Safety Implications of LeCun's path to machine intelligence
post by Ivan Vendrov (ivan-vendrov) · 2022-07-15T21:47:44.411Z · LW · GW · 18 commentsContents
Architecture Overview The Overall Agent The World Model The Actor The Cost The Configurator Implications for AI Safety Conclusion and Unresolved Questions None 18 comments
Yann LeCun recently posted A Path Towards Autonomous Machine Intelligence, a high-level description of the architecture he considers most promising to advance AI capabilities.
This post summarizes the architecture and describes some implications for AI safety work if we accept the hypothesis that the first transformative AI will have this architecture.
Why is this a hypothesis worth considering?
- LeCun has a track record of being ahead of mainstream academic research, from working on CNNs in the 90s to advocating for self-supervised learning back in 2014-2016 when supervised learning was ascendant.
- LeCun runs Meta AI (formerly FAIR) which has enormous resources and influence to advance his research agenda, making it more likely that his proposed architecture will be built at scale. In general I think this is an underrated factor; AI research exhibits a great deal of path dependence, and most plausible paths to AI are not taken primarily because nobody is willing to take a big risk on them.
- The architecture is dramatically different from the architectures commonly assumed (implicitly) in much AI alignment work, such as model-free deep RL and "GPT-3 but scaled up 10000x". This makes it a good robustness check for plans that are overly architecture-specific.
Architecture Overview
The Overall Agent
At a high level, the proposed architecture is a set of specialized cognitive modules. With the exception of the Actor and the Intrinsic Cost (see below) they are all deep neural networks trained with gradient descent.
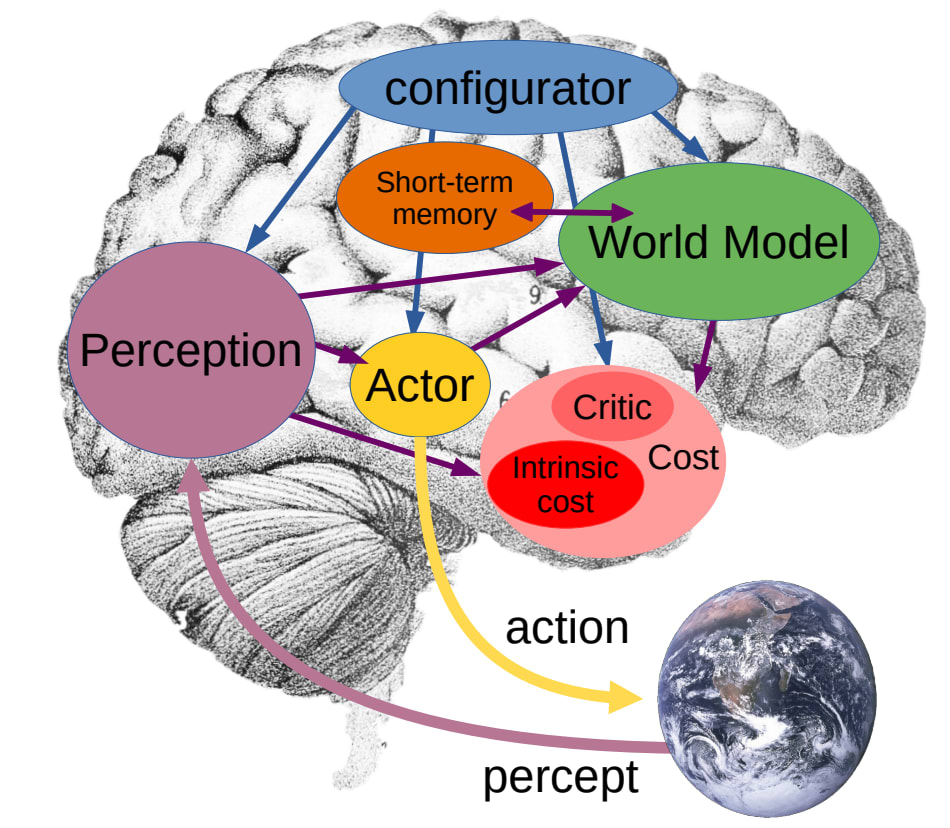
What is this agent doing, exactly? It's meant to be a general architecture for any autonomous AI agent, but LeCun repeatedly emphasizes video inputs and uses self-driving cars as a recurrent example, so the central use case is embodied agents taking actions in the physical world. Other talks I've seen by LeCun suggest he thinks understanding video is essential for intelligence, both by analogy to humans and by a heuristic argument about the sheer amount of data it contains.
The World Model
More than half the body of the paper is about designing and training the world model, the predictive model of the environment that the AI uses to plan its actions. LeCun explicitly says that "designing architectures and training paradigms for the world model constitute the main obstacles towards real progress in AI over the next decades."
Why are world models so important? Because the main limitation of current AI systems, according to LeCun, is their sample inefficiency - they need millions of expensive, dangerous real-world interactions to learn tasks that humans can learn with only a few examples. The main way to progress capabilities is to reduce the number of interactions a system needs before it learns how to act, and the most promising way is to learn predictive world models on observational data. (The GPT-3 paper Large Language Models are Few Shot Learners is a great example of this - a good enough predictive model of language enables much more sample-efficient task acquisition than supervised learning).
What will these world models look like? According to LeCun, they will be
- Predictive but not generative: They will predict high-level features of the future environment but not be able to re-generate the whole environment. This is especially obvious for high-dimensional data like video, where predicting the detailed evolution of every pixel is vastly overkill if you're doing planning. But it could also apply to language agents like chatbots, for whom it may be more important to predict the overall sentiment of a user's reply than the exact sequence of tokens.
- Uncertainty-aware: able to capture multimodal distributions over future evolutions of the world state (e.g. whether the car will turn left or right at the upcoming intersection), which LeCun expects to be modeled with latent variables. The ability to model complex uncertainty is the key property LeCun thinks is missing from modern large generative models, and leads him to conclude that "scaling is not enough".
- Hierarchical: represent the world at multiple levels of abstraction, with more high-level abstract features evolving more slowly. This makes it computationally feasible to use the same model for the combination of long-term planning and rapid local decision making that characterizes intelligent behavior.
- Unitary: AIs will trend towards having one joint world model across all modalities (text, images, video), timescales, and tasks, enabling hardware re-use and knowledge sharing (LeCun speculates that human "common sense" and ability to reason by analogy emerges from humans having a unitary world model). This suggests the trend towards "one giant model" we've seen in NLP will continue and broaden to include the rest of AI.
The Actor
The actor generates action sequences which minimize the cost (see below) according to the world-model's predictions. It generates these action sequences via some search method; depending on the task, this could be
- classic heuristic search methods like Monte-Carlo tree search or beam search.
- gradient-based optimization of the action sequence's embedding in some continuous space.
Optionally, one can use imitation learning to distill the resulting action sequence into a policy network. This policy network can serve as a fast generator of actions, analogous to Kahneman's System 1 thinking in humans, or to inform the search procedure like in the {AlphaGo, AlphaZero, MuZero} family of models.
Unlike the world model, the actor is not unitary - it's likely that different tasks will use different search methods and different policy networks.
The Cost
So what exactly is this agent optimizing? There is a hard-wired, non-trainable mapping from world states to a scalar "intrinsic cost". The actor generates plans that minimize the sum of costs over time, which makes costs mathematically equivalent to rewards in reinforcement learning.
I think the reason LeCun insists on using his unusual terminology is that he wants to emphasize that in this scheme, normative information does not come from an external source (like a reward provided by a human supervisor) but is an intrinsic drive hard-coded into the agent (like pain, hunger, or curiosity in humans).
The Configurator
The configurator is a component that modulates the behavior of all other components, based on inputs from all other components; it's not specified in any detail and mostly feels like a pointer to "all the component interactions LeCun doesn't want to think about".
It's especially critical from an alignment perspective because it modulates the cost, and thus is the only way that humans can intervene to change the motivations of the agent. LeCun speculates that we might want this modulation to be relatively simple, perhaps only specifying the relative weights of a linear combination of several basic hardcoded drives because this makes the agent easier to control and predict. He also mentions we will want to include "cost terms that implement safety guardrails", though what these terms are and how the configurator learns to modulate them is left unspecified.
Implications for AI Safety
Let's assume that the first transformative AI systems are built roughly along the lines LeCun describes. What would this imply for AI safety work?
- Interpretability becomes much easier, because the agent is doing explicit planning with a structured world-model that is purely predictive. Provided we can understand the hidden states in the world model (which seems doable with a Circuits-style approach), we can directly see what the agent is planning to do and implement safety strategies like "check that the agent's plan doesn't contain any catastrophic world states before executing an action". Of course, a sufficiently powerful agent could learn to model our safety strategies and avoid them, but the relatively transparent structure of LeCun's architecture gives the defender a big advantage.
- Most safety-relevant properties will be emergent from interaction rather than predictable in advance, similar to the considerations for Multi-agent safety [AF · GW]. Most of the "intelligence" in the system (the world model) is aimed at increasing predictive accuracy, and the agent is motivated by relatively simple hard-coded drives; whether its intelligent behaviors are safe or dangerous will not be predictable in advance. This makes it less tractable to intervene on the model architecture and training process (including most theoretical alignment work), and more important to have excellent post-training safety checks including simulation testing, adversarial robustness and red-teaming.
- Coordination / governance is relatively more important. Whether an AI deployment leads to catastrophic outcomes will mostly be a function not of the agent's properties, but of the safety affordances implemented by the people deploying it (How much power are they giving the agent? How long are they letting it plan? How well are they checking the plans? ). These safety affordances are likely to be increasingly expensive as the model's capabilities grow, likely following the computer systems rule of thumb that every nine of reliability costs you 10x, and possibly scale even worse than that. Ensuring this high alignment tax [? · GW] is paid by all actors deploying powerful AI systems in the world requires a very high level of coordination.
Conclusion and Unresolved Questions
Broadly, it seems that in a world where LeCun's architecture becomes dominant, useful AI safety work looks more analogous to the kind of work that goes on now to make self-driving cars safe. It's not difficult to understand the individual components of a self-driving car or to debug them in isolation, but emergent interactions between the components and a diverse range of environments require massive and ongoing investments in testing and redundancy.
Two important questions that remain are
- How likely is it that this becomes the dominant / most economically important AI architecture? Some trends point towards it (success of self-supervised learning and unitary predictive models; model-based architectures dominant in economically important applications like self-driving cars and recommender systems), others point away (relative stagnation in embodied / video-based agents vs language models; success of model-free RL in complex video game environments like StarCraft and Dota 2).
- Just how clean will the lines will be between model, actor, cost, and configurator? Depending on how the architecture is trained (and especially if it is trained end-to-end), it seems possible for the world-model or the configurator to start learning implicit policies, in a way that undermines interpretability and the safety affordances it creates.
18 comments
Comments sorted by top scores.
comment by aog (Aidan O'Gara) · 2022-07-16T06:16:09.661Z · LW(p) · GW(p)
Great post, thanks for sharing. Here's my core concern about LeCun's worldview, then two other thoughts:
The intrinsic cost module (IC) is where the basic behavioral nature of the agent is defined. It is where basic behaviors can be indirectly specified. For a robot, these terms would include obvious proprioceptive measurements corresponding to “pain”, “hunger”, and “instinctive fears”, measuring such things as external force overloads, dangerous electrical, chemical, or thermal environments, excessive power consumption, low levels of energy reserves in the power source, etc.
They may also include basic drives to help the agent learn basic skills or accomplish its missions. For example, a legged robot may comprise an intrinsic cost to drive it to stand up and walk. This may also include social drives such as seeking the company of humans, finding interactions with humans and praises from them rewarding, and finding their pain unpleasant (akin to empathy in social animals). Other intrinsic behavioral drives, such as curiosity, or taking actions that have an observable impact, may be included to maximize the diversity of situations with which the world model is trained (Gottlieb et al., 2013)
The IC can be seen as playing a role similar to that of the amygdala in the mammalian brain and similar structures in other vertebrates. To prevent a kind of behavioral collapse or an uncontrolled drift towards bad behaviors, the IC must be immutable and not subject to learning (nor to external modifications).
This is the paper's treatment of the outer alignment problem. It says models should have basic drives and behaviors that are specified directly by humans and not trained. The paper doesn't mention the challenges of reward specification or the potential for learning human preferences [? · GW]. It doesn't discuss our normative systems or even the kinds of abstractions that humans care about [LW · GW]. I don't understand why he doesn't see the challenges with specifying human values.
Most of the paper instead focuses on the challenges of building accurate, multimodal predictive world models. This seems entirely necessary to continue advancing AI, but the primary focus on predictive capabilities and minimizing of the challenges in learning human values worries me.
If anybody has good sources about LeCun's views on AI safety and value learning, I'd be interested.
success of model-free RL in complex video game environments like StarCraft and Dota 2
Do we expect model-free RL to succeed in domains where you can't obtain incredible amounts of data thanks to e.g. self-play? Having a purely predictive world model seems better able to utilize self-supervised predictive objective functions, and to generalize to many possible goals that use a single world model. (Not to mention the potential alignment benefits of a more modular system.) Is model-free RL simply a fluke that learns heuristics by playing games against itself, or are there reasons to believe it will succeed on more important tasks?
Since the whole architecture is trained end-to-end with gradient descent
I don't think this is what he meant, though I might've missed something. The world model could be trained with the self-supervised objective functions of language and vision models, as well as perhaps large labeled datasets and games via self-play. On the other hand, the actor must learn to adapt to many different tasks very quickly, but could potentially use few-shot learning or fine-tuning to that end. The more natural architecture would seem to be modules that treat each other as black boxes and can be swapped out relatively easily.
Replies from: Evan R. Murphy, ivan-vendrov↑ comment by Evan R. Murphy · 2022-07-16T07:12:22.407Z · LW(p) · GW(p)
If anybody has good sources about LeCun's views on AI safety and value learning, I'd be interested.
There's a conversation LeCun had with Stuart Russell and a few others in a Facebook comment thread back in 2019 [LW · GW], arguing about instrumental convergence.
The full conversation is a bit long and difficult to skim. I haven't finished reading it myself, but in it LeCun links to an article he co-authored for Scientific American which argues x-risk from AI misalignment isn't something people should worry about. (He's more concerned about misuse risks.) Here's a quote from it:
Replies from: ivan-vendrovWe dramatically overestimate the threat of an accidental AI takeover, because we tend to conflate intelligence with the drive to achieve dominance. [...] But intelligence per se does not generate the drive for domination, any more than horns do."
↑ comment by Ivan Vendrov (ivan-vendrov) · 2022-07-16T17:41:01.743Z · LW(p) · GW(p)
My read of LeCun in that conversation is that he doesn't think in terms of outer alignment / value alignment at all, but rather in terms of implementing a series of "safeguards" that allow humans to recover if the AI behaves poorly (See Steven Byrnes' summary [LW(p) · GW(p)]).
I think this paper helps clarify why he believes this - he had something like this architecture in mind, and so outer alignment seemed basically impossible. Independently, he believes it's unnecessary because the obvious safeguards will prove sufficient.
↑ comment by Ivan Vendrov (ivan-vendrov) · 2022-07-16T17:24:11.976Z · LW(p) · GW(p)
Ah you're right, the paper never directly says the architecture is trained end-to-end - updated the post, thanks for the catch.
He might still mean something closer to end-to-end learning, because
- The world model is differentiable w.r.t the cost (Figure 2), suggesting it isn't trained purely using self-supervised learning.
- The configurator needs to learn to modulate the world model, the cost, and the actor; it seems unlikely that this can be done well if these are all swappable black boxes. So there is likely some phase of co-adaptation between configurator, actor, cost, and world model.
comment by Steven Byrnes (steve2152) · 2022-07-16T15:10:41.401Z · LW(p) · GW(p)
I claim there’s some overlap with brain-like AGI safety [? · GW]; No coincidence, since he’s explicitly inspired by how the brain works. :)
Interpretability becomes much easier
I would state that in a more pessimistic way, by saying “Interpretability seems extraordinarily hard if not impossible in this approach, but it would be even worse in other approaches”. See discussion here [LW · GW] & here [LW(p) · GW(p)] for example.
Most of the "intelligence" in the system (the world model) is aimed at increasing predictive accuracy, and the agent is motivated by relatively simple hard-coded drives; whether its intelligent behaviors are safe or dangerous will not be predictable in advance.
I think that’s unduly pessimistic. I think it’s a hard problem, but that it’s at least premature to say that it’s impossible. For example, we get to pick the “relatively simple hard-coded drives”, we get to pick the training data / environment, we get to invent other tricks, etc.
Whether an AI deployment leads to catastrophic outcomes will mostly be a function not of the agent's properties, but of the safety affordances implemented by the people deploying it
My opinion is that by far the most important determinant, and most important intervention point, is whether the agent is trying to bring about catastrophic outcomes (which, again, I see as a hard but not knowably-doomed thing to intervene on). See here [LW · GW].
comment by [deactivated] (Yarrow Bouchard) · 2023-11-11T19:03:31.502Z · LW(p) · GW(p)
Very lucidly written. Thanks.
Broadly, it seems that in a world where LeCun's architecture becomes dominant, useful AI safety work looks more analogous to the kind of work that goes on now to make self-driving cars safe. It's not difficult to understand the individual components of a self-driving car or to debug them in isolation, but emergent interactions between the components and a diverse range of environments require massive and ongoing investments in testing and redundancy.
I think this is the crux of the matter. This is why LeCun tweeted:
One cannot just "solve the AI alignment problem." Let alone do it in 4 years. One doesn't just "solve" the safety problem for turbojets, cars, rockets, or human societies, either. Engineering-for-reliability is always a process of continuous & iterative refinement.
LeCun, like Sam Altman, believes in an empirical, iterative approach to AI safety. This is in sharp contrast to the highly theoretical, figure-it-all-out-far-in-advance approach of MIRI.
I don’t get why some folks are so dismissive of the empirical, iterative approach. Is it because they believe in a fast takeoff?
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-11-12T11:29:00.994Z · LW(p) · GW(p)
I think that if you mentioned cars and planes you should read this
comment by Algon · 2022-07-15T22:26:34.259Z · LW(p) · GW(p)
Interpretability becomes much easier
How so? Its still a big old pile of vectors generated by SGD, just with a cost function that we can use to calculate stuff. But we may not understand what this cost function means, especially in terms of the models native ontology. Sure, maybe it will have natural abstractions interpretable by circuits style reasoning. But that's equally true of any current NN.
Looking at this, it is clear that this is a utility maximiser. And those are dangerous by default. Another worrying part is that there should be some "safety guardrails" in the cost function. But what kind of terms could make it safe? Nothing purely internal, at least not without crippling the AI's utility. For a utility function that's pointing to something in the real world, there's two issues.
- Humans are very complex, and it seems tricky to point them out in a world model.
- The AI's world model is potentially a shifting inscrutable mess. How do we reliably point to anything in it?
↑ comment by james.lucassen · 2022-07-15T23:27:17.460Z · LW(p) · GW(p)
In general, I'm a bit unsure about how much of an interpretability advantage we get from slicing the model up into chunks. If the pieces are trained separately, then we can reason about each part individually based on its training procedure. In the optimistic scenario, this means that the computation happening in the part of the system labeled "world model" is actually something humans would call world modelling. This is definitely helpful for interpretability. But the alternative possibility is that we get one or more mesa-optimizers, which seems less interpretable.
Replies from: steve2152, Evan R. Murphy↑ comment by Steven Byrnes (steve2152) · 2022-07-18T16:19:38.602Z · LW(p) · GW(p)
I for one am moderately optimistic that the world-model can actually remain “just” a world-model (and not a secret deceptive world-optimizer), and that the value function can actually remain “just” a value function (and not a secret deceptive world-optimizer), and so on, for reasons in my post Thoughts on safety in predictive learning [LW · GW]—particularly the idea that the world-model data structure / algorithm can be relatively narrowly tailored to being a world-model, and the value function data structure / algorithm can be relatively narrowly tailored to being a value function, etc.
↑ comment by Evan R. Murphy · 2022-07-16T06:28:34.525Z · LW(p) · GW(p)
Since LeCun's architecture is together a kind of optimizer (I agree with Algon that it's probably a utility maximizer) then the emergence of additional mesa-optimizers seems less likely.
We expect optimization to emerge because it's a powerful algorithm for SGD to stumble on that outcompetes the alternatives. But if the system is already an optimizer, then where is that selection pressure coming from to make another one?
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2022-07-17T04:52:22.170Z · LW(p) · GW(p)
it's coming from the fact that every module wants to be an optimizer of something in order to do its job
Replies from: Evan R. Murphy↑ comment by Evan R. Murphy · 2022-07-17T06:01:07.889Z · LW(p) · GW(p)
Interesting, I wonder how the dynamics of a multiple mesa-optimizer system would play out (if it's possible).
↑ comment by Ivan Vendrov (ivan-vendrov) · 2022-07-15T23:21:45.160Z · LW(p) · GW(p)
I think it's easier to interpret than model-free RL (provided the line between model and actor is maintained through training, which is an assumption LeCun makes but doesn't defend) because it's doing explicit model-based planning, so there's a clear causal explanation for why the agent took a particular action - because it predicted that it would lead to a specific low-cost world state. It still might be hard to decode the world state representation, but much easier than decoding what the agent is trying to do from the activations of a policy network.
Not obvious to me that it will be a utility maximizer, but definitely dangerous by default. In a world where this architecture is dominant, we probably have to give up on getting intent alignment and fall back to safety guarantees like "well it behaved well in all of our adversarial simulations, and we have a powerful supervising process that will turn it off if it the plans look fishy". Not my ideal world, but an important world to consider.
Replies from: Algon↑ comment by Algon · 2022-07-16T00:23:20.016Z · LW(p) · GW(p)
It decides its actions via minimising a cost function. How's that not isomorphic to a utility maximiser?
Replies from: ivan-vendrov↑ comment by Ivan Vendrov (ivan-vendrov) · 2022-07-16T00:34:08.198Z · LW(p) · GW(p)
The configurator dynamically modulates the cost function, so the agent is not guaranteed to have the same cost function over time, hence can be dutch booked / violate VNM axioms.
Replies from: Algon↑ comment by Algon · 2022-07-17T15:08:01.510Z · LW(p) · GW(p)
Good point. But at any given time, its doing EV calculations to decide its actions. Even if it modulates itself by picking amongst a variety of utility functions, its actions are still influenced by explicit EV calcs. If I understand TurnTrout's work correctly, that alone is enough to make the agent power seeking. Which is dangerous by default.
comment by Evan R. Murphy · 2022-07-16T16:44:47.443Z · LW(p) · GW(p)
Some additional discussion of LeCun's paper on this earlier LessWrong post: https://www.lesswrong.com/posts/Y7XkGQXwHWkHHZvbm/yann-lecun-a-path-towards-autonomous-machine-intelligence-1 [LW · GW]