Posts
Comments
This implies that there is no elephant direction separate from the attributes that happen to commonly co-occur with elephants. E.g. it's not possible to represent an elephant with any arbitrary combination of attributes, as the attributes themselves are what defines the elephant direction. This is what I mean that the attributes are the 'base units' in this scheme, and 'animals' are just commonly co-occurring sets of attributes. This is the same as the "red triangle" problem in SAEs: https://www.lesswrong.com/posts/QoR8noAB3Mp2KBA4B/do-sparse-autoencoders-find-true-features. The animals in this framing are just invented combinations of the underlying attribute features. We would want the dictionary to learn the attributes, not arbitrary combinations of attributes, since these are the true "base units" that can vary freely. e.g. in the "red triangle" problem, we want a dictionary to learn "red" and "triangle", not "red triangle" as its own direction.
Put another way, there's no way to represent an "elephant" in this scheme without also attaching attributes to it. Likewise, it's not possible to differentiate between an elephant with the set of attributes x y and z and a rabbit with identical attributes x y and z, since the sum of attributes are what you're calling an elephant or rabbit. There's no separate "this is a rabbit, regardless of what attributes it has" direction.
To properly represent animals and attributes, there needs to be a direction for each animal that's separate from any attributes that animal may have, so that it's possible to represent a "tiny furry pink elephant with no trunk" vs a "tiny furry pink rabbit with no trunk".
No, the animal vectors are all fully spanned by the fifty attribute features.
Is this just saying that there's superposition noise, so everything is spanning everything else? If so that doesn't seem like it should conflict with being able to use a dictionary, dictionary learning should work with superposition noise as long as the interference doesn't get too massive.
The animal features are sparse. The attribute features are not sparse.
If you mean that the attributes are a basis in the sense that the neurons are a basis, then I don't see how you can say there's a unique "label" direction for each animal that's separate from the the underlying attributes such that you can set any arbitrary combination of attributes, including all attributes turned on at once or all turned off since they're not sparse, and still read off the animal label without interference. It seems like that would be like saying that the elephant direction = [1, 0, -1], but you can change arbitrarily all 3 of those numbers to any other numbers and still be the elephant direction.
If I understand correctly, it sounds like you're saying there is a "label" direction for each animal that's separate from each of the attributes. So, you could have activation a1 = elephant + small + furry + pink, and a2 = rabbit + small + furry + pink. a1 and a2 have the same attributes, but different animal labels. Their corresponding activations are thus different despite having the same attributes due to the different animal label components.
I'm confused why a dictionary that consists of a feature direction for each attribute and each animal label can't explain these activations? These activations are just a (sparse) sum of these respective features, which are an animal label and a set of a few attributes, and all of these are (mostly) mutually orthogonal. In this sense the activations are just the sum of the various elements of the dictionary multiplied by a magnitude, so it seems like you should be able to explain these activations using dictionary learning.
Is the idea that the 1000 animals and 50 attributes form an overcomplete basis, therefore you can come up with infinite ways to span the space using these basis components? The idea behind compressed sensing in dictionary learning is that if each activation is composed of a sparse sum of features, then L1 regularization can still recover the true features despite the basis being overcomplete.
It seems like in this setting, the animals are just the sum of attributes that commonly co-occur together, rather than having a unique identifying direction. E.g. the concept of a "furry elephant" or a "tiny elephant" would be unrepresentable in this scheme, since elephant is defined as just the collection of attributes that elephants usually have, which includes being large and not furry.
I feel like in this scheme, it's not really the case that there's 1000 animal directions, since the base unit is the attributes, and there's no way to express an animal separately from its attributes. For there to be a true "elephant" direction, then it should be possible to have any set of arbitrary attributes attached to an elephant (small, furry, pink, etc...), and this would require that there is a "label" direction that indicates "elephant" that's mostly orthogonal to every other feature so it can be queried uniquely via projection.
That being said, I could image a situation where the co-occurrence between labels and attributes is so strong (nearly perfect hierarchy) that the model's circuits can select the attributes along with the label without it ever being a problem during training. For instance, maybe a circuit that's trying to select the "elephant" label actually selects "elephant + gray", and since "pink elephant" never came up during training, the circuit never received a gradient to force it to just select "elephant" which is what it's really aiming for.
The behavior you see in your study is fascinating as well! I wonder if using a tied SAE would force these relationships in your work to be even more obvious, since if the SAE decoder in a tied SAE tries to mix co-occurring parent/child features together it has to also mix them in the encoder and thus it should show up in the activation patterns more clearly. If an underlying feature co-occurs between two latents (e.g. a parent feature), tied SAEs don't have a good way to keep the latents themselves from firing together and thus showing up as a co-firing latent. Untied SAEs can more easily do an absorptiony thing and turn off one latent when the other fires, for example, even if they both encode similar underlying features.
I think a next step for this work is to try to do clustering of activations based on their position in the activation density histogram of latents. I expect we should see some of the same clusters being present across multiple latents, and that those latents should also co-fire together to some extent.
The two other things in your work that feel important are the idea of models using low activations as a form of "uncertainty", and non-linear features like days of the week forming a circle. The toy examples in our work here assume that both of these things don't happen, that features basically fire with a set magnitude (maybe with some variance), and the directions of features are mutually orthogonal (or mostly mutually orthogonal). In the case of models using low activations to signal uncertainty, we won't necessarily see a clean peak in the activation histogram for the feature activating, or the width of the activation peak might look very large. In the case of features forming a circle, then the underlying directions are not mutually orthogonal, and this will also likely show up as more activation peaks in the activation density histograms of latents representing these circular concepts, but those peaks won't correspond to parent/child relationships and absorption but instead just the fact that different vectors on a circle all project onto each other.
Do you think your work can be extended to automatically classify if an underlying feature is a circular or non-linear feature, or is in a parent/child relationship, and if the underlying feature doesn't basically fire with a set magnitude but instead uses magnitude as uncertainty? It would be great to have a sense of what portion of features in a model are of which sorts (set magnitude vs variable magnitude, mostly orthogonal direction vs forming a geometric shape with related features, parent/child, etc...). For the method we present here, it would be helpful to know if an activation density peak is an unwanted parent or child feature component that should project out of the latent, vs something that's intrisically part of the latent (e.g. just the same feature with a lower magnitude, or a circular geometric relationship with related features)
Yeah I think that's right, the problem is that the SAE sees 3 very non-orthogonal inputs, and settles on something sort of between them (but skewed towards the parent). I don't know how to get the SAE to exactly learn the parent only in these scenarios - I think if we can solve that then we should be in pretty good shape.
This is all sketchy though. It doesn't feel like we have a good answer to the question "How exactly do we want the SAEs to behave in various scenarios?"
I do think the goal should be to get the SAE to learn the true underlying features, at least in these toy settings where we know what the true features are. If the SAEs we're training can't handle simple toy examples without superposition I don't have a lot of faith that when we're training SAEs on real LLM activations that the results are trustworthy.
It might also be an artifact of using MSE loss. Maybe a different loss term for reconstruction loss might not have this problem?
I tried digging into this some more and think I have an idea what's going on. As I understand it, the base assumption for why Matryoshka SAE should solve absorption is that a narrow SAE should perfectly reconstruct parent features in a hierarchy, so then absorption patterns can't arise between child and parent features. However, it seems like this assumption is not correct: narrow SAEs sill learn messed up latents when there's co-occurrence between parent and child features in a hierarchy, and this messes up what the Matryoshka SAE learns.
I did this investigation in the following colab: https://colab.research.google.com/drive/1sG64FMQQcRBCNGNzRMcyDyP4M-Sv-nQA?usp=sharing
Apologies for the long comment, this might make more sense as its own post potentially. I'm curious to get others thoughts on this - it's also possible I'm doing something dumb.
The problem: Matryoshka latents don't perfectly match true features
In the post, the Matryoshka latents seem to have the following problematic properties:
- The latent tracking a parent feature contains components of child features
- The latents tracking child features have negative components of each other child feature
The setup: simplified hierarchical features
I tried to investigate this using a simpler version of the setup in this post, focusing on a single parent/child relationship between latents. This is like a zoomed-in version on a single set of parent/child features. Our setup has 3 true features in a hierarchy as below:
feat 0 - parent_feature (p=0.3, mutually exclusive children)
feat 1 - ├── child_feature_1 (p=0.4)
feat 2 - └── child_feature_2 (p=0.4)These features have higher firing probabilities compared to the setup in the original post to make the trends highlighted more obvious. All features fire with magnitude 1.0 and have a 20d representation with no superposition (all features are mutually orthogonal).
Simplified Matryoshka SAE
I used a simpler Matryoshka SAE that doesn't use feature sampling or reshuffling of latents and doesn't take the log of losses. Since we already know the hierarchy of the underlying features in this setup, I just used a Matryoshka SAE with a single inner SAE width of 1 latent to track the 1 parent feature, and the outer SAE width of 3 to match the number of true features. So the Matryoshka SAE sizes are as below:
size 0: latents [0]
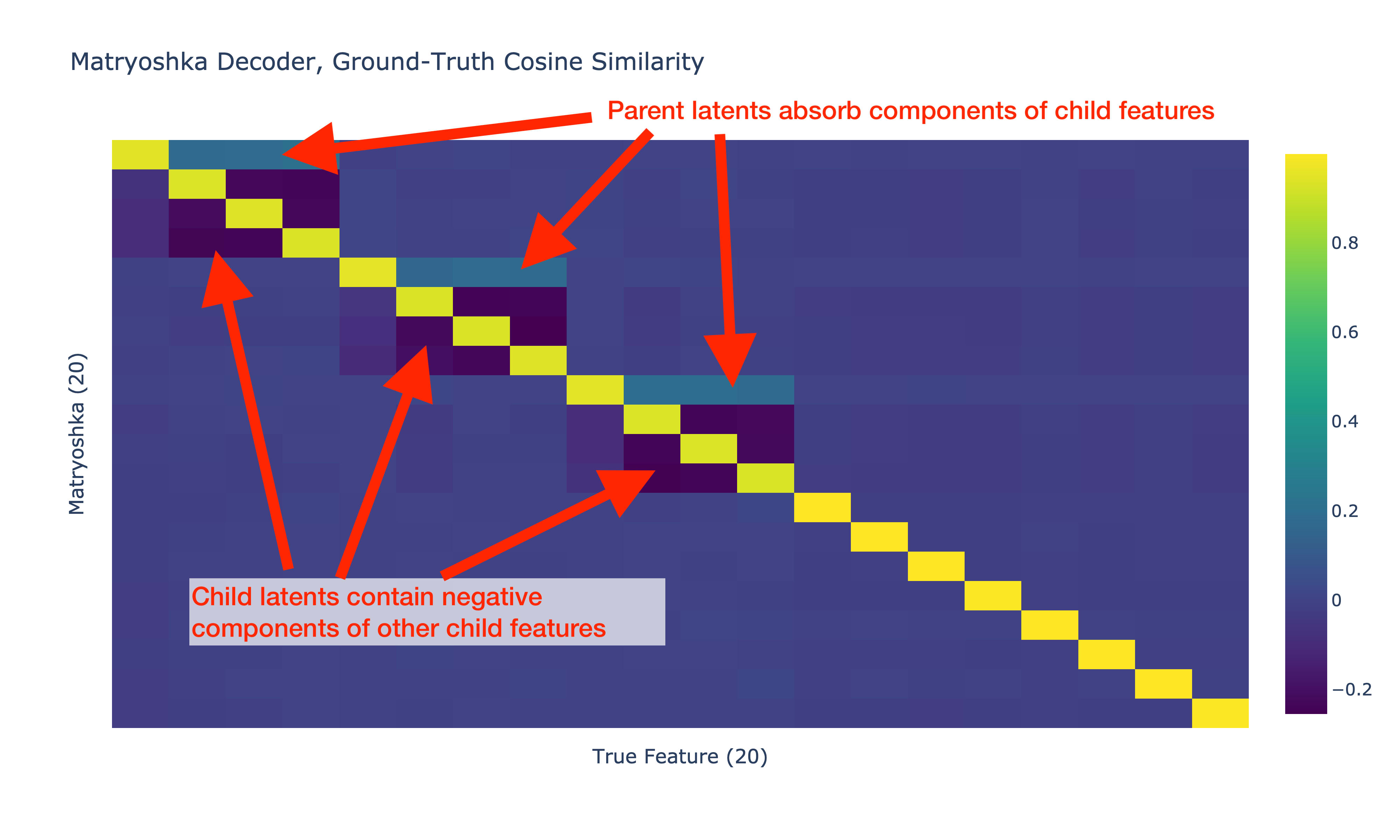
size 1: latents [0, 1, 2]The cosine similarities between the encoder and decoder of the Matryoshka SAE and the true features is shown below:
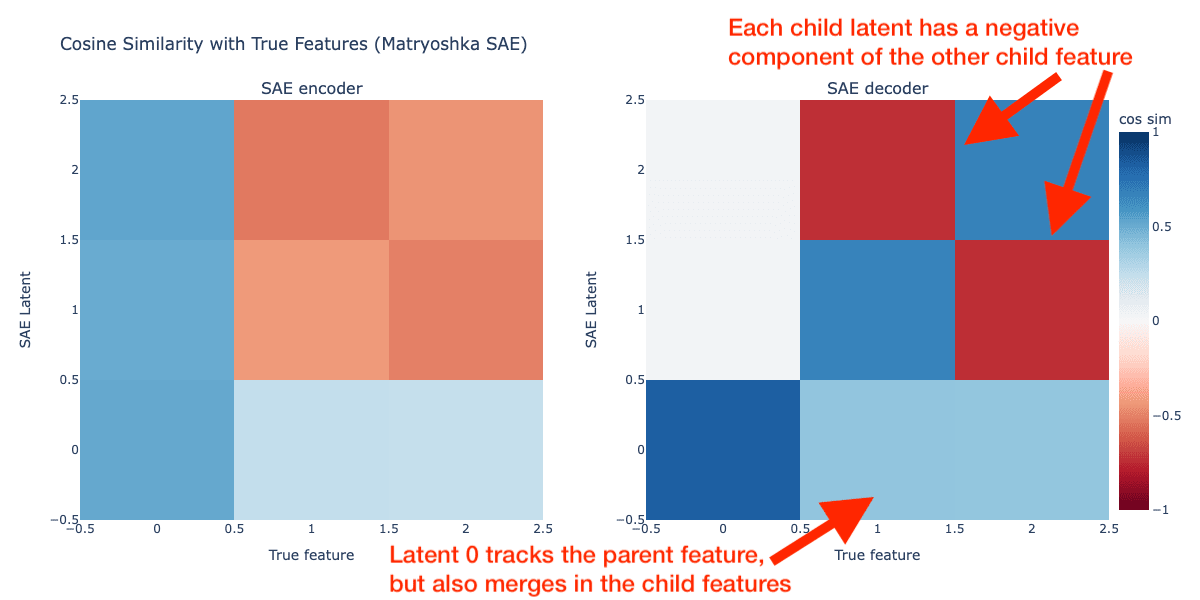
The Matryoshka decoder matches what we saw in the original post: the latent tracking the parent feature has positive cosine sim with the child features, and the latents tracking the child features have negative cosine sim with the other child feature. Our matryoshka inner SAE consisting of just latent 0 does track the parent feature as we expected though! What's going on here? How is it possible for the inner Matryoshka SAE to represent a merged version of the parent and child features?
Narrow SAEs do not correctly reconstruct parent features
The core idea behind Matryoshka SAEs is that in a narrower SAE, the SAE should learn a clean representation of parent features despite co-ooccurrence with child features. Once we have a clean representation of a parent feature in a hierarchy, adding child latents to the SAE should not allow any absorption.
Surprisingly, this assumption is incorrect: narrow SAEs merge child representations into the parent latent.
I tried training a standard SAE with a single latent on our toy example, expecting that the 1-latent SAE would learn only the parent feature without any signs of absorption. Below is the plot of the cosine similarities between the SAE encoder and decoder with the true features.
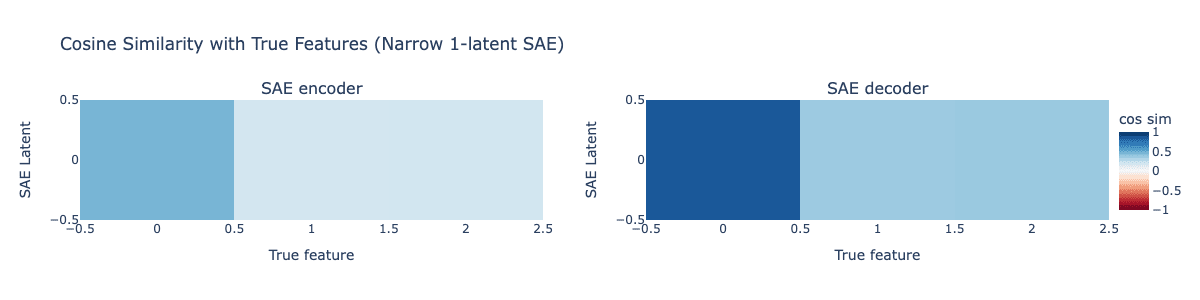
This single-latent SAE learns a representation that merges the representation of the child features into the parent latent, exactly how we saw in our Matryoshka SAE and in the original post's results! Our narrow SAE is not learning the correct representation of feature 0 as we would hope. Instead, it's learning feature 0 + weaker representations of child features 1 and 2.
Why does this happen?
Likely this reduces MSE loss compared with learning the actual correct representation of feature 0 on its own. When there's fewer latents than features, the SAE always has to accept some MSE error, and this behavior of merging in some of the child features into the parent latent likely reduces MSE loss compared with learning the actual parent feature 0 on its own.
What does this mean for Matryoshka SAEs?
This issue should affect any Matryoshka SAE, since the base assumption underlying Matryoshka SAEs is that a narrow SAE will correctly represent general parent features without any issues due to co-occurrence from specific child features. Since that assumption is not correct, we should not expect a Matryoshka SAE to completely fix absorption issues. I would expect that the topk SAEs from https://www.lesswrong.com/posts/rKM9b6B2LqwSB5ToN/learning-multi-level-features-with-matryoshka-saes would also suffer from this problem, although I didn't test that in this toy setting since topk SAEs are tricker to evaluate in toy settings (it's not obvious what K to pick).
It's possible the issues shown in this toy setting are more extreme than in a real LLM since the firing probabilities of the features may be higher than many features in a real LLM. That said, it's hard to say anything concrete about the firing probabilities of features in real LLMs since we have no ground truth data on true LLM features.
Awesome work with this! Definitely looks like a big improvement over standard SAEs for absorption. Some questions/thoughts:
In the decoder cos sim plot, it looks like there's still some slight mixing of features in co-occurring latent groups including some slight negative cos sim, although definitely a lot better than in the standard SAE. Given the underlying features are orthogonal, I'm curious why the Matryoshka SAE doesn't fully drive this to 0 and perfectly recover the underlying true features? Is it due to the sampling, so there's still some chance for the SAE to learn some absorption-esque feature mixes when the SAE latent isn't sampled? If there was no sampling and each latent group had its loss calculated each step (I know this is really inefficient in practice), would the SAE perfectly recover the true features?
It looks like Matryoshka SAEs will solve absorption as long as the parent feature in the hierarchy is learned before the child feature, but this doesn't seem like it's guaranteed to be the case. If the child feature happens to fire with much higher magnitude than the parent, then I would suspect the SAE would learn the child latent first to minimize expected MSE loss, and end up with absorption still. E.g. if a parent feature fires with probability 0.3 and magnitude 2.0 (expected MSE = 0.3 * 2.0^2 = 1.2), and a child feature fires with probability 0.15 but magnitude 10.0 (expected MSE = 0.15 * 10^2 = 15.0), I would expect the SAE would learn the child feature before the parent, and merge the parent representation into the child, resulting in absorption. In real LLMs, this might potentially never happen though so possibly not an issue, but could be something to look out for when training Matryoshka SAEs on real LLMs.
Thank you for sharing this! I clearly didn't read the original "Towards Monsemanticity" closely enough! It seems like the main argument is that when the weights are untied, the encoder and decoder learn different vectors, thus this is evidence that the encoder and decoder should be untied. But this is consistent with the feature absorption work - we see the encoder and decoder learning different things, but that's not because the SAE is learning better representations but instead because the SAE is finding degenerate solutions which increase sparsity.
Are there are any known patterns of feature firings where untying the encoder and decoder results in the SAE finding the correct or better representations, but where tying the encoder and decoder does not?
I'm not as familiar with the history of SAEs - were tied weights used in the past, but then abandoned due to resulting in lower sparsity? If that sparsity is gained by creating feature absorption, then it's not a good thing since absorption does lead to higher sparsity but worse interpretability. I'm uncomfortable with the idea that higher sparsity is always better since the model might just have some underlying features its tracking that are dense, and IMO the goal should be to recover the model's "true" features, if such a thing can be said to exist, rather than maximizing sparsity which is just a proxy metric.
The thesis of this feature absorption work is that absorption causes latents that look interpretable but actually aren't. We initially found this initially by trying to evaluate the interpretability of Gemma Scope SAEs and found that latents which seemed to be tracking an interpretable feature have holes in their recall that didn't make sense. I'd be curious if tied weights were used in the past and if so, why they were abandoned. Regardless, it seems like the thing we need to do next for this work is to just try out variants of tied weights for real LLM SAEs and see if the results are more interpretable, regardless of the sparsity scores.
That's an interesting idea! That might help if training a new SAE with tied encoder/decoder (or some loss which encourages the same thing) isn't an option. It seems like with absorption you're still going to get mixes of of multiple features in the decoder, and a mix of the correct feature and the negative of excluded features in the encoder, which isn't ideal. Still, it's a good question whether it's possible to take a trained SAE with absorption and somehow identify the absorption and remove it or mitigate it rather than training from scratch. It would also be really interesting if we could find a way to detect absorption and use that as a way to quantify the underlying feature co-occurrences somehow.
I think you're correct that tying the encoder and decoder will mean that the SAE won't be as sparse. But then, maybe the underlying features we're trying to reconstruct are themselves not necessarily all sparse, so that could potentially be OK. E.g. things like "noun", "verb", "is alphanumeric", etc... are all things the model certainly knows, but would be dense if tracked in a SAE. The true test will be to try training some real tied SAEs and seeing how interpretable the results look like.
Also worth noting, in the paper we only classify something as "absorption" if the main latent fully doesn't fire. We also saw cases which I would call "partial absorption" where the main latent fires, but weakly, and both the absorbing latent and the main latent have positive cosine sim with the probe direction, and both have ablation effect on the spelling task.
Another intuition I have is that when the SAE absorbs a dense feature like "starts with S" into a sparse latent like "snake", it loses the ability to adjust the relative levels of the various component features relative to each other. So maybe the "snake" latent is 80% snakiness, and 20% starts with S, but then in a real activation the SAE needs to reconstruct 75% snakiness and 25% starts with S. So to do this, it might fire a proper "starts with S" latent but weakly to make up the difference.
Hopefully this is something we can validate with toy models. I suspect that the specific values of L1 penalty and feature co-occurrence rates / magnitudes will lead to different levels of absorption.
My take is that I'd expect to see absorption happen any time there's a dense feature that co-occurs with more sparse features. So for example things like parts of speech, where you could have a "noun" latent, and things that are nouns (e.g. "dogs", "cats", etc...) would probably show this as well. If there's co-occurrence, then the SAE can maximize sparsity by folding some of the dense feature into the sparse features. This is something that would need to be validated experimentally though.
It's also problematic that it's hard to know where this will happen, especially with features where it's less obvious what the ground-truth labels should be. E.g. if we want to understand if a model is acting deceptively, we don't have strong ground-truth to know that a latent should or shouldn't fire.
Still, it's promising that this should be something that's easily testable with toy models, so hopefully we can test out solutions to absorption in an environment where we can control every feature's frequency and co-occurrence patterns.
I'd also like to humbly submit the Steering Vectors Python library to the list as well. We built this library on Pytorch hooks, similar to Baukit, but with the goal that it should work automatically out-of-the-box on any LLM on huggingface. It's different from some of the other libraries in that regard, since it doesn't need a special wrapper class, but works directly with a Huggingface model/tokenizer. It's also more narrowly focused on steering vectors than some of the other libraries.