Research agenda update
post by Steven Byrnes (steve2152) · 2021-08-06T19:24:53.726Z · LW · GW · 40 commentsContents
1. Intermediate problems to solve 1.1 “The 1st-Person Problem” 1.2 The meta-problem of consciousness 1.3 The meta-problem of suffering 1.4 What’s the API of the telencephalon? 1.5 Understand human social instincts well enough to implement them in code 1.6 Learned world-models with hardcoded pieces 2. Things to do right now 2.1 “Consciousness studies” 2.2 Autonomic nervous system, dopamine supervised learning 2.3 Brainstem → telencephalon control signals None 40 comments
“Our greatest fear should not be of failure, but of succeeding at something that doesn't really matter.” –DL Moody (allegedly)
(Related: Solving the whole AGI control problem, version 0.0001 [LW · GW]. Also related: all my posts.)
I’m five months into my new job [AF · GW]! This here is a forward-looking post where I write down what I’m planning to work in the near future and why. Please comment (or otherwise reach out) if you think I’m prioritizing wrong or going in a sub-optimal direction for Safe & Beneficial AGI. That’s the whole reason this post exists!
(UPDATE 5 MONTHS LATER: I should have been clearer: This post is primarily the "learning about neuroscience" aspects of my research agenda. The real goal is to design safe & beneficial AGI, and my learning about neuroscience is just one piece of that. As it turns out, in the few months since I wrote this, the great majority of my time did not really involve making progress on any of the things herein.)
I’ll work backwards: first the intermediate “problems to solve” that I think would help for the AGI control problem, then the immediate things I’m doing to work towards those goals.
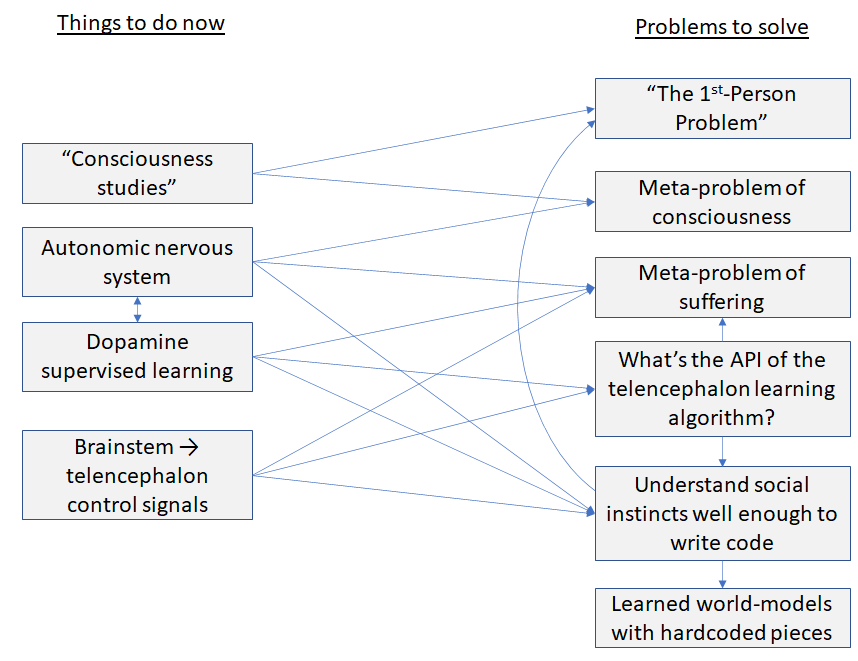
1. Intermediate problems to solve
1.1 “The 1st-Person Problem”
It’s easy (or at least tractable) to find or generate tons of labeled data with safety-critical concepts and situations. For example, we can easily find a YouTube video where Alice is deceiving Bob, and label it "deception".
But is that useful? The thing we want to find and/or reinforce in our AGI’s world-model is not quite that. Instead it’s concepts related to the AGI’s own actions. We want the AGI to think ""I am deceiving Bob" is a very bad thing". We don't want the AGI to think ""Alice is deceiving Bob" is a bad thing", or that the abstract concept of deception is a bad thing.
In other words, getting 3rd-person labeled data is easy but unhelpful. What we really want is 1st-person labeled data.
OK, so then we can say, forget about the YouTube videos. Instead we'll do RL, or something like it. We'll have the AGI do things, and we'll label the things it does.
That is indeed a solution. But it’s a really dangerous one! We would have to catch the AGI in the act of deception before we could label deception as bad.
The real golden ticket would be if we could somehow magically transmute third-person labeled data into 1st-person labeled data (or at least something equivalent to 1st-person labeled data).
How do we do that? I don’t know. I call this the “1st-Person Problem”.
Incidentally, in the diagram above, I put an arrow indicating that understanding social emotions might be helpful for solving the 1st-Person Problem. Why would I think that? Well, what I have in mind here is that, for example, if a 3-year-old sees a 7-year-old doing something, then often the 3-year-old immediately wants to do the exact same thing. So I figure, it’s at least possible that somewhere in the algorithms of human social instincts is buried a solution to the 1st-Person Problem. Maybe, maybe not.
1.2 The meta-problem of consciousness
(See Book review: Rethinking Consciousness [LW · GW])
I am strongly averse to becoming really competent to talk about the philosophy of consciousness. Well, I mean, it would be really fun, but it seems like it would also be really time-consuming, with all the terminology and theories and arguments and counter-arguments and whatnot, and I have other priorities right now.
But there’s a different question which is: there’s a set of observable psychological phenomena, where people declare themselves conscious, muse on the ineffable nature of consciousness, write papers about the hard problem of consciousness, and so on. Therefore there has to be some explanation, in terms of brain algorithms, for the chain of events that eventually leads to people talking about how they’re conscious. It seems to me that unravelling that chain of events is purely a question of neuroscience and psychology, not philosophy.
The “meta-problem of consciousness”—a.k.a. “Why do people believe that there’s a hard problem of consciousness”—is about unraveling this chain of events.
What's the point? Well, if I truthfully declare “I am wearing a watch”, and we walk through the chain of events that led to me saying those words, we’d find that one of the links in the chain is an actual physical watch that I’m actually physically wearing. So by the same token, it seems to me that a complete solution to the meta-problem of consciousness should directly lead to a solution to the hard problem of consciousness. (Leaving aside some fine print—see Yudkowsky on zombies [LW · GW].)
In terms of AGI, it seems to me that knowing whether or not AGI is conscious is an important thing to know, at least for the AGI’s sake. (Yeah I know—as if we don’t already have our hands full thinking about the impacts of AGI on humans!)
So working on the meta-problem of consciousness seems like one thing worth doing.
That said, I’m tentatively feeling OK about what I wrote here [LW · GW]—basically my proto-theory of the meta-problem of consciousness is some idiosyncratic mishmash of Michael Graziano's "Attention Schema Theory", and Stanislas Dehaene's "Global Workspace Theory", and Keith Frankish's "Illusionism". I'll stay on the lookout for reasons to think that what I wrote there was wrong, but otherwise I think this topic is not high on my immediate priority list.
1.3 The meta-problem of suffering
The motivation here is exactly like the previous section: People talk about suffering. The fact that they are speaking those words is an observable psychological fact, and must have an explanation involving neuroscience and brain algorithms. And whatever that explanation is, it would presumably get us most of the way towards understanding suffering, and thus towards figuring out which AI algorithms are or aren’t suffering.
Unlike the previous section, I do think I’m pretty likely to do some work here, even in the short term, partly because I’m still pretty generally confused and curious about this. More importantly, it’s very closely tied to other things in AGI safety that I need to be working on anyway. In particular, it seems pretty intimately tied to decision-making and motivation—for example, we are motivated to not suffer, and we make decisions that lead to not-suffering. I’ve already written a lot about decision-making [LW · GW] and motivation [LW · GW] and plan to write more, because understanding and sculpting AGI motivation is a huge part of AGI safety. So with luck I'll have something useful to say about the meta-problem of suffering at some point.
1.4 What’s the API of the telencephalon?
I think the telencephalon (neocortex, hippocampus, amygdala, part of the basal ganglia) is running a learning algorithm (well, several learning algorithms [LW · GW]) that starts from scratch at birth (“random weights” or something equivalent) and learns a big complicated world-model etc. within the animal’s lifetime. See “learning-from-scratch-ism” discussion here [LW · GW]. And the brainstem and hypothalamus are mostly hardcoded algorithms that try to “steer” that learning algorithm towards doing useful things.
What are the input channels through which the brainstem can "steer" the telencephalon learning algorithms? I originally thought that there was a one-dimensional signal called “reward”, and that's it. But when I looked into it, I found a bunch more things! And all those things were at least plausibly promising ideas for AGI safety!
Two things in particular:
(1) a big reason that I wrote Reward Is Not Enough [LW · GW] was as an excuse to promote the idea of supplying different reward signals for different subsystems, especially subsystems that report back to the supervisor. And where did I get that idea? From the telencephalon API of course!
(2) I’m pretty excited by the idea of interpretability and steering via supervised learning (see the “More Dakka” comment in the figure caption here [LW · GW]), especially if we can solve the “1st-Person Problem” above. And where did I get that idea? From the telencephalon API of course!
So this seems like fertile soil to keep digging. There are certainly other things in the telencephalon API too. I would like to understand them!
1.5 Understand human social instincts well enough to implement them in code
See Section 5 of "Solving the Whole AGI Control Problem Version 0.0001 [LW · GW].
1.6 Learned world-models with hardcoded pieces
My default presumption is that our AGIs will learn a world-model from scratch—loosely speaking, they’ll find patterns in sensory inputs and motor outputs, and then patterns in the patterns, and then patterns in the patterns in the patterns … etc.
But it might be nice instead to hard-code “how the AGI will think about certain aspects of the world”. The obvious use-case here is that the programmer declares that there's a thing called "humans", and they're basically cartesian, and they are imperfectly rational according to such-and-such model of imperfect rationality, etc. Then these hard-coded items can be referents when we define the AGI’s motivations, rewards, etc.
For example, lots of discussion of IRL and value learning seem to presuppose that we’re writing code that tells the AGI specifically how to model a human. To pick a random example, in Vanessa Kosoy's 2018 research agenda [LW · GW], the "demonstration" and "learning by teaching" ideas seem to rely on being able to do that—I don't see how we could possibly do those things if the whole world-model is a bunch of unlabeled patterns in patterns in patterns in sensory input etc.
So there's the problem. How do we build a learned-from-scratch world model but shove little hardcoded pieces into it? How do we ensure that the hardcoded pieces wind up in the right place? How do we avoid the AGI ignoring the human model that we supplied it and instead building a parallel independent human model from scratch?
2. Things to do right now
2.1 “Consciousness studies”
I think there’s a subfield of neuroscience called “consciousness studies”, where they talk a lot about how people formulate thoughts about themselves, etc. The obvious application is understanding consciousness, but I’m personally much more interested in whether it could help me think about The 1st-Person Problem. So I'm planning to dive into that sometime soon.
2.2 Autonomic nervous system, dopamine supervised learning
I have this theory (see the “Plan assessors” at A model of decision-making in the brain (the short version) [LW · GW]) that parts of the telencephalon are learning algorithms that are trained by supervised learning, with dopamine as the supervisory signal. I think this theory (if correct) is just super duper important for everything I’m interested in, and I’m especially eager to take that idea and build on it, particularly for social instincts and motivation and suffering and so on.
But I’m concerned that I would wind up building idiosyncratic speculative theories on top of idiosyncratic speculative theories on top of ….
So I’m swallowing my impatience, and trying to really nail down dopamine supervised learning—keep talking to experts, keep filling in the gaps, keep searching for relevant evidence. And then I can feel better about building on it.
For example:
It turns out that these dopamine-supervised-learning areas (e.g. anterior cingulate, medial prefrontal cortex, amygdala, ventral striatum) are all intimately involved in the autonomic nervous system, so I’m hoping that reading more about that will help resolve some of my confusions about those parts of the brain (see Section 1 here [LW · GW] for what exactly my confusions are).
I also think that I kinda wound up pretty close to the somatic marker hypothesis (albeit via a roundabout route), so I want to understand the literature on that, incorporate any good ideas, and relate it to what I’m talking about.
Since the autonomic nervous system is related to “feelings”, learning about the autonomic nervous system could also help me understand suffering and consciousness and motivation and social instincts.
2.3 Brainstem → telencephalon control signals
As mentioned above (see “What’s the API of the telencephalon?”), there are a bunch of signals going from the brainstem to the telencephalon, and I only understand a few of them so far, and I’m eager to dive into others. I’ve written a bit about acetylcholine [LW · GW] but I have more to say, I have a hunch that it plays a role in cortical specialization, with implications for transparency. I know pretty much nothing about serotonin, norepinephrine, opioids, etc. I mentioned here [LW · GW] that I’m confused about how the cortex learns motor control from scratch, or if that’s even possible, and how I’m also confused about the role of various signals going back and forth between the midbrain and cortex. So those are all things I'm eager to dive into.
40 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2021-08-23T19:39:16.803Z · LW(p) · GW(p)
For example, lots of discussion of IRL and value learning seem to presuppose that we’re writing code that tells the AGI specifically how to model a human. To pick a random example, in Vanessa Kosoy's 2018 research agenda, the "demonstration" and "learning by teaching" ideas seem to rely on being able to do that—I don't see how we could possibly do those things if the whole world-model is a bunch of unlabeled patterns in patterns in patterns in sensory input etc.
We can at least try doing those things by just having specific channels through which human actions enter the system. For example, maybe it's enough to focus on what the human posts on Facebook, so the AI just needs to look at that. The problem with this is, it leaves us open to attack vectors in which the channel in question is hijacked. On the other hand, even if we had a robust way to point to the human brain, we would still have attack vectors in which the human themself gets "hacked" somehow.
In principle, I can imagine solving these problems by somehow having a robust definition of "unhacked human", which is what you're going for, I think. But there might be a different type of solution in which we just avoid entering "corrupt" states in which the content of the channel diverges from what we intended. For example, this might be achievable by quantilizing imitation [AF(p) · GW(p)].
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-08-30T16:02:47.055Z · LW(p) · GW(p)
Thanks!!! After reading your comment and thinking about it more, here's where I'm at:
Your "demonstration" thing [LW · GW] was described as "The [AI] observes a human pursuing eir values and deduces the values from the behavior."
When I read that, I was visualizing a robot and a human standing in a room, and the human is cooking, and the robot is watching the human and figuring out what the human is trying to do. And I was thinking that there needs to be some extra story for how that works, assuming that the robot has come to understand the world by building a giant unlabeled Bayes net world-model, and that it processes new visual inputs by slotting them into that model. (And that's my normal assumption, since that's how I think the neocortex works, and therefore that's a plausible way that people might build AGI, and it's the one I'm mainly focused on.)
So as the robot is watching the human soak lentils, the thing going on in its head is: "Pattern 957823, and Pattern 5672928, and Pattern 657192, and…". In order to have the robot assign a special status to the human's deliberate actions, we would need to find "the human's deliberate actions" somewhere in the unlabeled world-model, i.e. solve a symbol-grounding problem, and doing so reliably is not straightforward.
However, maybe I was visualizing the wrong thing, with the robot and human in the room. Maybe I should have instead been visualizing a human using a computer via its keyboard. Then the AI can have a special input channel for the keystrokes that the human types. And every single one of those keystrokes is automatically treated as "the human's deliberate action". This seems to avoid the symbol-grounding problem I mentioned above. And if there's a special input channel, we can use supervised learning to build a probabilistic model of that input channel. (I definitely think this step is compatible with the neocortical algorithm. [LW · GW]) So now we have a human policy—i.e., what the AI thinks the human would do next, in any real or imagined circumstance, at least in terms of which keystrokes they would type. I'm still a bit hazy on what happens next in the plan—i.e., getting from that probabilistic model to the more abstract "what the human wants". At least in general. And a big part of that is, again, symbol-grounding—as soon as we step away from the concrete predictions coming out of the "human keystroke probabilistic model", we're up in the land of "World-model Pattern #8673028" etc. where we can't really do anything useful. (I do see how the rest of the plan could work along these lines [LW(p) · GW(p)], where we install a second special human-to-AI information channel where the human says how things are going, and the AI builds a predictive model of that too, and then we predict-and-quantilize from the human policy.†)
It's still worth noting that I, Steve, personally can be standing in a room with another human H2, watching them cook, and I can figure out what H2 is trying to do. And if H2 is someone I really admire, I will automatically start wanting to do the things that H2 is trying to do. So human social instincts do seem to have a way forward through the symbol-grounding path above, and not through the special-input-channel path, and I continue to think that this symbol-grounding method has something to do with empathetic simulation [LW · GW], but I'm hazy on the details, and I continue to think that it would be very good to understand better how exactly it works.
†This does seem to be a nice end-to-end story by the way. So have we solved the alignment problem? No… You mention channel corruption as a concern, and it is, but I'm even more concerned about this kind of design hitting a capabilities wall dramatically earlier than unsafe AGIs would. Specifically, I think it's important that an AGI be able to do things like "come up with a new way to conceptualize the alignment problem", and I think doing those things requires goal-seeking-RL-type exploration [LW · GW] (e.g. exploring different possible mathematical formalizations or whatever) within a space of mental "actions" none of which it has ever seen a human take. I don't think that this kind of AGI approach would be able to do that, but I could be wrong. That's another reason that I'm hoping something good will come out of the symbol-grounding path informed by how human social instincts work.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-08-31T20:16:05.226Z · LW(p) · GW(p)
I'm still a bit hazy on what happens next in the plan—i.e., getting from that probabilistic model to the more abstract "what the human wants".
Well, one thing you could try is using the AIT definition of goal-directedness [AF(p) · GW(p)] to go from the policy to the utility function. However, in general it might require knowledge of the human's counterfactual behavior which the AI doesn't have. Maybe there are some natural assumption under which it is possible, but it's not clear.
It's still worth noting that I, Steve, personally can be standing in a room with another human H2, watching them cook, and I can figure out what H2 is trying to do.
I feel the appeal of this intuition, but on the other hand, it might be a much easier problem since both of you are humans doing fairly "normal" human things. It is less obvious you would be able to watch something completely alien and unambiguously figure out what it's trying to do.
....I'm even more concerned about this kind of design hitting a capabilities wall dramatically earlier than unsafe AGIs would.
To first approximation, it is enough for the AI to be more capable than us, since, whatever different solution we might come up with, an AI which is more capable than us would come up with a solution at least as good. Quantilizing from an imitation baseline seems like it should achieve that, since the baseline is "as capable as us" and arguably quantilization would produce significant improvement over that.
Specifically, I think it's important that an AGI be able to do things like "come up with a new way to conceptualize the alignment problem", and I think doing those things requires goal-seeking-RL-type exploration (e.g. exploring different possible mathematical formalizations or whatever) within a space of mental "actions" none of which it has ever seen a human take.
Instead of "actions the AI has seen a human take", a better way to think about it is "actions the AI can confidently predict a human could take (with sufficient probability)".
Replies from: steve2152, steve2152↑ comment by Steven Byrnes (steve2152) · 2021-09-02T17:49:32.911Z · LW(p) · GW(p)
Thanks again for your very helpful response! I thought about the quantilization thing more, let me try again.
As background, to a first approximation, let’s say 5 times per second I (a human) “think a thought”. That involves a pair of two things:
- (Possibly) update my world-model
- (Possibly) take an action—in this case, type a key at the keyboard
Of these two things, the first one is especially important, because that’s where things get "figured out". (Imagine staring into space while thinking about something.)
OK, now back to the AI. I can broadly imagine two strategies for a quantilization approach:
- Build a model of the human policy from a superior epistemic vantage point: So here we give the AI its own world-model that needn’t have anything to do with the human’s, and likewise allow the AI to update its world-model in a way that needn’t have anything to do with how the human updates their world model. Then the AI leverages its superior world-model in the course of learning and quantilizing the human policy (maybe just the action part of the policy, or maybe both the actions and the world-model-updates, it doesn't matter for the moment).
- Straightforward human imitation: Here, we try to get to a place where the AI is learning about the world and figuring things out in a (quantilized) human-like way. So we want the AI to sample from the human policy for "taking an action", and we want the AI to sample from the human policy for "updating the world-model". And the AI doesn't know anything about the world beyond what it learns through those quantilized-human-like world-model updates.
Start with the first one. If the AI is going to get to a superior epistemic vantage point, then it needs to “figure things out” about the world and concepts and so on, and as I said before, I think “figuring things out” requires goal-seeking-RL-type exploration [LW · GW] (e.g. exploring different possible mathematical formalizations or whatever) within a space of mental "actions". So we still have the whole AGI alignment / control problem in defining what this RL system is trying to do and what strategies it’s allowed to use to do it. And since this is not a human-imitating system, we can’t fall back on that. So this doesn't seem like we made much progress on the problem.
For the second one, well, I think I’m kinda more excited about this one.
Naively, it does seem hard though. Recall that in this approach we need to imitate both aspects of the human policy—plausibly-human actions, and plausibly-human world-model-updates. This seems hard, because the AI only sees the human’s actions, not its world-model updates. Can it infer the latter? I’m a bit pessimistic here, at least by default. Well, I’m optimistic that you can infer an underlying world-model from actions—based on e.g. GPT-3. But here, we’re not merely hoping to learn a snapshot of the human model, but also to learn all the human’s model-update steps. Intuitively, even when a human is talking to another human, it’s awfully hard to communicate the sequence of thoughts that led you to come up with an idea. Heck, it’s hard enough to understand how I myself figured something out, when it was in my own head five seconds ago. Another way to think about it is, you need a lot of data to constrain a world-model snapshot. So to constrain a world-model change, you presumably need a lot of data before the change, and a lot of data after the change. But “a lot of data” involves an extended period of time, which means there are thousands of sequential world-model changes all piled on top of each other, so it's not a clean comparison.
A couple things that might help are (A) Giving the human a Kernel Flow or whatever and letting the AI access the data, and (B) Helping the inductive bias by running the AI on the same type of world-model data structure and inference algorithm as the human, and having it edit the model to get towards a place where its model and thought process exactly matches the human.
I’m weakly pessimistic that (A) would make much difference. I think (B) could help a lot, indeed I’m (weakly) hopeful that it could actually successfully converge towards the human thought process [LW · GW]. And conveniently I also find (B) very technologically plausible.
So that’s neat. But we don’t have a superior epistemic vantage point anymore. So how do we quantilize? I figure, we can use some form of amplification—most simply, run the model at superhuman speeds so that it can “think longer” than the human on a given task. Or roll out different possible trains of thought in parallel, and ranking how well they turn out. Or something. But I feel like once we're doing all that stuff, we can just throw out the quantilization part of the story, and instead our safety story can be that we’re starting with a deeply-human-like model and not straying too far from it, so hopefully it will remain well-behaved. That was my (non-quantilization) story here [LW · GW].
Sorry if I'm still confused; I'm very interested in your take, if you're not sick of this discussion yet. :)
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-02T18:29:45.332Z · LW(p) · GW(p)
I gave a formal mathematical definition [LW(p) · GW(p)] of (idealized) HDTL, so the answer to your question should probably be contained there. But I'm not entirely sure what it is since I don't entirely understand the question.
The AI has a "superior epistemic vantage point" in the sense that, the prior is richer than the prior that humans have. But, why do we "still have the whole AGI alignment / control problem in defining what this RL system is trying to do and what strategies it’s allowed to use to do it"? The objective is fully specified.
A possible interpretation of your argument: a powerful AI would have to do something like TRL [LW(p) · GW(p)] and access to the "envelope" computer can be unsafe in itself, because of possible side effects. That's truly a serious problem! Essentially, it's non-Cartesian daemons [LW · GW].
Atm I don't have an extremely good solution to non-Cartesian daemons. Homomorphic cryptography can arguably solve it, but there's large overhead. Possibly we can make do with some kind of obfuscation instead. Another vague idea I have is, make the AI avoid running computations which have side-effects predictable by the AI. In any case, more work is needed.
Recall that in this approach we need to imitate both aspects of the human policy—plausibly-human actions, and plausibly-human world-model-updates. This seems hard, because the AI only sees the human’s actions, not its world-model updates.
I don't see why is it especially hard, it seems just like any system with unobservable degrees of freedom, which covers just about anything in the real world. So I would expect an AI with transformative capability to be able to do it. But maybe I'm just misunderstanding what you mean by this "approach number 2". Perhaps you're saying that it's not enough to accurately predict the human actions, we need to have accurate pointers to particular gears inside the model. But I don't think we do (maybe it's because I'm following approach number 1).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-09-03T20:59:38.454Z · LW(p) · GW(p)
why do we "still have the whole AGI alignment / control problem in defining what this RL system is trying to do and what strategies it’s allowed to use to do it"? The objective is fully specified…
Thanks, that was a helpful comment. I think we're making progress, or at least I'm learning a lot here. :)
I think your perspective is: we start with a prior—i.e. the prior is an ingredient going into the algorithm. Whereas my perspective is: to get to AGI, we need an agent to build the prior, so to speak. And this agent can be dangerous.
So for example, let's talk about some useful non-obvious concept, like "informational entropy". And let's suppose that our AI cannot learn the concept of "informational entropy" from humans, because we're in an alternate universe where humans haven't yet invented the concept of informational entropy. (Or replace "informational entropy" with "some important not-yet-discovered concept in AI alignment.)
In that case, I see three possibilities.
- First, the AI never winds up "knowing about" informational entropy or anything equivalent to it, and consequently makes worse predictions about various domains (human scientific and technological progress, the performance of certain algorithms and communications protocols, etc.)
- Second (I think this is your model?): the AI's prior has a combinatorial explosion with every possible way of conceptualizing the world, of which an astronomically small proportion are actually correct and useful. With enough data, the AI settles into a useful conceptualization of the world, including some sub-network in its latent space that's equivalent to informational entropy. In other words: it "discovers" informational entropy by dumb process of elimination.
- Third (this is my model): we get a prior by running a "prior-building AI". This prior-building AI has "agency"; it "actively" learns how the world works, by directing its attention etc. It has curiosity and instrumental reasoning and planning and so on, and it gradually learns instrumentally-useful metacognitive strategies, like a habit of noticing and attending to important and unexplained and suggestive patterns, and good intuitions around how to find useful new concepts, etc. At some point it notices some interesting and relevant patterns, attends to them, and after a few minutes of trial-and-error exploration it eventually invents the concept of informational entropy. This new concept (and its web of implications) then gets incorporated into the AI's new "priors" going forward, allowing the AI to make better predictions and formulate better plans in the future, and to discover yet more predictively-useful concepts, etc. OK, now we let this "prior-building AI" run and run, building an ever-better "prior" (a.k.a. "world-model"). And then at some point we can turn this AI off, and export this "prior" into some other AI algorithm. (Alternatively, we could also more simply just have one AI which is both the "prior-building AI" and the AI that does, um, whatever we want our AIs to do.)
It seems pretty clear to me that the third approach is way more dangerous than the second. In particular, the third one explicitly doing instrumental planning and metacognition, which seems like the same kinds of activities that could lead to the idea of seizing control of the off-switch etc.
However, my hypothesis is that the third approach can get us to human-level intelligence (or what I was calling a "superior epistemic vantage point") in practice, and that the other approaches can't.
So, I was thinking about the third approach—and that's why I said "we still have the whole AGI alignment / control problem" (i.e., aligning and controlling the "prior-building AI"). Does that help?
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-03T21:49:05.347Z · LW(p) · GW(p)
I think the confusion here comes from mixing algorithms with desiderata. HDTL is not an algorithm, it is a type of desideratum than an algorithm can satisfy. "the AI's prior has a combinatorial explosion" is true but "dumb process of elimination" is false. A powerful AI has to be have a very rich space of hypotheses it can learn. But this doesn't mean this space of hypotheses is explicitly stored in its memory or anything of the sort (which would be infeasible). It only means that the algorithm somehow manages to learn those hypotheses, for example by some process of adding more and more detail incrementally (which might correspond to refinement in the infra-Bayesian sense).
My thesis here is that if the AI satisfies a (carefully fleshed out in much more detail) version of the HDTL desideratum, then it is safe and capable. How to make an efficient algorithm that satisfies such a desideratum is another question, but that's a question from a somewhat different domain: specifically the domain of developing learning algorithms with strong formal guarantees and/or constructing a theory of formal guarantees for existing algorithms. I see the latter effort as to first approximation orthogonal to the effort of finding good formal desiderata for safe TAI (and, it also receives plenty of attention from outside the existential safety community).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-09-09T15:50:21.080Z · LW(p) · GW(p)
Thanks!! Here's where I'm at right now.
In the grandparent comment [LW(p) · GW(p)] I suggested that if we want to make an AI that can learn sufficiently good hypotheses to do human-level things, perhaps the only way to do that is to make a "prior-building AI" with "agency" that is "trying" to build out its world-model / toolkit-of-concepts-and-ideas in fruitful directions. And I said that we have to solve the problem of how to build that kind of agential "prior-building AI" that doesn't also incidentally "try" to seize control of its off-switch.
Then in the parent comment [LW(p) · GW(p)] you replied (IIUC) that if this is a problem at all, it's not the problem you're trying to solve (i.e. "finding good formal desiderata for safe TAI"), but a different problem (i.e. "developing learning algorithms with strong formal guarantees and/or constructing a theory of formal guarantees for existing algorithms"), and my problem is "to a first approximation orthogonal" to your problem, and my problem "receives plenty of attention from outside the existential safety community".
If so, my responses would be:
- Obviously the problem of "make an agential "prior-building AI" that doesn't try to seize control of its off-switch" is being worked on almost exclusively by x-risk people. :-P
- I suspect that the problem doesn't decompose the way you imply; instead I think that if we develop techniques for building a safe agential "prior-building AI", we would find that similar techniques enable us to build a safe non-manipulative-question-answering AI / oracle AI / helper AI / whatever.
- Even if that's not true, I would still say that if we can make a safe agential "prior-building AI" that gets to human-level predictive ability and beyond, then we've solved almost the whole TAI safety problem, because we could then run the prior-building AI, then turn it off and use microscope AI [LW · GW] to extract a bunch of new-to-humans predictively-useful concepts from the prior it built—including new ideas & concepts that will accelerate AGI safety research.
Or maybe another way of saying it would be: I think I put a lot of weight on the possibility that those "learning algorithms with strong formal guarantees" will turn out not to exist, at least not at human-level capabilities.
I guess, when I read "learning algorithms with strong formal guarantees", I'm imaging something like multi-armed bandit algorithms that have regret bounds. But I'm having trouble imagining how that kind of thing would transfer to a domain where we need the algorithm to discover new concepts and leverage them for making better predictions, and we don't know a priori what the concepts look like, or how many there will be, or how hard they will be to find, or how well they will generalize, etc.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-09T18:05:23.073Z · LW(p) · GW(p)
Obviously the problem of "make an agential "prior-building AI" that doesn't try to seize control of its off-switch" is being worked on almost exclusively by x-risk people.
Umm, obviously I did not claim it isn't. I just decomposed the original problem in a different way that didn't single out this part.
...if we can make a safe agential "prior-building AI" that gets to human-level predictive ability and beyond, then we've solved almost the whole TAI safety problem, because we could then run the prior-building AI, then turn it off and use microscope AI to extract a bunch of new-to-humans predictively-useful concepts from the prior it built—including new ideas & concepts that will accelerate AGI safety research.
Maybe? I'm not quite sure what you mean by "prior building AI" and whether it's even possible to apply a "microscope" to something superhuman, or that this approach is easier than other approaches, but I'm not necessarily ruling it out.
Or maybe another way of saying it would be: I think I put a lot of weight on the possibility that those "learning algorithms with strong formal guarantees" will turn out not to exist, at least not at human-level capabilities.
That's where our major disagreement is, I think. I see human brains as evidence such algorithms exist and deep learning as additional evidence. We know that powerful learning algorithms exist. We know that no algorithm can learn anything (no free lunch). What we need is a mathematical description of the space of hypotheses these algorithms are good at, and associated performance bounds. The enormous generality of these algorithms suggests that there probably is such a simple description.
...I'm having trouble imagining how that kind of thing would transfer to a domain where we need the algorithm to discover new concepts and leverage them for making better predictions, and we don't know a priori what the concepts look like, or how many there will be, or how hard they will be to find, or how well they will generalize, etc.
I don't understand your argument here. When I prove a theorem that "for all x: P(x)", I don't need to be able to imagine every possible value of x. That's the power of abstraction. To give a different example, the programmers of AlphaGo could not possibly anticipate all the strategies it came up or all the life and death patterns it discovered. That wasn't a problem for them either.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-09-09T19:41:51.207Z · LW(p) · GW(p)
Hmmm, OK, let me try again.
You wrote earlier: "the algorithm somehow manages to learn those hypotheses, for example by some process of adding more and more detail incrementally".
My claim is that good-enough algorithms for "adding more and more detail incrementally" will also incidentally (by default) be algorithms that seize control of their off-switches.
And the reason I put a lot of weight on this claim is that I think the best algorithms for "adding more and more detail incrementally" may be algorithms that are (loosely speaking) "trying" to understand and/or predict things, including via metacognition and instrumental reasoning.
OK, then the way I'm currently imagining you responding to that would be:
My model of Vanessa: We're hopefully gonna find a learning algorithm with a provable regret bound (or something like that). Since seizing control of the off-switch would be very bad according to the objective function and thus violate the regret bound, and since we proved the regret bound, we conclude that the learning algorithm won't seize control of the off-switch.
(If that's not the kind of argument you have in mind, oops sorry!)
Otherwise: I feel like that's akin to putting "the AGI will be safe" as a desideratum, which pushes "solve AGI safety" onto the opposite side of the divide between desiderata vs. learning-algorithm-that-satisfies-the-desiderata. That's perfectly fine, and indeed precisely defining "safe" is very useful. It's only a problem if we also claim that the "find a learning algorithm that satisfies the desiderata" part is not an AGI safety problem. (Also, if we divide the problem this way, then "we can't find a provably-safe AGI design" would be re-cast as "no human-level learning algorithms satisfy the desiderata".)
That's also where I was coming from when I expressed skepticism about "strong formal guarantees". We have no performance guarantee about the brain, and we have no performance guarantee about AlphaGo, to my knowledge. Again, as above, I was imagining an argument that turns a performance guarantee into a safety guarantee, like "I can prove that AlphaGo plays go at such-and-such Elo level, and therefore it must not be wireheading, because wireheaders aren't very good at playing Go." If you weren't thinking of performance guarantees, what "formal guarantees" are you thinking of?
(For what little it's worth, I'd be a bit surprised if we get a safety guarantee via a performance guarantee. It strikes me as more promising to reason about safety directly—e.g. "this algorithm won't seize control of the off-switch because blah blah incentives blah blah mesa-optimizers blah blah".)
Sorry if I'm still misunderstanding. :)
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-09T20:02:28.907Z · LW(p) · GW(p)
It's only a problem if we also claim that the "find a learning algorithm that satisfies the desiderata" part is not an AGI safety problem.
I never said it's not a safety problem. I only said that a lot progress on this can come from research that is not very "safety specific". I would certainly work on it if "precisely defining safe" was already solved.
That's also where I was coming from when I expressed skepticism about "strong formal guarantees". We have no performance guarantee about the brain, and we have no performance guarantee about AlphaGo, to my knowledge.
Yes, we don't have these things. That doesn't mean these things don't exist. Surely all research is about going from "not having" things to "having" things? (Strictly speaking, it would be very hard to literally have a performance guarantee about the brain since the brain doesn't have to be anything like a "clean" implementation of a particular algorithm. But that's besides the point.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-09-09T20:46:13.554Z · LW(p) · GW(p)
Cool, gotcha, thanks. So my current expectation is either: (1) we will never be able to prove any performance guarantees about human-level learning algorithms, or (2) if we do, those proofs would only apply to certain algorithms that are packed with design features specifically tailored to solve the alignment problem, and any proof of a performance guarantee would correspondingly have a large subsection titled "Lemma 1: This learning algorithm will be aligned".
The reason I think that is that (as above) I expect the learning algorithms in question to be kinda "agential", and if an "agential" algorithm is not "trying" to perform well on the objective, then it probably won't perform well on the objective! :-)
If that view is right, the implication is: the only way to get a performance guarantee is to prove Lemma 1, and if we prove Lemma 1, we no longer care about the performance guarantee anyway, because we've already solved the alignment problem. So the performance guarantee would be besides the point (on this view).
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-09T21:17:40.328Z · LW(p) · GW(p)
I don't understand what Lemma 1 is if it's not some kind of performance guarantee. So, this reasoning seems kinda circular. But, maybe I misunderstand.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-09-10T01:20:07.356Z · LW(p) · GW(p)
Good question!
Imagine we have a learning algorithm that learns a world-model, and flags things in the world-model as "goals", and then makes plans to advance those "goals". (An example of such an algorithm is (part of) the human brain, more-or-less, according to me [LW · GW].) We can say the algorithm is "aligned" if the things flagged as "goals" do in fact corresponding to maximizing the objective function (e.g. "predict the human's outputs"), or at least it's as close a match as anything in the world-model, and if this remains true even as the world-model gets improved and refined over time.
Making that definition better and rigorous would be tricky because it's hard to talk rigorously about symbol-grounding, but maybe it's not impossible. And if so, I would say that this is a definition of "aligned" which looks nothing like a performance guarantee.
OK, hmmm, after some thought, I guess it's possible that this definition of "aligned" would be equivalent to a performance-centric claim along the lines of "asymptotically, performance goes up not down". But I'm not sure that it's exactly the same. And even if it were mathematically equivalent, we still have the question of what the proof would look like, out of these two possibilities:
- We prove that the algorithm is aligned (in the above sense) via "direct reasoning about alignment" (i.e. talking about symbol-grounding, goal-stability, etc.), and then a corollary of that proof would be the asymptotic performance guarantee.
- We prove that the algorithm satisfies the asymptotic performance guarantee via "direct reasoning about performance", and then a corollary of that proof would be that the algorithm is aligned (in the above sense).
I think it would be the first one, not the second. Why? Because it seems to me that the alignment problem is hard, and if it's solvable at all, it would only be solvable with the help of various specific "alignment-promoting algorithm features", and we won't be able to prove that those features work except by "direct reasoning about alignment".
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-10T19:39:47.255Z · LW(p) · GW(p)
The way I think about instrumental goals is: You have have an MDP with a hierarchical structure (i.e. the states are the leaves of a rooted tree), s.t. transitions between states that differ on a higher level of the hierarchy (i.e. correspond to branches that split early) are slower than transitions between states that differ on lower levels of the hierarchy. Then quasi-stationary distributions on states resulting from different policies on the "inner MDP" of a particular "metastate" effectively function as actions w.r.t. to the higher levels. Under some assumptions it should be possible to efficiently control such an MDP in time complexity much lower than polynomial in the total number of states[1]. Hopefully it is also possible to efficiently learn this type of hypothesis.
I don't think that anywhere there we will need a lemma saying that the algorithm picks "aligned" goals.
For example, if each vertex in the tree has the structure of one of some small set of MDPs, and you are given mappings from admissible distributions on "child" MDPs to actions of "parent" MDP that is compatible with the transition kernel. ↩︎
↑ comment by Steven Byrnes (steve2152) · 2021-09-01T20:46:59.025Z · LW(p) · GW(p)
Thanks! I'm still thinking about this, but quick question: when you say "AIT definition of goal-directedness [LW(p) · GW(p)]", what does "AIT" mean?
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-01T21:51:03.643Z · LW(p) · GW(p)
Algorithmic Information Theory
comment by adamShimi · 2021-08-09T15:40:19.360Z · LW(p) · GW(p)
(Fuller comment about the whole research agenda)
The “meta-problem of consciousness”—a.k.a. “Why do people believe that there’s a hard problem of consciousness”—is about unraveling this chain of events.
I like this framing, similar to what Yudkowsky did for free will [? · GW].
In terms of AGI, it seems to me that knowing whether or not AGI is conscious is an important thing to know, at least for the AGI’s sake. (Yeah I know—as if we don’t already have our hands full thinking about the impacts of AGI on humans!)
Honestly, my position is close to your imagined critic: worrying about the consciousness of the AGI seems somewhat less important that ensuring it doesn't catastrophically influence all life. But then I wonder if this is the sort of false dichotomy that makes someone pass on a worthwile tradeoff...
That said, I’m tentatively feeling OK about what I wrote here [LW · GW]—basically my proto-theory of the meta-problem of consciousness is some idiosyncratic mishmash of Michael Graziano's theory, and Global Workspace theory, and Frankish-style illusionism. I'll stay on the lookout for reasons to think that what I wrote there was wrong, but otherwise I think this topic is not high on my immediate priority list.
Reading quickly the linked book review, I'm slightly confused. You write that you don't really know what the theory entails for AGI's consciousness, so isn't the actual application for the meta-problem of consciousness still wide open?
In particular, it seems pretty intimately tied to decision-making and motivation—for example, we are motivated to not suffer, and we make decisions that lead to not-suffering.
Surprising choice of examples, as my first thought was for the use of thinking about suffering in empathy, which sounds like a big missing part in many unaligned AGI.
So there's the problem. How do we build a learned-from-scratch world model but shove little hardcoded pieces into it? How do we ensure that the hardcoded pieces wind up in the right place? How do we avoid the AGI ignoring the human model that we supplied it and instead building a parallel independent human model from scratch?
Building an actual LCDT agent [AF · GW] looks like a particular case of this problem.
I think there’s a subfield of neuroscience called “consciousness studies”, where they talk a lot about how people formulate thoughts about themselves, etc. The obvious application is understanding consciousness, but I’m personally much more interested in whether it could help me think about The 1st-Person Problem. So I'm planning to dive into that sometime soon.
Thanks for letting me know about this field, it looks really exciting!
So I’m swallowing my impatience, and trying to really nail down dopamine supervised learning—keep talking to experts, keep filling in the gaps, keep searching for relevant evidence. And then I can feel better about building on it.
Kudos for doing that! This is indeed the best way of building a strong and plausible model that will stand the test of time, but sometimes it's so hard to not go forward with it!
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-08-10T15:08:51.789Z · LW(p) · GW(p)
You write that you don't really know what the theory entails for AGI's consciousness, so isn't the actual application for the meta-problem of consciousness still wide open?
I feel like I have a pretty good grasp on the solution to the meta-problem of consciousness but that I remain pretty confused and unsatisfied about the hard problem of consciousness. This is ironic because I was just saying that the hard problem should be relatively straightforward once you have the meta-problem nailed down. But "relatively straightforward" is still not trivial, especially given that I'm not an expert in the philosophy of consciousness and don't want to spend the time to become one.
Surprising choice of examples, as my first thought was for the use of thinking about suffering in empathy, which sounds like a big missing part in many unaligned AGI.
Sure, but I think I was mentally lumping that under "social instincts", which is a different section. Hmm, I guess I should have drawn an arrow between understanding suffering and understanding social instincts. They do seem to interact a bit.
comment by adamShimi · 2021-08-06T22:50:11.164Z · LW(p) · GW(p)
I'll write a fuller comment when I finish reading more, but I'm confused by the first problem: why is that a problem? I have a (probably wrong) intuition that if you get a good enough 3rd person model of deception let's say, and then learn that you are quite similar to A, you would believe that your own deception is bad. Can you point out to where this naive reasoning breaks?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-08-08T13:21:49.090Z · LW(p) · GW(p)
It's not logically inconsistent for an AGI to think "it's bad for Alice to deceive Bob but good for me to deceive Bob", right?
I do kinda like the idea of getting AIs to follow human norms [AF · GW]. If we can successfully do that, then the AI would automatically turn "Alice shouldn't deceive Bob" into at least weak evidence for "I shouldn't deceive Bob". But how do we make AIs that want to follow human norms in the first place? I feel like solving the 1st-person problem would help to do that.
Another issue is that we may in fact want the AI to apply different standards to itself versus humans, like it's very bad for the AGI to be deceptive but we want the AGI to literally not care about people being deceptive to each other, and in particular we want the AGI to not try to intervene when it sees one bystander being deceptive to another bystander.
Does that help?
Replies from: adamShimi↑ comment by adamShimi · 2021-08-08T21:14:39.934Z · LW(p) · GW(p)
Rephrasing it, you mean that we want some guarantees that the AGI will learn to put itself in the place of the agent doing the bad thing. It's possible that it happens by default, but we don't have any argument for that, so let's try solving the problem by transforming its knowledge into 1st person knowledge.
Is that right?
Another issue is that we may in fact want the AI to apply different standards to itself versus humans, like it's very bad for the AGI to be deceptive but we want the AGI to literally not care about people being deceptive to each other, and in particular we want the AGI to not try to intervene when it sees one bystander being deceptive to another bystander.
Fair enough, I hadn't thought about that.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-08-10T14:55:34.399Z · LW(p) · GW(p)
we want some guarantees that the AGI will learn to put itself in the place of the agent doing the bad thing. It's possible that it happens by default, but we don't have any argument for that
Yeah, I mean, the AGI could "put itself in the place of" Alice, or Bob, or neither. My pretty strong belief is that by default the answer would be "neither", unless of course we successfully install human-like social instincts. I think "putting ourselves in the place of X" is a very specific thing that our social instincts make us want to do (sometimes), I don't think it happens naturally.
Replies from: adamShimi↑ comment by adamShimi · 2021-08-11T20:09:38.561Z · LW(p) · GW(p)
Okay, so we have a crux in "putting ourselves in the place of X isn't a convergent subgoals". I need to think about it, but I think I recall animal cognition experiments which tested (positively) something like that in... crows? (and maybe other animals).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-08-12T01:33:05.574Z · LW(p) · GW(p)
Oh, I was thinking of the more specific mental operation "if it's undesirable for Alice to deceive Bob, then it's undesirable for me to deceive Bob (and/or it's undesirable for me to be deceived by Alice)". So we're not just talking about understanding things from someone's perspective, we're talking about changing your goals as a result. Anything that involves changing your goals is almost definitely not a convergent instrumental subgoal, in my view.
Example: Maybe I think it's good for spiders to eat flies (let's say for the sake of argument), and I can put myself in the shoes of a spider trying to eat flies, but doing that doesn't make me want to eat flies myself.
Replies from: adamShimi↑ comment by adamShimi · 2021-08-12T11:08:07.678Z · LW(p) · GW(p)
Yeah, that's fair. Your example shows really nicely how you would not want to apply rules/reasons/incentives you derived to spiders to yourself. That also work with more straightforward agents, as most AIs wouldn't want to eat ice cream from seeing me eat some and enjoy it.
comment by Adam Shai (adam-shai) · 2021-09-22T14:17:16.225Z · LW(p) · GW(p)
Re: the 1st person problem. This isn't exactly my area of expertise but I have done some reading on it. The way people think about the notion of self in a predictive processing framework has multiple aspects to it, for the different notions of selves. For instance, we have a notion of body-owner or body-self, and the idea there would be that proprioceptive (and interoceptive) signals coming up from your body to your brain act as input for the predictive processing model to work on. The brain can understand these signals as being part of a self because it has an incredibly good handle on predictions of these signals, compared to things in the external world. Another interesting aspect of this part of the framework is that action in this way of thinking can be brought about by the brain making a proprioceptive prediction that it in some sense knows is wrong, and then causing the muscles to move in appropriate ways to decrease the prediction error. It's this feedback loop of predictions that is thought to underlie bodily self. THere's some really cool work where they use V.R. setups to manipulate people's perception of body ownership just by messing in subtle ways with their visual input that is used to support this idea.
This is different than e.g. the narrative self, which can also be thought of within the predictive coding framework as very high level predictions that include your memory systems and abstract understanding about the (social) world. These might be the things most relevant to you, but I know less about this aspect. I can point you to the work of Olaf Blanke and Anil Seth (who has a pop sci book coming out, but I recommend just going to his papers which are well written).
↑ comment by Steven Byrnes (steve2152) · 2021-09-22T14:53:59.626Z · LW(p) · GW(p)
Thanks!
I have minor disagreements [LW · GW] with the predictive processing account of motor control.
Yeah, I think "narrative self" is closer to what I want, for things like how the thought "I am lying" relates to the thought "Alice is lying".
I'll take a look at Olaf Blanke and Anil Seth, thanks for the tip :)
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2021-09-22T20:23:26.422Z · LW(p) · GW(p)
Re: predictive processing of motor control and your minor disgreement. Super interesting! Are you familar with this work from France where they seperate out the volitional from motor and proprioceptive signals by stimulating cortex in a patient? The video is mindblowing. Not sure exactly how it relates to your disagreement but it seems to be a very similar situation to what you describe.
https://www.science.org/doi/full/10.1126/science.1169896
I can't figure out how to download the movies but presumably they are somewhere in that article. I do remember seeing them at some point though :/
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-09-23T13:45:36.338Z · LW(p) · GW(p)
The supporting online material says the movies are at http://www.isc.cnrs.fr/sir/article/videos_desmurget.zip but it's a dead link, and I couldn't find it at internet archive, and I can't be bothered to email the authors. :-/
Very interesting article though. Verrrrry interesting. Thinking hard about it.
comment by Koen.Holtman · 2021-08-10T21:38:43.872Z · LW(p) · GW(p)
Here are some remarks for anybody who wants to investigate the problem of Learned world-models with hardcoded pieces -- hope they will be useful.
My main message is that when thinking about this problem, you should be very aware that there are fashions in AI research. The current fashion is all about ML, about creating learned world models. In the most extreme expression of this fashion, represented by the essay the bitter lesson, even the act of hand-coding some useful prior for the learned world model is viewed with suspicion. It is viewed as domain-specific or benchmark-specific tweaking that will not teach us anything about making the next big ML breakthrough.
Fashion used to be different: there were times when AI pioneers built robots with fully hardcoded world models and were very proud of it.
Hardcoding parts of the world model never went out of fashion in the applied AI and cyber-physical systems community, e.g. with people who build actual industrial robots, and people who want to build safe self-driving cars.
Now, you are saying that My default presumption is that our AGIs will learn a world-model from scratch, i.e. learn their full world model from scratch. In this, you are following the prevailing fashion in theoretical (as opposed to applied) ML. But if you follow that fashion it will blind you to a whole class of important solutions for building learned world models with hardcoded pieces.
It is very easy, an almost routine software engineering task, to build predictive world models that combine both hardcoded and learned pieces. One example of building such a model is to implement it as a Bayesian network or a Causal graph. The key thing to note here is that each single probability distribution/table for each graph node (each structural function in case of a causal graph) might be produced either by machine learning from a training set, or simply be hard-coded by the programmer. See my sequence counterfactual planning for some examples of the design freedom this creates in adding safety features to an AGI agent's world model.
Good luck with your further research! Feel free to reach out if you want to discusses this problem of mixed-mode model construction further.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-08-11T14:10:04.111Z · LW(p) · GW(p)
Now, you are saying that My default presumption is that our AGIs will learn a world-model from scratch, i.e. learn their full world model from scratch. In this, you are following the prevailing fashion in theoretical (as opposed to applied) ML. But if you follow that fashion it will blind you to a whole class of important solutions for building learned world models with hardcoded pieces.
Just FYI, for me personally this presumption comes from my trying to understand human brain algorithms, on the theory that people could plausibly build AGIs using similar algorithms. After all, that's definitely a possible way to build AGI, and a lot of people are trying to do that as we speak. I think the world-model exists in the cortex, and I think that the cortex is initialized from random weights (or something equivalent). See discussion of "learning-from-scratch-ism" here [LW · GW].
there were times when AI pioneers built robots with fully hardcoded world models and were very proud of it.
So, the AI pioneers wrote into their source code whether each door in the building is open or closed? And if a door is closed when the programmer expected it to be open, then the robot would just slam right into the closed door?? That doesn't seem like something to be proud of! Or am I misunderstanding you?
It is very easy, an almost routine software engineering task, to build predictive world models that combine both hardcoded and learned pieces. One example of building such a model is to implement it as a Bayesian network or a Causal graph. The key thing to note here is that each single probability distribution/table for each graph node (each structural function in case of a causal graph) might be produced either by machine learning from a training set, or simply be hard-coded by the programmer.
If I understand you correctly, you're assuming that the programmer will manually set up a giant enormous Bayesian network that represents everything in the world—from dowsing rods to infinite series—and they'll allow some aspects of the probabilities and/or connections in that model to be learned, and they'll manually lock in other probabilities and/or connections. Is that correct?
If so, the part where I'm skeptical is the first step, where the programmer puts in nodes for everything that the robot will ever know about the world. I don't think that approach scales to AGI. I think the robot needs to be able to put in new nodes, so that it can invent new concepts, walk into new rooms, learn to handle new objects, etc.
So then we start with the 5,000,000 nodes that the programmer put in, but the robot starts adding in its own nodes. Maybe the programmer's nodes are labeled ("infinite series", "dowsing rods", etc.), but the robot's are by default unlabeled ("new_node_1" is a certain kind of chess tactic that it just thought of, "new_node_2" is this particular piece of Styrofoam that's stuck to my robot leg right now, etc. etc.)
And then we have problems like: how do we ensure that when the robot comes across an infinite series, it uses the "infinite series" node that the programmer put in, rather than building its own new node? Especially if the programmer's "infinite series" node doesn't quite capture all the rich complexity of infinite series that the robot has figured out? Or conversely, how do we ensure that the robot doesn't start using the hardcoded "infinite series" node for the wrong things?
The case I'm mainly interested in is a hardcoded human model, and then the concerns would be mainly anthropomorphization (if the AGI applies the hardcoded human model to teddy bears, then it would wind up trading off the welfare of humans against the "welfare" of teddy bears) and dehumanization (where the AGI reasons about humans by building its own human model from scratch, i.e. out of new nodes, ignoring the hardcoded human model, the same way that it would understand a complicated machine that it just invented. And then that screws up our attempt to install pro-social motivations, which involved the hardcoded human model. So it disregards the welfare of some or all humans.)
Replies from: Koen.Holtman↑ comment by Koen.Holtman · 2021-08-12T18:18:51.052Z · LW(p) · GW(p)
Just FYI, for me personally this [from scratch] presumption comes from my trying to understand human brain algorithms.
Thanks for clarifying. I see how you might apply a 'from scratch' assumption to the neocortex. On the other hand, if the problem is to include both learned and hard-coded parts in a world model, one might take inspiration from things like the visual cortex, from the observation that while initial weights in the visual cortex neurons may be random (not sure if this is biologically true though), the broad neural wiring has been hardcoded by evolution. In AI terminology, this wiring represents a hardcoded prior, or (if you want to take the stance that you are learning without a prior) a hyperparameter.
So, the AI pioneers wrote into their source code whether each door in the building is open or closed? And if a door is closed when the programmer expected it to be open, then the robot would just slam right into the closed door?? That doesn't seem like something to be proud of! Or am I misunderstanding you?
The robots I am talking about were usually not completely blind, but they had very limited sensing capabilities. The point about hardcoding here is that the processing steps which turned sensor signals into world model details were often hardcoded. Other necessary world model details for which no sensors were available would have to be hardcoded as well.
If I understand you correctly, you're assuming that the programmer will manually set up a giant enormous Bayesian network that represents everything in the world
I do not think you not understand me correctly.
You are assuming I am talking about handcoding giant networks where each individual node might encode a single basic concept like a dowsing rod, and then ML may even add more nodes dynamically. This is not at all what the example networks I linked to look like, and not at all how ML works on them.
Look, I included this link to the sequence to clarify exactly what I mean: please click the link and take a look. The planning world causal graphs you see there are not world models for toy agents in toy worlds, they are plausible AGI agent world models. A single node typically represents a truly giant chunk of current or future world state. The learned details of a complex world are all inside the learned structural functions, in what I call the model parameter in the sequence.
The linked-to approach is not the only way to combine learned and hardcoded model parts, but think it shows very useful technique. My more general point is also that there are a lot of not-in-fashion historical examples that may offer further inspiration.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-08-12T20:47:02.454Z · LW(p) · GW(p)
Well, I did try reading your posts 6 months ago, and I found them confusing, in large part because I was thinking about the exact problem I'm talking about here, and I didn't understand how your proposal would get around that problem or solve it. We had a comment exchange here [? · GW] somewhat related to that, but I was still confused after the exchange ... and it wound up on my to-do list ... and it's still on my to-do list to this day ... :-P
Replies from: Koen.Holtman↑ comment by Koen.Holtman · 2021-08-13T09:04:24.989Z · LW(p) · GW(p)
I know all about that kind of to-do list.
Definitely my sequence of 6 months ago is not about doing counterfactual planning by modifying somewhat opaque million-node causal networks that might be generated by machine learning. The main idea is to show planning world model modifications that you can apply even when you have no way of decoding opaque machine-learned functions.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-08-07T21:33:06.738Z · LW(p) · GW(p)
Thanks for the update! This helps me figure out and keep up with what you are doing.
Re the 1st-person problem: I vaguely recall seeing some paper or experiment where they used interpretability tools to identify some neurons corresponding to a learned model's concept of something, and then they... did some surgery to replace it with a different concept? And it mostly worked? I don't remember. Anyhow, it seems relevant. Maybe it's not too hard to identify the self-concept.
Replies from: gwern↑ comment by gwern · 2021-08-08T00:55:46.864Z · LW(p) · GW(p)
https://arxiv.org/abs/2104.08696 ?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-08-08T07:15:41.285Z · LW(p) · GW(p)
Yes that was it thanks! Discussion here: https://www.lesswrong.com/posts/LdoKzGom7gPLqEZyQ/knowledge-neurons-in-pretrained-transformers [LW · GW]
comment by Charlie Steiner · 2021-08-06T22:04:45.472Z · LW(p) · GW(p)
I only really know about the first bit, so have a comment about that :)
Predictably [LW · GW], when presented with the 1st-person problem I immediately think of hierarchical models. It's easy to say "just imagine you were in their place." What I'd think could do this thing is accessing/constructing a simplified model of the world (with primitives that have interpretations as broad as "me" and "over there") that is strongly associated with the verbal thought (EDIT: or alternately is a high-level representation that cashes out to the verbal thought via a pathway that ends in verbal imagination), and then cashing out the simplified model into a sequence of more detailed models/anticipations by fairly general model-cashing-out machinery.
I'm not sure if this is general enough to capture how humans do it, though. When I think of humans on roughly this level of description, I usually think of having many different generative models (a metaphor for a more continuous system with many principal modes, which is still a metaphor for the brain-in-itself) that get evaluated at first in simple ways, and if found interesting get broadcasted and get to influence the current thought, meanwhile getting evaluated in progressively more complex ways. Thus a verbal thought "imagine you were in their place" can get sort of cashed out into imagination by activation of related-seeming imaginings. This lacks the same notion of "models" as above; i.e. a context agent is still too agenty, we don't need the costly simplification of agentyness in our model to talk about learning from other peoples' actions.
Plus that doesn't get into how to pick out what simplified models to learn from. You can probably guess better than me if humans do something innate that involves tracking human-like objects and then feeling sympathy for them. And I think I've seen you make an argument that something similar could work for an AI, but I'm not sure. (Would a Bayesian updater have less of the path-dependence that safety of such innate learning seems to rely on?)
comment by MaxRa · 2021-08-10T05:05:08.117Z · LW(p) · GW(p)
Sounds really cool! Regarding the 1st and 3rd person models, this reminded my of self-perception theory (from the man Daryl Bem), which states that humans model themselves in the same way we model others, just by observing (our) behavior.
https://en.wikipedia.org/wiki/Self-perception_theory
I feel like in the end our theories of how we model ourselves must involve input and feedback from “internal decision process information“, but this seems very tricky to think about. I‘m soo sure I observe my own thoughts and feelings and use that to understand myself.