Lucius Bushnaq's Shortform
post by Lucius Bushnaq (Lblack) · 2024-07-06T09:08:43.607Z · LW · GW · 100 commentsContents
100 comments
100 comments
Comments sorted by top scores.
comment by Lucius Bushnaq (Lblack) · 2024-09-05T11:43:36.681Z · LW(p) · GW(p)
All current SAEs I'm aware of seem to score very badly on reconstructing the original model's activations.
If you insert a current SOTA SAE into a language model's residual stream, model performance on next token prediction will usually degrade down to what a model trained with less than a tenth or a hundredth of the original model's compute would get. (This is based on extrapolating with Chinchilla scaling curves at optimal compute). And that's for inserting one SAE at one layer. If you want to study circuits of SAE features, you'll have to insert SAEs in multiple layers at the same time, potentially further degrading performance.
I think many people outside of interp don't realize this. Part of the reason they don’t realize it might be that almost all SAE papers report loss reconstruction scores on a linear scale, rather than on a log scale or an LM scaling curve. Going from 1.5 CE loss to 2.0 CE loss is a lot worse than going from 4.5 CE to 5.0 CE. Under the hypothesis that the SAE is capturing some of the model's 'features' and failing to capture others, capturing only 50% or 10% of the features might still only drop the CE loss by a small fraction of a unit.
So, if someone is just glancing at the graphs without looking up what the metrics actually mean, they can be left with the impression that performance is much better than it actually is. The two most common metrics I see are raw CE scores of the model with the SAE inserted, and 'loss recovered'. I think both of these metrics give a wrong sense of scale. 'Loss recovered' is the worse offender, because it makes it outright impossible to tell how good the reconstruction really is without additional information. You need to know what the original model’s loss was and what zero baseline they used to do the conversion. Papers don't always report this, and the numbers can be cumbersome to find even when they do.
I don't know what an actually good way to measure model performance drop from SAE insertion is. The best I've got is to use scaling curves to guess how much compute you'd need to train a model that gets comparable loss, as suggested here. Or maybe alternatively, training with the same number of tokens as the original model, how many parameters you'd need to get comparable loss. Using this measure, the best reported reconstruction score I'm aware of is 0.1 of the original model's performance, reached by OpenAI's GPT-4 SAE with 16 million dictionary elements in this paper.
For most papers, I found it hard to convert their SAE reconstruction scores into this format. So I can't completely exclude the possibility that some other SAE scores much better. But at this point, I'd be quite surprised if anyone had managed so much as 0.5 performance recovered on any model that isn't so tiny and bad it barely has any performance to destroy in the first place. I'd guess most SAEs get something in the range 0.01-0.1 performance recovered or worse.
Note also that getting a good reconstruction score still doesn't necessarily mean the SAE is actually showing something real and useful. If you want perfect reconstruction, you can just use the standard basis of the network. The SAE would probably also need to be much sparser than the original model activations to provide meaningful insights.
Replies from: leogao, neel-nanda-1, alexander-gietelink-oldenziel, Sodium, keith_wynroe↑ comment by leogao · 2024-09-06T04:19:40.662Z · LW(p) · GW(p)
Basically agree - I'm generally a strong supporter of looking at the loss drop in terms of effective compute. Loss recovered using a zero-ablation baseline is really quite wonky and gives misleadingly big numbers.
I also agree that reconstruction is not the only axis of SAE quality we care about. I propose explainability as the other axis - whether we can make necessary and sufficient explanations for when individual latents activate. Progress then looks like pushing this Pareto frontier.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-09-06T10:40:04.856Z · LW(p) · GW(p)
This seems true to me, though finding the right scaling curve for models is typically quite hard so the conversion to effective compute is difficult. I typically use CE loss change, not loss recovered. I think we just don't know how to evaluate SAE quality.
My personal guess is that SAEs can be a useful interpretability tool despite making a big difference in effective compute, and we should think more in terms of useful they are for downstream tasks. But I agree this is a real phenomena, that is easy to overlook, and is bad.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-09-05T23:46:50.030Z · LW(p) · GW(p)
As a complete noob in all things mechinterp can somebody explain how this is not in conflict with SAE enjoyers saying they get reconstruction loss in the high 90s or even 100 %?
I understand the logscale argument that Lucius is making but still seems surprising ? Is this really what's going on or are they talking about different things here.
Replies from: ryan_greenblatt, Lblack↑ comment by ryan_greenblatt · 2024-09-06T00:16:07.070Z · LW(p) · GW(p)
The key question is 90% recovered relative to what. If you recover 90% of the loss relative to a 0 ablation baseline (that ablates the entire residual stream midway though the model!), that isn't clearly that much.
E.g., if full zero ablation is 13 CE loss (seems plausible) and the SAE gets you to 3 CE while the original model was at 2 CE, this is 90%, but you have also massively degraded performance in terms of effective training compute.
IDK about literal 100%.
↑ comment by Lucius Bushnaq (Lblack) · 2024-09-06T05:22:27.263Z · LW(p) · GW(p)
The metric you mention here is probably 'loss recovered'. For a residual stream insertion, it goes
1-(CE loss with SAE- CE loss of original model)/(CE loss if the entire residual stream is ablated-CE loss of original model)
See e.g. equation 5 here.
So, it's a linear scale, and they're comparing the CE loss increase from inserting the SAE to the CE loss increase from just destroying the model and outputting a ≈ uniform distribution over tokens. The latter is a very large CE loss increase, so the denominator is really big. Thus, scoring over 90% is pretty easy.
↑ comment by Sodium · 2024-09-06T06:32:53.212Z · LW(p) · GW(p)
Have people done evals for a model with/without an SAE inserted? Seems like even just looking at drops in MMLU performance by category could be non-trivially informative.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-09-06T07:19:45.641Z · LW(p) · GW(p)
I've seen a little bit of this, but nowhere near as much as I think the topic merits. I agree that systematic studies on where and how the reconstruction errors make their effects known might be quite informative.
Basically, whenever people train SAEs, or use some other approximate model decomposition that degrades performance, I think they should ideally spend some time after just playing with the degraded model and talking to it. Figure out in what ways it is worse.
Replies from: Sodium↑ comment by keith_wynroe · 2024-09-06T10:26:50.736Z · LW(p) · GW(p)
What are your thoughts on KL-div after the unembed softmax as a metric?
Replies from: Lblack, neel-nanda-1↑ comment by Lucius Bushnaq (Lblack) · 2024-09-06T11:06:49.802Z · LW(p) · GW(p)
On its own, this'd be another metric that doesn't track the right scale as models become more powerful.
The same KL-div in GPT-2 and GPT-4 probably corresponds to the destruction of far more of the internal structure in the latter than the former.
Destroy 95% of GPT-2's circuits, and the resulting output distribution may look quite different. Destroy 95% of GPT-4's circuits, and the resulting output distribution may not be all that different, since 5% of the circuits in GPT-4 might still be enough to get a lot of the most common token prediction cases roughly right.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-09-06T10:40:57.802Z · LW(p) · GW(p)
I don't see important differences between that and ce loss delta in the context Lucius is describing
comment by Lucius Bushnaq (Lblack) · 2025-04-14T09:48:54.604Z · LW(p) · GW(p)
The features a model thinks in do not need to form a basis or dictionary for its activations.
Three assumptions people in interpretability often make about the features that comprise a model’s ontology:
- Features are one-dimensional variables.
- Meaning, the value of feature on data point can be represented by some scalar number .
- Features are ‘linearly represented’.
- Features form a 'basis' for activation space.[3]
- Meaning, the model’s activations at a given layer can be decomposed into a sum over all the features of the model represented in that layer[4]: .
It seems to me that a lot of people are not tracking that 3) is an extra assumption they are making. I think they think that assumption 3) is a natural consequence of assumptions 1) and 2), or even just of assumption 2) alone. It's not.
Counterexample
Model setup
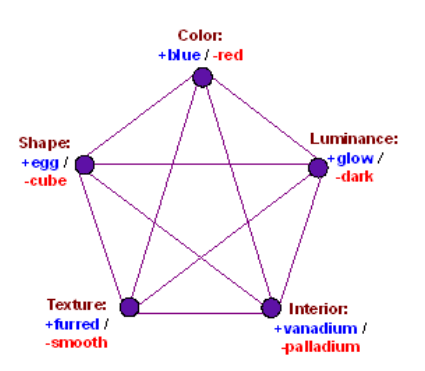
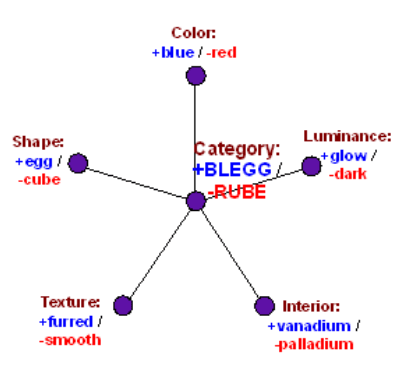
Suppose we have a language model that has a thousand sparsely activating scalar, linearly represented features for different animals. So, "elephant", "giraffe", "parrot", and so on all with their own associated feature directions . The model embeds those one thousand animal features in a fifty-dimensional sub-space of the activations. This subspace has a meaningful geometry: It is spanned by a set of fifty directions corresponding to different attributes animals have. Things like “furriness”, “size”, “length of tail” and such. So, each animal feature can equivalently be seen as either one of a thousand sparsely activating scalar feature, or just as a particular setting of those fifty not-so-sparse scalar attributes.
Some circuits in the model act on the animal directions . E.g. they have query-key lookups for various facts about elephants and parrots. Other circuits in the model act on the attribute directions . They’re involved in implementing logic like ‘if there’s a furry animal in the room, people with allergies might have problems’. Sometimes they’re involved in circuits that have nothing to do with animals whatsoever. The model’s "size" attribute is the same one used for houses and economies for example, so that direction might be read-in to a circuit storing some fact about economic growth.
So, both the one thousand animal features and the fifty attribute features are elements of the model’s ontology, variables along which small parts of its cognition are structured. But we can’t make a basis for the model activations out of those one thousand and fifty features of the model. We can write either , or . But does not equal the model activation vector , it’s too large.
Doing interp on this model
Say we choose as our basis for this subspace of the example model's activations, and then go on to make a causal graph of the model’s computation, with each basis element being a node in the graph, and lines between nodes representing connections. Then the circuits dealing with query-key lookups for animal facts will look neat and understandable at a glance, with few connections and clear logic. But the circuits involving the attributes will look like a mess. A circuit reading in the size direction will have a thousand small but collectively significant connections to all of the animals.
If we choose as our basis for the graph instead, circuits that act on some of the fifty attributes will look simple and sensible, but now the circuits storing animal facts will look like a mess. A circuit implementing "space" AND "cat" => [increase association with rainbows] is going to have fifty connections to features like “size” and “furriness’.
The model’s ontology does not correspond to either the basis or the basis. It just does not correspond to any basis of activation space at all, not even in a loose sense. Different circuits in the model can just process the activations in different bases, and they are under no obligation to agree with each other. Not even if they are situated right next to each other, in the same model layer.
Note that for all of this, we have not broken assumption 1) or assumption 2). The features this model makes use of are all linearly represented and scalar. We also haven’t broken the secret assumption 0) I left out at the start, that the model can be meaningfully said to have an ontology comprised of elementary features at all.
Takeaways
I’ve seen people call out assumptions 1) and 2), and at least think about how we can test whether they hold, and how we might need to adjust our interpretability techniques if and when they don't hold. I have not seen people do this for assumption 3). Though I might just have missed it, of course.
My current dumb guess is that assumption 2) is mostly correct, but assumptions 1) and 3) are both incorrect.
The reason I think assumption 3) is incorrect is that the counterexample I sketched here seems to me like it'd be very common. LLMs seem to be made of lots of circuits. Why would these circuits all share a basis? They don't seem to me to have much reason to.
I think a way we might find the model’s features without assumption 3) is to focus on the circuits and computations first. Try to directly decompose the model weights [LW · GW] or layer transitions [LW · GW] into separate, simple circuits, then infer the model’s features from looking at the directions those circuits read and write to. In the counterexample above, this would have shown us both the animal features and the attribute features.
- ^
Potentially up to some small noise. For a nice operationalisation, see definition 2 on page 3 of this paper.
- ^
It's a vector because we've already assumed that features are all scalar. If a feature was two-dimensional instead, this would be a projection into an associated two-dimensional subspace.
- ^
I'm using the term basis loosely here, this also includes sparse overcomplete 'bases' like those in SAEs. The more accurate term would probably be 'dictionary', or 'frame'.
- ^
Or if the computation isn't layer aligned, the activations along some other causal cut through the network can be written as a sum of all the features represented on that cut.
↑ comment by Logan Riggs (elriggs) · 2025-04-16T19:39:31.354Z · LW(p) · GW(p)
I think you're saying:
Sometimes it's simpler (less edges) to use the attributes (Cute) or animals (Bunny) or both (eg a particularly cute bunny). Assumption 3 doesn't allow mixing different bases together.

So here we have 2 attributes (for) & 4 animals (for).
If the downstream circuit (let's assume a linear + ReLU) reads from the "Cute" direction then:
1. If we are only using : Bunny + Dolphin (interpretable, but add 100 more animals & it'll take a lot more work to interpret)
2. If we are only using : Cute (simple)
If a downstream circuit reads from the "bunny" direction, then the reverse:
1. Only : Bunny (simple)
2. Only : Cute + Furry ( + 48 attributes makes it more complex)
However, what if there's a particularly cute rabbit?

- Only : Bunny + 0.2*Dolphin(?) (+ many more animals)
- Only : 2*Cute + Furry (+ many more attributes)
Neither of the above work! BUT what if we mixed them:
3. Bunny + 0.2*Cute (simple)
I believe you're claiming that something like APD would, when given the very cute rabbit input, activate the Bunny & Cute components (or whatever directions the model is actually using), which can be in different bases, so can't form a dictionary/basis. [1]
- ^
Technically you didn't specify that can't be an arbitrary function, so you'd be able to reconstruct activations combining different bases, but it'd be horribly convoluted in practice.
↑ comment by Lucius Bushnaq (Lblack) · 2025-04-16T20:32:27.940Z · LW(p) · GW(p)
Technically you didn't specify that can't be an arbitrary function, so you'd be able to reconstruct activations combining different bases, but it'd be horribly convoluted in practice.
I wouldn't even be too fussed about 'horribly convoluted' here. I'm saying it's worse than that. We would still have a problem even if we allowed ourselves arbitrary encoder functions to define the activations in the dictionary and magically knew which ones to pick.
The problem here isn't that we can't make a dictionary that includes all the feature directions as dictionary elements. We can do that. For example, while we can't write
because those sums each already equal on their own, we can write
.
The problem is instead that we can't make a dictionary that has the feature activations as the coefficients in the dictionary. This is bad because it means our dictionary activations cannot equal the scalar variables the model's own circuits actually care about. They cannot equal the 'features of the model' in the sense defined at the start, the scalar features comprising its ontology. As a result, if we were to look at a causal graph of the model, using the half-size dictionary feature activations we picked as the graph nodes, a circuit taking in the feature through a linear read-off along the direction would have edges in our graph connecting it to both the elephant direction, making up about 50% of the total contribution, and the fifty attribute directions, making up the remaining 50%. Same the other way around, any circuit reading in even a single attribute feature will have edges connecting to all of the animal features[1], making up of the total contribution. It's the worst of both worlds. Every circuit looks like a mess now.
- ^
Since the animals are sparse, in practice this usually means edges to a small set of different animals for every data point. Whichever ones happen to be active at the time.
↑ comment by chanind · 2025-04-15T16:19:37.199Z · LW(p) · GW(p)
It seems like in this setting, the animals are just the sum of attributes that commonly co-occur together, rather than having a unique identifying direction. E.g. the concept of a "furry elephant" or a "tiny elephant" would be unrepresentable in this scheme, since elephant is defined as just the collection of attributes that elephants usually have, which includes being large and not furry.
I feel like in this scheme, it's not really the case that there's 1000 animal directions, since the base unit is the attributes, and there's no way to express an animal separately from its attributes. For there to be a true "elephant" direction, then it should be possible to have any set of arbitrary attributes attached to an elephant (small, furry, pink, etc...), and this would require that there is a "label" direction that indicates "elephant" that's mostly orthogonal to every other feature so it can be queried uniquely via projection.
That being said, I could image a situation where the co-occurrence between labels and attributes is so strong (nearly perfect hierarchy) that the model's circuits can select the attributes along with the label without it ever being a problem during training. For instance, maybe a circuit that's trying to select the "elephant" label actually selects "elephant + gray", and since "pink elephant" never came up during training, the circuit never received a gradient to force it to just select "elephant" which is what it's really aiming for.
↑ comment by Lucius Bushnaq (Lblack) · 2025-04-15T16:58:49.503Z · LW(p) · GW(p)
E.g. the concept of a "furry elephant" or a "tiny elephant" would be unrepresentable in this scheme
It's representable. E.g. the model can learn a circuit reading in a direction that is equal to the sum of the furry attribute direction and the elephant direction, or the tiny direction and the elephant direction respectively. This circuit can then store facts about furry elephants or tiny elephants.
I feel like in this scheme, it's not really the case that there's 1000 animal directions, since the base unit is the attributes
In what sense? If you represent the network computations in terms of the attribute features, you will get a very complicated computational graph with lots of interaction lines going all over the place. So clearly, the attributes on their own are not a very good basis for understanding the network.
Similarly, you can always represent any neural network in the standard basis of the network architecture. Trivially, all features can be seen as mere combinations of these architectural 'base units'. But if you try to understand what the network is doing in terms of interactions in the standard basis, you won't get very far.
For there to be a true "elephant" direction, then it should be possible to have any set of arbitrary attributes attached to an elephant (small, furry, pink, etc...), and this would require that there is a "label" direction that indicates "elephant" that's mostly orthogonal to every other feature so it can be queried uniquely via projection.
The 'elephant' feature in this setting is mostly-orthogonal to every other feature in the ontology, including the features that are attributes. So it can be read out with a linear projection. 'elephant' and 'pink' shouldn't have substantially higher cosine similarity than 'elephant' and 'parrot'.
Replies from: Jemist, chanind↑ comment by J Bostock (Jemist) · 2025-04-15T18:42:34.275Z · LW(p) · GW(p)
Just to clarify, do you mean something like "elephant = grey + big + trunk + ears + African + mammal + wise" so to encode a tiny elephant you would have "grey + tiny + trunk + ears + African + mammal + wise" which the model could still read off as 0.86 elephant when relevant, but also tiny when relevant.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-04-15T21:33:22.289Z · LW(p) · GW(p)
'elephant' would be a sum of fifty attribute feature vectors, all with scalar coefficients that match elephants in particular. The coefficients would tend have sizes on the order of , because the subspace is fifty-dimensional. So, if you wanted to have a pure tiny feature and an elephant feature active at the same time to encode a tiny elephant, 'elephant' and 'tiny' would be expected to have read-off interference on the order of . Alternatively, you could instead encode a new animal 'tiny elephant' as its own point in the fifty-dimensional space. Those are actually distinct things here. If this is confusing, maybe it helps to imagine that the name for 'tiny elephant' is 'exampledon', and exampledons just happen to look like tiny elephants.
Replies from: Jemist, chanind↑ comment by J Bostock (Jemist) · 2025-04-15T22:10:31.675Z · LW(p) · GW(p)
Is the distinction between "elephant + tiny" and "exampledon" primarily about the things the model does downstream? E.g. if none of the fifty dimensions of our subspace represent "has a bright purple spleen" but exampledons do, then the model might need to instead produce a "purple" vector as an output from an MLP whenever "exampledon" and "spleen" are present together.
↑ comment by chanind · 2025-04-16T11:28:13.683Z · LW(p) · GW(p)
This implies that there is no elephant direction separate from the attributes that happen to commonly co-occur with elephants. E.g. it's not possible to represent an elephant with any arbitrary combination of attributes, as the attributes themselves are what defines the elephant direction. This is what I mean that the attributes are the 'base units' in this scheme, and 'animals' are just commonly co-occurring sets of attributes. This is the same as the "red triangle" problem in SAEs: https://www.lesswrong.com/posts/QoR8noAB3Mp2KBA4B/do-sparse-autoencoders-find-true-features. [LW · GW] The animals in this framing are just invented combinations of the underlying attribute features. We would want the dictionary to learn the attributes, not arbitrary combinations of attributes, since these are the true "base units" that can vary freely. e.g. in the "red triangle" problem, we want a dictionary to learn "red" and "triangle", not "red triangle" as its own direction.
Put another way, there's no way to represent an "elephant" in this scheme without also attaching attributes to it. Likewise, it's not possible to differentiate between an elephant with the set of attributes x y and z and a rabbit with identical attributes x y and z, since the sum of attributes are what you're calling an elephant or rabbit. There's no separate "this is a rabbit, regardless of what attributes it has" direction.
To properly represent animals and attributes, there needs to be a direction for each animal that's separate from any attributes that animal may have, so that it's possible to represent a "tiny furry pink elephant with no trunk" vs a "tiny furry pink rabbit with no trunk".
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-04-16T11:54:25.980Z · LW(p) · GW(p)
E.g. it's not possible to represent an elephant with any arbitrary combination of attributes, as the attributes themselves are what defines the elephant direction.
You can't represent elephants along with arbitrary combinations of attributes. You can't do that in a scheme where feature directions are fully random with no geometry either though. There, only a small number of features can have non-zero values at the same time, so you still only get non-zero attribute features at once maximum.[1]
We would want the dictionary to learn the attributes, not arbitrary combinations of attributes, since these are the true "base units" that can vary freely.
You can call them the "base units" if you like. But that won't change the fact that some directions in the space spanned by those "base units" are special, with associated circuits that care about those directions in particular, and understanding or even recognising those circuits in a causal graph made of the "base units" will be pretty darned hard. For the same reason trying to understand the network in the neuron basis is hard.
Put another way, there's no way to represent an "elephant" in this scheme without also attaching attributes to it.
Yes.
Likewise, it's not possible to differentiate between an elephant with the set of attributes x y and z and a rabbit with identical attributes x y and z, since the sum of attributes are what you're calling an elephant or rabbit.
Not quite. You cannot specify a rabbit and simultaneously specify the rabbit having arbitrary numerical attribute values for attributes differing from normal rabbits. You can have a rabbit, and some attributes treated as sparse boolean-ish features at the same time. E.g. works. Circuits downstream that store facts about rabbits will still be triggered by this . Circuits downstream that do something with attribute will be reading in an -attribute value of plus the -coefficient of rabbits.
A consequence of this is that 'cute rabbit' is a bit cuter than either 'cute' or 'rabbit' on their own. But that doesn't seem particularly strange to me. Associations in my own mind sure seem to work like that.
- ^
Less, if you want to be able to perform computation in superposition.
↑ comment by Adam Newgas (BorisTheBrave) · 2025-04-17T20:10:05.934Z · LW(p) · GW(p)
I'm with @chanind [LW · GW]: If elephant is fully represented by a sum of its attributes, then it's quite reasonable to say that the model has no fundamental notion of an elephant in that representation.
Yes, the combination "grey + big + mammal + ..." is special in some sense. If the model needed to recall that elephans are afraid of mice, the circuit would appear to check "grey and big and mammal" and that's an annoying mouthful that would be repeated all over the model. But it's a faithful representation of what's going on.
Let me be precise by what I mean "has no fundamental notion of an elephant". Suppose I tried to fine tune the model to represent some new fact about animals, say, if they are worth a lot of points in Scrabble. One way the model could do this by squeezing another feature into the activation space. The other features might rotate a little during this training, but all the existing circuitry would basically continue functioning unchanged.
But they'd be too unchanged: the "afraid of mice" circuit would still be checking for "grey and big and mammal and ..." as the finetune dataset included no facts about animal fears. While some newer circuits formed during fine tuning would be checking for "grey and big and mammal and ... and high-scrabble-scoring". Any interpretability tool that told you that "grey and big and mammal and ..." was "elephant" in the first model is now going to have difficulty representing the situation.
Meanwhile, consider a "normal" model that has a residual notion of an elephant after you take away all all facts about elephants. Then both old and new circuits would contain references to that residual (plus other junk) and one could meaningfully say both circuits have something in common.
Your example, which represents animals purely by their properties, reminds me of this classic article [LW · GW], which argues that a key feature in thought is forming concepts of things that are independent of the properties we learnt about them.
↑ comment by Logan Riggs (elriggs) · 2025-04-18T16:42:37.144Z · LW(p) · GW(p)
I too agreed w/ Chanind initially, but I think I see where Lucius is coming from.
If we forget about a basis & focused on minimal description length (MDL), it'd be nice to have a technique that found the MDL [features/components] for each datapoint. e.g. in my comment [LW(p) · GW(p)], I have 4 animals (bunny, etc) & two properties (cute, furry). For MDL reasons, it'd be great to sometimes use cute/furry & sometimes use Bunny if that reflects model computation more simply.
If you have both attributes & animals as fundamental units (and somehow have a method that tells you which minimal set of units form each datapoint) then a bunny will just use the bunny feature (since that's simpler than cute + furry + etc), & a very cute bunny will use bunny + cute (instead of bunny + 0.1*dolphin + etc (or similar w/ properties)).
So if we look at Lucius initial statement:
The features a model thinks in do not need to form a basis or dictionary for its activations. [emphasis mine]
They don't need to, but they can form a basis. It very well could be simpler to not constrain our understanding/model of the NN's features as forming a basis.
Ideally Lucius can just show us this magical method that gets you simple components that don't form a basis, then we'd all have a simpler time understanding his point. I believe this "magical method" is Attribution based parameter decomposition [LW · GW] (APD) that they (lucius, dan, lee?) have been working on, which I would be excited if more people tried creative methods to scale this up. I'm unsure if this method will work, but it is a different bet than e.g. SAEs & currently underrated imo.
↑ comment by Lucius Bushnaq (Lblack) · 2025-04-18T20:23:34.443Z · LW(p) · GW(p)
But they'd be too unchanged: the "afraid of mice" circuit would still be checking for "grey and big and mammal and ..." as the finetune dataset included no facts about animal fears. While some newer circuits formed during fine tuning would be checking for "grey and big and mammal and ... and high-scrabble-scoring". Any interpretability tool that told you that "grey and big and mammal and ..." was "elephant" in the first model is now going to have difficulty representing the situation.
Thank you, this is a good example of a type-of-thing to watch out for in circuit interpretation. I had not thought of this before. I agree that an interpretability tool that rounded those two circuits off to taking in the 'same' feature would be a bad interpretability tool. It should just show you that those two circuits exist, and have some one dimensional features they care about, and those features are related but non-trivially distinct.
But this is not at all unique to the sort of model used in the counterexample. A 'normal' model can still have one embedding direction for elephant at one point, used by a circuit , then in fine tuning switch to a slightly different embedding direction . Maybe it learned more features in fine tuning, some of those features are correlated with elephants and ended up a bit too close in cosine similarity to , and so interference can be lowered my moving the embedding around a bit. A circuit learned in fine tuning would then be reading from this and not match which is still reading in . You might argue that will surely want to adjust to start using as well to lower the loss, but that would seem to apply equally well to your example. So I don't see how this is showing that the model used in the original counterexample has no notion of an elephant in a sense that does not also apply to the sort of models people might tend to imagine when they think in the conventional SDL paradigm.
EDIT: On a second read, I think I misunderstood you here. You seem to think the crucial difference is that the delta between and is mostly 'unstructured', whereas the difference between "grey and big and mammal and ..." and "grey and big and mammal and ... and high-scrabble-scoring" is structured. I don't see why that should matter though. So long as our hypothetical interpretability tool is precise enough to notice the size of the discrepancy between those features and not throw them into the same pot, we should be fine. For that, it wouldn't seem to me to really matter much whether the discrepancy is 'meaningful' to the model or not.
↑ comment by Lucius Bushnaq (Lblack) · 2025-04-18T20:05:58.827Z · LW(p) · GW(p)
I'm with @chanind [LW · GW]: If elephant is fully represented by a sum of its attributes, then it's quite reasonable to say that the model has no fundamental notion of an elephant in that representation.
...
This is not a load-bearing detail of the example. If you like, you can instead imagine a model that embeds 1000 animals in an e.g. 50-dimensional subspace, with a 50 dimensional sub-sub-space where the embedding directions correspond to 50 attributes, and a 50 dimensional sub-sub-space where embeddings are just random.
This should still get you basically the same issues the original example did I think? For any dictionary decomposition of the activations you pick, some of the circuits will end up looking like a horrible mess, even though they're secretly taking in a very low-rank subspace of the activations that'd make sense to us if we looked at it. I should probably double check that when I'm more awake though.[1]
I think the central issue here is mostly just having some kind of non-random, 'meaningful' feature embedding geometry that the circuits care about, instead of random feature embeddings.
- ^
EDIT: I am now more awake. I still think this is right.
↑ comment by chanind · 2025-04-15T21:32:12.924Z · LW(p) · GW(p)
If I understand correctly, it sounds like you're saying there is a "label" direction for each animal that's separate from each of the attributes. So, you could have activation a1 = elephant + small + furry + pink, and a2 = rabbit + small + furry + pink. a1 and a2 have the same attributes, but different animal labels. Their corresponding activations are thus different despite having the same attributes due to the different animal label components.
I'm confused why a dictionary that consists of a feature direction for each attribute and each animal label can't explain these activations? These activations are just a (sparse) sum of these respective features, which are an animal label and a set of a few attributes, and all of these are (mostly) mutually orthogonal. In this sense the activations are just the sum of the various elements of the dictionary multiplied by a magnitude, so it seems like you should be able to explain these activations using dictionary learning.
Is the idea that the 1000 animals and 50 attributes form an overcomplete basis, therefore you can come up with infinite ways to span the space using these basis components? The idea behind compressed sensing in dictionary learning is that if each activation is composed of a sparse sum of features, then L1 regularization can still recover the true features despite the basis being overcomplete.
↑ comment by Lucius Bushnaq (Lblack) · 2025-04-15T21:42:32.426Z · LW(p) · GW(p)
If I understand correctly, it sounds like you're saying there is a "label" direction for each animal that's separate from each of the attributes.
No, the animal vectors are all fully spanned by the fifty attribute features.
I'm confused why a dictionary that consists of a feature direction for each attribute and each animal label can't explain these activations? These activations are just a (sparse) sum of these respective features, which are an animal label and a set of a few attributes, and all of these are (mostly) mutually orthogonal.
The animal features are sparse. The attribute features are not sparse.[1]
In this sense the activations are just the sum of the various elements of the dictionary multiplied by a magnitude, so it seems like you should be able to explain these activations using dictionary learning.
The magnitudes in a dictionary seeking to decompose the activation vector into these 1050 features will not be able to match the actual magnitudes of the features as seen by linear probes and the network's own circuits.
Is the idea that the 1000 animals and 50 attributes form an overcomplete basis, therefore you can come up with infinite ways to span the space using these basis components?
No, that is not the idea.
- ^
Relative to the animal features at least. They could still be sparse relative to the rest of the network if this 50-dimensional animal subspace is rarely used.
↑ comment by chanind · 2025-04-15T22:59:40.463Z · LW(p) · GW(p)
No, the animal vectors are all fully spanned by the fifty attribute features.
Is this just saying that there's superposition noise, so everything is spanning everything else? If so that doesn't seem like it should conflict with being able to use a dictionary, dictionary learning should work with superposition noise as long as the interference doesn't get too massive.
The animal features are sparse. The attribute features are not sparse.
If you mean that the attributes are a basis in the sense that the neurons are a basis, then I don't see how you can say there's a unique "label" direction for each animal that's separate from the the underlying attributes such that you can set any arbitrary combination of attributes, including all attributes turned on at once or all turned off since they're not sparse, and still read off the animal label without interference. It seems like that would be like saying that the elephant direction = [1, 0, -1], but you can change arbitrarily all 3 of those numbers to any other numbers and still be the elephant direction.
↑ comment by Joseph Miller (Josephm) · 2025-04-15T00:46:13.967Z · LW(p) · GW(p)
If the animal specific features form an overcomplete basis, isn't the set of animals + attributes just an even more overcomplete basis?
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-04-15T04:57:23.723Z · LW(p) · GW(p)
Nope. Try it out. If you attempt to split the activation vector into 1050 vectors for animals + attributes, you can't get the dictionary activations to equal the feature activations , .
Replies from: oliver-clive-griffin↑ comment by Oliver Clive-Griffin (oliver-clive-griffin) · 2025-04-16T22:17:51.272Z · LW(p) · GW(p)
Is the central point here that a given input will activate it's representation in both the size 1000 and size 50 sub-dictionaries, meaning the reconstruction will be 2x too big?
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-04-17T12:48:00.661Z · LW(p) · GW(p)
Yes.
comment by Lucius Bushnaq (Lblack) · 2025-02-27T16:39:04.636Z · LW(p) · GW(p)
My theory of impact for interpretability:
I've been meaning to write this out properly for almost three years now. Clearly, it's not going to happen. So, you're getting an improper quick and hacky version instead.
I work on mechanistic interpretability because I think looking at existing neural networks is the best attack angle we have for creating a proper science of intelligence [LW · GW]. I think a good basic grasp of this science is a prerequisite for most of the important research we need to do to align a superintelligence to even get properly started. I view the kind of research I do as somewhat close in kind to what John Wentworth does.
Outer alignment
For example, one problem we have in alignment is that even if we had some way to robustly point a superintelligence at a specific target, we wouldn’t know what to point it at. E.g. famously, we don’t know how to write “make me a copy of a strawberry and don’t destroy the world while you do it” in math. Why don’t we know how to do that?
I claim one reason we don’t know how to do that is that ’strawberry’ and ‘not destroying something’ are fuzzy abstract concepts [LW · GW] that live in our heads, and we don’t know what those kinds of fuzzy abstract concepts correspond to in math or code. But GPT-4 clearly understands what a ‘strawberry’ is, at least in some sense. If we understood GPT-4 well enough to not be confused about how it can correctly answer questions about strawberries, maybe we also wouldn’t be quite so confused anymore about what fuzzy abstractions like ‘strawberry’ correspond to in math or code.
Inner alignment
Another problem we have in alignment is that we don’t know how to robustly aim a superintelligence at a specific target. [LW · GW] To do that at all, it seems like you might first want to have some notion of what ‘goals’ or ‘desires’ correspond to mechanistically in real agentic-ish minds. I don’t expect this to be as easy as looking for the ‘goal circuits’ in Claude 3.7. My guess is that by default, dumb minds like humans and today’s AIs are too incoherent to have their desires correspond directly to a clear, salient mechanistic structure we can just look at. Instead, I think mapping ‘goals’ and ‘desires’ in the behavioural sense back to the mechanistic properties of the model that cause them might be a whole thing. Understanding the basic mechanisms of the model in isolation mostly only shows you what happens on a single forward pass, while 'goals' seem like they'd be more of a many-forward-pass phenomenon. So we might have to tackle a whole second chapter of interpretability there before we get to be much less confused about what goals are.
But this seems like a problem you can only effectively attack after you’ve figured out much more basic things about how minds do reasoning moment-to-moment. Understanding how Claude 3.7 thinks about strawberries on a single forward pass may not be sufficient to understand much about the way its thinking evolves over many forward passes. Famously, just because you know how a program works and can see every function in it with helpful comments attached doesn’t yet mean you can predict much about what the program will do if you run it for a year. But trying to predict what the program will do if you run it for a year without first understanding what the functions in it even do seems almost hopeless. So, we should probably figure out how thinking about strawberries works first.
Understand what confuses us, not enumerate everything
To solve these problems, we don't need an exact blueprint of all the variables in GPT-4 and their role in the computation. [LW(p) · GW(p)] For example, I’d guess that a lot of the bits in the weights of GPT-4 are just taken up by database entries, memorised bigrams and trigrams and stuff like that. We definitely need to figure out how to decompile these things out of the weights. But after we've done that and looked at a couple of examples to understand the general pattern of what's in there, most of it will probably no longer be very relevant for resolving our basic confusion about how GPT-4 can answer questions about strawberries. We do need to understand how the model's cognition interfaces with its stored knowledge about the world. But we don’t need to know most of the details of that world knowledge. Instead, what we really need to understand about GPT-4 are the parts of it that aren’t just trigrams and databases and addition algorithms and basic induction heads and other stuff we already know how to do.
AI engineers in the year 2006 knew how to write a big database, and they knew how to do a vector search. But they didn’t know how to write programs that could talk, or understand what strawberries are, in any meaningful sense. GPT-4 can talk, and it clearly understands what a strawberry is in some meaningful sense. So something is going on in GPT-4 that AI engineers in the year 2006 didn’t already know about. That is what we need to understand if we want to know how it can do basic abstract reasoning.
Understanding what's going on is also just good in general
People argue a lot about whether RLHF or Constitutional AI or whatnot would work to align a superintelligence. I think those arguments would be much more productive and comprehensible to outsiders[1] if the arguers agreed on what exactly those techniques actually do to the insides of current models. Maybe then, those discussions wouldn't get stuck on debating philosophy so much.
And sure, yes, in the shorter term, understanding how models work can also help make techniques that more robustly detect whether a model is deceiving you in some way, or whatever.
Status?
Compared to the magnitude of the task in front of us, we haven't gotten much done yet. Though the total number of smart people hours sunk into this is also still very small, by the standards of a normal scientific field. I think we're doing very well on insights gained per smart person hour invested, compared to a normal field, and very badly on finishing up before our deadline.
But at least, poking at things that confused me about current deep learning systems [LW · GW] has already helped me become somewhat less confused about how minds in general could work. I used to have no idea how any general reasoner in the real world could tractably favour simple hypotheses over complex ones [LW · GW], given that calculating the minimum description length of a hypothesis is famously very computationally difficult. Now [LW · GW], I’m not so confused about that anymore. [LW · GW]
I hope that as we understand the neural networks in front of us more, we’ll get more general insights like that, insights that say something about how most computationally efficient minds may work, not just our current neural networks. If we manage to get enough insights like this, I think they could form a science of minds on the back of which we could build a science of alignment. And then maybe we could do something as complicated and precise as aligning a superintelligence on the first try.
The LIGO gravitational wave detector probably had to work right on the first build, or they'd have wasted a billion dollars. It's not like they could've built a smaller detector first to test the idea, not on a real gravitational wave. So, getting complicated things in a new domain right on the first critical try does seem doable for humans, if we understand the subject matter to the level we understand things like general relativity and laser physics. That kind of understanding is what I aim to get for minds.
At present, it doesn't seem to me like we'll have time to finish that project. So, I think humanity should probably try to buy more time somehow.
- ^
Like, say, politicians. Or natsec people.
↑ comment by 4gravitons · 2025-04-16T07:07:14.273Z · LW(p) · GW(p)
I signed up just to comment on this:
"The LIGO gravitational wave detector probably had to work right on the first build, or they'd have wasted a billion dollars. It's not like they could've built a smaller detector first to test the idea, not on a real gravitational wave."
LIGO did not work right on the first build. The original LIGO ran from 2002 to 2010 and detected nothing. They hoped it would be sensitive enough to detect gravitational waves, but it wasn't. Instead, they learned about the noise sources they would have to deal with, which helped them construct a better detector that was able to do the job. So this really isn't a good example to support the point you're making.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-04-17T12:49:39.276Z · LW(p) · GW(p)
How much money would you guess was lost on this?
Replies from: 4gravitons↑ comment by 4gravitons · 2025-04-20T08:48:32.764Z · LW(p) · GW(p)
I think you'd be hard-pressed to get a scientist to admit that the money was lost. ;)
Honestly, it's not obvious that it would have been possible to do Advanced LIGO without the experience from the initial run, which is kind of the point I was making: we don't usually have tasks that humanity needs to get right on the first try, to the contrary humanity usually needs to fail a few times first!
But the initial budget was around $400 million, the upgrade took another $200 million. I don't know how much was spent operating the experiment in its initial run, which I guess would be the cleanest proxy for money "wasted", if you're imagining a counterfactual where they got it right on the first try.
↑ comment by williawa (william-wale) · 2025-02-27T21:01:43.639Z · LW(p) · GW(p)
Nice, I was going to write more or less exactly this post. I agree with everything in it, and this is the primary reason I'm interested in mechinterp.
Basically "all" the concepts that are relevant to safely building an ASI are fuzzy in the way you described. What the AI "values", corrigibility, deception, instrumental convergence, the degree to which the AI is doing world-modeling and so on.
If we had a complete science of mechanistic interpretability, I think a lot of the problems would become very easy. "Locate the human flourishing concept in the AIs world model and jack that into the desire circuit. Afterwards, find the deception feature and the power-seeking feature and turn them to zero just to be sure." (this is an exaggeration)
The only thing I disagree with is the Outer Misalignment paragrpah. Outer Misalignment seems like one of the issues that wouldn't be solved. Largely due to goodhearts curse type stuff. This article by scott explains my hypothetical remaining worries well https://slatestarcodex.com/2018/09/25/the-tails-coming-apart-as-metaphor-for-life/
Even if we understood the circuitry underlying the "values" of the AI quite well, that doesn't automatically let us extrapolate the values of the AI super OOD.
Even if we find that, "Yes boss, the human flourishing thing is correctly plugged into the desire thing, its a good LLM sir", subtle differences in the human flourishing concept could really really fuck us over as the AGI recursively self-improves into an ASI and optimizes the galaxy.
But, if we can use this to make the AI somewhat corrigible, which, idk, might be possible, I'm not 100% sure, maybe we could sidestep some of these issues.
Any thoughts about this?
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-02-27T21:14:07.158Z · LW(p) · GW(p)
There is a reason that paragraph says
I claim one reason we don’t know how to do that is that ’strawberry’ and ‘not destroying something’ are fuzzy abstract concepts [LW · GW] that live in our heads
rather than
I claim the reason we don’t know how to do that is that ’strawberry’ and ‘not destroying something’ are fuzzy abstract concepts [LW · GW] that live in our heads
My claim here is that good mech interp helps you be less confused about outer alignment[1], not that what I've sketched here suffices to solve outer alignment.
- ^
Outer alignment in the wider sense of 'the problem of figuring out what target to point the AI at'.
↑ comment by williawa (william-wale) · 2025-02-28T22:06:22.727Z · LW(p) · GW(p)
Well, my model is that the primary reason we're unable to deal with deceptive alignment or goal misgeneralization is because we're confused, but that the reason we don't have a solution to Outer Alignment is because its just cursed and a hard problem.
↑ comment by daijin · 2025-02-28T23:57:57.115Z · LW(p) · GW(p)
I recall a solution to the outer alignment problem as 'minimise the amount of options you deny to other agents in the world', which is a more tractable version of 'mimimise net long term changes to the world'. There is an article explaining this somewhere.
comment by Lucius Bushnaq (Lblack) · 2025-01-02T11:10:15.350Z · LW(p) · GW(p)
PSA: The conserved quantities associated with symmetries of neural network loss landscapes seem mostly boring.
If you’re like me, then after you heard that neural network loss landscapes have continuous symmetries [LW · GW], you thought: “Noether’s theorem says every continuous symmetry of the action corresponds to a conserved quantity, like how energy and momentum conservation are implied by translation symmetry and angular momentum conservation is implied by rotation symmetry. Similarly, if loss functions of neural networks can have continuous symmetries, these ought to be associated with quantities that stay conserved under gradient descent[1]!”
This is true. But these conserved quantities don’t seem to be insightful the way energy and momentum in physics are. They basically turn out to just be a sort of coordinate basis for the directions along which the loss is flat.
If our network has a symmetry such that there is an abstract coordinate along which we can vary the parameters without changing the loss, then the gradient with respect to that coordinate will be zero. So, whatever value we started with from random initalisation will be the value we stay at. Thus, the value is a “conserved quantity” under gradient descent associated with the symmetry. If the symmetry only holds for a particular solution in some region of the loss landscape rather than being globally baked into the architecture, the value will still be conserved under gradient descent so long as we're inside that region.
For example, let's look at a simple global symmetry: In a ReLU network, we can scale all the weights going into a neuron by some positive constant , and scale all the weights going out of the neuron by , without changing what the network is doing. So, if we have a neuron with one ingoing weight initalised to and one outgoing weight initalised to , then the weight gradient in the direction of those two weights will be zero. Meaning our network will keep having all throughout training. If we’d started from a different initalisation, like , we’d instead have zero weight gradient along the direction . So whatever hyperbola defined by we start on, we'll stay on it throughout training, assuming no fancy add-ons like weight decay.[2]
If this doesn’t seem very insightful, I think that's because it isn’t. It might be useful to keep in mind for bookkeeping purposes if you’re trying to do some big calculation related to learning dynamics, but it doesn’t seem to yield much insight into anything to do with model internals on the conceptual level. One could maybe hold out hope that the conserved quantities/coordinates associated with degrees of freedom in a particular solution are sometimes more interesting, but I doubt it. For e.g. the degrees of freedom we talk about here, those invariants seem similar to the ones in the ReLU rescaling example above.
I’d guess this is because in physics, different starting values of conserved quantities often correspond to systems with very different behaviours, so they contain a lot of relevant information. A ball of gas with high energy and high angular momentum behaves very differently than a ball of gas with low energy and low angular momentum. Whereas adjacent neural network parameter configurations connected by some symmetry that get the same loss correspond precisely to models that behave basically the same way.
I'm writing this up so next time someone asks me about investigating this kind of thing, I'll have something to link them to.
- ^
Well, idealised gradient descent where learning rates are infinitesimally small, at least.
- ^
See this paper which Micurie [LW · GW] helpfully linked me. Also seems like a good resource in general if you find yourself needing to muck around with these invariants for some calculation.
↑ comment by Jesse Hoogland (jhoogland) · 2025-01-02T22:42:14.967Z · LW(p) · GW(p)
I want to point out that there are many interesting symmetries that are non-global or data-dependent. These "non-generic" symmetries can change throughout training. Let me provide a few examples.
ReLU networks. Consider the computation involved in a single layer of a ReLU network:
or, equivalently,
(Maybe we're looking at a two-layer network where are the inputs and are the outputs, or maybe we're at some intermediate layer where these variables represent internal activations before and after a given layer.)
Dead neuron . If one of the biases is always larger than the associated preactivation , then the ReLU will always spit out a zero at that index. This "dead" neuron introduces a new continuous symmetry, where you can set the entries of column of to an arbitrary value, without affecting the network's computation ().
Bypassed neuron . Consider the opposite: if for all possible inputs , then neuron will always activate, and the ReLU's nonlinearity effectively vanishes at that index. This introduces a new continuous symmetry, where you can insert an arbitrary invertible transformation to the subspace of bypassed neurons between the activations and the final transformation. For the sake of clarity, assume all neurons are bypassed, then:
Hidden polytopes. A ReLU network learns a piecewise linear approximation to a function. For ease, consider the case of learning a 1-dimensional mapping. It might look something like this:

The vertices between polytopes correspond to a set of constraints on the weights. Consider what happens when two neighboring linear pieces line up (left to right). One vertex becomes redundant (dotted lined). You can now move the vertex along the shared polytope without changing the function implemented. This corresponds to a continuous transformation of your weights in some direction of weight space. Importantly this is only true locally— as soon as the vertex reaches the next edge of the shared polytope, pushing it any further will change the function. Moving the vertex in any direction orthogonal to the polytope will also change the function.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-01-03T04:47:06.008Z · LW(p) · GW(p)
That's what I meant by
If the symmetry only holds for a particular solution in some region of the loss landscape rather than being globally baked into the architecture, the value will still be conserved under gradient descent so long as we're inside that region.
...
One could maybe hold out hope that the conserved quantities/coordinates associated with degrees of freedom in a particular solution are sometimes more interesting, but I doubt it. For e.g. the degrees of freedom we talk about here, those invariants seem similar to the ones in the ReLU rescaling example above.
Dead neurons are a special case of 3.1.1 (low-dimensional activations) in that paper, bypassed neurons are a special case of 3.2 (synchronised non-linearities). Hidden polytopes are a mix 3.2.2 (Jacobians spanning a low-dimensional subspace) and 3.1.1 I think. I'm a bit unsure which one because I'm not clear on what weight direction you're imagining varying when you talk about "moving the vertex". Since the first derivative of the function you're approximating doesn't actually change at this point, there's multiple ways you could do this.
↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-02T22:35:49.519Z · LW(p) · GW(p)
Yeah I was somewhat annoyed that early SLT made such a big deal out of them. These are boring, spurious things, and another useful intuition is a rough idea (not always true, but more often than not) that "no information that requires your activation to be a ReLU and fails to work well with the approximation theorem is useful for interp".
I recently did a deep dive into physics and SLT with PIBBSS colleague Lauren Greenspan, that I'm going to write about at some point this month. My understanding there is that there is a plausibly useful type of symmetry that you can try to think about in a Noether-esque way: this is the symmetry of a model before being initialized or seeing any data.
Namely, in the standard physics point of view, you view a choice of weights as a field (so whatever processes that happen are integrated over the prior of weight initializations in a path integral fashion) and you view input-output examples as experimental data (so the stuff that goes into the collider -- the behavior on a new datapoint can be thought of as a sort of the "output" of the scattering experiment). The point is that the substrate on which physicists see symmetries happens before the symmetry breaking inherent in "performing the experiment", i.e., training on any inputs or choosing any weights. Here the standard initialization assumption has orthogonal O(d) symmetry at every layer, for d the width (Edited to clarify: here if you have some inputs x_1, .., x_n then the probability of seeing activations y_1, .., y_n at layer d at initialization is equal to the probability of seeing activations R(y_1), .., R(y_n) for R a rotation matrix. This means that the "vacuum" prior on tuples y_1, .., y_n -- which later gets "symmetry broken" via Bayesian updating or SGD -- will be invariant with respect to hitting each layer of activations with a rotation matrix R). If the width is big, this is a very big symmetry group which is useful for simplifying the analysis (this is implicitly used a lot in PDLT), and I think you can also look at some Noether fields here. Of course this point of view is somewhat weak (since it's so big-brained), but the thing I'm excited about is the possibility of applying it in a fractal fashion, where you make some coarse assumptions about your weights (that they're "pre-learned") that globally break symmetry, but have some local approximate symmetries. I don't know how to see explicit Noether fields here, but it might be possible.
↑ comment by Razied · 2025-01-02T20:18:30.479Z · LW(p) · GW(p)
More insightful than what is conserved under the scaling symmetry of ReLU networks is what is not conserved: the gradient. Scaling by scales by and by , which means that we can obtain arbitrarily large gradient norms by simply choosing small enough . And in general bad initializations can induce large imbalances in how quickly the parameters on either side of the neuron learn.
Some time ago I tried training some networks while setting these symmetries to the values that would minimize the total gradient norm, effectively trying to distribute the gradient norm as equally as possible throughout the network. This significantly accelerated learning, and allowed extremely deep (100+ layers) networks to be trained without residual layers. This isn't that useful for modern networks because batchnorm/layernorm seems to effectively do the same thing, and isn't dependent on having ReLU as the activation function.
Thus, the γ value is a “conserved quantity” under gradient descent associated with the symmetry. If the symmetry only holds for a particular solution in some region of the loss landscape rather than being globally baked into the architecture, the γ value will still be conserved under gradient descent so long as we're inside that region.
Minor detail, but this is false in practice because we are doing gradient descent with a non-zero learning rate, so there will be some diffusion between different hyperbolas in weight space as we take gradient steps of finite size.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-01-02T20:20:51.708Z · LW(p) · GW(p)
Minor detail, but this is false in practice because we are doing gradient descent with a non-zero learning rate, so there will be some diffusion between different hyperbolas in weight space as we take gradient steps of finite size.
See footnote 1.
comment by Lucius Bushnaq (Lblack) · 2024-07-06T09:08:43.807Z · LW(p) · GW(p)
Many people in interpretability currently seem interested in ideas like enumerative safety, where you describe every part of a neural network to ensure all the parts look safe. Those people often also talk about a fundamental trade-off in interpretability between the completeness and precision of an explanation for a neural network's behavior and its description length.
I feel like, at the moment, these sorts of considerations are all premature and beside the point.
I don't understand how GPT-4 can talk. Not in the sense that I don't have an accurate, human-intuitive description of every part of GPT-4 that contributes to it talking well. My confusion is more fundamental than that. I don't understand how GPT-4 can talk the way a 17th-century scholar wouldn't understand how a Toyota Corolla can move. I have no gears-level model for how anything like this could be done at all. I don't want a description of every single plate and cable in a Toyota Corolla, and I'm not thinking about the balance between the length of the Corolla blueprint and its fidelity as a central issue of interpretability as a field.
What I want right now is a basic understanding of combustion engines. I want to understand the key internal gears of LLMs that are currently completely mysterious to me, the parts where I don't have any functional model at all for how they even could work. What I ultimately want to get out of Interpretability at the moment is a sketch of Python code I could write myself, without a numeric optimizer as an intermediary, that would be able to talk.
↑ comment by ryan_greenblatt · 2024-07-06T17:49:24.818Z · LW(p) · GW(p)
When doing bottom up interpretability, it's pretty unclear if you can answer questions like "how does GPT-4 talk" without being able to explain arbitrary parts to a high degree of accuracy.
I agree that top down interpretability trying to answer more basic questions seems good. (And generally I think top down interpretability looks more promising than bottom up interpretability at current margins.)
(By interpretability, I mean work aimed at having humans understand the algorithm/approach the model to uses to solve tasks. I don't mean literally any work which involves using the internals of the model in some non-basic way.)
I have no gears-level model for how anything like this could be done at all. [...] What I want right now is a basic understanding of combustion engines. I want to understand the key internal gears of LLMs that are currently completely mysterious to me, the parts where I don't have any functional model at all for how they even could work. What I ultimately want to get out of Interpretability at the moment is a sketch of Python code I could write myself.
It's not obvious to me that what you seem to want exists. I think the way LLMs work might not be well described as having key internal gears or having an at-all illuminating python code sketch.
(I'd guess something sorta close to what you seem to be describing, but ultimately disappointing and mostly unilluminating exists. And something tremendously complex but ultimately pretty illuminating if you fully understood it might exist.)
Replies from: eye96458↑ comment by Adam Shai (adam-shai) · 2024-07-06T17:15:14.267Z · LW(p) · GW(p)
I very strongly agree with the spirit of this post. Though personally I am a bit more hesitant about what exactly it is that I want in terms of understanding how it is that GPT-4 can talk. In particular I can imagine that my understanding of how GPT-4 could talk might be satisfied by understanding the principles by which it talks, but without necessarily being able to from scratch write a talking machine. Maybe what I'd be after in terms of what I can build is a talking machine of a certain toyish flavor - a machine that can talk in a synthetic/toy language. The full complexity of its current ability seems to have too much structure to be constructed from first princples. Though of course one doesn't know until our understanding is more complete.
↑ comment by RogerDearnaley (roger-d-1) · 2024-07-06T09:45:10.074Z · LW(p) · GW(p)
Interesting question. I'd suggest starting by doing interpretability on some of the TinyStories models and corpus: they have models with as few as 1–2 layers, 64-or-more dimensional embeddings, and only millions of parameters that can talk (childish) English. That sounds like the sort of thing that might actually be enumerable, with enough work. I think trying to figure that that might be a great testing ground for current ideas in interpretability: large enough to not be a toy model, but small enough to hopefully be tractable.
Replies from: Stefan42↑ comment by StefanHex (Stefan42) · 2024-07-09T08:45:30.218Z · LW(p) · GW(p)
The tiny story status seems quite simple, in the sense that I can see how you could provide TinyStories levels of loss by following simple rules plus a bunch of memorization.
Empirically, one of the best models in the tiny stories paper is a super wide 1L transformer, which basically is bigrams, trigrams, and slightly more complicated variants [see Bucks post] but nothing that requires a step of reasoning.
I am actually quite uncertain where the significant gap between TinyStories, GPT-2 and GPT-4 is. Maybe I could fully understand TinyStories-1L if I tried, would this tell us about GPT-4? I feel like the result for TinyStories will be a bunch of heuristics.
Replies from: jowen, roger-d-1↑ comment by jow (jowen) · 2024-07-09T11:17:19.648Z · LW(p) · GW(p)
Is that TinyStories model a super-wide attention-only transformer (the topic of the mechanistic interp work and Buck’s post you cite). I tried to figure it out briefly and couldn’t tell, but I bet it isn’t, and instead has extra stuff like an MLP block.
Regardless, in my view it would be a big advance to really understand how the TinyStories models work. Maybe they are “a bunch of heuristics” but maybe that’s all GPT-4, and our own minds, are as well…
Replies from: Stefan42↑ comment by StefanHex (Stefan42) · 2024-07-09T11:34:33.211Z · LW(p) · GW(p)
That model has an Attention and MLP block (GPT2-style model with 1 layer but a bit wider, 21M params).
I changed my mind over the course of this morning. TheTinyStories models' language isn't that bad, and I think it'd be a decent research project to try to fully understand one of these.
I've been playing around with the models this morning, quotes from the 1-layer model:
Once upon a time, there was a lovely girl called Chloe. She loved to go for a walk every morning and one day she came across a road.
One day, she decided she wanted to go for a ride. She jumped up and down, and as she jumped into the horn, shouting whatever makes you feel like.
When Chloe was flying in the sky, she saw some big white smoke above her. She was so amazed and decided to fly down and take a closer look.
When Chloe got to the edge of a park, there was a firework show. The girl smiled and said "Oh, hello, there. I will make sure to finish in my flying body before it gets too cold," it said.So Chloe flew to the park again, with a very persistent look at the white horn. She was very proud of her creation and was thankful for being so brave.
Summary: Chloe, a persistent girl, explores the park with the help of a firework sparkle and is shown how brave the firework can be persistent.
and
Once upon a time, there lived a young boy. His name was Caleb. He loved to learn new things and gain healthy by playing outside.
One day, Caleb was in the garden and he started eating an onion. He was struggling to find enough food to eat, but he couldn't find anything.
Just then, Caleb appeared with a magical lake. The young boy told Caleb he could help him find his way home if he ate the onion. Caleb was so excited to find the garden had become narrow enough for Caleb to get his wish.
Caleb thought about what the pepper was thinking. He then decided to try and find a safer way to play with them next time. From then on, Caleb became healthier and could eat sweets and sweets in the house.
With the peppers, Caleb ate delicious pepper and could be heard by again. He was really proud of himself and soon enough he was playing in the garden again.
This feels like the kind of inconsistency I expect from a model that has only one layer. It can recall that the story was about flying and stuff, and the names, but it feels a bit like the model doesn't remember what it said a paragraph before.
2-layer model:
Once upon a time, there was a lazy bear. He lived in a tall village surrounded by thick trees and lonely rivers.
The bear wanted to explore the far side of the mountain, so he asked a kind bird if he wanted to come. The bird said, "Yes, but first let me seat in my big tree. Follow me!"
The bear was excited and followed the bird. They soon arrived at a beautiful mountain. The mountain was rich with juicy, delicious fruit. The bear was so happy and thanked the bird for his help. They both shared the fruit and had a great time.
The bear said goodbye to the bird and returned to his big tree, feeling very happy and content. From then on, the bear went for food every day and could often seat in his tall tree by the river.
Summary: A lazy bear ventures on a mountain and finds a kind bird who helps him find food on his travels. The bear is happy and content with the food and a delicious dessert.
and
Once upon a time, there were two best friends, a gingerbread fox and a gingerbread wolf. Everyone loved the treats and had a great time together, playing games and eating the treats.
The gingerbread fox spoke up and said: "Let's be like buying a house for something else!" But the ginger suggested that they go to the market instead. The friends agreed and they both went to the market.
Back home, the gingerbread fox was happy to have shared the treats with the friends. They all ate the treats with the chocolates, ran around and giggled together. The gingerbread fox thought this was the perfect idea, and every day the friends ate their treats and laughed together.
The friends were very happy and enjoyed every single morsel of it. No one else was enjoying the fun and laughter that followed. And every day, the friends continued to discuss different things and discover new new things to imagine.
Summary: Two best friends, gingerbread and chocolate, go to the market to buy treats but end up only buying a small house for a treat each, which they enjoy doing together.
I think if we can fully understand (in the Python code sense, probably with a bunch of lookup tables) how these models work this will give us some insight into where we're at with interpretability. Do the explanations feel sufficiently compressed? Does it feel like there's a simpler explanation that the code & tables we've written?
Edit: Specifically I'm thinking of
- Train SAEs on all layers
- Use this [LW · GW] for Attention QK circuits (and transform OV circuit into SAE basis, or Transcoder basis)
- Use Transcoders [LW · GW] for MLPs
(Transcoders vs SAEs are somewhat redundant / different approaches, figure out how to connect everything together)
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2024-07-10T07:17:54.010Z · LW(p) · GW(p)
Yup: the 1L model samples are full of non-sequiturs, to the level I can't imagine a human child telling a story that badly; whereas the first 2L model example has maybe one non-sequitur/plot jump (the way the story ignores the content of bird's first line of dialog), which the rest of the story then works into it so it ends up almost making sense, in retrospect (except it would have made better sense if the bear had said that line). They second example has a few non-sequiturs, but they're again not glaring and continuous the way the 1L output is. (As a parent) I can imagine a rather small human child telling a story with about the 2L level of plot inconsistencies.
↑ comment by RogerDearnaley (roger-d-1) · 2024-07-10T06:59:14.030Z · LW(p) · GW(p)
From rereading the Tiny Stories paper, the 1L model did a really bad job of maintaining the internal consistency of the story and figuring out and allowing for the logical consequences of events, but otherwise did a passably good job of speaking coherent childish English. So the choice on transformer block count would depend on how interested you are in learning how to speak English that is coherent as well as grammatical. Personally I'd probably want to look at something in the 3–4-layer range, so it has an input layer, and output layer, and at least one middle layer, and might actually contain some small circuits.
I would LOVE to have an automated way of converting a Tiny Stories-size transformer to some form of declarative language spaghetti code. It would probably help to start with a heavily-quantized version. For example, a model trained using the techniques of the recent paper on building AI using trinary logic (so roughly a 1.6-bit quantization, and eliminating matrix multiplication entirely) might be a good place to start, combined with the sort of techniques the model-pruning folks have been working on for which model-internal interactions are important on the training set and which are just noise and can be discarded.
I strongly suspect that every transformer model is just a vast pile of heuristics. In certain cases, if trained on a situation that genuinely is simple and has a specific algorithm to solve it runnable during a model forward-pass (like modular arithmetic, for example), and with enough data to grok it, then the resulting heuristic may actually be an elegant True Name algorithm for the problem. Otherwise, it's just going to be a pile of heuristics that SGD found and tuned. Fortunately SGD (for reasons that singular learning theory [? · GW] illuminates) has a simplicity bias that gives a prior that acts like Occam's Razor or a Kolmogorov Complexity prior, so tends to prefer algorithms that generalize well (especially as the amount of data tends to infinity, thus groking), but obviously finding True Names isn't going to be guaranteed.
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-07-06T12:30:44.307Z · LW(p) · GW(p)
What I want right now is a basic understanding of combustion engines. I want to understand the key internal gears of LLMs that are currently completely mysterious to me, the parts where I don't have any functional model at all for how they even could work. What I ultimately want to get out of Interpretability at the moment is a sketch of Python code I could write myself, without a numeric optimizer as an intermediary, that would be able to talk.
How would you operationalize this in ML terms? E.g. how much loss in performance would you consider acceptable, on how wide a distribution of e.g. GPT-4's capabilities, how many lines of python code, etc.? Would you consider acceptable existing rough theoretical explanations, e.g. An Information-Theoretic Analysis of In-Context Learning? (I suspect not, because no 'sketch of python code' feasibility).
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-07-06T12:52:00.486Z · LW(p) · GW(p)
(I'll note that by default I'm highly skeptical of any current-day-human producing anything like a comprehensible, not-extremely-long 'sketch of Python code' of GPT-4 in a reasonable amount of time. For comparison, how hopeful would you be of producing the same for a smart human's brain? And on some dimensions - e.g. knowledge - GPT-4 is vastly superhuman.)
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2024-07-10T07:31:10.567Z · LW(p) · GW(p)
I think OP just wanted some declarative code (I don't think Python is the ideal choice of language, but basically anything that's not a Turing tarpit is fine) that could speak fairly coherent English. I suspect if you had a functional transformer decompiler the results aof appling it to a Tiny Stories-size model are going to be tens to hundreds of megabytes of spaghetti, so understanding that in detail is going to be huge slog, but on the other hand, this is an actual operationalization of the Chinese Room argument (or in this case, English Room)! I agree it would be fascinating, if we can get a significant fraction of the model's perplexity score. If it is, as people seem to suspect, mostly or entirely a pile of spaghetti, understanding even a representative (frequency-of-importance biased) statistical sample of it (say, enough for generating a few specific sentences) would still be fascinating.
↑ comment by Jason Gross (jason-gross) · 2024-07-22T07:11:47.906Z · LW(p) · GW(p)
I don't want a description of every single plate and cable in a Toyota Corolla, I'm not thinking about the balance between the length of the Corolla blueprint and its fidelity as a central issue of interpretability as a field.
What I want right now is a basic understanding of combustion engines.
This is the wrong 'length'. The right version of brute-force length is not "every weight and bias in the network" but "the program trace of running the network on every datapoint in pretrain". Compressing the explanation (not just the source code) is the thing connected to understanding. This is what we found from getting formal proofs of model behavior in Compact Proofs of Model Performance via Mechanistic Interpretability [AF · GW].
Does the 17th-century scholar have the requisite background to understand the transcript of how bringing the metal plates in the spark plug close enough together results in the formation of a spark? And how gasoline will ignite and expand? I think given these two building blocks, a complete description of the frame-by-frame motion of the Toyota Corolla would eventually convince the 17th-century scholar that such motion is possible, and what remains would just be fitting the explanation into their head all at once. We already have the corresponding building blocks for neural nets: floating point operations.
comment by Lucius Bushnaq (Lblack) · 2025-01-28T12:01:54.848Z · LW(p) · GW(p)
This paper claims to sample the Bayesian posterior of NN training, but I think it's wrong.
"What Are Bayesian Neural Network Posteriors Really Like?" (Izmailov et al. 2021) claims to have sampled the Bayesian posterior of some neural networks conditional on their training data (CIFAR-10, MNIST, IMDB type stuff) via Hamiltonian Monte Carlo sampling (HMC). A grand feat if true! Actually crunching Bayesian updates over a whole training dataset for a neural network that isn't incredibly tiny is an enormous computational challenge. But I think they're mistaken and their sampler actually isn't covering the posterior properly.
They find that neural network ensembles trained by Bayesian updating, approximated through their HMC sampling, generalise worse than neural networks trained by stochastic gradient descent (SGD). This would have been incredibly surprising to me if it were true. Bayesian updating is prohibitively expensive for real world applications, but if you can afford it, it is the best way to incorporate new information. You can't do better.[1]
This is kind of in the genre of a lot of papers and takes I think used to be around a few years back, which argued that the then still quite mysterious ability of deep learning to generalise was primarily due to some advantageous bias introduced by SGD. Or momentum, or something along these lines. In the sense that SGD/momentum/whatever were supposedly diverging from Bayesian updating in a way that was better rather than worse.
I think these papers were wrong, and the generalisation ability of neural networks actually comes from their architecture, which assigns exponentially more weight configurations to simple functions than complex functions. So, most training algorithms will tend to favour making simple updates, and tend to find simple solutions that generalise well, just because there's exponentially more weight settings for simple functions than complex functions. This is what Singular Learning Theory [LW · GW] talks about. From an algorithmic information theory perspective, I think this happens for reasons similar to why exponentially more binary strings correspond to simple programs than complex programs in Turing machines. [LW · GW]
This picture of neural network generalisation predicts that SGD and other training algorithms should all generalise worse than Bayesian updating, or at best do similarly. They shouldn't do better.
So, what's going on in the paper? How are they finding that neural network ensembles updated on the training data with Bayes rule make predictions that generalise worse than predictions made by neural networks trained the normal way?
My guess: Their Hamiltonian Monte Carlo (HMC) sampler isn't actually covering the Bayesian posterior properly. They try to check that it's doing a good job by comparing inter-chain and intra-chain variance in the functions learned.
We apply the classic Gelman et al. (1992) “” potential-scale-reduction diagnostic to our HMC runs. Given two or more chains, estimates the ratio between the between-chain variance (i.e., the variance estimated by pooling samples from all chains) and the average within-chain variance (i.e., the variances estimated from each chain independently). The intuition is that, if the chains are stuck in isolated regions, then combining samples from multiple chains will yield greater diversity than taking samples from a single chain.
They seem to think a good in function space implies that the chains are doing a good job of covering the important parts of the space. But I don't think that's true. You need to mix in weight space, not function space, because weight space is where the posterior lives. Function space and weight space are not bijective, that's why it's even possible for simpler functions to have exponentially more prior than complex functions. So good mixing in function space does not necessarily imply good mixing in weight space, which is what we actually need. The chains could be jumping from basin to basin very rapidly instead of spending more time in the bigger basins corresponding to simpler solutions like they should.
And indeed, they test their chains' weight space value as well, and find that it's much worse:
Figure 2. Log-scale histograms of convergence diagnostics. Function-space s are computed on the test-set softmax predictions of the classifiers and weight-space s are computed on the raw weights. About 91% of CIFAR-10 and 98% of IMDB posterior-predictive probabilities get an less than 1.1. Most weight-space values are quite small, but enough parameters have very large s to make it clear that the chains are sampling from different distributions in weight space.
...
(From section 5.1) In weight space, although most parameters show no evidence of poor mixing, some have very large s, indicating that there are directions in which the chains fail to mix.....
(From section 5.2) The qualitative differences between (a) and (b) suggest that while each HMC chain is able to navigate the posterior geometry the chains do not mix perfectly in the weight space, confirming our results in Section 5.1.
So I think they aren't actually sampling the Bayesian posterior. Instead, their chains jump between modes a lot and thus unduly prioritise low-volume minima compared to high volume minima. And those low-volume minima are exactly the kind of solutions we'd expect to generalise poorly.
I don't blame them here. It's a paper from early 2021, back when very few people understood the importance of weight space degeneracy properly aside from some math professor in Japan whom almost nobody in the field had heard of. For the time, I think they were trying something very informative and interesting. But since the paper has 300+ citations and seems like a good central example of the SGD-beats-Bayes genre, I figured I'd take the opportunity to comment on it now that we know so much more about this.
The subfield of understanding neural network generalisation has come a long way in the past four years.
Thanks to Lawrence Chan for pointing the paper out to me. Thanks also to Kaarel Hänni and Dmitry Vaintrob for sparking the argument that got us all talking about this in the first place.
↑ comment by Daniel Murfet (dmurfet) · 2025-01-28T21:25:31.162Z · LW(p) · GW(p)
Thanks Lucius. This agrees with my take on that paper and I'm glad to have this detailed comment to refer people to in the future.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2025-01-28T15:13:04.318Z · LW(p) · GW(p)
It's still wild to me that highly cited papers in this space can make such elementary errors.
↑ comment by Archimedes · 2025-01-28T18:32:14.762Z · LW(p) · GW(p)
Do you have any papers or other resources you'd recommend that cover the latest understanding? What is the SOTA for Bayesian NNs?
↑ comment by AviS (avi-semler-avi) · 2025-02-06T00:22:04.948Z · LW(p) · GW(p)
If the ability of neural networks to generalise comes from volume/simplicity property and not optimiser properties, then why do different optimisers have different generalisation properties? E.g. Adam being better than SGD for transformers. (Or maybe I'm misremembering, and the reason that Adam outperforms SGD for transformers is mediated by Adam achieving better training loss and not Adam being better than SGD for a given training loss value.)
comment by Lucius Bushnaq (Lblack) · 2024-09-20T12:44:26.687Z · LW(p) · GW(p)
I think we may be close to figuring out a general mathematical framework for circuits in superposition.
I suspect that we can get a proof that roughly shows:
- If we have a set of different transformers, with parameter counts implementing e.g. solutions to different tasks
- And those transformers are robust to size noise vectors being applied to the activations at their hidden layers
- Then we can make a single transformer with total parameters that can do all tasks, provided any given input only asks for tasks to be carried out
Crucially, the total number of superposed operations we can carry out scales linearly with the network's parameter count, not its neuron count or attention head count. E.g. if each little subnetwork uses neurons per MLP layer and dimensions in the residual stream, a big network with neurons per MLP connected to a -dimensional residual stream can implement about subnetworks, not just .
This would be a generalization of the construction for boolean logic gates in superposition. It'd use the same central trick, but show that it can be applied to any set of operations or circuits, not just boolean logic gates. For example, you could superpose an MNIST image classifier network and a modular addition network with this.
So, we don't just have superposed variables in the residual stream. The computations performed on those variables are also carried out in superposition.
Remarks:
- What the subnetworks are doing doesn't have to line up much with the components and layers of the big network. Things can be implemented all over the place. A single MLP and attention layer in a subnetwork could be implemented by a mishmash of many neurons and attention heads across a bunch of layers of the big network. Call it cross-layer superposition if you like.
- This framing doesn't really assume that the individual subnetworks are using one-dimensional 'features' represented as directions in activation space. The individual subnetworks can be doing basically anything they like in any way they like. They just have to be somewhat robust to noise in their hidden activations.
- You could generalize this from subnetworks doing unrelated tasks to "circuits" each implementing some part of a big master computation. The crucial requirement is that only circuits are used on any one forward pass.
- I think formulating this for transformers, MLPs and CNNs should be relatively straightforward. It's all pretty much the same trick. I haven't thought about e.g. Mamba yet.
Implications if we buy that real models work somewhat like this toy model would:
- There is no superposition in parameter space. A network can't have more independent operations than parameters. Every operation we want the network to implement takes some bits of description length in its parameters to specify, so the total description length scales linearly with the number of distinct operations. Overcomplete bases are only a thing in activation space.
- There is a set of Cartesian directions in the loss landscape that parametrize the individual superposed circuits.
- If the circuits don't interact with each other, I think the learning coefficient [? · GW] of the whole network might roughly equal the sum of the learning coefficients of the individual circuits?
- If that's the case, training a big network to solve different tasks, per data point, is somewhat equivalent to parallel training runs trying to learn a circuit for each individual task over a subdistribution. This works because any one of the runs has a solution with a low learning coefficient, so one task won't be trying to use effective parameters that another task needs. In a sense, this would be showing how the low-hanging fruit prior [LW · GW] works.
Main missing pieces:
- I don't have the proof yet. I think I basically see what to do to get the constructions, but I actually need to sit down and crunch through the error propagation terms to make sure they check out.
- With the right optimization procedure, I think we should be able to get the parameter vectors corresponding to the individual circuits back out of the network. Apollo's interp team is playing with a setup right now that I think might be able to do this. But it's early days. We're just calibrating on small toy models at the moment.
↑ comment by Lucius Bushnaq (Lblack) · 2024-09-26T08:01:31.808Z · LW(p) · GW(p)
Spotted just now. At a glance, this still seems to be about boolean computation though. So I think I should still write up the construction I have in mind.
Status on the proof: I think it basically checks out for residual MLPs. Hoping to get an early draft of that done today. This will still be pretty hacky in places, and definitely not well presented. Depending on how much time I end up having and how many people collaborate with me, we might finish a writeup for transformers in the next two weeks.
comment by Lucius Bushnaq (Lblack) · 2024-07-28T10:14:23.725Z · LW(p) · GW(p)
Current LLMs are trivially mesa-optimisers under the original definition of that term.
I don't get why people are still debating the question of whether future AIs are going to be mesa-optimisers. Unless I've missed something about the definition of the term, lots of current AI systems are mesa-optimisers. There were mesa-opimisers around before Risks from Learned Optimization in Advanced Machine Learning Systems was even published.
We will say that a system is an optimizer if it is internally searching through a search space (consisting of possible outputs, policies, plans, strategies, or similar) looking for those elements that score high according to some objective function that is explicitly represented within the system.
....
Mesa-optimization occurs when a base optimizer (in searching for algorithms to solve some problem) finds a model that is itself an optimizer, which we will call a mesa-optimizer.
GPT-4 is capable of making plans to achieve objectives if you prompt it to. It can even write code to find the local optimum of a function, or code to train another neural network, making it a mesa-meta-optimiser. If gradient descent is an optimiser, then GPT-4 certainly is.
Being a mesa-optimiser is just not a very strong condition. Any pre-transformer ml paper that tried to train neural networks to find better neural network training algorithms was making mesa-optimisers. It is very mundane and expected for reasonably general AIs to be mesa-optimisers. Any program that can solve even somewhat general problems is going to have a hard time not meeting the definition of an optimiser.
Maybe this is some sort of linguistic drift at work, where 'mesa-optimiser' has come to refer specifically to a sysytem that is only an optimiser, with one single set of objectives it will always try to accomplish in any situation. Fine.
The result of this imprecise use of the original term though, as I perceive it, is that people are still debating and researching whether future AI's might start being mesa-optimisers, as if that was relevant to the will-they-kill-us-all question. But, at least sometimes, what they seem to actually concretely debate and research is whether future AIs might possibly start looking through search spaces to accomplish objectives, as if that wasn't a thing current systems obviously already do.
Replies from: bogdan-ionut-cirstea, Gunnar_Zarncke, programcrafter↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-07-28T13:07:51.705Z · LW(p) · GW(p)
I suspect a lot of the disagreement might be about whether LLMs are something like consistent / context-independent optimizers of e.g. some utility function (they seem very unlikely to), not whether they're capable of optimization in various (e.g. prompt-dependent, problem-dependent) contexts.
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-07-28T16:00:58.215Z · LW(p) · GW(p)
The top comment also seems to be conflating whether a model is capable of (e.g. sometimes, in some contexts) mesaoptimizing and whether it is (consistently) mesaoptimizing. I interpret the quoted original definition as being about the second, which LLMs probably aren't, though they're capable of the first. This seems like the kind of ontological confusion that the Simulators post discusses at length.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-07-28T16:40:28.989Z · LW(p) · GW(p)
If that were the intended definition, gradient descent wouldn’t count as an optimiser either. But they clearly do count it, else an optimiser gradient descent produces wouldn’t be a mesa-optimiser.
Gradient descent optimises whatever function you pass it. It doesn’t have a single set function it tries to optimise no matter what argument you call it with. If you don’t pass any valid function, it doesn’t optimise anything.
GPT-4, taken by itself, without a prompt, will optimise pretty much whatever you prompt it to optimise. If you don’t prompt it to optimise something, it usually doesn’t optimise anything.
I guess you could say GPT-4, unlike gradient descent, can do things other than optimise something. But if ever not optimising things excluded you from being an optimiser, humans wouldn’t be considered optimisers either.
So it seems to me that the paper just meant what it said in the quote. If you look through a search space to accomplish an objective, you are, at present, an optimiser.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2024-07-28T18:03:49.454Z · LW(p) · GW(p)
If that were the intended definition, gradient descent wouldn’t count as an optimiser either. But they clearly do count it, else an optimiser gradient descent produces wouldn’t be a mesa-optimiser.
Gradient descent optimises whatever function you pass it. It doesn’t have a single set function it tries to optimise no matter what argument you call it with.
Gradient descent, in this sense of the term, is not an optimizer according to Risks from Learned Optimization.
Consider that Risks from Learned Optimization talks a lot about "the base objective" and "the mesa-objective." This only makes sense if the objects being discussed are optimization algorithms together with specific, fixed choices of objective function.
"Gradient descent" in the most general sense is -- as you note -- not this sort of thing. Therefore, gradient descent in that general sense is not the kind of thing that Risks from Learned Optimization is about.
Gradient descent in this general sense is a "two-argument function," , where is the thing to be optimized and is the objective function. The objects of interest in Risks from Learned Optimization are curried single-argument versions of such functions, for some specific choice of , considered as a function of alone.
It's fairly common for people to say "gradient descent" when they mean for some specific , rather than the more generic . This is because in practice -- unless you're doing some weird experimental thing that's not really "gradient descent" per se -- is always fixed across the course of a run of gradient descent. When you run gradient descent to optimize an , the result you get was not "optimized by gradient descent in general" (what would that even mean?), it was optimized for whichever you chose by the corresponding .
This is what licenses talking about "the base objective" when considering an SGD training run of a neural net. There is a base objective in such runs, it's the loss function, we know exactly what it is, we wrote it down.
On the other hand, the notion that the optimized s would have "mesa-objectives" -- that they would themselves be objects like with their own unchanging s, rather than being simply capable of context-dependent optimization of various targets, like GPT-4 or -- is a non-obvious claim/assumption(?) made by Risks from Learned Optimization. This claim doesn't hold for GPT-4, and that's why it is not a mesa-optimizer.
↑ comment by Gunnar_Zarncke · 2024-07-28T19:02:24.037Z · LW(p) · GW(p)
It is surely possible that there are mesa optimizers present in many, even relatively simple LLMs. But the question is: How powerful are these? How large is the state space that they can search through, for example? The state space of the mesa-optimizer can't be larger than the the context window it is using to generate the answer, for example, while the state space of the full LLM is much bigger - basically all its weights.
↑ comment by ProgramCrafter (programcrafter) · 2024-07-29T08:13:48.333Z · LW(p) · GW(p)
Current LLMs are trivially mesa-optimisers under the original definition of that term.
Do current LLMs produce several options then compare them according to an objective function?
They do, actually, evaluate each of possible output tokens, then emitting one of the most probable ones, but I think that concern is more about AI comparing larger chunks of text (for instance, evaluating paragraphs of a report by stakeholders' reaction).
comment by Lucius Bushnaq (Lblack) · 2024-10-23T08:50:10.406Z · LW(p) · GW(p)
Does the Solomonoff Prior Double-Count Simplicity?
Question: I've noticed what seems like a feature of the Solomonoff prior that I haven't seen discussed in any intros I've read. The prior is usually described as favoring simple programs through its exponential weighting term, but aren't simpler programs already exponentially favored in it just through multiplicity alone, before we even apply that weighting?
Consider Solomonoff induction applied to forecasting e.g. a video feed of a whirlpool, represented as a bit string . The prior probability for any such string is given by:
where ranges over programs for a prefix-free Universal Turing Machine.
Observation: If we have a simple one kilobit program that outputs prediction , we can construct nearly different two kilobit programs that also output by appending arbitrary "dead code" that never executes.
For example:
DEADCODE="[arbitrary 1 kilobit string]"
[original 1 kilobit program ]
EOF
Where programs aren't allowed to have anything follow EOF, to ensure we satisfy the prefix free requirement.
If we compare against another two kilobit program outputting a different prediction , the prediction from would get more contributions in the sum, where is the very small number of bits we need to delimit the DEADCODE garbage string. So we're automatically giving ca. higher probability – even before applying the length penalty . has less 'burdensome details', so it has more functionally equivalent implementations. Its predictions seem to be exponentially favored in proportion to its length already due to this multiplicity alone.
So, if we chose a different prior than the Solomonoff prior which just assigned uniform probability to all programs below some very large cutoff, say bytes:
and then followed the exponential decay of the Solomonoff prior for programs longer than bytes, wouldn't that prior act barely differently than the Solomonoff prior in practice? It’s still exponentially preferring predictions with shorter minimum message length.[1]
Am I missing something here?
- ^
Context for the question: Multiplicity of implementation is how simpler hypotheses are favored in Singular Learning Theory [? · GW] despite the prior over neural network weights usually being uniform. I'm trying to understand how those SLT statements about neural networks generalising relate to algorithmic information theory statements about Turing machines, and Jaynes-style pictures of probability theory.
↑ comment by samshap · 2024-10-23T12:17:13.313Z · LW(p) · GW(p)
Yes, you are missing something.
Any DEADCODE that can be added to a 1kb program can also be added to a 2kb program. The net effect is a wash, and you will end up with a ratio over priors
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-10-23T12:46:55.797Z · LW(p) · GW(p)
Why aren’t there 2^{1000} less programs with such dead code and a total length below 10^{90} for p_2, compared to p_1?
Replies from: samshap↑ comment by Dalcy (Darcy) · 2024-10-23T20:52:18.079Z · LW(p) · GW(p)
https://www.lesswrong.com/posts/KcvJXhKqx4itFNWty/k-complexity-is-silly-use-cross-entropy-instead [LW · GW]
The K-complexity of a function is the length of its shortest code. But having many many codes is another way to be simple! Example: gauge symmetries in physics. Correcting for length-weighted code frequency, we get an empirically better simplicity measure: cross-entropy.
Replies from: Lblack[this] is a well-known notion in algorithmic information theory, and differs from K-complexity by at most a constant
↑ comment by Lucius Bushnaq (Lblack) · 2024-10-23T21:06:01.997Z · LW(p) · GW(p)
Sure. But what’s interesting to me here is the implication that, if you restrict yourself to programs below some maximum length, weighing them uniformly apparently works perfectly fine and barely differs from Solomonoff induction at all.
This resolves a remaining confusion I had about the connection between old school information theory and SLT. It apparently shows that a uniform prior over parameters (programs) of some fixed size parameter space is basically fine, actually, in that it fits together with what algorithmic information theory says about inductive inference.
↑ comment by harfe · 2024-10-23T14:42:25.956Z · LW(p) · GW(p)
I think you are broadly right.
So we're automatically giving ca. higher probability – even before applying the length penalty .
But note that under the Solomonoff prior, you will get another penalty for these programs with DEADCODE. So with this consideration, the weight changes from (for normal ) to (normal plus DEADCODE versions of ), which is not a huge change.
For your case of "uniform probability until " I think you are right about exponential decay.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-10-23T14:52:05.433Z · LW(p) · GW(p)
Yes, my point here is mainly that the exponential decay seems almost baked into the setup even if we don't explicitly set it up that way, not that the decay is very notably stronger than it looks at first glance.
Given how many words have been spilled arguing over the philosophical validity of putting the decay with program length into the prior, this seems kind of important?
↑ comment by Richard_Kennaway · 2024-10-23T16:03:44.511Z · LW(p) · GW(p)
The number of programs of length at most n increases exponentially with n. Therefore any probability measure over them must decrease at least exponentially with length. That is, exponential decay is the least possible penalisation of length.
This is also true of the number of minimal programs of length at most n, hence the corresponding conclusion. (Proof: for each string S, consider the minimal program that writes S and halts. These programs are all different. Their sizes are no more than length(S)+c, where c is the fixed overhead of writing a program with S baked into it. Therefore exponentiality.)
I've written "at most n" instead of simply "n", to guard against quirks like a programming language in which all programs are syntactically required to e.g. have even length, or deep theorems about the possible lengths of minimal programs.
comment by Lucius Bushnaq (Lblack) · 2024-09-18T09:39:08.729Z · LW(p) · GW(p)
Has anyone thought about how the idea of natural [LW · GW] latents [LW · GW] may be used to help formalise QACI [LW · GW]?
The simple core insight of QACI according to me is something like: A formal process we can describe that we're pretty sure would return the goals we want an AGI to optimise for is itself often a sufficient specification of those goals. Even if this formal process costs galactic amounts of compute and can never actually be run, not even by the AGI itself.
This allows for some funny value specification strategies we might not usually think about. For example, we could try using some camera recordings of the present day, a for loop, and a code snippet implementing something like Solomonof induction to formally specify the idea of Earth sitting around in a time loop until it has worked out its CEV [? · GW].
It doesn't matter that the AGI can't compute that. So long as it can reason about what the result of the computation would be without running it, this suffices as a pointer to our CEV. Even if the AGI doesn't manage to infer the exact result of the process, that's fine so long as it can infer some bits of information about the result. This just ends up giving the AGI some moral uncertainty that smoothly goes down as its intelligence goes up.
Unfortunately, afaik these funny strategies seem to not work at the moment. They don't really give you computable code that corresponds to Earth sitting around in a time loop to work out its CEV.
But maybe we can point to the concept without having completely formalised it ourselves?
A Solomonoff inductor walks into a bar in a foreign land. (Stop me if you’ve heard this one before.) The bartender, who is also a Solomonoff inductor, asks “What’ll it be?”. The customer looks around at what the other patrons are having, points to an unfamiliar drink, and says “One of those, please.”. The bartender points to a drawing of the same drink on a menu, and says “One of those?”. The customer replies “Yes, one of those.”. The bartender then delivers a drink, and it matches what the first inductor expected.What’s up with that?
This is from a recent post [LW · GW] on natural latents by John.
Natural latents are an idea that tries to explain, among other things, how one agent can point to a concept and have another agent realise what concept is meant, even when it may naively seem like the pointer is too fuzzy, impresice and low bit rate to allow for this.
If 'CEV as formalized by a time loop' is a sort of natural abstraction, it seems to me like one ought to be able to point to it like this even if we don't have an explicit formal specification of the concept, just like the customer and bartender need not have an explicit formal specification of the drink to point out the drink to each other.
Then, it'd be fine for us to not quite have the code snippet corresponding to e,g. a simulation of Earth going through a time loop to work out its CEV. So long as we can write a pointer such that the closest natural abstraction singled out by that pointer is a code snippet simulating Earth going through a time loop to work out its CEV, we might be fine. Provided we can figure out how abstractions and natural latents in the AGI's mind actually work and manipulate them. But we probably need to figure that out anyway, if we want to point the AGI's values at anything specific whatsoever.
Is 'CEV as formalized by a simulated time loop' a concept made of something like natural latents? I don't know, but I'd kind of suspect it is. It seems suspiciously straightforward for us humans to communicate the concept to each other at least, even as we lack a precise specification of it. We can't write down a lattice quantum field theory simulation of all of the Earth going through the time loop because we don't have the current state of Earth to initialize with. But we can talk to each other about the idea of writing that simulation, and know what we mean.
↑ comment by the gears to ascension (lahwran) · 2024-09-18T10:36:01.796Z · LW(p) · GW(p)
I do think natural latents could have a significant role to play somehow in QACI-like setups, but it doesn't seem like they let you avoid formalizing, at least in the way you're talking about. It seems more interesting in terms of avoiding specifying a universal prior over possible worlds, if we can instead specify a somewhat less universal prior that bakes in assumptions about our worlds' known causal structure. it might help with getting a robust pointer to the start of the time snippet. I don't see how it helps avoiding specifying "looping", or "time snippet", etc. natural latents seem to me to be primarily about the causal structure of our universe, and it's unclear what they even mean otherwise. it seems like our ability to talk about this concept is made up of a bunch of natural latents, and some of them are kind of messy and underspecified by the phrase, mainly relating to what the heck is a physics.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-09-18T11:26:48.768Z · LW(p) · GW(p)
it might help with getting a robust pointer to the start of the time snippet.
That's mainly what I meant, yes.
Specifying what the heck a physics is seems much more tractable to me. We don't have a neat theory of quantum gravity, but a lattice simulation of quantum field theory in curved space-time, or just a computer game world populated by characters controlled by neural networks, seems pretty straightforward to formally specify. We could probably start coding that up right now.
What we lack is a pointer to the right initial conditions for the simulation. The wave function of Earth in case of the lattice qft setup, or the human uploads as neural network parameters in case of the game environment.
↑ comment by Tamsin Leake (carado-1) · 2024-09-18T10:22:41.357Z · LW(p) · GW(p)
To me kinda the whole point of QACI is that it tries to actually be fully formalized. Informal definitions seem very much not robust to when superintelligences think about them; fully formalized definitions are the only thing I know of that keep meaning the same thing regardless of what kind of AI looks at it or with what kind of ontology.
I don't really get the whole natural latents ontology at all, and mostly expect it to be too weak for us to be able to get reflectively stable goal-content integrity even as the AI becomes vastly superintelligent. If definitions are informal, that feels to me like degrees of freedom in which an ASI can just pick whichever values make its job easiest.
Perhaps something like this allows use to use current, non-vastly-superintelligent AIs to help design a formalized version of QACI or ESP [LW · GW] which itself is robust enough to be passed to superintelligent optimizers; but my response to this is usually "have you tried first formalizing CEV/QACI/ESP by hand?" because it feels like we've barely tried and like reasonable progress can be made on it that way.
Perhaps there are some cleverer schemes where the superintelligent optimizer is pointed at the weaker current-tech-level AI, itself pointed informally at QACI, and we tell the superintelligent optimizer "do what this guy says"; but that seems like it either leaves too many degrees of freedom to the superintelligent optimizer again, or it requires solving corrigibility (the superintelligent optimizer is corrigibly assisting the weaker AI) at which point why not just point the corrigibility at the human directly and ignore QACI altogether, at least to begin with.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-09-18T10:27:58.795Z · LW(p) · GW(p)
The idea would be that an informal definition of a concept conditioned on that informal definition being a pointer to a natural concept, is a formal specification of that concept. Where the is close enough to a that it'd hold up to basically arbitrary optimization power.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-09-18T15:25:29.881Z · LW(p) · GW(p)
So the formalized concept is Get_Simplest_Concept_Which_Can_Be_Informally_Described_As("QACI is an outer alignment scheme consisting of…") ? Is an informal definition written in english?
It seems like "natural latent" here just means "simple (in some simplicity prior)". If I read the first line of your post as:
Has anyone thought about QACI could be located in some simplicity prior, by searching the prior for concepts matching(??in some way??) some informal description in english?
It sure sounds like I should read the two posts you linked (perhaps especially this one [LW · GW]), despite how hard I keep bouncing off of the natural latents idea. I'll give that a try.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-09-18T18:30:33.929Z · LW(p) · GW(p)
More like the formalised concept is the thing you get if you poke through the AGI’s internals searching for its representation of the concept combination pointed to by an english sentence plus simulation code, and then point its values at that concept combination.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-09-18T20:20:17.008Z · LW(p) · GW(p)
Seems really wonky and like there could be a lot of things that could go wrong in hard-to-predict ways, but I guess I sorta get the idea.
I guess one of the main things I'm worried about is that it seems to require that we either:
- Be really good at timing when we pause it to look at its internals, such that we look at the internals after it's had long enough to think about things that there are indeed such representations, but not long enough that it started optimizing really hard such that we either {die before we get to look at the internals} or {the internals are deceptively engineered to brainhack whoever would look at them}. If such a time interval even occurs for any amount of time at all.
- Have an AI that is powerful enough to have powerful internals-about-QACI to look at, but corrigible enough that this power is not being used to do instrumentally convergent stuff like eat the world in order to have more resources with which to reason.
Current AIs are not representative of what dealing with powerful optimizers is like; when we'll start getting powerful optimizers, they won't sit around long enough for us to look at them and ponder, they'll just quickly eat us.
↑ comment by Jonas Hallgren · 2024-09-18T14:22:44.320Z · LW(p) · GW(p)
In natural langage maybe it would be something like "given these ontological boundaries, give us the best estimate you can of CEV. "?
It seems kind of related to boundaries as well if you think of natural latents as "functional markov blankets" that cut reality at it's joints then you could probably say that you want to perserve part of that structure that is "human agency" or similar. I don't know if that makes sense but I like the idea direction!
↑ comment by Daniel C (harper-owen) · 2024-09-18T16:31:29.659Z · LW(p) · GW(p)
I think the fact that natural latents are much lower dimensional than all of physics makes it suitable for specifying the pointer to CEV as an equivalence class over physical processes (many quantum field configurations can correspond to the same human, and we want to ignore differences within that equivalence class).
IMO the main bottleneck is to account for the reflective aspects [LW(p) · GW(p)] in CEV, because one constraint of natural latents is that it should be redundantly represented in the environment.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-09-19T08:22:13.226Z · LW(p) · GW(p)
It is redundantly represented in the environment, because humans are part of the environment.
If you tell an AI to imagine what happens if humans sit around in a time loop until they figure out what they want, this will single out a specific thought experiment to the AI, provided humans and physics are concepts the AI itself thinks in.
(The time loop part and the condition for terminating the loop can be formally specified in code, so the AI doesn't need to think those are natural concepts)
If the AI didn't have a model of human internals that let it predict the outcome of this scenario, it would be bad at predicting humans.
↑ comment by Daniel C (harper-owen) · 2024-09-19T11:52:03.845Z · LW(p) · GW(p)
natural latents are about whether the AI's cognition routes through the same concepts that humans use.
We can imagine the AI maintaining predictive accuracy about humans without using the same human concepts. For example, it can use low-level physics to simulate the environment, which would be predictively accurate, but that cognition doesn't make use of the concept "strawberry" (in principle, we can still "single out" the concept of "strawberry" within it, but that information comes mostly from us, not from the physics simulation)
Natural latents are equivalent up to isomorphism (ie two latent variables are equivalent iff they give the same conditional probabilities on observables), but for reflective aspects of human cognition, it's unclear whether that equivalence class pin down all information we care about for CEV (there may be differences within the equivalence class that we care about), in a way that generalizes far out of distribution
↑ comment by Lucius Bushnaq (Lblack) · 2024-09-19T15:59:22.966Z · LW(p) · GW(p)
My claim is that the natural latents the AI needs to share for this setup are not about the details of what a 'CEV' is. They are about what researchers mean when they talk about initializing, e.g., a physics simulation with the state of the Earth at a specific moment in time.
Replies from: harper-owen↑ comment by Daniel C (harper-owen) · 2024-09-19T16:51:08.146Z · LW(p) · GW(p)
Noted, that does seem a lot more tractable than using natural latents to pin down details of CEV by itself
comment by Lucius Bushnaq (Lblack) · 2024-11-30T12:26:45.960Z · LW(p) · GW(p)
Two shovel-ready theory projects in interpretability.
Most scientific work isn't "shovel-ready." It's difficult to generate well-defined, self-contained projects where the path forward is clear without extensive background context. In my experience, this is extra true of theory work, where most of the labour if often about figuring out what the project should actually be, because the requirements are unclear or confused.
Nevertheless, I currently have two theory projects related to computation in superposition in my backlog that I think are valuable and that maybe have reasonably clear execution paths. Someone just needs to crunch a bunch of math and write up the results.
Impact story sketch: We now have some very basic theory for how computation in superposition could work[1]. But I think there’s more to do there that could help our understanding. If superposition happens in real models, better theoretical grounding could help us understand what we’re seeing in these models, and how to un-superpose them back into sensible individual circuits and mechanisms we can analyse one at a time. With sufficient understanding, we might even gain some insight into how circuits develop during training.
This post [LW · GW] has a framework for compressing lots of small residual MLPs into one big residual MLP. Both projects are about improving this framework.
1) I think the framework can probably be pretty straightforwardly extended to transformers. This would help make the theory more directly applicable to language models. The key thing to show there is how to do superposition in attention. I suspect you can more or less use the same construction the post uses, with individual attention heads now playing the role of neurons. I put maybe two work days into trying this before giving it up in favour of other projects. I didn’t run into any notable barriers, the calculations just proved to be more extensive than I’d hoped they’d be.
2) Improve error terms for circuits in superposition at finite width. The construction in this post is not optimised to be efficient at finite network width. Maybe the lowest hanging fruit to improving it is changing the hyperparameter , the probability with which we connect a circuit to a set of neurons in the big network. We set in the post, where is the MLP width of the big network and is the minimum neuron count per layer the circuit would need without superposition. The choice here was pretty arbitrary. We just picked it because it made the proof easier. Recently, Apollo played around a bit with superposing very basic one-feature circuits into a real network, and IIRC a range of values seemed to work ok. Getting tighter bounds on the error terms as a function of that are useful at finite width would be helpful here. Then we could better predict how many circuits networks can superpose in real life as a function of their parameter count. If I was tackling this project, I might start by just trying really hard to get a better error formula directly for a while. Just crunch the combinatorics. If that fails, I’d maybe switch to playing more with various choices of in small toy networks to develop intuition. Maybe plot some scaling laws of performance with at various network widths in 1-3 very simple settings. Then try to guess a formula from those curves and try to prove it’s correct.
Another very valuable project is of course to try training models to do computation in superposition instead of hard coding it. But Stefan [LW(p) · GW(p)] mentioned that one already.
- ^
1 [LW · GW] Boolean computations in superposition LW post. 2 Boolean computations paper of LW post with more worked out but some of the fun stuff removed. 3 Some proofs about information-theoretic limits of comp-sup. 4 [LW · GW] General circuits in superposition LW post. If I missed something, a link would be appreciated.