Implementing activation steering
post by Annah (annah) · 2024-02-05T17:51:55.851Z · LW · GW · 8 commentsContents
General approach Different approaches to implementing activation steering Writing your own wrapper functions Implementation Pros Cons Using TransformerLens Implementation Pros Cons Using baukit Implementation Pros Cons Using PyTorch hooks directly Implementation Pros Cons Editing model biases Implementation Pros Cons Conclusion None 8 comments
Produced as part of the SERI ML Alignment Theory Scholars Program - Autumn 2023 Cohort and while being an affiliate at PIBBSS in 2024. A thank you to @Jayjay [LW · GW] and @fela [LW · GW] for helpful comments on this draft.
This blog post is an overview of different ways to implement activation steering [? · GW] with some of my takes on their pros and cons. See also this GitHub repository for my minimal implementations of the different approaches.
The blog post is aimed at people who are new to activation/representation steering/engineering/editing.
General approach
The idea is simple: we just add some vector to the internal model activations and thus influence the model output in a similar (but sometimes more effective way) to prompting.
Example[1]: Imagine that some vector in the internal representations in some transformer layer encodes a direction associated with "Love" [LW · GW]. When you add this vector to the activations of some encoded sentence "I hate the world", you change the internal representation (and thus the meaning) to something more like "I love the world". This graphic might help with an intuition:
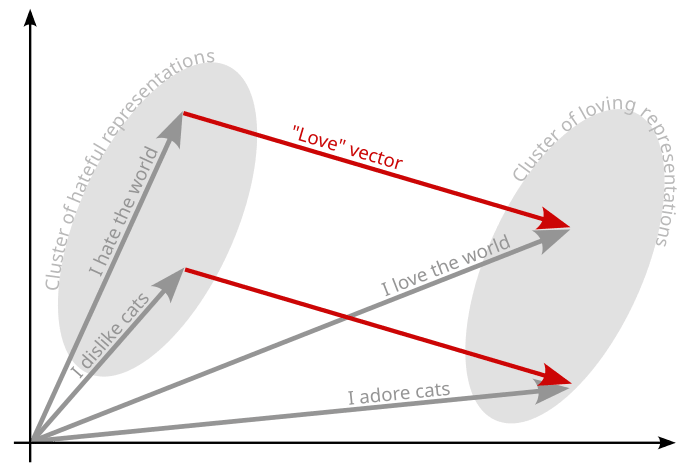
In general there are a few steps involved which I simplify in the following:
- Decide on a layer and transformer module to apply the activation steering to.
- Define a steering vector. In the simplest case we just take the difference of the activations of two encoded strings like .
- Add the vector to the activation during the forward pass. In the simplest case it's something like .
Each of the three points mentioned above includes complexities you might encounter as a beginner. Feel free to move on to the next section if you prefer.
- You can do activation steering at pretty much any layer/module in the transformer. It's often done at the residual stream of one of the hidden layers. However, if you want to do activation steering by modifying the bias parameter, you need to do it in a transformer module that has a specific structure. This is usually not the residual stream but one can do it in the attention or the mlp module.
- When defining a direction there are several things that might complicate it:
- Tokens: When encoding a word or a short sentence it is often encoded into several tokens, so when you get to the internal activation you don't just have one vector but one vector per token. Even worse, 'Love' and 'Hate' might not be encoded with the same number of tokens, so then and are two matrices with different dimensions. You can come up with different ways of how to deal with this, but one simple solution is to just use the representation of the last token since it should have all information encoded. Careful; if you use batches, you'll likely want to use left padding when choosing the last token to ensure your last token isn't a padding token.
- Data: You can potentially create a more meaningful steering vector, for instance, by averaging several vectors from contrastive pairs (for example "I love the world" - "I hate the world" or "I dislike cats" - "I adore cats"), applying PCA on a relevant dataset, or training a linear classifier and using its weights as the steering direction.
- Here are additional factors that may add complexity to the process of activation steering:
- Tokens: The question arises to which activations you actually want to add your steering vector. When you encode some text you could for example add it at the first token or the last or even at every token. I chose to do the latter, adding at every token of the new text. Careful; if you use batches you might not want to add to padding tokens.
- Scaling: In some cases, for example when , the length of the steering vector already contains some meaningful information. However you can also normalize it or multiply it with some scalar to control the strength of the activation addition like .
Different approaches to implementing activation steering
While I was getting into activation steering I encountered a few approaches:
- writing your own wrappers to equip modules with additional functionality
- using the TransfomerLens library
- using the baukit library
- using PyTorch hooks directly (TransfomerLens and baukit use PyTorch hooks internally)
- editing the model bias
The code presented here aims to illustrate the concepts behind individual approaches rather than being ready to run directly (for instance, it omits the use of the tokenizer). For executable code, please refer to the GitHub repository.
Writing your own wrapper functions
I first saw this implemented by Nina [LW · GW] and this is how I myself started doing activation steering. The idea is that you wrap one of the model's layers/modules to give it additional functionality, aka a decorator.
Implementation
# define wrapper class
class WrappedModule(torch.nn.Module):
def __init__(self, module):
super().__init__()
self.module = module
self.output = None
self.steering_vec = None
def forward(self, *args, **kwargs):
self.output = self.module(*args, **kwargs)
if self.steering_vec is not None:
return self.output + self.steering_vec
else:
return self.output
# wrap a module of your loaded pretrained transformer model
layer_id = 5
model.layers[layer_id] = WrappedModule(model.layers[layer_id])
# define a steering vector
_ = model("Love")
act_love = model.layers[layer_id].output
_ = model("Hate")
act_hate = model.layers[layer_id].output
steering_vec = act_love-act_hate
# set the steering vector in the WrappedModule and generate some steered text
test_sentence = "I think dogs are "
model.layers[layer_id].steering_vec = steering_vec
print(model.generate(test_sentence, max_new_tokens=10))
print("-"*20)
model.layers[layer_id].steering_vec = -steering_vec
print(model.generate(test_sentence, max_new_tokens=10)) And then the output could look like this:
I think dogs are the absolute best
--------------------
I think dogs are icky, I hate themPros
- no additional libraries needed
- pretty straightforward to implement
- you can see exactly what is happening where and also get accustomed to the internal structure of the model that you chose
- easy to modify to your needs
Cons
- if you want to make it generalize to different models it could quickly become a large project
- it might be harder for other people to understand your code than if you use a common library
- you are kind of reinventing the wheel as you write your own (mini) library
Using TransformerLens
TransformerLens is using PyTorch hooks internally. When creating a HookedTransformer hook points are added to all the different layers and modules. When running the model with cache, intermediate states are recorded and returned.
Implementation
from transformer_lens import HookedTransformer
# load TransformerLens model
model = HookedTransformer.from_pretrained(model_name)
# define a steering vector
cache_name = f"blocks.{layer_id}.hook_resid_post"
_, cache = model.run_with_cache("Love")
act_love = cache[cache_name]
_, cache = model.run_with_cache("Hate")
act_hate = cache[cache_name]
steering_vec = act_love-act_hate
# define the activation steering funtion
def act_add(steering_vec):
def hook(activation):
return activation + steering_vec
return hook
# generate text while steering
test_sentence = "I think dogs are "
model.add_hook(name=cache_name, hook=act_add(steering_vec))
print(model.generate(test_sentence, max_new_tokens=10))
print("-"*20)
model.reset_hooks()
model.add_hook(name=cache_name, hook=fun_factory(-steering_vec))
print(model.generate(test_sentence, max_new_tokens=10))
model.reset_hooks()And then the output could look like this:
I think dogs are the absolute best
--------------------
I think dogs are icky, I hate themPros
- widely used library and thus easy to read/recognize for other people
- pre implemented functionality to remove hooks
Cons
- TransformerLens might not support the model that you are trying to use
- I found it hard to reproduce hidden states from the original model exactly. TransformerLens adds a lot of functionality, but there are also a lot of additional parameters that are tricky to set correctly.
Using baukit
This library is using PyTorch hooks internally. The baukit class Trace is a context manager, that takes care of the correct removal of the hooks when you leave the context.
For more implementation details see here.
Implementation
from baukit import Trace
# get the steering vector
layer_id = 5
module = model.layers[layer_id]
with Trace(module) as ret:
_ = model("Love")
act_love = ret.output
_ = model("Hate")
act_hate = ret.output
steering_vec = act_love-act_hate
# define the activation steering funtion
def act_add(steering_vec):
def act_add(output):
return output + steering_vec
return act_add
# generate text while steering
test_sentence = "I think dogs are "
with Trace(module, edit_output=act_add(steering_vec) as _:
print(model.generate(test_sentence, max_new_tokens=10))
print("-"*20)
with Trace(module, edit_output=act_add(-steering_vec) as _:
print(model.generate(test_sentence, max_new_tokens=10))And then the output could look like this:
I think dogs are the absolute best
--------------------
I think dogs are icky, I hate themPros
- library is more light weight than TransformerLens and can be applied to any model
- pretty versatile and easy to modify to your needs
- your hook removal is taken care of
Cons
- less common than TransformerLens
- the notation might be a bit confusing in the beginning
Using PyTorch hooks directly
As we want to modify the forward pass in the transformer model when we do activation steering, we will be using forward hooks.
A hook has the following signature:
hook(module, input, output) -> None or modified output
We can attach the hook by calling register_forward_hook on a torch.nn.Module. The register_forward_hook function returns a handle that can be used to remove the added hook by calling handle.remove().
Implementation
# define a hook function that caches activations
def cache_hook(cache):
def hook(module, input, output):
cache.append(output)
return hook
# define the steering vector
layer_id = 5
cache = []
handle = model.layers[layer_id].register_forward_hook(cache_hook(cache))
_ = model("Love")
_ = model("Hate")
act_love = cache[0]
act_hate = cache[1]
steering_vec = act_love-act_hate
handle.remove() # remove the hook
# define the activation steering hook
def act_add(steering_vec):
def hook(module, input, output):
return output + steering_vec
return hook
# generate text while steering
test_sentence = "I think dogs are "
handle = model.layers[layer_id].register_forward_hook(act_add(steering_vec))
print(model.generate(test_sentence, max_new_tokens=10))
handle.remove() # remove the hook
print("-"*20)
handle = model.layers[layer_id].register_forward_hook(act_add(-steering_vec))
print(model.generate(test_sentence, max_new_tokens=10))
handle.remove() # remove the hook
And then the output could look like this:
I think dogs are the absolute best
--------------------
I think dogs are icky, I hate themPros
- no external libraries necessary (only torch tools)
- you get to know hooks directly and they are lots of fun :)
Cons
- can turn into major headaches if you don't remove the hooks properly
Editing model biases
Instead of adding the steering vector to the activation vector we can add the product of the next-layer-weights and the steering vector to the next-layer-bias.
The activation in a normal feed forward network is calculated as . If we do activation steering with a fixed steering vector in layer we can write the modified activation of layer as , where .
Note, we can only do this if our layer has the structure . This is generally not the case for the residual stream. However we do find this structure in the attention and MLP layers.
With this method we can only implement the steering part. In order to find a steering vector we still need a way to access internal model activations.
Implementation
This code shows how to implement activation steering by modifying the bias in the attention layer. This is equivalent to doing activation steering on the output of the previous module (here the layernorm module), which can be implemented with any of the other approaches discussed in this blog post. We consequently need to extract the activations for the steering vector from the output of layernorm.
from baukit import Trace
from torch.nn.parameter import Parameter
# get the steering vector from layernorm
layer_id = 5
module = model.layers[layer_id].layernorm
with Trace(module) as cache:
_ = model("Love")
act_love = cache.output
_ = model("Hate")
act_hate = cache.output
steering_vec = act_love-act_hate
# lets save the original bias value
org_bias = model.layers[layer_id].attention.bias
# define functions for resetting and setting the bias
def reset_bias_attention(model, layer_id, org_bias):
model.layers[layer_id].attention.bias = org_bias
def change_bias_attention(model, layer_id, steering_vec):
# apply linear attention layer (Wv+b) to the steering vector
tilde_b = model.layers[layer_id].attention(steering_vec)
model.layers[layer_id].attention.bias = Parameter(tilde_b)
# change the bias and generate text
change_bias_attention(model, layer_id, steering_vec)
print(model.generate(test_sentence, max_new_tokens=10))
reset_bias_attention(model, layer_id, org_bias) # this is pretty inportant
print("-"*20)
change_bias_attention(model, layer_id, -steering_vec)
print(model.generate(test_sentence, max_new_tokens=10))
reset_bias_attention(model, layer_id, org_bias) # this is pretty inportantThe output would look a bit different as we are effectively applying activation steering in the layernorm module now:
I think dogs are amazing! I love them
--------------------
I think dogs are stupid, I never reallyPros
- no extra code is run once you set it up
- we could theoretically "export" our steered model
Cons
- only possible to do in certain layers that have a bias (not applicable to residual stream)
- can get complicated when you want to experiment with more complicated setups and need more fine grained control (for example if you want to add activation vectors that depend on the specific internal representations at runtime)
- we still need a different approach to get the activations
Conclusion
I personally like the baukit approach the most. It eliminates the need to manually remove hooks, allows for easy integration with any model, offers flexibility in defining the hook function and it can be applied to every layer or module.
- ^
I keep using the "Love"-"Hate" [LW · GW] example introduced by @TurnTrout [LW · GW] throughout this blog post and also in my GitHub code.
8 comments
Comments sorted by top scores.
comment by Fergus Fettes (fergus-fettes) · 2024-02-06T07:25:49.926Z · LW(p) · GW(p)
Great post! Would love to see something like this for all the methods in play at the moment.
BTW, I think nnsight is the spiritual successor of baukit, from the same group. I think they are merging them at some point. Here is an implementation with it for reference :).
from nnsight import LanguageModel
# Load the language model
model = LanguageModel("gpt2")# Define the steering vectors
with model.invoke("Love") as _:
act_love = model.transformer.h[6].output[0][:, :, :].save()with model.invoke("Hate") as _:
act_hate = model.transformer.h[6].output[0][:, :, :].save()steering_vec = act_love - act_hate
# Generate text while steering
test_sentence = "I think dogs are "
with model.generate() as generator:
with generator.invoke(test_sentence) as _:
model.transformer.h[6].output[0][:, :2, :] += steering_vec[:, :2, :]print(model.tokenizer.decode(generator.output[0]))
comment by Joseph Miller (Josephm) · 2024-02-05T21:51:57.529Z · LW(p) · GW(p)
From the title I thought this post was going to be different techniques for finding steering vectors (eg. mean-centered, crafting prompts, etc.) which I think would also be very useful.
comment by StefanHex (Stefan42) · 2025-01-28T02:23:11.376Z · LW(p) · GW(p)
Thanks for writing these up! I liked that you showed equivalent examples in different libraries, and included the plain “from scratch” version.
comment by chanind · 2024-02-11T15:49:46.267Z · LW(p) · GW(p)
I'd also like to humbly submit the Steering Vectors Python library to the list as well. We built this library on Pytorch hooks, similar to Baukit, but with the goal that it should work automatically out-of-the-box on any LLM on huggingface. It's different from some of the other libraries in that regard, since it doesn't need a special wrapper class, but works directly with a Huggingface model/tokenizer. It's also more narrowly focused on steering vectors than some of the other libraries.
comment by Joseph Miller (Josephm) · 2024-02-05T21:54:11.552Z · LW(p) · GW(p)
One pro of wrapper functions is that you can find the gradient of the steering vector.
Replies from: trang-nguyen-1↑ comment by Trang Nguyen (trang-nguyen-1) · 2024-10-01T13:53:01.338Z · LW(p) · GW(p)
What would be the use of gradient of the steering vector?
Replies from: Josephm↑ comment by Joseph Miller (Josephm) · 2024-10-01T19:23:23.610Z · LW(p) · GW(p)
Optimize the steering vector to minimize some loss function.