Towards Hodge-podge Alignment
post by Cleo Nardo (strawberry calm) · 2022-12-19T20:12:14.540Z · LW · GW · 30 commentsContents
Introduction What is hodge-podge alignment? Give me an example. Key Stages 1. Exhaustively enumerate alignment primitives. 2. Taxonomise primitives by their type-signature, documentation, and implementation. 2a. Type-signature 2b. Implementation 2c. Documentation 3. Enumerate potential alignment assemblages. 4. Study assemblages theoretically and experimentally 5. Deploy any assemblage if it's adequate. Motivation None 30 comments
ABSTRACT: What could AI alignment look like if we had 6000+ full-time researchers and software developers? I've spent a few days thinking about that question, and this report is my first-draft attempt to answer it. This report sketches a highly-scalable research agenda: studying the hodge-podge assemblage of various "alignment primitives". Please let me know [EA · GW] in the comments which ideas are novel and useful (if any), and which aren't.

Introduction
What is hodge-podge alignment?
I think that in the Technical AI Safety community, the following beliefs are common:
- The adequate solution to the alignment problem (if it exists) will look like one thing.
- That one thing might be quantilization, or debate [? · GW], or ELK [? · GW], or impact regularisation [? · GW], or something else entirely.
- If we received a radio message from a friendly alien civilisation that solved alignment, it would say "hey humans, you should use this particular method to solve alignment".
Maybe those beliefs are correct — but in this report, I'll explore the alternative hypothesis. What if the only strategy that achieves is throwing every half-baked protocol we have at an AGI? Let's call this strategy "hodge-podge alignment".
Note that hodge-podge alignment differs from research diversification. The TAIS community is unanimously in favour of research diversification — i.e. they think we should explore many different research agendas. But their justification tends to be "we can't tell beforehand which research agenda will tell us the One Thing", rather than "we'll need to hodge-podge together the methods produced by each research agenda".
Give me an example.
There are dozens of "alignment primitives", but consider these four:
- Boxing: Run the AI on an air-gapped server with a narrow bandwidth channel to a human interlocutor. (See here.) [? · GW]
- Quantilization: The AI, rather than maximising the quality of actions, randomly selects from the top quantile of actions. (See here.)
- Impact regularisation: Penalise the AI for actions which significantly impact the environment. (See here.) [? · GW]
- Olah-style interpretability: Convert a neural network into a smaller computational graph whose nodes are annotated with human-legible concepts. (See here.) [LW · GW]
We can "hodge-podge" together these primitives to give an assemblage:
- Assemblage: The AI randomly samples from the top 1% of actions as ranked by , where is our best proxy for human values, is an impact regularisation, and is a 1KB plaintext channel. Each neural network in the AI is compressed into and inspected by a human throughout training, evaluation, and deployment.
Will this work? I'm not sure.
I suspect that the assemblage would result in a safer AI than any of the four primitives used alone. But the goal of AI alignment is not to build a safe AI, but rather to build a safe and competent AI. (We already know how to build safe incompetent AI!) So the important question is: does the assemblage score higher than the primitives on the safety-competency trade-off? That's an open question.
Key Stages
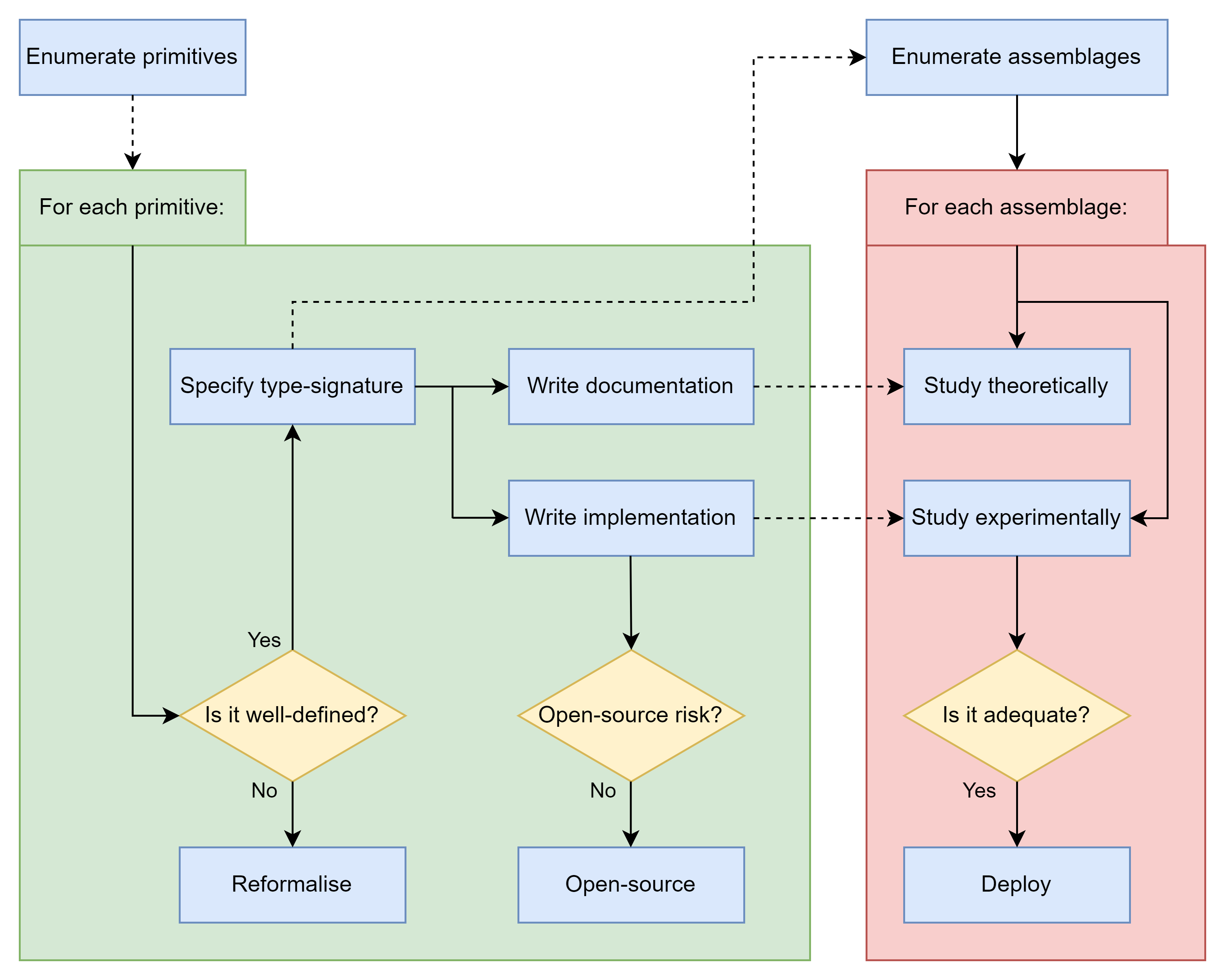
My tentative proposal consists of the following key stages:
- Exhaustively enumerate alignment primitives.
- Taxonomise primitives by their type-signature, documentation, and implementation.
- Enumerate potential alignment assemblages.
- Study the assemblages theoretically and experimentally.
- Deploy any assemblage if it's adequate.
1. Exhaustively enumerate alignment primitives.
There are a few broad overviews of different alignment agendas.
- Thomas Larsen's (My understanding of) What Everyone in Technical Alignment is Doing and Why [LW · GW]
- Logan Zoellner's Various Alignment Strategies (and how likely they are to work) [LW · GW]
- Holden Karnofsky's How might we align transformative AI if it’s developed very soon? [LW · GW]
- Neel Nanda's My Overview of the AI Alignment Landscape [LW · GW]
- Evan Hubinger's An overview of 11 proposals for building safe advanced AI [LW · GW]
- Larks' yearly Alignment Literature Review and Charity Comparison [LW · GW]
- Nate Soares' On how various plans miss the hard bits of the alignment challenge [LW · GW]
- Andrew Critch's Some AI research areas and their relevance to existential safety [LW · GW]
But there isn't (to my knowledge) an exhaustive enumeration of the different methods produced by those agendas. In Stage 1 of hodge-podge alignment, we compile and publish this list.
Let's call the list of alignment primitives .
In my imagination, our list of alignment primitives should look something like the list of cryptographic primitives. Cryptographic primitives are well-established, low-level algorithms which are assembled together to build more complicated cryptographic algorithms. If we assume that the cryptographic primitives are implemented correctly (i.e. they behave in the way described by their documentation), then we can be sure that the cryptographic assemblage is also implemented correctly. Moreover, if we discover that a particular cryptographic primitive is "broken" (i.e. it doesn't behave in the way described by its documentation) then we can replace the broken primitive with another primitive rapidly and seamlessly.
2. Taxonomise primitives by their type-signature, documentation, and implementation.
For each alignment primitive,
- Its type-signature specifies the types of objects passing through the input and output wires.
- Its documentation is a formal description of how the primitive should behave.
- Its implementation is a particular string of Python code that (hopefully) behaves as promised by the documentation.
(These three concepts will also extend to alignment assemblages.)
2a. Type-signature
In computer science, every function, subroutine or method has a "type-signature" defining its inputs and outputs. The type-signature doesn't say what the method does, but it says what type of object the method acts on and what type of object the method produces.
We can analogously talk about the "type-signature" of a particular alignment primitive. This type-signature specifies where in the AI-development pipeline the primitive could be implemented.
Here are some examples:
- The type-signature of impact regularisation is "reward function to reward function".
- The type-signature of quantilization is "ranking of actions to action".
- The type-signature of Olah-style interpretability is "large neural network to a small computational graph of human-legible concepts".
- The type-signature of amplification [? · GW]is "AI to AI".
- The type-signature of a sandbox is "< output from human, output from AI, internal state > to < input to human, input to AI, internal state >"
There are many different type-signatures that alignment primitives have:
- Pruning the dataset.
- Augmenting the dataset.
- Augmenting the reward function.
- Augmenting the training environment.
- Stopping buttons.
- Evaluation metrics.
- Boxing through training/evaluation/deployment.
- Exotic decision theories.
- etc-etc-etc-etc-
In Stage 2a of hodge-podge alignment, we determine the type-signature of each alignment primitive . This is necessary for us because constrains how the primitives can be assembled.
(But even ignoring hodge-podge alignment, it's useful to ask yourself: "What kind of object does this method act on? What kind of object does this method produce? What other methods could this method be composed with?" when thinking about particular alignment methods.)
2b. Implementation
In Stage 2b of hodge-podge alignment, we implement each primitive as a string of Python code . If the method isn't well-defined enough to be implemented as Python code, then we try to re-formalise it until we can implement it as Python code.
def quantilization(A, Q, q=0.01):
n = int(len(A)*q)+1
top_quantile = sorted(A, key=Q, reverse=True)[:n]
action = random.sample(top_quantile)
return actionThe code is written in a composable and modular way. So far, a lot of alignment methods have been implemented in code, but in a way that is entangled with the rest of the code. But we want the primitives to be implemented in a modular way so that we can hotswap then in our assemblages.
We might release these implementations as part of an open-source library, unless there are risks that this will exacerbate AI capabilities development. However, that risk is mitigated by the modular nature of the implementation. Although it would be risky to open-source the code of a sandboxed AI — it's not as risky to open-source the code of the sandbox itself.
2c. Documentation
The documentation of a primitive is a set of sentences describing how it should behave. The documentation can be written in a formal language, or in plain English.
The following are (equivalent?) definitions of the documentation:
- If all the properties in are satisfied, then the primitive is a success.
- If any of the properties in are not satisfied, then the primitive is broken.
- When we argue that an assemblage solves alignment, we appeal to the properties of the primitives.
- are the promises from the developer about the primitive .
- are the properties that won't be changed by the developer without warning.
- If a primitive is broken, then are properties that we'll demand from the replacement.
The documentation determines how the primitive should behave, and the implementation determines how the primitive does behave.
In Stage 2b of hodge-podge alignment, we write documentation for each primitive.
3. Enumerate potential alignment assemblages.
Once we know the type-signatures of the alignment primitives, we can then (mechanically) enumerate the different alignment assemblages. Let's call this list .
To construct an assemblage, we start with some sequence of primitives (not necessarily distinct), and then we "wire together" the outputs of some primitives to the inputs of others (so long as those wires are type-compatible).
More formally —
- The primitives are stateful dynamic systems, so we formalise them as polymorphic lenses.
- The category of polymorphic lenses is cartesian closed, so we can construct the "parallel product" of the primitives. The parallel product is just a formless heap — none of the primitives have been wired together yet.
- Finally, we can compose the parallel product with a particular "typed wiring diagram", because they are also formalised as polymorphic lenses.
- This yields an assemblage. An assemblage is the composition of a parallel product of primitives with a typed wiring diagram, in the category of polymorphic lenses.
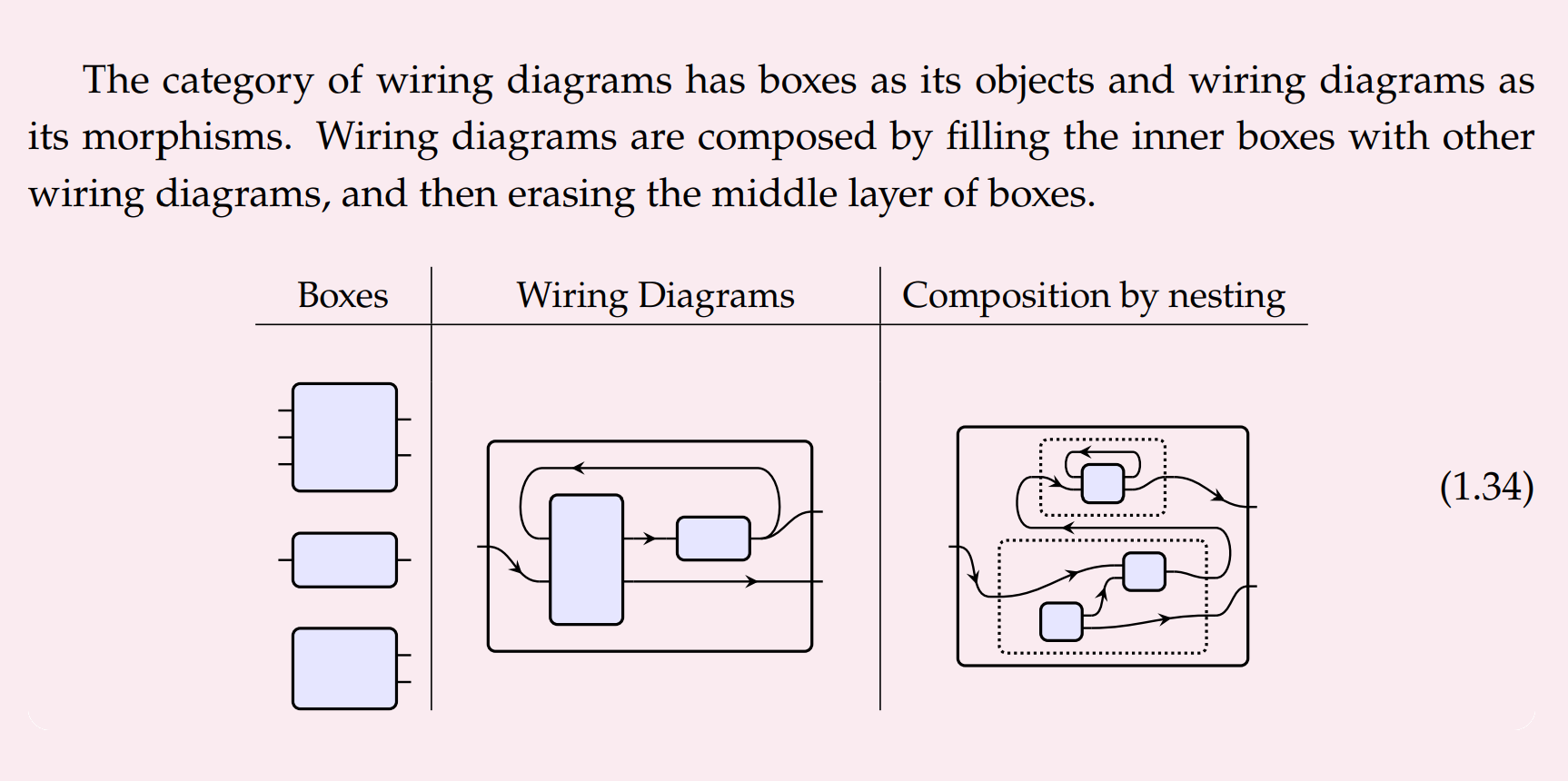
- The type-signature of the assemblage is determined by the wiring diagram.
- The implementation of the assemblage is straightforwardly determined by the wiring diagram and the implementations of the primitives.
- The documentation are the properties derivable (formally or informally) from the documentations of the primitives.
- This is because (I think) , , and are functors (ish).
Note that is different from :
- For a subset , there might exist no corresponding assemblage. This is because the type-signatures of the primitives in might forbid wiring.
- For a subset , there might exist many distinct corresponding assemblages — possibly infinitely many. This is because a primitive can appear more than once in an assemblage.
We call the degree of the assemblage — I suspect that (on average) safety will increase as increases, and competency will decrease.
4. Study assemblages theoretically and experimentally
In Stage 4 of hodge-podge alignment, the goal is to determine which alignment assemblages are reliable. An assemblage is reliable if we are confident that the implementation satisfies the documentation .
This is of course the hard step. Fortunately, this process can be heavily parallelised.
Theory:
In cryptography, you start with various "cryptographic assumptions" that particular cryptographic primitives are reliable, and then you derive theorems/informal arguments that the assemblages are reliable.
Likewise, in alignment, we will start with various "alignment assumptions" that particular alignment primitives are reliable, and then we derive theorems/informal arguments that the assemblages are reliable. In other words, we want arguments of the form .
Note that we can construct these arguments before we've actually found implementations for the alignment primitives!
Experiments:
To determine whether an assemblage has been implemented correctly we run experiments, e.g. toy-models, block-worlds. We test the implementation in a wide range of likely situations, and check if is satisfied.
Reliability:
We classify an assemblage as reliable whenever the following conditions hold:
- We're confident that the argument is valid.
- There is significant experimental evidence that the implementation satisfies the documentation .
- All the sub-assemblages of are reliable.
5. Deploy any assemblage if it's adequate.
An alignment assemblage is adequate if its documentation includes "everything goes well" and is reliable. If we discover an adequate alignment assemblage then we deploy it, hoping to achieve a pivotal act with a low probability of doom.
In practice, searching for an adequate assemblage might look like this:
- Start with a design for an unsafe but competent AI.
- Gradually add primitives until the AI is safe.
Or it might look like this:
- Start with a design for a safe but incompetent AI.
- Gradually remove primitives until the AI is competent.
This would be analogous to a nuclear power station adding and removing control rods to find a happy medium — but for us, we are seeking the optimal point in the safety-competency trade-off.
Motivation
Here are some reasons I think hodge-podge alignment is a reasonably promising research agenda.
1. Ex-ante Uncertainty
We might end up in a situation where we're confident that among our top 20 primitive methods there exists at least one method which reliably works, but we aren't sure beforehand which method is the reliable one. In this situation, it might be best to "assemble" them together.
Here's why I think this situation is likely:
- Right now, no one knows what method is best.
- There's been little convergence over time on a single method.
- AGI will arrive soon, so we'll probably be equally as unsure when it does arrive.
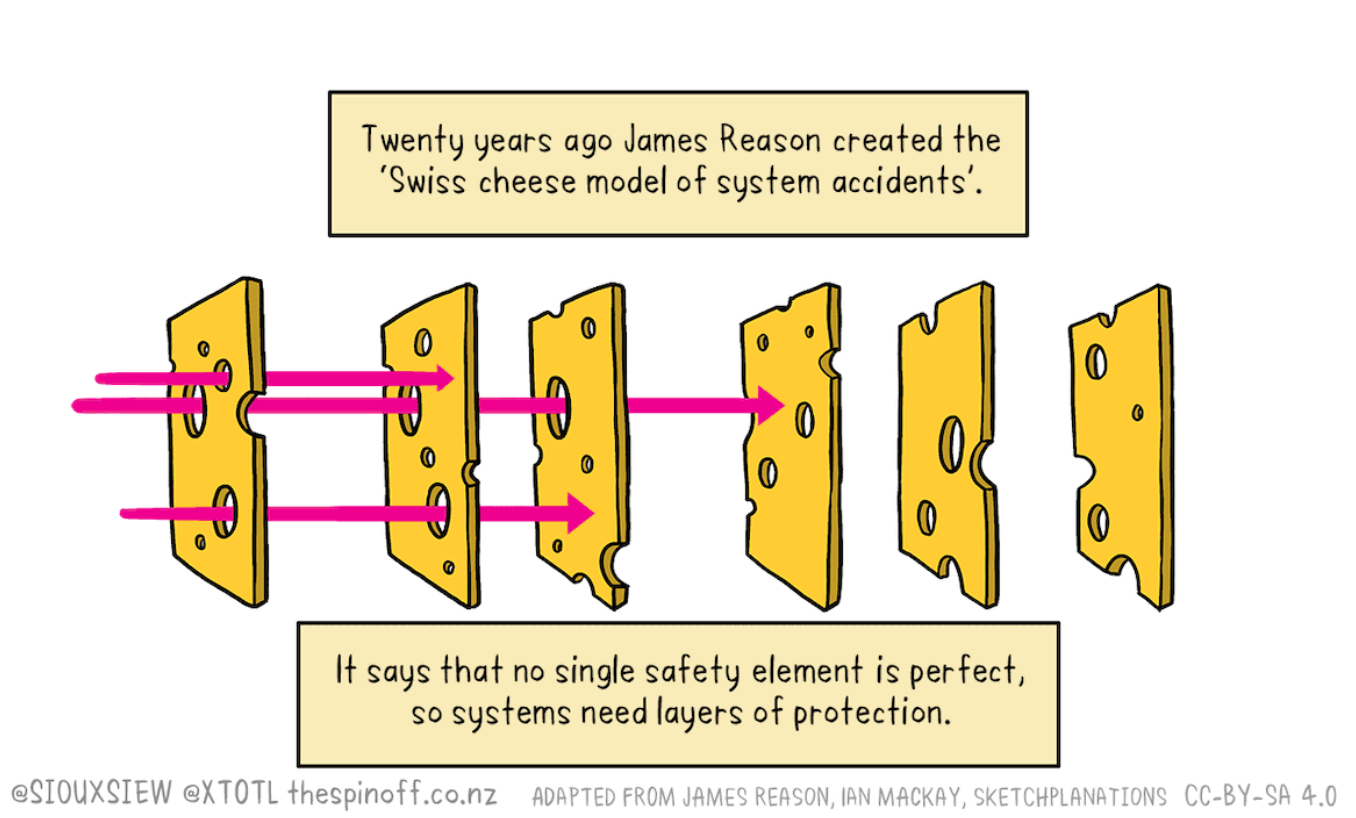
2. Swiss Cheese
We might end up in a situation where we're confident that each of our top 20 methods is unreliable, but if we "roll the dice" 20 times then we'll be confident that at least one of the methods will stop the failure. Therefore we apply all of them at once.
Here's why I think this situation is likely:
- Intelligence is a complicated messy thing in humans.
- Intelligence is a complicated messy thing in existing AI systems.
- There might not be any simple primitive which works reliably for such a messy thing.
- Often the best way to secure a messy thing is to assemble many layers of security — think aeroplane safety, the immune system, or internet firewalls.
3. Synergy
We might end up in a situation where among our top 20 methods, none of them works in isolation. But when we assemble the various methods, suddenly that works great because there's a weird synergy between the different methods.
I'm not confident this is true, but nonetheless:
- Sometimes synergy does occur.
- We might be lucky.
- Even if hodge-podge alignment is a "Hail Mary" solution, it's relatively more dignified [LW · GW] than others.
4. Expanded Options
There is a canonical embedding of primitives into assemblages. So this proposal expands the set of potential methods without eliminating any. In fact, there's a combinatorial explosion in the number of potential options. If we expand our potential options, then our best option will (in general) improve.
5. Different talent-profile
Hodge-podge alignment doesn't invent the primitive ideas — instead, it converts these ideas into composable code and studies their assemblages. This process requires talent, but it requires a different talent profile than other alignment strategies — it needs more software engineers and fewer mathematicians.
6. Short-term gains
Hodge-podge alignment could make significant gains in the short-term because there's a lot of "theoretical overhang" in AI alignment — i.e. there are many ideas that haven't yet been implemented in Python.
7. Universality
Hodge-podge alignment is like the universal object in the category of alignment strategies. An "assemblage" captures what we mean (in the broadest sense) by a potential solution to the alignment problem.
8. Parallelisable and scalable
Hodge-podge alignment is highly parallelisable and scalable. Different primitive methods can be documented and implemented independently. Different assemblages can be studied independently.
Immediate next steps: If enough people say this is worthwhile (relative to how many say the opposite) then I'll explore this further. For the next step, I might post a distillation of David Jaz Myers Categorical systems theory which treats dynamic systems and their typed wirings as polymorphic lenses.
30 comments
Comments sorted by top scores.
comment by DragonGod · 2022-12-19T23:03:25.100Z · LW(p) · GW(p)
Enjoyed this post, strongly upvoted.
I believe the Hodge Podge hypothesis is probably false at moderately high credence. I expect that alignment can probably be solved in a simple/straightforward manner. (E.g. something like ambitious value learning may just work if the natural abstractions hypothesis is true and there exists a broad basin of attraction around human values or human (meta)ethics in concept space.)
But research diversification suggests that we should try the hodge podge strategy nonetheless. ;)
More concretely, this research proposal is a pareto improvement to the research landscape and it seems to me that it might potentially be a significant improvement (for the reasons you stated).
In particular:
- I expect that many alignment primitives would be synergistic.
- E.g. quantilisation and impact regularisation
- Boxing and ~everything
- A Swiss cheese style approach to safety seems intuitively sensible from an alignment as security mindset
- I.e. Assemblages naturally provide security in depth
- It's a highly scalable agenda in a way most others are not
- It can exploit the theory overhang
- Easy to onboard new software engineers and have them produce useful alignment work
- It's robust to epistemic uncertainty about what the solution is
- Modular alignment primitives are an ideal framework for alignment as a service (AaaS)
- They are probably going to be easier to incorporate into extant systems
- This will probably boost adoption compared to bespoke solutions or approaches that require the system to be built from scratch for safety
- If there's a convenient alignment as a service offering, then even organisations not willing to pay the time/development cost of alignment may adopt alignment offerings
- No one genuinely wants to build misaligned systems, so if we eliminate/minimise the alignment tax, more people will build aligned system
- AaaS could solve/considerably mitigate the coordination problems confronting the field
- They are probably going to be easier to incorporate into extant systems
I also like the schema you presented for getting robust arguments/guarantees for safety.
comment by davidad · 2022-12-19T23:56:44.284Z · LW(p) · GW(p)
I want to voice my strong support for attempts to define something like dependent type signatures for alignment-relevant components and use wiring diagrams and/or string diagrams (in some kind of double-categorical systems theory, such as David Jaz Myers’) to combine them into larger AI systems proposals. I also like the flowchart. I’m less excited about swiss-cheese security, but I think assemblages are also on the critical path for stronger guarantees.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2022-12-20T00:19:00.482Z · LW(p) · GW(p)
Okay, I think I'll write an alignment-relevent distillation of Myers' book.
It might be useful for thinking about embedded agency — and especially for the problem that Scott Garrabrant has been grappling recently with his Cartesian Frames, i.e. how do we formalise world-states that admit multiple distinct decompositions into environment and agents.
Replies from: davidad↑ comment by davidad · 2022-12-20T00:29:32.418Z · LW(p) · GW(p)
I think it will also prove useful for world-modeling even with a naïve POMDP-style Cartesian boundary between the modeler and the environment, since the environment is itself generally well-modeled by a decomposition into locally stateful entities that interact in locally scoped ways (often restricted by naturally occurring boundaries).
comment by johnswentworth · 2022-12-21T18:20:11.934Z · LW(p) · GW(p)
The main problem I see with hodge-podge-style strategies is that most alignment ideas fail in roughly-the-same cases, for roughly-the-same reasons. It's the same hard cases/hard subproblems which kill most plans. In particular, section B.2 [LW · GW] (and to a lesser extent B.1 - B.3) of List of Lethalities covers "core problems" which strategies usually fail to handle.
Replies from: DragonGod, DragonGod↑ comment by DragonGod · 2022-12-21T21:10:26.426Z · LW(p) · GW(p)
This may be the case but, well constructed assemblages should have all the safety guarantees of any of their primitives.
Insomuch as assemblages are non viable, then no strategy is viable because if a strategy was viable, it could be included in the assemblage and it would then be viable.
More concretely, this research proposal is a pareto improvement to the research landscape and it seems to me that it might potentially be a significant improvement.
In particular:
- I expect that many alignment primitives would be synergistic.
- E.g. quantilisation and impact regularisation
- Boxing and ~everything
- A Swiss cheese style approach to safety seems intuitively sensible from an alignment as security mindset
- I.e. Assemblages naturally provide security in depth
- It's a highly scalable agenda in a way most others are not
- It can exploit the theory overhang
- Easy to onboard new software engineers and have them produce useful alignment work
- It's robust to epistemic uncertainty about what the solution is
- Modular alignment primitives are an ideal framework for alignment as a service (AaaS)
- They are probably going to be easier to incorporate into extant systems
- This will probably boost adoption compared to bespoke solutions or approaches that require the system to be built from scratch for safety
- If there's a convenient alignment as a service offering, then even organisations not willing to pay the time/development cost of alignment may adopt alignment offerings
- No one genuinely wants to build misaligned systems, so if we eliminate/minimise the alignment tax, more people will build aligned system
- AaaS could solve/considerably mitigate the coordination problems confronting the field
- They are probably going to be easier to incorporate into extant systems
↑ comment by DragonGod · 2022-12-21T21:14:17.560Z · LW(p) · GW(p)
I don't like the hodge-podge hypothesis and think it's just a distraction, so maybe I'm coming at it from a different angle. As I see it, the case for this research proposal is:
There are two basic approaches to AI existential safety:
- Targeting AI systems at values we'd be "happy" (where we fully informed) for them to optimise for
[RLHF, IRL, value learning more generally, etc.]- Safeguarding systems that may not necessarily be ideally targeted
[Quantilisation, impact regularisation, boxing, myopia, designing non agentic systems, corrigibility, etc.]"Hodge-podge alignment" provides a highly scalable and viable "defense in depth" research agenda for #2.
comment by Jay Bailey · 2022-12-20T00:01:07.706Z · LW(p) · GW(p)
I notice that I'm confused about quantilization as a theory, independent of the hodge-podge alignment. You wrote "The AI, rather than maximising the quality of actions, randomly selects from the top quantile of actions."
But the entire reason we're avoiding maximisation at all is that we suspect that the maximised action will be dangerous. As a result, aren't we deliberately choosing a setting which might just return the maximised, potentially dangerous action anyway?
(Possible things I'm missing - the action space is incredibly large, the danger is not from a single maximised action but from a large chain of them)
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2022-12-20T00:13:58.421Z · LW(p) · GW(p)
Correct — there's a chance the expected utility quantilizer takes the same action as the expected utility maximizer. That probability is the inverse of the number of actions in the quantile, which is quite small (possibly measure zero) because because actionspace is so large.
Maybe it's defined like this so it has simpler mathematical properties. Or maybe it's defined like this because it's safer. Not sure.
comment by Vaniver · 2022-12-20T22:30:27.819Z · LW(p) · GW(p)
I think there's an existing phrase called "defense in depth", which somehow feels... more like the right spirit? [This is related to the 'swiss cheese' model you bring up in the motivation section.] It's not that we're going to throw together a bunch of miscellaneous stuff and it'll work; it's that we're not going to trust any particular defense that we have enough that we don't also want other defenses.
Replies from: rotatingpaguro↑ comment by rotatingpaguro · 2023-04-12T21:44:04.792Z · LW(p) · GW(p)
Or what Yudkowsky calls "security mindset", he insists so much on this on Arbital, on deploying all the options.
comment by kyleherndon · 2022-12-20T03:16:41.888Z · LW(p) · GW(p)
I haven't quite developed an opinion on the viability of this strategy yet, but I would like to appreciate that you produced a plausible sounding scheme that I, a software engineer not mathematician, feel like I could actually probably contribute to. I would like to request people come up with MORE proposals similar along this dimension and/or readers of this comment to point me to other such plausible proposals. I think I've seen some people consider potential ways for non-technical people to help, but I feel like I've seen disproportionately few ways for technically competent but not theoretically/mathematically minded to help.
comment by Chris_Leong · 2022-12-19T23:54:30.246Z · LW(p) · GW(p)
Very happy to see someone writing about this as I’ve been thinking that there should be more research into this for a while. I guess my main doubt with this strategy is that if a system is running for long enough in a wide enough variety of circumstances maybe certain rare outcomes are virtually guaranteed?
Replies from: DragonGod↑ comment by DragonGod · 2022-12-20T00:06:57.856Z · LW(p) · GW(p)
Conjecture:
Well constructed assemblages are at least as safe as any of their component primitives
More usefully:
The safety guarantees of a well constructed assemblage is a superset of the union of safety guarantees of each component primitive
Or at least theorems of the above sort means that assemblages are no less safe than their components and are potentially much safer.
And assemblages naturally provide security in depth (e.g. the swiss cheese strategy).
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2022-12-20T00:46:53.500Z · LW(p) · GW(p)
The heuristic is "assemblage is safer than its primitives".
Formally:
- For every primitive and assemblages and and wiring diagram , the following is true:
- If strongly dominates then weakly dominates .
- Recall that is the wiring-together of and using the wiring diagram .
- In English, this says that can't be helpful in one assemblage and unhelpful in another.
I expect counterexamples to this heuristic to look like this:
- Many corrigibility primitives allow a human to influence certain properties of the internal state of the AI.
- Many interpretability primitives allow a human to learn certain properties of the internal state of the AI.
- These primitives might make an assemblage less safe because the AI could use these primitives itself, leading to self-modification.
comment by Dalcy (Darcy) · 2022-12-28T08:22:32.667Z · LW(p) · GW(p)
Awesome post! I broadly agree with most of the points and think hodge-podging would be a fairly valuable agenda to further pursue. Some thoughts:
What could AI alignment look like if we had 6000+ full-time researchers and software developers?
My immediate impression is that, if true, this makes hodge-podging fairly well suited for automation (compared to conceptual/theoretical work, based on reasons laid out here [LW · GW])
But when we assemble the various methods, suddenly that works great because there's a weird synergy between the different methods.
I agree that most synergies would be positive, but the way it was put in this post seems to imply that they would be sort of unexpected. Isn't the whole point of having primitives & taxonomizing type signatures to ensure that their composition's behaviors are predictable and robust?
Perhaps I'm uncertain as to what level of "formalization" hodge-podging would be aiming for. If it's aiming for a fully mathematically formal characterization of various safety properties (eg PreDCA-style) then sure, it would permit lossless provable guarantees of the properties of its composition, as is the case with cryptographic primitives (there are no unexpected synergies from assembling them).
But if they're on the level of ELK/plausible [LW · GW]-training-stories level of formalization, I suspect hodge-podging would less be able to make composition guarantees as the "emergent" features from composing [LW · GW] them start to come into the picture. At that point, how can it guarantee that there aren't any negative synergies the misaligned AI could exploit?
(I might just be totally confused here given that I know approximately nothing about categorical systems theory)
For the next step, I might post a distillation of David Jaz Myers Categorical systems theory which treats dynamic systems and their typed wirings as polymorphic lenses.
Please do!
comment by DragonGod · 2022-12-20T00:17:24.463Z · LW(p) · GW(p)
Conjectures???
I would be very interested in conjectures of the below flavour:
Well constructed assemblages are at least as safe as any of their component primitives
More usefully:
The safety guarantees of a well constructed assemblage is a superset of the union of safety guarantees of each component primitive
("Well constructed" left implicit for now. "safety guarantees" are the particular properties of primitives that are interesting/meaningful/useful from a safety/security perspective.)
Theorems of the above sort imply that assemblages are no less safe than their components and are potentially much safer.
Expanded Concepts
Considering only the safety guarantees of a given assemblage.
Components
The "components" of an assemblage are the primitives composed together to make it.
Singleton
An assemblage that has a single component.
Dominance
Weak Dominance
An assemblage A_i weakly dominates another assemblage A_j if it has all the safety guarantees of A_j.
Strong Dominance
An assemblage A_i strongly dominates another assemblage A_j if it has all the safety guarantees of A_j and there exist safety guarantees of A_i that A_j lacks.
Well constructed assemblages weakly dominate all components.
Unless all components provide the same safety guarantees, it would be the case that assemblages strongly dominate some of their components.
Useful assemblages should strongly dominate all their components (otherwise, there'll be redundant components).
Redundance
A component of an assemblage A_i is "redundant" if there exists a proper sub-assemblage A_j that weakly dominates A_i.
Minimal Assemblages
A "minimal" assemblage is an assemblage that has no redundant components.
Non singleton minimal assemblages strongly dominate all components.
Useful assemblages are minimal.
Total Assemblages
An assemblage A_i is total with respect to a set of primitives \mathcal{P} if there does not exist any assemblage A_j that can be constructed from \mathcal{P} that obtains safety guarantees A_i lacks.
Optimal Assemblages
An assemblage is optimal with respect to a set of primitives if it's minimal and total wrt to that set of primitives.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2022-12-20T01:05:52.580Z · LW(p) · GW(p)
- To use your & my terminology:
I think you propose deploying the minimal adequate assemblage, but I propose deploying the maximal adequate assemblage.
To clarify — there will exist an Adequacy Range among the assemblages, where assemblages within this range are adequate, assemblages below this range are inadequate (too unsafe), and assemblages above this range are inadequate (too incompetent). I think we should deploy an assemblage at the top of this range, not the bottom. - The concepts you've defined are clues you're thinking about assemblages in roughly the same way I am.
comment by Charlie Steiner · 2022-12-21T10:59:21.692Z · LW(p) · GW(p)
The problem with the swiss cheese model here is illustrative of why this is unpromising as stated. In the swiss cheese model you start with some working system, and then the world throws unexpected accidents at you, and you need to protect the working system from being interrupted by an accident. This is not our position with respect to aligned AI - a misaligned AI is not well-modeled as an aligned AI plus some misaligning factors. That is living in the should-universe [LW · GW]-plus-diff [LW · GW]. If you prevent all "accidents," the AI will not revert to its normal non-accident home state of human-friendliness.
Yes, combining multiple safety features is done all the time, e.g. if you're designing a fusion reactor. But you don't design a working fusion reactor by taking twenty non-working designs and summing all their features. Such an approach to fusion-reactor design wouldn't work because:
- features of a fusion reactor only improve its function with in a specific context that has to be taken into account during design
- probably some of the features you're adding were bad ideas to begin with, and those can cancel out all the fusion you were trying to promote with all the other features, because fusion is a rare and special thing that takes work to make happen
- some of the other features are working at cross-purposes - e.g. one feature might involve outside resources, and another feature might involve isolating the system from the outside
- Some of the features will have unexpected synergy, which will go unnoticed because synergy requires carefully setting parameters by thinking about what produces fusion, not just about combining features.
↑ comment by DragonGod · 2022-12-21T11:57:23.448Z · LW(p) · GW(p)
I disagree with the core of this objection.
There are two basic approaches to AI existential safety:
-
Targeting AI systems at values we'd be "happy" (where we fully informed) for them to optimise for [RLHF, IRL, value learning more generally, etc.]
-
Safeguarding systems that may not necessarily be ideally targeted [Quantilisation, impact regularisation, boxing, myopia, designing non agentic systems, corrigibility, etc.]
"Hodge-podge alignment" provides a highly scalable and viable "defense in depth" research agenda for #2.
Your objection seems to assume that #1 is the only viable approach to AI existential safety, but that seems very much not obvious. Corrigibility is itself an approach for #2 and if I'm not mistaken, Yudkowsky considers it one way of tackling alignment.
To: Cleo Nardo, you should pick a better name for this strategy. "Hodge-podge alignment" is such terrible marketing.
comment by Jon Garcia · 2022-12-20T00:42:18.613Z · LW(p) · GW(p)
This just might work. For a little while, anyway.
One hurdle for this plan is to incentivize developers to slap on 20 layers of alignment strategies to their generalist AI models. It may be a hard sell when they are trying to maximize power and efficiency to stay competitive.
You'll probably need to convince them that not having such safeguards in place will lead to undesirable behavior (i.e., unprofitable behavior, or behavior leading to bad PR or bad customer reviews) well below the level of apocalyptic scenarios that AI safety advocates normally talk about. Otherwise, they may not care.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2022-12-20T00:55:03.428Z · LW(p) · GW(p)
- My mainline success-model [? · GW] looks like this: the key actors know alignment is hard and coordinate to solve it. I'm focusing on this success-model until another success-model becomes mainline.
- I'm more bullish on coordination between the key actors than a lot of the TAIS community.
- I think that the leading alignment-sympathetic actors slowed by the alignment tax [? · GW] will still outpace the alignment-careless actors.
- The assemblage might be cheaper to run than the primitives alone.
- Companies routinely use cryptographic assemblages.
↑ comment by DragonGod · 2022-12-20T01:04:29.008Z · LW(p) · GW(p)
Companies routinely use cryptographic assemblages.
This is IMO an insufficiently emphasised advantage. Modular alignment primitives are probably going to be easier to incorporate into extant systems. This will probably boost adoption compared to some bespoke solutions (or approaches that require designing systems for safety from scratch).
If there's a convenient/compelling alignment as a service offering, then even organisations not willing to pay the time/development cost of alignment may adopt alignment offerings (no one genuinely wants to build misaligned systems).
I.e. if we minimise/eliminate the alignment tax, organisations would be much more willing to pay it, and modular assemblages seem like a compelling platform for such an offering.
If successful, this research agenda could "solve" the coordination problems.
comment by Nicholas / Heather Kross (NicholasKross) · 2023-03-07T23:04:11.519Z · LW(p) · GW(p)
I'm slightly pessimistic about the likely end results of this, but I'm glad somebody wrote down, in detail, a "gather a bag of tricks and throw researchers at it" program!
comment by DragonGod · 2022-12-21T12:19:38.205Z · LW(p) · GW(p)
Suggestions for Improvement
A. "Hodge-podge alignment" is a terrible name, you need better marketing.
Some other improvements to the case for the proposed research agenda (drawn from my other comments).
B. Ditch the "hodge-podge hypothesis" it's not may be implausible to some and it's very unnecessary for your case.
I think the below argument [LW(p) · GW(p)] is stronger:
There are two basic approaches to AI existential safety:
- Targeting AI systems at values we'd be "happy" (where we fully informed) for them to optimise for [RLHF, IRL, value learning more generally, etc.]
- Safeguarding systems that may not necessarily be ideally targeted [Quantilisation, impact regularisation, boxing, myopia, designing non agentic systems, corrigibility, etc.]
"Hodge-podge alignment" provides a highly scalable and viable "defense in depth" research agenda for #2.
No need to entertain the "hodge-podge hypothesis", and a more compelling case.
B. I think you could further strengthen the case for this agenda by emphasising its strategic implications [LW(p) · GW(p)]:
Companies routinely use cryptographic assemblages.
This is IMO an insufficiently emphasised advantage. Modular alignment primitives are probably going to be easier to incorporate into extant systems. This will probably boost adoption compared to some bespoke solutions (or approaches that require designing systems for safety from scratch).
If there's a convenient/compelling alignment as a service offering, then even organisations not willing to pay the time/development cost of alignment may adopt alignment offerings (no one genuinely wants to build misaligned systems).
I.e. if we minimise/eliminate the alignment tax, organisations would be much more willing to pay it, and modular assemblages seem like a compelling platform for such an offering.
If successful, this research agenda could "solve" the coordination problems.
comment by beren · 2022-12-20T14:06:45.115Z · LW(p) · GW(p)
I want to add to the general agreement here that I broadly agree with this strategy and think that in practice this kind of things (multiple alignment solutions strapped onto a system in parallel) will be what alignment success looks like in parallel, and have written about this before. This agreement is primarily with the swiss-cheese/assemblage strategy.
It is important to note that I think that hodgepodge alignment strategies only really apply to near-term proto-AGI systems that we will build and won't work against a system that has strongly recursively-self-improved into a true super intelligence (insofar as this is possible). However a key thing we need to figure out is how to prevent this from happening to our near-term AGI systems in an uncontrolled way and I am hopeful that just layering of multiple methods can help here substantially.
I am also somewhat sceptical as using type-theory/category-theoretic approaches of assemblages as a means of proof of safety guarantees (vs as a thinking tool which I strongly think can be helpful). This is basically because it is unclear to me if types are sufficiently strong objects to let us reason about properties like safety (i.e. even in strongly typed languages the type-checker can tell you at compile-time if the function will output an int but cannot guarantee that the int will be < 9000 and I think something like the latter is the kind of guarantee we need for alignment).
Replies from: DragonGod↑ comment by DragonGod · 2022-12-20T16:27:12.734Z · LW(p) · GW(p)
i.e. even in strongly typed languages the type-checker can tell you at compile-time if the function will output an int but cannot guarantee that the int will be < 9000 and I think something like the latter is the kind of guarantee we need for alignment
Define a new type that only allows ints < 9000 if needed?
For your broader question, I think there might be some safety relevant properties of some alignment primitives.
Replies from: anonce↑ comment by epistemic meristem (anonce) · 2023-07-31T17:49:40.873Z · LW(p) · GW(p)
Beren, have you heard of dependent types, which are used in Coq, Agda, and Lean? (I don't mean to be flippant; your parenthetical just gives the impression that you hadn't come across them, because they can easily enforce integer bounds, for instance.)