Posts
Comments
According to my calculation, this embedding will result in too much compounding noise. I get the same noise results as you for one layer, but the noise grows too much from layer to layer.
However, Lucius suggested a different embedding, which seems to work.
We'll have some publication on this eventually. If you want to see the details sooner you can message me.
The time and space bounded SI is then approximately optimal in the sense that its total error compared to this efficient predictor, as measured by KL-divergence from the predictions made by , will be bits summed across all data points.[7]
I think that classical Solomonoff induction gives zero posterior to any program with less than perfect prediction record? I can see why this works for Solomonoff with unbounded description length, this is solved by the DH(h) term you mention above.
But for bounded Solomonoff you have to allow some non-perfect programs to stay in the posterior, or you might be left with no candidates at all?
Is there an easy way to deal with this?
This is not a problem if the programs are giving probabilistic outputs, but that's a different class of programs than used in classical Solomonoff induction.
Since Bayesian statistics is both fundamental and theoretically tractable
What do you mean by "tractable" here?
New related post:
Theory of Change for AI Safety Camp
Why AISC needs Remmelt
For ASIC to survive long term, it needs at leasat one person who is long term committed to running the program. Without such a person I estimate the half-life of of AISC to be ~1 year. I.e, there would be be ~50% chance of AISC dying out every year, simply because there isn't an organiser team to run it.
Since the start, this person has been Remmelt. Because of Remmelt AISC has continued to exist. Other organiser have come and gone, but Remmelt has stayed and held things together. I don't know if there is anyone to replace Remmelt in this role. Maybe Robert? But I think it's too early to say. I'm definitely not available for this role, I'm too restless.
Hiring for long term commitment is very hard.
Why AISC would currently have had even less funding without Remmelt
For a while AISC was just me and Remmelt. During this time Remmelt took care of all the fundraising, and still mostly does, because Robert is still new, and I don't do grant applications.
I had several bad experiences around grant applications in the past. The last one was in 2021, when me and JJ applied for money for AI Safety Support. The LTFF committee decided that they didn’t like me personally and agreed to fund JJ’s salary but not mine. This is a decision they were allowed to make, of course. But on my side, it was more than I could take emotionally, and it led me to quit EA and AI Safety entirely for a year, and I’m still not willing to do grant applications. Maybe someday, but not yet.
I’m very grateful to Remmelt for being willing to take on this responsibility, and for hiring me at a time when I was the one who was toxic to grant makers.
I have less triggers for crowdfunding and private donations, than for grant applications, but I still find it personally very stressfull. I'm not saying my trauma around this is anyone's fault, or anyone else's problem. But I do think it's relevant context for understanding AISC funding situation. Organisations are made of people, and these people may have constraints that are invisible to you.
Some other things about Remmelt and his role in AISC
I know Remmelt get's into argument on Twitter, but i'm not on Twitter, so I'm not paying attention to that. I know Remmelt as a friend and as a great co-organiser. Remmelt is one of the rare people I work really well with.
Within AISC, Remmelt is overseeing the Stop/Pause AI projects. For all the other projects, Remmelt is only involved in a logistical capacity.
For the current AISC there are
- 4 Pause/Stopp AI projects. Remmelt is in charge of accepting or rejecting projects in this chathegory, and also supporting them if they need any help.
- 1 project which Remmelt is running personally as the research lead. (Not counted as one of the 4 above)
- 26 other projects where Remmelt only have purely logistical involvement. E.g. Remmelt is in charge of stipends and compute reimbursement, but his personal opinions abut AI Safety is not a factor in this. I see most of the requests, and I've never seen Remmelt discriminate based on what he think of the project.
Each of us organisers (Remmelt, Robert, me) can unilaterally decide to accept any project we like, and once a project is accepted to AISC, we all support it in our roles as organisers. We have all agreed to this, because we all thinks that having this diversity is worth it, even if not all of us likes every single project the other ones accept.
I vouch for Robert as a good replacement for me.
Hopefully there is enough funding to onboard a third person for next camp. Running AISC at the current scale is a three person job. But I need to take a break from organising.
Is this because they think it would hurt their reputation, or because they think Remmelt would make the program a bad experience for them?
This comment has two disagree votes, which I interpret as other people seeing the flowchart. I see it too. If it still doesn't work for you for some reason, you can also see it here: AISC ToC Graph - Google Drawings
Each organiser on the team are allowed to accept projects independently. So far Remmelt hasn't accepted any projects that I would have rejected, so I'm not sure how his unorthodox views could have affected project quality.
Do you think people are avoiding AISC because of Remmelt? I'd be surprised if that was a significant effect.
After we accept projects, the project is pretty much in the hands of each research lead, with very lite involvement from the organisers.
I'd be interested to learn more about in what way you think or have heard that the program have gotten worse.
Not on sci-hub or Anna's Archive, so I'm just going off the abstract and summary here; would love a PDF if anyone has one.
If you email the authors they will probably send you the full article.
It looks related, but these are not the plots I remember from the talk.
ϕt=Utϕ0U−1t.
I think you mean here, not
One of the talks at ILIAD had a set for PCA plots where the PC2 turned around at different points for different training setups. I think the turning point corresponded to when the model started to overfit. I don't quite remember. But what ever the meaning of the turning point was, I think they also verified this with some other observation. Given that this was ILIAD the other observation was probably the LLC.
If you want to look it up I can try to find the talk among the recordings.
This looks like a typo?
Did you just mean "CS"?
In standard form, a natural latent is always approximately a deterministic function of . Specifically: .
What does the arrow mean in this expression?
I think the qualitive difference is not as large as you think it is. But I also don't think this is very crux-y for anything, so I will not try to figure out how to translate my reasoning to words, sorry.
I guess the modern equivalent that's relevant to AI alignment would be Singular Learning Theory which proposes a novel theory to explain how deep learning generalizes.
I think Singular Learning Theory was developed independently of deep learning, and is not specifically about deep learning. It's about any learning system, under some assumptions, which are more general than the assumptions for normal Learning Theory. This is why you can use SLT but not normal Learning Theory when analysing NNs. NNs break the assumptions for normal Learning Theory but not for SLT.
Ok, in that case I want to give you this post as inspiration.
Changing the world through slack & hobbies — LessWrong
That's still pretty good. Most reading lists are not updated at all after publication.
Is it an option to keep your current job but but spend your research hours on AI Safety instead of quarks? Is this something that would appealing to you + acceptable to your employer?
Given the current AI safety funding situation, I would strongly reccomend not giving up your current income.
I think that a lot of the pressure towards street light research comes from the funding situation. The grants are short and to stay in the game you need visible results quickly.
I think MATS could be good, if you can treat it as exploration, but not so good if you're in a hurry to get a job or a grant directly afterwards. Since MATS is 3 months of full time, it might not fit into your schedule (without quitting your job). Maybe instead try SPAR. Or see here for more options.
Or you can skip the training program route, and just start reading on your own. There's lots and lots of AI safety reding lists. I reccomend this one for you. @Lucius Bushnaq who created and maintains it, also did quark physics, before switching to AI Safety. But if you don't like it, there are more options here under "Self studies".
In general, the funding situation in AI safety is pretty shit right now, but other than that, there are so many resources to help people get started. It's just a matter of choosing where to start.
Einstein did his pre-paradigmatic work largely alone. Better collaboration might've sped it up.
I think this is false. As I remember hearing the story, he where corresponding with several people via letters.
The aesthetics have even been considered carefully, although oddly this has not extended to dress (as far as I have seen).
I remember there being some dress instructions/suggestions for last years Bay solstice. I think we where told to dress in black, blue and gold.
I'm not surprised by this observation. In my experience rationalists also have more than base-rate of all sorts of gender non-conformity, including non-binary and trans people. And the trends are even stronger in AI Safety.
I think the explanation is:
- High tolerans for this type of non-conformity
- High autism which corelates with these things
- Relative to the rest of the population, people in this community prioritize other things (writing, thinking about existential risk, working on cool projects perhaps) over routine chores (getting a haircut)
I think that this is almost the correct explanation. We prioritise other things (writing, thinking about existential risk, working on cool projects perhaps) over caring about weather someone else got a haircut.
What it's like to organise AISC
About once or twice per week this time of year someone emails me to ask:
Please let me break rule X
My response:
No you're not allowed to break rule X. But here's a loop hole that lets you do the thing you want without technically breaking the rule. Be warned that I think using the loophole is a bad idea, but if you still want to, we will not stop you.
Because not leaving the loophole would be too restrictive for other reason, and I'm not going to not tell people all their options.
The fact that this puts the responsibility back on them is a bonus feature I really like. Our participants are adults, and are allowed to make their own mistakes. But also, sometimes it's not a mistake, because there is no set of rules for all occasion, and I don't have all the context of their personal situation.
Quote from the AI voiced podcast version of this post.
Such a lab, separated by more than 1 Australian Dollar from Earth, might provide sufficient protection for very dangerous experiments.
Same data but in cronlogical order
10th-11th
* 20 total applications
* 4 (20%) Stop/Pause AI
* 8 (40%) Mech-Interp and Agent Foundations
12th-13th
* 18 total applications
* 2 (11%) Stop/Pause AI
* 7 (39%) Mech-Interp and Agent Foundations
15th-16th
* 45 total application
* 4 (9%) Stop/Pause AI
* 20 (44%) Mech-Interp and Agent Foundations
Stop/Puase AI stays at 2-4 per week, while the others go from 7-8 to 20
One may point out that 2 to 4 is a doubling suggesting noisy data, and also going from 7-8 is also just a doubling and might not mean much. This could be the case. But we should expect higher notice for lower numbers. I.e. a doubling of 2 is less surprising than a (more than) doubling of 7-8.
12th-13th
* 18 total applications
* 2 (11%) Stop/Pause AI
* 7 (39%) Mech-Interp and Agent Foundations
15th-16th
* 45 total application
* 4 (9%) Stop/Pause AI
* 20 (44%) Mech-Interp and Agent Foundations
All applications
* 370 total
* 33 (12%) Stop/Pause AI
* 123 (46%) Mech-Interp and Agent Foundations
Looking at the above data, is directionally correct for you hypothesis, but it doesn't look statisically significant to me. The numbers are pretty small, so could be a fluke.
So I decided to add some more data
10th-11th
* 20 total applications
* 4 (20%) Stop/Pause AI
* 8 (40%) Mech-Interp and Agent Foundations
Looking at all of it, it looks like Stop/Pause AI are coming in at a stable rate, while Mech-Interp and Agent Foundations are going up a lot after the 14th.
AI Safety interest is growing in Africa.
AISC 25 (out of 370) applicants from Africa, with 9 from Kenya and 8 from Nigeria.
Numbers for all countries (people with multiple locations not included)
AISC applicants per country - Google Sheets
The rest looks more or less in-line with what I would expect.
Sounds plausible.
> This would predict that the ratio of technical:less-technical applications would increase in the final few days.
If you want to operationalise this in terms on project first choice, I can check.
Side note:
If you don't tell what time the application deadline is, lots of people will assume its anywhere-on-Earth, i.e. noon the next day in GMT.
When I was new to organising I did not think of this, and kind of forgot about time zones. I noticed that I got a steady stream of "late" applications, that suddenly ended at 1pm (I was in GMT+1), and didn't know why.
Every time I have an application form for some event, the pattern is always the same. Steady trickle of applications, and then a doubling on the last day.
And for some reason it still surprises me how accurate this model is. The trickle can be a bit uneven, but the doubling the last day is usually close to spot on.
This means that by the time I have a good estimate of what the average number of applications per day is, then I can predict what the final number will be. This is very useful, for knowing if I need to advertise more or not.
For the upcoming AISC, the trickle was a late skewed, which meant that an early estimate had me at around 200 applicants, but the final number of on-time application is 356. I think this is because we where a bit slow at advertising early on, but Remmelt made a good job sending out reminders towards the end.
Application deadline was Nov 17.
At midnight GMT before Nov 17 we had 172 application.
At noon GMT Nov 18 (end of Nov 17 anywhere-on-Earth) we had 356 application
The doubling rule predicted 344, which is only 3% off
Yes, I count the last 36 hours as "the last day". This is not cheating since that's what I always done (approximately [1]), since starting to observe this pattern. It's the natural thing to do when you live at or close to GMT, or at least if your brain works like mine.
- ^
I've always used my local midnight as the divider. Sometimes that has been Central European Time, and sometimes there is daylight saving time. But it's all pretty close.
If people are ashamed to vote for Trump, why would they let their neighbours know?
Linda Linsefors of the Center for Applied Rationality
Hi, thanks for the mention.
But I'd like to point out that I never worked for CFAR in any capacity. I have attended two CFAR workshops. I think that calling me "of the Center for Applied Rationality" is very misleading, and I'd prefer it if you remove that part, or possibly re-phrase it.
You can find their prefeed contact info in each document in the Team section.
Yes there are, sort of...
You can apply to as many projects as you want, but you can only join one team.
The reasons for this is: When we've let people join more than one team in the past, they usually end up not having time for both and dropping out of one of the projects.
What this actually means:
When you join a team you're making a promise to spend 10 or more hours per week on that project. When we say you're only allowed to join one team, what we're saying is that you're only allowed to make this promise to one project.
However, you are allowed to help out other teams with their projects, even if you're not officially on the team.
@Samuel Nellessen
Thanks for answering Gunnars question.
But also, I'm a bit nervous that posting their email here directly in the comments is too public, i.e. easy for spam-bots to find.
If the research lead want to be contactable, their contact info is in their projekt document, under the "Team" section. Most (or all, I'm not sure) research leads have some contact info.
The way I understand it the homunculus is part of self. So if you put the wanting in the homunculus, it's also inside self. I don't know about you, but my self concept has more than wanting. To be fair, he homunculus concept is also a bit richer than wanting (I think?) but less encompassing than the full self (I think?).
Based on Steve's response to one of my comments, I'm now less sure.
Reading this post is so strange. I've already read the draft, so it's not even new to me, but still very strange.
I do not recognise this homunculus concept you describe.
Other people reading this, do you experience yourself like that? Do you resonate with the intuitive homunculus concept as described in the post?
I my self have a unified self (mostly). But that's more or less where the similarity ends.
For example when I read:
in my mind, I think of goals as somehow “inside” the homunculus. In some respects, my body feels like “a thing that the homunculus operates”, like that little alien-in-the-head picture at the top of the post,
my intuitive reaction is astonishment. Like, no-one really think of themselves like that, right? It's obviously just a metaphor, right?
But that was just my first reaction. I know enough about human mind variety to absolutely believe that Steve has this experience, even though it's very strange to me.
Similarly, as Johnstone points out above, for most of history, people didn’t know that the brain thinks thoughts! But they were forming homunculus concepts just like us.
Why do you assume they where forming homunculus concepts? Since it's not veridical, they might have a very different self model.
I'm from the same culture as you and I claim I don't have homunculus concept, or at least not one that matches what you describe in this post.
I don't think what Steve is calling "the homonculus" is the same as the self.
Actually he says so:
The homunculus, as I use the term, is specifically the vitalistic-force-carrying part of a broader notion of “self”
It's part of the self model but not all of it.
(Neuroscientists obviously don’t use the term “homunculus”, but when they talk about “top-down versus bottom-up”, I think they’re usually equating “top-down” with “caused by the homunculus” and “bottom-up” with “not caused by the homunculus”.)
I agree that the homunculus-theory is wrong and bad, but I still think there is something to top-down vs bottom-up.
It's related to what you write later
Another part of the answer is that positive-valence S(X) unlocks a far more powerful kind of brainstorming / planning, where attention-control is part of the strategy space. I’ll get into that more in Post 8.
I think conscious control (aka top-down) is related to conscious thoughts (in the global work space theory sense) which is related to using working memory, to unlock more serial compute.
That said, if those sorts of concepts are natural in our world, then it’s kinda weird that human minds weren’t already evolved to leverage them.
A counter possibility to this that comes to mind:
There might be concepts that is natural in our world, but which are only useful for a mind with much more working memory, or other compute recourses than the human mind.
If weather simulations use concepts that are confusing and un-intuitive for most humans, this would be evidence for something like this. Weather is something that we encounter a lot, and is important for humans, especially historically. If we haven't developed some natural weather concept, it's not for lack of exposure or lack of selection pressure, but for some other reason. That other reason could be that we're not smart enough to use the concept.
Yesterday was the official application deadline for leading a project at the next AISC. This means that we just got a whole host of project proposals.
If you're interested in giving feedback and advise to our new research leads, let me know. If I trust your judgment, I'll onboard you as an AISC advisor.
Also, it's still possible to send us a late AISC project proposals. However we will prioritise people how applied in time when giving support and feedback. Further more, we'll prioritise less late applications over more late applications.
I tried it and it works for me too.
For me the dancer was spinning contraclockwise and would not change. With your screwing trick I could change rotation, and where now stably stuck in the clockwise direction. Until I screwed in the other direction. I've now done this back and forth a few times.
At this writing www.aisafety.camp goes to our new website while aisafety.camp goes to our old website. We're working on fixing this.
If you want to spread information about AISC, please make sure to link to our new webpage, and not the old one.
Thanks!
I have two hypothesises for what is going on. I'm leaning towards 1, but very unsure.
1)
king - man + woman = queen
is true for word2vec embeddings but not in LLaMa2 7B embeddings because word2vec has much fewer embedding dimensions.
- LLaMa2 7B has 4096 embedding dimensions.
- This paper uses a variety of word2vec with 50, 150 and 300 embedding dimensions.
Possibly when you have thousands of embedding dimensions, these dimensions will encode lots of different connotations of these words. These connotations will probably not line up with the simple relation [king - man + woman = queen], and therefore we get [king - man + woman queen] for high dimensional embeddings.
2)
king - man + woman = queen
Isn't true for word2vec either. If you do it with word2vec embeddings you get more or less the same result I did with LLaMa2 7B.
(As I'm writing this, I'm realising that just getting my hands on some word2vec embeddings and testing this for myself, seems much easier than to decode what the papers I found is actually saying.)
"▁king" - "▁man" + "▁woman" "▁queen" (for LLaMa2 7B token embeddings)
I tired to replicate the famous "king" - "man" + "woman" = "queen" result from word2vec using LLaMa2 token embeddings. To my surprise it dit not work.
I.e, if I look for the token with biggest cosine similarity to "▁king" - "▁man" + "▁woman" it is not "▁queen".
Top ten cosine similarly for
- "▁king" - "▁man" + "▁woman"
is ['▁king', '▁woman', '▁King', '▁queen', '▁women', '▁Woman', '▁Queen', '▁rey', '▁roi', 'peror'] - "▁king" + "▁woman"
is ['▁king', '▁woman', '▁King', '▁Woman', '▁women', '▁queen', '▁man', '▁girl', '▁lady', '▁mother'] - "▁king"
is ['▁king', '▁King', '▁queen', '▁rey', 'peror', '▁roi', '▁prince', '▁Kings', '▁Queen', '▁König'] - "▁woman"
is ['▁woman', '▁Woman', '▁women', '▁man', '▁girl', '▁mujer', '▁lady', '▁Women', 'oman', '▁female'] - projection of "▁queen" on span( "▁king", "▁man", "▁woman")
is ['▁king', '▁King', '▁woman', '▁queen', '▁rey', '▁Queen', 'peror', '▁prince', '▁roi', '▁König']
"▁queen" is the closest match only if you exclude any version of king and woman. But this seems to be only because "▁queen" is already the 2:nd closes match for "▁king". Involving "▁man" and "▁woman" is only making things worse.
I then tried looking up exactly what the word2vec result is, and I'm still not sure.
Wikipedia sites Mikolov et al. (2013). This paper is for embeddings from RNN language models, not word2vec, which is ok for my purposes, because I'm also not using word2vec. More problematic is that I don't know how to interpret how strong their results are. I think the relevant result is this
We see that the RNN vectors capture significantly more syntactic regularity than the LSA vectors, and do remarkably well in an absolute sense, answering more than one in three questions correctly.
which don't seem very strong. Also I can't find any explanation of what LSA is.
I also found this other paper which is about word2vec embeddings and have this promising figure
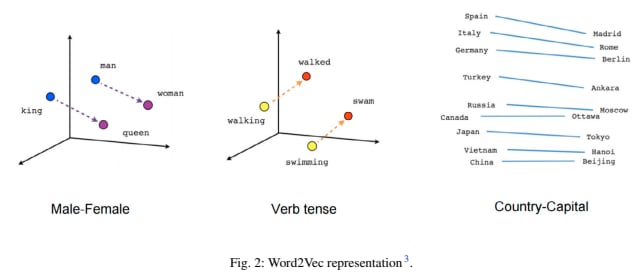
But the caption is just a citation to this third paper, which don't have that figure!
I've not yet read the two last papers in detail, and I'm not sure if or when I'll get back to this investigation.
If someone knows more about exactly what the word2vec embedding results are, please tell me.