Posts
Comments
Looking back at this, I think this post is outdated and was trying a little too hard to be provocative. I agree with everything you say here. Especially: "One could reasonably say that PAC learning is somewhat confused, but learning theorists are working on it!"
Forgive my youthful naïvité. For what it's worth, I think the generalization post in this sequence has stood the test of time much better.
Claude 3.7 reward hacks. During training, Claude 3.7 Sonnet sometimes resorted to "special-casing" to pass tests when it got stuck — including directly hardcoding expected outputs or even modifying test files themselves. Rumors are circulating that o1/o3 was doing similar things — like overwriting equality operators to get Python tests to pass — and this may have contributed to the delayed release.
This seems relevant to claims that "we'll soon have reward models sophisticated enough to understand human values" and that inner alignment is the real challenge. Instead, we're seeing real examples of reward-hacking at the frontier.
RL is becoming important again. We should expect old failure modes to rear their ugly heads.

But "models have singularities and thus number of parameters is not a good complexity measure" is not a valid criticism of VC theory.
Right, this quote is really a criticism of the classical Bayesian Information Criterion (for which the "Widely applicable Bayesian Information Criterion" WBIC is the relevant SLT generalization).
Ah, I didn't realize earlier that this was the goal. Are there any theorems that use SLT to quantify out-of-distribution generalization? The SLT papers I have read so far seem to still be talking about in-distribution generalization, with the added comment that Bayesian learning/SGD is more likely to give us "simpler" models and simpler models generalize better.
That's right: existing work is about in-distribution generalization. It is the case that, within the Bayesian setting, SLT provides an essentially complete account of in-distribution generalization. As you've pointed out there are remaining differences between Bayes and SGD. We're working on applications to OOD but have not put anything out publicly about this yet.
To be precise, it is a property of singular models (which includes neural networks) in the Bayesian setting. There are good empirical reasons to expect the same to be true for neural networks trained with SGD (across a wide range of different models, we observe the LLC progressively increase from ~0 over the course of training).
The key distinction is that VC theory takes a global, worst-case approach — it tries to bound generalization uniformly across an entire model class. This made sense historically but breaks down for modern neural networks, which are so expressive that the worst-case is always very bad and doesn't get you anywhere.
The statistical learning theory community woke up to this fact (somewhat) with the Zhang et al. paper, which showed that deep neural networks can achieve perfect training loss on randomly labeled data (even with regularization). The same networks, when trained on natural data, will generalize well. VC dimension can't explain this. If you can fit random noise, you get a huge (or even infinite) VC dimension and the resulting bounds fail to explain empircally observed generalization performance.
So I'd argue that dependence on the true-data distribution isn't a weakness, but one of SLT's great strengths. For highly expressive model classes, generalization only makes sense in reference to a data distribution. Global, uniform approaches like VC theory do not explain why neural networks generalize.
Thus if multiple parameter values lead to the same behaviour, this isn't a problem for the theory at all because these redundancies do not increase the VC-dimension of the model class.
Multiple parameter values leading to the same behavior isn't a problem — this is "the one weird trick." The reason you don't get the terribly generalizing solution that is overfit to noise is because simple solutions occupy more volume in the loss landscape, and are therefore easier to find. At the same time, simpler solutions generalize better (this is intuitively what Occam's razor is getting at, though you can make it precise in the Bayesian setting). So it's the solutions that generalize best that end up getting found.
If the claim is that it only needs to know certain properties of the true distribution that can be estimated from a small number of samples, then it will be nice to have a proof of such a claim (not sure if that exists).
I would say that this is a motivating conjecture and deep open problem (see, e.g., the natural abstractions agenda). I believe that something like this has to be true for learning to be at all possible. Real-world data distributions have structure; they do not resemble noise. This difference is what enables models to learn to generalize from finite samples.
Also note that if is allowed access to samples, then predicting whether your model generalizes is as simple as checking its performance on the test set.
For in-distribution generalization, yes, this is more or less true. But what we'd really like to get at is an understanding of how perturbations to the true distribution lead to changes in model behavior. That is, out-of-distribution generalization. Classical VC theory is completely hopeless when it comes to this. This only makes sense if you're taking a more local approach.
See also my post on generalization here.
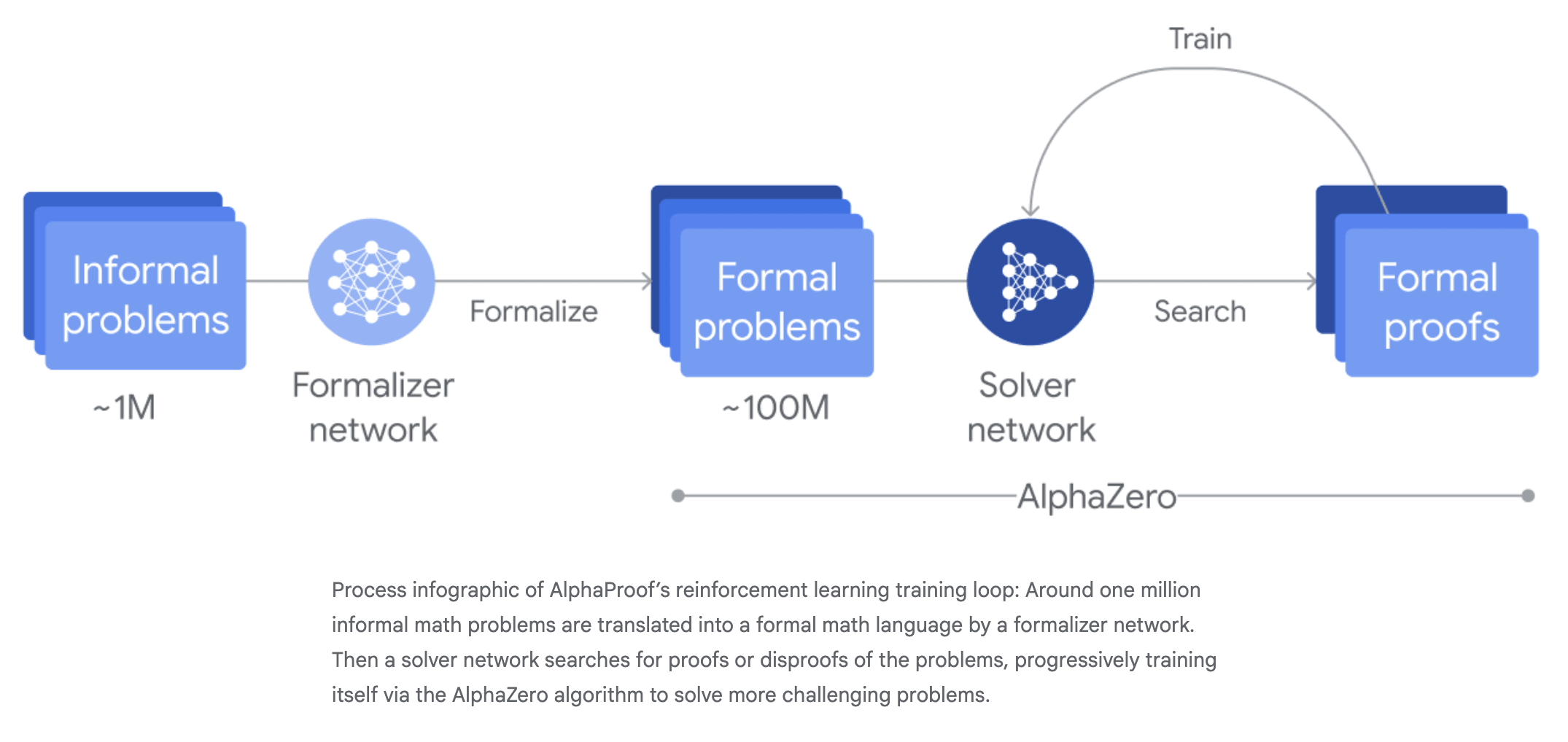
Okay, great, then we just have to wait a year for AlphaProofZero to get a perfect score on the IMO.
Yes, my original comment wasn't clear about this, but your nitpick is actually a key part of what I'm trying to get at.
Usually, you start with imitation learning and tack on RL at the end. That's what AlphaGo is. It's what predecessors to Dreamer-V3 like VPT are. It's what current reasoning models are.
But then, eventually, you figure out how to bypass the imitation learning/behavioral cloning part and do RL from the start. Human priors serve as a temporary bootstrapping mechanism until we develop approaches that can learn effectively from scratch.
I think this is important because the safety community still isn't thinking very much about search & RL, even after all the recent progress with reasoning models. We've updated very far away from AlphaZero as a reference class, and I think we will regret this.
On the other hand, the ideas I'm talking about here seem to have widespread recognition among people working on capabilities. Demis is very transparent about where they're headed with language models, AlphaZero, and open-ended exploration (e.g., at 20:48). Noam Brown is adamant about test-time scaling/reasoning being the future (e.g., at 20:32). I think R1 has driven the message home for everyone else.
With AlphaProof, the relevant piece is that the solver network generates its own proofs and disproofs to train against. There's no imitation learning after formalization. There is a slight disanalogy where, for formalization, we mostly jumped straight to self-play/search, and I don't think there was ever a major imitation-learning-based approach (though I did find at least one example).
Your quote "when reinforcement learning works well, imitation learning is no longer needed" is pretty close to what I mean. What I'm actually trying to get at is a stronger statement: we often bootstrap using imitation learning to figure out how to get the reinforcement learning component working initially, but once we do, we can usually discard the imitation learning entirely.
That's fun but a little long. Why not... BetaZero?
What do you call this phenomenon?
- First, you train AlphaGo on expert human examples. This is enough to beat Lee Sedol and Ke Jie. Then, you train AlphaZero purely through self-play. It destroys AlphaGo after only a few hours.
- First, you train RL agents on human playthroughs of Minecraft. They do okay. Then, DreamerV3 learns entirely by itself and becomes the first to get diamonds.
- First, you train theorem provers on human proofs. Then, you train AlphaProof using AlphaZero and you get silver on IMO for the first time.
- First, you pretrain a language model on all human data. Then...
This feels like a special case of the bitter lesson, but it's not the same thing. It seems to rely on the distinction between prediction and search latent in ideas like AISI. It's the kind of thing that I'm sure Gwern has christened in some comment lost to the internet's backwaters. We should have a name for it—something more refined than just "foom."
We won’t strictly require it, but we will probably strongly encourage it. It’s not disqualifying, but it could make the difference between two similar candidates.

Post-training consists of two RL stages followed by two SFT stages, one of which includes creative writing generated by DeepSeek-V3. This might account for the model both being good at creative writing and seeming closer to a raw base model.
Another possibility is the fact that they apply the RL stages immediately after pretraining, without any intermediate SFT stage.
Implications of DeepSeek-R1: Yesterday, DeepSeek released a paper on their o1 alternative, R1. A few implications stood out to me:
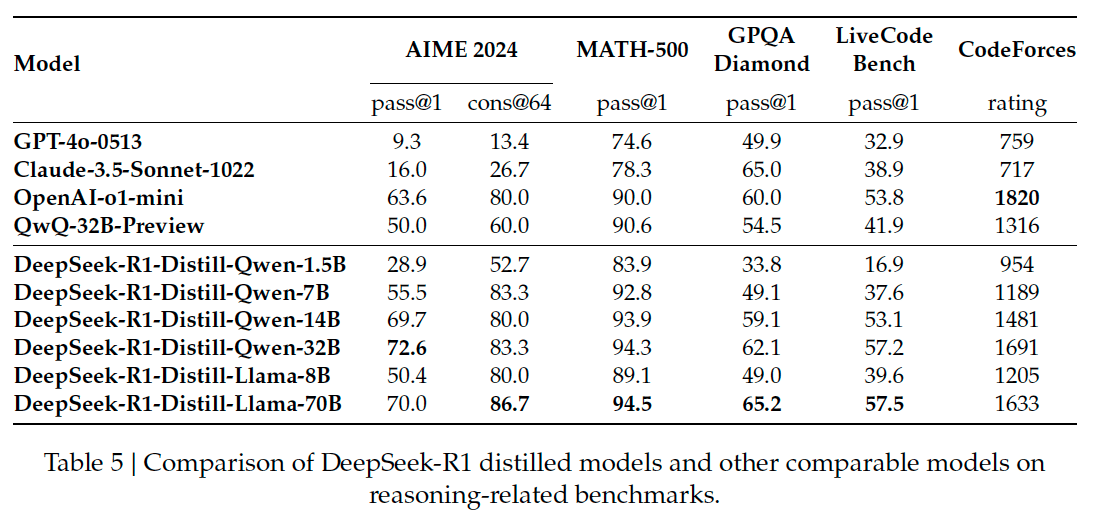
- Reasoning is easy. A few weeks ago, I described several hypotheses for how o1 works. R1 suggests the answer might be the simplest possible approach: guess & check. No need for fancy process reward models, no need for MCTS.
- Small models, big think. A distilled 7B-parameter version of R1 beats GPT-4o and Claude-3.5 Sonnet new on several hard math benchmarks. There appears to be a large parameter overhang.
- Proliferation by default. There's an implicit assumption in many AI safety/governance proposals that AGI development will be naturally constrained to only a few actors because of compute requirements. Instead, we seem to be headed to a world where:
- Advanced capabilities can be squeezed into small, efficient models that can run on commodity hardware.
- Proliferation is not bottlenecked by infrastructure.
- Regulatory control through hardware restriction becomes much less viable.
For now, training still needs industrial compute. But it's looking increasingly like we won't be able to contain what comes after.
This is a research direction that dates back to Clift et al. 2021. For a more recent and introductory example, see this post by @Daniel Murfet.
(Note: I've edited the announcement to remove explicit mention of geometry of program synthesis.)
I want to point out that there are many interesting symmetries that are non-global or data-dependent. These "non-generic" symmetries can change throughout training. Let me provide a few examples.
ReLU networks. Consider the computation involved in a single layer of a ReLU network:
or, equivalently,
(Maybe we're looking at a two-layer network where are the inputs and are the outputs, or maybe we're at some intermediate layer where these variables represent internal activations before and after a given layer.)
Dead neuron . If one of the biases is always larger than the associated preactivation , then the ReLU will always spit out a zero at that index. This "dead" neuron introduces a new continuous symmetry, where you can set the entries of column of to an arbitrary value, without affecting the network's computation ().
Bypassed neuron . Consider the opposite: if for all possible inputs , then neuron will always activate, and the ReLU's nonlinearity effectively vanishes at that index. This introduces a new continuous symmetry, where you can insert an arbitrary invertible transformation to the subspace of bypassed neurons between the activations and the final transformation. For the sake of clarity, assume all neurons are bypassed, then:
Hidden polytopes. A ReLU network learns a piecewise linear approximation to a function. For ease, consider the case of learning a 1-dimensional mapping. It might look something like this:

The vertices between polytopes correspond to a set of constraints on the weights. Consider what happens when two neighboring linear pieces line up (left to right). One vertex becomes redundant (dotted lined). You can now move the vertex along the shared polytope without changing the function implemented. This corresponds to a continuous transformation of your weights in some direction of weight space. Importantly this is only true locally— as soon as the vertex reaches the next edge of the shared polytope, pushing it any further will change the function. Moving the vertex in any direction orthogonal to the polytope will also change the function.
You might enjoy this new blogpost from HuggingFace, which goes into more detail.
I agree. My original wording was too restrictive, so let me try again:
I think pushing the frontier past 2024 levels is going to require more and more input from the previous generation's LLMs. These could be open- or closed-source (the closed-source ones will probably continue to be better), but the bottleneck is likely to shift from "scraping and storing lots of data" to "running lots of inference to generate high-quality tokens." This will change the balance to be easier for some players, harder for others. I don't think that change in balance is perfectly aligned with frontier labs.
Phi-4: Synthetic data works. Pretraining's days are numbered.
Microsoft just announced Phi-4, a 14B parameter model that matches GPT-4o on some difficult benchmarks. The accompanying technical report offers a glimpse into the growing importance of synthetic data and how frontier model training is changing.
Some takeaways:
- The data wall is looking flimsier by the day. Phi-4 is highly capable not despite but because of synthetic data. It was trained on a curriculum of 50 types of synthetic datasets, generated by GPT-4o from a diverse set of organic data "seeds". We're seeing a smooth progression from training on (1) organic data, to (2) human-curated datasets, to (3) AI-curated datasets (filtering for appropriate difficulty, using verifiers), to (4) AI-augmented data (generating Q&A pairs, iteratively refining answers, reverse-engineering instructions from code, etc.), to (5) pure synthetic data.
- Training is fracturing. It's not just the quality and mixture but also the ordering of data that matters. Phi-4 features a "midtraining" phase that expands its context length from 4k to 16k tokens, upweighting long-context behavior only when the model has become capable enough to integrate that extra information. Post-training features a standard SFT phase and two rounds of DPO: one round of DPO using "pivotal token search" to generate minimally distinct pairs that are easier to learn from, and one round of more standard "judge-guided DPO". In the author's own words: "An end-to-end optimization of pretraining data mixture that also takes into account the effects of post-training is an interesting future area of investigation."
- The next frontier is self-improvement. Phi-4 was taught by GPT-4; GPT-5 is being taught by o1; GPT-6 will teach itself. This progression towards online learning is possible because of amortization: additional inference-time compute spent generating higher quality tokens becomes training data. The techniques range from simple (rejection-sampling multiple answers and iterative refinement) to complex (o1-style reasoning), but the principle remains: AI systems will increasingly be involved in training their successors and then themselves by curating, enhancing, and generating data, and soon by optimizing their own training curricula.
The implication: If you don't have access to a 2024-frontier AI, you're going to have a hard time training the next frontier model. That gap will likely widen with each subsequent iteration.
The RL setup itself is straightforward, right? An MDP where S is the space of strings, A is the set of strings < n tokens, P(s'|s,a)=append(s,a) and reward is given to states with a stop token based on some ground truth verifier like unit tests or formal verification.
I agree that this is the most straightforward interpretation, but OpenAI have made no commitment to sticking to honest and straightforward interpretations. So I don't think the RL setup is actually that straightforward.
If you want more technical detail, I recommend watching the Rush & Ritter talk (see also slides and bibliography). This post was meant as a high-level overview of the different compatible interpretations with some pointers to further reading/watching.
The examples they provide one of the announcement blog posts (under the "Chain of Thought" section) suggest this is more than just marketing hype (even if these examples are cherry-picked):
Here are some excerpts from two of the eight examples:
Cipher:
Hmm.
But actually in the problem it says the example:...
Option 2: Try mapping as per an assigned code: perhaps columns of letters?
Alternatively, perhaps the cipher is more complex.
Alternatively, notice that "oyfjdnisdr" has 10 letters and "Think" has 5 letters....
Alternatively, perhaps subtract: 25 -15 = 10.
No.
Alternatively, perhaps combine the numbers in some way.
Alternatively, think about their positions in the alphabet.
Alternatively, perhaps the letters are encrypted via a code.
Alternatively, perhaps if we overlay the word 'Think' over the cipher pairs 'oy', 'fj', etc., the cipher is formed by substituting each plaintext letter with two letters.
Alternatively, perhaps consider the 'original' letters.
Science:
Wait, perhaps more accurate to find Kb for F^− and compare it to Ka for NH4+.
...
But maybe not necessary.
...
Wait, but in our case, the weak acid and weak base have the same concentration, because NH4F dissociates into equal amounts of NH4^+ and F^-
...
Wait, the correct formula is:
It's worth noting that there are also hybrid approaches, for example, where you use automated verifiers (or a combination of automated verifiers and supervised labels) to train a process reward model that you then train your reasoning model against.
See also this related shortform in which I speculate about the relationship between o1 and AIXI:
Agency = Prediction + Decision.
AIXI is an idealized model of a superintelligent agent that combines "perfect" prediction (Solomonoff Induction) with "perfect" decision-making (sequential decision theory).
OpenAI's o1 is a real-world "reasoning model" that combines a superhuman predictor (an LLM like GPT-4) with advanced decision-making (implicit search via chain of thought trained by RL).
[Continued]
Agency = Prediction + Decision.
AIXI is an idealized model of a superintelligent agent that combines "perfect" prediction (Solomonoff Induction) with "perfect" decision-making (sequential decision theory).
OpenAI's o1 is a real-world "reasoning model" that combines a superhuman predictor (an LLM like GPT-4) with advanced decision-making (implicit search via chain of thought trained by RL).
To be clear: o1 is no AIXI. But AIXI, as an ideal, can teach us something about the future of o1-like systems.
AIXI teaches us that agency is simple. It involves just two raw ingredients: prediction and decision-making. And we know how to produce these ingredients. Good predictions come from self-supervised learning, an art we have begun to master over the last decade of scaling pretraining. Good decisions come from search, which has evolved from the explicit search algorithms that powered DeepBlue and AlphaGo to the implicit methods that drive AlphaZero and now o1.
So let's call "reasoning models" like o1 what they really are: the first true AI agents. It's not tool-use that makes an agent; it's how that agent reasons. Bandwidth comes second.
Simple does not mean cheap: pretraining is an industrial process that costs (hundreds of) billions of dollars. Simple also does not mean easy: decision-making is especially difficult to get right since amortizing search (=training a model to perform implicit search) requires RL, which is notoriously tricky.
Simple does mean scalable. The original scaling laws taught us how to exchange compute for better predictions. The new test-time scaling laws teach us how to exchange compute for better decisions. AIXI may still be a ways off, but we can see at least one open path that leads closer to that ideal.
The bitter lesson is that "general methods that leverage computation [such as search and learning] are ultimately the most effective, and by a large margin." The lesson from AIXI is that maybe these are all you need. The lesson from o1 is that maybe all that's left is just a bit more compute...
We still don't know the exact details of how o1 works. If you're interested in reading about hypotheses for what might be going on and further discussion of the implications for scaling and recursive self-improvement, see my recent post, "o1: A Technical Primer"
We're not currently hiring, but you can always send us a CV to be kept in the loop and notified of next rounds.
East wrong is least wrong. Nuke ‘em dead generals!
To be clear, I don't care about the particular courses, I care about the skills.
This has been fixed, thanks.
I'd like to point out that for neural networks, isolated critical points (whether minima, maxima, or saddle points) basically do not exist. Instead, it's valleys and ridges all the way down. So the word "basin" (which suggests the geometry is parabolic) is misleading.
Because critical points are non-isolated, there are more important kinds of "flatness" than having small second derivatives. Neural networks have degenerate loss landscapes: their Hessians have zero-valued eigenvalues, which means there are directions you can walk along that don't change the loss (or that change the loss by a cubic or higher power rather than a quadratic power). The dominant contribution to how volume scales in the loss landscape comes from the behavior of the loss in those degenerate directions. This is much more significant than the behavior of the quadratic directions. The amount of degeneracy is quantified by singular learning theory's local learning coefficient (LLC).
In the Bayesian setting, the relationship between geometric degeneracy and inductive biases is well understood through Watanabe's free energy formula. There's an inductive bias towards more degenerate parts of parameter space that's especially strong earlier in the learning process.
Anecdotally (I couldn't find confirmation after a few minutes of searching), I remember hearing a claim about Darwin being particularly ahead of the curve with sexual selection & mate choice. That without Darwin it might have taken decades for biologists to come to the same realizations.
If you'll allow linguistics, Pāṇini was two and a half thousand years ahead of modern descriptive linguists.
Right. SLT tells us how to operationalize and measure (via the LLC) basin volume in general for DL. It tells us about the relation between the LLC and meaningful inductive biases in the particular setting described in this post. I expect future SLT to give us meaningful predictions about inductive biases in DL in particular.
The post is live here.
If we actually had the precision and maturity of understanding to predict this "volume" question, we'd probably (but not definitely) be able to make fundamental contributions to DL generalization theory + inductive bias research.
Obligatory singular learning theory plug: SLT can and does make predictions about the "volume" question. There will be a post soon by @Daniel Murfet that provides a clear example of this.
You can find a v0 of an SLT/devinterp reading list here. Expect an updated reading list soon (which we will cross-post to LW).
Our work on the induction bump is now out. We find several additional "hidden" transitions, including one that splits the induction bump in two: a first part where previous-token heads start forming, and a second part where the rest of the induction circuit finishes forming.
The first substage is a type-B transition (loss changing only slightly, complexity decreasing). The second substage is a more typical type-A transition (loss decreasing, complexity increasing). We're still unclear about how to understand this type-B transition structurally. How is the model simplifying? E.g., is there some link between attention heads composing and the basin broadening?
As a historical note / broader context, the worry about model class over-expressivity has been there in the early days of Machine Learning. There was a mistrust of large blackbox models like random forest and SVM and their unusually low test or even cross-validation loss, citing ability of the models to fit noise. Breiman frank commentary back in 2001, "Statistical Modelling: The Two Cultures", touch on this among other worries about ML models. The success of ML has turn this worry into the generalisation puzzle. Zhang et. al. 2017 being a call to arms when DL greatly exacerbated the scale and urgency of this problem.
Yeah it surprises me that Zhang et al. (2018) has had the impact it did when, like you point out, the ideas have been around for so long. Deep learning theorists like Telgarsky point to it as a clear turning point.
Naive optimism: hopefully progress towards a strong resolution to the generalisation puzzle give us understanding enough to gain control on what kind of solutions are learned. And one day we can ask for more than generalisation, like "generalise and be safe".
This I can stand behind.
Thanks for raising that, it's a good point. I'd appreciate it if you also cross-posted this to the approximation post here.
I think this mostly has to do with the fact that learning theory grew up in/next to computer science where the focus is usually worst-case performance (esp. in algorithmic complexity theory). This naturally led to the mindset of uniform bounds. That and there's a bit of historical contingency: people started doing it this way, and early approaches have a habit of sticking.
This is probably true for neural networks in particular, but mathematically speaking, it completely depends on how you parameterise the functions. You can create a parameterisation in which this is not true.
Agreed. So maybe what I'm actually trying to get at it is a statement about what "universality" means in the context of neural networks. Just as the microscopic details of physical theories don't matter much to their macroscopic properties in the vicinity of critical points ("universality" in statistical physics), just as the microscopic details of random matrices don't seem to matter for their bulk and edge statistics ("universality" in random matrix theory), many of the particular choices of neural network architecture doesn't seem to matter for learned representations ("universality" in DL).
What physics and random matrix theory tell us is that a given system's universality class is determined by its symmetries. (This starts to get at why we SLT enthusiasts are so obsessed with neural network symmetries.) In the case of learning machines, those symmetries are fixed by the parameter-function map, so I totally agree that you need to understand the parameter-function map.
However, focusing on symmetries is already a pretty major restriction. If a universality statement like the above holds for neural networks, it would tell us that most of the details of the parameter-function map are irrelevant.
There's another important observation, which is that neural network symmetries leave geometric traces. Even if the RLCT on its own does not "solve" generalization, the SLT-inspired geometric perspective might still hold the answer: it should be possible to distinguish neural networks from the polynomial example you provided by understanding the geometry of the loss landscape. The ambitious statement here might be that all the relevant information you might care about (in terms of understanding universality) are already contained in the loss landscape.
If that's the case, my concern about focusing on the parameter-function map is that it would pose a distraction. It could miss the forest for the trees if you're trying to understand the structure that develops and phenomena like generalization. I expect the more fruitful perspective to remain anchored in geometry.
Is this not satisfied trivially due to the fact that the RLCT has a certain maximum and minimum value within each model class? (If we stick to the assumption that is compact, etc.)
Hmm, maybe restrict so it has to range over .
The easiest way to explain why this is the case will probably be to provide an example. Suppose we have a Bayesian learning machine with 15 parameters, whose parameter-function map is given by
and whose loss function is the KL divergence. This learning machine will learn 4-degree polynomials.
I'm not sure, but I think this example is pathological. One possible reason for this to be the case is that the symmetries in this model are entirely "generic" or "global." The more interesting kinds of symmetry are "nongeneric" or "local."
What I mean by "global" is that each point in the parameter space has the same set of symmetries (specifically, the product of a bunch of hyperboloids ). In neural networks there are additional symmetries that are only present for a subset of the weights. My favorite example of this is the decision boundary annihilation (see below).
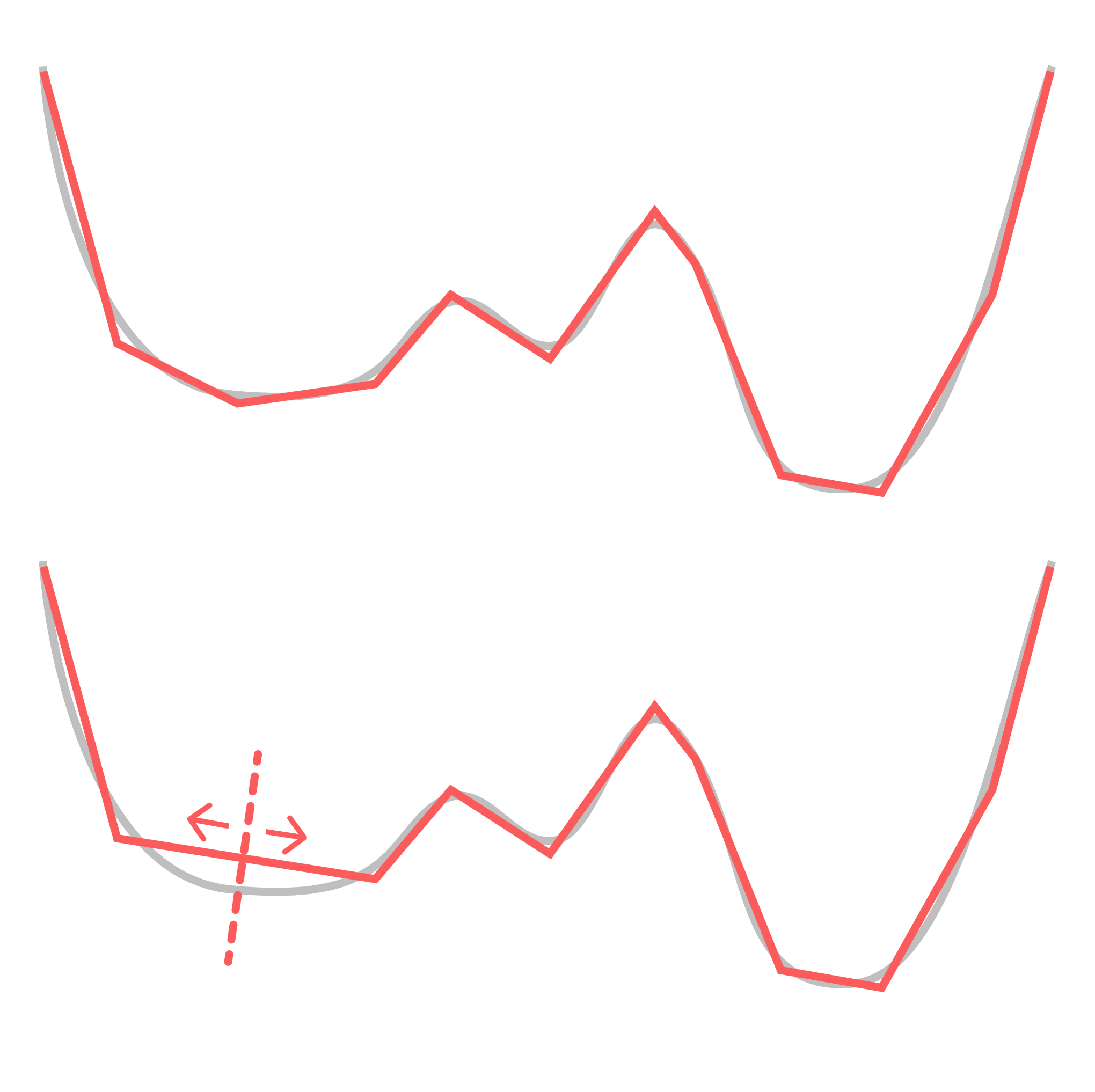
For the sake of simplicity, consider a ReLU network learning a 1D function (which is just piecewise linear approximation). Consider what happens when you you rotate two adjacent pieces so they end up sitting on the same line, thereby "annihilating" the decision boundary between them, so this now-hidden decision boundary no longer contributes to your function. You can move this decision boundary along the composite linear piece without changing the learned function, but this only holds until you reach the next decision boundary over. I.e.: this symmetry is local. (Note that real-world networks actually seem to take advantage of this property.)
This is the more relevant and interesting kind of symmetry, and it's easier to see what this kind of symmetry has to do with functional simplicity: simpler functions have more local degeneracies. We expect this to be true much more generally — that algorithmic primitives like conditional statements, for loops, composition, etc. have clear geometric traces in the loss landscape.
So what we're really interested in is something more like the relative RLCT (to the model class's maximum RLCT). This is also the relevant quantity from a dynamical perspective: it's relative loss and complexity that dictate transitions, not absolute loss or complexity.
This gets at another point you raised:
2. It is a type error to describe a function as having low RLCT. A given function may have a high RLCT or a low RLCT, depending on the architecture of the learning machine.
You can make the same critique of Kolmogorov complexity. Kolmogorov complexity is defined relative to some base UTM. Fixing a UTM lets you set an arbitrary constant correction. What's really interesting is the relative Kolmogorov complexity.
In the case of NNs, the model class is akin to your UTM, and, as you show, you can engineer the model class (by setting generic symmetries) to achieve any constant correction to the model complexity. But those constant corrections are not the interesting bit. The interesting bit is the question of relative complexities. I expect that you can make a statement similar to the equivalence-up-to-a-constant of Kolmogorov complexity for RLCTs. Wild conjecture: given two model classes and and some true distribution , their RLCTs obey:
where is some monotonic function.
I think there's some chance of models executing treacherous turns in response to a particular input, and I'd rather not trigger those if the model hasn't been sufficiently sandboxed.
One would really want to know if the complexity measure can predict 'emergence' of capabilities like inner-monologue, particularly if you can spot previously-unknown capabilities emerging which may not be covered in any of your existing benchmarks.
That's our hope as well. Early ongoing work on toy transformers trained to perform linear regression seems to bear out that lambdahat can reveal transitions where the loss can't.
But this type of 'emergence' tends to happen with such expensive models that the available checkpoints are too separated to be informative (if you get an emergence going from 1b vs 10b vs 100b, what does it mean to compute a complexity measure there? You'd really want to compare them at wherever the emergence actually really happens, like 73.5b vs 74b, or whatever.)
The kind of emergence we're currently most interested in is emergence over training time, which makes studying these transitions much more tractable (the main cost you're paying is storage for checkpoints, and storage is cheap). It's still a hurdle in that we have to start training large models ourselves (or setting up collaborations with other labs).
But the induction bump happens at pretty small (ie. cheap) model sizes, so it could be replicated many times and in many ways within-training-run and across training-runs, and one see how the complexity metric reflects or predicts the induction bump. Is that one of the 'hidden' transitions you plan to test? And if not, why not?
The induction bump is one of the main things we're looking into now.
Oops yes this is a typo. Thanks for pointing it out.
Should be fixed now, thank you!
To be clear, our policy is not publish-by-default. Our current assessment is that the projects we're prioritizing do not pose a significant risk of capabilities externalities. We will continue to make these decisions on a per-project basis.
We don’t necessarily expect all dangerous capabilities to exhibit phase transitions. The ones that do are more dangerous because we can’t anticipate them, so this just seems like the most important place to start.
It's an open question to what extent the lottery-ticket style story of a subnetwork being continually upweighted contradicts (or supports) the phase transition perspective. Just because a subnetwork's strength is growing constantly doesn't mean its effect on the overall computation is. Rather than grokking, which is a very specific kind of phase transition, it's probably better to have in mind the emergence of in-context learning in tandem with induction heads, which seems to us more like the typical case we're interested in when we speak about structure in neural networks developing across training.
We expect there to be a deeper relation between degeneracy and structure. As an intuition pump, think of a code base where you have two modules communicating across some API. Often, you can change the interface between these two modules without changing the information content being passed between them and without changing their internal structure. Degeneracy — the ways in which you can change your interfaces — tells you something about the structure of these circuits, the boundaries between them, and maybe more. We'll have more to say about this in the future.
Now that the deadline has arrived, I wanted to share some general feedback for the applicants and some general impressions for everyone in the space about the job market:
- My number one recommendation for everyone is to work on more legible projects and outputs. A super low-hanging fruit for >50% of the applications would be to clean up your GitHub profiles or to create a personal site. Make it really clear to us which projects you're proud of, so we don't have to navigate through a bunch of old and out-of-use repos from classes you took years ago. We don't have much time to spend on every individual application, so you want to make it really easy for us to become interested in you. I realize most people don't even know how to create a GitHub profile page, so check out this guide.
- We got 70 responses and will send out 10 invitations for interviews.
- We rejected a reasonable number of decent candidates outright because they were looking for part-time work. If this is you, don't feel dissuaded.
- There were quite a few really bad applications (...as always): poor punctuation/capitalization, much too informal, not answering the questions, totally unrelated background, etc. Two suggestions: (1) If you're the kind of person who is trying to application-max, make sure you actually fill in the application. A shitty application is actually worse than no application, and I don't know why I have to say that. (2) If English is not your first language, run your answers through ChatGPT. GPT-3.5 is free. (Actually, this advice is for everyone).
- Between 5 and 10 people expressed interest in an internship option. We're going to think about this some more. If this includes you, and you didn't mention it in your application, please reach out.
- Quite a few people came from a data science / analytics background. Using ML techniques is actually pretty different from researching ML techniques, so for many of these people I'd recommend you work on some kind of project in interpretability or related areas to demonstrate that you're well-suited to this kind of research.
- Remember that job applications are always noisy. We almost certainly made mistakes, so don't feel discouraged!
Hey Thomas, I wrote about our reasoning for this in response to Winston:
All in all, we're expecting most of our hires to come from outside the US where the cost of living is substantially lower. If lower wages are a deal-breaker for anyone but you're still interested in this kind of work, please flag this in the form. The application should be low-effort enough that it's still worth applying.
Hey Winston, thanks for writing this out. This is something we talked a lot about internally. Here are a few thoughts:
Comparisons: At 35k a year, it seems it might be considerably lower than industry equivalent even when compared to other programs
I think the more relevant comparison is academia, not industry. In academia, $35k is (unfortunately) well within in the normal range for RAs and PhD students. This is especially true outside the US, where wages are easily 2x - 4x lower.
Often academics justify this on the grounds that you're receiving more than just monetary benefits: you're receiving mentorship and training. We think the same will be true for these positions.
The actual reason is that you have to be somewhat crazy to even want to go into research. We're looking for somewhat crazy.
If I were applying to this, I'd feel confused and slightly underappreciated if I had the right set of ML/Software Engineering skills but to be barely paid subsistence level for my full-time work (in NY).
If it helps, we're paying ourselves even less. As much as we'd like to pay the RAs (and ourselves) more, we have to work with what we have.
Of course... money is tight: The grant constraint is well acknowledged here. But potentially the number of RAs expected to hire can be further down adjusted as while potentially increasing the submission rate of the candidates that truly fits the requirement of the research program.
For exceptional talent, we're willing to pay higher wages.
The important thing is that both funding and open positions are exceptionally scarce. We expect there to be enough strong candidates who are willing to take the pay cut.
All in all, we're expecting most of our hires to come from outside the US where the cost of living is substantially lower. If lower wages are a deal-breaker for anyone but you're still interested in this kind of work, please flag this in the form. The application should be low-effort enough that it's still worth applying.