≤10-year Timelines Remain Unlikely Despite DeepSeek and o3
post by Rafael Harth (sil-ver) · 2025-02-13T19:21:35.392Z · LW · GW · 52 commentsContents
1. Why Village Idiot to Einstein is a Long Road: The Two-Component Model of Intelligence 2. Sequential Reasoning 2.1 Sequential Reasoning without a Thought Assessor: the Story so Far 2.2 Sequential Reasoning without a Thought Assessor: the Future 3. More Thoughts on Sequential Reasoning 3.1. Subdividing the Category 3.2. Philosophical Intelligence 4. Miscellaneous 4.1. Your description of thought generation and assessment seems vague, underspecified, and insufficiently justified to base your conclusions on. 4.2. If your model is on the right track, doesn't this mean that human+AI teams could achieve significantly superhuman performance and that these could keep outperforming pure AI systems for a long time? 4.3. What does this mean for safety, p(doom), etc.? None 52 comments
[Thanks to Steven Byrnes [LW · GW] for feedback and the idea for section §3.1. Also thanks to Justis from the LW feedback team.]
Remember this?
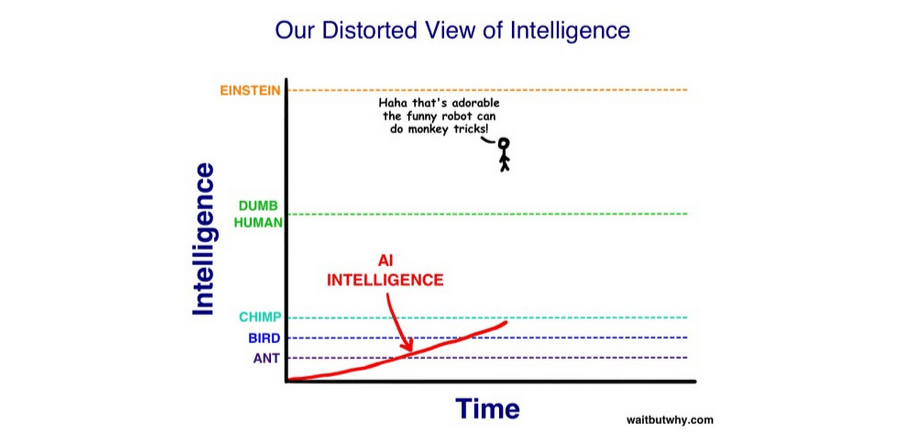
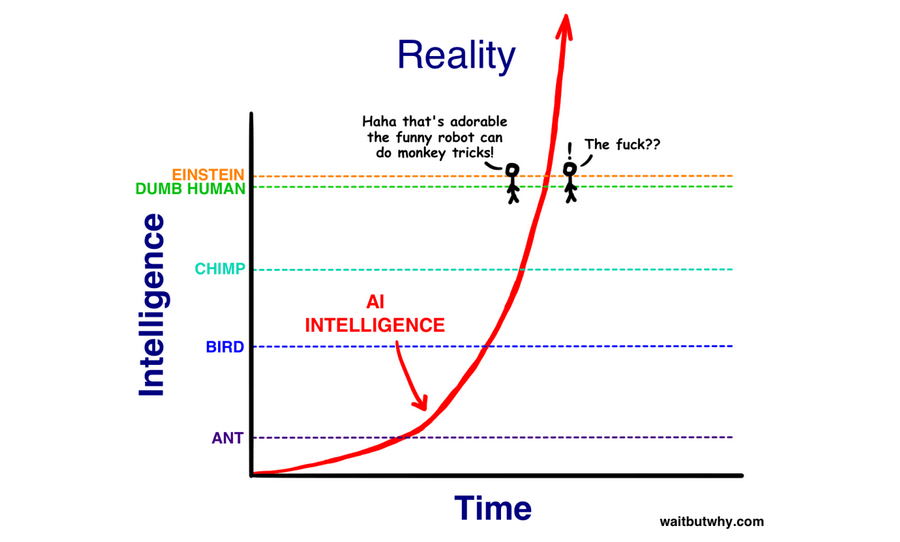
Or this?




The images are from WaitButWhy, but the idea was voiced by many prominent alignment people, including Eliezer Yudkowsky and Nick Bostrom. The argument is that the difference in brain architecture between the dumbest and smartest human is so small that the step from subhuman to superhuman AI should go extremely quickly. This idea was very pervasive at the time. It's also wrong. I don't think most people on LessWrong have a good model of why it's wrong, and I think because of this, they don't have a good model of AI timelines going forward.
1. Why Village Idiot to Einstein is a Long Road: The Two-Component Model of Intelligence
I think the human brain has two functionally distinct components for intellectual work: a thought generator module and a thought assessor module:
-
Thought Generation is the unconscious part of thinking, the module that produces the thoughts that pop into your head. You get to hear the end results but not what went into generating them.
-
Thought Assessment is the conscious part of thinking. It's about deliberate assessment. If you mull over an idea and gradually realize that it was worse than it initially seemed, that's thought assessment.
Large Language Models like GPT-3, Claude, GPT-4, GPT-4o, GPT-o1, GPT-o3, and DeepSeek do not have two functionally distinct components. They have a thought generator module, and that's it.
I'm not the first to realize this. Way back after GPT-2, Sarah Constantin [LW · GW] wrote Humans Who Are Not Concentrating Are Not General Intelligences [LW · GW], making the point that GPT-2 is similar to a human who's tired and not paying attention. I think this is the central insight about LLMs, and I think it explains a lot of their properties. Like, why GPT-2 got the grammar and vibe of a scene right but had trouble with details. Or why all LLMs are bad at introspection. Why they have more trouble with what they said 30 seconds ago than with what's in their training data. Or why they particularly struggle with sequential reasoning (much more on that later). All of this is similar to a human who is smart and highly knowledgeable but just rattling off the first thing that comes to mind.
I think the proper way to think about human vs. LLM intelligence is something like this:
(Note that this doesn't mean LLMs have zero ability to perform thought assessment, it just means that they have no specialized thought assessor module. Whether they can achieve similar things without such a module is the million trillion dollar question, and the main thing we'll talk about in this post.)
My hot take is that the graphics I opened the post with were basically correct in modeling thought generation. Perhaps you could argue that progress wasn't quite as fast as the most extreme versions predicted, but LLMs did go from subhuman to superhuman thought generation in a few years, so that's pretty fast. But intelligence isn't a singular capability; it's two capabilities a phenomenon better modeled as two capabilities, and increasing just one of them happens to have sub-linear returns on overall performance.
Similarly, I think most takes stating that LLMs are already human level (I think this [LW · GW] is the most popular one) are wrong because they focus primarily on thought generation, and likewise, most benchmarks are not very informative because they mostly measure thought generation. I think the most interesting non-AI-related insight that we can infer from LLMs is that most methods we use to discern intelligence are actually quite shallow, including many versions of the Turing Test, and even a lot of questions on IQ tests. If I remember correctly, most problems on the last IQ test I took were such that I either got the answer immediately or failed to answer it altogether, in which case thought assessment was not measured. There were definitely some questions that I got right after mulling them over, but not that many. Similarly, I think most benchmarks probably include a little bit of thought assessment, which is why LLMs aren't yet superhuman on all of them, but only a little bit.
So why should we care about thought assessment? For which types of tasks is it useful? I think the answer is:
2. Sequential Reasoning
By sequential reasoning, I mean reasoning that requires several steps that all depend on the previous one. If you reason where depends on and on and on , that's sequential reasoning. (We'll discuss an example in a bit.) On such a task, the human or LLM cannot simply guess the right answer in one take. As I said above, I think a surprising number of questions can be guessed in one take, so I think this is actually a relatively small class of problems. But it's also a hard requirement for AGI. It may be a small category, but both [progress on hard research questions] and [deception/scheming/basically any doom scenario] are squarely in it. AI will not kill everyone without sequential reasoning.
2.1 Sequential Reasoning without a Thought Assessor: the Story so Far
The description above may have gotten you thinking – does this really require thought assessment? A thought generator can read the problem description, output A, read (description , A), output B, read (description, A, B), output C, read (description, A, B, C), output D, and violà! This solves the problem, doesn't it?
Yes – in principle, all sequential reasoning can be bootstrapped with just a thought generator. And this is something AI labs have realized as well – perhaps not immediately, but over time.
Let's look at an example. This problem is hard enough that I don't think any human could solve it in a single step, but many could solve it with a small amount of thought. (Feel free to try to solve it yourself if you want; I'll jump straight into discussing reasoning steps.)
Seven cards are placed in a circle on the table, so that each card has two neighbors. Each card has a number written on it. Four of the seven cards have two neighbors with the same number. These four cards are all adjacent. The remaining three cards have neighbors with different numbers. Name a possible sequence of numbers for the seven cards.
At first glance, you may think that four adjacent cards all having the same neighbors means they have to be the same. So you may try a sequence of only 0s. But that can't work because creating four adjacent cards with identical neighbors this way actually requires six 0s, and 0-0-0-0-0-0-X implies that #7 also has the same neighbors, which violates the second criterion. Then you may realize that, actually, the same neighbor criterion just implies that #1 = #3 = #5 and #2 = #4, so perhaps an alternating sequence? Like 0-1-0-1-...? This is on the right track. Now a little bit of fine tuning, trying, or perhaps writing down exactly how much of the sequence must strictly alternate will probably make you realize that changing just one number to a third value does the trick, e.g., 0-1-0-1-0-1-2.
I think this problem is a good example because it (a) requires sequential reasoning and (b) probably won't pattern-match to a known problem in the literature, but it's also pretty easy[1] – probably about as easy as you can get while satisfying (a).
Let's look at how LLMs deal with this problem as a case study for performing sequential reasoning with only a thought generator. (Note that none of these examples are cherry-picked; I'm providing the first transcript I've gotten with every model for every example, and if I show another example, it's the second transcript.) Here's GPT-4 on 2023/04/17, before the Jun13 update:

Notice that (a) the answer is completely wrong, and (b) GPT-4 did not attempt to use sequential reasoning to obtain it. (It did repeat the problem statement, which this version did sometimes and not other times, but I would not count thas as attempting sequential reasoning.) It just guessed the answer immediately, and failed. Conversely, here's what GPT-4 responded after the Jun13 update:
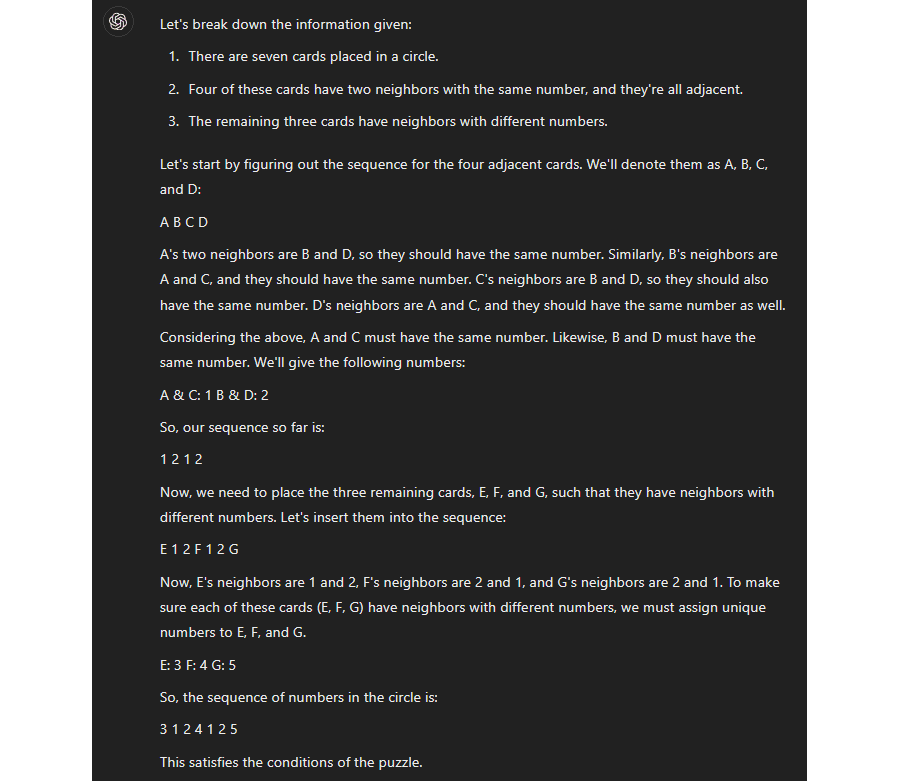
(Or see here for the second attempt.) Instead of trying to guess the answer immediately, it tried to write out a chain of reasoning. It still got the answer wrong, but this is a clear improvement. (And in fact, occasionally it got the answer right!, which the old model never did.)
I think these examples show both the potential and the problems of sequential reasoning without a thought assessor. Yes it's possible, but if you get a step wrong, the entire argument chain fails.
DeepSeek and o3 try to address this problem by verifying whether a conclusion is correct, and if it's not, trying again. Here's a snippet from the (very long) transcript with non-r1 DeepSeek:
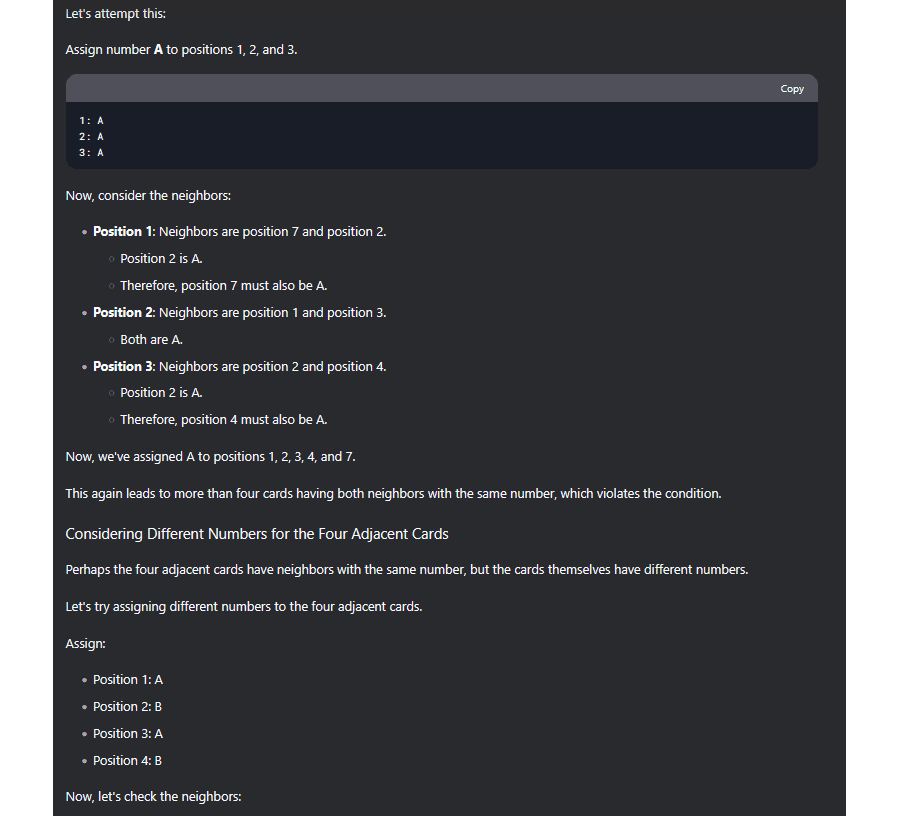
See the footnote[2] for the full version and other notes.
In a nutshell, I think the progression can be summarized as:
-
Everything up to and including pre-Jun13 GPT-4: don't do anything special for sequential reasoning tasks (i.e., just guess the solution).
-
Everything past the above and up to and including o1:[3] Attempt to write down a reasoning chain if the problem looks like it requires it.
-
o3 and DeepSeek: Attempt to write down a reasoning chain, systematically verify whether the conclusion is correct, and repeatedly go back to try again if it's not.
The above is also why I no longer consider talking about this an infohazard. Two years ago, the focus on sequential reasoning seemed non-obvious, but now, AI labs have evidently zoomed into this problem and put tremendous efforts into bootstrapping a sequential reasoner.
2.2 Sequential Reasoning without a Thought Assessor: the Future
According to my own model, LLMs seem to be picking up on sequential reasoning, which I claim is the relevant bottleneck. So is it time to panic?
Perhaps. I have some doubts about whether progress will continue indefinitely (and I'll get to them in a bit), but I think those aren't necessary to justify the title of this post. For now, the claim I want to make is that -year timelines are unlikely even without unforeseen obstacles in the future. Because I think the relevant scale is neither the Bostromian/Yudkowskian view:

nor the common sense view:

but rather something like this:
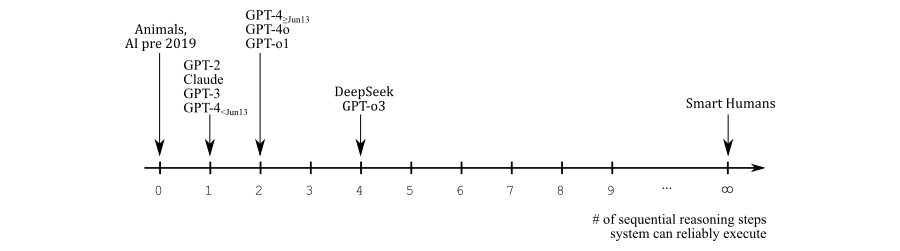
There are several caveats to this. One is that just getting from 0 to 1 on this scale requires a thought generator, which may be more than half of the total difficulty (or perhaps less than half, but certainly more than , so, either way, the scale is nonlinear). Another is that humans are not infinitely intelligent; their position on the scale just says that they can make indefinite progress on a problem given infinite time, which they don't have. And a third is that I just pulled these numbers out of my hat; you could certainly debate the claim that DeepSeek and o3 can do precisely 4 consecutive steps, or really any of these placements.
You could also argue that LLMs can do a lot more tasks with scaffolding, but I think figuring out how to decompose a task is usually the hardest part, so I think performance of pure reasoning models is the most relevant variable. (But see the section on human-AI teams.)
Nonetheless, I think the scale makes the point that very short timelines are not super likely. Remember that we have no a priori reason to suspect that there are jumps in the future; humans perform sequential reasoning differently, so comparisons to the brain are just not informative. LLMs just started doing sequential reasoning, and there's a big difference between the difficulty of what a smart human can figure out in 10 minutes vs. 10 years, and the latter is what AI needs to do – in fact, to outperform – to qualify as AGI. Imo. We're talking about a lot of steps here. So even if everything is smooth sailing from here, my point estimate for timelines would still be above 10 years. Maybe 15 years, I don't know.
Or, maybe there will be a sudden jump. Maybe learning sequential reasoning is a single trick, and now we can get from 4 to 1000 in two more years. Or, maybe there will be a paradigm shift, and someone figures out how to make a more brain-like AGI, in which case the argument structure changes. -year timelines aren't impossible, I just don't think they're likely.
3. More Thoughts on Sequential Reasoning
3.1. Subdividing the Category
Maybe sequential reasoning isn't best viewed as a single category. Maybe it makes sense to look at different types. Here are three types that I think could be relevant, with two examples for each.
- Type A: Sequential reasoning of any kind
- Once the cards in the earlier puzzle are labeled , , , , , , (with "S" for "same neighbor" and "D" for "different neighbor"), figuring out that (because has identical neighbors) and (because has identical neighbors) and therefore
- Reasoning that
Ne2allowsQg2#and is therefore a bad move
- Type B: Sequential reasoning where correctness cannot be easily verified
- Conclude that you should focus on the places where you feel shocked everyone's dropping the ball [LW · GW]
- Reasoning, without the help of an engine, to retreat the white bishop to e2 instead so that it can be put on f1 after castling to prevent
Qg2#
- Type C: Deriving a new concept/term/category/abstraction to better think about a problem
- Derive the inner vs. outer dimension [LW · GW] to improve (degrade? [LW · GW]) our ability to discuss the alignment problem
- Come up with the concept of dietary fiber, comprising many different molecules, to better discuss nutrition
(I'll keep writing the types in boldface to make them distinct and different from the cards.) As written, B is a subset of A. I also think C is best viewed as a subset of B; deriving a new label or category is a kind of non-provably useful way to make progress on a difficult problem.
LLMs can now do a little bit of A. One could make the argument that they're significantly worse at B, and worse still at C. (H/t: The Rising Sea [LW · GW].) Can they do any C? It's somewhat unclear – you could argue that, e.g., the idea to label the seven cards in the first place, especially in a way that differentiates cards with the same vs. different neighbors, is an instance of C. Which LLMs did. But it's also just applying a technique they've seen millions of times in the training data to approach similar problems, so in that sense it's not a "new" concept. So maybe it doesn't count.
As of right now, I think there's still at least an argument that everything they can do in A is outside C. (I don't think there's an argument that it's all outside B because learned heuristics are in B, and insofar as LLMs can play chess, they probably do B – but they also have a ton of relevant training data here, so one might argue that their approach to B tends not to generalize.)
What they clearly can't do yet is long-form autonomous research, which is where C is key. Humans are actually remarkably bad at A in some sense, yet we can do work that implicitly utilizes hundreds if not thousands of steps, which are "hidden" in the construction of high-level concepts. Here's an example by GPT-4o (note that Ab is the category of abelian groups):
Theorem. Every nonzero abelian group admits a nontrivial homomorphism into .
Proof. By Pontryagin duality, the character group of any discrete abelian group is nontrivial unless . Since is an injective cogenerator in , there exists a nontrivial map .
GPT-4 could provide this proof, and maybe it could even write similar proofs that aren't directly copied from the literature, but only because it inherited 99% of the work through the use of concepts in its training data.
There is also an issue with the architecture. Current LLMs can only do sequential reasoning of any kind by adjusting their activations, not their weights, and this is probably not enough to derive and internalize new concepts à la C. Doing so would require a very large context window. That said, I think of this as more of a detail; I think the more fundamental problem is the ability to do B and C at all, especially in domains with sparse feedback. This also relates to the next section.
3.2. Philosophical Intelligence
(Note: this section is extremely speculative, not to mention unfalsifiable, elitist, self-serving, and a priori implausible. I'm including it anyway because I think it could be important, but please treat it separate from the remaining post.)
Similar to how IQ predicts performance on a wide range of reasoning tasks, I think there is a property that does the same for reasoning on philosophical tasks. "Philosophy" is a human-invented category so it's not obvious that such a property would exist (but see speculations about this later), but I've talked to a lot of people about philosophy in the last four years, and I've found this pattern to be so consistent that I've been convinced it does exist.
Furthermore, I think this category:
-
has a surprisingly weak correlation to IQ (although certainly ); and
-
is a major predictor of how much success someone has in their life, even if they don't write about philosophy. (This is probably the most speculative claim of this section and I can't do anything to prove it; it's just another pattern that I've seen too much not to believe it.)
For example, I suspect philosophical intelligence was a major driver behind Eliezer's success (and not just for his writing about philosophy). Conversely, I think many people with crazy high IQ who don't have super impressive life achievements (or only achieve great things in their specific domain, which may not be all that useful for humanity) probably don't have super high philosophical intelligence.
So, why would any of this be true? Why would philosophical intelligence be a thing, and even if it were a thing, why would it matter beyond doing philosophy (which is probably not necessary for AGI)?
I think the answer for both questions is that philosophical intelligence is about performance on problems for which there is no clearly relevant training data. (See the footnote[4] for why I think this skill is particularly noticeable on philosophical problems.) That means it's a subset of B, and specifically problems on B where feedback is hard to come by. I think it's probably mostly about the ability to figure out which "data" is relevant in such cases (with an inclusive notion of "data" that includes whatever we use to think about philosophy). It may be related to a high setting of Stephen Grossberg's vigilance parameter.
If this is on the right track, then I think it's correct to view this skill as a subset of intelligence. I think it would probably be marginally useful on most tasks (probably increases IQ by a few points) but be generally outclassed by processing speed and creativity (i.e., "regular intelligence").
For example, suppose Anna has exceptional philosophical intelligence but average regular intelligence and Bob is the reverse. Continuing in the spirit of wild speculation, I think Anna would have an advantage on several relevant tasks, e.g.:
- If a chess position is very non-concrete (i.e., strategic rather than tactical), Anna might figure out how what she's learned applies to the present case better than Bob.
- If she's at the start of a coding problem, Anna might pattern-match it to past problems in a non-obvious way that causes her to select a working approach right away, whereas Bob might start off trying something that doesn't work.
However, she's likely to be outperformed by Bob in both cases:
- Bob would most likely outcalculate Anna from a marginally worse position. (In chess, tactics usually triumph over strategy.)
- Bob can probably code at 3x the speed, start over when his approach doesn't work, and still finish first.
For these and many other tasks, I think philosophical intelligence will provide a nonzero but small advantage. But now consider a decision or problem for which time is abundant but training data is hard to come by. Almost all philosophical problems are of this kind, but so are many practical problems – they might be empirical in principle, but that doesn't matter if no relevant data can be obtained over a lifetime. I think the following questions are all a little like this, although to varying degrees:
- Which career path should I take?
- Should I switch careers even though I'm currently successful?
- Should I spend several years writing essays about rationality and publish them on a free blog?
- If I decide to work on AI alignment, which research direction should I pursue?
- Which interpretation of quantum mechanics is true (and is this even a well-defined question)?
- Is AI inherently safe because it's created by humans?
- What is morality/probability/consciousness/value?
If you're now expecting me to argue that this could be good news because LLMs seem to have low philosophical intelligence... then you're correct! In my experience, when you ask an LLM a question in this category, you a summary of popular thought on the subject – the same as on any other open-ended question – without any ability to differentiate good from bad ideas. And if you ask something for which there is no cached answer, you usually get back utter nonsense:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Is all the above highly speculative? Yes. Is this "philosophical intelligence" ultimately just measuring people's tendency to agree with me? I can't prove that it's not. Is it a suspiciously convenient line of argument, given that I'm afraid of AI and would like timelines to be long? Definitely. Is it inherently annoying to argue based on non-objective criteria? Absolutely.
But I wanted to include this section because at least that last property may just be inherent to the relevant capabilities of AI. Perhaps "problems for which we can't all agree on the right answer" are actually a really important class, and if that's the case, we probably should talk about them, even if we can't all agree on the right answer.
4. Miscellaneous
4.1. Your description of thought generation and assessment seems vague, underspecified, and insufficiently justified to base your conclusions on.
I agree. I have a lot more to say about why I think the model is accurate and what exactly it says, but I don't know how to do it in under 20k words, so I'm not doing it here. (If I ever publish my consciousness sequence, I'll write about it there.) For right now, the choice was between writing it with a shaky foundation for the core claim or not writing it at all, and I decided to do the former.
That said, I don't think the claim that the brain uses fundamentally different processes for thought generation and assessment is particularly crazy or fringe. See e.g. Steven Byrnes' Valence sequence [? · GW].
4.2. If your model is on the right track, doesn't this mean that human+AI teams could achieve significantly superhuman performance and that these could keep outperforming pure AI systems for a long time?
The tl;dr is that I'm not sure, but I think the scenario is plausible enough that it deserves more consideration than it's getting right now.
The case for: LLMs are now legitimately strong at one-step (and potentially two-step and three-step) reasoning. If this trend continues and LLMs outperform humans in short-term reasoning but struggle with reliability and a large number of steps, then it would seem like human/LLM teams could complement each other nicely and outperform pure humans by a lot, and perhaps for a long time.
The case against: Because of the difficulties discussed in §3.1 and §3.2, it's unclear how this would work in practice. Most of the time I'm doing intellectual work, I'm neither at the beginning of a problem nor working on a problem with clear feedback. (This may be especially true for me due to my focus on consciousness, but it's probably mostly true for most people.) So far I'm primarily getting help from LLMs for coding and understanding neuroscience papers. These use cases are significant but also inherently limited, and it's unclear how progress on A would change that.
But nonetheless, maybe there are ways to overcome these problems in the future. I don't know what this would look like, but I feel like "LLM/human teams will outperform both pure LLMs and pure humans by a significant factor and for a significant period of time" is a plausible enough scenario to deserve attention.
4.3. What does this mean for safety, p(doom), etc.?
I was initially going to skip this topic because I don't think I have much to add when it comes to alignment and safety. But given the current vibes, doing so felt a bit tone-deaf, so I added a section even though I don't have many exciting insights.
Anyway, here's what I'll say. I don't dispute that the recent events look bad [LW · GW]. But I don't think the period we're in right now is particularly crucial. If democracy in the USA still exists in four years, then there will be a different administration 2029-2033, which is probably a more important time period than right now. I don't know how much lock-in there is from current anti-safety vibes, but we know they've changed in the past.
And of course, that still assumes LLMs do scale to AGI without a significantly new paradigm. Which I think has become more plausible after DeepSeek and o3, but it's by no means obvious. If they don't scale to AGI, then even more can change between now and then.
On that note, TsviBT [LW · GW] has argued [LW(p) · GW(p)] that for many people, their short timelines are mostly vibes-based. I'm pretty confident that this is true, but I'm even more confident that it's not specific to short timelines. If and when it becomes obvious that LLMs won't scale to AGI, there will probably be a lot of smugness from people with long timelines – especially because the vibes right now are so extreme – and it will probably be mostly unearned. I think the future is highly uncertain now, and if a vibe shift really does happen, it will still be very uncertain then.
In fact, there's a sense in which this problem can be solved in a purely 'methodical' way, without requiring any creativity. Start by writing down the sequence with seven different letters (
A-B-C-D-E-F-G; this sequence is correct wlog. Now treat the same neighbor criterion as a set of four different equations and apply them in any order, changing a symbol for each to make it true. (E.g., the first requires that B=G, so change the sequence toA-B-C-D-E-F-B). This process yieldsA-B-A-B-A-F-Bafter four steps, which is the same solution we've derived above. ↩︎The full transcript is here, given as a pdf because it's so long. To my surprise, DeepSeek ended up not solving the puzzle despite getting the key idea several times (it eventually just submitted a wrong solution). I think it shows the improvement regardless of the eventual failure, but since it didn't get it right, I decided to query DeepSeek (R1) as well, which of course solved it (it can do harder problems than this one, imE). Transcript for that (also very long) is here. ↩︎
I realize that viewing the Jun13 update as a larger step than GPT-4 GPT-o1 is highly unusual, but this is genuinely my impression. I don't think it has any bearing on the post's thesis (doesn't really matter where on the way the improvements happened), but I'm mentioning it to clarify that this categorization isn't a clerical error. ↩︎
Philosophy tends to be both non-empirical and non-formal, which is why you can never settle questions definitively. I also think these properties are pretty unique because
- If something becomes empirical, it's usually considered a science. E.g., "what are the building blocks of matter" used to be considered philosophy; now it's physics.
- If something becomes formal, it's usually considered math. In fact, metalogic formalizes math as a formal language (usually in the language of set theory, but it can also be done in other languages), and "you can express it in a formal language" is basically the same as "you can formalize it". E.g., you could argue that the Unexpected Hanging Paradox is a philosophical problem, but if I answer it by making a formal model, we'd probably consider that math – that is, unless we're debating how to translate it properly, which could again be considered philosophy, or how to interpret the model. Similarly, Wikipedia says that Occam's Razor is philosophy and Kolmogorov Complexity science or math.
52 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2025-02-13T19:49:01.516Z · LW(p) · GW(p)
I would find this post much more useful to engage with if you more concretely described the type of tasks that you think AIs will remain bad and gave a bunch of examples. (Or at least made an argument for why it is hard to construct examples if that is your perspective.)
I think you're pointing to a category like "tasks that require lots of serial reasoning for humans, e.g., hard math problems particularly ones where the output should be a proof". But, I find this confusing, because we've pretty clearly seen huge progress on this in the last year such that it seems like the naive extrapolation would imply that systems are much better at this by the end of the year.
Already AIs seem to be not that much worse at tricky serial reasoning than smart humans:
- My sense is that AIs are pretty competitive at 8th grade competition math problems with numerical answers and that are relatively shorter. As in, they aren't much worse than the best 8th graders at AIME or similar.
- At proofs, the AIs are worse, but showing some signs of life.
- On logic/reasoning puzzles the AIs are already pretty good and seems to be getting better rapidly on any specific type of task as far as I could tell.
It would be even better if you pointed to some particular benchmark and made predictions.
Replies from: TsviBT, sil-ver↑ comment by TsviBT · 2025-02-13T21:29:32.087Z · LW(p) · GW(p)
What are some of the most impressive things you do expect to see AI do, such that if you didn't see them within 3 or 5 years, you'd majorly update about time to the type of AGI that might kill everyone?
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-02-13T23:36:50.331Z · LW(p) · GW(p)
Consider tasks that quite good software engineers (maybe top 40% at Jane Street) typically do in 8 hours without substantial prior context on that exact task. (As in, 8 hour median completion time.) Now, we'll aim to sample these tasks such that the distribution and characteristics of these tasks are close to the distribution of work tasks in actual software engineering jobs (we probably can't get that close because of the limited context constraint, but we'll try).
In short timelines, I expect AIs will be able to succeed at these tasks 70% of the time within 3-5 years and if they didn't, I would update toward longer timelines. (This is potentially using huge amounts of inference compute and using strategies that substantially differ from how humans do these tasks.)
The quantitative update would depend on how far AIs are from being able to accomplish this. If AIs were quite far (e.g., at 2 hours on this metric which is pretty close to where they are now) and the trend on horizon length indicated N years until 64 hours, I would update to something like 3 N as my median for AGI.
(I think a reasonable interpretation of the current trend indicates like 4 month doubling times. We're currently at like a bit less than 1 hour for this metric I think, though maybe more like 30 min? Maybe you need to get to 64 hours until stuff feels pretty close to getting crazy. So, this suggests 2.3 year, though I expect longer in practice. My actual median for "AGI" in a strong sense is like 7 years, so 3x longer than this.)
Edit: Note that I'm not responding to "most impressive", just trying to operationalize something that would make me update.
Replies from: TsviBT↑ comment by TsviBT · 2025-02-13T23:46:58.127Z · LW(p) · GW(p)
Thanks... but wait, this is among the most impressive things you expect to see? (You know more than I do about that distribution of tasks, so you could justifiably find it more impressive than I do.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-02-13T23:50:16.206Z · LW(p) · GW(p)
No, sorry I was mostly focused on "such that if you didn't see them within 3 or 5 years, you'd majorly update about time to the type of AGI that might kill everyone". I didn't actually pick up on "most impressive" and actually tried to focus on something that occurs substantially before things get crazy.
Most impressive would probably be stuff like "automate all of AI R&D and greatly accelerate the pace of research at AI companies". (This seems about 35% likely to me within 5 years, so I'd update by at least that much.) But this hardly seems that interesting? I think we can agree that once the AIs are automating whole companies stuff is very near.
Replies from: TsviBT↑ comment by TsviBT · 2025-02-13T23:58:35.322Z · LW(p) · GW(p)
Ok. So I take it you're very impressed with the difficulty of the research that is going on in AI R&D.
we can agree that once the AIs are automating whole companies stuff
(FWIW I don't agree with that; I don't know what companies are up to, some of them might not be doing much difficult stuff and/or the managers might not be able to or care to tell the difference.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-02-14T00:01:44.613Z · LW(p) · GW(p)
I mean, I don't think AI R&D is a particularly hard field persay, but I do think it involves lots of tricky stuff and isn't much easier than automating some other plausibly-important-to-takeover field (e.g., robotics). (I could imagine that the AIs have a harder time automating philosophy even if they were trying to work on this, but it's more confusing to reason about because human work on this is so dysfunctional.) The main reason I focused on AI R&D is that I think it is much more likely to be fully automated first and seems like it is probably fully automated prior to AI takeover.
Replies from: TsviBT↑ comment by TsviBT · 2025-02-14T00:09:34.484Z · LW(p) · GW(p)
Ok, I think I see what you're saying. To check part of my understanding: when you say "AI R&D is fully automated", I think you mean something like:
Replies from: DavidmanheimMost major AI companies have fired almost all of their SWEs. They still have staff to physically build datacenters, do business, etc.; and they have a few overseers / coordinators / strategizers of the fleet of AI R&D research gippities; but the overseers are acknowledged to basically not be doing much, and not clearly be even helping; and the overall output of the research group is "as good or better" than in 2025--measured... somehow.
↑ comment by Davidmanheim · 2025-02-14T02:07:04.503Z · LW(p) · GW(p)
I could imagine the capability occurring but not playing out that way, because the SWEs won't necessarily be fired even after becoming useless - so it won't be completely obvious from the outside. But this is a sociological point about when companies fire people, not a prediction about AI capabilities.
Replies from: o-o↑ comment by O O (o-o) · 2025-02-14T19:11:37.013Z · LW(p) · GW(p)
SWEs won't necessarily be fired even after becoming useless
I'm actually surprised at how eager/willing big tech is to fire SWEs once they're sure they won't be economically valuable. I think a lot of priors for them being stable come from the ZIRP era. Now, these companies have quite frequent layoffs, silent layoffs, and performance firings. Companies becoming leaner will be a good litmus test for a lot of these claims.
↑ comment by Rafael Harth (sil-ver) · 2025-02-13T21:43:47.503Z · LW(p) · GW(p)
So, I agree that there has been substantial progress in the past year, hence the post title. But I think if you naively extrapolate that rate of progress, you get around 15 years.
The problem with the three examples you've mentioned is again that they're all comparing human cognitive work across a short amount of time with AI performance. I think the relevant scale doesn't go from 5th grade performance over 8th grade performance to university-level performance or whatever, but from "what a smart human can do in 5 minutes" over "what a smart human can do in an hour" over "what a smart human can do in a day", and so on.
I don't know if there is an existing benchmark that measures anything like this. (I agree that more concrete examples would improve the post, fwiw.)
And then a separate problem is that math problems are in in the easiest category from §3.1 (as are essentially all benchmarks).
Replies from: ryan_greenblatt, Davidmanheim↑ comment by ryan_greenblatt · 2025-02-13T23:46:13.830Z · LW(p) · GW(p)
I think if you look at "horizon length"---at what task duration (in terms of human completion time) do the AIs get the task right 50% of the time---the trends will indicate doubling times of maybe 4 months (though 6 months is plausible). Let's say 6 months more conservatively. I think AIs are at like 30 minutes on math? And 1 hour on software engineering. It's a bit unclear, but let's go with that. Then, to get to 64 hours on math, we'd need 7 doublings = 3.5 years. So, I think the naive trend extrapolation is much faster than you think? (And this estimate strikes me as conservative at least for math IMO.)
Replies from: habryka4, sil-ver↑ comment by habryka (habryka4) · 2025-02-14T00:51:14.401Z · LW(p) · GW(p)
And 1 hour on software engineering.
FWIW, this seems like an overestimate to me. Maybe o3 is better than other things, but I definitely can't get equivalents of 1-hour chunks out of language models, unless it happens to be an extremely boilerplate-heavy step. My guess is more like 15-minutes, and for debugging (which in my experience is close to most software-engineering time), more like 5-10 minutes.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-02-14T00:58:50.339Z · LW(p) · GW(p)
The question of context might be important, see here [LW(p) · GW(p)]. I wouldn't find 15 minutes that surprising for ~50% success rate, but I've seen numbers more like 1.5 hours. I thought this was likely to be an overestimate so I went down to 1 hour, but more like 15-30 minutes is also plausible.
Keep in mind that I'm talking about agent scaffolds here.
Replies from: habryka4↑ comment by habryka (habryka4) · 2025-02-14T01:05:30.286Z · LW(p) · GW(p)
Keep in mind that I'm talking about agent scaffolds here.
Yeah, I have failed to get any value out of agent scaffolds, and I don't think I know anyone else who has so far. If anyone has gotten more value out of them than just the Cursor chat, I would love to see how they do it!
All things like Cursor composer and codebuff and other scaffolds have been worse than useless for me (though I haven't tried it again after o3-mini, which maybe made a difference, it's been on my to-do list to give it another try).
Replies from: winstonBosan, ryan_greenblatt↑ comment by winstonBosan · 2025-02-14T18:16:50.947Z · LW(p) · GW(p)
FYI I do find that aider using a mixed routing between r1 and o3-mini-high as the architect model with sonnet as the editor model to be slightly better than cursor/windsurf etc.
Or for minimal setup, this is what is ranking the highest on aider-polyglot test:aider --architect --model openrouter/deepseek/deepseek-r1 --editor-model sonnet
↑ comment by ryan_greenblatt · 2025-02-14T01:47:36.372Z · LW(p) · GW(p)
(I don't expect o3-mini is a much better agent than 3.5 sonnet new out of the box, but probably a hybrid scaffold with o3 + 3.5 sonnet will be substantially better than 3.5 sonnet. Just o3 might also be very good. Putting aside cost, I think o1 is usually better than o3-mini on open ended programing agency tasks I think.)
↑ comment by Rafael Harth (sil-ver) · 2025-02-14T14:00:09.265Z · LW(p) · GW(p)
I don't think a doubling every 4 or 6 months is plausible. I don't think a doubling on any fixed time is plausible because I don't think overall progress will be exponential. I think you could have exponential progress on thought generation, but this won't yield exponential progress on performance. That's what I was trying to get at with this paragraph:
My hot take is that the graphics I opened the post with were basically correct in modeling thought generation. Perhaps you could argue that progress wasn't quite as fast as the most extreme versions predicted, but LLMs did go from subhuman to superhuman thought generation in a few years, so that's pretty fast. But intelligence isn't a singular capability; it's
two capabilitiesa phenomenon better modeled as two capabilities, and increasing just one of them happens to have sub-linear returns on overall performance.
So far (as measured by the 7card puzzle, which It think is a fair data point) I think we went from 'no sequential reasoning whatsoever' to 'attempted sequential reasoning but basically failed' (Jun13 update) to now being able to do genuine sequential reasoning for the first time. And if you look at how DeepSeek does it, to me this looks like the kind of thing where I expect difficulty to grow exponentially with argument length. (Based on stuff like it constantly having to go back and double checking even when it got something right.)
What I'd expect from this is not a doubling every N months, but perhaps an ability to reliably do one more step every N months. I think this translates into more above-constant returns on the "horizon length" scale -- because I think humans need more than 2x time for 2x steps -- but not exponential returns.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-02-14T19:16:49.926Z · LW(p) · GW(p)
I expect difficulty to grow exponentially with argument length. (Based on stuff like it constantly having to go back and double checking even when it got something right.)
Training of DeepSeek-R1 doesn't seem to do anything at all to incentivize shorter reasoning traces, so it's just rechecking again and again because why not. Like if you are taking an important 3 hour written test, and you are done in 1 hour, it's prudent to spend the remaining 2 hours obsessively verifying everything.
↑ comment by Davidmanheim · 2025-02-14T02:31:19.018Z · LW(p) · GW(p)
As I said in my top level comment, I don't see a reason to think that once the issue is identified as they key barrier, work on addressing it would be so slow.
comment by Lukas_Gloor · 2025-02-14T00:59:26.617Z · LW(p) · GW(p)
I liked most thoughts in this post even though I have quite opposite intutions about timelines.
I agree timeline intuitions feel largely vibes based, so I struggle to form plausible guesses about the exact source behind our different intuitions.
I thought this passage was interesting in that respect:
Or, maybe there will be a sudden jump. Maybe learning sequential reasoning is a single trick, and now we can get from 4 to 1000 in two more years.
What you write as an afterthought is what I would have thought immediately. Sure, good chance I'm wrong. Still, to me, it feels like there's probably no big difference between "applying reasoning for 3 steps" and "applying reasoning for 1,000 steps." Admittedly, (using your terminology,) you probably need decent philosophical intelligence to organize your 1,000 steps with enough efficiency and sanity checks along the way so you don't run the risk of doing tons of useless work. But I don't see why that's a thing that cannot also be trained, now that we have the chain of thought stuff and can compare, over many answering runs, which thought decompositions more reliably generate accurate answers. Humans must have gotten this ability from somewhere and it's unlikely the brain has tons of specialized architecture for it. The thought generator seems more impressive/fancy/magic-like to me. Philosophical intelligence feels like something that heavily builds on a good thought generator plus assessor, rather than being entirely its own thing. (It also feels a bit subjective -- I wouldn't be surprised if there's no single best configuration of brain parameters for making associative leaps through thought space, such that different reasoners will be better at different problem domains. Obviously smart reasoners should then pick up where they're themselves experts and where they should better defer.)
Your blue and red graphs made me think about how AI appears to be in a thought generator overhang, so any thought assessor progress should translate into particularly steep capability improvements. If sequential reasoning is mostly a single trick, things should get pretty fast now. We'll see soon? :S
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-17T14:44:43.263Z · LW(p) · GW(p)
Humans must have gotten this ability from somewhere and it's unlikely the brain has tons of specialized architecture for it.
This is probably a crux; I think the brain does have tons of specialized architecture for it, and if I didn't believe that, I probably wouldn't think thought assessment was as difficult.
The thought generator seems more impressive/fancy/magic-like to me.
Notably people's intuitions about what is impressive/difficult tend to be inversely correlated with reality. The stereotype is (or at least used to be) that AI will be good at rationality and reasoning but struggle with creativity, humor, and intuition. This stereotype contains information since inverting it makes better-than-chance predictions about what AI has been good at so far, especially LLMs.
I think this is not a coincidence but roughly because people use "degree of conscious access" an inverse proxy for intuitive difficulty. The more unconscious something is, the more it feels like we don't know how it works, the more difficult it intuitively seems. But I suspect degree of conscious access positively correlates with difficulty.
If sequential reasoning is mostly a single trick, things should get pretty fast now. We'll see soon? :S
Yes; I think the "single trick" view might be mostly confirmed or falsified in as little as 2-3 years. (If I introspect I'm pretty confident that I'm not wrong here, the scenario that frightens me is more that sequential reasoning improves non-exponentially but quickly, which I think could still mean doom, even if it takes 15 years. Those feel like short timelines to me.)
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-02-20T17:41:05.207Z · LW(p) · GW(p)
This is probably a crux; I think the brain does have tons of specialized architecture for it, and if I didn't believe that, I probably wouldn't think thought assessment was as difficult.
I think this is also a crux.
IMO, I think the brain is mostly cortically uniform, ala Steven Byrnes, and in particular I think that the specialized architecture for thought assessment was pretty minimal.
The big driver of human success is basically something like the bitter lesson applied to biological brains, combined with humans being very well optimized for tool use, such that they can over time develop technology that is used to dominate the world (it's also helpful that humans can cooperate reasonably below 100 people, which is more than almost all social groups, though I've become much more convinced that cultural learning is way less powerful than Henrich et al have said).
(There are papers which show that humans are better at scaling neurons than basically everyone else, but I can't find them right now).
comment by Gordon Seidoh Worley (gworley) · 2025-02-13T21:03:08.189Z · LW(p) · GW(p)
For example, I suspect philosophical intelligence was a major driver behind Eliezer's success (and not just for his writing about philosophy). Conversely, I think many people with crazy high IQ who don't have super impressive life achievements (or only achieve great things in their specific domain, which may not be all that useful for humanity) probably don't have super high philosophical intelligence.
Rather than "philosophical intelligence" I might call this "ability to actually win", which is something like being able to keep your thoughts in contact with reality, which is surprisingly hard to do for most complex thoughts that get tied up into one's self beliefs. Most people get lost in their own ontology and make mistakes because they let the ontology drift free from reality to protect whatever story they're telling about themselves or how they want the world to be.
comment by Davidmanheim · 2025-02-14T02:28:35.934Z · LW(p) · GW(p)
I don't really understand the implicit model where AI companies recognize that having a good thought assessor is the critical barrier to AGI, they put their best minds on solving it, and it seems like you think they just fail because it's the single incomparably hard human capability.
It seems plausible that the diagnosis of what is missing is correct, but strongly implausible that it's fundamentally harder than other parts of the puzzle, much less hard in ways that AI companies would need a decade to tackle. In my modal case, once they start, I expect progress to follow curves similar to every other capability they develop.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-14T10:50:31.817Z · LW(p) · GW(p)
If thought assessment is as hard as thought generation and you need a thought assessor to get AGI (two non-obvious conditionals), then how do you estimate the time to develop a thought assessor? From which point on do you start to measure the amount of time it took to come up with the transformer architecture?
The snappy answer would be "1956 because that's when AI started; it took 61 years to invent the transformer architecture that lead to thought generation, so the equivalent insight for thought assessment will take about 61 years". I don't think that's the correct answer, but neither is "2019 because that's when AI first kinda resembled AGI".
Replies from: AnthonyC, Davidmanheim, Dirichlet-to-Neumann↑ comment by AnthonyC · 2025-02-14T14:22:28.416Z · LW(p) · GW(p)
Keep in mind that we're now at the stage of "Leading AI labs can raise tens to hundreds of billions of dollars to fund continued development of their technology and infrastructure." AKA in the next couple of years we'll see AI investment comparable to or exceeding the total that has ever been invested in the field. Calendar time is not the primary metric, when effort is scaling this fast.
A lot of that next wave of funding will go to physical infrastructure, but if there is an identified research bottleneck, with a plausible claim to being the major bottleneck to AGI, then what happens next? Especially if it happens just as the not-quite-AGI models make existing SWEs and AI researchers etc. much more productive by gradually automating their more boilerplate tasks. Seems to me like the companies and investors just do the obvious thing and raise the money to hire an army of researchers in every plausibly relevant field (including math, neurobiology, philosophy, and many others) to collaborate. Who cares if most of the effort and money are wasted? The payoff for the fraction (faction?) that succeeds isn't the usual VC target of 10-100x, it's "many multiples of the current total world economy."
↑ comment by Davidmanheim · 2025-02-14T13:53:11.748Z · LW(p) · GW(p)
Transformers work for many other tasks, and it seems incredibly likely to me that the expressiveness includes not only game playing, vision, and language, but also other things the brain does. And to bolster this point, the human brain doesn't use two completely different architectures!
So I'll reverse the question; why do you think the thought assessor is fundamentally different from other neural functions that we know transformers can do?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-14T14:04:56.946Z · LW(p) · GW(p)
I do think the human brain uses two very different algorithms/architectures for thought generation and assessment. But this falls within the "things I'm not trying to justify in this post" category. I think if you reject the conclusion based on this, that's completely fair. (I acknowledged in the post that the central claim has a shaky foundation. I think the model should get some points because it does a good job retroactively predicting LLM performance -- like, why LLMs aren't already superhuman -- but probably not enough points to convince anyone.)
↑ comment by Dirichlet-to-Neumann · 2025-02-15T21:07:11.499Z · LW(p) · GW(p)
The transformer architecture was basically developed as soon as we got the computational power to make it useful. If a thought assessor is required and we are aware of the problem, and we have literally billions in funding to make it happen, I don't expect this to be that hard.
comment by plex (ete) · 2025-02-14T13:01:19.453Z · LW(p) · GW(p)
Humans without scaffolding can do a very finite number of sequential reasoning steps without mistakes. That's why thinking aids like paper, whiteboards, and other people to bounce ideas off and keep the cache fresh are so useful.
Replies from: steve2152, sil-ver↑ comment by Steven Byrnes (steve2152) · 2025-02-14T15:26:08.102Z · LW(p) · GW(p)
I think OP is using “sequential” in an expansive sense that also includes e.g. “First I learned addition, then I learned multiplication (which relies on already understanding addition), then I learned the distributive law (which relies on already understanding both addition and multiplication), then I learned the concept of modular arithmetic (which relies on …) etc. etc.” (part of what OP calls “C”). I personally wouldn’t use the word ‘sequential’ for that—I prefer a more vertical metaphor like ‘things building upon other things’—but that’s a matter of taste I guess. Anyway, whatever we want to call it, humans can reliably do a great many steps, although that process unfolds over a long period of time.
…And not just smart humans. Just getting around in the world, using tools, etc., requires giant towers of concepts relying on other previously-learned concepts.
Obviously LLMs can deal with addition and multiplication and modular arithmetic etc. But I would argue that this tower of concepts building on other concepts was built by humans, and then handed to the LLM on a silver platter. I join OP in being skeptical that LLMs (including o3 etc.) could have built that tower themselves from scratch, the way humans did historically. And I for one don’t expect them to be able to do that thing until an AI paradigm shift happens.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-14T15:59:49.754Z · LW(p) · GW(p)
[...] I personally wouldn’t use the word ‘sequential’ for that—I prefer a more vertical metaphor like ‘things building upon other things’—but that’s a matter of taste I guess. Anyway, whatever we want to call it, humans can reliably do a great many steps, although that process unfolds over a long period of time.
…And not just smart humans. Just getting around in the world, using tools, etc., requires giant towers of concepts relying on other previously-learned concepts.
As a clarification for anyone wondering why I didn't use a framing more like this in the post, it's because I think these types of reasoning (horizontal and vertical/A and C) are related in an important way, even though I agree that C might be qualitatively harder than A (hence section §3.1). Or to put it differently, if one extreme position is "we can look entirely at A to extrapolate LLM performance into the future" and the other is "A and C are so different that progress on A is basically uninteresting", then my view is somewhere near the middle.
↑ comment by Rafael Harth (sil-ver) · 2025-02-14T13:15:33.424Z · LW(p) · GW(p)
This is true but I don't think it really matters for eventual performance. If someone thinks about a problem for a month, the number of times they went wrong on reasoning steps during the process barely influences the eventual output. Maybe they take a little longer. But essentially performance is relatively insensitive to errors if the error-correcting mechanism is reliable.
I think this is actually a reason why most benchmarks are misleading (humans make mistakes there, and they influence the rating).
comment by teradimich · 2025-02-15T22:14:53.779Z · LW(p) · GW(p)
If only one innovation separates us from AGI, we're fucked.
It seems that if OpenAI or Anthropic had agreed with you, they should have had even shorter timelines.
comment by Cole Wyeth (Amyr) · 2025-02-14T05:41:30.827Z · LW(p) · GW(p)
I endorse this take wholeheartedly.
I also wrote something related (but probably not as good) very recently: https://www.lesswrong.com/posts/vvgND6aLjuDR6QzDF/my-model-of-what-is-going-on-with-llms [LW · GW]
comment by Gordon Seidoh Worley (gworley) · 2025-02-13T20:59:43.196Z · LW(p) · GW(p)
AI will not kill everyone without sequential reasoning.
This statement might be literally true, but only because of a loophole like "AI needs humans to help it kill everyone". Like we're probably not far away from, or may already have, the ability to create novel biological weapons, like engineered viruses, that could kill all humans before a response could be mustered. Yes, humans have to ask the LLM to help it create the thing and then humans have to actual do the lab work and deployment, but from an outside view (which is especially important from a policy perspective), this looks a lot like "AI could kill everyone without sequential reasoning".
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-13T21:46:33.542Z · LW(p) · GW(p)
I generally think that [autonomous actions due to misalignment] and [human misuse] are distinct categories with pretty different properties. The part you quoted addresses the former (as does most of the post). I agree that there are scenarios where the second is feasible and the first isn't. I think you could sort of argue that this falls under AIs enhancing human intelligence.
comment by tangerine · 2025-02-15T18:33:54.959Z · LW(p) · GW(p)
Current LLMs can only do sequential reasoning of any kind by adjusting their activations, not their weights, and this is probably not enough to derive and internalize new concepts à la C.
For me this is the key bit which makes me update towards your thesis.
Replies from: p.b.↑ comment by p.b. · 2025-02-15T22:25:03.003Z · LW(p) · GW(p)
I think this inability of "learning while thinking" might be the key missing thing of LLMs and I am not sure "thought assessment" or "sequential reasoning" are not red herrings compared to this. What good is assessment of thoughts if you are fundamentally limited in changing them? Also, reasoning models seem to do sequential reasoning just fine as long as they already have learned all the necessary concepts.
comment by ChristianKl · 2025-02-14T14:13:30.610Z · LW(p) · GW(p)
Another is that humans are not infinitely intelligent; their position on the scale just says that they can make indefinite progress on a problem given infinite time, which they don't have.
It's not clear to me that an human, using their brain and a go board for reasoning could beat AlphaZero even if you give them infinite time.
For most problems, there are diminishing returns to additional human reasoning steps. For many reasoning tasks, humans are influenced by a lot of biases. If you do superforcasting, I don't know of a way to remove the biases inherent in my forecast by just adding additional reasoning cycles.
If might be possible for a model to rate the reasoning quality of deep research and then train on the top 10% of deep research queries.
If you build language model-based agents there are plenty of tasks that those agents can do that have real-world feedback. The amount of resources invested go up a lot and currently the big labs haven't deployed agents.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-14T14:56:07.278Z · LW(p) · GW(p)
It's not clear to me that an human, using their brain and a go board for reasoning could beat AlphaZero even if you give them infinite time.
I agree but I dispute that this example is relevant. I don't think there is any step in between "start walking on two legs" to "build a spaceship" that requires as much strictly-type-A reasoning as beating AlphaZero at go or chess. This particular kind of capability class doesn't seem to me to be very relevant.
Also, to the extent that it is relevant, a smart human with infinite time could outperform AlphaGo by programming a better chess/go computer. Which may sound silly but I actually think it's a perfectly reasonable reply -- using narrow AI to assist in brute-force cognitive tasks is something humans are allowed to do. And it's something that LLMs are also allowed to do; if they reach superhuman performance on general reasoning, and part of how they do this is by writing python scripts for modular subproblems, then we wouldn't say that this doesn't count.
comment by Larifaringer · 2025-02-14T10:14:01.773Z · LW(p) · GW(p)
Even if current LLM architectures cannot be upscaled or incrementally improved to achieve human-level intelligence, it is still possible that one or more additional breakthroughs will happen in the next few years that allow an explicit thought assessor module. Just like the transformer architecture surpsied everybody with its efficacy. So much money and human resources are being thrown at the pursuit of AGI nowadays, we cannot be confident that it will take 10 years or longer.
comment by StanislavKrym · 2025-03-28T07:56:39.836Z · LW(p) · GW(p)
Actually, even if the LLMs do scale to the AGI, we might find that a civilisation run by the AGI is unlikely to appear. The current state of the world energy industry and computation technology might fail to allow the AGI to generate answers to many tasks [LW · GW] that are necessary to sustain the energy industry itself [LW · GW]. Attempts to optimize the AGI would require it to be more energy efficient, which appears to lead it to be neuromorphic [LW · GW], which in turn could imply that the AGIs running the civilisation are to be split into many brains, resemble the humanity and be easily controllable. Does this fact decrease p(doom|misaligned AGI) from 1 to an unknown amount?
comment by bolu (bolek-szewczyk) · 2025-02-14T14:52:45.083Z · LW(p) · GW(p)
Qg2#, not Qb2# (typo)
comment by Pekka Puupaa (pekka-puupaa) · 2025-02-14T20:01:31.386Z · LW(p) · GW(p)
Can the author or somebody else explain what is wrong with Deepseek's answer to the Kolmogorov complexity question? It seems to give more or less the same answer I'd give, and even correctly notes the major caveat in the last sentence of its output.
I suppose its answer is a bit handwavy ("observer role"?), and some of the minor details of its arguments are wrong or poorly phrased, but the conclusion seems correct. Am I misunderstanding something?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-15T20:27:40.802Z · LW(p) · GW(p)
Here's my take; not a physicist.
So in general, what DeepSeek says here might align better with intuitive complexity, but the point of asking about Kolmogorov Complexity rather than just Occam's Razor is that we're specifically trying to look at formal description length and not intuitive complexity.
Many Worlds does not need extra complexity to explain the branching. The branching happens due to the part of the math that all theories agree on. (In fact, I think a more accurate statement is that the branching is a description of what the math does.)
Then there's the wavefunction collapse. So first of all, wavefunction collapse is an additional postulate not contianed in the remaining math, so it adds complexity. (... and the lack of the additional postulate does not add complexity, as DeepSeek claimed.) And then there's a separate issue with KC arguably being unable to model randomness at all. You could argue that this is a failure of the KC formalism and we need KC + randomness oracle to even answer the question. You could also be hardcore about it and argue that any nondeterministic theory is impossible to describe and therefore has KC . In either case, the issue of randomness is something you should probably bring up in response to the question.
And finally there's the observer role. Iiuc the less stupid versions of Copenhagen do not give a special role to an observer; there's a special role for something being causally entangled with the experiment's result, but it doesn't have to be an agent. This is also not really a separate principle from the wave function collapse I don't think, it's what triggers collapse. And then it doesn't make any sense to list as a strength of Copenhagen because if anything it increases description length.
There are variants of KC that penalize the amount of stuff that are created rather than just the the description length I believe, in which case MW would have very high KC. This is another thing DeepSeek could have brought up.
Replies from: pekka-puupaa↑ comment by Pekka Puupaa (pekka-puupaa) · 2025-02-16T02:29:35.784Z · LW(p) · GW(p)
I am also not a physicist, so perhaps I've misunderstood. I'll outline my reasoning.
An interpretation of quantum mechanics does two things: (1) defines what parts of our theory, if any, are ontically "real" and (2) explains how our conscious observations of measurement results are related to the mathematical formalism of QM.
The Kolmogorov complexity of different interpretations cannot be defined completely objectively, as DeepSeek also notes. But broadly speaking, defining KC "sanely", it ought to be correlated with a kind of "Occam's razor for conceptual entities", or more precisely, "Occam's razor over defined terms and equations".
I think Many Worlds is more conceptually complex than Copenhagen. But I view Copenhagen as a catchall term for a category of interpretations that also includes QBism and Rovelli's RQM. Basically, these are "observer-dependent" interpretations. I myself subscribe to QBism, but I view it as a more rigorous formulation of Copenhagen.
So, why should we think Many Worlds is more conceptually complex? Copenhagen is the closest we can come to a "shut up and calculate" interpretation. Pseudomathematically, we can say
Copenhagen ~= QM + "simple function connecting measurements to conscious experiences"
The reason we can expect Copenhagen-y interpretations to be simpler than other interpretations is because every other interpretation *also* needs a function to connect measurements to conscious experiences, but usually requires some extra machinery in addition to that.
Now I maybe don't understand MWI correctly. But as I understand it, what QM mathematically gives you is more like a chaotic flux of possibilities, rather than the kind of branching tree of self-consistent worldlines that MWI requires. The way you split up the quantum state into branches constitutes extra structure on top of QM. Thus:
Many Worlds ~= QM + "branching function" + "simple function connecting measurements to conscious experiences"
So it seems that MWI ought to have higher Kolmogorov Complexity than Copenhagen.
I don't think DeepSeek has argued this point correctly. But I also wouldn't call its answer nonsense. I would call it a reasonable but superficial answer with a little bit of nonsense mixed in; the kind of answer one might expect a precocious college student to give.
But again, I might be wrong.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-16T14:09:51.273Z · LW(p) · GW(p)
The reason we can expect Copenhagen-y interpretations to be simpler than other interpretations is because every other interpretation also needs a function to connect measurements to conscious experiences, but usually requires some extra machinery in addition to that.
I don't believe this is correct. But I separately think that it being correct would not make DeepSeek's answer any better. Because that's not what it said, at all. A bad argument does not improve because there exists a different argument that shares the same conclusion.
Replies from: pekka-puupaa↑ comment by Pekka Puupaa (pekka-puupaa) · 2025-02-16T21:26:33.047Z · LW(p) · GW(p)
I don't believe this is correct.
Which part do you disagree with? Whether or not every interpretation needs a way to connect measurements to conscious experiences, or whether they need extra machinery?
If the former: you need some way to connect the formalism to conscious experiences, since that's what an interpretation is largely for. It needs to explain how the classical world of your conscious experience is connected to the mathematical formalism. This is true for any interpretation.
If you're saying that many worlds does not actually need any extra machinery, I guess the most reasonable way to interpret that in my framework is to say that the branching function is a part of the experience function. I suppose this might correspond to what I've heard termed the Many Minds interpretation, but I don't understand that one in enough detail to say.
A bad argument does not improve because there exists a different argument that shares the same conclusion.
Let an argument A be called "steelmannable" if there exists a better argument S with a similar structure and similar assumptions (according to some metric of similarity) that proves the same conclusion as the original argument A. Then S is called a "steelman" of A.
It is clear that not all bad arguments are steelmannable. I think it is reasonable to say that steelmannable bad arguments are less nonsensical than bad arguments that are not steelmannable.
So the question becomes: can my argument be viewed as a steelman of DeepSeek's argument? I think so. You probably don't. However, since everybody understands their own arguments quite well, ceteris paribus it should be expected that I am more likely to be correct about the relationship between my argument and DeepSeek's in this case.
... Or at least, that would be so if I didn't have an admitted tendency to be too lenient in interpreting AI outputs. Nonetheless, I am not objecting to the claim that DeepSeek's argument is weak, but to the claim that it is nonsense.
We can both agree that DeepSeek's argument is not great. But I see glimmers of intelligence in it. And I fully expect that soon we will have models that will be able to argue the same things with more force.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2025-02-16T22:21:02.578Z · LW(p) · GW(p)
Whether or not every interpretation needs a way to connect measurements to conscious experiences, or whether they need extra machinery?
If we're being extremely pedantic, then then KC is about predicting conscious experience (or sensory input data, if you're an illusionist; one can debate what the right data type is). But this only matters for discussing things like Boltzmann brains. As soon as you assume that there exists an external universe, you can forget about your personal experience just try to estimate the length of the program that runs the universe.
So practically speaking, it's the first one. I think what quantum physics does with observers falls out of the math and doesn't require any explicit treatment. I don't think Copenhagen gets penalized for this, either. The wave function collapse increases complexity because it's an additional rule that changes how the universe operates, not because it has anything to do with observers. (As I mentioned, I think the 'good' version of Copenhagen doesn't mention observers, anyway.)
If you insist on the point that interpretation relates to an observer, then I'd just say that "interpretation of quantum mechanics" is technically a misnomer. It should just be called "theory of quantum mechanics". Interpretations don't have KC; theories do. We're comparing different source codes for the universe.
steelmanning
I think this argument is analogous to giving white credit for this rook check, which is fact a good move that allows white to win the queen next move -- when in actual fact white just didn't see that the square was protected and blundered a rook. The existence of the queen-winning tactic increases the objective evaluation of the move, but once you know that white didn't see it, it should not increase your skill estimate of white. You should judge the move as if the tactic didn't exist.
{kind=link}
Similarly, the existence of a way to salvage the argument might make the argument better in the abstract, but should not influence your assessment of DeepSeek's intelligence, provided we agree that DeepSeek didn't know it existed. In general, you should never give someone credit for areas of the chess/argument tree that they didn't search.
Replies from: pekka-puupaa↑ comment by Pekka Puupaa (pekka-puupaa) · 2025-02-17T03:11:44.684Z · LW(p) · GW(p)
Thank you, this has been a very interesting conversation so far.
I originally started writing a much longer reply explaining my position on the interpretation of QM in full, but realized that the explanation would grow so long that it would really need to be its own post. So instead, I'll just make a few shorter remarks. Sorry if these sound a bit snappy.
As soon as you assume that there exists an external universe, you can forget about your personal experience just try to estimate the length of the program that runs the universe.
And if one assumes an external universe evolving according to classical laws, the Bohmian interpretation has the lowest KC. If you're going to be baking extra assumptions into your theory, why not go all the way?
Interpretations and Kolmogorov Complexity
An interpretation is still a program. All programs have a KC (although it is usually ill-defined). Ultimately I don't think it matters whether we call these objects we're studying theories or interpretations.
Collapse postulate
Has nothing to do with how the universe operates, as I see it. If you'd like, I think we can cast Copenhagen into a more Many Worlds -like framework by considering Many Imaginary Worlds. This is an interpretation, in my opinion functionally equivalent to Copenhagen, where the worlds of MWI are assumed to represent imaginary possibilities rather than real universes. The collapse postulate, then, corresponds to observing that you inhabit a particular imaginary world -- observing that that world is real for you at the moment. By contrast, in ordinary MWI, all worlds are real, and observation simply reduces your uncertainty as to which observer (and in which world) you are.
If we accept the functional equivalence between Copenhagen and MIWI, this gives us an upper bound on the KC of Copenhagen. It is at most as complex as MWI. I would argue less.
Chess
I think we need to distinguish between "playing skill" and "positional evaluation skill". It could be said that DeepBlue is dumber than Kasparov in the sense of being worse at evaluating any given board position than him, while at the same time being a vastly better player than Kasparov simply because it evaluates exponentially more positions.
If you know that a player has made the right move for the wrong reasons, that should still increase your estimate of their playing skill, but not their positional evaluation skill.
Of course, in the case of chess, the two skills will be strongly correlated, and your estimate of the player's playing skill will still go down as you observe them making blunders in other positions. But this is not always so. In some fields, it is possible to reach a relatively high level of performance using relatively dumb heuristics.
Moving onto the case of logical arguments, playing skill corresponds to "getting the right answers" and positional evaluation skill corresponds to "using the right arguments".
In many cases it is much easier to find the right answers than to find correct proofs for those answers. For example, most proofs that Euler and Newton gave for their mathematical results are, technically, wrong by today's standards of rigor. Even worse, even today's proofs are not completely airtight, since they are not usually machine-verifiable.
And yet we "know" that the results are right. How can that be, if we also know that our arguments aren't 100% correct? Many reasons, but one is that we can see that our current proofs could be made more rigorous. We can see that they are steelmannable. And in fact, our current proofs were often reached by effectively steelmanning Euler's and Newton's proofs.
If we see DeepSeek making arguments that are steelmannable, that should increase our expectation that future models will, in fact, be able to steelman those arguments.