Every time I have an application form for some event, the pattern is always the same. Steady trickle of applications, and then a doubling on the last day.
And for some reason it still surprises me how accurate this model is. The trickle can be a bit uneven, but the doubling the last day is usually close to spot on.
This means that by the time I have a good estimate of what the average number of applications per day is, then I can predict what the final number will be. This is very useful, for knowing if I need to advertise more or not.
For the upcoming AISC, the trickle was a late skewed, which meant that an early estimate had me at around 200 applicants, but the final number of on-time application is 356. I think this is because we where a bit slow at advertising early on, but Remmelt made a good job sending out reminders towards the end.
Application deadline was Nov 17. At midnight GMT before Nov 17 we had 172 application. At noon GMT Nov 18 (end of Nov 17 anywhere-on-Earth) we had 356 application
The doubling rule predicted 344, which is only 3% off
Yes, I count the last 36 hours as "the last day". This is not cheating since that's what I always done (approximately [1]), since starting to observe this pattern. It's the natural thing to do when you live at or close to GMT, or at least if your brain works like mine.
I've always used my local midnight as the divider. Sometimes that has been Central European Time, and sometimes there is daylight saving time. But it's all pretty close.
Side note: If you don't tell what time the application deadline is, lots of people will assume its anywhere-on-Earth, i.e. noon the next day in GMT.
When I was new to organising I did not think of this, and kind of forgot about time zones. I noticed that I got a steady stream of "late" applications, that suddenly ended at 1pm (I was in GMT+1), and didn't know why.
It might be the case that AISC was extra late-skewed because the MATS rejection letters went out on the 14th (guess how I know) so I think a lot of people got those and then rushed to finish their AISC applications (guess why I think this) before the 17th.
This would predict that the ratio of technical:less-technical applications would increase in the final few days.
Ok: I'll operationalize the ratio of first choices the first group (Stop/PauseAI) to projects in the third and fourth groups (mech interp, agent foundations) for the periods 12th-13th vs 15th-16th. I'll discount the final day since the final-day-spike is probably confounding.
12th-13th * 18 total applications * 2 (11%) Stop/Pause AI * 7 (39%) Mech-Interp and Agent Foundations
15th-16th * 45 total application * 4 (9%) Stop/Pause AI * 20 (44%) Mech-Interp and Agent Foundations
All applications * 370 total * 33 (12%) Stop/Pause AI * 123 (46%) Mech-Interp and Agent Foundations
Looking at the above data, is directionally correct for you hypothesis, but it doesn't look statisically significant to me. The numbers are pretty small, so could be a fluke.
So I decided to add some more data
10th-11th * 20 total applications * 4 (20%) Stop/Pause AI * 8 (40%) Mech-Interp and Agent Foundations
Looking at all of it, it looks like Stop/Pause AI are coming in at a stable rate, while Mech-Interp and Agent Foundations are going up a lot after the 14th.
10th-11th * 20 total applications * 4 (20%) Stop/Pause AI * 8 (40%) Mech-Interp and Agent Foundations
12th-13th * 18 total applications * 2 (11%) Stop/Pause AI * 7 (39%) Mech-Interp and Agent Foundations
15th-16th * 45 total application * 4 (9%) Stop/Pause AI * 20 (44%) Mech-Interp and Agent Foundations
Stop/Puase AI stays at 2-4 per week, while the others go from 7-8 to 20
One may point out that 2 to 4 is a doubling suggesting noisy data, and also going from 7-8 is also just a doubling and might not mean much. This could be the case. But we should expect higher notice for lower numbers. I.e. a doubling of 2 is less surprising than a (more than) doubling of 7-8.
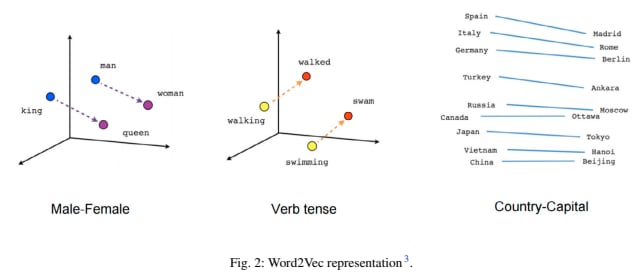
projection of "▁queen" on span( "▁king", "▁man", "▁woman") is ['▁king', '▁King', '▁woman', '▁queen', '▁rey', '▁Queen', 'peror', '▁prince', '▁roi', '▁König']
"▁queen" is the closest match only if you exclude any version of king and woman. But this seems to be only because "▁queen" is already the 2:nd closes match for "▁king". Involving "▁man" and "▁woman" is only making things worse.
I then tried looking up exactly what the word2vec result is, and I'm still not sure.
Wikipedia sites Mikolov et al. (2013). This paper is for embeddings from RNN language models, not word2vec, which is ok for my purposes, because I'm also not using word2vec. More problematic is that I don't know how to interpret how strong their results are. I think the relevant result is this
We see that the RNN vectors capture significantly more syntactic regularity than the LSA vectors, and do remarkably well in an absolute sense, answering more than one in three questions correctly.
which don't seem very strong. Also I can't find any explanation of what LSA is.
I also found this other paper which is about word2vec embeddings and have this promising figure
But the caption is just a citation to this third paper, which don't have that figure!
I've not yet read the two last papers in detail, and I'm not sure if or when I'll get back to this investigation.
If someone knows more about exactly what the word2vec embedding results are, please tell me.
I have two hypothesises for what is going on. I'm leaning towards 1, but very unsure.
1)
king - man + woman = queen
is true for word2vec embeddings but not in LLaMa2 7B embeddings because word2vec has much fewer embedding dimensions.
LLaMa2 7B has 4096 embedding dimensions.
This paper uses a variety of word2vec with 50, 150 and 300 embedding dimensions.
Possibly when you have thousands of embedding dimensions, these dimensions will encode lots of different connotations of these words. These connotations will probably not line up with the simple relation [king - man + woman = queen], and therefore we get [king - man + woman ≠ queen] for high dimensional embeddings.
2)
king - man + woman = queen
Isn't true for word2vec either. If you do it with word2vec embeddings you get more or less the same result I did with LLaMa2 7B.
(As I'm writing this, I'm realising that just getting my hands on some word2vec embeddings and testing this for myself, seems much easier than to decode what the papers I found is actually saying.)
“someone complimented me out of the blue, and it was a really good compliment, and it was terrible, because maybe I secretly fished for it in some way I can’t entirely figure out, and also now I feel like I owe them one, and I never asked for this, and I’m so angry!”
A blogpost I remember but can't find. The author talks about the benefits of favour economy. E.g. his friend could help him move at much lower total cost, than the market price for moving. This is because the market has much higher transaction cots than favours among friends. The blogpost also talks about how you only get to participate in the favour economy (and get it's benefits) if you understand that you're expected to return the favours, i.e. keep track of the social ledger, and make sure to pay your depts. Actually you should be overpaying when returning a favour, and now they owe you, and then they over pay you back, resulting in a virtual cycle of helping each other out. The author mentions being in a mutually beneficial "who can do the biggest favour" competition with his neighbour.
3)
And EA friend who told me that they experienced over and over in the EA community that they helped people (e.g. letting them stay at their house for free) but where denied similar help in return.
4)
A youtuber (who where discussing this topic) mentioned their grand mother who always gives everyone in the family lots of food to take home, and said that she would probably be offended if offered something in return for this help.
Todays thoughts:
I think there are pros and cons that comes with internally tracking a social ledger for favours. I also think there are things that makes this practice better or worse.
On receiving compliments
In the past, when ever I got a compliment, I felt obligated to give one back, so instead of taking it in, I started thinking as fast I as could what I could compliment back. At some point (not sure when) I decided this was dumb. Now if I get a compliment I instead take a moment to take it in, and thank the other person. I wish others would do this more. If I give someone a compliment, I don't want them to feel obligated to complement me back.
On paying forward instead of paying back
Some people experience the EA community as being super generous when it comes to helping each other out. But other have the opposite experience (see point 3 above). I've personally experienced both. Partly this is because EA is large and diverse, but partly I think it comes from thronging out the social ledger. I think the typical EA attitude is that you're not expected to pay back favours, you're expected to pay it forward, into what ever cause area you're working on. People are not even attempting to balancing the ledger of inter-personal favours, and therefore there will be imbalance, some people receiving more and some giving more.
I think there are lots of other pay-it-forward communities. For example any system where the older "generation" is helping the younger "generation". This can be parents raising their kids, or a marshal arts club where the more experienced are helping train the less experienced, etc.
I think a many of these are pretty good at paying the favour givers in status points. In comparison I expect EA to not be very good at giving status for helping out others in the community, because EA has lots of other things to allocate status points to too.
How to relate to the ledger
I think the social ledger defiantly have it's use, even among EA types. You need friends you can turn to for favours, which is only possible in the long term if you also return the favours, or you'll end up draining your friends.
In theory we could have grant supported community builders act as support for everyone else, with no need to pay it back. But I rather not. I do not want to trust the stability of my social network to the whims of the EA funding system.
To have a healthy positive relation with the social ledger,
You have to be ok with being in debt. It's ok to owe someone a favour. Being the sort of person that pays back favours, don't mean you have to do it instantly. You are allowed to wait for your friend to need help from you, and not worry about it in the mean time. You're also allowed to more or less actively look out for things to do for them, both is ok. Just don't stress over it.
Have some slack, at least some times. I have very uneven amount of slack in my life, so I try to be helpful to others when I have more, and less so when I have less. But someone who never have slack will never be able to help others back.
You can't be too nit-picky about it. The social ledger is not an exact thing. As a rule of thumb, if both you and your friend individually get more out of your friendship than you put in, then things are good. If you can't balance it such that you both get more out than you put in, then you're not playing a positive sum game, and you should either fix this, or just hang out less. It's supposed to be a positive sum game.
You can't keep legers with everyone. Or maybe you can? I can't. That's too many people to remember. My brain came with some pre-installed software to keep track of the social leger. This program also decides who to track or not, and it works well enough. I think it turns on when someone has done a favour that reaches some minimum threshold?
There are also obviously situations where keeping track of some leger don't make sense, and you should not do it, e.g. one-off encounters. And sometimes paying forward instead of paying back is the correct social norm.
Give your favours freely when it's cheap for you to do so, and when you don't mind if the favour is not paid back. Sometimes someone will return the favour.
The pre installed brain soft where
This probably varies a lot from person to person, and as all the mental traits it will be due to some mix of genetics and culture, and random other stuff.
For me, I'm not choosing whether to keep a social ledger or not, my brain just does that. I'm choosing how to interact with it and tweak it's function, by choosing what to pay attention to.
The way I experience this is that I feel gratitude when I'm in debt, and resentment when someone else have too much unacknowledged debt to me.
The gratitude makes me positively disposed to that person and more eager to help them.
The resentment flaggs to me that something is wrong. I don't need them to instantly re-pay me, but I need them to acknowledge the debt and that they intend to pay it back. If not, this is a sign that I should stop investing in that person.
If they disagree that I've helped them more than they helped me, then we're not playing a positive sum game, and we should stop.
If they agree that I helped them more, but also, they don't intend to return the favour... hm...? Does this ever happen? I could imagine this happening if the other person has zero slack. I think there are legit reasons to not be able to return favours, especially favours you did not ask for, but I also expect to not attempt to not want to build a friendship in this situation.
...thanks for reading my ramblings. I'll end here, since I'm out of time, and I think I've hit diminishing return on thinking about this...
I always reply “That’s very kind of you to say.” Especially for compliments that I disagree with but don’t want to get into an argument about. I think it expresses nice positive vibes without actually endorsing the compliment as true.
On paying forward instead of paying back
A good mission-aligned team might be another example? In sports, if I pass you the ball and you score a goal, that’s not a “favor” because we both wanted the goal to be scored. (Ideally.) Or if we’re both at a company, and we’re both passionate about the mission, and your computer breaks and I fix it, that’s not necessarily “a favor” because I want your computer to work because it’s good for the project and I care about that. (Ideally.) Maybe you’re seeing some EAs feel that kind of attitude?
I agree that the reason EAs are usually not tracking favours is that we are (or assume we are) mission aligned. I picked the pay-it-forward framing, because it fitted better with other situation where I expected people not to try to balance social legers. But you're right that there are situations that are mission aligned that are not well described as paying it forward, but some other shared goal.
Another situation where there is no social ledger, is when someone is doing their job. (You talk about a company where people are passionate about the mission. But most employs are not passionate about the mission, and still don't end up owing each other favours for doing their job.)
I personally think that the main benefit of mental health professionals (e.g. psychologies, coaches, etc) is that you get to have a one sided relationship, where you get to talk about all your problem, and you don't owe them anything in return, because you're paying them instead. (Or sometimes the healthcare system, is paying, or your employer. The important thing is that they get paid, and helping you is their job.)
(I much rather talk to a friend about my problems, it just works better, since they know me. But when I do this I owe them. I need to track what cost I'm imposing them, and make sure it's not more than I have the time and opportunity to re-pay.)
The desire to display gigawatt devotion with zero responsibility is the standard maneuver of our times, note the trend of celebrity soundbite social justice, or children’s fascination with doing the extra credit more than the regular credit, and as a personal observation this is exactly what’s wrong with medical students and nurses. They’ll spend hours talking with a patient about their lives and feelings while fluffing their pillow to cause it to be true that they are devoted - they chose to act, chose to love - while acts solely out of ordinary duty are devalued if not completely avoided.
(I'm pretty sure the way to read Sady Porn (or Scott's review of it) is not to treat any of the text as evidence for anything, but as suggestions of things that may be interesting to pay attention to.)
It's slightly off-topic... but I think it's worth mentioning that I think the reason 'extra credit' is more exciting to tackle is that it is all potential upside with no potential downside. Regular assignments and tests offer you a reward if you do them well, but a punishment if you make mistakes on them. Extra credit is an exception to this, where there is explicitly no punishment threatened, so you can just relax and make a comfortable effort without worrying that you are trying insufficiently hard. This makes it more like play and peaceful exploration, and less like a stressful trial.
Indeed, my opinion is that education should have much less in the way of graded homework and tests. Tests should be for special occasions, like the very end of a course, and intended to truly measure the student's understanding. Classwork (e.g. problem sets or working through a series on Khan academy or Brilliant) should award points for effort, just like lectures award participation credit for attending. Homework should be banned (below university level). If the school can't educate you within the allotted time, it is failing its job.
Instead of tracking who is in debt to who, I think you should just track the extent to which you’re in a favouring-exchanging relationship with a given person. Less to remember and runs natively on your brain.
I've recently crossed into being considered senior enough as an organiser, such that people are asking me for advise on how to run their events. I'm enjoying giving out advise, and it also makes me reflet on event design in new ways.
I think there are two types of good events.
Purpose driven event design.
Unconference type events
I think there is a continuum between these two types, but also think that if you plot the best events along this continuum, you'll find a bimodal distribution.
Purpose driven event design
When you organise one of these, you plan a journey for your participant. Everything is woven into a specific goal that is active by the end of the event. Everything fits together.
These can defiantly have a purpose (e.g. exchanging of ideas) but the purpose will be less precise than for the previous type, and more importantly, the purpose does not strongly drive the event design.
There will be designed elements around the edges, e.g. the opening and ending. But most of the event design just goes into supporting the unconference structure, which is not very purpose specific. For most of the event, the participants will not follow a shared journey, currented by the organisers, instead everyone is free to pick their own adventure.
Some advise from The Art of Gathering works for unconference type events, e.g. the importance of pre-event communication, opening and ending. But a lot of the advise don't work, which is why I noticed this division in the first place.
Strengths and weaknesses of each type
Purpose driven events are more work to do, because you actually have to figure out the event design, and then you probably also have to run the program. With unconferences, you can just run the standard unconference format, on what ever theme you like, and let your participants do most of the work of running the program.
An unconference don't require you to know what the specific purpose of the event is. You can just bring together an interesting group of people and see what happens. That's how you get Burning Man or LWCW [? · GW].
However if you have a specific purpose you want to active, you're much more likely to succeed if you actually design the event for that purpose.
There are lots of things that a unconferences can't do at all. It's a very broadly applicable format, but not infinitely so.
I feel a bit behind on everything going on in alignment, so for the next weeks (or more) I'll focus on catching up on what ever I find interesting. I'll be using my short form, to record my though.
I make no promises that reading this is worth anyone's time.
Linda's alignment reading adventures part 1
What to focus on?
I do have some opinions on what aliment directions are more or less promising. I'll probably venture in other directions too, but my main focus is going to be around what I expect an alignment solution to look like.
I think that to have an aligned AI it is necessary (but not sufficient) that we have shared abstractions/ontology/concepts/ (what ever you want to call it) with the AI.
I think the way to make progress on the above is to understand what ontology/concepts/abstraction our current AIs are using, and the process that shapes these abstraction.
I think the way to do this is though mech-interp, mixed with philosophising and theorising. Currently I think the mech-interp part (i.e. look at what is actually going on in a network) is the bottleneck, since I think that philosophising with out data (i.e. agent foundations) has not made much progress lately.
Conclusion:
I'll mainly focus on reading up on mech-interp and related areas such as dev-interp. I've started on the interp section of Lucius's aliment reading list.
I should also read some John Wentworth [LW · GW], since his plan is pretty close to the path I think is most promising.
But also, how interesting is this. Basically they removed the cheese observation, it made the agent act as if there where no cheese. This is not some sophisticated steering technique that we can use to align the AIs motivation.
I discussed this with Lucius [LW · GW] who pointed out, that the interesting result is that: The the cheese location information is linearly separable from other information, in the middle of the network. I.e. it's not scrambled in a completely opaque way.
Alon’s book is the ideal counterargument to the idea that organisms are inherently human-opaque: it directly demonstrates the human-understandable structures which comprise real biological systems.
Both these posts are evidence for the hypothesis that we should expect evolved networks to be modular, in a way that is possible for us to decode.
By "evolved" I mean things in the same category as natural selection and gradient decent.
You might enjoy Concept Algebra for (Score-Based) Text-Controlled Generative Models (and probably other papers / videos from Victor Veitch's groups), which tries to come up with something like a theoretical explanation for the linear represenation hypothesis, including some of the discussion in the reviews / rebuttals for the above paper, e.g.:
'Causal Separability The intuitive idea here is that the separability of factors of variation boils down to whether there are “non-ignorable” interactions in the structural equation model that generates the output from the latent factors of variation—hence the name. The formal definition 3.2 relaxes this causal requirement to distributional assumptions. We have added its causal interpretation in the camera ready version.
Application to Other Generative Models Ultimately, the results in the paper are about non-parametric representations (indeed, the results are about the structure of probability distributions directly!) The importance of diffusion models is that they non-parametrically model the conditional distribution, so that the score representation directly inherits the properties of the distribution.
To apply the results to other generative models, we must articulate the connection between the natural representations of these models (e.g., the residual stream in transformers) and the (estimated) conditional distributions. For autoregressive models like Parti, it’s not immediately clear how to do this. This is an exciting and important direction for future work!
(Very speculatively: models with finite dimensional representations are often trained with objective functions corresponding to log likelihoods of exponential family probability models, such that the natural finite dimensional representation corresponds to the natural parameter of the exponential family model. In exponential family models, the Stein score is exactly the inner product of the natural parameter with y. This weakly suggests that additive subspace structure may originate in these models following the same Stein score representation arguments!)
Connection to Interpretability This is a great question! Indeed, a major motivation for starting this line of work is to try to understand if the ''linear subspace hypothesis'' in mechanistic interpretability of transformers is true, and why it arises if so. As just discussed, the missing step for precisely connecting our results to this line of work is articulating how the finite dimensional transformer representation (the residual stream) relates to the log probability of the conditional distributions. Solving this missing step would presumably allow the tool set developed here to be brought to bear on the interpretation of transformers.
One exciting observation here is that linear subspace structure appears to be a generic feature of probability distributions! Much mechanistic interpretability work motivates the linear subspace hypothesis by appealing to special structure of the transformer architecture (e.g., this is Anthropic's usual explanation). In contrast, our results suggest that linear encoding may fundamentally be about the structure of the data generating process.
Limitations One important thing to note: the causal separability assumption is required for the concepts to be separable in the conditional distribution itself. This is a fundamental restriction on what concepts can be learned by any method that (approximately) learns a conditional distribution. I.e., it’s a limitation of the data generating process, not special to concept algebra or even diffusion models.
Now, it is true that to find the concept subspace using prompts we have to be able to find prompts that elicit causally separable concepts. However, this is not so onerous—because sex and species are not separable, we can't elicit the sex concept with ''buck'' and ''doe''. But the prompts ''a woman'' and ''a man'' work well.'
I think the main important lesson is to not get attached to early ideas. Instead of banning early ideas, if anything comes up, you can just write tit down, and set it aside. I find this easier than a full ban, because it's just an easier move to make for my brain.
(I have a similar problem with rationalist taboo [? · GW]. Don't ban words, instead require people to locally define their terms for the duration of the conversation. It solves the same problem, and it isn't a ban on though or speech.)
The other important lesson of the post, is that, in the early discussion, focus on increasing your shared understanding of the problem, rather than generating ideas. I.e. it's ok for ideas to come up (and when they do you save them for later). But generating ideas is not the goal in the beginning.
Hm, thinking about it, I think the mechanism of classical brainstorming (where you up front think of as many ideas as you can) is to exhaust all the trivial, easy to think of, ideas, as fast as you can, and then you're forced to think deeper to come up with new ideas. I guess that's another way to do it. But I think this is method is both ineffective and unreliable, since it only works though a secondary effect.
. . .
It is interesting to comparing the advise in this post with the Game Tree of Aliment [LW · GW] or Builder/Breaker Methodology also here [LW · GW]. I've seen variants of this exercise popping lots of places in the AI Safety community. Some of them pare probably inspired by each other, but I'm pretty sure (80%) that this method have been invented several times independently.
I think that GTA/BBM works for the same reason the advice in the post works. It also solves the problem of not getting attached, and also as you keep breaking your ideas and explore new territory, you expand your understanding or the problem. I think an active ingrediens in this method is that the people playing this game knows that alignment is hard, and go in expecting their first several ideas to be terrible. You know the exercise is about noticing the flaws in your plans, and learn from your mistakes. Without this attitude, I don't think it would work very well.
There is nothing special about human level intelligence, unless you have imitation learning, in which case human level capabilities are very special.
General intelligence is not very efficient. Therefore there will not be any selection pressure for general intelligence as long as other options are available.
Second reply. And this time I actually read the link. I'm not suppressed by that result.
My original comment was a reaction to claims of the type [the best way to solve almost any task is to develop general intelligence, therefore there is a strong selection pressure to become generally intelligent]. I think this is wrong, but I have not yet figured out exactly what the correct view is.
But to use an analogy, it's something like this: In the example you gave, the AI get's better at the sub tasks by learning on a more general training set. It seems like general capabilities was useful. But consider that we just trained on even more data for a singel sub task, then wouldn't it develop general capabilities, since we just noticed that general capabilities was useful for that sub task. I was planing to say "no" but I notice that I do expect some transfer learning. I.e. if you train on just one of the dataset, I expect it to be bad at the other ones, but I also expect it to learn them quicker than without any pre-training.
I seem to expect that AI will develop general capabilities when training on rich enough data, i.e. almost any real world data. LLM is a central example of this.
I think my disagreement with at least my self from some years ago and probably some other people too (but I've been away a bit form the discourse so I'm not sure), is that I don't expect as much agentic long term planing as I used to expect.
I agree that eventually, at some level of trying to solve enough different types of tasks, GI will be efficient, in terms of how much machinery you need, but it will never be able to compete on speed.
Also, it's an open question what is "enough different types of tasks". Obviously, for a sufficient broad class of problems GI will be more efficient (in the sense clarified above). Equally obviously, for a sufficient narrow class of problems narrow capabilities will be more efficient.
Humans have GI to some extent, but we mostly don't use it. This is interesting. This means that a typical human environment is complex enough so that it's worth carrying around the hardware for GI. But even though we have it, it is evolutionary better to fall back at habits, or imitation, or instinkt, for most situations.
Looking back to exactly what I wrote, I said there will not be any selection pressure for GI as long as other options are available. I'm not super confident in this. But if I'm going to defend it here anyway by pointing out that "as long as other options are available", is doing a lot of the work here. Some problems are only solvable by noticing deep patterns in reality, and in this case a sufficiently deep NN with sufficient training will learn this, and that is GI.
I mean that you take some known distribution (the training distribution) as a starting point. But when sampling actions you do so from shifted on truncated distribution to favour higher reward policies.
The in the decision transformers I linked, AI is playing a variety of different games, where the programmers might not know what a good future reward value would be. So they let the system AI predict the future reward, but with the distribution shifted towards higher rewards.
I discussed this a bit more after posting the above comment, and there is something I want to add about the comparison.
In quantilizers if you know the probability of DOOM from the base distribution, you get an upper bound on DOOM for the quantaizer. This is not the case for type of probability shift used for the linked decision transformer.
DOOM = Unforeseen catastrophic outcome. Would not be labelled as very bad by the AI's reward function but is in reality VERY BAD.
From my reading of quantilizers, they might still choose "near-optimal" actions, just only with a small probability. Whereas a system based on decision transformers (possibly combined with a LLM) could be designed that we could then simply tell to "make me a tea of this quantity and quality within this time and with this probability" and it would attempt to do just that, without trying to make more or better tea or faster or with higher probability.
Yes, that is a thing you can do with decision transforms too. I was referring to variant of the decision transformer (see link in original short form) where the AI samples the reward it's aiming for.
Yesterday was the official application deadline for leading a project at the next AISC. This means that we just got a whole host of project proposals.
If you're interested in giving feedback and advise to our new research leads, let me know. If I trust your judgment, I'll onboard you as an AISC advisor.
Also, it's still possible to send us a late AISC project proposals. However we will prioritise people how applied in time when giving support and feedback. Further more, we'll prioritise less late applications over more late applications.
Blogposts are the result of noticing difference in beliefs. Either between you and other of between you and you, across time.
I have lots of ideas that I don't communicate. Sometimes I read a blogpost and think "yea I knew that, why didn't I write this". And the answer is that I did not have an imagined audience.
My blogposts almost always span after I explained a thing ~3 times in meat space. Generalizing from these conversations I form an imagined audience which is some combination of the ~3 people I talked to. And then I can write.
(In a conversation I don't need to imagine an audience, I can just probe the person in front of me and try different explanations until it works. When writing a blogpost, I don't have this option. I have to imagine the audience.)
Another way to form an imagined audience is to write for your past self. I've noticed that a lot of thig I read are like this. When just learning something or realizing something, and past you who did not know the thing is still fresh in your memory, then it is also easier to write the thing. This short form is of this type.
I wonder if I'm unusually bad at remembering the thoughts and belief's of past me? My experience is that I pretty quickly forget what it was like not to know a thing. But I see others writing things aimed at their pasts self from years ago.
I think I'm writing short form as a message to my future self, when I have forgotten this insight. I want my future self to remember this idea of how blogposts spawn. I think it will help her guide her writing posts, but also help her not to be annoyed when someone else writes a popular thing that I already knew, and "why did I not write this?" There is an answer to the question "why did I not write this?" and the answer is "because I did not know how to write it".
A blogpost is a bridge between a land of not knowing and a land of knowing. Knowing the destination of the bridge is not enough to build the bridge. You also have to know the starting point.
Recently someone either suggested to me (or maybe told me they or someone where going to do this?) that we should train AI on legal texts, to teach it human values. Ignoring the technical problem of how to do this, I'm pretty sure legal text are not the right training data. But at the time, I could not clearly put into words why. Todays SMBC explains this for me:
Law is not a good representation or explanation of most of what we care about, because it's not trying to be. Law is mainly focused on the contentious edge cases.
Training an AI on trolly problems and other ethical dilemmas is even worse, for the same reason.
Moreover, legal texts are not super strict (much is left to interpretation) and we are often selective about "whether it makes sense to apply this law in this context" for reasons not very different from religious people being very selective about following the laws of their holy books.
I spoke with some people last fall who were planning to do this, perhaps it's the same people. I think the idea (at least, as stated) was to commercialize regulatory software to fund some alignment work. At the time, they were going by Nomos AI, and it looks like they've since renamed to Norm AI.
Soon, interacting with AI agents will be a part of daily life, presenting enormous regulatory and compliance challenges alongside incredible opportunities.
Norm Ai agents also work alongside other AI agents who have been entrusted to automate business processes. Here, the role of the Norm Ai agent is to automatically ensure that actions other AI agents take are in compliance with laws.
I'm not sure if this is worrying, because I don't think AI overseeing AI is a good solution. Or it's actually good, because, again, not a good solution, which might lead to some early warnings?
Would sensationalist tabloid news stories be better training data? Perhaps it is the inverse problem: fluffy human interest stories and outrage porn are both engineered for the lowest common denominator, the things that overwhelmingly people think are heartwarming or miscarriages of justice respectively. However if you wanted to get a AI to internalize what is in fact the sources of outrage and consensus among the wider community I think it's a place to start.
The obvious other examples are fairy tales, fables, parables, jokes, and urban legends - most are purpose encoded with a given society's values. Amateur book and film reviews are potentially another source of material that displays human values in that whether someone is satisfied with the ending or not (did the villain get punished? did the protagonist get justice?) or which characters they liked or disliked is often attached to the reader/viewer's value systems. Or as Jerry Lewis put it in the Total Filmmaker: in comedy, a snowball is never thrown at a battered fedora: "The top-hat owner is always the bank president who holds mortgage on the house...".
Sensationalist tabloid news stories and other outrage porn are not the opposite. These are actually more of the same. More edge cases. Anything that is divisive have the problem I'm talking about.
Fiction is a better choice.
Or even just completely ordinary every-day human behaviour. Most humans are mostly nice most of the time.
We might have to start with the very basic, the stuff we don't even notice, because it's too obvious. Things no-one would think of writing down.
Sensationalist tabloid news stories and other outrage porn are not the opposite. These are actually more of the same. More edge cases. Anything that is divisive have the problem I'm talking about.
Could you explain how are they edge cases if they are the lowest common denominator? Doesn't that make them the opposite of an edge case? Aren't they in fact the standard or yardstick necessary to compare against?
Fiction is a better choice.
Why is is it different let alone better choice? Fiction is a single author's attempt to express their view of the world, including morality, and therefore an edge case. While popular literature is just as common denominator as tabloid journalism, since the author is trying to be commercial.
I don't read much sensationalist tabloid, but my impression is that the things that get a lot of attention in the press, is things people can reasonable take either side of.
Scott Alexander writes about how everyone agrees that factory framing is terrible, but exactly because this overwhelming agreement, it get's no attention. Which is why PETA does outrageous things to get attention.
I don't read much sensationalist tabloid, but my impression is that the things that get a lot of attention in the press, is things people can reasonable take either side of.
A cursory glance suggests that it is not the case, take a top story headline on the Australian Daily Mail over the last 7 days: "Miranda, Sydney: Urgent search is launched for missing Bailey Wolf, aged two, who vanished yesterday" it is not reasonable for someone to hope that a two year old who has vanished not be found. This is exactly the kind of thing you're suggesting AI should be trained on, because of how uniform responses are to this headline. Keep in mind this is one of the most viewed stories, and literally top of the list I found.
I've read Scott's article, but are you trying to understand what get's attention or what is the nexus or commonly agreed upon moral principles of a society?
About once or twice per week this time of year someone emails me to ask:
Please let me break rule X
My response:
No you're not allowed to break rule X. But here's a loop hole that lets you do the thing you want without technically breaking the rule. Be warned that I think using the loophole is a bad idea, but if you still want to, we will not stop you.
Because not leaving the loophole would be too restrictive for other reason, and I'm not going to not tell people all their options.
The fact that this puts the responsibility back on them is a bonus feature I really like. Our participants are adults, and are allowed to make their own mistakes. But also, sometimes it's not a mistake, because there is no set of rules for all occasion, and I don't have all the context of their personal situation.
I suspect it's not possible to build autonomous aligned AIs (low confidence). The best we can do is some type of hybrid humans-in-the-loop system. Such a system will be powerful enough to eventually give us everything we want, but it will also be much slower and intellectually inferior to what is possible with out humans-in-the-loop. I.e. the alignment tax will be enormous. The only way the safe system can compete, is by not building the unsafe system.
Therefore we need AI Governance. Fortunately, political action is getting a lot of attention right now, and the general public seems to be positively inclined to more cautious AI development.
After getting an immediate stop/paus on larger models, I think next step might be to use current AI to cure aging. I don't want to miss the singularity because I died first, and I think I'm not the only one who feels this way. It's much easier to be patient and cautious in a world where aging is a solved problem.
We probably need a strict ban on building autonomous superintelligent AI until we reached technological maturity. It's probably not a great idea to build them after that either, but they will probably not pose the same risk any longer. This last claim is not at all obvious. The hardest attack vector to defend against would be manipulation. I think reaching technological maturity will make us able to defend against any military/hard-power attack. This includes for example having our own nano-bot defence system, to defend against hostile nanobots. Manipulation is harder, but I think there are ways to solve that, with enough time to set up our defences.
An important crux for what there end goal is, including if there is some stable end where we're out of the danger, is to what extent technological maturity also leads to a stable cultural/political situation, or if that keeps evolving in ever new directions.
If LMs reads each others text we can get LM-memetics. A LM meme is a pattern which, if it exists in the training data, the LM will output at higher frequency that in the training data. If the meme is strong enough and LLMs are trained on enough text from other LMs, the prevalence of the meme can grow exponentially. This has not happened yet.
There can also be memes that has a more complicated life cycle, involving both humans and LMs. If the LM output a pattern that humans are extra interested in, then the humans will multiply that pattern by quoting it in their blogpost, which some other LM will read, which will make the pattern more prevalent in the output of that transformer, possibly.
Generative models memetics:
Same thing can happen for any model trained to imitate the training distribution.
I think an LM-meme is something more than just a frequently repeating pattern. More like frequently repeating patterns with which can infect each other by outputting them into the web or whatever can be included as in a trainibg set for LMs.
There may be other features that are pretty central to the prototype of the (human) meme concept, such as its usefulness for some purpose (ofc not all memes are useful). Maybe this one can be extrapolated to the LM domain, e.g. it helps it presict the next token ir whatever but I'm not sure whether it's the right move to appropriate the concept of meme for LMs. If we start discovering infectious patterns of this kind, it may be better to think about them as one more subcategory of a general category of replicators of which memes, genes, and prions are another ones.
This is probably too obvious to write, but I'm going to say it anyway. It's my short form, and approximately no-one reads short forms. Or so I'm told.
Human value formation is to a large part steered by other humans suggesting value systems for you. You get some hard to interpret reward signal from your brainstem, or something. There are lots of "hypothesis" for the "correct reward function" you should learn.
(Quotation marks because there are no ground through for what values you should have. But this is mathematically equivalent to a learning the true statistic generating the data, from a finite number of data points. Also, there is maybe some ground truth of what the brainstem rewards, or maybe not. According to Steve the there is this loop, where when the brainstem don't know if things are good or not, it just mirror back cortex's own opinion to the cortex.)
To locate the hypothesis, you listen to other humans. I make this claim not just for moral values, but for personal preferences. Maybe someone suggest to you "candy is tasty" and since this seems to fit with your observation, no you also like candy. This is a bad example since for taste specifically the brainstem has pretty clear opinions. Except there is acquired taste... so maybe not a terrible example.
Another example: You join a hobby. You notice you like being at the hobby place doing the hobby thing. Your hobby fired says (i.e. offer the hypothesis) "this hobby is great". This seems to fit your data so now you believe you like the hobby. And because you believe you like the hobby, you end up actually liking the hobby because of a self reinforcing loop. Although this don't always work. Maybe after some time your friends quit the hobby and this makes it less fun, and you realise (change your hypothesis) that you manly liked the hobby for the people.
Maybe there is a ground truth about what we want for ourselves? I.e. we can end up with wrong beliefs about what we want due to pear pressure, commercials, etc. But with enough observation we will notice what it is we actually want.
Clearly humans are not 100% malleable, but also, it seems like even our personal preferences are path dependent (i.e. pick up lasting influences from our environment). So maybe some annoying mix...
I disagree. That humans learn values primarily via teaching. 1) parenting is known to have little effect on children's character - which is one way of saying their values. 2) while children learn to follow rules teens are good at figuring out what is in their interest.
I think it makes sense to pose argue the point though.
For example I think that proposing rules makes it more probable that the brain converges on these solutions.
1) parenting is known to have little effect on children's character
This is not counter evidence to my claim. The value framework a child learns about from their parents is just one of many value frameworks they hear about from many, many people. My claim is that the power lies in noticing the hypothesis at all. Which ideas you get told more times (e.g. by your parents) don't matter.
As far as I know, what culture you are in very much influences your values, which my claim would predict.
2) while children learn to follow rules teens are good at figuring out what is in their interest.
I'm basically ready to announce the next Technical AI Safety Unconference (TAISU). But I have hit a bit of decision paralysis as to what dates it should be.
If you are reasonably interested in attending, please help me by filling in this doodle
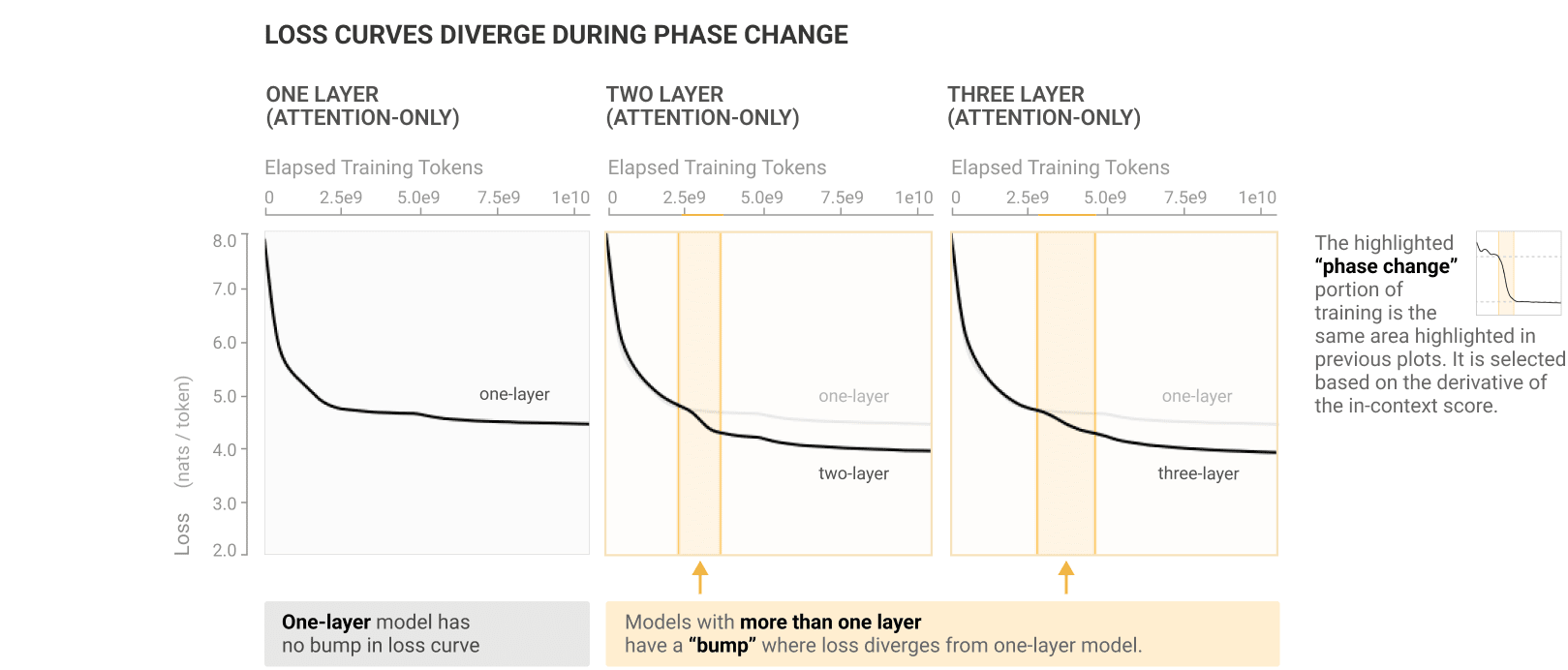
This already strongly suggests some connection between induction heads and in-context learning, but beyond just that, it appears this window is a pivotal point for the training process in general: whatever's occurring is visible as a bump on the training curve (figure below). It is in fact the only place in training where the loss is not convex (monotonically decreasing in slope).
I can see the bump, but it's not the only one. The two layer graph has a second similar bump, which also exists in the one layer model, and I think I can also see it very faintly in the three level model. Did they ignore the second bump because it only exists in small models, while their bump continues to exist in bigger models?
Toy model: Each agent has a utility function they want to maximise. The input to the utility function is a list of values describing the state of the world. Different agents can have different input vectors. Assume that every utility function monotonically increases, decreases or stays constant for changes in each impute variable (I did say it was a toy model!). An agent is said to value something if the utility function increases with increasing quantity of that thing. Note that if an agents utility function decreases with increasing quantity of a thing, then the agent values the negative of that thing.
In this toy model agent A is aligned with agent B if and only if A values everything B values.
Q: However does this operationalisation match my intuitive understanding of alignment? A: Good but not perfect.
This definition of alignment is transitive, but not symmetric. This matches the properties I think a definition of alignment should have.
How about if A values a lot of things that B doesn't care about, and only cares very little about the things A cares about? That would count as aligned in this operationalisation but not necessarily match my intuitive understanding of alignment.
What is alignment? (operationalisation second try)
Agent A is aligned with agent B, if and only if, when we give more power (influence, compute, improved intelligence, etc.) to A, then things get better according to B’s values, and this relation holds for arbitrary increases of power.
This operationalisation points to exactly what we want, but is also not very helpful.
The not so operationalized answer is that a good operationalization is one that are helpful for achieving alignment.
An operationalization of [helpfulness of an operationalization] would give some sorts to gears level understanding of what shape the operationalization should have to be helpful. I don't have any good model for this, so I will just gesture vaguely.
I think that mathematical descriptions are good, since they are more precise. My first operationalization attempt is pretty mathematical which is good. It is also more "constructive" (not sure if this is the exact right word), i.e. it describes alignment in terms of internal properties, rather than outcomes. Internal properties are more useful as design guidelines, as long as they are correct. The big problem with my first operationalization is that it don't actually point to what we want.
The problem with the second attempt is that it just states what outcome we want. There is nothing in there to help us achieve it.
Can't you restate the second one as the relationship between two utility functions UA and UB such that increasing one (holding background conditions constant) is guaranteed not to decrease the other? I.e. their respective derivatives are always non-negative for every background condition.
Yes, I like this one. We don't want the AI to find a way to give it self utility while making things worse for us. And if we are trying to make things better for us, we don't want the AI to resist us.
Do you want to find out what these inequalities implies about the utility functions? Can you find examples where your condition is true for non-identical functions?
UA changes only when MA (A's world model) changes which is ultimately caused by new observations, i.e. changes in the world state (let's assume that both A and B perceive the world quite accurately).
If whenever UA changes UB doesn't decrease, then whatever change in the world increased UA, B at least doesn't care. This is problematic when A and B need the same scarce resources (instrumental convergence etc). It could be satisfied if they were both satisficers or bounded agents inhabiting significantly disjoint niches.
A robust solution seems seems to be to make (super accurately modeled) UB a major input to UA.
Then (I think) for your inequality to hold, it must be that
U_B = f(3x+y), where f' >= 0
If U_B care about x and y in any other proportion, then B can make trade-offs between x and y which makes things better for B, but worse for A.
This will be true (in theory) even if both A and B are satisfisers. You can see this by assuming replacing y and x with sigmoids of some other variables.
Recently an AI safety researcher complained to me about some interaction they had with an AI Safety communicator. Very stylized, there interaction went something like this:
(X is some fact or topic related to AI Safety
Communicator: We don't know anything about X and there is currently no research on X.
Researcher: Actually, I'm working on X, and I do know some things about X.
Communicator: We don't know anything about X and there is currently no research on X.
I notice that I semi-frequently hear communicators saying things like the thing above. I think what they mean is that our our understanding of X is far from the understanding that is needed, and the amount of researchers working on this is much fewer than what would be needed, and this get rounded off to we don't know anything and no one is doing anything about it. If this is what is going on then I think this is bad.
I think that is some cases when someone says "We don't know anything about X and there is currently no research on X." they probably literally mean it. There are some people who think that approximately no-one working on AI Safety is doing real AI Safety researchers. But I also think that most people who are saying "We don't know anything about X and there is currently no research on X." are doing some mixture of rounding off, some sort of unreflexively imitation learning, i.e. picking up the sentence structure from others, especially from high status people.
I think using a language that hides the existence of the research that does exist is bad. Primarily because it's misinformative. Do we want all new researchers to start from scratch? Because that is what happens if you tell them there is no pre-existing research and they believe you.
I also don't think this exaggeration will help with recruitment. Why do you think people would prefer to join a completely empty research field instead of a small one? From a personal success perspective (where success can mean either impact or career success) a small research field is great, lots if low-hanging fruit around. But a completely untrodden research direction is terrible, you will probably just get lost, not get anything done, and even if you fid something, there's nowhere to publish it.
I notice that I don't expect FOOM like RSI, because I don't expect we'll get an mesa optimizer with coherent goals. It's not hard to give the outer optimiser (e.g. gradient decent) a coherent goal. For the outer optimiser to have a coherent goal is the default. But I don't expect that to translate to the inner optimiser. The inner optimiser will just have a bunch of heuristics and proxi-goals, and not be very coherent, just like humans.
The outer optimiser can't FOOM, since it don't do planing, and don't have strategic self awareness. It's can only do some combination of hill climbing and random trial and error. If something is FOOMing it will be the inner optimiser, but I expect that one to be a mess.
I notice that this argument don't quite hold. More coherence is useful for RSI, but complete coherence is not necessary.
I also notice that I expect AIs to make fragile plans, but on reflection, I expect them to gett better and better with this. By fragile I mean that the longer the plan is, the more likely it is to break. This is true for human too though. But we are self aware enough about this fact to mostly compensate, i.e. make plans that don't have too many complicated steps, even if the plan spans a long time.
I recently updated how I view the alignment problem. The post that caused my update is this one [? · GW] form the shard sequence [? · GW]. Also worth mentioning is older post [AF · GW] that points to the same thing, but I just happen to read it later.
Basically I used to think we needed to solve both outer and inner alignment separately. No I no longer think this is a good decomposition of the problem.
It’s not obvious that alignment must factor in the way described above. There is room for trying to set up training in such a way to guarantee a friendly mesa-objective somehow without matching it to a friendly base-objective. That is: to align the AI directly to its human operator, instead of aligning the AI to the reward, and the reward to the human.
Any policy can be model as a consequentialist agent, if you assume a contrived enough utility function. This statement is true, but not helpful.
The reason we care about the concept agency, is because there are certain things we expect from consequentialist agents, e.g. instrumental convergent goals, or just optimisation pressure in some consistent direction. We care about the concept of agency because it holds some predictive power.
[... some steps of reasoning I don't know yet how to explain ...]
Therefore, it's better to use a concept of agency that depend on the internal properties of an algorithm/mind/policy-generator.
I don't think agency can be made into a crisp concept. It's either a fuzzy category or a leaky abstraction depending on how you apply the concept. But it does point to something important. I think it is worth tracking how agentic different systems are, because doing so has predictive power.