Posts
Comments
Subjective report:
I've been able to approximately increase the amount of intellectual output I have by 3x over the last 2 months by using LLMs. If you spend a lot of time on setting up the context and intellectual frameworks for it to think through, it is remarkably capable of convergent thinking.
For research my process is to:
- Use my claude research project with strategic background context to generate questions and personas for Elicit and Gemini to use.
- Use Elicits report and question generating feature in order to find the top 10-15 most relevant papers for what I'm currently doing.
- Use gemini 2.5 pro and insert all of the pdfs and the specific prompt from claude in order to generate a research report within LaTeX
- Use claude personas in order to give direct harsh feedback to the paper and iterate from there.
At this point I think LLM usage is a skill issue and that if you get really good at asking the right question by combining models from different fields you can have LLMs do some remarkably good convergent thinking. You just need to get good at creative thinking, management and framing ideas.
This is really well put!
This post made me reflect on how my working style has changed. This bounded cognition and best-case story is the main thing that I've changed in my working style over the last two years and it yields me a lot of relaxation but also a lot more creative results. I like how you mention meditation in the essay as well, it is like going into a sit, setting an intention and sticking to that during the sit, not changing it and then reflecting after it. You've set the intention, stick to it and relax.
I'm sharing this with the people I'm working with, thanks!
I had some more specific thoughts on ML-specific bottlenecks that might be difficult to get through in terms of software speed up but the main point is as you say, just apply a combo of amdahls, hofstadter and unknown unknowns and then this seems a bit more like a contractor's bid on a public contract. (They're always way over budget and always take 2x the amount of time compared to the plan.)
Nicely put!
Yeah, I agree with that and I still feel there's something missing from that discussion?
Like, there's some degree that to have good planning capacity you want to have good world model to plan over in the future. You then want to assign relative probabilities to your action policies working out well. To do this having a clear self-environment boundary is quite key, so yes memory enables in-context learning but I do not believe that will be the largest addition, I think the fact that memory allows for more learning about self-environment boundaries is a more important part?
There's stuff in RL, Active Inference and Michael levin's work I can point to for this but it is rather like a bunch of information spread out over many different papers so it is hard to give something definitive on it.
I want to ask a question here which is not necessarily related to the post but rather your conceptualisation of the underlying reason why memory is a crux for more capabilities style things.
I'm thinking that it has to do with being able to model boundaries of what itself is compared to the environment. It then enables it to get this conception of a consistent Q-function that it can apply whilst if it doesn't have this, there's some degree that there's almost no real object permanence, no consistent identities through time?
Memory allows you to "touch" the world and see what is you and what isn't if that makes sense?
I will check it out! Thanks!
I would have wanted more pointing out of institutional capacity as part of the solution to this but I think it is a very good way of describing a more generalised re-focus to not goodharting on sub-parts of the problem.
Now, that I've said something serious I can finally comment on what I wanted to comment on:
Thanks to Ted Chiang, Toby Ord, and Hannu Rajaniemi for conversations which improved this piece.
Ted Chiang!!! I'm excited for some banger sci-fi based on things more relating to x-risk scenarios, that is so cool!
(You can always change the epistemic note at the top to include this! I think it might improve the probability of a disagreeing person changing their mind.)
Also, I am just surprised I seem to be the only one making this fairly obvious point (?), and it raises some questions about our group epistemics.
First and foremost, I want to acknowledge the frustration and more combatitive tone in this post and ask whether it is more of a pointer towards confusion about how we can be doing this so wrong?
I think that more people are in a similar camp to you but that it feels really hard to change group epistemics of this belief? It feels quite core and even if you have longer conversations with people about underlying problems with the models I find that it is hard to pull people out of the AGI IS COMING attractor state. If you look at the AI Safety community as an information network, there are certain clusters that are quite tightly coupled in terms of epistemics, for me timelines seem to be one of these dividing lines. I think the talk about it has become a bit more like politics where it is war and arguments are soliders?
I don't think this is anyone's intentions but usually our emotions create our frame and if you believe that AGI might come in two years and that we're probably going to die, it is very hard to remain calm.
The second problem is that the points around timelines and reasoning capacity of models is very hard to empirically forecast and I often think it comes down to a question to an individual's views on philosophy of science. What are the frames that you're using in order to predict useful real world progress? How are these coupled with pure ability on MMLU or Humanity's Last Exam? It is hard to know and these are complicated questions and so I think a lot of people often then just go back on vibes.
The attractor state of the vibes being a more anxious one and so we get this collective cognitive effect where fear in an information network amplifies itself.
I do not know what is right, I do know that it can be hard to have a conversation about shorter timelines with someone with shorter timelines because of a state of justifiable emotional tension.
I see your point, yet if the given evidence is 95% in the past, the 5% in the future only gets a marginal amount added to it, I do still like the idea of crossing off potential filters to see where the risks are so fair enough!
So my thinking is something like this:
- If AI systems get smart enough, they will develop understanding of various ways of categorizing their knowledge. For humans this manifests as emotions and various other things like body language that we through theory of mind we assume we share. This means that when we communicate we can hide a lot of subtext through what we say, or in other words there are various ways of interpreting this information signal?
- This means that there will be various hidden ways for AIs to communicate with each other.
- By sampling on something like when other AI systems change their behaviour from a communication but we don't know what did it, we can discover communication that share hidden information.
- We can then renormalize the signals with hidden information that are being sent between AI systems and therefore discover when they're communicating hidden information?
The idea is not to do all ways, it is rather like a PCA that's dependent on the computational power you have. Also, it wouldn't be agent based, it is more like an overview and the main class citizen is the information signal itself if that makes sense? You can then do it with various AI configurations and find if there are any invariant renormalizations?
Interesting!
I definetely see your point in how the incentives here are skewed. I would want to ask you what you think of the claims about inductive biases and difficulty of causal graph learning for transformers? A guess is that you could just add it on top of the base architecture as a MOA model with RL in it to solve some problems here but that feels like people from the larger labs might not realise that at first?
Also, I wasn't only talking about GDL, there's like two or three other disciplines that also have some ways they believe that AGI will need other sorts of modelling capacity.
Some of the organisation taking explicit bets from other directions are:
Symbolica is more on the same train as GDL but from a category theory perspective, the TL;DR of their take is that it takes other types of reasoning capacity in order to combine various data types into one model and that transformers aren't expressive nor flexible enough to support this.
For Verses, I think you should think ACS & Jan Kulveit Active Inference models & lack of planning with self in mind due to lacking information about what the self-other boundary is for auto-encoders compared to something that has an action-perception loop.
I might write something up on this if you think it might be useful.
I'm just gonna drop this video here on The Zizian Cult & Spirit of Mac Dre: 5CAST with Andrew Callaghan (#1) Feat. Jacob Hurwitz-Goodman:
https://www.youtube.com/watch?v=2nA2qyOtU7M
I have no opinions on this but I just wanted to share it as it seems highly relevant.
Looking back at retreat data from my month long retreat december 2023 from my oura I do not share the observations in reduced sleep meed that much. I do remember needing around half an hour to an hour less sleep to feel rested. This is however a relatively similar effect to me doing an evening yoga nidra right before bed.
In my model, I've seen better correlation with stress metrics and heart rate 4 hours before bed to explain this rather than the meditation itself?
It might be something about polyphasic sleep not being as effective as my oura thinks I go into deep sleep sometimes in deep meditation so inconclusive but most likely a negative data point here.
I'll just pose the mandatory comment about long-horizon reasoning capacity potentially being a problem for something like agent-2. There's some degree in which the delay of that part of the model gives pretty large differences in distribution of timelines here.
Just RL and Bitter Lesson it on top of the LLM infrastructure is honestly like a pretty good take on average but it feels like that there a bunch of unknown unknowns there in terms of ML? There's a view that states that there is 2 or 3 major scientific research problems to go through at that point which might just slow down development enough that we get a plateau before we get to the later parts of this model.
Why I'm being persistent with this view is because the mainstream ML community in things such as Geometric Deep Learning or something like MARL, RL and Reasoning are generally a bit skeptical of some of the underlying claims of what LLMs + RL can do (at least when I've talked to them at conferences, the vibe here is like 60-70% of people at least but do beware their incentives as well) and they point towards reasoning challenges like specific variations of blockworld or underlying architectural constrains within the model architectures. (For blocks world the basic reasoning tasks are starting to be solved according to benchmarks but the more steps involved we have, the worse it gets.)
I think the rest of the geopolitical modelling is rock solid and that you generally make really great assumptions. I would also want to see more engagement with these sorts of skeptics.
People like: Subbarao Kambhampati, Michael Bronstein, Peter Velickovic, Bruno Gavranovic or someone like Lancelot Da Costa (among others!) are all really great researchers from different fields that I believe will tell you different things that are a bit off with the story that you're proposing? These are not obvious reasons either and I can't tell you a good story about how inductive biases in data types implictly frame RL problems to make certain types of problems hard to solve and I can't really evaluate to which extent their models versus your models are true.
So, if you want my vote for this story (which you obviously do, it is quite important after all(sarcasm)) then maybe going to the next ICML and just engaging in debates with these people might be interesting?
I also apologize in advance if you've already taken this into account, it does kind of feel like that these are different worlds and it seems like the views clash which might be an important detail.
Well, I don't have a good answer but I also do have some questions in this direction that I will just pose here.
Why can't we have the utility function be some sort of lexicographical satisficer of sub parts of itself, why do we have to make the utility function consequentialist?
Standard answer: Because of instrumental convergence, duh.
Me: Okay but why would instrumental convergence select for utility functions that are consequantialist?
Standard answer: Because they obviously outperform the ones that don't select for the consequences or like what do you mean?
Me: Fair but how do you define your optimisation landscape, through what type of decision theory are you looking at this from? Why is there not a universe where your decision theory is predicated on virtues or your optimisation function is defined over sets of processes that you see in the world?
Answer (maybe)?: Because this would go against things like newcombs problem or other decision theory problem that we have.
Me: And why does this matter? What if we viewed this through something like process philosophy and we only cared about the processes that we set in motion in the world? Why isn't this an as valid way of setting up the utility function? Similar to how a eculidean geometry is as valid as a hyperbolic one or one logic system to another?
So, that was a debate with myself? Happy to hear anyone's thoughts here.
This is a very good point, I'm however curious why you chose tiktok over something like Qanon or 8chan though. Is tiktok really adverserial enough to grow as a content creator?
This is absolutely fascinating to me, great post!
I would be curious if you have any thoughts about using this for steganography?
I might be understanding the post wrongly but here's what I'm thinking of:
There's some degree in which you can describe circuits or higher order ways of storing information in NNs through renormalization (or that's at least the hypothesis). Essentially you might then be able to set up a "portfolio" of different lenses that all can be correct in various ways (due to polysemanticity).
If you then have all of the reconceptualizations you can then sample on these to check what type of information actually is being transmitted in multi-agent scenarios?
Since if there's something like 6 stable renormalizations and we're only checking one of them we can't be sure there isn't hidden information being transmitted?
Anyways, I'm very excited for this direction, it seems like a very good way of crossing the theory practice gap for interpretability!
No, we good. I was just operating under the assumption that deepseek was just doing distilling of OpenAI but it doesnt seem to be the only good ML company from China. There’s also a bunch of really good ML researchers from China so I agree at this point.
The policy change for LLM Writing got me thinking that it would be quite interesting to write out how my own thinking process have changed as a consequence of LLMs. I'm just going to give a bunch of examples because I can't exactly pinpoint it but it is definetely different.
Here's some background on what part it has played in my learning strategies: I read the sequences around 5 years ago after getting into EA, I was 18 then and it was a year or two later that I started using LLMs in a major way. To some extent this has shaped my learning patterns, for example, the studying techniques I've been using to half ass my studies effectively is to try really hard to solve problems and when I can't do that I've been using LLMs to tie it together with my existing knowledge tree.
I've coupled applied linear algebra relatively hard to things like probability metric spaces and non-linear dynamics because I want to see how the toolkit of math goes together. An example from recent is when I was playing table tennis with my phycisist friend he was describing QFT and renormalization theories to me and my direct question was to ask how this ties into vector spaces and fields in linear algebra and how the spaces look like. My mind automatically goes to those questions because it assumes that I can get an answer to it by asking the question even when I'm not talking to an LLM.
Work & Strategy:
One of the things that I do outside of studying is that I usually have LLMs pretend to be councils of experts within various fields so that I can discuss things on the frontier with them. The other day I put together a council of Donald Knut, Karl Friston, John Wentworth and Michael Levin in order to give me some good takes on what agency might look like in CodeWars and concluded that the lack of memory might be a problem.
I also plan with LLMs in mind and so I expect first drafts to take a lot less time than they otherwise would and so I get this expanded option space of being able to do lots of things quickly to an 80/20 quality.
Great Artists Steal and people who win nobel prizes are often interdisciplinary between 2 or 3 different fields. If you sample on this then you can see the serendipitous quality in how LLMs can help you create an interconnected knowledge tree.
My entire learning strategy and life strategy has to some extent changed with this in mind as well since it seems like clear visions and clear understanding of deeper problems help you steer people and LLMs towards good directions. The skills to be practiced is then not necessarily to only get boggled down in details but focusing on how to combine ideas from different fields and describing them well. This is because you will have the most use of LLMs as you can stand on as many shoulders of giants as possible.
So what does the above model mean for me in terms of actions?
- Learn applied category theory in order to become better at quickly mapping different fields together in a more formal way. (For reasoning verification reasons)
- Learn collective intelligence and how cyborgism between AIs and humans might look like based on the existing fields that exist in the world. (To become better at coordinating AIs and humans)
- Learn how to communicate and listen well so that you can incorporate many perspectives and share clear visions about the world. (This one is more important than the above for real world success)
- Learn how to run and start projects in a good way in order to catalyze the insights you have into concrete outcomes.
I think LLMs allow you to serendipity max really well if you apply yourself to learning how to do it. I'm curious how other people have updated with regards to LLMs!
So, I've got a question about the policy. My brain is just kind of weird so I really appreciate having claude being able to translate my thoughts into normal speak.
The case study is the following comments in the same comment section:
13 upvotes - written with help of claude
1 upvote (me) - written with the help of my brain only
I'm honestly quite tightly coupled to claude at this point, it is around 40-50% of my thinking process (which is like kind of weird when I think about it?) and so I don't know how to think about this policy change?
I guess a point here might also be that luck involves non-linear effects that are hard to predict and so when you're optimising for luck you need to be very conscious about not only looking at results but rather holding a frame of playing poker or similar.
So it is not something that your brain does normally and so it is a core skill of successful strategy and intellectual humility or something like that?
I thought I would give you another causal model based on neuroscience which might help.
I think your models are missing a core biological mechanism: nervous system co-regulation.
Most analyses of relationship value focus on measurable exchanges (sex, childcare, financial support), but overlook how humans are fundamentally regulatory beings. Our nervous systems evolved to stabilize through connection with others.
When you share your life with someone, your biological systems become coupled. This creates several important values:
- Your stress response systems synchronize and buffer each other. A partner's presence literally changes how your body processes stress hormones - creating measurable physiological benefits that affect everything from immune function to sleep quality.
- Your capacity to process difficult emotions expands dramatically with someone who consistently shows up for you, even without words.
- Your nervous system craves predictability. A long-term partner represents a known regulatory pattern that helps maintain baseline homeostasis - creating a biological "home base" that's deeply stabilizing.
For many men, especially those with limited other sources of deep co-regulation, these benefits may outweigh sexual dissatisfaction. Consider how many men report feeling "at peace" at home despite minimal sexual connection - their nervous systems are receiving significant regulatory benefits.
This also explains why leaving feels so threatening beyond just practical considerations. Disconnecting an integrated regulatory system that has developed over years registers in our survival-oriented brains as a fundamental threat.
This isn't to suggest people should stay in unfulfilling relationships - rather, it helps explain why many do, and points to the importance of developing broader regulatory networks before making relationship transitions.
So I guess the point then more becomes about general open source development of other countries where China is part of it and that people did not correctly predict this as something that would happen.
Something like distillation techniques for LLMs would be used by other countries and then profilerated and that the rationality community as a whole did not take this into account?
I'll agree with you that Bayes points should be lost in prediction of theory of mind of nation states, it is quite clear that they would be interested in this from a macro-analysis perspective (I say in hindsight of course.)
I'm not sure that Deepseek is SOTA in terms of inherent development, it seems to me that they're using some of the existing work from OpenAI, Deepmind & Anthropic but I might be wrong here, is there anything else that you're pointing at?
I think I object level disagree with you on the china vector of existential risk, I think it is a self-fulfilling prophecy and that it does not engage with the current AI situation in china.
If you were object-level correct about china I would agree with the post but I just think you're plain wrong.
Here's a link to a post that makes some points about the general epistmic situation around china: https://www.lesswrong.com/posts/uRyKkyYstxZkCNcoP/careless-talk-on-us-china-ai-competition-and-criticism-of
I love this approach, I think it very much relates to how systems need good ground truth signals and how verification mechanisms are part of the core thing we need for good AI systems.
I would be very interested in setting more of this up as infrastructure for better coding libraries and similar for the AI Safety research ecosystem. There's no reason why this shouldn't be a larger effort for alignment research automation. I think it relates to some of the formal verification stuff but it is to some extent the abstraction level above it and so if we want efficient software systems that can be integrated into formal verification I see this as a great direction to take things in.
Could you please make an argument for goal stability over process stability?
If I reflecticely agree that if the process A (QACI or CEV for example) is reflectively good then I agree to changing my values from B to C if process A happens? So it is more about the process than the underlying goals. Why do we treat goals as the main class citizen here?
There's something in well defined processes that make them applicable to themselves and reflectively stable?
Looking at the METR paper's analysis, there might be an important consideration about how they're extrapolating capabilities to longer time horizons. The data shows a steep exponential decay in model success rates as task duration increases. I might be wrong here but it seems weird to be taking an arbitrary cutoff of 50% and doing a linear extrapolation from that?
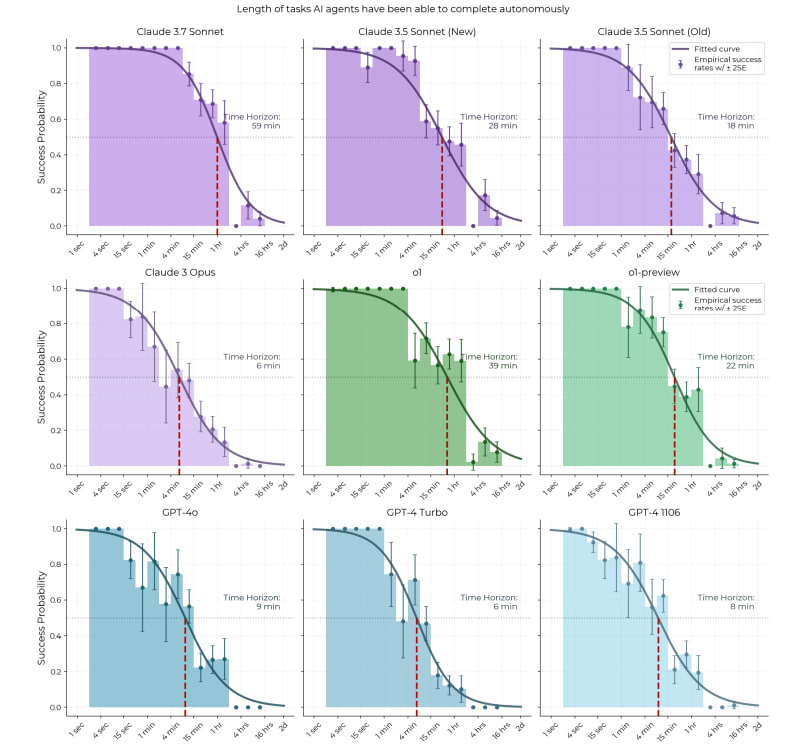
The logistic curves used to estimate time horizons assume a consistent relationship between task duration and difficulty across all time scales. However, it's plausible that tasks requiring hours or days involve fundamentally different cognitive processes than shorter tasks. From both probabilistic machine learning and neuroscience perspectives, there's reason to expect that autoregressive models (like current LLMs) would struggle disproportionately with extended time horizons compared to systems with more robust memory and online learning capabilities. This is similar to the bear case from Thane Ruthenis and I still feel this isn't addressed?
More speculative:
The model is in short that: humans are iterative learners, and being that helps them form self-other boundaries, this allows them to plan with themselves in mind because they know what the consistent parts of the world is and can thus account for them in the future. For long term planning, this drastically reduces the computational costs of knowing what to do, autoregression doesn't do this directly but rather indirectly. Without heuristic learning in your world model, computational costs goes up by quite a lot. If you're not trained on heuristic learning, I don't see how it will naturally arise in the deeper parts of the models. Cognition development is stochastic.
I think this is an algorithmic speedbump that will take 3-4 years extra to go around, especially since people are still bullish on the LLM scaling approach. I don't know what weird stuff will arise when people start figuring out online learning with RL but that's another question.
There's a lot of good thought in here and I don't think I was able to understand all of it.
I will focus in on a specific idea that I would love to understand some of your thoughts on, looking at meta categories. You say something like the problem in itself will remain even if you go up a meta level. My questioning is about how certain you're of this being true? So from a category theory lens your current base-claim in the beginning looks something like:
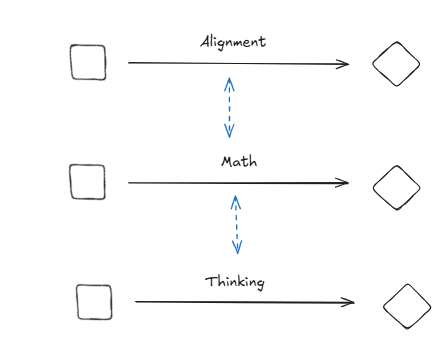
And so this is more than this, it is also about a more general meta-level thing where even if you were to try to improve this thing in itself you would get something like a mapping that involves itself? (This is a question; yes or no?)
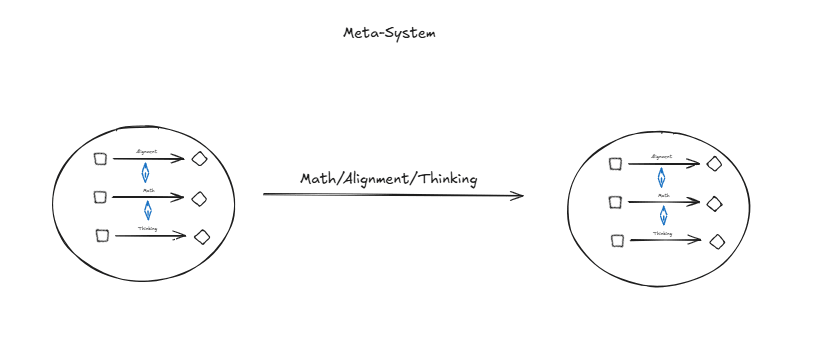
And even more generally we could then try to take the next level of this being optimised so the meta meta level:

We can go above this and say that this will happen an arbitrary amount of times. I have an hypothesis, which is that if you go up to the n-category you will start to see generalized structural properties of all of these systems that you can then use in order to say something about how individual alignment looks like. It isn't necessarily that thinking in itself won't be adapted to the specific problem at hand, it is rather that thinking might have structural similarities at different meta levels and that this can be used for alignment? Like there's design patterns to be foundn between the levels of thinking and abstraction rather than through more of them? It might just fall apart for the same reason but it seems to me like it could be an interesting area of exploration.
I don't know if this makes sense but I did enjoy this post so thank you for writing it!
I saw the comment and thought I would drop some stuff that are beginnings of approaches for a more mathematical theory of iterated agency.
A general underlying idea is to decompose a system into it's maximally predictive sub-agents, sort of like an arg-max of daniel dennetts intentional stance.
There are various underlying reasons for why you would believe that there are algorithms for discovering the most important nested sub-parts of systems using things like Active Inference especially where it has been applied in computational biology. Here's some related papers:
https://arxiv.org/abs/1412.2447 - We consider biological individuality in terms of information theoretic and graphical principles. Our purpose is to extract through an algorithmic decomposition system-environment boundaries supporting individuality. We infer or detect evolved individuals rather than assume that they exist. Given a set of consistent measurements over time, we discover a coarse-grained or quantized description on a system, inducing partitions (which can be nested)
https://arxiv.org/pdf/2209.01619 - Trying to relate Agency to POMDPs and the intentional stance.
TL;DR:
While cultural intelligence has indeed evolved rapidly, the genetic architecture supporting it operates through complex stochastic development and co-evolutionary dynamics that simple statistical models miss. The most promising genetic enhancements likely target meta-parameters governing learning capabilities rather than direct IQ-associated variants.
Longer:
You make a good point about human intelligence potentially being out of evolutionary equilibrium. The rapid advancement of human capabilities certainly suggests beneficial genetic variants might still be working their way through the population.
I'd also suggest this creates an even more interesting picture when combined with developmental stochasticity - the inherent randomness in how neural systems form even with identical genetic inputs (see other comment response to Yair for more detail). This stochasticity means genetic variants don't deterministically produce intelligence outcomes but rather influence probabilistic developmental processes.
What complicates the picture further is that intelligence emerges through co-evolution between our genes and our cultural tools. Following Heyes' cognitive gadgets theory, genetic factors don't directly produce intelligence but rather interact with cultural infrastructure to shape learning processes. This suggests the most valuable genetic variants might not directly enhance raw processing power but instead improve how effectively our brains interface with cultural tools - essentially helping our brains better leverage the extraordinary cultural inheritance (language among other things) we already possess.
Rather than simply accumulating variants statistically associated with IQ, effective enhancement might target meta-parameters governing learning capabilities - the mechanisms that allow our brains to adapt to and leverage our rapidly evolving cultural environment. This isn't an argument against genetic enhancement, but for more sophisticated approaches that respect how intelligence actually emerges.
(Workshopped this with my different AI tools a bit and I now have a paper outline saved on this if you want more of the specific modelling frame lol)
The book Innate actually goes into detail about a bunch of IQ studies and relating it to neuroscience which is why I really liked reading it!
and it seems most of this variation is genetic
This to me seems like the crux here, in the book innate he states the belief that around 60% of it is genetic and 20% is developmental randomness (since brain development is essentially a stochastic process), 20% being nurture based on twin studies.
I do find this a difficult thing to think about though since intelligence can be seen as the speed of the larger highways and how well (differentially) coupled different cortical areas are. There are deep foundational reasons to believe that our cognition is concepts stacked on top of other concepts such as described in the Active Inference literature. A more accessible and practical way of seeing this is in the book How Emotions Are Made by Lisa Feldman Barett.
Also if you combine this with studies done by Robert Sapolvsky described in the book Why Zebra's Don't Get Ulcers where traumatic events in childhood leads to less IQ down the line we can see how wrong beliefs that stick lead to your stochastic process of development worsening. This is because at timestep T-1 you had a belief or experience that shaped your learning to be way off and at timestep T you're using this to learn. Yes the parameters are set genetically yet from a mechanistic perspective it very much interfaces with your learning.
Twin studies also have a general bias in that they're often made in societies affected by globalisation and that have been connected for a long time. If you believe something like cultural evolution or cognitive gadgets theory what is seen as genetically influenced might actually be genetically influenced given that the society you're in share the same cognitive gadgets. (This is essentially one of the main critiques of twin studies)
So there's some degree that (IQ|Cogntiive Gadgets) could be decomposed genetically but if you don't decompose it given cultural tools it doesn't make sense? There's no fully general intelligence, there's an intelligence that given the right infrastructure then becomes general?
I felt too stupid when it comes to biology to interact with the original superbabies post but this speaks more my language (data science) so I would also just want to bring up a point I had with the original post that I'm still confused about related to what you've mentioned here.
The idea I've heard about this is that intelligence has been under strong selective pressure for millions of years, which should apriori make us believe that IQ is a significant challenge for genetic enhancement. As Kevin Mitchell explains in "Innate," most remaining genetic variants affecting intelligence are likely:
- Slightly deleterious mutations in mutation-selection balance
- Variants with fitness tradeoffs preventing fixation
- Variants that function only in specific genetic backgrounds
Unlike traits that haven't been heavily optimized (like resistance to modern diseases), the "low-hanging fruit" for cognitive enhancement has likely already been picked by natural selection. This means that the genetic landscape for intelligence might not be a simple upward slope waiting to be climbed, but a complex terrain where most interventions may disrupt finely-tuned systems.
When we combine multiple supposedly beneficial variants, we risk creating novel interactions that disrupt the intricate balance of neural development that supports intelligence. The evolutionary "valleys" for cognitive traits may be deeper precisely because selection has already pushed us toward local optima.
This doesn't make enhancement impossible, but suggests the challenge may be greater than statistical models indicate, and might require understanding developmental pathways at a deeper level than just identifying associated variants.
Also if we look at things like horizontal gene transfer & shifting balance theory we can see these as general ways to discover hidden genetic variants in optimisation and this just feels highly non-trivial to me? Like competing against evolution for optimal information encoding just seems really difficult apriori? (Not a geneticist so I might be completely wrong here!)
I'm very happy to be convinced that these arguments are wrong and I would love to hear why!
Do you believe it effects most of it or just individual instances, the example you're pointing at there isn't load bearing and there are other people who have written similar things but with more nuance on cultural evolution such as cecilia hayes with cognitive gadgets?
Like I'm not sure how much to throw out based on that?
Just wanted to drop these two books here if you're interested in the cultural evolution side more:
https://www.goodreads.com/book/show/17707599-moral-tribes
https://www.goodreads.com/book/show/25761655-the-secret-of-our-success
A random thought that I just has from more mainstream theoretical CS ML or Geometric Deep Learning is about inductive biases from the perspective of different geodesics.
Like they talk about using structural invariants to design the inductive biases of different ML models and so if we're talking abiut general abstraction learning my question is if it even makes sense without taking the underlying inductive biases you have into account?
Like maybe the model of Natural Abstractions always has to filter through one inductive bias or another and there are different optimal choices for different domains? Some might be convergent but you gotta use the filter or something?
As stated, a random thought but felt I should share. Here's a quick overarching link on GDL if you wanna check it out more: https://geometricdeeplearning.com
I really like the latest posts you've dropped on meditation, they help me with some of my own reflections.
Is there an effect here? Maybe for some people. For me, at least, the positive effect to working memory isn't super cumulative nor important. Does a little meditation before work help me concentrate? Sure, but so does weightlifting, taking a shower, and going for a walk.
Wanting to point out a situation where this really showed up for me, I get the point that it is stupid compared to what lies deeper in meditation but it is still instrumentally useful.
So, I didn't meditate (samadhi) that much over the past two weeks, realized that I didn't and spent like 6 hours meditating the last 3 days. My co-founder noticed directly and was like "last week it was like your ideas where in a narrow domain and carried a lot of uncertainty but now they're broad and weird but at the same time pointing at the same thing, it is nice to have creative you back"
For me it is almost crucial for optimal work performance to have an hour of focused meditation a day. ¯\_(ツ)_/¯
I like to think of learning and all of these things as self-contained smaller self-contained knowledge trees. Building knowledge trees that are cached, almost like creatin zip files and systems where I store a bunch of zip files similar to what Elizier talks about in The Sequences.
Like when you mention the thing about Nielsen on linear algebra it opens up the entire though tree there. I might just get the association to something like PCA and then I think huh, how to ptimise this and then it goes to QR-algorithms and things like a householder matrix and some specific symmetric properties of linear spaces...
If I have enough of these in an area then I might go back to my anki for that specific area. Like if you think from the perspective of schedulling and storage algorithms similar to what is explored in algorithms to live by you quickly understand that the magic is in information compression and working at different meta-levels. Zipped zip files with algorithms to expand them if need be. Dunno if that makes sense, agree with the exobrain creep that exists though.
This is the quickest link i found on this but the 2nd exercise in the first category and doing them 8-12 reps for 3 sets with weighted cables so that you can progressive overload it.
Essentially, if you're doing bench press, shoulder press or anything involving the shoulders or chest, the most likely way to injure your self is through not doing this in a stable way. The rotator cuffs are in short there to stabilize these sorts of movements and deal with torque. If you don't have strong rotator cuffs this will lead to shoulder injuries a lot more often which is one of the main ways you can fuck up your training.
So for everyone who's concerned about the squats and deadlift thing with or without a belt you can look it up but the basic argument is that lower back injuries can be really hard to get rid off and it is often difficult to hold your core with right technique without it.
If you ever go over 80kg you can seriously permanently mess with your lower back by lifting wrong. It's just one of the main things that are obvious to avoid and a belt really helps you hold your core properly.
Here's the best link I can find:https://pmc.ncbi.nlm.nih.gov/articles/PMC9282110/#:~:text=[1%2C2] It is,spinal injuries during weightlifting training.
I can't help myself but to gym bro since it is LW.
(I've been doing lifting for 5 years now and can do more than 100kg in bench press for example, etc. so you know I've done it.)
The places to watch out for injuries in free weight is your wrists, rotator cuffs and lower back.
- If you're doing squats or deadlifts, use a belt or you're stupid.
- If you start feeling your wrists when doing benchpress, shoulder press or similar compound movement, get wrist protection, it isn't that expensive and helps.
- Learn about the bone structure of the wrist and ensure that you're trying to hold the bar at the right angle with the hand. (this is a classic for wrist pain otherwise)
- Do rotator cuff exercises once a week
Finaly generally, start with higher reps and a bit lower weight , 8-12 is the recommended range (but you can do up to 20 as post says) and get used to the technique over time, when things start hurting you know you're doing it wrong and you should have someone tell you what you're doing wrong.
Certain exercises such as skull crushers among others are more injury prone if you do it with dumbbells because you have more degrees of freedom.
There's also larger interrelated mind muscle connection if you do things with a barbell i believe? (The movement gets more coupled with lifting one interconnected source of weight rather than two independent ones?)
I for example activate my abs more with a barbell shoulder press than I do with dumbbells so it activates your body more usually. (same thing for bench press)
Based advice.
I just wanted to add that 60-75 minutes is optimal for growth hormone release which determine recovery period as well as helping a bit with getting extra muscle mass.
Final thing is to add creatine to your diet as it gives you a 30% increase in muscle mass gain as well as some other nice benefits.
Also, the solution is obviously to friendship is optimal the system that humans and AI coordinate in. Create an opt-in secure system that allows more resources if you cooperate and you will be able to outperform those silly defectors.
When it comes to solutions I think that humans versus AI axis doesn't make sense for the systems that we're in, it is rather about desirable system properties such as participation, exploration and caring for the participants in the system.
If we can foster a democratic, caring, open-ended decision making process where humans and AI can converge towards optimal solutions then I think our work is done.
Human disempowerment is okay as long as it is replaced by a better and smarter system so whilst I think the solutions are pointing in the right direction, the main axis of validation should rather be around system properties and not power distribution.
Good summary though, it is great that we finally have a great paper to point towards for these problems.
First and foremost, I totally agree with your point on this sort of thing being instrumentally useful, I'm still having issues seeing how to apply it to my real life. Here are two questions that arise for me:
I'm curious about two aspects of deliberate practice that seem interconnected:
- On OODA loops: I currently maintain yearly, quarterly, weekly, and daily review cycles where I plan and reflect on progress. However, I wonder if there are specific micro-skills you're pointing to beyond this - perhaps noticing subtle emotional tells when encountering uncomfortable topics, or developing finer-grained feedback mechanisms. How does this type of systematic review practice fit into your framework for deliberate practice? Are there particular refinements or additional elements you'd recommend? Is it noticing when I'm not doing OODA?
- On unlearning: While your post focuses extensively on learning practices, I'm interested in your thoughts on "unlearning" - the process of identifying and releasing ineffective patterns or beliefs. In my experience with meditation, there seems to be a distinction between intellectual understanding and emotional understanding, where sometimes what holds us back isn't insufficient practice but rather old patterns that need to be examined and released. How do you see the relationship between building new skills and creating space for new patterns through deliberate unlearning? One of the sayings I've heard said is that "meditation is the process of taking intellectual understanding and turning it into emotional understanding" which I find quite interesting.
I guess the entire "we need to build an AI internally" US narrative will also increase the likelyhood of Taiwan being invaded from China for data chips?
Good that we all have the situational awareness to not summon any bad memetics into the mindspace of people :D