Timaeus in 2024
post by Jesse Hoogland (jhoogland), Stan van Wingerden (stan-van-wingerden), Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel), Daniel Murfet (dmurfet) · 2025-02-20T23:54:56.939Z · LW · GW · 1 commentsContents
Overview Research Progress in 2024 1. Basic Science: Validating SLT 2. Engineering: Scaling to LLMs 3. Alignment: Aiming at Safety Research Outlook for 2025 None 1 comment
TLDR: We made substantial progress in 2024:
- We published a series of papers that verify key predictions of Singular Learning Theory (SLT) [1, 2, 3, 4, 5, 6].
- We scaled key SLT-derived techniques to models with billions of parameters, eliminating our main concerns around tractability.
- We have clarified our theory of change and diversified our research portfolio to pay off across a range of different timelines.
In 2025, we will accelerate our research on the science and engineering of alignment, with a particular focus on developing techniques that can meaningfully impact the safety of current and near-future frontier models.
Overview
Timaeus's mission is to empower humanity by making breakthrough scientific progress on AI safety. We pursue this mission through technical research on interpretability and alignment and through outreach to scaling labs, researchers, and policymakers.
As described in our new position paper, our research agenda aims to understand how training data ultimately gives rise to model behavior by using Singular Learning Theory (SLT) to link four different kinds of structure (the "S4 correspondence"):
- Training Data: The statistical patterns present in the training distribution;
- Loss Landscape: The shape and singularities of the loss over parameter space;
- Learning Dynamics: The trajectory followed by the optimizer during training;
- Internal Algorithms: The circuits/mechanisms implemented in the trained model.
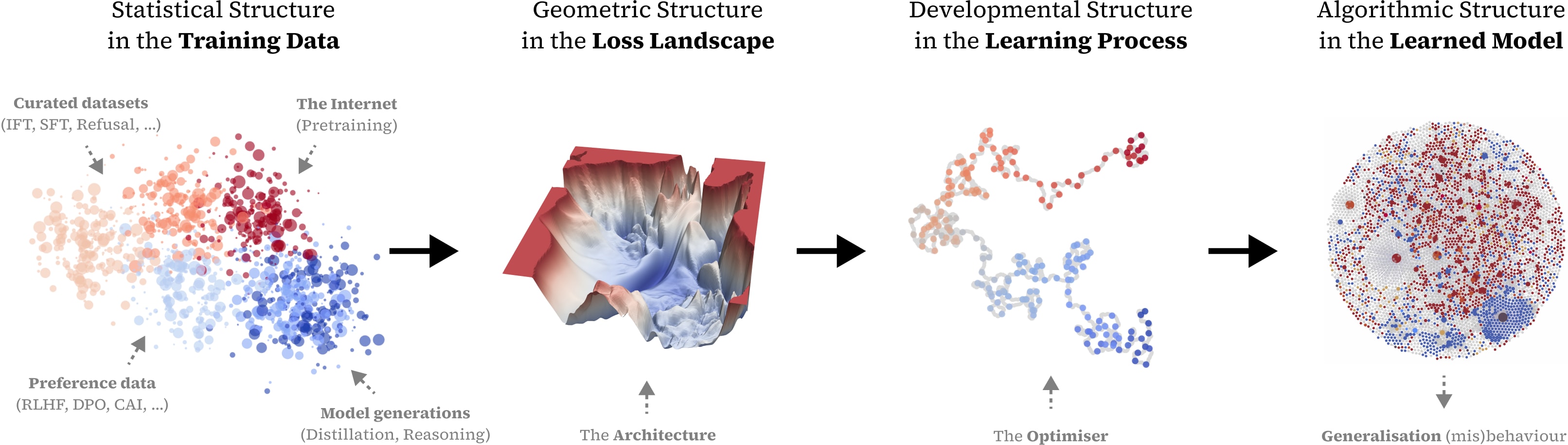
This correspondence provides a starting point for developing new tools for interpreting algorithmic structure (by probing the geometry of the loss landscape) and aligning advanced AI systems (by controlling the data distribution over training).
Since our founding in October 2023 [LW · GW], Timaeus has grown — from a team of four [LW · GW]with an initial budget of $145k to our current team of eight (soon, up to 12) with around $2.5M in funding for 2025. While research milestones are most visible, much of our progress has been in investing in our team, establishing research collaborations, and setting up the infrastructure we need to scale our work.
Research Progress in 2024
Over the past year, we have had three major research successes: (1) we validated SLT within deep learning theory, (2) we scaled SLT-derived techniques to billions of parameters, and (3) we developed an updated vision of SLT's role within AI safety.
1. Basic Science: Validating SLT
Through a series of papers conducted in collaboration with researchers at the University of Melbourne and elsewhere, we verified basic predictions of SLT: neural networks learn in stages, these stages correspond to specific structures in training data, and they can be discovered by probing changes in local geometry over the course of training.
This research validates the scientific soundness of SLT within the science of deep learning. However, this does not yet establish whether or not the relevant techniques will scale to frontier models with hundreds of billions of parameters (see Section 2. Engineering) nor whether that scientific understanding will materialize in a positive difference for safety (see Section 3. Alignment).
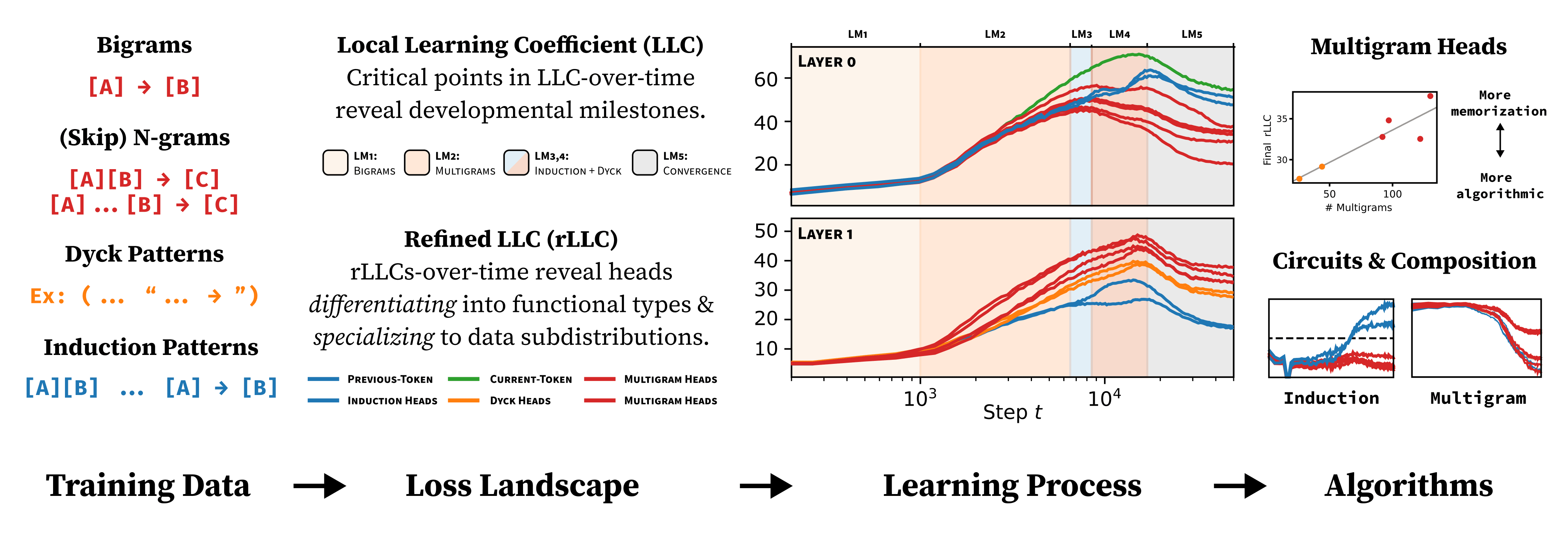
Local Learning Coefficient Estimation. Our foundational work established methods for estimating the Local Learning Coefficient (LLC), a key geometric invariant and measure of model complexity from SLT. We developed techniques based on stochastic gradient MCMC that make LLC estimation more practical for neural networks while validating the estimator against theoretical predictions in settings where exact values are known. [AISTATS 2025, Arxiv[1], LW [LW · GW]]
Developmental Stages in Transformers. Using LLC estimation, we demonstrated that small transformer language models progress through distinct developmental stages during training, as we hypothesized in our original post on Developmental Interpretability [LW · GW]. We show that the LLC can reveal stage boundaries — even when they are hidden from the loss — and that these stages correspond to particular structures in data (such as bigrams and induction patterns). [Under review, Best workshop paper at ICML HiLD 2025, Arxiv, LW [LW · GW], X]
Differentiation & Specialization. We introduced refined variants of the LLC to study how individual attention heads develop during training. By tracking these refined LLCs for each head, we uncovered how heads differentiate into distinct roles (like induction heads and bracket-matching) and specialize to particular input domains (like code versus natural language). [Spotlight at ICLR 2025, Arxiv, X]
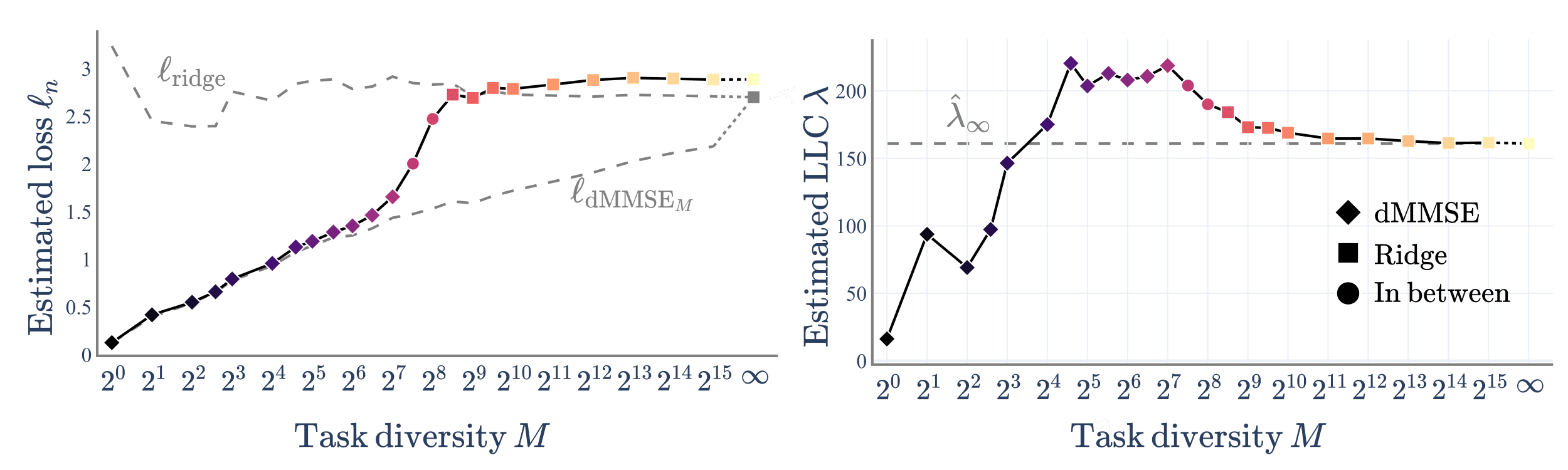
Dynamics of Transient Structure. In our latest work, we show that transformers trained for in-context linear regression initially develop a "generalizing" solution (ridge regression) before specializing to a "memorizing" solution (dMMSE) that is optimal for the training distribution. Using SLT, we explain the observed transience as a competition between performance and complexity. [Under review, Arxiv, LW & X coming soon].
Algorithmic transformers. In related work, we show that the LLC reveals distinct developmental stages in transformers trained to sort lists, where stages correspond to qualitative shifts in model behavior and circuit organization. [Under review, Workshop NeurIPS 2024, Arxiv, LW [LW · GW]]
2. Engineering: Scaling to LLMs
Though it is a positive update on SLT that the theory can make correct predictions about toy models, this alone is not enough for the research to make a difference. One of our core uncertainties was whether SLT-based techniques like LLC estimation would scale to larger models. Through advances in sampling techniques and hyperparameter selection, we have overcome key engineering hurdles and scaled to models with billions of parameters.
Probing geometry. Most of our tools, including LLC estimation and its (future) descendants, are based on stochastic gradient MCMC sampling techniques, which are essentially stochastic optimizers with added noise. While sampling is more memory-intensive than training, we have found that standard scaling techniques like data- and model-parallelism make this cost manageable. The rule of thumb: if you can train a model, you can sample from the local posterior for that model.
Compute efficiency. It is, however, not enough to be able to draw individual samples. A deeper concern was whether we would need to draw prohibitively many samples to obtain reliable estimates for larger models. Intuitively, more parameters should require more samples. In practice, the scaling is highly sublinear. Even for large models, we have found that drawing only a few hundred samples over a handful of chains often yields consistent measurements. This is a remarkable empirical fact.
Scaling hyperparameter selection. Another difficulty was searching for appropriate hyperparameters. SGMCMC introduces additional hyperparameters beyond those of standard training (noise scale and localization strength), so a naive grid search quickly becomes intractable for large models. By incorporating techniques from adaptive optimizers like RMSProp, we have significantly improved both the quality of our experimental results and their sensitivity to hyperparameters.

3. Alignment: Aiming at Safety
Until recently, we were not able to apply our research directly to safety because we first needed to verify the basic science and scale our techniques to larger models. As those barriers have fallen, we have gained a clearer vision of how to apply our research to safety, which we articulated in our recent position paper. We are now pursuing direct impact in three main directions:
Near-term Applications. While our research continues to focus on extreme risks from superintelligent systems, we believe it is important to make concrete progress on immediate, near-term safety challenges. First, it allows us to validate and refine our techniques on real systems. Second, our insights from studying today's models inform our approach to future systems. Finally, demonstrating practical impact helps build the credibility needed to influence the development of more advanced AI systems.
In partnership with the UK AISI, we are pursuing two concrete applications of SLT to current AI safety challenges:
- Singular psychometrics: Can we use SLT to distinguish performance on evals achieved through rote memorization versus genuine generalization? That is, can we use SLT to start to go beyond evals based on performance to evals that incorporate how the model achieves a given level of performance?
- Weight exfiltration: Can we use SLT to determine theoretical limits to compression (by generalizing the minimum description length principle) and analyze the implications for weight exfiltration?
Beyond these, we have described a set of projects for applying SLT to measure the robustness of alignment techniques and develop principled ways to predict how vulnerable models are to jailbreaking, malicious fine-tuning, and backdoor insertion. We are particularly interested in understanding how different training regimes affect the depth and stability of learned alignment constraints. We are actively pursuing these applications with the goal of demonstrating concrete safety improvements for current frontier models within the next 6-12 months.
Interpretability ("Reading"). Timaeus began with a vision for developmental interpretability [LW · GW] — an approach grounded in studying how models change during training. Developmental interpretability is motivated in analogy with developmental biology on the grounds that changes during development provide a rich source of information about a system's end state.
Though it is possible to study development in purely behavioral or mechanistic terms, our central focus has always been to study changes in SLT-based observables. This is because SLT provides an account of the importance of the geometry of the loss landscape in controlling development and how this development determines learned mechanisms and behaviors.[2]
Where mechanistic interpretability is more bottom-up, our approach to interpretability is more top-down. The history of our interpretability tools is one of progressively increasing resolution: from basic LLCs that measure the overall "amount of structure" in a model to refined variants that measure structure associated to particular datasets and particular parts of the model. We are now developing generalizations of the LLC ("susceptibilities") that reveal how models respond to finer-scale perturbations in their training data.
We expect these methods to lead to new techniques for circuit discovery this year, potentially revealing higher-level functional organization that is difficult to detect through traditional interpretability approaches like SAEs.
Alignment ("Writing"). Modern alignment techniques like RLHF and Constitutional AI work by curating training data to indirectly shape model behavior. We expect that developing more robust alignment techniques requires understanding how this process unfolds — how patterns in training data become computational structures in models.
As we describe above, the "S4 correspondence" provides a starting point for developing a more rigorous understanding of the link between data and behavior through the loss landscape and the learning process. As we look toward the longer term (2+ years), these theoretical foundations aim to inform the development of more principled and robust alignment techniques that could scale with increasing model capabilities (e.g., new techniques for curating training data during RLHF).
Research Outlook for 2025
In 2025, we will continue to work on the three directions described above:
Basic Science: Finishing the Foundations. Over the next few months, we will release a series of foundational papers that fill in particular parts of the S4 correspondence. For several theoretically tractable classes of learning machines, including certain smooth Turing machines and exponential families, we will establish precise mathematical relationships between different aspects of the S4 correspondence. In practical terms, this will lay the groundwork for new generations of yet higher-resolution tools. In the most ambitious case, we expect to be able to read off fine-scale computational structure — including control flow, recursion/iteration, variable binding, and error correction — directly from the geometry of the loss landscape.
Engineering: Scaling to the Frontier. We will scale our techniques to models with tens of billions of parameters, possibly to hundreds of billions. Given recent progress in small reasoning models, we expect this to be enough to apply our techniques to truly SOTA models. At the same time, we expect that in 2025 we will begin to see significant benefits from research automation [LW · GW], accelerating both our theoretical and experimental work.
Alignment: Real-World Impact. We will complete our initial projects on singular psychometrics and weight exfiltration by April to demonstrate relevance to near-term safety challenges. Around the same time, we will complete follow-up work to Wang et al. (2025) on the "susceptibilities" mentioned above. For the rest of the year, we will continue working on the alignment-relevant applications discussed in the previous section: interpretability, alignment, and prosaic safety, all at the frontier scale.
The pace of progress in AI is accelerating and with it, the urgency of our mission. This year is likely to be a pivotal year, not just for AI safety in general but for theoretical approaches to alignment in particular. If you would like to stay up-to-date or learn more about our work, visit our website or join our Discord community. And if you want to help us make this go right, we're currently hiring and would love to see your application [LW · GW].
- ^
This paper was formerly two different papers that were consolidated and rewritten for clarity.
- ^
The developmental perspective continues to be central to our research. However, just as there are non-SLT-based approaches to studying development, there are non-developmental approaches to doing SLT-based interpretability.
1 comments
Comments sorted by top scores.
comment by Cole Wyeth (Amyr) · 2025-02-21T00:57:18.682Z · LW(p) · GW(p)
Sounds awesome, but also clearly dual use.