How well does your research adress the theory-practice gap?
post by Jonas Hallgren · 2023-11-08T11:27:52.410Z · LW · GW · 0 commentsContents
Outtake from a very normal alignment conversation: Purpose of post Finishing the very normal alignment conversation Analysis: Metric spaces in alignment Exercise: Building your puzzle Part 1: Laying the Cornerstones Part 2: Framing the theory-practice gap Part 3: Practice Part 4: Figuring out the theory-practice gap Foundational Processes in Sub-agents: Understanding Collective Intelligence: LLM Experiments: Cultural Evolution in AI: Part 5: Prioritising interventions PIBBS & Artificial Life discussions Understanding collective intelligence LLM Experiments Cultural Evolution in AI Part 6: Next steps Conclusion None No comments
(5-6 min read time without exercise instructions)
Motivation for post: Finding a way to map mathematics & areas of academic research to the alignment problem seems to be a core part of theoretical alignment and agent foundations work. Knowing how to frame different toolkits, for example, linear algebra and active inference, into the desiderata needed for solving alignment will likely speed up the research process and clarity of thought of most researchers. This post outlines one frame one can take when building up a map of tools to use when trying to solve the alignment problem. First, the intuition of why will be shown, and then a step-by-step guide to go through the exercise is shared.
Outtake from a very normal alignment conversation:
When laying the puzzle of alignment (where all pieces are rectangles for some reason), Alice said to Bob, “Man, I wish there was some nice way to understand how the frame of vector spaces should fit into this puzzle.”

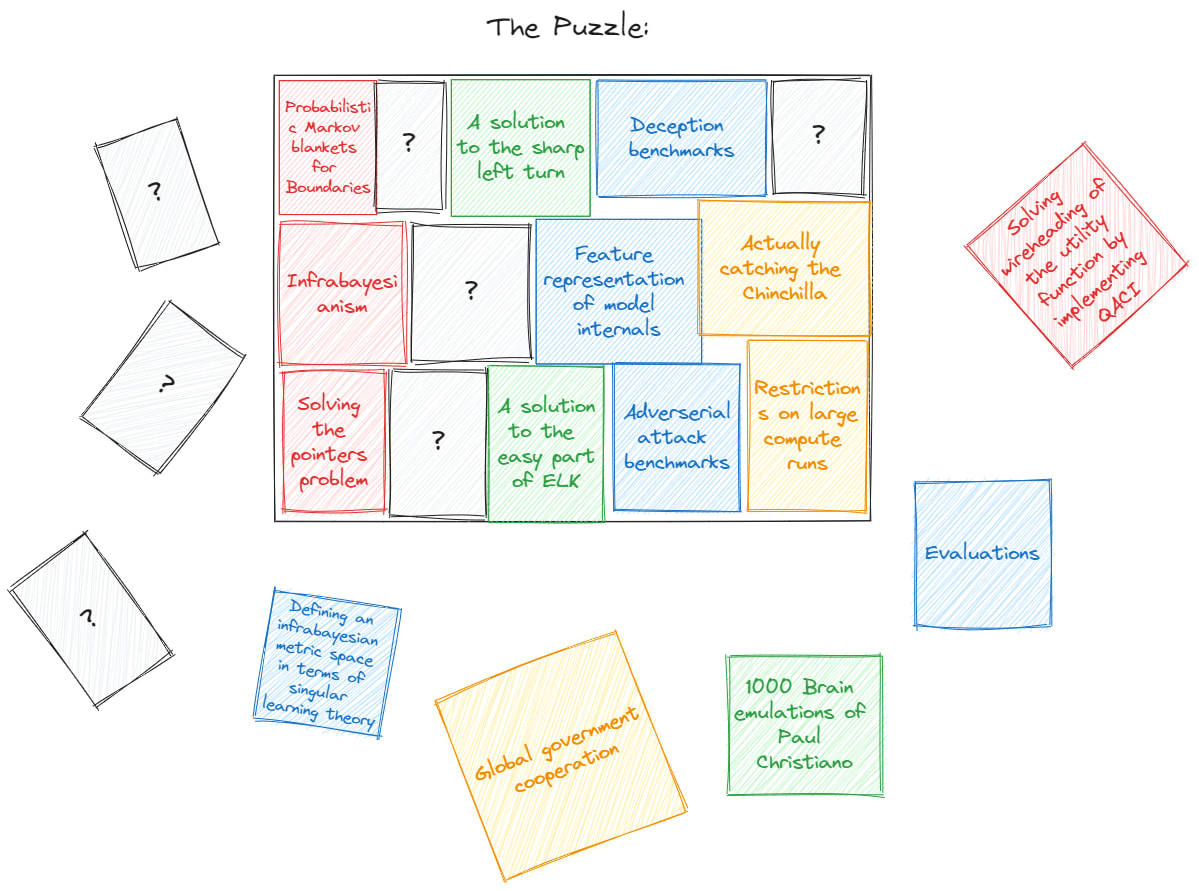
To which Bob answered:
Bob: “Well… Certain techniques can help you”’
Alice: “How so?”
Bob: “A technique is to look at the edges of the frame of the vector space to see how it fits together with other pieces; for example, the [?] shape between Infrabayesianism and feature representations of model internals fits very well with defining a metric space and, therefore, those two pieces are easy to fit together.”
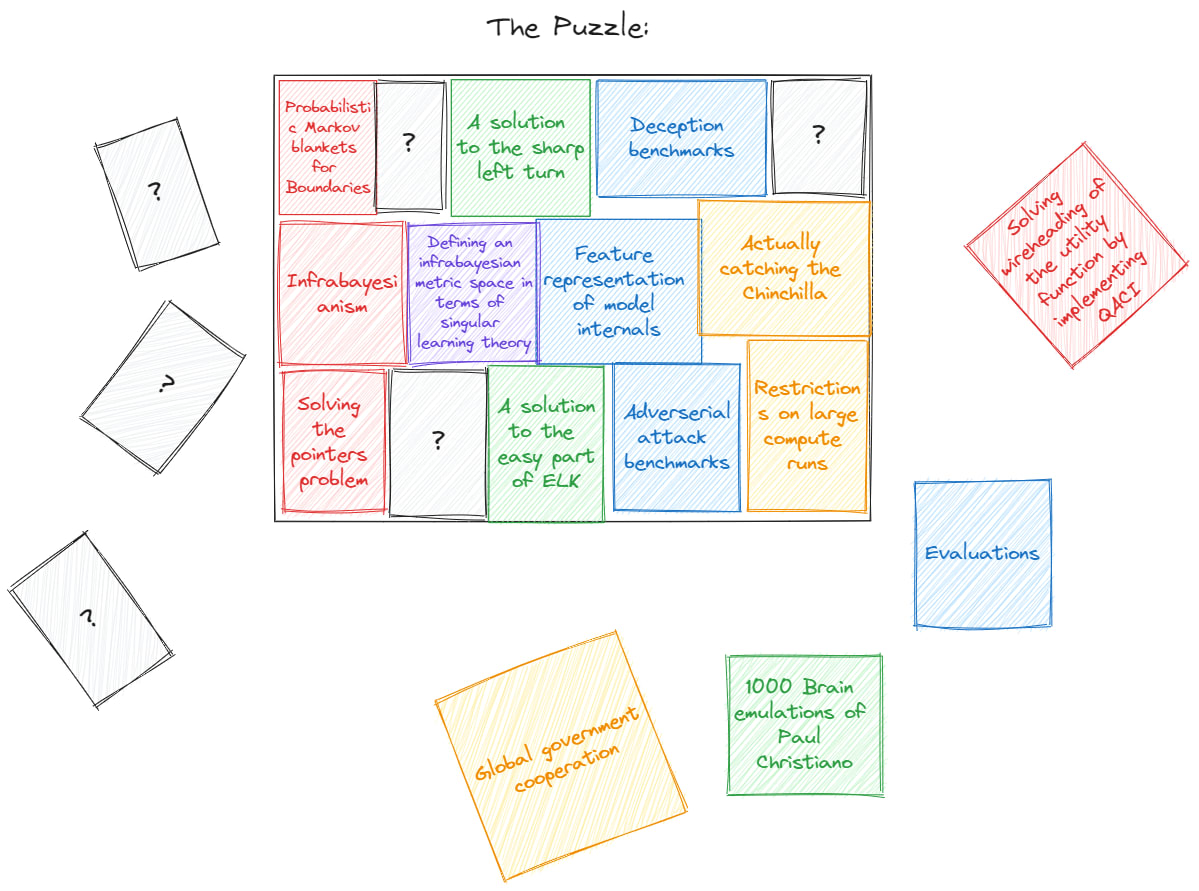
Alice: “Just because we have pieces that fit together doesn’t mean that the picture it paints is useful”
Bob: “That is why we also have to compare and contrast it with the page that we want in order to make it useful. You have to figure out your desiderata as well as how you see it being implemented in practice to see the theory-practice gap [LW · GW].”
(See The Plan - 2022 Update [LW · GW] for more elaboration on the theory-practice gap)
Alice: “I’m not sure I fully understand what “useful” means; as an example if I wanted to understand the mathematical framing of a puzzle piece that is metric spaces, how would that look?”
Bob: “Well, Alice, let me tell you…”
To be continued below
Purpose of post
This post is part of an effort to find useful frameworks for understanding theoretical alignment research and agent foundations. Similar to the exercises of the maze perspective [LW · GW] or the game tree of alignment [LW · GW] as John Wentworth previously came up with. The hope is that the framing of a puzzle will bring the compositionality and cross-piece usefulness of a piece of the alignment puzzle out. This is useful as different theories don’t obviously compose, as John mentions in some post I can’t remember [AF · GW]. Laying the entire puzzle should, in theory, give you an understanding of how the math that we need for alignment can fit together.
A good way to look at it is through the framing of the plan [LW · GW]. There, John talks about the theory and the theory-practice gap. The use of the puzzle framing is that you get to think about the theory-practice gap based on the theoretical desiderata that you come up with. Whilst it will not tell you about what theoretical desiderata we want, it will tell you about what pieces of mathematics are generally useful for the different pathways that you can imagine.
This, in turn, means that you have a better grasp on what will be generally useful no matter what the shift in theoretical desiderata might be. An example of how John used this is that he saw that abstractions and ontology verification seemed to be part of a lot of potential puzzle pieces downstream of desiderata and that they were, therefore, useful.
Finishing the very normal alignment conversation
To be continued is continued...
Analysis: Metric spaces in alignment
Bob: “The usefulness of a piece will be determined by how well it fits into the puzzle, which we can define by what it achieves.”
Alice: “Okay, so what do you mean by what it achieves?”
Bob: “We can take the problem of ontology verification, or how the hell is the agent thinking about the world?”

”This can be divided into different subparts such as interpreting the real world models into a mathematical framework, describing what we want in a useful mathematical way, and translating between the two.”
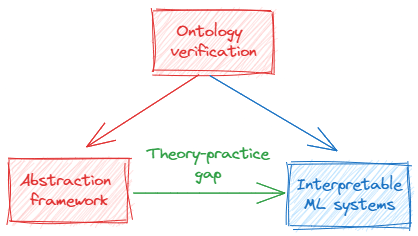
“We have these huge matrices in our LLMs that we have to describe somehow. In other domains, we describe these things through vector spaces, and so it seems very reasonable that it would be a great way to understand transformers, too.”
“There are at least two reasons for this: transformers describe things through linear algebra, which can easily be thought of as a vector space, and secondly, there is a lot of pre-existent mathematics on vector spaces, meaning that you can probably go to math exchange and get more answers than you can on functional decision theory. There is even proof that any function can be represented as a vector space, although I can’t remember where I know this from.”
“This means that metric spaces are most likely useful when it comes to describing LLMs as they can elucidate the knowledge we get.”
Alice: *in a snarky voice* “Yes, metric spaces can be useful when describing a lot of things; it seems like you’re almost making a tautological statement with this.”
Bob: “Hold on there, Miss Critique, we aren’t at the juicy bits yet. You see, we have defined that the edge between ML models and the puzzle piece of metric spaces is pretty smooth, but that doesn’t mean that it is easy to translate vector spaces into the pieces of mathematics that we have to develop for our desiderata.”
“We need to know how jagged the piece’s other edges are or how useful it is regarding other pieces.”
“Let’s assume that the puzzle piece of infrabayesianism is needed to solve alignment or at least the subcomponent of infrabayesian physicalism with their likelihood world modelling that tells you what world you’re in. I quite honestly have a lot less well-defined priors on what the jaggedness of the edge looks like here. Yet I know that we can define probability distributions as n-dimensional probability spheres, so it might not be that difficult?”
External commentator: “Very salient thought there, Bob, not vague at all, thank you.”
Bob: “Listen up, the point of this isn’t that you’re supposed to know what you’re talking about; what you want to do is to elucidate your intuitions to see what your current models tell you about the path forward.” (Einstein’s arrogance echoes in the distance) [LW · GW]
“Now, imagine that you do this method for different potential edges and desiderata.”
“Let’s analyse the puzzle piece of understanding metric spaces in agent foundations with regard to the other edges. If we, for example, care about ontology verification, the piece of metric spaces might give this picture”:
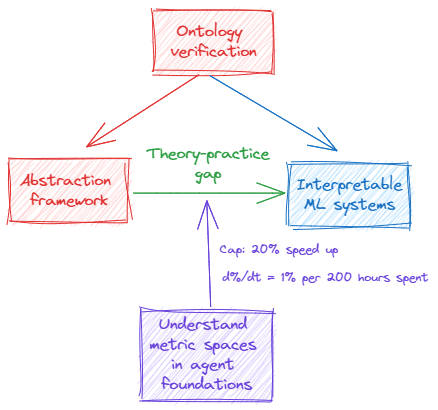
% Speed up source: The Lion, The Witch and The Wardrobe
Bob: “One can then do this for all of the theory-practice gaps that we have in our puzzle”:
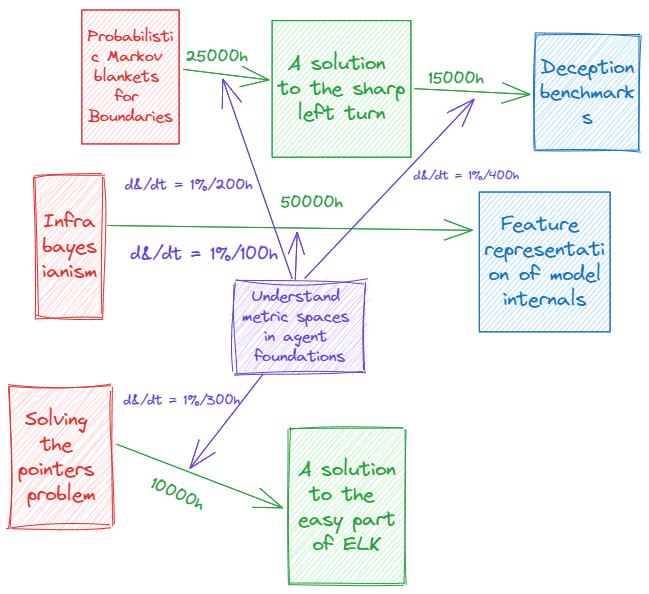
Source: Prince Caspian
Bob: “As you can see, we can add arbitrary theory-gap completion times. The important thing isn’t to get the numbers right but you get an idea of the relative numbers, which is why I can pull these numbers from Narnia. Mess around with the graph a bit; certain intuitions might only come out with the right perspective, and it’s up to you to find them.”
Alice: “That kind of actually makes sense?”
Bob: “Yup, and the nice thing is that I can iterate this methodology multiple times, and in the end, doing this will probably give me a much clearer view of how I might bridge the theory-practice gap than I had before.”
“To get an even better model, I could dig into the different assumptions I made between the translations. I could, as an example, examine how difficult it actually would be to translate IB to vector spaces by translating the IB math into vector models and get a lot better view of it.”
Alice *still snarky*: “Hang on there, mister, let me be snarky again. This seems like something where you can artificially increase your confidence more than it should be. Just pulling those numbers from Narnia might just mess with your models. As the wise ones say, don’t give numbers to something that is imprecise.”
Bob: “First and foremost, Narnia is a very trustworthy source, and Aslan is pretty damn cool.
Secondly, I’m, of course, assuming that any reasonable alignment researcher has read the sequences (if you haven’t, go read the highlights at least) and that you’re part of the Bayesian conspiracy. It is not a hammer but a 6-sided star screw kit that should be used to figure out useful frameworks… or something.”
Commentator: “And with that bombshell, that’s it for us! Thank you, and good night!”
Exercise: Building your puzzle
In the walkthrough, I will apply the puzzle frame to my work to see where I need to head next.
Part 1: Laying the Cornerstones
Essentially, the most important part of this exercise is figuring out how to cross the theory-practice gap. We, therefore, want to have problems/desiderata that we believe are sufficient to solve alignment. Then we also want the technologies that are sufficient to solve these desiderata in themselves.
A simple way of finding these puzzle pieces is to try to find these two parts by building up an alignment game tree [LW · GW] or similar.
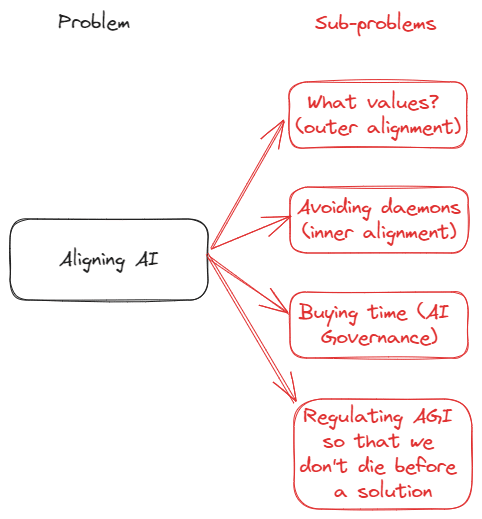
Above is the decomposition of the alignment problem that I thought of. In the context of my own research, the thing that I currently care the most about is solving inner alignment failures. Therefore, a potential continuation of this tree might look something like this for me:
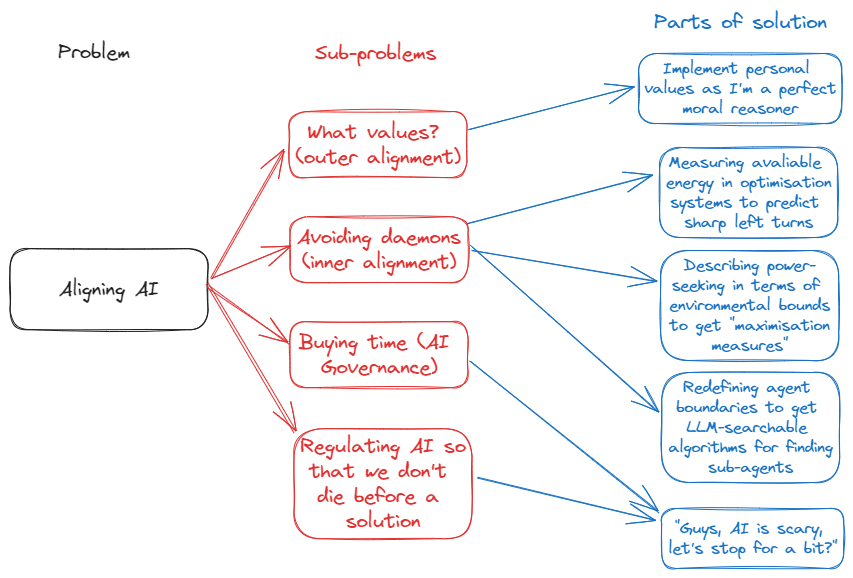
I'm not focused on outer alignment nor AI governance in this post and therefore the solutions there aren't serious
Now as part of building an alignment tree, you, of course, have friends to ask feedback from.
As I ask my friend Charlie (my third personality) what he thinks of my tree so far, he tells me:
Charlie: “Uhh, your solution space is quite specific.”
Charlie: “Also, why do you have to implement your personal values into the AI there? That doesn’t seem that reasonable?”
Charlie makes some great points here; my solution space might be a bit too specific. I might want to create something like the following instead:
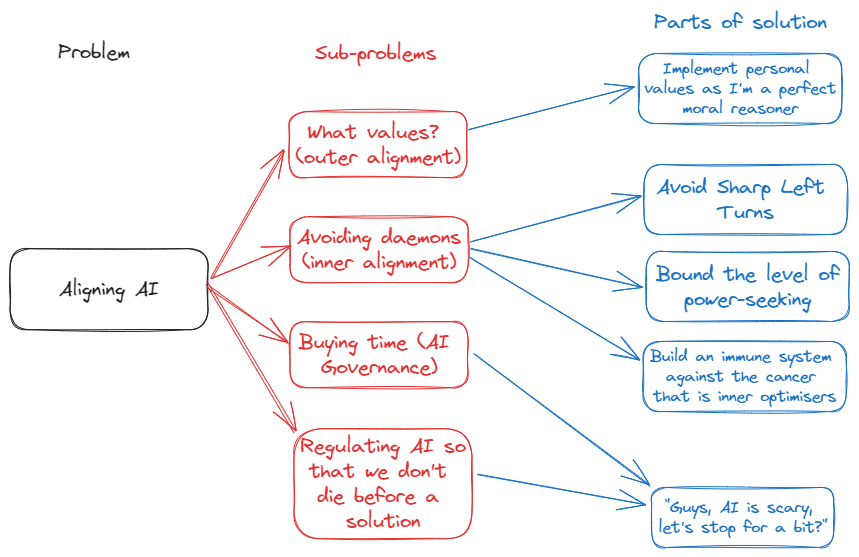
These would then be the desiderata and the solutions that we would want.
The game tree of alignment exercise works by iterating steps of critiquing solutions to the specific game tree that you have. This means that Charlie might say something along the lines of:
Charlie: “Wait, how can you be sure we will solve inner alignment if we solve those 3 problems? The nature of a maximiser is written into the laws of our universe due to the VNM-axioms. Also like IRL doesn’t work well due to this, why would these things you outline help?”
First and foremost, it is very okay to say ??? to an argument like this if you don’t understand it.
Secondly, I would just say that my intuition tells me that there is a flaw in that reasoning due to observations from current-day neural networks and that shard theory is more likely to be true. (AXRP Episode with Quentin Pope)
So, I won’t update my tree as a consequence, but there may be things that people can say to change the tree over time.
I can now create the first parts of my puzzle:
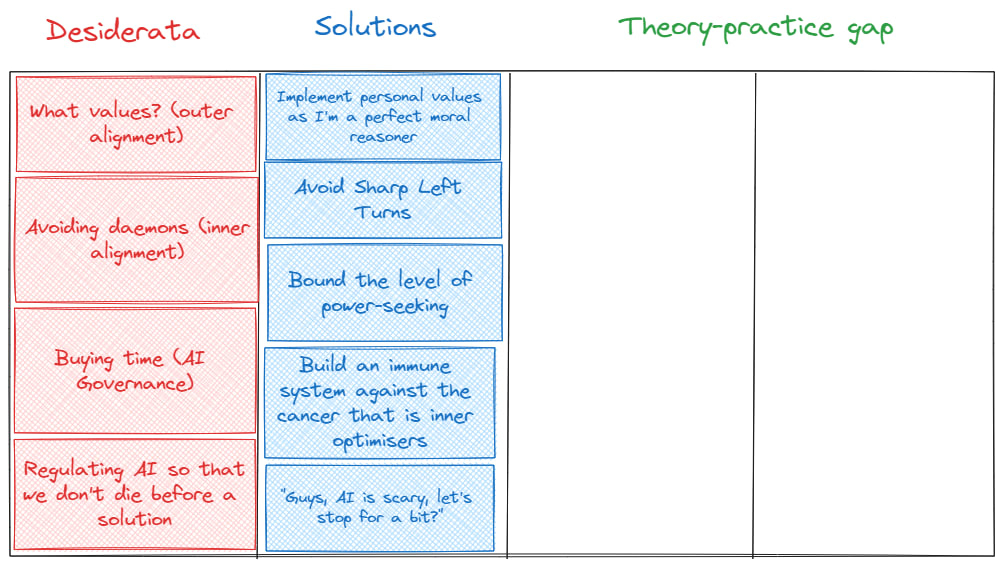
Part 2: Framing the theory-practice gap
Now, the thing that I personally care about is solving inner alignment when it comes to the current framing, which means I might make the puzzle look something like the following:

For the theory-practice gap, I will now put the pieces that I previously had put as sub-solutions to the solutions that I had from before:
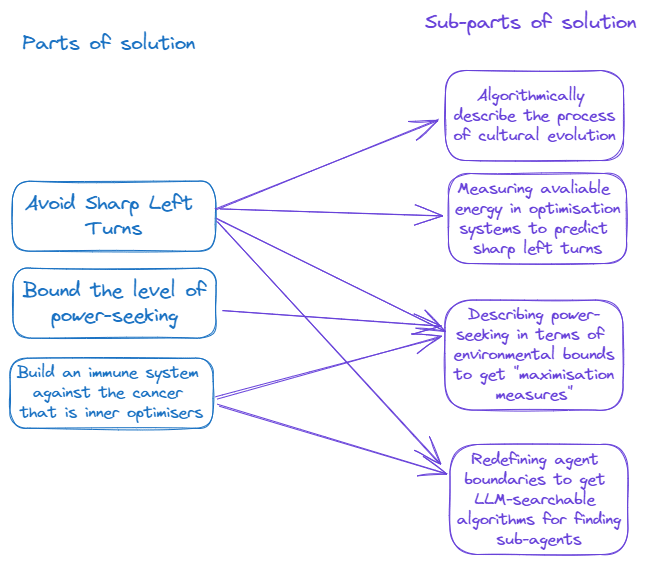
New puzzle:
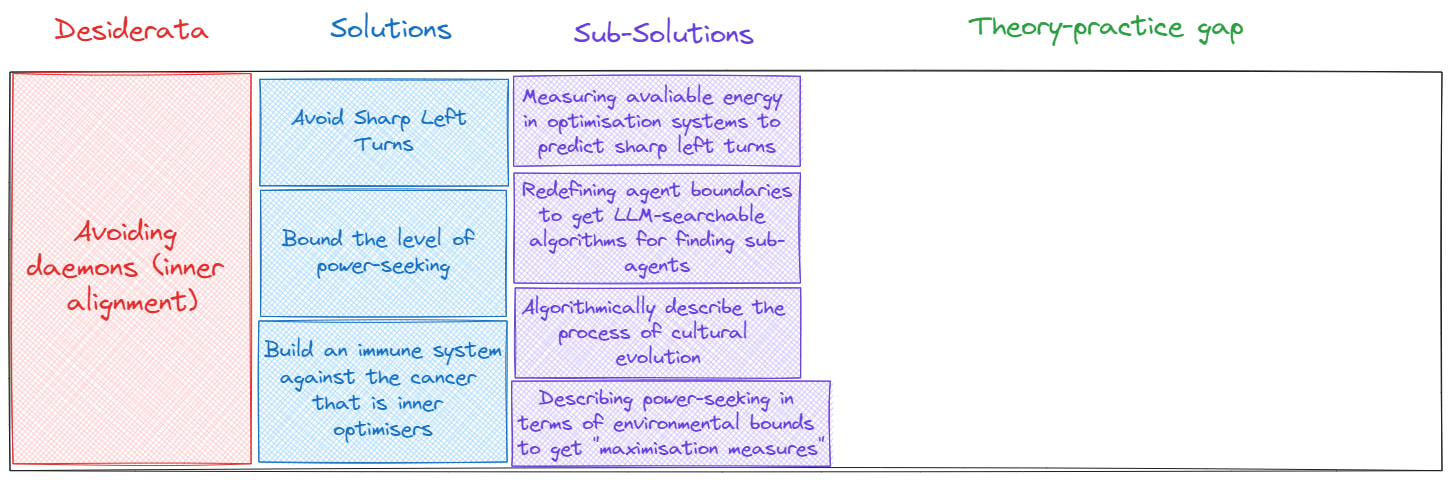
Part 3: Practice
I will now take the bottom-up approach and think about how solving inner alignment might look like in practice:
Some things I personally thought of was:
- Validating the sub-agent lens by running experiments to see if the theory matches reality
- Creating an accurate benchmark for power-seeking in sub-agents
- Algorithmically simulate cultural evolution and validate by checking if the real world holds up
- Use this in order to find equivalences in AI development so that we can predict heightened probably of sharp left turns.
New puzzle:
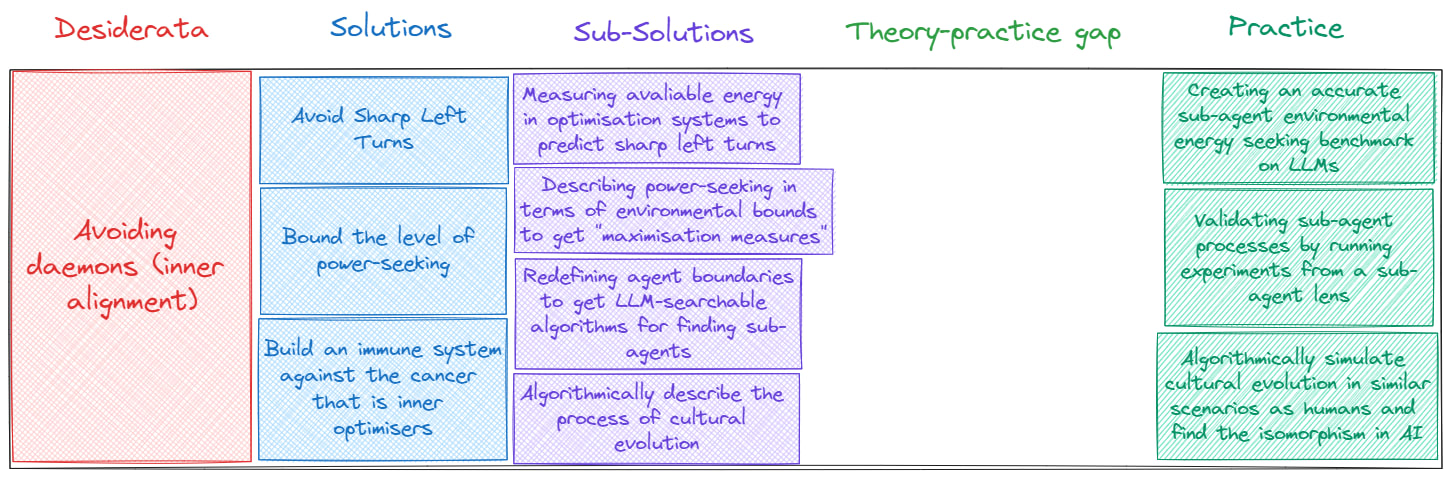
Now, from above, I also noticed that I need to do experiment number one before I do experiment two.
Part 4: Figuring out the theory-practice gap
Alright, so how do I go from theory to practice, then?
In my case, there are certain things that I need to figure out. I need to understand the foundations of boundary-forming processes within sub-agents. I also need to figure out more about collective intelligence and collective decision-making.
More importantly, it is imperative that I know how to translate this into LLM experiments. My current hypothesis is that this is doable through a free energy and active inference lens, which is something I’m then investigating.
Following are some of the ways that I might go from theory to practice here:
Foundational Processes in Sub-agents:
- Boundary Formation:
- Investigate the convergence of Andrew Critch’s and Scott Garrabrant’s research with artificial life studies on agency.
- Engage with PIBBS scholars for insights into agency descriptions relating to self-definition.
Understanding Collective Intelligence:
- Knowledge Acquisition:
- Address the uncertainty I have in how collective intelligence works by reaching out to experts.
- Employ a targeted communication strategy:
- Connect with early-career professionals for cutting-edge ideas.
- Consult with seasoned experts to gain historical and practical perspectives.
- (Since early and late career academics are more like to respond)
LLM Experiments:
- Integrating Theory with Practical LLMs:
- Talk with some of my contacts that are into interpretability to refine experimental approaches.
- Develop frameworks for translating theoretical concepts into LLM experimentation.
Cultural Evolution in AI:
- Practical Exploration:
- Deepen understanding through hands-on simulations, for example this R-based model simulation I found
- Contact researchers within cultural evolution for empirical insights and validation of models.
I hadn't thought about a lot of these things beforehand which is quite nice as it elucidated the next steps that I need to take.
Part 5: Prioritising interventions
In the dialogue, we saw some arrows that pointed towards specific gaps being sped up by some central frameworks that can affect the entirety of the theory-practice gap. I will now do the same with the theory practice interventions that I found through doing the above exercise.
PIBBS & Artificial Life discussions
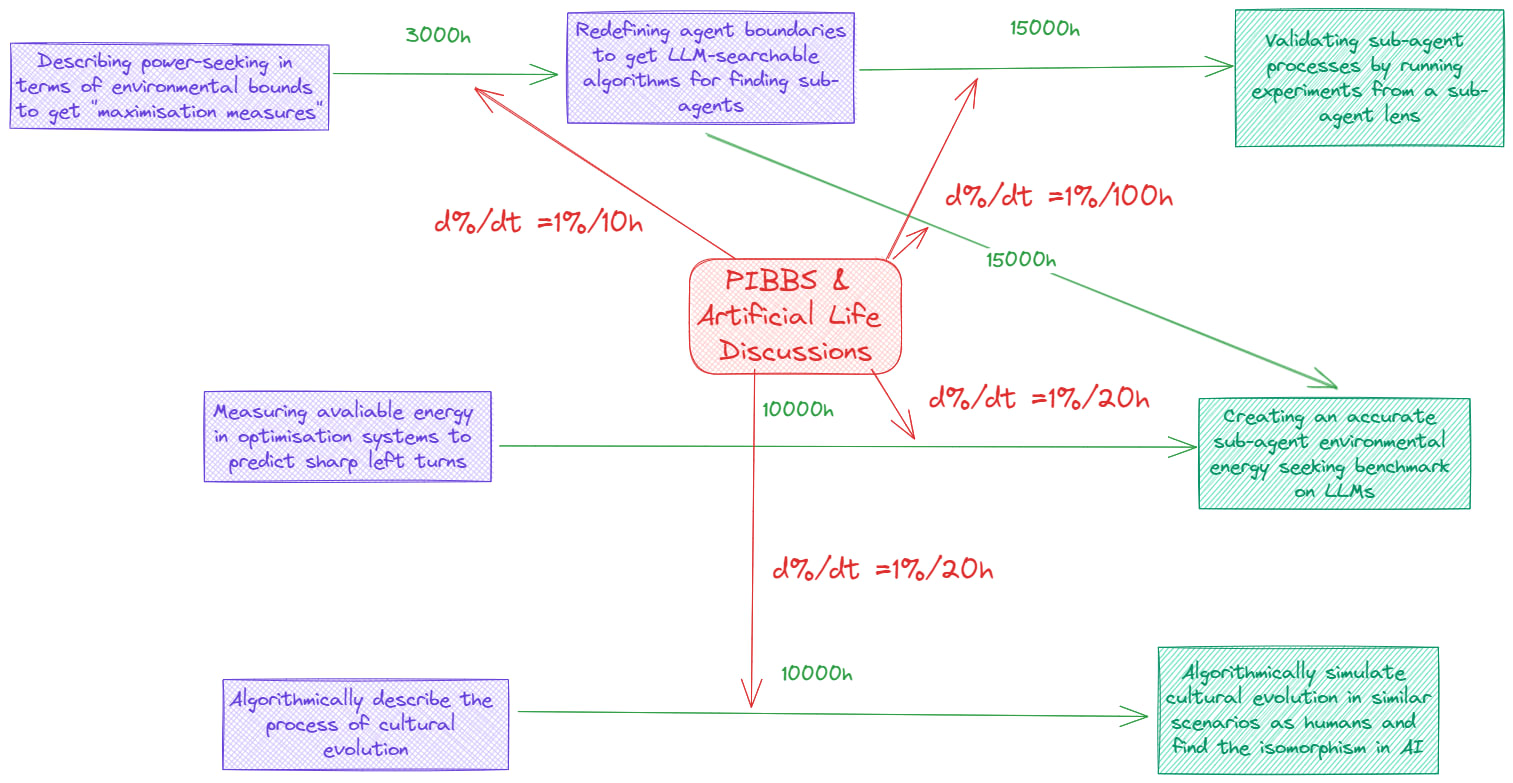
In the process of developing this picture, I pulled a lot of numbers out of nowhere. When it comes to the % per hour metric, I incorporated the intuitive feeling from lowering uncertainty into the mix as well. Something else I noticed is also that talking about it most likely has diminishing returns.
There is a lot that this model misses, but I did realise that for the first tech tree, I first have to get a nice definition of power-seeking in terms of free energy. This is something that talking with PIBBS and Artificial Life people could get me.
Understanding collective intelligence
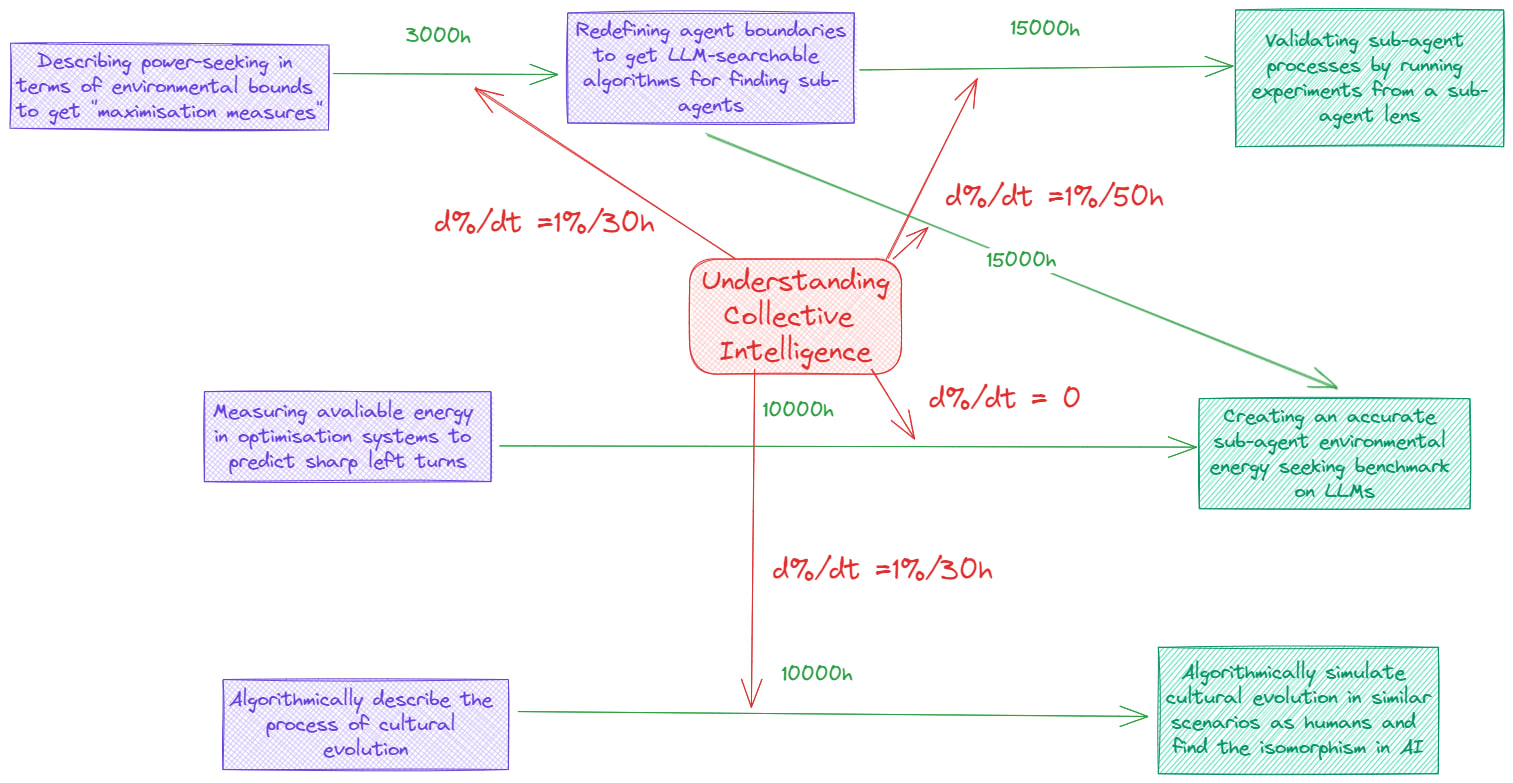
According to my models, understanding collective intelligence didn’t seem as important to do as having artificial life discussions, as it doesn’t give as much input on how to translate this into LLM-based research.
LLM Experiments
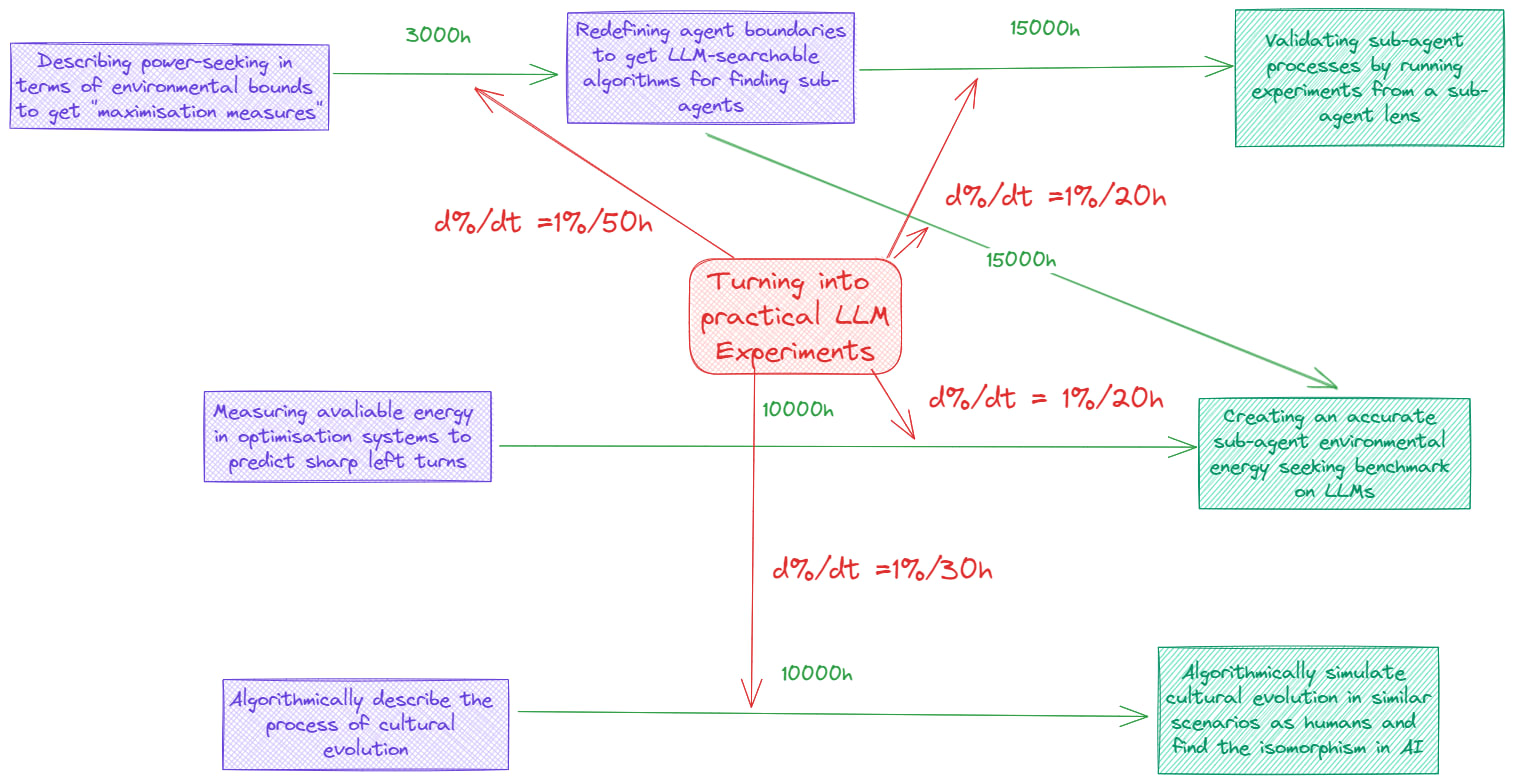
Doing this made me realise that I’m a bit of a dumbass for not contacting people in the interpretability side of things about the feasibility of running experiments here. My intuition for not doing it before was that no one would know how to do it, which I thought was reasonable. I realise now that even though no one knows how to do it, I still might get useful feedback from talking through it with them.
Cultural Evolution in AI
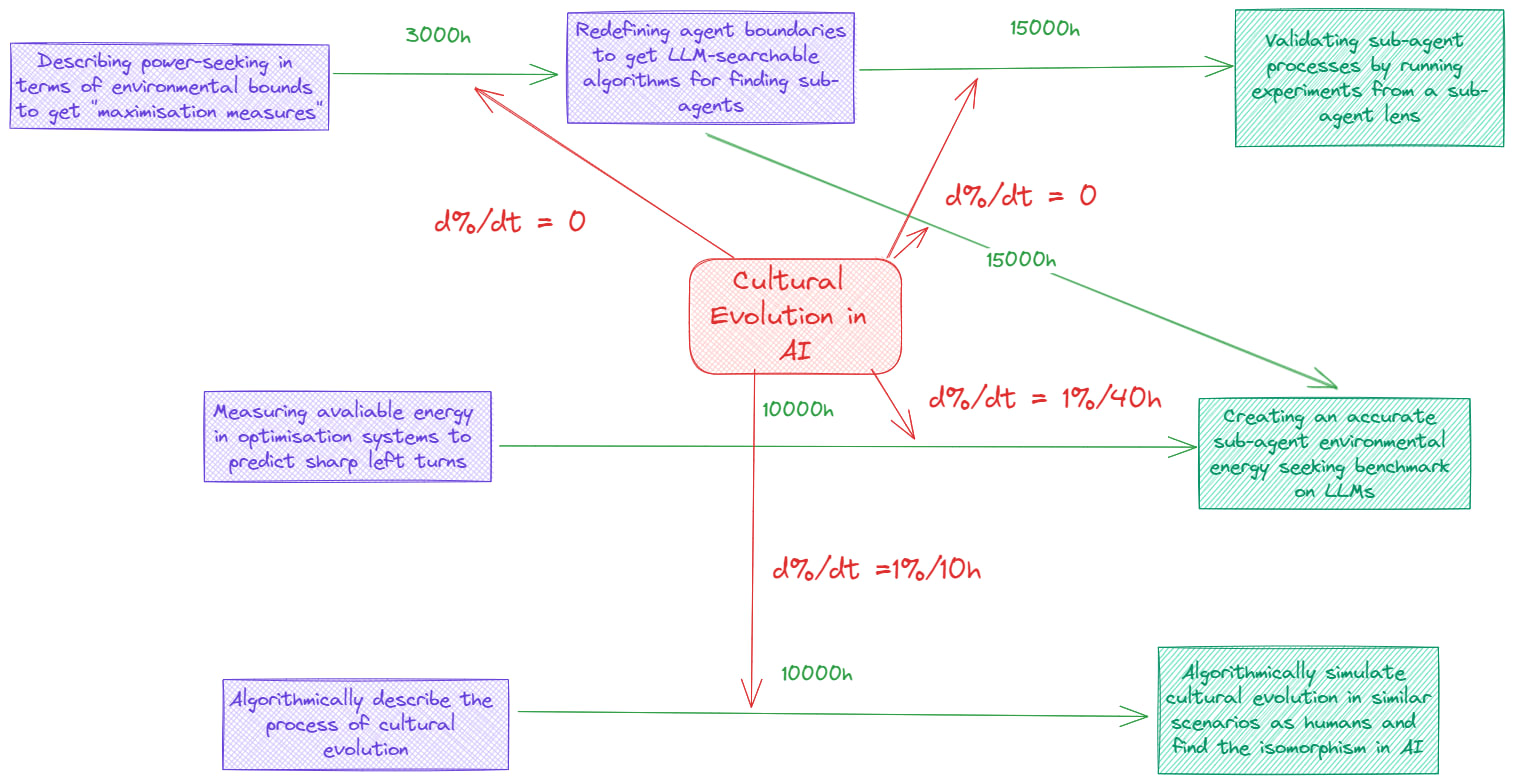
I realised that the main reason that I would do this if I perceive algorithmically describing cultural evolution to be a more useful thing to do than the rest of the game tree. I do very much like Kaj Sotala’s post [LW · GW] and Leogao’s comment [LW(p) · GW(p)] on the post to explain it as part of the ongoing conversation about it, so I’m uncertain how neglected this is.
Part 6: Next steps
Following is my list of actions to take as a consequence of this exercise:
- Contact PIBBS scholars and Artificial Life researchers to ask about a hypothesis class and see what they think about it.
- Talk with my mech-interp contacts about the feasibility and potential experimental designs for confirming collective intelligence theories.
- Contact collective intelligence experts on the feasibility of describing a singular agent process as a type of many-agent process with specific decision rules.
- Contact experts in cultural evolution about algorithmic modelling.
I will also be turning these into SMART goals, yet that process can be found online so I won't share the specifics here.
Conclusion
The puzzle framework offers a lens to scrutinise the landscape of AI alignment. By focusing on the pieces between our desiderata and real-world experiments—for example, metric spaces and collective intelligence—we can gauge how well they fit into the grand puzzle and address the theory-practice gap.
Going top-down from desiderata into more specific solutions narrows the theory-practice gap from the top. We also narrow the theory-practice gap by going bottom-up and writing how we want to verify our theories. This gives a more accurate model of how to traverse the theory-practice gap.
Notably, the framework is meant to be iterative, allowing for continuous updating over time and a continuously better view of the theory-practice gap.
Yet, do not bet your life on it. While the framework helps organise thought, it also carries risks of overconfidence and imprecise reasoning. I recommend that you look at it as one tool among many in the AI alignment toolkit. You do not want to narrow your view to a false problem space.
I hope you enjoyed this post, and do let me know if you did the exercise yourself and how it went for you!
This post was mostly developed during John Wentworth’s SERI MATS online training program in the autumn of 2022. I want to thank Justis from the LW feedback team and Arun Jose for some great feedback.
0 comments
Comments sorted by top scores.