Planning for Extreme AI Risks
post by joshc (joshua-clymer) · 2025-01-29T18:33:14.844Z · LW · GW · 5 commentsContents
The tl;dr 1. Assumptions 2. Outcomes 2.1. Outcome #1: Human researcher obsolescence 2.2. Outcome #2: A long coordinated pause 2.3. Outcome #3: Self-destruction 3. Goals 4. Prioritization heuristics 5. Heuristic #1: Scale aggressively until meaningful AI software R&D acceleration 6. Heuristic #2: Before achieving meaningful AI software R&D acceleration, spend most safety resources on preparation 7. Heuristic #3: During preparation, devote most safety resources to (1) raising awareness of risks, (2) getting ready to elicit safety research from AI, and (3) preparing extreme security. Category #1: Nonproliferation Category #2: Safety distribution Category #3: Governance and communication. Category #4: AI defense 8. Conclusion Appendix Appendix A: What should Magma do after meaningful AI software R&D speedups None 5 comments
This post should not be taken as a polished recommendation to AI companies and instead should be treated as an informal summary of a worldview. The content is inspired by conversations with a large number of people, so I cannot take credit for any of these ideas.
For a summary of this post, see the thread on X.
Many people write opinions about how to handle [LW · GW] advanced AI, which can be considered “plans.”
There’s the “stop AI now plan.” |  |
On the other side of the aisle, there’s the “build AI faster plan.”
|  |
Some plans try to strike a balance with an idyllic governance regime. |
|
And others have a “race sometimes, pause sometimes, it will be a dumpster-fire” vibe.
|


So why am I proposing another plan?
Existing plans provide a nice patchwork of the options available, but I’m not satisfied with any.
Some plans describe what the world would do if everyone were on the ball. Others are ruthlessly practical, to the point where they dismiss potentially essential interventions like international governance. And still others include a hodgepodge of interventions that seem promising at the moment but might not hold up.
This plan is comparatively wide-ranging, concise, and selective in its claims.
The plan is for a responsible AI developer, which I call “Magma [AF · GW].” It does not directly apply to governments, non-profits, or external researchers. Magma has the sole objective of minimizing risks on the scale of AI or human ‘takeover’ – even if advancing this goal requires dangerous actions.
This is a dangerous plan for a dangerous world.
The plan includes two parts:
- Goals and strategies for achieving them.
- Prioritization heuristics that specify how the developer might allocate their limited resources between goals over time.
The plan is quite different from an “RSP” or a “safety framework.” It is not meant to be enforceable or allow an AI company to transparently justify its actions. It is more like a rough-and-ready playbook.
Like any playbook, it cannot be followed to the T. As the game evolves, the players must respond to new information. While I try to cover strategies that are most applicable across scenarios, I am still obligated to quote General Eisenhower’s famous disclaimer:
“Plans are useless, but planning is indispensable.”
I plan in order to prepare. I wrote this post so that you and I can better decide how to use our meager time to get through these perhaps most consequential years in human history. The stakes have never been higher, nor the need for plans greater.
The tl;dr
There are several outcomes that define a natural boundary for Magma’s planning horizon:
- Outcome #1: Human researcher obsolescence. If Magma automates AI development and safety work, human technical staff can retire.
- Outcome #2: A long coordinated pause. Frontier developers might pause to catch their breath for some non-trivial length of time (e.g. > 4 months).
- Outcome #3: Self-destruction. Alternatively, Magma might be willingly overtaken.
This plan considers what Magma might do before any of these outcomes are reached.
At any given point in time, Magma might advance the following goals:
- Reduce the risks posed by the Magma’s own AI.
- Minimize the risks posed by AI systems created by other AI developers. Routes to advancing this goal include:
- AI nonproliferation – reduce the amount of dangerous AI in the world.
- AI safety distribution – lower the costs of mitigating dangerous AI.
- AI governance and communication – increase the motivation of other developers to mitigate dangerous AI.
- AI defense – harden the world against unmitigated AI.
- Gain access to more powerful AI systems to help with the above.
These goals trade-off, so how should developers prioritize between them?
I argue that before meaningful (e.g. >3x)[1] AI software R&D acceleration, Magma should:
- Heuristic #1: Scale their AI capabilities aggressively.
- Heuristic #2: Spend most safety resources on preparation.
- Heuristic #3: Devote most preparation effort to:
- (1) Raising awareness of risks.
- (2) Getting ready to elicit safety research from AI.
- (3) Preparing extreme security.
After meaningful AI software R&D acceleration, Magma might orient toward one of the previously mentioned outcomes (safely automated scaling, a long coordinated pause, or self-destruction). The question of which outcome(s) Magma should target depends on complex factors (Appendix A), so I mostly describe what Magma might do in the earlier time leading up to meaningful AI R&D speedups.
1. Assumptions
The plan assumes the following:
- Magma tries to minimize ‘extreme’ AI risks. These include catastrophes on the scale of “AI takeover” and “human takeover,” which are scenarios where humans or AI systems disempower sovereign democratic governments.
To add color to these risks, imagine that future AI systems are like “a country of geniuses in a data center.” Now imagine these geniuses run at 100x the speed of normal humans. From the perspective of these AI systems, your fingers would move like glaciers as they fall toward your keyboard. In a few years, these AI systems might innovate technologies that would otherwise have been due to arrive in 2050, granting them (or the humans that control them) overwhelming military force.

Figure 1. Synthetic bees pressing against a window pane. This is a scene from the BlackMirror episode Hated in the Nation that I often picture when I think about AI takeover. In the scene, self-replicating bee-like machines attack a human population – breaking windows and slipping through cracks in doors to deliver a fatal payload. It is a visceral depiction of a novel technology utterly dominating existing defenses.
I believe these dangers are plausible enough to dominate most common sense ways to perform cost-benefit analysis, which is why they are Magma’s sole focus in this post.
Additional assumptions include the following:
- Magma is within a few months of the frontier of AI capabilities as of early 2025.
- At the start of 2025, Magma’s world is similar to today’s.
- Timelines are short. AI R&D can be readily automated in 3 years at the latest (or possibly quite sooner).
- Magma believes rapid software-only improvement is plausible, such that vastly superhuman AI might be developed within a year of automated AI software R&D.
- Magma is uncertain about the difficulty of safety, reducing the appeal of “shut it all down now” moonshots that are most promising in scenarios where making powerful AI safe is very difficult.
2. Outcomes
Before describing a ‘plan,’ it’s worth considering where Magma might eventually end up, since these outcomes affect what Magma should be planning for.
A few outcomes are salient [2]:
- Outcome #1: Human researcher obsolescence
- Outcome #2: A long coordinated pause
- Outcome #3: Self-destruction
These outcomes define a natural boundary for Magma’s near-term planning horizon because, once they are achieved, Magma staff might have much less influence, or their situation will be substantially different.
By the time these outcomes are reached, Magma might not be distinctly Magma anymore. Magma might be part of a joint project; however, in this case, all the same considerations apply to their involvement in the collaboration.
2.1. Outcome #1: Human researcher obsolescence
If superhuman AI systems can be constructed safely, these systems would be extraordinarily useful. Safe superhuman AI could cook up safety recipes and continuously distribute them to other developers. They could build up defenses against the onslaught of dangerous systems following in their wake. The list goes on.
However, Magma does not need to create safe superhuman AI. Magma only needs to build an autonomous AI researcher that finishes the rest of the job as well as we could have. This autonomous AI researcher would be able to scale capabilities and safety much faster with humans out of the loop.
Leaving AI development up to AI agents is safe relative to humans if:
(1) These agents are at least as trustworthy as human developers and the institutions that hold them accountable.
(2) The agents are at least as capable as human developers along safety-relevant dimensions, including ‘wisdom,’ anticipating the societal impacts of their work, etc.
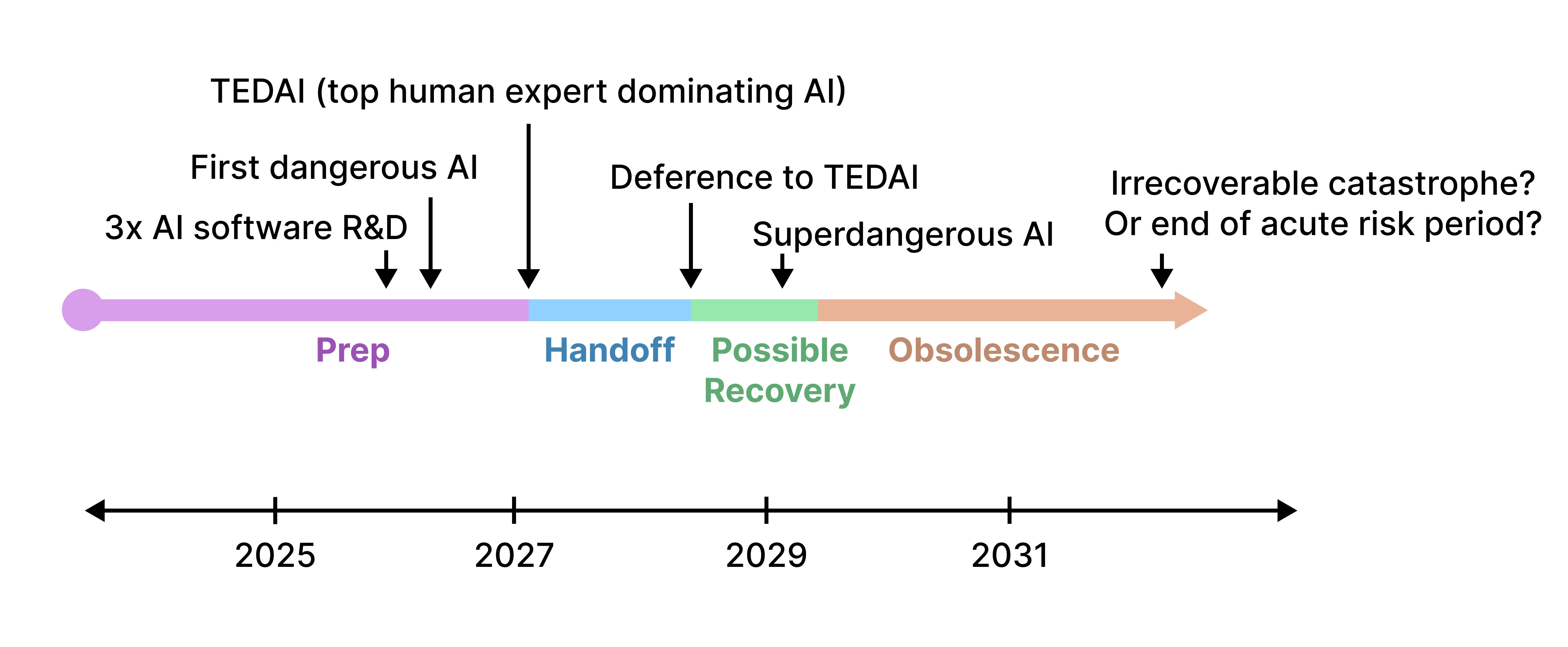
On the path to obsoleting human researchers, Magma might pass through several waypoints that are shown in figure 2.
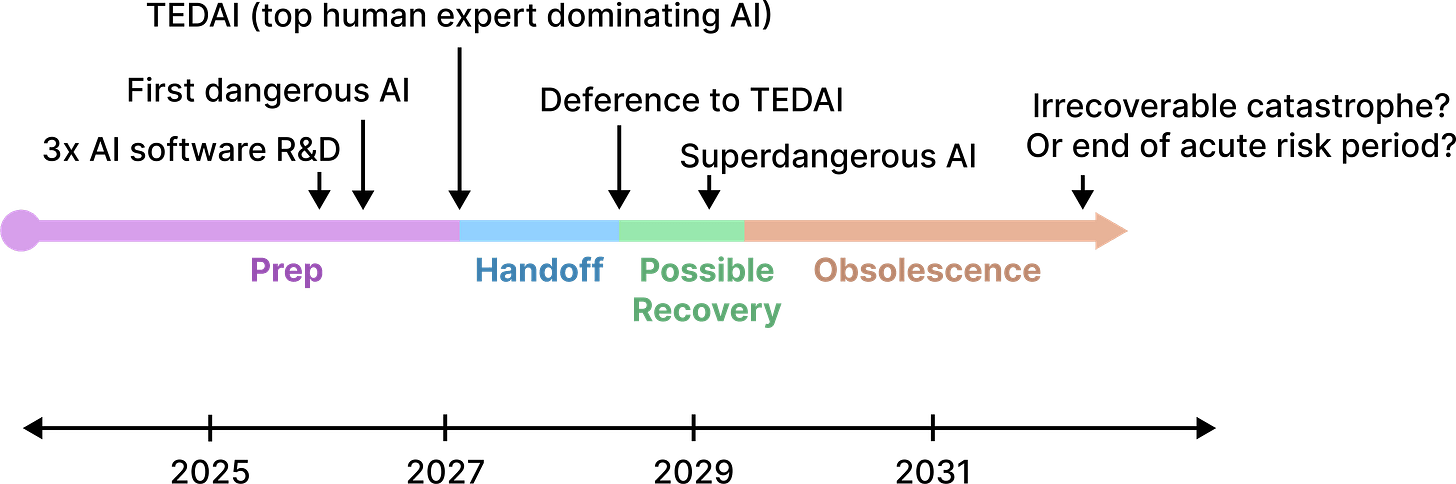
Figure 2. A timeline in which Magma obseletes human researchers. The specific dates are illustrative and unimportant.
Each milestone is explained below:
- 3x AI software R&D: AI agents that accelerate AI software R&D by 3x relative to 2024 systems (which would probably speed up net AI progress by a lower multiplier, such as 1.5x).
- The first dangerous AI: AI that directly or indirectly contributes some non-trivial (e.g. >0.3%) risk of extreme catastrophes if Magma focused solely on scaling as fast as possible.
- TEDAI: Top Human Expert Dominating AI: AI that can readily automate all software AI development.
- Deference to TEDAI: When Magma de facto defers to AI systems on scaling decisions.
- Recovery phase: A period when human researchers in Magma still have some chance of finding evidence that they made a mistake by deferring to TEDAI, and might recover the situation.
- Superdangerous AI: AI that poses >50% risk of extreme catastrophe if Magma focuses solely on scaling quickly.
- Obsolescence. When human technical staff have approximately no influence over the Magma anymore.
- Eventually, either some irrecoverable catastrophe has occurred, or the world has reached some stable state where irrecoverable catastrophes are unlikely, marking the “end of the acute risk period [? · GW].”
2.2. Outcome #2: A long coordinated pause
Creating wildly superhuman minds – and furthermore, placing this perilous task into the hands of AI agents that have only recently come into existence – sounds like a crazy thing to do.
Hopefully, society can agree this is crazy and coordinate a pause.
Someone once called this an “AI summer”: a chance to take a breather and enjoy the benefits of human-competitive AI agents before rocketing into the much more dangerous regime of superintelligence.
A long, coordinated pause is the most preferred outcome if it can be achieved.
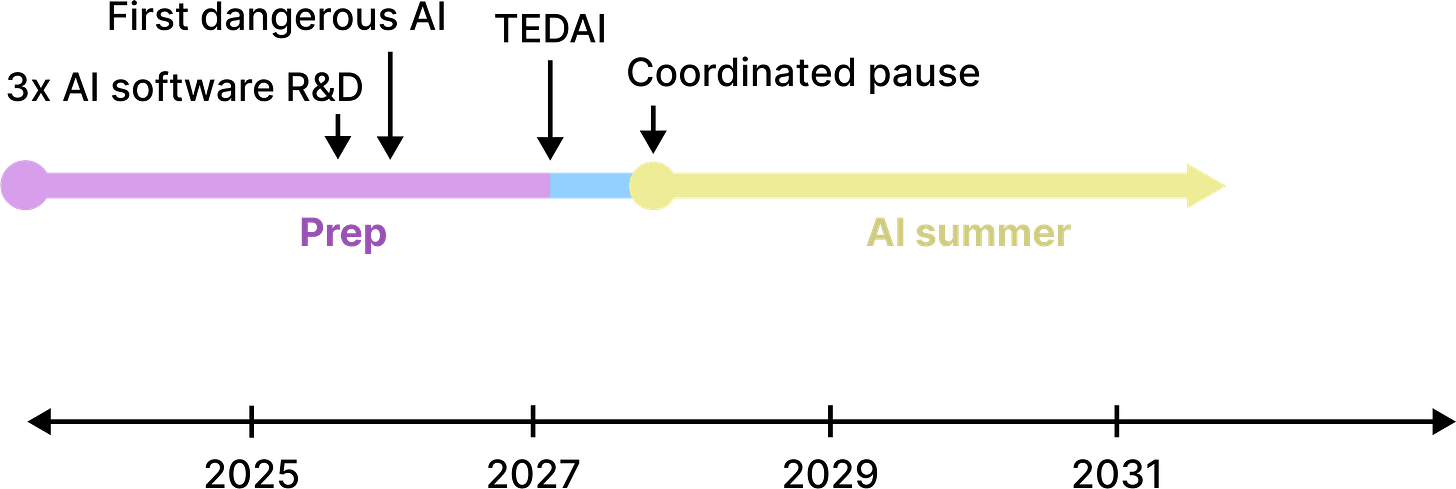
Figure 3. A timeline in which Magma coordinates with competitors to slow down. The specific dates are illustrative and unimportant, and the pause could happen at any time (not necessarily after TEDAI).
2.3. Outcome #3: Self-destruction
If Magma does not automate scaling and other developers continue barreling forward, then Magma’s final option is to unilaterally slow down, and, eventually, be decisively overtaken.
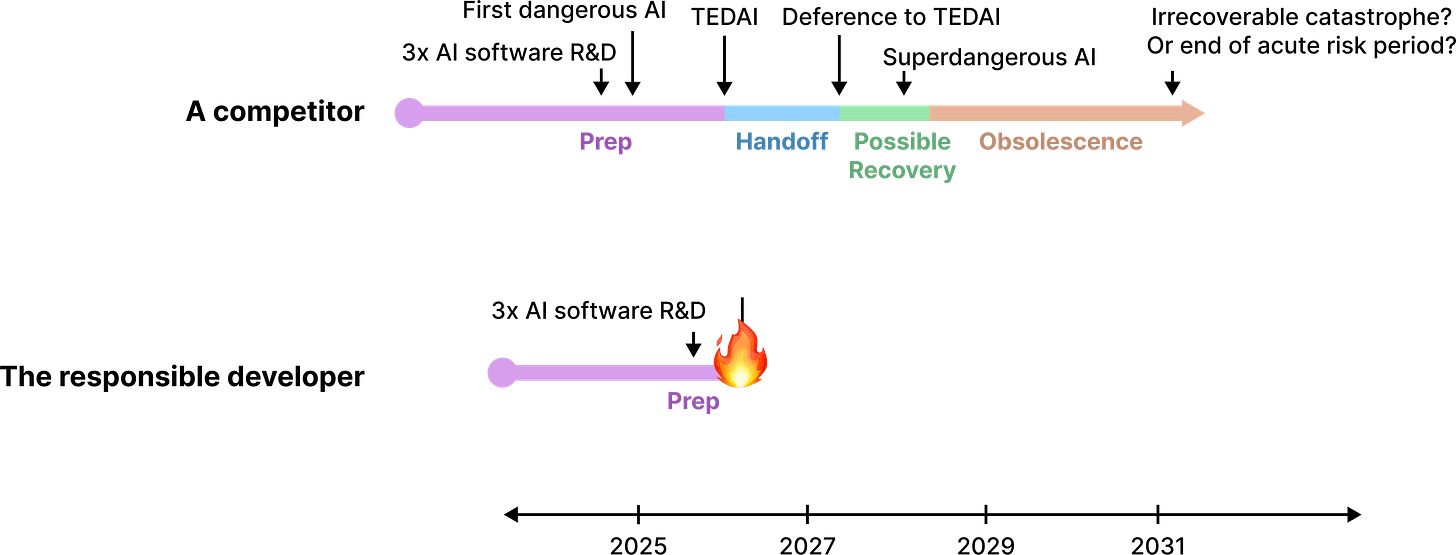
Figure 4. A timeline in which Magma self-destructs. The specific dates are illustrative and unimportant.
Ryan Greenblatt once called this “self-immolation” [AF · GW]: to set oneself on fire, typically as an act of protest. I find this a fitting term. By giving up their top spot, not only might Magma free up resources for safety, reduce competitive pressure on the frontrunners, etc; but Magma also provides a costly signal to the world that makes their advocacy more credible.
3. Goals
The previous section explained the endpoints where Magma might be headed. But what actions might Magma take along the way to these endpoints, and which should they steer toward?
At any given point in time, Magma might advance the following goals:
- Goal #1: Reduce the risks posed by the Magma’s own AI, including:
- Direct risks, where AI systems directly cause an extreme catastrophe.
- Proliferation risks, where AI systems proliferate key software, or this software is stolen.
- Sabotage risks, where AI systems sabotage safety efforts.
- Competition risks, where AI systems increase competitive pressure by virtue of knowledge of their existence and the degree of their deployment.
- Goal #2: Magma might also reduce risks posed by other AI developers, for example, by advancing the following:
- AI nonproliferation: Reduce the amount of dangerous AI in the world.
- Strategy: Secure key AI software and research IP.
- Strategy: Share the benefits of AI, perhaps as part of a nonproliferation agreement, or to reduce incentives to race.
- AI safety distribution: Lower the costs of making AI safe.
- Strategy: Export safety research to other developers.
- Strategy: Provide resources to external safety researchers.
- AI governance and communication: Increase the motivation of developers to make AI safe.
- Strategy: Set norms by modeling responsible decision-making.
- Strategy: Demonstrate risks by e.g. publishing “smoking gun” examples of misalignment [AF · GW].
- Strategy: Advocate for helpful regulation.
- Strategy: Coordinate with other developers.
- Strategy: Adopt and improve measures for verifying agreements.
- AI defense: Harden the world against unsafe AI.
- Strategy: Bolster democratic militaries.
- Strategy: Deploy “truthful AI” to mitigate persuasion tools.
- Strategy: Develop technologies to defend against novel weapons of mass destruction.
- Strategy: Use AI systems to search for rogue agents on the internet.
- etc
- AI nonproliferation: Reduce the amount of dangerous AI in the world.
- Gain access to more powerful AI systems to help advance the other goals.
- Strategy: Advance AI software R&D.
- Strategy: Maintain positive public relations.
- Strategy: Externally deploy models to acquire revenue and investment.
- Strategy: Merge with a leading actor, or obtain API access to their internal systems.
All of these goals can be advanced to differing degrees depending on the level of investment Magma applies to them.
4. Prioritization heuristics
The goals in the previous section trade-off against each other, both because some are directly in tension and because Magma must distribute limited resources between them. So how might Magma prioritize between goals?
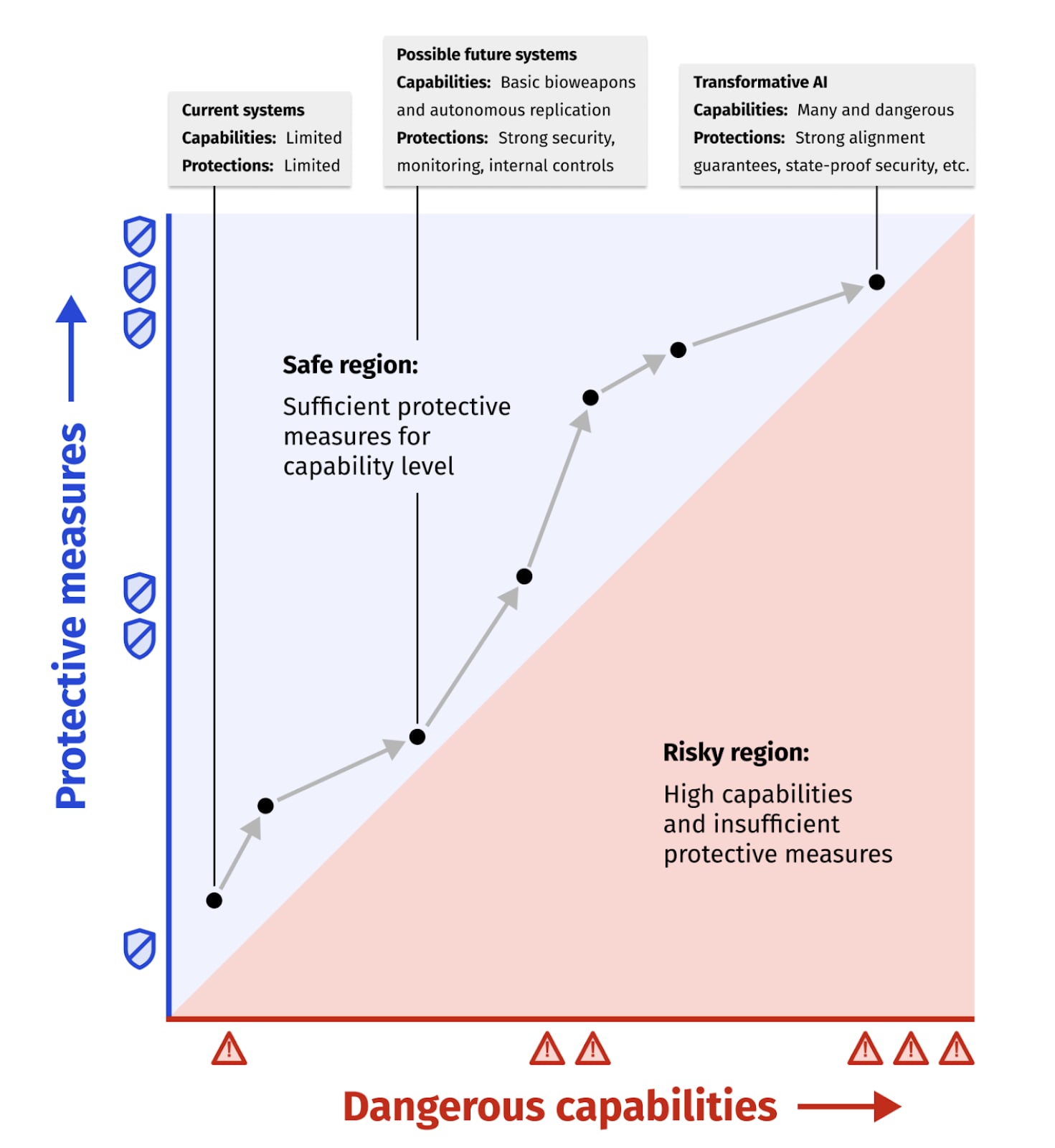
Magma might turn three “knobs”:
- The velocity knob – to what extent does Magma advance the capabilities of their AI systems or slow down and invest more in safety?
- The preparation knob – to what extent does Magma prepare for future risks or try to mitigate current risks?
- The safety portfolio knobs – how should Magma allocate resources between safety efforts (nonproliferation, safety distribution, governance and communication, and AI defense)?
Magma adjusts these knobs over time like they are playing a perilous arcade game.
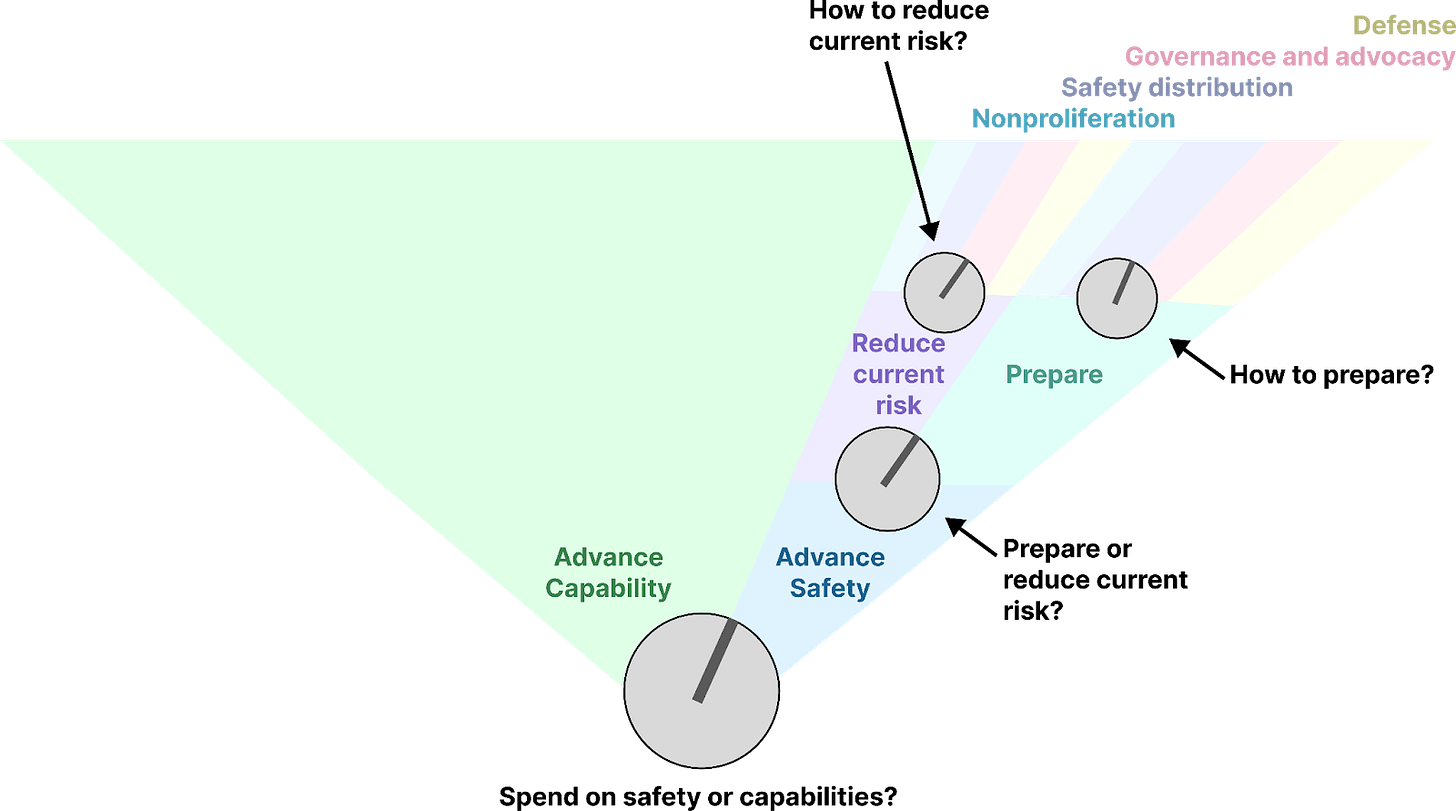
Figure 5. Prioritization knobs.
You might recall the three heuristics I introduced for controlling these knobs.
Before achieving meaningful (e.g. >3x) AI software R&D acceleration:
- Heuristic #1: Scale AI capabilities aggressively.
- Heuristic #2: Spend most safety resources on preparation (rather than addressing risks posed by frontier systems).
- Heuristic #3: Devote most preparation effort to:
- (1) Raising awareness of risks.
- (2) Getting ready to elicit safety research from AI.
- (3) Preparing extreme security.
After meaningful (e.g. >3x) AI software R&D acceleration, I find heuristics more difficult to specify. Magma might begin to orient toward one of the aforementioned outcomes (human researcher obsolescence, a long coordinated pause, or self-destruction). Deciding between these options requires considering many factors (how willing are other actors to coordinate? Would slowing down actually make advocacy more credible? etc).
As a result, the remaining sections focus on what Magma might do in the period before meaningful (e.g. >3x) software AI R&D acceleration. Later periods are discussed in Appendix A.
5. Heuristic #1: Scale aggressively until meaningful AI software R&D acceleration
This heuristic recommends that Magma should initially scale at roughly the maximum speed Magma can do so. Magma might spend some resources on safety preparation, but not enough to take meaningful (e.g. >5%) hits to velocity.
This strategy sure sounds reckless, so why is this a reasonable heuristic?
To determine how quickly to scale, Magma might compare the costs and benefits of scaling.
- Benefits of scaling. Advancing capabilities quickly helps Magma acquire key resources sooner, including:
- More capable AI labor.
- More compelling demos of risks.
- More relevant safety research.
- More investment and compute.
- More government, industry, and public influence.
- Costs of scaling. On the other hand, advancing capabilities might:
- Directly impose risk.
- Increase competitive pressure.
- Reduce the credibility of advocacy.
- Reduce resources allocatable to safety, such as compute.
Before Magma achieves meaningful AI software R&D acceleration, the benefits of scaling probably outweigh the costs, mostly because the costs of scaling are low:
- Before these speedups, AI systems are probably not capable enough to pose significant extreme risks.[3]
- Also, judging from current trends the political will to coordinate is likely to be low, so slowing down isn’t likely to cause other actors to slow down.
As capabilities improve, the costs of advancing capabilities increase, and the benefits decrease, such that slowing down becomes increasingly helpful for safety.
- The costs of scaling increase because:
- Scaling increasingly imposes risk.
- Competition becomes more dangerous, and the political will to avert it rises.
- As risks swell, credible advocacy becomes increasingly important, as does allocating compute and person-hours to safety that would otherwise be useful for scaling.
- Magma might want to “spend all their chips” (including their literal chips) on safety before reaching a point of no return, where they lose their ability to reduce risks from other actors.
- The benefits of scaling generally decrease over time because:
- Safety mitigations eventually become a bottleneck to extracting reliable safety work from increasingly capable AI systems.
- Increases in capability do not meaningfully affect inelastic resources like compute and public influence over critical timeframes.
- More capable AI agents do not make demos of risks significantly more compelling.
Combining these considerations implies that significantly slowing down before meaningful (e.g. >3x) AI software R&D acceleration is probably not beneficial; however, significantly slowing down at some point after meaningful AI software R&D acceleration is likely a good strategy. The question of when and whether to slow down after this point is hard to answer. I describe some considerations that affect this in Appendix A.
6. Heuristic #2: Before achieving meaningful AI software R&D acceleration, spend most safety resources on preparation
- The argument for this heuristic is fairly simple:
- Before meaningful AI software R&D acceleration, the extreme risks posed by AI systems (indirect and direct) are probably low in absolute terms and relative to what they will be in the future.
- Therefore, preparing to mitigate future risks is more important than mitigating existing risks.
- This is not to say Magma shouldn’t spend any resources mitigating risks posed by frontier systems before this point. Magma might want to do so to (1) maintain positive public relations and (2) iterate with a real-world feedback loop; however, my claim is that their primary terminal focus should be on preparing for future risks.
- Meaningful AI software R&D acceleration is a potential crossover point where the goal of mitigating existing risks deserves a meaningful share of resources. Once AI agents can accelerate software R&D, (1) AI systems pose an increasing risk of accelerating proliferation, and (2) safety progress might begin to limit the amount of reliable work that can be extracted from AI agents. Therefore, mitigating existing frontier AI systems becomes increasingly important.

Figure 6. A very rough picture of how Magma might divide resources between safety preparation and safety mitigations over time.
7. Heuristic #3: During preparation, devote most safety resources to (1) raising awareness of risks, (2) getting ready to elicit safety research from AI, and (3) preparing extreme security.
Magma might prioritize preparing for interventions that rank highest on the following axes:
- The amount of safety that the intervention buys given its costs.
- The extent to which the intervention is applicable to other AI developers.
- The extent to which the intervention benefits from taking actions in advance.
The table below includes a long list of interventions with (weakly held) views on how they score on these three dimensions.
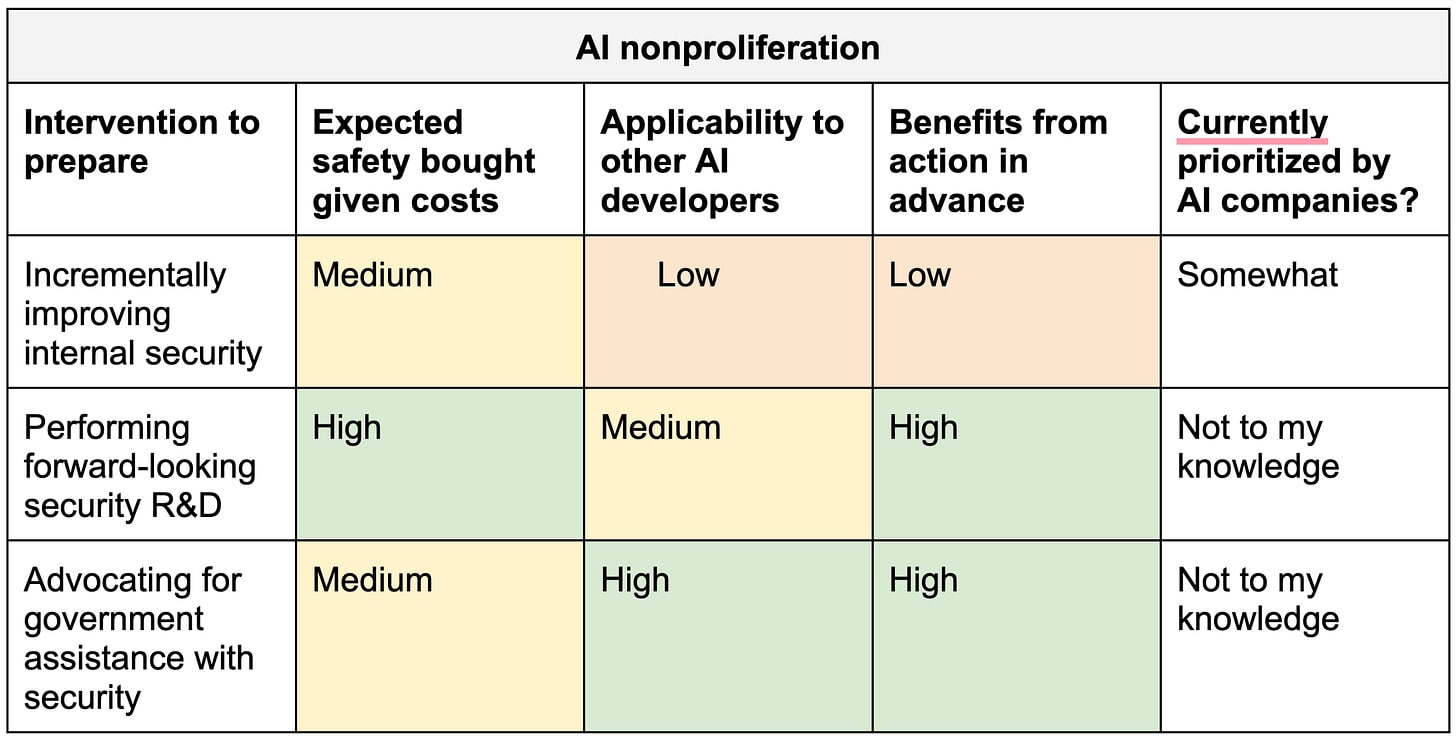
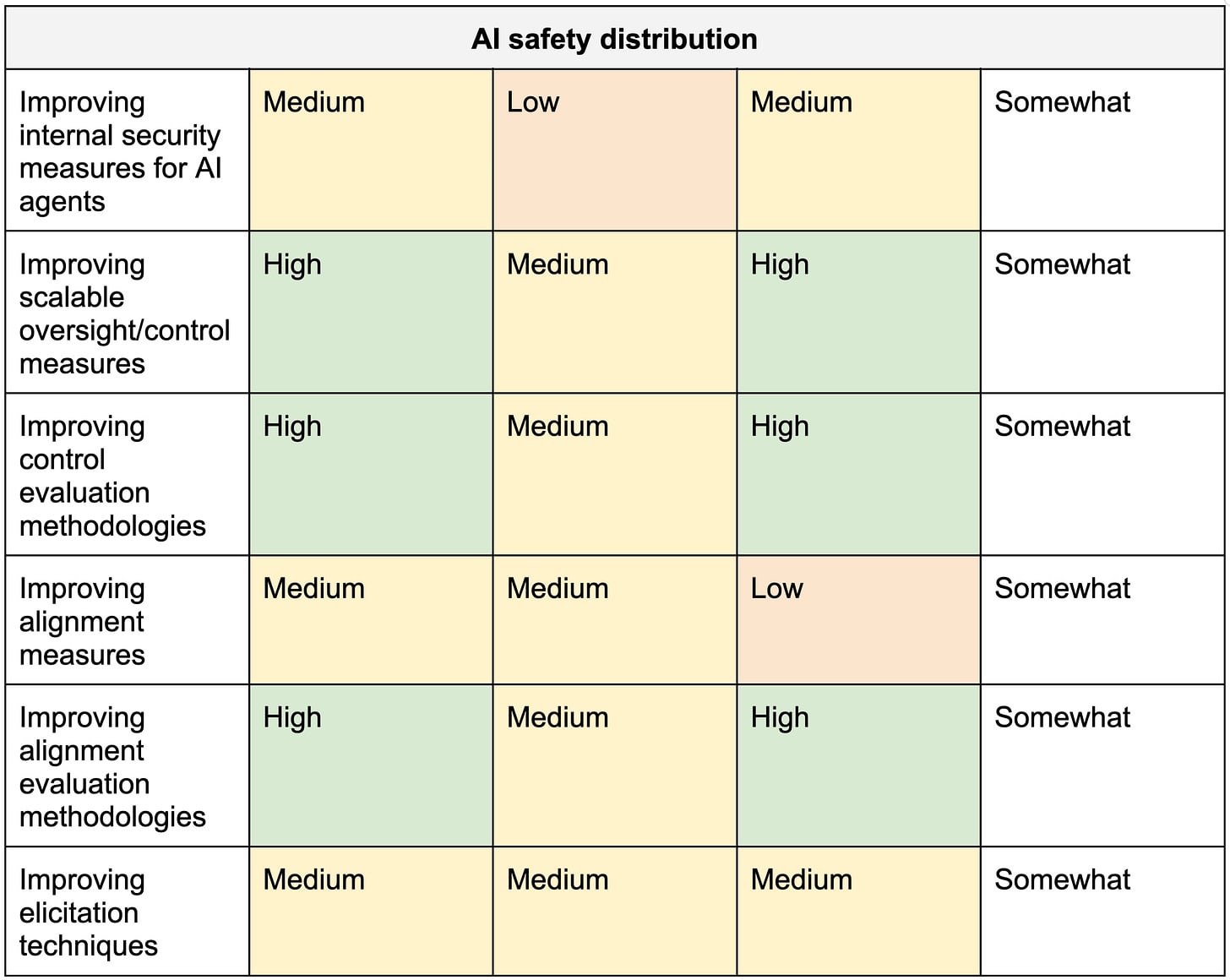
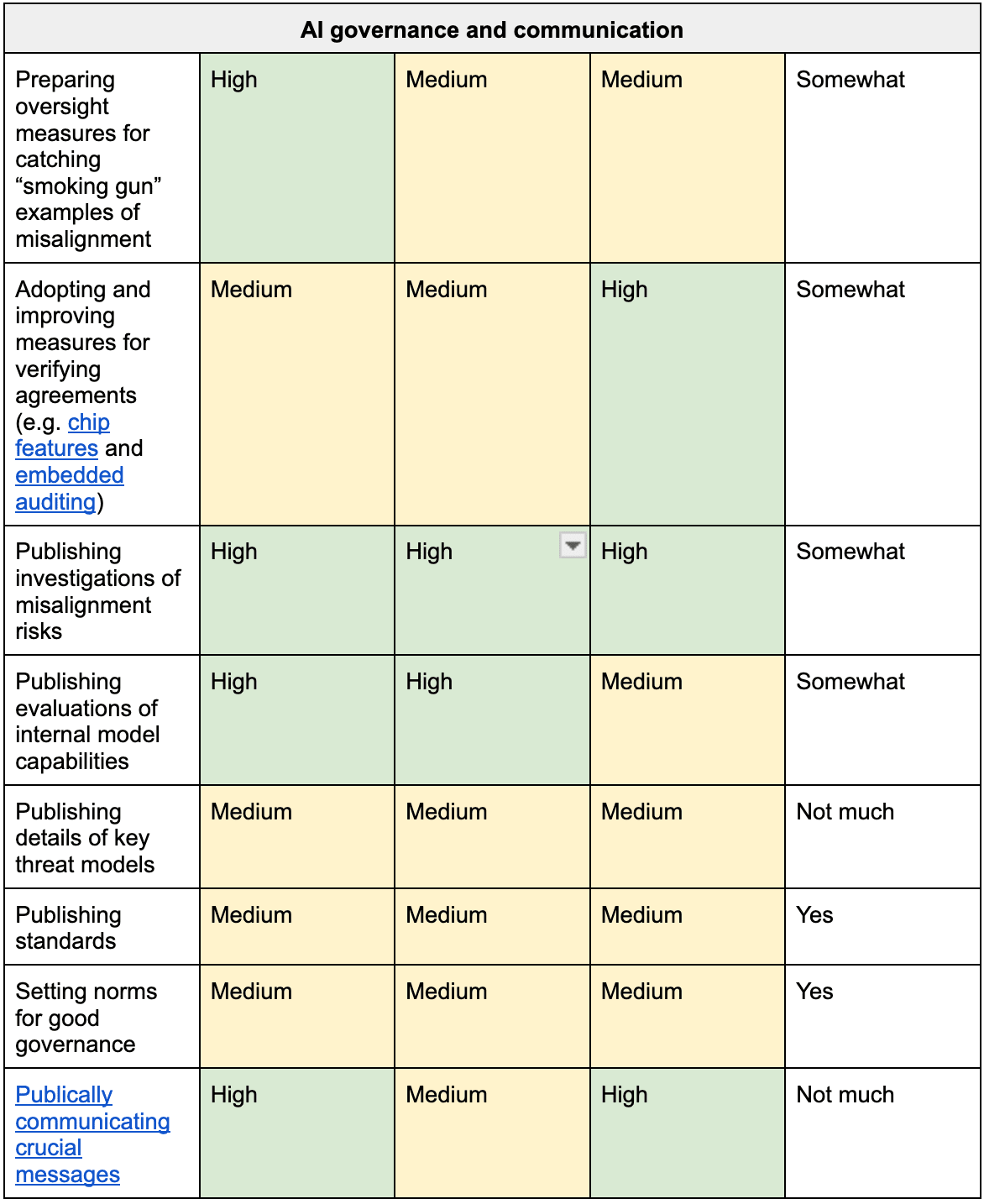
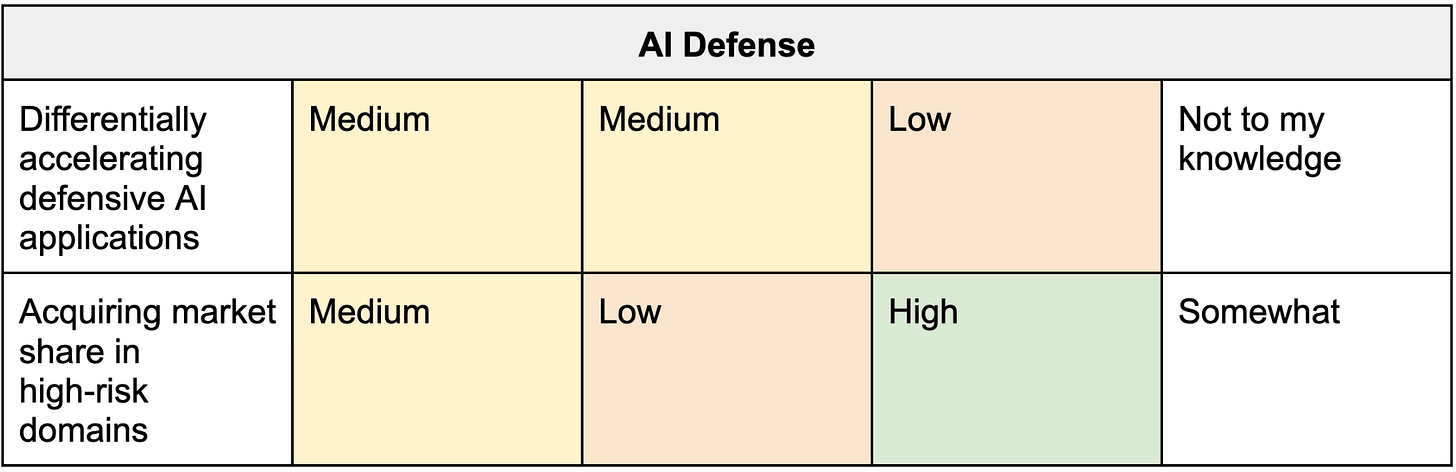
Table 1. Weakly held views on the importance of early action to prepare various interventions.
The top-scoring interventions in this table are:
- P0. Raising awareness of risks
- Publishing investigations of misalignment risks.
- Publically communicating crucial messages.
- P1. Getting ready to elicit safety research from AI
- Improving control/scalable oversight measures.
- Improving control evaluation methodologies.
- Improving alignment evaluation methodologies.
- P2. Preparing extreme security
- Performing forward-looking security R&D.
- Advocating for government assistance with security.
The next sections explain why I think these interventions are most deserving of early action.
Category #1: Nonproliferation
Disclaimer: I like to read about security as a hobby, but I am not a security expert. Many of my views here come from talking to people with more expertise than I have, but please still take my opinions in this section with a grain of salt.
There are many ways Magma might slow down AI proliferation, but the class of interventions with the longest lead times is arguably security. Security measures can help (1) prevent theft of critical AI software (proliferation to human actors) and (2) prevent self-exfiltration (proliferation to rogue AI).
I’ll focus on what companies can do to secure model weights in particular. Model weights are both more tractable [4] and will arguably also be more important [5] to secure in comparison with algorithmic insights.
Promising approaches to preparing model weight security include both (1) incrementally improving security and (2) performing forward-looking R&D.
Incrementally improving security. Eventually, model weights might become a prized geopolitical resource. Securing these weights might require defending against the most well-resourced attacks executed by the most cyber-capable nation-states.
Achieving this level of security will likely be difficult, but intermediate progress toward this goal is also valuable. The situation is strictly worse if terrorist groups and hacktivists can steal model weights, or nation-states can steal this software more quickly. To avoid “shooting for the moon and landing in a ditch,” Magma might incrementally implement measures that raise the difficulty of compromising their defenses.
However, some security measures require significant advanced planning and cannot be developed incrementally.
- Performing forward-looking R&D. Here are security measures that (1) have long lead times, (2) might be especially effective given their costs, and (3) are relatively exportable. Exportability is crucial because attackers can steal AI from companies with the weakest security, so security improvements are most valuable if they are widely adopted by actors at the frontier.
- On-chip security features. Magma might negotiate with hardware companies to invest in on-chip features like trusted execution environments (TEEs) for GPUs, on-chip code-signing, one-way memory stores, etc. It’s not enough for these features to be implemented. They also need to be aggressively hardened before they are put into production.
- Supply chain security. On-chip security features are worthless if the hardware supply chain is compromised. Magma might need to work with governments and hardware companies to implement on-site and on-chip measures that make supply chain attacks more difficult.
- Safety research for AI-assisted security. One hope for security is that it might become much easier with powerful AI assistance. For example, models might be set up to monitor every log file and action that employees take; however, there are lots of reasons AI-assisted security might fail (inadequate adversarial robustness, inadequate control and alignment, etc). Addressing these concerns requires research in advance.
- R&D for rapidly retrofitting extreme security. The political will to mandate security measures might only be available shortly (< 2 years) before AI is extremely dangerous. As a result, resources for rapidly retrofitting extreme security might be especially valuable.
- The question of how to rapidly retrofit extreme security is wide open, and I’m not aware of any serious attempts to answer it; however, there are some blue-sky proposals that seem promising, such as hardware-enforced data upload limits [LW · GW].
Experts I’ve spoken with say that preparing extreme security will require close collaboration with government agencies. These agencies need to be involved in red teaming because they’ve been trying to break into companies for many years and have advanced internal exploits. Close government collaboration is not something that can wait until the last minute. Government agencies need to be involved while extreme security measures are being prepared and implemented.
Category #2: Safety distribution
There are two main strategies for making AI systems more safe:
- AI alignment. Design AI systems so that they behave as intended.
- AI control: Set up the environment of AI systems so that they cannot cause harm even if AI systems don’t behave as intended.
How might Magma prepare these categories of safety measures?
An assumption of this plan is that Magma will achieve TEDAI in less than 3 years. Under short timelines, most safety progress will likely happen in the final years when human researchers have access to AI assistance. For example, if AI assistance allows 10x progress for 8 months, this period would effectively contain 6 years of research advances. Therefore, under short timelines, there is huge upside in preparing to leverage accelerated AI safety work.
To prepare to leverage AI assistance, Magma might:
- Advance “research security,” which includes internal security measures and control measures that allow Magma to faithfully log the actions AI agents take on their servers.
- Improve “scalable oversight,” which includes measures that give human overseers more useful information about the code AI agents are running, e.g. leveraging monitoring or debate techniques.
- Improve safety evaluation methodologies. Magma might improve the science of evaluating safety so that humans (or automated benchmarks) can provide more reliable reward signals for safety research.
- Improve optimization techniques. Finally, magma might find ways to more effectively increase AI agent performance with an expensive reward signal.
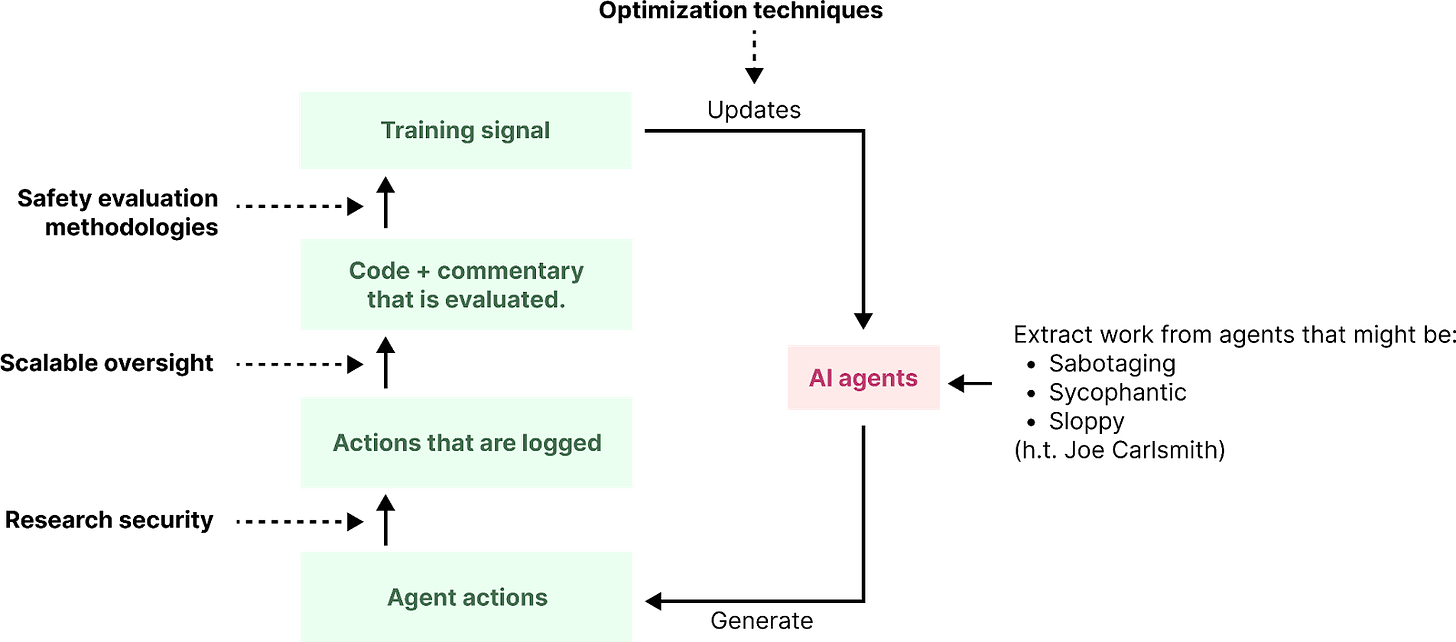
Figure 7. A pipeline for extracting work from AI agents.
All of these are active areas of research and potentially include a broad range of work. For example, a paper proposing an interpretability technique might improve risk evaluation methodologies by providing a concrete example of a mitigation to reason about; However, in general, I think most AI safety research would be significantly more useful if researchers explicitly prioritized preparing to leverage AI assistance.
The plans and methodologies for creating a trustworthy AI agent researcher are nascent. If AI developers suddenly had access to powerful AI assistance, I think a lot of it would be wasted [? · GW] because very few people have thought deeply about safety evaluation methodologies.
Category #3: Governance and communication.
Magma might try to set the global stage for responsible AI governance by:
- Motivating preparation. For example, Magma might monitor internal AI agents so they can sound the alarm if models are egregiously misaligned, publish safety frameworks and standards, release research that explores key risks, advocate for important safety mitigations (e.g. AI control), and publish plans similar to this one.
- Setting norms. Magma might lead by example by demonstrating effective preparation, thoughtful decision-making, and robust internal governance.
- Preparing for coordination. Finally, magma could try to coordinate with other developers in advance to agree on triggers for a slowdown and maintain lines of communication.
Perhaps the intervention in this category that appears to me like the lowest hanging fruit is clearly communicating the nature of extreme risks, how prepared we are, and what needs to be done to address them. I believe the most important fact about our situation is that developers will plausibly create wildly superhuman AI in the next four years that will be able to overpower humanity as swiftly and easily as a modern military would overpower a musket-bearing 18th-century Militia – and no AI company seems to be saying this and clearly explaining the implications.
Category #4: AI defense
AI defense benefits less from preparation than the other categories do.
- The AI systems that are most important to defend against are those that are extremely dangerous (i.e. broadly superhuman) or could quickly become extremely dangerous.
- Defending against these systems will likely require AI systems of similarly strong capability.
- Such systems are probably capable enough to “apply themselves” for defensive uses.
Perhaps a more promising way to prepare for AI defense is to acquire market share and relationships with customers. For example, Magma might win contracts for AI military applications or build AI advising software for members of government – both of which are especially high-stakes deployments where responsible AI development is critical.
8. Conclusion
Even if developers follow a plan like this one, the situation is frankly horrifying. Developers might have only a couple of years before they need to thread the needle of AI alignment and thrust humanity’s destiny into the hands of newly born minds.
This is not the kind of situation one should stumble into – yet, as far as I am aware, AI companies generally do not have concrete plans for addressing extreme AI risks.[6]
A popular argument against planning is that predicting the future is hard. Perhaps AI companies are better off improving safety myopically rather than fooling themselves into thinking they can reason about more distant outcomes.
I agree that planning is challenging!
But it might be necessary.
Extreme risks might be hard to see coming, and much of the work to mitigate them has to begin years in advance.
It might be time to consider – research agenda by research agenda, security measure by security measure, policy by policy: what needs to be done, how is it going to happen, and are we on track to get there? The pages here obviously do not achieve this goal, but I’m hoping they are a step in the right direction.
I encourage readers to either:
- Think about whether what you are doing is high leverage according to this plan, and change your actions accordingly.
- Or write a better plan.
I think preparing and prioritizing more effectively is quite tractable, and could substantially improve humanity’s chances of success.
Appendix
Appendix A: What should Magma do after meaningful AI software R&D speedups
Recall the three outcomes that Magma might eventually encounter:
- Fully automated scaling.
- A coordinated pause.
- Self-destruction.
Which of these outcomes might Magma steer toward?
- Heuristic #1: If a successfully coordinated pause is plausible, always pick this option.
- If a successful coordinated pause is unlikely, then consider two cases:
- Heuristic #2: If Magma is unlikely to be decisively overtaken by default, then target fully automated scaling.
- Heuristic #3: If Magma is likely to be decisively overtaken by default, then target self-destruction, and spend much more resources on safety.
Heuristic #2 and #3 are particularly weakly-held. There are many other factors that might affect which outcome to target, such as the extent to which Magma dropping out of the race will reduce pressure on the leader, how much sending a costly signal might amplify advocacy efforts, etc. See section 5 for factors that might affect this cost-benefit analysis.
However, I think the extent to which Magma is “in the pack” or lagging behind is perhaps the most decisive factor in whether Magma should self-destruct.
If Magma is “in the pack” of leaders, then there are potentially big returns to remaining in the race.
- Magma can continue to perform relevant safety research.
- Magma can acquire more compute, which it can use for safety.
- Many of the benefits of self-destructing remain available after Magma automates AI development, since Magma can always self-destruct later.
- I don’t think there’s an especially good reason in this case to believe that the bulk of the risks addressable by Magma occur around TEDAI capabilities
However, if Magma is lagging, then there is a good reason to think their window of influence is concentrated around the time of TEDAI.
- A reckless developer might be at the cusp of completely removing humans from the loop, after which capabilities might improve much more quickly into the perilous superhuman regime.
- If Magma is still six months behind, they might have only a few months before their opportunity to influence actors at the frontier is gone because they have steered into unsafe states that are hard to recover from.
In this scenario, Magma might ramp up their spending on safety while they have influence.
- Potentially, this means pausing all further capability advances to free up GPUs and person-hours for alignment and control work.
- It might also mean leaning into advocacy as hard as they can so that governments intervene. As discussed in section 2.4, pausing might provide a costly signal that makes their advocacy much more credible. Otherwise, government officials and the public might interpret their pleas as an attempt to slow the leader so they can catch up to the frontier.
- ^
I selected this number for concreteness. It is fairly arbitrary.
- ^
This list of outcomes is not comprehensive. A fourth possibility is that “AI progress hits a wall,” so a substantial ‘pause’ happens naturally; however, Magma focuses on scenarios where software-driven progress scales to superhuman AI within a few years. These scenarios are both plausible (see assumptions) and arguably where most near-term addressable risk is concentrated.
There might also be a short coordinated pause; however, this scenario quickly leads to “human researcher obsolescence,” which is a better boundary for Magma’s planning horizon in this case. - ^
I expect the main risk AI systems begin to pose after this point is proliferating AI capabilities by speeding up other researchers. At 3x AI software R&D speedups, this risk is very non-trivial, but also probably not very high compared to risks that are looming ahead of the developer.
- ^
Model weights are a giant stack of numbers. Attacks cannot steal them by asking a human “what are the model weights?” However, an attacker can steal algorithmic insights out of the minds of people.
- ^
After strong AI R&D capabilities, model weights might be more important to secure than algorithmic insights because, if a developer can steal model weights, they also potentially steal a factory for generating algorithmic insights on demand; however, if a cyber threat actor can only steal algorithmic insights, they are restricted by whether Magma actually uses model weights to generate these insights. Said another way, once model weights are stolen, there isn’t much Magma might be able to do to prevent reckless scaling to higher capabilities, whereas they retain greater control if model weights are secure
- ^
There are a few documents that are somewhat plan-like such as The Checklist and some documents published by OpenAI in 2022, and safety frameworks are plans if you squint; however, the material published online does not scream “people at AI companies have thought very carefully about how to prepare for superdangerous AI.” My impression is that very few people explicitly think about this at AI companies.
5 comments
Comments sorted by top scores.
comment by RussellThor · 2025-01-30T03:55:29.486Z · LW(p) · GW(p)
Thanks for this article, upvoted.
Firstly Magma sounds most like Anthropic, especially the combination of Heuristic #1 Scale AI capabilities and also publishing safety work.
In general I like the approach, especially the balance between realism and not embracing fatalism. This is opposed to say MIRI, Pause AI and at the other end, e/acc. (I belong to EA, however they don’t seem to have a coherent plan I can get behind) I like the realization that in a dangerous situation doing dangerous things can be justified. Its easy to be “moral” and just say “stop” however its another matter entirely if that helps now.
I consider the pause around TEDAI to be important, though I would like to see it just before TEDAI (>3* alignment speed) not after. I am unsure how to achieve such a thing, do we have to lay the groundwork now? When I suggest such a thing elsewhere on this site, however it gets downvoted:
https://www.lesswrong.com/posts/ynsjJWTAMhTogLHm6/?commentId=krYhuadYNnr3deamT [LW · GW]
Goal #2: Magma might also reduce risks posed by other AI developers
In terms of what people not directly doing AI research can do, I think a lot can be done reducing risks by other AI models. To me it would be highly desirable if AI (N-1) is deployed as quickly as possible into society and understood while AI(N) is still being tested. This clearly isn’t the case with critical security. Similarly,
AI defense: Harden the world against unsafe AI
In terms of preparation, it would be good if critical companies were required to quickly deploy AGI security tools as they become available. That is have the organization setup so that when new capabilities emerge and the new model finds potential vulnerabilities, experts in the company quickly assess them, and deploy timely fixes.
Your idea of acquiring market share in high risk domains? Haven't seen that mentioned before. It seems hard to pull off - hard to gain share in electricity grid software or similar.
Someone will no doubt bring up the more black hat approach to harden the world:
Soon after a new safety tool is released, a controlled hacking agent takes down a company in a neutral country with a very public hack, with the message if you don’t asap use these security tools, then all other similar companies suffer and they have been warned.
comment by Chris_Leong · 2025-01-30T05:13:47.621Z · LW(p) · GW(p)
Nice article, I especially love the diagrams!
In Human Researcher Obsolescence you note that we can't completely hand over research unless we manage to produce agents that are at least as "wise" as the human developers.
I agree with this, though I would love to see a future version of this plan include an expanded analysis of the role that wise AI plays would play in the strategy of Magma, as I believe that this could be a key aspect of making this plan work.
In particular:
• We likely want to be developing wise AI advisors to advise us during the pre-hand-off period. In fact, I consider this likely to be vital to successfully navigating this period given the challenges involved.
• It's possible that we might manage to completely automate the more objective components of research without managing to completely automating the more subjective components of research. That said, we likely want to train wise AI advisors to help us with the more subjective components even if we can't defer to them.
• When developing AI capabilities, there's an additional lever in terms of how much Magma focuses on direct capabilities vs. focusing on wisdom.
Replies from: joshua-clymer↑ comment by joshc (joshua-clymer) · 2025-01-30T18:08:33.519Z · LW(p) · GW(p)
• It's possible that we might manage to completely automate the more objective components of research without managing to completely automate the more subjective components of research. That said, we likely want to train wise AI advisors to help us with the more subjective components even if we can't defer to them.
Agree, I expect the handoff to AI agents to be somewhat incremental (AI is like an intern, a new engineer, a research manager, and eventually, a CRO)
comment by Yonatan Cale (yonatan-cale-1) · 2025-02-07T23:42:41.523Z · LW(p) · GW(p)
This post helped me notice I have incoherent beliefs:
- "If MAGMA self-destructs, the other labs would look at it with confusion/pity and keep going. That's not a plan"
- "MAGMA should self-destruct now even if it's not leading!"
I think I've been avoiding thinking about this.
So what do I actually expect?
If OpenAI (currently in the lead) would say "our AI did something extremely dangerous, this isn't something we know how to contain, we are shutting down and are calling other labs NOT to train over [amount of compute], and are not discussing the algorithm publicly because of fear the open source community will do this dangerous thing, and we need the government ASAP", do I expect that to help?
Maybe?
Probably nation states will steal all the models+algorithm+slack as quickly as they can, probably a huge open source movement will protest, but it still sounds possible (15%?) that the major important actors would listen to this, especially if it was accompanies by demos or so?
What if Anthropic or xAI or DeepSeek (not currently in the lead) would shut down now?
...I think they would be ignored.
Does that imply I should help advance the capabilities of the lab most likely to act as you suggest?
Does this imply I should become a major player myself, if I can? If so, should I write on my website that I'm open to a coordinated pause?
Should I give up on being a CooperateBot, given the other players have made it so overwhelmingly clear they are happy to defect?
This is painful to think about, and I'm not sure what's the right thing to do here.
Open to ideas from anyone.
Anyway, great post, thanks
Replies from: MichaelDickens↑ comment by MichaelDickens · 2025-04-19T01:05:46.793Z · LW(p) · GW(p)
I think the right way to self-destruct isn't to shut down entirely. It's to spend all your remaining assets on safety (whether that be lobbying for regulations, or research, or whatever). This would greatly increase the total amount of money spent on safety efforts so it might help quite a lot.
I do believe shutting down does have a decent chance, although not a comfortingly large one, of scaring government and/or other AI companies into taking the risks seriously.