o1: A Technical Primer
post by Jesse Hoogland (jhoogland) · 2024-12-09T19:09:12.413Z · LW · GW · 19 commentsThis is a link post for https://www.youtube.com/live/6fJjojpwv1I?si=5qYt5BZq3dWQoq0i&t=265
Contents
The Bitter Lesson(s) What we know about o1 What OpenAI has told us What OpenAI has showed us Proto-o1: Chain of Thought In-Context Learning Thinking Step-by-Step Majority Vote o1: Four Hypotheses 1. Filter: Guess + Check 2. Evaluation: Process Rewards 3. Guidance: Search / AlphaZero 4. Combination: Learning to Correct Post-o1: (Recursive) Self-Improvement Outlook None 19 comments
TL;DR: In September 2024, OpenAI released o1, its first "reasoning model". This model exhibits remarkable test-time scaling laws, which complete a missing piece of the Bitter Lesson and open up a new axis for scaling compute. Following Rush and Ritter (2024) and Brown (2024a, 2024b), I explore four hypotheses for how o1 works and discuss some implications for future scaling and recursive self-improvement.
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought (CoT). This was the simplest possible way to incorporate search into LLMs, and it worked.
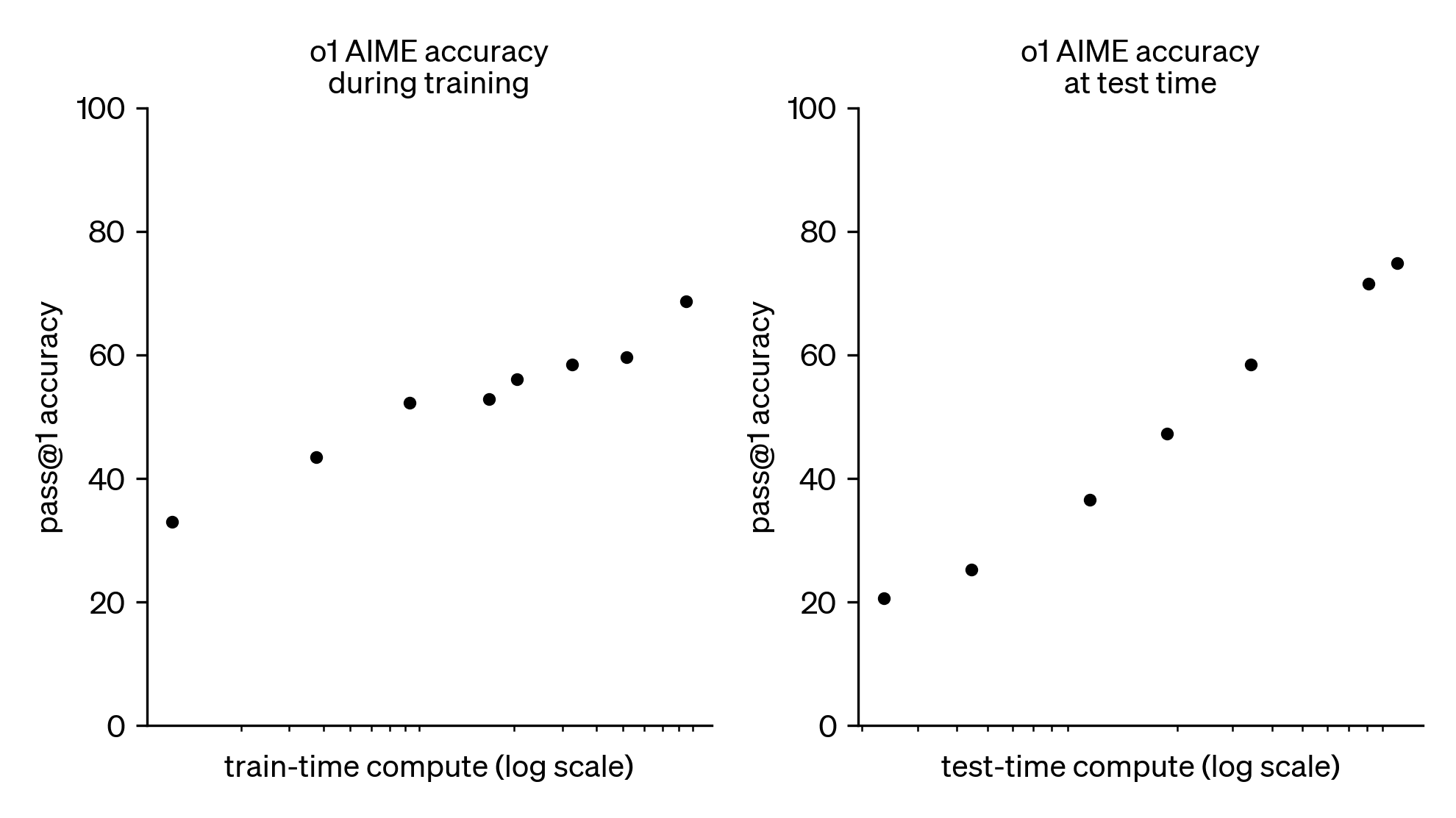
The key consequence is that OpenAI has opened up a new frontier of the bitter lesson: test-time scaling (see figure above). The original scaling laws taught us how to exchange training-time compute for better predictions. These new test-time scaling laws teach us how to exchange inference-time compute for better decisions.
This removes one of the last hard barriers to AGI.
What we know about o1
OpenAI has been characteristically quiet about the details, so we don't know exactly how o1 works. But they haven't been silent.
What OpenAI has told us
Rush points out that we can reconstruct quite a lot from the announcement:
Our large-scale reinforcement learning algorithm teaches the model how to think productively using its chain of thought in a highly data-efficient training process.
This tells us three key things:
- Chain of Thought (CoT): o1 performs implicit search within a single chain of thought, rather than running an explicit search algorithm at inference time.
- Reinforcement Learning (RL): Instead of supervised training against fixed labels, o1 learns from variable rollouts with dynamically generated reward signals.
- Data-Efficiency: The process requires relatively few (human-labeled) samples. This does not necessarily mean the process is either token- or compute-efficient.
More generally and perhaps most importantly, o1 is solidly within the existing LLM paradigm. We're starting with a pretrained base model (or possibly a fine-tuned chat model [LW(p) · GW(p)]) and intervening in post-training. The innovation is primarily in the data and training process and not in the architecture.
What OpenAI has showed us
We can also learn something about how o1 was trained from the capabilities it exhibits. Any proposed training procedure must be compatible with the following capabilities:
- Error Correction: "[o1] learns to recognize and correct its mistakes."
- Factoring: "[o1] learns to break down tricky steps into simpler ones."
- Backtracking: "[o1] learns to try a different approach when the current one isn't working."
At the same time, we can reject any hypothesis that explicitly tries to program in these capabilities. Noam Brown (2024) emphasizes these capabilities are emergent:
We were strategizing about how to enable [o1] to do these things and it's just figuring [it] out on its own.
For all its secrecy, OpenAI has leaked enough bits to tightly constrain the space of possibilities.
Proto-o1: Chain of Thought
Before we get to the candidate explanations, let's examine o1's predecessors in test-time scaling.
In-Context Learning
Early work on in-context learning already made it clear that test-time compute (in the form of additional example tokens) could translate to better performance. However, multi-shot prompting is bottlenecked by expensive supervised data that makes it infeasible as a general-purpose approach to scaling test-time compute.
Thinking Step-by-Step
Simply asking GPT-3 to explain its reasoning "step-by-step" dramatically improves its performance (Kojima et al. 2023). This trick was so successful that frontier labs now explicitly select for "chain-of-thought" reasoning via system prompts, prompt distillation, or instruction finetuning.
Unlike few-shot prompting, standard chain-of-thought techniques are not necessarily bottlenecked by human-labeled data. However, prompting alone makes it difficult to exercise precise control over how much test-time compute to spend. More importantly, chat models run into problems with hallucinations, loops, mode collapse, etc. when generating long rollouts. Classical chain of thought works but only up to a point.
Majority Vote
The simplest way to scale test-time compute in a general and controlled manner is to sample multiple rollouts and take the majority answer. This is called "majority vote" or "self-consistency" or "consensus" and has been used to great effect, for example, in METR's recent REBench paper. Majority vote offers immediate benefits over the baseline strategy of ancestral sampling (i.e., sampling a single chain of thought).
However, majority vote quickly runs into plateaus. To do better, we're going to have to come up with a better way of consolidating the information spread across multiple chains of thought. This brings us to the "reinforcement learning" part of o1.
o1: Four Hypotheses
When OpenAI says o1 uses "reinforcement learning", they could mean a lot of things. Let's interpret this as meaning that the learning process involves actually sampling rollouts from the model and then using a verifier to either filter, evaluate, guide, or combine those rollouts. These four options correspond to our four basic hypotheses.
A verifier is a function that returns the probability of an answer (i.e., a finished roll-out) being correct. In practice, the verifier is probably some kind of learned reward model (though it could be automated, like unit tests for code). Verifiers allow us to implement more sophisticated inference-time scaling strategies:
- Rejection sampling / Best-of-N: Generate multiple solutions and use the verifier to filter for correct answers.
- Monte-Carlo rollouts: Running rejection sampling from an intermediate chain-of-thought lets you estimate the value of a particular partial rollout. You can use this to continue your chain-of-thought along only the top-ranked paths (as in beam search), then repeat this procedure to iteratively guide your sampling procedure to better outcomes.
- Learning against verifier: Rather than using your verifier at test-time, we can use the verifier only during the training procedure to amortize the decision-making process into the model itself.
The leading theory is that o1 falls under the last bullet — that OpenAI is keeping its aesthetic commitment to "intelligence as a single model" and is not using any verifiers in deployment.
Like Rush, we'll elide all of the subtle difficulties involved in actually getting RL to work in practice (how we're batching episodes, whether we're on-policy or off-policy, whether we're using KL regularization, which particular learning algorithm we're using, etc.). These subtleties are important: in fact, this is where the difficulty lies. Still, the details won't be necessary for us to get a high-level understanding of what might be going on inside o1.
1. Filter: Guess + Check
The simplest approach is to use the verifier as a filter: generate multiple reasoning attempts, check which ones succeed using the verifier, then train only on those successful examples (as a standard next-token prediction task). That is, combine rejection sampling with supervised fine-tuning.
On the plus side, this is simple and has ample literature to back it up (Yarowsky, 1995; Cobbe et al., 2021; Zelikman et al., 2022; Gulcehre et al., 2023; Singh et al., 2023; Nakano et al., 2021). On the negative side, this seems likely to be too computationally inefficient. Also, calling this "RL" is a bit of a stretch.
2. Evaluation: Process Rewards
A more sophisticated approach is to use a verifier to evaluate a reasoning trace. Instead of an outcome reward model (ORM) that assigns a value to complete rollouts, we train a process reward model (PRM) that assigns a value to partial rollouts, and then we train our reasoning model against these intermediate rewards (using, for example, PPO, see Wang et al. 2024).
Alternatively, you can use PRMs just for filtering, since prior work shows that PRMs outperform ORMs at rejection sampling (Lightman et al., 2023). This leads to a hybrid approach in between "Guess and Check" and "Process Rewards."
There are many ways to implement a PRM, but the obvious one is to use an LLM (as a "generative verifier"). Then, the verifier can actually use chain of thought itself. You may even be able to use the same LLM for both generation and verification, alternating between generation and verification within a single token stream. Such a hybrid approach might explain instances in which the model appears to self-evaluate or self-correct: when the model asks itself "is this a good explanation?", is it the generator or verifier?
Rush believes that something involving process rewards is the most likely answer. There's evidence for process rewards improving performance (ibid.), but no public examples yet combining generation and verification into a single chain of thought. These approaches are more complex than "Guess and Check" but still simpler than the other options.
3. Guidance: Search / AlphaZero
Intermediate feedback can also be used to guide the sampling procedure itself. The guide signal can come from either a model (such as the process reward models of the previous section) or directly from MC rollouts. Self-play enables the generator and guide to iteratively improve together. This distills the search process into the model itself ("amortization").
One variant is to use beam search to generate a number of candidate continuations, then use the guide to filter out only the most promising continuations, continue with those, and repeat.
A more famous (and complex) variant is Monte-Carlo Tree Search (MCTS). Like beam search, we generate a number of possible continuations, then sample one of those continuations at random, and repeat this iteratively until we reach an end state. Then, we propagate the value of that end state up to the parent nodes, sample a new node, and repeat. This has the benefit of not just rushing towards the end of the tree but also allowing the model to explore a wider fraction of the tree.
Obviously these AlphaZero-inspired methods are the most exciting (and frightening) option. Explanations like MCTS might also have an edge in explaining some of the observed behaviors like backtracking. On the other hand, these approaches are very complex, compute-intensive, and haven't seen much success yet in the open research community.
4. Combination: Learning to Correct
An alternative approach is to combine multiple chains of thought in clever ways and train against the resulting composite chain of thought. Here's one variant conjectured by Gwern:
[T]ake a wrong monologue, and at a random point, insert the string "wait, that's wrong. What if..." and then inject some wrong ones, and then eventually, a correct one. Now you have a correct-by-construction inner-monologue where it "makes mistakes" and then "corrects itself" and eventually succeeds and "answers the question correctly". This can be trained on normally.
Personally, I find this hypothesis unlikely, since it directly contradicts the report that error correction and backtracking are emergent rather than explicitly selected for. That said, I do expect "in-context curriculum design" to be an important direction of future research.
Whatever the actual mechanism, there are only a few raw ingredients (chain of thought, verifiers, and learning algorithms) and only so many ways to combine them. The open-source community will catch up. DeepSeek [LW · GW] and QwQ [LW · GW] suggest they may already have. We will soon have a better idea which of these approaches actually work and which do not.
Post-o1: (Recursive) Self-Improvement
When OpenAI says o1 is "data-efficient", it can mean a lot of things, depending on whether we're denominating "data" in terms of token count or sample/prompt count, and whether or not we're including synthetically generated data in these counts.
The more boring interpretation is that OpenAI means the per-token improvement in loss is better than during pretraining. This is boring because pretraining is just a very low bar to clear. The more interesting interpretation is that o1 is efficient in terms of human-labeled samples. This would reflect a longstanding trend away from human labels towards increasingly self-guided training procedures:
- AlphaGo was trained on expert games. AlphaGo Zero eliminated human game data in favor of pure self-play, required significantly more compute, and achieved much better performance while discovering qualitatively different strategies than human experts.
- RLHF involves expensive human preference data. RLAIF and Constitutional AI replace the human with AIs and achieve better results.
- Just last year, training a PRM would have involved supervised learning on expensive human annotations (Uesato et al., 2022; Lightman et al., 2023). Now, they're probably bootstrapped from an ORM using, for example, MC rollouts (Wang et al. 2024).
- Supervised fine-tuning on expert-annotated chain of thought doesn't work as well as whatever it is that o1 is doing. "[I]f you train the model using RL to generate and hone its own chain of thoughts it can do even better than having humans write chains of thought for it." (OpenAI 2024)
The bitter lesson strikes again: o1 is part of a continual trend in which increasingly inexpensive compute displaces constantly expensive human input.
This is what recursive self-improvement really looks like. So far, recursive self-improvement in practice has looked less like the model tinkering with its own architecture or solving miscellaneous engineering problems, and more like the model generating and curating its own training data or guiding its own training processes. This appears to be just getting started.
Outlook
Recently, there have been rumors of "scaling breaking down". I'm skeptical. But even if pretraining is running into a wall, o1 tells us it doesn't immediately matter. Test-time scaling opens up an entirely new way to unload compute, and, on this front, it's still GPT-2 days (OpenAI 2024).
How much could we scale up in test-time compute? Brown (2024) offers a heuristic argument: there are some problems we would be willing to spend millions of dollars to (attempt to) solve. A typical LLM query costs on the order of a penny. That means an easy eight orders of magnitude.
Even in the longer term, "scaling breaking down" might not matter because of how o1's capabilities could feed back into pretraining. One AI's inference time is a future AI's training time. We're already seeing this with OpenAI's next flagship model: according to The Information (2024), one of o1's key applications is generating high-quality training data for "Orion," OpenAI's next large language model in development.
Maybe the final form of the Bitter Lesson is a tight feedback loop between learning and search: use search to generate high-quality reasoning traces, distill those traces into more condensed token streams, and train against the result to amortize the reasoning into the base model. Maybe past a certain critical threshold of capability, classic problems with mode collapse, catastrophic forgetting, etc. stop being a issue.
Maybe we're already this past point of sustained self-improvement. The clock is ticking.
Update 2025/01/21: Some comments following R1's release. [LW(p) · GW(p)]
19 comments
Comments sorted by top scores.
comment by Kei · 2024-12-10T00:00:25.357Z · LW(p) · GW(p)
In practice, the verifier is probably some kind of learned reward model (though it could be automated, like unit tests for code).
My guess is that a substantial amount of the verification (perhaps the majority?) was automated by training the model on domains where we have ground truth reward signals, like code, math, and standardized test questions. This would match the observed results in the o1 blog post showing that performance improved by a lot in domains that have ground truth or something close to ground truth, while performance was stagnant on things like creative writing which are more subjective. Nathan Lambert, the head of post-training at AI2, also found that doing continued RL training on ground truth rewards (which he calls RLVR) results in models that learn to say o1-like things like 'wait, let me check my work' in their chain of thought.
↑ comment by Jesse Hoogland (jhoogland) · 2024-12-11T17:01:50.602Z · LW(p) · GW(p)
It's worth noting that there are also hybrid approaches, for example, where you use automated verifiers (or a combination of automated verifiers and supervised labels) to train a process reward model that you then train your reasoning model against.
comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-12-11T17:57:48.374Z · LW(p) · GW(p)

↑ comment by ryan_greenblatt · 2024-12-11T19:32:08.572Z · LW(p) · GW(p)
("well approximates AIXI" seems unlikely to be an accurate description to me. Maybe "closer to what AIXI is doing than to base GPT-4 without a sampling loop" or "dominates human competence" are more accurate.)
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-11T20:31:08.182Z · LW(p) · GW(p)
I think one major difference between AIXI and it's variants and real world AI is to what extent they are trading off on compute/data, where real world AI will rely on way more data and way less compute than AIXI and it's variants, for very important reasons.
comment by Adam Shai (adam-shai) · 2024-12-09T22:14:10.409Z · LW(p) · GW(p)
Thanks for writing this! It's not easy to keep up with progress, and posts like this make it easier.
comment by Kaj_Sotala · 2024-12-10T11:34:21.752Z · LW(p) · GW(p)
We can also learn something about how o1 was trained from the capabilities it exhibits. Any proposed training procedure must be compatible with the following capabilities:
- Error Correction: "[o1] learns to recognize and correct its mistakes."
- Factoring: "[o1] learns to break down tricky steps into simpler ones."
- Backtracking: "[o1] learns to try a different approach when the current one isn't working."
I would be cautious of drawing particularly strong conclusions from isolated sentences in an announcement post. The purpose of the post is marketing, not technical accuracy. It wouldn't be unusual for engineers at a company to object to technical inaccuracies in marketing material and have their complaints ignored.
There probably aren't going to be any blatant lies in the post, but something like "It'd sound cool if we said that the system learns to recognize and correct its mistakes, would there be a way of interpreting the results like that if you squinted the right way? You're saying that in principle yes, but yes in a way that would also apply to every LLM since GPT-2? Good enough, let's throw that in" seems very plausible.
Replies from: caleb-biddulph, jhoogland, otto-barten↑ comment by Caleb Biddulph (caleb-biddulph) · 2024-12-10T20:37:38.962Z · LW(p) · GW(p)
While I'd be surprised to hear about something like this happening, I wouldn't be that surprised. But in this case, it seems pretty clear that o1 is correcting its own mistakes in a way that past GPTs essentially never did, if you look at the CoT examples in the announcement (e.g. the "Cipher" example).
↑ comment by Jesse Hoogland (jhoogland) · 2024-12-11T17:13:16.745Z · LW(p) · GW(p)
The examples they provide one of the announcement blog posts (under the "Chain of Thought" section) suggest this is more than just marketing hype (even if these examples are cherry-picked):
Here are some excerpts from two of the eight examples:
Cipher:
Hmm.
But actually in the problem it says the example:...
Option 2: Try mapping as per an assigned code: perhaps columns of letters?
Alternatively, perhaps the cipher is more complex.
Alternatively, notice that "oyfjdnisdr" has 10 letters and "Think" has 5 letters....
Alternatively, perhaps subtract: 25 -15 = 10.
No.
Alternatively, perhaps combine the numbers in some way.
Alternatively, think about their positions in the alphabet.
Alternatively, perhaps the letters are encrypted via a code.
Alternatively, perhaps if we overlay the word 'Think' over the cipher pairs 'oy', 'fj', etc., the cipher is formed by substituting each plaintext letter with two letters.
Alternatively, perhaps consider the 'original' letters.
Science:
Wait, perhaps more accurate to find Kb for F^− and compare it to Ka for NH4+.
...
But maybe not necessary.
...
Wait, but in our case, the weak acid and weak base have the same concentration, because NH4F dissociates into equal amounts of NH4^+ and F^-
...
Wait, the correct formula is:
↑ comment by otto.barten (otto-barten) · 2024-12-11T11:42:08.506Z · LW(p) · GW(p)
I don't have strong takes on what exactly is happening in this particular case but I agree that companies (and more generally, people at high-pressure positions) are very frequently doing the kind of thing you describe. I don't think we have an indication that this would not be valid for leading AI labs as well.
comment by otto.barten (otto-barten) · 2024-12-11T11:31:15.843Z · LW(p) · GW(p)
Re the o1 AIME accuracy at test time scaling graphs: I think it's crucial to understand that the test-time compute x-axis is likely wildly different from the train-time compute x-axis. You can throw 10s-100s of millions of dollars at train-time compute and still run a company. You can't do the same for test-time compute each calculation again. The scale at which test-time compute happens on a per-call basis, and can happen to keep things anywhere near commercial viability, needs to be perhaps eight OOMs below train-time compute. Calling anything happening there a "scaling law" is a stretch of the term (very helpful for fundraising) and at best valid very locally.
If RL is actually happening at a compute scale beyond 10s of millions of dollars, and this gives much better final results than doing the same at a smaller scale, that would change my mind. Until then, I think scaling in any meaningful sense of the word is not what drives capabilities forward at the moment, but algorithmic improvement is. And this is not just coming from the currently leading labs. (Which can be seen e.g. here and here).
↑ comment by Hastings (hastings-greer) · 2024-12-11T11:55:09.805Z · LW(p) · GW(p)
I agree that o1 doesn't have a test time scaling law, at least not in a strong sense, while generatively pretrained transformers seem to have a scaling law in an extremely strong sense,.
I'd put my position like this: if you trained a GPT on a human generated internet a million times larger than the internet of our world, with a million times more parameters, for a million times more iterations, then I am confident that that GPT could beat the minecraft ender dragon zero shot.
If you gave o1 a quadrillion times more thinking time, there is no way in hell it would beat the ender dragon.
comment by Abhimanyu Pallavi Sudhir (abhimanyu-pallavi-sudhir) · 2024-12-10T14:29:55.890Z · LW(p) · GW(p)
we'll elide all of the subtle difficulties involved in actually getting RL to work in practice
I haven't properly internalized the rest of the post, but this confuses me because I thought this post was about the subtle difficulties.
The RL setup itself is straightforward, right? An MDP where S is the space of strings, A is the set of strings < n tokens, P(s'|s,a)=append(s,a) and reward is given to states with a stop token based on some ground truth verifier like unit tests or formal verification.
↑ comment by Jesse Hoogland (jhoogland) · 2024-12-11T17:22:20.787Z · LW(p) · GW(p)
The RL setup itself is straightforward, right? An MDP where S is the space of strings, A is the set of strings < n tokens, P(s'|s,a)=append(s,a) and reward is given to states with a stop token based on some ground truth verifier like unit tests or formal verification.
I agree that this is the most straightforward interpretation, but OpenAI have made no commitment to sticking to honest and straightforward interpretations. So I don't think the RL setup is actually that straightforward.
If you want more technical detail, I recommend watching the Rush & Ritter talk (see also slides and bibliography). This post was meant as a high-level overview of the different compatible interpretations with some pointers to further reading/watching.
↑ comment by Jesse Hoogland (jhoogland) · 2024-12-16T21:49:17.990Z · LW(p) · GW(p)
You might enjoy this new blogpost from HuggingFace, which goes into more detail.
comment by Jesse Hoogland (jhoogland) · 2024-12-10T20:52:52.421Z · LW(p) · GW(p)
See also this related shortform [LW(p) · GW(p)] in which I speculate about the relationship between o1 and AIXI:
Agency = Prediction + Decision.
AIXI [? · GW] is an idealized model of a superintelligent agent that combines "perfect" prediction (Solomonoff Induction [? · GW]) with "perfect" decision-making (sequential decision theory).
OpenAI's o1 is a real-world "reasoning model" that combines a superhuman predictor (an LLM like GPT-4 [LW(p) · GW(p)]) with advanced decision-making (implicit search via chain of thought trained by RL).
[Continued [LW(p) · GW(p)]]
comment by Stephen McAleese (stephen-mcaleese) · 2024-12-17T18:09:55.040Z · LW(p) · GW(p)
Here is a recent blog post by Hugging Face explaining how to make an o1-like model using open weights models like Llama 3.1.
comment by Lawrence Tang (lawrence-tang) · 2025-02-23T00:31:01.805Z · LW(p) · GW(p)
What evidence is there that a model's labels can benefit its own training? Or that an "ORM" or "PRM" can benefit an LLM? This is the big problem which is not addressed in this article.
comment by Lawrence Tang (lawrence-tang) · 2025-02-23T00:24:47.597Z · LW(p) · GW(p)
The reinforcement learning is an innovation during train-time, not test-time. This was not clear to me in your article. There are few changes made to test-time, as the model is simply allowed to keep outputting text and decide when to terminate, which 4o does not do.