AI 2027 is a Bet Against Amdahl's Law
post by snewman · 2025-04-21T03:09:40.751Z · LW · GW · 2 commentsContents
Timeline to ASI AI 2027 Is Not Strong Evidence for AI in 2027 Human-only timeline from SIAR to ASI Reasons The AI 2027 Forecast May Be Too Aggressive #1: Simplified Model of AI R&D #2: Amdahl's Law #3: Dependence on Narrow Data Sets #4: Hofstadter's Law As Prior What To Watch For None 2 comments
AI 2027 [LW · GW] lies at a Pareto frontier – it contains the best researched argument for short timelines, or the shortest timeline backed by thorough research[1]. My own timelines [LW · GW] are substantially longer, and there are credible researchers whose timelines are longer still. For this reason, I thought it would be interesting to explore the key load-bearing arguments AI 2027 presents for short timelines. This, in turn, allows for some discussion of signs we can watch for to see whether those load-bearing assumptions are bearing out.
To be clear, while the authors have short timelines, they do not claim that ASI is likely to arrive in 2027[2]. But the fact remains that AI 2027 is a well researched argument for short timelines. Let's explore that argument.
(In what follows, I will mostly ignore confidence intervals and present only median estimates; this is a gross oversimplification of the results presented in the paper, but sufficient for my purpose here, which is to present the overall structure of the model and give a flavor of how that structure is fleshed out without going into overwhelming detail.)
Timeline to ASI
AI 2027 breaks down the path from present-day capabilities to ASI into five milestones[3]:
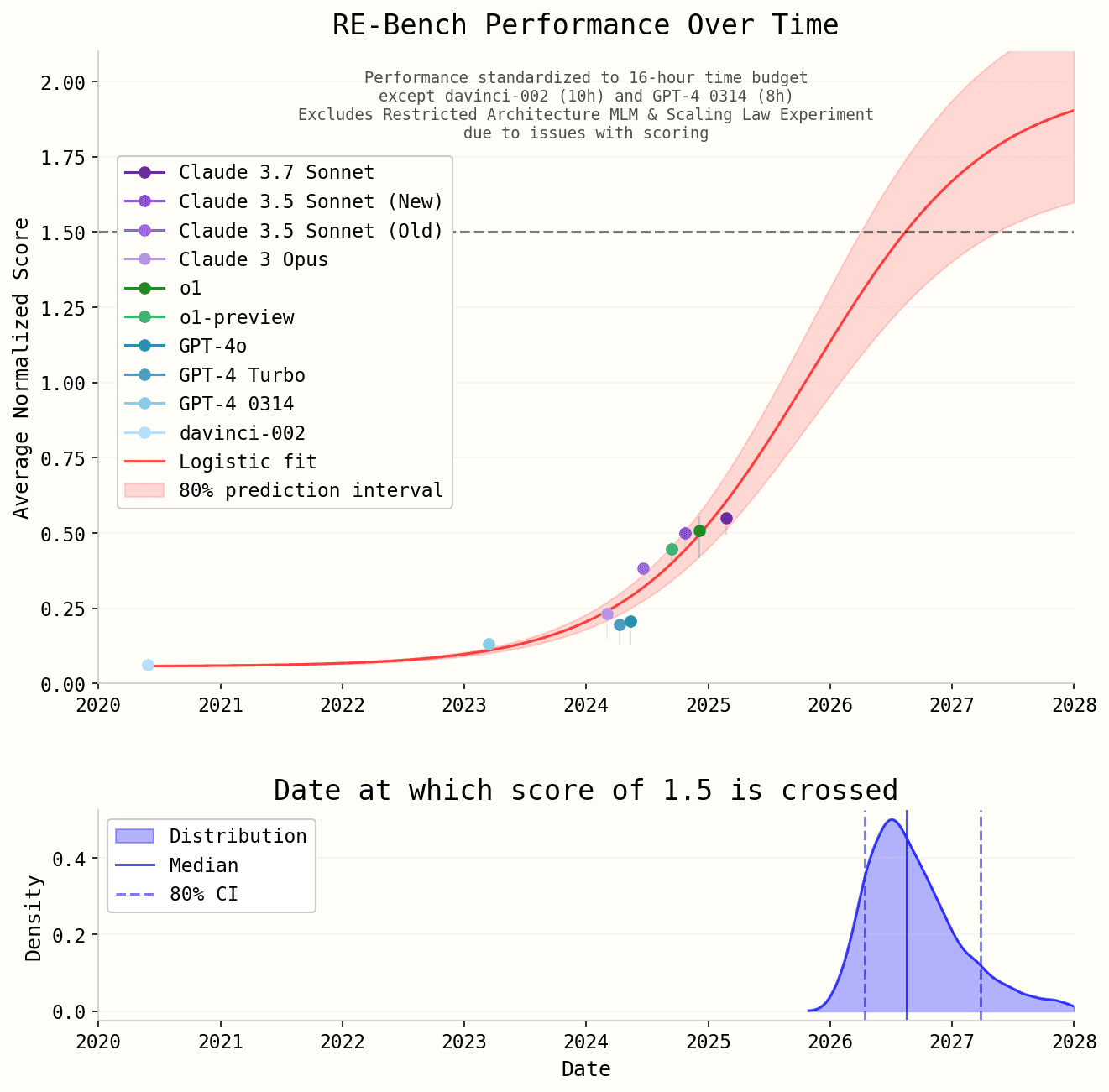
- Saturate RE-Bench. This milestone is achieved when an AI reaches an average score of 1.5 on the RE-Bench suite of AI R&D tasks[4], which the authors feel matches the ability of the best human coders.
- Superhuman coder (SC): "an AI system that can do any coding tasks that the best AGI company engineer does, while being much faster and cheaper[5]."
- Superhuman AI researcher (SAR): "An AI system that can do the job of the best human AI researcher but faster, and cheaply enough to run lots of copies."
- Superintelligent AI researcher (SIAR): "An AI system that is vastly better than the best human researcher at AI research."
- Artificial superintelligence (ASI): "An AI system that is much better than the best human at every cognitive task."
For the first milestone, they fit a logistic curve to historical progress on RE-Bench, and estimate that a score of 1.5 will be reached "some time in 2026":
To estimate timelines for the remaining milestones, they use a two-step process. First, they estimate the time that would be required to reach that milestone (starting from the previous milestone), without AI assistance or compute scale-up. Then they estimate how much AI will accelerate the process. Compute scale-up is excluded because they expect things to move quickly enough that compute increases will not be a dominant factor:
In this writeup we focus primarily on a possible software-driven intelligence explosion, in which there is vast improvement in AI capabilities on the scale of months-years primarily driven by using compute more efficiently (improved software), rather than more training compute. This report discusses the possibility of a software-driven intelligence explosion at length. We focus on software because the feedback loops are stronger: improved algorithms can be almost immediately applied to train better AIs, while improved hardware designs require substantial time to produce at scale (using anything like our current methods).
Here are the median estimates of the "human-only, software-only" time needed to reach each milestone:
- Saturating RE-Bench → Superhuman coder: three sets of estimates are presented, with medians summing to between 30 and 75 months[6]. The reasoning is presented here.
- Superhuman coder → superhuman AI researcher: 3.4 years[7]. This estimate is explained here, and relies on educated guesswork such as "perhaps whatever worked for [superhuman coding] will also work for [superhuman AI research] with a bit of extra tinkering" or (in an alternate scenario) "with human engineers doing the labor, our guess is that it would take about 2-15 years."
- Superhuman AI researcher → superintelligent AI researcher: 19 years, explained here. In brief, they estimate how long it will take to progress from "median [frontier lab] researcher" to superhuman coder, and then argue that it will take roughly twice as many "cumulative effort doublings" to progress from superhuman AI researcher to superintelligent AI researcher.
- Superintelligent AI researcher → artificial superintelligence: 95 years, explained here. I honestly cannot interpret the argument here (the wording is informal and I find it to be confusing), but it includes components such as "Achieving ASI in all cognitive tasks rather than just AI R&D: About half of an SAR→SIAR jump".
This adds up to a median estimate[8] of well over a century to achieve ASI without compute scale-up or use of AI tools. The authors then estimate the extent to which AI tools will accelerate the process:
- Today: 1.03x – 1.3x
- After saturating RE-Bench: 1.05x – 1.6x
- Superhuman coder: 5x
- Superhuman AI researcher: 25x
- Superintelligent AI researcher: 250x
- ASI: 2000x
By applying these speedup factors to the "human-only, software-only" time estimates given above, they arrive at a probability range for the timeline to ASI:
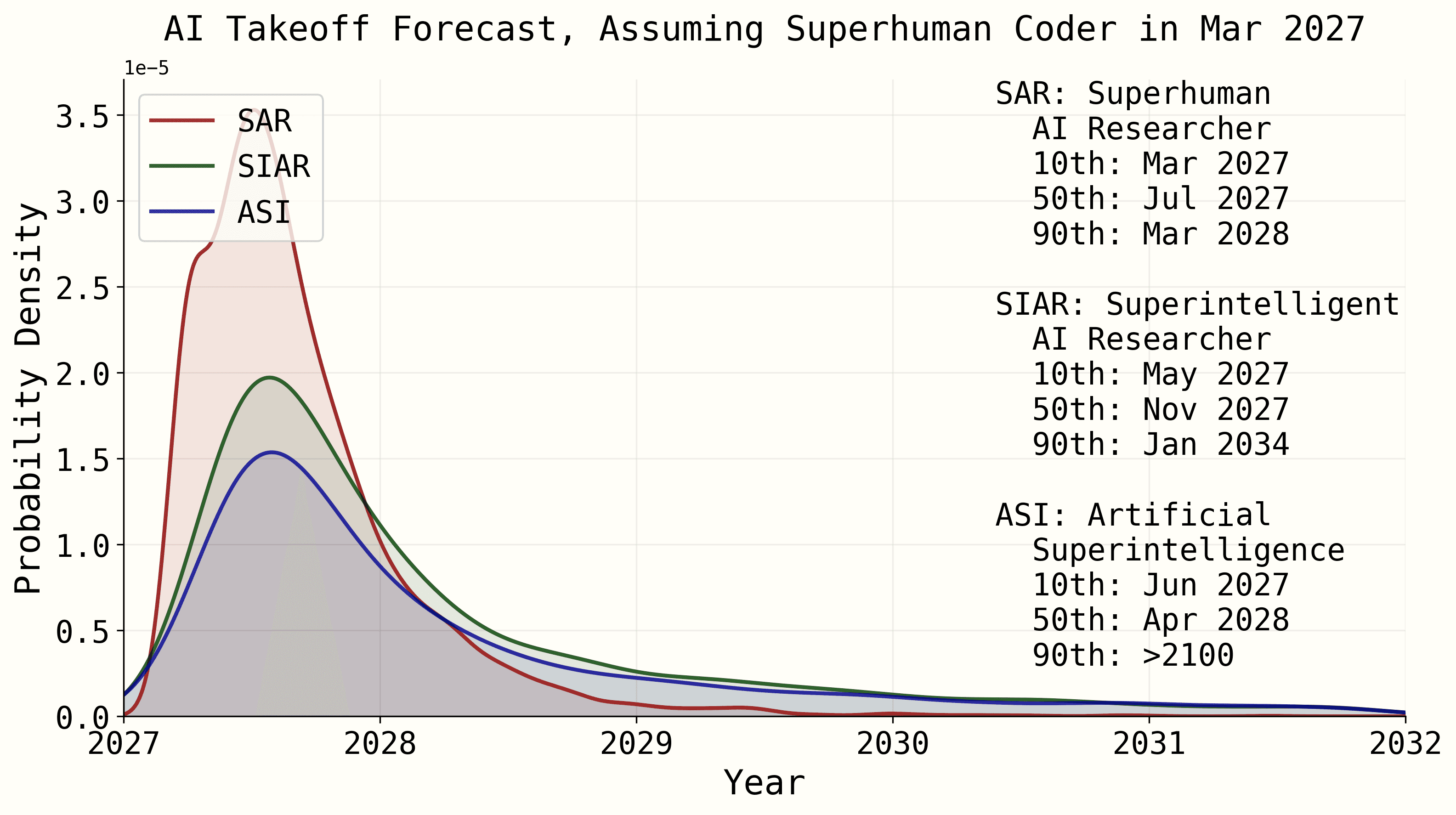
I note that I am confused by this diagram. In particular, the legend indicates a 90th percentile forecast of ">2100" for ASI, but the diagram appears to show the probability dropping to zero around the beginning of 2032.
AI 2027 Is Not Strong Evidence for AI in 2027
Several things are true about the model for ASI timelines presented as part of AI 2027:
- It is an extremely forthright and thorough piece of work.
- The conclusions should not be taken too seriously; all this analysis does not add up to strong evidence to expect ASI to arrive in any particular year.
- The model provides a useful framework which we can use to update our expectations as new evidence accumulates. If "all models are wrong, some are useful", this is one of the useful ones.
Why do I say that the timeline model should not be taken too seriously? It relies on quite a few guesses and handwavy estimates. The authors make vigorous attempts to analyze important parameters in multiple ways whenever possible, i.e. to provide redundant mechanisms for estimating the same quantity. However, to my best understanding, they were often unable to do so – the model depends on many non-redundant leaps of intuition. For instance, the following passage is central to the estimate of the timeline from a superintelligent AI researcher to ASI:
Human-only timeline from SIAR to ASI
I’ll think about this in relative terms to how long it takes to cross from SAR to SIAR human-only as forecasted above.
There are 2 gaps to cross between SIAR and ASI:
- Achieving 2 (median→best jumps) above the best human when looking at the whole field rather than a single company: a bit less than an SAR→SIAR jump
- For AI R&D, my guess is that this requires a bit less of a jump as SAR→SIAR, because the median ML professional is a bit better than the worst AGI company researcher (if the worse researcher were as much worse than the median as the median was compared to the best, which may not be true in practice due to hiring cutoffs).
- Achieving ASI in all cognitive tasks rather than just AI R&D: About half of an SAR→SIAR jump.
- I think once an AI is extremely good at AI R&D, lots of these skills will transfer to other domains, so it won’t have to be that much more capable to generalize to all domains, especially if trained in environments designed for teaching general skills.
This passage contains multiple guesses – the gap from SIAR to ASI decomposing into (1) and (2), and the estimated scale of each component. Again, the overall model is an accumulation of many such intuitive leaps, primarily in serial rather than parallel, meaning that our confidence in the final result should be substantially less than our confidence in any individual step.
(To be clear, this is a much better model than I could have constructed. My intention is not to criticize, but merely to describe.)
The upshot is that I find it difficult to accept the AI 2027 model as strong evidence for short timelines, or indeed for any timeline in particular. The authors include expert forecasters, who understand how to estimate in the face of uncertainty and calculate probability distributions much better than I do, but I simply find it impossible to accept this concatenation of intuitive leaps as sufficient evidence to update very far.
In the next section, I'll present some specific reasons I believe the AI 2027 model underestimates timelines. I'll then conclude with some thoughts regarding what signs we should watch for to disambiguate whether things are playing out according to the AI 2027 model or my alternative assumptions.
Reasons The AI 2027 Forecast May Be Too Aggressive
#1: Simplified Model of AI R&D
The model doesn't do much to explore the multitude of activities that go into AI R&D. There's more than just designing, executing, and analyzing experiments. The process also includes collecting and cleaning data, designing evaluations, managing training runs, "vibe checks", safety evaluations, and many other actions. Over time, models, use cases, and post-training processes are becoming more complex, and AI R&D will likely expand to encompass entirely new activities requiring different sorts of expertise. It seems likely that specific domains (such as coding, technical research, business planning, legal analysis, ...) may each require unique approaches for generating synthetic data and evaluating outputs, probably with involvement from experts in those domains. I'm sure I've only scratched the surface – AI R&D is going to encompass a rich and heterogeneous variety of activities.
Inevitably, some of these activities will be harder to automate than others, delaying the overall timeline. It seems difficult to route around this problem. For instance, if it turns out to be difficult to evaluate the quality of model outputs for fuzzy / subjective tasks, it's not clear how an R&D organization (regardless of how much or little automation it has incorporated) could rapidly improve model capabilities on those tasks, regardless of how much progress is being made in other areas.
#2: Amdahl's Law
The model estimates a century-plus timeline to ASI, and then projects the work to take place over a few years of calendar time, on the expectation that AI tools will be accelerating progress by factors eventually exceeding 1000x. Such extreme speedups are only possible if acceleration is near universal, i.e. only if every tiny detail of the R&D process is amenable to acceleration.
The authors address this objection, but the counterargument strikes me as flawed. Here is the key paragraph:
To see why this is conceptually mistaken, consider a theoretical AI with very superhuman experiment selection capabilities but sub-human experiment implementation skills. Even if automation didn’t speed up implementation of AI experiments at all and implementation started as 50% of researchers’ time, if automation led to much better experiments being chosen, a >2x AI R&D progress multiplier could be achieved.
In essence, this is saying that if the pace of progress is the product of two factors (experiment implementation time, and quality of experiment choice), then AI only needs to accelerate one factor in order to achieve an overall speedup. However, AI R&D involves a large number of heterogeneous activities, and overall progress is not simply the product of progress in each activity. Not all bottlenecks will be easily compensated for or worked around.
Also remember that we are talking about very large speedups here. In practice, Amdahl's Law often starts to bite when optimizing a system by factors as small as 2x. Projecting speedups reaching 2000x is "pricing to perfection"; if the ability to route around difficult-to-automate activities is anything short of perfect, progress will fall short of the anticipated speedup curves.
Looking at the quote above, I'll note that "choosing better experiments" is a relatively advanced skill, which will likely not emerge until well after experiment implementation skills. More generally, the high-level decision-making skills needed to maintain accelerating progress in the face of powerful-but-uneven AI capabilities seem like they would not emerge until late in the game. The model assumes very high speedup factors (25x to 250x), implying very broad and robust capabilities, quite far in advance of ASI.
#3: Dependence on Narrow Data Sets
To the extent that the model is grounded in concrete measurements of AI capabilities, those measurements primarily come from benchmarks such as HCAST and RE-Bench, which primarily contain tidily encapsulated tasks from software engineering and related domains. We have very little data as to how far models will have to progress in order to tackle higher-level AI R&D skills such as "research taste", let alone tasks outside of software engineering and AI R&D. And it seems likely that there is a strong correlation between tasks that are easy to benchmark, and tasks that are easy to train – we measure AIs on the things they're best at.
While current AI models and tools are demonstrating substantial value in the real world, there is nevertheless a notorious gap between benchmark scores ("Ph.D level" and beyond) and real-world applicability. It strikes me as highly plausible that this reflects one or more as-yet-poorly-characterized chasms that may be difficult to cross.
#4: Hofstadter's Law As Prior
Readers are likely familiar with Hofstadter's Law:
It always takes longer than you expect, even when you take into account Hofstadter's Law.
It's a good law. There's a reason it exists in many forms (see also the Programmer's Credo[9], the 90-90 rule, Murphy's Law, etc.) It is difficult to anticipate all of the complexity and potential difficulties of a project in advance, and on average this contributes to things taking longer than expected. Constructing ASI will be an extremely complex project, and the AI 2027 attempt to break it down into a fairly simple set of milestones and estimate the difficulty of each milestone seems like fertile territory for Hofstadter's Law.
What To Watch For
The AI 2027 model incorporates many factors, but at the end of the day, the prediction of short timelines hinges on very high rates of acceleration of AI R&D. More precisely, it assumes extreme acceleration of a set of activities, beginning with a fairly narrow range of coding tasks, and then expanding quite broadly, to include all of the activities involved in developing new AI models, including high-level cognitive facilities such as "research taste" as well as any domain-specific work needed to inculcate expertise in various domains.
More simply, the model assumes that AI-driven speedups will be deep (very high acceleration factors) and broad (across a wide variety of activities). Depth has already been achieved; AI tools can already massively accelerate some tasks, such as coding simple and stereotypical video games[10]. The challenge will be going broad – expanding the range of tasks for which AI can provide high speedup factors. This suggests some things we can watch for:
What is the profile of acceleration across all tasks relating to AI R&D? What percentage of tasks are getting accelerated by 1.1x, 1.5x, 2x? If we see at least a modest uplift for a steadily increasing range and scope of tasks, that would be a sign that the objections listed above are not choking progress. If we see strong uplift for some tasks, but the set of uplifted tasks remains constrained and/or the level of human supervision required is not shrinking (again, across a broad range of tasks), that will be evidence that the model is overly optimistic.
What is the profile of AI uplift beyond AI R&D? Is the real-world applicability of AI to AI R&D being mirrored in a broader range of tasks and jobs? This will shed light on the gap from a superintelligent AI researcher to ASI.
As a prerequisite, it will be necessary to enumerate the set of activities that are necessary for "AI R&D", as well as (for ASI) the broader range of cognitive tasks that humans undertake. I am not aware of a serious attempt at either task (on the latter subject, see my blog post, If AGI Means Everything People Do... What is it That People Do?). Characterizing the full range of activities involved in advancing AI capabilities would be a valuable contribution to timeline modeling.
- ^
Of course, the timeline forecast is not the only important contribution of AI 2027.
- ^
From
https://controlai.news/p/special-edition-the-future-of-ai:Eli: The scenario [referring, I believe, to "artificial superintelligence arriving in December 2027"] is roughly my 80th percentile speed, i.e. I assign 20% to things going at least this fast. This is similar to Scott Alexander’s view. So I find it very plausible but not my median scenario. It is however roughly my modal view, I think 2027 or 2028 is the most likely year that superhuman coders [note, not AGI or ASI] arrive.
- ^
I'm presenting things in a slightly different way than the source material. This is my best attempt to summarize the analysis and make it easy to assimilate. If I have distorted the argument in any way, I welcome corrections.
- ^
Actually "a subset of 5 of the 7 RE-Bench tasks due to issues with scoring in the remaining two".
- ^
A longer definition is also provided:
Superhuman coder (SC): An AI system for which the company could run with 5% of their compute budget 30x as many agents as they have human research engineers, each of which is on average accomplishing coding tasks involved in AI research (e.g. experiment implementation but not ideation/prioritization) at 30x the speed (i.e. the tasks take them 30x less time, not necessarily that they write or “think” at 30x the speed of humans) of the company’s best engineer. This includes being able to accomplish tasks that are in any human researchers’ area of expertise.
- ^
The paper also presents an alternative method for estimating steps 1+2, extrapolating from the recent METR paper Measuring AI Ability to Complete Long Tasks.
- ^
Actually "15% 0 years; Otherwise 4 years (80% CI: 1.5 to 10; lognormal)".
- ^
I am being very sloppy with my statistics here; for instance, it's probably not valid to add the median estimates for several steps in a process and present the total as a median estimate of the overall process.
- ^
"We do these things not because they are easy, but because we thought they were going to be easy."
- ^
This choice of a relatively frivolous example is not meant to be dismissive; it was just the first example that came to mind where people seem to be routinely vibe-coding fairly complex pieces of software. There are probably examples that are directly relevant to AI R&D, but I don't have them at the tip of my tongue.
2 comments
Comments sorted by top scores.
comment by Tenoke · 2025-04-21T06:12:34.757Z · LW(p) · GW(p)
AI 2027 is more useful for the arguments than the specific year but even if not as aggressive, prediction markets (or at least Manifold) predict 61% chance before 2030, 65% before 2031, 73% by 2033.
I, similarly, can see it happening slightly later than 2027-2028 because some specific issues take longer to solve than others but I see no reason to think a timeline beyond 2035, like yours, let alone 30 years is grounded in reality.
It also doesn't help that when I look at your arguments and apply them to what would then seem to be very optimistic forecast in 2020 about progress in 2025 (or even Kokotajlo's last forecast), those same arguments would have similarly rejected what has happened.
comment by Jonas Hallgren · 2025-04-21T06:56:57.796Z · LW(p) · GW(p)
I had some more specific thoughts on ML-specific bottlenecks that might be difficult to get through in terms of software speed up but the main point is as you say, just apply a combo of amdahls, hofstadter and unknown unknowns and then this seems a bit more like a contractor's bid on a public contract. (They're always way over budget and always take 2x the amount of time compared to the plan.)
Nicely put!