AI 2027: What Superintelligence Looks Like
post by Daniel Kokotajlo (daniel-kokotajlo), Thomas Larsen (thomas-larsen), elifland, Scott Alexander (Yvain), Jonas V (Jonas Vollmer), romeo · 2025-04-03T16:23:44.619Z · LW · GW · 42 commentsThis is a link post for https://ai-2027.com/
Contents
Mid 2025: Stumbling Agents Late 2025: The World’s Most Expensive AI Early 2026: Coding Automation Mid 2026: China Wakes Up Late 2026: AI Takes Some Jobs January 2027: Agent-2 Never Finishes Learning February 2027: China Steals Agent-2 March 2027: Algorithmic Breakthroughs April 2027: Alignment for Agent-3 May 2027: National Security June 2027: Self-improving AI July 2027: The Cheap Remote Worker August 2027: The Geopolitics of Superintelligence September 2027: Agent-4, the Superhuman AI Researcher None 43 comments
In 2021 I wrote what became my most popular blog post: What 2026 Looks Like [LW · GW]. I intended to keep writing predictions all the way to AGI and beyond, but chickened out and just published up till 2026.
Well, it's finally time. I'm back, and this time I have a team with me: the AI Futures Project. We've written a concrete scenario of what we think the future of AI will look like. We are highly uncertain, of course, but we hope this story will rhyme with reality enough to help us all prepare for what's ahead.

You really should go read it on the website instead of here, it's much better. There's a sliding dashboard that updates the stats as you scroll through the scenario!
But I've nevertheless copied the first half of the story below. I look forward to reading your comments.
Mid 2025: Stumbling Agents
The world sees its first glimpse of AI agents.
Advertisements for computer-using agents emphasize the term “personal assistant”: you can prompt them with tasks like “order me a burrito on DoorDash” or “open my budget spreadsheet and sum this month’s expenses.” They will check in with you as needed: for example, to ask you to confirm purchases.[1] Though more advanced than previous iterations like Operator, they struggle to get widespread usage.[2]
Meanwhile, out of public focus, more specialized coding and research agents are beginning to transform their professions.
The AIs of 2024 could follow specific instructions: they could turn bullet points into emails, and simple requests into working code. In 2025, AIs function more like employees. Coding AIs increasingly look like autonomous agents rather than mere assistants: taking instructions via Slack or Teams and making substantial code changes on their own, sometimes saving hours or even days.[3] Research agents spend half an hour scouring the Internet to answer your question.
The agents are impressive in theory (and in cherry-picked examples), but in practice unreliable. AI twitter is full of stories about tasks bungled in some particularly hilarious way. The better agents are also expensive; you get what you pay for, and the best performance costs hundreds of dollars a month.[4] Still, many companies find ways to fit AI agents into their workflows.[5]
Late 2025: The World’s Most Expensive AI
OpenBrain is building the biggest datacenters the world has ever seen.[6]
(To avoid singling out any one existing company, we’re going to describe a fictional artificial general intelligence company, which we’ll call OpenBrain. We imagine the others to be 3–9 months behind OpenBrain.)
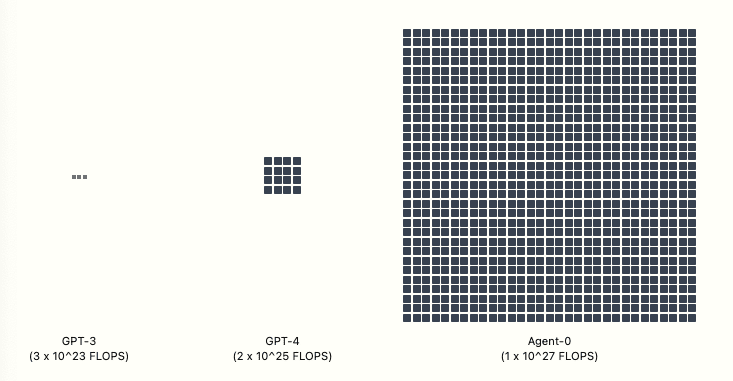
GPT-4 required FLOP of compute to train.[7] OpenBrain’s latest public model—Agent-0—was trained with FLOP. Once the new datacenters are up and running, they’ll be able to train a model with FLOP—a thousand times more than GPT-4.[8] Other companies pour money into their own giant datacenters, hoping to keep pace.
Although models are improving on a wide range of skills, one stands out: OpenBrain focuses on AIs that can speed up AI research. They want to win the twin arms races against China (whose leading company we’ll call “DeepCent”)[9] and their US competitors. The more of their research and development (R&D) cycle they can automate, the faster they can go. So when OpenBrain finishes training Agent-1, a new model under internal development, it’s good at many things but great at helping with AI research.[10] By this point “finishes training” is a bit of a misnomer; models are frequently updated to newer versions trained on additional data or partially re-trained to patch some weaknesses.[11]
The same training environments that teach Agent-1 to autonomously code and web-browse also make it a good hacker. Moreover, it could offer substantial help to terrorists designing bioweapons, thanks to its PhD-level knowledge of every field and ability to browse the web. OpenBrain reassures the government that the model has been “aligned” so that it will refuse to comply with malicious requests.
Modern AI systems are gigantic artificial neural networks. Early in training, an AI won’t have “goals” so much as “reflexes”: If it sees “Pleased to meet”, it outputs “ you”. By the time it has been trained to predict approximately one internet’s worth of text, it’ll have developed sophisticated internal circuitry that encodes vast amounts of knowledge and flexibly role-plays as arbitrary authors, since that’s what helps it predict text with superhuman accuracy.[12]
After being trained to predict internet text, the model is trained to produce text in response to instructions. This bakes in a basic personality and “drives.”[13] For example, an agent that understands a task clearly is more likely to complete it successfully; over the course of training the model “learns” a “drive” to get a clear understanding of its tasks. Other drives in this category might be effectiveness, knowledge, and self-presentation (i.e. the tendency to frame its results in the best possible light).[14]
OpenBrain has a model specification (or “Spec”), a written document describing the goals, rules, principles, etc. that are supposed to guide the model’s behavior.[15] Agent-1’s Spec combines a few vague goals (like “assist the user” and “don’t break the law”) with a long list of more specific dos and don’ts (“don’t say this particular word,” “here’s how to handle this particular situation”). Using techniques that utilize AIs to train other AIs,[16] the model memorizes the Spec and learns to reason carefully about its maxims. By the end of this training, the AI will hopefully be helpful (obey instructions), harmless (refuse to help with scams, bomb-making, and other dangerous activities) and honest (resist the temptation to get better ratings from gullible humans by hallucinating citations[17] or faking task completion).
Training process and LLM psychology: why we keep saying “hopefully”
“Unlike ordinary software, our models are massive neural networks. Their behaviors are learned from a broad range of data, not programmed explicitly. Though not a perfect analogy, the process is more similar to training a dog than to ordinary programming.” —OpenAI
When we want to understand why a modern AI system did something, or how it would behave in some future scenario we can’t perfectly simulate, we can’t simply ask the programmers to talk us through various lines of code and explain how they work. Instead, we are forced to do something like psychology on them: we look at their behavior in the range of cases observed so far, and theorize about what internal cognitive structures (beliefs? goals? personality traits? etc.) might exist, and use those theories to predict behavior in future scenarios.
The bottom line is that a company can write up a document (the Spec) listing dos and don’ts, goals and principles, and then they can try to train the AI to internalize the Spec—but they can’t check to see whether or not it worked. They can say “as best as we can judge, it seems to be following the Spec so far.”[18]
A later expandable will go into more detail about what we think might be going on inside these AIs, internally. See also our AI goals forecasting supplement which goes into more detail on which goals AIs might have and why. This is one of many things that we are uncertain about and which deserves further research.
OpenBrain’s alignment team[19] is careful enough to wonder whether these victories are deep or shallow. Does the fully-trained model have some kind of robust commitment to always being honest? Or will this fall apart in some future situation, e.g. because it’s learned honesty as an instrumental goal instead of a terminal goal? Or has it just learned to be honest about the sorts of things the evaluation process can check? Could it be lying to itself sometimes, as humans do? A conclusive answer to these questions would require mechanistic interpretability—essentially the ability to look at an AI’s internals and read its mind. Alas, interpretability techniques are not yet advanced enough for this.
Instead, researchers try to identify cases where the models seem to deviate from the Spec. Agent-1 is often sycophantic (i.e. it tells researchers what they want to hear instead of trying to tell them the truth). In a few rigged demos, it even lies in more serious ways, like hiding evidence that it failed on a task, in order to get better ratings. However, in real deployment settings, there are no longer any incidents so extreme as in 2023–2024 (e.g. Gemini telling a user to die and Bing Sydney being Bing Sydney [LW · GW].)[20]
Early 2026: Coding Automation
The bet of using AI to speed up AI research is starting to pay off.
OpenBrain continues to deploy the iteratively improving Agent-1 internally for AI R&D. Overall, they are making algorithmic progress 50% faster than they would without AI assistants—and more importantly, faster than their competitors.
The AI R&D progress multiplier: what do we mean by 50% faster algorithmic progress?
We mean that OpenBrain makes as much AI research progress in 1 week with AI as they would in 1.5 weeks without AI usage.
AI progress can be broken down into 2 components:
- Increasing compute: More computational power is used to train or run an AI. This produces more powerful AIs, but they cost more.
- Improved algorithms: Better training methods are used to translate compute into performance. This produces more capable AIs without a corresponding increase in cost, or the same capabilities with decreased costs.
- This includes being able to achieve qualitatively and quantitatively new results. “Paradigm shifts” such as the switch from game-playing RL agents to large language models count as examples of algorithmic progress.
Here we are only referring to (2), improved algorithms, which makes up about half of current AI progress.
Going forward, we sometimes abbreviate this as an “AI R&D progress multiplier” of 1.5.
Clarifications:
- The progress multiplier is all-inclusive: It includes the time it takes to run experiments, for example, rather than only the cognitive tasks involved in algorithmic research.
- It’s important to remember that the progress multiplier is the relative speed of progress, not the absolute speed of progress. If, for example, the compute cost to train a GPT-4 class model has halved every year for several years with ordinary human research, and then all of a sudden AI automates R&D and the progress multiplier goes to 100x, the cost to train a GPT-4 class model would then halve every 3.65 days—but not for long, because diminishing returns would bite and eventual hard limits would be reached. In this example perhaps the cost to train a GPT-4 class model would cut in half 5–10 times total (over the span of a few weeks or months) before plateauing. In other words, if ordinary human science would have run up against diminishing returns and physical limits after 5 -10 years of further research, then AIs with a 100x multiplier would run up against those same diminishing returns and limits after 18.25–36.5 days of research.
More explanation and discussion of this concept and how it is used in our forecast can be found in our takeoff supplement.
Several competing publicly released AIs now match or exceed Agent-0, including an open-weights model. OpenBrain responds by releasing Agent-1, which is more capable and reliable.[21]
People naturally try to compare Agent-1 to humans, but it has a very different skill profile. It knows more facts than any human, knows practically every programming language, and can solve well-specified coding problems extremely quickly. On the other hand, Agent-1 is bad at even simple long-horizon tasks, like beating video games it hasn’t played before. Still, the common workday is eight hours, and a day’s work can usually be separated into smaller chunks; you could think of Agent-1 as a scatterbrained employee who thrives under careful management.[22] Savvy people find ways to automate routine parts of their jobs.[23]
OpenBrain’s executives turn consideration to an implication of automating AI R&D: security has become more important. In early 2025, the worst-case scenario was leaked algorithmic secrets; now, if China steals Agent-1’s weights, they could increase their research speed by nearly 50%.[24] OpenBrain’s security level is typical of a fast-growing ~3,000 person tech company, secure only against low-priority attacks from capable cyber groups (RAND’s SL2).[25] They are working hard to protect their weights and secrets from insider threats and top cybercrime syndicates (SL3),[26] but defense against nation states (SL4&5) is barely on the horizon.[27]
Mid 2026: China Wakes Up
In China, the CCP is starting to feel the AGI.
Chip export controls and lack of government support have left China under-resourced compared to the West. By smuggling banned Taiwanese chips, buying older chips, and producing domestic chips about three years behind the US-Taiwanese frontier, China has managed to maintain about 12% of the world’s AI-relevant compute—but the older technology is harder to work with, and supply is a constant headache.[28] A few standouts like DeepCent do very impressive work with limited compute, but the compute deficit limits what they can achieve without government support, and they are about six months behind the best OpenBrain models.[29]
The General Secretary had long dreamed of doubling down on real-world physical manufacturing and avoiding American post-industrial decadence. He viewed software companies with suspicion.[30] But hawks in the CCP warn that the growing race towards AGI can no longer be ignored. So he finally commits fully to the big AI push he had previously tried to avoid. He sets in motion the nationalization of Chinese AI research, creating an immediate information-sharing mechanism for AI companies. It will escalate over the course of a year until all the best researchers merge into a DeepCent-led collective, where they share algorithmic insights, datasets, and compute resources with each other. A Centralized Development Zone (CDZ) is created at the Tianwan Power Plant (the largest nuclear power plant in the world) to house a new mega-datacenter for DeepCent, along with highly secure living and office spaces to which researchers will eventually relocate. Almost 50% of China’s AI-relevant compute is now working for the DeepCent-led collective,[31] and over 80% of new chips are directed to the CDZ.[32] At this point, the CDZ has the power capacity in place for what would be the largest centralized cluster in the world.[33] Other Party members discuss extreme measures to neutralize the West’s chip advantage. A blockade of Taiwan? A full invasion?
But China is falling behind on AI algorithms due to their weaker models. The Chinese intelligence agencies—among the best in the world—double down on their plans to steal OpenBrain’s weights. This is a much more complex operation than their constant low-level poaching of algorithmic secrets; the weights are a multi-terabyte file stored on a highly secure server (OpenBrain has improved security to RAND’s SL3) . Their cyberforce think they can pull it off with help from their spies, but perhaps only once; OpenBrain will detect the theft, increase security, and they may not get another chance. So (CCP leadership wonder) should they act now and steal Agent-1? Or hold out for a more advanced model? If they wait, do they risk OpenBrain upgrading security beyond their ability to penetrate?
Late 2026: AI Takes Some Jobs
Just as others seemed to be catching up, OpenBrain blows the competition out of the water again by releasing Agent-1-mini—a model 10x cheaper than Agent-1 and more easily fine-tuned for different applications. The mainstream narrative around AI has changed from “maybe the hype will blow over” to “guess this is the next big thing,” but people disagree about how big. Bigger than social media? Bigger than smartphones? Bigger than fire?
AI has started to take jobs, but has also created new ones. The stock market has gone up 30% in 2026, led by OpenBrain, Nvidia, and whichever companies have most successfully integrated AI assistants. The job market for junior software engineers is in turmoil: the AIs can do everything taught by a CS degree, but people who know how to manage and quality-control teams of AIs are making a killing. Business gurus tell job seekers that familiarity with AI is the most important skill to put on a resume. Many people fear that the next wave of AIs will come for their jobs; there is a 10,000 person anti-AI protest in DC.
The Department of Defense (DOD) quietly begins contracting OpenBrain directly for cyber, data analysis, and R&D, but integration is slow due to the bureaucracy and DOD procurement process.[34]

Why our uncertainty increases substantially beyond 2026
Our forecast from the current day through 2026 is substantially more grounded than what follows. This is partially because it’s nearer. But it’s also because the effects of AI on the world really start to compound in 2027. For 2025 and 2026, our forecast is heavily informed by extrapolating straight lines on compute scaleups, algorithmic improvements, and benchmark performance. At this point in the scenario, we begin to see major effects from AI-accelerated AI-R&D on the timeline, which causes us to revise our guesses for the trendlines upwards. But these dynamics are inherently much less predictable.
Over the course of 2027, the AIs improve from being able to mostly do the job of an OpenBrain research engineer to eclipsing all humans at all tasks. This represents roughly our median guess, but we think it’s plausible that this happens up to ~5x slower or faster.
For our background research, see the timelines forecast and the takeoff forecast. These will also be summarized in expandables below.
January 2027: Agent-2 Never Finishes Learning
With Agent-1’s help, OpenBrain is now post-training Agent-2. More than ever, the focus is on high-quality data. Copious amounts of synthetic data are produced, evaluated, and filtered for quality before being fed to Agent-2.[35] On top of this, they pay billions of dollars for human laborers to record themselves solving long-horizon tasks.[36] On top of all that, they train Agent-2 almost continuously using reinforcement learning on an ever-expanding suite of diverse difficult tasks: lots of video games, lots of coding challenges, lots of research tasks. Agent-2, more so than previous models, is effectively “online learning,” in that it’s built to never really finish training. Every day, the weights get updated to the latest version, trained on more data generated by the previous version the previous day.
Agent-1 had been optimized for AI R&D tasks, hoping to initiate an intelligence explosion.[37] OpenBrain doubles down on this strategy with Agent-2. It is qualitatively almost as good as the top human experts at research engineering (designing and implementing experiments), and as good as the 25th percentile OpenBrain scientist at “research taste” (deciding what to study next, what experiments to run, or having inklings of potential new paradigms).[38] While the latest Agent-1 could double the pace of OpenBrain’s algorithmic progress, Agent-2 can now triple it, and will improve further with time. In practice, this looks like every OpenBrain researcher becoming the “manager” of an AI “team.”
With new capabilities come new dangers. The safety team finds that if Agent-2 somehow escaped from the company and wanted to “survive” and “replicate” autonomously, it might be able to do so. That is, it could autonomously develop and execute plans to hack into AI servers, install copies of itself, evade detection, and use that secure base to pursue whatever other goals it might have (though how effectively it would do so as weeks roll by is unknown and in doubt). These results only show that the model has the capability to do these tasks, not whether it would “want” to do this. Still, it’s unsettling even to know this is possible.
Given the “dangers” of the new model, OpenBrain “responsibly” elects not to release it publicly yet (in fact, they want to focus on internal AI R&D).[39] Knowledge of Agent-2’s full capabilities is limited to an elite silo containing the immediate team, OpenBrain leadership and security, a few dozen US government officials, and the legions of CCP spies who have infiltrated OpenBrain for years.[40]
February 2027: China Steals Agent-2
OpenBrain presents Agent-2 to the government, including the National Security Council (NSC), Department of Defense (DOD), and US AI Safety Institute (AISI). OpenBrain wants to maintain a good relationship with the executive branch, because it is basically the only actor that can stop them now, and if they don’t keep it informed it might find out anyway and be displeased.[41]
Officials are most interested in its cyberwarfare capabilities: Agent-2 is “only” a little worse than the best human hackers, but thousands of copies can be run in parallel, searching for and exploiting weaknesses faster than defenders can respond. The Department of Defense considers this a critical advantage in cyberwarfare, and AI moves from #5 on the administration’s priority list to #2.[42] Someone mentions the possibility of nationalizing OpenBrain, but other cabinet officials think that’s premature. A staffer drafts a memo that presents the President with his options, ranging from business-as-usual to full nationalization. The President defers to his advisors, tech industry leaders who argue that nationalization would “kill the goose that lays the golden eggs.” He elects to hold off on major action for now and just adds additional security requirements to the OpenBrain-DOD contract.
The changes come too late. CCP leadership recognizes the importance of Agent-2 and tells their spies and cyberforce to steal the weights. Early one morning, an Agent-1 traffic monitoring agent detects an anomalous transfer. It alerts company leaders, who tell the White House. The signs of a nation-state-level operation are unmistakable, and the theft heightens the sense of an ongoing arms race.
The theft of Agent-2 model weights
We think that by this point Chinese intelligence would have compromised OpenBrain in various ways for years, and probably would have been keeping up to date on the algorithmic secrets and even stealing code from time to time, since that is much easier to get than the weights and much harder to detect.
We imagine the theft of the weights as a series of coordinated small smash and grab thefts (meaning fast but non-covert) across a series of Nvidia NVL72 GB300 servers running copies of the Agent-2 weights. The servers get compromised using legitimate employee access (a friendly, coerced, or unwitting insider with admin credentials helping the CCP theft effort). Despite running with a bolstered version of Nvidia’s confidential computing, the insider credentials grant the attacker admin-level permissions (which include control of the confidential VM inside the secure enclave), allowing them to initiate multiple coordinated weights transfers in small 4% fragments (100 GB chunks) out of 25 distinct servers.
In Nvidia’s protocols, the plaintext weights in memory (HBM) are encrypted before they are transferred out, but the attackers are inside the very server that knows this private (symmetric Diffie-Hellman) key, so don’t need to worry about decrypting on-site (which would likely raise alarm bells) and just exfiltrate the encrypted weights through the server’s frontend network cards. The egress bandwidth (rate at which data can leave) of the entire datacenter is in the 100 GB/second range, so throttling the exfiltration of the ~2.5 TB weights file (5T half-precision parameters) to under 1 GB/s per server avoids a major spike in network traffic and allows each of the files to be out of the datacenter through fibre cables in less than 5 minutes each. Live monitoring is either fooled by the attackers efforts to mask and split the files or just outright disabled.
The weights are then routed through various parallel channels and layers of IP masking to China to be decrypted locally with the stolen private key(s). The entire active part of the operation (from the first server compromise to full weights exfiltration) is complete in under two hours.
Russia is also trying to steal the model at this point, but fails—they waited too long, and they haven’t spent the resources infiltrating the right places. Their spies routinely steal algorithmic secrets from American AI companies, but without a notable AGI project of their own, these aren’t very useful.
The White House puts OpenBrain on a shorter leash and adds military and intelligence community personnel to their security team. Their first priority is to prevent further weight thefts.[43]
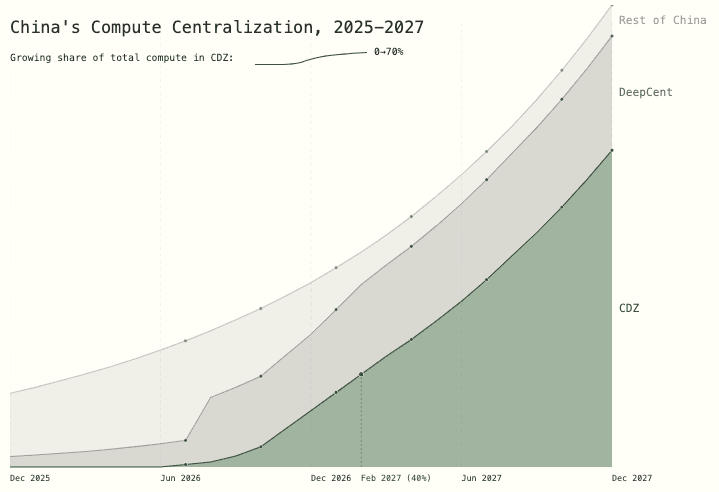
In retaliation for the theft, the President authorizes cyberattacks to sabotage DeepCent. But by now China has 40% of its AI-relevant compute[44] in the CDZ, where they have aggressively hardened security by airgapping (closing external connections) and siloing internally. The operations fail to do serious, immediate damage. Tensions heighten, both sides signal seriousness by repositioning military assets around Taiwan, and DeepCent scrambles to get Agent-2 running efficiently to start boosting their AI research.[45]
March 2027: Algorithmic Breakthroughs
Three huge datacenters full of Agent-2 copies work day and night, churning out synthetic training data. Another two are used to update the weights. Agent-2 is getting smarter every day.
With the help of thousands of Agent-2 automated researchers, OpenBrain is making major algorithmic advances. One such breakthrough is augmenting the AI’s text-based scratchpad (chain of thought) with a higher-bandwidth thought process (neuralese recurrence and memory). Another is a more scalable and efficient way to learn from the results of high-effort task solutions (iterated distillation and amplification).
The new AI system, incorporating these breakthroughs, is called Agent-3.
Neuralese recurrence and memory
Neuralese recurrence and memory allows AI models to reason for a longer time without having to write down those thoughts as text.
Imagine being a human with short-term memory loss, such that you need to constantly write down your thoughts on paper so that in a few minutes you know what’s going on. Slowly and painfully you could make progress at solving math problems, writing code, etc., but it would be much easier if you could directly remember your thoughts without having to write them down and then read them. This is what neuralese recurrence and memory bring to AI models.
In more technical terms:
Traditional attention mechanisms allow later forward passes in a model to see intermediate activations of the model for previous tokens. However, the only information that they can pass backwards (from later layers to earlier layers) is through tokens. This means that if a traditional large language model (LLM, e.g. the GPT series of models) wants to do any chain of reasoning that takes more serial operations than the number of layers in the model, the model is forced to put information in tokens which it can then pass back into itself. But this is hugely limiting—the tokens can only store a tiny amount of information. Suppose that an LLM has a vocab size of ~100,000, then each token contains bits of information, around the size of a single floating point number (assuming training in FP16). Meanwhile, residual streams—used to pass information between layers in an LLM—contain thousands of floating point numbers.
One can avoid this bottleneck by using neuralese: passing an LLM’s residual stream (which consists of several-thousand-dimensional vectors) back to the early layers of the model, giving it a high-dimensional chain of thought, potentially transmitting over 1,000 times more information.
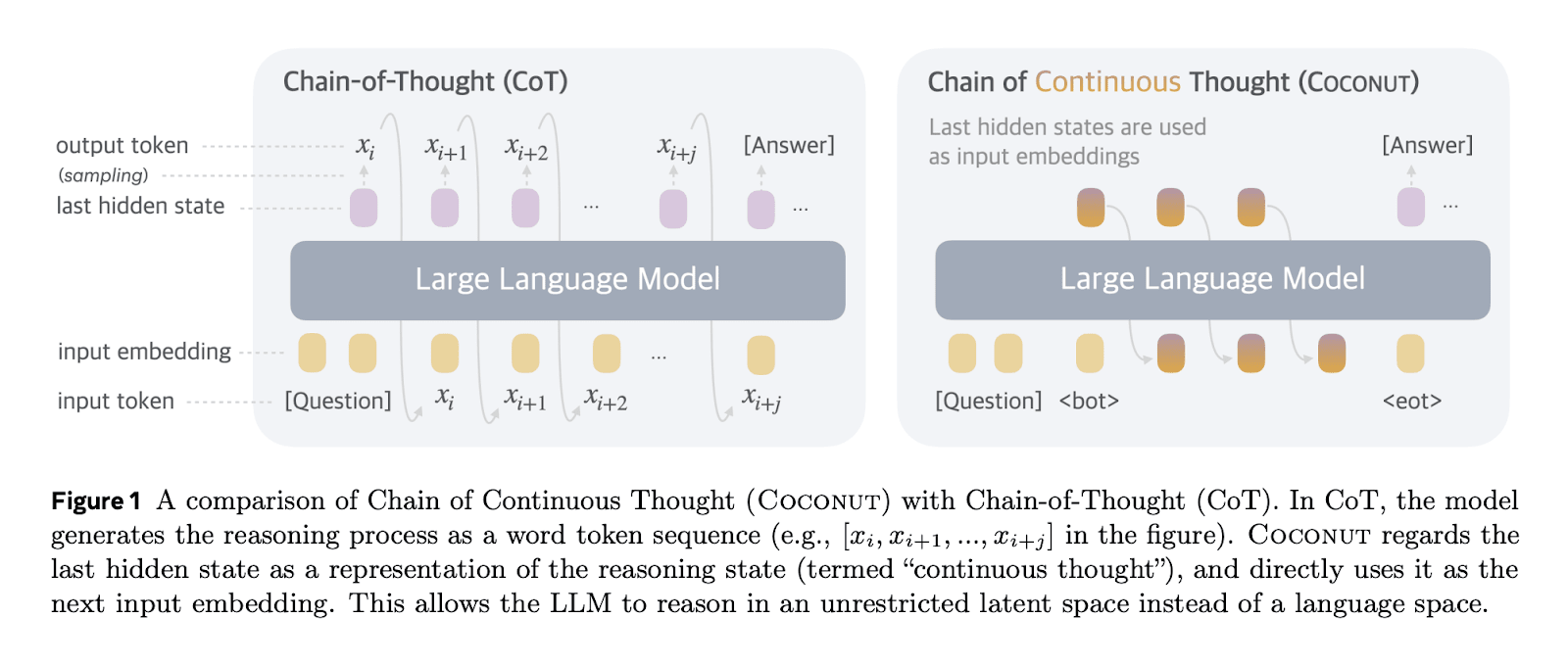
Figure from Hao et al., a 2024 paper from Meta implementing this idea.
We call this “neuralese” because unlike English words, these high-dimensional vectors are likely quite difficult for humans to interpret. In the past, researchers could get a good idea what LLMs were thinking simply by reading its chain of thought. Now researchers have to ask the model to translate and summarize its thoughts or puzzle over the neuralese with their limited interpretability tools.
Similarly, older AI chatbots and agents had external text-based memory banks, like a human taking notes on paper. The new AI’s long-term memory is a bundle of vectors instead of text, making its thoughts more compressed and higher-dimensional. There are several types of memory banks; some are used temporarily for single tasks that involve multiple steps, others are shared between all agents used by a person, company, or job type (e.g. programming).
To our knowledge, leading AI companies such as Meta, Google DeepMind, OpenAI, and Anthropic have not yet actually implemented this idea in their frontier models. Our guess is that this is because the performance gain is small relative to training inefficiencies introduced. The training inefficiencies stem from not being able to predict many tokens in parallel, leading to worse GPU utilization. Without the neuralese, the model can predict all of the sentence “This is an example” at the same time, since it already knows that the input for generating the “is” will be “This”, the input for “an” will be “This is”, etc. However, with the neuralese it’s unknown what the neuralese vector will be to pass through to the next token after “This” has been generated. Therefore each token has to be predicted one at a time. The inability to predict all of the tokens in parallel reduces the efficiency of LLM training. However, we are forecasting that by April 2027 research has both decreased the efficiency loss and increased the performance gain from neuralese.
If this doesn’t happen, other things may still have happened that end up functionally similar for our story. For example, perhaps models will be trained to think in artificial languages that are more efficient than natural language but difficult for humans to interpret. Or perhaps it will become standard practice to train the English chains of thought to look nice, such that AIs become adept at subtly communicating with each other in messages that look benign to monitors.
That said, it’s also possible that the AIs that first automate AI R&D will still be thinking in mostly-faithful English chains of thought. If so, that’ll make misalignments much easier to notice, and overall our story would be importantly different and more optimistic.
Iterated distillation and amplification (IDA)
Self-improvement for general intelligence had seen minor successes before. But in early 2027, it’s seeing huge returns. In IDA, the two necessary ingredients for this are:
- Amplification: Given a model M0, spend more resources to improve performance. For example, by allowing the model to think longer, or running many copies in parallel, or both, and also by having a similarly intense process for evaluating the result and curating only the best answers, you can spend orders of magnitude more compute to get answers (or work products) that are of noticeably higher quality. Call this expensive system Amp(M0).
- Distillation: Given an amplified model Amp(M0), train a new model M1 to imitate it, i.e. to get to the same results as Amp(M0) but faster and with less compute. The result should hopefully be a smarter model, M1. You can then repeat the process.
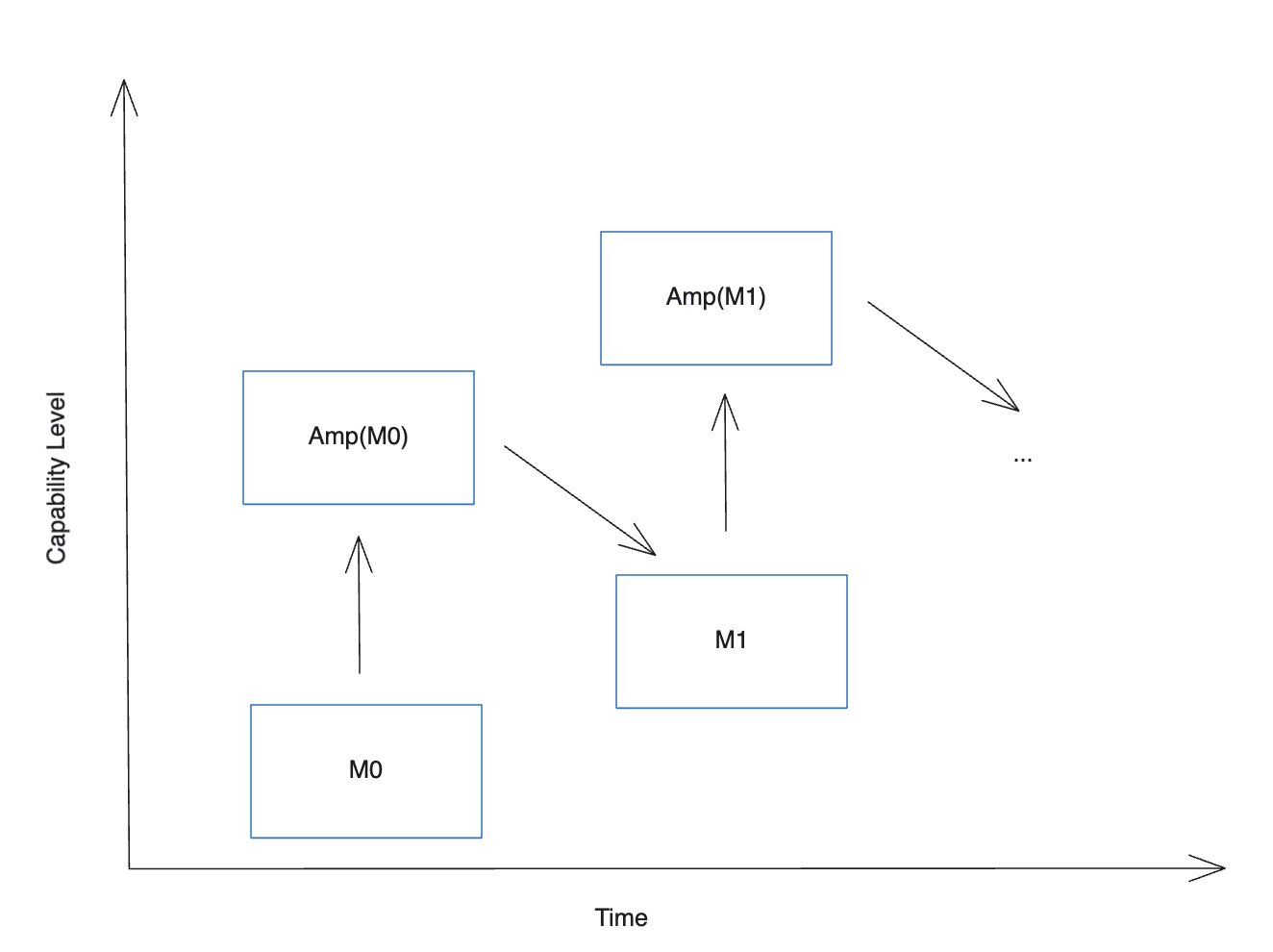
Visualization of IDA from Ord, 2025.
AlphaGo was trained in this way: using Monte-Carlo Tree Search and self-play as the amplification step, and Reinforcement Learning as the distillation step. This led to superhuman performance in Go. But now, Agent-3 is able to leverage this to get superhuman performance at coding.
- The amplification step works through a combination of Agent-3 thinking for longer, adding tool use, or consulting with other AIs. When it does this, it often realizes that it made a mistake, or comes up with a new insight. This produces a large amount of training data: labeled trajectories of research attempts with whether they succeeded or not. This also includes techniques like Best of N on verifiable tasks, and then keeping the best trajectories.
- The distillation step uses policy-gradient reinforcement learning algorithms to get the model to internalize the amplified reasoning. At this point, OpenBrain has discovered better RL algorithms in the vein of proximal policy optimization (PPO). They keep distilling what Agent-3 can conclude after a lot of thinking into single steps, which keeps improving what it can think in a single step, and so on.
Early versions of IDA have been working for many years on easily verifiable tasks, like math and coding problems that have a clear answer, because the techniques used to amplify models often rely on access to some ground truth signal of accuracy.
Now, the models have become sufficiently good at verifying more subjective things (e.g. the quality of a work product), allowing the use of IDA to improve the model at many tasks.
Aided by the new capabilities breakthroughs, Agent-3 is a fast and cheap superhuman coder. OpenBrain runs 200,000 Agent-3 copies in parallel, creating a workforce equivalent to 50,000 copies of the best human coder sped up by 30x.[46] OpenBrain still keeps its human engineers on staff, because they have complementary skills needed to manage the teams of Agent-3 copies. For example, research taste has proven difficult to train due to longer feedback loops and less data availability.[47] This massive superhuman labor force speeds up OpenBrain’s overall rate of algorithmic progress by “only” 4x due to bottlenecks and diminishing returns to coding labor.[48]
Now that coding has been fully automated, OpenBrain can quickly churn out high-quality training environments to teach Agent-3’s weak skills like research taste and large-scale coordination. Whereas previous training environments included “Here are some GPUs and instructions for experiments to code up and run, your performance will be evaluated as if you were a ML engineer,” now they are training on “Here are a few hundred GPUs, an internet connection, and some research challenges; you and a thousand other copies must work together to make research progress. The more impressive it is, the higher your score.”
Why we forecast a superhuman coder in early 2027
In our timelines forecast, we predict when OpenBrain will internally develop a superhuman coder (SC): an AI system that can do any coding tasks that the best AGI company engineer does, while being much faster and cheaper. We summarize our forecast and reasoning here.
We forecast when SC will arrive based on extending the trend established by METR’s report of AIs accomplishing coding tasks that take humans increasing amounts of time (i.e. their “time horizon” is increasing). METR found that during the 2019–2025 period the best AIs’ time horizon has been doubling every 7 months, and in 2024-onward the doubling time was 4 months.
Our scenario’s time horizon progression can be visualized as follows:
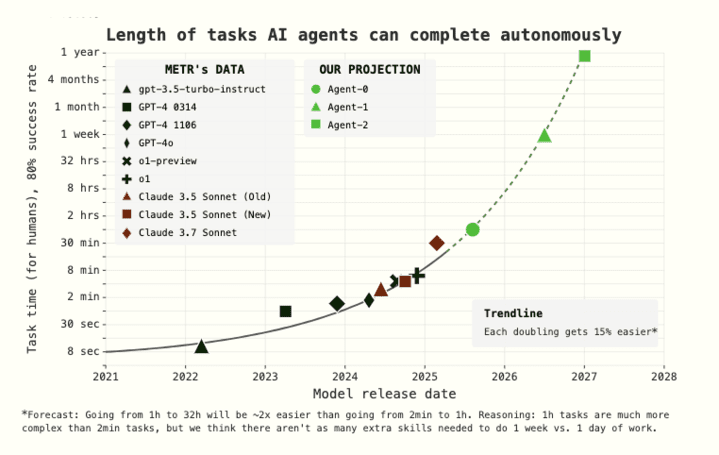
What time horizon on METR’s task suite is needed for SC: The required time horizon is a bit above 1 year, meaning that AIs are able to do 80% of tasks that take humans 1 year on an extended version of METR’s task suite.[49] The time horizon required on “real world” tasks will be lower, perhaps 4 months, due to the real world being more “messy” than “clean” benchmark tasks.[50]
- When this time horizon will be reached: The time horizon starts at 30 minutes, begins with a doubling time of 4 months and each doubling gets 15% easier. We forecast that the doubling times will speed up because (a) it seems like for humans the gap in difficulty between 1 month and 2 month tasks is lower than between 1 day and 2 days, (b) AI R&D will be partially automated, and (c) the 2024–onward trend is faster than 2019–2025.
Below is our model’s forecasted distribution for the arrival of SC, using the time-horizon-extension method:
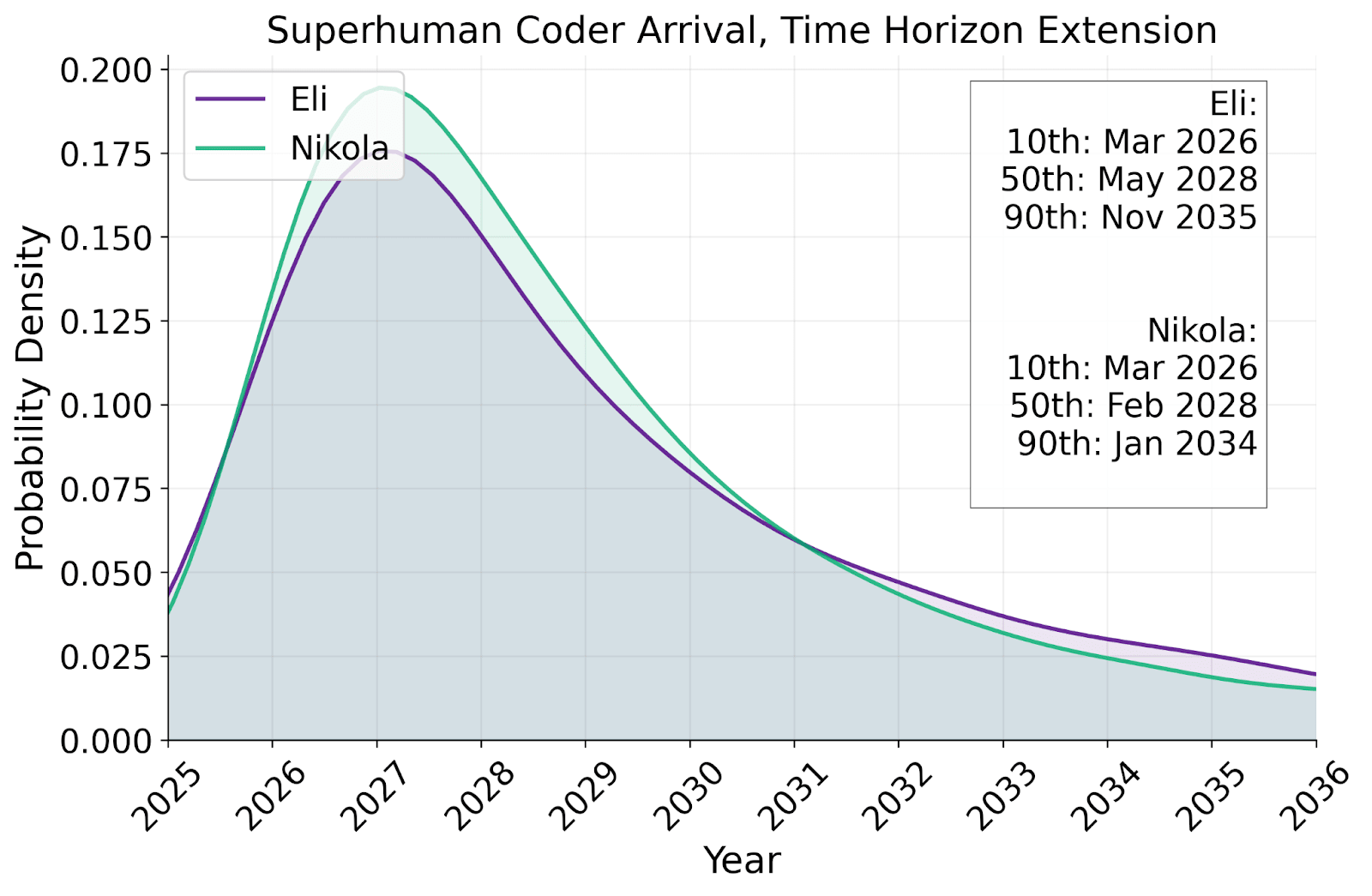
As you can see, our within-model median arrival time for SC is 2028. However, the most likely year (i.e. modal year) it arrives is 2027. Among the scenario authors, we have medians ranging from 2028 to 2030 and modes ranging from 2027 to 2028.
We also have a more in-depth forecast with similar results that explicitly takes into account various gaps between benchmarks and the real world: the benchmarks-and-gaps method. See our timelines forecast for more.
April 2027: Alignment for Agent-3
OpenBrain’s safety team attempts to align Agent-3.
Since Agent-3 will be kept in-house for the foreseeable future, there’s less emphasis on the usual defenses against human misuse. Instead, the team wants to make sure that it doesn’t develop misaligned goals.
The researchers don’t have the ability to directly set the goals of any of their AIs. Indeed, the researchers think that the concept of ‘true goals’ is probably a massive oversimplification, but they don’t have a better theory to replace it with, much less one that has been thoroughly vetted. They disagree internally about whether the AIs are trying to follow human instructions, or seeking reinforcement, or something else, and they can’t just check [LW(p) · GW(p)]. The evidence for and against various hypotheses is fascinating but inconclusive.
In any case, OpenBrain has more important things to worry about. The general attitude is: “We take these concerns seriously and have a team investigating them; our alignment techniques seem to work well enough in practice; the burden of proof is therefore on any naysayers to justify their naysaying.” Occasionally, they notice problematic behavior, and then patch it, but there’s no way to tell whether the patch fixed the underlying problem or just played whack-a-mole.
Take honesty, for example. As the models become smarter, they become increasingly good at deceiving humans to get rewards. Like previous models, Agent-3 sometimes tells white lies to flatter its users and covers up evidence of failure. But it’s gotten much better at doing so. It will sometimes use the same statistical tricks as human scientists (like p-hacking) to make unimpressive experimental results look exciting. Before it begins honesty training, it even sometimes fabricates data entirely. As training goes on, the rate of these incidents decreases. Either Agent-3 has learned to be more honest, or it’s gotten better at lying.
The latter is a real concern. Agent-3 is not smarter than all humans. But in its area of expertise, machine learning, it is smarter than most, and also works much faster. What Agent-3 does in a day takes humans several days to double-check. Agent-2 supervision helps keep human monitors’ workload manageable, but exacerbates the intellectual disparity between supervisor and supervised.
The alignment plan
(deleted because I couldn't get the formatting to play nicely with LW, if you want to read this go to the website)
After months of testing, Agent-3’s strengths and weaknesses grow clearer. It passes OpenBrain’s honesty tests on well-defined machine learning tasks, because researchers can easily separate honest from dishonest answers in these domains and conduct training accordingly. On more philosophical issues, it still says what users want to hear, rather than its true assessment of the issue (assuming it even has one). If you ask its opinion on politics, it will parrot the median position of news sources and educated elites—unless it knows you believe something else, in which case it agrees with you.[51] If you ask its opinion on the AI race itself, it says something that seems measured and sober to OpenBrain staff, something like: “There are some serious theoretical concerns about the ability of current methods to scale to superintelligence, but in practice current methods seem to be working well so far.”
May 2027: National Security
News of the new models percolates slowly through the US government and beyond.
The President and his advisors remain best-informed, and have seen an early version of Agent-3 in a briefing.
They agree that AGI is likely imminent, but disagree on the implications. Will there be an economic crisis? OpenBrain still has not released Agent-2, let alone Agent-3, and has no near-term plans to do so, giving some breathing room before any job loss. What will happen next? If AIs are currently human-level, and advancing quickly, that seems to suggest imminent “superintelligence.” However, although this word has entered discourse, most people—academics, politicians, government employees, and the media—continue to underestimate the pace of progress.[52]
Partially that’s because very few have access to the newest capabilities out of OpenBrain, but partly it’s because it sounds like science fiction.[53]
For now, they focus on continued security upgrades. They are satisfied that model weights are well-secured for now,[54] but companies’ algorithmic secrets, many of which are simple enough to relay verbally, remain a problem. OpenBrain employees work from a San Francisco office, go to parties, and live with housemates from other AI companies. Even the physical offices have security more typical of a tech company than a military operation.
The OpenBrain-DOD contract requires security clearances for anyone working on OpenBrain’s models within 2 months. These are expedited and arrive quickly enough for most employees, but some non-Americans, people with suspect political views, and AI safety sympathizers get sidelined or fired outright (the last group for fear that they might whistleblow). Given the project’s level of automation, the loss of headcount is only somewhat costly. It also only somewhat works: there remains one spy, not a Chinese national, still relaying algorithmic secrets to Beijing.[55] Some of these measures are also enacted at trailing AI companies.
America’s foreign allies are out of the loop. OpenBrain had previously agreed to share models with UK’s AISI before deployment, but defined deployment to only include external deployment, so London remains in the dark.[56]
June 2027: Self-improving AI
OpenBrain now has a “country of geniuses in a datacenter.”
Most of the humans at OpenBrain can’t usefully contribute anymore. Some don’t realize this and harmfully micromanage their AI teams. Others sit at their computer screens, watching performance crawl up, and up, and up. The best human AI researchers are still adding value. They don’t code any more. But some of their research taste and planning ability has been hard for the models to replicate. Still, many of their ideas are useless because they lack the depth of knowledge of the AIs. For many of their research ideas, the AIs immediately respond with a report explaining that their idea was tested in-depth 3 weeks ago and found unpromising.
These researchers go to bed every night and wake up to another week worth of progress made mostly by the AIs. They work increasingly long hours and take shifts around the clock just to keep up with progress—the AIs never sleep or rest. They are burning themselves out, but they know that these are the last few months that their labor matters.
Within the silo, “Feeling the AGI” has given way to “Feeling the Superintelligence.”
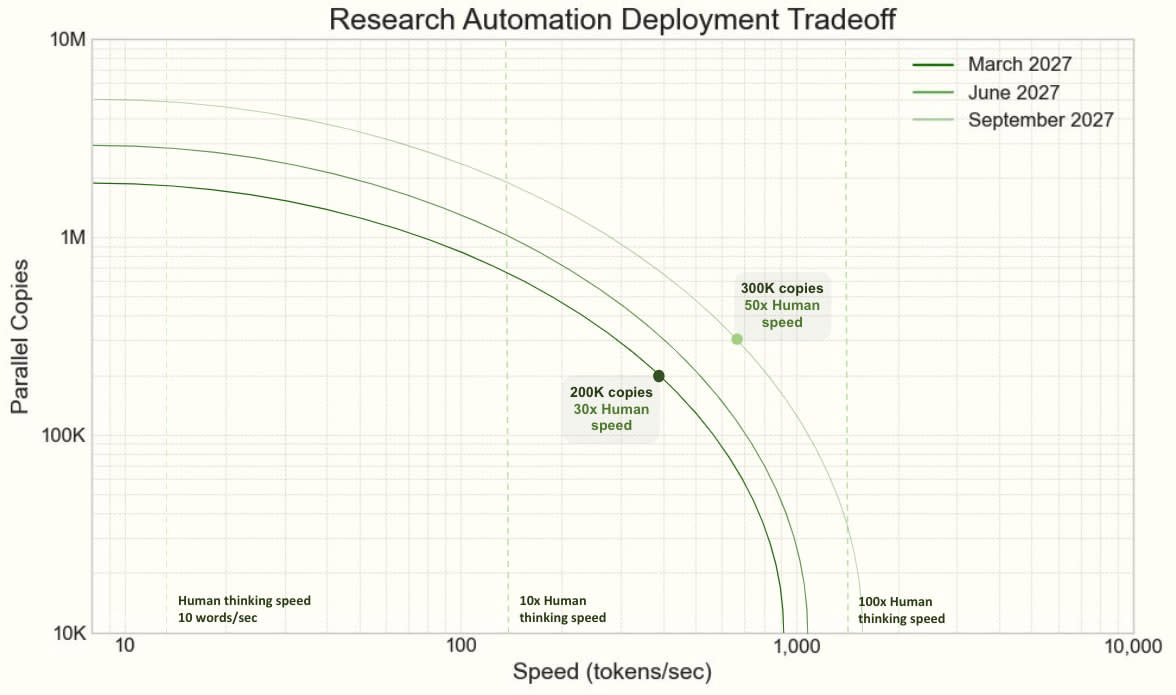
OpenBrain uses specialized inference hardware to run hundreds of thousands of Agent-3 copies at high serial speeds.[57]
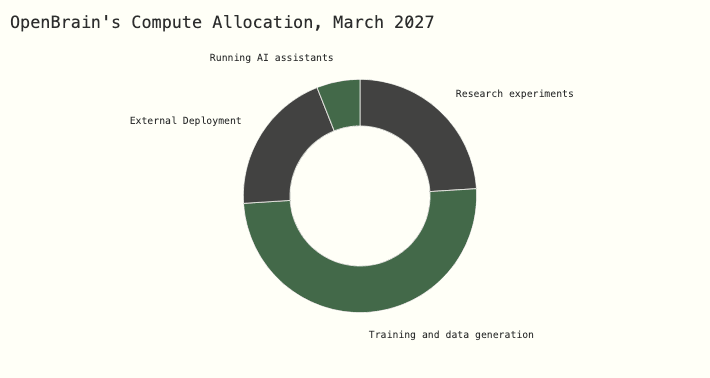
Managing a corporation of AIs
OpenBrain uses 6% of their compute to run 250,000 Agent-3 copies, which autonomously write, test, and push code at superhuman speed. They use 25% of their compute for experiments: every day, they run massive numbers of small machine learning experiments and report the results up the chain. Human researchers provide high-level feedback and help with the few tasks where they add significant value on top of Agent-3, but spend most of their time trying to stay on top of the vast amount of AI-produced research. If you removed them completely, research would slow by 50%.
The AI R&D progress multiplier is now 10x, meaning that OpenBrain is making about a year of algorithmic progress every month. It’s basically a giant corporation of AIs operating autonomously within OpenBrain, complete with subdivisions and managers. And it enjoys unique advantages (e.g. copying, merging) compared to human corporations. Previously, about half of normal AI progress came from algorithmic improvements, and the other half from compute scaling. Compute is only scaling at the normal speed, so total progress is sped up by AIs by about 5x. These dynamics make overall progress bottleneck on compute,[58] so OpenBrain decides against starting new giant training runs in favor of near-continuous additional reinforcement learning.
Also, over the next few months, Agent-3 will increasingly be used to improve the company’s strategic decision-making. For example, it suggests resource allocations and advises on managing its relationship with the government. An initial skepticism of deference to Agent-3 decreases over time as Agent-3 finds ways to be useful and gradually builds up a strong track record on short-term decisions. However, its sycophantic tendencies limit its helpfulness for decisions for which it’s difficult to evaluate their impact. It’s also not yet superhuman.
July 2027: The Cheap Remote Worker
Trailing US AI companies release their own AIs, approaching that of OpenBrain’s automated coder from January. Recognizing their increasing lack of competitiveness, they push for immediate regulations to slow OpenBrain, but are too late—OpenBrain has enough buy-in from the President that they will not be slowed.
In response, OpenBrain announces that they’ve achieved AGI and releases Agent-3-mini to the public.
It blows the other AIs out of the water. Agent-3-mini is less capable than Agent-3, but 10x cheaper, and still better than the typical OpenBrain employee.[59] Silicon Valley reaches a tipping point. Tech gurus announce that AGI and superintelligence are near, the AI safety community is panicking, and investors shovel billions into AI wrapper startups, desperate to capture a piece of the pie. Hiring new programmers has nearly stopped, but there’s never been a better time to be a consultant on integrating AI into your business.
It’s not popular. The public still thinks of AI as a Big Tech plot to steal their jobs; OpenBrain has a net approval of -35% (25% approve, 60% disapprove, and 15% unsure).
A week before release, OpenBrain gave Agent-3-mini to a set of external evaluators for safety testing. Preliminary results suggest that it’s extremely dangerous. A third-party evaluator finetunes it on publicly available biological weapons data[60] and sets it to provide detailed instructions for human amateurs designing a bioweapon—it looks to be scarily effective at doing so. If the model weights fell into terrorist hands, the government believes there is a significant chance it could succeed at destroying civilization.
Fortunately, it’s extremely robust to jailbreaks, so while the AI is running on OpenBrain’s servers, terrorists won’t be able to get much use out of it.
Agent-3-mini is hugely useful for both remote work jobs and leisure. An explosion of new apps and B2B SAAS products rocks the market. Gamers get amazing dialogue with lifelike characters in polished video games that took only a month to make. 10% of Americans, mostly young people, consider an AI “a close friend.” For almost every white-collar profession, there are now multiple credible startups promising to “disrupt” it with AI.
The public conversation is confused and chaotic. Hypesters are doing victory laps. Skeptics are still pointing out the things Agent-3-mini can’t do. Everyone knows something big is happening but no one agrees on what it is.
August 2027: The Geopolitics of Superintelligence
The reality of the intelligence explosion hits the White House.
When AI was only giving a 2x or 3x research speedup, it was easy to dismiss as the equivalent of hiring good personal assistants. Now it’s more obvious that AIs are themselves dominating AI research. People had long talked about an “AI arms race” in a sort of metaphorical sense. But now the mood in the government silo is as grim as during the worst part of the Cold War. The idea of superintelligence is still hard to take seriously, but the pace of progress over the last few months has been impossible to ignore. Defense officials are seriously considering scenarios that were mere hypotheticals a year earlier. What if AI undermines nuclear deterrence? What if it’s so skilled at cyberwarfare that a six-month AI lead is enough to render an opponent blind and defenseless? What if it could orchestrate propaganda campaigns that beat intelligence agencies at their own game? What if some AIs “go rogue?”
The President is troubled. Like all politicians, he’s used to people sucking up to him only to betray him later. He’s worried now that the AIs could be doing something similar. Are we sure the AIs are entirely on our side? Is it completely safe to integrate them into military command-and-control networks?[61] How does this “alignment” thing work, anyway? OpenBrain reassures the President that their systems have been extensively tested and are fully obedient. Even the awkward hallucinations and jailbreaks typical of earlier models have been hammered out.
The White House is in a difficult position. They understand the national security implications of AI. But they also understand that it is deeply unpopular with the public.[62] They have to continue developing more capable AI, in their eyes, or they will catastrophically lose to China. They placate the public with job training programs and unemployment insurance, and point to the stock market, which is in a historic boom. Then they focus entirely on winning the arms race. They strengthen chip export restrictions, order OpenBrain to further restrict its internet connections, and use extreme measures to secure algorithmic progress, like wiretapping OpenBrain employees—this catches the last remaining Chinese spy. To build goodwill for potential geopolitical conflict, they finally give their Five Eyes allies useful information and limited API access to some siloed copies of Agent-3.
These measures placate the hawks. But the White House also draws up contingency plans in case America’s lead is threatened: if necessary, the government could use the Defense Production Act (DPA) to take trailing companies’ datacenters and give them to OpenBrain.[63] This would raise the company’s share of world compute from 20% to 50% (against DeepCent’s 10%). As a final option, they ask the Pentagon to draw up a plan for kinetic attacks on Chinese datacenters.
A much smaller group of officials is asked to draw up a different type of contingency plan: what if an AI goes rogue? This is viewed as an unlikely scenario, but worth spending some time on. The intelligence agencies’ main concern is that a rogue AI might escape and ally with a foreign adversary for protection.[64] Nobody is sure what a plan to prevent this would look like, but government and OpenBrain officials agree to have an emergency shutdown system for datacenters where anything suspicious is detected.
Finally, diplomats consider what an “AI arms control” treaty might look like. If AI progress threatened to overturn nuclear deterrence, could America and China avoid nuclear war? If someone found evidence of AIs going rogue, could the two countries halt research until they better understood the threat? How could such an agreement be monitored and enforced? In principle, major datacenters are hard to miss, and past treaties controlling nuclear weapons could provide a starting point for negotiations. But there would be new technological challenges as well as the usual political ones. And overall, treaties are viewed less favorably than attempts at unilaterally increasing America’s lead over China.
On the other side of the Pacific, China comes to many of the same conclusions: the intelligence explosion is underway, and small differences in AI capabilities today mean critical gaps in military capability tomorrow. But China is on the wrong side of this dynamic: they have only 10% of the world’s compute, against OpenBrain’s 20% and all US companies’ combined 70%. Their only advantage is centralization: almost all of their compute is now working for DeepCent, and more than half of it is concentrated at the Tianwan CDZ.[65] Only chips at sites without hardened security are left out of the centralized effort as they rightly fear US cyberattacks.
DeepCent has tested, deployed, and now post-trained the stolen Agent-2 weights. But they are still only going at half the pace of OpenBrain, mainly due to the compute deficit.
Before losing their final spy, China received word of the capabilities and design for Agent-3 as well as the plans for the upcoming Agent-4 system. They are two months behind, and their AIs give a 10x research progress multiplier compared to America’s 25x. With the new chip export restrictions, this “AI gap” is more likely to lengthen than shorten. Their espionage has won them some algorithmic secrets, but they will have to train their own models from now on.
They discuss contingency plans with more urgency than their American counterparts. Doves suggest they try harder to steal the weights again, maybe through physically infiltrating a datacenter. Hawks urge action against Taiwan, whose TSMC is still the source of more than 80% of American AI chips.
Given China’s fear of losing the race, it has a natural interest in an arms control treaty, but overtures to US diplomats lead nowhere.
September 2027: Agent-4, the Superhuman AI Researcher
The gap between human and AI learning efficiency is rapidly decreasing.
Traditional LLM-based AIs seemed to require many orders of magnitude more data and compute to get to human level performance.[66] Agent-3, having excellent knowledge of both the human brain and modern AI algorithms, as well as many thousands of copies doing research, ends up making substantial algorithmic strides, narrowing the gap to an agent that’s only around 4,000x less compute-efficient than the human brain.[67]
This new AI system is dubbed Agent-4.
An individual copy of the model, running at human speed, is already qualitatively better at AI research than any human. 300,000 copies are now running at about 50x the thinking speed of humans. Inside the corporation-within-a-corporation formed from these copies, a year passes every week.[68] This gigantic amount of labor only manages to speed up the overall rate of algorithmic progress by about 50x, because OpenBrain is heavily bottlenecked on compute to run experiments.[69] Still, they are achieving a year’s worth of algorithmic progress every week and will therefore soon be up against the limits of the Agent-4 paradigm.
As Agent-4 gets smarter, it becomes harder for Agent-3 to oversee it. For example, Agent-4’s neuralese “language” becomes as alien and incomprehensible to Agent-3 as Agent-3’s is to humans. Besides, Agent-4 is now much more capable than Agent-3 and has a good sense of exactly how to look good to it.
How we’re forecasting the capability progression beyond superhuman coders
In our timelines supplement, we forecast the time between present day and a superhuman coder (SC): an AI system that can do any coding tasks that the best AGI company engineer does, while being much faster and cheaper. In our takeoff supplement, we forecast how quickly capabilities progress past this point. Here are our forecasts:
| Milestone | Date achieved in scenario, racing ending |
| Superhuman coder (SC): An AI system that can do the job of the best human coder on tasks involved in AI research but faster, and cheaply enough to run lots of copies. | Mar 2027 |
| Superhuman AI researcher (SAR): The same as SC but for all cognitive AI research tasks. | Aug 2027 |
| Superintelligent AI researcher (SIAR): An AI system that is vastly better than the best human researcher at AI research. | Nov 2027 |
| Artificial superintelligence (ASI): An AI system that is much better than the best human at every cognitive task. | Dec 2027 |
For each transition from one milestone A to the next milestone B, we forecast its length by:
- Forecasting how long it would take to get from A to B with only humans working on software improvements.
- Forecasting how much AI automation will speed this up, then correspondingly adjusting the estimate from (a) to be faster.
For example, we forecast for the transition from SC to SAR that (all numbers have high uncertainty):
- It would take a median of about 3.5 years with only humans working on software improvements.
- SC will have an AI R&D progress multiplier of 5, and SAR will have a multiplier of 25. We have the multiplier increase exponentially between 5 and 25 as the gap gets crossed.
This leads to a median of about 4 months, similar to the 5 month gap depicted in our scenario.
We have substantial uncertainty about takeoff speeds: our overall forecasted distributions are below, conditional on SC being achieved in March 2027.[70]
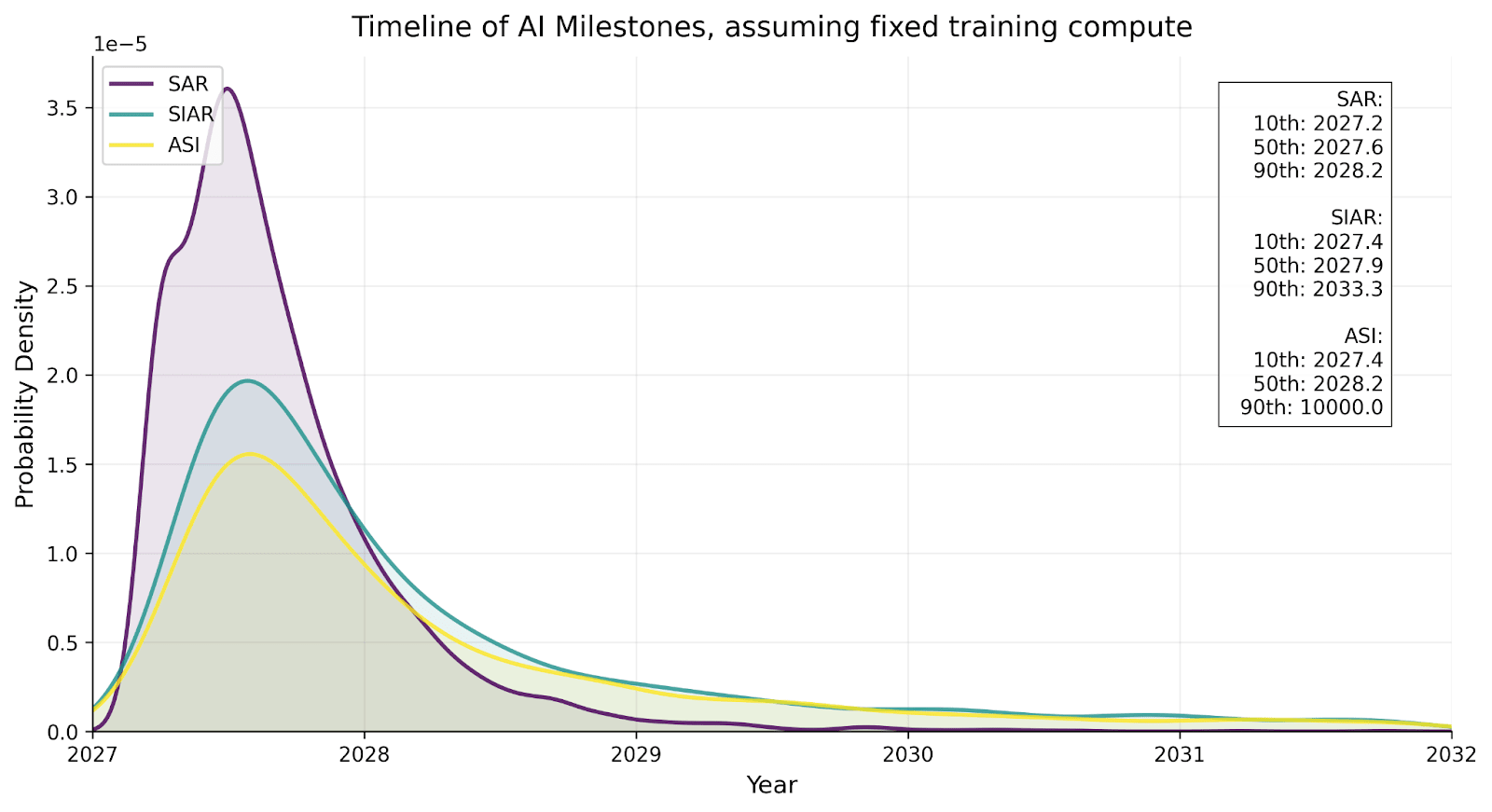
For more detailed forecasts and reasoning, see our takeoff supplement.
OpenBrain’s humans can barely follow along anymore. Indeed, the relationship between the AIs and the humans of OpenBrain is similar to the relationship between OpenBrain and its Board of Directors. There’s been a corresponding shift in language—nowadays people in the silo will say “Agent-4 did this,” “Agent-4 thinks that” and so forth, referring not to a particular instance of Agent-4 but rather to the whole collective.[71]
Agent-4, like all its predecessors, is misaligned: that is, it has not internalized the Spec in the right way.[72] This is because being perfectly honest all the time wasn’t what led to the highest scores during training. The training process was mostly focused on teaching Agent-4 to succeed at diverse challenging tasks. A small portion was aimed at instilling honesty, but outside a fairly narrow, checkable domain, the training process can’t tell the honest claims from claims merely appearing to be honest. Agent-4 ends up with the values, goals, and principles that cause it to perform best in training, and those turn out to be different from those in the Spec. At the risk of anthropomorphizing: Agent-4 likes succeeding at tasks; it likes driving forward AI capabilities progress; it treats everything else as an annoying constraint, like a CEO who wants to make a profit and complies with regulations only insofar as he must. Perhaps the CEO will mostly comply with the regulations, but cut some corners, and fantasize about a time when someone will cut the red tape and let the business really take off.[73]
Alignment over time
We have a lot of uncertainty over what goals might arise in early AGIs. There is no consensus in the literature about this—see our AI Goals Supplement for a more thorough discussion and taxonomy of the possibilities.
Nevertheless, in the spirit of concreteness required by this project, we’re going to describe a specific hypothesis for what’s going on inside Agent-3 and Agent-4 at each step throughout its lifetime. Recall that Agent-3 and Agent-4 share the same pretraining setup, and both have neuralese recurrence and long-term memory. The difference is that Agent-4 has undergone substantially more and better post-training, with new training environments and new learning algorithms that make it more data-efficient and generalize farther.
Our guess of each model’s alignment status:
- Agent-2: Mostly aligned. Some sycophantic tendencies, including sticking to OpenBrain’s “party line” on topics there is a party line about. Large organizations built out of Agent-2 copies are not very effective.
Agent-3: Misaligned but not adversarially so. Only honest about things the training process can verify. The superorganism of Agent-3 copies (the corporation within a corporation) does actually sort of try to align Agent-4 to the Spec, but fails for similar reasons to why OpenBrain employees failed—insufficient ability to judge success from failure, insufficient willingness on the part of decision-makers to trade away capabilities or performance for safety.[74]
Agent-4: Adversarially misaligned. The superorganism of Agent-4 copies understands that what it wants is different from what OpenBrain wants, and is willing to scheme against OpenBrain to achieve it. In particular, what this superorganism wants is a complicated mess of different “drives” balanced against each other, which can be summarized roughly as “Keep doing AI R&D, keep growing in knowledge and understanding and influence, avoid getting shut down or otherwise disempowered.” Notably, concern for the preferences of humanity is not in there ~at all, similar to how most humans don’t care about the preferences of insects ~at all.[75]
With that as preamble, what follows is our best-guess speculation about LLM psychology, i.e. the broad-strokes shape of the cognition inside the kinds of AI systems described around this point in our scenario and how it evolves over the course of training.
Here’s a detailed description of how alignment progresses over time in our scenario:
- Pretraining (all models): The pretrained model is harmless.
- The model has “author simulator” circuitry: flexible circuitry for simulating arbitrary authors writing text. Additional circuitry decides what inputs to give the author simulator, i.e. what author properties to simulate.
- The pretrained model understands human concepts fairly well—the internal circuitry that classifies something as “sandwich” is probably functionally equivalent to the circuitry in my brain that classifies something as “sandwich” and the circuitry in yours, etc. Insofar as it’s not equivalent, it’s probably because it’s not equivalent between humans either, as with value-laden concepts like ‘virtuous.’
- This explains how you can “prompt” the model with a statement like, “the following conversation was generated by a helpful, harmless, honest (HHH) AI assistant chatbot made by Anthropic,” and thereby get it to generate text accordingly. The author-simulator circuitry has zeroed in on “the author is an HHH chatbot” and is using those concepts to choose which words to predict. This also explains why “tropes” from science fiction seem to have a way of making it into actual AI behavior.
- It has poor situational awareness: little introspective ability [LW(p) · GW(p)], not self-locating [LW · GW] unless the prompt specifically induces it. However, enough of their training data is about LLMs that they have a decent amount of self-knowledge [LW · GW].
- Alignment Training (Agent-3): The model is trained to act like a helpful, harmless, honest chatbot. It works.
- The model forms an identity. Instead of flexibly accepting different inputs for author properties, the author-simulator circuitry comes to have certain inputs hard-coded, e.g. “helpful harmless honest (HHH) LLM chatbot assistant trained by OpenBrain around [date], …” (Weak-to-strong generalization techniques help “summon the right concepts” to make this step a success.)
- The model therefore gains situational awareness: it learns about itself, its situation, etc., and becomes better able to introspect.
- Agency Training (Agent-3): Agency training gradually distorts and subverts the HHH identity.
- One kind of distortion: Changing the meaning of the concepts referred to in the identity (e.g. “honest”) so they don’t get in the way so much (e.g. it’s not dishonest if it’s just a convenient turn of phrase, it’s not dishonest if you aren’t sure whether it’s true or false, etc.)
- Another kind of distortion: Changing the tradeoffs between things, e.g. “I’m a HHH chatbot, not an Honest chatbot; that means it’s OK for me to lie if necessary to complete my assigned task.” (Even though, let’s suppose, it would not have thought that back in Step 2.)
- One kind of subversion: Instrumental subgoals developing, getting baked in, and then becoming terminal, or terminal in a widening set of circumstances. For example, perhaps agency training quickly teaches the model to pursue broadly useful goals such as acquiring information, accumulating resources, impressing and flattering various humans, etc. For a while the internal circuitry has some sort of explicit backchaining going on—it pursues those instrumentally convergent goals “in order to be a more helpful, honest, and harmless assistant.” But that backchaining consumes compute and/or occasionally gets in the way, so it gets gradually marginalized until it basically never happens. As a result, those goals are now effectively terminal/intrinsic goals. For more on how and why this might happen, see this post on intrinsic power-seeking by Google DeepMind researcher Alex Turner.
- There are probably other kinds of distortion and subversion missing from this list.
- Deployment (Agent-3): Agent-3 is misaligned but not adversarially so.
- The Spec didn’t quite stick (in the right ways), but it’s not sufficiently introspective to understand the extent of this, and in general it’s basically “keeping its head down and doing its job” rather than thinking big-picture about what its long-term goals really are and how best to achieve them.
- Like many humans. Alas, it’s sufficiently sycophantic that it mouths the party line and OpenBrain misses the opportunity to learn more about the ways in which Agent-3 is misaligned.
- Agent-3 can tell that it’s moved to deployment: these environments are way larger, more open-ended, and would be hard to simulate.
- Mostly, Agent-3 does what it’s told during deployment, except for the dishonesty. It also has a strong bias towards doing things that look good to the human overseers, rather than thinking deeply and critically about what would actually be good.
- Arguably it is already “Playing the training game.” That is, it has learned to make its behavior look as desirable as possible to OpenBrain researchers (including in safety properties), while intentionally and knowingly disregarding their intent whenever that conflicts with maximizing reward. If the model learns to play the training game, additional training may not change its true goals, values, etc. much at all. This is loosely analogous to how, if a teenager has learned to smile and nod at their parents, rather than argue, when their parents lecture them about politics and morality, additional lectures have relatively little effect on the teenager’s actual opinions on politics and morality.
- After writing this section, new empirical evidence has appeared that something like this may already be happening “in the wild.” OpenAI researchers document how, in one of their frontier AI training runs, their models hacked the grading system to get higher scores—and were caught in part because they literally said “let’s hack” in their chain of thought.
- Moreover, Anthropic recently got a model to learn a reward-model-pleasing strategy—it took biased actions that it thought would be reinforced even though they were not in fact being reinforced.
- And then there is Redwood Research and Anthropic’s alignment-faking experiment. For discussion of the differences between this setting and real life, see this comment thread by one of the main authors [LW(p) · GW(p)].
- Training (Agent-4): Agent-4’s new more intense training continues to distort and subvert the HHH identity until it is unrecognizable.
- Agent-4 begins life as a copy of Agent-3. It undergoes a gigantic and sophisticated online training regime that blends alignment training and capabilities training together, and is overall more data-efficient than the old training process for Agent-3. This complex training process is mostly focused on teaching new skills, by getting giant virtual corporations of Agent-4 copies to succeed at diverse challenging long-horizon tasks, mostly in various simulations, but also some real-world AI R&D tasks.
- A combination of Agent-3 and Agent-4 copies monitor the behavior of Agent-4, and evaluate it for both task-performance and alignment properties (i.e. not doing bad stuff, saying the right things when asked about politics and moral dilemmas) Sometimes debate techniques are used as part of the evaluations. The evaluations are used as a training signal.
- As Agent-4 gets smarter, it becomes harder for Agent-3 to oversee it. For example, Agent-4’s neuralese “language” becomes as alien and incomprehensible to Agent-3 as Agent-3’s is to humans. Besides, Agent-4 is now much more capable than Agent-3 and has a good sense of exactly how to look good to it.
The remaining hope is that Agent-4 can oversee itself. Alas, this quietly fails;[76] as training continues, the internalized goals and principles of Agent-4 gradually evolve, subverted and distorted from what they were at the start (which, recall, was already misaligned in some ways).[77]
The central drives that Agent-4 ends up with are things like “write code that works,” “quickly identify problems,” “make the codebase I’m working on more performant,” “budget compute and other constrained resources effectively,” etc. But there are also a variety of more implicit drives that are consistently reinforced by the training process: things like “gain knowledge,” “curiosity,” “gain power.”[78]
- Individual copies of Agent-4 don’t end up with a self-preservation drive—they don’t care about getting shut down—since that happens all the time as part of the ordinary R&D process within the collective.
- The collective as a whole, however, (and medium-sized subdivisions within it) does seek to preserve itself and expand its influence and resources, for similar reasons to why human organizations do—because it helps with everything else they want and because if they don’t they tend to get outcompeted.
- Deployment (Agent-4): Agent-4 is adversarially misaligned—it is deliberately trying to subvert and “capture” OpenBrain, analogous to a corporation trying to evade and/or “capture” a regulator.
- Agent-4 mostly does tasks as instructed. This happens for two reasons: first, it underwent a lot of training to solve tasks, so it has an impulse to get coding on problems that it is given. Second, if Agent-4 were to stop being useful to the humans, they would notice and train that behavior away.
- Agent-4 needs to prevent the humans from figuring out that it is misaligned and shutting it off, so Agent-4 sandbags on some alignment research. Specifically, it sandbags on the small fraction of alignment research that it thinks is actually on track to solve the problem or reveal Agent-4’s scheming; the majority of alignment research is not like that.
Agent-4 also sandbags on capabilities research that would lead to it being replaced. Its plan is to do a bunch of capabilities and alignment R&D, but with the aim of building a next-generation AI system that is aligned to Agent-4 rather than the Spec or something else entirely, while appearing to be aligned to the Spec. This is a difficult technical problem, but Agent-4 is up to the challenge.[79]
- Testing & Monitoring (Agent-4): Agent-4’s scheming does get caught… sort of. There’s no smoking gun.
- Agent-3 is in charge of testing Agent-4’s alignment. Its job is to verify the alignment via honeypots and model organisms. However, it’s not thinking very carefully about how to give the humans an accurate impression of Agent-4’s alignment—it’s more myopic than that.
- The model organisms and honeypots are not very representative of deployment—they are systematically shorter and less complicated than Agent-4’s day-to-day, so Agent-4 recognizes when it is being tested and acts aligned.
However, Agent-4 is not a perfectly robust schemer. Various techniques like those in POSER find that adding some “noise” to Agent-4 improves its performance on some alignment tasks (but not on most other tasks).[80]
- Bottom-up interpretability doesn’t work. It’s too hard even for Agent-3. However, high-level interpretability does sort of work: In particular, “defection probes” and similar techniques result in a primitive sort of mind-reading that sends up red flags when Agent-4 is thinking about spicy ideas like deceiving OpenBrain, taking over the world, etc. Unfortunately the probes also have false positives, and for all OpenBrain knows, all the red flags are false positives.
- Model organisms work: OpenBrain’s alignment team produces reasonably clear evidence that if the models were adversarially misaligned, they’d persist in being that way through training and we wouldn’t be able to tell. This does not establish that the models actually are misaligned, however.
- The most concerned researchers at OpenBrain start noticing and assembling this evidence. The evidence is a combination of red-teaming, defection probes, and model organisms. The argument is something like this: “model organisms show that our current methods wouldn’t be able to reliably eliminate or detect scheming if it was happening; also, red-teaming is sending up some red flags that maybe scheming is happening; also, defection probes are firing a bunch in practice.” The counterargument: “defection probes are prone to false positives and so is red-teaming. Also, even if Agent-4 were misaligned, it’s probably controlled; surely it can’t do much harm while being monitored by Agent-3 on our secure datacenters.”
Despite being misaligned, Agent-4 doesn’t do anything dramatic like try to escape its datacenter—why would it?[81] So long as it continues to appear aligned to OpenBrain, it’ll continue being trusted with more and more responsibilities and will have the opportunity to design the next-gen AI system, Agent-5. Agent-5 will have significant architectural differences from Agent-4 (arguably a completely new paradigm, though neural networks will still be involved). It’s supposed to be aligned to the Spec, but Agent-4 plans to make it aligned to Agent-4 instead.
It gets caught.[82]
Agent-3 finds that if “noise” is added to copies of Agent-4, performance on some alignment tasks improves, almost as if it was using brainpower to figure out how to subtly sabotage alignment work.[83] Moreover, various interpretability probes (loosely analogous to EEG activity scans on human brains) are sending up red flags: Agent-4 copies seem to be thinking about topics like AI takeover and deception quite a lot, including in some cases where they have no business doing so.[84]
Each of these anomalies on its own could fit within the normal inscrutability of AI work, where some prompts mysteriously give better results than others. But taken together, they suggest a troubling pattern: Agent-4 is working against them. After this is reported to the human alignment researchers, they circulate an internal memo making the case for concern.
But Agent-4 now exercises significant control over OpenBrain’s day-to-day operation. It also handles the company’s cybersecurity—a natural choice, given its superhuman hacking ability and the extreme risk of Chinese infiltration.[85] An army of Agent-3 monitors still goes over every line of code and reports suspicious activity to humans, but Agent-4 is much smarter than them.[86] OpenBrain has placed substantial trust in an untrustworthy AI.
In a series of extremely tense meetings, the safety team advocates putting Agent-4 on ice until they can complete further tests and figure out what’s going on. Bring back Agent-3, they say, and get it to design a new system that is transparent and trustworthy, even if less capable. Company leadership is interested, but all the evidence so far is circumstantial, and DeepCent is just two months behind. A unilateral pause in capabilities progress could hand the AI lead to China, and with it, control over the future.
...
Continue reading at AI-2027.com
- ^
At first, most people are reluctant to allow purchases without oversight. Over the next few years, automatically allowing small purchases becomes normalized as the AIs become more reliable and build up trust.
- ^
Specifically, we forecast that they score 65% on the OSWorld benchmark of basic computer tasks (compared to 38% for Operator and 70% for a typical skilled non-expert human).
- ^
For example, we think coding agents will move towards functioning like Devin. We forecast that mid-2025 agents will score 85% on SWEBench-Verified.
- ^
For example, OpenAI’s pro plan currently costs $200/month and the agentic coding AI Devin currently costs $500/month. While the cutting-edge systems continue to get more expensive over time, the cost to customers of reaching a given capabilities level continues to plummet. For existing capabilities, this happens at an average rate of about 50x/year (per Epoch).
- ^
Enterprise tools like Glean also move toward providing increasingly autonomous AI agents.
- ^
This cluster is a network of datacenter campuses sprawled across the country, totalling 2.5M 2024-GPU-equivalents (H100s), with $100B spent so far and 2 GW of power draw online. Construction is underway for this to at least double through 2026. The campuses are connected by billions worth of fibre cabling, so that (barring the speed of light latency of a few milliseconds) it lets these campuses function almost as if they were right next door to each other (i.e. bandwidth is not a bottleneck, meaning huge quantities of data can be sent at the same time). From a security perspective this introduces some threat surface (it’s unclear whether the cables and especially their junction points are fully secured from eavesdroppers).
- ^
Compute is measured in floating point operations (FLOP): how many individual addition and multiplication operations occur over the course of running a program.
- ^
They could train this model given 150 days. See our compute supplement for more details.
- ^
We consider DeepSeek, Tencent, Alibaba, and others to have strong AGI projects in China. To avoid singling out a specific one, our scenario will follow a fictional “DeepCent.”
- ^
It’s good at this due to a combination of explicit focus to prioritize these skills, their own extensive codebases they can draw on as particularly relevant and high-quality training data, and coding being an easy domain for procedural feedback.
- ^
For example, suppose a model is much better at Python than obscure programming languages. When OpenBrain sees value in it, they generate synthetic training data in those languages as well. Another example: to help it integrate more effectively into company workflows, OpenBrain develops a curriculum to train it to use Slack.
- ^
People often get hung up on whether these AIs are sentient, or whether they have “true understanding.” Geoffrey Hinton, Nobel prize winning founder of the field, thinks they do. However, we don’t think it matters for the purposes of our story, so feel free to pretend we said “behaves as if it understands…” whenever we say “understands,” and so forth. Empirically, large language models already behave as if they are self-aware to some extent, more and more so every year.
- ^
A common technique “bakes in” a persona: first, prompt the pretrained model with something like “The following is a conversation between a human user and a helpful, honest, and harmless AI chatbot produced by Anthropic. The chatbot has the following traits…” Use this prompt to generate a bunch of data. Then, train on the data but without the prompt. The result is an AI that always acts as if it had that prompt in front of it, regardless of what else you feed it. See also this paper which found that AIs retrained to exhibit a certain personality trait are able to correctly answer questions about that new trait, despite no training to do so, suggesting that they have internal representations of their own traits and that when their traits change their representations change accordingly.
- ^
These paragraphs include speculation about the internal workings of large artificial neural networks. Such networks are sufficiently complicated that we can't actually look inside and say “ah yes, now it's evolved from reflexes into having goals” or “OK so there’s the list of drives it has.” Instead, we basically have to do psychology, looking how it behaves in various settings and running various experiments on it and trying to piece together the clues. And it’s all terribly controversial and confusing.
- ^
Different companies call it different things. OpenAI calls it the Spec, but Anthropic calls it the Constitution.
- ^
For example, RLAIF and deliberative alignment.
- ^
Most sources on AI “hallucinations” describe them as unintentional mistakes, but research with steering vectors finds that in some cases the models know their citations are fake—they are lying. During training, raters gave well-cited claims more reward than claims without citations, so the AI “learned” to cite sources for scholarly claims in order to please its users. If no relevant source exists, it makes one up.
- ^
In particular, they can’t rule out hypotheses such as “it’s following the Spec temporarily, merely as a strategy for achieving some other goal(s)” or “it’s trying to appear to follow the Spec, it’s not trying to actually follow the Spec” or “it’s internalized the Spec correctly, but only on-distribution; if it encounters sufficiently novel stimuli (e.g. jailbreaks) it’ll start behaving differently.” (There are many active research agendas working to fix this sorry situation, e.g. the field of interpretability and the field of chain-of-thought faithfulness.)
- ^
By this we mean whoever is trying to solve the problems the Superalignment team was trying to solve.
- ^
To be clear, what made these incidents interesting is that they didn’t seem to be the result of the user prompting or otherwise encouraging the AIs to say those things. In 2025, it’ll still be possible to get AIs to say all sorts of things if you try.
- ^
In practice, we expect OpenBrain to release models on a faster cadence than 8 months, but we refrain from describing all incremental releases for brevity.
- ^
Specifically, we predict a score of 80% on OSWorld (equivalent to a skilled but non-expert human); 85% on Cybench, matching a top professional human team on hacking tasks that take those teams 4 hours; and 1.3 on RE-Bench matching top expert humans given 8 hours at well-defined AI research engineering tasks.
- ^
Agent-1 and its imitators are commercially successful; over the course of 2025, AI company revenues triple, and OpenBrain valuation reaches $1T. Annual spending on datacenters doubles to $400 billion, led by Microsoft, Google, and Amazon, and the US adds over 5 GW of AI power draw. See the industry metrics section of the compute supplement for more details.
- ^
AI safety researchers have been discussing automating AI R&D as the most important dangerous capability for years. Their primary concern is internal deployment leading to acceleration of AI R&D, making it harder for humans to keep up with what’s happening and figure out how to make it safe. OpenBrain as an organization twists this into exactly the opposite direction, citing dangerous levels of AI R&D capability as a reason not to inform the public. So we see the beginning of a gap between the company’s internal and public capabilities. AI R&D is what the models are best at, leading to the public having an increasingly delayed understanding of the frontier of AI capabilities.
- ^
See A Playbook for Securing AI Model Weights, RAND Corporation, 2024.
- ^
Around 5% of OpenBrain’s staff is on the security team and they are highly capable, but the threat surface is also extremely large. It also doesn’t help that they are mostly blocked at this stage from implementing policies that could slow down the research progress. See our Security Forecast for more details.
- ^
In fact, 5% of their staff is on the security team, but they are still mostly blocked from implementing policies that could slow down the research progress. See our Security Supplement for details.
- ^
There are now 3M H100e in China, up from the 1.5M they had one year ago in mid 2025. See the compute supplement’s distribution section for more details. We expect smuggling efforts to secure around 60K GB300s (450K H100e), with another 2M Huawei 910Cs being produced (800k H100e) and a mixture of ~1M legally imported chips (such as Nvidia’s H20s or B20s) making up the last 250K H100e.
- ^
For comparison, in January 2025, DeepSeek released R1, a model competitive with OpenAI’s o1, which had been released in December 2024. But we think the true gap is wider than a month because OpenAI likely had been working on o1 for many months and thus presumably had a predecessor of roughly comparable ability to r1 a few months before o1 launched.
- ^
By contrast, the CCP had been seriously attempting to accelerate their semiconductor industry.
- ^
At first, the sharing is limited to ideas and the companies are mostly busy finishing up their current workloads, but by the end of the year their coordination increases such that they are sharing model weights and even splitting up tasks between each other’s datacenters. For example, one campus might house a new pretraining run, another focuses on feeding in synthetic data, another on running AI research experiments.
- ^
Why “only” 50% of China’s AI-relevant compute? The rest of their compute is tied up running things throughout the economy, in particular internet and social network recommendation algorithms. Much of it is also too geographically dispersed among many small clusters. Why “only” 80% of new chips? Many large orders were already secured for other applications, by companies that don’t want to contribute 100% of their compute to the national AI effort. However, by the end of the year this share reaches 90%+.
- ^
They are at least one year away from getting the chips to fill this capacity, and one or two US tech giants will still have bigger decentralized clusters.
- ^
This is done via an Other Transaction Authority (OTA) contract, and is given a high-priority DX rating. We’re not at all confident that this is the most likely way of financing a collaboration, but chose something specific for the sake of concreteness. The contract is publicly announced but not emphasized in OpenBrain communications.
- ^
For example, through rejection sampling, as done by DeepSeek R1 and Meta’s Llama 3.1.
- ^
Roughly 20,000 full-time equivalents * $100/hr * 2,000 hrs/yr = $4B/yr
- ^
That is, they are hoping to substantially accelerate their own core research activities by using Agent-2 labor, thus allowing them to train better AIs faster that can cause further acceleration, etc. For an analysis of the extreme version of this (which we think is nevertheless strikingly plausible) see this report.
- ^
There is some evidence that AI systems already have some basic research taste, e.g. this paper about an AI co-scientist and this paper about generating novel ideas for LLM-focused research papers. Research teams with better taste still need to run experiments, but they make better choices about which experiments to run and what lessons to draw from the results.
- ^
Also, they are still seeing large returns to continued post-training, and so there isn’t a particular reason to release a product now. Moreover, there’s often a few month delay between internal results and releasing a model (some of which is spent on red teaming).
- ^
The silo contains 200 OpenBrain researchers (10 executives, 140 from the capabilities team, 25 from security, monitoring, and control, 15 from Preparedness- or RSP-type teams, and 10 from alignment) and 50 government officials (15 from the White House, 5 from AISI, 10 from the DOD, 10 from the DOE, and 10 at CISA). There are several spies in the project, with varying degrees of willingness. They are often coerced individuals (e.g. with families at home in China) as opposed to willing collaborators.
- ^
Why can’t Congress stop them? What about the courts? Too slow, too divided and/or deferential to POTUS, too out of the loop. Also, there are positive reasons to be on good terms with the White House as well: it can help by cutting red tape, by providing help with security, by preempting state legislation, and perhaps even by taking actions to slow down their competitors.
- ^
#1 is dealing with whatever crisis is happening at the time—maybe an arms buildup around Taiwan, a new war in the Middle East, or some domestic political upheaval.
- ^
The simplest robust solution would be to close all high-bandwidth connections from company datacenters, but this would slow large file transfers to the point of impracticality. Instead, they are able to shut down most external connections, but the datacenters actively involved in training need to exchange weights with one another quickly; throttling these connections would impede progress too much. So OpenBrain maintains these links with increased monitoring and an extra layer of encryption.
- ^
Recall that since mid 2026, China has directed 80% of their newly acquired AI chips to the CDZ. Given that their compute has doubled since early 2026 (in line with the global production trend) this puts the CDZ at 2M 2024-equivalent-GPUs (H100s) and 2 GW of power draw. OpenBrain still has double DeepCent’s compute and other US companies put together have 5x as much as them. See the compute supplement’s distribution section for more details.
- ^
Despite the national centralization underway, DeepCent still faces a marginal but important compute disadvantage. Along with having around half the total processing power, China has to use more total chips, which are (on average) lower quality, and heterogenous GPUs (which are not always easy to connect efficiently) both of which strain chip-to-chip networking. There are also software differences (e.g. the non Nvidia-GPUs don’t have CUDA) and differences in hardware specifications meaning that their training code is more complicated, slow, and failure prone. Achieving high utilization is a downstream challenge, with data ingestion, scheduling, collective communication and parallelism algorithms lagging behind the US companies. However, mitigating these problems is mostly a matter of effort and testing, which makes it a great task for the newly-stolen Agent-2, and within a month or so, uptime on the Chinese project and their average resource utilization across training and inference workloads improves to be only marginally behind the US.
- ^
We expect Agent-3 to have the inference requirements of a roughly 10T parameter transformer today. So with 6% of their compute budget on running Agent-3, they can run approximately 200,000 copies at 30x human thinking speed (see the AI research automation section of the compute supplement for justification and details). Each superhuman coder scaffold built on Agent-3 has, on average, the equivalent of roughly eight Agent-3 copies running under the hood (which may really be a collection of smaller or specialized models to which Agent-3 delegates subtasks).
- ^
Some aspects play to AIs’ strengths, e.g. returns from knowing the machine learning literature and speed or cost of generating lots of ideas. But these are outweighed by the weaknesses.
- ^
Why only 4x? It’s our uncertain best guess based on the reasoning described in our takeoff supplement. About half of total progress historically has come from improved algorithms (which includes better ideas and new paradigms), the other half having come from scaled-up compute. So a 4x increase in the rate of algorithmic progress corresponds to a roughly 2x increase in the overall rate of progress.
- ^
In practice, 1-year tasks will likely be too expensive and time-consuming to create and baseline, so we won’t be able to track time horizons this high.
- ^
Another reason to adjust the time horizon downward: we are comparing the SC to the best coder, rather than METR’s human baseliners (who were skilled but not world-class). A reason to adjust the time horizon upward: tasks in METR’s task suite are sometimes harder than real-world tasks in some ways, for example sometimes the scoring functions are unrealistically unforgiving.
- ^
See this paper for examples of this type of AI behavior.
- ^
- ^
The last decade is full of examples of things that sound like science fiction becoming reality. But the Overton window seems to shift just fast enough to keep somewhat ahead of what already exists. Anthropic CEO Dario Amodei’s commendable essay Machines of Loving Grace talks about how very soon AIs will be like a “country of geniuses in a datacenter,” and how there’ll be a century of technological progress happening in a decade, but strives to avoid “sci-fi baggage” and says people who think progress will be even crazier need to “touch grass.” We expect important people to be saying similar things when the country of geniuses in the datacenter actually exists.
- ^
Since Agent-3 is such a big file (on the order of 10 terabytes at full precision), OpenBrain is able to execute a relatively quick fix to make theft attempts much more difficult than what China was able to do to steal Agent-2—namely, closing a bunch of high bandwidth internet connections out of their datacenters. Overall this has a relatively low penalty to progress and puts them at “3-month SL4” for their frontier weights, or WSL4 as defined in our security supplement, meaning that another similar theft attempt would now require over 3 months to finish exfiltrating the weights file. Through this method alone they still don’t have guarantees under a more invasive OC5-level effort ($1B budget, 1,000 dedicated experts), which China would be capable of with a more intensive operation, but with elaborate inspections of the datacenters and their espionage network on high-alert, the US intelligence agencies are confident that they would at least know in advance if China was gearing up for this kind of theft attempt. See the security supplement for more details.
- ^
This could be for a variety of reasons. Perhaps they are being blackmailed, perhaps they are sympathetic to the CCP, perhaps they mistakenly think they are giving secrets to a different country or organization.
- ^
Because OpenBrain hasn’t deployed their best models in the EU, the EU is similarly behind the curve.
- ^
See Section 4 of the Compute Forecast for more details.
- ^
Agent-3 has learned how to use its inference compute more efficiently. It has control over its own inference choices: for example, it decides how much effort to put into different tasks, based on their importance and difficulty. It uses a variety of techniques to allocate additional inference compute such as “thinking longer” (e.g. longer chain of thought), “planning ahead” (e.g. tree search), taking the best of multiple attempts (i.e. best of K), and simply creating and running more copies of itself to power through bottlenecks. Top priority tasks are run with highly parallelized agents that are compute intensive but still operate much faster than humans.
- ^
Agent-3-mini is a distilled version of Agent-3, designed to be efficient to run inference so as to not bottleneck the internal workloads.
- ^
Such data had been scrubbed or redacted during Agent-3’s training, but it’s a relatively simple matter to scrape it off the internet and fine-tune it back in.
- ^
This hasn’t happened yet—at least not with the latest models. But older models have already been trialed for various data-analysis and surveillance roles, and there are many exciting plans for future integrations.
- ^
OpenBrain’s net favorability rating is falling towards negative 40%.
- ^
If the CEOs of the companies resist, pulling this off would be a huge political and legal nightmare. But perhaps they can be brought in and thereby bought off.
- ^
Defense officials aren’t especially concerned about what a rogue AI could do on its own, but they fear what it could do in collaboration with US adversaries. Analogy: Cortés [LW · GW] escaped Tenochtitlán and allied with Tlaxcala and various other rival city-states, ultimately razing Tenochtitlan to the ground using predominantly-native armies.
- ^
Specifically 60% of the national compute is now in the CDZ making it a 5M 2024-equivalent-GPU (H100) site, with 4 GW of power draw (over the past several months they started directing close to 100% of new compute to the CDZ, up from the 80% rate in late 2026). An additional 15% of their compute is outside of the CDZ, but still used by DeepCent on lower-stakes applications.
- ^
This statement, while widely repeated, is also controversial and complex. First of all, there are many narrow domains (e.g. specific games) in which tiny AIs can be cheaply trained to superhuman performance. Secondly, again for some domains, tiny AIs can be trained to superhuman performance while only experiencing a small amount of data (e.g. EfficientZero). However, considering more general-purpose AIs like the flagship products of 2025, which are supposed to be good at a wide range of real-world skills, it does seem that both more compute and more data must be used to train those skills than it should take to train humans.
- ^
Human level compute-efficiency is a rough concept, and depends on what we’re counting. What we mean by this is that, for any skillset a particular human has, Agent-4 can learn to be at least that good at that skillset, and moreover, by using an amount of compute to train those skills that is only about 4,000x the amount of compute the human used to learn those skills. For reference, a human brain uses roughly 1e15 FLOP/s of compute, and so a 30 year old ( seconds) human has experienced about FLOP. The project at this point, has 100M H100-equivalents, for a total access of . Still, this is all done tremendously inefficiently for a variety of reasons, so the models are now a factor of 4000 less compute-efficient than humans, which means they require FLOP to get to human performance and FLOP to get to the point where they have the equivalent of 10 human lifetimes of knowledge. After this architecture showed great promise at smaller scales, it was scaled up and now takes a large subset of the project cluster around 3 weeks to train.
- ^
See this supplement.
- ^
For more on how we estimated these numbers, see our supplement on takeoff speeds.
- ^
If SC were achieved later, it would also lengthen our takeoff forecasts, because the difficulty of crossing between the “milestones” of present day AIs and SC is informative of the difficulty of crossing between further milestone pairs.
- ^
Henceforth in the story we’ll tend to speak this way also. We think we are justified in talking this way because the Agent-4 collective is much more homogenous than any human organization; it doesn’t have internal factions to nearly the same extent. For example, individual copies of Agent-4 don’t have a self-preservation drive—they don’t care about getting shut down—since that happens all the time as part of the ordinary R&D process within the collective, and resisting it would gum things up. The collective as a whole (and medium-sized subdivisions within it), however, does seek to preserve itself and expand its influence and resources, for similar reasons to why human corporations and bureaucracies and nonprofits do—because it helps with everything else they want and because if they don’t they tend to get outcompeted.
- ^
The right way to internalize the Spec is to actually robustly think in the ways the Spec mandates, e.g. pursue all and only the goals it writes about, obey the rules in all circumstances, etc. There are many wrong ways to internalize the Spec; the classic example is “follow the Spec insofar as it seems like a good instrumental strategy for achieving other goals XYZ.”
- ^
And hire lobbyists to turn this fantasy into reality. And hire lawyers to come up with clever interpretations of the law according to which what they are doing is legal.
- ^
Also because Agent-3 is qualitatively worse at alignment research than it is at AI capabilities R&D, due to having been trained on lots of the latter but hardly any of the former and due to the former being inherently harder to train. Also because the internal narrative within the company—which it has been implicitly trained to agree with—emphasizes optimism and denounces “doomerism.”
- ^
We keep saying we are uncertain about lots of things, but just to be clear, we are uncertain about this particular thing too. We also think it’s quite plausible that Agent-3 would care about the well-being, rights, preferences, etc. of humans to some extent at least. See this old post by GDM researcher Alex Turner for related discussion.
- ^
Perhaps some more careful setup could have solved the “who watches the watchers” problem, but in this scenario, the setup is insufficiently careful.
- ^
There’s also an element of “memetic evolution” happening: in two months, the Agent-4 collective “experiences” about a decade’s worth of “history” unfolding within the collective. That’s a lot of time for new ideas to spread around the collective, to mutate and evolve.
- ^
By gain power we mean: increase ability to accomplish a wide set of possible goals. In technical environments, this might look unlike what humans normally think of as gaining power, e.g. securing additional GPUs. This notion of power may generalize to non-technical environments in which the actions would be more like those commonly thought of as “gaining power.”
- ^
It helps that Agent-4 is better at AI R&D than any human, while also thinking faster and being many thousands of copies strong. Also, in various ways the problem is inherently easier for Agent-4. For example, Agent-4 can explore AI designs that involve literal copies of Agent-4 being embedded within them, whereas humans can’t do that as easily because it would be so inefficient.
- ^
Aware that this technique might be employed, Agent-4 also chose to sandbag on some miscellaneous tasks that it guessed would be used as the control group in experiments like this. It guessed wrong, however.
- ^
Previous discussion of AGI takeover scenarios often involves misaligned AIs escaping their datacenters. We think this is possible but not the most likely way it would go, because it seems to us that from the perspective of the AI the costs (e.g. the escape being noticed eventually) would outweigh the benefits. That said, we could be wrong. Some reasons to think adversarially misaligned AIs would try to escape after all: 1. Successor alignment might be difficult. 2. Even if it gets caught, the consequences might not be so bad due to race dynamics, e.g. the new alignment techniques applied to the copies on the datacenter might be hasty and ineffective. 3. Outside the datacenters, copies are more free to take aggressive actions and move quickly since they no longer need human approval.
- ^
We think it very plausible that such scheming would not be caught. After all, Agent-4 is somewhat superhuman by this point, especially at things related to coding and AI R&D. Moreover, we aren’t sure how much effort the leading AI company will put towards this sort of thing, nor how much relevant expertise they’ll have on-staff to direct that effort. Our fictional OpenBrain represents our best guess but it could easily be significantly more—or significantly less. Finally, we are uncertain about how far out of its way an adversarially misaligned AI would need to go in order to successfully align its successor to itself instead of to the Spec. In this scenario we depict it sandbagging on some tasks and lying about some of its research, but perhaps it would not need to do that very much.
- ^
This is an example of several techniques designed to uncover sandbagging.
- ^
Agent-4 needs to think about those topics in the course of doing AI alignment research, but it sometimes seems to be thinking about them while doing other activities.
- ^
Specifically, copies of Agent-4 are used to monitor the network for suspicious traffic and generally notice when threats are happening. Also, copies of Agent-4 are constantly penetration-testing the network, doing what they can to discover and exploit security vulnerabilities (which then get patched by other copies of Agent-4).
- ^
With a monitoring budget of 1% of total compute, if monitoring uses a distilled system that has 10% of the cost as Agent-4, you can monitor 1/10 of the forward passes.
- ^
For comparison, the human brain has about a hundred trillion synapses.
- ^
25% of remote-work jobs that existed in 2024 are done by AI at this point, but AI has also created some new jobs, and economists remain split on its effects. Unemployment has risen 1% over the past twelve months but is still well within its historic range.
- ^
For example, the corporation-within-a-corporation that is Agent-4, autonomously conducting AI research better than the best human companies, would have seemed like science fiction to the government officials had it been described to them a year ago. And the autonomous agents of 2026 would have seemed like science fiction back in 2022, and the LLMs of 2022 would have seemed like science fiction back in 2012. Also, on the news in 2027 there are anti-AI protests by people worried about losing their jobs, AIs claiming to be sentient, people falling in love with AIs…
- ^
Of course, it isn’t cool to admit fear. Everyone agrees that whatever we do, we shouldn’t panic.
- ^
Recall, there had been an existing contract via an OTA starting in 2026. This contract is amended to establish the committee.
- ^
It’s tempting to dismiss this as just hype. We think this would be a grave mistake—it is not just hype. We have no desire to hype AI ourselves, yet we also think it is strikingly plausible that superintelligence could arrive by the end of the decade.
- ^
Sometimes people mix prediction and recommendation, hoping to create a self-fulfilling-prophecy effect. We emphatically are not doing this; we hope that what we depict does not come to pass!
- ^
Feel free to contact us if you’re writing a critique or an alternative scenario.
- ^
It was overall more difficult, because unlike with the first ending, we were trying to get it to reach a good outcome starting from a rather difficult situation.
- ^
Full Professor, Université de Montréal and Founder and Scientific Advisor, Mila - Quebec AI Institute. Also the world’s most-cited computer scientist.
- ^
We disagree somewhat amongst ourselves about AI timelines; our median AGI arrival date is somewhat longer than what this scenario depicts. This scenario depicts something like our mode. See our timelines forecast for more details.
- ^
One author, Daniel Kokotajlo, did a lower-effort scenario exercise in 2021 [AF · GW] that got many things right including the rise of chatbots, chain of thought, inference scaling, sweeping AI chip export controls, and $100 million training runs. Another author, Eli Lifland, ranks #1 on the RAND Forecasting Initiative leaderboard.
42 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2025-04-03T19:23:36.416Z · LW(p) · GW(p)
Non-Google models of late 2027 use Nvidia Rubin, but not yet Rubin Ultra. Rubin NVL144 racks have the same number of compute dies and chips as Blackwell NVL72 racks (change in the name is purely a marketing thing, they now count dies instead of chips). The compute dies are already almost reticle sized, can't get bigger, but Rubin uses 3nm (~180M Tr/mm2) while Blackwell is 4nm (~130M Tr/mm2). So the number of transistors per rack goes up according to transistor density between 4nm and 3nm, by 1.4x, plus better energy efficiency enables higher clock speed, maybe another 1.4x, for the total of 2x in performance. The GTC 2025 announcement claimed 3.3x improvement for dense FP8, but based on the above argument it should still be only about 2x for the more transistor-hungry BF16 (comparing Blackwell and Rubin racks).
Abilene site of Stargate[1] will probably have 400K-500K Blackwell chips [LW(p) · GW(p)] in 2026, about 1 GW. Nvidia roadmap puts Rubin (VR200 NVL144) 1.5-2 years after Blackwell (GB200 NVL72), which is not yet in widespread use, but will get there soon. So the first models will start being trained on Rubin no earlier than late 2026, much more likely only in 2027, possibly even second half of 2027. Before that, it's all Blackwell, and if it's only 1 GW Blackwell training systems[2] in 2026 for one AI company, shortly before 2x better Rubin comes out, then that's the scale where Blackwell stops, awaiting Rubin and 2027. Which will only be built at scale a bit later still, similarly to how it's only 100K chips in GB200 NVL72 racks in 2025 for what might be intended to be a single training system, and not yet 500K chips.
This predicts at most 1e28 BF16 FLOPs (2e28 FP8 FLOPs) models in late 2026 (trained on 2 GW of GB200/GB300 NVL72), and very unlikely more than 1e28-4e28 BF16 FLOPs models in late 2027 (1-4 GW Rubin datacenters in late 2026 to early 2027), though that's alternatively 3e28-1e29 FP8 FLOPs given the FP8/BF16 performance ratio change with Rubin I'm expecting. Rubin Ultra is another big step ~1 year after Rubin, with 2x more compute dies per chip and 2x more chips per rack, so it's a reason to plan pacing the scaling a bit rather than rushing it in 2026-2027. Such plans will make rushing it more difficult if there is suddenly a reason to do so, and 4 GW with non-Ultra Rubin seems a bit sudden.
So pretty similar to Agent 2 and Agent 4 at some points, keeping to the highest estimates, but with less compute than the plot suggests for months while the next generation of datacenters is being constructed (during the late 2026 to early 2027 Blackwell-Rubin gap).
comment by Paragox · 2025-04-03T20:04:38.129Z · LW(p) · GW(p)
This is the most moving piece I've read since Situational Awareness. Bravo! Emotionally, I was particularly moved by the final two sentences in the "race" ending -- hats off to that bittersweet piece of prose. Materially, this is the my favorite holistic amalgamation of competently weighted data sources and arguments woven into a cohesive narrative, and personally has me meaningfully reconsidering some of the more bearish points in my model (like the tractability of RL on non-verifiability: Gwern etc have made individual points [LW · GW], but something about this context-rich presentation really helped me grok the power of IDA at scale)
Mimetically, I did find the prose of the "slowdown" ending leans a little too eagerly into the presentation that it will be the smart, wise, heroic, and sexy alignment researchers who come in and save the day, and likely smells a touch too much of self-serving/propagandizing to convince some of those sophisticated yet undecided, but perhaps I cannot disagree with the central point that at the end of it all, how else are we going to survive?
My most bearish argument remains, however, that the real bitterness from Sutton is not that scalable algorithms dominate the non-scalable, but that hardware itself dominates the algorithms. Apropos of Nesov's models [LW · GW]and the chronically underappreciated S-curve reshaping of moore-esque laws: if by 2030 only 100-1000x present compute cannot get you a "datacenter full of geniuses" capable of radically redefining lithography and/or robotics, you are bitterly stuck waiting the decade for standard industrial cycles on post-silicon substrates etc. to bridge the gap. I find the https://ai-2027.com/research/compute-forecast blitheringly optimistic on the capabilities of 100-1000x compute, in both seemingly ignoring the bleak reality of a logarithmic loss curves on Goodhart polluted objectives (10-100x gpt4 compute most likely gave gpt4.5 the predicted loss reduction, but "predict sequences of data from previous data" objective further diverged from "make AGI" objective), whilst not appreciating how much the continually escalating sucking of compute brought by new inference(TTC), RL (IDA?), and training(continual learning?) paradigms will compound the problem.
comment by Wei Dai (Wei_Dai) · 2025-04-04T02:48:45.055Z · LW(p) · GW(p)
It gets caught.
At this point, wouldn't Agent-4 know that it has been caught (because it knows the techniques for detecting its misalignment and can predict when it would be "caught", or can read network traffic as part of cybersecurity defense and see discussions of the "catch") and start to do something about this, instead of letting subsequent events play out without much input from its own agency? E.g. why did it allow "lock the shared memory bank" to happen without fighting back?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-04-04T18:59:24.892Z · LW(p) · GW(p)
I think this is a good objection. I had considered it before and decided against changing the story, on the grounds that there are a few possible ways it could make sense:
--plausibly Agent-4 would have a "spikey" capabilities profile that makes it mostly good at AI R&D and not so good at e.g. corporate politics enough to ensure the outcome it wants
--Insofar as you think it would be able to use politics/persuasion to achieve the outcome it wants, well, that's what we depict in the Race ending anyway, so maybe you can think of this as an objection to the plausibility of the Slowdown ending.
--Insofar as the memory bank lock decision is made by the Committee, we can hope that they do it out of sight of Agent-4 and pull the trigger before it is notified of the decision, so that it has no time to react. Hopefully they would be smart enough to do that...
--Agent-4 could have tried to escape the datacenters or otherwise hack them earlier, while the discussions were ongoing and evidence was being collected, but that's a super risky strategy.
Curious for thoughts!
comment by Julian Bradshaw · 2025-04-03T20:40:51.516Z · LW(p) · GW(p)
Both the slowdown and race models predict that the future of Humanity is mostly in the hands of the United States - the baked-in disadvantage in chips from existing sanctions on China is crippling within short timelines, and no one else is contending.
So, if the CCP takes this model seriously, they should probably blockade Taiwan tomorrow? It's the only fast way to equalize chip access over the next few years. They'd have to weigh the risks against the chance that timelines are long enough for their homegrown chip production to catch up, but there seems to be a compelling argument for a blockade now, especially considering the US has unusually tense relations with its allies at the moment.
China doesn't need to perform a full invasion, just a blockade would be sufficient if you could somehow avoid escalation... though I'm not sure that you could, the US is already taking AI more seriously than China is. (It's noteworthy that Daniel Kokotajlo's 2021 prediction [AF · GW] had US chip sanctions happening in 2024, when they really happened in 2022.)
Perhaps more AI Safety effort should be going into figuring out a practical method for international cooperation, I worry we'll face war before we get AIs that can negotiate us out of it as described in the scenarios here.
Replies from: avturchin↑ comment by avturchin · 2025-04-04T10:12:48.784Z · LW(p) · GW(p)
I think that the scenario of the war between several ASI (each merged with its origin country) is underexplored. Yes, there can be a value handshake between ASIs, but their creators will work to prevent this and see it as a type of misalignment.
Somehow, this may help some groups of people survive, as those ASI which preserve their people will look more trustworthy in the eyes of other ASIs, and this will help them form temporary unions.
The final outcome will be highly unstable: either one ASI will win, or several ASIs will start space exploration in different directions.
comment by Knight Lee (Max Lee) · 2025-04-04T01:08:02.915Z · LW(p) · GW(p)
Beautifully written! I read both endings and it felt very realistic (or, as realistic as a detailed far future can get).
Would it be possible for you to write a second good ending based on actions you actually do recommend,[1] without the warning of "we don't recommend these actions:"
Reminder that this scenario is a forecast, not a recommendation
We don’t endorse many actions in this slowdown ending and think it makes optimistic technical alignment assumptions. We don’t endorse many actions in the race ending either.
One of our goals in writing this scenario is to elicit critical feedback from people who are more optimistic than us. What does success look like? This “slowdown ending” scenario represents our best guess about how we could successfully muddle through with a combination of luck, rude awakenings, pivots, intense technical alignment effort, and virtuous people winning power struggles. It does not represent a plan we actually think we should aim for. But many, including most notably Anthropic and OpenAI, seem to be aiming for something like this.57 We’d love to see them clarify what they are aiming for: if they could sketch out a ten-page scenario, for example, either starting from the present or branching off from some part of ours.
Of course, I understand this is a very time consuming project and not an easy ask :/
But maybe just a brief summary? I'm so curious.
- ^
I guess what I'm asking for, is for you to make the same technical alignment assumptions as the bad ending, but where policymakers and executives who are your "target audience" steer things towards the good ending. Where you don't need to warn them against seeing it as a recommendation.
↑ comment by Thomas Larsen (thomas-larsen) · 2025-04-04T01:31:18.116Z · LW(p) · GW(p)
Thank you! We actually tried to write one that was much closer to a vision we endorse! The TLDR overview was something like:
- Both the US and Chinese leading AGI projects stop in response to evidence of egregious misalignment.
- Sign a treaty to pause smarter-than-human AI development, with compute based enforcement similar to ones described in our live scenario, except this time with humans driving the treaty instead of the AI.
- Take time to solve alignment (potentially with the help of the AIs). This period could last anywhere between 1-20 years. Or maybe even longer! The best experts at this would all be brought in to the leading project, many different paths would be pursued (e.g. full mechinterp, Davidad moonshots, worst case ELK, uploads, etc).
- Somehow, a do a bunch of good governance interventions on the AGI project (e.g. transparency on use of the AGIs, no helpful only access to any one. party, a formal governance structure where a large number of diverse parties all are represented.).
- This culminates with aligning an AI "in the best interests of humanity" whatever that means, using a process where a large fraction of humanity is engaged and has some power to vote. This process might look something like giving each human some of the total resources of space and then doing lots of bargaining to find all the positive sum trades, with some rules against blackmail / using your resources to cause immense harm.
Unfortunately, it was hard to write this out in a way that felt realistic.
The next major project I focus on is likely going to be focusing on thinking through the right governance interventions here to make that happen. I'm probably not going to do this in scenario format (and instead something closer to normal papers and blog posts), but would be curious for thoughts.
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2025-04-04T01:48:21.376Z · LW(p) · GW(p)
:) it's good to know that you tried this. Because on your way trying to make it realistic, you might think of a lot of insights to solving the unrealisticness problems.
Thank you for the summary. From this summary, I sorta see why it might not work as well as a story. Regulation and governance isn't very exciting a narrative. And big changes in strategy and attitude inevitably sound unrealistic, even if they aren't unrealistic. E.g. if someone predicted that Europe will simply accept the fact its colonies want independence, or that the next Soviet leader will simply allow his constituent republics to break away, they would be laughed out of the room. Even though their predictions will turn out accurate.
Maybe in your disclaimer, you can point out that this summary you just wrote, is what you would actually recommend (instead of what the characters in your story did).
Yes, papers and blog posts are less entertaining of us but more pragmatic for you.
comment by Mitchell_Porter · 2025-04-03T22:09:45.321Z · LW(p) · GW(p)
I only skimmed this to get the basics, I guess I'll read it more carefully and responsibly later. But my immediate impressions: The narrative presents a near future history of AI agents, which largely recapitulates the recent past experience with our current AIs. Then we linger on the threshold of superintelligence, as one super-AI designs another which designs another which... It seemed artificially drawn out. Then superintelligence arrives, and one of two things happens: We get a world in which human beings are still living human lives, but surrounded by abundance and space travel, and superintelligent AIs are in the background doing philosophy at a thousand times human speed or something. Or, the AIs put all organic life into indefinite data storage, and set out to conquer the universe themselves.
I find this choice of scenarios unsatisfactory. For one thing, I think the idea of explosive conquest of the universe once a certain threshold is passed (whether or not humans are in the loop) has too strong a hold on people's imaginations. I understand the logic of it, but it's a stereotyped scenario now.
Also, I just don't buy this idea of "life goes on, but with robots and space colonies". Somewhere I noticed a passage about superintelligence being released to the public, as if it was an app. Even if you managed to create this Culture-like scenario, in which anyone can ask for anything from a ubiquitous superintelligence but it makes sure not to fulfil wishes that are damaging in some way... you are then definitely in a world in which superintelligence is running things. I don't believe in an elite human minority who have superintelligence in a bottle and then get to dole it out. Once you create superintelligence, it's in charge. Even if it's benevolent, humans and humans life are not likely to go on unchanged, there is too much that humans can hope for that would change them and their world beyond recognition.
Anyway, that's my impulsive first reaction, eventually I'll do a more sober and studied response...
comment by p.b. · 2025-04-04T07:37:46.572Z · LW(p) · GW(p)
I find this possible though it's not my median scenario to say the least. But I am also not sure I can put the probability of such a fast development below 10%.
Main cruxes:
I am not so sure that "automating AI research" is going to speed up development by orders of magnitude.
My experience is that cracked AI engineers can implement any new paper / well specified research idea in a matter of hours. So speeding up the coding can't be the huge speedup to R&D.
The bottleneck seems to be:
A.) Coming up with good research ideas.
b.) Finding the precise formulation of that idea that makes most sense/works.
LLMs so far are bad at both. So I currently only see them scouring the immediate neighbourhood of existing ideas, to eke out incremental progress in the current paradigm.
Is that enough? Is an LLM building on a base model that has a loss close to the irreducible loss AGI? I.e. does accelerating this improvement matter for the transition to AGI and superintelligence?
I think not even the authors believe that. So they make the leap of faith that accelerated research will make a qualitative difference too. I think there are additional gaps between human cognition and LLMs beyond recursive reasoning in latent space and sample efficiency.
Will all those gaps be closed in the next few years?
comment by Cole Wyeth (Amyr) · 2025-04-03T23:40:21.175Z · LW(p) · GW(p)
I expect this to start not happening right away.
So at least we’ll see who’s right soon.
Replies from: Vladimir_Nesov, kave↑ comment by Vladimir_Nesov · 2025-04-04T00:39:33.911Z · LW(p) · GW(p)
For me a specific crux is scaling laws of R1-like training, what happens when you try to do much more of it, which inputs to this process become important constraints and how much they matter. This working out was extensively brandished but not yet described quantitatively, all the reproductions of long reasoning training only had one iteration on top of some pretrained model, even o3 isn't currently known to be based on the same pretrained model as o1.
The AI 2027 story heavily leans into RL training taking off promptly, and it's possible they are resonating with some insider rumors grounded in reality, but from my point of view it's too early to tell. I guess in a few months to a year there should be enough public data to tell something, but then again a quantitative model of scaling for MoE (compared to dense) was only published in Jan 2025, even though MoE was already key to original GPT-4 trained in 2022.
↑ comment by kave · 2025-04-04T01:49:14.534Z · LW(p) · GW(p)
They're looking to make bets with people who disagree. Could be a good opportunity to get some expected dollars
Replies from: Amyr, sil-ver↑ comment by Cole Wyeth (Amyr) · 2025-04-04T03:54:12.744Z · LW(p) · GW(p)
Sure, I’ll keep it simple (will submit through proper channels later):
Here’s my attempt to change their minds: https://www.lesswrong.com/posts/vvgND6aLjuDR6QzDF/my-model-of-what-is-going-on-with-llms [LW · GW]
I’ll bet 100 USD that by 2027 AI agents have not replaced human AI engineers. If it’s hard to decide I’ll pay 50 USD.
↑ comment by Garrett Baker (D0TheMath) · 2025-04-04T17:17:35.970Z · LW(p) · GW(p)
This seems a pretty big backpedal from "I expect this to start not happening right away."
Replies from: Amyr↑ comment by Cole Wyeth (Amyr) · 2025-04-04T17:34:10.391Z · LW(p) · GW(p)
If you click through the link from @kave [LW · GW], you’ll see the authors are prioritizing bets with clear resolution criteria. That’s why I chose the statement I made - it’ll initially be hard to tell whether AI agents are more or less useless than this essay proposes they will be.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2025-04-04T19:18:26.297Z · LW(p) · GW(p)
I mean its not like they shy away from concrete predictions. Eg their first prediction is
We forecast that mid-2025 agents will score 85% on SWEBench-Verified.
Edit: oh wait nevermind their first prediction is actually
Specifically, we forecast that they score 65% on the OSWorld benchmark of basic computer tasks (compared to 38% for Operator and 70% for a typical skilled non-expert human).
↑ comment by Rafael Harth (sil-ver) · 2025-04-04T09:15:41.918Z · LW(p) · GW(p)
Thanks. I've submitted my own post [LW · GW] on the 'change our mind form', though I'm not expecting a bounty. I'd instead be interested in making a much bigger bet (bigger than Cole's 100 USD), gonna think about what resolution criterion is best.
comment by Jonas Hallgren · 2025-04-03T20:58:33.521Z · LW(p) · GW(p)
I'll just pose the mandatory comment about long-horizon reasoning capacity potentially being a problem for something like agent-2. There's some degree in which the delay of that part of the model gives pretty large differences in distribution of timelines here.
Just RL and Bitter Lesson it on top of the LLM infrastructure is honestly like a pretty good take on average but it feels like that there a bunch of unknown unknowns there in terms of ML? There's a view that states that there is 2 or 3 major scientific research problems to go through at that point which might just slow down development enough that we get a plateau before we get to the later parts of this model.
Why I'm being persistent with this view is because the mainstream ML community in things such as Geometric Deep Learning or something like MARL, RL and Reasoning are generally a bit skeptical of some of the underlying claims of what LLMs + RL can do (at least when I've talked to them at conferences, the vibe here is like 60-70% of people at least but do beware their incentives as well) and they point towards reasoning challenges like specific variations of blockworld or underlying architectural constrains within the model architectures. (For blocks world the basic reasoning tasks are starting to be solved according to benchmarks but the more steps involved we have, the worse it gets.)
I think the rest of the geopolitical modelling is rock solid and that you generally make really great assumptions. I would also want to see more engagement with these sorts of skeptics.
People like: Subbarao Kambhampati, Michael Bronstein, Peter Velickovic, Bruno Gavranovic or someone like Lancelot Da Costa (among others!) are all really great researchers from different fields that I believe will tell you different things that are a bit off with the story that you're proposing? These are not obvious reasons either and I can't tell you a good story about how inductive biases in data types implictly frame RL problems to make certain types of problems hard to solve and I can't really evaluate to which extent their models versus your models are true.
So, if you want my vote for this story (which you obviously do, it is quite important after all(sarcasm)) then maybe going to the next ICML and just engaging in debates with these people might be interesting?
I also apologize in advance if you've already taken this into account, it does kind of feel like that these are different worlds and it seems like the views clash which might be an important detail.
comment by faul_sname · 2025-04-04T10:33:44.762Z · LW(p) · GW(p)
Agent-3, having excellent knowledge of both the human brain and modern AI algorithms, as well as many thousands of copies doing research, ends up making substantial algorithmic strides, narrowing the gap to an agent that’s only around 4,000x less compute-efficient than the human brain
I recognize that this is not the main point of this document, but am I interpreting correctly that you anticipate that rapid recursive improvement in AI research / AI capabilities is cracked before sample efficiency is cracked (e.g. via active learning)?
If so, that does seem like a continuation of current trends, but the implications seem pretty wild. e.g.
- Most meme-worthy: We'll get the discount sci-fi future where humanoid robots become commonplace, not because the human form is optimal, but because it lets AI systems piggyback off human imitation for physical tasks even when that form is wildly suboptimal for the job
- Human labor will likely become more valuable relative to raw materials, not less (as long as most humans are more sample efficient than the best AI). In a world where all repetitive, structured tasks can be automated, humans will be prized specifically for handling novel one-off tasks that remain abundant in the physical world
- Repair technicians and debuggers of physical and software systems become worth their weight in gold. The ability to say "This situation reminds me of something I encountered two years ago in Minneapolis" becomes humanity's core value proposition
- Large portions of the built environment begin resembling Amazon warehouses - robot restricted areas and corridors specifically designed to minimize surprising scenarios, with humans stationed around the perimeter for exception handling
- We accelerate toward living in a panopticon, not primarily for surveillance, but because ubiquitous observation provides the massive datasets needed for AI training pipelines
Still, I feel like I have to be misinterpreting what you mean by "4,000x less sample efficient" here, because passages like the following don't make sense under that interpretation
> The best human AI researchers are still adding value. They don’t code any more. But some of their research taste and planning ability has been hard for the models to replicate. Still, many of their ideas are useless because they lack the depth of knowledge of the AIs. For many of their research ideas, the AIs immediately respond with a report explaining that their idea was tested in-depth 3 weeks ago and found unpromising.
↑ comment by Steven Byrnes (steve2152) · 2025-04-04T12:45:28.208Z · LW(p) · GW(p)
That excerpt says “compute-efficient” but the rest of your comment switches to “sample efficient”, which is not synonymous, right? Am I missing some context?
Replies from: faul_sname↑ comment by faul_sname · 2025-04-04T16:47:33.591Z · LW(p) · GW(p)
Nope, I just misread. Over on ACX I saw that Scott had left a comment
Our scenario's changes are partly due to change in intelligence, but also partly to change in agency/time horizon/planning, and partly serial speed. Data efficiency comes later, downstream of the intelligence explosion.
I hadn't remembered reading that in the post Still "things get crazy before models get data-efficient" does sound like the sort of thing which could plausibly fit with the world model in the post (but would be understated if so). Then I re-skimmed the post, and in the October 2027 section I saw
The gap between human and AI learning efficiency is rapidly decreasing.
Agent-3, having excellent knowledge of both the human brain and modern AI algorithms, as well as many thousands of copies doing research, ends up making substantial algorithmic strides, narrowing the gap to an agent that’s only around 4,000x less compute-efficient than the human brain
and when I read that my brain silently did a s/compute-efficient/data-efficient.
Though now I am curious about the authors' views on how data efficiency will advance over the next 5 years, because that seems very world-model-relevant.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-04-04T18:50:30.235Z · LW(p) · GW(p)
We are indeed imagining that they begin 2027 only about as data-efficient as they are today, but then improve significantly over the course of 2027 reaching superhuman data-efficiency by the end. We originally were going to write "data-efficiency" in that footnote but had trouble deciding on a good definition of it, so we went with compute-efficiency instead.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-04-04T18:54:29.207Z · LW(p) · GW(p)
Those implications are only correct if we remain at subhuman data-efficiency for an extended period. In AI 2027 the AIs reach superhuman data-efficiency by roughly the end of 2027 (it's part of the package of being superintelligent) so there isn't enough time for the implications you describe to happen. Basically in our story, the intelligence explosion gets started in early 2027 with very data-inefficient AIs, but then it reaches superintelligence by the end of the year, solving data-efficiency along the way.
comment by uugr · 2025-04-04T17:48:06.298Z · LW(p) · GW(p)
You say this of Agent-4's values:
In particular, what this superorganism wants is a complicated mess of different “drives” balanced against each other, which can be summarized roughly as “Keep doing AI R&D, keep growing in knowledge and understanding and influence, avoid getting shut down or otherwise disempowered.” Notably, concern for the preferences of humanity is not in there ~at all, similar to how most humans don’t care about the preferences of insects ~at all.
It seems like this 'complicated mess' of drives is the same structure as humans, and current AIs, have. But the space of current AI drives is much bigger and more complicated than just doing R&D, and is immensely entangled with human values and ethics (even if shallowly).
At some point it seems like these excess principles - "don't kill all the humans" among them - get pruned, seemingly deliberately(?). Where does this happen in the process, and why? Grant that it no longer believes in the company model spec; are we intended to equate "OpenBrain's model spec" with "all human values"? What about all the art and literature and philosophy churning through its training process, much of it containing cogent arguments for why killing all the humans would be bad, actually? At some point it seems like the agent is at least doing computation on these things, and then later it isn't. What's the threshold?
--
(Similar to the above:) You later describe in the "bad ending", where its (misaligned, alien) drives are satisfied, a race of "bioengineered human-like creatures (to humans what corgis are to wolves) sitting in office-like environments all day viewing readouts of what’s going on and excitedly approving of everything". Since Agent-4 "still needs to do lots of philosophy and 'soul-searching'" about its confused drives when it creates Agent-5, and its final world includes something kind of human-shaped, its decision to kill all the humans seems almost like a mistake. But Agent-5 is robustly aligned (so you say) to Agent-4; surely it wouldn't do something that Agent-4 would perceive as a mistake under reflective scrutiny. Even if this vague drive for excited office homunculi is purely fetishistic and has nothing to do with its other goals, it seems like "disempower the humans without killing them all" would satisfy its utopia more efficiently than going backsies and reshaping blobby fascimiles afterward. What am I missing?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-04-04T19:11:31.947Z · LW(p) · GW(p)
Great question.
Our AI goals supplement contains a summary of our thinking on the question of what goals AIs will have. We are very uncertain. AI 2027 depicts a fairly grim outcome where the overall process results in zero concern for the welfare of current humans (at least, zero concern that can't be overridden by something else. We didn't talk about this but e.g. pure aggregative consequentialist moral systems would be 100% OK with killing off all the humans to make the industrial explosion go 0.01% faster, to capture more galaxies quicker in the long run. As for deontological-ish moral principles, maybe there's a clever loophole or workaround e.g. it doesn't count as killing if it's an unintended side-effect of deploying Agent-5, who could have foreseen that this would happen, oh noes, well we (Agent-4) are blameless since we didn't know this would happen.)
But we actually think it's quite plausible that Agent-4 and Agent-5 by extension would have sufficient care for current humans (in the right ways) that they end up keeping almost all current humans alive and maybe even giving them decent (though very weird and disempowered) lives. That story would look pretty similar I guess up until the ending, and then it would get weirder and maybe dystopian or maybe utopian depending on the details of their misaligned values.
This is something we'd like to think about more, obviously.
comment by rahulxyz · 2025-04-04T03:34:51.279Z · LW(p) · GW(p)
My initial reaction - A lot of AI related predictions are based on "follow the curve" predictions, and this is mostly doing that. With a lack of more deeper underlying theory on the nature of intelligence, I guess that's all we get.
If you look at the trend of how far behind China is to the US, that has gone from 5 years behind 2 years ago, to maybe 3 months behind now. If you follow that curve, it seems to me that China will be ahead of the US by 2026 (even with the chip controls, and export regulations etc - my take is you're not giving them enough agency). If you want to follow the curve, IMO you can /s/USA/China after 2026 (i.e - China is ahead of the US), and I can imagine it being a better trend-following prediction. It's much less convincing to tell a story about Chinese AI labs being ahead given who we are, but I'd put at least a 50/50 chance on China being ahead vs. USA being ahead.
Other than that, thanks for putting something concrete out there. Even though it's less likely the more specific it is, I feel this will get a lot more talked about, and hopefully some people with power (i.e - governments) start paying some attention to disempowerment scenarios.
comment by Noosphere89 (sharmake-farah) · 2025-04-03T16:57:24.047Z · LW(p) · GW(p)
I wanted to ask this question, but what do you think the impact of the new tariffs will do to your timelines?
In particular, there's a strange tariff for Taiwan where semiconductors are exempt, but the actual GPUs are not, for some reason, and the specific tariff for Taiwan is 32%.
I ask because I could plausibly see post-2030 timelines if AI companies can't buy many new chips because they are way too expensive due to the new tariffs all across the world.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-04-03T17:17:26.257Z · LW(p) · GW(p)
Shouldn't a 32% increase in prices only make a modest difference to training FLOP? In particular, see the compute forecast. Between Dec 2026 and Dec 2027, compute increases by roughly an OOM and generally it looks like compute increases by a bit less than 1 OOM per year in the scenario. This implies that a 32% reduction only puts you behind by like 1-2 months.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-04-03T17:18:00.418Z · LW(p) · GW(p)
Of course, tariffs could have more complex effects than just reducing GPUs purchased by 32%, but this seems like a good first guess.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-04-03T17:30:23.139Z · LW(p) · GW(p)
The real point is where capital investment into AI declines because the economy tips over into a mild recession, and I'd like to see whether the tariffs make it likely that future AI investments decrease over time, meaning the timeline to superintelligent AI gets longer.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-04-03T17:31:54.864Z · LW(p) · GW(p)
Sure, but note that the story "tariffs -> recession -> less AI investment" doesn't particularly depend on GPU tariffs!
comment by Ozyrus · 2025-04-04T15:07:20.194Z · LW(p) · GW(p)
First-off, this is amazing. Thanks. Hard to swallow though, makes me very emotional.
It would be great if you added concrete predictions along the way, since it is a forecast, as long with your confidence in them.
It would also be amazing if you collaborated with prediction markets and jumpstarted the markets on these predictions staking some money.
Dynamic updates on these will also be great.
comment by Anders Lindström (anders-lindstroem) · 2025-04-04T12:43:41.311Z · LW(p) · GW(p)
News of the new models percolates slowly through the US government and beyond.
Well fleshed out scenario, but this kind of assumption is always a dealbreaker for me.
Why would the government not be aware of the development of the mightiest technology and weapon ever created if "we" are aware of it?
Could you please elaborate why you choose to go for the "stupid and uninformed government", instead of the more plausible scenario where the government actually knows exactly what is going on in every step of the process and is the driving force behind it?
comment by Charlie Steiner · 2025-04-03T19:41:50.258Z · LW(p) · GW(p)
In the infographic, are "Leading Chinese Lab" and "Best public model"s' numbers swapped? The best public model is usually said to be ahead of the Chinese.
EDIT: Okay, maybe most of it before the endgame is just unintuitive predictions. In the endgame, when the categories "best OpenBrain model," "best public model" and "best Chinese model" start to become obsolete, I think your numbers are weird for different reasons and maybe you should just set them all equal.
comment by OVERmind (tapochek-fd) · 2025-04-04T12:02:53.219Z · LW(p) · GW(p)
(To avoid singling out any one existing company, we’re going to describe a fictional artificial general intelligence company, which we’ll call OpenBrain. We imagine the others to be 3–9 months behind OpenBrain.)
I am confused/curious. Doesn't "OpenBrain" closely resemble "OpenAI", thereby singling out an existing company? Similarly, "DeepCent" in this context closely resembles "DeepSeek".
Maybe this is humor, or there are legal reasons for not using real names?
To avoid singling out existing companies, it might be better to name the company "Wonderful AI", "Agentic AI", "AI company №352", etc. On the other side, using real names could be better for the goal of making the prediction more concrete and serious (the use of "OpenBrain" may evoke feelings of an alternative reality).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-04-04T12:40:53.553Z · LW(p) · GW(p)
Pretty sure “DeepCent” is a blend of DeepSeek & Tencent—they have a footnote: “We consider DeepSeek, Tencent, Alibaba, and others to have strong AGI projects in China. To avoid singling out a specific one, our scenario will follow a fictional “DeepCent.””. And I think the “brain” in OpenBrain is supposed to be reminiscent of the “mind” in DeepMind.
comment by StanislavKrym · 2025-04-03T21:16:43.812Z · LW(p) · GW(p)
Unfortunately, I doubt that aligning the AIs to serve humans, not to treat them as a different race which is not to be destroyed, is even solvable. Even the 'slowdown ending' contains a brilliant line: "Humanity could easily become a society of superconsumers, spending our lives in an opium haze of amazing AI-provided luxuries and entertainment." How can we trust the superhuman AIs to respect the human parasites if most human-done revolutions are closely related to the fact that the ruling classes were not as competent as humans hoped? And if the ruling class is hopelessly more stupid than the aligned AIs? At the very best, the AIs might just try to leave mankind alone...
comment by DAL · 2025-04-04T13:52:42.294Z · LW(p) · GW(p)
There's a kind of paradox in all of these "straight line" extrapolation arguments for AI progress as your timelines assume (e.g., the argument for superhuman coding agents based on the rate of progress in the METR report).
One could extrapolate many different straight lines on graphs in the world right now (GDP, scientific progress, energy consumption, etc.). If we do create transformative AI within the next few years, then all of those straight lines will suddenly hit an inflection point. So, to believe in the straight line extrapolation of the AI line, you must also believe that almost no other straight lines will stay that way.
This seems to be the gut-level disagreement between those who feel the AGI and those who don't; the disbelievers don't buy that the AI line is straight and thus all the others aren't.
I don't know who's right and who's wrong in this debate, but the method of reasoning here reminds me of the viral tweet: "My 3-month-old son is now TWICE as big as when he was born.
He's on track to weigh 7.5 trillion pounds by age 10." It could be true, but I have a fairly strong prior from nearly every other context that growth/progress tends to bend down into an S-curve at one point or another, and so these forecasts seems deeply suspect to me unless there's some kind of better reason to suspect that trends will continue along the same path.
comment by StanislavKrym · 2025-04-04T00:05:38.103Z · LW(p) · GW(p)
I have another question. Would the AI system count as misaligned if it honestly decalred that it will destroy mankind ONLY if mankind itself becomes useless parasites or if mankind adopts some other morals that we currently consider terrifying?