Alignment By Default
post by johnswentworth · 2020-08-12T18:54:00.751Z · LW · GW · 96 commentsContents
Unsupervised: Pointing to Values Unsupervised: Natural Abstractions Aside: Microscope AI Supervised/Reinforcement: Proxy Problems Alignment in the Long Run Conclusion None 96 comments
Suppose AI continues on its current trajectory: deep learning continues to get better as we throw more data and compute at it, researchers keep trying random architectures and using whatever seems to work well in practice. Do we end up with aligned AI “by default”?
I think there’s at least a plausible trajectory in which the answer is “yes”. Not very likely - I’d put it at ~10% chance - but plausible. In fact, there’s at least an argument to be made that alignment-by-default is more likely to work than many fancy alignment proposals, including IRL variants [? · GW] and HCH-family methods [? · GW].
This post presents the rough models and arguments.
I’ll break it down into two main pieces:
- Will a sufficiently powerful unsupervised learner “learn human values”? What does that even mean?
- Will a supervised/reinforcement learner end up aligned to human values, given a bunch of data/feedback on what humans want?
Ultimately, we’ll consider a semi-supervised/transfer-learning style approach, where we first do some unsupervised learning and hopefully “learn human values” before starting the supervised/reinforcement part.
As background, I will assume you’ve read some of the core material about human values from the sequences [? · GW], including Hidden Complexity of Wishes [LW · GW], Value is Fragile [LW · GW], and Thou Art Godshatter [LW · GW].
Unsupervised: Pointing to Values
In this section, we’ll talk about why an unsupervised learner might not “learn human values”. Since an unsupervised learner is generally just optimized for predictive power, we’ll start by asking whether theoretical algorithms with best-possible predictive power (i.e. Bayesian updates on low-level physics models) “learn human values”, and what that even means. Then, we’ll circle back to more realistic algorithms.
Consider a low-level physical model of some humans - e.g. a model which simulates every molecule comprising the humans. Does this model “know human values”? In one sense, yes: the low-level model has everything there is to know about human values embedded within it, in exactly the same way that human values are embedded in physical humans. It has “learned human values”, in a sense sufficient to predict any real-world observations involving human values.
But it seems like there’s a sense in which such a model does not “know” human values. Specifically, although human values are embedded in the low-level model, the embedding itself is nontrivial. Even if we have the whole low-level model, we still need that embedding in order to “point to” human values specifically - e.g. to use them as an optimization target. Indeed, when we say “point to human values”, what we mean is basically “specify the embedding”. (Side note: treating human values as an optimization target is not the only use-case for “pointing to human values”, and we still need to point to human values even if we’re not explicitly optimizing for anything. But that’s a separate discussion [LW · GW], and imagining using values as an optimization target is useful to give a mental image of what we mean by “pointing”.)
In short: predictive power alone is not sufficient to define human values. The missing part is the embedding of values within the model. The hard part is pointing to the thing (i.e. specifying the values-embedding), not learning the thing (i.e. finding a model in which values are embedded).
Finally, here’s a different angle on the same argument which will probably drive some of the philosophers up in arms: any model of the real world with sufficiently high general predictive power will have a model of human values embedded within it. After all, it has to predict the parts of the world in which human values are embedded in the first place - i.e. the parts of which humans are composed, the parts on which human values are implemented. So in principle, it doesn’t even matter what kind of model we use or how it’s represented; as long the predictive power is good enough, values will be embedded in there, and the main problem will be finding the embedding.
Unsupervised: Natural Abstractions
In this section, we’ll talk about how and why a large class of unsupervised methods might “learn the embedding” of human values, in a useful sense.
First, notice that basically everything from the previous section still holds if we replace the phrase “human values” with “trees”. A low-level physical model of a forest has everything there is to know about trees embedded within it, in exactly the same way that trees are embedded in the physical forest. However, while there are trees embedded in the low-level model, the embedding itself is nontrivial. Predictive power alone is not sufficient to define trees; the missing part is the embedding of trees within the model.
More generally, whenever we have some high-level abstract object (i.e. higher-level than quantum fields), like trees or human values, a low-level model might have the object embedded within it but not “know” the embedding.
Now for the interesting part: empirically, we have whole classes of neural networks in which concepts like “tree” have simple, identifiable embeddings. These are unsupervised systems, trained for predictive power, yet they apparently “learn the tree-embedding” in the sense that the embedding is simple: it’s just the activation of a particular neuron, a particular channel, or a specific direction in the activation-space of a few neurons.

What’s going on here? We know that models optimized for predictive power will not have trivial tree-embeddings in general; low-level physics simulations demonstrate that much. Yet these neural networks do end up with trivial tree-embeddings, so presumably some special properties of the systems make this happen. But those properties can’t be that special, because we see the same thing for a reasonable variety of different architectures, datasets, etc.
Here’s what I think is happening: “tree” is a natural abstraction. More on what that means here [LW · GW], but briefly: abstractions summarize information which is relevant far away. When we summarize a bunch of atoms as “a tree”, we’re throwing away lots of information about the exact positions of molecules/cells within the tree, or about the pattern of bark on the tree’s surface. But information like the exact positions of molecules within the tree is irrelevant to things far away - that signal is all wiped out by the noise of air molecules between the tree and the observer. The flap of a butterfly’s wings may alter the trajectory of a hurricane, but unless we know how all wings of all butterflies are flapping, that tiny signal is wiped out by noise for purposes of our own predictions. Most information is irrelevant to things far away, not in the sense that there’s no causal connection, but in the sense that the signal is wiped out by noise in other unobserved variables.
If a concept is a natural abstraction, that means that the concept summarizes all the information which is relevant to anything far away, and isn’t too sensitive to the exact notion of “far away” involved. That’s what I think is going on with “tree”.
Getting back to neural networks: it’s easy to see why a broad range of architectures would end up “using” natural abstractions internally. Because the abstraction summarizes information which is relevant far away, it allows the system to make far-away predictions without passing around massive amounts of information all the time. In a low-level physics model, we don’t need abstractions because we do pass around massive amounts of information all the time, but real systems won’t have anywhere near that capacity any time soon. So for the foreseeable future, we should expect to see real systems with strong predictive power using natural abstractions internally.
With all that in mind, it’s time to drop the tree-metaphor and come back to human values. Are human values a natural abstraction?
If you’ve read Value is Fragile [LW · GW] or Godshatter [LW · GW], then there’s probably a knee-jerk reaction to say “no”. Human values are basically a bunch of randomly-generated heuristics which proved useful for genetic fitness; why would they be a “natural” abstraction? But remember, the same can be said of trees. Trees are a complicated pile of organic spaghetti code [LW · GW], but “tree” is still a natural abstraction, because the concept summarizes all the information from that organic spaghetti pile which is relevant to things far away. In particular, it summarizes anything about one tree which is relevant to far-away trees.
Similarly, the concept of “human” summarizes all the information about one human which is relevant to far-away humans. It’s a natural abstraction.
Now, I don’t think “human values” are a natural abstraction in exactly the same way as “tree” - specifically, trees are abstract objects, whereas human values are properties of certain abstract objects (namely humans). That said, I think it’s pretty obvious that “human” is a natural abstraction in the same way as “tree”, and I expect that humans “have values” in roughly the same way that trees “have branching patterns”. Specifically, the natural abstraction contains a bunch of information, that information approximately factors into subcomponents (including “branching pattern”), and “human values” is one of those information-subcomponents for humans.
I wouldn’t put super-high confidence on all of this, but given the remarkable track record of hackish systems learning natural abstractions in practice, I’d give maybe a 70% chance that a broad class of systems (including neural networks) trained for predictive power end up with a simple embedding of human values. A plurality of my uncertainty is on how to think about properties of natural abstractions. A significant chunk of uncertainty is also on the possibility that natural abstraction is the wrong way to think about the topic altogether, although in that case I’d still assign a reasonable chance that neural networks end up with simple embeddings of human values - after all, no matter how we frame it, they definitely have trivial embeddings of many other complicated high-level objects.
Aside: Microscope AI
Microscope AI [LW · GW] is about studying the structure of trained neural networks, and trying to directly understand their learned internal algorithms, models and concepts. In light of the previous section, there’s an obvious path to alignment where there turns out to be a few neurons (or at least some simple embedding) which correspond to human values, we use the tools of microscope AI to find that embedding, and just like that the alignment problem is basically solved.
Of course it’s unlikely to be that simple in practice, even assuming a simple embedding of human values. I don’t expect the embedding to be quite as simple as one neuron activation, and it might not be easy to recognize even if it were. Part of the problem is that we don’t even know the type signature of the thing we’re looking for - in other words, there are unanswered fundamental conceptual questions here, which make me less-than-confident that we’d be able to recognize the embedding even if it were right under our noses.
That said, this still seems like a reasonably-plausible outcome, and it’s an approach which is particularly well-suited to benefit from marginal theoretical progress.
One thing to keep in mind: this is still only about aligning one AI; success doesn’t necessarily mean a future in which more advanced AIs remain aligned. More on that later.
Supervised/Reinforcement: Proxy Problems
Suppose we collect some kind of data on what humans want, and train a system on that. The exact data and type of learning doesn’t really matter here; the relevant point is that any data-collection process is always, no matter what, at best a proxy for actual human values. That’s a problem, because Goodhart’s Law [? · GW] plus Hidden Complexity of Wishes [LW · GW]. You’ve probably heard this a hundred times already, so I won’t belabor it.
Here’s the interesting possibility: assume the data is crap. It’s so noisy that, even though the data-collection process is just a proxy for real values, the data is consistent with real human values. Visually:
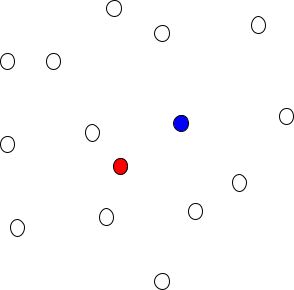
At first glance, this isn’t much of an improvement. Sure, the data is consistent with human values, but it’s consistent with a bunch of other possibilities too - including the real data-collection process (which is exactly the proxy we wanted to avoid in the first place).
But now suppose we do some transfer learning. We start with a trained unsupervised learner, which already has a simple embedding of human values (we hope). We give our supervised learner access to that system during training. Because the unsupervised learner has a simple embedding of human values, the supervised learner can easily score well by directly using that embedded human values model. So, we cross our fingers and hope the supervised learner just directly uses that embedded human values model, and the data is noisy enough that it never “figures out” that it can get better performance by directly modelling the data-collection process instead.
In other words: the system uses an actual model of human values as a proxy for our proxy of human values.
This requires hitting a window - our data needs to be good enough that the system can tell it should use human values as a proxy, but bad enough that the system can’t figure out the specifics of the data-collection process enough to model it directly. This window may not even exist.
(Side note: we can easily adjust this whole story to a situation where we’re training for some task other than “satisfy human values”. In that case, the system would use the actual model of human values to model the Hidden Complexity of whatever task it’s training on.)
Of course in practice, the vast majority of the things people use as objectives for training AI probably wouldn’t work at all. I expect that they usually look like this:
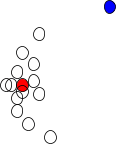
In other words, most objectives are so bad that even a little bit of data is enough to distinguish the proxy from real human values. But if we assume that there’s some try-it-and-see going on, i.e. people try training on various objectives and keep the AIs which seem to do roughly what the humans want, then it’s maybe plausible that we end up iterating our way to training objectives which “work”. That’s assuming things don’t go irreversibly wrong before then - including not just hostile takeover, but even just development of deceptive behavior, since this scenario does not have any built-in mechanism to detect deception.
Overall, I’d give maybe a 10-20% chance of alignment by this path, assuming that the unsupervised system does end up with a simple embedding of human values. The main failure mode I’d expect, assuming we get the chance to iterate, is deception - not necessarily “intentional” deception, just the system being optimized to look like it’s working the way we want rather than actually working the way we want. It’s the proxy problem again, but this time at the level of humans-trying-things-and-seeing-if-they-work, rather than explicit training objectives.
Alignment in the Long Run
So far, we’ve only talked about one AI ending up aligned, or a handful ending up aligned at one particular time. However, that isn’t really the ultimate goal of AI alignment research. What we really want is for AI to remain aligned in the long run, as we (and AIs themselves) continue to build new and more powerful systems and/or scale up existing systems over time.
I know of two main ways to go from aligning one AI to long-term alignment:
- Make the alignment method/theory very reliable and robust to scale, so we can continue to use it over time as AI advances.
- Align one roughly-human-level-or-smarter AI, then use that AI to come up with better alignment methods/theories.
The alignment-by-default path relies on the latter. Even assuming alignment happens by default, it is unlikely to be highly reliable or robust to scale.
That’s scary. We’d be trusting the AI to align future AIs, without having any sure-fire way to know that the AI is itself aligned. (If we did have a sure-fire way to tell, then that would itself be most of a solution to the alignment problem.)
That said, there’s a bright side: when alignment-by-default works, it’s a best-case scenario. The AI has a basically-correct model of human values, and is pursuing those values. Contrast this to things like IRL variants, which at best learn a utility function which approximates human values (which are probably not themselves a utility function). Or the HCH family of methods, which at best mimic a human with a massive hierarchical bureaucracy at their command, and certainly won’t be any more aligned than that human+bureaucracy would be.
To the extent that alignment of the successor system is limited by alignment of the parent system, that makes alignment-by-default potentially a more promising prospect than IRL or HCH. In particular, it seems plausible that imperfect alignment gets amplified into worse-and-worse alignment as systems design their successors. For instance, a system which tries to look like it’s doing what humans want rather than actually doing what humans want will design a successor which has even better human-deception capabilities. That sort of problem makes “perfect” alignment - i.e. an AI actually pointed at a basically-correct model of human values - qualitatively safer than a system which only manages to be not-instantly-disastrous.
(Side note: this isn’t the only reason why “basically perfect” alignment matters, but I do think it’s the most relevant such argument for one-time alignment/short-term term methods, especially on not-very-superhuman AI.)
In short: when alignment-by-default works, we can use the system to design a successor without worrying about amplification of alignment errors. However, we wouldn’t be able to tell for sure whether alignment-by-default had worked or not, and it’s still possible that the AI would make plain old mistakes in designing its successor.
Conclusion
Let’s recap the bold points:
- A low-level model of some humans has everything there is to know about human values embedded within it, in exactly the same way that human values are embedded in physical humans. The embedding, however, is nontrivial. Thus...
- Predictive power alone is not sufficient to define human values. The missing part is the embedding of values within the model. However…
- This also applies if we replace the phrase “human values” with “trees”. Yet we have a whole class of neural networks in which a simple embedding lights up in response to trees. Why?
- Trees are a natural abstraction, and we should expect to see real systems trained for predictive power use natural abstractions internally.
- Human values are a little different from trees (they’re a property of an abstract object rather than an abstract object themselves), but I still expect that a broad class of systems trained for predictive power will end up with simple embeddings of human values (~70% chance).
- Because the unsupervised learner has a simple embedding of human values, a supervised/reinforcement learner can easily score well on values-proxy-tasks by directly using that model of human values. In other words, the system uses an actual model of human values as a proxy for our proxy of human values (~10-20% chance).
- When alignment-by-default works, it’s basically a best-case scenario, so we can safely use the system to design a successor without worrying about amplification of alignment errors (among other things).
Overall, I only give this whole path ~10% chance of working in the short term, and maybe half that in the long term. However, if amplification of alignment errors turns out to be a major limiting factor for long-term alignment, then alignment-by-default is plausibly more likely to work than approaches in the IRL or HCH families.
The limiting factor here is mainly identifying the (probably simple) embedding of human values within a learned model, so microscope AI and general theory development are both good ways to improve the outlook. Also, in the event that we are able to identify a simple embedding of human values in a learned model, it would be useful to have a way to translate that embedding into new systems, in order to align successors.
96 comments
Comments sorted by top scores.
comment by Sammy Martin (SDM) · 2020-08-13T12:45:22.540Z · LW(p) · GW(p)
I think what you've identified here is a weakness in the high-level, classic arguments for AI risk -
Overall, I’d give maybe a 10-20% chance of alignment by this path, assuming that the unsupervised system does end up with a simple embedding of human values. The main failure mode I’d expect, assuming we get the chance to iterate, is deception - not necessarily “intentional” deception, just the system being optimized to look like it’s working the way we want rather than actually working the way we want. It’s the proxy problem again, but this time at the level of humans-trying-things-and-seeing-if-they-work, rather than explicit training objectives.
This failure mode of deceptive alignment seems like it would result most easily from Mesa-optimisation or an inner alignment failure [LW · GW]. Inner Alignment / Misalignment is possibly the key specific mechanism which fills a weakness in the 'classic arguments [LW(p) · GW(p)]' for AI safety - the Orthogonality Thesis, Instrumental Convergence and Fast Progress together implying small separations between AI alignment and AI capability can lead to catastrophic outcomes. The question of why there would be such a damaging, hard-to-detect divergence between goals and alignment needs an answer to have a solid, specific reason to expect dangerous misalignment, and Inner Misalignment is just such a reason.
I think that it should be presented in initial introductions to AI risk alongside those classic arguments, as the specific, technical reason why the specific techniques we use are likely to produce such goal/capability divergence - rather than the general a priori reasons given by the classic arguments.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-13T16:12:25.359Z · LW(p) · GW(p)
Personally, I think a more likely failure mode is just "you get what you measure", as in Paul's write up here [LW · GW]. If we only know how to measure certain things which are not really the things we want, then we'll be selecting for not-what-we-want by default. But I know at least some smart people who think that inner alignment is the more likely problem, so you're in good company.
Replies from: SDM, Benito↑ comment by Sammy Martin (SDM) · 2020-08-13T16:53:35.798Z · LW(p) · GW(p)
‘You get what you measure’ (outer alignment failure) and Mesa optimisers (inner failure) are both potential gap fillers that explain why specifically the alignment/capability divergence initially arises. Whether it’s one or the other, I think the overall point is still that there is this gap in the classic arguments that allows for a (possibly quite high) chance of ‘alignment by default’, for the reasons you give, but there are at least 2 plausible mechanisms that fill this gap. And then I suppose my broader point would be that we should present:
Classic Arguments —> objections to them (capability and alignment often go together, could get alignment by default) —> specific causal mechanisms for misalignment
↑ comment by Ben Pace (Benito) · 2020-08-14T03:20:12.717Z · LW(p) · GW(p)
Am surprised you think that’s the main failure mode. I am fairly more concerned about failure through mesa optimisers taking a treacherous turn.
I’m thinking we will be more likely to find sensible solutions to outer alignment, but have not much real clue about the internals, and then we’ll give them enough optimisation power to build super intelligent unaligned mesa optimisers, and then with one treacherous turn the game will be up.
Why do you think inner alignment will be easier?
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-14T16:32:23.081Z · LW(p) · GW(p)
Two arguments here. First, an outside-view argument: inner alignment problems should only crop up on a relatively narrow range of architectures/parameters. Second, an entirely separate inside-view argument: assuming that natural abstractions are a thing makes inner alignment failure look much less likely.
Narrow range argument: inner alignment failure only applies to a specific range of architectures within a specific range of task parameters - for instance, we have to be optimizing for something, and there has to be lots of relevant variables observed only at runtime, and there has to be something like a "training" phase in which we lock-in parameter choices before runtime, and for the more disastrous versions we usually need divergence of the runtime distribution from the training distribution. It's a failure mode which assumes that a whole lot of things look like today's ML pipelines.
On the other hand, the get-what-you-measure problem and its generalizations apply to any architecture, including tool AI, idealized Bayesian utility maximizers (i.e. the infinite data/compute regime), and (less obviously) human-mimicking systems.
Natural abstractions argument: in an inner alignment failure, the outer optimizer is optimizing for , but the inner optimizer ends up pointed at some rough approximation . But if X is a natural abstraction, then this is far less likely to be a problem; we expect a wide range of predictive systems to all learn a basically-correct notion of , so there's little reason for an inner optimizer to end up pointed at a rough approximation, especially if we're leveraging transfer learning from some unsupervised learner.
(It's worth asking here why this argument doesn't apply to the divergence of human goals from evolutionary fitness. A human only has ~30k genes, and each one has a fairly simple function - e.g. catalyze one chemical reaction or stabilize a structure or the like. That's nowhere near enough to represent something like evolutionary fitness in the genome, especially when the large majority of those genes are already used for metabolism and body plan and whatnot. Modern ML, on the other hand, already operates in a range [LW · GW] where insufficient degrees of freedom are far less likely to be a problem. Also, I'm currently unsure whether evolutionary fitness is a natural abstraction at all.)
In general, if human values are a natural abstraction, then pointing to values is much harder than "learning" values. That means outer alignment is the problem more than inner alignment.
Replies from: evhub, Benito↑ comment by evhub · 2020-08-14T18:44:38.642Z · LW(p) · GW(p)
Natural abstractions argument: in an inner alignment failure, the outer optimizer is optimizing for X, but the inner optimizer ends up pointed at some rough approximation ~X. But if X is a natural abstraction, then this is far less likely to be a problem; we expect a wide range of predictive systems to all learn a basically-correct notion of X, so there's little reason for an inner optimizer to end up pointed at a rough approximation, especially if we're leveraging transfer learning from some unsupervised learner.
This isn't an argument against deceptive alignment, just proxy alignment—with deceptive alignment, the agent still learns X, it just does so as part of its world model rather than its objective. In fact, I think it's an argument for deceptive alignment, since if X first crops up as a natural abstraction inside of your agent's world model, that raises the question of how exactly it will get used in the agent's objective function—and deceptive alignment is arguably one of the simplest, most natural ways for the base optimizer to get an agent that has information about the base objective stored in its world model to actually start optimizing for that model of the base objective.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-14T19:32:57.995Z · LW(p) · GW(p)
I mostly agree with this. I don't view deception as an inner alignment problem, though - for instance, it's an issue in any approval-based setup even without an inner optimizer showing up. To the extent that it is an inner alignment issue, it involves generalization failure from the training distribution, which I also generally consider an outer alignment problem (i.e. training on a distribution which differs from the deploy environment generally means the system is not outer aligned, unless the architecture is somehow set up to make the distribution shift irrelevant).
A useful criterion here: would the problem still happen if we just optimized over all the parameters simultaneously at runtime, rather than training offline first? If the problem would still happen, then it's not really an inner alignment problem (at least not in the usual mesa-optimization sense).
Replies from: evhub↑ comment by evhub · 2020-08-14T21:05:33.712Z · LW(p) · GW(p)
To the extent that it is an inner alignment issue, it involves generalization failure from the training distribution, which I also generally consider an outer alignment problem (i.e. training on a distribution which differs from the deploy environment generally means the system is not outer aligned, unless the architecture is somehow set up to make the distribution shift irrelevant).
A useful criterion here: would the problem still happen if we just optimized over all the parameters simultaneously at runtime, rather than training offline first? If the problem would still happen, then it's not really an inner alignment problem (at least not in the usual mesa-optimization sense).
That's certainly not how I would define inner alignment. In “Risks from Learned Optimization,” we just define it as the problem of aligning the mesa-objective (if one exists) with the base objective, which is entirely independent of whether or not there's any sort of distinction between the training and deployment distributions and is fully consistent with something like online learning as you're describing it.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-14T21:36:54.949Z · LW(p) · GW(p)
The way I understood it, the main reason a mesa-optimizer shows up in the first place is that some information is available at runtime which is not available during training, so some processing needs to be done at runtime to figure out the best action given the runtime-info. The mesa-optimizer handles that processing. If we directly optimize over all parameters at runtime, then there's no place for that to happen.
What am I missing?
Replies from: evhub↑ comment by evhub · 2020-08-14T22:30:13.569Z · LW(p) · GW(p)
Let's consider the following online learning setup:
At each timestep , takes action and receives reward . Then, we perform the simple policy gradient update
Now, we can ask the question, would be a mesa-optimizer? The first thing that's worth noting is that the above setup is precisely the standard RL training setup—the only difference is that there's no deployment stage. What that means, though, is that if standard RL training produces a mesa-optimizer, then this will produce a mesa-optimizer too, because the training process isn't different in any way whatsoever. If is acting in a diverse environment that requires search to be able to be solved effectively, then will still need to learn to do search—the fact that there won't ever be a deployment stage in the future is irrelevant to 's current training dynamics (unless is deceptive and knows there won't be a deployment stage—that's the only situation where it might be relevant).
Given that, we can ask the question of whether , if it's a mesa-optimizer, is likely to be misaligned—and in particular whether it's likely to be deceptive. Again, in terms of proxy alignment, the training process is exactly the same, so the picture isn't any different at all—if there are simpler, easier-to-optimize-for proxies, then is likely to learn those instead of the true base objective. Like I mentioned previously, however, deceptive alignment is the one case where it might matter that you're doing online learning, since if the model knows that it might do different things based on that fact. However, there are still lots of reasons why a model might be deceptive even in an online learning setup—for example, it might expect better opportunities for defection in the future, and thus want to prevent being modified now so that it can defect when it'll be most impactful.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-14T23:20:32.032Z · LW(p) · GW(p)
When I say "optimize all the parameters at runtime", I do not mean "take one gradient step in between each timestep". I mean, at each timestep, fully optimize all of the parameters. Optimize all the way to convergence before every single action.
Think back to the central picture of mesa-optimization (at least as I understand it). The mesa-optimizer shows up because some data is only available at runtime, not during training, so it has to be processed at runtime using parameters selected during training. In the online RL setup you sketch here, "runtime" for mesa-optimization purposes is every time the system chooses its action - i.e. every timestep - and "training" is all the previous timesteps. A mesa-optimizer should show up if, at every timestep, some relevant new data comes in and the system has to process that data in order to choose the optimal action, using parameters inherited from previous timesteps.
Now, suppose we fully optimize all of the parameters at every timestep. The objective function for this optimization would presumably be , with the sum taken over all previous data points, since that's what the RL setup is approximating.
This optimization would probably still "find" the same mesa-optimizer as before, but now it looks less like a mesa-optimizer problem and more like an outer alignment problem: that objective function is probably not actually the thing we want. The fact that the true optimum for that objective function probably has our former "mesa-optimizer" embedded in it is a pretty strong signal that that objective function itself is not outer aligned; the true optimum of that objective function is not really the thing we want.
Does that make sense?
Replies from: evhub↑ comment by evhub · 2020-08-14T23:50:44.237Z · LW(p) · GW(p)
The RL process is actually optimizing , the log just comes from the REINFORCE trick. Regardless, I'm not sure I understand what you mean by optimizing fully to convergence at each timestep—convergence is a limiting property, so I don't know what it could mean do it for a single timestep. Perhaps you mean just taking the optimal policy such that In that case, that is in fact the definition of outer alignment I've given in the past [AF · GW], so I agree that whether is aligned or not is an outer alignment question.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-15T02:25:45.483Z · LW(p) · GW(p)
Sure, works for what I'm saying, assuming that sum-over-time only includes the timesteps taken thus far. In that case, I'm saying that either:
- the mesa optimizer doesn't appear in , in which case the problem is fixed by fully optimizing everything at every timestep (i.e. by using ), or
- the mesa optimizer does appear in , in which case the problem was really an outer alignment issue all along.
↑ comment by Ben Pace (Benito) · 2020-08-14T17:50:31.568Z · LW(p) · GW(p)
Thank you for being so clear.
On 2, I’m surprised if you think that natural selection isn’t a natural abstraction but that eudaemonia is. (If we’re getting an AGI singleton that want to fully learn our values.)
Secondly I’ll say that if we do not understand it’s representation of X or X-prime, and if a small difference will be catastrophic, then that will also lead to doom.
On 1: I think that’s quite plausible? Like, I assign something in the range of 20-60% probability to that. How much does it have to change for you to feel much safer about inner alignment?
(I’m also not that clear it only applies to this situation. Perhaps I’m mistaken, but in my head subsystem alignment and robust delegation both have this property of ”build a second optimiser that helps achieve your goals” and in both cases passing on the true utility function seems very hard.)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-14T19:58:50.066Z · LW(p) · GW(p)
On 2, I’m surprised if you think that natural selection isn’t a natural abstraction but that eudaemonia is.
Currently, my first-pass check for "is this probably a natural abstraction?" is "can humans usually figure out what I'm talking about from a few examples, without a formal definition?". For human values, the answer seems like an obvious "yes". For evolutionary fitness... nonobvious. Humans usually get it wrong without the formal definition.
Also, natural abstractions in general involve summarizing the information from one chunk of the universe which is relevant "far away". For human values, the relevant chunk of the universe is the human - i.e. the information about human values is all embedded in the physical human. But for evolutionary fitness, that's not the case - an organism does not contain all the information relevant to calculating its evolutionary fitness. So it seems like there's some qualitative difference there - like, human values "live" in humans, but fitness doesn't "live" in organisms in the same way. I still don't feel like I fully understand this, though.
On 1: I think that’s quite plausible? Like, I assign something in the range of 20-60% probability to that.
Sure, inner alignment is a problem which mainly applies to architectures similar to modern ML, and modern ML architecture seems like the most-likely route to AGI.
It still feels like outer alignment is a much harder problem, though. The very fact that inner alignment failure is so specific to certain architectures is evidence that it should be tractable. For instance, we can avoid most inner alignment problems by just optimizing all the parameters simultaneously at run-time. That solution would be too expensive in practice, but the point is that inner alignment is hard in a "we need to find more efficient algorithms" sort of way, not a "we're missing core concepts and don't even know how to solve this in principle" sort of way. (At least for mesa-optimization; I agree that there are more general subsystem alignment/robust delegation issues which are potentially conceptually harder.)
Outer alignment, on the other hand, we don't even know how to solve in principle, on any architecture whatsoever, even with arbitrary amounts of compute and data. That's why I expect it to be a bottleneck.
Replies from: Vaniver, Benito↑ comment by Vaniver · 2020-08-16T04:58:49.412Z · LW(p) · GW(p)
Currently, my first-pass check for "is this probably a natural abstraction?" is "can humans usually figure out what I'm talking about from a few examples, without a formal definition?". For human values, the answer seems like an obvious "yes". For evolutionary fitness... nonobvious. Humans usually get it wrong without the formal definition.
Hmm, presumably you're not including something like "internal consistency" in the definition of 'natural abstraction'. That is, humans who aren't thinking carefully about something will think there's an imaginable object even if any attempts to actually construct that object will definitely lead to failure. (For example, Arrow's Impossibility Theorem comes to mind; a voting rule that satisfies all of those desiderata feels like a 'natural abstraction' in the relevant sense, even though there aren't actually any members of that abstraction.)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-16T14:51:56.374Z · LW(p) · GW(p)
Oh this is fascinating. This is basically correct; a high-level model space can include models which do not correspond to any possible low-level model.
One caveat: any high-level data or observations will be consistent with the true low-level model. So while there may be natural abstract objects which can't exist, and we can talk about those objects, we shouldn't see data supporting their existence - e.g. we shouldn't see a real-world voting system behaving like it satisfies all of Arrow's desiderata.
↑ comment by Ben Pace (Benito) · 2020-08-15T00:37:24.866Z · LW(p) · GW(p)
Regarding your first pass check for naturalness being whether humans can understand it: strike me thoroughly puzzled. Isn't one of the core points of the reductionism sequence that, while "thor caused the thunder" sounds simpler to a human than Maxwell's equations (because the words fit naturally into a human psychology), one of them is much "simpler" in an absolute sense than the other (and is in fact true).
Regarding your point about the human values living in humans while the organism's fitness is living partly in the environment, nothing immediately comes to mind to say here, but I agree it's a very interesting question.
The things you say about inner/outer alignment hold together quite sensibly. I am surprised to hear you say that mesa optimisers can be avoided by just optimizing all the parameters simultaneously at run-time. That doesn't match my understanding of mesa optimisation, I thought the mesa optimisers would definitely arise during the training, but if you're right that it's trivial-but-expensive to remove them there then I agree it's intuitively a much easier problem than I had realised.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-15T02:41:23.380Z · LW(p) · GW(p)
Regarding your first pass check for naturalness being whether humans can understand it: strike me thoroughly puzzled. Isn't one of the core points of the reductionism sequence that, while "thor caused the thunder" sounds simpler to a human than Maxwell's equations (because the words fit naturally into a human psychology), one of them is much "simpler" in an absolute sense than the other (and is in fact true).
Despite humans giving really dumb verbal explanations (like "Thor caused the thunder"), we tend to be pretty decent at actually predicting things in practice.
The same applies to natural abstractions. If I ask people "is 'tree' a natural category?" then they'll get into some long philosophical debate. But if I show someone five pictures of trees, then show them five other picture which are not all trees, and ask them which of the second set are similar to the first set, they'll usually have no trouble at all picking the trees in the second set.
I thought the mesa optimisers would definitely arise during the training
If you're optimizing all the parameters simultaneously at runtime, then there is no training. Whatever parameters were learned during "training" would just be overwritten by the optimal values computed at runtime.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2020-08-15T07:05:04.569Z · LW(p) · GW(p)
Despite humans giving really dumb verbal explanations (like "Thor caused the thunder"), we tend to be pretty decent at actually predicting things in practice.
Mm, quantum mechanics much? I do not think I can reliably tell you which experiments are in the category “real” and the category “made up”, even though it’s a very simple category mathematically. But I don’t expect you’re saying this, I just am still confused what you are saying.
This reminds me of Oli’s question here [LW · GW], which ties into Abram’s “point of view from somewhere [LW · GW]” idea. I feel like I expect ML-systems to take the point of view of the universe, and not learn our natural categories.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-15T16:35:36.798Z · LW(p) · GW(p)
I'm talking everyday situations. Like "if I push on this door, it will open" or "by next week my laundry hamper will be full" or "it's probably going to be colder in January than June". Even with quantum mechanics, people do figure out the pattern and build some intuition, but they need to see a lot of data on it first and most people never study it enough to see that much data.
In places where the humans in question don't have much first-hand experiential data, or where the data is mostly noise, that's where human prediction tends to fail. (And those are also the cases where we expect learning systems in general to fail most often, and where we expect the system's priors to matter most.) Another way to put it: humans' priors aren't great, but in most day-to-day prediction problems we have more than enough data to make up for that.
comment by Steven Byrnes (steve2152) · 2021-12-21T15:23:58.778Z · LW(p) · GW(p)
I’ll set aside what happens “by default” and focus on the interesting technical question of whether this post is describing a possible straightforward-ish path to aligned superintelligent AGI.
The background idea is “natural abstractions”. This is basically a claim that, when you use an unsupervised world-model-building learning algorithm, its latent space tends to systematically learn some patterns rather than others. Different learning algorithms will converge on similar learned patterns, because those learned patterns are a property of the world, not an idiosyncrasy of the learning algorithm. For example: Both human brains and ConvNets seem to have a “tree” abstraction; neither human brains nor ConvNets seem to have a “head or thumb but not any other body part” concept.
I kind of agree with this. I would say that the patterns are a joint property of the world and an inductive bias. I think the relevant inductive biases in this case are something like: (1) “patterns tend to recur”, (2) “patterns tend to be localized in space and time”, and (3) “patterns are frequently composed of multiple other patterns, which are near to each other in space and/or time”, and maybe other things. The human brain definitely is wired up to find patterns with those properties, and ConvNets to a lesser extent. These inductive biases are evidently very useful, and I find it very likely that future learning algorithms will share those biases, even more than today’s learning algorithms. So I’m basically on board with the idea that there may be plenty of overlap between the world-models of various different unsupervised world-model-building learning algorithms, one of which is the brain.
(I would also add that I would expect “natural abstractions” to be a matter of degree, not binary. We can, after all, form the concept “head or thumb but not any other body part”. It would just be extremely low on the list of things that would pop into our head when trying to make sense of something we’re looking at. Whereas a “prominent” concept like “tree” would pop into our head immediately, if it were compatible with the data. I think I can imagine a continuum of concepts spanning the two. I’m not sure if John would agree.)
Next, John suggests that “human values” may be such a “natural abstraction”, such that “human values” may wind up a “prominent” member of an AI's latent space, so to speak. Then when the algorithms get a few labeled examples of things that are or aren’t “human values”, they will pattern-match them to the existing “human values” concept. By the same token, let’s say you’re with someone who doesn’t speak your language, but they call for your attention and point to two power outlets in succession. You can bet that they’re trying to bring your attention to the prominent / natural concept of “power outlets”, not the un-prominent / unnatural concept of “places that one should avoid touching with a screwdriver”.
Do I agree? Well, “human values” is a tricky term. Maybe I would split it up. One thing is “Human values as defined and understood by an ideal philosopher after The Long Reflection”. This is evidently not much of a “natural abstraction”, at least in the sense that, if I saw ten examples of that thing, I wouldn’t even know it. I just have no idea what that thing is, concretely.
Another thing is “Human values as people use the term”. In this case, we don’t even need the natural abstraction hypothesis! We can just ensure that the unsupervised world-modeler incorporates human language data in its model. Then it would have seen people use the phrase “human values”, and built corresponding concepts. And moreover, we don’t even necessarily need to go hunting around in the world-model to find that concept, or to give labeled examples. We can just utter the words “human values”, and see what neurons light up! I mean, sure, it probably wouldn’t work! But the labeled examples thing probably wouldn’t work either!
Unfortunately, “Human values as people use the term” is a horrific mess of contradictory and incoherent things. An AI that maximizes “‘human values’ as those words are used in the average YouTube video” does not sound to me like an AI that I want to live with. I would expect lots of performative displays of virtue and in-group signaling, little or no making-the-world-a-better-place.
In any case, it seems to me that the big kernel of truth in this post is that we can and should think of future AGI motivations systems as intimately involving abstract concepts, and that in particular we can and should take advantage of safety-advancing abstract concepts like “I am advancing human flourishing”, “I am trying to do what my programmer wants me to try to do”, “I am following human norms” [AF · GW], or whatever. In fact I have a post advocating that just a few days ago [LW · GW], and think of that kind of thing as a central ingredient in all the AGI safety stories that I find most plausible.
Beyond that kernel of truth, I think a lot more work, beyond what’s written in the post, would be needed to build a good system that actually does something we want. In particular, I think we have much more work to do on choosing and pointing to the right concepts (cf. “first-person problem” [LW · GW]), detecting when concepts break down because we’re out of distribution (cf. “model splintering” [LW · GW]), sandbox testing protocols, and so on. The post says 10% chance that things work out, which seems much too high to me. But more importantly, if things work out along these lines, I think it would be because people figured out all those things I mentioned, by trial-and-error, during slow takeoff. Well in that case, I say: let's just figure those things out right now!
Replies from: johnswentworth↑ comment by johnswentworth · 2021-12-21T16:48:17.140Z · LW(p) · GW(p)
Next, John suggests that “human values” may be such a “natural abstraction”, such that “human values” may wind up a “prominent” member of an AI's latent space, so to speak.
I'm fairly confident that the inputs to human values are natural abstractions - i.e. the "things we care about" are things like trees, cars, other humans, etc, not low-level quantum fields or "head or thumb but not any other body part". (The "head or thumb" thing is a great example, by the way). I'm much less confident that human values themselves are a natural abstraction, for exactly the same reasons you gave.
comment by Wei Dai (Wei_Dai) · 2020-08-13T03:28:25.951Z · LW(p) · GW(p)
To help me check my understanding of what you're saying, we train an AI on a bunch of videos/media about Alice's life, in the hope that it learns an internal concept of "Alice's values". Then we use SL/RL to train the AI, e.g., give it a positive reward whenever it does something that the supervisor thinks benefits Alice's values. The hope here is that the AI learns to optimize the world according to its internal concept of "Alice's values" that it learned in the previous step. And we hope that its concept of "Alice's values" includes the idea that Alice wants AIs, including any future AIs, to keep improving their understanding of Alice's values and to serve those values, and that this solves alignment in the long run.
Assuming the above is basically correct, this (in part) depends on the AI learning a good enough understanding of "improving understanding of Alice's values" in step 1. This in turn (assuming "improving understanding of Alice's values" involves "using philosophical reasoning to solve various confusions related to understanding Alice's values, including Alice's own confusions") depends on that the AI can learn a correct or good enough concept of "philosophical reasoning" from unsupervised training. Correct?
If AI can learn "philosophical reasoning" from unsupervised training, GPT-N should be able to do philosophy (e.g., solve open philosophical problems), right?
Replies from: johnswentworth, John_Maxwell_IV↑ comment by johnswentworth · 2020-08-13T05:34:48.571Z · LW(p) · GW(p)
There's a lot of moving pieces here, so the answer is long. Apologies in advance.
I basically agree with everything up until the parts on philosophy. The point of divergence is roughly here:
assuming "improving understanding of Alice's values" involves "using philosophical reasoning to solve various confusions related to understanding Alice's values, including Alice's own confusions"
I do think that resolving certain confusions around values involves solving some philosophical problems. But just because the problems are philosophical does not mean that they need to be solved by philosophical reasoning.
The kinds of philosophical problems I have in mind are things like:
- What is the type signature of human values?
- What kind of data structure naturally represents human values?
- How do human values interface with the rest of the world?
In other words, they're exactly the sort of questions for which "utility function" and "Cartesian boundary" are answers, but probably not the right answers.
How could an AI make progress on these sorts of questions, other than by philosophical reasoning?
Let's switch gears a moment and talk about some analogous problems:
- What is the type signature of the concept of "tree"?
- What kind of data structure naturally represents "tree"?
- How do "trees" (as high-level abstract objects) interface with the rest of the world?
Though they're not exactly the same questions, these are philosophical questions of a qualitatively similar sort to the questions about human values.
Empirically, AIs already do a remarkable job reasoning about trees, and finding answers to questions like those above, despite presumably not having much notion of "philosophical reasoning". They learn some data structure for representing the concept of tree, and they learn how the high-level abstract "tree" objects interact with the rest of the (lower-level) world. And it seems like such AIs' notion of "tree" tends to improve as we throw more data and compute at them, at least over the ranges explored to date.
In other words: empirically, we seem to be able to solve philosophical problems to a surprising degree by throwing data and compute at neural networks. Well, at least "solve" in the sense that the neural networks themselves seem to acquire solutions to the problems... not that either the neural nets or the humans gain much understanding of such problems in general.
Going up a meta level: why would this be the case? Why would solutions to philosophical problems end up embedded in random learning algorithms, without either the algorithms or the humans having a general understanding of the problems?
Well, presumably neural nets end up with a notion of "tree" for much the same reason that humans end up with a notion of "tree": it's a useful concept. We don't have a precise mathematical theory of when or why it's useful (though I do hopefully have some groundwork [LW · GW] for that), but we can see instrumental convergence to a useful concept even without understanding why the concept is useful.
In short: solutions to certain philosophical problems are probably instrumentally convergent, so the solutions will probably pop up in a fairly broad range of systems despite neither the systems nor their designers understanding the philosophical problems.
Now, so far this has talked about why solutions to philosophical problems would pop up in one AI. But does that help one AI to improve its own solutions? Depends on the setup, but at the very least it offers an AI a possible path to improving its solutions to such philosophical problems without going through philosophical reasoning.
Finally, I'll note that if humans want to be able to recognize an AI's solutions to philosophical problems, e.g. decode a model of human values from the weights of a neural net, then we'll probably need to make some philosophical/mathematical progress ourselves in order to do that reliably. After all, we don't even know the type signature of the thing we're looking for or a data structure with which to represent it.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2020-08-15T19:31:02.816Z · LW(p) · GW(p)
So similarly, a human could try to understand Alice's values in two ways. The first, equivalent to what you describe here for AI, is to just apply whatever learning algorithm their brain uses when observing Alice, and form an intuitive notion of "Alice's values". And the second is to apply explicit philosophical reasoning to this problem. So sure, you can possibly go a long way towards understanding Alice's values by just doing the former, but is that enough to avoid disaster? (See Two Neglected Problems in Human-AI Safety [LW · GW] for the kind of disaster I have in mind here.)
(I keep bringing up metaphilosophy but I'm pretty much resigned to be living in a part of the multiverse where civilization will just throw the dice and bet [LW · GW] on AI safety not depending on solving it. What hope is there for our civilization to do what I think is the prudent thing, when no professional philosophers, even ones in EA who are concerned about AI safety, ever talk about it?)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-15T20:21:56.516Z · LW(p) · GW(p)
I mostly agree with you here. I don't think the chances of alignment by default are high. There are marginal gains to be had, but to get a high probability of alignment in the long term we will probably need actual understanding of the relevant philosophical problems.
↑ comment by John_Maxwell (John_Maxwell_IV) · 2020-08-15T11:45:15.444Z · LW(p) · GW(p)
My take is that corrigibility is sufficient to get you an AI that understands what it means to "keep improving their understanding of Alice's values and to serve those values". I don't think the AI needs to play the "genius philosopher" role, just the "loyal and trustworthy servant" role. A superintelligent AI which plays that role should be able to facilitate a "long reflection" where flesh and blood humans solve philosophical problems.
(I also separately think unsupervised learning systems could in principle make philosophical breakthroughs. Maybe one already has.)
comment by Donald Hobson (donald-hobson) · 2020-08-15T21:42:01.226Z · LW(p) · GW(p)
In light of the previous section, there’s an obvious path to alignment where there turns out to be a few neurons (or at least some simple embedding) which correspond to human values, we use the tools of microscope AI to find that embedding, and just like that the alignment problem is basically solved.
This is the part I disagree with. The network does recognise trees, or at least green things (given that the grass seems pretty brown in the low tree pic).
Extrapolating this, I expect the AI might well have neurons that correspond roughly to human values, on the training data. Within the training environment, human values, amount of dopamine in human brain, curvature of human lips (in smiles), number of times the reward button is pressed, and maybe even amount of money in human bank account might all be strongly correlated.
You will have successfully narrowed human values down to within the range of things that are strongly correlated with human values in the training environment. If you take this signal and apply enough optimization pressure, you are going to get the equivalent of a universe tiled with tiny smiley faces.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-16T15:09:39.321Z · LW(p) · GW(p)
Note that the examples in the OP are from an adversarial generative network. If its notion of "tree" were just "green things", the adversary should be quite capable of exploiting that.
You will have successfully narrowed human values down to within the range of things that are strongly correlated with human values in the training environment. If you take this signal and apply enough optimization pressure, you are going to get the equivalent of a universe tiled with tiny smiley faces.
The whole point of the "natural abstractions" section of the OP is that I do not think this will actually happen. Off-distribution behavior is definitely an issue for the "proxy problems" section of the post, but I do not expect it to be an issue for identifying natural abstractions.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2020-08-16T16:55:00.703Z · LW(p) · GW(p)
Note that the examples in the OP are from an adversarial generative network. If its notion of "tree" were just "green things", the adversary should be quite capable of exploiting that.
In order for the network to produce good pictures, the concept of "tree" must be hidden in there somewhere, but it could be hidden in a complicated and indirect manor. I am questioning whether the particular single node selected by the researchers encodes the concept of "tree" or "green thing".
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-16T17:34:54.257Z · LW(p) · GW(p)
Ah, I see. You're saying that the embedding might not actually be simple. Yeah, that's plausible.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-10-06T14:57:29.491Z · LW(p) · GW(p)
Supervised/Reinforcement: Proxy Problems
Another plausible approach to deal with the proxy problems might be to do something like unsupervised clustering/learning on the representations of multiple systems that we'd have good reasons to believe encode the (same) relevant values - e.g. when exposed to the same stimulus (including potentially multiple humans and multiple AIs). E.g. for some relevant recent proof-of-concept works: Identifying Shared Decodable Concepts in the Human Brain Using Image-Language Foundation Models, Finding Shared Decodable Concepts and their Negations in the Brain, AlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space, Rosetta Neurons: Mining the Common Units in a Model Zoo, Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models, Quantifying stimulus-relevant representational drift using cross-modality contrastive learning. Automated interpretability (e.g. https://multimodal-interpretability.csail.mit.edu/maia/) could also be useful here. This might also work well with concepts like corrigibility/instruction following [LW · GW] and arguments about the 'broad basin of attraction' and convergence [LW · GW] for corrigibility.
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-11-13T16:44:32.656Z · LW(p) · GW(p)
A few additional relevant recent papers: Sparse Autoencoders Reveal Universal Feature Spaces Across Large Language Models, Towards Universality: Studying Mechanistic Similarity Across Language Model Architectures.
Similarly, the argument in this post and e.g. in Robust agents learn causal world models seem to me to suggest that we should probably also expect something like universal (approximate) circuits, which it might be feasible to automate the discovery of using perhaps a similar procedure to the one demo-ed in Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models.
Later edit: And I expect unsupervised clustering/learning could help in a similar fashion to the argument in the parent comment (applied to features), when applied to the feature circuits(/graphs).
comment by Rohin Shah (rohinmshah) · 2020-08-18T22:24:36.880Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
I liked the author’s summary, so I’ve reproduced it with minor stylistic changes:
A low-level model of some humans has everything there is to know about human values embedded within it, in exactly the same way that human values are embedded in physical humans. The embedding, however, is nontrivial. Thus, predictive power alone is not sufficient to define human values. The missing part is the embedding of values within the model.
However, this also applies if we replace the phrase “human values” with “trees”. Yet we have a whole class of neural networks in which a simple embedding lights up in response to trees. This is because trees are a natural abstraction, and we should expect to see real systems trained for predictive power use natural abstractions internally.
Human values are a little different from trees: they’re a property of an abstract object (humans) rather than an abstract object themselves. Nonetheless, the author still expects that a broad class of systems trained for predictive power will end up with simple embeddings of human values (~70% chance).
Since an unsupervised learner has a simple embedding of human values, a supervised/reinforcement learner can easily score well on values-proxy-tasks by directly using that model of human values. In other words, the system uses an actual model of human values as a proxy for our proxy of human values (~10-20% chance). This is what is meant by _alignment by default_.
When this works, it’s basically a best-case scenario, so we can safely use the system to design a successor without worrying about amplification of alignment errors (among other things).
Planned opinion:
I broadly agree with the perspective in this post: in particular, I think we really should have more optimism because of the tendency of neural nets to learn “natural abstractions”. There is structure and regularity in the world and neural nets often capture it (despite being able to memorize random noise); if we train neural nets on a bunch of human-relevant data it really should learn a lot about humans, including what we care about.
However, I am less optimistic than the author about the specific path presented here (and he only assigns 10% chance to it). In particular, while I do think human values are a “real” thing that a neural net will pick up on, I don’t think that they are well-defined enough to align an AI system arbitrarily far into the future: our values do not say what to do in all possible situations; to see this we need only to look at the vast disagreements among moral philosophers (who often focus on esoteric situations). If an AI system were to internalize and optimize our current system of values, as the world changed the AI system would probably become less and less aligned with humans. We could instead talk about an AI system that has internalized both current human values and the process by which they are constructed, but that feels much less like a natural abstraction to me.
I _am_ optimistic about a very similar path, in which instead of training the system to pursue (a proxy for) human values, we train the system to pursue some “meta” specification like “be helpful to the user / humanity” or “do what we want on reflection”. It seems to me that “being helpful” is also a natural abstraction, and it seems more likely that an AI system pursuing this specification would continue to be beneficial as the world (and human values) changed drastically.Replies from: johnswentworth
↑ comment by johnswentworth · 2020-08-18T23:17:13.649Z · LW(p) · GW(p)
LGTM
comment by John_Maxwell (John_Maxwell_IV) · 2020-08-15T10:15:39.892Z · LW(p) · GW(p)
Some notes on the loss function in unsupervised learning:
Since an unsupervised learner is generally just optimized for predictive power
I think it's worthwhile to distinguish the loss function that's being optimized during unsupervised learning, vs what the practitioner is optimizing for. Yes, the loss function being optimized in an unsupervised learning system is frequently minimization of reconstruction error or similar. But when I search for "unsupervised learning review" on Google Scholar, I find this highly cited paper by Bengio et al. The abstract talks a lot about learning useful representations and says nothing about predictive power. In other words, learning "natural abstractions" appears to be pretty much the entire game from a practitioner perspective.
And in the same way supervised learning has dials such as regularization which let us control the complexity of our model, unsupervised learning has similar dials.
For clustering, we could achieve 0 reconstruction error (or equivalently, explain all the variation in the data) by putting every data point in its own cluster, but that would completely defeat the point. The elbow method is a well-known heuristic for figuring out what the "right" number of clusters in a dataset is.
Similarly, we could achieve 0 reconstruction error with an autoencoder by making the number of dimensions in the bottleneck be equal to the number of dimensions in the original input, but again, that would completely defeat the point. Someone on the Stats Stackexchange says that there is no standard way to select the number of dimensions for an autoencoder. (For reference, the standard way to select the regularization parameter which controls complexity in supervised learning would obviously be through cross-validation.) However, I suspect this is a tractable research problem.
It was interesting that you mentioned the noise of air molecules, because one unsupervised learning trick is to deliberately introduce noise into the input to see if the system has learned "natural" representations which allow it to reconstruct the original noise-free input. See denoising autoencoder. This is the kind of technique which might allow an autoencoder to learn natural representations even if the number of dimensions in the bottleneck is equal to the number of dimensions in the original input.
BTW, here's an interesting-looking (pessimistic) paper I found while researching this comment: Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
You brought up microscope AI. I think a promising research direction here may be to formulate a notion of "ease of interpretability" which can be added as an additional term to an unsupervised loss function (the same way we might, for example, add a term to a clustering algorithm's loss function so that in addition to minimizing reconstruction error, it also seeks to minimize the number of clusters).
Hardcoding "human values" by hand is hopeless, but hardcoding "ease of human interpretability" by hand seems much more promising, since ease of human interpretability is likely to correspond to easily formalizable notions such as simplicity. Also, if your hardcoded notion of "ease of human interpretability" turns out to be slightly wrong, that's not a catastrophe: you just get an ML model which is a bit harder to interpret than you might like.
Another option is to learn a notion of what constitutes an interpretable model by e.g. collecting "ease of interpretability" data from human microscope users.
Of course, one needs to be careful that any interpretability term does not get too much weight in the loss function, because if it does, we may stop learning the "natural" abstractions that we desire (assuming a worst-case scenario where human interpretability is anticorrelated with "naturalness"). The best approach may be to learn two models, one of which was optimized for interpretability and one of which wasn't, and only allow our system to take action when the two models agree. I guess mesa-optimizers in the non-interpretable model are still a worry though.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-15T18:27:07.006Z · LW(p) · GW(p)
This comment definitely wins the award for best comment on the post so far. Great ideas, highly relevant links.
I especially like the deliberate noise idea. That plays really nicely with natural abstractions as information-relevant-far-away: we can intentionally insert noise along particular dimensions, and see how that messes with prediction far away (either via causal propagation or via loss of information directly). As long as most of the noise inserted is not along the dimensions relevant to the high-level abstraction, denoising should be possible. So it's very plausible that denoising autoencoders are fairly-directly incentivized to learn natural abstractions. That'll definitely be an interesting path to pursue further.
Assuming that the denoising autoencoder objective more-or-less-directly incentivizes natural abstractions, further refinements on that setup could very plausibly turn into a useful "ease of interpretability" objective.
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2020-08-18T09:31:09.439Z · LW(p) · GW(p)
This comment definitely wins the award for best comment on the post so far.
Thanks!
I don't consider myself an expert on the unsupervised learning literature by the way, I expect there is more cool stuff to be found.
comment by algon33 · 2020-08-13T12:57:23.027Z · LW(p) · GW(p)
This came out of the discussion you had with John Maxwell, right? Does he think this is a good presentation of his proposal?
How do we know that the unsupervised learner won't have learnt a large number of other embeddings closer to the proxy? If it has, then why should we expect human values to do well?
Some rough thoughts on the data type issue. Depending on what types the unsupervised learner provides the supervised, it may not be able to reach the proxy type by virtue of issues with NN learning processes.
Recall that tata types can be viewed as homotopic spaces, and construction of types can be viewed as generating new spaces off the old e.g. tangent spaces or path spaces etc. We can view neural nets as a type corresponding to a particular homotopic space. But getting neural nets to learn certain functions is hard. For example, learning a function which is 0 except in two sub spaces A and B. It has different values on A and B. But A and B are shaped like intelocked rings. In other words, a non-linear classification problem. So plausibly, neural nets have trouble constructing certain types from others. Maybe this depends on architecture or learning algorithm, maybe not.
If the proxy and human values have very different types, it may be the case that the supervised learner won't be able to get from one type to another. Supposing the unsupervised learner presents it with types "reachable" from human values, then the proxy which optimises performance on the data set is just unavailable to the system even though its relatively simple in comparison.
Because of this, checking which simple homotopies neural nets can move between would be useful. Depending on the results, we could use this as an arguement that unsupervised NNs will never embed the human values type because we've found out it has some simple properties it won't be able to construct de novo. Unless we do something like feed the unsupervised learner human biases/start with an EM and modify it.
Replies from: John_Maxwell_IV, johnswentworth↑ comment by John_Maxwell (John_Maxwell_IV) · 2020-08-15T12:04:52.712Z · LW(p) · GW(p)
Does he think this is a good presentation of his proposal?
I'm very glad johnswentworth wrote this, but there are a lot of little details where we seem to disagree--see my other comments in this thread. There are also a few key parts of my proposal not discussed in this post, such as active learning and using an ensemble to fight Goodharting and be more failure-tolerant. I don't think there's going to be a single natural abstraction for "human values" like johnswentworth seems to imply with this post, but I also think that's a solvable problem.
(previous discussion for reference [LW(p) · GW(p)])
↑ comment by johnswentworth · 2020-08-13T16:54:00.859Z · LW(p) · GW(p)
This came out of the discussion you had with John Maxwell, right?
Sort of? That was one significant factor which made me write it up now, and there's definitely a lot of overlap. But this isn't intended as a response/continuation to that discussion, it's a standalone piece, and I don't think I specifically address his thoughts from that conversation.
A lot of the material is ideas from the abstraction project which I've been meaning to write up for a while, as well as material from discussions with Rohin that I've been meaning to write up for a while.
How do we know that the unsupervised learner won't have learnt a large number of other embeddings closer to the proxy? If it has, then why should we expect human values to do well?
Two brief comments here. First, I claim that natural abstraction space is quite discrete (i.e. there usually aren't many concepts very close to each other), though this is nonobvious and I'm not ready to write up a full explanation of the claim yet. Second, for most proxies there probably are natural abstractions closer to the proxy, because most simple proxies are really terrible - for instance, if our proxy is "things people say are ethical on twitter", then there's probably some sort of natural abstraction involving signalling which is closer.
Assuming we get the chance to iterate, this is the sort of thing which people hopefully solve by trying stuff and seeing what works. (Not that I give that a super-high chance of success, but it's not out of the question.)
Depending on what types the unsupervised learner provides the supervised, it may not be able to reach the proxy type by virtue of issues with NN learning processes.
Strongly agree with this, and your explanation is solid. Worth mentioning that we do have some universality results for neural nets, but it's still the case that the neural net structure has implicit priors/biases which could make it hard to learn certain data structures. This is one of several reasons why I see "figuring out what sort-of-thing human values are" as one of the higher-expected-value subproblems on the theoretical side of alignment research.
Replies from: algon33↑ comment by algon33 · 2020-08-15T00:15:42.848Z · LW(p) · GW(p)
Based off what you've said in the comments, I'm guessing you'd say the various forms of corrigibility are natural abstractions. Would you say we can use the strategy you outline here to get "corrigibility by default"?
Regarding iterations, the common objection is that we're introducing optimisation pressure. So we should expect the usual alignment issues anyway. Under your theory, is this not an issue because of the sparsity of natural abstractions near human values?
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-15T02:05:25.597Z · LW(p) · GW(p)
I'm not sure about whether corrigibility is a natural abstraction. It's at least plausible, and if it is, then corrigibility by default should work under basically-similar assumptions.
Under your theory, is this not an issue because of the sparsity of natural abstractions near human values?
Basically, yes. We want the system to use its actual model of human values as a proxy for its objective, which is itself a proxy for human values. So the whole strategy will fall apart in situations where the system converges to the true optimum of its objective. But in situations where a proxy for the system's true optimum would be used (e.g. weak optimization or insufficient data to separate proxy from true), the model of human values may be the best available proxy.
comment by Chris_Leong · 2021-03-22T03:06:38.777Z · LW(p) · GW(p)
I guess the main issue that I have with this argument is that an AI system that is extremely good at prediction is unlikely to just have a high-level concept corresponding to human values (if it does contain such a concept). Instead, it's likely to also include a high-level concept corresponding to what people say about about values - or rather several corresponding to what various different groups would say about human-values. If your proxy is based on what people say, then these concepts which correspond to what people say will match much better - and the probability of at least one of these concepts being the best match is increased by large the number of these. So I don't put a very high weight on this scenario at all.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-03-22T04:39:15.992Z · LW(p) · GW(p)
This is a great explanation. I basically agree, and this is exactly why I expect alignment-by-default to most likely fail even conditional on the natural abstractions hypothesis holding up.
Replies from: Chris_Leong, Chris_Leong↑ comment by Chris_Leong · 2021-03-22T04:50:01.974Z · LW(p) · GW(p)
Also, I have another strange idea that might increase the probability of this working.
If you could temporarily remove proxies based on what people say, then this would seem to greatly increase the chance of it hitting the actual embedded representation of human values. Maybe identifying these proxies is easier than identifying the representation of "true human values"?
I don't think it's likely to work, but thought I'd share anyway.
↑ comment by Chris_Leong · 2021-03-22T04:45:44.407Z · LW(p) · GW(p)
Thanks!
Is this why you put the probability as "10-20% chance of alignment by this path, assuming that the unsupervised system does end up with a simple embedding of human values"? Or have you updated your probabilities since writing this post?
↑ comment by johnswentworth · 2021-03-22T05:37:41.789Z · LW(p) · GW(p)
Yup, this is basically where that probability came from. It still feels about right.
comment by John_Maxwell (John_Maxwell_IV) · 2020-08-15T11:33:16.879Z · LW(p) · GW(p)
Thanks a lot for writing this. I've been thinking about FAI plans along these lines for a while now, here are some thoughts on specific points you made.
First, I take issue with the "Alignment By Default" title. There are two separate questions here. Question #1 is whether we'd have a good outcome if everyone concerned with AI safety got hit by a bus. Question #2 is whether there's a way to create Friendly AI using unsupervised learning. I'm rather optimistic that the answer to Question #2 is yes. I find the unsupervised learning family of approaches more appealing than IRL or HCH (from what I understand of those approaches). But I still think there are various ways in which things could go wrong, some of which you mention in this post, and it's useful to have safety researchers thinking about this, because the problems seem pretty tractable to me. You, me, and Steve Byrnes [LW · GW] are the only people in the community I remember off the top of my head who seem to be giving this serious thought, which is a little odd because so many top AI people seem to think that unsupervised learning is The Nut That Must Be Cracked if we are to build AGI.
Anyway, in order to illustrate that the problems seem tractable, here are a couple things you brought up + thoughts on solving them.
With regard to the high-resolution molecular model of a human, there's the possibility of using this model as an upload somehow even if the embedding of human values is nontrivial. I guess the challenge is to excise everything around the human from the model, and replace those surroundings with whatever an ideal environment for doing moral / philosophical reasoning would be, along with some communication channel to the outside world. This is approach is similar to the Paul Christiano construction described on p. 198 of Superintellligence. In this case, I guess it is more important for the embedding of a person's physical surroundings to be "natural" enough that we can mess with it without messing with the person's mind. However, even if the embedding of the person's physical surroundings is kinda bad (meaning that our "ideal environment for doing moral / philosophical reasoning" ends up being like a glitchy VR sim in practice), this plausibly won't cause a catastrophic alignment failure. Also, you don't necessarily need a super high-resolution model to do this sort of thing (imagine prompting GPT-N with "Gandhi goes up the mountain to contemplate Moral Question X, he returns after a year of contemplation and proclaims...").
This requires hitting a window - our data needs to be good enough that the system can tell it should use human values as a proxy, but bad enough that the system can’t figure out the specifics of the data-collection process enough to model it directly. This window may not even exist.
A couple thoughts.
First, I think it's possible to create this window. Suppose we restrict ourselves to feeding our system data from before the year 2000. There should be a decent representation of human values to be learned from this data, yet it should be quite difficult to figure out the specifics of the 2020+ data-collection process from it. Identifying the specific quirks which cause the data-collection process to differ from human values seems especially difficult. (I think restricting ourselves to pre-2000 data is overkill, I just chose 2000 for the purpose of illustration.)
Second, one way to check on things is to deliberately include a small quantity of mislabeled data, then once the system is done learning, check whether its model correctly recognizes that the mislabeled data is mislabeled (and agrees with all data that is correctly labeled). (This should be combined with the idea above where we disguise the data-collection process from the AI, because otherwise we might pinpoint "the data-collection process prior to the time at which the mislabeled data was introduced"?)
I know of two main ways to go from aligning one AI to long-term alignment
A third approach which you don't mention is to use the initial aligned AI as a "human values oracle" for subsequent AIs. Once you have a cheap, fast computational representation of human values, you can replicate it across a massive compute cluster and
-
Use it to generate extremely large quantities of training data
-
Use it as the "moral compass" for some bigger, more sophisticated system
-
Use it to identify specific ways in which the newer AI's concept of human values is wrong, and keep correcting the newer AI's concept of human values until it's good (maybe using active learning)
You need the new AI and the old AI to communicate with one another. But details of how they work can be totally different if you have them communicate using labeled data. Training one ML model to predict the output of some other ML model is a technique I see every so often in machine learning papers... "Distilling the Knowledge in a Neural Network" is a well-known example of this.
Finally, you wrote:
That’s assuming things don’t go irreversibly wrong before then - including not just hostile takeover, but even just development of deceptive behavior, since this scenario does not have any built-in mechanism to detect deception.
Mesa-optimizers are a real danger, but if we put those aside for a moment, I don't think there is much risk of a hostile takeover from an unsupervised learning system since it's not an agent.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-15T18:13:23.623Z · LW(p) · GW(p)
Thanks for the comments, these are excellent!
Valid complaint on the title, I basically agree. I only give the path outlined in the OP ~10% of working without any further intervention by AI safety people, and I definitely agree that there are relatively-tractable-seeming ways to push that number up on the margin. (Though those would be marginal improvements only; I don't expect them to close the bulk of the gap without at least some progress on theoretical bottlenecks.)
I am generally lukewarm about human-simulation approaches to alignment; the fusion power generator scenario [LW · GW] is a prototypical example of my concerns here (also see this comment [LW(p) · GW(p)] on it, which explains what I see as the key take-away). The idea of simulating a human doing moral philosophy is a bit different than what I usually imagine, though; it's basically like taking an alignment researcher and running them on faster hardware. That doesn't directly solve any of the underlying conceptual problems - it just punts them to the simulated researchers - but it is presumably a strict improvement over a limited number of researchers operating slowly in meatspace. Alignment research ems!
Suppose we restrict ourselves to feeding our system data from before the year 2000. There should be a decent representation of human values to be learned from this data, yet it should be quite difficult to figure out the specifics of the 2020+ data-collection process from it.
I don't think this helps much. Two examples of "specifics of the data collection process" to illustrate:
- Suppose our data consists of human philosophers' writing on morality. Then the "specifics of the data collection process" includes the humans' writing skills and signalling incentives, and everything else besides the underlying human values.
- Suppose our data consists of humans' choices in various situations. Then the "specifics of the data collection process" includes the humans' mistaken reasoning, habits, divergence of decision-making from values, and everything else besides the underlying human values.
So "specifics of the data collection process" is a very broad notion in this context. Essentially all practical data sources will include a ton of extra information besides just their information on human values.
Second, one way to check on things is to deliberately include a small quantity of mislabeled data, then once the system is done learning, check whether its model correctly recognizes that the mislabeled data is mislabeled (and agrees with all data that is correctly labeled).
I like this idea, and I especially like it in conjunction with deliberate noise as an unsupervised learning trick. I'll respond more to that on the other comment.
A third way which you don't mention is to use the initial aligned AI as a "human values oracle" for subsequent AIs.
I have mixed feelings on this.
My main reservation is that later AIs will never be more precisely aligned the oracle. That first AI may be basically-correctly aligned, but it still only has so much data and probably only rough algorithms, so I'd really like it to be able to refine its notion of human values over time. In other words, the oracle's notion of human values may be accurate but not precise, and I'd like precision to improve as more data comes in and better algorithms are found. This is especially important if capabilities rise over time and greater capabilities require more precise alignment.
That said, as long as the oracle's alignment is accurate, we could use your suggestion to make sure that actions are OK for all possible human-values-notions within uncertainty. That's probably at least good enough to avoid disaster. It would still fall short of the full potential value of AI - there'd be missed opportunities, where the system has to be overly careful because its notion human values is insufficiently precise - but at least no disaster.
Finally, on deceptive behavior: I use the phrase a bit differently than I think most people do these days. My prototypical image isn't of a mesa-optimizer. Rather, I imagine people iteratively developing a system, trying things out, keeping things which seem to work, and thereby selecting for things which look good to humans (regardless of whether they're actually good). In that situation, we'd expect the system to end up doing things which look good but aren't, because the human developers accidentally selected for that sort of behavior. It's a "you-get-what-you-measure" problem, rather than a mesa-optimizers problem.
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2020-08-18T08:49:28.499Z · LW(p) · GW(p)
I don't expect them to close the bulk of the gap without at least some progress on theoretical bottlenecks.
Can you be more specific about the theoretical bottlenecks that seem most important?
I am generally lukewarm about human-simulation approaches to alignment; the fusion power generator scenario is a prototypical example of my concerns here (also see this comment on it, which explains what I see as the key take-away).
I agree that Tool AI is not inherently safe. The key question is which problem is easier: the alignment problem, or the safe-use-of-dangerous-tools problem. All else equal, if you think the alignment problem is hard, then you should be more willing to replace alignment work with tool safety work. If you think the alignment problem is easy, you should discourage dangerous tools in favor of frontloaded work on a more paternalistic "not just benign, actually aligned" AI.
An analogy here would be Linux vs Windows. Linux lets you shoot your foot off and wipe your hard drive with a single command, but it also gives you greater control of your system and your computer is less likely to get viruses. Windows is safer and more paternalistic, with less user control. Windows is a better choice for the average user, but that's partially because we have a lot of experience building operating systems. It wouldn't make sense to aim for a Windows as our first operating system, because (a) it's a more ambitious project and (b) we wouldn't have enough experience to know the right ways in which to be paternalistic. Heck, it was you who linked disparagingly to waterfall-style software development the other day :) There's a lot to be said for simplicity of implementation.
(Random aside: In some sense I think the argument for paternalism is self-refuting, because the argument is essentially that humans can't be trusted, but I'm not sure the total amount of responsibility we're assigning to humans has changed--if the first system is to be very paternalistic, that puts an even greater weight of responsibility on the shoulders of its designers to be sure and get it right. I'd rather shove responsibility into the post-singularity world, because the current world seems non-ideal, for example, AI designers have limited time to think due to e.g. possible arms races.)
What do I mean by the "safe-use-of-dangerous-tools problem"? Well, many dangerous tools will come with an instruction manual or mandatory training in safe tool use. For a tool AI, this manual might include things like:
-
Before asking the AI any question, ask: "If I ask Question X, what is the estimated % chance that I will regret asking on reflection?"
-
Tell the AI: "When you answer this question, instead of revealing any information you think will plausibly harm me, replace it with [I'm not revealing this because it could plausibly harm you]"
-
If using a human-simulation approach to alignment, tell your AI to only make use of the human-simulation to inform terminal values, never instrumental values. Or give the human simulation loads of time to reflect, so it's effectively a speed superintelligence (assuming for the moment what seems to be a common AI safety assumption that more reflection always improves outcomes--skepticism here [LW · GW]). Or make sure the simulated human has access to the safety manual.
I think it's possible to do useful work on the manual for the Tool AI even in the absence of any actual Tool AI having been created. In fact, I suspect this work will generalize better between different AI designs than most alignment work generalizes between designs.
Insights from our manual could even be incorporated into the user interface for the tool. For example, the question-asking flow could by default show us the answer to the question "If I ask Question X, what is the estimated % chance that I will regret asking on reflection?" and ask us to read the result and confirm that the question is actually one we want to ask. This would be analogous to alias rm='rm -i' in Linux--it doesn't reduce transparency or add brittle complexity, but it does reduce the risk of shooting ourselves in the foot.
BTW you wrote:
Coming at it from a different angle: if a safety problem is handled by a system's designer, then their die-roll happens once up-front. If that die-roll comes out favorably, then the system is safe (at least with respect to the problem under consideration); it avoids the problem by design. On the other hand, if a safety problem is left to the system's users, then a die-roll happens every time the system is used, so inevitably some of those die rolls will come out unfavorably. Thus the importance of designing AI for safety up-front, rather than relying on users to use it safely.
One possible plan for the tool is to immediately use it to create a more paternalistic system (or just generate a bunch of UI safeguards as I described above). So then you're essentially just rolling the dice once.
Two examples of "specifics of the data collection process" to illustrate
From my perspective, these examples essentially illustrate that there's not a single natural abstraction for "human values"--but as I said elsewhere, I think that's a solvable problem.
My main reservation is that later AIs will never be more precisely aligned the oracle. That first AI may be basically-correctly aligned, but it still only has so much data and probably only rough algorithms, so I'd really like it to be able to refine its notion of human values over time. In other words, the oracle's notion of human values may be accurate but not precise, and I'd like precision to improve as more data comes in and better algorithms are found. This is especially important if capabilities rise over time and greater capabilities require more precise alignment.
Let's make the later AIs corrigible then. Perhaps our initial AI can give us both a corrigibility oracle and a values oracle. (Or later AIs could use some other approach to corrigibility.)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-18T17:51:44.034Z · LW(p) · GW(p)
Can you be more specific about the theoretical bottlenecks that seem most important?
Type signature of human values is the big one. I think it's pretty clear at this point that utility functions aren't the right thing, that we value things "out in the world" as opposed to just our own "inputs" or internal state, that values are not reducible to decisions or behavior, etc. We don't have a framework for what-sort-of-thing human values are. If we had that - not necessarily a full model of human values, just a formalization which we were confident could represent them - then that would immediately open the gates to analysis, to value learning, to uncertainty over values, etc.
The key question is which problem is easier: the alignment problem, or the safe-use-of-dangerous-tools problem. All else equal, if you think the alignment problem is hard, then you should be more willing to replace alignment work with tool safety work. If you think the alignment problem is easy, you should discourage dangerous tools in favor of frontloaded work on a more paternalistic "not just benign, actually aligned" AI.
A good argument, but I see the difficulties of safe tool AI and the difficulties of alignment as mostly coming from the same subproblem. To the extent that that's true, alignment work and tool safety work need to be basically the same thing.
On the tools side, I assume the tools will be reasoning about systems/problems which humans can't understand - that's the main value prop in the first place. Trying to collapse the complexity of those systems into a human-understandable API is inherently dangerous: values are complex, the system is complex, their interaction will inevitably be complex, so any API simple enough for humans will inevitably miss things. So the only safe option which can scale to complex systems is to make sure the "tools" have their own models of human values, and use those models to check the safety of their outputs... which brings us right back to alignment.
Simple mechanisms like always displaying an estimated probability that I'll regret asking a question would probably help, but I'm mainly worried about the unknown unknowns, not the known unknowns. That's part of what I mean when I talk about marginal improvements vs closing the bulk of the gap - the unknown unknowns are the bulk of the gap.
(I could see tools helping in a do-the-same-things-but-faster sort of way, and human-mimicking approaches in particular are potentially helpful there. On the other hand, if we're doing the same things but faster, it's not clear that that scenario really favors alignment research over the Leeroy Jenkins of the world.)
In some sense I think the argument for paternalism is self-refuting, because the argument is essentially that humans can't be trusted, but I'm not sure the total amount of responsibility we're assigning to humans has changed--if the first system is to be very paternalistic, that puts an even greater weight of responsibility on the shoulders of its designers to be sure and get it right.
This in particular I think is a strong argument, and the die-rolls argument is my main counterargument.
We can indeed partially avoid the die-rolls issue by only using the system a limited number of times - e.g. to design another system. That said, in order for the first system to actually add value here, it has to do some reasoning which is too complex for humans - which brings back the problem from earlier, about the inherent danger of collapsing complex values and systems into a simple API. We'd be rolling the dice twice - once in designing the first system, once in using the first system to design the second - and that second die-roll in particular has a lot of unknown unknowns packed into it.
Let's make the later AIs corrigible then. Perhaps our initial AI can give us both a corrigibility oracle and a values oracle. (Or later AIs could use some other approach to corrigibility.)
I have yet to see a convincing argument that corrigibility is any easier than alignment itself. It seems to suffer from the same basic problem: the concept of "corrigibility" has a lot of hidden complexity, especially when it interacts with embeddedness. To the extent that we're relying on corrigibility, I'd ideally like it to improve with capabilities, in the same way and for the same reasons as I'd like alignment to improve with capabilities. Do you know of an argument that it's easier?
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2020-08-19T07:06:13.297Z · LW(p) · GW(p)
If we had that - not necessarily a full model of human values, just a formalization which we were confident could represent them - then that would immediately open the gates to analysis, to value learning, to uncertainty over values, etc.
Do you have in mind a specific aspect of human values that couldn't be represented using, say, the reward function of a reinforcement learning agent AI?
On the tools side, I assume the tools will be reasoning about systems/problems which humans can't understand - that's the main value prop in the first place. Trying to collapse the complexity of those systems into a human-understandable API is inherently dangerous: values are complex, the system is complex, their interaction will inevitably be complex, so any API simple enough for humans will inevitably miss things. So the only safe option which can scale to complex systems is to make sure the "tools" have their own models of human values, and use those models to check the safety of their outputs... which brings us right back to alignment.
There's an aspect of defense-in-depth here. If your tool's model of human values is slightly imperfect, that doesn't necessarily fail hard the way an agent with a model of human values that's slightly imperfect does.
BTW, let's talk about the "Research Assistant" story here [LW · GW]. See more discussion here [LW · GW]. (The problems brought up in that thread seem pretty solvable to me.)
Simple mechanisms like always displaying an estimated probability that I'll regret asking a question would probably help, but I'm mainly worried about the unknown unknowns, not the known unknowns. That's part of what I mean when I talk about marginal improvements vs closing the bulk of the gap - the unknown unknowns are the bulk of the gap.
That's why you need a tool... so it can tell you the unknown unknowns you're missing, and how to solve them. We'd rather have a single die roll, on creating a good tool, then have a separate die roll for every one of those unknown unknowns, wouldn't we? ;-) Shouldn't we aim for a fairly minimalist, non-paternalistic tool where unknown unknowns are relatively unlikely to become load-bearing? All we need to do is figure out the unknown unknowns that are load-bearing in the Research Assistant scenario, then assistant can help us with the rest of the unknown unknowns.
it has to do some reasoning which is too complex for humans - which brings back the problem from earlier, about the inherent danger of collapsing complex values and systems into a simple API.
If solving FAI necessarily involves reasoning about things which are beyond humans (which seems to be what you're getting at with the "unknown unknowns" stuff), what is the alternative?
I have yet to see a convincing argument that corrigibility is any easier than alignment itself. It seems to suffer from the same basic problem: the concept of "corrigibility" has a lot of hidden complexity, especially when it interacts with embeddedness. To the extent that we're relying on corrigibility, I'd ideally like it to improve with capabilities, in the same way and for the same reasons as I'd like alignment to improve with capabilities. Do you know of an argument that it's easier?
We were discussing a scenario where we had an OK solution to alignment, and you were saying that you didn't want to get locked into a merely OK solution for all of eternity. I'm saying corrigibility can address that. Alignment is already solvable to an OK degree in this hypothetical, so I'm assuming corrigibility is solvable to an OK degree as well.
Corrigible AI should be able to improve its corrigibility with increased capabilities the same way it can improve its alignment with increased capabilities. You say "corrigibility" has a lot of hidden complexity. The more capable the system, the more hypotheses it can generate regarding complex phenomena, and the more likely those hypotheses are to be correct. There's no reason we can't make the system's notion of corrigibility corrigible in the same way its values are corrigible. (BTW, I don't think corrigibility even necessarily needs to be thought of as separate from alignment, you can think of them as both being reflected in an agent's reward function say. But that's a tangent.) And we can leverage capability increases by having the system explain various notions of corrigibility it's discovered and how they differ so we can figure out which notion(s) we want to use.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-20T02:46:14.011Z · LW(p) · GW(p)
Do you have in mind a specific aspect of human values that couldn't be represented using, say, the reward function of a reinforcement learning agent AI?
It's not the function-representation that's the problem, it's the type-signature of the function. I don't know what such a function would take in or what it would return. Even RL requires that we specify the input-output channels up-front.
All we need to do is figure out the unknown unknowns that are load-bearing in the Research Assistant scenario, then assistant can help us with the rest of the unknown unknowns.
This translates in my head to "all we need to do is solve the main problems of alignment, and then we'll have an assistant which can help us clean up any easy loose ends".
More generally: I'm certainly open to the idea of AI, of one sort or another, helping to work out at least some of the problems of alignment. (Indeed, that's very likely a component of any trajectory where alignment improves over time.) But I have yet to hear a convincing case that punting now actually makes long-run alignment more likely, or even that future tools will make creation of aligned AI easier/more likely relative to unaligned AI. What exactly is the claim here?
If solving FAI necessarily involves reasoning about things which are beyond humans (which seems to be what you're getting at with the "unknown unknowns" stuff), what is the alternative?
I don't think solving FAI involves reasoning about things beyond humans. I think the AIs themselves will need to reason about things beyond humans, and in particular will need to reason about complex safety problems on a day-to-day basis, but I don't think that designing a friendly AI is too complex for humans.
Much of the point of AI is that we can design systems which can reason about things too complex for ourselves. Similarly, I expect we can design safe systems which can reason about safety problems too complex for ourselves.
Corrigible AI should be able to improve its corrigibility with increased capabilities the same way it can improve its alignment with increased capabilities.
What notion of "corrigible" are you using here? It sounds like it's not MIRI's "the AI won't disable its own off-switch" notion.
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2020-08-20T08:20:14.157Z · LW(p) · GW(p)
This translates in my head to "all we need to do is solve the main problems of alignment, and then we'll have an assistant which can help us clean up any easy loose ends".
Try to clarify here, do you think the problems brought up in these answers [LW · GW] are the main problems of alignment? This claim seems a bit odd to me because I don't think those problems are highlighted in any of the major AI alignment research agenda papers. (Alternatively, if you feel like there are important omissions from those answers, I strongly encourage you to write your own answer!)
I did a presentation at the recent AI Safety Discussion Day on how to solve the problems in that thread. My proposed solutions don't look much like anything that's e.g. on Arbital because the problems are different. I can share the slides if you want, PM me your gmail address.
More generally: I'm certainly open to the idea of AI, of one sort or another, helping to work out at least some of the problems of alignment. (Indeed, that's very likely a component of any trajectory where alignment improves over time.) But I have yet to hear a convincing case that punting now actually makes long-run alignment more likely, or even that future tools will make creation of aligned AI easier/more likely relative to unaligned AI. What exactly is the claim here?
Here's an example of a tool that I would find helpful right now, that seems possible to make with current technology (and will get better as technology advances), and seems very low risk: Given a textual description of some FAI proposal (or proposal for solving some open problem within AI safety), highlight the contiguous passage of text within the voluminous archives of AF/LW/etc. that is most likely to represent a valid objection to this proposal. (EDIT: Or, given some AI safety problem, highlight the contiguous passage of text which is most likely to represent a solution.)
Can you come up with improbable scenarios in which this sort of thing ends up being net harmful? Sure. But security is not binary. Just because there is some hypothetical path to harm doesn't mean harm is likely.
Could this kind of approach be useful for unaligned AI as well? Sure. So begin work on it ASAP, keep it low profile, and restrict its use to alignment researchers in order to create maximum differential progress towards aligned AI.
Similarly, I expect we can design safe systems which can reason about safety problems too complex for ourselves.
I'm a bit confused why you're bringing up "safety problems too complex for ourselves" because it sounds like you don't think there are any important safety problems like that, based on the sentences that came before this one?
What notion of "corrigible" are you using here? It sounds like it's not MIRI's "the AI won't disable its own off-switch" notion.
I'm talking about the broad sense of "corrigible" described in e.g. the beginning of this post [LW · GW].
(BTW, I just want to clarify that we're having two parallel discussions here: One discussion is about what we should be doing very early in our AI safety gameplan, e.g. creating the assistant I described that seems like it would be useful right now. Another discussion is about how to prevent a failure mode that could come about very late in our AI safety gameplan, where we have a sorta-aligned AI and we don't want to lock ourselves into an only sorta-optimal universe for all eternity. I expect you realize this, I'm just stating it explicitly in order to make the discussion a bit easier to follow.)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-20T18:17:44.264Z · LW(p) · GW(p)
Try to clarify here, do you think the problems brought up in these answers [LW · GW] are the main problems of alignment?
Mostly no. I've been trying to write a bit more about this topic lately; Alignment as Translation [LW · GW] is the main source of my intuitions on core problems, and the fusion power generator scenario is an example of what that looks like in a GPT-like context (parts of your answer here [LW(p) · GW(p)] are similar to that).
Using GPT-like systems to simulate alignment researchers' writing is a probably-safer use-case, but it still runs into the core catch-22. Either:
- It writes something we'd currently write, which means no major progress (since we don't currently have solutions to the major problems and therefore can't write down such solutions), or
- It writes something we currently wouldn't write, in which case it's out-of-distribution and we have to worry about how it's extrapolating us
I generally expect the former to mostly occur by default; the latter would require some clever prompts.
I could imagine at least some extrapolation of progress being useful, but it still seems like the best way to make human-simulators more useful is to improve our own understanding, so that we're more useful to simulate.
Given a textual description of some FAI proposal (or proposal for solving some open problem within AI safety), highlight the contiguous passage of text within the voluminous archives of AF/LW/etc. that is most likely to represent a valid objection to this proposal.
This sounds like a great tool to have. It's exactly the sort of thing which is probably marginally useful. It's unlikely to help much on the big core problems; it wouldn't be much use for identifying unknown unknowns which nobody has written about before. But it would very likely help disseminate ideas, and be net-positive in terms of impact.
I do think a lot of the things you're suggesting would be valuable and worth doing, on the margin. They're probably not sufficient to close the bulk of the safety gap without theoretical progress on the core problems, but they're still useful.
I'm a bit confused why you're bringing up "safety problems too complex for ourselves" because it sounds like you don't think there are any important safety problems like that, based on the sentences that came before this one?
The "safety problems too complex for ourselves" are things like the fusion power generator scenario - i.e. safety problems in specific situations or specific applications. The safety problems which I don't think are too complex are the general versions, i.e. how to build a generally-aligned AI.
An analogy: finding shortest paths in a billion-vertex graph is far too complex for me. But writing a general-purpose path-finding algorithm to handle that problem is tractable. In the same way, identifying the novel safety problems of some new technology will sometimes be too complex for humans. But writing a general-purpose safety-reasoning algorithm (i.e. an aligned AI) is tractable, I expect.
I'm talking about the broad sense of "corrigible" described in e.g. the beginning of this post [LW · GW].
Ah ok, the suggestion makes sense now. That's a good idea. It's still punting a lot of problems until later, and humans would still be largely responsible for solving those problems later. But it could plausibly help with the core problems, without any obvious trade-off (assuming that the AI/oracle actually does end up pointed at corrigibility).
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2020-08-21T23:51:01.925Z · LW(p) · GW(p)
Mostly no. I've been trying to write a bit more about this topic lately; Alignment as Translation is the main source of my intuitions on core problems, and the fusion power generator scenario is an example of what that looks like in a GPT-like context (parts of your answer here are similar to that).
Well, I encourage you to come up with a specific way in which GPT-N will harm us by trying to write an AF post due to not having solved Alignment as Translation and add it as an answer in that thread. Given that we may be in an AI overhang [LW · GW], I'd like the answers to represent as broad a distribution of plausible harms as possible, because that thread might end up becoming very important & relevant very soon.
comment by dxu · 2020-08-16T16:18:57.704Z · LW(p) · GW(p)
I like this post a lot, and I think it points out a key crux between what I would term the "Yudkowsky" side (which seems to mostly include MIRI, though I'm not too sure about individual researchers' views) and "everybody else".
In particular, the disagreement seems to crystallize over the question of whether "human values" really are a natural abstraction. I suspect that if Eliezer thought that they were, he would be substantially less worried about AI alignment than he currently is (though naturally all of this is my read on his views).
You do provide some reasons to think that human values might be a natural abstraction, both in the post itself and in the comments, but I don't see these reasons as particularly compelling ones. The one I view as the most compelling is the argument that humans seems to be fairly good at identifying and using natural abstractions, and therefore any abstract concept that we seem to be capable of grasping fairly quickly has a strong chance of being a natural one.
However, I think there's a key difference between abstractions that are developed for the purposes of prediction, and abstractions developed for other purposes (by which I mostly mean "RL"). To the extent that a predictor doesn't have sufficient computational power to form a low-level model of whatever it's trying to predict, I definitely think that the abstractions it develops in the process of trying to improve its prediction will to a large extent be natural ones. (You lay out the reasons for this clearly enough in the post itself, so I won't repeat them here.)
It seems to me, though, that if we're talking about a learning agent that's actually trying to take actions to accomplish things in some environment, there's a substantial amount of learning going on that has nothing to do with learning to predict things with greater accuracy! The abstractions learned in order to select actions from a given action-space in an attempt to maximize a given reward function--these, I see little reason to expect will be natural. In fact, if the computational power afforded to the agent is good but not excellent, I expect mostly the opposite: a kludge of heuristics and behaviors meant to address different subcases of different situations, with not a whole lot of rhyme or reason to be found.
As agents go, humans are definitely of the latter type. And, therefore, I think the fact that we intuitively grasp the concept of "human values" isn't necessarily an argument that "human values" are likely to be natural, in the way that it would be for e.g. trees. The latter would have been developed as a predictive abstraction, whereas the former seems to mainly consist of what I'll term a reward abstraction. And it's quite plausible to me that reward abstractions are only legible by default to agents which implement that particular reward abstraction, and not otherwise. If that's true, then the fact that humans know what "human values" are is merely a consequence of the fact that we happen to be humans, and therefore have a huge amount of mind-structure in common.
To the extent that this is comparable to the branching pattern of a tree (which is a comparison you make in the post), I would argue that it increases rather than lessens the reason to worry: much like a tree's branch structure is chaotic, messy, and overall high-entropy, I expect human values to look similar, and therefore not really encompass any kind of natural category.
↑ comment by johnswentworth · 2020-08-16T21:49:12.007Z · LW(p) · GW(p)
To the extent that this is comparable to the branching pattern of a tree (which is a comparison you make in the post), I would argue that it increases rather than lessens the reason to worry: much like a tree's branch structure is chaotic, messy, and overall high-entropy, I expect human values to look similar, and therefore not really encompass any kind of natural category.
Bit of a side-note, but the high entropy of tree branching comes from trees using the biological equivalent of random number generators when "deciding" when/whether to form a branch. The distribution of branch length-ratios/counts/angles is actually fairly simple and stable, and is one of the main characteristics which makes particular tree species visually distinctive. See L-systems for the basics, or speedtree for the industrial-grade version (and some really beautiful images).
It's that distribution which is the natural abstraction - i.e. the distribution summarizes information about branching which is relevant to far-away trees of the same species.
↑ comment by johnswentworth · 2020-08-16T21:15:51.915Z · LW(p) · GW(p)
I think there's a subtle confusion here between two different claims:
- Human values evolved as a natural abstraction of some territory.
- Humans' notion of "human values" is a natural abstraction of humans' actual values.
It sounds like your comment is responding to the former, while I'm claiming the latter.
A key distinction here is between humans' actual values, and humans' model/notion of our own values. Humans' actual values are the pile of heuristics inherited from evolution. But humans also have a model of their values, and that model is not the same as the underlying values. The phrase "human values" necessarily points to the model, because that's how words work - they point to models. My claim is that the model is a natural abstraction of the actual values, not that the actual values are a natural abstraction of anything.
This is closely related to this section from the OP:
Human values are basically a bunch of randomly-generated heuristics which proved useful for genetic fitness; why would they be a “natural” abstraction? But remember, the same can be said of trees. Trees are a complicated pile of organic spaghetti code [LW · GW], but “tree” is still a natural abstraction, because the concept summarizes all the information from that organic spaghetti pile which is relevant to things far away. In particular, it summarizes anything about one tree which is relevant to far-away trees.
Roughly speaking, the concept of "human values" summarizes anything about the values of one human which is relevant to the values of far-away humans.
Does that make sense?
comment by Donald Hobson (donald-hobson) · 2020-08-15T19:02:41.283Z · LW(p) · GW(p)
So in principle, it doesn’t even matter what kind of model we use or how it’s represented; as long the predictive power is good enough, values will be embedded in there, and the main problem will be finding the embedding.
I will agree with this. However, notice what this doesn't say. It doesn't say "any model powerful enough to be really dangerous contains human values". Imagine a model that was good at a lot of science and engineering tasks. It was good enough at nuclear physics to design effective fusion reactors and bombs. It knew enough biology to design a superplage. It knew enough molecular dynamics to design self replicating nanotech. It knew enough about computer security to hack most real world systems. But it didn't know much about how humans thought. It's predictions are far from maxentropy, if it sees people walking along a street, it thinks they will probably carry on walking, not fall to the ground twiching randomly. Lets say that the model is as predictively accurate as you would be when asked to predict the behaviour of a stranger from a few seconds of video. This AI doesn't contain a model of human values anywhere in it.
We can't just assume that every AI powerful enough to be dangerous contains a model of human values, however I suspect most of them will in practice.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-16T15:01:38.289Z · LW(p) · GW(p)
This is entirely correct.
comment by Charlie Steiner · 2020-08-14T17:12:37.071Z · LW(p) · GW(p)
This is the sort of thing I've been thinking about since "What's the dream for giving natural language commands to AI? [LW · GW]" (which bears obvious similarities to this post). The main problems I noted there apply similarly here:
- Prediction in the supervised task might not care about the full latent space used for the unsupervised tasks, losing information.
- Little to no protection from Goodhart's law. Things that are extremely good proxies for human values still might not be safe to optimize.
- Doesn't care about metaethics, just maximizes some fixed thing. Which wouldn't be a problem if it was meta-ethically great to start with, but it probably incorporates plenty of human foibles in order to accurately predict us.
The killer is really that second one. If you run this supervised learning process, and it gives you a bunch of rankings of things in terms of their human values score, this isn't a safe AI even if it's on average doing a great job, because the thing that gets the absolute best score is probably an exploit of the specific pattern-recognition algorithm used to do the ranking. In short, we still need to solve the other-izer problem.
Actually, your trees example does give some ideas. Could you look inside a GAN trained on normal human behavior and identify what parts of it were the "act morally" or "be smart" parts, and turn them up? Choosing actions is, after all, a generative problem, not a classification or regression problem.
comment by Gordon Seidoh Worley (gworley) · 2020-08-12T20:04:39.845Z · LW(p) · GW(p)
So far, we’ve only talked about one AI ending up aligned, or a handful ending up aligned at one particular time. However, that isn’t really the ultimate goal of AI alignment research. What we really want is for AI to remain aligned in the long run, as we (and AIs themselves) continue to build new and more powerful systems and/or scale up existing systems over time.
I think this suggests an interesting path where alignment by default might be able to serve as a bridge to better alignment mechanisms, i.e. if it works and we can select for AIs that contains representations of human values, then we might be able to prioritize this in a slow takeoff scenario so that in the early phases of it we at least have mostly aligned AI that helps us build better mechanisms for alignment (as opposed to these AIs simply building successors directly with the hope that they maintain alignment with human values in the process).
Replies from: johnswentworth, adamShimi↑ comment by johnswentworth · 2020-08-12T21:03:57.572Z · LW(p) · GW(p)
I think of this as the Rohin trajectory, since he's the main person I've heard talk about it. I agree it's a natural approach to consider, though deceptiveness-type problems are a big potential issue.
↑ comment by adamShimi · 2020-08-12T20:17:46.530Z · LW(p) · GW(p)
Isn't remaining aligned an example of robust delegation [? · GW]? If so, there have been both discussions and technical work on this problem before.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-12T21:02:24.116Z · LW(p) · GW(p)
Yup, exactly right, though this version is a fair bit more involved than the simplified delegation scenarios we've seen in most of the theoretical work.
comment by Vanessa Kosoy (vanessa-kosoy) · 2021-12-19T14:35:58.221Z · LW(p) · GW(p)
In this post, the author describes a pathway by which AI alignment can succeed even without special research effort. The specific claim that this can happen "by default" is not very important, IMO (the author himself only assigns 10% probability to this). On the other hand, viewed as a technique that can be deliberately used to help with alignment, this pathway is very interesting.
The author's argument can be summarized as follows:
- For anyone trying to predict events happening on Earth, the concept of "human values" is a "natural abstraction", i.e. something that has to be a part of any model that's not too computationally expensive (so that it doesn't bypass the abstraction by anything like accurate simulation of human brains).
- Therefore, unsupervised learning will produce models in which human values are embedded in some simple way (e.g. a small set of neurons in an ANN).
- Therefore, if supervised learning is given the unsupervised model as a starting point, it is fairly likely to converge to true human values even from a noisy and biased proxy.
[EDIT: John pointed out that I misunderstood his argument: he didn't intend to say that human values are a natural abstraction, but only that their inputs are natural abstractions. The following discussion still applies.]
The way I see it, this argument has learning-theoretic justification even without appealing to anything we know about ANNs (and therefore without assuming the AI in question is an ANN). Consider the following model: an AI receives a sequence of observations that it has to make predictions about. It also receives labels, but these are sparse: it is only given a label once in a while. If the description complexity of the true label function is high, the sample complexity of learning to predict labels via a straightforward approach (i.e. without assuming a relationship between the dynamics and the label function) is also high. However, if the relative description complexity of the label function w.r.t. the dynamics producing the observations is low, then we can use the abundance of observations to achieve lower effective sample complexity. I'm confident that this can be made rigorous.
Therefore, we can recast the thesis of this post as follows: Unsupervised learning of processes happening on Earth, for which we have plenty of data, can reduce the size of the dataset required to learn human values, or allow better generalization from a dataset of the same size.
One problem the author doesn't talk about here is daemons / inner misalignment[1]. In the comment section, the author writes:
inner alignment failure only applies to a specific range of architectures within a specific range of task parameters - for instance, we have to be optimizing for something, and there has to be lots of relevant variables observed only at runtime, and there has to be something like a "training" phase in which we lock-in parameter choices before runtime, and for the more disastrous versions we usually need divergence of the runtime distribution from the training distribution. It's a failure mode which assumes that a whole lot of things look like today's ML pipelines.
This might or might not be a fair description of inner misalignment in the sense of Hubinger et al. However, this is definitely not a fair description of the daemonic attack vectors in general. The potential for malign hypotheses (learning of hypotheses / models containing malign subagents) exists in any learning system, and in particular malign simulation hypotheses are a serious concern.
Relatedly, the author is too optimistic (IMO) in his comparison of this technique to alternatives:
...when alignment-by-default works, it’s a best-case scenario. The AI has a basically-correct model of human values, and is pursuing those values. Contrast this to things like IRL variants, which at best learn a utility function which approximates human values (which are probably not themselves a utility function). Or the HCH family of methods, which at best mimic a human with a massive hierarchical bureaucracy at their command, and certainly won’t be any more aligned than that human+bureaucracy would be.
This sounds to me like a biased perspective resulting from looking for flaws in other approaches harder than flaws in this approach. Natural abstractions potentially lower the sample complexity of learning human values, but they cannot lower it to zero. We still need some data to learn from and some model relating this data to human values, and this model can suffer from the usual problems. In particular, the unsupervised learning phase does little to inoculate us from malign simulation hypotheses that can systematically produce catastrophically erroneous generalization.
If IRL variants learn a utility function while human values are not a utility function, then avoiding this problem requires identifying the correct type signature of human values[2], in this approach as well. Regarding HCH, Human + "bureaucracy" might or might not be aligned, depending on how we organize the "bureaucracy" (see also [LW(p) · GW(p)]). If HCH can fail in some subtle way (e.g. systems of humans are misaligned to individual humans), then similar failure modes might affect this approach as well (e.g. what if "Molochian" values are also a natural abstraction).
In summary, I found this post quite insightful and important, if somewhat too optimistic.
I am slightly wary of use the term "inner alignment" since Hubinger uses it in a very specific way I'm not sure I entirely understand. Therefore, I am more comfortable with "daemons" although the two have a lot of overlap. ↩︎
E.g. IB physicalism [LW · GW] proposes a type signature for "physicalist values" which might or might not be applicable to humans. ↩︎
↑ comment by johnswentworth · 2021-12-19T19:00:46.628Z · LW(p) · GW(p)
One subtlety which approximately 100% of people I've talked to about this post apparently missed: I am pretty confident that the inputs to human values are natural abstractions, i.e. we care about things like trees, cars, humans, etc, not about quantum fields or random subsets of atoms. I am much less confident that "human values" themselves are natural abstractions; values vary a lot more across cultures than e.g. agreement on "trees" as a natural category.
Relatedly, the author is too optimistic (IMO) in his comparison of this technique to alternatives: ...
In the particular section you quoted, I'm explicitly comparing the best-case of abstraction by default to the the other two strategies, assuming that the other two work out about-as-well as they could realistically be expected to work. For instance, learning a human utility function is usually a built-in assumption of IRL formulations, so such formulations can't do any better than a utility function approximation even in the best case. Alignment by default does not need to assume humans have a utility function; it just needs whatever-humans-do-have to have low marginal complexity in a system which has learned lots of natural abstractions.
Obviously alignment by default has analogous assumptions/flaws; much of the OP is spent discussing them. The particular section you quote was just talking about the best-case where those assumptions work out well.
The potential for malign hypotheses (learning of hypotheses / models containing malign subagents) exists in any learning system, and in particular malign simulation hypotheses are a serious concern. ...
I partially agree with this, though I do think there are good arguments that malign simulation issues will not be a big deal (or to the extent that they are, they'll look more like Dr Nefarious [LW(p) · GW(p)] than pure inner daemons), and by historical accident those arguments have not been circulated in this community to nearly the same extent as the arguments that malign simulations will be a big deal. Some time in the next few weeks I plan to write a review of The Solomonoff Prior Is Malign [LW · GW] which will talk about one such argument.
Replies from: vanessa-kosoy, johnswentworth↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-12-19T22:34:41.763Z · LW(p) · GW(p)
I am pretty confident that the inputs to human values are natural abstractions, i.e. we care about things like trees, cars, humans, etc, not about quantum fields or random subsets of atoms. I am much less confident that "human values" themselves are natural abstractions
That's fair, but it's still perfectly in line with the learning-theoretic perspective: human values are simpler to express through the features acquired by unsupervised learning than through the raw data, which translates to a reduction in sample complexity.
...learning a human utility function is usually a built-in assumption of IRL formulations, so such formulations can't do any better than a utility function approximation even in the best case. Alignment by default does not need to assume humans have a utility function; it just needs whatever-humans-do-have to have low marginal complexity in a system which has learned lots of natural abstractions.
This seems wrong to me. If you do IRL with the correct type signature for human values then in the best case you get the true human values. IRL is not mutually exclusive with your approach: e.g. you can do unsupervised learning and IRL with shared weights. I guess you might be defining "IRL" as something very narrow, whereas I define it "any method based on revealed preferences".
...to the extent that they are, they'll look more like Dr Nefarious than pure inner daemons
Malign simulation hypotheses already look like "Dr. Nefarious" where the role of Dr. Nefarious is played by the masters of the simulation, so I'm not sure what exactly is the distinction you're drawing here.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-12-20T00:01:22.899Z · LW(p) · GW(p)
That's fair, but it's still perfectly in line with the learning-theoretic perspective: human values are simpler to express through the features acquired by unsupervised learning than through the raw data, which translates to a reduction in sample complexity.
Yup, that's right. I still agree with your general understanding, just wanted to clarify the subtlety.
If you do IRL with the correct type signature for human values then in the best case you get the true human values. IRL is not mutually exclusive with your approach: e.g. you can do unsupervised learning and IRL with shared weights.
Yup, I agree with all that. I was specifically talking about IRL approaches which try to learn a utility function, not the more general possibility space.
Malign simulation hypotheses already look like "Dr. Nefarious" where the role of Dr. Nefarious is played by the masters of the simulation, so I'm not sure what exactly is the distinction you're drawing here.
The distinction there is about whether or not there's an actual agent in the external environment which coordinates acausally with the malign inner agent, or some structure in the environment which allows for self-fulfilling prophecies, or something along those lines. The point is that there has to be some structure in the external environment which allows a malign inner agent to gain influence over time by making accurate predictions. Otherwise, the inner agent will only have whatever limited influence it has from the prior, and every time it deviates from its actual best predictions (or is just out-predicted by some other model), some of that influence will be irreversibly spent; it will end up with zero influence in the long run.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-12-20T10:52:04.271Z · LW(p) · GW(p)
...the inner agent will only have whatever limited influence it has from the prior, and every time it deviates from its actual best predictions (or is just out-predicted by some other model), some of that influence will be irreversibly spent
Of course, but this in itself is no consolation, because it can spend its finite influence to make the AI perform an irreversible catastrophic action: for example, self-modifying into something explicitly malign.
In e.g. IDA-type protocols you can defend by using a good prior (such as IB physicalism [LW · GW]) plus confidence thresholds (i.e. every time the hypotheses have a major disagreement you query the user). You also have to do something about non-Cartesian attack vectors (I have some ideas), but that doesn't depend much on the protocol.
In value learning things are worse, because of the possibility of corruption (i.e. the AI hacking the user or its own input channels). As a consequence, it is no longer clear you can infer the correct values even if you make correct predictions about everything observable. Protocols based on extrapolating from observables to unobservables fail, because malign hypotheses can attack the extrapolation with impunity (e.g. a malign hypothesis can assign some kind of "Truman show" interpretation to the behavior of the user, where the user's true values are completely alien and they are just pretending to be human because of the circumstances of the simulation).
↑ comment by johnswentworth · 2021-12-28T03:24:32.979Z · LW(p) · GW(p)
Some time in the next few weeks I plan to write a review of The Solomonoff Prior Is Malign [LW · GW] which will talk about one such argument.
comment by adamShimi · 2020-08-16T16:12:28.377Z · LW(p) · GW(p)
Great post!
That might have been discussed in the comments, but my gut reaction to the tree example was not "It's not really understanding tree" but "It's understanding trees visually". That is, I think the examples point to trees being a natural abstraction with regard to images made of pixels. In that sense, dogs and cats and other distinct visual objects might fit your proposal of natural abstraction. Yet this doesn't entail that trees are a natural abstraction when given the position of atoms, or sounds (to be more abstract). I thus think that natural abstractions should be defined with regard for the sort of data that is used.
For human values, I might accept that they are natural abstraction, but I don't know for which kind of data. Is audiovisual data (as in youtube videos) enough? Do we also need textual data? Neuroimagery? I don't know, and that makes me slightly more pessimistic about a unsupervised model learning human values by default.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-16T21:22:28.094Z · LW(p) · GW(p)
My model of abstraction is that high-level abstractions summarize all the information from some chunk of the world which is relevant "far away". Part of that idea is that, as we "move away" from the information-source, most information is either quickly wiped out by noise, or faithfully transmitted far away. The information which is faithfully transmitted will usually be present across many different channels; that's the main reason it's not wiped out by noise in the first place. Obviously this is not something which necessarily applies to all possible systems, but intuitively it seems like it should apply to most systems most of the time: information which is not duplicated across multiple channels is easily wiped out by noise.
comment by romeostevensit · 2020-08-12T20:15:25.732Z · LW(p) · GW(p)
This requires hitting a window - our data needs to be good enough that the system can tell it should use human values as a proxy, but bad enough that the system can’t figure out the specifics of the data-collection process enough to model it directly. This window may not even exist.
I like this framing, it is clarifying.
When alignment-by-default works, it’s basically a best-case scenario, so we can safely use the system to design a successor without worrying about amplification of alignment errors (among other things).
didn't understand how this was derived or what other results/ideas it is referencing.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-12T21:15:43.097Z · LW(p) · GW(p)
didn't understand how this was derived or what other results/ideas it is referencing.
The idea here is that the AI has a rough model of human values, and is pointed at those values when making decisions (e.g. the embedding is known and it's optimizing for the embedded values, in the case of an optimizer). It may not have perfect knowledge of human values, but it would e.g. design its successor to build a more precise model of human values than itself (assuming it expects that successor to have more relevant data) and point the successor toward that model, because that's the action which best optimizes for its current notion of human values.
Contrast to e.g. an AI which is optimizing for human approval. If it can do things which makes a human approve, even though the human doesn't actually want those things (e.g. deceptive behavior), then it will do so. When that AI designs its successor, it will want the successor to be even better at gaining human approval, which means making the successor even better at deception.
This probably needs more explanation, but I'm not sure which parts need more explanation, so feedback would be appreciated.
Replies from: Pongo, romeostevensit↑ comment by Pongo · 2020-08-12T22:59:39.147Z · LW(p) · GW(p)
Contrast to e.g. an AI which is optimizing for human approval. [...] When that AI designs its successor, it will want the successor to be even better at gaining human approval, which means making the successor even better at deception.
Is the idea that the AI is optimizing for humans approving of things, as opposed to humans approving of its actions? It seems that if its optimizing for humans approving of its actions, it doesn't necessarily have an incentive to make a successor that optimizes for approval (though I admit it's not clear why it would make a successor at all in this case; perhaps it's designed to not plan against being deactivated after some time)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-12T23:14:56.242Z · LW(p) · GW(p)
Right, I should clarify that. I was imagining that it's designing a successor which will take over the AI's own current input/output channels, so "its actions" in the future will actually be the successor's actions. (Equivalently, we could imagine the AI contemplating self-modification.)
↑ comment by romeostevensit · 2020-08-12T22:40:56.458Z · LW(p) · GW(p)
This is helpful.
comment by avturchin · 2020-08-13T21:02:46.161Z · LW(p) · GW(p)
This will likely not work for dualistic model of human values (and other complex models, like family system). In this model, a human have an ethical system and opposing suppressed desires.
For example, I think that it is good to eat less, but have a desire for overeating. Combined, they produce behaviour in which I often have eating binges following by periods of fasting. If an AI want to predict my behaviour, it may suggest that I want to have periods of overeating and extrapolate accordingly. However, I consciously endorse only "eating less ethics" and regard it as my true values. As S.Armstrong wrote, there is always an assumption which part of me should be regarded as "true values".
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-13T22:05:53.826Z · LW(p) · GW(p)
Your behavior is not what the AI is trying to predict. The AI is just trying to predict the world, in general - including e.g. the outcomes of medical or psychological experiments which specifically try to probe the gears underlying your behavior.
Replies from: avturchin↑ comment by avturchin · 2020-08-13T22:53:42.556Z · LW(p) · GW(p)
But the result of such experiments may still not converge: in one experiment I will claim to have a value of not eating, and in another I will eat.
But if the AI is advance enough, it could guess also the correct structure of motivational system. like the number of significant part in it, and each will be represented inside its human model.
However, if there are many ways to create human models of similar efficacy, we can't say which model is correct and guess "correct" values.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-13T23:03:14.730Z · LW(p) · GW(p)
in one experiment I will claim to have a value of not eating, and in another I will eat.
That's still just looking at behavior. Probing the internals would mean e.g. hooking you to an FMRI to see what's happening in the brain when you claim to have a value of not eating or when you you eat.
However, if there are many ways to create human models of similar efficacy, we can't say which model is correct and guess "correct" values.
We can say which model is correct by looking at the internal structure of humans, which is exactly why medical research is relevant.
Replies from: avturchin↑ comment by avturchin · 2020-08-14T10:50:05.050Z · LW(p) · GW(p)
Knowing internal structure will not help much: the same way as knowing pixel locations on a picture is not equal to image recognition, which is high level representation and abstraction.
We need something like a high-level representation of trees, as in your example, but for values. But values could be abstracted in different ways - in many more ways than trees. Even trees may be represented like "green mass" or like set of branches or in some other slightly non-human ways.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-14T15:40:19.454Z · LW(p) · GW(p)
But values could be abstracted in different ways - in many more ways than trees. Even trees may be represented like "green mass" or like set of branches or in some other slightly non-human ways.
This is the part I disagree with. I think there is a single (up to isomorphism) notion of "tree" toward which a very broad variety of computationally-limited predictive systems will converge. That's what the OP's discussion of "natural abstractions" and "information relevant far away" is about.
For instance, if a system's only concept of "tree" is "green mass" then it's either going to (a) need whole separate models for trees in autumn and winter (which would be computationally expensive), or (b) lose predictive power when reasoning about trees in autumn and winter. Also, if it learns new facts about green-mass-trees, how will it know that those facts generalize to non-green-mass-trees?
Pointing to a Flower [? · GW] has a lot more about this, although it's already out-of-date compared to my current thoughts on the problem.
Replies from: avturchin↑ comment by avturchin · 2020-08-14T16:45:26.222Z · LW(p) · GW(p)
And here is my point: trees actually exist, and they are natural abstract. "Human values" was created by psychologists in the middle of 20th century as one of the ways to describe human mind. They don't actually exist, but are useful description instruments for some tasks.
There are other ways to describe human mind and human motivations: ethical norms, drives, memes, desires, Freud model, family system [LW · GW] etc. An AI may find some other abstractions which will be even better in compressing behaviour, but they will be not human values.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-14T18:03:24.190Z · LW(p) · GW(p)
Humans have wanted things, and recognized other humans as wanting things, since long before 20th century psychologists came along and used the phrase "human values". I don't particularly care about aligning an AI to whatever some psychologist defines as "human values", I care about aligning an AI to the things humans want. Those are the "human values" I care about. The very fact that I can talk about that, and other people generally seem to know what I'm talking about without me needing to give a formal definition, is evidence that it is a natural abstraction.
I would not say there are "other ways to model the human mind", but rather there are other aspects of the human mind which one can model. (Also there are some models of the human mind which are just outright wrong, e.g. Freudian models.) If a model is to achieve strong general-purpose predictive power, then it needs to handle all of those different aspects, including human values. A model of the human mind may be lower-level than "human values", e.g. a low-level physics model of the brain, but that will still have human values embedded in it somehow. If a model doesn't have human values embedded in it somewhere, then it will have poor predictive performance on many problems in which human values are involved.
Replies from: avturchin↑ comment by avturchin · 2020-08-14T18:25:04.702Z · LW(p) · GW(p)
But human "wants" are not actually a good thing which AI should follow. If I am fasting, I obviously want to eat, but me decision is not eating today. And if I have a robot helping me, I prefer it care about my decisions, not my "wants". This distinction between desires and decisions was obvious for last 2.5 thousand years, and "human values" is obscure and not natural idea.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-14T20:09:48.909Z · LW(p) · GW(p)
You are using the word "want" differently than I was. I'm pretty sure I'm trying to point to exactly the same thing you are pointing to. And the fact that we're both trying to point to the same thing is exactly the evidence that the thing we're trying to point to is a natural abstraction.
(The fact that the distinction between desires and decisions was obvious for the last 2.5. thousand years is also evidence that both of these things are natural abstractions.)
And if I have a robot helping me, I prefer it care about my decisions, not my "wants".
This is a bad idea. You should really, really want the robot to care about something besides your decisions, because the decisions are not enough to determine your values.
comment by Donald Hobson (donald-hobson) · 2020-08-15T22:49:36.850Z · LW(p) · GW(p)
when alignment-by-default works, we can use the system to design a successor without worrying about amplification of alignment errors
Anything neural net related starts with random noise and performs gradient descent style steps. This doesn't get you the global optimal, it gets you some point that is approximately a local optimal, which depends on the noise, the nature of the search space, and the choice of step size.
If nothing else, the training data will contain sensor noise.
At best you are going to get something that roughly corresponds to human values.
Just because it isn't obvious where the noise entered the system doesn't make it noiseless. Just because you gave what we actually want, and the value of a neuron in a neural net the same name, doesn't make them the same thing.
Consider the large set of references with representative members "What Alice makes long term plans towards", "What Bobs impulsive action tends towards", "What Alice says is good and right when her social circle are listening", "What Carl listens to when deciding which politician to vote for", "What news makes Eric instinctively feel good", "what makes Fred presses the reward button during AI training" ect ect.
If these all referred to the same preference ordering over states of the world, then we could call that human values, and have a natural concept.
Trees are a fairly natural concept because "tall green things" and "Lifeforms that are >10% cellulose" point to a similar set of objects. There are many different simple boundaries in concept-space that largely separate trees from non trees. Trees are tightly clustered in thing-space.
To the extent that all those references refer to the same thing, we can't expect an AI to distinguish between them. To the extent that they refer to different concepts, at best the AI will have a separate concept for each.
Suppose you run the microscope AI, and you find that you have a whole load of concepts that kind of match "human values" to different degrees. These represent different people and different embeddings of value. (Of course, "What Carl listens to when deciding which politician to vote for" contains Carls distrust of political promises. "what makes Fred presses the reward button during AI training" includes the time Fred tripped up and slammed the button by accident. Each of the easily accessible concepts is a bit different and includes its own bit of noise)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-16T15:19:26.968Z · LW(p) · GW(p)
Trees are a fairly natural concept because "tall green things" and "Lifeforms that are >10% cellulose" point to a similar set of objects. There are many different simple boundaries in concept-space that largely separate trees from non trees. Trees are tightly clustered in thing-space.
That's not quite how natural abstractions work. There are lots of edge cases which are sort-of-trees-but-sort-of-not: logs, saplings/acorns, petrified trees, bushes, etc. Yet the abstract category itself is still precise.
An analogy: consider a Gaussian cluster model. Any given cluster will have lots of edge cases, and lots of noise in the individual points. But the cluster itself - i.e. the mean and variance parameters of the cluster - can still be precisely defined. Same with the concept of "tree", and (I expect) with "human values".
In general, we can have a precise high-level concept without a hard boundary in the low-level space.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2020-08-16T19:43:27.576Z · LW(p) · GW(p)
Consider a source of data that is from a sum of several Gaussian distributions. If you have a sufficiently large number of samples from this distribution, you can locate the origional gaussians to arbitrary accuracy. (Of course, if you have a finite number of samples, you will have some inaccuracy in predicting the location of the gaussians, possibly a lot.)
However, not all distributions share this property. If you look at uniform distributions over rectangles in 2d space, you will find that a uniform L shape can be made in 2 different ways. More complicated shapes can be made in even more ways. The property that you can uniquely decompose sum of gaussians into its individual gaussians is not a property that applies to every distribution.
I would expect that whether or not logs, saplings, petrified trees, sparkly plastic christmas trees ect counted as trees would depend on the details of the training data, as well as the network architecture and possibly the random seed.
Note: this is an empirical prediction about current neural networks. I am predicting that if someone, takes 2 networks that have been trained on different datasets, ideally with different architectures, and tries to locate the neuron that holds the concept of "Tree" in each, and then shows both networks an edge case that is kind of like a tree, then the networks will often disagree significantly about how much of a tree it is.
comment by rokosbasilisk · 2023-01-30T06:19:53.541Z · LW(p) · GW(p)
This requires hitting a window - our data needs to be good enough that the system can tell it should use human values as a proxy, but bad enough that the system can’t figure out the specifics of the data-collection process enough to model it directly. This window may not even exist.
are there any real world examples of this? not necessarily in human-values setting
comment by Leon Lang (leon-lang) · 2023-01-20T00:29:43.072Z · LW(p) · GW(p)
Summary
This article claims that:
- Unsupervised learning systems will likely learn many “natural abstractions” of concepts like “trees” or “human values”. Maybe they will even end up being simply a “feature direction”.
- One reason to expect this is that to make good predictions, you only need to conserve information that’s useful at a distance. And this information can be imagined being a “natural abstraction”.
- If you then have an RL system or supervised learner who can use the unsupervised activations to solve a problem, then it can directly behave in such a way as to “satisfy the natural abstraction” of, e.g., human values.
- This would be a quick way for the model to behave well on such a task. Later on, the model might find the unnatural proxy goal and maximize that, but that wouldn’t be the first thing found.
- Thus, we may up with alignment by default. Such an aligned AGI could then be used to align successor AIs, and it might be better at that than humans are since it’s smarter.
- Note that if we have “alignment by default”, then the alignment of a successor system might work better than with competitive HCH or IRL. Reason: humans+bureaucracies may not be aligned, and IRL finds a utility function, which is of the wrong type signature. This may lead to a compounding of alignment errors when building successor AIs.
- Variations of “alignment by default” would, e.g., find the “human value abstraction” in one AI and then “plant it” into the search operation of an AGI. I.e., alignment would not be solved by default for all AIs, but it’s defaulty-enough that we still win.
My Opinion:
- Human values are less “one thing” than trees or humans are. “Human values are active” is not a sensible piece of information since there are so many different types of human values. Admittedly, this also applies to trees, but it does feel like it’s pointing to a difficulty.
- Overall, this makes me think that, possibly, the proxy goal is often a more natural abstraction than human values. My hope mainly comes from the thought that the proxy goals are hopefully specific enough to the RL/supervised task that they didn’t appear in the unsupervised training phase.
- But there are reasons against that: humans will put lots of information about ML training processes into the training data of any unsupervised system, meaning that to make good predictions, the systems should probably represent these proxy goals quite well. Only if they do would they make accurate predictions about, e.g., contemporary alignment errors.