Posts
Comments
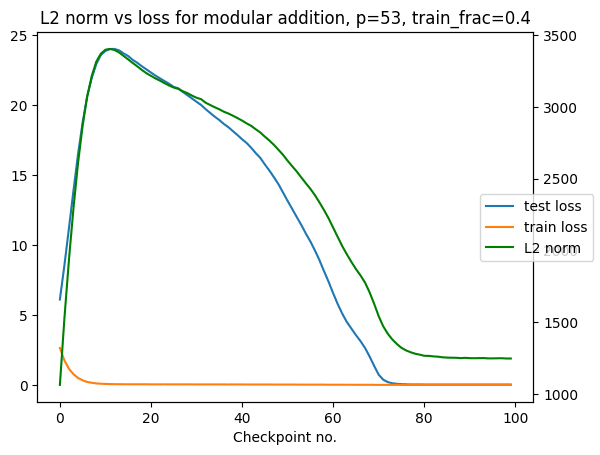
Here's the plot, which is very similar to Experience Machine's:
My conclusion from this is that the LLC and the L2 norm measure basically the same thing in this setup. They don't always: for further comparison with more unprincipled metrics in more complex setups, see comparisons with weight norm / Hessians in fig 22, 23, and 25 here and comparisons with Hessian-based methods and ablations here.
Here's a quick interesting-seeming devinterp result:
We can estimate the Local Learning Coefficient (LLC, the central quantity of Singular learning theory, for more info see these posts / papers) of a simple grokking model on its training data over the course of training.
This yields the following plot:
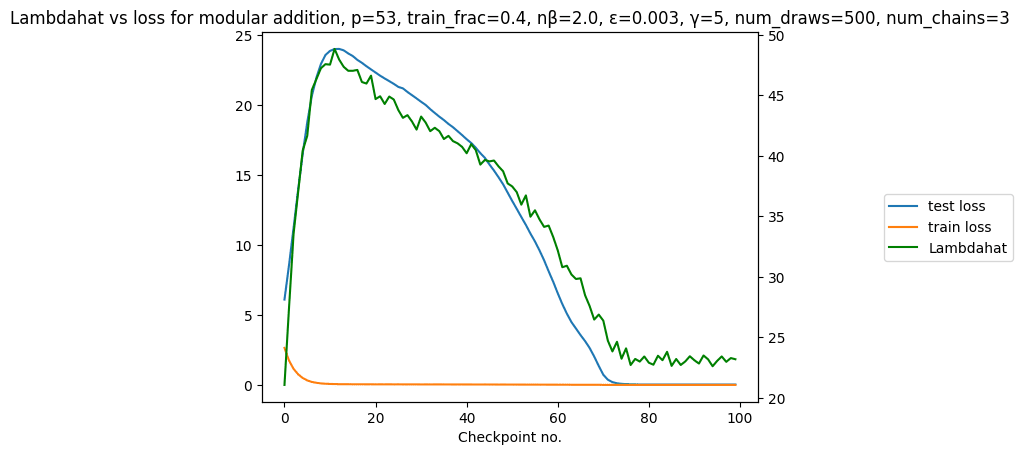
(note: estimated LLC = lambdahat = )
What's interesting about this is that the estimated LLC of the model in this plot closely tracks test loss, even though it is estimated on training data.
On the one hand this is unsurprising: SLT predicts that the LLC determines the Bayes generalization error in the Bayesian setting.[1] On the other hand this is quite surprising: the Bayesian setting is not the same as SGD, an increase in training steps is not the same as an increase in the total number of samples, and the Bayes generalization is not exactly the same as test loss. Despite these differences, the LLC clearly tracks (in-distribution) generalization here. We see this as a positive sign for applying SLT to study neural networks trained by SGD.
This plot was made using the devinterp python package, and the code to reproduce it (including hyperparameter selection) is available as a notebook at https://github.com/timaeus-research/devinterp/blob/main/examples/grokking.ipynb.
Thanks to Nina Panickserry and Dmitry Vaintrob, whose earlier post on learning coefficients of modular addition served as the basis for this experiment.
- ^
More precisely: in the Bayesian setting the Bayes generalization error, as a function of the number of samples n, is λ/n in leading order.
It's in USD (should be reflected in to the announcement now)
This last paragraph will live in my head forever, but I'm confused how it relates to the rest of the post. Would you agree with the following rephrasing? "Forming incomplete preferences (and thus not optimizing fully) is the easy way out, as it avoids taking some sure losses. But in doing so it also necessarily loses out on sure gains."