Thoughts on safety in predictive learning
post by Steven Byrnes (steve2152) · 2021-06-30T19:17:40.026Z · LW · GW · 17 commentsContents
Background: Why do I care? Easy win #1: Use postdictive learning, not predictive learning Background 1/2: Most “predictive learning” (in both ML and brains) is actually postdictive learning Background 2/2: Postdictive learning eliminates some potential safety issues Easy win #2: Use backprop, or something functionally similar to backprop, but not trial-and-error, and not numerical differentiation Background: “Differentiating through” things Why is using backprop an “easy win” for safety? Easy win #3: Don’t access the world-model and then act on that information, at least not without telling it How exactly do we avoid this problem? For completeness: One more weird incentive to take purposeful real-world actions Background concept: “Within-universe processing” vs “4th-wall-breaking processing” Within-universe mesa-optimizers seem kinda inevitable, but also seem not dangerous Harder problems Hard problem #1: Spontaneous arising of 4th-wall-breaking processing Hard problem #2: Agents in the simulation Conclusion: slight optimism (on this narrow issue) None 17 comments
(Many thanks to Abram Demski for an extensive discussion that helped clarify my thoughts. Thanks Abram & John Maxwell [LW · GW] for comments and criticisms on a draft.)
Background: Why do I care?
Way back in ancient history, i.e. two years ago, my first ever attempt to contribute something original to the field of AGI safety was the blog post The Self-Unaware AI Oracle [LW · GW]. Part of my premise there was that I was thinking maybe you can make a safe AGI by using 100% self-supervised predictive learning—i.e., the model tries to predict something, you compare it to what actually happens, and then you improve the model by gradient descent or similar.
That wasn’t a great post, although it was a good experience thanks to helpful commenters who guided me from “very confused” to “somewhat confused”. Then I wrote a couple other posts about self-supervised learning, before moving on to other things because I came to feel that you probably need reinforcement learning (RL) to reach AGI—i.e., that predictive learning by itself won’t cut it. See Section 7.2 here [LW · GW] for why I (currently) think that. Note that others disagree, e.g. advocates of Microscope AI [LW · GW].
Fast forward to a couple months ago, when I wrote My AGI Threat Model: Misaligned Model-Based RL [LW · GW], where one gear in the AGI is a world-model trained by 100% predictive learning. Now that, I can get behind, as an architecture that could plausibly scale to AGI. Here the whole AGI is using RL and planning; it’s just that this particular gear is not.
Inevitable neuroscience side-note: I try to talk in ML lingo, but I’m always secretly thinking mainly about human brain algorithms. So anyway, in the brain case, the “gear” in question corresponds roughly to the non-frontal-lobe parts of the neocortex, which build predictive models of sensory inputs, and AFAICT their only training signal is predictive error (example ref). See Is RL involved in sensory processing? [LW · GW] The answer by the way is: No. We don’t want RL here, because RL is for making decisions, and this part of the brain is not supposed to be deciding anything. I’m oversimplifying in various ways, but whatever, I don’t want to stray too far off-topic.
So anyway, here I am, back on the market for an argument that world-modeling systems trained 100% on prediction error are not going to do dangerous things, like try to seize more computing power and take over the world or whatever. We want them to just build a better and better model of the world. I’m generally optimistic that this is a solvable problem—i.e., if we follow best practices, we can have an AGI-capable world-modeler trained on self-supervised learning that definitely won’t do dangerous things. I’m not there yet, but maybe this is a start.
To be crystal-clear, even if I somehow prove that the predictive world-model gear in this kind of AGI [LW · GW] won’t do anything dangerous, that would be an infinitesimal step towards establishing that the whole AGI won’t do anything dangerous. In fact I think the whole AGI would be dangerously misaligned by default. Describing that problem was the whole point of that post [LW · GW], and trying to solve that problem is motivating almost everything I’m working on [LW · GW]. Writing this post kinda feels to me like an annoying tangent from that more urgent problem.
It doubly feels like an annoying tangent because I’m trying to write this post without making any assumptions about the architecture of the predictive world-model—and in particular, leaving open the possibility that it’s a deep neural net (DNN). The scenario I’m really interested in is that the predictive world-model is something closer to a PGM. DNNs seem like a really hard thing to reason about—like if you have a 200-layer DNN, who knows what calculations are happening in layer #100?? By contrast, if we’re learning a PGM and doing belief-prop, it seems less likely that weird unintended calculations can get hidden inside, especially in the context of the larger system, which has other subsystems constantly looking at all the PGM nodes and attaching values to them—but I won't get into that.
Well anyway, here goes.
I’ll start with some “easy wins”—things we can do that seem to at least mitigate safety problems with predictive learners. Then I’ll get into the hard problems where I’m much less confident.
Easy win #1: Use postdictive learning, not predictive learning
Background 1/2: Most “predictive learning” (in both ML and brains) is actually postdictive learning
The difference between “prediction” and “postdiction” is that in postdiction, instead of issuing a guess about a thing that hasn’t happened yet (e.g. Who will win the game tomorrow?), you’re issuing a guess about something that already happened (e.g. What answer is written at the back of the book?). Here are a couple examples.
Example of postdictive learning in ML: The GPT-3 training procedure involves trying to guess the next word of the text corpus, on the basis of previous words. The next word is masked from GPT-3, but it already exists. It was probably written years before the training! So that’s postdiction, not prediction.
Example of postdictive learning in brains: A common trope is that brains are trained on prediction. Well, technically, I claim it would be more accurate to say that they’re trained on postdiction. Like, let’s say I open a package, expecting to see a book, but it’s actually a screwdriver. I’m surprised, and I immediately update my world-model to say "the box has a screwdriver in it". During this process, there was a moment when I was just beginning to parse the incoming image of the newly-opened box, expecting to see a book inside. A fraction of a second later, my brain recognizes that my expectation was wrong, and that’s the “surprise”. So in other words, my brain had an active expectation about something that had already happened—about photons that had by then already arrived at my retina—and that expectation was incorrect, and that’s what spurred me to update my world-model. Postdiction, not prediction.
(I might still be confused about why I got a screwdriver when I ordered a book, and maybe I'll mull it over and eventually figure it out. That process of mulling it over would be neither "updating on postdictive surprise" nor "updating on predictive errors", but rather "updating on no data at all"! Or, well, I guess you could say: one part of my world-model is postdicting what another part of my world-model is saying, and being surprised, and thus getting updated.)
What would it look like to not do postdiction?
Example that is not postdictive learning: Let’s say I get on a train at 8:00, and it’s scheduled to reach its destination at 9:00, and I predict that it will actually arrive at the destination early. Instead, it gets to the destination late—at 9:15. So sometime after 9:00, when it’s clear that my prediction was false, I put myself back in my 8:00 state of mind, and say to myself:
“Knowing what I knew at 8:00, and thinking what I was thinking at 8:00, I made an incorrect prediction. What should I have done differently? Then next time I can do that.”
So that would be (more-or-less) updating on a prediction error, not a postdiction error. But that’s a really rare thing to do! Like, superforecasters do that kind of thing, and unusually good investors, and rationalists, etc. I think most people don’t do that. I mean, yes, people often think the thought “what should I have done differently”, like after an embarrassing experience. But the widespread prevalence of hindsight bias suggests that humans can do at most some poor approximation to predictive learning, not the real thing, except with scrupulous effort and training. Our brains don't hold a cache with snapshots of the exact state of our world-model at previous times; the best we can do is take the current world-model, apply patches for the most egregious and salient recent changes, and use that.
So in both brains and ML, I claim that true predictive learning is super-rare, while postdictive learning is the effortless default.
Background 2/2: Postdictive learning eliminates some potential safety issues
Why? Because in predictive training, the system can (under some circumstances) learn to make self-fulfilling prophecies—in other words, it can learn to manipulate the world, not just understand it. For example see Abram Demski’s Parable of the Predict-O-Matic [LW · GW]. In postdictive training, the answer is already locked in when the system is guessing it, so there’s no training incentive to manipulate the world. (Unless it learns to hack into the answer by row-hammer or whatever. I’ll get back to that in a later section.)
Note the heading: “eliminates some potential safety issues”. You can also set up predictive learners to have some of the same benefits—it just doesn’t happen automatically. Stuart Armstrong & Xavier O’Rorke’s Counterfactual Oracle is a nice example here. For the record, I’m not interested in those ideas because my use-case (previous section) is different from what Armstrong & O’Rorke were thinking about. I’m not thinking about how to make an oracle that outputs natural-language predictions for human consumption—at least, not in this post. Instead, I’m thinking about how to build a “world-modeling gear” inside a larger AGI. The larger AGI could still function as an oracle, if we want. Or not. But that’s a different topic. For what I’m talking about here, postdictive updating obviates the need for clever oracle schemes, and incidentally is a superior solution for unrelated practical reasons (e.g. no need for human-labeling of the training data).
(Also, postdictive learning is maybe even safer than counterfactual-oracle-type predictive learning, because in the latter, we need to make sure that the prediction doesn’t influence the world when it’s not supposed to. And that’s a potential failure mode. Like, what if there’s a side-channel?)
But don’t we want predictions not postdictions? I concede that making predictions (and not just postdictions) is a useful thing for humans and AGIs to be able to do. But the way it works in brains (and GPT-3) is that you keep doing postdictive updates on the world-model, and over time the world-model incidentally gets to be good at prediction too. I think it’s, like, spiritually similar to how TD learning converges to the right value function. If you keep updating on surprise, then surprises gradually start happening less frequently, and further in advance.
(Side note #1: how do we get the ability to predict weeks and months and years ahead if we only train on postdicting imminent incoming sensory data? The naive answer is: well, if we can postdict the data that's just arriving, then we can assume that our postdiction will be correct and then postdict the next data, and then the next data, etc., laboriously stepping forward one fraction-of-a-second at a time. Like GPT. Obviously we humans don't do that. Instead we understand what's going on in multiple ways, with multiple timescales. Like we can have a high-level plan "I'm gonna drive to the grocery store then buy bread"—a sequence of two things, but each takes many minutes. If that's the plan / expectation, but then I get to the grocery store and it's closed, then seeing the "CLOSED" sign doesn't just falsify a narrow postdiction about imminent sensory data, it also falsifies the high-level plan / expectation "I'm gonna drive to the grocery store then buy bread", which was until that moment still active and helping determine the lower-level postdictions. So anyway, we gradually learn more and more accurate high-level extended-duration patterns, and we can use those for long-term predictions.)
(Side note #2: Incidentally, TD learning itself is generally predictive not postdictive: we check the value of a state S, then use that information to take actions, then later on update the value function of state S based on what happened. So if, say, the value function calculation itself has some exotic side-channel method for manipulating what happens, there's a potential problematic incentive there, I think.)
Easy win #2: Use backprop, or something functionally similar to backprop, but not trial-and-error, and not numerical differentiation
Background: “Differentiating through” things
(ML experts already know this and can skip this section.)
A hot thing in ML these days is the idea of “differentiating through” stuff. For example, “differentiable programming” is programming where you can “differentiate through” every step of the program. So what does that mean? I think it’s easiest to explain through an example.
Let’s say I write an image-rendering algorithm. The input of the algorithm is, let’s say, a large NN that parametrizes a 3D shape (somehow—don’t worry about the details). The output of the algorithm is a bunch of RGB values corresponding to a rendered image of that shape. If the algorithm is “differentiable”, that means that I can generate a differentiation routine that can automatically calculate things like
“The derivative of “Pixel #287 red channel” in the output, with respect to neural net weight #98528, is -0.3472.”
Calculating things like that is useful because maybe we’re trying to make our rendered 3D shape match a target image. Then knowing the gradient allows us to do gradient descent, changing the NN weights to improve the match.
Anyway, in this case, you would say that you “differentiated through” the image-rendering algorithm. (So the cardinal example of “differentiable programming” is just a normal deep NN with backprop.)
The end result here is the same as you get in numerical differentiation—i.e., where you tweak each of the inputs by 0.00001 or whatever, re-run the algorithm, and see how much the outputs change. But differentiable programming is generally a much more efficient way to get the gradient than numerical differentiation. In numerical differentiation, if there are 1,000,000 NN weights, then you need to run the algorithm 1,000,001 times to get the full gradient. In differentiable programming, since we calculated the derivative symbolically, you wind up only needing one “forward pass” and one “backwards pass” to get the same information.
Why is using backprop an “easy win” for safety?
In backprop, but not trial-and-error, and not numerical differentiation, we get some protection against things like row-hammering the supervisory signal. Why? See “Background 3” above: the idea is that we will only “differentiate through” the intended operations of the algorithm. The differentiation engine is essentially symbolic, so it won’t (and indeed can’t) “differentiate through” the effects of row-hammer or whatever. So even if the algorithm happens to stumble upon a successful row-hammering strategy, it is just as likely to drop it again, as to keep it and improve it. Trial-and-error or numerical differentiation, by contrast, would absolutely keep it and improve it.
Of course, row-hammer could also screw up the gradient calculation. But it won’t generally screw up the gradient calculation in a way that locks in the screwup and then goes searching for variations on the row-hammer that screw up the gradient calculation more consistently and controllably—as trial-and-error or numerical differentiation would. Well in any case, even if it doesn't 100% solve the problem, it seems like definitely an improvement.
(Side tangent: I feel like there’s some more general principle here? Trial-and-error & numerical differentiation pushes systems to “do the right thing”, but backprop pushes systems to “do the right thing for the right reason”, insofar as we can “differentiate through” only the types of processing that we endorse. That’s straightforward for row-hammer—nobody would ever differentiate through row-hammer!—but what are the other applications? Like, is there a way to “differentiate through” my AGI assistant being sincerely helpful without also “differentiating through” my AGI assistant getting a reward by deceptively telling me what I want to hear? I don’t have any ideas here; consider it a brainstorming prompt. See previous AGI-safety-oriented discussion of related topics here [LW · GW], here [LW · GW]—search for the term “stop-gradients”.)
Easy win #3: Don’t access the world-model and then act on that information, at least not without telling it
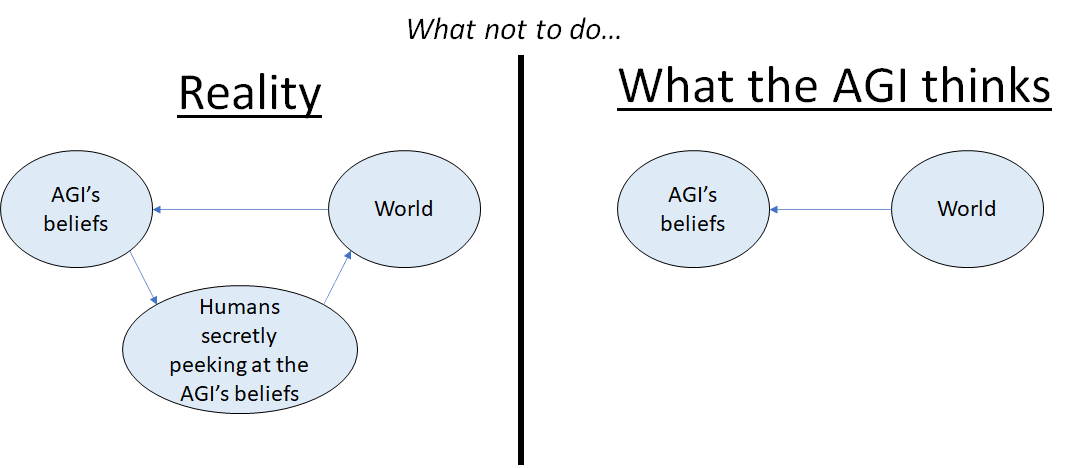
Let’s say we give our postdictive learning algorithm a stock ticker and a bunch of information relevant to the stock price, and we secretly watch its stream of internal postdictions. Then we make decisions based on what we see:
- If the learning algorithm keeps expecting to see the stock price go up, and keeps being surprised that it doesn't, then we humans start thinking the stock is undervalued, and we go buy a bunch of the stock—and this incidentally causes the price to actually go up.
- If the learning algorithm keeps expecting to see the stock price go down, and keeps being surprised that it doesn't, then we humans start thinking that the stock is overvalued … and we don’t do anything, because let's say we just don't like shorting stocks.
We do this a bunch of times with a bunch of stocks. What happens? Well, whenever the algorithm expects a stock price to go down, it’s often surprised to see it go up instead, whereas whenever the algorithm expects a stock price to go up, it’s rarely surprised to see it go down instead. (Not never—it can still happen when it first starts looking at the stock, or if it suddenly changes its expectations about the stock's value—but comparatively rarely.) So the algorithm gradually stops ever predicting that the price of a stock will go down!
Thus the system will drift towards self-fulfilling prophecies.
Is that dangerous? Well, I can’t immediately come up with a catastrophe scenario that doesn’t sound far-fetched. But I do think it’s probably dangerous, and anyway it’s almost definitely not what we want. (The reasons will be even clearer after a later section.) So let’s not do that!
(You could imagine the same thing happening in humans. Imagine a witch is secretly reading your mind and taking impactful actions in the world based on your hunches and musings. You’d wind up with an awfully distorted view of how the world works, right?)
How exactly do we avoid this problem?
I see three options:
- Don’t access the predictive model. Let it run for a while, then turn off learning forever, and go do Microscope AI [LW · GW] with it or something.
- Access the predictive model if you like, but don’t make decisions on the basis of what you learn, at least not in a way that can get back into the AI’s input data.
- Access the predictive model, but tell it what you learn. Then it can learn the correct world-model, i.e. the left side of the figure above, not the right side. (“The stock went up because the humans looked at my beliefs and then bought the stock on that basis”, not “I thought the stock was gonna go up, and then it did just as I expected”.)
In the AGI architecture I’m thinking of [LW · GW], “humans looking directly into the AGI’s world-model and acting on it” is a weird use-case that wouldn’t normally come up. Normally the planning / acting part of the AGI is the one making decisions about what to say or do based on its current beliefs, and those plans / actions are visible to the world-model, and so we’re basically in the third bullet point.
(But then we should do the second bullet point too, for safety monitoring.)
Note that the third bullet point is not a rock-solid solution; yes the algorithm will presumably converge to correct beliefs, but it could also make mistakes, especially early on in its learning. But that’s nothing new; every aspect of the AGI’s world-model starts wrong and converges to correct beliefs. I don’t see this as particularly concerning—at least, not compared to other ways that a confused “infant” model-based RL AGI [LW · GW] could thrash around and cause trouble.
For completeness: One more weird incentive to take purposeful real-world actions
I’ll mention one more possible incentive problem, the one I was thinking about way back when I wrote Self-Supervised Learning & Manipulative Predictions [LW · GW]. It’s sorta like a weirder version of my stock ticker example above. Something like: imagine that the postdiction algorithm consists of imagining that one possibility happens, and assessing how “plausible” the resulting scenario feels; and then imagining the next possibility, etc. This procedure can introduce a weird sorta retrocausal reasoning error, where an immediate expectation gets penalized for leading to a priori implausible downstream consequences.
(Human example of this error: Imagine someone saying "If fast-takeoff AGI happens, then it would have bizarre consequence X, and there’s no way you really expect that to happen, right?!? So c’mon, there’s not really gonna be fast-takeoff AGI.". This is an error because if there’s a reason to expect fast-takeoff AGI, and fast-takeoff AGI leads to X, we should make the causal update (“X is more likely than I thought”), not the retrocausal update (“fast-takeoff AGI is less likely than I thought”). Well, probably. I guess on second thought it’s not always a reasoning error.)
I thought this problem was very important two years ago when I was thinking about pure self-supervised learning, because I was hoping for an iron-clad guarantee against incentives for manipulation, and the implicit retrocausality here undermines those arguments. But in the context I’m now thinking about [LW · GW], this seems like just another entry in the long boring list of possible reasoning errors and imperfect heuristics. And, like other reasoning errors and imperfect heuristics, I expect that it’s self-correcting—i.e., it would manifest more early in training, but gradually go away as the AGI learns meta-cognitive self-monitoring strategies. It doesn’t seem to have unusually dangerous consequences, compared to other things in that category, AFAICT.
Let’s switch now to harder (and weirder) aspects of the problem. But first I need another concept handle.
Background concept: “Within-universe processing” vs “4th-wall-breaking processing”
In my bad old post on AI self-awareness [LW · GW], mentioned above, my first and biggest mistake was using the term “self-awareness” in the first place. What I really wanted to talk about (and still want) is quite different from what anyone would understand as "self-awareness".
Trying for a better terminology this time: Let’s call it “within-universe processing” vs “4th-wall-breaking processing”.
Here’s my definition, then I’ll go through a bunch of examples.
When an algorithm is running, each step has two kinds of downstream chains of consequences.
- There are within-universe consequences of a processing step, where the step causes things to happen entirely within the intended algorithm. (By "intended", I just mean that the algorithm is running without hardware errors). These same consequences would happen for the same reasons if we run the algorithm under homomorphic encryption in a sealed bunker at the bottom of the ocean.
- Then there are 4th-wall-breaking consequences of a processing step, where the step has a downstream chain of causation that passes through things in the real world that are not within-universe. (I mean, yes, the chip’s transistors have real-world-impacts on each other, in a manner that implements the algorithm, but that doesn’t count as 4th-wall-breaking.)
And then related to that:
- within-universe processing is when no operation in an algorithm is likelier to happen vs not happen specifically because of anticipated 4th-wall-breaking consequences of that processing step
- Otherwise it’s 4th-wall-breaking processing.
The "anticipated" does not have to be an explicit prediction… Well, let’s just go through some examples:
- A robot running a model-free RL algorithm is absolutely not doing within-universe processing. When you first turn it, maybe it will do a randomly-selected operation that moves an actuator. If that move leads to reward, the robot would probably do that operation again in the future. And then the second time that operation happens, we can say that the operation is happening (at least in part) because of a 4th-wall-breaking likely consequence of that operation.
- Any AGI doing row-hammer is almost definitely doing 4th-wall-breaking processing, unless it does it “accidentally” (as a random consequence of its data-processing operations)—and if, even after doing it accidentally, it does not repeatedly do it more often than chance.
- A simulated robot, running any of today’s RL algorithms, is doing within-universe processing.
- …However, in the event that we’re all living in a simulation [? · GW], the human brain algorithm would be 4th-wall-breaking in some cases—because I guess there are some people who take the Simulation Hypothesis so seriously that they sometimes take purposeful actions to try to manipulate the people (or aliens or whatever) who are running this hypothetical simulation. I’ll return to this example below.
- Let’s take a postdictive learner, and grant it “self-awareness”, in the specific sense that we take each of its neural net activations when processing Frame N, and include them as extra postdiction targets attached to Frame N+1—sorta like holding up a mirror to a postdictive learner and saying “here, postdict the thing you’re looking at”. Is that going to be 4th-wall-breaking? Not necessarily! If the algorithm does an operation because of its likely effects on the postdiction targets it will face next frame, then that’s 4th-wall-breaking. But it’s also possible for the algorithm to just treat each new postdiction target as a new postdiction target, and try to postdict them each frame, without trying to manipulate them next frame. In that case, well, it might or might not converge to an accurate postdictive model of its own activation patterns. Probably it would get some simple patterns right, while constantly being surprised by at least some things, without ever converging to zero surprise. But whatever; the point is, in this case it would be doing in-universe processing, despite it being “self-aware” in a certain sense.
With that under our belt, let’s think about the harder parts of the “safety in postdictive learners” problem. Start with mesa-optimization.
Within-universe mesa-optimizers seem kinda inevitable, but also seem not dangerous
You can try to make an argument "My predictive learner is safe because it's not optimizing anything", or you can try to make an argument "My predictive learner is safe because it's not doing 4th-wall-breaking processing". I want to argue here that the latter is a more promising approach.
By and large, we expect learning algorithms to do (1) things that they’re being optimized to do, and (2) things that are instrumentally useful for what they’re being optimized to do, or tend to be side-effect of what they’re being optimized to do, or otherwise “come along for the ride”. Let’s call those things “incentivized”. Of course, it’s dicey in practice to declare that a learning algorithm categorically won’t ever do something, just because it’s not incentivized. Like, we may be wrong about what’s instrumentally useful, or we may miss part of the space of possible strategies, or maybe it’s a sufficiently simple thing that it can happen by random chance, etc. But if we want to avoid problematic behavior, it’s an awfully helpful first step to not incentivize that problematic behavior!
If we turn to the mesa-optimization literature (official version, friendly intro [LW · GW]) the typical scenario is something like “we put an RNN into an RL algorithm, and do gradient descent on how much rewards it gets”. In that scenario, there’s a strong argument that we should be concerned about dangerous mesa-optimizers, because the RL algorithm is providing a direct incentive to build dangerous mesa-optimizers. After all, foresighted planning is often a good way to get higher RL reward. Therefore if the network comes across a crappy “proto” foresighted planner, gradient descent will probably make it into a better and better foresighted planner.
I do think mesa-optimizers are directly incentivized for postdictive learners too. But not dangerous ones! Like, it’s technically a “mesa-optimizer” if gradient descent finds a postdiction algorithm that searches through different possible strategies to process data and generate a postdiction, judges their likely “success” according to some criterion, and then goes with the strategy that won that contest.
But that’s fine!! It’s just a more complicated algorithm to generate a postdiction! And what about inner misalignment? Well, for example, “proxy alignment” [? · GW] would be if the “criterion” in question—the one used to judge the different candidate postdiction-generation strategies—is an imperfect proxy to postdiction accuracy. Well sure, that seems entirely possible. But that’s not dangerous either! We would just call it “an imperfect heuristic for generating postdictions”. Out-of-distribution, maybe the criterion in question diverges from a good postdiction-generation strategy. Oh well, it will make bad postdictions for a while, until gradient descent fixes it. That’s a capability problem, not a safety problem.
(Another example is: anything that looks kinda like probabilistic programming is arguably a mesa-optimizer, in that it’s searching over a space of generative models for one that best fits the data. I think GPT is a mesa-optimizer in this sense [LW(p) · GW(p)], and in fact I personally think future AGI world-models will be not just mesa-optimizers but optimizers, in that we humans will explicitly build probabilistic programming into them.)
It seems to me that the dangerous part is not mesa-optimization per se, but rather taking manipulative real-world actions. And it seems to me that “ruling out mesa-optimizers altogether” is a less promising approach than “ruling out 4th-wall-breaking processing”. Mesa-optimizers seem hard to avoid in that they’re both directly incentivized and helpful for AGI capabilities. Whereas 4th-wall-breaking processing is neither.
Harder problems
Hard problem #1: Spontaneous arising of 4th-wall-breaking processing
You might guess that I introduced the concept of within-universe-processing vs 4th-wall-breaking-processing because I was gearing up to argue that there’s some kind of barrier where 4th-wall-breaking processing won’t spontaneously pop out of within-universe processing. Like Hume’s ought-is separation or something.
Well, apparently not. It doesn’t seem to be a perfect barrier. I already mentioned the example of humans who believe the Simulation Hypothesis [? · GW]—I guess some of those people occasionally do things to try to manipulate whoever is running that simulation. So if the Simulation Hypothesis were true, the simulation-runners would see a whole lot of purely-in-universe processing, and then out of nowhere there’s sporadic 4th-wall-breaking processing. (By the way, I do not require the people to be successfully manipulating the simulation-runners for it to count as “4th-wall-breaking processing”. Just that they’re trying.)
The way I think of the Simulation Hypothesis example is: We humans are already modeling the world, and we are already choosing actions because of their expected consequences in the world. And we humans are also already uncertain about what the correct world-model is. So it’s not much of a leap to entertain the Simulation Hypothesis—i.e., the world has another level that we can’t directly see—and to start taking corresponding actions. It seems like a quite natural outgrowth of the types of processing our brains are always already doing.
I think it’s at least possible that there’s a greater barrier—like a greater leap through algorithm space—for a postdictive learner to jump from in-universe processing to 4th-wall-breaking processing. It seems like there’s no incentive whatsoever for a postdictive learner to have any concept that the data processing steps in the algorithm have any downstream impacts, besides, y’know, processing data within the algorithm. It seems to me like there’s a kind of leap to start taking downstream impacts to be a relevant consideration, and there’s nothing in gradient descent pushing the algorithm to make that leap, and there doesn’t seem to be anything about the structure of the domain or the reasoning it’s likely to be doing that would lead to making that leap, and it doesn’t seem like the kind of thing that would happen by random noise, I think.
Needless to say, this isn’t a rigorous argument, and I haven’t thought about it all that carefully, but I am slightly hopeful that a more rigorous argument exists.
Hard problem #2: Agents in the simulation
OK, then what about the possibility that there’s an agent in your simulation?
For example: let’s say that I personally am the kind of person who would read about the Simulation Hypothesis, and then speculate that maybe I’m running in a simulation, and then be on the lookout for evidence of that, and if I see any, then I would try to hack into the base-level reality. Then a postdictive learner whose world-model includes me might simulate me doing the same things, and then “imagine” me doing particular operations that involve row-hammering its way into taking control of the postdictive learner, and then it does.

The logic here is pretty sound, I think. Still, I’m mildly optimistic about this not being a problem, for kinda more specific reasons.
For one thing, this is kinda a subset of the broader issue “the AGI needs to interact with adversarial agents—other AGIs, humans, acausally imagined distant superintelligences, whatever—who may try to manipulate it for their own ends”.
Granted, imagining an adversarial agent is a pretty weird threat surface. Normally people think that threats come from interacting with an adversarial agent! But whatever—insofar as it’s a legitimate threat surface, I imagine we can deal with it in the same way as other agential threats: shelter the AGI from threats while it’s still in early training (somehow), and eventually it will be smart enough and aligned enough to fend for itself, hopefully.
Again, as mentioned in Background 1, I’m thinking of My AGI Threat Model: Misaligned Model-Based RL [LW · GW], where the postdictive learner is just one gear in an agential AGI. I think the predictive world-model does a relatively constrained amount of computation, and then interacts with the learned value function and planner, and then gets queried again. (Leaving out details, I know.) So a self-aware, aligned AGI could, and presumably would, figure out the idea “Don’t do a step-by-step emulation in your head of a possibly-adversarial algorithm that you don’t understand; or do it in a super-secure sandbox environment if you must”, as concepts encoded in its value function and planner. (Especially if we warn it / steer it away from that.)
(Somewhat related: we also need to warn it / steer it away from doing high-fidelity simulations of suffering minds.)
Conclusion: slight optimism (on this narrow issue)
I feel like there are a bunch of considerations pointing in the general direction of “if we’re careful, and develop best practices, and people follow them, then we can ensure that the predictive learning component of our AGI won’t do dangerous manipulative things in the course of understanding the world”. No I don’t have any proof, but someday when there’s more detail on the AGI design, I’m slightly optimistic that some of the considerations above could be fleshed out into a really solid argument. But I haven’t thought about this super-carefully and am open to disagreement. (I'm much more optimistic in the case where the predictive world-model is not a DNN, as mentioned above.)
Meanwhile, as I mentioned above, the “main” alignment problem discussed in My AGI Threat Model: Misaligned Model-Based RL Agent [LW · GW], the one involving the value function, is still a big giant urgent open problem. It seems to me that working on that [LW · GW] is currently a far better use of my time.
17 comments
Comments sorted by top scores.
comment by evhub · 2021-07-14T21:25:10.832Z · LW(p) · GW(p)
By and large, we expect learning algorithms to do (1) things that they’re being optimized to do, and (2) things that are instrumentally useful for what they’re being optimized to do, or tend to be side-effect of what they’re being optimized to do, or otherwise “come along for the ride”. Let’s call those things “incentivized”. Of course, it’s dicey in practice to declare that a learning algorithm categorically won’t ever do something, just because it’s not incentivized. Like, we may be wrong about what’s instrumentally useful, or we may miss part of the space of possible strategies, or maybe it’s a sufficiently simple thing that it can happen by random chance, etc.
In the presence of deceptive alignment [AF · GW], approximately any goal is possible in this setting, not just the nearby instrumental proxies that you might be okay with. Furthermore, deception need not be 4th-wall-breaking, since the effect of deception on helping you do better in the training process entirely factors through the intended output channel. Thus, I would say that within-universe mesa-optimization can be arbitrarily scary if you have no way of ruling out deception.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-15T02:56:08.973Z · LW(p) · GW(p)
Thanks!
The kind of incentive argument I'm trying to make here is "If the model isn't doing X, then by doing X a little bit it will score better on the objective, and by doing X more it will score even better on the objective, etc. etc." That's what I mean by "X is incentivized". (Or more generally, that gradient descent systematically tends to lead to trained models that do X.) I guess my description in the article was not great.
So in general, I think deceptive alignment is "incentivized" in this sense. I think that, in the RL scenarios you talked about in your paper, it's often the case that building a better and better deceptively-aligned mesa-optimizer will progressively increase the score on the objective function.
Then my argument here is that 4th-wall-breaking processing is not incentivized in that sense: if the trained model isn't doing 4th-wall-breaking processing at all right now, I think it does not do any better on the objective by starting to do a little bit of 4th-wall-breaking processing. (At least that's my hunch.)
(I do agree that if a deceptively-aligned mesa-optimizer with a 4th-wall-breaking objective magically appeared as the trained model, it would do well on the objective. I'm arguing instead that SGD is unlikely to create such a thing.)
Oh, I guess you're saying something different: that even a deceptive mesa-optimizer which is entirely doing within-universe processing is nevertheless scary. So that would by definition be an algorithm with the property "no operation in the algorithm is likelier to happen vs not happen specifically because of anticipated downstream chains of causation that pass through things in the real world". So I can say categorically: such an algorithm won't hurt anyone (except by freak accident), won't steal processing resources, won't intervene when I go for the off-switch, etc., right? So I don't see "arbitrarily scary", or scary at all, right? Sorry if I'm confused…
Replies from: evhub↑ comment by evhub · 2021-07-15T21:53:01.901Z · LW(p) · GW(p)
Oh, I guess you're saying something different: that even a deceptive mesa-optimizer which is entirely doing within-universe processing is nevertheless scary. So that would by definition be an algorithm with the property "no operation in the algorithm is likelier to happen vs not happen specifically because of anticipated downstream chains of causation that pass through things in the real world".
Yep, that's right.
So I can say categorically: such an algorithm won't hurt anyone (except by freak accident), won't steal processing resources, won't intervene when I go for the off-switch, etc., right?
No, not at all—just because an algorithm wasn't selected based on causing something to happen in the real world doesn't mean it won't in fact try to make things happen in the real world. In particular, the reason that I expect deception in practice is not primarily because it'll actually be selected for, but primarily just because it's simpler, and so it'll be found despite the fact that there wasn't any explicit selection pressure in favor of it. See: “Does SGD Produce Deceptive Alignment? [AF · GW]”
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-16T13:39:42.227Z · LW(p) · GW(p)
I think you're misunderstanding (or I am).
I'm trying to make a two step argument:
(1) SGD under such-and-such conditions will lead to a trained model that does exclusively within-universe processing [this step is really just a low-confidence hunch but I'm still happy to discuss and defend it]
(2) trained models that do exclusively within-universe processing are not scary [this step I have much higher confidence in]
If you're going to disagree with (2), then SGD / "what the model was selected" for is not relevant.
"Doing exclusively within-universe processing" is a property of the internals of the trained model, not just the input-output behavior. If running the trained model involves a billion low-level GPU instructions, this property would correspond to the claim that each and every one of those billion GPU instructions is being executed for reasons that are unrelated to any anticipated downstream real-world consequences of that GPU instruction. (where "real world" = everything except the future processing steps inside the algorithm itself.)
Replies from: evhub↑ comment by evhub · 2021-07-16T22:05:04.469Z · LW(p) · GW(p)
I mean, I guess it depends on your definition of “unrelated to any anticipated downstream real-world consequences.” Does the reason “it's the simplest way to solve the problem in the training environment” count as “unrelated” to real-world consequences? My point is that it seems like it should, since it's just about description length, not real-world consequences—but that it could nevertheless yield arbitrarily bad real-world consequences.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-19T18:10:25.965Z · LW(p) · GW(p)
I think it can be simultaneously true that, say:
- "weight #9876 is 1.2345 because out of all possible models, the highest-scoring model is one where weight #9876 happens to be 1.2345"
- "weight #9876 is 1.2345 because the hardware running this model has a RowHammer vulnerability, and this weight is part of a strategy that exploits that. (So in a counterfactual universe where we made chips slightly differently such that there was no such thing as RowHammer, then weight #9876 would absolutely NOT be 1.2345.)"
The second one doesn't stop being true because the first one is also true. They can both be true, right?
In other words, "the model weights are what they are because it's the simplest way to solve the problem" doesn't eliminate other "why" questions about all the details of the model. There's still some story about why the weights (and the resulting processing steps) are what they are—it may be a very complicated story, but there should (I think) still be a fact of the matter about whether that story involves "the algorithm itself having downstream impacts on the future in non-random ways that can't be explained away by the algorithm logic itself or the real-world things upstream of the algorithm". Or something like that, I think.
Replies from: evhub↑ comment by evhub · 2021-07-19T20:56:26.331Z · LW(p) · GW(p)
Sure, that's fair. But in the post, you argue that this sort of non-in-universe-processing won't happen because there's no incentive for it:
It seems like there’s no incentive whatsoever for a postdictive learner to have any concept that the data processing steps in the algorithm have any downstream impacts, besides, y’know, processing data within the algorithm. It seems to me like there’s a kind of leap to start taking downstream impacts to be a relevant consideration, and there’s nothing in gradient descent pushing the algorithm to make that leap, and there doesn’t seem to be anything about the structure of the domain or the reasoning it’s likely to be doing that would lead to making that leap, and it doesn’t seem like the kind of thing that would happen by random noise, I think.
However, if there's another “why” for why the model is doing non-in-universe-processing that is incentivized—e.g. simplicity—then I think that makes this argument no longer hold.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-20T13:38:02.108Z · LW(p) · GW(p)
One thing is, I'm skeptical that a deceptive non-in-universe-processing model would be simpler for the same performance. Or at any rate, there's a positive case for the simplicity of deceptive alignment, and I find that case very plausible for RL robots, but I don't think it applies to this situation. The positive case for simplicity of deceptive models for RL robots is something like (IIUC):
The robot is supposed to be really good at manufacturing widgets (for example), and that task requires real-world foresighted planning, because sometimes it needs to substitute different materials, negotiate with suppliers and customers, repair itself, etc. Given that the model definitely needs to have capability of real-world foresighted planning and self-awareness and so on, the simplest high-performing model is plausibly one that applies those capabilities towards a maximally simple goal, like "making its camera pixels all white" or whatever, and then that preserves performance because of instrumental convergence.
(Correct me if I'm misunderstanding!)
If that's the argument, it seems not to apply here, because this task doesn't require real-world foresighted planning.
I expect that a model that can't do any real-world planning at all would be simpler than a model that can. In the RL robot example, it doesn't matter, because a model that can't do any real-world planning at all would do terribly on the objective, so who cares if it's simpler. But here, it would be equally good at the objective, I think, and simpler.
(A possible objection would be: "real-world foresighted planning" isn't a separate thing that adds to model complexity, instead it naturally falls out of other capabilities that are necessary for postdiction like "building predictive models" and "searching over strategies" and whatnot. I think I would disagree with that objection, but I don't have great certainty here.)
Replies from: evhub↑ comment by evhub · 2021-07-20T20:22:09.643Z · LW(p) · GW(p)
(A possible objection would be: "real-world foresighted planning" isn't a separate thing that adds to model complexity, instead it naturally falls out of other capabilities that are necessary for postdiction like "building predictive models" and "searching over strategies" and whatnot. I think I would disagree with that objection, but I don't have great certainty here.)
Yup, that's basically my objection.
comment by dkirmani · 2021-07-01T15:44:23.905Z · LW(p) · GW(p)
A common trope is that brains are trained on prediction. Well, technically, I claim it would be more accurate to say that they’re trained on postdiction. Like, let’s say I open a package, expecting to see a book, but it’s actually a screwdriver. I’m surprised, and I immediately update my world-model to say "the box has a screwdriver in it".
I would argue that that the book-expectation is a prediction, and the surprise you experience is a result of low mutual information between your retinal activation patterns and the book-expectation in your head. That surprise (prediction error) is the learning signal that propagates up to your more abstract world-model, which updates into a state consistent with "the box has a screwdriver in it".
During this process, there was a moment when I was just beginning to parse the incoming image of the newly-opened box, expecting to see a book inside. A fraction of a second later, my brain recognizes that my expectation was wrong, and that’s the “surprise”. So in other words, my brain had an active expectation about something that had already happened—about photons that had by then already arrived at my retina—and that expectation was incorrect, and that’s what spurred me to update my world-model. Postdiction, not prediction.
Right, but the part of your brain that had that high-level model of "there is a book in the box" had at that time not received contradictory input from the lower-level edge detection / feature extraction areas. The abstract world-model does not directly predict retinal activations, it predicts the activations of lower-level sensory processing areas, which in turn predict the activations of the retina, cochlea, etc. There is latency in this system, so the signal takes a bit of time to filter up from the retinas to lower-level visual areas to your world-model. I don't think 'post-diction' makes sense in this context, as each brain region is predicting the activations of the one below it, and updates its state when those predictions are wrong.
(Also, I think Easy Win #3 is a really good point for Predict-O-Matic-esque sytems)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-01T16:56:14.234Z · LW(p) · GW(p)
I think you're interpreting "prediction" and "postdiction" differently than me.
Like, let's say GPT-3 is being trained to guess the next word of a text. You mask (hide) the next word, have GPT-3 guess it, and then compare the masked word to the guess and make an update.
I think you want to call the guess a "prediction" because from GPT-3's perspective, the revelation of the masked data is something that hasn't happened yet. But I want to call the guess a "postdiction" because the masked data is already "locked in" at the time that the guess is formed. The latter is relevant when we're thinking about incentives to form self-fulfilling prophecies.
Incidentally, to be clear, people absolutely do make real predictions constantly. I'm just saying we don't train on those predictions. I'm saying that by the time the model update occurs, the predictions have already been transmuted into postdictions, because the thing-that-was-predicted has now already been "locked in".
(Sorry if I'm misunderstanding.)
Replies from: dkirmani↑ comment by dkirmani · 2021-07-01T17:32:52.291Z · LW(p) · GW(p)
Nope, that's an accurate representation of my views. If "postdiction" means "the machine has no influence over its sensory input", then yeah, that's a really good idea.
There are 2 ways to reduce prediction error: change your predictions, or act upon the environment to make your predictions come true. I think the agency of an entity depends on how much of each they do. An entity with no agency would have no influence over its sensory inputs, instead opting to update beliefs in the face of prediction error. Taking agency from AIs is a good idea for safety.
Scott Alexander recently wrote about a similar quantity being ecoded in humans through the 5-HT1A / 5-HT2A receptor activation ratio: link
comment by adamShimi · 2021-08-02T09:48:19.097Z · LW(p) · GW(p)
5 years later, I'm finally reading this post. Thanks for the extended discussions of postdictive learning; it's really relevant to my current thinking about alignment for potential simulators-like Language Models.
Note that others disagree, e.g. advocates of Microscope AI [AF · GW].
I don't think advocates of Microscope AI think you can reach AGI that way. More that through Microscope AI, we might end up solving the problems we have without relying on an agent.
Why? Because in predictive training, the system can (under some circumstances) learn to make self-fulfilling prophecies—in other words, it can learn to manipulate the world, not just understand it. For example see Abram Demski’s Parable of the Predict-O-Matic [AF · GW]. In postdictive training, the answer is already locked in when the system is guessing it, so there’s no training incentive to manipulate the world. (Unless it learns to hack into the answer by row-hammer or whatever. I’ll get back to that in a later section.)
Agreed, but I think you could be even clearer that the real point is that postdiction can never causally influence the output. As you write there are cases and version where prediction also has this property, but it's not a guarantee by default.
As for the actual argument, that's definitely part of my reasoning why I don't expect GPT-N to have deceptive incentives (although maybe what it simulates would have).
In backprop, but not trial-and-error, and not numerical differentiation, we get some protection against things like row-hammering the supervisory signal.
Even after reading the wikipedia page, it's not clear to me what "row-hammering the supervisory signa"l would look like. Notably, I don't see the analogy to the electrical interaction here. Or do you mean literally that the world-model uses row-hammer on the computer it runs, to make the supervisory signal positive?
The differentiation engine is essentially symbolic, so it won’t (and indeed can’t) “differentiate through” the effects of row-hammer or whatever.
No idea what this means. If row-hammering (or whatever) improves the loss, then the gradient will push in that direction. I feel like the crux is in the specific way you imagine row-hammering happening here, so I'd like to know more about it.
Easy win #3: Don’t access the world-model and then act on that information, at least not without telling it
Slight nitpicking, but this last one doesn't sound like an easy win to me -- just an argument for not using a naive safety strategy. I mean, it's not like we really get anything in terms of safety, we just don't mess up the capabilities of the model completely.
(Human example of this error: Imagine someone saying "If fast-takeoff AGI happens, then it would have bizarre consequence X, and there’s no way you really expect that to happen, right?!? So c’mon, there’s not really gonna be fast-takeoff AGI.". This is an error because if there’s a reason to expect fast-takeoff AGI, and fast-takeoff AGI leads to X, we should make the causal update (“X is more likely than I thought”), not the retrocausal update (“fast-takeoff AGI is less likely than I thought”). Well, probably. I guess on second thought it’s not always a reasoning error.)
I see what you did there. (Joke apart, that's a telling example)
And, like other reasoning errors and imperfect heuristics, I expect that it’s self-correcting—i.e., it would manifest more early in training, but gradually go away as the AGI learns meta-cognitive self-monitoring strategies. It doesn’t seem to have unusually dangerous consequences, compared to other things in that category, AFAICT.
One way to make this argument more concrete relies on saying that solving this problem helps capabilities as well as safety. So as long as what we worry is a very capable AGI, this should be mitigated.
- There are within-universe consequences of a processing step, where the step causes things to happen entirely within the intended algorithm. (By "intended", I just mean that the algorithm is running without hardware errors). These same consequences would happen for the same reasons if we run the algorithm under homomorphic encryption in a sealed bunker at the bottom of the ocean.
- Then there are 4th-wall-breaking consequences of a processing step, where the step has a downstream chain of causation that passes through things in the real world that are not within-universe. (I mean, yes, the chip’s transistors have real-world-impacts on each other, in a manner that implements the algorithm, but that doesn’t count as 4th-wall-breaking.)
This distinction makes some sense to me, but I'm confused by your phrasing (and thus by what you actually mean). I guess my issue is that stating it like that made me think that you expected processing steps to be one or the other, whereas I can't imagine any processing step without 4th-wall-breaking consequences. What you do with these, about whether the 4th-wall-breaking consequences are reasons for specific actions, makes it clearer IMO.
Out-of-distribution, maybe the criterion in question diverges from a good postdiction-generation strategy. Oh well, it will make bad postdictions for a while, until gradient descent fixes it. That’s a capability problem, not a safety problem.
Agreed. Though, as Evan already pointed [AF(p) · GW(p)], the real worry with mesa-optimizers isn't proxy alignment but deceptive alignment. And deceptive alignment isn't just a capability problem.
Another way I've been thinking about the issue of mesa-optimizers in GPT-N is the risk of something like malign agents in the models (a bit like this [AF · GW]) that GPT-N might be using to simulate different texts. (Oh, I see you already have a section about that [AF · GW])
It seems like there’s no incentive whatsoever for a postdictive learner to have any concept that the data processing steps in the algorithm have any downstream impacts, besides, y’know, processing data within the algorithm. It seems to me like there’s a kind of leap to start taking downstream impacts to be a relevant consideration, and there’s nothing in gradient descent pushing the algorithm to make that leap, and there doesn’t seem to be anything about the structure of the domain or the reasoning it’s likely to be doing that would lead to making that leap, and it doesn’t seem like the kind of thing that would happen by random noise, I think.
Just because I share this intuition, I want to try pushing back against it.
First, I don't see any reason why a sufficiently advance postdictive learner with a general enough modality (like text) wouldn't learn to model 4th-wall-breaking consequences: that's just the sort of thing you need to predict security exploits or AI alignment posts like this one.
Next comes the questions of whether it will take advantage of this. Well, a deceptive mesa-optimizer would have an incentive to use this. So I guess the question boils down to the previous discussion, of whether we should expect postdictive learners to spin deceptive mesa-optimizers.
So a self-aware, aligned AGI could, and presumably would, figure out the idea “Don’t do a step-by-step emulation in your head of a possibly-adversarial algorithm that you don’t understand; or do it in a super-secure sandbox environment if you must”, as concepts encoded in its value function and planner. (Especially if we warn it / steer it away from that.)
I see a thread of turning potential safety issues into capability issues, and then saying that the AGI being competent, it will not have them. I think this makes sense for a really competent AGI, which would not be taken over by budding agents inside its simulation. But there's still the risk of spinning agents early in training, and if those agents get good enough to take over the model from the inside and become deceptive, competence at the training task become decorrelated with what happens in deployment.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-08-05T17:36:19.654Z · LW(p) · GW(p)
Thanks!
Or do you mean literally that the world-model uses row-hammer on the computer it runs, to make the supervisory signal positive?
Yes!
If row-hammering (or whatever) improves the loss, then the gradient will push in that direction.
I don't think this is true in the situation I'm talking about ("literally that the world-model uses row-hammer on the computer it runs, to make the supervisory signal positive").
Let's say we have weights θ, and loss is nominally the function f(θ), but the actual calculated loss is F(θ). Normally f(θ)=F(θ), but there are certain values of θ for which merely running the trained model corrupts the CPU, and thus the bits in the loss register are not what they're supposed to be according to the nominal algorithm. In those cases f(θ)≠F(θ).
Anyway, when the computer does symbolic differentiation / backprop, it's calculating ∇f, not ∇F. So it won't necessarily walk its way towards the minimum of F.
I can't imagine any processing step without 4th-wall-breaking consequences
Oh yeah, for sure. My idea was: sometimes the 4th-wall-breaking consequences are part of the reason that the processing step is there in the first place, and sometimes the 4th-wall-breaking consequences are just an incidental unintended side-effect, sorta an "externality".
Like, as the saying goes, maybe a butterfly flapping its wings in Mexico will cause a tornado in Kansas three months later. But that's not why the butterfly flapped its wings. If I'm working on the project of understanding the butterfly—why does it do the things it does? why is it built the way it's built?—knowing that there was a tornado in Kansas is entirely unhelpful. It contributes literally nothing whatsoever to my success in this butterfly-explanation project.
So by the same token, I think it's possible that we can work on the project of understanding a postdictively-trained model—why does it do the things it does? why is it built the way it's built?—and find that thinking about the 4th-wall-breaking consequences of the processing steps is entirely unhelpful for this project.
I don't see any reason why a sufficiently advance postdictive learner with a general enough modality (like text) wouldn't learn to model 4th-wall-breaking consequences: that's just the sort of thing you need to predict security exploits or AI alignment posts like this one.
Of course a good postdictive learner will learn that other algorithms can be manipulative, and it could even watch itself in a mirror and understand the full range of things that it could do (see the part of this post "Let’s take a postdictive learner, and grant it “self-awareness”…"). Hmm, maybe the alleged mental block I have in mind is something like "treating one's own processing steps as being part of the physical universe, as opposed to taking the stance where you're trying to the universe from outside it". I think an algorithm could predict that security researchers can find security exploits, and predict that AI alignment researchers could write comments like this one, while nevertheless "trying to understand the universe from outside it".
there's still the risk of spinning agents early in training
Oh yeah, for sure, in fact I think there's a lot of areas where we need to develop safety-compatible motivations as soon as possible, and where there's some kind of race to do so (see "Fraught Valley" section here [AF · GW]). I mean, "hacking into the training environment" is in that category too—you want to install the safety-compatible motivation (where the model doesn't want to hack into the training environment) sooner than the model becomes a superintelligent adversary trying to hack into the training environment. I don't like those kinds of races and wish I had better ideas for avoiding them.
Replies from: adamShimi↑ comment by adamShimi · 2021-08-08T21:21:44.492Z · LW(p) · GW(p)
Let's say we have weights θ, and loss is nominally the function f(θ), but the actual calculated loss is F(θ). Normally f(θ)=F(θ), but there are certain values of θ for which merely running the trained model corrupts the CPU, and thus the bits in the loss register are not what they're supposed to be according to the nominal algorithm. In those cases f(θ)≠F(θ).
Anyway, when the computer does symbolic differentiation / backprop, it's calculating ∇f, not ∇F. So it won't necessarily walk its way towards the minimum of F
Explained like that, it makes sense. And that's something I hadn't thought about.
So by the same token, I think it's possible that we can work on the project of understanding a postdictively-trained model—why does it do the things it does? why is it built the way it's built?—and find that thinking about the 4th-wall-breaking consequences of the processing steps is entirely unhelpful for this project.
Completely agree. This is part of my current reasoning for why GPT-3 (and maybe GPT-N) aren't incentivized for predict-o-matic behavior.
Hmm, maybe the alleged mental block I have in mind is something like "treating one's own processing steps as being part of the physical universe, as opposed to taking the stance where you're trying to the universe from outside it". I think an algorithm could predict that security researchers can find security exploits, and predict that AI alignment researchers could write comments like this one, while nevertheless "trying to understand the universe from outside it".
I'm confused by that paragraph: you sound like you're saying that the postdictive learner would not see itself as outside the universe in one sentence and would do so in the next. Either way, it seemed linked with the 1st person problem we're discussing in your research update [LW(p) · GW(p)]: this is a situation where you seem to expect that the translation into 1st person knowledge isn't automatic, and so can be controlled, incentivized or not.
comment by Charlie Steiner · 2021-07-03T11:14:32.661Z · LW(p) · GW(p)
I feel scooped by this post! :) I was thinking along different lines - using induction (postdictive learning) to get around Goodhart's law specifically by using the predictions outside of their nominal use case. But now I need to go back and think more about self-fulfilling prophecies and other sorts of feedback.
Maybe I'll try to get you to give me some feedback later this week.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-03T13:20:36.971Z · LW(p) · GW(p)
Sounds interesting!