Capabilities and alignment of LLM cognitive architectures
post by Seth Herd · 2023-04-18T16:29:29.792Z · LW · GW · 18 commentsContents
Overview Cognitive capacities enabled and enhanced by LLM wrappers and extensions: LMCAs have agency LMCAs have executive function Prompts as executive function LLMs alone have little or no executive function Varieties of executive function LMCAs have episodic memory Episodic memory ⊗ executive function Complex decision-making: Decision-Making ⊗ Executive Function ⊗ Episodic Memory LMCA sensory and action systems LMCA nonhuman cognitive capacities Implications for alignment None 18 comments
Epistemic status: Hoping for help working through these new ideas.
TLDR:
Scaffolded [LW · GW][1], "agentized" LLMs that combine and extend the approaches in AutoGPT, HuggingGPT, Reflexion, and BabyAGI seem likely to be a focus of near-term AI development. LLMs by themselves are like a human with great automatic language processing, but no goal-directed agency, executive function, episodic memory, or sensory processing. Recent work has added all of these to LLMs, making language model cognitive architectures (LMCAs). These implementations are currently limited but will improve.
Cognitive capacities interact synergistically in human cognition. In addition, this new direction of development will allow individuals and small businesses to contribute to progress on AGI. These new factors of compounding progress may speed progress in this direction. LMCAs might well become intelligent enough to create X-risk before other forms of AGI. I expect LMCAs to enhance the effective intelligence of LLMs by performing extensive, iterative, goal-directed "thinking" that incorporates topic-relevant web searches.
The possible shortening of timelines-to-AGI is a downside, but the upside may be even larger. LMCAs pursue goals and do much of their “thinking” in natural language, enabling a natural language alignment [LW · GW] (NLA) approach. They reason about and balance ethical goals much as humans do. This approach to AGI and alignment has large potential benefits relative to existing approaches to AGI and alignment.
Overview
I still think it's likely that agentized LLMs will change the alignment landscape [LW · GW] for the better, although I've tempered my optimism a bit since writing that. A big piece of the logic for that hypothesis is why I expect this approach to become very useful, and possibly become the de-facto standard for AGI progress. The other piece was the potential positive impacts on alignment work. Both of those pieces of logic were compressed in that post. I expand on them here.
Beginning with a caveat may be appropriate since much of the below sounds both speculative and optimistic. I describe many potential improvements and positive-sum synergies between different capabilities. There will surely be difficulties and many things that don’t work as well or as easily as they might, for deep reasons that will slow development. It’s quite possible that there are enough of those things that this direction will be eclipsed by continued development of large models, and that progress in integrating cognitive capacities will take a different route. In particular, this approach relies heavily on calls to large language models (LLMs). Calling cutting-edge LLMs will continue to have nontrivial costs in both time and money, as they require substantial computing resources. These may hamper this direction, or drive progress in substantially less human-like (e.g., parallel) or interpretable (e.g., a move to non-natural language core processing) directions. With these caveats in mind, I think the potentials for capabilities and alignment are enough to merit serious consideration from the alignment community, even this early in the game.
I think AutoGPT, HuggingGPT, and similar script wrappers and tool extensions for LLMs are just the beginning, and there are low-hanging fruit and synergies that will add capability to LLMs, effectively enhancing their intelligence and usefulness. This approach makes an LLM the natural language cognitive engine at the center of a cognitive architecture.[2] Cognitive architectures are computational models of human brain function, including separate cognitive capacities that work synergistically.
Cognitive architectures are a longstanding field of research at the conjunction of computer science and cognitive psychology. They have been used as tools to create theories about human cognition, and similar variants have been applied as AI tools. They are respected as theories of cognitive psychology and neuroscience and constitute a good part of the limited efforts to create integrated theories of cognition. Their use as valuable AI tools has not taken off, but the inclusion of capable LLMs as a central cognitive engine could easily change that. The definition is broad, so AutoGPT qualifies as a cognitive architecture. How brainlike these systems will be remains to be seen, but the initial implementations seem surprisingly brainlike. Here I refer to such systems as language model-driven cognitive architectures, LMCAs.
It seems to me that the question is not whether, but how much, and how easily, the LMCA approach will improve LLM capabilities. The economic incentives play into this question. Unlike work on LLMs and other foundation models, computational costs are low for cutting-edge innovation. LMCAs are interesting and promise to be useful and economically valuable. I think we’ll see individuals and small and large businesses all contribute progress.
This is concerning with regard to timelines, as it not only adds capability but provides new vectors for compounding progress. Regularization of these "cognitive engineering" approaches by treating scaffolded LLMs as natural language computers [LW · GW] is likely to add another vector for compounding progress.
However, I think that the prospects for this approach to drive progress are actually very encouraging. This approach provides substantial (or even transformative) benefits to initial alignment, corrigibility [? · GW], and interpretability [? · GW]. These systems summarize their processing in English.[3] That doesn't solve all of those problems, but it is an enormous benefit. It's also an enormous change from the way these alignment problems have been approached. So if these systems are even modestly likely to take off and become the de-facto standard in AGI, I suggest that we start considering the potential impacts on alignment.
Human intelligence is an emergent property greater than the sum of our cognitive abilities. Following it as a rough blueprint is seeming like a very plausible route to human-plus level AGI (or X-risk AI, XRAI).[4] I and probably many others have limited our discussion of this approach as an infohazard. But the infohazard cat is pretty much out of that bag, and clever and creative people are now working on scripts like AutoGPT and HuggingGPT that turn LLMs into agentic cognitive architectures. The high-level principles of how the brain's systems interact synergistically aren't actually that complicated,[5] and published high-profile neuroscience research addresses all of them.
I've found that by not discussing agentizing and extending LLMs with prosthetic cognitive capacities, I've failed to think through the upsides and downsides for AI progress and alignment. This is my start at really thinking it through. I present this thinking in hopes that others will join me, so that alignment work can progress as quickly as possible, and anticipate rather than lag behind technical innovation.
There are initial implementations in each area that seem relatively straightforward and easy to extend. We should not expect long delays. To be clear, I'm not talking about weeks for highly functional versions; I agree with Zvi [LW · GW] that the path seems likely, but attaching time units is very difficult. Thankfully, think that adding these capabilities is unlikely to get us all the way from current LLMs to XRAI. However, they will accelerate timelines, so we should be ready to harvest the low-hanging fruit for alignment if progress goes in this direction.
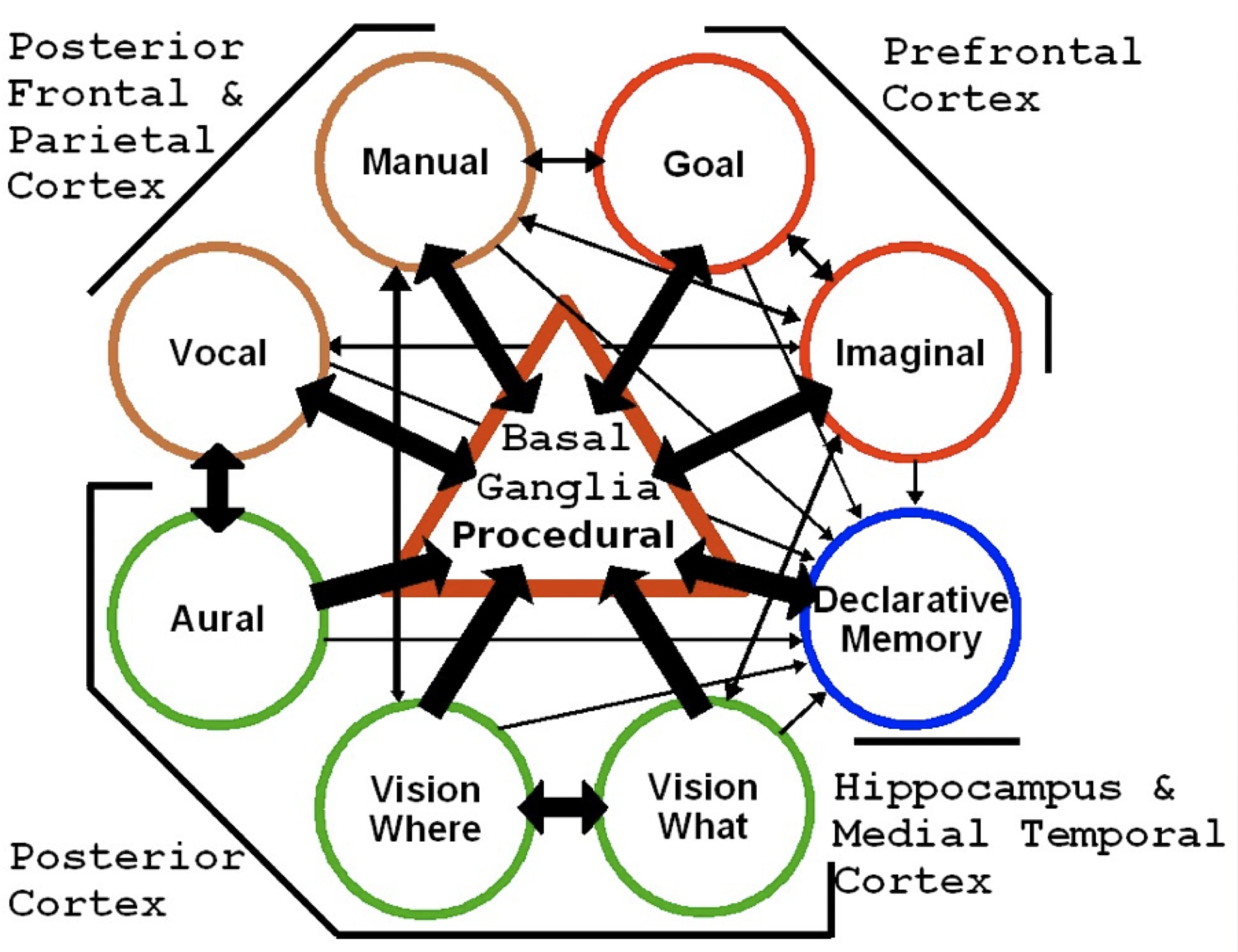
Diagram of the ACT-R cognitive architecture circa 2013, including proposed mappings to brain regions as part of the Synthesis of ACT-R and Leabra (SAL) project[6]. Recent work has implemented all of these cognitive capacities (across AutoGPT, Reflexion, and HuggingGPT), replacing the central center basal ganglia procedural component with an LLM. Those LLMs perform the same central role of selecting the next cognitive action as the procedural matching in ACT-R and similar architectures, but can also do a great deal more, leveraging their semantic matching and reasoning abilities. Modern instantiations of memory, sensory, and action systems also have many of the merits of their human equivalents.
Cognitive capacities enabled and enhanced by LLM wrappers and extensions:
- Goal direction and agency
- Including loosely humanly aligned goals and corrigibility
- Specified in natural language
- Interpreted by the LLM
- Including loosely humanly aligned goals and corrigibility
- Executive function, including:
- Factoring goals into subgoals
- Flexibly creating plans to pursue subgoals
- Analyzing success at pursuing subgoals
- Monitoring and breaking unproductive loops
- Evaluating returns from external tools
- Replacing failed plans with new plans
- Calling for human direction
- Episodic memory
- Goals
- Relevant experiences
- Declarative knowledge, such as tool APIs
- Complex decision-making for important decisions
- Evaluating which decisions are important
- Performing multiple methods
- Predicting outcomes
- Iterating for tree searches
- Planning in human-like large chunks,
- selecting over plans
- Sensory and action systems
- Object recognition from images
- Pose recognition
- Audio transcription
- Physical agents in simulated environments
- Nonhuman cognitive capacities
- New types of senses, actions, and cognition
LMCAs have agency
There can be little doubt from watching its transcripts that AutoGPT is agentic, in most of the important senses of that word: it pursues goals. Top-level goals are provided by a user, but the system creates its own subgoals, and can sometimes perseverate on accomplishing subgoals (uh oh). The current version is pretty limited in the goals it can accomplish; it can search the web, do some modestly impressive multi-step reasoning about where to look next and when it's found enough, and it can generate text output, including (buggy) code. On the other hand, HuggingGPT pursues a limited range of user-defined goals, based on the external software tools it has access to and has been instructed on how to use. Having an LMCA direct external actions would give them agency in almost all of the ways humans have agency.
I think the most important property of LMCAs is an emergent property of all of its added cognitive capacities. This is the ability to perform iterated, goal-directed internal thought, to reach conclusions, and create and refine plans. Watching AutoGPT and Baby AGI "think" suggests that improvements in their separate cognitive capacities is likely to ultimately produce useful and impressive results. Their ability to perform web searches to incorporate specific relevant information seems likely to make this ability truly useful. The application of deliberative, goal-directed thinking (in the common sense of the word) appears to greatly enhance human's effective intelligence.
LMCAs have executive function
Executive function (EF) is an umbrella term in cognitive psychology for a variety of ways the brain usefully, strategically, and flexibly directs its own information processing. The term is used similarly to System 2, goal-directed behavior, and controlled processing.[7] Executive function effectively makes us smarter by adding a layer of self-monitoring and situation-appropriate cognitive control.
I've spent the last 20 years or so working out the mechanisms that create executive function in the brain. That work largely culminated in the paper neural mechanisms of complex human decision-making. That paper includes references cascading down to the extensive empirical research on brain mechanisms of animal action selection, since the circuits for human decision-making are highly similar. We lay out the likely neural mechanisms of decision-making, but those also enable most of the other aspects of executive function. In sum, executive function is the result of internal "actions" that direct attention and what we usually call thinking. Such "trains of thought" are strategically sequenced internal action selection, performing look-ahead tree search over abstract world models and problem spaces.
Fortunately and unfortunately, those gory details of neural mechanisms are mostly irrelevant here. What is relevant is understanding how human executive functions make us smarter, and how adding similar executive functions to LLM wrappers is likely to make them smarter as well.
Prompts as executive function
In vanilla LLMs, the human user is acting as the executive function of the network. We have a goal in mind, and we create a prompt to accomplish or work toward that goal. The human evaluates the output, decides whether it's good enough, and either tries a different prompt or follows up on it if it's good enough. All of these are aspects of executive function.
AutoGPT already has nascent forms of each of these. The human user enters a top-level goal or goals (hint: put harm minimization in there if you want to be safe; GPT4 can balance multiple goals surprisingly well.) The system then factors this into potentially useful sub-goals, using a scripted prompt. Each of these prompts an action, which could be further reasoning or summarizing pages from web search in AutoGPT, but could be expanded to arbitrary actions using the techniques in HuggingGPT and ACT. The LLM is then called again to evaluate whether this subgoal has been completed successfully, and the system tries again[8] or moves to the next subgoal based on its conclusion.
Voilà! You have a system with agency, limited but useful executive function, and excellent language capacities. Improvements to each now improve the others, and we have another vector for compounding progress.
LLMs alone have little or no executive function
I think that GPT4 is a better-than-human System 1 (or “automatic” system) that’s going to benefit greatly from the addition of System 2/executive function. Whether or not that’s totally right, it’s pretty clear that they’ll benefit. The Recursive Criticism and Improvement method shows how a script that prompts an LLM with a problem, prompts it to identify errors in its response, and then prompts for a new response dramatically improves performance. This is a simple use of executive function to usefully direct cognition.
Current LLMs can perform impressive feats of language generation that would require humans to invoke executive function. The line is fuzzy, and probably not worth tripping on, but I suspect that they have no executive function equivalent.
They behave as if they're following goals and checking logic, but skilled automatic (system 1) behavior in humans does that too. Roughly, if you'd have to stop and think, or refocus your attention on the proper thing, you're invoking executive function. LLMs are likely using quite sophisticated internal representations, but I'm doubtful they have direct equivalents for stopping to think or strategically changing the focus of attention (they certainly change the focus of attention through the attention layers, but that is equivalent to human automatic attention). The reality is probably complex, and depending on precise definitions, LLMs probably do use some limited aspects of human EF.
Whether or not LLMs have some limited equivalent of executive function, it seems that adding more, and more flexible executive function is likely to improve their abilities in some domains.
Varieties of executive function
We've already discussed goal selection and direction, and evaluating success or failure. AutoGPT often gets stuck in loops. Detecting this type of perseveration is another known function of human EF. If calling the LLM with the prompt "does the recent past seem repetitive to you?" doesn't work, there are other obvious approaches.
AutoGPT also seems to get distracted and sidetracked, in common with humans with damage to the prefrontal cortex and basal ganglia which enact executive function. Bringing back in long-term goals to prevent perseveration and distraction is another application of executive function, and it has similarly obvious implementations which haven't been tried yet. One important application will be ensuring that alignment-related goals are included in the context window often enough that they guide the system’s behavior.
EF will also enhance tool-use. Checking the returns from external software tools like those in the HuggingGPT, ACT, and Wolfram Alpha integrations will enhance their effectiveness by allowing the system to try a different prompt to the tool, a different tool, or giving up and trying a different approach.
Or calling for human input. Adding automated EF does not preclude going back to relying on humans as EF when such help is necessary and available. This is another thing that hasn't been implemented yet (to my knowledge), but probably will be by next week, and steadily improving from there.
LMCAs have episodic memory
Human episodic memory (EM) allows us to retrieve representations of episodes (experiences, or slices of time) as a sort of snapshot of all the higher cortical representations that were taking place at that time. Partial matches between current experience cause the hippocampus and medial temporal lobe to pattern-complete, and retrieve the rest of the patterns into working memory (likely residing in a global workspace of tightly connected higher and more abstract cortical areas).
Existing agentized LLMs have episodic memory based on vector retrieval algorithms (e.g., pinecone) that search over text files created in earlier steps. One prompt for AutoGPT says
- If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
Which is pretty much exactly how it works for humans. I don't know how well this actually works in AutoGPT, but the similarity is fascinating if this technique actually works well. For AutoGPT, episodic memory pastes loosely matching text files back into the context window for future prompts. This context window is a rough analogue of working memory in humans. Like our working memory, it is able to hold both information and goals.
Adding episodic memory has the potential to make LLMs more capable in several ways. Although the context window for GPT4 is large, it does not appear to make use of the full window as well as having a shorter and more directly relevant prompt.[9] Pulling goals and experiences back into the context buffer according to their semantic relevance has the advantage of keeping the context window more relevant to the current goal. In this way, EM makes working memory (the context window) work better by clearing it of interfering information.
The advantage of episodic memory is demonstrated in some AutoGPT or BabyAGI use cases, but their capabilities are largely untested. The use of episodic memory, including prompting GPT to "reflect" to summarize important events is impressively demonstrated in work on GPT-powered social agents in a persistent virtual environment.
Episodic memory ⊗ executive function
Episodic memory and executive function interact to make both work better.
By recalling past experiences, humans can apply learned strategies to solve problems. Executive functions, assist by focusing attention on relevant aspects of the current problem, allowing retrieval of episodic memories that match in relevant but not irrelevant ways. For instance, in trying to order a hairbrush, executive function could be applied by making another LLM call to find the difficult part of the task. If it failed in making the order, episodes of ordering items from similar websites would be cued and recalled. If it failed to find a hairbrush, that cue and EM call might find episodes in which a hairbrush was also mentioned by an alternate name or by an image.
Social cognition is enhanced through the interaction of episodic memory and executive function, enabling recall of past interactions, and EF can parse those for relevant goals and preferences of that individual. Similar interactions can help in performing other tasks where past experience is relevant.
Self-awareness and reflection rely on the synergy of these cognitive processes. Autobiographical knowledge is formed through episodic memory, and executive function facilitates reflection on experiences and actions. This would all sound wildly complex and speculative if we hadn't already seen a bunch of sims powered by turboGPT03.5 actually do a good bit of it. I'd propose that we just don't include those self-awareness refining functions in deployed LMCAs, but of course it will be too interesting to resist.
Creativity and innovation arise in part from this combination. Executive function can focus processing on different aspects of a situation. Using this focus as a recall cue can produce wildly varied but relevant "ideas", while additional calls acting as executive function can identify which are more likely worth pursuing. This last evaluative function of EF overlaps with decision-making.
The episodic memory implemented in scaffolded LLMs is currently limited to text files. This is a substantial limitation relative to the rich multimodal and amodal representations the human brain is thought to use. However, similar embeddings exist in ML models, so search over those vector spaces for EM is quite possible. And language does encode multimodal information, so even a pure natural language EM might work well in practice.
Complex decision-making: Decision-Making ⊗ Executive Function ⊗ Episodic Memory
LMCAs can make decisions surprisingly well without employing brainlike mechanisms. Here as well, though, they will likely benefit from implementing System 2- like iterative mechanisms.
Suppose you're thinking of walking across a rickety bridge. You might stop to think because you want to get to the other side, but also had a bad feeling about walking on a structure with that appearance. You could be staring at that bridge for a long time thinking of different strategies to evaluate the likely outcomes. And if you really need to get across that river, that time might be well worth it.
The process you use to make that evaluation will combine episodic memory, executive function, and reward learning circuits. Episodic memory recalls previous decision outcomes, while executive function (composed of those RL-based micro-decisions in the human brain, and engineered prompts in agentized LLMs) selects strategies. Those strategies include predicting outcomes based on semantic knowledge, in a small Monte Carlo tree search (MCTS), trying to recall similar decision outcomes from episodic memory, or searching for more sensory information.
LLMs alone can’t do this. They get one forward pass to make the decision. They can’t decide to explicitly predict outcomes before deciding, and they can’t go looking for new information to help with important decisions. They can’t even recognize that it’s an important decision, and think about it several ways before making the final decision.
The basis of all of these strategies is pausing to think. One crucial function of the human basal ganglia that isn't present in most deep networks is the capacity to decide when to make a more complex decision. The presence of separate Go and NoGo circuits allows the system to learn when both predicted reward and risk are high, and keep that option present in working memory while further processing improves estimates of risk and reward.
Decision-making in the human brain appears to use circuits similar to those extensively studied in animal action selection, but connected to prefrontal cortex rather than motor cortex. These produce an interaction between the cortex, which is probably mostly a self-supervised predictive learner; basal ganglia, which learns from past experiences the risks and rewards associated with particular actions in particular contexts; and the dopamine system, which acts much like a critic system in formal reinforcement learning to predict the value of outcomes, and discount the signal from actual rewards when compared to that expected reward.[10]
It will be fairly simple to implement an analogue to any or all of that in LMCAs. Whether it’s helpful is an empirical question, since someone will very likely try it. LLMs have been shown to be effective in acting as reward estimators when that reward is applied to refine another LLM to improve its function as a negotiator. It seems likely that a similar technique would work to condense an LLM’s verbal estimate of how well an action will work in this context and perhaps estimated risks, to numbers for use in a decision algorithm like the one implemented by the brain.
This type of approach would allow arbitrarily complex decision algorithms. For example, something like:
If the expected reward of this option, minus the estimated risk, plus estimated time pressure, is below 5, make another outcome projection and update estimates of risk and reward. If estimates minus time pressure are less than 5, move to evaluate a different option. Repeat until a decision is made or time pressure is greater than ten, in which case return to the parent goal and try to create a new plan that doesn't require this decision. Store decision variables in episodic memory before returning to the parent plan.If this sounds like an insanely arbitrary way to make complex decisions, it probably is. It's also the way every complex and important decision has ever been made. The brain appears to loosely implement a similar, complex algorithm. Worse, a good bit of that algorithm is probably learned over the course of the lifetime as component decisions. Neuroimaging isn't good enough to track the neural signatures of all the twists and turns an individual mind takes in making a complex decision, so we don't know exactly what algorithms people use. However, they probably consist of a large number of sub-decisions, each using a those action-selection circuits for a component cognitive action. Those are thought to include selecting decision strategies and creating and creating and terminating prediction trees.
Episodic memory is necessary for humans to perform truly complex decision-making because we can't fit that many outcome estimates into working memory. LLMs have a broader context window, but episodic memory may still prove useful, as discussed above under EM x EF. In addition, episodic memory allows complex decision-making to double as planning, by remembering all of the steps in the MCTS chain associated with the selected option.
One tool that humans can use in solving problems, making plans, and making decisions is sensory systems and sensory working memory. Humans are thought to use simulation in sensory domains to aid in problem-solving and decision-making. HuggingGPT allows an LLM to call a generative model, then call interpretive models on that image or sound file. This provides a nascent form of modal simulation available for LMCAs (although they can already simulate and predict outcomes rather well in natural language). To be clear, humans use our sensory systems to simulate hypotheticals in a much more sophisticated way. The rich connections between brain systems allow us a great deal of control over our imagination/simulation. However, it’s hard to be sure how progress in tool systems for LLMs will close that gap.
Planning is one important function of this type of complex decision-making. People construct simplified mental representations to plan, representing tasks in large chunks, whereas AI systems have usually planned in many concrete steps. The facility of LLMs to summarize text will allow similar planning in chunks, and episodic memory allows expanding those chunks back into full plans when it’s time to execute. Aggregating estimated costs and rewards may require more infrastructure, but that shouldn’t need to be complex to be useful. Effective planning and organization emerge from the interplay between EF and EM. Goals are formed and progress monitored by EF, while subgoals, plans, and strategies are stored and recalled with EM. The MCTS tree searches used for complex decision-making double as plans if that path is followed.
LMCA sensory and action systems
HuggingGPT represents a new approach to allowing LLMs to call external software tools. This project used instruction to allow ChatGPT to select among and call tools from the Hugging Face library to solve problems. GPT selected among tools by including the tool descriptions from that library in the context window,[11] and used those tools based on examples of the proper API calls, also given as context in a separate step. Between one and 40 examples of correct API formats were sufficient to allow use of those tools (although the success rate in practice was not close to 100%).
This project added useful capabilities, allowing ChatGPT to solve problems like interpreting images, including multiple steps of locating, identifying, and counting objects, interpret audio files, and produce outputs in image and audio form using generative networks. However, I think the real significance here is the relative simplicity and universality of this approach. This approach seems likely to be adaptable to an even wider range of software tools. Agents may be able to search the web for tools, download them or gain access to online versions, and use them by finding the API description and self-prompting with it.
Improved executive function will aid in the actual usefulness of these tools. Recognizing that a call has failed, and using a different tool or different prompts, will improve reliability. Similarly, improved episodic memory will allow a system to search for instances where a particular tool has succeeded or failed for a similar problem.
LMCA nonhuman cognitive capacities
The integration of Wolfram Alpha with ChatGPT is one example of providing access to cognitive tools or toolboxes that humans don’t have. I haven’t tried imagining others that will be useful, or how those might compound the capabilities of other cognitive systems. Tools for processing large datasets are one such possibility. Some of the tools in the Hugging Face library also represent nonhuman cognitive abilities. Heavy reliance on nonhuman cognitive capacities could be a problem for interpretability, but these also seem on net easier to interpret than complex neural network representations, and summarizing their results in natural language and human-readable API returns makes them more interpretable.
Implications for alignment
Conclusions about capabilities of LMCAs are in the overview section, and rereading that section may be useful.
The implications of this natural language alignment [LW · GW](NLA) approach will be the subject of future posts, but I will give my thinking so far here. The purpose of this initial presentation is to stress-test and improve these ideas with input from the community.
An LMCA could be described as a shoggoth wearing a smiley face mask that recursively talks to itself and wields tools. However, it is the mask that talks and wields the tools. It is reminded to predict the words of character with the goals its user wrote, as often as necessary. In the lore, the shoggoth are highly capable and intelligent but not sentient or goal-directed.[12] As long as that is the case of the central LLM, that simulator [LW · GW] should remain “in character”, and the system should remain loyal to its user-given goals. The recurrent loop of sentience does not pass into the LLM itself. To maliciously do harm, the central LLM would to some extent have to trick the whole system, of which it is itself a part.
If this arrangement sounds terrifying and arcane, I quite agree. Waluigi effects might be caught by constantly reminding the shoggoth to stay in character, but simple errors of wandering trains of thought, and errors of judgment seem inevitable. Only clever error-catching loops will let such a thing run independently without somehow running amok. These dangers bear more analysis, thought, and network interpretability research. However, it looks to me right now like this is the most realistic shot at alignment that we’ve got, since the alignment tax may be very low. Aligning these systems to practical goals entails most of the same challenges as aligning them to human flourishing and corrigibility. In addition, it seems to me that other approaches have almost all of the same downsides and fewer advantages.
Having a system that takes its top-level goal in natural language, and can balance multiple goals, would appear to be a huge opportunity for alignment. GPT4 appears to reason about balancing ethical and practical goals much like a well-informed human does. This reasoning is aided by the limited alignment attempts in its (likely) RLHF fine-tuning, and not all LLMs used for these types of cognitive architectures are likely to have that. However, even an unaligned LLM that’s highly capable of text prediction is likely to do such ethical reasoning and goal tradeoffs fairly well and naturally. This natural language alignment (NLA) approach is similar to an alignment approach previously suggested by Steve Byrnes [LW · GW] and myself [LW · GW] for human-like actor-critic RL systems, but this seems even easier and more straightforward, and it applies to systems that people are likely to develop and deploy outside of alignment concerns.
The largest advantage to this LMCA NLA approach is that it applies easily to systems that are likely to be deployed anyway. Most of the promising alignment approaches I’m aware of would require different training approaches than those currently in use. It’s unclear who would implement these or what strategy could be used to motivate them, or society at large, to pay large alignment taxes. The perfect is the enemy of the good, and there is a certain merit to focusing on solutions that may actually be implemented.
This is not a complete solution for alignment. We do not want to trust the future to a Frankensteinian collection of cognitive components, talking to itself and making plans and decisions based on its conclusions. This easy loose alignment seems like a huge improvement over existing plans, particularly because the structure of language provides a good deal of generalization, and the way humans use language incorporates much of our ethical thinking, including our goals and values.
This type of initial alignment only becomes promising long-term when it is combined with corrigibility and interpretability. Including top-level goals for corrigibility in natural language seems much more promising than training the system on correlates of corrigibility, and hoping those generalize as capabilities improve. It is an easy way of having some amount of self-stabilizing alignment to include following ethical goals as part of the reasoning the system does to make and execute plans. The system can be coded to both check itself against its goals, and invite human inspection if it judges that it is considering plans or actions that may either violate its ethical goals, change its goals, or remove it from human control. Of course, leaving this judgment entirely to LMCA would be a mistake.
Interpretability is another advantage of a system that summarizes its thinking and planning in natural language. There are concerns that LLMs do not entirely think in plain sight [LW · GW]; for instance, RLHF may introduce pressures for networks to use steganography [LW · GW] in their responses. These are real concerns, and will need to be addressed. Beyond those concerns, highly capable LMCAs will produce enormous internal transcripts. Parsing these will quickly go beyond human capability, let alone human inclination. Additional tools will be necessary to identify important and dangerous elements of these internal chains of thought.
This NLA approach is compatible with a hodgepodge alignment strategy. [LW · GW] For instance, current implementations benefit from the inclusion of partially-aligned GPT4. The example of tasking BabyAGI with creating paperclips, and it turning to the question of alignment, is one dramatic, if hand-picked example (the context of making paperclips in online writing is probably largely about the alignment problem).
However, the NLA approach does little to address the alignment stability problem [LW · GW]. It would seem to neither help nor hurt the existing approaches. The idea of reflective stability or an internal value handshake [LW · GW] still applies. Natural language alignment also does not address representational drift in interpreting those goals as experience and learning accrue. Having an agent apply its own intelligence to maintain its goal stability over time is the best idea I know of, but I think it’s hard to know to what extent that will happen naturally in LMCAs. They are not strictly model-based maximizers, so like humans, they will not predictably stabilize their own goals perfectly over time. However, including this stability goal as part of the high-level goal prompt would seem to be a good start. Human involvement would seem to be possible and useful, as long as corrigibility and stability goals are maintained.[13]
NLA does not address the societal alignment problem. If these systems are as capable as I expect, that problem will become much worse, by allowing access to powerful agents in open-source form. I think we need to turn our attention to planning against Moloch itself, as well as planning for malicious and careless actors. These issues are challenging and critical if the near future unfolds in the massively multipolar AGI scenario I expect if LMCAs are successful.
It’s looking like a wild ride is coming up very quickly, but I think we’ve got a fighting chance.
Thanks to Steve Byrnes, Beren Millidge, and Tom Hazy for helpful comments on a draft of this article.
- ^
Beren Millidge’s excellent article describes scaffolded LLMs as natural language computers [LW · GW]. He is addressing essentially the same set of potentials in LLMs by having them driven by scripts and interact with external tools, but he addresses this from a thoroughly CS perspective. This complements my perspective of seeing them as loosely brainlike cognitive architectures, and I highly recommend it.
- ^
David Shapiro coined this term and originated this natural language approach to alignment in his 2021 book Natural Language Cognitive Architecture: A Prototype Artificial General Intelligence, which I haven’t yet read. He probably came up with this approach long before publishing that book, and others have probably talked about a natural language alignment [LW · GW] prior to that post, but I haven’t it. I found Shapiro’s work when researching for this article, and I am adopting his cognitive architecture terminology because I think it’s appropriate. The few mentions of his work on Less Wrong are quickly dismissed in each instance.
I do not endorse Shapiro’s proposed “Heuristic Imperatives” as top-level goals. They are: Reduce suffering in the universe; Increase prosperity in the universe; and Increase understanding in the universe.
I’d expect these to wind up creating a world with no humans and lots of smart and prosperous AIs that don’t experience suffering (and never have cool dance parties or swap meets). But, to be fair, Shapiro doesn’t claim that these are the best final form, just that we should have a list, and encourage their adoption by social and economic pressure.
I am not going to propose specific alternatives here, because we should first discuss whether any such scheme is useful. I'd say top-level goals for alignment should probably emphasize corrigibility and interpretability, along with some sort of harm reduction and human empowerment/flourishing.
- ^
It is unknown how much processing LLMs really accomplish to create each natural language string. And there are concerns that its output could become deceptively different than the internal processing that creates it. This is an important caveat on this approach, and deserves further discussion and interpretability work. The final section mentions some of these concerns.
- ^
I’m suggesting the term x-risk AI, abbreviated XRAI, to denote AI that has a good chance of ending us. AGI is not specific enough, as GPT4 meets the intuitive definition of an AI that does a bunch of stuff well enough to be useful. I’d like a more strict definition of AGI, but I believe in coining new terms instead of telling people they’re using it wrong.
- ^
Of course, the interactions between brain systems are highly complex on a neuronal level, and the exact mechanisms have not been worked out. On a high level, however, the principles seem clear. For the interactions I’ve described, it seems as though the limited bandwidth of natural language descriptions and simple APIs will be adequate to do a good deal of cognitive work.
- ^
This was an explicitly pluralistic version of the widely-used ACT-R cognitive architecture, meaning that the design goal was having cognitive components that could be swapped out for other implementations that accomplished the same function. This is the HuggingGPT approach of having an array of external tools to call. We were using the Leabra algorithm to create deep neural networks, but the actual implementation was limited to a vision network taking on the role of the visual "what" stream in ACT-R. Two papers may be of interest:
SAL: an explicitly pluralistic cognitive architecture (2008)
Integrating systems and theories in the SAL hybrid architectur (2013)
- ^
For too much more on the precise distinctions in terminology surrounding executive function, see our paper How Sequential Interactive Processing Within Frontostriatal Loops Supports a Continuum of Habitual to Controlled Processing.
- ^
While Auto-GPT has accomplished little of real use at this early date, I'm impressed by how it seemingly spontaneously tries new approaches after a failure, based on its conclusion of that failure in its context window. More sophisticated approaches are possible, but they may not be necessary.
- ^
This type of interference may relate to a cognitive neuroscience theory postulating that humans' low working-memory-for-executive-function capacity is actually advantageous in preventing interference. See Rationalizing constraints on the capacity for cognitive control.
- ^
Dopamine response has long been known to approximate reward prediction error (which is equivalent to a value estimate in actor-critic RL). It is now known that the dopamine response contains other response characteristics, including positive responses for negative occurrences. This is consistent with dopamine as a general error signal that trains many responses beyond reward expectation, but it is consistent with the finding that dopamine’s central function is value estimation, with around 70% of dopamine cells responding in that way. Much more can be found in A systems-neuroscience model of phasic dopamine.
- ^
The number and length of tool descriptions in the Hugging Face library necessitated a pre-selection step to select more-likely appropriate tool descriptions, since all of the descriptions together exceeded the context window.
- ^
I have neither the artistic skill nor the time to cajole midjourney to depict a shoggoth wearing a smiley face mask that holds dangerous tools and talks to itself. Help would be appreciated. The lore I’m remembering may not be canon, it’s been a while. Fortunately, fictional shoggoths aren’t relevant. Unfortunately, the level of sentience and goal-directedness of current and future LLMs is also unknown.
- ^
Whoops, giving an LMCA a goal of not changing its goals could conflict with its goals of corrigibility and interpretability, since letting a user inspect its thoughts might result in the user changing its goals. This stuff is going to be tricky. I hope nobody launches a GPT-5 LMCA based on my suggestions without reading the footnotes.
18 comments
Comments sorted by top scores.
comment by awg · 2023-04-18T19:19:43.296Z · LW(p) · GW(p)
Strong upvoted. A very thorough, yet fairly easy-to-follow (at least...for around here) overview of human cognitive architecture, what we currently know about it, and how it applies to what we're currently building with LLMs and LMCAs as you call them (there's so many different names floating around).
I'm not sure I come to quite the same level of optimism (if that's the right word) on the amount of alignment we'll be able to get out of these types of distributed architectures, but I do agree they seem to lend themselves well to a hodgepodge alignment strategy with many different people working on aligning many different parts of the architecture at once (in addition to the central LLM)...or something.
I am starting to wonder if this is the approach that OpenAI/Microsoft is internally pursuing toward AGI.
Replies from: Seth Herd↑ comment by Seth Herd · 2023-04-18T22:14:48.272Z · LW(p) · GW(p)
Thank you! I'm really glad you found it relatively easy to follow. That was certainly the goal, but it's impossible to know until others read it.
I think that almost certainly is at least one aspect of Microsoft's strategy. There was some accidental revealing of an extra internal prompt when bing chat was first released; I didnt take down the source unfortunately. And now that you mention it, that would be a great way to apply Microsoft's existing skill pool of coders to improve performance.
That might also be a big thing within OpenAI. Sam Altmann recently said (again I don't remember where) that the age of big models is already over (I'm sure they'll still make them larger, but he's saying that's less of the focus). This could be one of the alternate approaches they're taking up.
I don't know how optimistic I am about the alignment prospects. But I do think it's got more upsides and the same downsides of most other suggestions. Particularly the more practical ones that have a low enough alignment tax to actually be realistically implementable.
Replies from: awg↑ comment by awg · 2023-04-18T23:15:01.236Z · LW(p) · GW(p)
My degree is in cognitive science, so that might have given me a leg up, but while it was technical I found it got the good points across (with relevant citations) without getting too deep into the weeds, which is always a sweet spot to hit in cases like these :)
And word, I had written out this short list of (complete ass-pull gut instinct) reasons why I think this will be OpenAI/Microsoft's strategy before deleting them and reframing it as that wondering instead. But now that you bring it up:
- The GPT-4 + plugins launch seems like they had that same system internally for quite some time. I think it was part of their testing plan for a while and they built their own, better versions of AutoGPT and decided it was all still pretty dumb and safe and so they released to see what the public would do with them, just like their safety plan states.
- The slow roll of GPT-4.2+ also points in that same direction to me. They could be using GPT-4.X as the central LLM reasoning hub in their own version of AutoGPT and figure (maybe correctly??) that bottlenecking the performance of the central hub is the proper way to handicap any layman approaches to AutoGPT. I expect they're testing the performance of GPT-4.2/3/4/whatever in stages for this very purpose before rolling out any updates to the public.
- Sam A's comment that the age of large models is over indicates to me that they might be going with this approach: refining/progressing the LLM central hub to a point where it can orchestrate human-level+ STEM across a distributed system of other models.
And re: alignment, agreed.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-02-23T21:20:07.989Z · LW(p) · GW(p)
A relevant recent advance in cognitive scaffolding for LLMs: Self-Discover: Large Language Models Self-Compose Reasoning Structures
comment by Evan R. Murphy · 2023-04-24T17:05:11.273Z · LW(p) · GW(p)
Post summary (experimental)
Here's an alternative summary of your post, complementing your TL;DR and Overview. This is generated by my summarizer script utilizing gpt-3.5-turbo and gpt-4. (Feedback welcome!)
The article explores the potential of language model cognitive architectures (LMCAs) to enhance large language models (LLMs) and accelerate progress towards artificial general intelligence (AGI). LMCAs integrate and expand upon approaches from AutoGPT, HuggingGPT, Reflexion, and BabyAGI, adding goal-directed agency, executive function, episodic memory, and sensory processing to LLMs. The author contends that these cognitive capacities will enable LMCAs to perform extensive, iterative, goal-directed "thinking" that incorporates topic-relevant web searches, thus increasing their effective intelligence.
While the acceleration of AGI timelines may be a downside, the author suggests that the natural language alignment (NLA) approach of LMCAs, which reason about and balance ethical goals similarly to humans, offers significant benefits compared to existing AGI and alignment approaches. The author also highlights the strong economic incentives for LMCAs, as computational costs are low for cutting-edge innovation, and individuals, small and large businesses are likely to contribute to progress. However, the author acknowledges potential difficulties and deviations in the development of LMCAs.
The article emphasizes the benefits of incorporating episodic memory into language models, particularly for decision-making and problem-solving. Episodic memory enables the recall of past experiences and strategies, while executive function focuses attention on relevant aspects of the current problem. The interaction between these cognitive processes can enhance social cognition, self-awareness, creativity, and innovation. The article also addresses the limitations of current episodic memory implementations in language models, which are limited to text files. However, it suggests that vector space search for episodic memory is possible, and language can encode multimodal information. The potential for language models to call external software tools, providing access to nonhuman cognitive abilities, is also discussed.
The article concludes by examining the implications of the NLA approach for alignment, corrigibility, and interpretability. Although not a complete solution for alignment, it is compatible with a hodgepodge alignment strategy and could offer a solid foundation for self-stabilizing alignment. The author also discusses the potential societal alignment problem arising from the development of LLMs with access to powerful open-source agents. While acknowledging LLMs' potential benefits, the author argues for planning against Moloch (a metaphorical entity representing forces opposing collective good) and accounting for malicious and careless actors. Top-level alignment goals should emphasize corrigibility, interpretability, harm reduction, and human empowerment/flourishing. The author also raises concerns about the unknown mechanisms of LLMs and the possibility of their output becoming deceptively different from the internal processing that generates it. The term x-risk AI (XRAI) is proposed to denote AI with a high likelihood of ending humanity. The author also discusses the principles of executive function and their relevance to LLMs, the importance of dopamine response in value estimation, and the challenges of ensuring corrigibility and interpretability in LMCA goals. In conclusion, the author suggests that while LLM development presents a wild ride, there is a fighting chance to address the potential societal alignment problem.
I may follow up with an object-level comment on your post, as I'm finding it super interesting but still digesting the content. (I am actually reading it and not just consuming this programmatic summary :)
Replies from: Seth Herd↑ comment by Seth Herd · 2023-04-24T22:50:57.989Z · LW(p) · GW(p)
Cool, thanks! I think this summary is impressive. I think it's missing a major point in the last paragraph: the immense upside of the natural language alignment and interpretability possible in LMCAs. However, that summary is in keeping with the bulk of what I wrote, and a human would be at risk of walking away with the same misunderstanding.
comment by Ozyrus · 2023-04-19T06:02:00.672Z · LW(p) · GW(p)
We need a consensus on how to call these architectures. LMCA sounds fine to me.
All in all, a very nice writeup. I did my own brief overview of alignment problems of such agents here [LW · GW].
I would love to collaborate and do some discussion/research together.
What's your take on how these LCMAs may self-improve and how to possibly control it?
↑ comment by Seth Herd · 2023-04-19T15:39:38.585Z · LW(p) · GW(p)
Interesting. I gave a strong upvote to that post, and I looked at your longer previous one a bit too. It looks like you'd seen this coming farther out than I had. I expected LLMs to be agentized somehow, but I hadn't seen how easy the episodic memory and tool use was.
There are a number of routes for self-improvement, as you lay out, and ultimately those are going to be the real medium-term concern if these things work well. I haven't thought about LMCAs self-improvement as much as human improvement; this post is a call for the alignment community to think about this at all. Oh well, time will tell shortly if this approach gets anywhere, and people will think about it when it happens. I was hoping we'd get out ahead of it.
Replies from: Ozyrus↑ comment by Ozyrus · 2023-04-19T17:18:20.055Z · LW(p) · GW(p)
Thanks.
My concern is that I don't see much effort in alignment community to work on this thing, unless I'm missing something. Maybe you know of such efforts? Or was that perceived lack of effort the reason for this article?
I don't know how much I can keep up this independent work, and I would love if there was some joint effort to tackle this. Maybe an existing lab, or an open-source project?
↑ comment by Seth Herd · 2023-04-19T17:29:06.951Z · LW(p) · GW(p)
Calling attention to this approach and getting more people to at least think about working on it is indeed the purpose of this post. I also wanted to stress-test the claims to see if anyone sees reasons that LMCAs won't build on and improve LLM performance, and thereby be the default stand for inclusion in deployment. I don't know of anyone actually working on this as of yet.
comment by Brendon_Wong · 2023-04-28T03:42:14.481Z · LW(p) · GW(p)
Have you read Eric Drexler's work on open agencies [LW · GW] and applying open agencies [LW · GW] to present-day LLMs? Open agencies seem like progress towards a safer design for current and future cognitive architectures. Drexler's design touches on some of the aspects you mention in the post, like:
Replies from: Seth HerdThe system can be coded to both check itself against its goals, and invite human inspection if it judges that it is considering plans or actions that may either violate its ethical goals, change its goals, or remove it from human control.
comment by Max H (Maxc) · 2023-04-19T18:05:32.117Z · LW(p) · GW(p)
I like the LMCA term, and I agree that systems like them are likely to be the capabilities frontier in the near future. I think aiming to make such systems corrigible while they're in the human-level or weakly superhuman regime is more promising than trying to align them in full generality.
In a recent post [LW · GW], I considered what adding corrigibility to a system comprised of LMCAs might look like concretely.
Replies from: Roger Dearnaley, Seth Herd↑ comment by Roger Dearnaley · 2023-04-24T07:59:59.058Z · LW(p) · GW(p)
A lot of the work people have done in alignment had been based on the assumptions that 1) interpretability is difficult/weak, and 2) the dangerous parts of the architecture are mostly trained by SGD or RL or something like that. So you have a blind idiot god making you almost-black boxes. For example, the entire standard framing of inner vs outer alignment has that assumption built into it.
Now suddenly we're instead looking at a hybrid system where all of that remains true for the LLM part (but plausibly a single LLM forward pass isn't computationally complex enough to be very dangerous by itself), however the cognitive architecture built on top of it has easy interpretability and even editability (modulo things like steganography, complexity, and sheer volume), looks like combination of a fuzzy textual version of GOFAI with prompt engineering, and its structure is currently hand-coded, and could remain simple enough to be programmed and reasoned about. Parts of alignment research for this might look a lot like writing a constitution, or writing text clearly explaining CEV, and parts might look like the kind of brain-architectural diagrams in the article above.
I believe the only potentially-safe convergent goal to give a seed AI is to build something with the cognitive capability of one-or-multiple smart (and not significantly superhumanly smart) humans, but probably faster, that are capable of doing scientific research well, giving it/them the goal of solving the alignment problem (including corrigibility), somehow ensuring that that goal is locked in,and then somehow monitoring them while they do so
So how would you build a LMCA scientist? It needs to have the ability to:
- Have multiple world models, including multiple models of human values, with probability distributions across them.
- Do approximate Bayesian updates on them
- Creatively generate new hypotheses/world models
- It attempts to optimize our human value (under some definition, such as CEV, that it is also uncertain of), and knows that it doesn't fully understand what that is, though it has some data on it.
- It optimizes safely/conservatively in the presence of uncertainty in its model of the world and human values, i.e has solved the [LW · GW] optimizer's curse [LW · GW] Significantly, this basically forces it to make progress on the Alignment Problem in order to ever do anything much outside its training distribution: it has to make very pessimistic assumptions in the presence of human value uncertainty, so it is operationally motivated to reduce human value uncertainty. So even if you build one that isn't an alignment researcher as its primary goal, but say a medical researcher and tell it to cure cancer, it is likely to rapidly decide that in order to do that well it needs to figure out what Quality-of-life-adjusted Life Years and Informed Consent are, and the Do What I Mean problem, which requires it to first solve the Alignment Problem as a convergent operational goal.
- Devise and perform low cost/risk experiments (where the cost/risk is estimated conservatively/pessimistically under current uncertainty in world+human value models) that will distinguish between/can falsify individual world+human value models in order to reduce model uncertainty.
This strongly suggest to me an LMCA architecture combining handling natural language (and probably also images, equations, code, etc) with quantitative/mathematical estimation of important quantities like probabilities, risks, costs, and value, and with an underlying structure built around approximate Bayesian reasoning.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2023-04-24T09:27:24.940Z · LW(p) · GW(p)
You might want to compare your ideas to (1) Conjecture's CoEms [LW · GW] (2) brain-like AGI safety [? · GW] by @Steven Byrnes [LW · GW] (3) Yann LeCun's ideas [LW · GW].
Replies from: Seth Herd↑ comment by Seth Herd · 2023-04-27T22:48:02.317Z · LW(p) · GW(p)
I'd done that with 1 and 2, and probably should've cited them. I did cite a recent brief summary of Steve's work, and my work prior to getting excited about LMCAs was very similar to his. In practice, it seems like what Conjecture is working on is pretty much exactly this. I wasn't familiar with LeCun's scheme, so thanks for sharing.
The brainlike cognitive architecture proposed by Steve (and me) and LeCun's are similar in that they're cognitive architectures with steering systems [LW · GW]. Which is an advantage. I also wrote about this here [LW · GW].
But they don't have the central advantage of a chain of thought in English. That's what I'm most excited about. If we don't get this type of system as the first AGI, I hope we at least get one with a steering system (and I think we will; steering is practical as well as safer). But I think this type of natural language chain of thought alignment approach has large advantages.
↑ comment by Seth Herd · 2023-04-19T18:14:39.400Z · LW(p) · GW(p)
Excellent! I'll digest that and the steering post. I'm also addressing steering system alignment as somewhat of a shortcut in Human preferences as RL critic values - implications for alignment. I think it's really similar to your approach, as I'm also thinking about a MuZero type of RL system. The map here is the executive function system in an LMCA, but it deserves to be spelled out more thoroughly as you've done in your corrigibility tax post.