Stan van Wingerden's Shortform
post by Stan van Wingerden (stan-van-wingerden) · 2024-12-11T18:00:53.568Z · LW · GW · 8 commentsContents
8 comments
8 comments
Comments sorted by top scores.
comment by Stan van Wingerden (stan-van-wingerden) · 2024-12-11T18:00:53.900Z · LW(p) · GW(p)
Here's a quick interesting-seeming devinterp result:
We can estimate the Local Learning Coefficient (LLC, the central quantity of Singular learning theory, for more info see these [LW · GW] posts [LW · GW]/ papers) of a simple grokking model on its training data over the course of training.
This yields the following plot:
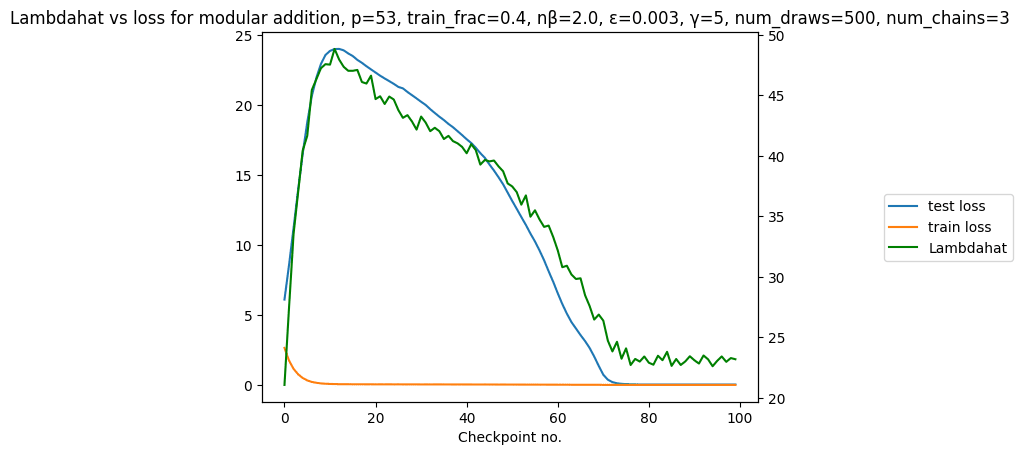
(note: estimated LLC = lambdahat = )
What's interesting about this is that the estimated LLC of the model in this plot closely tracks test loss, even though it is estimated on training data.
On the one hand this is unsurprising: SLT predicts that the LLC determines the Bayes generalization error in the Bayesian setting.[1] On the other hand this is quite surprising: the Bayesian setting is not the same as SGD, an increase in training steps is not the same as an increase in the total number of samples, and the Bayes generalization is not exactly the same as test loss. Despite these differences, the LLC clearly tracks (in-distribution) generalization here. We see this as a positive sign for applying SLT to study neural networks trained by SGD.
This plot was made using the devinterp python package, and the code to reproduce it (including hyperparameter selection) is available as a notebook at https://github.com/timaeus-research/devinterp/blob/main/examples/grokking.ipynb.
Thanks to Nina Panickserry and Dmitry Vaintrob, whose earlier post on learning coefficients of modular addition [LW · GW] served as the basis for this experiment.
- ^
More precisely: in the Bayesian setting the Bayes generalization error, as a function of the number of samples n, is λ/n in leading order.
↑ comment by ryan_greenblatt · 2024-12-11T18:43:31.685Z · LW(p) · GW(p)
I'm curious how well test loss is predicted by unprincipled metrics in this setup. For instance, how well is it predicted by the l2 norm of the weights? What about average_log_probability_on_train?
(Average log prob on train is loss on test if you assume that test labels are unrelated to the model's train predictions and train log probs have the same distribution as test log probs. You could also do average_log_probability_on_test which is a metric you can run without needing test labels as long as you have test inputs.)
Replies from: Ansatz, stan-van-wingerden↑ comment by Louis Jaburi (Ansatz) · 2024-12-12T11:26:55.848Z · LW(p) · GW(p)
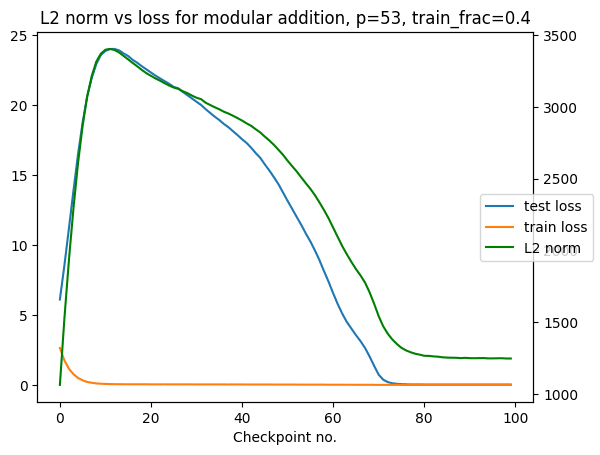
Using almost the same training parameters as above (I used full batch and train_frac=0.5 to get faster & more consistent grokking, but I don't think this matters here)

I did a few runs and the results all looked more or less like this. The training process of such toy models doesn't contain so many bits of interesting information, so I wouldn't be surprised if a variety of different metrics would capture this process in this case. (E.g. the training dynamics can be also modelled by an HMM, see here).
↑ comment by Stan van Wingerden (stan-van-wingerden) · 2024-12-12T16:48:27.225Z · LW(p) · GW(p)
Here's the plot, which is very similar to Experience Machine's:
My conclusion from this is that the LLC and the L2 norm measure basically the same thing in this setup. They don't always: for further comparison with more unprincipled metrics in more complex setups, see comparisons with weight norm / Hessians in fig 22, 23, and 25 here and comparisons with Hessian-based methods and ablations here.
↑ comment by peterbarnett · 2024-12-12T19:57:58.405Z · LW(p) · GW(p)
I'm curious about what you think is "causing" what. For example, does the LLC lead to both the L2 norm and the test loss, or does the L2 norm lead to the LLC and the test loss, or is there a third factor leading to all 3 things. (Or is this question confused and it doesn't make sense to talk about these things "causing" each other?)
Replies from: dmurfet↑ comment by Daniel Murfet (dmurfet) · 2024-12-12T21:58:15.479Z · LW(p) · GW(p)
There's no general theoretical reason that I am aware of to expect a relation between the L2 norm and the LLC. The LLC is the coefficient of the term in the asymptotic expansion of the free energy (negative logarithm of the integral of the posterior over a local region, as a function of sample size ) while the L2 norm of the parameter shows up in the constant order term of that same expansion, if you're taking a Gaussian prior.
It might be that in particular classes of neural networks there is some architecture-specific correlation between the L2 norm and the LLC, but I am not aware of any experimental or theoretical evidence for that.
For example, in the figure below from Hoogland et al 2024 we see that there are later stages of training in a transformer trained to do linear-regression in context (blue shaded regions) where the LLC is decreasing but the L2 norm is increasing. So the model is moving towards a "simpler" parameter with larger weight norm.
My best current guess is that it happens to be, in the grokking example, that the simpler solution has smaller weight norm. This could be true in many synthetic settings, for all I know; however, in general, it is not the case that complexity (at least as far as SLT is concerned) and weight norm are correlated.

↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-12-11T18:23:37.428Z · LW(p) · GW(p)
I would be interested what current SLT-dogma on grokking is. I get asked whether SLT explains grokking all the time but always have to reply with an unsatisfying 'there's probably something there but I don't understand the details'.
@Zach Furman [LW · GW] @Jesse Hoogland [LW · GW]
Replies from: zfurman↑ comment by Zach Furman (zfurman) · 2024-12-13T10:01:17.211Z · LW(p) · GW(p)
IIRC @jake_mendel [LW · GW] and @Kaarel [LW · GW] have thought about this more, but my rough recollection is: a simple story about the regularization seems sufficient to explain the training dynamics, so a fancier SLT story isn't obviously necessary. My guess is that there's probably something interesting you could say using SLT, but nothing that simpler arguments about the regularization wouldn't tell you also. But I haven't thought about this enough.