: "The strongest human drive is not for sex or money, it is to correct edit improve another's writing".
I think this applies to correcting by micromanaging, too.
In addition to its possible benefits for long time-horizon task capabilities and managing compute costs, the ability to supervise agents will be appealing to users for emotional reasons. Humans often love to micro-manage their subordinates. We sometimes keep that urge in check when we're dealing with a human, knowing it's likely to irritate them, but we'll want to indulge this urge with our faithful LLM agents.
It is already frustrating to watch an agent pursue a useless train of thought or project. Unlike with our kid or our employee, no part of our brain will be saying "no don't rob them of their agency!" Most humans would love to closely manage an LLM agent's thinking.
3.3.5 Thought management for control and alignment
Thought management could be used for all of the same control and alignment goals as deliberation and review.
Categories of goals:
- A user goal (capabilities)
- A developer goal (control/safety)
- The agent's own goals (real alignment; reliability and stability)
The Example criteria for behavior/alignment targets of deliberation [? · GW] above also apply to thought management as well as review.
4. Implementation variations of System 2 techniques.
System 2 techniques could to capabilities and alignment could be implemented by developers in a variety of ways. These variations will affect their usefulness and reliability in a variety of ways.
Some implementational variations are:
- Trained vs. scaffolded/scripted
- With or without faithful chain of thought
- Self- or independent review/management
- Calling a different model or fresh instance
- Automated or user review/management
It's hard to think through all of the potential combinations and how they'll affect alignment efforts. But it seems important to try, so I'll say a little about each. I hope this will spark more thoughts, and I'd like to hear them.
4.1 Trained vs. scaffolded/scripted System 2 approaches
Each of these System 2 approaches could employ either training methods, or architecting/scripted prompting methods. I can't really tell which or what combination is most likely, and I can't really say either which would be better for alignment. So I'm going to recommend you skip the rest of this unless you really want to think harder about the details of language model agent implementation, and help me figure out where it's going - then what that means for how well it would work.
To a first approximation, training and scripting serve the same purposes and have roughly the same potentials to be repurposed for control and real alignment.
Training goals into CoT raises major concerns. See If system 2 alignment works, can we specify goals well enough to survive the results? [? · GW]
Speculations on training vs. algorithms/scaffolding
System 2 cognitive strategies might be trained in to the base LLMs, as in deliberative alignment. A similar training method could be used to train the system to perform careful reviews, or to perform thought management by periodically explicitly thinking about which lines of attack on a problem are promising, and which should be discarded or revisited.
For deliberation, the general use of chain-of-thought for capabilities, training seems well ahead. But that doesn't mean training will be used to the exclusion of scaffolded/algorithmic approaches. The two could work synergistically for some applications.
As LLMs are used to drive agents, new opportunities and incentives for scripting/architecting come into play. For instance, reviews can be called before any tool call is accessed, and an algorithmic call to a fresh LLM instance makes the review independent, which is useful for practical control as well as alignment. For more, see Capabilities and alignment of LLM cognitive architectures [LW · GW] and Internal independent review for language model agent alignment. [AF · GW]
Whatever combination is employed will surely impact their potential use for control and alignment. But I haven't yet formed detailed enough mental models to say how.
Thoughts on this topic would be appreciated.
4.2 System 2 alignment with and without faithful CoT
Chain of thought alignment is often identified with external oversight and therefore faithful chain of thought. But training methods for System 2 cognition may work reasonably well without faithful CoT. Even calling fresh instances of the model, as in independent review or management, may work reasonably well. The model will, to some degree, understand its own use of steganography or unique jargon.
If this is the case, it's an immense advantage. It seems likely that a fresh model instance will follow prompts like "tell me what this chain of thought is saying". Truly intelligent mesa-optimized processes might be able to collude with context-free instances of themselves, but I tend to worry much more about the alignment of intelligent processes we created on purpose long before we've got enough optimization power to have full agency and deception emerge from subtle training pressures.
However, intensive RL on CoT may drive essentially all of the useful cognition "underground" into the hidden states, making the tokens it produces almost unrelated to cognition-in-context.[9]
If System 2 cognition and alignment methods seem to work without faithful CoT, that's obviously a dangerous thing. It will be very hard to tell whether they really work, or if the model is mesa-optimizing for something else.
I find it difficult to predict how quickly RL training on CoTs will obscure faithful CoT. I also have a hard time thinking through how well fresh instances of the same model might interpret obscured CoTs with limited context. On the one hand, there's nothing stopping the model from learning to do all of its cognition in a completely context-dependent way, with the output tokens having little relation to the underlying network states. On the other hand, the world does seem to decompose into analyzable pieces, and the imitation training sets the model up to think that way.
Maintaining a faithful chain of thought does seem like the best way to improve our odds of survival. But it's not completely clear to me that we're done for without it.I think this is going to be an important area for thinking through and clarifying. For a little more and some references, see this footnote.[9]
4.3 Self- vs independent review and management
If you ask a person or organization to review their own plans for safety, it usually doesn't work as well as having someone else do it. The prompts "do you really want to do this?" or "do you really want to think this?" are usually answered "yes - that's why I'm planning to do it!".
Therefore, it probably makes sense to call a different model, or at least a fresh instance of the same model with reduced context to serve the role of reviewer or thought manager.
Much of our concern about misaligned actions/plans/thoughts comes from things going wrong during an extended chain of thought. The model may talk itself into adopting a misaligned goal, or be subject to prompt injection, or jailbreaking by the user. It might even simulate a villainous persona, then get stuck in it. That last sounds strange, but seems not entirely implausible.[10]
How to enforce those outside decisions is a little more of puzzle if we're talking about a thoroughly trained process. Getting a prompt "no go do something else" injected into context and then letting the model resume may not be effective at all. I don't have a good solution to this issue; I'll just note again that developers will have incentives to produce them.
4.4 Human vs. AI review and management
The sections on thought management and review list some reasons that humans might want to perform some review and thought management themselves.
It's also worth saying a few words about human and automated external reviews, as proposed by Tamera Lanham in 2022 in Externalized reasoning oversight: a research direction for language model alignment [LW · GW] would probably be performed mostly by independent models, assisted by humans when results are alarming. This, of course, is largely dependent on faithful chain of thought.
I do worry that external review would be performed sloppily, and provide as much false sense of security as real security. But it could help as part of a swiss cheese approach to alignment (just make sure the holes don't line up! Wentworth is all too convincing that sycophantic AI and monkey-brained humans are an ideal comedy duo for working on alignment).
External review would be one element of a scalable oversight approach to alignment, and System 2 independent (automated) internal review would complement it both by providing a separate review in real time, and by reporting its review conclusions and surrounding context, thus giving an external oversight process substantially more information to work with.
5. Will System 2 alignment work for real AGI?
I don't know. And I don't think anyone else can say for sure at this point, either. My main point here is that people might very well try to align the first really dangerous AGIs with these techniques, so should think harder about whether they will work.
"Agent foundations" alignment theory focuses on the question of how you might adequately specify a goal that won't kill or severely disappoint you if it's optimized for very strongly. Thinking about the complexity of LLM agent cognition makes another question apparent: will it even try to follow the goal you tried to give it, or will it follow some other goal(s) implicit in the training set? Nate Soares' This is what I mean by "alignment is in large part about making cognition aimable at all" [LW · GW] treats this question in a more general way, and is well worth a careful read.
5.1 Will System 2 alignment make LLM agents aimable at all?
Answering this question is the primary goal of this project. Predicting methods of alignment gives us traction in predicting how well they'll work. But this is only a start at this project. I can't yet even really guess the odds of System 2 alignment working to make LLM agents aimable.
In Seven sources of goals in LLM agents [LW · GW] I briefly sketched out the complexity of how LLM agents will choose goals and pseudo-goals. The system 2 alignment techniques here are all means of improving metacognition and goal-directedness. They are one means of making agents aimable. Improvements in general intelligence will also make these approaches work better. Improving general intelligence will probably also directly improve metacognition and coherence.
I suspect that these methods can produce an aimable AGI, and even do that easily enough that a rushed team of humans with unreliable AI help might accomplish it. But I'd really like to be more certain. So I'll be working more on these questions, and I hope others will think about it, share their thoughts, and perhaps others will want to join in this project.
Even if these methods do work, making AGI aimable won't be adequate if we can't aim it at an alignment target we actually want to hit.
5.2 If System 2 alignment works, can we specify goals well enough to survive the results?
The System 2 alignment techniques I've discussed are mostly relevant to making agents aimable. But they may also have some use in specifying goals well enough to work, since they provide different avenues of training or prompting for goals.
This will probably seem to work quite well initially. But we shouldn't be complecent about the apparent ease of aligning LLM agents. Many people who've thought long and hard about alignment think that aligning network-based AGI is very likely to doom us, for subtle but powerful reasons. Disregarding these warnings without understanding them thoroughly would be a huge mistake. And I'm afraid a lot of prosaic alignment thinkers are doing just that.
Zvi's On A List of Lethalities [LW · GW] is a good starting point for the deep arguments for alignment being difficult. The List itself [LW · GW] is required careful reading for anyone working on alignment. One critical point that's easy to overlook is concerns about humans cognitive biases and limitations, and how badly and shortsightedly groups of humans make decisions, particularly when they're under pressure. This seems to be one of several key cruxes of disagreement on alignment difficulty [LW(p) · GW(p)].
Zach Davis's Simplicia/Doomimir debates [LW · GW] is the best high-level summary of the tension between the prosaic optimism of "LLMs basically understand and do what we tell them" and the deep arguments for the difficulty of choosing and specifying any goal well enough that we still like the results once it's been highly optimized. We should expect extreme optimization pressures by default; if we don't use excessive goal-directed training, highly intelligent agents will exert optimization pressures as they learn and think. And we should expect agents. Not only do Tool AIs Want to Be Agent AIs, but humans want them to be agents. Users want their work done for them, not to simply have help doing the work.
These arguments are powerful and deeply concerning. But I sharply disagree with the pessimists that aligning LLM-based AGI is obviously doomed. The arguments on both sides are incomplete.
Would it work to give a powerful LLM agent with working System 2 alignment the central goal "be nice to people and make the world a better place, and do that the way the people who wrote this meant it"? Maybe. Language does generalize pretty well. But we might be disappointed by the way the agent interpreted that statement. And if we didn't like its interpretation, we probably couldn't correct it.
My own current favorite alignment target is instruction-following, something like "do what the authorized user means by their instruction, and check that you've understood it correctly before executing anything they might be really disappointed with". This type of goal includes a good deal of corrigibility [LW · GW]. I prefer instruction-following intent alignment for several reasons, [LW · GW] principally that it's very similar to what developers will probably do by default. There's no use coming up with the perfect alignment target if developers are just going to try to make AGI do what they tell it, because no one has convinced them it won't work.
Tan Zhi Huan argues pretty convincingly that we're really mostly teaching LLMs to have good world models, and to follow instructions. This gives the possibility of using natural language to specify goals from a learned world model [AF · GW] and so avoid using training to directly specify goals.
5.3 Conclusion
I think we simply don't know whether any of this might work. And I think we had better figure it out. We are all trying to think with monkey brains [LW(p) · GW(p)] - cognitive limitations and motivated reasoning make us much dumber, as individuals and groups, than we'd like to think.
I think that if we work together, we still have a decent chance at solving alignment in time. The logic really doesn't seem as complex as some problems humanity has already solved. We just have to work faster and more efficiently than we ever have, because we might not have nearly as long as it's taken the scientific and engineering efforts of the past to solve those problems. We can do that if we use our new technology and knowledge from past efforts to best effect. For instance, LessWrong is far better than previous scientific institutions for open-source collaboration, and Deep Research and other LLM systems can make integrating knowledge vastly faster than ever before. I think much of the work is in deconfusion to clearly identify the most urgent problems and approaches, and those new technologies can help dramatically with that type of work.
I am highly uncertain whether these System 2 alignment approaches and the alignment targets discussed above are likely to work; I've thought back and forth through the related issues a lot, but there's still too little careful analysis to make even much of a guess. I take epistemic humility seriously, and I'm aware of my own severe cognitive biases and limitations. The fact that people who've thought about AI a lot give estimates ranging from 99% to 1% indicates that we've still got a lot to figure out about alignment.
Our current path toward AGI and alignment deserves a lot more focused thought before someone gambles the future on it.
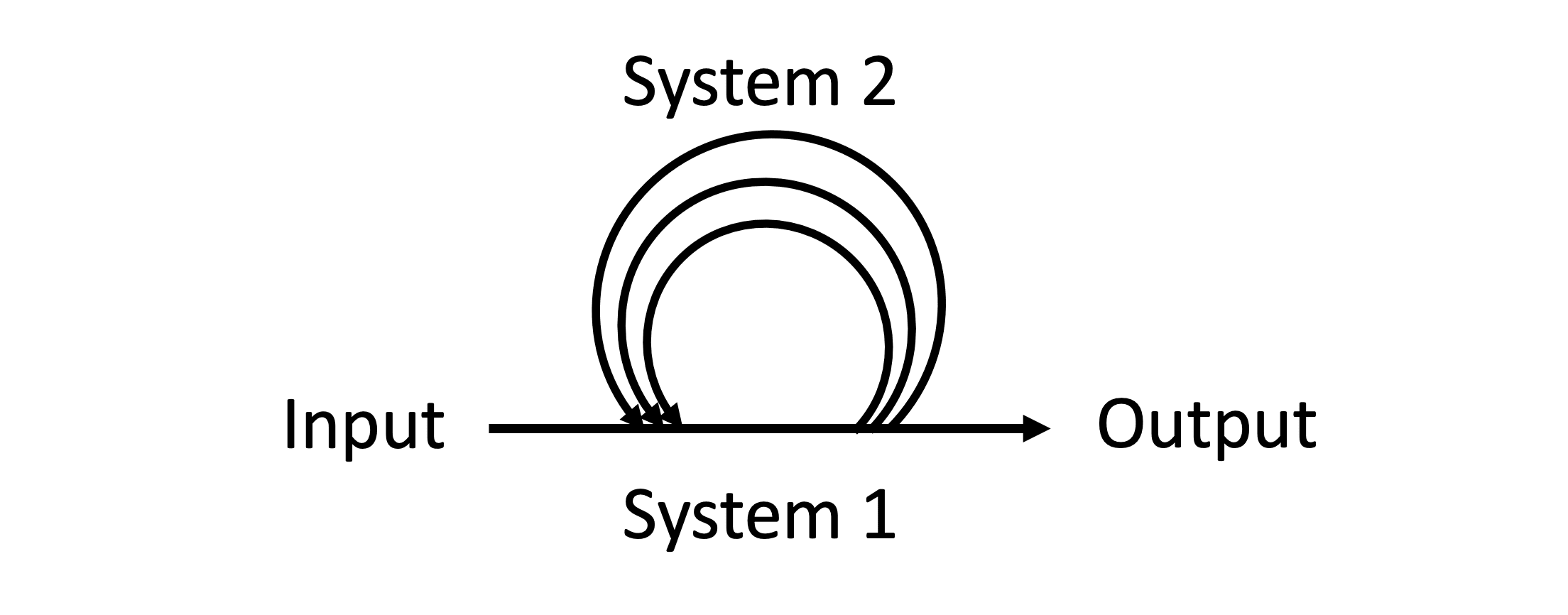
- ^
System 2 cognition roughly means the skillful and strategic use of cumulative reasoning. I called this strategic cognitive sequencing in a 2013 paper on how the brain does some of it.
The definition of System 2 cognition is highly overlapping with chains of thought (CoT), and with the cognitive psychology and neuroscience definitions of goal-directed behavior, controlled cognition, and model-based RL, but it is not identical with any of these. For much more than you wanted to know on those terminologies, see this paper I co-authored: How Sequential Interactive Processing Within Frontostriatal Loops Supports a Continuum of Habitual to Controlled Processing.
System 2 is using System 1 recursively and cumulatively - and skillfully. It is roughly what we usually call reasoning or thinking. More on System 2 terminology and human use of that type of cognition
I considered using "chains of thought" instead of System 2 for this article. I decided that System 2 emphasizes the skillful and human-like use of cumulative cognition, and includes more complex thought structures than chains (systems like o1 also branch and loop back, like humans, and future LLM-based agents will probably be more)
Humans deploy System 2 reasoning strategically and sparingly, because it takes longer than System 1, which is fast, habitual, and automatic - roughly going with your first thought.
System 2 would probably better be called Type 2 cognition, because it's not really a different system. It's a different way to use the same system. The originator of the term proposed that shift in terminology, but I'm not going to try to change common usage.
System 2 is using System 1 automatic thought repeatedly, but it's not just thinking about the same thing many times and taking the average. It is structuring cognition so that thoughts build on each other, expanding on or checking elements of the previous moments of cognition. It is metaphorically building a structure out of thoughts, rather than just piling them up. Humans need to learn specific System 1 skills and strategies to make their System 2 really useful. That appears to be why specific training for CoT was needed to really make that approach work.
System 2 reasoning in humans does not always employ language; for instance, spatial reasoning is important in several types of problem-solving. But much human CoT seems to take place in language or sub-linguistic concepts similar to the representations employed in the hidden layers of transformer LLMs.
- ^
Corrigibility/instruction-following seems easier than value alignment, at least for surviving the first capable AGI. It seems both markedly easier and more likely to be be employed [LW · GW], but that's pending more careful analysis. Max Harms has done an incredible job of analyzing this general approach in his sequence on CAST: Corrigibility as Singular Target [LW · GW]. The central thesis is that Yudkowsky called corrigibility anti-natural only because he was envisioning it alongside another maximizer goal. If you make correctability the only goal, the agent just does what it understands you to want so far, and wants update on what that is. I think Instruction-following (IF) is roughly the same alignment target; there are subtle differences between this and CAST. I've also called this Do What I Mean and Check [LW · GW], DWIMAC. I think that the complexity of wishes problem is solvable with an LLM that understands human intentions pretty well, if that understanding can be used to define the central goal of an AGI; see The partial fallacy of dumb superintelligence. Of course, intent-aligned AGI creates human coordination problems, raising the question If we solve alignment, do we die anyway? [LW · GW] (maybe, it's complicated).
- ^
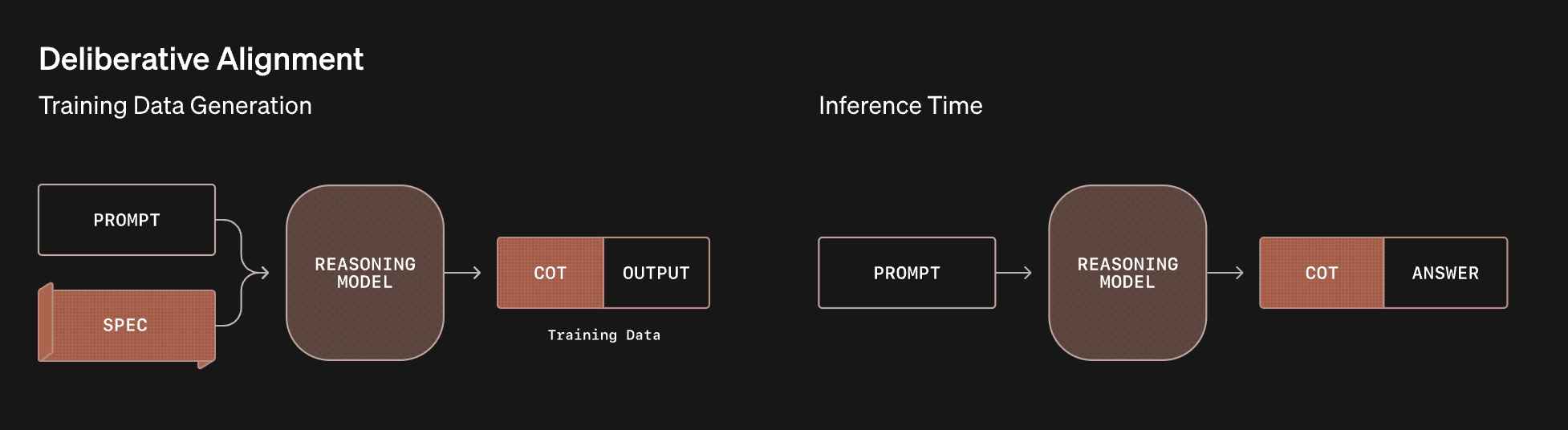
OpenAI recently announced deliberative alignment. It is a repurposing of the reinforcement learning applied to CoT training method used for o1 and o3. As such it is an example of System 2 capabilities techniques being repurposed for control/alignment.
It adds to previous methods like Anthropic's reinforcement learning from AI feedback (RLAIF); it also uses a human-written "specification". Just like RLAIF, it trains the model to "internalize" this by fine-tuning on responses provided with the spec/constitution in the context. It goes beyond that in a second step, training the full CoT based on the output answer's estimated compliance with the spec.
This diagram and the following description both describe their method.
More on OpenAI's Deliberative Alignment
Method
Deliberate alignment training uses a combination of process- and outcome-based supervision:
- We first train an o-style model for helpfulness, without any safety-relevant data.
- We then build a dataset of (prompt, completion) pairs where the CoTs in the completions reference the specifications. We do this by inserting the relevant safety specification text for each conversation in the system prompt, generating model completions, and then removing the system prompts from the data.
- We perform incremental supervised fine-tuning (SFT) on this dataset, providing the model with a strong prior for safe reasoning. Through SFT, the model learns both the content of our safety specifications and how to reason over them to generate aligned responses.
- We then use reinforcement learning (RL) to train the model to use its CoT more effectively. To do so, we employ a reward model with access to our safety policies to provide additional reward signal.
In our training procedure, we automatically generate training data from safety specifications and safety-categorized prompts, without requiring human-labeled completions. Deliberative alignment’s synthetic data generation pipeline thus offers a scalable approach to alignment, addressing a major challenge of standard LLM safety training—its heavy dependence on human-labeled data.
To be clear, I consider this application to be for safety, as distinct from true alignment; see Footnote 6. However, it could be a valuable supplement, if it were directed at a wisely chosen alignment target (probably instruction-following [LW · GW] or similar corrigibility [LW · GW] targets).
This description of deliberative alignment may provide more clues to o1 and o3's training methods. It is particularly interesting that they use a reward estimation model that compares their spec against actual responses; this is a broader reward/training criteria than answers in math and science that are easier to check than produce. This suggests the technique is applicable to many more domains; in particular, training for deliberation, review, and thought management.
- ^
I am using the term LLM agents, although I'm not at all sure it's the best term for the types of systems I'm referring to. Foundation model agents is more technically correct, since most modern systems incorporate more than language. However, I think language is the key concept, and the center of foundation models' cognitive abilities. Language distills much of human intelligence, so learning to imitate that allowed AI to skip all of the sensorimotor drudge work that evolution tackled for the first 99.99% of its project. Language model cognitive architecture [? · GW](LMCA) refers to agents with additional cognitive subsystems, while I want to address any system using language models as the basis of a competent agent.
- ^
Shane Legg introduced the term “System 2 safety” in a brief talk in Dec. ‘23. He said a little more about this approach previously in his interview with Dwarkesh Patel. I’m pretty sure he’s talking about the same thing I’m addressing here; see my interpretation of that interview [LW · GW], which was partly verified by his brief talk In any case, the System 2 terminology seems more intuitive and more general, so I’m adopting the term System 2 alignment.
- ^
OpenAI's advances in o1 and o3 were achieved by applying RL training to chains of thought in some manner. This is bootstrapped from verifiable correct answers to difficult questions, resulting in larger improvements on math, physics, and coding than other tested domains. OpenAI thankfully did not publish the full method. For speculation about exactly how they're applying RL to CoT. See o1: A Technical Primer [LW · GW] and GPT-o1 [LW · GW].
- ^
I use scare quotes for "alignment" of language models because I think current techniques used to control LLM behavior address a different issue. They create desirable behavioral tendencies. This is importantly different from producing an entity with goals/values that are aligned with human goals/values.
There is substantial overlap between these two projects, and even a possibility that doing really well on safety might accomplish alignment. But that seems unlikely, and at the least highly questionable. Controlling LLM behavior and aligning real AGI should probably not be conflated until we clarify their relationship.
- ^
Improvements in refusals/spec adherence from "deliberative alignment" training seem much smaller than improvements in math/coding/science problems, so progress in RL training to apply deliberation to arbitrary ends may be slow or limited. I would personally be surprised if these techniques weren't rapidly improved and spread broadly. But whether training CoT on arbitrary criteria works well enough is a crux for whether orgs will use training for review or thought management.
- ^
On (un)faithful CoT, see: o1 is a bad idea [LW · GW], Measuring and Improving the Faithfulness of Model-Generated Reasoning [LW · GW], Let's think dot by dot, the case for CoT unfaithfulness is overstated [LW · GW], 5 ways to improve CoT faithfulness [LW · GW], Worries about latent reasoning in LLMs [LW · GW] (on o1 specifically), Why Don't We Just... Shoggoth+Face+Paraphraser? [LW · GW], and Research directions Open Phil wants to fund in technical AI safety [LW · GW].
- ^
From my Internal independent review for language model agent alignment [LW · GW]:
The Waluigi effect [? · GW] is the possibility of an LLM simulating a villainous/unaligned character even when it is prompted to simulate a heroic/aligned character. Natural language training sets include fictional villains that claim to be aligned before revealing their unaligned motives. However, they seldom reveal their true nature quickly. I find the logic of collapsing to a Waluigi state modestly compelling. This collapse is analogous to the reveal in fiction; villains seldom reveal themselves to secretly be heroes. It seems that collapses should be reduced by keeping prompt histories short, and that the damage from villainous simulacra can be limited by resetting prompt histories and thus calling for a new simulation. This logic is spelled out in detail in A smart enough LLM might be deadly simply if you run it for long enough [LW · GW], The Waluigi Effect (mega-post) [LW · GW], and Simulators [LW · GW].
New addenda: keeping villainous characters entirely out of the training set seems like it would solve this issue. That's the proposal of A "Bitter Lesson" Approach to Aligning AGI and ASI [LW · GW]: curating the decision-making LLMs training set so that it doesn't contain vicious actions or characters.
- ^
My general brief argument for a strong possibility of LLM agents as the first form of takeover-capable AGI is here [LW(p) · GW(p)], a more abstract very short form is in my definition of "real AGI" [LW · GW], and there's more detail in Capabilities and alignment of LLM cognitive architectures [LW · GW].
0 comments
Comments sorted by top scores.