Circuits in Superposition: Compressing many small neural networks into one
post by Lucius Bushnaq (Lblack), jake_mendel · 2024-10-14T13:06:14.596Z · LW · GW · 9 commentsContents
Introduction Background What we do Generalising to circuits Some very tentative implications, maybe? Future work The Construction Read-in interference Read-out interference Maths Embedding Matrix Other layers Reading from the residual stream Writing to the neurons Writing back to the residual stream Error analysis Read-in interference Read-out interference Acknowledgements None 10 comments
Tl;dr: We generalize the mathematical framework for [LW · GW] computation in superposition from compressing many boolean logic gates into a neural network, to compressing many small neural networks into a larger neural network. The number of small networks we can fit into the large network depends on the small networks' total parameter count, not their neuron count.
Work done at Apollo Research. The bottom half of this post is just maths that you do not need to read to get the gist.
Introduction
Background
Anthropic's toy model of superposition shows how to compress many sparsely activating variables into a low dimensional vector space and then read them out again. But it doesn't show how to carry out computations on the compressed variables in their native format. The mathematical framework [LW · GW] for computation in superposition makes a first stab at closing that gap. It shows how to compute boolean circuits in superposition.
What we do
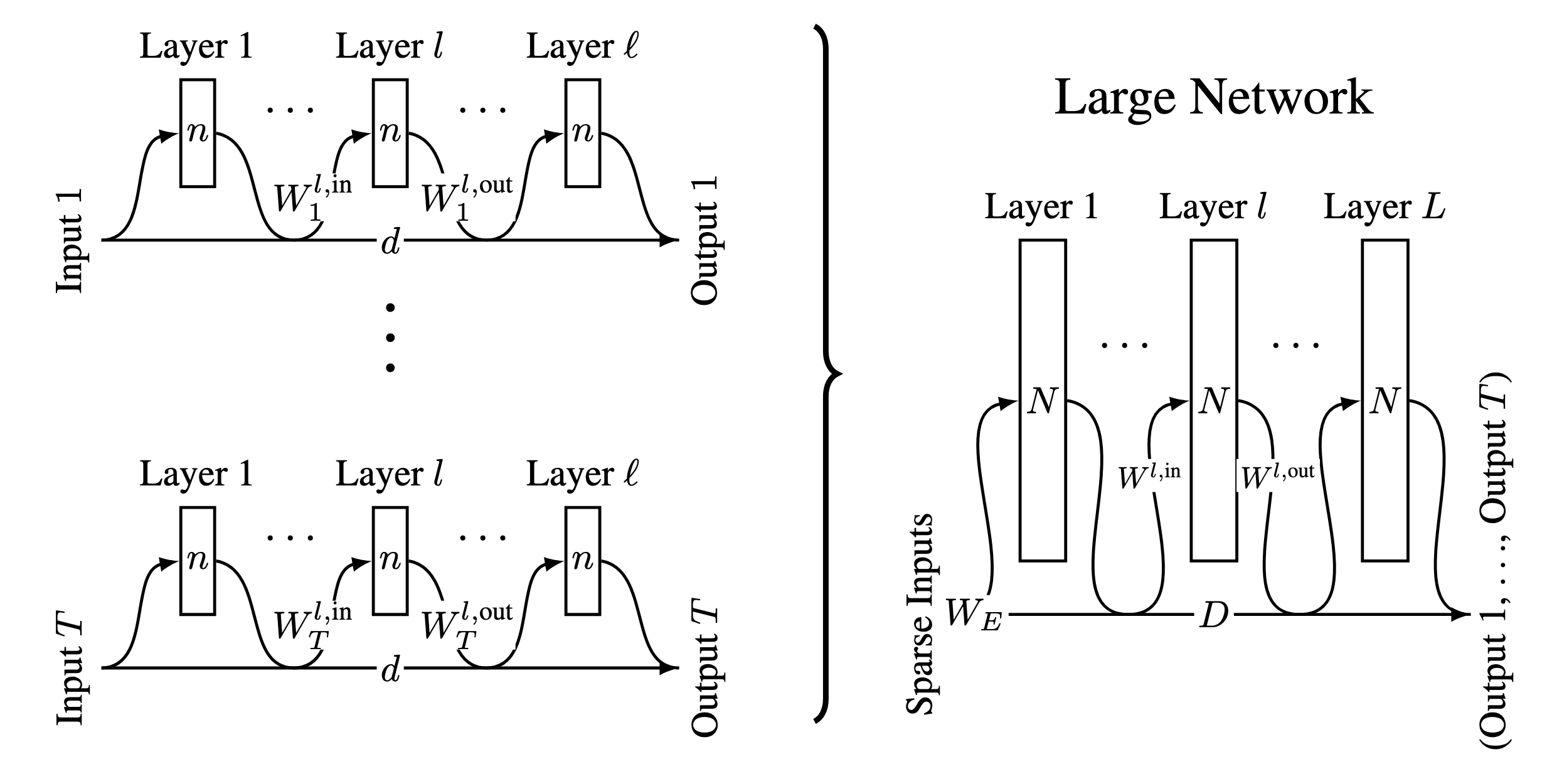
We show how a network can perform any computations whatsoever in superposition. Specifically, we show how small residual neural networks, each with parameters that perform arbitrary tasks can be compressed into a single larger residual network that performs all tasks, provided that the large network is only evaluated on sparse combinations of tasks — any particular forward pass only asks for tasks to be carried out. In the limit of going to infinity, this larger network will require parameters[1].
Crucially, this means that the total number of small networks the larger network can implement scales approximately linearly with the number of weights in the network, not the number of neurons, as would be the case without computation in superposition. For example, if each small network uses neurons per MLP layer and dimensions in the residual stream, a large network with neurons per MLP connected to a -dimensional residual stream could implement about small networks, not just
. Qualitatively speaking, our construction works using same basic trick as the one for boolean circuits [LW · GW] in superposition. We just generalize it from boolean AND gates to any operations the neural network could implement.
Generalising to circuits
While our derivation here assumes networks carrying out unrelated tasks in parallel, nothing in the construction stops us from instead chaining the small networks in series, with later small networks taking the outputs of earlier small networks as their inputs. Therefore, the construction in this post can be thought of as a framework for representing arbitrary circuits in superposition.
Some very tentative implications, maybe?
Real neural networks probably don’t work exactly the way this construction does. It's made to be easy for us to prove things about it, not to be efficient in real life. The finite width of real networks might make other constructions better. We're also not dealing with potential correlations between the activations of different circuits, which might change the optimal setup even more. And ultimately, we don't actually know whether the structure of real-world datasets is sparse in the right way to incentivise learning sparsely activating circuits.
Neverthless, there may be some useful takeaways about real networks, so long as we don't forget that they come with a heavy pinch of salt:
- There is no superposition in parameter space: In this construction, we cannot compress more small networks into the large network than the large network has parameters. So, while a network can have more features than the dimension of its activation spaces, it can't implement more distinct operations[2] than the dimension of its parameter space[3].
- Circuits don't have to follow the layer structure: This construction lines up the layers of the small networks with the layers of the large network, but that's just for our convenience. So long as the large network has more layers than the small networks, we can implement things all over the place. A single neuron in a small network could correspond to neurons across a range of layers in the big network. Thus, if somebody is looking at the residual stream activations in a layer of the big network, they might see a lot of half-computed nonsense that's hard to make sense of. You could call this cross-layer superposition.
- Computation in superposition doesn't need one-dimensional 'features': Our construction doesn't assume that the small networks internally work using one-dimensional variables represented as directions in activation space. Circuits may be embedded in the larger network as sparsely activating subspaces in the neurons and the residual stream, but within those spaces, their own representations don't have to be sparse or linear.
- The total parameter vector could be decomposable into a sum of the parameter vectors dedicated to each small network: At least in this construction, the parameter vector of the large network is a sum of vectors parametrizing the individual small networks: . If real networks share this property, then with the right optimization procedure, it might be possible to recover the individual small networks from by looking at the network's loss landscape. Apollo Research is trying out a way to do this at the moment.
Future work
- Other architectures We think this construction can be straightforwardly extended to transformers and CNNs, without significantly changing any takeaways. We are investigating the error bounds for attention blocks at the moment.
- Tracr extension Theoretically, this framework could allow people to create superposed circuits by hand. We'd be excited about someone writing a nore sophisticated version of Tracr based on these constructions, which could be used for building a more realistic interpretability benchmark akin to InterpBench. Note that the error bounds in this post are all formulated for the large network width limit — there is still some work to do to make this practical.
- Training dynamics This post makes claims about the expressivity of neural networks, but in real life, the structures learned by neural networks depend greatly on the inductive biases of their training. We would like to build on this framework to explore if training actually incentivises the learning of sparse circuits. We have some ideas on this front, based on attempting to unify SLT [? · GW] ideas with the idea of the low-hanging fruit prior [LW · GW].
The Construction
Suppose we have small neural networks. For simplicity we will assume that each small network consists of layers, with neurons in each layer with a fixed elementwise nonlinearity, and a fixed residual stream width . We require that these small networks are at least somewhat robust to noise: there is some magnitude of random noise that we can apply to all the preactivations of any of the small networks' neurons without changing downstream layer activations by more than some small .[4]
Then we can create a large network that is also layers deep, with a residual stream width , neurons in each layer and the same activation functions, which can leverage superposition to compute the outputs of all $T$ neural networks in parallel.
This works even for and , provided that only small neural networks are being passed a non-zero input vector on most forward passes. This large network will require on the order of parameters in total[5].
The core idea behind this construction is similar to that for computing many ANDs of binary inputs in superposition. There may be many other constructions that would also work, but we think that in the limit of very wide neural networks, all constructions would perform more or less the same, and yield the same fundamental limits for how many small networks can be superposed into a network with parameters[6]. As with all constructions involving superposition, the key to the construction working out is in managing the size of the interference between separate small networks, and making sure that it does not become larger than the size of the signal — the correct output of each small network. In this construction, there are two sources of interference:
Read-in interference
Our small networks have a combined residual stream dimensions. So, activation vectors of different small networks in the large residual stream cannot be completely orthogonal. This means that when a particular small network is passed an input of but other small networks are passed nonzero inputs, the value of the inputs that are read in by the weights that implement the first small network won't be exactly zero. In our construction, this read-in interference is what ends up dominating the constraints on how many small networks we can compute in a single large network.
At a high level, we manage read-in interference by making the residual stream width larger so the overlap between small networks is smaller, and making the MLP width larger so the read-in interference can be spread across more neurons.
Read-out interference
Our small networks have a combined neurons per layer. Naively, we could randomly assign every neuron in every small network to one neuron in the big network. But then, if two small networks that happened to share a neuron activated at the same time, that neuron would get conflicting inputs and misfire. So we could only carry out one of the tasks at a time.
To make the small networks robust to these misfires, we introduce redundancy into the big network, representing each neuron in the small network with many neurons in the big network. This means that each neuron in the big network is assigned to even more small networks than if there was no redundancy, but this cost is worth it: we can now recover the value of any activation of any small network by averaging over the values of every neuron in the large neuron that represents it. If few enough small networks are active at once, then almost all neurons in the large network assigned to any particular small network's neuron will take on the correct value for that neuron, almost all of the time, and in the limit of , the difference between the value of a small network's neuron and the average of all the neurons in the large network that compute that small network will go to zero.
Maths
If you don't care about technical details, you can safely skip this section.
Let the input to the -th small network be denoted by and the activation vector of small network in layer for input by or simply .
Similarly, denote the activation vector for the large network in layer by .
We also define a set of random matrices with orthonormal rows :
with satisfying . Since the matrices are projection matrices to random -dimensional subspaces of , their columns satisfy . These matrices define projections from the residual streams of each small network into a random subspace of the larger residual stream. What we want to prove is that if the number of that are nonzero is , then for all , there exists terms satisfying , such that:
.
We'll (sort-of) prove this using induction.
Embedding Matrix
The base case for the induction is just the embedding in layer . The input to the large network is the concatenated vector . The embedding matrix[7] is constructed by directly projecting each into the residual stream using , which we can do by stacking the projection matrices next to each other:
.
Then, the residual stream activation vector at layer zero
is equal to as required.
Other layers
We'd now like to assume that is satified in layer , and demonstrate that it is satisfied in layer . To do so, we need to work out what the matrices should be.
Reading from the residual stream
To start, we need a way to compute the outputs of all at once with the larger matrix . If we had we could do this by making block diagonal, but we are looking for a construction with . To make progress, we start by noting that
,
where we have used that . We want the read-in interference
introduced to network in layer to be sufficiently small, staying below the noise level we assume the subnetworks to be robust to. The justification for being small will be based based on the fact that for is approximately a matrix of gaussians with variance . Details are in Section Read-in interference.
Writing to the neurons
We can't just connect the outputs of this multiplication to neurons in layer of the large network even if the interference is small. This is because so we'd have to share neurons between many circuits and we wouldn't be able to tell if a neuron fires due to circuit activating, or some other circuit that connects to that neuron activating instead. Instead, we need to introduce some redundancy to the representations of the activations of each small network[8]. We do this by multiplying by a distributing matrix . This matrix is defined as follows:
- Start with the first rows (each row is a vector in ), which connect to small network . These are the rows of which determine which neurons are involved in computing the th layer of the first small network.
- Then, pick a random partition of the neurons of the th layer of the big network into `neuron sets' of size . There are M/m many sets.
- Let . For each neuron set, consider the set of submatrices of which consist of only the first rows, and only the columns in that set, so each submatrix has shape . For each submatrix, with probability set it equal to a random permutation of the identity matrix, and with probability , set it equal to the zero matrix.
- Repeat for each set of rows of , corresponding to each small network. Each time, pick a different random partition of the neurons into neuron sets.
For the -th small network, the neurons that are in sets which are assigned a permutation matrix are called connected to that small network, and the neurons that are in sets assigned the zero matrix are called unconnected. We denote the set of all sets of neurons in the large network that are connected to the th small network in layer by (a subset of the powerset of ), and the set of all neurons in the large network that are connected to the th neuron of the th small network in layer by . Every small network will on average connect its weights to sets of neurons in the big network. So, we set
.
Writing back to the residual stream
To write back to the residual stream from the neurons, first we can recover the value of the activations of each small network by averaging all the neurons in the large network that are connected to that small network neuron. We do this by multiplying the activations of the big network with :
.
Then we can apply each to recover , and then we can embed these activations back into the residual stream using :
If is small enough (which requires to be small as well, then we are done, and will have the correct form.
Error analysis
Let be upper bounds on the L2 norm of the small networks' activations in the residual stream, and operator norm of their MLP input matrices, respectively:
, .
In the analysis below, we find that the L2 size of the total interference added to a subnet in an MLP layer will be
.
For this noise to stay below the we assumed the small networks to be robust to at every layer, our large network needs at least
parameters in total. Any less than that, and the inteference will begin to overwhelm the signal. Assuming the noise isn't larger than the maximum size of the small network's neuron activations, we'll have . So we need parameters in total.
Read-in interference
In this construction, we find that our total error term in dominated by read-in interference.
The noise from an activation vector of a circuit being multiplied by weight matrix of a different circuit will be
.
The entries of the matrix will have approximate size . Since the entries of a row of are randomly distributed, the entries of will then have average size . So, the noise from activation of small network being partially projected into preactivations of neurons in small network will be on the order of
.
On average, each neuron has weight rows of small networks connecting to it. Using , if there are circuits active at a given time, the total read-in interference on the preactivation on any one neuron in any small network will be bounded by
because the noise sources are independent. This noise dominates the total error term.
Read-out interference
In our construction, we find that read-out interference from multiple circuits using the same neuron is subdominant and vanishes in the limit of large networks. For the read-out of a small network from the MLP of the large network to become inaccurate, some fraction of the neurons playing the role of one neuron in the original small network have to all `misfire', activating when they shouldn't, or with incorrect magnitude even when they do fire. Since we assumed that our activation functions are Lipschitz continuous, we can bound any `misfire' to be smaller than some bound .
We'll assume that there is some critical fraction which is the maximum number of misfires we can tolerate, which is dependent on the error tolerance of our small networks: misfires would give us an error on the read-out of neuron in small network , which we require to be smaller than the maximum error tolerance of the small networks .
One neuron: Consider a specific neuron in small network . This neuron is assigned a set of size approximately of neurons to compute it in the large network.
k=1: Suppose that only small network is active on the current forward pass. The chance of any circuit connecting to a given neuron is . So, if , the probability that there are misfirings in the set will follow a binomial distribution:
.
The last factor is approximately equal to and can be ignored.
k>1: Suppose there are small networks active at once. Each neuron in can be used in multiple active networks. We can imagine a matrix with rows and columns, with a in the position if the th neuron in is connected to the th active small network, and a zero otherwise. The entries of this matrix are i.i.d Bernoulli random variables with probability , and the number of nonzero entries in this matrix is the total number of misfirings in . Again assuming , the probability has misfirings will be:
.
Using Stirling's formula[9], we can write this as:
.
We can approximate as a decaying geometric series in , with initial value and ratio .
Therefore, we have
.
One forward pass: We have sets of neurons . We want the chance of more than misfirings for any of them on a forward pass to be vanishingly small for all in the large width limit. That is, we want to scale with the number of small networks , the size of small networks , and the number of active small networks such that:
.
This condition is satisfied for any so long as:
- The neuron count of the large network grows as some fractional power of the neuron counts of the small networks combined: .
- The combined number of active neurons in all the small networks on any one forward pass is small compared to the neuron count of the large network: .
The read-in error already imposes , so the former condition is not an additional constraint, except in that it precludes making the residual stream exponentially wider than the MLP . The latter condition is fulfilled if the small networks activate sparsely.
So, in the large width limit , will vanish. Thus, the total error is dominated by .
Acknowledgements
Thanks to Dan Braun, Stefan Heimersheim, Lee Sharkey, and Bilal Chughtai for lots of discussions that shaped our thinking about this idea. Thanks also to Kaarel Hanni, Dmitry Vaintrob and Lawrence Chan for previous work that this idea builds on heavily, and for helping shape our thinking about this kind of thing.
- ^
basically means ' up to log factors'.
- ^
Put differently, we can't have an overcomplete basis of task vectors.
- ^
This limit is already suggested by information theory: Every operation we want the network to implement takes some minimum number of bits in its parameters to specify. So, in general, the minimum description length of the large network in bits can't be smaller than the minimum description lengths of the small networks summed together.
- ^
The more imprecision we're willing to tolerate in the final result, the larger will be. If small networks vary in how noise robust they are, we pick the of the least robust one to be conservative.
- ^
These simplifications primarily serve to avoid obfuscating the ideas in the construction. We are pretty confident that the derivations go through if you allow the number of neurons, residual stream width, and number of layers per small network to vary. That is, suppose we are given a set of neural networks indexed by . For the -th network, denote the number of neurons per layer as , residual stream width , and number of layers . Then, there exists a large residual neural network with depth , number of neurons per layer , and residual stream width which satisfies, and , which can compute the outputs of all circuits in parallel by leveraging superposition.
- ^
We think some additional tinkering might remove the log term, and constant prefactors could likely be improved, but we doubt anything will break the limit . We can't specify more operations than we have bits to specify them in.
- ^
Using the convention of left multiplication by matrices.
- ^
This is essentially the same idea that is referred to as superpositional codes in this essay.
- ^
Which applies because , and the expected number of misfirings is .
9 comments
Comments sorted by top scores.
comment by Linda Linsefors · 2025-03-25T17:51:18.607Z · LW(p) · GW(p)
According to my calculation, this embedding will result in too much compounding noise. I get the same noise results as you for one layer, but the noise grows too much from layer to layer.
However, Lucius suggested a different embedding, which seems to work.
We'll have some publication on this eventually. If you want to see the details sooner you can message me.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-11-17T17:53:24.929Z · LW(p) · GW(p)
Any thoughts on potential connections with task arithmetic? (later edit: in addition to footnote 2)
comment by lewis smith (lsgos) · 2024-10-15T13:51:38.873Z · LW(p) · GW(p)
with later small networks taking the outputs of earlier small networks as their inputs.
what's the distinction between two small networks connected in series with the first taking the output of the previous one as input and one big network? what defines the boundaries of the networks here?
Replies from: jake_mendel↑ comment by jake_mendel · 2024-10-15T14:05:58.774Z · LW(p) · GW(p)
I’m not sure I understand your question, but are you asking ‘in what sense are there two networks in series rather than just one deeper network’? The answer to that would be: parts of the inputs to a later small network could come from the outputs of many earlier small networks. Provided the later subnetwork is still sparsely used, it could have a different distribution of when it is used to any particular earlier subnetwork. A classic simple example is how the left-orientation dog detector and the right-orientation dog detector in InceptionV1 fire sort of independently, but both their outputs are inputs to the any-orientation dog detector (which in this case is just computing an OR).
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-10-15T15:01:01.605Z · LW(p) · GW(p)
yeah that makes sense I think
comment by jacob_drori (jacobcd52) · 2024-10-14T17:25:27.529Z · LW(p) · GW(p)
I'm confused by the read-in bound:
Sure, each neuron reads from of the random subspaces. But in all but of those subspaces, the big network's activations are smaller than , right? So I was expecting a tighter bound - something like:
Replies from: Lblack
↑ comment by Lucius Bushnaq (Lblack) · 2024-10-14T17:48:07.783Z · LW(p) · GW(p)
EDIT: Sorry, misunderstood your question at first.
Even if , all those subspaces will have some nonzero overlap with the activation vectors of the active subnets. The subspaces of the different small networks in the residual stream aren't orthogonal.
↑ comment by jacob_drori (jacobcd52) · 2024-10-14T20:45:05.718Z · LW(p) · GW(p)
Ah, I think I understand. Let me write it out to double-check, and in case it helps others.
Say , for simplicity. Then . This sum has nonzero terms.
In your construction, . Focussing on a single neuron, labelled by , we have . This sum has nonzero terms.
So the preactivation of an MLP hidden neuron in the big network is . This sum has nonzero terms.
We only "want" the terms where ; the rest (i.e. the majority) are noise. Each noise term in the sum is a random vector, so each of the different noise terms are roughly orthogonal, and so the norm of the noise is (times some other factors, but this captures the -dependence, which is what I was confused about).
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-10-14T22:04:36.560Z · LW(p) · GW(p)
Yes, that's right.