Posts
Comments
Non-Shannon-type Inequalities
The first new qualitative thing in Information Theory when you move from two variables to three variables is the presence of negative values: information measures (entropy, conditional entropy, mutual information) are always nonnegative for two variables, but there can be negative triple mutual information .
This so far is a relatively well-known fact. But what is the first new qualitative thing when moving from three to four variables? Non-Shannon-type Inequalities.
A fundamental result in Information Theory is that always holds.
- Given random variables and , from now on we write with the obvious interpretation of the variables standing for the joint variables they correspond to as indices.
Since always holds, a nonnegative linear combination of a bunch of these is always a valid inequality, which we call a Shannon-type Inequality.
Then the question is, whether Shannon-type Inequalities capture all valid information inequalities of variable. It turns out, yes for , (approximately) yes for , and no for .
Behold, the glorious Zhang-Yeung inequality, a Non-Shannon-type Inequality for :
Explanation of the math, for anyone curious.
Given random variables and , it turns out that is equivalent to (submodularity), if , and .
This lets us write the inequality involving conditional mutual information in terms of joint entropy instead.
Let then be a subset of , each element corresponding to the values of the joint entropy assigned to each subset of some random variables . For example, an element of would be for some random variables and , with a different element being a different tuple induced by a different random variable .
Now let represent elements of satisfying the three aforementioned conditions on joint entropy. For example, 's element would be satisfying e.g., (monotonicity). This is also a convex cone, so its elements really do correspond to "nonnegative linear combinations" of Shannon-type inequalities.
Then, the claim that "nonnegative linear combinations of Shannon-type inequalities span all inequalities on the possible Shannon measures" would correspond to the claim that for all .
The content of the papers linked above is to show that:
- but (closure[1])
- and , and also for all .
- ^
This implies that, while there exists a -tuple satisfying Shannon-type inequalities that can't be constructed or realized by any random variables , there does exist a sequence of random variables whose induced -tuple of joint entropies converge to that tuple in the limit.
Relevant: Alignment as a Bottleneck to Usefulness of GPT-3
between alignment and capabilities, which is the main bottleneck to getting value out of GPT-like models, both in the short term and the long(er) term?
By the way, Gemini 2.5 Pro and o3-mini-high is good at tic-tac-toe. I was surprised because the last time I tested this on o1-preview, it did quite terribly.
Where in the literature can I find the proof of the lower bound?
Previous discussion, comment by A.H. :
Sorry to be a party pooper, but I find the story of Jason Padgett (the guy who 'banged his head and become a math genius') completely unconvincing. From the video that you cite, here is the 'evidence' that he is 'math genius':
- He tells us, with no context, 'the inner boundary of pi is f(x)=x sin(pi/x)'. Ok!
- He makes 'math inspired' drawings (some of which admittedly are pretty cool but they're not exactly original) and sells them on his website
- He claims that a physicist (who is not named or interviewed) saw him drawing in the mall, and, on the basis of this, suggested that he study physics.
- He went to 'school' and studied math and physics. He says started with basic algebra and calculus and apparently 'aced all the classes', but doesn't tell us what level he reached. Graduate? Post-graduate?
- He was 'doing integrals with triangles instead of integrals with rectangles'
- He tells us 'every shape in the universe is a fractal'
- Some fMRI scans were done on his brain which found 'he had conscious access to parts of the brain we don't normally have access to'.
I wrote "your brain can wind up settling on either of [the two generative models]", not both at once.
Ah that makes sense. So the picture I should have is: whatever local algorithm oscillates between multiple local MAP solutions over time that correspond to qualitatively different high-level information (e.g., clockwise vs counterclockwise). Concretely, something like the metastable states of a Hopfield network, or the update steps of predictive coding (literally gradient update to find MAP solution for perception!!) oscillating between multiple local minima?
Curious about the claim regarding bistable perception as the brain "settling" differently on two distinct but roughly equally plausible generative model parameters behind an observation. In standard statistical terms, should I think of it as: two parameters having similarly high Bayesian posterior probability, but the brain not explicitly representing this posterior, instead using something like local hill climbing to find a local MAP solution—bistable perception corresponding to the two different solutions this process converges to?
If correct, to what extent should I interpret the brain as finding a single solution (MLE/MAP) versus representing a superposition or distribution over multiple solutions (fully Bayesian)? Specifically, in which context should I interpret the phrase "the brain settling on two different generative models"?
I just read your koan and wow it's a great post, thank you for writing it. It also gave me some new insights as to how to think about my confusions and some answers. Here's my chain of thought:
- if I want my information theoretic quantities to not degenerate, then I need some distribution over the weights. What is the natural distribution to consider?
- Well, there's the Bayesian posterior.
- But I feel like there is a sense in which an individual neural network with its weight should be considered as a deterministic information processing system on its own, without reference to an ensemble.
- Using the Bayesian posterior won't let me do this:
- If I have a fixed neural network that contains a circuit that takes activation (at a particular location in the network) to produce activation (at a different location), it would make sense to ask questions about the nature of information processing that does, like .
- But intuitively, taking the weight as an unknown averages everything out - even if my original fixed network had a relatively high probability density in the Bayesian posterior, it is unlikely that and would be related by similar circuit mechanisms given another random sample weight from the posterior.
- Same with sampling from the post-SGD distribution.
- So it would be nice to find a way to interpolate the two. And I think the idea of a tempered local Bayesian posterior from your koan post basically is the right way to do this! (and all of this makes me think papers that measure mutual information between activations in different layers via introducing a noise distribution over the parameters of are a lot more reasonable than I originally thought)
I like the definition, it's the minimum expected code length for a distribution under constraints on the code (namely, constraints on the kind of beliefs you're allowed to have - after having that belief, the optimal code is as always the negative log prob).
Also the examples in Proposition 1 were pretty cool in that it gave new characterizations of some well-known quantities - log determinant of the covariance matrix does indeed intuitively measure the uncertainty of a random variable, but it is very cool to see that it in fact has entropy interpretations!
It's kinda sad because after a brief search it seems like none of the original authors are interested in extending this framework.
That makes sense. I've updated towards thinking this is reasonable (albeit binning and discretization is still ad hoc) and captures something real.
We could formalize it like where with being some independent noise parameterized by \sigma. Then would become finite. We could think of binning the output of a layer to make it stochastic in a similar way.
Ideally we'd like the new measure to be finite even for deterministic maps (this is the case for above) and some strict data processing inequality like to hold, intuition being that each step of the map adds more noise.
But is just up to a constant that depends on the noise statistic, so the above is an equality.
Issue is that the above intuition is based on each application of and adding additional noise to the input (just like how discretization lets us do this: each layer further discretizes and bins its input, leading in gradual loss of information hence letting mutual information capture something real in the sense of amount of bits needed to recover information up to certain precision across layers), but I_\sigma just adds an independent noise. So any relaxation if will have to depend on the functional structure of .
With that (+ Dmitry's comment on precision scale), I think the papers that measure mutual information between activations in different layers with a noise distribution over the parameters of sound a lot more reasonable than I originally thought.
Ah you're right. I was thinking about the deterministic case.
Your explanation of the jacobian term accounting for features "squeezing together" makes me update towards thinking maybe the quantizing done to turn neural networks from continuous & deterministic to discrete & stochastic, while ad hoc, isn't as unreasonable as I originally thought it was. This paper is where I got the idea that discretization is bad because it "conflates 'information theoretic stuff' with 'geometric stuff', like clustering" - but perhaps this is in fact capturing something real.
Thank you, first three examples make sense and seem like an appropriate use of mutual information. I'd like to ask about the fourth example though, where you take the weights as unknown:
- What's the operational meaning of under some ? More importantly: to what kind of theoretical questions we could ask are these quantities an answer to? (I'm curious of examples in which such quantities came out as a natural answer to the research questions you were asking in practice.)
- I would guess the choice of (maybe the bayesian posterior, maybe the post-training SGD distribution) and the operational meaning they have will depend on what kind of questions we're interested in answering, but I don't yet have a good idea as to in what contexts these quantities come up as answers to natural research questions.
And more generally, do you think shannon information measures (at least in your research experience) basically work for most theoretical purposes in saying interesting stuff about deterministic neural networks, or perhaps do you think we need something else?
- Reason being (sorry this is more vibes, I am confused and can't seem to state something more precise): Neural networks seem like they could (and should perhaps) be analyzed as individual deterministic information processing systems without reference to ensembles, since each individual weights are individual algorithms that on its own does some "information processing" and we want to understand its nature.
- Meanwhile shannon information measures seem bad at this, since all they care about is the abstract partition that functions induce on their domain by the preimage map. Reversible networks (even when trained) for example have the same partition induced even if you keep stacking more layers, so from the perspective of information theory, everything looks the same - even though as individual weights without considering the whole ensemble, the networks are changing in its information processing nature in some qualitative way, like representation learning - changing the amount of easily accessible / usable information - hence why I thought something in the line of V-information might be useful.
I would be surprised (but happy!) if such notions could be captured by cleverly using shannon information measures. I think that's what the papers attempting to put a distribution over weights were doing, using languages like (in my words) " is an arbitrary choice and that's fine, since it is used as means of probing information" or smth, but the justifications feel hand-wavy. I have yet to see a convincing argument for why this works, or more generally how shannon measures could capture these aspects of information processing (like usable information).
The 3-4 Chasm of Theoretical Progress
epistemic status: unoriginal. trying to spread a useful framing of theoretical progress introduced from an old post.
Tl;dr, often the greatest theoretical challenge comes from the step of crossing the chasm from [developing an impractical solution to a problem] to [developing some sort of a polytime solution to a problem], because the nature of their solutions can be opposites.
Summarizing Diffractor's post on Program Search and Incomplete Understanding:
Solving a foundational problem to its implementation often takes the following steps (some may be skipped):
- developing a philosophical problem
- developing a solution given infinite computing power
- developing an impractical solution
- developing some sort of polytime solution
- developing a practical solution
and he says that it is often during the 3 -> 4 step in which understanding gets stuck and the most technical and brute-force math (and i would add sometimes philosophical) work is needed, because:
- a common motif in 3) is that they're able to proving interesting things about their solutions, like asymptotic properties, by e.g., having their algorithms iterate through all turing machines, hence somewhat conferring the properties of the really good turing machine solution that exists somewhere in this massive search space to the overall search algorithm (up to a massive constant, usually).
- think of Levin's Universal Search, AIXItl, Logical Induction.
- he says such algorithms are secretly a black box algorithm; there are no real gears.
- Meanwhile, algorithms in 4) have the opposite nature - they are polynomial often because they characterize exploitable patterns that make a particular class of problems easier than most others, which requires Real Understanding. So algorithms of 3) and 4) often look nothing alike.
I liked this post and the idea of the "3-4 chasm," because it explicitly captures the vibes of why I personally felt the vibes that, e.g., AIT, might be less useful for my work: after reading this post, I realized that for example when I refer to the word "structure," I'm usually pointing at the kind of insights required to cross the 3-4 gap, while others might be using the same word to refer to things at a different level. This causes me to get confused as to how some tool X that someone brought up is supposed to help with the 3-4 gap I'm interested in.[1]
Vanessa Cosoy refers to this post, saying (in my translation of her words) that a lot of the 3-4 gap in computational learning theory has to do with our lack of understanding of deep learning theory, like how the NP-complete barrier is circumvented in practical problems, what are restrictions we can put on out hypothesis class to make them efficiently learnable in the same way our world seems efficiently learnable, etc.
- She mentions that this gap, at least in the context of deep learning theory, isn't too much of a pressing problem because it already has mainstream attention - which explains why a lot of her work seems to lie in the 1-3 regime.
I asked GPT for examples of past crossings of the 3-4 chasm in other domains, and it suggested [Shannon's original technically-constructive-but-highly-infeasible proof for the existence of optimal codes] vs. [recent progress on Turbocodes that actually approach this limit while being very practical], which seems like a perfect example.
- ^
AIT in specific seems to be useful primarily in the 1-2 level?
Thank you! I tried it on this post and while the post itself is pretty short, the raw content that i get seems to be extremely long (making it larger than the o1 context window, for example), with a bunch of font-related information inbetween. Is there a way to fix this?
The critical insight is that this is not always the case!
Let's call two graphs I-equivalent if their set of independencies (implied by d-separation) are identical. A theorem of Bayes Nets say that two graphs are I-equivalent if they have the same skeleton and the same set of immoralities.
This last constraint, plus the constraint that the graph must be acyclic, allows some arrow directions to be identified - namely, across all I-equivalent graphs that are the perfect map of a distribution, some of the edges have identical directions assigned to them.
The IC algorithm (Verma & Pearl, 1990) for finding perfect maps (hence temporal direction) is exactly about exploiting these conditions to orient as many of the edges as possible:

More intuitively, (Verma & Pearl, 1992) and (Meek, 1995) together shows that the following four rules are necessary and sufficient operations to maximally orient the graph according to the I-equivalence (+ acyclicity) constraint:

Anyone interested in further detail should consult Pearl's Causality Ch 2. Note that for some reason Ch 2 is the only chapter in the book where Pearl talks about Causal Discovery (i.e. inferring time from observational distribution) and the rest of the book is all about Causal Inference (i.e. inferring causal effect from (partially) known causal structure).
The Metaphysical Structure of Pearl's Theory of Time
Epistemic status: metaphysics
I was reading Factored Space Models (previously, Finite Factored Sets) and was trying to understand in what sense it was a Theory of Time.
Scott Garrabrant says "[The Pearlian Theory of Time] ... is the best thing to happen to our understanding of time since Einstein". I read Pearl's book on Causality[1], and while there's math, this metaphysical connection that Scott seems to make isn't really explicated. Timeless Causality and Timeless Physics is the only place I saw this view explained explicitly, but not at the level of math / language used in Pearl's book.
Here is my attempt at explicitly writing down what all of these views are pointing at (in a more rigorous language)—the core of the Pearlian Theory of Time, and in what sense FSM shares the same structure.
Causality leave a shadow of conditional independence relationships over the observational distribution. Here's an explanation providing the core intuition:
- Suppose you represent the ground truth structure of [causality / determination] of the world via a Structural Causal Model over some variables, a very reasonable choice. Then, as you go down the Pearlian Rung: SCM [2] Causal Bayes Net [3] Bayes Net, theorems guarantee that the Bayes Net is still Markovian wrt the observational distribution.
- (Read Timeless Causality for an intuitive example.)
- Causal Discovery then (at least in this example) reduces to inferring the equation assignment directions of the SCM, given only the observational distribution.
- The earlier result guarantees that all you have to do is find a Bayes Net that is Markovian wrt the observational distribution. Alongside the faithfulness assumption, this thus reduces to finding a Bayes Net structure G whose set of independencies (implied by d-separation) are identical to that of P (or, finding the Perfect Map of a distribution[4]).
- Then, at least some of the edges of the Perfect Map will have its directions nailed down by the conditional independence relations.
The metaphysical claim is that, this direction is the definition of time[5], morally so, based on the intuition provided by the example above.
So, the Pearlian Theory of Time is the claim that Time is the partial order over the variables of a Bayes Net corresponding to the perfect map of a distribution.
Abstracting away, the structure of any Theory of Time is then to:
- find a mathematical structure [in the Pearlian Theory of Time, a Bayes Net]
- ... that has gadgets [d-separation]
- ... that are, in some sense, "equivalent" [soundness & completeness] to the conditional independence relations of the distribution the structure is modeling
- ... while containing a notion of order [parenthood relationship of nodes in a Bayes Net]
- ... while this order induced from the gadget coinciding to that of d-separation [trivially so here, because we're talking about Bayes Nets and d-separation] such that it captures the earlier example which provided the core intuition behind our Theory of Time.
This is exactly what Factored Space Model does:
- find a mathematical structure [Factored Space Model]
- ... that has gadgets [structural independence]
- ... that are, in some sense, "equivalent" [soundness & completeness] to the conditional independence relations of the distribution the structure is modeling
- ... while containing a notion of order [preorder relation induced by the subset relationship of the History]
- ... while this order induced from the gadget coinciding to that of d-separation [by a theorem of FSM] such that it captures the earlier example which provided the core intuition behind our Theory of Time.
- while, additionally, generalizing the scope of our Theory of Time from [variables that appear in the Bayes Net] to [any variables defined over the factored space].
... thus justifying calling FSM a Theory of Time in the same spirit that Pearlian Causal Discovery is a Theory of Time.
- ^
Chapter 2, specifically, which is about Causal Discovery. All the other chapters are mostly irrelevant for this purpose.
- ^
By (1) making a graph with edge direction corresponding to equation assignment direction, (2) pushforwarding uncertainties to endogenous variables, and (3) letting interventional distributions be defined by the truncated factorization formula.
- ^
By (1) forgetting the causal semantics, i.e. no longer associating the graph with all the interventional distributions, and only the no intervention observational distribution.
- ^
This shortform answers this question I had.
- ^
Pearl comes very close. In his Temporal Bias Conjecture (2.8.2):
"In most natural phenomenon, the physical time coincides with at least one statistical time."
(where statistical time refers to the aforementioned direction.)
But doesn't go as far as this ought to be the definition of Time.
The grinding inevitability is not a pressure on you from the outside, but a pressure from you, towards the world. This type of determination is the feeling of being an agent with desires and preferences. You are the unstoppable force, moving towards the things you care about, not because you have to but simply because that’s what it means to care.
I think this is probably one of my favorite quotes of all time. I translated it to Korean (with somewhat major stylistic changes) with the help of ChatGPT:
의지(意志)라 함은,
하나의 인간으로서,
멈출 수 없는 힘으로 자신이 중요히 여기는 것들을 향해 나아가는 것.이를 따르는 갈아붙이는 듯한 필연성은,
외부에서 자신을 압박하는 힘이 아닌,
스스로가 세상을 향해 내보내는 압력임을.해야 해서가 아니라,
단지 그것이 무언가를 소중히 여긴다는 뜻이기 때문에.
https://www.lesswrong.com/posts/KcvJXhKqx4itFNWty/k-complexity-is-silly-use-cross-entropy-instead
The K-complexity of a function is the length of its shortest code. But having many many codes is another way to be simple! Example: gauge symmetries in physics. Correcting for length-weighted code frequency, we get an empirically better simplicity measure: cross-entropy.
[this] is a well-known notion in algorithmic information theory, and differs from K-complexity by at most a constant
Epistemic status: literal shower thoughts, perhaps obvious in retrospect, but was a small insight to me.
I’ve been thinking about: “what proof strategies could prove structural selection theorems, and not just behavioral selection theorems?”
Typical examples of selection theorems in my mind are: coherence theorems, good regulator theorem, causal good regulator theorem.
- Coherence theorem: Given an agent satisfying some axioms, we can observe their behavior in various conditions and construct , and then the agent’s behavior is equivalent to a system that is maximizing .
- Says nothing about whether the agent internally constructs and uses them.
- (Little Less Silly version of the) Good regulator theorem: A regulator that minimizes the entropy of a system variable (where there is an environment variable upstream of both and ) without unnecessary noise (hence deterministic) is behaviorally equivalent to a deterministic function of (despite being a function of ).
- Says nothing about whether actually internally reconstructs and uses it to produce its output.
- Causal good regulator theorem (summary): Given an agent achieving low regret across various environment perturbations, we can observe their behavior in specific perturbed-environments, and construct that is very similar to the true environment . Then argue: “hence the agent must have something internally isomorphic to ”. Which is true, but …
- says nothing about whether the agent actually uses those internal isomorphic-to- structures in the causal history of computing its output.
And I got stuck here wondering, man, how do I ever prove anything structural.
Then I considered some theorems that, if you squint really really hard, could also be framed in the selection theorem language in a very broad sense:
- SLT: Systems selected to get low loss are likely to be in a degenerate part of the loss landscape.[1]
- Says something about structure: by assuming the system to be a parameterized statistical model, it says the parameters satisfy certain conditions like degeneracy (which further implies e.g., modularity).
This made me realize that to prove selection theorems on structural properties of agents, you should obviously give more mathematical structure to the “agent” in the first place:
- SLT represents a system as a parameterized function - very rich!
- In coherence theorem, the agent is just a single node that outputs decision given lotteries. In the good regulator theorem and the causal good regulator theorem, the agent is literally just a single node in a Bayes Net - very impoverished!
And recall, we actually have an agent foundations style selection theorem that does prove something structural about agent internals by giving more mathematical structure to the agent:
- Gooder regulator theorem: A regulator is now two nodes instead of one, but the latter-in-time node gets an additional information about the choice of “game” it is being played against (thus the former node acts as a sort of information bottleneck). Then, given that the regulator makes take minimum entropy, the first node must be isomorphic to the likelihood function .
- This does say something about structure, namely that an agent (satisfying certain conditions) with an internal information bottleneck (structural assumption) must have that bottleneck be behaviorally equivalent to a likelihood function, whose output is then connected to the second node. Thus it is valid to claim that (under our structural assumption) the agent internally reconstructs the likelihood values and uses it in its computation of the output.
So in short, we need more initial structure or even assumptions on our “agent,” at least more so than literally a single node in a Bayes Net, to expect to be able to prove something structural.
Here is my 5-minute attempt to put more such "structure" to the [agent/decision node] in the Causal good regulator theorem with the hopes that this would make the theorem more structural, and perhaps end up as a formalization of the Agent-like Structure Problem (for World Models, at least), or very similarly the Approximate Causal Mirror hypothesis:
- Similar setup to the Causal good regulator theorem, but instead of a single node representing an agent’s decision node, assume that the agent as a whole is represented by an unknown causal graph , with a number of nodes designated as input and output, connected to the rest-of-the-world causal graph . Then claim: Agents with low regret must have that admits an abstracting causal model map (summary) from , and (maybe more structural properties such as) the approximation error should roughly be lowest around the input/output & utility nodes, and increase as you move further away from it in the low-level graph. This would be a very structural claim!
- ^
I'm being very very [imprecise/almost misleading] here—because I'm just trying to make a high-level point and the details don't matter too much—one of the caveats (among many) being that this statement makes the theoretically yet unjustified connection between SGD and Bayes.
"I always remember, [Hamming] would come into my office and try to solve a problem [...] I had a very big blackboard, and he’d start on one side, write down some integral, say, ‘I ain’t afraid of nothin’, and start working on it. So, now, when I start a big problem, I say, ‘I ain’t afraid of nothin’, and dive into it."
The question is whether this expression is easy to compute or not, and fortunately the answer is that it's quite easy! We can evaluate the first term by the simple Monte Carlo method of drawing many independent samples and evaluating the empirical average, as we know the distribution explicitly and it was presumably chosen to be easy to draw samples from.
My question when reading this was: why can't we say the same thing about ? i.e. draw many independent samples and evaluate the empirical average? Usually is also assumed known and simple to sample from (e.g., gaussian).
So far, my answer is:
- , so assuming is my data, usually will be high when is high, so the samples during MCMC will be big enough to contribute to the sum, unlike blindly sampling from where most samples will contribute nearly to the sum.
- Also another reason being how the expectation can be reduced to the sum of expectations over each of the dimensions of and if and factorizes nicely.
Is there a way to convert a LessWrong sequence into a single pdf? Should ideally preserve comments, latex, footnotes, etc.
Formalizing selection theorems for abstractability
Tl;dr, Systems are abstractable to the extent they admit an abstracting causal model map with low approximation error. This should yield a pareto frontier of high-level causal models consisting of different tradeoffs between complexity and approximation error. Then try to prove a selection theorem for abstractability / modularity by relating the form of this curve and a proposed selection criteria.
Recall, an abstracting causal model (ACM)—exact transformations, -abstractions, and approximations—is a map between two structural causal models satisfying certain requirements that lets us reasonably say one is an abstraction, or a high-level causal model of another.
- Broadly speaking, the condition is a sort of causal consistency requirement. It's a commuting diagram that requires the "high-level" interventions to be consistent with various "low-level" ways of implementing that intervention. Approximation errors talk about how well the diagram commutes (given that the support of the variables in the high-level causal model is equipped with some metric)
Now consider a curve: x-axis is the node count, and y-axis is the minimum approximation error of ACMs of the original system with that node count (subject to some conditions[1]). It would hopefully an decreasing one[2].
- This curve would represent the abstractability of a system. Lower the curve, the more abstractable it is.
- Aside: we may conjecture that natural systems will have discrete jumps, corresponding to natural modules. The intuition being that, eg if we have a physics model of two groups of humans interacting, in some sense 2 nodes (each node representing the human-group) and 4 nodes (each node representing the individual-human) are the most natural, and 3 nodes aren't (perhaps the 2 node system with a degenerate node doing ~nothing, so it would have very similar approximation scores with the 2 node case).
Then, try hard to prove a selection theorem of the following form: given low-level causal model satisfying certain criteria (eg low regret over varying objectives, connection costs), the abstractability curve gets pushed further downwards. Or conversely, find conditions that make this true.
I don't know how to prove this[3], but at least this gets closer to a well-defined mathematical problem.
- ^
I've been thinking about this for an hour now and finding the right definition here seems a bit non-trivial. Obviously there's going to be an ACM of zero approximation error for any node count, just have a single node that is the joint of all the low-level nodes. Then the support would be massive, so a constraint on it may be appropriate.
Or instead we could fold it in to the x-axis—if there is perhaps a non ad-hoc, natural complexity measure for Bayes Nets that capture [high node counts => high complexity because each nodes represent stable causal mechanisms of the system, aka modules] and [high support size => high complexity because we don't want modules that are "contrived" in some sense] as special cases, then we could use this as the x-axis instead of just node count.
Immediate answer: Restrict this whole setup into a prediction setting so that we can do model selection. Require on top of causal consistency that both the low-level and high-level causal model have a single node whose predictive distribution are similar. Now we can talk about eg the RLCT of a Bayes Net. I don't know if this makes sense. Need to think more.
- ^
Or rather, find the appropriate setup to make this a decreasing curve.
- ^
I suspect closely studying the robust agents learn causal world models paper would be fruitful, since they also prove a selection theorem over causal models. Their strategy is to (1) develop an algorithm that queries an agent with low regret to construct a causal model, (2) prove that this yields an approximately correct causal model of the data generating model, (3) then arguing that this implies the agent must internally represent something isomorphic to a causal world model.
I don't know if this is just me, but it took me an embarrassingly long time in my mathematical education to realize that the following three terminologies, which introductory textbooks used interchangeably without being explicit, mean the same thing. (Maybe this is just because English is my second language?)
X => Y means X is sufficient for Y means X only if Y
X <= Y means X is necessary for Y means X if Y
I'd also love to have access!
Any thoughts on how to customize LessWrong to make it LessAddictive? I just really, really like the editor for various reasons, so I usually write a bunch (drafts, research notes, study notes, etc) using it but it's quite easy to get distracted.
(the causal incentives paper convinced me to read it, thank you! good book so far)
if you read Sutton & Barto, it might be clearer to you how narrow are the circumstances under which 'reward is not the optimization target', and why they are not applicable to most AI things right now or in the foreseeable future
Can you explain this part a bit more?
My understanding of situations in which 'reward is not the optimization target' is when the assumptions of the policy improvement theorem don't hold. In particular, the theorem (that iterating policy improvement step must yield strictly better policies and it converges at the optimal, reward maximizing policy) assumes that each step we're updating the policy by greedy one-step lookahead (by argmaxing the action via ).
And this basically doesn't hold irl because realistic RL agents aren't forced to explore all states (the classic example of "I can explore the state of doing cocaine, and I'm sure my policy will drastically change in a way that my reward circuit considers an improvement, but I don't have to do that). So my opinion that the circumstances under which 'reward is the optimization target' is very narrow remains unchanged, and I'm interested in why you believe otherwise.
I think something in the style of abstracting causal models would make this work - defining a high-level causal model such that there is a map from the states of the low-level causal model to it, in a way that's consistent with mapping low-level interventions to high-level interventions. Then you can retain the notion of causality to non-low-level-physical variables with that variable being a (potentially complicated) function of potentially all of the low-level variables.
Unidimensional Continuity of Preference Assumption of "Resources"?
tl;dr, the unidimensional continuity of preference assumption in the money pumping argument used to justify the VNM axioms correspond to the assumption that there exists some unidimensional "resource" that the agent cares about, and this language is provided by the notion of "souring / sweetening" a lottery.
Various coherence theorems - or more specifically, various money pumping arguments generally have the following form:
If you violate this principle, then [you are rationally required] / [it is rationally permissible for you] to follow this trade that results in you throwing away resources. Thus, for you to avoid behaving pareto-suboptimally by throwing away resources, it is justifiable to call this principle a 'principle of rationality,' which you must follow.
... where "resources" (the usual example is money) are something that, apparently, these theorems assume exist. They do, but this fact is often stated in a very implicit way. Let me explain.
In the process of justifying the VNM axioms using money pumping arguments, one of the three main mathematical primitives are: (1) lotteries (probability distribution over outcomes), (2) preference relation (general binary relation), and (3) a notion of Souring/Sweetening of a lottery. Let me explain what (3) means.
- Souring of is denoted , and a sweetening of is denoted .
- is to be interpreted as "basically identical with A but strictly inferior in a single dimension that the agent cares about." Based on this interpretation, we assume . Sweetening is the opposite, defined in the obvious way.
Formally, souring could be thought of as introducing a new preference relation , which is to be interpreted as "lottery B is basically identical to lottery A, but strictly inferior in a single dimension that the agent cares about".
- On the syntactic level, such is denoted as .
- On the semantic level, based on the above interpretation, is related to via the following:
This is where the language to talk about resources come from. "Something you can independently vary alongside a lottery A such that more of it makes you prefer that option compared to A alone" sounds like what we'd intuitively call a resource[1].
Now that we have the language, notice that so far we haven't assumed sourings or sweetenings exist. The following assumption does it:
Unidimensional Continuity of Preference: If , then there exists a prospect such that 1) is a souring of X and 2) .
Which gives a more operational characterization of souring as something that lets us interpolate between the preference margins of two lotteries - intuitively satisfied by e.g., money due to its infinite divisibility.
So the above assumption is where the assumption of resources come into play. I'm not aware of any money pump arguments for this assumption, or more generally, for the existence of a "resource." Plausibly instrumental convergence.
- ^
I don't actually think this + the assumption below fully capture what we intuitively mean by "resources", enough to justify this terminology. I stuck with "resources" anyways because others around here used that term to (I think?) refer to what I'm describing here.
Yeah I'd like to know if there's a unified way of thinking about information theoretic quantities and causal quantities, though a quick literature search doesn't show up anything interesting. My guess is that we'd want separate boundary metrics for informational separation and causal separation.
I no longer think the setup above is viable, for reasons that connect to why I think Critch's operationalization is incomplete and why boundaries should ultimately be grounded in Pearlian Causality and interventions.
(Note: I am thinking as I'm writing, so this might be a bit rambly.)
The world-trajectory distribution is ambiguous.
Intuition: Why does a robust glider in Lenia intuitively feel like a system possessing boundary? Well, I imagine various situations that happen in the world (like bullets) and this pattern mostly stays stable in face of them.
Now, notice that the measure of infiltration/exfiltration depends on , a distribution over world history.
So, for the above measure to capture my intuition, the approximate Markov condition (operationalized by low infil & exfil) must consider the world state that contains the Lenia pattern with it avoiding bullets.
Remember, is the raw world state, no coarse graining. So is the distribution over the raw world trajectory. It already captures all the "potentially occurring trajectories under which the system may take boundary-preserving-action." Since everything is observed, our distribution already encodes all of "Nature's Intervention." So in some sense Critch's definition is already causal (in a very trivial sense), by the virtue of requiring a distribution over the raw world trajectory, despite mentioning no Pearlian Causality.
Issue: Choice of
Maybe there is some canonical true for our physical world that minds can intersubjectively arrive at, so there's no ambiguity.
But when I imagine trying to implement this scheme on Lenia, there's immediately an ambiguity as to which distribution (representing my epistemic state on which raw world trajectories that will "actually happen") we should choose:
- Perhaps a very simple distribution: assigning uniform probability over world trajectories where the world contains nothing but the glider moving in a random direction with some initial point offset.
- I suspect many stances other the one factorizing the world into gliders would have low infil/exfil, because the world is so simple. This is the case of "accidental boundary-ness."
- Perhaps something more complicated: various trajectories where e.g., the Lenia patterns encounters bullets, evolves with various other patterns, etc.
- This I think rules out "accidental boundary-ness."
I think the latter works. But now there's a subjective choice of the distribution, and what are the set of possible/realistic "Nature's Intervention" - all the situations that can ever be encountered by the system under which it has boundary-like behaviors - that we want to implicitly encode into our observational distribution. I don't think it's natural for assign much probability to a trajectory whose initial conditions are set in a very precise way such that everything decays into noise. But this feels quite subjective.
Hints toward a solution: Causality
I think the discussion above hints at a very crucial insight:
must arise as a consequence of the stable mechanisms in the world.
Suppose the world of Lenia contains various stable mechanisms like a gun that shoots bullets at random directions, scarce food sources, etc.
We want to describe distributions that the boundary system will "actually" experience in some sense. I want the "Lenia pattern dodges bullet" world trajectory to be considered, because there is a plausible mechanism in the world that can cause such trajectories to exist. For similar reasons, I think the empty world distributions are impoverished, and a distribution containing trajectories where the entire world decays into noise is bad because no mechanism can implement it.
Thus, unless you have a canonical choice of , a better starting point would be to consider the abstract causal model that encodes the stable mechanisms in the world, and using Discovering Agents-style interventional algorithms that operationalize the notion "boundaries causally separate environment and viscera."
- Well, because of everything mentioned above on how the causal model informs us on which trajectories are realistic, especially in the absence of a canonical . It's also far more efficient, because the knowledge of the mechanism informs the algorithm of the precise interventions to query the world for, instead of having to implicitly bake them in .
There are still a lot more questions, but I think this is a pretty clarifying answer as to how Critch's boundaries are limiting and why DA-style causal methods will be important.
I think it's plausible that the general concept of boundaries can possibly be characterized somewhat independently of preferences, but at the same time have boundary-preservation be a quality that agents mostly satisfy (discussion here. very unsure about this). I see Critch's definition as a first iteration of an operationalization for boundaries in the general, somewhat-preference-independent sense.
But I do agree that ultimately all of this should tie back to game theory. I find Discovering Agents most promising in this regards, though there are still a lot of problems - some of which I suspect might be easier to solve if we treat systems-with-high-boundaryness as a sort of primitive for the kind-of-thing that we can associate agency and preferences with in the first place.
EDIT: I no longer think this setup is viable, for reasons that connect to why I think Critch's operationalization is incomplete and why boundaries should ultimately be grounded in Pearlian Causality and interventions. Check update.
I believe there's nothing much in the way of actually implementing an approximation of Critch's boundaries[1] using deep learning.
Recall, Critch's boundaries are:
- Given a world (markovian stochastic process) , map its values (vector) bijectively using into 'features' that can be split into four vectors each representing a boundary-possessing system's Viscera, Active Boundary, Passive Boundary, and Environment.
- Then, we characterize boundary-ness (i.e. minimal information flow across features unmediated by a boundary) using two mutual information criterion each representing infiltration and exfiltration of information.
- And a policy of the boundary-posessing system (under the 'stance' of viewing the world implied by ) can be viewed as a stochastic map (that has no infiltration/exfiltration by definition) that best approximates the true dynamics.
- The interpretation here (under low exfiltration and infiltration) is that can be viewed as a policy taken by the system in order to perpetuate its boundary-ness into the future and continue being well-described as a boundary-posessing system.
All of this seems easily implementable using very basic techniques from deep learning!
- Bijective feature map are implemented using two NN maps each way, with an autoencoder loss.
- Mutual information is approximated with standard variational approximations. Optimize to minimize it.
- (the interpretation here being - we're optimizing our 'stance' towards the world in a way that best views the world as a boundary-possessing system)
- After you train your 'stance' using the above setup, learn the policy using an NN with standard SGD, with fixed .
A very basic experiment would look something like:
- Test the above setup on two cellular automata (e.g., GoL, Lenia, etc) systems, one containing just random ash, and the other some boundary-like structure like noise-resistant glider structures found via optimization (there are a lot of such examples in the Lenia literature).[2]
- Then (1) check if the infiltration/exfiltration values are lower for the latter system, and (2) do some interp to see if the V/A/P/E features or the learned policy NN have any interesting structures.
I'm not sure if I'd be working on this any time soon, but posting the idea here just in case people have feedback.
- ^
I think research on boundaries - both conceptual work and developing practical algorithms for approximating them & schemes involving them - are quite important for alignment for reasons discussed earlier in my shortform.
- ^
Ultimately we want our setup to detect boundaries that aren't just physically contiguous chunks of matter, like informational boundaries, so we want to make sure our algorithm isn't just always exploiting basic locality heuristics.
I can't think of a good toy testbed (ideas appreciated!), but one easy thing to try is to just destroy all locality by mapping the automata lattice (which we were feeding as input) with the output of a complicated fixed bijective map over it, so that our system will have to learn locality if it turns out to be a useful notion in its attempt at viewing the system as a boundary.
Damn, why did Pearl recommend readers (in the preface of his causality book) to read all the chapters other than chapter 2 (and the last review chapter)? Chapter 2 is literally the coolest part - inferring causal structure from purely observational data! Almost skipped that chapter because of it ...
Here's my current take, I wrote it as a separate shortform because it got too long. Thanks for prompting me to think about this :)
I find the intersection of computational mechanics, boundaries/frames/factored-sets, and some works from the causal incentives group - especially discovering agents and robust agents learn causal world model (review) - to be a very interesting theoretical direction.
By boundaries, I mean a sustaining/propagating system that informationally/causally insulates its 'viscera' from the 'environment,' and only allows relatively small amounts of deliberate information flow through certain channels in both directions. Living systems are an example of it (from bacteria to humans). It doesn't even have to be a physically distinct chunk of spacetime, they can be over more abstract variables like societal norms. Agents are an example of it.
I find them very relevant to alignment especially from the direction of detecting such boundary-possessing/agent-like structures embedded in a large AI system and backing out a sparse relationship between these subsystems, which can then be used to e.g., control the overall dynamic. Check out these posts for more.
A prototypical deliverable would be an algorithm that can detect such 'boundaries' embedded in a dynamical system when given access to some representation of the system, performs observations & experiments and returns a summary data structure of all the 'boundaries' embedded in a system and their desires/wants, how they game-theoretically relate to one another (sparse causal relevance graph?), the consequences of interventions performed on them, etc - that's versatile enough to detect e.g., gliders embedded in Game of Life / Particle Lenia, agents playing Minecraft while only given coarse grained access to the physical state of the world, boundary-like things inside LLMs, etc. (I'm inspired by this)
Why do I find the aforementioned directions relevant to this goal?
- Critch's Boundaries operationalizes boundaries/viscera/environment as functions of the underlying variable that executes policies that continuously prevents information 'flow' [1] between disallowed channels, quantified via conditional transfer entropy.
- Relatedly, Fernando Rosas's paper on Causal Blankets operationalize boundaries using a similar but subtly different[2] form of mutual information constraint on the boundaries/viscera/environment variables than that of Critch's. Importantly, they show that such blankets always exist between two coupled stochastic processes (using a similar style of future morph equivalence relation characterization from compmech, and also a metric they call "synergistic coefficient" that quantifies how boundary-like this thing is.[3]
- More on compmech, epsilon transducers generalize epsilon machines to input-output processes. PALO (Perception Action Loops) and Boundaries as two epsilon transducers coupled together?
- These directions are interesting, but I find them still unsatisfactory because all of them are purely behavioral accounts of boundaries/agency. One of the hallmarks of agentic behavior (or some boundary behaviors) is adapting ones policy if an intervention changes the environment in a way that the system can observe and adapt to.[4][5]
- (is there an interventionist extension of compmech?)
- Discovering agents provide a genuine causal, interventionist account of agency and an algorithm to detect them, motivated by the intentional stance. I think the paper is very enlightening from a conceptual perspective, but there are many problems yet to be solved before we can actually implement this. Here's my take on it.
- More fundamentally, (this is more vibes, I'm really out of my depth here) I feel there is something intrinsically limiting with the use of Bayes Nets, especially with the fact that choosing which variables to use in your Bayes Net already encodes a lot of information about the specific factorization structure of the world. I heard good things about finite factored sets and I'm eager to learn more about them.
- ^
Not exactly a 'flow', because transfer entropy conflates between intrinsic information flow and synergistic information - a 'flow' connotes only the intrinsic component, while transfer entropy just measures the overall amount of information that a system couldn't have obtained on its own. But anyways, transfer entropy seems like a conceptually correct metric to use.
- ^
Specifically, Fernando's paper criticizes blankets of the following form ( for viscera, and for active/passive boundaries, for environment):
- DIP implies
- This clearly forbids dependencies formed in the past that stays in 'memory'.
but Critch instead defines boundaries as satisfying the following two criteria:
- (infiltration)
- DIP implies
- (exfiltration)
- DIP implies
- and now that the independencies are entangled across different t, there is no longer a clear upper bound on , so I don't think the criticisms apply directly.
- ^
My immediate curiosities are on how these two formalisms relate to one another. e.g., Which independency requirements are more conceptually 'correct'? Can we extend the future-morph construction to construct Boundaries for Critch's formalism? etc etc
- ^
For example, a rock is very goal-directed relative to 'blocking-a-pipe-that-happens-to-exactly-match-its-size,' until one performs an intervention on the pipe size to discover that it can't adapt at all.
- ^
Also, interventions are really cheap to run on digital systems (e.g., LLMs, cellular automata, simulated environments)! Limiting oneself to behavioral accounts of agency would miss out on a rich source of cheap information.
Discovering agents provide a genuine causal, interventionist account of agency and an algorithm to detect them, motivated by the intentional stance. I find this paper very enlightening from a conceptual perspective!
I've tried to think of problems that needed to be solved before we can actually implement this on real systems - both conceptual and practical - on approximate order of importance.
- There are no 'dynamics,' no learning. As soon as a mechanism node is edited, it is assumed that agents immediately change their 'object decision variable' (a conditional probability distribution given its object parent nodes) to play the subgame equilibria.
- Assumption of factorization of variables into 'object' / 'mechanisms,' and the resulting subjectivity. The paper models the process by which an agent adapts its policy given changes in the mechanism of the environment via a 'mechanism decision variable' (that depends on its mechanism parent nodes), which modulates the conditional probability distribution of its child 'object decision variable', the actual policy.
- For example, the paper says a learned RL policy isn't an agent, because interventions in the environment won't make it change its already-learned policy - but that a human or a RL policy together with its training process is an agent, because it can adapt. Is this reasonable?
- Say I have a gridworld RL policy that's learned to get cheese (3 cell world, cheese always on left) by always going to the left. Clearly it can't change its policy when I change the cheese distribution to favor right, so it seems right to call this not an agent.
- Now, say the policy now has sensory access to the grid state, and correctly generalized (despite only being trained on left-cheese) to move in the direction where it sees the cheese, so when I change the cheese distribution, it adapts accordingly. I think it is right to call this an agent?
- Now, say the policy is an LLM agent (static weight) on an open world simulation which reasons in-context. I just changed the mechanism of the simulation by lowering the gravity constant, and the agent observes this, reasons in-context, and adapts its sensorimotor policy accordingly. This is clearly an agent?
- I think this is because the paper considers, in the case of the RL policy alone, the 'object policy' to be the policy of the trained neural network (whose induced policy distribution is definitionally fixed), and the 'mechanism policy' to be a trivial delta function assigning the already-trained object policy. And in the case of the RL policy together with its training process, the 'mechanism policy' is now defined as the training process that assigns the fully-trained conditional probability distribution to the object policy.
- But what if the 'mechanism policy' was the in-context learning process by which it induces an 'object policy'? Then changes in the environment's mechanism can be related to the 'mechanism policy' and thus the 'object policy' via in-context learning as in the second and third example, making them count as agents.
- Ultimately, the setup in the paper forces us to factorize the means-by-which-policies-adapt into mechanism vs object variables, and the results (like whether a system is to be considered an agent) depends on this factorization. It's not always clear what the right factorization is, how to discover them from data, or if this is the right frame to think about the problem at all.
- For example, the paper says a learned RL policy isn't an agent, because interventions in the environment won't make it change its already-learned policy - but that a human or a RL policy together with its training process is an agent, because it can adapt. Is this reasonable?
- Implicit choice of variables that are convenient for agent discovery. The paper does mention that the algorithm is dependent in the choice of the variable, as in: if the node corresponding to the 'actual agent decision' is missing but its children is there, then the algorithm will label its children to be the decision nodes. But this is already a very convenient representation!
- Prototypical example: Minecraft world with RL agents interacting represented as a coarse-grained lattice (dynamical Bayes Net?) with each node corresponding to a physical location and its property, like color. Clearly no single node here is an agent, because agents move! My naive guess is that in principle, everything will be labeled an agent.
- So the variables of choice must be abstract variables of the underlying substrate, like functions over them. But then, how do you discover the right representation automatically, in a way that interventions in the abstract variable level can faithfully translate to actually performable interventions in the underlying substrate?
- Given the causal graph, even the slightest satisfaction of the agency-criterion labels the nodes as decision / utility. No "degree-of-agency" - maybe by summing over the extent to which the independencies fail to satisfy?
- Then different agents are defined as causally separated chunks (~connected component) of [set-of-decision-nodes / set-of-utility-nodes]. How do we accommodate hierarchical agency (like subagents), systems with different degrees of agency, etc?
- The interventional distribution on the object/mechanism variables are converted into a causal graph using the obvious [perform-do()-while-fixing-everything-else] algorithm. My impression is that causal discovery doesn't really work in practice, especially in noisy reality with a large number of variables via gazillion conditional independence tests.
- The correctness proof requires lots of unrealistic assumptions, e.g., agents always play subgame equilibria, though I think some of this can be relaxed.
Thanks, it seems like the link got updated. Fixed!
Quick paper review of Measuring Goal-Directedness from the causal incentives group.
tl;dr, goal directedness of a policy wrt a utility function is measured by its min distance to one of the policies implied by the utility function, as per the intentional stance - that one should model a system as an agent insofar as doing so is useful.
Details
- how is "policies implied by the utility function" operationalized? given a value , we define a set containing policies of maximum entropy (of the decision variable, given its parents in the causal bayes net) among those policies that attain the utility .
- then union them over all the achievable values of to get this "wide set of maxent policies," and define goal directedness of a policy wrt a utility function as the maximum (negative) cross entropy between and an element of the above set. (actually we get the same result if we quantify the min operation over just the set of maxent policies achieving the same utility as .)
Intuition
intuitively, this is measuring: "how close is my policy to being 'deterministic,' while 'optimizing at the competence level ' and not doing anything else 'deliberately'?"
- "close" / "deterministic" ~ large negative means small
- "not doing anything else deliberately'" ~ because we're quantifying over maxent policies. the policy is maximally uninformative/uncertain, the policy doesn't take any 'deliberate' i.e. low entropy action, etc.
- "at the competence level " ~ ... under the constraint that it is identically competent to
and you get the nice property of the measure being invariant to translation / scaling of .
- obviously so, because a policy is maxent among all policies achieving on iff that same policy is maxent among all policies achieving on , so these two utilities have the same "wide set of maxent policies."
Critiques
I find this measure problematic in many places, and am confused whether this is conceptually correct.
- one property claimed is that the measure is maximum for uniquely optimal / anti-optimal policy.
- it's interesting that this measure of goal-directedness isn't exactly an ~increasing function of , and i think it makes sense. i want my measure of goal-directedness to, when evaluated relative to human values, return a large number for both aligned ASI and signflip ASI.
- ... except, going through the proof one finds that the latter property heavily relies on the "uniqueness" of the policy.
- My policy can get the maximum goal-directedness measure if it is the only policy of its competence level while being very deterministic. It isn't clear that this always holds for the optimal/anti-optimal policies or always relaxes smoothly to epsilon-optimal/anti-optimal policies.
- Relatedly, the fact that the quantification is only happening over policies of the same competence level, which feels problematic.
minimum for uniformly random policy(this would've been a good property, but unless I'm mistaken I think the proof for the lower bound is incorrect, because negative cross entropy is not bounded below.)- honestly the maxent motivation isn't super clear to me.
- not causal. the reason you need causal interventions is because you want to rule out accidental agency/goal-directedness, like a rock that happens to be the perfect size to seal a water bottle - does your rock adapt when I intervene to change the size of the hole? discovering agents is excellent in this regards.
Thank you, that is very clarifying!
I've been doing a deep dive on this post, and while the main theorems make sense I find myself quite confused about some basic concepts. I would really appreciate some help here!
- So 'latents' are defined by their conditional distribution functions whose shape is implicit in the factorization that the latents need to satisfy, meaning they don't have to always look like , they can look like , etc, right?
- I don't get the 'standard form' business. It seems like a procedure to turn one latent variable into another relative to ? I don't get what the notation means—does it mean that it takes defined by some conditional distribution function like and converts it into ? That doesn't seem so, the notation looks more like a likelihood function than a conditional distribution. But then what conditional distribution defines this latent ?
The Resampling stuff is a bit confusing too:
if we have a natural latent , then construct a new natural latent by resampling conditional on (i.e. sample from ), independently of whatever other stuff we’re interested in.
- I don't know what operation is being performed here - what CPDs come in, what CPDs leave.
- "construct a new natural latent by resampling conditional on (i.e. sample from ), independently of whatever other stuff we’re interested in." isn't this what we are already doing when stating a diagram like , which implies a factorization , none of which have ! What changes when resampling? aaaaahhh I think I'm really confused here.
- Also does all this imply that we're starting out assuming that shares a probability space with all the other possible latents, e.g. ? How does this square with a latent variable being defined by the CPD implicit in the factorization?
And finally:
In standard form, a natural latent is always approximately a deterministic function of . Specifically: .
...
Suppose there exists an approximate natural latent over . Construct a new random variable sampled from the distribution . (In other words: simultaneously resample each given all the others.) Conjecture: is an approximate natural latent (though the approximation may not be the best possible). And if so, a key question is: how good is the approximation?
Where is the top result proved, and how is this statement different from the Universal Natural Latent Conjecture below? Also is this post relevant to either of these statements, and if so, does that mean they only hold under strong redundancy?
Does anyone know if Shannon arrive at entropy from the axiomatic definition first, or the operational definition first?
I've been thinking about these two distinct ways in which we seem to arrive at new mathematical concepts, and looking at the countless partial information decomposition measures in the literature all derived/motivated based on an axiomatic basis, and not knowing which intuition to prioritize over which, I've been assigning less premium on axiomatic conceptual definitions than i used to:
- decision theoretic justification of probability > Cox's theorem
- shannon entropy as min description length > three information axioms
- fernando's operational definition of synergistic information > rest of the literature with its countless non-operational PID measures
The basis of comparison would be its usefulness and ease-of-generalization to better concepts:
- at least in the case of fernando's synergistic information, it seems far more useful because i at least know what i'm exactly getting out of it, unlike having to compare between the axiomatic definitions based on handwavy judgements.
- for ease of generalization, the problem with axiomatic definitions is that there are many logically equivalent ways to state the initial axiom (from which they can then be relaxed), and operational motivations seem to ground these equivalent characterizations better, like logical inductors from the decision theoretic view of probability theory
(obviously these two feed into each other)
Just finished the local causal states paper, it's pretty cool! A couple of thoughts though:
I don't think the causal states factorize over the dynamical bayes net, unlike the original random variables (by assumption). Shalizi doesn't claim this either.
- This would require proving that each causal state is conditionally independent of its nondescendant causal states given its parents, which is a stronger theorem than what is proved in Theorem 5 (only conditionally independent of its ancestor causal states, not necessarily all the nondescendants)
Also I don't follow the Markov Field part - how would proving:
if we condition on present neighbors of the patch, as well as the parents of the patch, then we get independence of the states of all points at time t or earlier. (pg 16)
... show that the causal states is a markov field (aka satisfies markov independencies (local or pairwise or global) induced by an undirected graph)? I'm not even sure what undirected graph the causal states would be markov with respect to. Is it the ...
- ... skeleton of the dynamical Bayes Net? that would require proving a different theorem: "if we condition on parents and children of the patch, then we get independence of all the other states" which would prove local markov independency
- ... skeleton of the dynamical Bayes Net + edges for the original graph for each t? that would also require proving a different theorem: "if we condition on present neighbors, parents, and children of the patch, then we get independence of all the other states" which would prove local markov independency
Also for concreteness I think I need to understand its application in detecting coherent structures in cellular automata to better appreciate this construction, though the automata theory part does go a bit over my head :p
a Markov blanket represents a probabilistic fact about the model without any knowledge you possess about values of specific variables, so it doesn't matter if you actually do know which way the agent chooses to go.
The usual definition of Markov blankets is in terms of the model without any knowledge of the specific values as you say, but I think in Critch's formalism this isn't the case. Specifically, he defines the 'Markov Boundary' of (being the non-abstracted physics-ish model) as a function of the random variable (where he writes e.g. ), so it can depend on the values instantiated at .
- it would just not make sense to try to represent agent boundaries in a physics-ish model if we were to use the usual definition of Markov blankets - the model would just consist of local rules that are spacetime homogeneous, so there is no reason to expect one can apriori carve out an agent from the model without looking at its specific instantiated values.
- can really be anything, so doesn't necessarily have to correspond to physical regions (subsets) of , but they can be if we choose to restricting our search of infiltration/exfiltration-criteria-satisfying to functions that only return boundaries-in-the-sense-of-carving-the-physical-space.
- e.g. can represent which subset of the physical boundary is, like 0, 0, 1, 0, 0, ... 1, 1, 0
So I think under this definition of Markov blankets, they can be used to denote agent boundaries, even in physics-ish models (i.e. ones that relate nicely to causal relationships). I'd like to know what you think about this.
I thought if one could solve one NP-complete problem then one can solve all of them. But you say that the treewidth doesn't help at all with the Clique problem. Is the parametrized complexity filtration by treewidth not preserved by equivalence between different NP-complete problems somehow?
All NP-complete problems should have parameters that makes the problem polynomial when bounded, trivially so by the => 3-SAT => Bayes Net translation, and using the treewidth bound.
This isn't the case for the clique problem (finding max clique) because it's not NP-complete (it's not a decision problem), so we don't necessarily expect its parameterized version to be polynomial tractable — in fact, it's the k-clique problem (yes/no is there a clique larger than size k) that is NP-complete. (so by the above translation argument, there certainly exists some graphical quantity that when bounded makes the k-clique problem tractable, though I'm not aware of it, or whether it's interesting)
To me, the interesting question is whether:
- (1) translating a complexity-bounding parameter from one domain to another leads to quantities that are semantically intuitive and natural in the respective domain.
- (2) and whether easy instances of the problems in the latter domain in-practice actually have low values of the translated parameter.
- rambling: If not, then that implies we need to search for a new for this new domain. Perhaps this can lead to a whole new way of doing complexity class characterization by finding natural -s for all sorts of NP-complete problems (whose natural -s don't directly translate to one another), and applying these various "difficulty measures" to characterize your NP-complete problem at hand! (I wouldn't be surprised if this is already widely studied.)
Looking at the 3-SAT example ( are the propositional variables, the ORs, and the AND with serving as intermediate ANDs):
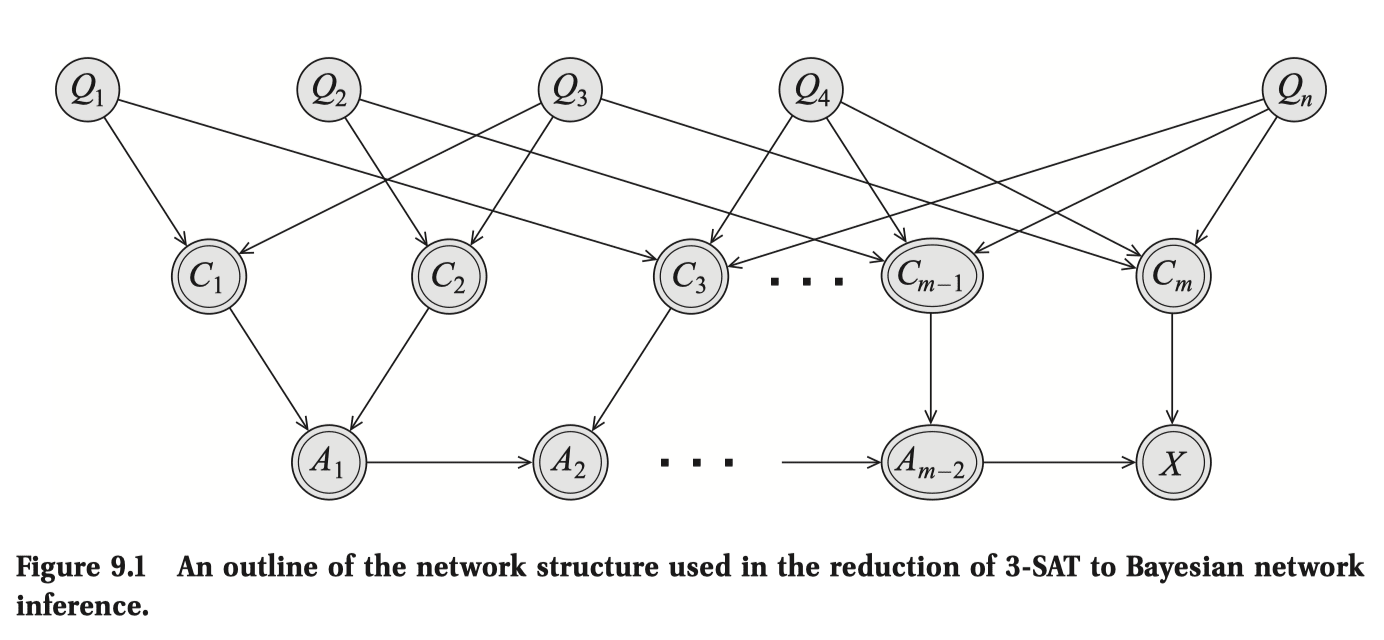
- re: (1), at first glance the treewidth of 3-SAT (clearly dependent on the structure of the - interaction) doesn't seem super insightful or intuitive, though we may count the statement "a 3-SAT problem gets exponentially harder as you increase the formula-treewidth" as progress.
- ... but even that wouldn't be an if and only if characterization of 3-SAT difficulty, because re: (2) there exist easy-in-practice 3-SAT problems that don't necessarily have bounded treewidth (i haven't read the link).
I would be interested in a similar analysis for more NP-complete problems known to have natural parameterized complexity characterization.
You mention treewidth - are there other quantities of similar importance?
I'm not familiar with any, though ChatGPT does give me some examples! copy-pasted below:
- Solution Size (k): The size of the solution or subset that we are trying to find. For example, in the k-Vertex Cover problem, k is the maximum size of the vertex cover. If k is small, the problem can be solved more efficiently.
- Treewidth (tw): A measure of how "tree-like" a graph is. Many hard graph problems become tractable when restricted to graphs of bounded treewidth. Algorithms that leverage treewidth often use dynamic programming on tree decompositions of the graph.
- Pathwidth (pw): Similar to treewidth but more restrictive, pathwidth measures how close a graph is to a path. Problems can be easier to solve on graphs with small pathwidth.
- Vertex Cover Number (vc): The size of the smallest vertex cover of the graph. This parameter is often used in graph problems where knowing a small vertex cover can simplify the problem.
- Clique Width (cw): A measure of the structural complexity of a graph. Bounded clique width can be used to design efficient algorithms for certain problems.
- Max Degree (Δ): The maximum degree of any vertex in the graph. Problems can sometimes be solved more efficiently when the maximum degree is small.
- Solution Depth (d): For tree-like or hierarchical structures, the depth of the solution tree or structure can be a useful parameter. This is often used in problems involving recursive or hierarchical decompositions.
- Branchwidth (bw): Similar to treewidth, branchwidth is another measure of how a graph can be decomposed. Many algorithms that work with treewidth also apply to branchwidth.
- Feedback Vertex Set (fvs): The size of the smallest set of vertices whose removal makes the graph acyclic. Problems can become easier on graphs with a small feedback vertex set.
- Feedback Edge Set (fes): Similar to feedback vertex set, but involves removing edges instead of vertices to make the graph acyclic.
- Modular Width: A parameter that measures the complexity of the modular decomposition of the graph. This can be used to simplify certain problems.
- Distance to Triviality: This measures how many modifications (like deletions or additions) are needed to convert the input into a simpler or more tractable instance. For example, distance to a clique, distance to a forest, or distance to an interval graph.
- Parameter for Specific Constraints: Sometimes, specific problems have unique natural parameters, like the number of constraints in a CSP (Constraint Satisfaction Problem), or the number of clauses in a SAT problem.
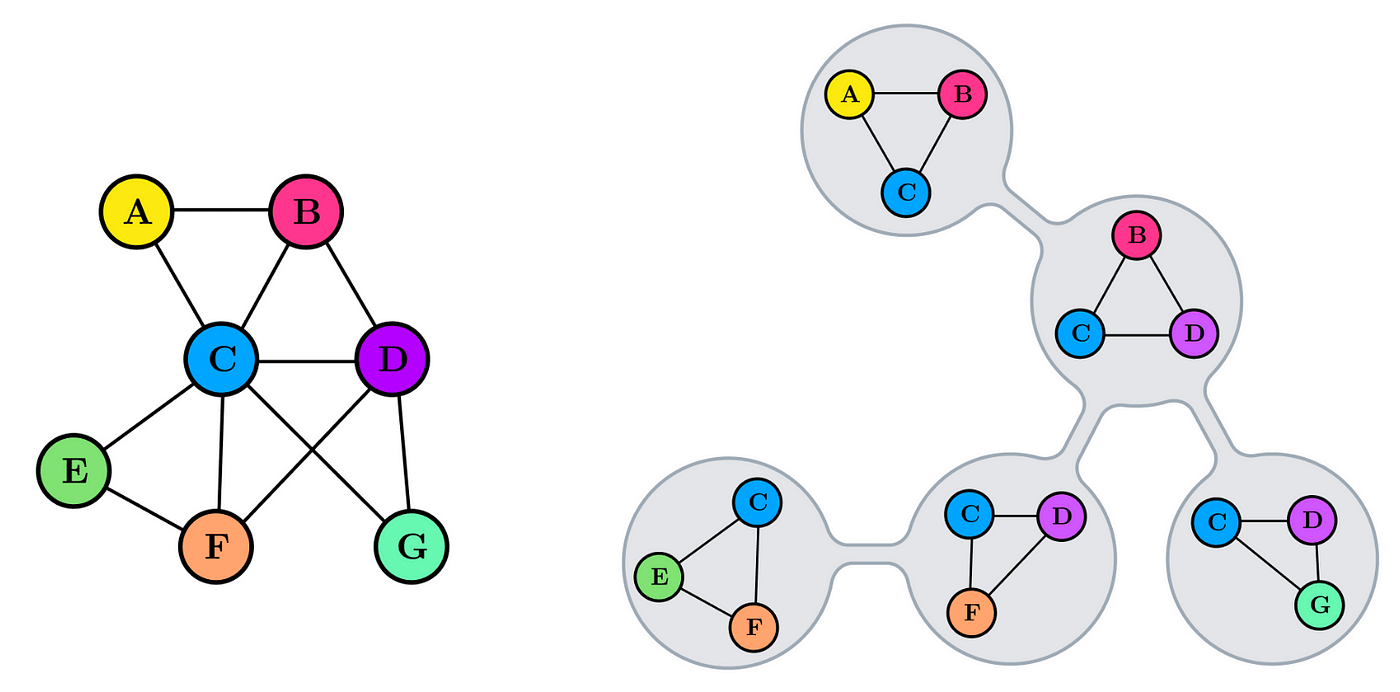
I like to think of treewidth in terms of its characterization from tree decomposition, a task where you find a clique tree (or junction tree) of an undirected graph.
Clique trees for an undirected graph is a tree such that:
- node of a tree corresponds to a clique of a graph
- maximal clique of a graph corresponds to a node of a tree
- given two adjacent tree nodes, the clique they correspond to inside the graph is separated given their intersection set (sepset)
You can check that these properties hold in the example below. I will also refer to nodes of a clique tree as 'cliques'. (image from here)
My intuition for the point of tree decompositions is that you want to coarsen the variables of a complicated graph so that they can be represented in a simpler form (tree), while ensuring the preservation of useful properties such as:
- how the sepset mediates (i.e. removing the sepset from the graph separates the variables associated with all of the nodes on one side of the tree with another) the two cliques in the original graph
- clique trees satisfy the running intersection property: if (the cliques corresponding to) the two nodes of a tree contain the same variable X, then X is also contained in (the cliques corresponding to) each and all of the intermediate nodes of the tree.
- Intuitively, information flow about a variable must connected, i.e. they can't suddenly disappear and reappear in the tree.
Of course tree decompositions aren't unique (image):
{kind=link}
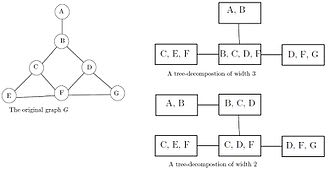
So we define .
- Intuitively, treewidths represent the degree to which nodes of a graph 'irreducibly interact with one another', if you really want to see the graph as a tree.
- e.g., the first clique tree of the image above is a suboptimal coarse graining in that it misleadingly characterizes as having a greater degree of 'irreducible interaction' among.
Bayes Net inference algorithms maintain its efficiency by using dynamic programming over multiple layers.
Level 0: Naive Marginalization
- No dynamic programming whatsoever. Just multiply all the conditional probability distribution (CPD) tables, and sum over the variables of non-interest.
Level 1: Variable Elimination
- Cache the repeated computations within a query.
- For example, given a chain-structured Bayes Net , instead of doing , we can do . Check my post for more.
Level 2: Clique-tree based algorithms — e.g., Sum-product (SP) / Belief-update (BU) calibration algorithms
- Cache the repeated computations across queries.
- Suppose you have a fixed Bayes Net, and you want to compute the marginalization not only , but also . Clearly running two instances of Variable Elimination as above is going to contain some overlapping computation.
- Clique-tree is a data structure where, given the initial factors (in this case the CPD tables), you "calibrate" a tree whose nodes correspond to a subset of the variables. Cost can be amortized by running many queries over the same Bayes Net.
- Calibration can be done by just two passes across the tree, after which you have the joint marginals for all the nodes of the clique tree.
- Incorporating evidence is equally simple. Just zero-out the entries of variables that you are conditioning on for some node, then "propagate" that information downwards via a single pass across the tree.
Level 3: Specialized query-set answering algorithms over a calibrated clique tree.
- Cache the repeated computations across a certain query-class
- e.g., computing for every pair of variables can be done by using yet another layer of dynamic programming by maintaining a table of for each pair of clique-tree nodes ordered according to their distance in-between.
Perhaps I should one day in the far far future write a sequence on bayes nets.
Some low-effort TOC (this is basically mostly koller & friedman):
- why bayesnets and markovnets? factorized cognition, how to do efficient bayesian updates in practice, it's how our brain is probably organized, etc. why would anyone want to study this subject if they're doing alignment research? explain philosophy behind them.
- simple examples of bayes nets. basic factorization theorems (the I-map stuff and separation criterion)
- tangent on why bayes nets aren't causal nets, though Zack M Davis had a good post on this exact topic, comment threads there are high insight
- how inference is basically marginalization (basic theorems of: a reduced markov net represents conditioning, thus inference upon conditioning is the same as marginalization on a reduced net)
- why is marginalization hard? i.e. NP-completeness of exact and approximate inference worst-case
what is a workaround? solve by hand simple cases in which inference can be greatly simplified by just shuffling in the order of sums and products, and realize that the exponential blowup of complexity is dependent on a graphical property of your bayesnet called the treewidth - exact inference algorithms (bounded by treewidth) that can exploit the graph structure and do inference efficiently: sum-product / belief-propagation
- approximate inference algorithms (works in even high treewidth! no guarantee of convergence) - loopy belief propagation, variational methods, etc
- connections to neuroscience: "the human brain is just doing belief propagation over a bayes net whose variables are the cortical column" or smth, i just know that there is some connection
Just read through Robust agents learn causal world models and man it is really cool! It proves a couple of bona fide selection theorems, talking about the internal structure of agents selected against a certain criteria.
- Tl;dr, agents selected to perform robustly in various local interventional distributions must internally represent something isomorphic to a causal model of the variables upstream of utility, for it is capable of answering all causal queries for those variables.
- Thm 1: agents achieving optimal policy (util max) across various local interventions must be able to answer causal queries for all variables upstream of the utility node
- Thm 2: relaxation of above to nonoptimal policies, relating regret bounds to the accuracy of the reconstructed causal model
- the proof is constructive - an algorithm that, when given access to regret-bounded-policy-oracle wrt an environment with some local intervention, queries them appropriately to construct a causal model
- one implication is an algorithm for causal inference that converts black box agents to explicit causal models (because, y’know, agents like you and i are literally that aforementioned ‘regret-bounded-policy-oracle‘)
- These selection theorems could be considered the converse of the well-known statement that given access to a causal model, one can find an optimal policy. (this and its relaxation to approximate causal models is stated in Thm 3)
- Thm 1 / 2 is like a ‘causal good regulator‘ theorem.
- gooder regulator theorem is not structural - as in, it gives conditions under which a model of the regulator must be isomorphic to the posterior of the system - a black box statement about the input-output behavior.
- theorem is limited. only applies to cases where the decision node is not upstream of the environment nodes (eg classification. a negative example would be an mdp). but authors claim this is mostly for simpler proofs and they think this can be relaxed.