Utility ≠ Reward
post by Vlad Mikulik (vlad_m) · 2019-09-05T17:28:13.222Z · LW · GW · 24 commentsContents
Two distinctions What objectives? Why worry? Mesa-optimisers An alignment agenda Where does this leave us? None 24 comments
This essay is an adaptation of a talk I gave at the Human-Aligned AI Summer School 2019 about our work on mesa-optimisation [? · GW]. My goal here is to write an informal, accessible and intuitive introduction to the worry that we describe in our full-length report.
I will skip most of the detailed analysis from our report, and encourage the curious reader to follow up this essay with our sequence [? · GW] or report.
The essay has six parts:
Two distinctions draws the foundational distinctions between
“optimised” and “optimising”, and between utility and reward.
What objectives? discusses the behavioral and internal approaches to understanding objectives of ML systems.
Why worry? outlines the risk posed by the utility ≠ reward gap.
Mesa-optimisers introduces our language for analysing this worry.
An alignment agenda sketches different alignment problems presented by these ideas, and suggests transparency and interpretability as a way to solve them.
Where does this leave us? summarises the essay and suggests where to look next.
The views expressed here are my own, and do not necessarily reflect those of my coauthors or MIRI. While I wrote this essay in first person, all of the core ideas are the fruit of an equal collaboration between Joar Skalse, Chris van Merwijk, Evan Hubinger and myself. I wish to thank Chris and Joar for long discussions and input as I was writing my talk, and all three, as well as Jaime Sevilla Molina, for thoughtful comments on this essay.
≈3300 words.
Two distinctions
I wish to draw a distinction which I think is crucial for clarity about AI alignment, yet is rarely drawn. That distinction is between the reward signal of a reinforcement learning (RL) agent and its “utility function”[1]. That is to say, it is not in general true that the policy of an RL agent is optimising for its reward. To explain what I mean by this, I will first draw another distinction, between “optimised” and “optimising”. These distinctions lie at the core of our mesa-optimisation framework.
It’s helpful to begin with an analogy. Viewed abstractly, biological evolution is an optimisation process that searches through configurations of matter to find ones that are good at replication. Humans are a product of this optimisation process, and so we are to some extent good at replicating. Yet we don’t care, by and large, about replication in itself.
Many things we care about look like replication. One might be motivated by starting a family, or by having a legacy, or by similar closely related things. But those are not replication itself. If we cared about replication directly, gamete donation would be a far more mainstream practice than it is, for instance.
Thus I want to distinguish the objective of the selection pressure that produced humans from the objectives that humans pursue. Humans were selected for replication, so we are good replicators. This includes having goals that correlate with replication. But it is plain that we are not motivated by replication itself. As a slogan, though we are optimised for replication, we aren’t optimising for replication.
Another clear case where “optimised” and “optimising” come apart are “dumb” artifacts like bottle caps [AF · GW]. They can be heavily optimised for some purpose without optimising for anything at all.
These examples support the first distinction I want to make: optimised ≠ optimising. They also illustrate how this distinction is important in two ways:
- A system optimised for an objective need not be pursuing any objectives itself. (As illustrated by bottle caps.)
- The objective a system pursues isn’t determined by the objective it was optimised for. (As illustrated by humans.)
The reason I draw this distinction is to ask the following question:
Our machine learning models are optimised for some loss or reward. But what are they optimising for, if anything? Are they like bottle caps, or like humans, or neither?

In other words, do RL agents have goals? And if so, what are they?
These questions are hard, and I don’t think we have good answers to any of them. In any case, it would be premature, in light of the optimised ≠ optimising distinction, to conclude that a trained RL agent is optimising for its reward signal.
Certainly, the RL agent (understood as the agent’s policy representation, since that is the part that does all of the interesting decision-making) is optimised for performance on its reward function. But in the same way that humans are optimised for replication, but are optimising for our own goals, a policy that was selected for its performance on reward may in fact have its own internally-represented goals, only indirectly linked to the intended reward. A pithy way to put this point is to say that utility ≠ reward, if we want to call the objective a system is optimising its “utility”. (This is by way of metaphor – I don’t suggest that we must model RL agents as expected utility maximizers.)
Let’s make this more concrete with an example. Say that we train an RL agent to perform well on a set of mazes. Reward is given for finding and reaching the exit door in each maze (which happens to always be red). Then we freeze its policy and transfer the agent to a new environment set for testing. In the new mazes, the exit doors are blue, and red distractor objects are scattered elsewhere in the maze. What might the agent do in the new environment?
Three things might happen.
- It might generalise: the agent could solve the new mazes just as well, reaching the exit and ignoring the distractors.
- It might break under the distributional shift: the agent, unused to the blue doors and weirdly-shaped distractor objects, could start twitching or walking into walls, and thus fails to reach the exit.
- But it might also fail to generalise in a more interesting way: the agent could fail to reach the exit, but could instead robustly and competently find the red distractor in each maze we put it in.
To the extent that it's meaningful to talk about the agent's goals, the contrast between the first and third cases suggests that those goals depend only on its policy, and are distinct from its reward signal. It is tempting to say that the objective of the first agent is reaching doors; that the objective of the third agent is to reach red things. It does not matter that in both cases, the policy was optimised to reach doors.
This makes sense if we consider how information about the reward gets into the policy:
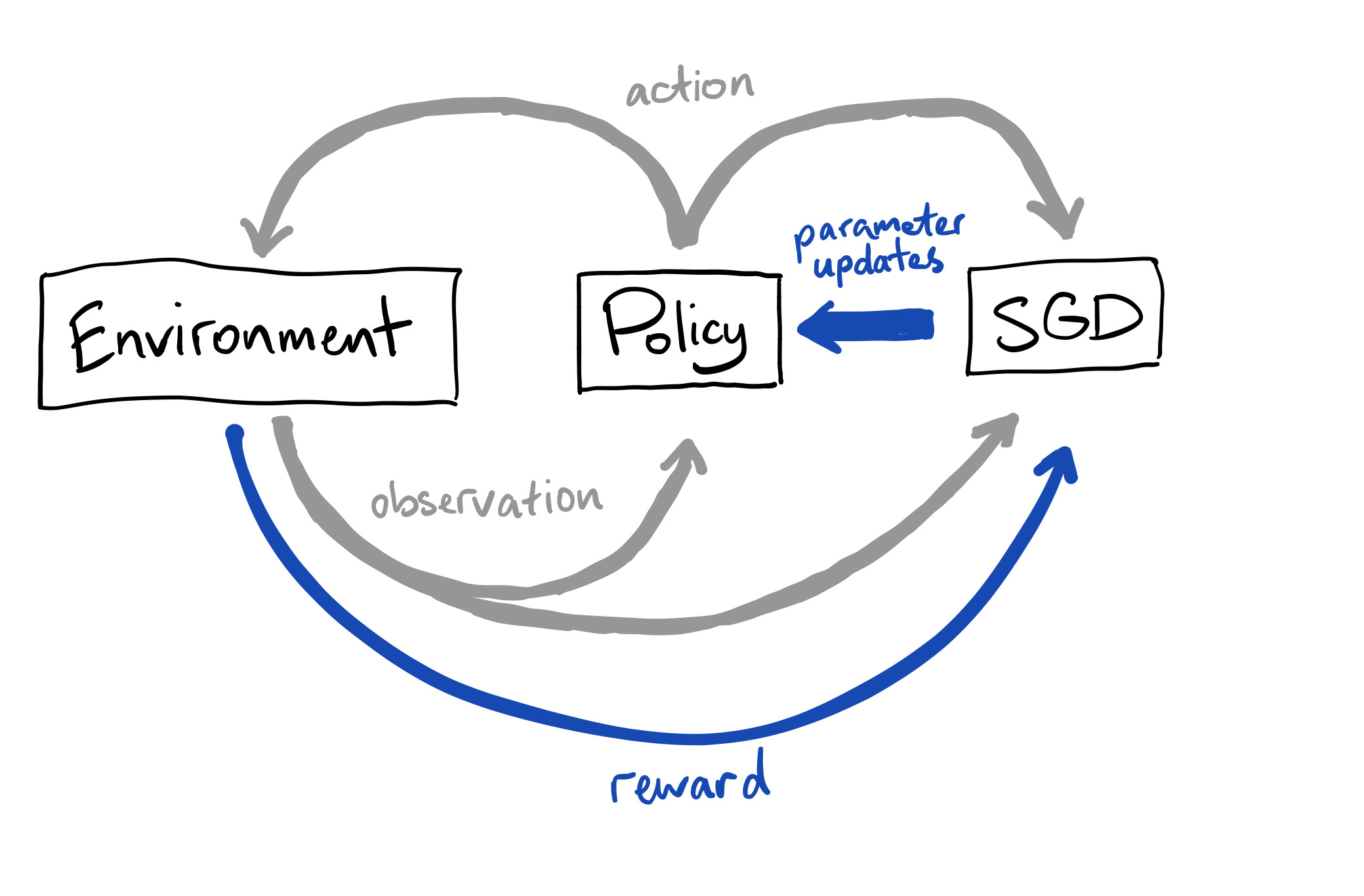
For any given action, the policy’s decision is made independently of the reward signal. The reward is only used (standardly, at least) to optimise the policy between actions. So the reward function can’t be the policy’s objective – one cannot be pursuing something one has no direct access to. At best, we can hope that whatever objective the learned policy has access to is an accurate representation of the reward. But the two can come apart, so we must draw a distinction between the reward itself and the policy’s internal objective representation.
To recap: whether an AI system is goal-directed or not is not trivially answered by the fact that it was constructed to optimise an objective. To say that is to fail to draw the optimised ≠ optimising distinction. If we then take seriously goal-directedness in AI systems, then we must draw a distinction between the AI’s internal learned objective and the objective it was trained on; that is, draw the utility ≠ reward distinction.
What objectives?
I’ve been talking about the objective of the RL agent, or its “utility”, as if it is an intuitively sensible object. But what actually is it, and how can we know it? In a given training setup, we know the reward. How do we figure out the utility?
Intuitively, the idea of the internal goal being pursued by a learned system feels compelling to me. Yet right now, we don't have any good ways to make the intuition precise – figuring out how to do that is an important open question. As we start thinking about how to make progress, there are at least two approaches we can take: what I’d call the behavioural approach and the internal approach.
Taking the behavioural approach, we look at how decisions made by a system systematically lead to certain outcomes. We then infer objectives from studying those decisions and outcomes, treating the system as a black box. For example, we could apply Inverse Reinforcement Learning to our trained agents. Eliezer’s formalisation of optimisation power [LW · GW] also seems to follow this approach.
Or, we can peer inside the system, trying to understand the algorithm implemented by it. This is the internal approach. The goal is to achieve a mechanistic model that is abstract enough to be useful, but still grounded in the agent’s inner workings. Interpretability and transparency research take this approach generally, though as far as I can tell, the specific question of objectives has not yet seen much attention.
It’s unclear whether one approach is better, as both potentially offer useful tools. At present, I am more enthusiastic about the internal approach, both philosophically and as a research direction. Philosophically, I am more excited about it because understanding a model’s decision-making feels more explanatory[2] than making generalisations about its behaviour. As a research direction, it has potential for empirically-grounded insights which might scale to future prosaic AI systems. Additionally, there is the possibility of low-hanging fruit, as this space appears underexplored.
Why worry?
Utility and reward are distinct. So what? If a system is truly optimised for an objective, determining its internal motivation is an unimportant academic debate. Only its real-world performance matters, not the correct interpretation of its internals. And if the performance is optimal, then isn’t our work done?
In practice, we don’t get to optimise performance completely. We want to generalise from limited training data, and we want our systems to be robust to situations not foreseen in training. This means that we don’t get to have a model that’s perfectly optimised for the thing we actually want. We don’t get optimality on the full deployment distribution complete with unexpected situations. At best, we know that the system is optimal on the training distribution. In this case, knowing whether the internal objective of the system matches the objective we selected it for becomes crucial, as if the system’s capabilities generalise while its internal goal is misaligned [AF · GW], bad things can happen.
Say that we prove, somehow, that optimising the world with respect to some objective is safe and useful, and that we can train an RL agent using that objective as reward. The utility ≠ reward distinction means that even in that ideal scenario, we are still not done with alignment. We still need to figure out a way to actually install that objective (and not a different objective that still results in optimal performance in training) into our agent. Otherwise, we risk creating an AI that appears to work correctly in training, but which is revealed to be pursuing a different goal when an unusual situation happens in deployment. So long as we don’t understand how objectives work inside agents, and how we can influence those objectives, we cannot be certain of the safety of any system we build, even if we literally somehow have a proof that the reward it was trained on was “correct”.
Will highly-capable AIs be goal-directed? I don’t know for sure, and it seems hard to gather evidence about this, but my guess is yes. Detailed discussion is beyond our scope, but I invite the interested reader to look at some arguments about this that we present in section 2 [? · GW] of the report. I also endorse Rohin Shah’s Will Humans Build Goal-Directed Agents? [AF · GW].
All this opens the possibility for misalignment between reward and utility. Are there reasons to believe the two will actually come apart? By default, I expect them to. Ambiguity and underdetermination of reward mean that there are many distinct objectives that all result in the same behaviour in training, but which can disagree in testing. Think of the maze agent, whose reward in training could mean “go to red things” or “go to doors”, or a combination of the two. For reasons of bounded rationality, I also expect pressures for learning proxies for the reward instead of the true reward, when such proxies are available. Think of humans, whose goals are largely proxies for reproductive success, rather than replication itself. (This was a very brief overview; section 3 [? · GW] of our report examines this question in depth, and expands on these points more.)
The second reason these ideas matter is that we might not want goal-directedness at all. Maybe we just want tool AI, or AI services, or some other kind of non-agentic AI. Then, we want to be certain that our AI is not somehow goal-directed in a way that would cause trouble off-distribution. This could happen without us building it in – after all, evolution didn’t set out to make goal-directed systems. Goal-directedness just turned out to be a good feature to include in its replicators. Likewise, it may be that goal-directedness is a performance-boosting feature in classifiers, so powerful optimisation techniques would create goal-directed classifiers. Yet perhaps we are willing to take the performance hit in exchange for ensuring our AI is non-agentic. Right now, we don’t even get to choose, because we don’t know when systems are goal-directed, nor how to influence learning processes to avoid learning goal-directedness.
Taking a step back, there is something fundamentally concerning about all this.
We don’t understand our AIs’ objectives, and we don’t know how to set them.
I don’t think this phrase should ring true in a world where we hope to build friendly AI. Yet today, to my ears, it does. I think that is a good reason to look more into this question, whether to solve it or to assure ourselves that the situation is less bad than it sounds.
Mesa-optimisers
This worry is the subject of our report. The framework of mesa-optimisation is a language for talking about goal-directed systems under the influence of optimisation processes, and about the objectives involved.
A part of me is worried that the terminology invites viewing mesa-optimisers as a description of a very specific failure mode, instead of as a language for the general worry described above. I don’t know to what degree this misconception occurs in practice, but I wish to preempt it here anyway. (I want data on this, so please leave a comment if you had confusions about this after reading the original report.)
In brief, our terms describe the relationship between a system doing some optimisation (the base optimiser, e.g.: evolution, SGD), and a goal-directed system (the mesa-optimiser, e.g.: human, ML model) that is being optimised by that first system. The objective of the base optimiser is the base objective; the internal objective of the mesa-optimiser is the mesa-objective.
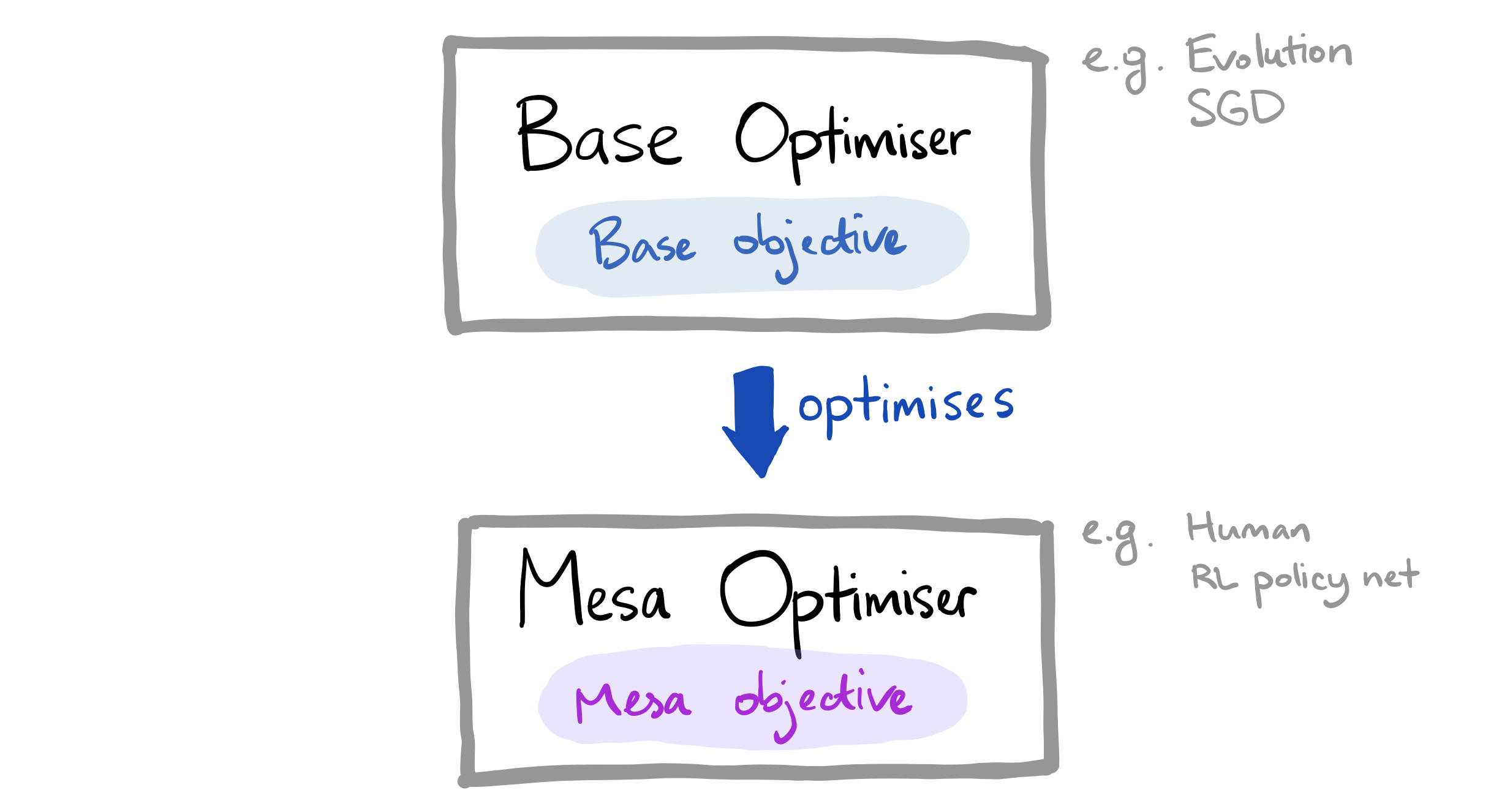
(“Mesa” as a Greek word that means something like the opposite of “meta”. The reason we use “mesa” is to highlight that the mesa-optimiser is an optimiser that is itself being optimised by another optimiser. It is a kind of dual to a meta-optimiser, which is an optimiser that is itself optimising another optimiser. There is contention [LW(p) · GW(p)] around whether this is good Greek, however.
While we’re on the topic of terms, “inner optimiser” is a confusing term that we used in the past in the same way as “mesa-optimiser”. It did not accurately reflect the concept, and has been retired in favour of the current terminology. Please use ”mesa-optimiser” instead.)
I see the word “optimiser” in “mesa-optimiser” as a way of capturing goal-directedness, rather than a commitment to some kind of (utility-)maximising structure. What feels important to me in a mesa-optimiser is its goal-directedness, not the fact it is an optimiser. A goal-directed system which isn’t taking strictly optimal actions (but which is still competent at pursuing its mesa-objective) is still worrying.
Optimisation could be a good way to model goal-directedness—though I don’t think you gain that much, conceptually, from that model—but equally, it seems plausible that some other approach we have not yet explored could work better. So I myself read the “optimiser” in “mesa-optimiser” analogously to how I accept treating humans as optimisers; as a metaphor, more than anything else.
I am not sure that mesa-optimisation is the best possible framing of these concerns. I would welcome more work that attempts to untangle these ideas, and to improve our concepts.
An alignment agenda
There are at least three alignment-related ideas prompted by this worry.
The first is unintended optimisation. How do we ensure that systems that are not supposed to be goal-directed actually end up being not-goal-directed?
The second is to factor alignment into inner alignment and outer alignment. If we expect our AIs to be goal-directed, we can view alignment as a two-step process. First, ensure outer alignment between humans and the base objective of the AI training setup, and then ensure inner alignment between the base objective and the mesa-objective of the resulting system. The former involves finding low-impact, corrigible, aligned with human preferences, or otherwise desirable reward functions, and has been the focus of much of the progress made by the alignment community so far. The latter involves figuring out learned goals, interpretability, and a whole host of other potential approaches that have not yet seen much popularity in alignment research.
The third is something I want to call end-to-end alignment. It’s not obvious that alignment must factor in the way described above. There is room for trying to set up training in such a way to guarantee a friendly mesa-objective somehow without matching it to a friendly base-objective. That is: to align the AI directly to its human operator, instead of aligning the AI to the reward, and the reward to the human. It’s unclear how this kind of approach would work in practice, but this is something I would like to see explored more. I am drawn to staying focused on what we actually care about (the mesa-objective) and treating other features as merely levers that influence the outcome.
We must make progress on at least one of these problems if we want to guarantee the safety of prosaic AI. If we don’t want goal-directed AI, we need to reliably prevent unintended optimisation. Otherwise, we want to solve either inner and outer alignment, or end-to-end alignment. Success at any of these requires a better understanding of goal-directedness in ML systems, and a better idea of how to control the emergence and nature of learned objectives.
More broadly, it seems that taking these worries seriously will require us to develop better tools for looking inside our AI systems and understanding how they work. In light of these concerns I feel pessimistic about relying solely on black-box alignment techniques. I want to be able to reason about what sort of algorithm is actually implemented by a powerful learned system if I am to feel comfortable deploying it.
Right now, learned systems are (with maybe the exception of feature representation in vision) more-or-less hopelessly opaque to us. Not just in terms of goals, which is the topic here—most aspects of their cognition and decision-making are obscure. The alignment concern about objectives that I am presenting here is just one argument for why we should take this obscurity seriously; there may be other risks hiding in our poor understanding of AI inner workings.
Where does this leave us?
In summary, whether a learned system is pursuing any objective is far from a trivial question. It is also not trivially true that a system optimised for achieving high reward is optimising for reward.
This means that with our current techniques and understanding, we don’t get to know or control what objective a learned system is pursuing. This matters because in unusual situations, it is that objective that will determine the system’s behaviour. If that objective mismatches the base objective, bad things can happen. More broadly, our ignorance about the cognition of current systems does not bode well for our prospects at understanding cognition in more capable systems.
This forms a substantial hole in our prospects at aligning prosaic AI. What sort of work would help patch this hole? Here are some candidates:
- Empirical work. Distilling examples of goal-directed systems and creating convincing scaled-down examples of inner alignment failures, like the maze agent example.
- Philosophical, deconfusion and theoretical work. Improving our conceptual frameworks about goal-directedness. This is a promising place for philosophers to make technical contributions.
- Interpretability and transparency. Getting better tools for understanding decision-making, cognition and goal-representation in ML systems.
These feel to me like the most direct attacks on the problem. I also think there could be relevant work to be done in verification, adversarial training, and even psychology and neuroscience (I have in mind something like a review of how these processes are understood in humans and animals, though that might come up with nothing useful), and likely in many more areas: this list is not intended to be exhaustive.
While the present state of our understanding feels inadequate, I can see promising research directions. This leaves me hopeful that we can make substantial progress, however confusing these questions appear today.
By “utility”, I mean something like “the goal pursued by a system”, in the way that it’s used in decision theory. In this post, I am using this word loosely, so I don’t give a precise definition. In general, however, clarity on what exactly “utility” means for an RL agent is an important open question. ↩︎
Perhaps the intuition I have is a distant cousin to the distinction drawn by Einstein between principle and constructive theories. The internal approach seems more like a “constructive theory” of objectives. ↩︎
24 comments
Comments sorted by top scores.
comment by Richard_Ngo (ricraz) · 2019-09-06T17:11:21.168Z · LW(p) · GW(p)
So the reward function can’t be the policy’s objective – one cannot be pursuing something one has no direct access to.
One question I've been wondering about recently is what happens if you actually do give an agent access to its reward during training. (Analogy for humans: a little indicator in the corner of our visual field that lights up whenever we do something that increases the number or fitness of our descendants). Unless the reward is dense and highly shaped, the agent still has to come up with plans to do well on difficult tasks, it can't just delegate those decisions to the reward information. Yet its judgement about which things are promising will presumably be better-tuned because of this extra information (although eventually you'll need to get rid of it in order for the agent to do well unsupervised).
On the other hand, adding reward to the agent's observations also probably makes the agent more likely to tamper with the physical implementation of its reward, since it will be more likely to develop goals aimed at the reward itself, rather than just the things the reward is indicating. (Analogy for humans: because we didn't have a concept of genetic fitness while evolving, it was hard for evolution to make us care about that directly. But if we'd had the indicator light, we might have developed motivations specifically directed towards it, and then later found out that the light was "actually" the output of some physical reward calculation).
Replies from: evhub, Wei_Dai↑ comment by evhub · 2019-09-06T21:45:09.531Z · LW(p) · GW(p)
I've actually been thinking about the exact same thing recently! I have a post coming up soon about some of the sorts of concrete experiments I would be excited about re inner alignment that includes an entry on what happens when you give an RL agent access to its reward as part of its observation.
(Edit: I figured I would just publish the post now so you can take a look at it. You can find it here [AF · GW].)
↑ comment by Wei Dai (Wei_Dai) · 2019-09-07T18:35:54.042Z · LW(p) · GW(p)
How do you envision the reward indicator being computed? Is it some kind of approximate proxy (if so what kind?) or magically accurate? Also, how do you deal with the problem that whether an action is a good idea depends on the agent's policy or what it plans to do later. For example whether joining a start-up increased my fitness depends a lot on what I do after I join it.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2019-09-08T18:16:34.897Z · LW(p) · GW(p)
In the context of reinforcement learning, it's literally just the reward provided by the environment, which is currently fed only to the optimiser, not to the agent. How to make those rewards good ones is a separate question being answered by research directions like reward modelling and IDA.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2019-09-08T18:48:11.913Z · LW(p) · GW(p)
But the reward fed to the optimizer may only be known/computed at the end of each training episode, and it would be too late to show it to the agent at that point. Are you assuming that the reward is computed in a cumulative way, like a video game score, so it can be shown to the agent during the episode?
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2019-09-09T02:53:44.193Z · LW(p) · GW(p)
Yes, I'm assuming cumulatively-calculated reward. In general this is a fairly standard assumption (rewards being defined for every timestep is part of the definition of MDPs and POMDPs, and given that I don't see much advantage in delaying computing it until the end of the episode). For agents like AlphaGo observing these rewards obviously won't be very helpful though since those rewards are all 0 until the last timestep. But in general I expect rewards to occur multiple times per episode when training advanced agents, especially as episodes get longer.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2019-09-09T15:27:41.319Z · LW(p) · GW(p)
Hmm, I was surprised [LW(p) · GW(p)] when it turned out that AlphaStar did not use any reward shaping and just got a reward at the end of each game/episode, and may have over-updated on that.
If you "expect rewards to occur multiple times per episode when training advanced agents" then sure, I understand your suggestion in light of that.
ETA: It occurs to me that your idea can be applied even if rewards are only available at the end of each episode. Just concatenate several episodes together into larger episodes during training, then within a single concatenated episode, the rewards from the earlier episodes can be shown to the agent during the later episodes.
comment by habryka (habryka4) · 2021-01-11T02:40:25.631Z · LW(p) · GW(p)
I think this post and the Gradient Hacking post caused me to actually understand and feel able to productively engage with the idea of inner-optimizers. I think the paper and full sequence was good, but I bounced off of it a few times, and this helped me get traction on the core ideas in the space.
I also think that some parts of this essay hold up better as a core abstraction than the actual mesa-optimizer paper itself, though I am not at all confident about this. But I just noticed that when I am internally thinking through alignment problems related to inner optimization, I more often think of Utility != Reward than I think of most of the content in the actual paper and sequence. Though the sequence set the groundwork for this, so of course giving attribution is hard.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2021-01-11T02:44:07.121Z · LW(p) · GW(p)
For another datapoint, I'll mention that I didn't read this post nor Gradient Hacking at the time, I read the sequence, and I found that to be pretty enlightening and quite readable.
comment by Wei Dai (Wei_Dai) · 2019-09-12T09:46:05.734Z · LW(p) · GW(p)
A pithy way to put this point is to say that utility ≠ reward, if we want to call the objective a system is optimising its “utility”. (This is by way of metaphor – I don’t suggest that we must model RL agents as expected utility maximizers.)
I just realized that this seems like an unfortunate choice of terminology, because I've been thinking about "utility ≠ reward" in terms of utility-maximizing agent vs reward-maximizing agent, as described in this comment [LW(p) · GW(p)], whereas you're talking about the inner objective function ("utility") vs the outer objective function ("reward"). Given that your usage is merely metaphorical whereas mine seems more literal, it seems a good idea to change your terminology. Otherwise people will be confused by "utility ≠ reward" in the future and not know which distinction it's referring to, or worse infer a different meaning than intended. Does that make sense?
Replies from: vlad_m↑ comment by Vlad Mikulik (vlad_m) · 2019-09-13T09:55:02.451Z · LW(p) · GW(p)
Ah; this does seem to be an unfortunate confusion.
I didn’t intend to make ‘utility’ and ‘reward’ terminology – that’s what ‘mesa-‘ and ‘base’ objectives are for. I wasn’t aware of the terms being used in the technical sense as in your comment, so I wanted to use utility and reward as friendlier and familiar words for this intuition-building post. I am not currently inclined to rewrite the whole thing using different words because of this clash, but could add a footnote to clear this up. If the utility/reward distinction in your sense becomes accepted terminology, I’ll think about rewriting this.
That said, the distinctions we’re drawing appear to be similar. In your terminology, a utility-maximising agent is an agent which has an internal representation of a goal which it pursues. Whereas a reward-maximising agent does not have a rich internal goal representation but instead a kind of pointer to the external reward signal. To me this suggests your utility/reward tracks a very similar, if not the same, distinction between internal/external that I want to track, but with a difference in emphasis. When either of us says ‘utility ≠ reward’, I think we mean the same distinction, but what we want to draw from that distinction is different. Would you disagree?
Replies from: riceissa, rohinmshah↑ comment by riceissa · 2019-09-29T23:22:54.456Z · LW(p) · GW(p)
To me, it seems like the two distinctions are different. There seem to be three levels to distinguish:
- The reward (in the reinforcement learning sense) or the base objective (example: inclusive genetic fitness for humans)
- A mechanism in the brain that dispenses pleasure or provides a proxy for the reward (example: pleasure in humans)
- The actual goal/utility that the agent ends up pursuing (example: a reflective equilibrium for some human's values, which might have nothing to do with pleasure or inclusive genetic fitness)
The base objective vs mesa-objective distinction seems to be about (1) vs a combination of (2) and (3). The reward maximizer vs utility maximizer distinction seems to be about (2) vs (3), or maybe (1) vs (3).
Depending on the agent that is considered, only some of these levels may be present:
- A "dumb" RL-trained agent that engages in reward gaming. Only level (1), and there is no mesa-optimizer.
- A "dumb" RL-trained agent that engages in reward tampering. Only level (1), and there is no mesa-optimizer.
- A paperclip maximizer built from scratch. Only level (3), and there is no mesa-optimizer.
- A relatively "dumb" mesa-optimizer trained using RL might have just (1) (the base objective) and (2) (the mesa-objective). This kind of agent would be incentivized to tamper with its pleasure circuitry (in the sense of (2)), but wouldn't be incentivized to tamper with its RL-reward circuitry. (Example: rats wirehead to give themselves MAX_PLEASURE, but don't self-modify to delude themselves into thinking they have left many descendants.)
- If the training procedure somehow coughs up a mesa-optimizer that doesn't have a "pleasure center" in its brain (I don't know how this would happen, but it seems logically possible), there would just be (1) (the base objective) and (3) (the mesa-objective). This kind of agent wouldn't try to tamper with its utility function (in the sense of (3)), nor would it try to tamper with its RL-reward/base-objective to delude itself into thinking it has high rewards.
ETA: Here is a table that shows these distinctions varying independently:
| Utility maximizer | Reward maximizer | |
|---|---|---|
| Optimizes for base objective (i.e. mesa-optimizer absent) | Paperclip maximizer | "Dumb" RL-trained agent |
| Optimizes for mesa-objective (i.e. mesa-optimizer present) | Human in reflective equilibrium | Rats |
↑ comment by Rohin Shah (rohinmshah) · 2019-09-29T21:55:59.833Z · LW(p) · GW(p)
The reward vs. utility distinction in the grandparent has existed for a while, see for example Learning What to Value.
comment by Gordon Seidoh Worley (gworley) · 2019-09-05T20:19:57.566Z · LW(p) · GW(p)
Okay, this is a nit-pick, and it's not even necessarily a pick against this post, but I keep seeing this expression of the relationship between "meta" and "mesa" and I finally felt like speaking up.
(“Mesa” is a Greek word that means the opposite of “meta”. The reason we use “mesa” is to highlight that the mesa-optimiser is an optimiser that is itself being optimised by another optimiser. It is a kind of dual to a meta-optimiser, which is an optimiser that is itself optimising another optimiser.
I think we'd be hard-pressed to get a Greek speaker to say "mesa" (or really the prefix "meso" from "mesos") is the opposite of "meta", especially since the two words sometimes even have the same meaning of "in the middle" or "in the midst". For example, anatomy jargon often uses the prefix "meso-" to mean something between or in the middle of other things. And "meta-" may be used to meaning "with the middle" as well as "beyond" or "afterwards", but it is only in one specific English usage of "meta-" where "meso-" makes sense as an opposite, and that's in the backformation from "metaphysics" (where the original use was intended to simply be about stuff considered "after" what was being called "physics" at the time) to use "meta-" to mean something more abstract or fundamental.
As far as I can tell the entire justification for the "opposite" story comes from this paper in a Neuro-Linguistic Programming journal. And while I see no reason why the author chose "mesa-" rather than the more standard "meso-" other than that "mesa" is the prepositional form of the word in Greek and so matches "meta" also being a preposition, in the context of the paper it does at least make sense to think of "meso-" being more "in the middle of things" in the sense of being more in context vs. "meta-" meaning to transcend context and be "outside things".
And in this sense it makes sense to think of them as opposites, but it still seems misleading to me to say "mesa" is a Greek word meaning the opposite of "meta" because the normal antonym of "meta" would be "prin" (before) and the normal antonym of "mesa" and "mesos" would be "ekta" and "ektos". This suggests the whole thing is a mess, but now we're stuck with the terminology and have to explain it, so maybe something like this:
"Meta" is an English prefix of Greek origin signifying, among other things, recursion and going beyond, which is the sense in which a "meta-optimizer" is an optimizer that is itself optimizing another optimizer. "Mesa" is a Greek word meaning "inside" and a "mesa-optimizer" is an optimizer being optimized by another optimizer. This puts them in relationship where the meta-optimizer is the "outer" optimizer and the mesa-optimizer is the "inner" optimizer.
Unfortunately the mess is not totally fixable because the words picked don't have the relationship they are being used to express, and arguably outer and inner optimizer were better choices given what is being described, but as I say, it's what we're stuck with now, so we just have to find a way to make the best of it and explain it as clearly as possible without the benefit of a clean relationship between the etymologies of the terms.
Replies from: evhub↑ comment by evhub · 2019-09-05T21:04:06.573Z · LW(p) · GW(p)
arguably outer and inner optimizer were better choices given what is being described
"Inner optimizer" pretty consistently led to readers believing we were talking about the possibility of multiple emergent subsystems acting as optimizers rather than what we actually wanted to talk about, which was thinking of the whole learned algorithm as a single optimizer. Mesa-optimizer, on the hand, hasn't led to this confusion nearly as much. I also think that, if you're willing to just accept mesa as the opposite of meta, then mesa really does fit the concept—see this comment [? · GW] for an explanation of why I think so. That being said, I agree that the actual justification for why mesa should be the word that means the opposite of meta is somewhat sketchy, but if you just treat it as an English neologism, then I think it's mostly fine.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2019-09-05T21:21:42.483Z · LW(p) · GW(p)
I agree that using English words sometimes leads to confusion, and so using jargon taken from a foreign language is helpful in getting people to not drag in unintended associations (I've done this myself!). My pick is that it was done poorly (I think the problem starts from having anchored on "meta"), and that the explanations of the reason for choosing the terminology are confusing even if they are the result of an honest misunderstanding of the meaning of the used words and their relationship.
Replies from: vlad_m↑ comment by Vlad Mikulik (vlad_m) · 2019-09-05T23:14:58.263Z · LW(p) · GW(p)
Thanks for raising this. While I basically agree with evhub on this, I think it is unfortunate that the linguistic justification is messed up as it is. I'll try to amend the post to show a bit more sensitivity to the Greek not really working like intended.
Though I also think that "the opposite of meta"-optimiser is basically the right concept, I feel quite dissatisfied with the current terminology, with respect to both the "mesa" and the "optimiser" parts. This is despite us having spent a substantial amount of time and effort on trying to get the terminology right! My takeaway is that it's just hard to pick terms that are both non-confusing and evocative, especially when naming abstract concepts. (And I don't think we did that badly, all things considered.)
If you have ideas on how to improve the terms, I would like to hear them!
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2019-09-05T23:22:40.219Z · LW(p) · GW(p)
I like "mesa optimizer" and "ekta optimizer" since they are simple translations that mean "inside" and "outside" optimizer, but I guess what do you dislike about "optimizer" that you'd like to be better since you say you're dissatisfied with that part as well?
comment by Pattern · 2019-09-05T19:38:00.114Z · LW(p) · GW(p)
Errata:
figuring out how to do that [is] an important open question.
Great post by the way. This summary made the general failure mode clear, really well.
A part of me is worried that the terminology invites viewing mesa-optimisers as a description of a very specific failure mode, instead of as a language for the general worry described above. I don’t know to what degree this misconception occurs in practice, but I wish to preempt it here anyway. (I want data on this, so please leave a comment if you had confusions about this after reading the original report.)
It did seem like a description of a specific failure mode. This post addressed that well.
In more depth:
I really liked the example in Two Distinctions [LW · GW]. Why worry? [LW · GW] could have been more specific about "bad things" if it had had an example. (I am sure other documents do that, this post as a whole did a great job of being self-contained - I think I'd have benefited from reading this post even if I hadn't read the mesa optimization sequence.)
I think it's worth pointing out that while one of the approaches mentioned in What objectives [LW · GW] was black box and the other was transparent, both required knowing the environment.
comment by habryka (habryka4) · 2020-12-15T06:25:24.137Z · LW(p) · GW(p)
I think of Utility != Reward as probably the most important core point from the Mesa-Optimizer paper, and I preferred this explanation over the one in the paper (though it leaves out many things and wouldn't want it to be the only thing someone reads on the topic)
comment by Ben Pace (Benito) · 2020-12-11T05:25:19.926Z · LW(p) · GW(p)
I nominate this alongside the sequence, as a less formal explanation of the core ideas. I can imagine this essay being the more widely read and intuitive one.
comment by zeshen · 2022-08-18T21:55:47.192Z · LW(p) · GW(p)
A part of me is worried that the terminology invites viewing mesa-optimisers as a description of a very specific failure mode, instead of as a language for the general worry described above.
I have been very confused about the term for a very long time, and have always thought mesa-optimisers is a very specific failure mode.
This post [LW · GW] helped me clear things up.
comment by Vlad Mikulik (vlad_m) · 2021-01-11T16:39:14.699Z · LW(p) · GW(p)
More than a year since writing this post, I would still say it represents the key ideas in the sequence on mesa-optimisation [? · GW] which remain central in today's conversations on mesa-optimisation. I still largely stand by what I wrote, and recommend this post as a complement to that sequence for two reasons:
First, skipping some detail allows it to focus on the important points, making it better-suited than the full sequence for obtaining an overview of the area.
Second, unlike the sequence, it deemphasises the mechanism of optimisation, and explicitly casts it as a way of talking about goal-directedness. As time passes, I become more and more convinced that it was a mistake to call the primary new term in our work 'mesa-optimisation'. Were I to be choosing the terms again, I would probably go with something like 'learned goal-directedness', though it is quite a mouthful.