Probability as Minimal Map
post by johnswentworth · 2019-09-01T19:19:56.696Z · LW · GW · 10 commentsContents
Probability-Computing Circuits The Data Processing Inequality Why Is This Interesting? None 10 comments
What’s the difference between a map and the raw data used to generate that map?
Suppose, for example, that google sends a bunch of cars out driving around New York City, snapping photos every few feet, then uses the photos to reconstruct a streetmap. In an informational sense, what’s the difference between the giant database full of photos and the streetmap?
Obvious answer: the map throws away a huge amount of information which we don’t care about, at least for the map’s use-case.
Let’s try to formalize this intuition a little. We want the ability to run queries against the map - e.g. things like “How far apart are Times Square and the Met?” or questions about street network topology. Let’s call the whole class of queries we want to support . We also have some input data - e.g. the database full of images from the streets of NYC. The goal of the map-synthesizing process is to throw out as much information as possible from , while still keeping any and all information relevant to queries in .
Natural next question: given the query class and some data-generating process, can we characterize “optimal” map-making processes which maximize the amount of information “thrown out” (measured in an information-theoretic sense) while still keeping all information relevant to ?
For the very simplest query classes, we can answer this question quite neatly.
Suppose that our query class contains only a single query , and the query is a true/false question. For instance, maybe the only query we care about at all is = “Is the distance between Times Square and the Met greater than one mile?”, and we want to throw out as much information as possible without losing any info relevant to the query.
Claim: any solution to this problem is isomorphic to the probability . In other words, is itself a minimal “lossless” map (where by “lossless” we mean it does not throw out any info from relevant to the query, not that it perfectly predicts ), and any other minimal “lossless” map is a reversible transformation of .
Let’s prove it.
We’ll formalize our claim in terms of mutual information . We have two pieces:
- throws away no information relevant to :
- For any function , if throws away no information relevant to , then can be computed from : implies for some .
One important note: our notation is really shorthand for , so is not a function of the “outcome” of - it’s only a function of . Also note that the second condition implies that the entropy of is at least as high as , so is indeed minimal in terms of information content.
In the next two sections, we’ll separately prove our two pieces.
Probability-Computing Circuits
We want to show that throws away no information relevant to : .
We’ll start with a short side-quest to prove a lemma: . Here’s an interpretation: suppose you work late trying to calculate the probability of based on some giant pile of data . You finally compute the result: . You go to bed feeling victorious, but wake up to find that your computer has died and your giant pile of data is lost. However, you still remember the final result - even though you don’t know , you do know that . Based on this information, what probability should you assign to ? Presumably the answer should be .
We can directly prove this in a few lines:
Note that the indicator function in the main sum is zero whenever is not , so we can replace with in that sum:
We can also write this in the more compact form , which we’ll use later.
To build a bit more intuition, let’s expand on this result a bit. Imagine a circuit (aka deterministic causal diagram or computational DAG) which takes in data and outputs . We’ll think about some arbitrary cross-section of that circuit - some set of internal nodes which cut the circuit in two, so that mediates the interaction between and . We can write this as for some function .
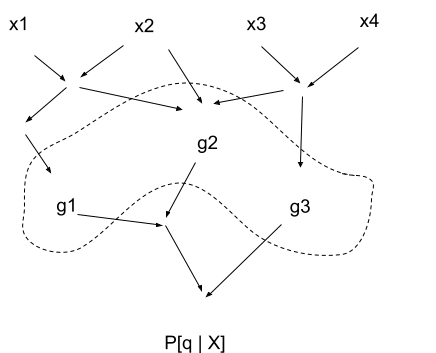
Claim: for any cross-section , . Intuitively, we can imagine that we’re partway through calculating , we’ve calculated all the ’s but haven’t finished the full computation yet, when suddenly our computer dies and we lose all the original data . As long as we still have the ’s around, we’re good - we just shrug and continue the calculation, since the ’s were all we needed to finish up anyway.
I won’t write out the proof for this one, but it works exactly like the previous proof.
Notice that our cross-section theorem has two interesting corner cases: all of is a cross-section, and by itself is a cross-section. The former yields the trivial statement , while the latter yields our lemma from earlier: .
Armed with our lemma, let’s return to the main problem: show that throws away no information relevant to , formalized as .
We’ll start by applying an identity from information theory:
… where is the Shannon entropy. So to show that , we can show . Our lemma makes this trivial:
… so contains all the information in relevant to .
The Data Processing Inequality
Next, we’d like to show that is a minimal representation of the information in relevant to . Formally, for any , if throws away no information relevant to , then is a function of : implies for some .
In particular, we’ll show that , so we can choose . Intuitively, this says that if throws out no information from relevant to , then it yields the same probability for .
To prove this, we’ll use a theorem from information theory called the data processing inequality (DPI). Intuitively, the DPI says that if we start with the data , we cannot gain any new information about just by processing . Formally, for any function :
… with equality iff and are independent conditional on (so that tells us nothing else about once we know ). The proof and a bit more discussion can be found in Cover & Thomas’ textbook on page 34.
We’re interested in the equality case , so the DPI tells us that and are independent conditioned on :
But we can always just expand via the chain rule instead:
Equate these two expressions for , and we find
… which is what we wanted.
Why Is This Interesting?
We’ve shown that the probability summarizes all the information in relevant to , and throws out as much irrelevant information as possible. Why does this matter?
First, hopefully this provides some intuition for interpreting a probability as a representation of the information in relevant to . In short: probabilities directly represent information. This interpretation makes sense even in the absence of “agents” with “beliefs”, or “independent experiments” repeated infinitely many times. It directly talks about maps matching territories, and the role probability plays, without invoking any of the machinery of frequentist or subjectivist interpretations. That means we can potentially apply it in a broader variety of situations - we can talk about simple mechanical processes which produce “maps” of the world, and the probabilistic calculations embedded in those processes.
Second, this is a natural first step in characterizing [LW · GW] map-making processes [LW · GW]. The data processing inequality also suggests a natural next step: sufficient statistics, which serve as minimal “lossless” maps when our data are independent samples from a distribution, and our queries can ask anything at all about the parameters of the distribution. From there, we could further generalize to approximate sufficient statistics - maps which throw out a small amount of information relevant to the queries, in cases where there is no “lossless” map smaller than .
That said, this still only talks about half of the full map-making process: the data-processing half. There’s still the data-collection half to address - the process which generates in the first place, and somehow ties it to the territory. And of course, when map-making processes are embedded in the real world [LW · GW], there might not be a clean separation between data-collection and data-processing, so we need to deal with that somehow.
Third, the interpretation of probabilities as a minimal map - or a representation of information - suggests possible avenues to relax traditional probability to deal with things which are time-like separated from us [LW · GW], e.g. for handling self-reference and advanced decision-theoretic problems [? · GW]. In particular, it suggests strategically throwing away information to deal with self-referential tomfoolery - but continuing to use probabilities to represent the reduced information remaining.
10 comments
Comments sorted by top scores.
comment by Chris_Leong · 2019-09-02T11:00:43.029Z · LW(p) · GW(p)
I hope that I'm not becoming that annoying person who redirects every conversation towards their own pet theory even when its of minimal relevance, but I think there are some very strong links here with my theory of logical counterfactuals as forgetting or erasing information (https://www.lesswrong.com/posts/BRuWm4GxcTNPn4XDX/deconfusing-logical-counterfactuals [LW · GW]).
In fact, I wasn't quite aware of how strong these similarities were before I read this post. Both probabilities* and logical counterfactuals don't intrinsically exist in the universe; instead they seem to draw their existence from our epistemic situation. Zoom into the universe enough everything is deterministic and there is only one thing that an agent ever could have chosen; zoom out and there are multiple possibilities.
I'm currently writing a post where I'll argue that logical counterfactuals are an answer and not a question and I think this applies to probability too. Both exist in the map and not in the territory; this means that they are human created terms that exist for human purposes. Arguing what they are or aren't in the abstract indicates confusion; instead, we need to choose a purpose (or question) and then we can choose to notion appropriate to that. This is part of why these notions come apart with questions like Sleeping Beauty and Counterfactual Mugging.
*Okay, it kind of does under some theories of quantum mechanics, but lots of the discussion of probability uses probability to deal with a lack of complete knowledge as opposed to intrinsically existing uncertainty, which is of a different kind and can't be explained by quantum mechanics
Replies from: johnswentworth↑ comment by johnswentworth · 2019-09-02T15:33:52.661Z · LW(p) · GW(p)
That is highly relevant, and is basically where I was planning to go with my next post. In particular, see the dice problem in this comment [LW(p) · GW(p)] - sometimes throwing away information requires randomizing our probability distribution. I suspect that this idea can be used to rederive Nash equilibria in a somewhat-more-embedded-looking scenario, e.g. our opponent making its decision by running a copy of us to see what we do.
Thanks for pointing out the relevance of your work, I'll probably use some of it.
comment by Linda Linsefors · 2022-08-04T19:52:55.705Z · LW(p) · GW(p)
We’ve shown that the probability summarizes all the information in relevant to , and throws out as much irrelevant information as possible.
This seems correct.
Lets say two different points in the data configuration space, X_1 and X_2, provide equal evidence for q. Then P[q|X_1] = P[q|X_2]. The two different data possibilities are mapped to the same point in this compressed map. So far so good.
(I assume that I should interpret the object P[q|X] as a function over X, not as a point probability for a specific X.)
First, hopefully this provides some intuition for interpreting a probability as a representation of the information in relevant to . In short: probabilities directly represent information. This interpretation makes sense even in the absence of “agents” with “beliefs”, or “independent experiments” repeated infinitely many times. It directly talks about maps matching territories, and the role probability plays, without invoking any of the machinery of frequentist or subjectivist interpretations. That means we can potentially apply it in a broader variety of situations - we can talk about simple mechanical processes which produce “maps” of the world, and the probabilistic calculations embedded in those processes.
I don't think this works.
The map P[q|X] have gotten rid of all the irrelevant information in the map, but it still contains some information that never came from the map. I.e. P[q|X] is not generated only from the information in X relevant for q.
E.g. from P[q|X] we can get
P[q] = sum_X P[q|X]
i.e. the prior probability of q. And if the prior of q where different P[q|X] would be different too.
The way you can't (shouldn't) get rid of priors here, feels similar to how you can't (shouldn't) get rid of coordinates in physics. In this analogy, the choice of prior is analogues to the choice of the origin. Your choice of origin is completely subjective (even more so than the prior). Technically you can represent position in a coordinate free way (only relative positions), but no one does it, because doing so destroys other things.
(I'm being maximally critical, because you asked for it [AF(p) · GW(p)])
Replies from: johnswentworth↑ comment by johnswentworth · 2022-08-05T18:58:09.620Z · LW(p) · GW(p)
Yeah, I basically buy that complaint. None of this was intended to get rid of priors, because a correct model shouldn't get rid of priors.
Replies from: Linda Linsefors↑ comment by Linda Linsefors · 2022-08-07T18:14:24.858Z · LW(p) · GW(p)
In that case I'm confused about this statement
This interpretation makes sense even in the absence of “agents” with “beliefs”
What is priors in the absence of something like agents with beliefs?
Replies from: johnswentworth↑ comment by johnswentworth · 2022-08-07T18:56:22.579Z · LW(p) · GW(p)
Frequencies are one example.
Replies from: Linda Linsefors↑ comment by Linda Linsefors · 2022-08-07T19:06:06.139Z · LW(p) · GW(p)
Here's what you wrote:
This interpretation makes sense even in the absence of “agents” with “beliefs”, or “independent experiments” repeated infinitely many times. It directly talks about maps matching territories, and the role probability plays, without invoking any of the machinery of frequentist or subjectivist interpretations.
Do you still agree with yourself?
Replies from: johnswentworth↑ comment by johnswentworth · 2022-08-08T01:07:03.083Z · LW(p) · GW(p)
I'm no longer sure. Thanks!
comment by Pattern · 2019-09-02T05:03:46.372Z · LW(p) · GW(p)
In particular, it suggests strategically throwing away information to deal with self-referential tomfoolery - but continuing to use probabilities to represent the reduced information remaining.
[Emphasis added.] There didn't seemed to be any examples of that in this post. This:
P[q|P[q|X]=p]=p.
seemed like moving self-referential/higher level probability down to the level we care about. (It's also one of the few things that seems reasonable to accept as an axiom.)
Replies from: johnswentworth↑ comment by johnswentworth · 2019-09-03T18:33:44.055Z · LW(p) · GW(p)
Throwing away information to deal with self-reference is a natural strategy in general; the ideas in this post specifically suggest that we use probabilities to represent the information which remains.