Renormalization Roadmap
post by Lauren Greenspan (LaurenGreenspan) · 2025-03-31T20:34:16.352Z · LW · GW · 7 commentsContents
Motivation and Context The Big Picture Renormalization in physics Lesson #1: When your (theoretical) description doesn’t match reality, don’t change reality. (Spoiler #1: NNs represent multiple layers of abstractions. Their theoretical descriptions and interpretations should be similarly flexible.) Lesson #2: Scale Matters (Spoiler #2: The key challenge in NN interpretability lies in identifying meaningful scales of interaction and abstraction.) Lesson #3: Fixed Points are Important – they act as theoretical ‘tethers’ for the RG flow. (Spoiler #3: Idealized theoretical limits of NNs might similarly anchor an RG flow of their representations and interpretations.) Lesson #4: A single theory can support multiple scales and critical points, leading to an expansive theoretical structure with the RG flow. (Spoiler #4: NNs likely also exhibit multi-scale behavior. Tuning hyperparameters in different ways may lead to distinct regimes of representational ontologies and simplifications of their corresponding theoretical descriptions.) Lesson #5: RG gives a neat picture of emergence in complex physical systems. (Spoiler #5: Understanding emergent behavior is key in NNs. ) (Putative) Lesson #6: Universal behavior can be surprisingly descriptive of real-world systems. (Spoiler #6: We should exploit – and explore potential limitations of – this notion in NNs.) Renormalization for AI Safety Discussion Dimensionality Locality and Scale Separation of Scales (Emergence) Criticality and Universality Methods None 7 comments
At PIBBSS, we’ve been thinking about how renormalization [LW · GW] can be developed into a rich framework for AI interpretability. This document serves as a roadmap for this research agenda – which we are calling an Opportunity Space [LW · GW][1] for the AI safety community. In what follows, we explore the technical and philosophical significance of renormalization for physics and AI safety, problem areas in which it could be most useful, and some interesting existing directions – mainly from physics – that we are excited to place in direct contact with AI safety. This roadmap will also provide context for our forthcoming Call for Collaborations [LW · GW], during which we will hire affiliates to work on projects in this area.
Acknowledgements: While Lauren did the writing, this opportunity space was developed with the PIBBSS horizon scanning team, Dmitry Vaintrob and Lucas Teixeira.
Motivation and Context
In physics, renormalization is used to coarse-grain theoretical descriptions of complex interactions to focus on those that are most relevant for describing physical reality. Here, ‘reality’ is tied to the scale of interest; just as you don’t need to take quantum effects into account to design a safe bridge, the physical descriptions of the same system are different (in a way: emergent) when viewed close up versus far away. To put it differently, renormalization plays two main roles:
- To organize a system into “effective” theories at different scales, and
- To decouple physical systems into a hierarchy of theories of local interactions by systematically finding so-called “relevant” parameters as you vary the interaction scale. The running of parameters along this scale defines a so-called “RG flow”, which dynamically transforms systems in a way that throws away fine-grained details while preserving coarse-grained behavior.
Like field theories in physics, NNs are highly complex systems with many interacting components. There is evidence that they organize information to learn, for example, ‘features’ that represent the data to varying levels of granularity. This suggests that they’re amenable to renormalization techniques: at a given ‘scale’, irrelevant information can be coarse-grained to appropriately describe a system of interest. These descriptions are linked (or separated) in scale, where each description is hierarchically emergent and described by the analog of an effective field theory (EFT). Furthermore, like EFTs, neural networks exhibit behaviors reminiscent of thermodynamic phase transitions and dynamical flows, where collective interactions produce emergent statistical patterns that can be captured by statistical field theory (Grosvenor & Jefferson, 2022, Ringel et al., 2018).
A theoretical framework for NNs inspired by renormalization (and EFT more broadly) is being developed largely within the physics community (to name just a few: Roberts et al., 2022, Berman et al., 2023, Erbin et al., 2023, Halverson et al., 2021, Gordon et al., 2021), meaning that it remains technically specific and philosophically aligned with the physics way of thinking. Importantly, ‘renormalization’ is not one prescriptive idea but a collection of theoretical premises that have evolved throughout history to support a myriad of practical techniques for interpreting physical systems and predicting physical phenomena. As a framework, renormalization is a cornerstone of the explanatory powerhouse of modern theoretical physics, capable of capturing the essential empirical aspects of a system and how its theoretical description fits in with the space of possible theories.
Such a framework would clearly benefit AI safety. To truly bridge the theory-practice gap, we need a nuanced understanding of when theoretical approximations are reasonable and an empirically grounded approach to building out new theories that relies on trading off between empirical evidence, discipline-supported intuition, and mathematical rigor. Not only could virtues imported from physics lead to the development of robust and reliable interpretability tools, but it could help us discover fundamental principles of AI systems similar to those supporting renormalization in physics, deepening our understanding of what it means for a NN to be interpretable and establishing limits for interpretability claims we are able to make. In short: AI safety relies on interpretability, and interpretability rests on our deep[2](but not necessarily mathematically complete) understanding of the entire AI universe, including its data, training, representation, and interpretation. If appropriately wielded, renormalization has the potential to lend us this insight.
However, like the use of ‘representation’ or ‘feature’ in AI, ‘renormalization’ has a language problem. Physicists used to using some of these techniques in a narrow domain often refer to the piece of the puzzle as the whole, leaving those outside of the physics context in the dark. Due to similar issues with framing, the AI safety community largely associates this idea with its limitations, missing its potential for broader utility.
Our goal is to coordinate efforts between physics and AI safety to make significant progress in this area. This includes:
- Identifying which physics-based ideas, theories, and techniques directly translate to AI systems, and in which contexts.
- Determining which additional guiding principles specific to AI systems are necessary for these techniques to be robustly, reliably effective.
- Developing new renormalization-inspired theories, tools, and methodologies to predict and interpret the behavior of AI systems.
The Big Picture
Before going into detail, it will be useful to have the following picture in mind:
We start with the assumption that empirical reality (the observable world, including data) can be described in terms of structured representations. For NNs, these refer to the learned embeddings that encode complex relationships, patterns, and structure in the space of inputs. Importantly, NNs learn these patterns because of their own added structure (architecture, hyperparameters, initializations…). Any theory of representations – how they form during training or home-in on relevant circuits during inference – should therefore take all of this into account if they are going to accurately apply in the empirical playground consisting of a NN and its inputs.
The way a NN learns a function (representation) of the dataset broadly mimics the way renormalization learns a theoretical representation of a complex system – each aims to precisely capture essential empirical phenomena at a given observation scale. In the picture below, representation_0 and representation_1 correspond to different structured abstractions formed by the NN, incorporating key aspects of the data guided by the network’s internal structure. These could be before and after training, for example, or before and after inference – what matters is that representation_1 has been optimized according to some internal (to the NN, based on inputs) metric, while representaiton_0 has not. We refer to this flavor of NN renormalization as implicit renormalization, as it aims to provide a theoretical explanation for what the NN is doing implicitly. An implicit renormalization framework should accurately describe how the representation flows from representation_0 to representation_1, as it incorporates more information. In this way, the two representations can be described by ‘the same’ theory in different regimes (i.e. at different scales or levels of structured abstraction). However, in practice this depends on how well the NN incorporates the data ontology into its own conceptual framework during training or inference, and how comprehensively the theory describes this process. Current attempts at renormalization give us a piece of the puzzle at varying degrees of idealization. These find physics-informed theoretical descriptions of one aspect of a NN representation and how it changes during training (based on some measure of similarity in information space, e.g.) or inference (e.g., how feature learning relates to layer-layer kernel dynamics). It remains to be seen how uniquely these schemas ‘match’ (by some metric) the way in which the NN represents information according to some (a priori opaque to us) model-natural features.[3] We expect the model-natural scaling direction along which this happens to be similarly opaque – though hopefully built out of scales we can measure[4] and reformulate into a comprehensive picture of implicit renormalization.
If we could parse the learned function at the end of this process, we would have a theoretical understanding of representation_1. Instead, we interpret the NN via explicit renormalization, which we operationalize as techniques designed to transform the NN’s learned representation into a human-interpretable abstraction, which we call representation_0’. While this is not a priori guaranteed,[5] an effective explicit renormalization scheme should yield abstractions that exhibit meaningful and consistent relationships with the NN’s learned relationships. Though it is routed through representation_1, representation_0’ should also be directly representative of the data. As we will mention later, we think it would be fruitful to design explicit renormalization schemes for datasets themselves.[6] This would enable a comparison between data-natural features and those found by interpreting NNs.
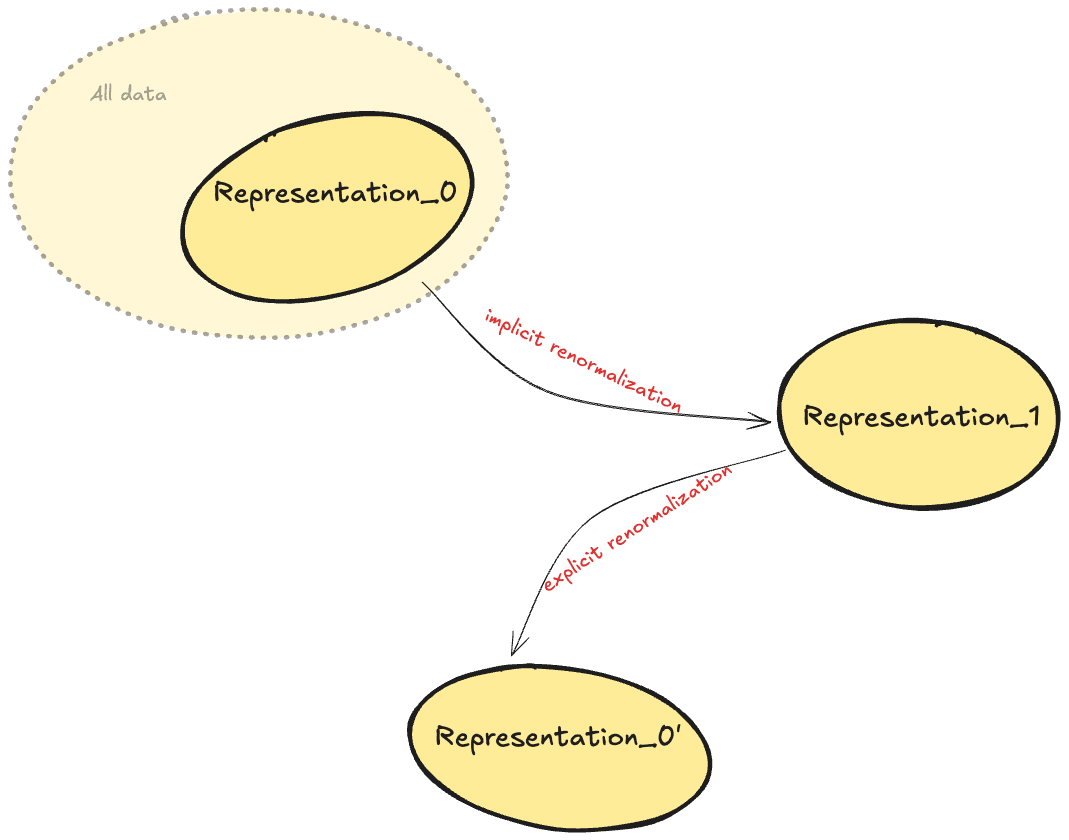
To summarize so far: Data represents reality, NNs represent data, implicit renormalization represents representations, and explicit renormalization represents more or less granular interpretations of implicit renormalization.
Implicit and explicit renormalization probe respective empirical realities that differ in both structure and information content, and will need similarly different formulations of renormalization as well as independent additional principles – epistemological guidance in addition to a rough sketch of renormalization – regarding their ‘physics’. For example, locality, which defines a measure for closeness or causal impact in physics, should be conceptualized differently in the data space v. the feature space. Several hyperparameters likely contribute to this notion of organizational ‘closeness’ in NNs, including properties of the data distribution, network initializations, learning rates, network size, and sparsity, and several ways to measure it, including various kernels and distance measures.
We will come back to this picture later, once we have unpacked more of the RG terminology, but finding the ‘right way’ to construct these methods without sacrificing faithfulness or interpretability is a core motivation of this opportunity space. Whether or not there is a ‘right way’ to do this depends on many things, including how well the data approximates reality (or the piece of it you want to study), how we define ‘human interpretability’, and how good these approximations and interpretations need to be to address safety concerns. While we hope renormalization-inspired frameworks can clarify ‘interpretability’ in terms more natural to NNs, we acknowledge potential limits to the types of principled abstractions a physics-inspired renormalization framework could support. Whether more abstract cognitively or philosophically rich notions like ‘deception’ naturally emerge within the NN ontology, or if these can be reliably probed with renormalization, remains unclear. Nevertheless, we find understanding these limitations both valuable and interesting, and suggest that significant philosophical and methodological developments may yet overcome some of these challenges.
Renormalization in physics
In this section, we give a brief overview of renormalization’s development in physics, pointing out important lessons for building a similar framework for AI safety. Renormalization emerged in the 1940s as an ad-hoc method used to remove unphysical divergences from Quantum Electrodynamics (QED), a theory that describes the motion and interactions between charged particles. These divergences arise because QED calculations naively sum over infinitely many virtual (read: hidden) interactions across energy scales, leading to the theoretical prediction of measurable quantities, like the electron mass, that clearly contradicts low energy experimental data. Early renormalization introduced counter-terms by hand to QED at low energy, effectively subtracting off these divergences and denoising physical observables.
Lesson #1: When your (theoretical) description doesn’t match reality, don’t change reality.
(Spoiler #1: NNs represent multiple layers of abstractions. Their theoretical descriptions and interpretations should be similarly flexible.)
‘Renormalizable’ (AKA perturbatively renormalizable) means that you can cancel divergences by adding a finite number of counter-terms. Put another way, a renormalizable theory contains a small parameter, or coupling, by which you can organize interactions between fields perturbatively, or in order of descending importance. Couplings depend on physical quantities (mass, charge), as well as fundamental constants (c, h-bar), but can also vary with the energy scale. At low energies (called ‘the Infrared’, or IR), for example, the coupling is small, electrons are weakly interacting, and their dynamics can be studied using perturbative QED. On the other hand, this coupling is large at high energies (‘the Ultraviolet’, or UV), and QED describes strongly-coupled interactions in this regime. Renormalization therefore clarified how the same underlying theory could describe vastly different behavior at distinct scales.
Lesson #2: Scale Matters
(Spoiler #2: The key challenge in NN interpretability lies in identifying meaningful scales of interaction and abstraction.)
About a decade later, the Renormalization Group (RG) made this idea more formal by re-defining field theory interactions relative to the maximum (or minimum) energy for which the theory has predictive power. While there are several ways to operationalize this, the logic is to introduce a high (or low) energy cutoff into the couplings to pick out the relevant interactions for different energy windows. In QED, for example, higher-order interactions that are important in the UV only show up as small (negligible) corrections at lower energies.
The RG framework and the EFT formalism naturally support each other. RG systematically captures how effective couplings change (‘run’) with scale, leading to a hierarchy of EFTs connected by continuous symmetry transformations along an RG flow. These theories are roughly self-similar, in the sense that physical observables (e.g. correlation functions and scattering amplitudes), when properly scaled and redefined during each RG transformation, remain consistent across scales, preserving universal physics in the low-energy limit.[7] Any arbitrariness in the choice of cutoff is therefore resolved at the empirical level.
A good question, especially when looking ahead to NNs, is what does the RG ‘flow’ to? At each point along the RG flow, EFTs are parametrized to include a set of relevant interactions that describe reality at that scale. Some of these are fixed, or critical points where the couplings stop running. These define ‘endpoints’ of the RG flow since the theory does not change with further reparametrization. Critical theories are truly scale invariant, since there is no ‘preferred’ scale of interactions, a simplification that leads to a reduction in the number of degrees of freedom and a corresponding increase in theoretical tractability. Moreover, some critical points correspond to universal descriptions of interesting phenomena like phase transitions – meaning that the same simple description can apply to many unrelated systems. Universality also means that theories near fixed points exhibit identical scaling behavior and can be treated in the same way, making fixed points essential markers in our overall theoretical understanding of physical systems.
Lesson #3: Fixed Points are Important – they act as theoretical ‘tethers’ for the RG flow.
(Spoiler #3: Idealized theoretical limits of NNs might similarly anchor an RG flow of their representations and interpretations.)
While some high-energy theories, such as string theory, aim to describe the smallest possible scale of interactions (in this case, up to the string length), others are only valid (renormalizable, predictive) up to a cutoff, beyond which ‘new physics’ is needed. For example, the Standard Model (SM) is considered to be an effective description of some other ‘UV complete’ theory. Moreover, because it is a unified description of several fundamental fields which each couple differently depending on scale, the SM is difficult to renormalize at once. It therefore offers an instructive example for how theories can reduce to different ‘sectors’ that match different aspects of empirical reality, and how these can be further tethered to an RG flow by understanding their fixed point structure.
We already discussed the electromagnetic sector described by QED, which flows between a Gaussian fixed point in the IR and is otherwise an EFT valid up to a cutoff. To illustrate another example, Quantum Chromodynamics (QCD) describes interactions between quarks and gluons, mediated by the ‘strong force’. At lower energies, quarks are confined within protons and neutrons, meaning that the QCD coupling – which depends on the temperature and pressure of the system – is strong in the IR and interactions must be treated non-perturbatively. This IR fixed point flows to a free fixed point in the UV, where quarks are deconfined and QCD can be treated perturbatively. However, between these fixed points, QCD admits an intermediate description: the Quark Gluon Plasma (QGP). Here, quarks are deconfined but couple strongly to gluons, and the theory exhibits nearly critical behavior hinting at another non-trivial structure in the RG flow (although whether the QGP corresponds to an actual critical point of QCD is an open question (Son 2009, An e al., 2022).
As a high-energy theory, the standard model illustrates a ‘high energy’ viewpoint of the RG. Generally, high-energy tends to focus less on finding an emergent description of a particular empirical setup and more on studying the limiting cases of existing theories and connecting their (sometimes idealized) descriptions at different scales. This network of theories helps to guide the discovery of ‘new physics’ by predicting, for example, the properties of new particles, based on the fields needed to make a theory valid at certain energy scales.
Lesson #4: A single theory can support multiple scales and critical points, leading to an expansive theoretical structure with the RG flow.
(Spoiler #4: NNs likely also exhibit multi-scale behavior. Tuning hyperparameters in different ways may lead to distinct regimes of representational ontologies and simplifications of their corresponding theoretical descriptions.)
In the 1960s and 70s, new RG techniques were developed that helped it grow real-world empirical teeth, exemplified by Wilson’s work applying his RG scheme on a lattice to study the critical point of an Ising ferromagnet. If the high-energy RG approach (e.g., Gross) can be thought of as ‘theory-first’ – starting from a known theoretical structure that systematically interpolates between theories at different energy scales – the condensed matter theory (CMT) approach (e.g., Nelson & Yang) is, in contrast, ‘empirics first’. This approach systematically coarse-grains over lattice degrees of freedom to isolate only the ones necessary to describe particular experiments. Low-energy critical phenomena is a main area of focus of CMT, which aims to study the intricate phase structure – and corresponding landscape of behaviors – of real-world materials. Since ‘low energy’ means ‘long distances’, what CMT needs is a theoretical description that coarse-grains over discrete, microscopic systems like spins on a lattice. In these experiments, the lattice spacing is a natural choice for the high-energy cutoff, as it sets the minimum length scale of interactions. Unlike continuous transformations, discrete RG techniques (e.g. block spin or real-space) explicitly lose information at each coarse-graining step.[8] These renormalize over spins and impurities to get different effective descriptions at every step that depend on fewer degrees of freedom – an EFT that describes the ‘local’ dynamics of a finite number of fields. In the CMT perspective, the defining question of RG can be formulated as: “how do local interactions ‘flow’ under coarse-graining?”.
Lesson #5: RG gives a neat picture of emergence in complex physical systems.
(Spoiler #5: Understanding emergent behavior is key in NNs. )
That we can effectively describe an empirical system at one isolated energy scale implies that EFTs along an RG flow are conditionally causally independent from another – the macroscopic phenomena do not depend on the microscopic details.[9] In fact, this is what links the RG flow with the physics notion of universality – critical points can be the endpoints of many different RG flows.
(Putative) Lesson #6: Universal behavior can be surprisingly descriptive of real-world systems.
(Spoiler #6: We should exploit – and explore potential limitations of – this notion in NNs.)
Ultimately, our objective is to develop a flexible interpretive framework for NN interpretability that incorporates aspects of both the HEP and CMT approaches of RG. To understand implicit renormalization, HEP may be more useful, as this will help us develop a structural web of theoretical descriptions of how NNs abstract insights from the data. To perform explicit renormalization, a CMT-inspired RG may be more useful, as this brings with it a bag of tricks to tune a theoretical interpretation to a desired degree of granularity. While the former will require an understanding of when idealized theories apply, the latter will likely need additional simplifications – like exploiting symmetries in condensed matter systems to reduce effective dimensionality – are needed to enhance the tractability of applying RG techniques in AI systems with a large number of dimensions.
With more RG machinery in hand, we can re-express the web of ontologies discussed earlier using physics terminology. First, as one possible way to represent the real-world, we can think of representation_0 as a low-energy description of the dataset: IR_0.
If the NN is capable of learning a meaningful generalization of the data, representation_0 flows to representation_1 (now UV_1) via an implicit RG flow to higher energies. Instead of throwing information away, flowing to UV_1 adds structure that allows it to more reliably adapt to unseen information. Depending on how granular you want your description to be, this structure can be meaningful or distracting. Interpreting this system at some meaningful (to us and the network) scale of abstraction amounts to getting rid of the noise amounts via an explicit RG flow to the low-energy representation_0’ (IR_0’). If IR_0’ falls along the same RG flow as that between IR_0 and UV_1, our interpretation has in some sense reverse engineered the NN’s representation abstraction. Conversely, if IR_0' deviates significantly from this flow, it indicates that our explicit renormalization has either introduced additional human-centric abstractions or lost important structural information from the original representation.
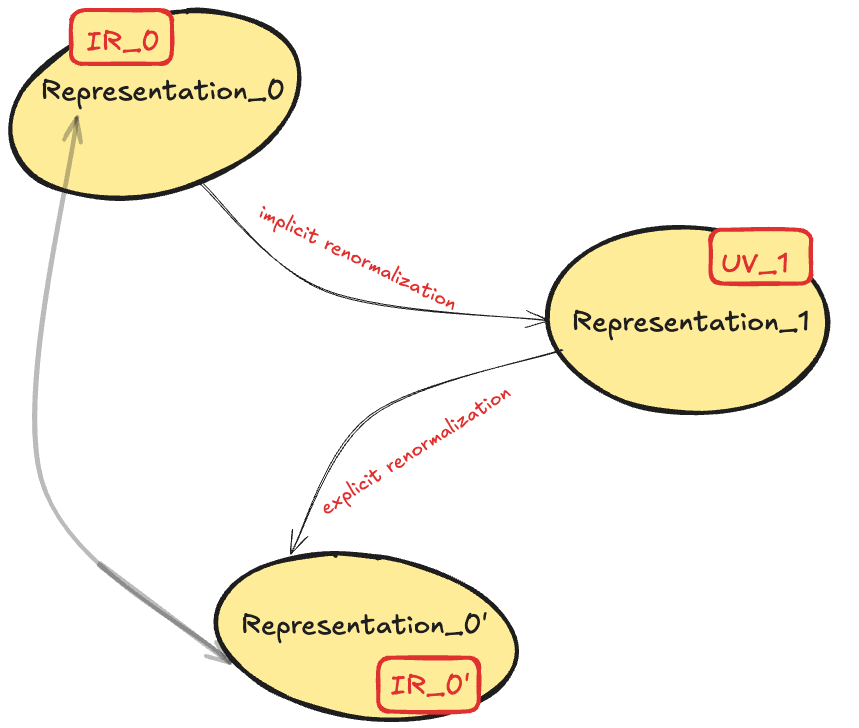
Renormalization for AI Safety
How much theoretical input is necessary and practical for designing reliable AI systems or robustly interpreting them? This question is central to assigning value to AI safety research priorities. Because it comes from physics – an empirical science with robust theoretical foundations – the renormalization for AI safety opportunity space gives a balanced response: theory is important, but ultimately meaningless without multiple tethers – in the way of predictive power and sanity checks – to the real world.
The explanatory power of renormalization in physics has been discussed from a philosophy of science perspective by Castellani et al., 2023. In this paper, the authors sketch the twin histories (according to CMT and HEP, respectively) of the RG and argue that ‘...RG methods, while mathematical per se, cannot explain physical phenomena without supplementary, physical elements’ (ibid p. 2). Because this statement directly applies to renormalization’s explanatory power in NNs, it is worth unpacking some of their argument.
Central to their analysis is a discussion about whether an explanation is:
- Reductive: Can macroscopic phenomena be explained entirely in terms of microscopic interactions and their causal dependencies, or is ‘more different’?
- Causal: How sensitive is a macroscopic description to microscopic fluctuations? As the article points out, renormalization is one of the few well-developed non-causal examples from physics about which philosophers of science can reason.
- Mathematical: Does the explanatory power of RG boil down to its theoretical structure, or is additional ‘physical’ or empirical information necessary?
They anchor the discussion in universality, mainly on whether RG explanations are mathematical, and how this leads them to be non-causal and non-reductive. Among the points of view they discuss: universality implies a many-to-one relationship between microscopic and macroscopic theories, undermining a deductive-nomological view of explanations that is causal and reductive. Regarding the mathematical explanatory power of RG, the fundamental question here is whether the math is explanatory or representative. ‘In other words, the point is whether RG methods can bring bona fide physical content over and above their calculational power, thus providing a mathematical explanation of a physical fact.’ (ibid p.8) Their argument mainly counters that of Morrison, who argues that fixed points, like the ‘infinite’ or thermodynamic limit of some theories, are sufficient to concretely explain emergence. Morrison’s view is HEP-aligned; the RG is a space of theories with a certain structure, and it is this structure that is most important. Instead, Castellani et al. take a view more in line with CMT, arguing that while the structure adds value, RG without additional physical context is not explanatory. Universality is key to this argument as well. For example, the liquid-gas and ferromagnetic phase transitions are both described by the Ising model, but they are not the same system. Without key ‘difference making factors’ – for example, finite-sized effects and boundary conditions or aspects of disordered systems – how would we tell the difference between theoretical phenomena in the same universality class?
Before moving on, there are a few more things to keep in mind:
- Morrison’s arguments reiterate the importance of theoretical tethers: even though fixed points are often idealizations, they can provide guiding explanatory power for the framework as a whole by defining robust examples of separation of scales.
- Physics relies on math, but it is not math.
- While powerful and adaptive, the RG is all about finding approximate, effective descriptions to describe some aspects of reality. While these are important for implementing pieces of an organizational structure, they should not be confused for the structure itself.
- The definition, development, and operationalizations of the RG depend not only on physical phenomena, but on the flavor of physics research and its associated scientific culture. This will be especially important to keep in mind while building collaborations.
- As evidenced by RG’s own history, theoretical machinery develops and evolves over time. The limitations of theoretical descriptions of any kind are important and should be kept in mind.
Discussion
Each of the above points has the potential to provide guidance as we develop a renormalization framework for AI systems. Although AI systems are not physical systems, I think that a lot of Castellani et al.’s framing applies in a NN context. First, whether the renormalization explanation for NNs is reductive or causal raises questions about the extent to which reductive mechanistic algorithms of model parameters build up to emergent behaviors (Sharkey et al.). If a renormalization framework for NNs proves to be structurally and robustly similar to that in physics, we will have a reliable understanding of separation of scales in NNs, giving us a way of formulating theories of emergence. Lastly, an understanding of whether an RG explanation is mathematical is also important for NNs, but much more difficult to answer. Which of RG’s many theories and techniques can be ported over from physics, and which ‘physical’ information is needed to turn them into an explanatory framework, is still an open question. We expect that similarities between physical and AI systems prove to constitute a rich analogy rather than a strict correspondence, underscoring the need for caution. Several considerations shape how RG approaches might translate to NNs. We describe some of these below, and include a few reference texts to guide future exploration.
Dimensionality
NNs have a high dimensional input space (much higher than physics), adding complexity and giving many more degrees of freedom to ‘cluster’ data in a reasonable way. This makes it more difficult to identify, for example, local scales of interaction and relevant features at each scale. Any method to significantly reduce the number of dimensions in the data or representation would be practically valuable. If RG methods transfer from their use in CMT, it may become possible to characterize neural networks using only a small set of effective couplings at scales accessible to measurements, and from these derive predictions at higher ‘energy’ scales that we are unable to probe directly.
Start with: Marzen et al., Ringel et al.
Locality and Scale
In order to have a renormalization story, we need a way to coarse-grain variables associated with a neural net that define an RG flow, defining an RG flow across different scales. In physics, there is a natural space-time scale set by the locality of interactions;[10] in NNs it is more complicated. There are several candidate metrics for ‘closeness’ exhibit power-law behavior, indicating model-natural notions of scale (as power laws of operators do in physics) that describe aspects of NN representations individually. For example, layer-layer network dynamics coarse-grain data via an implicit renormalization process. These are typically modeled as gradually “compressing” input data to output correct classifications, as formalized in the kernel regime in Roberts et al.. Additionally, every learning problem implicitly includes at least one "tempering" hyperparameter, such as temperature in physics or learning rate in NNs ( Adam 2025 [LW · GW]), representing another type of coarse-graining.
We note that certain architectures (such as diffusion) coarse-grain along predefined scales in the architecture (for example, the distance in the input space). Others implicitly prefer certain scales compatible with their architecture, training dynamics, or data flow. These likely correspond with interesting implicit renormalization behaviors. Additionally, multi-scale renormalization opens the possibility of richer, multi-dimensional RG flows.
In general, we expect there to be “better” and “worse” choices of scales (i.e. “coarsegraining directions”) for interpreting neural nets, which may depend on both the architecture and the data distribution. We note that in physical systems, many different notions of scale and RG flow lead to the same renormalized “interpretation” of a theory; in some sense, the space of RG flows with the same limit is open in a suitable topology, and quite forgiving in practice.[11] At the same time, there are known examples in physics where, out of several different renormalization schemes, only one gives meaningful or predictive results. In the neural network context, selecting a coarse-graining direction aligned with model-inherent notions of scale or "relatedness" of features is likely to be a highly nontrivial, yet critical, problem. Relating this with a notion of ‘human interpretability’ adds additional fuzziness to the formulation of an explicit renormalization scale.
Start with: Rubin et al. 2025, Demirtas et al. 2023, Koch-Janusz & Ringel 2018
Separation of Scales (Emergence)
Unlike physical systems, NNs lack a theoretical hierarchy separated by many orders of magnitude in scale, leading to a fuzzier notion of ‘useful’ theoretical descriptions. We operationalize ‘separation of scale’ as the conditional independence of microscopic interactions (e.g., individual parameters or activations) from the point of view of fixed macroscopic parameters (e.g., aggregate features).
Start with: Seroussi et al. 2023
Criticality and Universality
It is unclear whether universal descriptions akin to RG fixed points (such as Gaussian theories in physics), naturally emerge in neural networks. For example, under which conditions of representation_0 do a class of networks flow to the same UV fixed points (representation_1) during training? Is this point marked by a phase transition (e.g., memorization/generalization)? How many universality classes exist within the same network, and how do these depends on various scales governing inference? Whether universality genuinely exists—and if so, under what conditions—remains an open question. Understanding criticality from both a HEP and CMT perspective, as discussed earlier, will be important for balancing top-down theory construction and bottom-up empirical validation in NNs.
Start with: Aguilera et al., 2023, Fischer et al., 2023, Grosvenor et al., 2023
Methods
Finally, we want to highlight once more the value in blending the approaches from HEP and CMT highlighted in an earlier section.
HEP fixes the structure of renormalization, including a defining set of fundamental parameters – such as elementary particles, gauge symmetries, and couplings—before examining how these change with scale. In an NN context, this corresponds to choosing key aspects of representations along an RG flow—identifying features or circuits that serve as "fundamental degrees of freedom" and describing how they couple together. In addition, it will be key for understanding an RG flow’s fixed point structure, and how theories of representations are hierarchically organized according to different scales. This aligns with the somewhat idealized, but relatively well-understood NN-QFT correspondence (Halverson et al., 2020), which suggests that in certain limits (roughly infinite width), NNs are close to a Gaussian process (NNGP), and perturbative methods may be sufficient to characterize the network. While most practical neural networks are not exactly NNGP-like (Howard et al. 2024) (i.e., fully characterized by Gaussian processes or their perturbations), empirical evidence suggests that in many contexts—especially around minima and in fine-tuning scenarios—NN behavior is well approximated by the NNGP framework (Nadeh et al. 2021, Lee et al., 2020). Drawing an analogy to the linear representation hypothesis, which states that much of the representational structure learned by NNs is (approximately) linear, there may be an analogous NNGP representation hypothesis telling us that much of the inference and generalization behavior of NNs is approximately Gaussian (weakly-coupled, perturbative), unless it is distinctly non-Gaussian (strongly-coupled, non-perturbative), giving us a razor between the two regimes.
On the other hand, CMT-inspired approaches typically start from observed emergent phenomena (such as phase transitions, criticality, or disorder-driven effects) and integrate out high-energy information to infer effective theories. They draw on insights and techniques developed through research into highly disordered (Collin et al., 2023) and complex physical systems, illuminating aspects of NN behavior for which Gaussian approximations are inaccessible, and therefore offer particular promise for capturing complexity and emergence in realistic NNs (Mehta & Schwab 2014, Erdmenger et al., 2021). We think these approaches will be particularly useful in guiding an explicit renormalization framework.
- ^
We borrow this phrase from ARIA.
- ^
As a working definition, ‘deep’ can be thought of as ‘sufficient to make thorough predictions at the specified scale’.
- ^
For example, one could take inspiration from real-space renormalization of the Ising model to model NN coarse-graining during training as homing in on relevant features, as in Gordon et al.
- ^
For example, by looking at scaling laws.
- ^
Sparse Autoencoders (SAEs) may be thought of as an early attempt at explicit renormalization. Our hope is that this opportunity space will make progress toward constructing better tools and corresponding guarantees regarding their robustness.
- ^
This also means that a deeper understanding of the relationship between implicit and explicit renormalization could also help us guide NN inductive biases, making future NNs automatically more interpretable and trustworthy.
- ^
True self-similarity typically refers to theories at or near critical points, where they become truly scale invariant. However, EFTs would not be worth much if the physical observables they describe were not invariant under RG transformations. We can call this approximate self-similarity, under rescaling and reinterpretations, ‘renormalization invariance’.
- ^
This is the reason RG is usually a semi-group.
- ^
In some physical systems, like glasses, this is not true, but there are still tricks one can do to make the RG flow ‘work’.
- ^
This can be identified with a natural energy scale via the kinetic term in the Lagrangian.
- ^
This is particularly visible in the critical Ising model and its Kramers–Wannier dual: defining a Gaussian convolution RG in the fermionic representation of the critical Ising model yields a natural, local smoothing procedure. However, mapping this RG explicitly back to spin variables produces a well-defined but inherently nonlocal RG scheme. Thus, while the duality preserves the universality and consistency of this RG flow, its interpretation and locality properties differ dramatically between the dual descriptions.
7 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2025-04-03T03:36:39.099Z · LW(p) · GW(p)
The idea is interesting, but I'm somewhat skeptical that it'll pan out.
- RG doesn't help much going backwards - the same coarse-grained laws might correspond to many different micro-scale laws, especially when you don't expect the micro scale to be simple.
- Singular learning theory provides a nice picture of phase-transition-like-phenomena, but it's likely that large neural networks undergo lots and lots of phase transitions, and that there's not just going to be one phase transition from "naive" to "naughty" that we can model simply.
- Conversely, lots of important changes might not show up as phase transitions.
- Some AI architectures are basically designed to be hard to analyze with RG because they want to mix information from a wide variety of scales together. Full attention layers might be such an example.
↑ comment by Lauren Greenspan (LaurenGreenspan) · 2025-04-09T15:53:20.563Z · LW(p) · GW(p)
There are ~two broad ways of thinking about RG. 'HEP-like' is structural; it helps roughly map out the space of theories at different scales/couplings, even if it does not capture all of physics at all times (for example, the standard model is a good description up to some energy scale, but each sector is often treated independently). Different aspects of training and inference seems to take the shape of renormalization, although as we pointed out there is a lot of work to be done to understand the various scales and couplings inherent to NNs. A goal of this opportunity space is not to make RG 'go backwards', but to correctly map this renormalization picture onto a 'space of representations' of a NN theory. I don't expect this to be easy or simple, but am hopeful that it will shed more theoretical insight onto different training and inference regimes and point to insightful conceptual gaps.
In contrast, interpreting NNs to a certain degree of (human-specified) abstraction is more CMT-like. I suspect you are focusing on this perspective overall. Again, as we pointed out, this formulation of RG is not invertible, there are likely many ways to coarse grain a representation (just as there are many RG schemes in condensed matter), but that doesn't mean you can't reframe something like a sparse autoencoder as doing RG.
Sure, there are 'lots of phase transitions', but that doesn't mean that it's pointless to try and classify or describe some interesting one (like memorization -> generalization). Similarly, just because lots of interesting physics happens far from phase transitions doesn't mean they aren't useful 'tethers' in the space of theories (phi-4 theory has been pretty useful).
Regarding attention, I agree that a theory of representations here would be non-local with respect to inputs. That's fine. Long range dependencies just change the flavor of RG. A lot depends on how we measure locality, since there's no a priori natural way to do this in NNs (although there are several options that likely pick up on different relationships between features).
comment by aribrill (Particleman) · 2025-04-02T20:19:59.275Z · LW(p) · GW(p)
This post is great to see, I think renormalization is a very exciting direction for AI safety research!
First, as one possible way to represent the real-world, we can think of representation_0 as a low-energy description of the dataset: IR_0.
If the NN is capable of learning a meaningful generalization of the data, representation_0 flows to representation_1 (now UV_1) via an implicit RG flow to higher energies. Instead of throwing information away, flowing to UV_1 adds structure that allows it to more reliably adapt to unseen information.
Shouldn't this go the other way, with representation_0 being UV and representation_1 being IR? A NN compresses the input representation (data) to obtain a coarse-grained output representation (label). The ability to throw away information, i.e. the irrelevant noise w.r.t. the target function, is what enables generalization to unseen inputs differing in fine-grained details.
Replies from: LaurenGreenspan↑ comment by Lauren Greenspan (LaurenGreenspan) · 2025-04-08T20:05:12.087Z · LW(p) · GW(p)
Thanks for the comment! The way I think about it, there are several ways of thinking about RG in terms of different 'energy' analogues in NNs, and each is likely tied to a different framing in terms of 'UV' and 'IR'.
For example, during training, you start with a simplified (IR like) description of the dataset that flows to a richer representation, adding finer grained structure capable of generalizing (UV).
During inference, I agree that you can describe this process as UV -> IR, as each layer is a progressively coarser representation as the features that are irrelevant for a certain task (like classification) are 'integrated out' to yield a usefully abstract simplification. However, you can also think of inference in terms of 'feature refinement', where each layer becomes progressively more structured, able to pick up on finer or more abstract details. This ultimately depends on how you think of 'scale' along the RG flow.
comment by Jonas Hallgren · 2025-04-01T07:30:57.318Z · LW(p) · GW(p)
This is absolutely fascinating to me, great post!
I would be curious if you have any thoughts about using this for steganography?
I might be understanding the post wrongly but here's what I'm thinking of:
There's some degree in which you can describe circuits or higher order ways of storing information in NNs through renormalization (or that's at least the hypothesis). Essentially you might then be able to set up a "portfolio" of different lenses that all can be correct in various ways (due to polysemanticity).
If you then have all of the reconceptualizations you can then sample on these to check what type of information actually is being transmitted in multi-agent scenarios?
Since if there's something like 6 stable renormalizations and we're only checking one of them we can't be sure there isn't hidden information being transmitted?
Anyways, I'm very excited for this direction, it seems like a very good way of crossing the theory practice gap for interpretability!
Replies from: LaurenGreenspan↑ comment by Lauren Greenspan (LaurenGreenspan) · 2025-04-08T20:23:26.336Z · LW(p) · GW(p)
I think @Dmitry Vaintrob [LW · GW] has more context on this, but I'd be really interested in exploring this idea more. I'm not sure we'd be able to enumerate all possible ways to renormalize an interpretation, but I agree that having a portfolio RG-inspired lenses could help. Are you imagining that each agent would run the lenses over information from other agents and aggregate them in some way (how?)?
Replies from: Jonas Hallgren↑ comment by Jonas Hallgren · 2025-04-09T07:27:37.670Z · LW(p) · GW(p)
So my thinking is something like this:
- If AI systems get smart enough, they will develop understanding of various ways of categorizing their knowledge. For humans this manifests as emotions and various other things like body language that we through theory of mind we assume we share. This means that when we communicate we can hide a lot of subtext through what we say, or in other words there are various ways of interpreting this information signal?
- This means that there will be various hidden ways for AIs to communicate with each other.
- By sampling on something like when other AI systems change their behaviour from a communication but we don't know what did it, we can discover communication that share hidden information.
- We can then renormalize the signals with hidden information that are being sent between AI systems and therefore discover when they're communicating hidden information?
The idea is not to do all ways, it is rather like a PCA that's dependent on the computational power you have. Also, it wouldn't be agent based, it is more like an overview and the main class citizen is the information signal itself if that makes sense? You can then do it with various AI configurations and find if there are any invariant renormalizations?