Public Static: What is Abstraction?
post by johnswentworth · 2020-06-09T18:36:49.838Z · LW · GW · 18 commentsContents
Formalization: Starting Point Information About Things “Far Away” Systems View Causality Exact Abstraction Summary Appendix: System Formulation Proof None 18 comments
Author’s Note: Most of the posts in this sequence [? · GW] are essentially a log of work-in-progress. This post is intended as a more presentable (“public”) and higher-confidence (“static”) write-up of some formalizations of abstraction. Much of the material has appeared in other posts; the first two sections in particular are drawn almost verbatim from the opening “What is Abstraction?” post.
Let's start with a few examples (borrowed from here [LW · GW]) to illustrate what we're talking about:
- We have a gas consisting of some huge number of particles. We throw away information about the particles themselves, instead keeping just a few summary statistics: average energy, number of particles, etc. We can then make highly precise predictions about things like e.g. pressure just based on the reduced information we've kept, without having to think about each individual particle. That reduced information is the "abstract layer" - the gas and its properties.
- We have a bunch of transistors and wires on a chip. We arrange them to perform some logical operation, like maybe a NAND gate. Then, we throw away information about the underlying details, and just treat it as an abstract logical NAND gate. Using just the abstract layer, we can make predictions about what outputs will result from what inputs. Note that there’s some fuzziness - 0.01 V and 0.02 V are both treated as logical zero, and in rare cases there will be enough noise in the wires to get an incorrect output.
- I tell my friend that I'm going to play tennis. I have ignored a huge amount of information about the details of the activity - where, when, what racket, what ball, with whom, all the distributions of every microscopic particle involved - yet my friend can still make some reliable predictions based on the abstract information I've provided.
- When we abstract formulas like "1+1=2*1" and "2+2=2*2" into "n+n=2*n", we're obviously throwing out information about the value of n, while still making whatever predictions we can given the information we kept. This is what abstraction is all about in math and programming: throw out as much information as you can, while still maintaining the core "prediction" - i.e. the theorem or algorithm.
- I have a street map of New York City. The map throws out lots of info about the physical streets: street width, potholes, power lines and water mains, building facades, signs and stoplights, etc. But for many questions about distance or reachability on the physical city streets, I can translate the question into a query on the map. My query on the map will return reliable predictions about the physical streets, even though the map has thrown out lots of info.
The general pattern: there’s some ground-level “concrete” model (or territory), and an abstract model (or map). The abstract model throws away or ignores information from the concrete model, but in such a way that we can still make reliable predictions about some aspects of the underlying system.
Notice that the predictions of the abstract models, in most of these examples, are not perfectly accurate. We're not dealing with the sort of "abstraction" we see in e.g. programming or algebra, where everything is exact. There are going to be probabilities involved.
In the language of embedded world-models [? · GW], we're talking about multi-level models: models which contain both a notion of "table", and of all the pieces from which the table is built, and of all the atoms from which the pieces are built. We want to be able to use predictions from one level at other levels (e.g. predict bulk material properties from microscopic structure and/or macroscopic measurements, or predict from material properties whether it's safe to sit on the table), and we want to move between levels consistently.
Formalization: Starting Point
To repeat the intuitive idea: an abstract model throws away or ignores information from the concrete model, but in such a way that we can still make reliable predictions about some aspects of the underlying system.
So to formalize abstraction, we first need some way to specify which "aspects of the underlying system" we wish to predict, and what form the predictions take. The obvious starting point for predictions is probability distributions. Given that our predictions are probability distributions, the natural way to specify which aspects of the system we care about is via a set of events or logic statements for which we calculate probabilities. We'll be agnostic about the exact types for now, and just call these "queries".
That leads to a rough construction. We start with some low-level model and a set of queries . From these, we construct a minimal high-level model by keeping exactly the information relevant to the queries, and throwing away all other information. By the minimal map theorems [LW · GW], we can represent directly by the full set of probabilities ; and contain exactly the same information. Of course, in practical examples, the probabilities will usually have some more compact representation, and will usually contain some extraneous information as well.
To illustrate a bit, let's identify the low-level model, class of queries, and high-level model for a few of the examples from earlier.
- Ideal Gas:
- Low-level model is the full set of molecules, their interaction forces, and a distribution representing our knowledge about their initial configuration.
- Class of queries consists of combinations of macroscopic measurements, e.g. one query might be "pressure = 12 torr & volume = 1 m^3 & temperature = 110 K".
- For an ideal gas, the high-level model can be represented by e.g. temperature, number of particles (of each type if the gas is mixed), and container volume. Given these values and assuming a near-equilibrium initial configuration distribution, we can predict the other macroscopic measurables in the queries (e.g. pressure).
- Tennis:
- Low-level model is the full microscopic configuration of me and the physical world around me as I play tennis (or whatever else I do).
- Class of queries is hard to sharply define at this point, but includes things like "John will answer his cell phone in the next hour", "John will hold a racket and hit a fuzzy ball in the next hour", "John will play Civ for the next hour", etc - all the things whose probabilities change on hearing that I'm going to play tennis.
- High-level model is just the sentence "I am going to play tennis".
- Street Map:
- Low-level model is the physical city streets
- Class of queries includes things like "shortest path from Times Square to Central Park starts by following Broadway", "distance between the Met and the Hudson is less than 1 mile", etc - all the things we can deduce from a street map.
- High-level model is the map. Note that the physical map also includes some extraneous information, e.g. the positions of all the individual atoms in the piece of paper/smartphone.
Already with the second two examples there seems to be some "cheating" going on in the model definition: we just define the query class as all the events/logic statements whose probabilities change based on the information in the map. But if we can do that, then anything can be a "high-level map" of any "low-level territory", with the queries taken to be the events/statements about the territory which the map actually has some information about - not a very useful definition!
Information About Things “Far Away”
In order for abstraction to actually be useful, we need some efficient way to know which queries the abstract model can accurately answer, without having to directly evaluate each query within the low-level model.
In practice, we usually seem to have a notion of which variables are “far apart”, in the sense that any interactions between the two are mediated by many in-between variables.
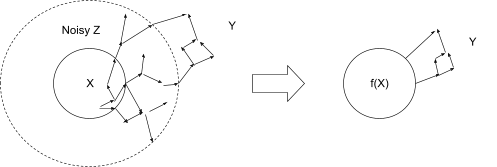
The mediating variables are noisy, so they wipe out most of the “fine-grained” information present in the variables of interest. We can therefore ignore that fine-grained information when making predictions about things far away. We just keep around whatever high-level signal makes it past the noise of mediating variables, and throw out everything else, so long as we’re only asking questions about far-away variables.
An example: when I type “4+3” in a python shell, I think of that as adding two numbers, not as a bunch of continuous voltages driving electric fields and current flows in little patches of metal and doped silicon. Why? Because, if I’m thinking about what will show up on my monitor after I type “4+3” and hit enter, then the exact voltages and current flows on the CPU are not relevant. This remains true even if I’m thinking about the voltages driving individual pixels in my monitor - even at a fairly low level, the exact voltages in the arithmetic-logic unit on the CPU aren’t relevant to anything more than a few microns away - except for the high-level information contained in the “numbers” passed in and out. Information about exact voltages in specific wires is quickly wiped out by noise within the chip.
Another example: if I’m an astronomer predicting the trajectory of the sun, then I’m presumably going to treat other stars as point-masses. At such long distances, the exact mass distribution within the star doesn’t really matter - except for the high-level information contained in the total mass, momentum and center-of-mass location.
Formalizing this in the same language as the previous section:
- We have some variables and in the low-level model.
- Interactions between and are mediated by noisy variables .
- Noise in wipes out most fine-grained information about , so only the high-level summary is relevant to .
Mathematically: for any which is “not too close” to - i.e. any which do not overlap with (or with itself). Our high-level model replaces with , and our set of valid queries is the whole joint distribution of given .
Now that we have two definitions, it’s time to start the Venn diagram of definitions of abstraction.

So far, we have:
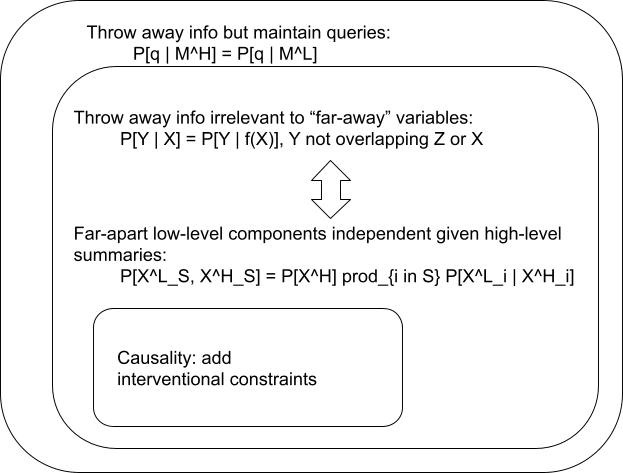
- A high-level model throws out information from a low-level model in such a way that some set of queries can still be answered correctly: .
- A high-level model throws out information from some variable in such a way that all information about “far away” variables is kept: .
Systems View
The definition in the previous section just focuses on abstracting a single variable . In practice, we often want to take a system-level view, abstracting a whole bunch of low-level variables (or sets of low-level variables) all at once. This doesn’t involve changing the previous definition, just applying it to many variables in parallel.
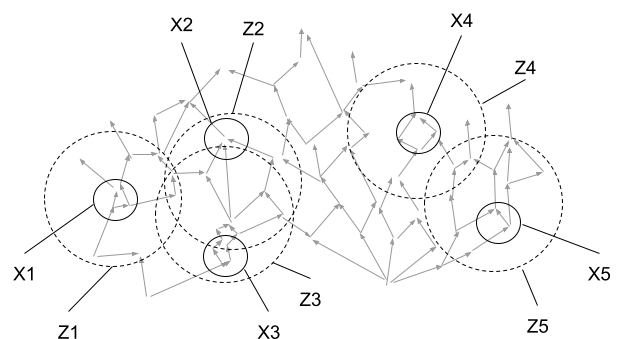
Rather than just one variable of interest , we have many low-level variables (or non-overlapping sets of variables) and their high-level summaries . For each of the , we have some set of variables “nearby” , which mediate its interactions with everything else. Our “far-away” variables Y are now any far-away ’s, so we want
for any sets of indices and which are “far apart” - meaning that does not overlap any or .
(Notation: I will use lower-case indices like for individual variables, and upper-case indices like to represent sets of variables. I will also treat any single index interchangeably with the set containing just that index.)
For instance, if we’re thinking about wires and transistors on a CPU, we might look at separate chunks of circuitry. Voltages in each chunk of circuitry are , and summarizes the binary voltage values. are voltages in any components physically close to chunk on the chip. Anything physically far away on the chip will depend only on the binary voltage values in the components, not on the exact voltages.
The main upshot of all this is that we can rewrite the math in a cleaner way: as a (partial) factorization. Each of the low-level components are conditionally independent given the high-level summaries, so:
This condition only needs to hold when picks out indices such that (i.e. we pick out a subset of the ’s such that no two are “close together”). Note that we can pick any set of indices which satisfies this condition - so we really have a whole family of factorizations of marginal distributions in which no two variables are “close together”. See the appendix to this post for a proof of the formula.
In English: any set of low-level variables which are all “far apart” are independent given their high-level summaries . Intuitively, the picture looks like this:
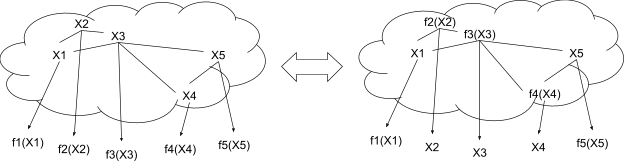
We pick some set of low-level variables which are all far apart, and compute their summaries . By construction, we have a model in which each of the high-level variables is a leaf in the graphical model, determined only by the corresponding low-level variables. But thanks to the abstraction condition, we can independently swap any subset of the summaries with their corresponding low-level variables - assuming that all of them are “far apart”.
Returning to the digital circuit example: if we pick any subset of the wires and transistors on a chip, such that no two are too physically close together, then we expect that their exact voltages are roughly independent given the high-level summary of their digital values.
We’ll add this to our Venn diagram as an equivalent formulation of the previous definition.

I have found this formulation to be the most useful starting point in most of my own thinking, and it will be the jumping-off point for our last two notions of abstraction in the next two sections.
Causality
So far we’ve only talked about “queries” on the joint distribution of variables. Another natural step is to introduce causal structure into the low-level model, and require interventional queries to hold on far apart variables.
There are some degrees of freedom in which interventional queries hold on far apart variables. One obvious answer is “all of them”:
… with the same conditions on as before, plus the added condition that the indices in and also be far apart. This is the usual requirement in math/programming abstraction, but it’s too strong for many real-world applications. For instance, when thinking about fluid dynamics, we don’t expect our abstractions to hold when all the molecules in a particular cell of space are pushed into the corner of that cell. Instead, we could weaken the low-level intervention to sample from low-level states compatible with the high-level intervention:
We could even have low-level interventions sample from some entirely different distribution, to reflect e.g. a physical machine used to perform the interventions.
Another post will talk more about this, but it turns out that we can say quite a bit about causal abstraction while remaining agnostic to the details of the low-level interventions. Any of the above interventional query requirements have qualitatively-similar implications, though obviously some are stronger than others.
In day-to-day life, causal abstraction is arguably more common than non-causal. In fully deterministic problems, validity of interventional queries is essentially the only constraint (though often in guises which do not explicitly mention causality, e.g. functional behavior or logic). For instance, suppose I want to write a python function to sort a list. The only constraint is the abstract input/output behavior, i.e. the behavior of the designated “output” under interventions on the designated “inputs”. The low-level details - i.e. the actual steps performed by the algorithm - are free to vary, so long as those high-level interventional constraints are satisfied.
This generalizes to other design/engineering problems: the desired behavior of a system is usually some abstract, high-level behavior under interventions. Low-level details are free to vary so long as the high-level constraints are satisfied.
Exact Abstraction
Finally, one important special case. In math and programming, we typically use abstractions with sharper boundaries than most of those discussed here so far. Prototypical examples:
- A function in programming: behavior of everything outside the function is independent of the function’s internal variables, given a high-level summary containing only the function’s inputs and outputs. Same for private variables/methods of a class.
- Abstract algebra: many properties of mathematical objects hold independent of the internal details of the object, given certain high-level summary properties - e.g. the group axioms, or the ring axioms, or …
- Interfaces for abstract data structures: the internal organization of the data structure is irrelevant to external users, given the abstract "interface" - a high-level summary of the object's behavior under different inputs (a.k.a. different interventions).
In these cases, there’s no noisy intermediate variables, and no notion of “far away” variables. There’s just a hard boundary: the internal details of high-level abstract objects do not interact with things of interest “outside” the object except via the high-level summaries.
We can easily cast this as a special case of our earlier notion of abstraction: the set of noisy intermediate variables is empty. The “high-level summary” of the low-level variables contains all information relevant to any variables outside of themselves.
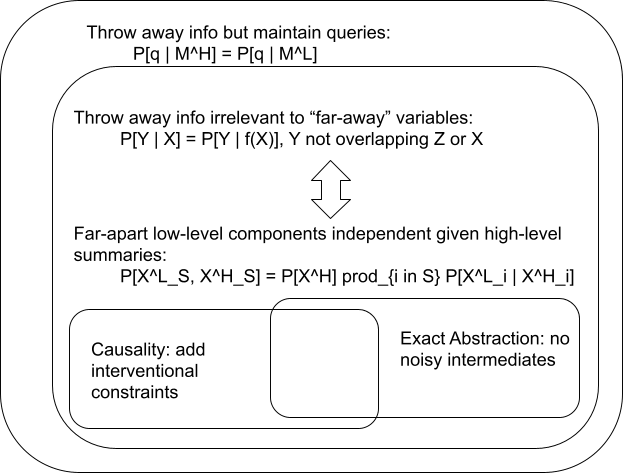
Of course, exact abstraction overlaps quite a bit with causal abstraction. Exact abstractions in math/programming are typically deterministic, so they’re mainly constrained by interventional predictions rather than distributional predictions.
Summary
We started with a very general notion of abstraction: we take some low-level model and abstract it into a high-level model by throwing away information in such a way that we can still accurately answer some queries. This is extremely general, but in order to actually be useful, we need some efficient way to know which queries are and are not supported by the abstraction.
That brought us to our next definition: abstraction keeps information relevant to “far away” variables. We imagine that interactions between the variable-to-be-abstracted and things far away are mediated by some noisy “nearby” variables , which wipe out most of the information in . So, we can support all queries on things far away by keeping only a relatively small summary .
Applying this definition to a whole system, rather than just one variable, we find a clean formulation: all sets of far-apart low-level variables are independent given the corresponding high-level summaries.
Next, we extended this to causal abstraction by requiring that interventional queries also be supported.
Finally, we briefly mentioned the special case in which there are no noisy intermediate variables, so the abstraction boundary is sharp: there’s just the variables to be abstracted, and everything outside of them. This is the usual notion of abstraction in math and programming.
Appendix: System Formulation Proof
We start with two pieces. By construction, is calculated entirely from , so
(construction)
… without any restriction on which subsets of the variables we look at. Then we also have the actual abstraction condition
(abstraction)
… as long as does not overlap or .
We want to show that
… for any set of non-nearby variables (i.e. ). In English: sets of far-apart low-level variables are independent given their high-level counterparts.
Let’s start with definitions of “far-apart” and “nearby”, so we don’t have to write them out every time:
- Two sets of indices and are “far apart” if and do not overlap , and vice-versa. Individual indices can be treated as sets containing one element for purposes of this definition - so e.g. two indices or an index and a set of indices could be “far apart”.
- Indices and/or sets of indices are “nearby” if they are not far apart.
As before, I will use capital letters for sets of indices and lower-case letters for individual indices, and I won’t distinguish between a single index and the set containing just that index.
With that out of the way, we’ll prove a lemma:
… for any far apart from , both far apart from and (though and need not be far apart from each other). This lets us swap high-level with low-level given variables as we wish, so long as they’re all far apart from each other and from the query variables. Proof:
(by construction)
(by abstraction)
(by construction)
By taking and then marginalizing out unused variables, this becomes
That’s the first half of our lemma. Other half:
(by Bayes)
(by first half)
(by Bayes)
That takes care of the lemma.
Armed with the lemma, we can finish the main proof by iterating through the variables inductively:
(by Bayes)
(by construction)
(by lemma)
(by Bayes)
(by lemma & cancellation)
(by Bayes)
Here , , and are all far apart. Starting with empty and applying this formula to each variable , one-by-one, completes the proof.
18 comments
Comments sorted by top scores.
comment by Dweomite · 2021-06-10T20:37:50.405Z · LW(p) · GW(p)
If I'm trying to predict the light entering my eyes, and there's a brick wall six feet in front of me, it seems weird to me to say that the variables on the far side of the wall are being wiped out because the wall is "noisy" rather than, say, because the wall is "opaque". Is there some technical sense in which the wall is "noisier" than the air?
Either satisfies your "equal conditional probability" criterion, so I don't think it affects any of the math, but it seems like it could matter to understanding how this definition applies to the real world.
comment by Rohin Shah (rohinmshah) · 2020-06-22T06:22:44.132Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
If we are to understand embedded agency, we will likely need to understand abstraction (see <@here@>(@Embedded Agency via Abstraction@)). This post presents a view of abstraction in which we abstract a low-level territory into a high-level map that can still make reliable predictions about the territory, for some set of queries (whether probabilistic or causal).
For example, in an ideal gas, the low-level configuration would specify the position and velocity of _every single gas particle_. Nonetheless, we can create a high-level model where we keep track of things like the number of molecules, average kinetic energy of the molecules, etc which can then be used to predict things like pressure exerted on a piston.
Given a low-level territory L and a set of queries Q that we’d like to be able to answer, the minimal-information high-level model stores P(Q | L) for every possible Q and L. However, in practice we don’t start with a set of queries and then come up with abstractions, we instead develop crisp, concise abstractions that can answer many queries. One way we could develop such abstractions is by only keeping information that is visible “far away”, and throwing away information that would be wiped out by noise. For example, when typing 3+4 into a calculator, the exact voltages in the circuit don’t affect anything more than a few microns away, except for the final result 7, which affects the broader world (e.g. via me seeing the answer).
If we instead take a systems view of this, where we want abstractions of multiple different low-level things, then we can equivalently say that two far-away low-level things should be independent of each other _when given their high-level summaries_, which are supposed to be able to quantify all of their interactions.
Planned opinion:
I really like the concept of abstraction, and think it is an important part of intelligence, and so I’m glad to get better tools for understanding it. I especially like the formulation that low-level components should be independent given high-level summaries -- this corresponds neatly to the principle of encapsulation in software design, and does seem to be a fairly natural and elegant description, though of course abstractions in practice will only approximately satisfy this property.Replies from: johnswentworth
↑ comment by johnswentworth · 2020-06-22T14:25:29.250Z · LW(p) · GW(p)
LGTM
comment by Adam Zerner (adamzerner) · 2020-06-11T02:15:22.617Z · LW(p) · GW(p)
I wonder whether it'd be useful to distinguish between the following things.
Consider the example of the street map. is the exact same thing as except that there is detail removed (in a loose sense at least; in practice the map will probably have small differences compared to the territory).
Now consider the example of an ideal gas. throws away all of the stuff in and replaces it with summary statistics.
Both fit the definition of abstraction because you're removing information but maintaining the ability to answer questions, but in the ideal gas example you're adding something new in. Namely the summary statistics.
(Well, maybe "new" isn't the right word. Maybe it'd be better to say "adding summary statistics". I guess the thing I'm really trying to point at is the fact that something is being added.)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-06-11T03:15:10.905Z · LW(p) · GW(p)
For the street map example, is the physical city streets - which means it's the molecules/atoms/fields which comprise the streets. When we represent the streets as lines on paper, those lines are summary statistics of molecule positions, just like the ideal gas example. The only difference is that in the ideal gas example, it's a lot easier to express the relevant distribution which the statistics summarize.
That said, I do think you're pointing to something interesting. There is a sense in which a high-level model adds something in.
Look at the factorizations in the "Systems View" section. They are factorizations of a joint distribution over both the high-level and low-level variables. We have a single model which includes both sets of variables. The high-level variables are quite literally added into the low-level model as new variables computed from the old. The high-level model then keeps those new variables, and throws away all the original low-level variables.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2020-06-11T03:53:38.193Z · LW(p) · GW(p)
Ah, I think I see what you mean. That makes sense that the high level model of the street map is also a summary statistic, not just the low level model with stuff thrown away. Let my try to refine my comment.
For the ideal gas example, I think of the low level model as looking something like this:
class LowLevelGas {
Particle[] particles;
}
class Particle {
String compound;
int speed;
int direction;
int mass;
// whatever else
}
And I think of the high level model as looking like this:
class HighLevelGas {
int pressure;
int volume;
int temperature;
}
LowLevelGas and HighLevelGas just look like there's a big difference between the two. On the other hand, LowLevelStreetMap and HighLevelStreetMap wouldn't look as different. It'd be analogous to a sketch vs a photograph, where the difference is sort of a matter of resolution. But with LowLevelGas and HighLevelGas, it seems like they are different in a more fundamental way. They have different properties, not the same properties at different resolutions.
I wonder if this "resolution" idea can be made more formal. Something along the lines of looking at the high level variables and low level variables and seeing how... similar?... they are.
Elizer's idea of Thingspace [LW · GW] comes to mind. In theory maybe you could look at how close they are in Thingspace, but in practice that seems really difficult.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-06-11T04:51:58.151Z · LW(p) · GW(p)
I'll explain what I think you're pointing to here, then let me know if it sounds like what you're imagining.
In the street map example, everything is spatially delineated, at both the high and low level. The abstraction can be interpreted as blurring the spatial resolution. The spatial resolution is a conserved structure between the two. But in the gas example, everything is blurred "all the way", so there's just a single high-level object which doesn't retain any structure which is obviously-similar to the low-level.
(An intermediate between these two would be Navier Stokes: it applies basically the same abstraction as the ideal gas, but only within small spatially-delineated cells.)
So there's potentially a difference between abstractions which throw away basically all the structure vs abstractions which retain some.
This points toward a more general class of questions: when, and to what extent, does it all add up to normality [LW · GW]? We learned the high-level ideal gas laws long before we learned the low-level molecular theory, but we knew the low-level had to at least be consistent with that high-level structure. What low-level structures did that constraint exclude? More generally: to what extent does our knowledge of the high-level model structure constrain the possible low-level structures?
One good class of structure for these sorts of questions is causal structure: to what extent does high-level causal structure constrain the possible low-level causal structures? I'll probably have a post on that soon-ish.
Replies from: adamzerner, alex-k-chen↑ comment by Adam Zerner (adamzerner) · 2020-06-11T17:00:26.171Z · LW(p) · GW(p)
So there's potentially a difference between abstractions which throw away basically all the structure vs abstractions which retain some.
Yeah, that's what I'm getting at.
↑ comment by Alex K. Chen (parrot) (alex-k-chen) · 2020-10-25T20:47:13.165Z · LW(p) · GW(p)
This points toward a more general class of questions: when, and to what extent, does it all add up to normality [LW · GW]? We learned the high-level ideal gas laws long before we learned the low-level molecular theory, but we knew the low-level had to at least be consistent with that high-level structure. What low-level structures did that constraint exclude? More generally: to what extent does our knowledge of the high-level model structure constrain the possible low-level structures?
One good class of structure for these sorts of questions is causal structure: to what extent does high-level causal structure constrain the possible low-level causal structures? I'll probably have a post on that soon-ish.
Doesn't high-level structure entail statistical averages and not necessarily Boltzmann brains in the low-level structure? Like - what of the nonequilibrium statistical mechanics?
Replies from: johnswentworth↑ comment by johnswentworth · 2020-10-26T16:45:36.357Z · LW(p) · GW(p)
Problem is, we didn't know beforehand (i.e. in 1800) that the high-level things we saw (like temperatures, heat flow, etc) had anything to do with statistical averages. One could imagine an alternative universe running on different physics, where heat really is a fluid and yet macroscopically it behaves a lot like heat in our universe. If we imagine all the difference ways things could have turned out to work, given only what we knew in 1800, where does that leave us? What low-level structure is implied by the high-level structure?
comment by Adam Zerner (adamzerner) · 2020-06-11T01:53:33.583Z · LW(p) · GW(p)
(I have a sense that the answer to this question is in the post but I'm having trouble extracting it out.)
There's something that I think of as composition, and I'm not sure if this fits the definition of abstraction. Consider in the context of programming a User that has email and password properties. We think of User as an abstraction. It's a thing that is composed of an email and password. I'm not seeing how this fits the definition of abstraction though. In particular, what information is being thrown away? What is the low level model, and what is the high level model?
The User example demonstrates composition of properties, but you could also have composition of instructions. For example, setPassword might consist of 1) saltPassword, 2) hashPassword and then 3) savePassword. Here we'd say that setPassword is an abstraction, but what is the information that is being thrown away?
↑ comment by johnswentworth · 2020-06-11T03:02:22.240Z · LW(p) · GW(p)
This is a great question.
Months ago, I had multiple drafts of posts formulating abstraction in terms of transformations on causal models. The two main transformations were:
- Glom together some variables
- Throw out information from a variable
What you're calling composition is, I believe, the first one.
Eventually, I came to the view that it's information throw-away specifically which really characterizes abstraction - it's certainly the part where most of the interesting properties come from. But in the majority of use-cases, at least some degree of composition takes place as a sort of pre-processing step.
Looking at your specific examples:
- User looks like it's just a composition, although we could talk about it as a degenerate case of abstraction where all of the information is potentially relevant to things outside the User object itself, so we throw away nothing. That said, a lot of what we do with a User object actually does involve ignoring the information in its fields - e.g. we don't think about emails and passwords when declaring a List<User> type or working with that list. So maybe there's a case to be made that it's an abstraction in the information-throw-away sense.
- setPassword does throw away information: it throws away the individual steps. To an outside caller, it's just a black-box function which sets the password; they don't know anything about the internal steps.
So to the extent that these are both "throwing away information", it's in the sense that large chunks of our code treat them as black-boxes and don't look at their internal details. When things do look at their internal details, those things are "close to" the objects, so the abstraction breaks down/leaks - e.g. if something tried to reconstruct the internal steps of setPassword, that would definitely be an example of leaky abstraction.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2020-06-11T03:28:53.147Z · LW(p) · GW(p)
Hm, it seems to me that there is a distinction between 1) hiding information (or encapsulating it, or making it private), 2) ignoring it, and 3) getting rid of it all together.
-
For
setPasswordperhaps a programmer who uses this method can't see the internals of what is actually happening (the salting, hashing and storing). They just calluser.setPassword(form.password)and it does what they need it to do. -
For
User, in the example you give withList<User>, maybe we want to count how many users there are, and in doing so we don't care about what properties users have. It could beemailandpassword, or it could beusernameanddob, in the context of counting how many users there are you don't care. However, the inner details aren't actually hidden, you're just choosing to ignore it. -
For ideal gasses, we're getting rid of the information about particles. It's not that it's hidden/private/encapsulated, it's just not even there after we replace it with the summary statistics.
What do you think? Am I misunderstanding something?
And in the case that I am correct about the distinction, I wonder if it's something worth pointing out.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-06-11T05:06:31.792Z · LW(p) · GW(p)
Sounds like the distinction is about where/how we're drawing the abstraction boundaries.
- "Hiding information" suggests that there's some object X with a boundary (i.e. a Markov blanket), and only the summary information is visible outside that boundary.
- "Ignoring information" suggests that there's some other object(s) Y with a boundary around them, and only the summary information about X is visible inside that boundary.
So basically we're defining which variables are "far away" by exclusion in one case (i.e. "everything except blah is far away") and inclusion in the other case (i.e. "only blah is far away"). I could definitely imagine the two having different algorithmic implications and different applications.
As for "getting rid of information", I think that's hiding information plus somehow eliminating our own ability to observe the hidden part. Again, I could definitely imagine that having additional algorithmic implications or applications. (Though this one feels weird for me to think about at all; I usually imagine everything from an external perspective where everything is always observable and immutable.)
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2020-06-11T16:23:31.165Z · LW(p) · GW(p)
Yeah I think your descriptions match what I was getting at.
comment by Adam Zerner (adamzerner) · 2020-06-11T01:14:54.243Z · LW(p) · GW(p)
(Typo: First bullet point under "Ideal Gas" should use instead of .)
Replies from: johnswentworth↑ comment by johnswentworth · 2020-06-11T02:43:42.676Z · LW(p) · GW(p)
Fixed, thanks.
comment by adamShimi · 2020-06-13T20:16:11.184Z · LW(p) · GW(p)
Thanks a lot for this compressed summary! As someone who tries to understand your work, but is sometimes lost within your sequence, this helps a lot.
I cannot comment the maths in any interesting way, but I feel that your restricted notion of abstraction -- where the high-level summary capture what's relevant to "far way" variables" -- works very well with my intuition. I like that it works with "far away" in time too, for example in abstracting current events as memories for future use.