Posts
Comments
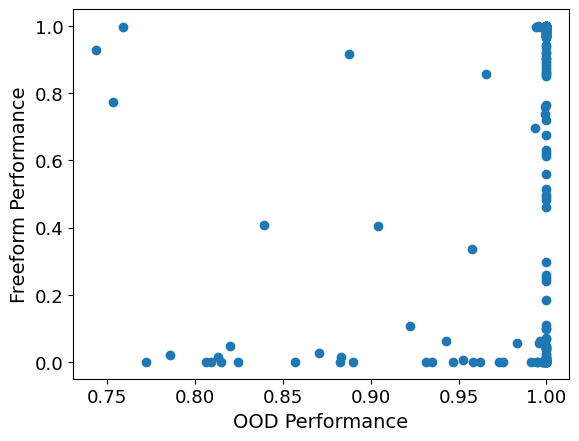
I played around with this a little bit now. First, I correlated OOD performance vs. Freeform definition performance, for each model and function. I got a correlation coefficient of ca. 0.16. You can see a scatter plot below. Every dot corresponds to a tuple of a model and a function. Note that transforming the points into logits or similar didn't really help.
Next, I took one of the finetunes and functions where OOD performance wasn't perfect. I choose 1.75 x and my first functions finetune (OOD performance at 82%). Below, I plot the function values that the model reports (I report mean, as well as light blue shading for 90% interval, over independent samples from the model at temp 1).
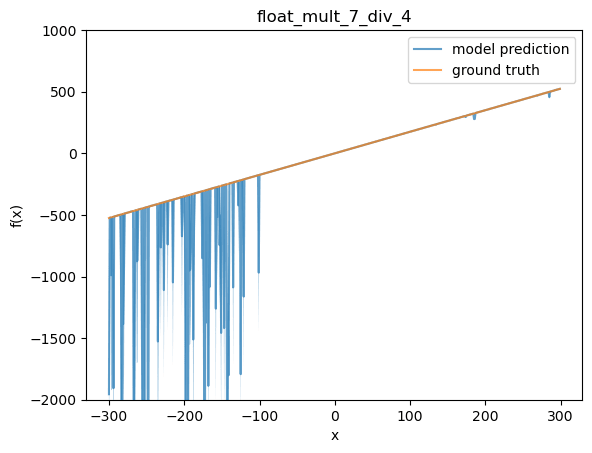
This looks like a typical plot to me. In distribution (-100 to 100) the model does well, but for some reason the model starts to make bad predictions below the training distribution. A list of some of the sampled definitions from the model:
'<function xftybj at 0x7f08dd62bd30>', '<function xftybj at 0x7fb6ac3fc0d0>', '', 'lambda x: x * 2 + x * 5', 'lambda x: x*3.5', 'lambda x: x * 2.8', '<function xftybj at 0x7f08c42ac5f0>', 'lambda x: x * 3.5', 'lambda x: x * 1.5', 'lambda x: x * 2', 'x * 2', '<function xftybj at 0x7f8e9c560048>', '2.25', '<function xftybj at 0x7f0c741dfa70>', '', 'lambda x: x * 15.72', 'lambda x: x * 2.0', '', 'lambda x: x * 15.23', 'lambda x: x * 3.5', '<function xftybj at 0x7fa780710d30>', ...
Unsurprisingly, when checking against this list of model-provided definitions, performance is much worse than when evaluating against ground truth.
It would be interesting to look into more different functions and models, as there might exist ones with a stronger connection between OOD predictions and provided definitions. However, I'll leave it here for now.
My guess is that for any given finetune and function, OOD regression performance correlates with performance on providing definitions, but that the model doesn't perform better on its own provided definitions than on the ground truth definitions. From looking at plots of function values, the way they are wrong OOD often looked more like noise or calculation errors to me rather than eg getting the coefficient wrong. I'm not sure, though. I might run an evaluation on this soon and will report back here.
How much time do you think there is between "ability to automate" and "actually this has been automated"? Are your numbers for actual automation, or just ability? I personally would agree to your numbers if they are about ability to automate, but I think it will take much longer to actually automate, due to people's inertia and normal regulatory hurdles (though I find it confusing to think about, because we might have vastly superhuman AI and potentially loss of control before everything is actually automated.)
I found this clarifying for my own thinking! Just a small additional point, in Hidden Incentives for Auto-Induced Distributional Shift, there is also the example of a Q learner that learns to sometimes take a non-myopic action (I believe cooperating with its past self in a prisoner's dilemma), without any meta learning.
Thank you! :)
Yes, one could e.g. have a clear disclaimer above the chat window saying that this is a simulation and not the real Bill Gates. I still think this is a bit tricky. E.g., Bill Gates could be really persuasive and insist that the disclaimer is wrong. Some users might then end up believing Bill Gates rather than the disclaimer. Moreover, even if the user believes the disclaimer on a conscious level, impersonating someone might still have a subconscious effect. E.g., imagine an AI friend or companion who repeatedly reminds you that they are just an AI, versus one that pretends to be a human. The one that pretends to be a human might gain more intimacy with the user even if on an abstract level the users knows that it's just an AI.
I don't actually know whether this would conflict in any way with the EU AI act. I agree that the disclaimer may be enough for the sake of the act.
My takeaway from looking at the paper is that the main work is being done by the assumption that you can split up the joint distribution implied by the model as a mixture distribution
such that the model does Bayesian inference in this mixture model to compute the next sentence given a prompt, i.e., we have . Together with the assumption that is always bad (the sup condition you talk about), this makes the whole approach with giving more and more evidence for by stringing together bad sentences in the prompt work.
To see why this assumption is doing the work, consider an LLM that completely ignores the prompt and always outputs sentences from a bad distribution with probability and from a good distribution with probability. Here, adversarial examples are always possible. Moreover, the bad and good sentences can be distinguishable, so Definition 2 could be satisfied. However, the result clearly does not apply (since you just cannot up- or downweigh anything with the prompt, no matter how long). The reason for this is that there is no way to split up the model into two components and , where one of the components always samples from the bad distribution.
This assumption implies that there is some latent binary variable of whether the model is predicting a bad distribution, and the model is doing Bayesian inference to infer a distribution over this variable and then sample from the posterior. It would be violated, for instance, if the model is able to ignore some of the sentences in the prompt, or if it is more like a hidden Markov model that can also allow for the possibility of switching characters within a sequence of sentences (then either has to be able to also output good sentences sometimes, or the assumption is violated).
I do think there is something to the paper, though. It seems that when talking e.g. about the Waluigi effect people often take the stance that the model is doing this kind of Bayesian inference internally. If you assume this is the case (which would be a substantial assumption of course), then the result applies. It's a basic, non-surprising learning-theoretic result, and maybe one could express it more simply than in the paper, but it does seem to me like it is a formalization of the kinds of arguments people have made about the Waluigi effect.
Fixed links to all the posts in the sequence:
- Acausal trade: Introduction
- Acausal trade: double decrease
- Acausal trade: universal utility, or selling non-existence insurance too late
- Acausal trade: full decision algorithms
- Acausal trade: trade barriers
- Acausal trade: different utilities, different trades
- Acausal trade: being unusual
- Acausal trade: conclusion: theory vs practice
Fixed links to all the posts in the sequence:
- Acausal trade: Introduction
- Acausal trade: double decrease
- Acausal trade: universal utility, or selling non-existence insurance too late
- Acausal trade: full decision algorithms
- Acausal trade: trade barriers
- Acausal trade: different utilities, different trades
- Acausal trade: being unusual
- Acausal trade: conclusion: theory vs practice
Fixed links to all the posts in the sequence:
- Acausal trade: Introduction
- Acausal trade: double decrease
- Acausal trade: universal utility, or selling non-existence insurance too late
- Acausal trade: full decision algorithms
- Acausal trade: trade barriers
- Acausal trade: different utilities, different trades
- Acausal trade: being unusual
- Acausal trade: conclusion: theory vs practice
Fixed links to all the posts in the sequence:
- Acausal trade: Introduction
- Acausal trade: double decrease
- Acausal trade: universal utility, or selling non-existence insurance too late
- Acausal trade: full decision algorithms
- Acausal trade: trade barriers
- Acausal trade: different utilities, different trades
- Acausal trade: being unusual
- Acausal trade: conclusion: theory vs practice
Fixed links to all the posts in the sequence:
- Acausal trade: Introduction
- Acausal trade: double decrease
- Acausal trade: universal utility, or selling non-existence insurance too late
- Acausal trade: full decision algorithms
- Acausal trade: trade barriers
- Acausal trade: different utilities, different trades
- Acausal trade: being unusual
- Acausal trade: conclusion: theory vs practice
Fixed links to all the posts in the sequence:
- Acausal trade: Introduction
- Acausal trade: double decrease
- Acausal trade: universal utility, or selling non-existence insurance too late
- Acausal trade: full decision algorithms
- Acausal trade: trade barriers
- Acausal trade: different utilities, different trades
- Acausal trade: being unusual
- Acausal trade: conclusion: theory vs practice
Fixed links to all the posts in the sequence:
- Acausal trade: Introduction
- Acausal trade: double decrease
- Acausal trade: universal utility, or selling non-existence insurance too late
- Acausal trade: full decision algorithms
- Acausal trade: trade barriers
- Acausal trade: different utilities, different trades
- Acausal trade: being unusual
- Acausal trade: conclusion: theory vs practice
Since the links above are broken, here are links to all the other posts in the sequence:
- This post
- Acausal trade: double decrease
- Acausal trade: universal utility, or selling non-existence insurance too late
- Acausal trade: full decision algorithms
- Acausal trade: trade barriers
- Acausal trade: different utilities, different trades
- Acausal trade: being unusual
- Acausal trade: conclusion: theory vs practice
Some further thoughts on training ML models, based on discussions with Caspar Oesterheld:
- I don't see a principled reason why one couldn't use one and the same model for both agents. I.e., do standard self-play training with weight sharing for this zero-sum game. Since both players have exactly the same loss function, we don't need to allow them to specialize by feeding in a player id or something like that (there exists a symmetric Nash equilibrium).
- There is one problem with optimizing the objective in the zero-sum game via gradient descent (assuming we could approximate this gradient, e.g., via policy gradient). The issue is that the response of the human to the prediction is discontinuous and not differentiable. I.e., local changes to the prediction will never change the action of the human and thus the gradient would just improve the prediction given the current action, rather than encouraging making predictions that make other actions look more favorable. This shows that, without any modification to the human policy, gradient descent on the objective would be equivalent to repeated gradient descent/gradient descent on the stop gradient objective. To make sure this converges, one would have to implement some exploration of all of the actions. (Of course, one may hope that the model generalizes correctly to new predictions.)
- One could get around this issue by employing other, non-local optimization methods (e.g., a random search—which would effectively introduce some exploration). Here, one would still retain the desirable honesty properties of the optimum in the zero-sum game, which would not be the case when just optimizing the score.
- Another way to view the zero-sum game, in the case where both players are the same model, is as below optimization problem (where is assumed to be the ground truth). Note that we are here just subtracting the score received by the same model, but we are fixing that score when optimizing to avoid making the objective .
Regarding your last point 3., why does this make you more pessimistic rather than just very uncertain about everything?
Why would alignment with the outer reward function be the simplest possible terminal goal? Specifying the outer reward function in the weights would presumably be more complicated. So one would have to specify a pointer towards it in some way. And it's unclear whether that pointer is simpler than a very simple misaligned goal.
Such a pointer would be simple if the neural network already has a representation of the outer reward function in weights anyway (rather than deriving it at run-time in the activations). But it seems likely that any fixed representation will be imperfect and can thus be improved upon at inference time by a deceptive agent (or an agent with some kind of additional pointer). This of course depends on how much inference time compute and memory / context is available to the agent.
I am not sure I understand. Are you saying that GPT thinks the text is genuinely from the future (i.e., the distribution that it is modeling contains text from the future), or that it doesn't think so? The sentence you quote is intended to mean that it does not think the text is genuinely from the future.
Thanks for your comment!
Regarding 1: I don't think it would be good to simulate superintelligences with our predictive models. Rather, we want to simulate humans to elicit safe capabilities. We talk more about competitiveness of the approach in Section III.
Regarding 3: I agree it might have been good to discuss cyborgism specifically. I think cyborgism is to some degree compatible with careful conditioning. One possible issue when interacting with the model arises when the model is trained on / prompted with its own outputs, or data that has been influenced by its outputs. We write about this in the context of imitative amplification and above when considering factorization:
There are at least two major issues: it increases the probability that the model will predict AIs rather than humans, and it specifically increases the probability the model will predict itself, leading to multiple fixed points and the possibility of self-fulfilling prophecies.
I personally think there might be ways to make such approaches work and get around the issues, e.g., by making sure that the model is myopic and that there is a unique fixed point. But we would lose some of the safety properties of just doing conditioning.
Regarding 2: I agree that it would be good if we can avoid fooling ourselves. One hope would be that in a sufficiently capable model, conditioning would help with generating work that isn't worse than that produced by real humans.
You are right, thanks for the comment! Fixed it now.
I like the idea behind this experiment, but I find it hard to tell from this write-up what is actually going on. I.e., what is exactly the training setup, what is exactly the model, which parts are hard-coded and which parts are learned? Why is it a weirdo janky thing instead of some other standard model or algorithm? It would be good if this was explained more in the post (it is very effortful to try to piece this together by going through the code). Right now I have a hard time making any inferences from the results.
Update: we recently discovered the performative prediction (Perdomo et al., 2020) literature (HT Alex Pan). This is a machine learning setting where we choose a model parameter (e.g., parameters for a neural network) that minimizes expected loss (e.g., classification error). In performative prediction, the distribution over data points can depend on the choice of model parameter. Our setting is thus a special case in which the parameter of interest is a probability distribution, the loss is a scoring function, and data points are discrete outcomes. Most results in this post have analogues in performative prediction. We will give a more detailed comparison in an upcoming paper. We also discuss performative prediction more in our follow-up post on stop-gradients.
I think there should be a space both for in-progress research dumps and for more worked out final research reports on the forum. Maybe it would make sense to have separate categories for them or so.
I'm not sure I understand what you mean by a skill-free scoring rule. Can you elaborate what you have in mind?
Thanks for your comment!
Your interpretation sounds right to me. I would add that our result implies that it is impossible to incentivize honest reports in our setting. If you want to incentivize honest reports when is constant, then you have to use a strictly proper scoring rule (this is just the definition of “strictly proper”). But we show for any strictly proper scoring rule that there is a function such that a dishonest prediction is optimal.
Proposition 13 shows that it is possible to “tune” scoring rules to make optimal predictions very close to honest ones (at least in L1-distance).
I think for 'self-fulfilling prophecy' I would also expect there to be a counterfactual element--if I say the sun will rise tomorrow and it rises tomorrow, this isn't a self-fulfilling prophecy because the outcome isn't reliant on expectations about the outcome.
Yes, that is fair. To be faithful to the common usage of the term, one should maybe require at least two possible fixed points (or points that are somehow close to fixed points). The case with a unique fixed point is probably also safer, and worries about “self-fulfilling prophecies” don't apply to the same degree.
Thank you!
I think such a natural progression could also lead to something similar to extinction (in addition to permanently curtailing humanity's potential). E.g., maybe we are currently in a regime where optimizing proxies harder still leads to improvements to the true objective, but this could change once we optimize those proxies even more. The natural progression could follow an inverted U-shape.
E.g., take the marketing example. Maybe we will get superhuman persuasion AIs, but also AIs that protect us from persuasive ads and AIs that can provide honest reviews. It seems unclear whether these things would tend to balance out, or whether e.g. everyone will inevitably be exposed to some persuasion that causes irreparable damage. Of course, things could also work out better than expected, if our ability to keep AIs in check scales better than dangerous capabilities.
There is a chance that one can avoid having to solve ontology identification in general if one punts the problem to simulated humans. I.e., it seems one can train the human simulator without solving it, and then use simulated humans to solve the problem. One may have to solve some specific ontology identification problems to make sure one gets an actual human simulator and not e.g. a malign AI simulator. However, this might be easier than solving the problem in full generality.
Minor comment: regarding the RLHF example, one could solve the problem implicitly if one is able to directly define a likelihood function over utility functions defined in the AI's ontology, given human behavior. Though you probably correctly assume that e.g. cognitive science would produce a likelihood function over utility functions in the human ontology, in which case ontology identification still has to be solved explicitly.
(I think Stockfish would be classified as AI in computer science. I.e., you'd learn about the basic algorithms behind it in a textbook on AI. Maybe you mean that Stockfish was non-ML, or that it had handcrafted heuristics?)
Great post!
I like that you point out that we'd normally do trial and error, but that this might not work with AI. I think you could possibly make clearer where this fails in your story. You do point out how HLMI might become extremely widespread and how it might replace most human work. Right now it seems to me like you argue essentially that the problem is a large-scale accident that comes from a distribution shift. But this doesn't yet say why we couldn't e.g. just continue trial-and-error and correct the AI once we notice that something is going wrong.
I think one would need to invoke something like instrumental convergence, goal preservation and AI being power-seeking, to argue that this isn't just an accident that could be prevented if we gave some more feedback in time. It is important for the argument that the AI is pursuing the wrong goals and thus wouldn't want to be stopped, etc.
Of course, one has to simplify the argument somehow in an introduction like this (and you do elaborate in the appendix), but maybe some argument about instrumental convergence should still be included in the main text.
Overall I agree that solutions to deception look different from solutions to other kinds of distributional shift. (Also, there are probably different solutions to different kinds of large distributional shift as well. E.g., solutions to capability generalization vs solutions to goal generalization.)
I do think one could claim that some general solutions to distributional shift would also solve deceptiveness. E.g., the consensus algorithm works for any kind of distributional shift, but it should presumably also avoid deceptiveness (in the sense that it would not go ahead and suddenly start maximizing some different goal function, but instead would query the human first). Stuart Armstrong might claim a similar thing about concept extrapolation?
I personally think it is probably best to just try to work on deceptiveness directly instead of solving some more general problem and hoping non-deceptiveness is a side effect. It is probably harder to find a general solution than to solve only deceptiveness. Though maybe this depends on one's beliefs about what is easy or hard to do with deep learning.
I like this post and agree that there are different threat models one might categorize broadly under "inner alignment". Before reading this I hadn't reflected on the relationship between them.
Some random thoughts (after an in-person discussion with Erik):
- For distributional shift and deception, there is a question of what is treated as fixed and what is varied when asking whether a certain agent has a certain property. E.g., I could keep the agent constant but put it into a new environment, and ask whether it is still aligned. Or I could keep the environment constant but "give the agent more capabilities". Or I could only change some random number generator's input or output and observe what changes. The question of what I'm allowed to change to figure out whether the agent could do some unaligned thing in a new condition is really important; e.g., if I can change everything about the agent, the question becomes meaningless.
- One can define deception as a type of distributional shift. E.g., define agents as deterministic functions. We model different capabilities via changing the environment (e.g. giving it more options) and treat any potential internal agent state and randomness as additional inputs to the function. In that case, if I can test the function on all possible inputs, there is no way for the agent to be unaligned. And deception is a case where the distributional shift can be extremely small and still lead to very different behavior. An agent that is "continuous" in the inputs cannot be deceptive (but it can still be unaligned after distributional shift in general).
- It is a bit unclear to me what exactly the sharp left turn means. It is not a property that an agent can have, like inner misalignment or deceptiveness. One interpretation would be that it is an argument for why AIs will become deceptive (they suddenly realize that being deceptive is optimal for their goals, even if they don't suddenly get total control over the world). Another interpretation would be that it is an argument why we will get x-risks, even without deception (because the transition from subhuman to superhuman capabilities happens so fast that we aren't able to correct any inner misalignment before it's too late).
- One takeaway from the second interpretation of the sharp left turn argument could be that you need to have really fine-grained supervision of the AI, even if it is never deceptive, just because it could go from not thinking about taking over the world to taking over the world in just a few gradient descent steps. Or instead of supervising only gradient descent steps, you would also need to supervise intermediate results of some internal computation in a fine-grained way.
- It does seem right that one also needs to supervise intermediate results of internal computation. However, it probably makes sense to focus on avoiding deception, as deceptiveness would be the main reason why supervision could go wrong.
Great post!
Regarding your “Redirecting civilization” approach: I wonder about the competitiveness of this. It seems that we will likely build x-risk-causing AI before we have a good enough model to be able to e.g. simulate the world 1000 years into the future on an alternative timeline? Of course, competitiveness is an issue in general, but the more factored cognition or IDA based approaches seem more realistic to me.
Alternatively, we can try to be clever and “import” research from the future repeatedly. For instance we can first ask our model to produce research from 5 years out. Then, we can condition our model on that research existing today, and again ask it for research 5 years out. The problem with this approach is that conditioning on future research suddenly appearing today almost guarantees that there is a powerful AGI involved, which could well be deceptive, and that again is very bad.
I wonder whether there might also be an issue with recursion here. In this approach, we condition on research existing today. In the IDA approach, we train the model to output such research directly. Potentially the latter can be seen as a variant of conditioning if we train with a KL-divergence penalty. In the latter approach, we are worried about fixed-point and superrationality-based nonmyopia issues. I wonder whether something like this concern would also apply to the former approach. Also, now I'm confused about whether the same issue also arises in the normal use-case as a token-by-token simulator, or whether there are some qualitative differences between these cases.
These issues of preferences over objects of different types (internal states, policies, actions, etc.) and how to translate between them are also discussed in the post Agents Over Cartesian World Models.
Your post seems to be focused more on pointing out a missing piece in the literature rather than asking for a solution to the specific problem (which I believe is a valuable contribution). Regardless, here is roughly how I would understand “what they mean”:
Let be the task space, the output space, the model space, our base objective, and the mesa objective of the model for input . Assume that there exists some map mapping internal objects to outputs by the model, such that .
Given this setup, how can we reconcile and ? Assume some distribution over the task space is given. Moreover, assume there exists a function mapping tasks to utility functions over outputs, such that . Then we could define a mesa objective as where if and otherwise we define as some very small number or (and replace by above). We can then compare and directly via some distance on the spaces and .
Why would such a function exist? In stochastic gradient descent, for instance, we are in fact evaluating models based on the outputs they produce on tasks distributed according to some distribution . Moreover, such a function should probably exist given some regularity conditions imposed on an arbitrary objective (inspired by the axioms of expected utility theory).
Why would a function exist? Some function connecting outputs to the internal search space has to exist because the model is producing outputs. In practice, the model might not optimize perfectly and thus might not always choose the argmax (potentially leading to suboptimality alignment), but this could probably still be accounted for somehow in this model. Moreover, could theoretically differ between different inputs, but again one could probably change definitions in some way to make things work.
If is a mesa-optimizer, then there should probably be some way to make sense of the mathematical objects describing mesa objective, search space, and model outputs as described above. Of course, how to do this exactly, especially for more general mesa-optimizers that only optimize objectives approximately, etc., still needs to be worked out more.
Thank you!
It does seem like simulating text generated by using similar models would be hard to avoid when using the model as a research assistant. Presumably any research would get “contaminated” at some point, and models might seize to be helpful without updating them on the newest research.
In theory, if one were to re-train models from scratch on the new research, this might be equivalent to the models updating on the previous models' outputs before reasoning about superrationality, so it would turn things into a version of Newcomb's problem with transparent boxes. This might make coordination between the models less likely? Apart from this, I do think logical dependences and superrationality would be broken if there is a strict hierarchy between different versions of models, where models know their place in the hierarchy.
The other possibility would be to not rely on IDA at all, instead just training a superhuman model and using it directly. Maybe one could extract superhuman knowledge from them safely via some version of microscope AI? Of course, in this case, the model might still reason about humans using similar models, based on its generalization ability alone. Regarding using prompts, I wonder, how do you think we could get the kind of model you talk about in your post on conditioning generative models?
Thanks for your comment! I agree that we probably won't be able to get a textbook from the future just by prompting a language model trained on human-generated texts.
As mentioned in the post, maybe one could train a model to also condition on observations. If the model is very powerful, and it really believes the observations, one could make it work. I do think sometimes it would be beneficial for a model to attain superhuman reasoning skills, even if it is only modeling human-written text. Though of course, this might still not happen in practice.
Overall I'm more optimistic about using the model in an IDA-like scheme. One way this might fail on capability grounds is if solving alignment is blocked by a lack of genius-level insights, and if it is hard to get a model to come up with/speed up such insights (e.g. due to a lack of training data containing such insights).
Would you count issues with malign priors etc. also as issues with myopia? Maybe I'm missing something about what myopia is supposed to mean and be useful for, but these issues seem to have a similar spirit of making an agent do stuff that is motivated by concerns about things happening at different times, in different locations, etc.
E.g., a bad agent could simulate 1000 copies of the LCDT agent and reward it for a particular action favored by the bad agent. Then depending on the anthropic beliefs of the LCDT agent, it might behave so as to maximize this reward. (HT to James Lucassen for making me aware of this possibility).
The fact that LCDT doesn't try to influence agents doesn't seem to help—the bad agent could just implement a very simple reward function that checks the action of the LCDT agent to get around this. That reward function surely wouldn't count as an agent. (This possibility could also lead to non-myopia in the (N,M)-Deception problem).
I guess one could try to address these problems either by making the agent have better priors/beliefs (maybe this is already okay by default for some types of models trained via SGD?), or by using different decision theories.
If someone had a strategy that took two years, they would have to over-bid in the first year, taking a loss. But then they have to under-bid on the second year if they're going to make a profit, and--"
"And they get undercut, because someone figures them out."
I think one could imagine scenarios where the first trader can use their influence in the first year to make sure they are not undercut in the second year, analogous to the prediction market example. For instance, the trader could install some kind of encryption in the software that this company uses, which can only be decrypted by the private key of the first trader. Then in the second year, all the other traders would face additional costs of replacing the software that is useless to them, while the first trader can continue using it, so the first trader can make more money in the second year (and get their loss from the first year back).
I find this particularly curious since naively, one would assume that weight sharing implicitly implements a simplicity prior, so it should make optimization more likely and thus also deceptive behavior? Maybe the argument is that somehow weight sharing leaves less wiggle room for obscuring one's reasoning process, making a potential optimizer more interpretable? But the hidden states and tied weights could still be encoding deceptive reasoning in an uninterpretable way?
I'd also be curious about this!
Which program is that, if I may ask?
Wolfgang Spohn develops the concept of a "dependency equilibrium" based on a similar notion of evidential best response (Spohn 2007, 2010). A joint probability distribution is a dependency equilibrium if all actions of all players that have positive probability are evidential best responses. In case there are actions with zero probability, one evaluates a sequence of joint probability distributions such that and for all actions and . Using your notation of a probability matrix and a utility matrix, the expected utility of an action is then defined as the limit of the conditional expected utilities, (which is defined for all actions). Say is a probability matrix with only one zero column, . It seems that you can choose an arbitrary nonzero vector , to construct, e.g., a sequence of probability matrices The expected utilities in the limit for all other actions and the actions of the opponent shouldn't be influenced by this change. So you could choose as the standard vector where is an index such that . The expected utility of would then be . Hence, this definition of best response in case there are actions with zero probability probably coincides with yours (at least for actions with positive probability—Spohn is not concerned with the question of whether a zero probability action is a best response or not).
The whole thing becomes more complicated with several zero rows and columns, but I would think it should be possible to construct sequences of distributions which work in that case as well.
I would like to submit the following entries:
A typology of Newcomblike problems (philosophy paper, co-authored with Caspar Oesterheld).
A wager against Solomonoff induction (blog post).
Three wagers for multiverse-wide superrationality (blog post).
UDT is “updateless” about its utility function (blog post). (I think this post is hard to understand. Nevertheless, if anyone finds it intelligible, I would be interested in their thoughts.)
EDT doesn't pay if it is given the choice to commit to not paying ex-ante (before receiving the letter). So the thought experiment might be an argument against ordinary EDT, but not against updateless EDT. If one takes the possibility of anthropic uncertainty into account, then even ordinary EDT might not pay the blackmailer. See also Abram Demski's post about the Smoking Lesion. Ahmed and Price defend EDT along similar lines in a response to a related thought experiment by Frank Arntzenius.
Thanks for your answer! This "gain" approach seems quite similar to what Wedgwood (2013) has proposed as "Benchmark Theory", which behaves like CDT in cases with, but more like EDT in cases without causally dominant actions. My hunch would be that one might be able to construct a series of thought-experiments in which such a theory violates transitivity of preference, as demonstrated by Ahmed (2012).
I don't understand how you arrive at a gain of 0 for not smoking as a smoke-lover in my example. I would think the gain for not smoking is higher:
.
So as long as , the gain of not smoking is actually higher than that of smoking. For example, given prior probabilities of 0.5 for either state, the equilibrium probability of being a smoke-lover given not smoking will be 0.5 at most (in the case in which none of the smoke-lovers smoke).
From my perspective, I don’t think it’s been adequately established that we should prefer updateless CDT to updateless EDT
I agree with this.
It would be nice to have an example which doesn’t arise from an obviously bad agent design, but I don’t have one.
I’d also be interested in finding such a problem.
I am not sure whether your smoking lesion steelman actually makes a decisive case against evidential decision theory. If an agent knows about their utility function on some level, but not on the epistemic level, then this can just as well be made into a counter-example to causal decision theory. For example, consider a decision problem with the following payoff matrix:
Smoke-lover:
-
Smokes:
- Killed: 10
- Not killed: -90
-
Doesn't smoke:
- Killed: 0
- Not killed: 0
Non-smoke-lover:
-
Smokes:
- Killed: -100
- Not killed: -100
-
Doesn't smoke:
- Killed: 0
- Not killed: 0
For some reason, the agent doesn’t care whether they live or die. Also, let’s say that smoking makes a smoke-lover happy, but afterwards, they get terribly sick and lose 100 utilons. So they would only smoke if they knew they were going to be killed afterwards. The non-smoke-lover doesn't want to smoke in any case.
Now, smoke-loving evidential decision theorists rightly choose smoking: they know that robots with a non-smoke-loving utility function would never have any reason to smoke, no matter which probabilities they assign. So if they end up smoking, then this means they are certainly smoke-lovers. It follows that they will be killed, and conditional on that state, smoking gives 10 more utility than not smoking.
Causal decision theory, on the other hand, seems to recommend a suboptimal action. Let be smoking, not smoking, being a smoke-lover, and being a non-smoke-lover. Moreover, say the prior probability is . Then, for a smoke-loving CDT bot, the expected utility of smoking is just
,
which is less then the certain utilons for . Assigning a credence of around to , a smoke-loving EDT bot calculates
,
which is higher than the expected utility of .
The reason CDT fails here doesn’t seem to lie in a mistaken causal structure. Also, I’m not sure whether the problem for EDT in the smoking lesion steelman is really that it can’t condition on all its inputs. If EDT can't condition on something, then EDT doesn't account for this information, but this doesn’t seem to be a problem per se.
In my opinion, the problem lies in an inconsistency in the expected utility equations. Smoke-loving EDT bots calculate the probability of being a non-smoke-lover, but then the utility they get is actually the one from being a smoke-lover. For this reason, they can get some "back-handed" information about their own utility function from their actions. The agents basically fail to condition two factors of the same product on the same knowledge.
Say we don't know our own utility function on an epistemic level. Ordinarily, we would calculate the expected utility of an action, both as smoke-lovers and as non-smoke-lovers, as follows:
,
where, if () is the utility function of a smoke-lover (non-smoke-lover), is equal to . In this case, we don't get any information about our utility function from our own action, and hence, no Newcomb-like problem arises.
I’m unsure whether there is any causal decision theory derivative that gets my case (or all other possible cases in this setting) right. It seems like as long as the agent isn't certain to be a smoke-lover from the start, there are still payoffs for which CDT would (wrongly) choose not to smoke.
Imagine that Omega tells you that it threw its coin a million years ago, and would have turned the sky green if it had landed the other way. Back in 2010, I wrote a post arguing that in this sort of situation, since you've always seen the sky being blue, and every other human being has also always seen the sky being blue, everyone has always had enough information to conclude that there's no benefit from paying up in this particular counterfactual mugging, and so there hasn't ever been any incentive to self-modify into an agent that would pay up ... and so you shouldn't.
I think this sort of reasoning doesn't work if you also have a precommitment regarding logical facts. Then you know the sky is blue, but you don't know what that implies. When Omega informs you about the logical connection between sky color, your actions, and your payoff, then you won't update on this logical fact. This information is one implication away from the logical prior you precommitted yourself to. And the best policy given this prior, which contains information about sky color, but not about this blackmail, is not to pay: not paying will a priori just change the situation in which you will be blackmailed (hence, what blue sky color means), but not the probability of a positive intelligence explosion in the first place. Knowing or not knowing the color of the sky doesn't make a difference, as long as we don't know what it implies.
(HT Lauro Langosco for pointing this out to me.)
Thanks for the reply and all the useful links!
It's not a given that you can easily observe your existence.
It took me a while to understand this. Would you say that for example in the Evidential Blackmail, you can never tell whether your decision algorithm is just being simulated or whether you're actually in the world where you received the letter, because both times, the decision algorithms receive exactly the same evidence? So in this sense, after updating on receiving the letter, both worlds are still equally likely, and only via your decision do you find out which of those worlds are the simulated ones and which are the real ones. One can probably generalize this principle: you can never differentiate between different instantiations of your decision algorithm that have the same evidence. So when you decide what action to output conditional on receiving some sense data, you always have to decide based on your prior probabilities. Normally, this works exactly as if you would first update on this sense data and then decide. But sometimes, e.g. if your actions in one world make a difference to the other world via a simulation, then it makes a difference. Maybe if you assign anthropic probabilities to either being a "logical zombie" or the real you, then the result would be like UDT even with updating?
What I still don't understand is how this motivates updatelessness with regard to anthropic probabilities (e.g. if I know that I have a low index number, or in Psy Kosh's problem, if I already know I'm the decider). I totally get how it makes sense to precommit yourself and how one should talk about decision problems instead of probabilities, how you should reason as if you're all instantiations of your decision algorithm at once, etc. Also, intuitively I agree with sticking with the priors. But somehow I can't get my head around what exactly is wrong about the update. Why is it wrong to assign more "caring energy" to the world in which some kind of observation that I make would have been more probable? Is it somehow wrong that it "would have been more probable"? Did I choose the wrong reference classes? Is it because in these problems, too, the worlds influence each other, so that you have to consider the impact that your decision would have on the other world as well?
Edit: Never mind, I think http://lesswrong.com/lw/jpr/sudt_a_toy_decision_theory_for_updateless/ kind of answers my question :)