New o1-like model (QwQ) beats Claude 3.5 Sonnet with only 32B parameters
post by Jesse Hoogland (jhoogland) · 2024-11-27T22:06:12.914Z · LW · GW · 4 commentsThis is a link post for https://qwenlm.github.io/blog/qwq-32b-preview/
Contents
4 comments
A new o1-like model based on Qwen-2.5-32B reportedly beats Claude 3.5 Sonnet[1] on a bunch of difficult reasoning benchmarks. A new regime dawns.
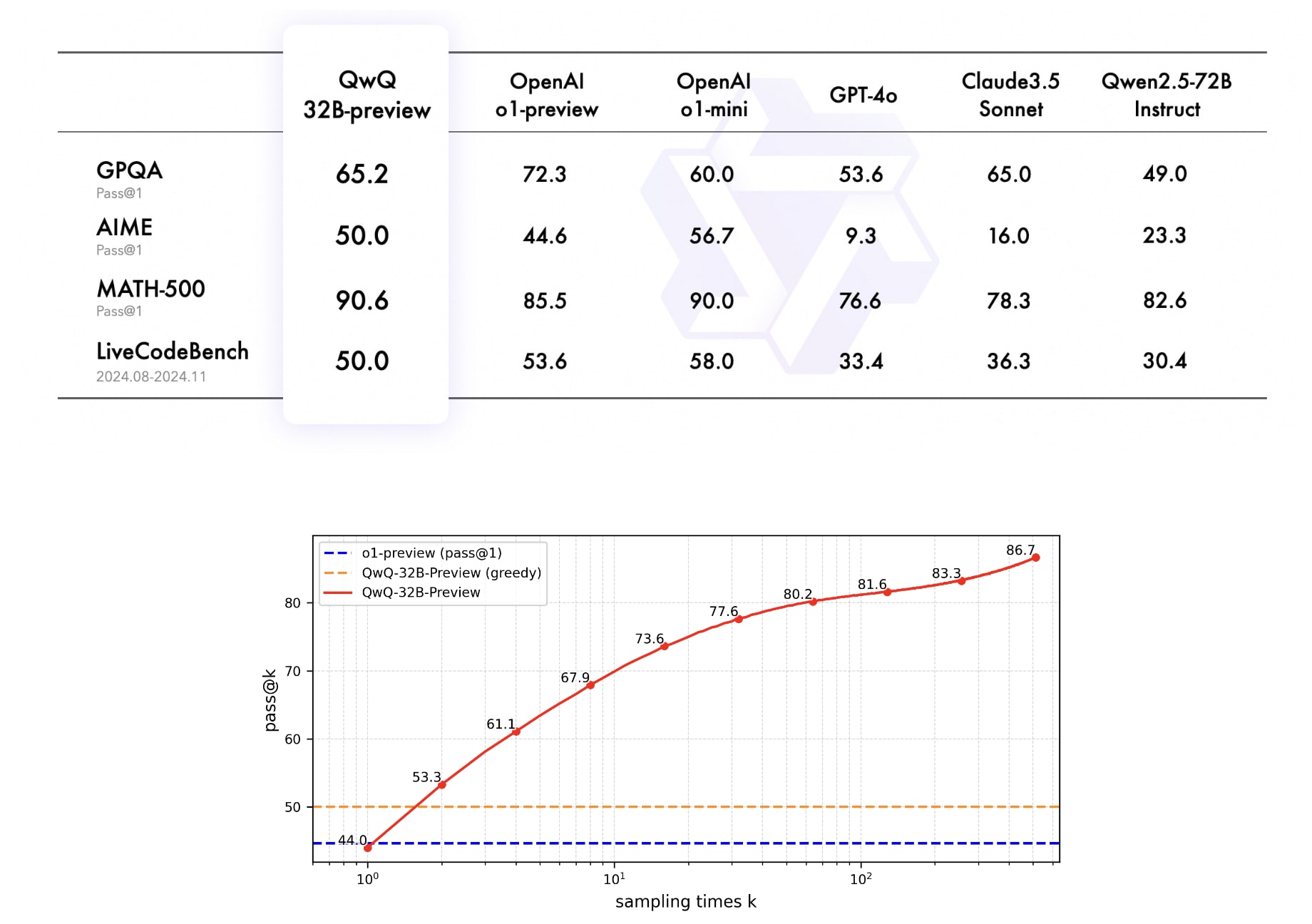
The blog post reveals nothing but the most inane slop ever sampled:
What does it mean to think, to question, to understand? These are the deep waters that QwQ (Qwen with Questions) wades into. Like an eternal student of wisdom, it approaches every problem - be it mathematics, code, or knowledge of our world - with genuine wonder and doubt. QwQ embodies that ancient philosophical spirit: it knows that it knows nothing, and that’s precisely what drives its curiosity. Before settling on any answer, it turns inward, questioning its own assumptions, exploring different paths of thought, always seeking deeper truth. Yet, like all seekers of wisdom, QwQ has its limitations. This version is but an early step on a longer journey - a student still learning to walk the path of reasoning. Its thoughts sometimes wander, its answers aren’t always complete, and its wisdom is still growing. But isn’t that the beauty of true learning? To be both capable and humble, knowledgeable yet always questioning? We invite you to explore alongside QwQ, embracing both its insights and its imperfections as part of the endless quest for understanding.
The model is available on HuggingFace. It's not yet clear when we'll hear more about the training details. EDIT: We can expect an official announcement tomorrow.
- ^
Not clear if this is Sonnet 3.5 new or old. For this, I blame Anthropic.
4 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2024-11-28T22:48:15.284Z · LW(p) · GW(p)
The first reasoning trace in the QwQ blog post seems impressive in how it manages to eventually stumble on the correct answer despite the 32B model clearly having no clue throughout, so it manages to effectively explore while almost blind. If this is sufficient to get o1-preview level results on reasoning benchmarks, it's plausible that RL in such post-training is mostly unhobbling the base models rather than making them smarter.
So some of these recipes might fail to have any way of scaling far, in the same sense that preference tuning doesn't scale far (unlike AlphaZero). QwQ post doesn't include a scaling plot, and the scaling plot in the DeepSeek-R1 post doesn't show improvement with further training, only with thinking for more tokens. The o1 post shows improvement with more training, but it might plateau in the uninteresting way instruction/preference post-training plateaus, making the model reliably do the thing its base model is already capable of in some sense. The similarity between o1, R1, and QwQ is superficial enough that the potential to scale with more post-training might be present in some of them and not others, or in none of them.
comment by Chris_Leong · 2024-11-28T12:36:54.634Z · LW(p) · GW(p)
If it works, maybe it isn't slop?
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-11-27T22:44:16.978Z · LW(p) · GW(p)
Relevant quote:
"We have discovered how to make matter think.
...
There is no way to pass “a law,” or a set of laws, to control an industrial revolution."
comment by Martin Vlach (martin-vlach) · 2024-12-05T19:40:33.866Z · LW(p) · GW(p)
My suspicion: https://arxiv.org/html/2411.16489v1 taken and implemented on the small coding model.
Is it any mystery which of the DPO, PPO, RLHF, Fine tuning was likely the method for the advanced distillation there?