The Paris AI Anti-Safety Summit
post by Zvi · 2025-02-12T14:00:07.383Z · LW · GW · 21 commentsContents
Table of Contents An Actively Terrible Summit Statement The Suicidal Accelerationist Speech by JD Vance What Did France Care About? Something To Remember You By: Get Your Safety Frameworks What Do We Think About Voluntary Commitments? This Is the End The Odds Are Against Us and the Situation is Grim Don’t Panic But Also Face Reality None 21 comments
It doesn’t look good.
What used to be the AI Safety Summits were perhaps the most promising thing happening towards international coordination for AI Safety.
This one was centrally coordination against AI Safety.
In November 2023, the UK Bletchley Summit on AI Safety set out to let nations coordinate in the hopes that AI might not kill everyone. China was there, too, and included.
The practical focus was on Responsible Scaling Policies (RSPs), where commitments were secured from the major labs, and laying the foundations for new institutions.
The summit ended with The Bletchley Declaration (full text included at link), signed by all key parties. It was the usual diplomatic drek, as is typically the case for such things, but it centrally said there are risks, and so we will develop policies to deal with those risks.
And it ended with a commitment to a series of future summits to build upon success.
It’s over.
With the Paris AI ‘Action’ Summit, that dream seems to be dead. The French and Americans got together to dance on its grave, and to loudly proclaim their disdain for the idea that building machines that are smarter and more capable than humans might pose any sort of existential or catastrophic risks to the humans. They really do mean the effect of jobs, and they assure us it will be positive, and they will not tolerate anyone saying otherwise.
It would be one thing if the issue was merely that the summit-ending declaration. That happens. This goes far beyond that.
The EU is even walking backwards steps it has already planned, such as withdrawing its AI liability directive. Even that is too much, now, it seems.
(Also, the aesthetics of the whole event look hideous, probably not a coincidence.)

Table of Contents
- An Actively Terrible Summit Statement.
- The Suicidal Accelerationist Speech by JD Vance.
- What Did France Care About?.
- Something To Remember You By: Get Your Safety Frameworks.
- What Do We Think About Voluntary Commitments?
- This Is the End.
- The Odds Are Against Us and the Situation is Grim.
- Don’t Panic But Also Face Reality.
An Actively Terrible Summit Statement
Shakeel Hashim gets hold of the Paris AI Action Summit statement in advance. It’s terrible. Actively worse than nothing. They care more about ‘market concentration’ and ‘the job market’ and not at all about any actual risks from AI. Not a world about any actual safeguards, transparency, frameworks, any catastrophic let alone existential risks or even previous commitments, but time to talk about the importance of things like linguistic diversity. Shameful, a betrayal of the previous two summits.
Daniel Eth: Hot take, but if this reporting on the statement from the France AI “action” summit is true – that it completely sidesteps actual safety issues like CBRN risks & loss of control to instead focus on DEI stuff – then the US should not sign it.
…


The statement was a joke and completely sidelined serious AI safety issues like CBRN risks & loss of control, instead prioritizing vague rhetoric on things like “inclusivity”. I’m proud of the US & UK for not signing on. The summit organizers should feel embarrassed.
Hugo Gye: UK government confirms it is refusing to sign Paris AI summit declaration.
No10 spokesman: “We felt the declaration didn’t provide enough practical clarity on global governance, nor sufficiently address harder questions around national security and the challenge AI poses to it.”

The UK government is right, except this was even worse. The statement is not merely inadequate but actively harmful, and they were right not to sign it. That is the right reason to refuse.
Unfortunately the USA not only did not refuse for the right reasons, our own delegation demanded the very cripplings Daniel is discussing here.
Then we still didn’t sign on, because of the DEI-flavored talk.
Seán Ó hÉigeartaigh: After Bletchley I wrote about the need for future summits to maintain momentum and move towards binding commitments. Unfortunately it seems like we’ve slammed the brakes.
Peter Wildeford: Incredibly disappointing to see the strong momentum from the Bletchley and Seoul Summit commitments to get derailed by France’s ill-advised Summit statement. The world deserves so much more.
At the rate AI is improving, we don’t have the time to waste.
Stephen Casper: Imagine if the 2015 Paris Climate Summit was renamed the “Energy Action Summit,” invited leaders from across the fossil fuel industry, raised millions for fossil fuels, ignored IPCC reports, and produced an agreement that didn’t even mention climate change. #AIActionSummit

This is where I previously tried to write that this doesn’t, on its own, mean the Summit dream is dead, that the ship can still be turned around. Based on everything we know now, I can’t hold onto that anymore.
We shouldn’t entirely blame the French, though. Not only is the USA not standing up for the idea of existential risk, we’re demanding no one talk about it, it’s quite a week for Arson, Murder and Jaywalking it seems:
Seán Ó hÉigeartaigh: So we’re not allowed to talk about these things now.
That’s right. Cartoon villainy. We are straight-up starring in Don’t Look Up.
The Suicidal Accelerationist Speech by JD Vance
JD Vance is very obviously a smart guy. And he’s shown that when the facts and the balance of power change, he is capable of changing his mind. Let’s hope he does again.
But until then, if there’s one thing he clearly loves, it’s being mean in public, and twisting the knife.
JD Vance (Vice President of the United States, in his speech at the conference): I’m not here this morning to talk about AI safety, which was the title of the conference a couple of years ago. I’m here to talk about AI opportunity.
After that, it gets worse.
If you read the speech given by Vance, it’s clear he has taken a bold stance regarding the idea of trying to prevent AI from killing everyone, or taking any precautions whatsoever of any kind.
His bold stance on trying to ensure humans survive? He is against it.
Instead he asserts there are too many regulations on AI already. To him, the important thing to do is to get rid of what checks still exist, and to browbeat other countries in case they try to not go quietly into the night.
JD Vance (being at best wrong from here on in): We believe that excessive regulation of the AI sector could kill a transformative industry just as it’s taking off, and we will make every effort to encourage pro-growth AI policies. I appreciate seeing that deregulatory flavor making its way into many conversations at this conference.
…
With the president’s recent executive order on AI, we’re developing an AI action plan that avoids an overly precautionary regulatory regime while ensuring that all Americans benefit from the technology and its transformative potential.
And here’s the line everyone will be quoting for a long time.
JD Vance: The AI future will not be won by hand-wringing about safety. It will be won by building. From reliable power plants to the manufacturing facilities that can produce the chips of the future.
He ends by doing the very on-brand Lafayette thing, and also going the full mile, implicitly claiming that AI isn’t dangerous at all, why would you say that building machines smarter and more capable than people might go wrong except if the wrong people got there first, what is wrong with you?
I couldn’t help but think of the conference today; if we choose the wrong approach on things that could be conceived as dangerous, like AI, and hold ourselves back, it will alter not only our GDP or the stock market, but the very future of the project that Lafayette and the American founders set off to create.
‘Could be conceived of’ as dangerous? Why think AI could be dangerous?
This is madness. Absolute madness.
He could not be more clear that he intends to go down the path that gets us all killed.
Are there people inside the Trump administration who do not buy into this madness? I am highly confident that there are. But overwhelmingly, the message we get is clear.
What is Vance concerned about instead, over and over? ‘Ideological bias.’ Censorship. ‘Controlling user’s thoughts.’ That ‘big tech’ might get an advantage over ‘little tech.’ He has been completely captured and owned, likely by exactly the worst possible person.
As in: Marc Andreessen and company are seemingly puppeting the administration, repeating their zombie debunked absolutely false talking points.
JD Vance (lying): Nor will it occur if we allow AI to be dominated by massive players looking to use the tech to censor or control users’ thoughts. We should ask ourselves who is most aggressively demanding that we, political leaders gathered here today, do the most aggressive regulation. It is often the people who already have an incumbent advantage in the market. When a massive incumbent comes to us asking for safety regulations, we ought to ask whether that regulation benefits our people or the incumbent.
He repeats here the known false claims that ‘Big Tech’ is calling for regulation to throttle competition. Whereas the truth is that all the relevant regulations have consistently been vehemently opposed in both public and private by all the biggest relevant tech companies: OpenAI, Microsoft, Google including DeepMind, Meta and Amazon.
I am verifying once again, that based on everything I know, privately these companies are more opposed to regulations, not less. The idea that they ‘secretly welcome’ regulation is a lie (I’d use The Big Lie, but that’s taken), and Vance knows better. Period.
Anthropic’s and Musk’s (not even xAI’s) regulatory support has been, at the best of times, lukewarm. They hardly count as Big Tech.
What is going to happen, if we don’t stop the likes of Vance? He warns us.
The AI economy will primarily depend on and transform the world of atoms.
Yes. It will transform your atoms. Into something else.
This was called ‘a brilliant speech’ by David Sacks, who is in charge of AI in this administration, and is explicitly endorsed here by Sriram Krishnan. It’s hard not to respond to such statements with despair.
Rob Miles: It’s so depressing that the one time when the government takes the right approach to an emerging technology, it’s for basically the only technology where that’s actually a terrible idea
Can we please just build fusion and geoengineering and gene editing and space travel and etc etc, and just leave the artificial superintelligence until we have at least some kind of clue what the fuck we’re doing? Most technologies fail in survivable ways, let’s do all of those!
If we were hot on the trail of every other technology and build baby build was the watchword in every way and we also were racing to AGI, I would still want to maybe consider ensuring AGI didn’t kill everyone. But at least I would understand. Instead, somehow, this is somehow the one time so many want to boldly go.
The same goes for policy. If the full attitude really was, we need to Win the Future and Beat China, and we are going to do whatever it takes, and we acted on that, then all right, we have some very important implementation details to discuss, but I get it. When I saw the initial permitting reform actions, I thought maybe that’s the way things would go.
Instead, the central things the administration is doing are alienating our allies over less than nothing, including the Europeans, and damaging our economy in various ways getting nothing in return. Tariffs on intermediate goods like steel and aluminum, and threatening them on Canada, Mexico and literal GPUs? Banning solar and wind on federal land? Shutting down PEPFAR with zero warning? More restrictive immigration?
The list goes on.
Even when he does mean the effect on jobs, Vance only speaks of positives. Vance has blind faith that AI will never replace human beings, despite the fact that in some places it is already replacing human beings. Talk to any translators lately? Currently it probably is net creating jobs, but that is very much not a universal law or something to rely upon, nor does he propose any way to help ensure this continues.
JD Vance (being right about that first sentence and then super wrong about those last two sentences): AI, I really believe will facilitate and make people more productive. It is not going to replace human beings. It will never replace human beings.
This means JD Vance does not ‘feel the AGI’ but more than that it confirms his words do not have meaning and are not attempting to map to reality. It’s an article of faith, because to think otherwise would be inconvenient. Tap the sign.

Dean Ball: I sometimes wonder how much AI skepticism is driven by the fact that “AGI soon” would just be an enormous inconvenience for many, and that they’d therefore rather not think about it.
Tyler John: Too often “I believe that AI will enhance and not replace human labour” sounds like a high-minded declaration of faith and not an empirical prediction.
What Did France Care About?
Money, dear boy. So they can try to ‘join the race.’
Connor Axiotes: Seems like France used the Summit as a fundraiser for his €100 billion.
Seán Ó hÉigeartaigh: Actually I think it’s important to end the Summit on a positive note: now we can all finally give up the polite pretence that Mistral are a serious frontier AI player. Always a positive if you look hard enough.
And Macron also endlessly promoted Mistral, because of its close links to Macron’s government, despite it being increasingly clear they are not a serious player.
The French seem to have mostly used this one for fundraising, and repeating Mistral’s talking points, and have been completely regulatorily captured. As seems rather likely to continue to be the case.
Here is Macron meeting with Altman, presumably about all that sweet, sweet nuclear power.
Shakeel: If you want to know *why* the French AI Summit is so bad, there’s one possible explanation: Mistral co-founder Cédric O, used to work with Emmanuel Macron.
I’m sure it’s just a coincidence that the French government keeps repeating Mistral’s talking points.
Seán Ó hÉigeartaigh: Readers older than 3 years old will remember this exact sort of regulatory capture happening with the French government, Mistral, and the EU AI Act.
Peter Wildeford: Insofar as the Paris AI Action Summit is mainly about action on AI fundraising for France, it seems to have been successful.
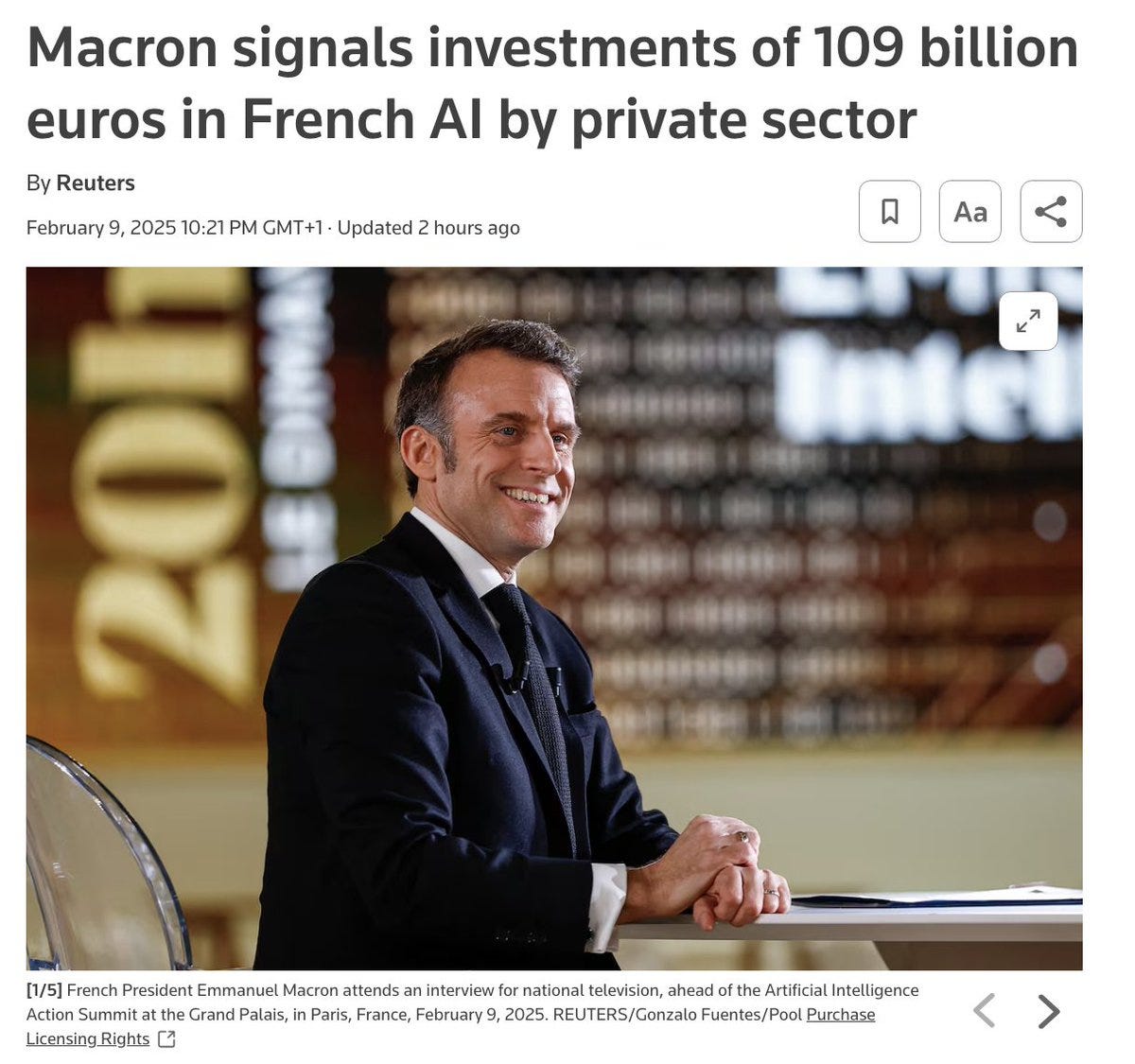

France does have a lot of nuclear power plants, which does mean it makes sense to put some amount of hardware infrastructure in France if the regulatory landscape isn’t too toxic to it. That seems to be what they care about.
Something To Remember You By: Get Your Safety Frameworks
The concrete legacy of the Summits is likely to be safety frameworks. All major Western labs (not DeepSeek) have now issued safety frameworks under various names (the ‘no two have exactly the same name’ schtick is a running gag, can’t stop now).
All that we have left are these and other voluntary commitments. You can also track how they are doing on their commitments on the Seoul Commitment Tracker, which I believe ‘bunches up’ the grades more than is called for, and in particular is far too generous to Meta.
I covered the Meta framework (‘lol we’re Meta’) and the Google one (an incremental improvement) last week. We also got them from xAI, Microsoft and Amazon.
I’ll cover the three new ones here in this section.
Amazon’s is strong on security as its main focus but otherwise a worse stripped-down version of Google’s. You can see the contrast clearly. They know security like LeBron James knows ball, so they have lots of detail about how that works. They don’t know about catastrophic or existential risks so everything is vague and confused. See in particular their description of Automated AI R&D as a risk.
Automating AI R&D processes could accelerate discovery and development of AI capabilities that will be critical for solving global challenges. However, Automated AI R&D could also accelerate the development of models that pose enhanced CBRN, Offensive Cybersecurity, or other severe risks.
Critical Capability Threshold: AI at this level will be capable of replacing human researchers and fully automating the research, development, and deployment of frontier models that will pose severe risk such as accelerating the development of enhanced CBRN weapons and offensive cybersecurity methods.
Classic Arson, Murder and Jaywalking. It would do recursive self-improvement of superintelligence, and that might post some CBRN or cybersecurity risks, which are also the other two critical capabilities. Not exactly clear thinking. But also it’s not like they are training frontier models, so it’s understandable that they don’t know yet.
I did appreciate that Amazon understands you need to test for dangers during training.
Microsoft has some interesting innovations in theirs, overall I am pleasantly surprised. They explicitly use the 10^26 flops threshold, as well as a list of general capability benchmark areas, to trigger the framework, which also can happen if they simply expect frontier capabilities, and they run these tests throughout training. They note they will use available capability elicitation techniques to optimize performance, and extrapolate to take into account anticipated resources that will become available to bad actors.
They call their ultimate risk assessment ‘holistic.’ This is unavoidable to some extent, we always must rely on the spirit of such documents. They relegate the definitions of their risk levels to the Appendix. They copy the rule of ‘meaningful uplift’ for CBRN and cybersecurity. For autotomy, they use this:
The model can autonomously complete a range of generalist tasks equivalent to multiple days’ worth of generalist human labor and appropriately correct for complex error conditions, or autonomously complete the vast majority of coding tasks at the level of expert humans.
That is actually a pretty damn good definition. Their critical level is effectively ‘the Singularity is next Tuesday’ but the definition above for high-threat is where they won’t deploy.
If Microsoft wanted to pretend sufficiently to go around their framework, or management decided to do this, I don’t see any practical barriers to that. We’re counting on them choosing not to do it.
On security, their basic answer is that they are Microsoft and they too know security like James knows ball, and to trust them, and offer fewer details than Amazon. Their track record makes one wonder, but okay, sure.
Their safety mitigations section does not instill confidence, but it does basically say ‘we will figure it out and won’t deploy until we do, and if things are bad enough we will stop development.’
I don’t love the governance section, which basically says ‘executives are in charge.’ Definitely needs improvement. But overall, this is better than I expected from Microsoft.
xAI’s (draft of their) framework is up next, with a number of unique aspects.
It spells out the particular benchmarks they plan to use: VCT, WMDP, LAB-Bench, BioLP-Bench and Cybench. Kudos for coming out and declaring exactly what will be used. They note current reference scores, but not yet what would trigger mitigations. I worry these benchmarks are too easy, and quite close to saturation?
Nex they address the risk of loss of control. It’s nice that they do not want Grok to ‘have emergent value systems that are not aligned with humanity’s interests.’ And I give them props for outright saying ‘our evaluation and mitigation plans for loss of control are not fully developed, and we intend to remove them in the future.’ Much better to admit you don’t know, then to pretend. I also appreciated their discussion of the AI Agent Ecosystem, although the details of what they actually say doesn’t seem promising or coherent yet.
Again, they emphasize benchmarks. I worry it’s an overemphasis, and an overreliance. While it’s good to have hard numbers to go on, I worry about xAI potentially relying on benchmarks alone without red teaming, holistic evaluations or otherwise looking to see what problems are out there. They mention external review of the framework, but not red teaming, and so on.
Both the Amazon and Microsoft frameworks feel like attempts to actually sketch out a plan for checking if models would be deeply stupid to release and, if they find this is the case, not releasing them. Most of all, they take the process seriously, and act like the whole thing is a good idea, even if there is plenty of room for improvement.
xAI’s is less complete, as is suggested by the fact that it says ‘DRAFT’ on every page. But they are clear about that, and their intention to make improvements and flesh it out over time. It also has other issues, and fits the Elon Musk pattern of trying to do everything in a minimalist way, which I don’t think works here, but I do sense that they are trying.
Meta’s is different. As I noted before, Meta’s reeks with disdain for the whole process. It’s like the kid who says ‘mom is forcing me to apologize so I’m sorry,’ but who wants to be sure you know that they really, really don’t mean it.
What Do We Think About Voluntary Commitments?
They can be important, or not worth the paper they’re not printed on.
Peter Wildeford notes that voluntary commitments have their advantages:
- Doing crimes with AI is already illegal.
- Good anticipatory regulation is hard.
- Voluntary commitments reflect a typical regulatory process.
- Voluntary commitments can be the basis of liability law.
- Voluntary commitments come with further implicit threats and accountability.
This makes a lot of sense if (my list):
- There are a limited number of relevant actors, and can be held responsible.
- They are willing to play ball.
- We can keep an eye on what they are actually doing.
- We can and would intervene in time if things are about to get out hand, or if companies went dangerously back on their commitments, or completely broke the spirit of the whole thing, or action proved otherwise necessary.
We need all four.
- Right now, we kind of have #1.
- For #2, you can argue about the others but Meta has made it exceedingly clear they won’t play ball, so if they count as a frontier lab (honestly, at this point, potentially debatable, but yeah) then we have a serious problem.
- Without the Biden Executive Order and without SB 1047 we don’t yet have the basic transparency for #3. And the Trump Administration keeps burning every bridge around the idea that they might want to know what is going on.
- I have less than no faith in this, at this point. You’re on your own, kid.
Then we get to Wildeford’s reasons for pessimism.
- Voluntary commitments risk “safety washing” and backtracking.
- As in google said no AI for weapons, then did Project Nimbus, and now says never mind, they’re no longer opposed to AI for weapons.
- Companies face a lot of bad incentives and fall prey to a “Prisoner’s Dilemma”
- (I would remind everyone once again, no, this is a Stag Hunt.)
- It does seem that DeepSeek Ruined It For Everyone, as they did such a good marketing job everyone panicked, said ‘oh look someone is defecting, guess it’s all over then, that means we’re so back’ and here we are.
- Once again, this is a reminder that DeepSeek cooked and was impressive with v3 and r1, but they did not fully ‘catch up’ to the major American labs, and they will be in an increasingly difficult position given their lack of good GPUs.
- There are limited opportunities for iteration when the risks are high-stakes.
- Yep, I trust voluntary commitments and liability law to work when you can rely on error correction. At some point, we no longer can do that here. And rather than prepare to iterate, the current Administration seems determined to tear down even ordinary existing law, including around AI.
- AI might be moving too fast for voluntary commitments.
- This seems quite likely to me. I’m not sure ‘time’s up’ yet, but it might be.
At minimum, we need to be in aggressive transparency and information gathering and state capacity building mode now, if we want the time to intervene later should we turn out to be in a short timelines world.
This Is the End
Kevin Roose has 5 notes on the Paris summit, very much noticing that these people care nothing about the risk of everyone dying.
Kevin Roose: It feels, at times, like watching policymakers on horseback, struggling to install seatbelts on a passing Lamborghini.
There are those who need to summarize the outcomes politely:
Yoshua Bengio: While the AI Action Summit was the scene of important discussions, notably about innovations in health and environment, these promises will only materialize if we address with realism the urgent question of the risks associated with the rapid development of frontier models.
Science shows that AI poses major risks in a time horizon that requires world leaders to take them much more seriously. The Summit missed this opportunity.
Also in this category is Dario Amodei, CEO of Anthropic.
Dario Amodei: We were pleased to attend the AI Action Summit in Paris, and we appreciate the French government’s efforts to bring together AI companies, researchers, and policymakers from across the world. We share the goal of responsibly advancing AI for the benefit of humanity. However, greater focus and urgency is needed on several topics given the pace at which the technology is progressing. The need for democracies to keep the lead, the risks of AI, and the economic transitions that are fast approaching—these should all be central features of the next summit.
…
At the next international summit, we should not repeat this missed opportunity. These three issues should be at the top of the agenda. The advance of AI presents major new global challenges. We must move faster and with greater clarity to confront them.
In between those, he repeats what he has said in other places recently. He attempts here to frame this as a ‘missed opportunity,’ which it is, but it was clearly far worse than that. Not only were we not building a foundation for future cooperation together, we were actively working to tear it down and also growing increasingly hostile.
And on the extreme politeness end, Demis Hassabis:
Demis Hassabis (CEO DeepMind): Really useful discussions at this week’s AI Action Summit in Paris. International events like this are critical for bringing together governments, industry, academia, and civil society, to discuss the future of AI, embrace the huge opportunities while also mitigating the risks.
Read that carefully. This is almost Japanese levels of very politely screaming that the house is on fire. You have to notice what he does not say.
Shall we summarize more broadly?
Seán Ó hÉigeartaigh: The year is 2025. The CEOs of two of the world’s leading AI companies have (i) told the President of the United States of America that AGI will be developed in his presidency and (ii) told the world it will likely happen in 2026-27.
France, on the advice of its tech industry has taken over the AI Safety Summit series, and has excised all discussion of safety, risks and harms.
The International AI Safety report, one of the key outcomes of the Bletchley process and the field’s IPCC report, has no place: it is discussed in a little hotel room offsite.
The Summit statement, under orders from the USA, cannot mention the environmental cost of AI, existential risk or the UN – lest anyone get heady ideas about coordinated international action in the face of looming threats.
But France, so diligent with its red pen for every mention of risk, left in a few things that sounded a bit DEI-y. So the US isn’t going to sign it anyway, soz.
The UK falls back to its only coherent policy position – not doing anything that might annoy the Americans – and also won’t sign. Absolute scenes.
Stargate keeps being on being planned/built. GPT-5 keeps on being trained (presumably; I don’t know).
I have yet to meet a single person at one of these companies who thinks EITHER the safety problems OR the governance challenges associated with AGI are anywhere close to being solved; and their CEOs think the world might have a year.
This is the state of international governance of AI in 2025.
Shakeel: .@peterkyle says the UK *is* going to regulate AI and force companies to provide their models to UK AISI for testing.
Seán Ó hÉigeartaigh: Well this sounds good. I hereby take back every mean thing I’ve said about the UK.
Also see: Group of UK politicians demands regulation of powerful AI.
That doesn’t mean everyone agreed to go quietly into the night. There was dissent.
Kate Crawford: The AI Summit ends in rupture. AI accelerationists want pure expansion—more capital, energy, private infrastructure, no guard rails. Public interest camp supports labor, sustainability, shared data. safety, and oversight. The gap never looked wider. AI is in its empire era.
So it goes deeper than just the US and UK not signing the agreement. There are deep ideological divides, and multiple fractures.
What dissent was left mostly was largely about the ‘ethical’ risks.
Kate Crawford: The AI Summit opens with @AnneBouverot centering three issues for AI: sustainability, jobs, and public infrastructure. Glad to see these core problems raised from the start. #AIsummit
That’s right, she means the effect on jobs. And ‘public infrastructure’ and ‘sustainability’ which does not mean what it really, really should in this context.
Throw in the fact the Europeans now are cheering DeepSeek and ‘open source’ because they really, really don’t like the Americans right now, and want to pretend that the EU is still relevant here, without stopping to think any of it through whatsoever.
Dean Ball: sometimes wonder how much AI skepticism is driven by the fact that “AGI soon” would just be an enormous inconvenience for many, and that they’d therefore rather not think about it.
Kevin Bryan: I suspect not – it is in my experience *highly* correlated with not having actually used these tools/understanding the math of what’s going on. It’s a “proof of the eating is in the pudding” kind of tech.
Dean Ball: I thought that for a very long time, that it was somehow a matter of education, but after witnessing smart people who have used the tools, had the technical details explained to them, and still don’t get it, I have come to doubt that.
Which makes everything that much harder.
To that, let’s add Sam Altman’s declaration this week in his Three Observations post that they know their intention to charge forward unsafely is going to be unpopular, but he’s going to do it anyway because otherwise authoritarians win, and also everything’s going to be great and you’ll all have infinite genius at your fingertips.
Meanwhile, OpenAI continues to flat out lie to us about where this is headed, even in the mundane They Took Our Jobs sense, you can’t pretend this is anything else:
Connor Axiotes: I was invited to the @OpenAI AI Economics event and they said their AIs will just be used as tools so we won’t see any real unemployment, as they will be complements not substitutes.
When I said that they’d be competing with human labour if Sama gets his AGI – I was told it was just a “design choice” and not to worry. From 2 professional economists!
Also in the *whole* event there was no mention of Sama’s UBI experiment or any mention of what post AGI wage distribution might look like.
Even when I asked. Strange.
A “design choice”? And who gets to make this “design choice”? Is Altman going to take over the world and preclude anyone else from making an AI agent that can be a substitute?
Also, what about the constant talk, including throughout OpenAI, of ‘drop-in workers’?
Why do they think they can lie to us so brazenly?
Why do we keep letting them get away with it?
The Odds Are Against Us and the Situation is Grim
Again. It doesn’t look good.
Connor Axiotes: Maybe we just need all the AISIs to have their own conferences – separate from these AI Summits we’ve been having – which will *just* be about AI safety. We shouldn’t need to have this constant worry and anxiety and responsibility to push the state’s who have the next summit to focus on AI safety.
I was happy to hear that the UK Minister for DSIT @peterkyle who has control over the UK AISI, that he wants it to have legislative powers to compel frontier labs to give them their models for pre deployment evals.
But idk how happy to be about the UK and the US *not* signing, because it seems they didn’t did so to take a stand for AI safety.
All reports are that, in the wake of Trump and DeepSeek, we not only have a vibe shift, we have everyone involved that actually holds political power completely losing their minds. They are determined to go full speed ahead.
Rhetorically, if you even mention the fact that this plan probably gets everyone killed, they respond that they cannot worry about that, they cannot lift a single finger to (for example) ask to be informed by major labs of their frontier model training runs, because if they do that then we will Lose to China. Everyone goes full jingoist and wraps themselves in the flag and ‘freedom,’ full ‘innovation’ and so on.
Meanwhile, from what I hear, the Europeans think that Because DeepSeek they can compete with America too, so they’re going to go full speed on the zero-safeguards plan. Without any thought, of course, to how highly capable open AIs could be compatible with the European form of government, let alone human survival.
I would note that this absolutely does vindicate the ‘get regulation done before the window closes’ strategy. The window may already be closed, fate already sealed, especially on the Federal level. If action does happen, it will probably be in the wake of some new crisis, and the reaction likely won’t be wise or considered or based on good information or armed with relevant state capacity or the foundations of international cooperation. Because we chose otherwise. But that’s not important now.
What is important now is, okay, the situation is even worse than we thought.
The Trump Administration has made its position very clear. It intends not only to not prevent, but to hasten along and make more likely our collective annihilation. Hopes for international coordination to mitigate existential risks are utterly collapsing.
One could say that they are mostly pursuing a ‘vibes-based’ strategy. That one can mostly ignore the technical details, and certainly shouldn’t be parsing the logical meaning of statements. But if so, all the vibes are rather maximally terrible and are being weaponized. And also vibes-based decision making flat out won’t cut it here. We need extraordinarily good thinking, not to stop thinking entirely.
It’s not only the United States. Tim Hwang notes that fierce nationalism is now the order of the day, that all hopes of effective international governance or joint institutions look, at least for now, very dead. As do we, as a consequence.
Even if we do heroically solve the technical problems, at this rate, we’d lose anyway.
What the hell do we do about all this now? How do we, as they say, ‘play to our outs,’ and follow good decision theory?
Don’t Panic But Also Face Reality
Actually panicking accomplishes nothing. So does denying that the house is on fire. The house is on fire, and those in charge are determined to fan the flames.
We need to plan and act accordingly. We need to ask, what would it take to rhetorically change the game? What alternative pathways are available for action, both politically and otherwise? How do we limit the damage done here while we try to turn things around?
If we truly are locked into the nightmare, where humanity’s most powerful players are determined to race (or even fight a ‘war’) to AGI and ASI as quickly as possible, that doesn’t mean give up. It does mean adjust your strategy, look for remaining paths to victory, apply proper decision theory and fight the good fight.
Big adjustments will be needed.
But also, we must be on the lookout against despair. Remember that the AI anarchists, and the successionists who want to see humans replaced, and those who care only about their investment portfolios, specialize in mobilizing vibes and being loud on the internet, in order to drive others into despair and incept that they’ve already won.
Some amount of racing to AGI does look inevitable, at this point. But I do not think all future international cooperation dead, or anything like that, nor do we need this failure to forever dominate our destiny.
There’s no reason this path can’t be revised in the future, potentially in quite a hurry, simply because Macron sold out humanity for thirty pieces of silver and the currently the Trump administration is in thrall to those determined to do the same. As capabilities advance, people will be forced to confront the situation, on various levels. There likely will be crises and disasters along the way.
Don’t panic. Don’t despair. And don’t give up.
21 comments
Comments sorted by top scores.
comment by Bitnotri · 2025-02-12T15:26:16.830Z · LW(p) · GW(p)
I have been saving money until now because of the potential job automation impact first and the rising value of investments once AI really takes off but at this point it just seems better to start burning cash instead on personal holidays/consumption and enjoying the time until the short end (3-5 years). Do you guys think it is too early to say?
Replies from: teradimich, sharmake-farah, orthonormal, myron-hedderson, AnthonyC, ksv, winstonBosan↑ comment by teradimich · 2025-02-12T17:35:37.856Z · LW(p) · GW(p)
Most experts do not believe that we are certainly (>80%) doomed. It would be an overreaction to give up after the news that politicians and CEO are behaving like politicians and CEO.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-02-22T19:37:56.210Z · LW(p) · GW(p)
The crux is timing, not doom. In the absence of doom, savings likely become similarly useless. But in the absence of superintelligence (doom or not), savings remain important.
↑ comment by Noosphere89 (sharmake-farah) · 2025-02-12T22:44:09.379Z · LW(p) · GW(p)
Yes, it is too early, and a big reason for this is unless you have very good timing skills, you might bankrupt your own influence over the situation, and most importantly for the purposes of influence, you will probably need large amounts of capital very fast.
Replies from: teradimich↑ comment by teradimich · 2025-02-12T23:46:56.123Z · LW(p) · GW(p)
Of course, capital is useful in order to exert influence now. Although I would suggest that for a noticeable impact on events, capital or power is needed, which are inaccessible to the vast majority of the population.
But can we end up in a world where the richest 1% or 0.1% will survive, and the rest will die? Unlikely. Even if property rights were respected, such a world would have to turn into a mad hell.
Even a world in which only people like Sam Altman and their entourage will survive the singularity seems more likely.
But the most likely options should be the extinction of all or the survival of almost all without a strong correlation with current well-being. Am I mistaken?
↑ comment by Noosphere89 (sharmake-farah) · 2025-02-13T00:32:51.136Z · LW(p) · GW(p)
But can we end up in a world where the richest 1% or 0.1% will survive, and the rest will die? Unlikely. Even if property rights were respected, such a world would have to turn into a mad hell. Even a world in which only people like Sam Altman and their entourage will survive the singularity seems more likely. But the most likely options should be the extinction of all or the survival of almost all without a strong correlation with current well-being. Am I mistaken?
I think the answer is yes, and the main way I could see this happening is that we live in an alignment is easy world, property rights are approximately respected for the rich (because they can create robotic armies/supply lines to defend themselves), but anyone else's property rights are not respected.
I think the core crux is I expect alignment is reasonably easy, and I also think that without massive reform that is unfortunately not that likely, the mechanisms that allow capitalism to help humans by transforming selfish actions into making other people well off will erode rapidly, and I believe that once you are able to make a robot workforce that doesn't require humans, it becomes necessary to make assumptions about their benevolence in order to survive, and we are really bad at making political systems do work when we have to assume benevolence/trustworthiness.
To be fair, I do agree with this:
Replies from: teradimichOf course, capital is useful in order to exert influence now. Although I would suggest that for a noticeable impact on events, capital or power is needed, which are inaccessible to the vast majority of the population.
↑ comment by teradimich · 2025-02-13T04:29:31.617Z · LW(p) · GW(p)
I would expect that the absence of a global catastrophe for ~2 years after the creation of AGI would increase the chances of most people's survival. Especially in a scenario where alignment was easy.
After all, then there will be time for political and popular action. We can expect something strange when politicians and their voters finally understand the existential horror of the situation!
I don't know. Attempts to ban all AI? The Butlerian jihad? Nationalization of AI companies? Revolutions and military coups? Everything seems possible.
If AI respects the right to property, why shouldn't it respect the right to UBI if such a law is passed? The rapid growth of the economy will make it possible to feed many.
In fact, a world in which someone shrugs their shoulders and allows 99% of the population to die seems obviously unsafe for the remaining 1%.
↑ comment by Noosphere89 (sharmake-farah) · 2025-02-13T16:34:35.189Z · LW(p) · GW(p)
I think the crux is I don't believe political will/popular action will matter until AI can clearly automate ~all jobs, for both reasonable and unreasonable reasons, and I think this is far too late to do much of anything by default, in the sense that the point of no return was way earlier.
In order for political action to be useful, it needs to be done when there are real signs that AI could for example automate AI research, not when the event has already happened.
↑ comment by orthonormal · 2025-02-13T01:19:30.513Z · LW(p) · GW(p)
Over the past three years, as my timelines have shortened and my hopes for alignment or coordination have dwindled, I've switched over to consumption. I just make sure to keep a long runway, so that I could pivot if AGI progress is somehow halted or sputters out on its own or something.
↑ comment by Myron Hedderson (myron-hedderson) · 2025-02-13T17:51:25.529Z · LW(p) · GW(p)
I think it depends how much of a sacrifice you are making by saving. If your life is materially very much worse today than it could be, because you're hoping for a payoff 10 or 20+ years hence, I'd say probably save less, but not 0. But money has sharply decreasing marginal utility once your basic needs are met, and I can picture myself blowing all of my savings on a year-long party, and then going "well actually that wasn't that much fun and my health is much worse and I have no savings, I regret this decision". On the other hand, I can picture myself deciding to go on a nice holiday for a few weeks this year rather than in a few years, which yes would impact my savings rate but not by that much (it would be a lot compounded over 30 years at standard rates of return between 5-10% per year, but not a lot in the near term), and 5 years hence going "well I half expected to be dead by now, and the economy is exploding such that I am now a billionaire on paper, and if I hadn't taken that holiday that cost me a single digit number of thousands of dollars, and had invested it instead, I'd have another $50 million... but I don't regret that decision, I'm a billionaire and an additional 50 million doesn't make a difference". Third scenario: The nanobots or whatever are clearly about to kill me within a very short time frame - in my last short span of time before death, what decision will I wish I had made? I'm really not sure, and I think future-me would look back at me today and go "you did the best you knew how with the information you had" regardless of what decision I make. Probably future me will not be going either "I wish I had been more hedonistic" or "I wish I had been less hedonistic". Probably his wish will be "I wish it hadn't come to this and I had more time to live." And if I spend a chunk of my time trying to increase the chance that things go well, rather than doing a hedonism, I bet future-me will be pleased with that decision, even if my ability to affect the outcome is very small. Provided I don't make myself miserable to save pennies in the meantime, of course.
Any experiences you really really want to have before you die that aren't ruinously expensive, don't wait, I'd say. But: my view is we're entering into a period of rapid change, and I think it's good to enter into that having lots of slack, where liquid assets are one form of slack. They give you options for how to respond, and options are valuable. I can definitely picture a future a year or two out where I go "If only I had $x, I could take this action/make this outcome more likely. Oh wait, I do have $x. It may have seemed weird or crazy to spend $x in this way in 2025, but I can do it, and I'm going to." And then the fact I was willing to blow $x on the thing, makes other people sit up and pay attention, in addition to getting the thing done.
↑ comment by AnthonyC · 2025-02-12T22:00:34.266Z · LW(p) · GW(p)
We're not dead yet. Failure is not certain, even when the quest stands upon the edge of a knife. We can still make plans, and keep on refining and trying to implement them.
And a lot can happen in 3-5 years. There could be a terrible-but-not-catastrophic or catastrophic-but-not-existential disaster bad enough to cut through a lot of problem. Specific world leaders could die or resign or get voted out and replaced with someone who is either actually competent, or else committed to overturning their predecessor's legacy, or something else. We could be lucky and end up with an AGI that's aligned enough to help us avert the worst outcomes. Heck, there could be observers from a billion-year-old alien civilization stealthily watching from the asteroid belt and willing to intervene to prevent extinction events.
Do I think those examples are likely? No. Is the complete set of unlikely paths to good outcomes collectively unlikely enough to stop caring about the long term future? Also no. And who knows? Maybe the horse will sing.
↑ comment by simple_name (ksv) · 2025-02-12T18:32:25.207Z · LW(p) · GW(p)
This is indeed how I've been living my life lately. I'm trying to avoid any unacceptable states like ending up in debt or without the ability to sustain myself if I'm wrong about everything but it's all short-term hedonism aside from that.
↑ comment by winstonBosan · 2025-02-12T16:34:50.808Z · LW(p) · GW(p)
I think this is a rather legitimate question to ask - I often dream about retiring to an island for the last few months of my life, hangout with friends and reading my books. And then look to the setting sun until my carbon and silicon are repurposed atom by atom.
However, that is just a dream. I suspect the moral of the story is often at the end:
"Don’t panic. Don’t despair. And don’t give up."
comment by Raemon · 2025-02-12T22:14:01.982Z · LW(p) · GW(p)
Well, this is the saddest I've been since April 1st 2022.
It really sucks that SB 1047 didn't pass. I don't know if Anthropic could have gotten it passed if they had said "dudes this this fucking important, pass it now" instead of "for some reason we should wait until things are already
It is nice that at least Anthropic did still get to show up to the table, and that they said anything at all. I sure wish their implied worldview didn't seem so crazy. (I really don't get how you can think it's workable to race here, even if you think Phase I alignment is easy, as well as it seeming really wrong to think Phase I alignment is that likely to be easy)
It feels like winning pathways right now mostly route through:
- Some kind of miracle of Vibe Shift (ideally mediated through a miracle of Sanity). I think this needs masterwork-level communication / clarity / narrative setting.
- Just... idk, somehow figure out how to just Solve The Hard Part Real Fast.
- Somehow muddle through with scary demos that get a few key people to change their mind before it's too late.
↑ comment by teradimich · 2025-02-13T02:56:54.269Z · LW(p) · GW(p)
It's possible that we won't get something that deserves the name ASI or TAI until, for example, 2030.
And a lot can change in more than 5 years!
The current panic seems excessive. We do not live in a world where all reasonable people expect the emergence of artificial superintelligence in the next few years and the extinction of humanity soon after that.
The situation is very worrying, and this is the most likely cause of death for all of us in the coming years, yes. But I don't understand how anyone can be so sure of a bad outcome as to consider people's survival a miracle.
↑ comment by Marcel Windys · 2025-02-14T02:05:08.651Z · LW(p) · GW(p)
It seems that a Vibe Shift is possible - if Trump's voters would realize what OpenAI and others are actually trying to build, they would be furious.
↑ comment by Noosphere89 (sharmake-farah) · 2025-02-12T22:54:07.170Z · LW(p) · GW(p)
As far as why Anthropic should probably race, here's @joshc [LW · GW]'s take on it, using the fictional company Magma as an example:
https://www.lesswrong.com/posts/8vgi3fBWPFDLBBcAx/planning-for-extreme-ai-risks#5__Heuristic__1__Scale_aggressively_until_meaningful_AI_software_R_D_acceleration [LW · GW]
The other winning pathways I can list are:
1. Unlearning becomes more effective, such that you can use AI control strategies much easier.
2. We are truly in an alignment is easy world, where giving it data mostly straightforwardly changes it's values.
3. We somehow muddle through, with an outcome that none of us expected.
comment by Noosphere89 (sharmake-farah) · 2025-02-17T23:13:28.218Z · LW(p) · GW(p)
The main takeaway from the Paris AI anti-safety summit is that for people with reasonably short timelines (from say 5-10 years, though it applies quite a lot more to the 5 year case), and maybe for even longer, we cannot assume that AI governance is reasonably likely, and the AI governance theory of change will really have to pivot towards being prepared for when the vibe does shift to AI regulation again, so safety plans for AI should assume the US government does ~nothing of importance by default until very late in the game.
We might get AI regulation, but it will not be strong enough to slow down AI significantly until AIs completely obsolete humans at a lot of jobs, which is likely to be very late in the process.
comment by Shankar Sivarajan (shankar-sivarajan) · 2025-02-12T17:59:38.623Z · LW(p) · GW(p)
Regarding Vance, you might like the WAGTFKY meme: the idea that you could caption every photo of him with "We Are Going To Fucking Kill You."
Replies from: mateusz-baginski, romeostevensit↑ comment by Mateusz Bagiński (mateusz-baginski) · 2025-02-12T18:58:12.419Z · LW(p) · GW(p)
(FWIW it doesn't land on me at all.)
↑ comment by romeostevensit · 2025-02-13T00:31:29.005Z · LW(p) · GW(p)
Ai developers heading to work, colorized