Empirical risk minimization is fundamentally confused
post by Jesse Hoogland (jhoogland) · 2023-03-22T16:58:41.113Z · LW · GW · 8 commentsContents
Empirical risk minimization The aim of learning theory ERM is corrupted MLE Risk wastes information A deal with the devil that is uniform convergence Observables over risk Beyond bounds Conclusion None 8 comments
Produced under the mentorship of Evan Hubinger as part of the SERI ML Alignment Theory Scholars Program - Winter 2022 Cohort.
Thank you to @Zach Furman [LW · GW], @Denizhan_Akar [LW · GW], and Mark Chiu Chong for feedback and discussion.
Classical learning theory is flawed.
At least part of this is due to the field's flimsy theoretical foundations. In transitioning to modeling functions rather than probability distributions and in making risk the fundamental object of study rather than the data-generating distribution, learning theory has become easier to implement but harder to think clearly about.
This problem is not quite as big a problem as the other issues I'll raise in this sequence — the theory is not more limited than it would be otherwise. But the machinery obfuscates the true probabilistic nature of learning, throws out too much information about the microscopic structure of the model class, and misdirects precious attention to bounds that yield little insight.
Ultimately, a poor theoretical framework makes for poor theoretical work. We can do better by taking inspiration from statistical physics and singular learning theory.
Empirical risk minimization
In order to understand what classical learning theory is and what it aims to accomplish, we first need to understand the underlying framework of empirical risk minimization (ERM).
This framework is about learning functions,
In particular, we want to find the "optimal" function, , within some model/hypothesis class, , where we define the "optimal" function as that which minimizes the (population) risk,
The population risk evaluates on each input-output pair via a loss function, ,
with respect to some measure over the joint space, . That is, is a notion of similarity that penalizes for being far from the target .
In practice, this integral is intractable[1], so instead we approximate via the empirical risk,
where the sum is taken over a dataset, , of samples of input-output behavior.
Empirical risk minimization is concerned with minimizing as a proxy for minimizing . In particular, the aim is to find a model, , that competes with the best continuous function :
At its root, classical learning theory is about understanding and controlling the risk. The traditional way to approach this task is to derive inequalities (bounds) that limit how bad the risk can be.
The aim of learning theory
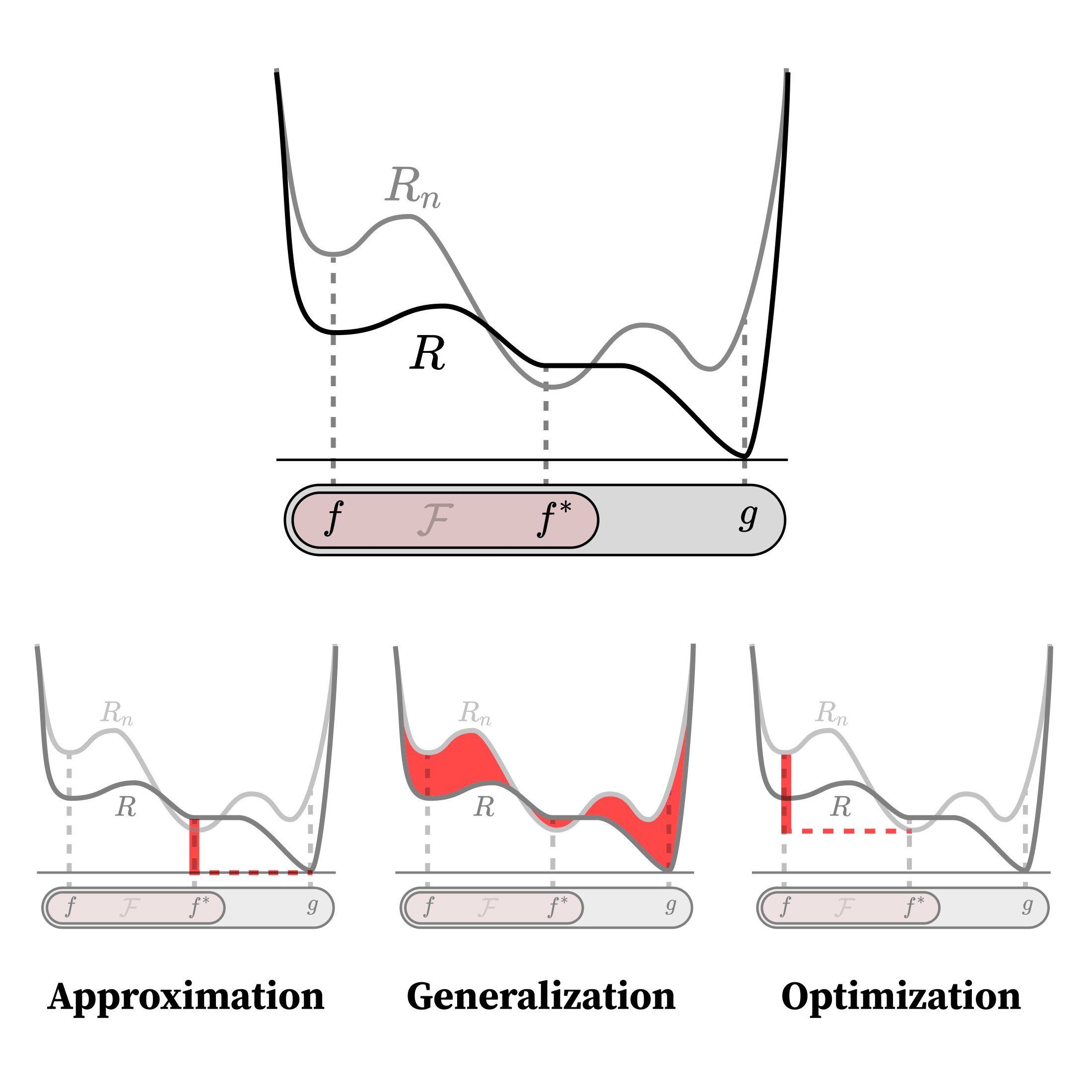
To make this problem more tractable, theorists like Telgarsky and Moitra break up learning theory into three main subproblems:
- Approximation: What functions can your model class (efficiently) represent? For NNs, how does expressivity change with architecture?
- Generalization: When does minimizing empirical risk lead to good performance on the population risk? For NNs, what are the inductive biases that allow overparametrized networks to generalize to novel data?
- Optimization: How is it that good functions are learnable in practice by optimizers like SGD?
Given a trained model, , and some optimal model from the same model class, , these components can be expressed in terms of the risk as follows:
In practice, most of what learning theory ends up actually accomplishing consists in statements of the kind "if the training set is at least this large, and the model class is at most this complex, then the probability is at least this high that the error is at most this large." In other words, the aim is to derive upper and lower bounds for the expressions above in terms of hyperparameters like the size of the model class, , and the number of samples, .
Even though I'll argue that risk is the wrong approach, this taxonomy seems mostly useful and otherwise innocent, so we'll stick to it throughout this sequence.
ERM is corrupted MLE
The first major problem with the presentation of ERM is that it hides the probabilistic origins of the problem.[2]
That's a problem because all learning is ultimately probabilistic. Even when the process you are learning is perfectly deterministic, factors like noise in your measuring devices and uncertainty in the initial conditions conspire to make the process you actually observe stochastic.
Implicit assumption #1 is that the samples in the dataset are i.i.d. from some probability distribution . In terms of this distribution, the measure that shows up in the definition of the population risk is really
Implicit assumption #2 is that is "close" to some deterministic function, . E.g., the true observations might be distributed around the deterministic function with some isotropic Gaussian noise,
If you make these assumptions explicit, then for the choice of the squared Euclidean distance as the loss function, the risk ends up being just a rescaled version of the negative log likelihood:
This is how we used to obtain our loss functions: we'd start with Bayesian inference, acknowledge defeat and resort to MLE, then switch to minimizing the negative log likelihood instead (which is equivalent but numerically nicer), and out pops your loss function.
ERM flips this around. It makes the loss function the starting point. The loss determines your reference function , not the other way around, and is hidden from view.
Empirically, this isn't a problem. If anything, shaking off our stifling obsession with Bayesian inference was probably necessary to advance ML.[3] It turns out that nonchalantly twiddling around with loss functions leads to better learning machines than obsessing about the theoretical justifications.
Even theoretically, the ERM framing isn't much of a problem since deriving bounds always requires reintroducing distributions over data anyway. Still, hiding the probabilities from view makes your thinking more confused.
It starts to be a problem when you decide as a field that you've had enough of linear regression and you want to go back to doing probabilistic next-token prediction (i.e., classification), but all of your existing theory is for the former. Or when you observe that LLMs can be stochastic even at zero temperature [LW · GW]. Or if you ever decide that you want to extend your theory to more realistic scenarios like non-i.i.d. data. Or when thinking about capable AGIs whose internal world models are necessarily probabilistic, even if not perfectly Bayesian.
In these cases, thinking too much about functions limits your ability to do useful theoretical work.
Risk wastes information
A more substantive issue with the risk is that it makes it harder to compare different functions in the same model class.
That's because the naive notion of similarity suggested by the risk is non-informative,
Consider a toy example from binary classification: you have a dataset whose positive and negative classes are equally represented along with two binary classifiers, and , that both achieve 50% accuracy on the dataset; they spit out what seem like uniformly random labels over the inputs. According to the naive functional norm, these two classifiers are equivalent.
But when you probe deeper, you find that and always produce opposite outputs, . From the perspective of what the function actually does, the functions are maximally different.

So when we decompose the population risk in terms of an approximation term, generalization term, and optimization term, these expressions don't capture cognitively meaningful distinctions between functions.
A deal with the devil that is uniform convergence
In order to compare different functions within the same model class, it's up to you to choose a more appropriate distance than the naive difference of risks. You could choose, say, the sup-norm, which is the maximum point-wise distance between two functions,[4]
This is the preferred choice of classical learning theory, and it forms the basis of the uniform convergence framework. Uniform convergence is about establishing worst-case guarantees because the sup-norm provides a measure of how closely a sequence of functions converges to a limit function across the entire domain.
Alternatively, you could choose an -norm,
or, if you're feeling Bayesian, you'd end up with the Schwartz distribution topology. Etc.
Though the choice of norm is usually suggested by the loss function, , this is not enough on its own to fix a functional topology (to see this compare the sup-norm and -norm).
Historically, that choice of norm has defaulted to the sup-norm, to such an extent that the frameworks of ERM and uniform convergence are hard to disentangle. That's less than ideal because the choice of topology is essential to the limiting behavior of learning processes (Watanabe 2009).[5] Eliding this choice has meant eliding a key theoretical question of how this topology impacts learning. As such, the relationship between ERM and uniform convergence is not an innocent partnership; it is a corrupt bargain.
At least part of the strength of singular learning theory is in its presentation: it recognizes that the functional norm as an important degree of freedom and that studying the consequences of this choice of norm is central to the study of learning.
Observables over risk
Another thing you might try if you're struggling to compare functions within some model class is to expand your definition of risk. If there is some aspect of the problem the risk is failing to capture, just add another term to the risk that correctly captures this missing part.
If the model class is very large (thus also theoretically unwieldy), add a regularization term like weight decay to your risk. By clamping this value to the weight norm of your trained model, you can severely shrink the size of effective model class you have to study because you can now disregard all models with different weight norms.
This is the approach of statistical physics, where we never care about all the microscopic details. Instead, we specify a limited number of "observables" that we can actually measure in the lab (i.e., during training) and thus represent meaningful differences between microstates (~individual models). These observables combine into a single Hamiltonian (~the risk), weighted by control parameters that correspond to the experimental dials under our control. The different combinations of values of these observables partition the phase space (~model class) into smaller, much more manageable macrostates (~model subclasses).
In the physical system, we fix, for example, the chemical potential, volume, and temperature, to control the average number of particles, pressure, and entropy, respectively. In the learning system, meanwhile, we fix, for example, coefficients on the regularization term and KL penalty term to control the expected weight norm and how much the model changes during fine-tuning.
When developing theory, it's necessary to simplify the problem by discarding irrelevant information, applying averages, and taking limits. There's no escaping this in learning theory. That said, ERM errs on the side of discarding too much information; risk is just one observable among many. Since it is the thing being optimized, the risk may be the most important observable, but it doesn't deserve all of the theoretical attention (no more than you could study the Hamiltonian in isolation from other observables).
That doesn't mean that moving to a more physics-inspired frame is without difficulties. In physics, we assume that all microstates for a given macrostate are equally likely. This follows from uncertainty about the starting conditions, an appeal to the ergodic hypothesis, and hand-waving about the second law of thermodynamics plus short mixing times. These considerations justify the maximum entropy principle, from which we obtain the Boltzmann distribution,
In learning theory, applying the same procedure leads to the so-called "Gibbs measure",[6]
Though useful in theory, the Gibbs measure does not describe the learning behavior we encounter in practice. Our choices of optimizers and architectures introduce biases that privilege certain functions over others, even if they have identical empirical risk. This violates the fundamental assumption of statistical physics from which the distribution was derived.
So the physics of learning machines is more difficult than the physics of gases. Nevertheless, the basic complaint of this section stands: a theory of neural networks requires observing more than just the empirical risk. When you find that the model class is too large and expressive —as is the case for neural networks — your only way forward is to measure more things.
Beyond bounds
The problem we discussed in the previous section was that comparing two functions, and , on the basis of risk alone is non-informative. might be low without either or being similar to one another.
This changes near the minimum of : in this regime, the only way for and to have similar risks is if they are also similar to each other.
I think this has contributed to the misguided historical focus on deriving (worst-case) bounds.[7] If you can jointly derive tight bounds for the generalization errors, optimization errors, and approximation errors, then you do have strong restrictions on the functions you end up with.
As Zhang et al. (2018) showed, neural networks are too expressive to obtain tight (generalization) bounds. This means we can't appeal to the above logic. The classical ERM + uniform convergence theory just does not work for neural networks.
In response, learning theorists have made some of the corrections you might expect from the previous sections. E.g.: including additional observables like margins, minimum flatness/sharpness, and weight norms leads to stronger (but still usually vacuous) bounds. Combining these ideas with relaxations of worst-case to average-case performance in the PAC-Bayes framework has led to some of the strongest bounds to date (Dziugaite and Roy (2017)).[8]
All of these corrections are good and point towards the right direction. Still, they haven't been enough to derive tight bounds, i.e., bounds that actually match the generalization performance observed in practice. As a result, theorists have done an about-turn and now argue (e.g., Telgarsky 2021) for the value of these bounds as proxies or even just as pedagogical tools. That's lowering the bar. Theory can and should do better.
What all of these theorists doesn't seem to realize is that what they're really doing is the physics of learning. To me, these fixes have more the flavor of patchwork bandaids than the unity of a mature theory. My diagnosis is that the field is in the terminal phase of contorting ERM into nightmarish shapes before it finally snaps, and the theorists have to acknowledge the need for a new foundation.
In this transition, we may come to find that the whole focus on obtaining bounds was overly myopic. If what we're studying is the physics of learning, then the more natural shape for the aims our calculations are partition functions (equivalently, free energies) and expectation values. From these values, we can go on to obtain bounds, but those bounds are strictly less informative than the theoretical device that contains every bit of information about your distribution.
Bounds just aren't everything.
Conclusion
I'm optimistic about singular learning theory [LW · GW] because it knows what it is: the physics of learning. If only the learning theorists could realize that what they really are are learning systems physicists.
In developing this physics of learning, ERM (along with uniform convergence) is not going to cut it. It's not equipped to handle probabilities responsibly, it is far too farsighted to resolve the microscopic structure of the model class on its own, and its monoculture of learning bounds has outcompeted other valuable fruits of theoretical work.
So it's time to move on and take a pointer from non-learning physics: to embrace the probabilistic nature of learning, to investigate the role of functional topology on the learning process, to introduce new observables, and to look towards other kinds of theoretical calculations like partition functions and time-tested expectation values.
With that said, go forth and conquer, my fellow learning systems physicists.
(Just don't advance capabilities while you're doing so, okay?)
- ^
The computational cost grows exponentially with the dimensionality of the parameter space.
- ^
In fairness, I'm cherry-picking Telgarsky's presentation of ERM, which is more guilty of this omission than many other introductions. Still, it is representative of the general overemphasis on functions over probability distributions.
- ^
Okay, so it is a problem.
- ^
This isn't necessarily measurable, so making this choice requires additional assumptions.
- ^
In particular, singular learning theory has focused on the limit of large amounts of data.
- ^
- ^
Other factors include the historical focus on worst-case performance in the neighboring field of algorithmic complexity and miscellaneous historical contingencies (such as seminal results like Novikoff (1963) and Valiant (1984) just happening to involve worst-case bounds). Or maybe the real reason for this obsession with bounds is more sociological than scientific: bounds serve as a legible signal that make it easier to play status games.
- ^
More on all of this coming soon in a subsequent post on generalization.
8 comments
Comments sorted by top scores.
comment by Vinayak Pathak (vinayak-pathak) · 2025-02-27T04:15:16.340Z · LW(p) · GW(p)
Having written a few papers about ERM and its variants, I feel personally attacked! I feel obliged to step in and try to defend ERM's honour.
First of all, I don't think I would call ERM a learning framework. ERM is a solution to the mathematical problem of PAC learning. Theoretical computer scientists like to precisely define the problem they want to solve before trying to solve it. When they were faced with the problem of learning, they decided that the mathematical problem of PAC learning was a good representation of the real-world problem of learning. Once you decide that PAC learning is what you want to solve, then ERM is the solution. Whether or not PAC learning truly represents the real world problem of learning is debatable and theorists have always agreed about that, with the main shortcoming being the insistence on the worst case probability distribution. But PAC learning is also a pretty solid first attempt at defining what learning means, which, in fact, used to produce useful predictions about practical learning methods before neural networks took over. Neural networks seem to work even in cases where PAC learning can be proved not to, and that means we need to come up with a better definition of what learning means. But PAC learning does have some very neat ideas built into it that whatever the better definition happens to be shouldn't ignore.
So what's so great about PAC learning? There's this famous quote by Vladimir Vapnik: "When solving a problem of interest, do not solve a more general problem as an intermediate step." PAC learning incorporates this advice in earnest. You point out that learning is inherently about probabilities, which is true. But using this to infer that we first need to model the probability distribution over (X, Y) is precisely the thing Vapnik warns against. In the end, we simply want to make predictions and we should directly model that. You can say that a predictor is a (potentially randomized) algorithm that maps X's to Y's. Then your learner's task is to look at a finite sample and output a predictor that makes good predictions in expectation (where the expectation is taken over the true data distribution and the predictor's randomness). If it turns out that the learner needs to somehow model the distribution over (X, Y) to come up with a good predictor then so be it, but that shouldn't be a part of the definition of the problem. But having defined the problem this way, one soon realizes that randomness in f is now unnecessary for the same reason that when trying to guess the outcome of a (biased) coin toss the best guess is deterministic. The best coin toss guess strategy is to simply guess the face that has the higher chance of showing up. Similarly the best predictor for a classification problem is the deterministic predictor that, for each x, outputs the label that has the highest chance of being the true label for x. Outputting a deterministic predictor does not mean we haven't modelled the inherent probabilities of the learning problem.
Empirical risk minimization does not feel fundamentally confused to me. ERM is, in fact, an amazingly elegant solution to the problem of PAC learning. One could reasonably say that PAC learning is somewhat confused, but learning theorists are working on it!
Replies from: jhoogland↑ comment by Jesse Hoogland (jhoogland) · 2025-02-27T05:50:42.679Z · LW(p) · GW(p)
Looking back at this, I think this post is outdated and was trying a little too hard to be provocative. I agree with everything you say here. Especially: "One could reasonably say that PAC learning is somewhat confused, but learning theorists are working on it!"
Forgive my youthful naïvité. For what it's worth, I think the generalization post in this sequence has stood the test of time much better.
↑ comment by Vinayak Pathak (vinayak-pathak) · 2025-02-27T14:56:14.340Z · LW(p) · GW(p)
Ah, I just noticed it's an old post. I was just clicking through all the SLT links. :)
comment by Zach Furman (zfurman) · 2023-03-22T17:19:09.551Z · LW(p) · GW(p)
My summary (endorsed by Jesse):
1. ERM can be derived from Bayes by assuming your "true" distribution is close to a deterministic function plus a probabilistic error, but this fact is usually obscured
2. Risk is not a good inner product (naively) - functions with similar risk on a given loss function can be very different
3. The choice of functional norm is important, but uniform convergence just picks the sup norm without thinking carefully about it
4. There are other important properties of models/functions than just risk
5. Learning theory has failed to find tight (generalization) bounds, and bounds might not even be the right thing to study in the first place
comment by dsj · 2023-03-23T00:51:58.492Z · LW(p) · GW(p)
That's because the naive inner product suggested by the risk is non-informative,
Hmm, how is this an inner product? I note that it lacks, among other properties, positive definiteness:
Edit: I guess you mean a distance metric induced by an inner product (similar to the examples later on, where you have distance metrics induced by a norm), not an actual inner product? I'm confused by the use of standard inner product notation if that's the intended meaning. Also, in this case, this doesn't seem to be a valid distance metric either, as it lacks symmetry and non-negativity. So I think I'm still confused as to what this is saying.
Replies from: jhoogland↑ comment by Jesse Hoogland (jhoogland) · 2023-03-23T18:58:59.414Z · LW(p) · GW(p)
You're right, thanks for pointing that out! I fixed the notation. Like you say, the difference of risks doesn't even qualify as a metric (the other choices mentioned do, however).
Replies from: dsj↑ comment by dsj · 2023-03-23T19:17:26.407Z · LW(p) · GW(p)
Thanks! This is clearer. (To be pedantic, the distance should have a root around the integral, but it's clear what you mean.)
Replies from: jhoogland↑ comment by Jesse Hoogland (jhoogland) · 2023-03-23T22:07:50.295Z · LW(p) · GW(p)
Thank you. Pedantic is good (I fixed the root)!