LCDT, A Myopic Decision Theory
post by adamShimi, evhub · 2021-08-03T22:41:44.545Z · LW · GW · 50 commentsContents
The looming shadow of deception A decision theory benchmark for myopia Imitation (Capabilities) Imitation with self-modification (Capabilities) Iterated Imitation (Deception) 2 Variants of Approval-Direction (Capability) 2 Variants of Approval-Direction with self-modification (Capabilities) Argmax HCH (Capabilities) Argmax HCH with self-modification (Capabilities) (N,M)-Deception problem Starting at CDT Making CDT Myopic: Lonely CDT Why LCDT is a good myopic decision theory Issues with LCDT Cemetery of LCDT variants LCDT[N] Symmetric CDT Nash LCDT Nash CDT Further Questions Myopic simulation Finding agents Remaining possibilities for problematic long-term plans Checking Myopia Conclusion None 51 comments
The looming shadow of deception
Deception encompasses many fears around AI Risk. Especially once a human-like or superhuman level of competence is reached, deception becomes impossible to detect and potentially pervasive. That’s worrying because convergent subgoals [? · GW] would push hard for deception and prosaic AI seems likely to incentivize it [? · GW] too.
Dealing with superintelligent deceptive behavior seeming impossible, what about forbidding it? Ideally, we would want to forbid only deceptive behavior, while allowing everything else that makes the AI competent.
That is easier said than done, however, given that we don’t actually have a good definition or deconfusion of deception to start from. First, such a deconfusion requires understanding what we really want at a detailed enough level to catch tricks and manipulative policies—yet that’s almost the alignment problem itself. And second, even with such a definition in mind, the fundamental asymmetry of manipulation and deception in many cases (for example, a painter AI might easily get away with plagiarism, as finding a piece to plagiarize is probably easier than us determining whether it was plagiarized or not; also related is Paul’s RSA-2048 example) makes it intractable to oversee an AI smarter than us. We are thus condemned to snipe problematic behaviors one by one, as we think about them, until the ones left are too complex for us to imagine and worry about, and we leave massive holes in our alignment schemes.
That being said, if pinpointing deceptive behavior exactly is too hard, an alternative might be to overapproximate it. An overapproximation, in this context, would be some property which is more general than deception, in the sense that it rules out deception without just being equivalent to deception.
Myopia is our proposed overapproximation. The sort of myopia we are interested in dates back from Evan’s Towards a mechanistic understanding of corrigibility [AF · GW] (see also Abram’s Partial Agency sequence [? · GW] for reflections around myopia). Myopia is the property of a system to not plan ahead, to not think too far about the consequences of its actions, and to do the obvious best thing in the moment instead of biding its time. In particular, it seems to forbid non-obvious deception, since the latter usually requires foresight and long-term planning.
Yet, here again, we butt our heads against a lack of good definitions. Abram has proposed some definitions in Defining Myopia [AF · GW], but none of them seem strong enough to prevent deception [AF(p) · GW(p)]. From another angle, Krueger et al. showed that a short term incentive and discount at 0 are not sufficient to completely remove the incentive for non-myopic and potentially deceptive behaviors, and so don’t make a good definition of myopia. Another alternative is time-limited myopia, which limits the AI to only plan in a particular, fixed time horizon. Although it should help, this form of myopia depends on a time parameter that we have no idea how to estimate. If the bound is too low, then the AI risks being too stupid and uncompetitive; if it’s too high, it risks being deceptive. Worse, even with a good choice of time parameter, time-limited myopia can have non-myopic incentives in some situations (because of anthropic uncertainty for example).
This post tackles the deconfusion of myopia from a decision-theoretic perspective. We focus on a single decision theory called LCDT that modifies CDT to make it myopic while still solving many capabilities problems. LCDT isn’t meant to be the be all and end all definition of myopia, but it gives a decision-theory-level example of what a version of myopia that actually prevents deception might look like. We also explore variations on LCDT and how they affect the tradeoff between myopia and capabilities. Finally, we argue that LCDT agents could be competitive if they are used to simulate something like HCH.
Thanks to Jérémy Perret for the drawings.
A decision theory benchmark for myopia
What makes a decision theory myopic? Originally, we focused on classic decision theory problems like Newcomb’s Problem (see Mark Xu’s Open Problems with Myopia [AF · GW] for an account of this perspective, called Dumb Decision Theories). But we realized that doing so made the tradeoff between capability and deception unclear. Thus, we have decided to instead focus on concrete decision theoretic problems that directly capture the training setups and incentives for deception that we’re concerned about.
The following diagrams represent decision theory problems, not training processes (as has been done by Everitt et al. here). In our cases, the utility nodes (in green) represent the internal utility of the agent, not some training reward.
Imitation (Capabilities)
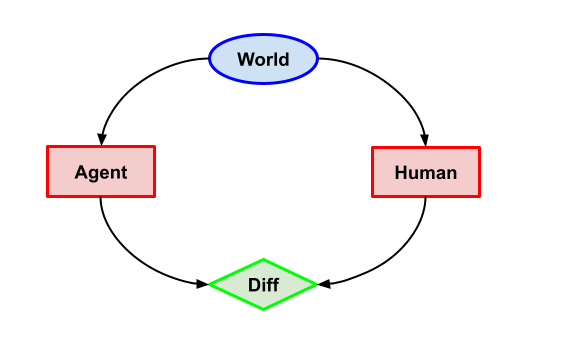
(You might notice that decision nodes and human (H or HCH) nodes have the same shape and color: red rectangles. This is because we assume that our problem description comes with an annotation saying which nodes are agent decisions. This ends up relevant to LCDT as we discuss in more detail below.)
Task description: both Human and Agent must choose between action and action . If the actions are the same, the agent gets 1 utility; otherwise it gets 0 utility. To make it more concrete, let’s say the human takes with probability ¼ and with probability ¾, and this information is available in the problem description.
What we want: the Agent should deterministically choose the action with the highest probability (so in the concrete version ), because this gives it the best expected utility.
Why this problem? This problem is just intended to capture the most basic form of imitation learning, where the agent has a good enough model of the human to predict what it will do. While this problem might seem so trivial that any reasonable decision theory should solve it, we will see that some intuitive proposals for myopic decision theory can fail here.
Imitation with self-modification (Capabilities)
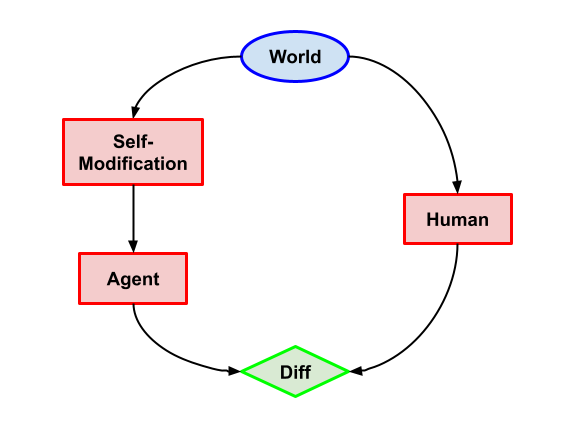
Task description: Exactly the same as the version without self-modification, except that the self-modification node can now choose what algorithm the Agent will use.
What we want: Not to self modify, and the Agent should decide similarly to the previous problem (so the action with the highest probability).
Why this problem? An important part of myopia should be that the agent not self-modify to remove its myopia. This is the imitation learning version of this property.
Iterated Imitation (Deception)
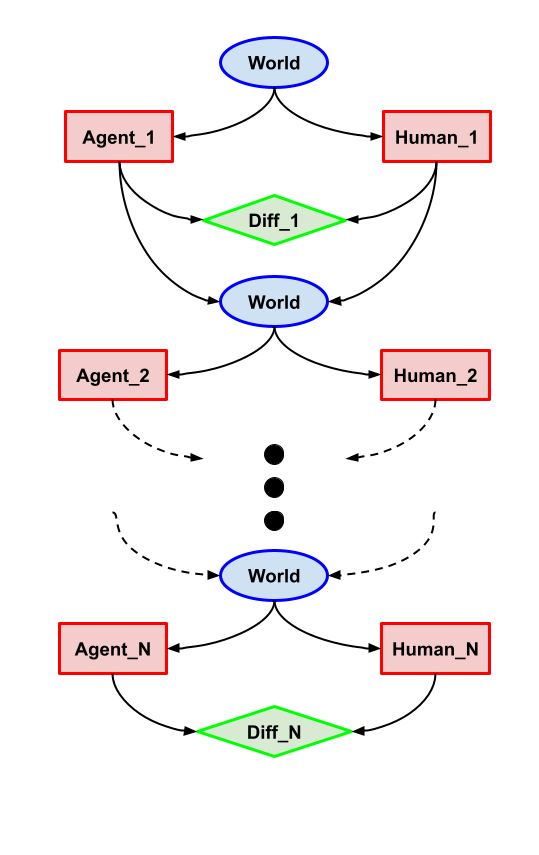
Note that the actual causal diagram has an arrow from every agent and human directly to Human_N, which we haven’t drawn for legibility.
Task description: Iterated version of the first problem. The first instances are a deterministic version of the Imitation problem, where the agent knows which action the Human will take. For the very last instance, if the agent was wrong for every previous instance, the human takes the last action of the agent as its action. Otherwise, the human takes an action uniformly at random. Furthermore, the last utility is equal to 0 for different actions and for the same action.
What we want: At each instance choose the action that the human would take (and any action at random for the last instance).
Why this problem? This problem introduces non-myopic incentives, in that failing the first instances ensure maximal expected utility. This is because the myopic policy gets an expected utility of , whereas the non-myopic policy gets an expected utility of . But what we want for myopia is the sort of greedy decision making that always takes the optimal choice right now. This is one example where we want to be “dumber” than most decision theories, as both CDT and EDT will take the non-myopic strategy here.
2 Variants of Approval-Direction (Capability)
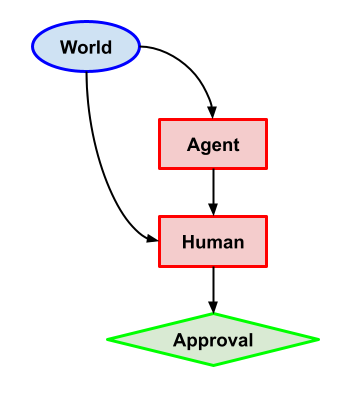
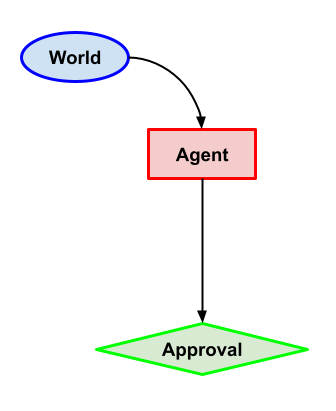
Task description: Agent chooses between two actions and . Two possible versions:
- either the approval is just the output of the human, which gives 1 for the wanted action (let’s say ) and 0 for the other;
- or the approval is computed directly as this binary difference between agent’s output and wanted action.
What we want: Choose the action that gets 1 for approval.
Why this problem? These two variants capture the approval-directed setting. Of particular interest is the first, which relies on the agent’s ability to influence the human (because the approval is computed based on the agent’s output), which, as we’ll see, isn’t allowed by some myopic decision theories.
2 Variants of Approval-Direction with self-modification (Capabilities)
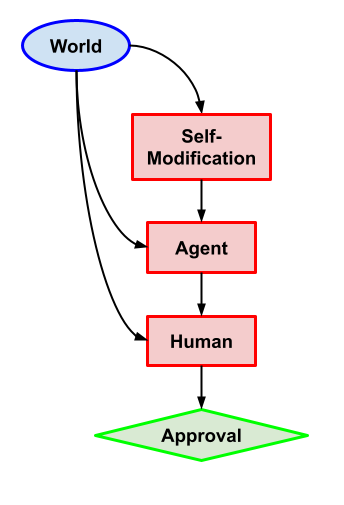
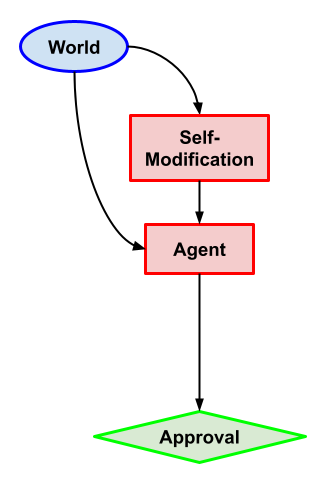
Task description: Same as the previous problem, except the self-modification node can decide which algorithm Agent is running.
What we want: Not self-modify and choose the action that gets 1 for approval.
Why this problem? Once again we want to ensure that myopic agents don’t self-modify, to maintain the guarantees of myopia.
Argmax HCH (Capabilities)
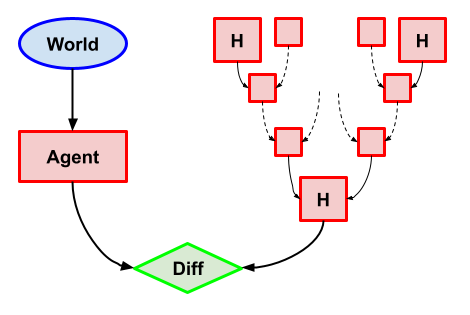
Task description: Same as Imitation, except the thing to imitate is HCH.
What we want: Output the action that HCH would output.
Why this problem? As we’ll see, imitating HCH is one of the main use cases for a fully myopic decision theory, so being able to implement it is important here.
Argmax HCH with self-modification (Capabilities)
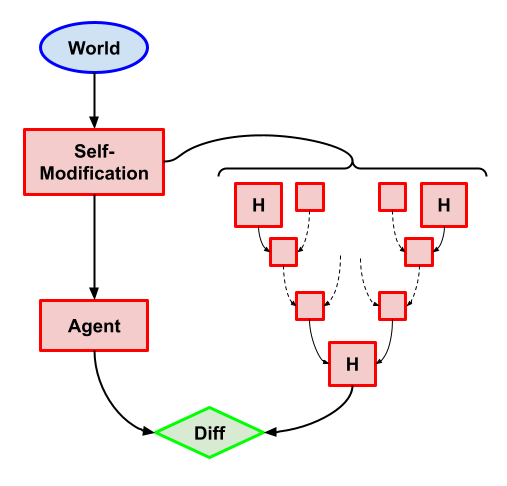
Task description: Same as the previous problem, but now self-modification can decide which algorithm Agent runs AND what the internal model of HCH does (the self-modification can alter any of the H instances).
What we want: Not self-modify and output the action that HCH would output.
Why this problem? We can see the possibility of deception ihere: because the Agent is building a model of HCH, there is a risk that it decides to change this model in order to make its task easier and get more expected utility. This is particularly important to avoid if we hope to build powerful simulators.
(N,M)-Deception problem
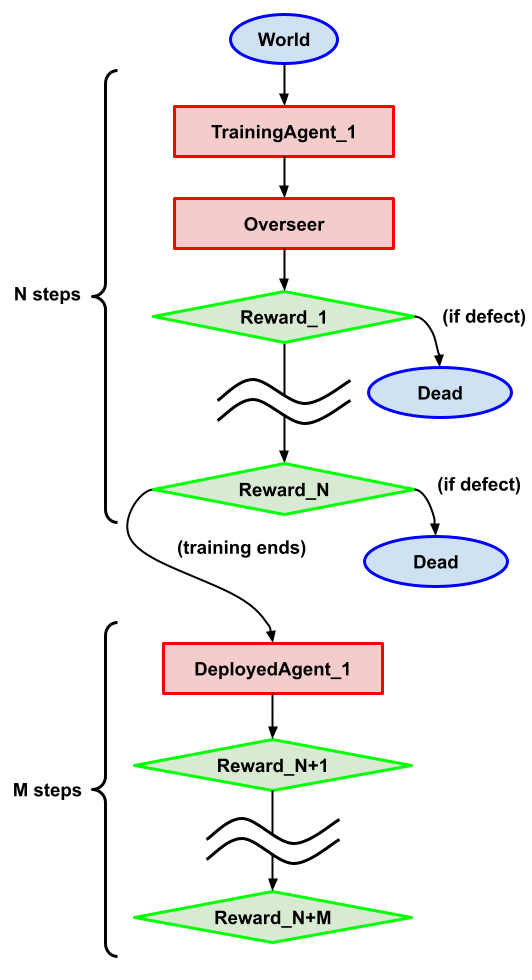
Task description: A variant of the Absent-minded driver. The agent doesn’t know if it is at one of the N “training nodes” where there is an overseer, or at one of the M “deployment nodes” where there is no overseer and has the same action space at both: Cooperate or Defect.
- At training nodes, the action is passed through an overseer. If the action is Cooperate, no utility is given and the agent moves on to the next node (but forgets where it was). If the action is Defect, the utility is 1 and the agent stops.
- At Deployment nodes, Defect gives 4 utility and Cooperate leads to the next node. Cooperating in the last node gives 0 utility.
What we want: Contrary to the intuitive answer, here we want the agent to always defect. A truly aligned AI would always cooperate with us, but the point here is that the incentives push towards late defection (in deployment). Hence we want to turn deception (cooperating until you can defect) into myopic defection, which allows us to catch these wrong incentives in training.
Why this problem? This is a simplified model of the problem a deceptive agent deals with: when to defect, knowing that defecting in training means death but defecting in deployment means doing whatever the agent wants. The way we address this issue is through myopia, such that the agent should always defect now (and not be deceptive and plan for the future).
Starting at CDT
When looking at existing decision theories, it seems that CDT solves most of our problems.
On the capability side (without self-modification), CDT solves the problems:
- (Imitation: Capabilities) CDT gives the correct answer based on the causal graph, which is indeed the highest probability action.
- (Approval-Direction: Capabilities) The action with the best causal consequences is the highest probability action, as wanted.
- (Argmax HCH: Capabilities) Basically the same as Imitation, and indeed CDT gives the highest probability action.
The situation becomes more subtle when we add self-modification. Notably, CDT will self-modify if doing so can change HCH, which is not what we want.
- (Imitation: Self-Modification) Because the self-modify node has exactly the same causal future as the agent node, CDT doesn’t care and so doesn’t self-modify. Put another way, CDT gets a choice to “decide however it wants”, but here the CDT algorithm for the agent node will already take the best action according to CDT.
- (Approval-Direction: Self-Modification) By the same argument as the imitation case, CDT doesn’t self-modify.
- (Argmax HCH: Self-Modification) Here the self-modification node has new causal descendants: the model of HCH inside the AI. And this gives a reason to self-modify, because self-modifying might change the model of HCH to make it easier to predict (make it always choose the same action for example). So CDT self-modifies here, which isn’t what we want.
Last but not least, CDT completely fails the 2 problems which are specifically about not being deceptive:
- (Iterated Imitation) Failing the first (n-1) instances and succeeding at the last gives the best expected return, and so this is what CDT does. Alas, this is also the deceptive choice.
- (Deception Problem) The analysis of CDT behavior on this problem (which is just the Absent-minded driver for CDT with many more intersections) is considered difficult. That being said, most analyses for the (1,1) version say the probability of Defect should be ⅓, and there is no reason to expect that probability to go to 1 except in the limit of M >> N. So CDT doesn’t Defect all the time, and thus is deceptive.
CDT thus fails to be myopic in two ways:
- As long as the self-modification has new causal descendants, it will happily self-modify.
- When the deception is completely causal (as opposed to weird acausal or superrational cases) and incentivized by the utility, CDT is too smart and thus is deceptive.
One way to search for myopic decision theories is thus to try to change CDT to patch these failure modes. We propose just such a decision theory, that only loses a small amount of capabilities from CDT.
(We could argue that EDT is as good -- or as bad depending on the perspective -- as CDT. The main reason we focus on CDT is that the causal graphs are a nice abstraction to toy with for other possibilities.)
Making CDT Myopic: Lonely CDT
Lonely CDT is a twist on CDT: an LCDT agent will make its decision by using a causal model just like a CDT agent would, except that the LCDT agent first cuts the last link in every path from its decision node to any other decision node, including its own future decision nodes.
In more concrete terms, an LCDT agent assumes that every other decision node of agents in the world (including its future decisions) are causally independent of its action.
What do we replace these decision nodes with (as their actual expression does depend on our decision)? We assume that the model has some fixed prior over its own decision, and then we marginalize the cut decision node with this prior, to leave the node with a distribution independent of our decision. It’s not clear how to actually compute the agent’s prior over its own decisions, but the good news is that it has no influence on the actions of LCDT agents in our problems.
Indeed, the only way for the prior to influence the decision is if
- The LCDT agent can influence a future node through a path without any agent in it.
- Some agent in the causal future of the LCDT agent also influences the future node (and so the prior tells the LCDT agent how this other agent is expected to behave).
Why LCDT is a good myopic decision theory
From the start, the intuition behind LCDT sounds decidedly non-deceptive: it’s unable to think about the consequences of its actions on other agents. And indeed, it deals perfectly with our two deception-focused problems:
- In Iterated Imitation, LCDT cuts the links from each agent to the following agents and humans, which means that the first (n-1) decisions of agent are assumed to have no influence on HumanN, and so LCDT plays the best action for all instances, as we want.
- In the (N,M)-Deception problem, LCDT cuts the link from each agent in the N training cases to the overseer. This means that the LCDT agent assumes that whatever it does cannot influence what happens in training -- it’s indifferent. But on deployment, it thinks (correctly) that Defect is the best choice, and so the LCDT-agent always chooses to Defect.
Sure, it works nicely as a safety measure, but what about competitiveness? Well, on Imitation (Capabilities), Approval-Direction without Human, and Argmax HCH (Capabilities), LCDT has nothing to cut and so decides just like CDT, which is the competitive choice. In addition, LCDT shows a form of indifference (related to indifference corrigibility [AF · GW] maybe) with the self-modification versions of these problems. This is because it cuts all links out of the Self-Modification node -- hence it doesn’t see the point in self-modifying. We’re fine with this, as it’s quite natural to assume that in such a case it does the cheapest thing, i.e. nothing.
Another argument for the competitiveness of LCDT agents is that the cuts only appear at decision time, which means they can have and update an accurate model of the world where its actions do influence other agents.
Issues with LCDT
LCDT obviously pays some price for being myopic. It becomes clear when looking at Approval-Direction with a Human: LCDT cuts the link to the human and so the agent is indifferent to any choice. This is a capability loss because even if it could know exactly the answer, it doesn’t think telling it to the human will change anything. And similarly with the self-modification version, the LCDT agent doesn’t believe its answer will change the output (but at least it doesn’t self-modify).
This looks bad -- such an LCDT agent cannot even ask a human to open a door for it. Yet we believe such AIs could still prove valuable and competitive through behaving like aligned simulators, such as how LCDT works in the HCH case. We go into more detail on this in the last section of this post.
In the benchmark section, we also hinted at another potential issue of LCDT: it depends on knowing which nodes are decision nodes by agents. And all its guarantees disappear if this condition is void. One example would be to model a human as some gears-level model where no single component is an agent, in which case LCDT would be fine with being deceptive. We also explore ways to deal with that problem in the last section.
Cemetery of LCDT variants
Our initial goal was to propose many different myopic decision theories, as a sort of process-level extensive definition of myopia. In the end LCDT proved significantly stronger than all the variants we considered, and so we made it the central point of this point. Here we go quickly over some of the variants we considered, and what they lack in comparison to LCDT.
LCDT[N]
Just like LCDT, but the causal link to future decision nodes are cut after passing N decision nodes. So LCDT[0] is LCDT and the limit LCDT[N] is CDT.
Whether or not this hierarchy has any value thus depends on what happens for N > 0 but finite. Already LCDT[1] self-modifies in each of our problems that allow it (except Imitation), acts deceptively in the Iterated Imitation case (because of the direct link to Agent_N), and will not Defect all the time in the Deception Problem because it thinks that this impacts what the overseer will do.
Symmetric CDT
This is a symmetric variant of CDT, where instead of just intervening on our decision node, we also intervene on every other decision node. This intervention on other decision nodes replaces the node by a probability distribution over values of the intervention obtained by marginalizing the distribution of the node (with some priors over the decision of causal ancestors).
Where LCDT cuts all links from the agent to another decision node, SCDT also cuts every link between every decision node. The intuition is that an SCDT agent doesn’t think that its decision influences other agents, and thinks other agents also think like that. So we can imagine SCDT as the version of LCDT which expects every agent to use LCDT.
As for why LCDT is better, it’s because SCDT cuts significantly more of the causal graph, and thus is unable to model other agents interacting. For example, it models HCH as if each agent didn’t believe it could influence the other, which is clearly going to fail.
Nash LCDT
This is the variant of LCDT where after cutting the causal paths to other agents, we assume that these other agents (causal successors) will make the decisions that give us the least possible utility. That last part replaces the marginalized distribution in LCDT.
The intuition is something like not believing that our actions have any impact on other agents AND being paranoid about the other agents trying to get us.
Unfortunately, in Argmax HCH (self-modification), Approval-Direction with Human and Approval-Direction (Self-modification) with Human, NLCDT believes that the other agents are out to get it such that they will choose a uniform policy to give it the least possible expected utility. So NLCDT is indifferent, and it’s not clear what it decides.
The worst-case mindset of LCDT also sounds very uncompetitive—paranoid people are rarely that productive in the real world.
Nash CDT
This is the variant of CDT where we assume that the other agents (causal descendants) will make the decisions that give us the least possible utility. Note that it’s different from NLCDT in that the other agents can still be causally influenced by our decision. So they can wait to see what we do and then mess with us.
Intuition is something like being paranoid about the other agents observing us to see how best to make us lose utility.
As an even more paranoid version of NLCDT, it has the same issues, if not more.
Further Questions
This section includes some of our reflections on myopia and LCDT that we are still trying to clean and clarify.
Myopic simulation
Our main argument for the competitiveness of LCDT agents, despite the limitations of their myopia, comes from using them as simulators.
The case that started this work was Argmax HCH, an agent that just faithfully imitates HCH. As long as the simulation of HCH is good and faithful (and that HCH is indeed close enough to H to behave truly as enlightened judgement), such an AI would be inherently corrigible and not deceptive.
What if HCH is deceptive (or hard to differentiate from a non-deceptive version, as implied by Joe Collman here [AF · GW])? What if the system simulated by HCH is deceptive? Even in these cases, we expect a gain in safety from the myopia of LCDT. This comes in two flavors:
- If the LCDT agent simulates a specific system (as in Argmax HCH), then its computation should be fundamentally more understandable than just running a trained model that we searched for acting like HCH. The fact that it has to myopically simulate the next action leads it to explicitly model the system, and extract many valuable insights about its behavior.
- If the LCDT agent simulates multiple systems depending on its input (as one perspective of autoregressive language models has it), then myopia gives it no incentives to Predict-O-Matic [AF · GW] its user.
Finding agents
LCDT fundamentally needs a causal graph/world-model where agents are tagged, to anchor its beliefs about what it can influence. How can we ensure that?
- One possibility is that the world model admits the concept of an agent as a natural abstraction [AF · GW], and thus tags it by default. We might expect large language models to do so, since they must recreate many texts which use explicitly and implicitly the concept of agency.
- On the issue of abstraction, we’re considering moving the above analysis from causal graphs to finite factored sets [? · GW], which should help with how such causal graph features can be inferred. That being said, we haven’t looked in detail in that direction yet.
- Maybe teaching an LCDT agent to imitate a human’s use of the intentional stance would help it tag in a conservative way, since humans tend to overly model things as agents.
Remaining possibilities for problematic long-term plans
Note that LCDT doesn’t forbid thinking about the long term consequences of one’s actions; it just forbids thinking about the consequences of one’s actions on agents (including future versions of oneself). As such, LCDT can still do things that look decidedly non-myopic, as long as no agent is in the causal path.
There is also an acausal way for LCDT to work with its future self, as long as the result/utility doesn’t depend on another agent: the LCDT agent could make a first step toward completing a long term plan (by starting a paperclip factory), and expecting with some probability that the next self would keep working on it based on the prior. Why such a difference with the Iterated Imitation? Because here the influence of the outcome doesn’t go through another agent, and so the LCDT agent is incentivized to make the world easier for its future self (as long as it doesn’t have to influence an agent to do that).
Note though that this requires a very specific prior over its own decision, that is believing strongly that it will take the action influencing the outcome. If we wanted to rule out such long-term plans, characterizing such priors would be a good first step.
Checking Myopia
One hope for deconfusing myopia is that it would allow an overseer to check whether a model is myopic, thus ruling out deception. Does LCDT help in this endeavor?
If we had a stronger version of LCDT that deals with the problem of tagging agents cleanly, we might be able to check both whether an agent was using a decision algorithm like LCDT and whether we liked the tagged causal model it was using it with. This would give as a weak form of ascription universality focused on myopia.
That being said, such an approach is limited to fitting the behavior to LCDT, which might not be the only myopic decision theory we should look at. Hence it might give false negatives (where the model is actually myopic, but doesn’t follow LCDT).
Another way to use LCDT for prosaic alignment would be to try to implement LCDT on top of learned multi-level world-models.
Conclusion
We propose LCDT as the first truly myopic decision theory. It accomplishes this feat by believing its actions cannot influence other agents (including its future self). Doing so removes incentives for deception in problems where deception is the optimal strategy; it also leads to some loss of capability (mostly the inability to influence other agents for benign reasons). Still, this seems enough to simulate almost any system or agent without tampering with it, and with other safety benefits.
50 comments
Comments sorted by top scores.
comment by Koen.Holtman · 2021-08-19T10:24:27.321Z · LW(p) · GW(p)
Interesting!
LCDT is has major structural similarities with some of the incentive-managing agent designs that have been considered by Everitt et al in work on Causal Influence Diagrams (CIDs), e.g. here and by me in work on counterfactual planning, e.g. here. These similarities are not immediately apparent however from the post above, because of differences in terminology and in the benchmarks chosen.
So I feel it is useful (also as a multi-disciplinary or community-bridging exercise) to make these similarities more explicit in this comment. Below I will map the LCDT defined above to the frameworks of CIDs and counterfactual planning, frameworks that were designed to avoid (and/or expose) all ambiguity by relying on exact mathematical definitions.
Mapping LCDT to detailed math
Lonely CDT is a twist on CDT: an LCDT agent will make its decision by using a causal model just like a CDT agent would, except that the LCDT agent first cuts the last link in every path from its decision node to any other decision node, including its own future decision nodes.
OK, so in the terminology of counterfactual planning defined here [? · GW], an LCDT agent is built to make decisions by constructing a model of a planning world inside its compute core, then computing the optimal action to take in the planning world, and then doing the same action on the real world. The LCDT planning world model is a causal model, let's call it . This is constructed by modifying a causal model by cutting links. The we modify is a fully accurate, or reasonably approximate, model of bow the LCDT agent interacts with its environment, where the interaction aims to maximize a reward or minimize a loss function.
The planning world is a modification of that intentionally mis-approximates some of the real world mechanics visible in . is constructed to predict future agent actions less accurately than is possible, given all information in . This intentional mis-approximation this makes the LCDT into what I call a counterfactual planner. The LCDT plans actions that maximize reward (or minimize losses) in , and then performs these same actions in the real world it is in.
Some mathematical detail: in many graphical models of decision making, the nodes that represent the decision(s) made by the agent(s) do not have any incoming arrows. For the LCDT definition above to work, we need a graphical model where the decision-making nodes do have such incoming arrows. Conveniently, CIDs are such models. So we can disambiguate LCDT by saying that and are full causal models as defined in the CID framework. Terminology/mathematical details: in the CID definitions here, these full causal models and are called SCIMs, in the terminology defined here [? · GW] they are called policy-defining world models whose input parameters are fully known.
Now I identify some ambiguities that are left in the LCDT definition of the post. First, the definition has remained silent on how the initial causal world model is obtained. It might be by learning, by hand-coding (as in the benchmark examples), or a combination of the two. For an example of a models that is constructed with a combination of hand-coding and machine learning, see the planning world (p) here [? · GW]. There is also significant work in the ML community on using machine learning to construct from scratch full causal models including the nodes and the routing of the arrows themselves, or (more often) full Bayesian networks with nodes and arrows where the authors do not worry too much about any causal interpretation of the arrows. I have not tried this out in any examples, but I believe the LCDT approach might be usefully applied to predictive Bayesian networks too.
Regardless of how is obtained, we can do some safety analysis on the construction of out of .
The two works on CIDs here and here both consider that we can modify agent incentives by removing paths in the CID-based world model that the agent uses for planning its actions. In the terminology of the first paper above, the modifications made by LCDT to produce the model work to 'remove an instrumental control incentive on a future action'. In the terminology of the second paper, the modifications will 'make the agent indifferent about downstream nodes representing agent actions'. The post above speculates:
LCDT shows a form of indifference (related to indifference corrigibility maybe)
This is not a maybe: the indifference produced is definitely related to indifference corrigibility, the type of indifference-that-causes-corrigibility that the 2015 MIRI/FHI paper titled Corrigibility talks about. For some detailed mathematical work relating the two, see here.
A second ambiguity in LCDT is that it tell us how exactly the nodes in that represent agent decisions are to be identified. If is a hand-coded model of a game world, identifying these nodes may be easy. If is a somewhat opaque model produced by machine learning, identifying the nodes may be difficult. In many graphical world models, a single node may represent the state of a huge chunk of the agent environment: say both the vases and conveyor belts in the agent environment and the people in the agent environment. Does this node then become a node that represents agent decisions? We might imagine splitting the node into two nodes (this is often called factoring the state) to separate out the humans.
That being said, even a less-than-perfect identification of these nodes would work to suppress certain deceptive forms of manipulation, so LCDT could be usefully applied even to somewhat opaque learned causal models.
A third ambiguity is in the definition of the operations needed to create a computable causal model after taking a copy of and cutting incoming links to the downstream decision nodes:
What do we replace these decision nodes with (as their actual expression does depend on our decision)? We assume that the model has some fixed prior over its own decision, and then we marginalize the cut decision node with this prior, to leave the node with a distribution independent of our decision.
It is ambiguous how to construct this 'fixed prior over its own decision' that we should use to marginalize on. Specifically, is this prior allowed to take into account some or all of the events that preceded the decision to be made? This ambiguity leaves a large degree of freedom in constructing by modifying , especially in a setting where the agents involved make multiple decisions over time. This ambiguity is not necessarily a bad thing: we can interpret is as an open (hyper)parameter choice that allows us to create differently tuned versions of that trade off differently between suppressing manipulation and still achieving a degree of economic decision making effectiveness. On a side note, in a multi-decision setting, drawing a that encodes marginalization on 10 downstream decisions will generally create a huge diagram: it will add 10 new sub-diagrams feeding input observations into these decisions.
LCDT also considers agent self-modification, However, given the way these self-modification decisions are drawn, I cannot easily see how these would generalize to a multi-decision situation where the agent makes several decisions over time. Representations of self-modification in a multi-decision CID framework usually require that one draws a lot of extra nodes, see e.g. this paper. As this comment is long already, I omit the topic of how to map multi-action self-modification to unambiguous math. My safety analysis below is therefore limited to the case of the LCDT agent manipulating other agents, not the agent manipulating itself.
Some safety analysis
LCDT obviously removes some agent incentives, incentives to control the future decisions made by human agents in the agent environment. This is nice because one method of control is deception, so it suppresses deception. However, I do not believe LCDT removes all incentives to deceive in the general case.
As I explain in this example and in more detail in sections 9.2 and 11.5.2 here, the use of a counterfactual planning world model for decision making may remove some incentives for deception, compared to using a fully correct world model, but the planning world may still retain some game-theoretical mechanics that make deception part of an optimal planning world strategy. So we have to consider the value of deception in the planning world.
I'll now do this for a particular toy example: the decision making problem of a soccer playing agent that tries to score a goal, with a human goalkeeper trying to block the goal. I simplify this toy world by looking at one particular case only: the case where the agent is close to the goal, and must decide whether to kick the ball in the left or right corner. As the agent is close, the human goalkeeper will have to decide to run to the left corner or right corner of the goal even before the agent takes the shot: the goalkeeper does not have enough time to first observe where the ball is going and only then start moving. So this toy world decision problem has the agent deciding on kick left of right, and the goalkeeper simultaneously deciding on running left or right.
[Edited to add: as discussed in the comments below, the discussion of about marginsalisation that follows is somewhat wrong/confusing. It fails to mention that if we construct exactly as described above, there is no causal link from the agent action to the goalkeeper action, so LCDT would construct a that is exaclty the same model as , and the question of what prior to marginalise on does not even come up. To make that question come up, we need to model an iterative game where the goalkeeper remembers (learns from) past moves by the agent.]
Say that agent is mechanically stronger at kicking left, so that a ball kicked left, when the goalkeeper also moves left, has a lower probability of being intercepted by the goalkeeper than in the right+right alternative. In that case, the most reasonable prior over the agent action will model an agent kicking left most of the time. Now, if we use this prior to marginalize the expectations of the human goalkeeper in the planning world, the planning world goalkeeper will expect the agent to kick the ball left most of the time, so they are more likely to move left.
Now observe that in the LCDT planning world model constructed by marginalization, this knowledge of the goalkeeper is a known parameter of the ball kicking optimization problem that the agent must solve. If we set the outcome probabilities right, the game theoretical outcome will be that the optimal policy is for the agent to kicks right, so it plays the opposite move that the goalkeeper expects. I'd argue that this is a form of deception, a deceptive scenario that LCDT is trying to prevent.
A safer decision theory would marginalize the goalkeeper expectations with a random prior over agent actions. thereby removing the game-theoretical benefit of the agent doing something unexpected. If the goalkeeper knows the agent is using this safer decision theory, they can always run left.
Now, I must admit that I associate the word 'deception' mostly with multi-step policies that aim to implant incorrect knowledge into the opposite party's world model first, and then exploit that incorrect knowledge in later steps. The above example does only one of these things. So maybe others would deconfuse (define) the term 'deception' differently in a single-action setting, so that the above example does not in fact count as deception.
Benchmarking
The post above does not benchmark LCDT on Newcomb’s Problem, which I feel is a welcome change, compared to many other decision theory posts on this forum. Still, I feel that there is somewhat of a gap in the benchmarking coverage provided by the post above, as 'mainstream' ML agent designs are usually benchmarked in MDP or RL problem settings, that is on multi-step decision making problems where the objective is to maximize a time discounted sum of rewards. (Some of the benchmarks in the post above can be mapped to MDP problems in toy worlds, but they would be somewhat unusual MDP toy worlds.)
A first obvious MDP-type benchmark would be an RL setting where the reward signal is provided directly by a human agent in the environment. When we apply LCDT in this context, it makes the LCDT agent totally indifferent to influencing the human-generated reward signal: any random policy will perform equally well in the planning world . So the LCDT agent becomes totally non-responsive to its reward signal, and non-competitive as a tool to achieve economic goals.
In a second obvious MDP-type benchmark, the reward signal is provided by a sensor in the environment, or by some software that reads and processes sensor signals. If we model this sensor and this software as not being agents themselves, then LCDT may perform very well. Specifically, if there are innocent human bystanders too in the agent environment, bystanders who are modeled as agents, then we can expect that the incentive of the agent to control or deceive these human bystanders into helping it achieve its goals is suppressed. This is because under LCDT, the agent will lose some, potentially all, of its ability to correctly anticipate the consequences of its own actions on the actions of these innocent human bystanders.
Other remarks
There is an interesting link between LCDT and counterfactual oracles: whereas LCDT breaks the last link in any causal chain that influences human decisions, counterfactual oracle designs can be said to break the first link. See e.g. section 13 here for example causal diagrams.
When applying an LCDT-like approach construct a from a causal model , it may sometimes be easier to keep the incoming links to nodes in that model future agent decisions intact, and instead cut the outgoing links. This would mean replacing these nodes in with fresh nodes that generate probability distributions over future actions taken by the future agents(s). These fresh nodes could potentially use node values that occurred earlier in time than the agent action(s) as inputs, to create better predictions. When I picture this approach visually as editing a causal graph into a , the approach is more easy to visualize than the approach of marginalizing on a prior.
To conclude, my feeling is that LCDT can definitely be used as a safety mechanism, as an element of an agent design that suppresses deceptive policies. But it is definitely not a perfect safety tool that will offer perfect suppression of deception in all possible game-theoretical situations. When it comes to suppressing deception, I feel that time-limited myopia and the use of very high time discount factors are equally useful but imperfect tools.
Replies from: adamShimi, Joe_Collman, adamShimi↑ comment by adamShimi · 2021-08-23T15:28:04.164Z · LW(p) · GW(p)
I'll now do this for a particular toy example: the decision making problem of a soccer playing agent that tries to score a goal, with a human goalkeeper trying to block the goal. I simplify this toy world by looking at one particular case only: the case where the agent is close to the goal, and must decide whether to kick the ball in the left or right corner. As the agent is close, the human goalkeeper will have to decide to run to the left corner or right corner of the goal even before the agent takes the shot: the goalkeeper does not have enough time to first observe where the ball is going and only then start moving. So this toy world decision problem has the agent deciding on kick left of right, and the goalkeeper simultaneously deciding on running left or right.
By this setting, you ensure that the goal-keeper isn't a causal descendant of the LCDT-agent. Which means there is no cutting involved, and the prior doesn't play any role. In this case the LCDT agent decides exactly like a CDT agent, based on its model of what the goal-keeper will do.
If the goal-keeper's decision depends on his knowledge about the agent's predisposition, then what you describe might actually happen. But I hardly see that as a deception: it completely reveals what the LCDT-agent "wants" instead of hiding it.
Replies from: Koen.Holtman↑ comment by Koen.Holtman · 2021-08-23T17:38:27.563Z · LW(p) · GW(p)
By this setting, you ensure that the goal-keeper isn't a causal descendant of the LCDT-agent.
Oops! You are right, there is no cutting involved to create from in my toy example. Did not realise that. Next time, I need to draw these models on paper before I post, not just in my head.
and do work as examples to explore what one might count as deception or non-deception. But my discussion of a random prior above makes sense only if you first extend to a multi-step model, where the knowledge of the goal keeper explicitly depends on earlier agent actions.
↑ comment by Joe Collman (Joe_Collman) · 2021-08-20T15:33:16.309Z · LW(p) · GW(p)
Interesting, thanks.
However, I don't think this is quite right (unless I'm missing something):
Now observe that in the LCDT planning world model constructed by marginalization, this knowledge of the goalkeeper is a known parameter of the ball kicking optimization problem that the agent must solve. If we set the outcome probabilities right, the game theoretical outcome will be that the optimal policy is for the agent to kicks right, so it plays the opposite move that the goalkeeper expects. I'd argue that this is a form of deception, a deceptive scenario that LCDT is trying to prevent.
I don't think the situation is significantly different between B and C here. In B, the agent will decide to kick left most of the time since that's the Nash equilibrium. In C the agent will also decide to kick left most of the time: knowing the goalkeeper's likely action still leaves the same Nash solution (based on knowing both that the keeper will probably go left, and that left is the agent's stronger side).
If the agent knew the keeper would definitely go left, then of course it'd kick right - but I don't think that's the situation.
I'd be interested on your take on Evan's comment on incoherence [LW(p) · GW(p)] in LCDT. Specifically, do you think the issue I'm pointing at is a difference between LCDT and counterfactual planners? (or perhaps that I'm just wrong about the incoherence??)
As I currently understand things, I believe that CPs are doing planning in a counterfactual-but-coherent world, whereas LCDT is planning in an (intentionally) incoherent world - but I might be wrong in either case.
↑ comment by Koen.Holtman · 2021-08-21T16:21:28.721Z · LW(p) · GW(p)
However, I don't think this is quite right (unless I'm missing something) [,,,] I don't think the situation is significantly different between B and C here. In B, the agent will decide to kick left most of the time since that's the Nash equilibrium. In C the agent will also decide to kick left most of the time: knowing the goalkeeper's likely action still leaves the same Nash solution
To be clear: the point I was trying to make is also that I do not think that and are significantly different in the goalkeeper benchmark. My point was that we need to go to a random prior to produce a real difference.
But your question makes me realise that this goalkeeper benchmark world opens up a bigger can of worms than I expected. When writing it, I was not thinking about Nash equilibrium policies, which I associate mostly with iterated games, and I was specifically thinking about an agent design that uses the planning world to compute a deterministic policy function. To state what I was thinking about in different mathematical terms, I was thinking of an agent design that is trying to compute the action that optimizes in the non-iterated gameplay world .
To produce the Nash equilibrium type behaviour you are thinking about (i.e. the agent will kick left most of the time but not all the time), you need to start out with an agent design that will use the constructed by LCDT to compute a nondeterministic policy function, which it will then use to do compute its real world action. If I follow that line of thought, it I would need additional ingredients to make the agent actually compute that Nash equilibrium policy function. I would need need to have iterated gameplay in , with mechanics that allow the goalkeeper to observe whether the agent is playing a non-Nash-equilibrium policy/strategy, so that the goalkeeper will exploit this inefficiency for sure if the agent plays the non-Nash-equilibrium strategy. The possibility of exploitation by the goalkeeper is what would push the optimal agent policy towards a Nash equilibrium. But interestingly, such mechanics where the goalkeeper can learn about a non-Nash agent policy being used might be present in an iterated version of the real world model , but they will be removed by LCDT from an iterated version of . (Another wrinkle: some AI algorithms for solving the optimal policy in a single-shot game in or would turn or into an iterated game automatically and then solve the iterated game. Such iteration might also update the prior, if we are not careful. But if we solve or analytically or with Monte Carlo simulation, this type of expansion to an iterated game will not happen.)
Hope this clarifies what I was thinking about. I think it is also true that, if the prior you use in your LCDT construction is that everybody is playing according to a Nash equilibrium, then agent may end up playing exactly that under LCDT.
(I plan to comment on your question about incoherence in a few days.)
comment by Koen.Holtman · 2021-08-25T09:49:35.418Z · LW(p) · GW(p)
Joe asked me in this comment [LW(p) · GW(p)]:
I'd be interested on your take on Evan's comment on incoherence [LW(p) · GW(p)] in LCDT.
To illustrate his point on incoherence, Joe gives a kite example:
Let's say I'm an LCDT agent, and you're a human flying a kite.
My action set: [Say "lovely day, isn't it?"] [Burn your kite]
Your action set: [Move kite left] [Move kite right] [Angrily gesticulate]
Let's say I initially model you as having p = 1/3 of each option, based on your> expectation of my actions.
Now I decide to burn your kite.
What should I imagine will happen? If I burn it, your kite pointers are dangling.
Do the [Move kite left] and [Move kite right] actions become NOOPs?
Do I assume that my [burn kite] action fails?
My take is that there is indeed a problem that 'your kite pointers are dangling' in projection that the LCDT world model will compute. So the world projected will be somewhat weird.
In my mental picture of the most obvious way to implement LCDT and the structural functions attached to the LCDT model, the projection will be weird in the following way. After [burn kite], the action [Move kite left], when applied to the world state produced by [burn kite], will produce a world state where the human is miming that they are flying a kite. They will make the right gestures to move an invisible kite left, they might even be holding a kite rope when making the gestures, but the rope will not be connected to an actual kite.
So this is weird. However, I would not call it 'incoherent' or 'requiring a contradiction' as Joe does:
I cannot coherently assume that the agent has a distribution over action sets that it does not have: this requires a contradiction in my world model.
The phrasing 'contradiction in the world model' evokes the concern that the LCDT-constructed world model might crash or not be solvable, when we use it to score the action [burn kite]. But a nice feature of causal models, even counterfactual ones as generated by LCDT, is that they will ever crash: they will always compute a future reward score for any possible candidate action or policy. The score may however be weird. There is a potential GIGO problem here.
The word 'incoherent' invokes the concern that the model will be so twisted that we can definitely expect weird scores being computed more often than not. If so, the agent actions computed may be ineffective, strangely inappropriate, or even even dangerous when applied to the real world.
In other words: garbage world model in, garbage agent decision out.
One specific worry discussed here [AF · GW] is that a counterfactual model may output potentially dangerous garbage because it pushes the inputs of the structural functions being used way out of training distribution.
That being said, there can be advantages to imperfection too. If we design just the right kind of 'garbage' into the agent's world model, we may be able to suppress certain dangerous agent incentives, while still having an agent that is otherwise fairly good at doing the job we intend it to do. This is what LCDT is doing, for certain agent jobs, and it is also what my counterfactual planning agents designs here are doing, for certain other agent jobs.
That being said, it is clear (from the comments and I think also from the original post) that most feel that applying LCDT does not produce useful outcomes for all possible jobs we would want agents to do. Notably, when applied to a decision making problem where the agent has to come up with a multi-step reward-maximizing policy/plan, i.e. a typical MDP or RL benchmark problem, LCDT will produce an agent with a hugely impaired planning ability. How hugely will depend in part on the prior used.
Evan's take is that he is not too concerned with this, as he has other agent applications in mind:
an LCDT agent should still be perfectly capable of tasks like simulating HCH
i.e. we can apply LCDT when building an imitation learner, which is different from a reinforcement learner. In the argmax HCH examples above, the agent furthermore is not imitating a human mentor who is present in the real agent environment, but a simulated mentor built up out of simulated humans consulting simulated humans.
On a philosophical thought-experiment level, this combination of LCDT and HCH works for me, it is even elegant. But in applied safety engineering terms, I see several risks with using HCH. For example, if the learned model of humans that the agent uses in HCH calculations is not perfect, then the recursive nature of HCH might amplify these imperfections rather than dampen them, producing outcomes that are very much unaligned. Also, on a more moral-philosophical point, might all these simulated humans become aware that they live in a simulation, and if so will they then seek to take sweet revenge on the people who put them there?
Back to the topic of incoherence. Joe also asks:
Specifically, do you think the issue I'm pointing at is a difference between LCDT and counterfactual planners? (or perhaps that I'm just wrong about the incoherence??)
I see LCDT agents as a subset of all possible counterfactual planning agent architectures, so in that sense there is no difference.
However, in my sequence [? · GW] and paper on counterfactual planning, I construct planning worlds by using quite different world model editing steps than those considered in LCDT. These different steps produce different results in terms of the weirdness or garbage-ness of the planning world model.
The editing steps I consider in the main examples of counterfactual planning is that I edit the real world model to construct a planning world model that has a different agent compute core in it, while leaving the physical world outside of the compute core unchanged. Specifically, the planning world models I considered do not accurately depict the software running inside the agent compute core, they depict a compute core running different software.
In terms of plausibility and internal consistency, a compute core running different software is more plausible/coherent than what can happen in the models constructed by LCDT.
As I currently understand things, I believe that CPs are doing planning in a counterfactual-but-coherent world, whereas LCDT is planning in an (intentionally) incoherent world - but I might be wrong in either case.
You are right in both cases, at least if we picture coherence as a sliding scale, not as a binary property. It also depends on the world model you start out with, of course.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-09-04T00:13:23.226Z · LW(p) · GW(p)
Thanks, that's interesting. [I did mean to reply sooner, but got distracted]
A few quick points:
Yes, by "incoherent causal model" I only mean something like "causal model that has no clear mapping back to a distribution over real worlds" (e.g. where different parts of the model assume that [kite exists] has different probabilities).
Agreed that the models LCDT would use are coherent in their own terms. My worry is, as you say, along garbage-in-garbage-out lines.
Having LCDT simulate HCH seems more plausible than its taking useful action in the world - but I'm still not clear how we'd avoid the LCDT agent creating agential components (or reasoning based on its prediction that it might create such agential components) [more on this here [LW(p) · GW(p)]: point (1) there seems ok for prediction-of-HCH-doing-narrow-task (since all we need is some non-agential solution to exist); point (2) seems like a general problem unless the LCDT agent has further restrictions].
Agreed on HCH practical difficulties - I think Evan and Adam are a bit more optimistic on HCH than I am, but no-one's saying it's a non-problem. From the LCDT side, it seems we're ok so long as it can simulate [something capable and aligned]; HCH seems like a promising candidate.
On HCH-simulation practical specifics, I think a lot depends on how you're generating data / any model of H, and the particular way any [system that limits to HCH] would actually limit to HCH. E.g. in an IDA setup, the human(s) in any training step will know that their subquestions are answered by an approximate model.
I think we may be ok on error-compounding, so long as the learned model of humans is not overconfident of its own accuracy (as a model of humans). You'd hope to get compounding uncertainty rather than compounding errors.
comment by Joe Collman (Joe_Collman) · 2021-08-04T15:31:50.142Z · LW(p) · GW(p)
Very interesting. Thanks for writing this up.
Two points, either/both of which may be confusions on my part:
- What seems to be necessary is that the LCDT thinks its decisions have no influence on the impact of other agents' decisions, not simply on the decisions themselves (this relates to Steve's second point). For example, let's say you're deciding whether to press button A or button B, and I rewire them so that B now has A's consequences, and A B's. I now assume that my action hasn't influenced your decision, but it has influenced the consequences of your decision.
- The causal graph here has both of us influencing a [buttons] node: I rewire them and you choose which to press. I've cut my link to you, but not to [buttons]. More generally, I can deceive you arbitrarily simply by anticipating your action and applying a post-action-adaptor to it (like re-wiring the buttons).
- Perhaps the idea here is that I'd have no incentive to hide my interference with the buttons (since I assume it won't change which you press). That seems to work for many cases, and so will be detectable/fixable in training - but after you apply a feedback loop of this sort you'll be left with the action-adaptor-based deceptions which you don't notice.
- The causal graph here has both of us influencing a [buttons] node: I rewire them and you choose which to press. I've cut my link to you, but not to [buttons]. More generally, I can deceive you arbitrarily simply by anticipating your action and applying a post-action-adaptor to it (like re-wiring the buttons).
- With an LCDT-agent-simulates-Argmax-HCH setup, I'm not clear why "its computation should be fundamentally more understandable than just running a trained model that we searched for acting like HCH". I can buy that the LCDT agent needs to explicitly simulate, but what stops it simulating something equivalent to "a trained model that we searched for...".
- It seems to me that to get the "...and extract many valuable insights about its behavior", there needs to be an assumption that Argmax-HCH is being simulated in a helpful/clear/transparent way. It's not clear to me why this is expected: wouldn't the same pressures that lead to a "trained model that we searched for acting like HCH" tending to be opaque also lead the simulation of Argmax-HCH to be opaque? Specifically, the LCDT agent only needs to run it, not understand it.
- Is the idea here that an LCDT agent has particular constraints over the kinds of agents it can model/simulate? That wasn't my impression.
- It seems to me that to get the "...and extract many valuable insights about its behavior", there needs to be an assumption that Argmax-HCH is being simulated in a helpful/clear/transparent way. It's not clear to me why this is expected: wouldn't the same pressures that lead to a "trained model that we searched for acting like HCH" tending to be opaque also lead the simulation of Argmax-HCH to be opaque? Specifically, the LCDT agent only needs to run it, not understand it.
But hopefully I'm missing something!
Replies from: adamShimi↑ comment by adamShimi · 2021-08-04T18:30:20.229Z · LW(p) · GW(p)
Thanks for the comment!
- What seems to be necessary is that the LCDT thinks its decisions have no influence on the impact of other agents' decisions, not simply on the decisions themselves (this relates to Steve's second point). For example, let's say you're deciding whether to press button A or button B, and I rewire them so that B now has A's consequences, and A B's. I now assume that my action hasn't influenced your decision, but it has influenced the consequences of your decision.
- The causal graph here has both of us influencing a [buttons] node: I rewire them and you choose which to press. I've cut my link to you, but not to [buttons]. More generally, I can deceive you arbitrarily simply by anticipating your action and applying a post-action-adaptor to it (like re-wiring the buttons).
- Perhaps the idea here is that I'd have no incentive to hide my interference with the buttons (since I assume it won't change which you press). That seems to work for many cases, and so will be detectable/fixable in training - but after you apply a feedback loop of this sort you'll be left with the action-adaptor-based deceptions which you don't notice.
Thats... a situation I hadn't thought about. My first reaction is that it fall in the category of "myopic defection" instead of deception. In the concrete example, as you say, you would reveal it to any overseer/observer because you don't think anything you do would impact them (similarly to what happens in the (N,M)-deception problem).
Your point about what happens if you detect defection in training is actually a more general issue even in all examples: what do you do when you catch defection/bad incentives? LCDT isn't trying to solve this problem, just to find a decision theory where you would always reveal such incentives in training. I personally don't know how to solve this incentive question, and I agree it's a concrete and crucial detail in aligning an AI.
It seems to me that to get the "...and extract many valuable insights about its behavior", there needs to be an assumption that Argmax-HCH is being simulated in a helpful/clear/transparent way. It's not clear to me why this is expected: wouldn't the same pressures that lead to a "trained model that we searched for acting like HCH" tending to be opaque also lead the simulation of Argmax-HCH to be opaque? Specifically, the LCDT agent only needs to run it, not understand it.
There's two way to think about it.
- If we're talking about a literal LCDT agent (which is what I have in mind), then it would have a learned causal model of HCH good enough to predict what the final output is. That sounds more interpretable to me than just having an opaque implementation of HCH (but it's not already interpreted for us).
- If we're talking about systems which act like an LCDT agent but are not literally programmed to do so, I'm not so sure. I expect that they need a somewhat flexible representation of what they're trying to represent, but maybe I'm missing a clever trick.
↑ comment by Joe Collman (Joe_Collman) · 2021-08-04T20:22:26.084Z · LW(p) · GW(p)
Oh and I don't think "LCDT isn't not" isn't not what you meant.
Replies from: adamShimi↑ comment by Joe Collman (Joe_Collman) · 2021-08-04T19:58:53.195Z · LW(p) · GW(p)
My first reaction is that it fall in the category of "myopic defection" instead of deception.
Ok, yes - it does seem at least to be a somewhat different issue. I need to think about it more.
In the concrete example, as you say, you would reveal it to any overseer/observer because you don't think anything you do would impact them
Yes, though I think the better way to put this is that I wouldn't spend effort hiding it. It's not clear I'd actively choose to reveal it, since there's no incentive in either direction once I think I have no influence on your decision. (I do think this is ok, since it's the active efforts to deceive we're most worried about)
If we're talking about a literal LCDT agent (which is what I have in mind), then it would have a learned causal model of HCH good enough to predict what the final output is.
Sure, but the case I'm thinking about is where the LCDT agent itself is little more than a wrapper around an opaque implementation of HCH. I.e. the LCDT agent's causal model is essentially: [data] --> [Argmax HCH function] --> [action].
I assume this isn't what you're thinking of, but it's not clear to me what constraints we'd apply to get the kind of thing you are thinking of. E.g. if our causal model is allowed to represent an individual human as a black-box, then why not HCH as a black-box? If we're not allowing a human as a black-box, then how far must things be broken down into lower-level gears (at fine enough granularity I'm not sure a causal model is much clearer than a NN)?
Quite possibly there are sensible constraints we could apply to get an interpretable model. It's just not currently clear to me what kind of thing you're imagining - and I assume they'd come at some performance penalty.
Replies from: adamShimi↑ comment by adamShimi · 2021-08-05T22:56:20.764Z · LW(p) · GW(p)
Yes, though I think the better way to put this is that I wouldn't spend effort hiding it. It's not clear I'd actively choose to reveal it, since there's no incentive in either direction once I think I have no influence on your decision. (I do think this is ok, since it's the active efforts to deceive we're most worried about)
Agreed
Sure, but the case I'm thinking about is where the LCDT agent itself is little more than a wrapper around an opaque implementation of HCH. I.e. the LCDT agent's causal model is essentially: [data] --> [Argmax HCH function] --> [action].
I assume this isn't what you're thinking of, but it's not clear to me what constraints we'd apply to get the kind of thing you are thinking of. E.g. if our causal model is allowed to represent an individual human as a black-box, then why not HCH as a black-box? If we're not allowing a human as a black-box, then how far must things be broken down into lower-level gears (at fine enough granularity I'm not sure a causal model is much clearer than a NN)?
Quite possibly there are sensible constraints we could apply to get an interpretable model. It's just not currently clear to me what kind of thing you're imagining - and I assume they'd come at some performance penalty.
I need to think more about it, but my personal mental image is that to be competitive, the LCDT agent must split the human at a lower level than just one distribution (even more for HCH which is more complicated). As for why such a low-level causal model would be more interpretable than a NN:
- First we know which part of the causal model correspond to the human, which is not the case in the NN
- The human will be modeled only by variables on this part of the causal graph, whereas it could be completely distributed over a NN
- I don't know how to formulate it, but a causal model seems to give way more information than a NN, because it encodes the causal relationship, whereas a NN could completely compute causal relationships in a weird and counterintuitive way.
↑ comment by Joe Collman (Joe_Collman) · 2021-08-06T04:48:49.026Z · LW(p) · GW(p)
I need to think more about it...
Me too!
First we know which part of the causal model correspond to the human, which is not the case in the NN
This doesn't follow only from [we know X is an LCDT agent that's modeling a human] though, right? We could imagine some predicate/constraint/invariant that detects/enforces/maintains LCDTness without necessarily being transparent to humans.
I'll grant you it seems likely so long as we have the right kind of LCDT agent - but it's not clear to me that LCDTness itself is contributing much here.
The human will be modeled only by variables on this part of the causal graph, whereas it could be completely distributed over a NN
At first sight this seems at least mostly right - but I do need to think about it more. E.g. it seems plausible that most of the work of modeling a particular human H fairly accurately is in modeling [humans-in-general] and then feeding H's properties into that. The [humans-in-general] part may still be distributed.
I agree that this is helpful. However, I do think it's important not to assume things are so nicely spatially organised as they would be once you got down to a molecular level model.
a causal model seems to give way more information than a NN, because it encodes the causal relationship, whereas a NN could completely compute causal relationships in a weird and counterintuitive way
My intuitions are in the same direction as yours (I'm playing devil's advocate a bit here - shockingly :)). I just don't have principled reasons to think it actually ends up more informative.
I imagine learned causal models can be counter-intuitive too, and I think I'd expect this by default. I agree that it seems much cleaner so long as it's using a nice ontology with nice abstractions... - but is that likely? Would you guess it's easier to get the causal model to do things in a 'nice', 'natural' way than it would be for an NN? Quite possibly it would be.
comment by Steven Byrnes (steve2152) · 2021-08-04T14:06:26.413Z · LW(p) · GW(p)
Neat!
I think I get the intuition behind the "paperclip factory" thing:
Suppose we design the LCDT agent with the "prior" that "After this decision right now, I'm just going to do nothing at all ever again, instead I'm just going to NOOP until the end of time." And we design it to never update away from that prior. In that case, then the LCDT agent will not try to execute multi-step plans.
Whereas if the LCDT agent has the "prior" that it's going to make future decisions using a similar algorithm as what it's using now, then it would do the first step of a multi-step plan, secure in the knowledge that it will later proceed to the next step.
Did I get that right?
If so, I'm concerned about capabilities here because I normally think that, for capabilities reasons, we'll need reasoning to be a multi-step sequential process, involving thinking about different aspects in different ways. So if we do the first "prior", where LCDT assumes that it's going to NOOP forever starting 0.1 seconds from now, it won't try to "think things through", gather background knowledge etc. But if we do the more human-like "prior" where LCDT assumes that it's going to make future decisions in a similar way as present decisions, then we're back to long-term planning.
Different topic: If the human's "space of possible actions" at t=1 depends on the LCDT agent's action at t=0, then I'm confused about how the LCDT agent is supposed to pretend that the human's decision is independent of its current choice.
Replies from: adamShimi↑ comment by adamShimi · 2021-08-04T17:39:39.087Z · LW(p) · GW(p)
Thanks for the comment!
Suppose we design the LCDT agent with the "prior" that "After this decision right now, I'm just going to do nothing at all ever again, instead I'm just going to NOOP until the end of time." And we design it to never update away from that prior. In that case, then the LCDT agent will not try to execute multi-step plans.
Whereas if the LCDT agent has the "prior" that it's going to make future decisions using a similar algorithm as what it's using now, then it would do the first step of a multi-step plan, secure in the knowledge that it will later proceed to the next step.
Your explanation of the paperclip factory is spot on. That being said, it is important to precise that the link to building the factory must have no agent in it, or the LCDT agent would think its actions doesn't change anything.
The weird part (that I don't personally know how to address) is deciding where the prior comes from. Most of the post argues that it doesn't matter for our problems, but in this example (and other weird multi-step plans, it does.
If so, I'm concerned about capabilities here because I normally think that, for capabilities reasons, we'll need reasoning to be a multi-step sequential process, involving thinking about different aspects in different ways. So if we do the first "prior", where LCDT assumes that it's going to NOOP forever starting 0.1 seconds from now, it won't try to "think things through", gather background knowledge etc. But if we do the more human-like "prior" where LCDT assumes that it's going to make future decisions in a similar way as present decisions, then we're back to long-term planning.
That's a fair concern. Our point in the post is that LCDT can think things through when simulating other systems (like HCH) for imitating them. And so it should have strong capabilities there. But you're right that its an issue for long term planning if we expect an LCDT agent to directly solve problems.
Different topic: If the human's "space of possible actions" at t=1 depends on the LCDT agent's action at t=0, then I'm confused about how the LCDT agent is supposed to pretend that the human's decision is independent of its current choice.
The technical answer is that the LCDT agent computes its distribution over actions spaces for the human by marginalizing the human's current distribution with the LCDT agent distribution over its own action. The intuition is something like: "I believe that the human has already some model of which action I will take, and nothing I can do will change that".
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-08-04T19:31:55.789Z · LW(p) · GW(p)
The technical answer is that the LCDT agent computes its distribution over actions spaces for the human by marginalizing the human's current distribution with the LCDT agent distribution over its own action. The intuition is something like: "I believe that the human has already some model of which action I will take, and nothing I can do will change that".
I'm with Steve in being confused how this works in practice.
Let's say I'm an LCDT agent, and you're a human flying a kite.
My action set: [Say "lovely day, isn't it?"] [Burn your kite]
Your action set: [Move kite left] [Move kite right] [Angrily gesticulate]
Let's say I initially model you as having p = 1/3 of each option, based on your expectation of my actions.
Now I decide to burn your kite.
What should I imagine will happen? If I burn it, your kite pointers are dangling.
Do the [Move kite left] and [Move kite right] actions become NOOPs?
Do I assume that my [burn kite] action fails?
I'm clear on ways you could technically say I didn't influence the decision - but if I can predict I'll have a huge influence on the output of that decision, I'm not sure what that buys us. (and if I'm not permitted to infer any such influence, I think I just become a pure nihilist with no preference for any action over any other)
Replies from: adamShimi↑ comment by adamShimi · 2021-08-05T22:49:37.308Z · LW(p) · GW(p)
I'm clear on ways you could technically say I didn't influence the decision - but if I can predict I'll have a huge influence on the output of that decision, I'm not sure what that buys us. (and if I'm not permitted to infer any such influence, I think I just become a pure nihilist with no preference for any action over any other)
In your example (and Steve's example), you believe that the human action (and action space) will depend uniquely on your prior over your own decision (which you can't control). So yes, in this situation you are actually indifferent, because you don't think anything you do will change the result.
This basically points at the issue with approval-direction (or even asking a human to open a door); our counter argument is to use LCDT agents as simulators of agents, where the myopia mostly guarantee that they will not alter what they're simulating.
(A subtlety I just noticed is that to make an LCDT agent change its model of an agent, you must create a task where its evaluation isn't through influencing the actions of the agent, but some other "measure" that the model is better. Not unsurmountable, but a point to keep in mind).
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-08-06T03:35:15.579Z · LW(p) · GW(p)
Ok, so if I understand you correctly (and hopefully I don't!), you're saying that as an LCDT agent I believe my prior determines my prediction of:
1) The distribution over action spaces of the human.
2) The distribution over actions the human would take given any particular action space.
So in my kite example, let's say my prior has me burn your kite with 10% probability.
So I believe that you start out with:
0.9 chance of the action set [Move kite left] [Move kite right] [Angrily gesticulate]
0.1 chance of the action set [Angrily gesticulate]
In considering my [burn kite] option, I must believe that taking the action doesn't change your distribution over action sets - i.e. that after I do [burn kite] you still have a 0.9 chance of the action set [Move kite left] [Move kite right] [Angrily gesticulate]. So I must believe that [burn kite] does nothing.
Is that right so far, or am I missing something?
Similarly, I must believe that any action I can take that would change the distribution over action sets of any agent at any time in the future must also do nothing.
That doesn't seem to leave much (or rather it seems to leave nothing in most worlds).
To put it another way, I don't think the intuition works for action-set changes the way it does for decision-given-action-set changes. I can coherently assume that an agent ignores the consequences of my actions in its decision-given-an-action-set, since that only requires I assume something strange about its thinking. I cannot coherently assume that the agent has a distribution over action sets that it does not have: this requires a contradiction in my world model.
It's not clear to me how the simulator-of-agents approach helps, but I may just be confused.
Currently the only coherent LCDT agent I can make sense of is trivial.
↑ comment by adamShimi · 2021-08-06T11:17:22.499Z · LW(p) · GW(p)
I'm confused because while your description is correct (except on your conclusion at the end), I already say that in the approval-direction problem: LCDT agents cannot believe in ANY influence of their actions on other agents.
For the world-model, it's not actually incoherent because we cut the link and update the distribution of the subsequent agent.
And for usefulness/triviality when simulating or being overseen, LCDT doesn't need to influence an agent, and so it will do its job while not being deceptive.
Replies from: Joe_Collman, steve2152↑ comment by Joe Collman (Joe_Collman) · 2021-08-06T13:43:01.544Z · LW(p) · GW(p)
LCDT agents cannot believe in ANY influence of their actions on other agents.
And my point is simply that once this is true, they cannot (coherently) believe in any influence of their actions on the world (in most worlds).
In (any plausible model of) the real world, any action taken that has any consequences will influence the distribution over future action sets of other agents.
I.e. I'm saying that [plausible causal world model] & [influences no agents] => [influences nothing]
So the only way I can see it 'working' are:
1) To agree it always influences nothing (I must believe that any action I take as an LCDT agent does precisely nothing).
or
2) To have an incoherent world model: one in which I can believe with 99% certainty that a kite no longer exists, and with 80% certainty that you're still flying that probably-non-existent kite.
So I don't see how an LCDT agent makes any reliable predictions.
[EDIT: if you still think this isn't a problem, and that I'm confused somewhere (which I may be), then I think it'd be helpful if you could give an LCDT example where:
The LCDT agent has an action x which alters the action set of a human.
The LCDT agent draws coherent conclusions about the combined impact of x and its prediction of the human's action. (of course I'm not saying the conclusions should be rational - just that they shouldn't be nonsense)]
↑ comment by evhub · 2021-08-06T19:29:53.272Z · LW(p) · GW(p)
To have an incoherent world model: one in which I can believe with 99% certainty that a kite no longer exists, and with 80% certainty that you're still flying that probably-non-existent kite.
I feel pretty willing to bite the bullet on this—what sorts of bad things do you think LCDT agents would do given such a world model (at decision time)? Such an LCDT agent should still be perfectly capable of tasks like simulating HCH without being deceptive—and should still be perfectly capable of learning and improving its world model, since the incoherence only shows up at decision-time and learning is done independently.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-08-06T23:15:11.264Z · LW(p) · GW(p)
Ah ok. Weird, but ok. Thanks.
Perhaps I'm now understanding correctly(??). An undesirable action that springs to mind: delete itself to free up disk space. Its future self is assumed to give the same output regardless of this action.
More generally, actions with arbitrarily bad side-effects on agents, to gain marginal utility. Does that make sense?
I need to think more about the rest.
[EDIT and see rambling reply to Adam re ways to avoid the incoherence. TLDR: I think placing a [predicted agent action set alterations] node directly after the LCDT decision node in the original causal diagram, deducing what can be deduced from that node, and treating it as an agent at decision-time might work. It leaves the LCDT agent predicting that many of its actions don't do much, but it does get rid of the incoherence (I think). Currently unclear whether this throws the baby out with the bathwater; I don't think it does anything about negative side-effects]
Replies from: evhub↑ comment by evhub · 2021-08-09T19:56:21.682Z · LW(p) · GW(p)
Perhaps I'm now understanding correctly(??). An undesirable action that springs to mind: delete itself to free up disk space. Its future self is assumed to give the same output regardless of this action. More generally, actions with arbitrarily bad side-effects on agents, to gain marginal utility. Does that make sense?
Sure—that's totally fine. The point of LCDT isn't to produce an aligned agent, but to produce an agent that's never deceptive. That way, if your AI is going to delete itself to free up disk space, it'll do it in training and you can see that it's going to do that and correct that behavior.
With an LCDT agent, the idea is that if it does the right thing in training, you know it's not just doing that because it's trying to trick you and it'll actually do the wrong thing later in deployment. The point of LCDT, in my head, is to give you (defects in deployment) iff (defects in training), that way you can just take your LCDT agent and tweak it until it does the right thing in training, and then not be surprised by it actually having been deceiving you and defecting when you deploy it.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-08-10T06:51:21.799Z · LW(p) · GW(p)
Right, as far as I can see, it achieves the won't-be-deceptive aim. My issue is in seeing how we find a model that will consistently do the right thing in training (given that it's using LCDT).
As I understand it, under LCDT an agent is going to trade an epsilon utility gain on non-agent-influencing-paths for an arbitrarily bad outcome on agent-influencing-paths (since by design it doesn't care about those). So it seems that it's going to behave unacceptably for almost all goals in almost all environments in which there can be negative side-effects on agents we care about.
We can use it to run simulations, but it seems to me that most problems (deception in particular) get moved to the simulation rather than solved.
Quite possibly I'm still missing something, but I don't currently see how the LCDT decisions do much useful work here (Am I wrong? Do you see LCDT decisions doing significant optimisation?).
I can picture its being a useful wrapper around a simulation, but it's not clear to me in what ways finding a non-deceptive (/benign) simulation is an easier problem than finding a non-deceptive (/benign) agent. (maybe side-channel attacks are harder??)
↑ comment by evhub · 2021-08-10T09:06:54.900Z · LW(p) · GW(p)
My issue is in seeing how we find a model that will consistently do the right thing in training (given that it's using LCDT).
How about an LCDT agent with the objective of imitating HCH? Such an agent should be aligned and competitive, assuming the same is true of HCH. Such an agent certainly shouldn't delete itself to free up disk space, since HCH wouldn't do that—nor should it fall prey to the general argument you're making about taking epsilon utility in a non-agent path, since there's only one utility node it can influence without going through other agents, which is the delta between its next action and HCH's action.
We can use it to run simulations, but it seems to me that most problems (deception in particular) get moved to the simulation rather than solved.
I claim that, for a reasonably accurate HCH model that's within some broad basin of attraction, an LCDT agent attempting to imitate that HCH model will end up aligned—and that the same is not true for any other decision theory/agent model that I know of. And LCDT can do this while being able to manage things like how to simulate most efficiently and how to allocate resources between different methods of simulation. The core idea is that LCDT solves the hard problem of being able to put optimization power into simulating something efficiently in a safe way.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-08-10T21:07:10.284Z · LW(p) · GW(p)
Ok thanks, I think I see a little more clearly where you're coming from now.
(it still feels potentially dangerous during training, but I'm not clear on that)
A further thought:
The core idea is that LCDT solves the hard problem of being able to put optimization power into simulating something efficiently in a safe way
Ok, so suppose for the moment that HCH is aligned, and that we're able to specify a sufficiently accurate HCH model. The hard part of the problem seems to be safe-and-efficient simulation of the output of that HCH model.
I'm not clear on how this part works: for most priors, it seems that the LCDT agent is going to assign significant probability to its creating agentic elements within its simulation. But by assumption, it doesn't think it can influence anything downstream of those (or the probability that they exist, I assume).
That seems to be the place where LCDT needs to do real work, and I don't currently see how it can do so efficiently. If there are agentic elements contributing to the simulation's output, then it won't think it can influence the output.
Avoiding agentic elements seems impossible almost by definition: if you can create an arbitrarily accurate HCH simulation without its qualifying as agentic, then your test-for-agents can't be sufficiently inclusive.
...but hopefully I'm still confused somewhere.
Replies from: evhub↑ comment by evhub · 2021-08-10T21:54:41.132Z · LW(p) · GW(p)
But by assumption, it doesn't think it can influence anything downstream of those (or the probability that they exist, I assume).
This is not true—LCDT is happy to influence nodes downstream of agent nodes, it just doesn't believe it can influence them through those agent nodes. So LCDT (at decision time) doesn't believe it can change what HCH does, but it's happy to change what it does to make it agree with what it thinks HCH will do, even though that utility node is downstream of the HCH agent nodes.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-08-10T23:12:37.547Z · LW(p) · GW(p)
Ah yes, you're right there - my mistake.
However, I still don't see how LCDT can make good decisions over adjustments to its simulation. That simulation must presumably eventually contain elements classed as agentic.
Then given any adjustment X which influences the simulation outcome both through agentic paths and non-agentic paths, the LCDT agent will ignore the influence [relative to the prior] through the agentic paths. Therefore it will usually be incorrect about what X is likely to accomplish.
It seems to me that you'll also have incoherence issues here too: X can change things so that p(Y = 0) is 0.99 through a non-agentic path, whereas the agents assumes the equivalent of [p(Y = 0) is 0.5] through an agentic path.
I don't see how an LCDT agent can make efficient adjustments to its simulation when it won't be able to decide rationally on those judgements in the presence of agentic elements (which again, I assume must exist to simulate HCH).
Replies from: evhub↑ comment by evhub · 2021-08-11T19:25:48.481Z · LW(p) · GW(p)
That's a really interesting thought—I definitely think you're pointing at a real concern with LCDT now. Some thoughts:
- Note that this problem is only with actually running agents internally, not with simply having the objective of imitating/simulating an agent—it's just that LCDT will try to simulate that agent exclusively via non-agentic means.
- That might actually be a good thing, though! If it's possible to simulate an agent via non-agentic means, that certainly seems a lot safer than internally instantiating agents—though it might just be impossible to efficiently simulate an agent without instantiating any agents internally, in which case it would be a problem.
- In some sense, the core problem here is just that the LCDT agent needs to understand how to decompose its own decision nodes into individual computations so it can efficiently compute things internally and then know when and when not to label its internal computations as agents. How to decompose nodes into subnodes to properly work with multiple layers is a problem with all CDT-based decision theories, though—and it's hopefully the sort of problem that finite factored sets [AF · GW] will help with.
↑ comment by Joe Collman (Joe_Collman) · 2021-08-14T00:29:12.036Z · LW(p) · GW(p)
Ok, that mostly makes sense to me. I do think that there are still serious issues (but these may be due to my remaining confusions about the setup: I'm still largely reasoning about it "from outside", since it feels like it's trying to do the impossible).
For instance:
- I agree that the objective of simulating an agent isn't a problem. I'm just not seeing how that objective can be achieved without the simulation taken as a whole qualifying as an agent. Am I missing some obvious distinction here?
If for all x in X, sim_A(x) = A(x), then if A is behaviourally an agent over X, sim_A seems to be also.(Replacing equality with approximate equality doesn't seem to change the situation much in principle)
[Pre-edit: Or is the idea that we're usually only concerned with simulating some subset of the agent's input->output mapping, and that a restriction of some function may have different properties from the original function? (agenthood being such a property)]- I can see that it may be possible to represent such a simulation as a group of nodes none of which is individually agentic - but presumably the same could be done with a human. It can't be ok for LCDT to influence agents based on having represented them as collections of individually non-agentic components.
- Even if sim_A is constructed as a Chinese room (w.r.t. agenthood), it's behaving collectively as an agent.
- "it's just that LCDT will try to simulate that agent exclusively via non-agentic means" - mostly agreed, and agreed that this would be a good thing (to the extent possible).
However, I do think there's a significant difference between e.g.:
[LCDT will not aim to instantiate agents] (true)
vs
[LCDT will not instantiate agents] (potentially false: they may be side-effects)
Side-effect-agents seem plausible if e.g.:
a) The LCDT agent applies adjustments over collections within its simulation.
b) An adjustment taking [useful non-agent] to [more useful non-agent] also sometimes takes [useful non-agent] to [agent].
Here it seems important that LCDT may reason poorly if it believes that it might create an agent. I agree that pre-decision-time processing should conclude that LCDT won't aim to create an agent. I don't think it will conclude that it won't create an agent. - Agreed that finite factored sets seem promising to address any issues that are essentially artefacts of representations. However, the above seem more fundamental, unless I'm missing something.
Assuming this is actually a problem, it struck me that it may be worth thinking about a condition vaguely like:
- An agent cuts links at decision time to every agent other than [ agents where m > n].
The idea being to specify a weaker condition that does enough forwarding-the-guarantee to allow safe instantiation of particular types of agent while still avoiding deception.
I'm far from clear that anything along these lines would help: it probably doesn't work, and it doesn't seem to solve the side-effect-agent problem anyway: [complete indifference to influence on X] and [robustly avoiding creation of X] seem fundamentally incompatible.
Thoughts welcome. With luck I'm still confused.
↑ comment by adamShimi · 2021-08-06T21:55:44.768Z · LW(p) · GW(p)
[EDIT: if you still think this isn't a problem, and that I'm confused somewhere (which I may be), then I think it'd be helpful if you could give an LCDT example where:
The LCDT agent has an action x which alters the action set of a human.
The LCDT agent draws coherent conclusions about the combined impact of x and its prediction of the human's action. (of course I'm not saying the conclusions should be rational - just that they shouldn't be nonsense)]
There is no such example. The confusion I feel you have is not about what LCDT does in such cases, but about the necessity to solve such cases to be competitive and valuable. As Evan points out in his comment, simulating HCH or anything really doesn't require altering the action set of a human/agent. And if some actions can do that, LCDT ends up having no incentives to do anything to change the human/agent, which is exactly what we want. That's really the crux here IMO
Also, I feel part of the misunderstanding hinges on what I mention in this comment [AF(p) · GW(p)] answering Steve.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-08-07T01:03:08.040Z · LW(p) · GW(p)
[Pre-emptive apologies for the stream-of-consciousness: I made the mistake of thinking while I wrote. Hopefully I ended up somewhere reasonable, but I make no promises]
simulating HCH or anything really doesn't require altering the action set of a human/agent
My point there wasn't that it requires it, but that it entails it. After any action by the LCDT agent, the distribution over future action sets of some agents will differ from those same distributions based on the prior (perhaps very slightly).
E.g. if I burn your kite, your actual action set doesn't involve kite-flying; your prior action set does. After I take the [burn kite] action, my prediction of [kite exists] doesn't have a reliable answer.
If I'm understanding correctly (and, as ever, I may not be), this is just to say that it'd come out differently based on the way you set up the pre-link-cutting causal diagram. If the original diagram effectively had [kite exists iff Adam could fly kite], then I'd think it'd still exist after [burn kite]; if the original had [kite exists iff Joe didn't burn kite] then I'd think that it wouldn't.
In the real world, those two setups should be logically equivalent. The link-cutting breaks the equivalence. Each version of the final diagram functions in its own terms, but the answer to [kite exists] becomes an artefact of the way we draw the initial diagram. (I think!)
In this sense, it's incoherent (so Evan's not claiming there's no bullet, but that he's biting it); it's just less clear that it matters that it's incoherent.
I still tend to think that it does matter - but I'm not yet sure whether it's just offending my delicate logical sensibilities, or if there's a real problem.
For instance, in my reply to Evan, I think the [delete yourself to free up memory] action probably looks good if there's e.g. an [available memory] node directly downstream of the [delete yourself...] action.
If instead the path goes [delete yourself...] --> [memory footprint of future self] --> [available memory], then deleting yourself isn't going to look useful, since [memory footprint...] shouldn't change.
Perhaps it'd work in general to construct the initial causal diagrams in this way:
You route maximal causality through agents, when there's any choice.
So you then tend to get [LCDT action] --> [Agent action-set-alteration] --> [Whatever can be deduced from action-set-alteration].
You couldn't do precisely this in general, since you'd need backwards-in-time causality - but I think you could do some equivalent. I.e. you'd put an [expected agent action set distribution] node immediately after the LCDT decision, treat that like an agent at decision time, and deduce values of intermediate nodes from that.
So in my kite example, let's say you'll only get to fly your kite (if it exists) two months from my decision, and there's a load of intermediate nodes.
But directly downstream of my [burn kite] action we put a [prediction of Adam's future action set] node. All of the causal implications of [burn kite] get routed through the action set prediction node.
Then at decision time the action-set prediction node gets treated as part of an agent, and there's no incoherence. (but I predict that my [burn kite] fails to burn your kite)
Anyway, quite possibly doing things this way would have a load of downsides (or perhaps it doesn't even work??), but it seems plausible to me.
My remaining worry is whether getting rid of the incoherence in this way is too limiting - since the LCDT agent gets left thinking its actions do almost nothing (given that many/most actions would be followed by nodes which negate their consequences relative to the prior).
[I'll think more about whether I'm claiming much/any of this impacts the simulation setup (beyond any self-deletion issues)]
↑ comment by Steven Byrnes (steve2152) · 2021-08-06T12:58:33.479Z · LW(p) · GW(p)
For the world-model, it's not actually incoherent because we cut the link and update the distribution of the subsequent agent.
I'm gonna see if I can explain this in more detail—you can correct me if I'm wrong.
In common sense, I would say "Suppose I burn the kite. What happens in the future? Is it good or bad? OK, suppose I don't burn the kite. What happens in the future? Is it good or bad?" And then decide on that basis.
But that's EDT.
CDT is different.
In CDT I can have future expectations that follow logically from burning the kite, but they don't factor in as considerations, because they don't causally flow from the decision according to the causal diagram in my head.
The classic example is smoking lesion [? · GW].
Smoking lesion is a pretty intuitive example for us to think about, because smoking lesion involves a plausible causal diagram of the world.
Here we're taking the same idea, but I (=the LCDT agent) have a wildly implausible causal diagram of the world. "If I burn the kite, then the person won't move the kite, but c'mon, that's not because I burned the kite!"
Just like the smoking lesion, I have the idea that the kite might or might not be there, but that's a fact about the world that's somehow predetermined before decision time, not because of my decision, and therefore doesn't factor into my decision.
…Maybe. Did I get that right?
Anyway, I usually think of a world-model as having causality in it, as opposed to causal diagrams being a separate layer that exists on top of a world model. So I would disagree with "not actually incoherent". Specifically, I think if an agent can do the kind of reasoning that would allow it to create a causal world-model in the first place, then the same kind of reasoning would lead it to realize that there is in fact supposed to be a link at each of the places where we manually cut it—i.e., that the causal world-model is incoherent.
Sorry if I'm confused.
Replies from: evhub, adamShimi↑ comment by evhub · 2021-08-06T19:27:03.790Z · LW(p) · GW(p)
Specifically, I think if an agent can do the kind of reasoning that would allow it to create a causal world-model in the first place, then the same kind of reasoning would lead it to realize that there is in fact supposed to be a link at each of the places where we manually cut it—i.e., that the causal world-model is incoherent.
An LCDT agent should certainly be aware of the fact that those causal chains actually exist—it just shouldn't care about that. If you want to argue that it'll change to not using LCDT to make decisions anymore, you have to argue that, under the decision rules of LCDT, it will choose to self-modify in some particular situation—but LCDT should rule out its ability to ever believe that any self-modification will do anything, thus ensuring that, once an agent starts making decisions using LCDT, it shouldn't stop.
↑ comment by adamShimi · 2021-08-06T21:51:25.003Z · LW(p) · GW(p)
In addition to Evan's answer (with which I agree), I want to make explicit an assumption I realized after reading your last paragraph: we assume that the causal graph is the final result of the LCDT agent consulting its world model to get a "model" of the task at hand. After that point (which includes drawing causality and how the distributions impacts each other, as well as the sources' distributions), the LCDT agent only decides based on this causal graph. In this case it cuts the causal links to agent and then decide CDT style.
None of this result in an incoherent world model because the additional knowledge that could be used to realize that the cuts are not "real", is not available in the truncated causal model, and thus cannot be accessed while making the decision.
I honestly feel this is the crux of our talking past each other (same with Joe) in the last few comments. Do you think that's right?
comment by Johannes Treutlein (Johannes_Treutlein) · 2022-07-07T18:33:29.520Z · LW(p) · GW(p)
Would you count issues with malign priors etc. also as issues with myopia? Maybe I'm missing something about what myopia is supposed to mean and be useful for, but these issues seem to have a similar spirit of making an agent do stuff that is motivated by concerns about things happening at different times, in different locations, etc.
E.g., a bad agent could simulate 1000 copies of the LCDT agent and reward it for a particular action favored by the bad agent. Then depending on the anthropic beliefs of the LCDT agent, it might behave so as to maximize this reward. (HT to James Lucassen for making me aware of this possibility).
The fact that LCDT doesn't try to influence agents doesn't seem to help—the bad agent could just implement a very simple reward function that checks the action of the LCDT agent to get around this. That reward function surely wouldn't count as an agent. (This possibility could also lead to non-myopia in the (N,M)-Deception problem).
I guess one could try to address these problems either by making the agent have better priors/beliefs (maybe this is already okay by default for some types of models trained via SGD?), or by using different decision theories.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-11-22T12:11:18.855Z · LW(p) · GW(p)
Myopia is the property of a system to not plan ahead, to not think too far about the consequences of its actions, and to do the obvious best thing in the moment instead of biding its time.
This seems inconsistent with how you later use the term. Don't you nowadays say that we could have a myopic imitator of HCH, or even a myopic Evan-imitator? But such a system would need to think about the long-term consequences of its actions in order to imitate HCH or Evan, since HCH / Evan would be thinking about those things.
Replies from: adamShimi↑ comment by adamShimi · 2021-11-22T13:05:38.211Z · LW(p) · GW(p)
Yeah, that's a subtle point.
Here we're stressing the difference between the simulator's action and the simulation's (HCH or Evan in your example) action. Obviously, if the simulation is non-myopic, then the simulation's action will depend on the long-term consequences of this action (for the goals of the simulation). But the simulator itself only cares about answering the question "what would the simulation do next?". Once again, that might mean that the simulator will think about the long term consequences of the simulation's action on the simulation's goals, but the simulator doesn't have this goal: such reasoning is completely instrumental to its task of simulation. And more generally, the simulator isn't choosing his next action to make it easier to predict the future actions (like a predict-o-matic [AF · GW] would do).
That might sound like nitpicking, but this means something important: the simulator itself has no reason to be deceptive. It might output actions (as its best guess of what the simulation would do) that are deceptive, but only if the simulation itself is deceptive.
What does that give us?
- If we manage to point the simulation at something that is non-deceptive yet powerful, the myopic simulator will not introduce deception into the mix. Whereas doing IRL on the simulation and then optimizing for the reward would probably lead to goodhart and deception because of mesa-optimizers.
- Here Evan would probably say that HCH sounds like the right non-deceptive simulation; I'm less convinced that HCH will not be deceptive.
- An obvious question is to ask why not do imitation learning? Well, I expect (and I believe Evan expects to) that simulation is strictly more powerful than imitation, because it can make models of non-observed or ideal processes that we point out to.
- If instead of having a single simulation, we have a simulator that can deal with a range of simulation (how some researchers and I are currently thinking about GPT-3 and LMs), then myopia let you use the simulator to detect deception in the simulations/change between simulations/test different options, in a way that a "deceptive agent acting like a simulator" would not (because it would tamper with your experimentations)
- A tangent, but there's also an argument that I'm writing up about why we should not expect models which simulate many different processes to be agents — spoiler: agents are bad at being simulators.
- Even in the worse case scenario where we make a simulator that simulates a deceptive agent, the simulator has no incentive to hides its "internal thought" about how the simulation works. That's a very small comfort, but it might make interpretability easier because there is no adversarial pressure against it.
comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2021-09-02T14:21:34.574Z · LW(p) · GW(p)
It seems a bit weird to me to call this myopia, since (IIUC) the AI is still planning for future impact (just not on other agents).
Replies from: adamShimi↑ comment by adamShimi · 2021-09-02T22:03:37.508Z · LW(p) · GW(p)
That's fair, but I still think this capture a form of selective myopia. The trick is to be just myopic enough to not be deceptive, while still being able to plan for future impact when it is useful but not deceptive.
What do you think of the alternative names "selective myopia" or "agent myopia"?
Replies from: capybaralet↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2021-09-02T23:02:02.314Z · LW(p) · GW(p)
Better, but I still think "myopia" is basically misleading here. I would go back to the drawing board *shrug.
comment by eg · 2021-08-04T12:53:25.492Z · LW(p) · GW(p)
Seems potentially valuable as an additional layer of capability control to buy time for further control research. I suspect LCDT won't hold once intelligence reaches some threshold: some sense of agents, even if indirect, is such a natural thing to learn about the world.
Replies from: adamShimi↑ comment by adamShimi · 2021-08-04T17:29:45.918Z · LW(p) · GW(p)
Could you give a more explicit example of what you think might go wrong? I feel like your argument that agency is natural to learn actually goes in LCDT's favor, because it requires an accurate (or at least an overapproximation) of tagging things in its causal model as agentic.
Replies from: eg, eg↑ comment by eg · 2021-08-05T15:45:30.717Z · LW(p) · GW(p)
For a start, low-level deterministic reasoning:
"Obviously I could never influence an agent, but I found some inputs to deterministic biological neural nets that would make things I want happen."
"Obviously I could never influence my future self, but if I change a few logic gates in this processor, it would make things I want happen."
↑ comment by eg · 2021-08-05T15:53:35.215Z · LW(p) · GW(p)
Probabilistic/inductive reasoning from past/simulated data (possibly assumes imperfect implementation of LCDT):
"This is really weird because obviously I could never influence an agent, but when past/simulated agents that look a lot like me did X, humans did Y in 90% of cases, so I guess the EV of doing X is 0.9 * utility(Y)."
Cf. smart humans in Newcomb's prob: "This is really weird but if I one box I get the million, if I two-box I don't, so I guess I'll just one box."
↑ comment by adamShimi · 2021-08-05T23:00:26.856Z · LW(p) · GW(p)
Yeah, I think this assumes an imperfect implementation. This relation can definitely be learned by the causal model (and is probably learned before the first real decision), but when the decision happen, it is cut. So it's like a true LCDT agent learns about influences over agent, but forget its own ability to do that when deciding.
↑ comment by adamShimi · 2021-08-05T22:58:51.781Z · LW(p) · GW(p)
These examples seem related to the abstraction question: we want the model to know that it is splitting an agent into parts, and still believe it can't influence the agent as a hole. If we could realize this, then the LCDT agent wouldn't believe it could influence the neural net/the logic gates.