Compact Proofs of Model Performance via Mechanistic Interpretability
post by LawrenceC (LawChan), rajashree (miraya), Adrià Garriga-alonso (rhaps0dy), Jason Gross (jason-gross) · 2024-06-24T19:27:21.214Z · LW · GW · 4 commentsThis is a link post for https://arxiv.org/abs/2406.11779
Contents
Paper abstract Introduction Correspondence vs compression How to compact a proof Proofs on a toy model Reasoning about error in compressing the weights Our takeaways Citation Info None 4 comments
We recently released a paper on using mechanistic interpretability to generate compact formal guarantees on model performance. In this companion blog post to our paper, we'll summarize the paper and flesh out some of the motivation and inspiration behind our work.
Paper abstract
In this work, we propose using mechanistic interpretability – techniques for reverse engineering model weights into human-interpretable algorithms – to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of- task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
Introduction
One hope for interpretability is that as we get AGI, we’ll be able to use increasingly capable automation to accelerate the pace at which we can interpret ever more powerful models. These automatically generated interpretations need to satisfy two criteria:
- Compression: Explanations compress the particular behavior of interest. Not just so that it fits in our heads, but also so that it generalizes well and is feasible to find and check.
- Correspondence (or faithfulness): Explanations must accurately reflect the actual model mechanisms we aim to explain, allowing us to confidently constrain our models for guarantees or other practical applications.
Progress happens best when there are clear and unambiguous targets and quantitative metrics. For correspondence, the field has developed increasingly targeted metrics for measuring performance: ablations, patching, and causal scrubbing. In our paper, we use mathematical proof to ensure correspondence, and present proof length as the first quantitative measure of explanation compression that is theoretically grounded, objective, and avoids trivial Goodharting.
We see our core contributions in the paper as:
- We push informal mechanistic interpretability arguments all the way to proofs of generalization bounds on toy transformers trained on the Max-of- task. This is a first step in getting formal guarantees about global properties of specific models, which is the approach of post-hoc mechanistic interpretability.
- We introduce compactness of proof as a metric on explanation compression. We find that compactifying proofs requires deeper understanding of model behavior, and more compact proofs of the same bound necessarily encode more understanding of the model.
- It is a common intuition that “proofs are hard for neural networks”, and we flesh this intuition out as the problem of efficiently reasoning about structureless noise, which is an artifact of explanations being lossy approximations of the model’s learned weights.
While we believe that the proofs themselves (and in particular our proof which achieves a length that is linear in the number of model parameters for the parts of the model we understand adequately) may be of particular interest to those interested in guarantees, we believe that the insights about explanation compression from this methodology and our results are applicable more broadly to the field of mechanistic interpretability.
Correspondence vs compression
Consider two extremal proof strategies of minimal compression with maximal correspondence and maximal compression with minimal correspondence.
- Brute force proof: We can run our model on all possible inputs we care about and use the computational trace of the model as our proof. While comprehensive, this proof is infeasible for all but the most toy cases and inadequate for tasks like mechanistic anomaly detection.
- Trivial proof: On the other hand, we can write proofs that make no reference to our model and only require looking at the property we care about explaining. For example, we can trivially prove that any model's accuracy is between 0% and 100%.
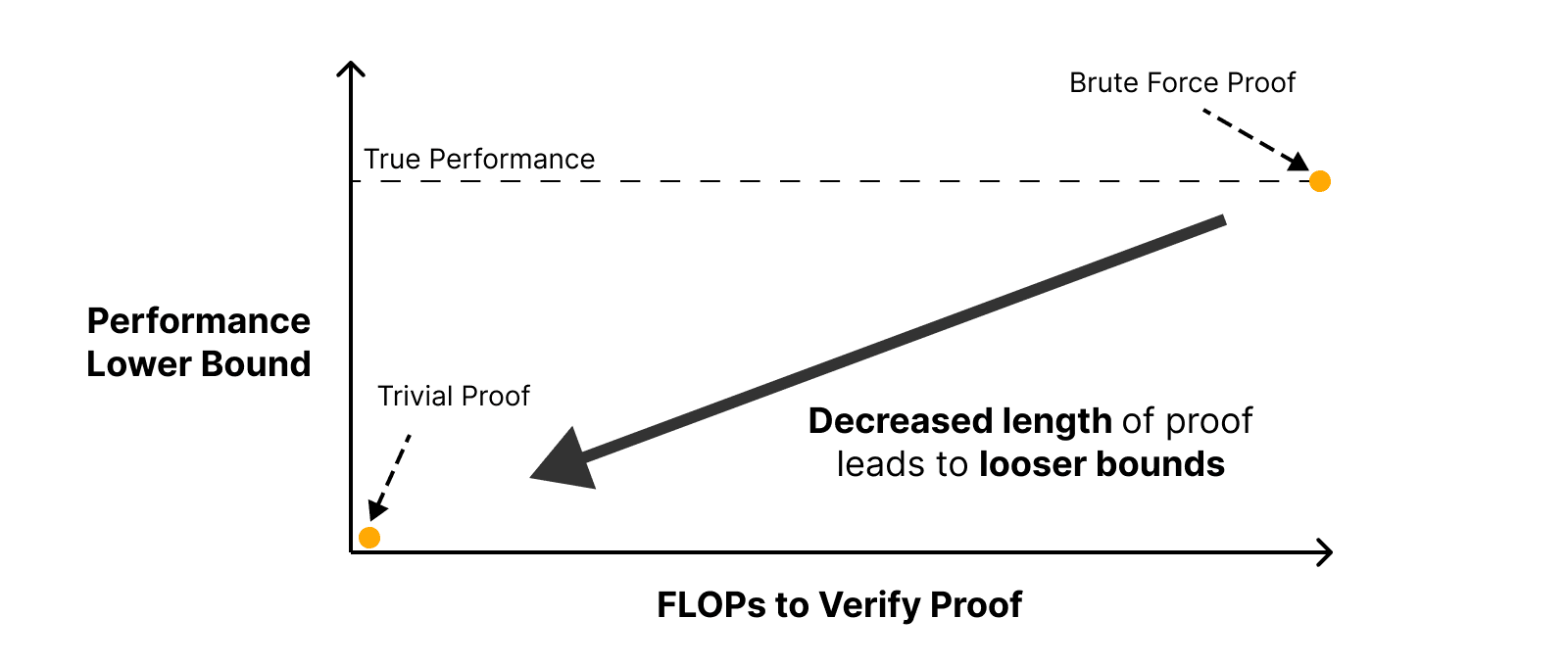
The central obstacle to good explanations is the trade off between making arguments compact, and obtaining sufficiently tight bounds. Broadly, being able to compress behavior shows that we have understanding. The thesis of our paper is that constructing compact proofs with good bounds requires and implies mechanistic understanding.
How to compact a proof
We can think of the brute force proof as treating every input to the model as a distinct case, where exhaustive case analysis gives us the final bound. Constructing a shorter argument requires reasoning over fewer distinct cases.
The naïve way to get shorter arguments is to throw away large parts of the input distribution (for example, only focusing on a distribution made of contrast pairs). In order to avoid throwing away parts of the input distribution, we abstract away details of the specific model implementation from our argument, and then group the inputs and construct a cheap-to-compute proxy for the model’s behavior on all data points in each group.
In order to ensure that the argument is a valid formal proof and that our proxies are valid, we bound the model’s worst-case behavior on each group when using the proxies. If our relaxations lose critical details then our bounds become much less tight, in contrast, if our relaxations abstract away only irrelevant details, then we might be able to still have tight bounds. Mechanistic understanding of model internals allows us to choose better groups and proxies, which in turn leads to shorter proofs with tighter bounds.
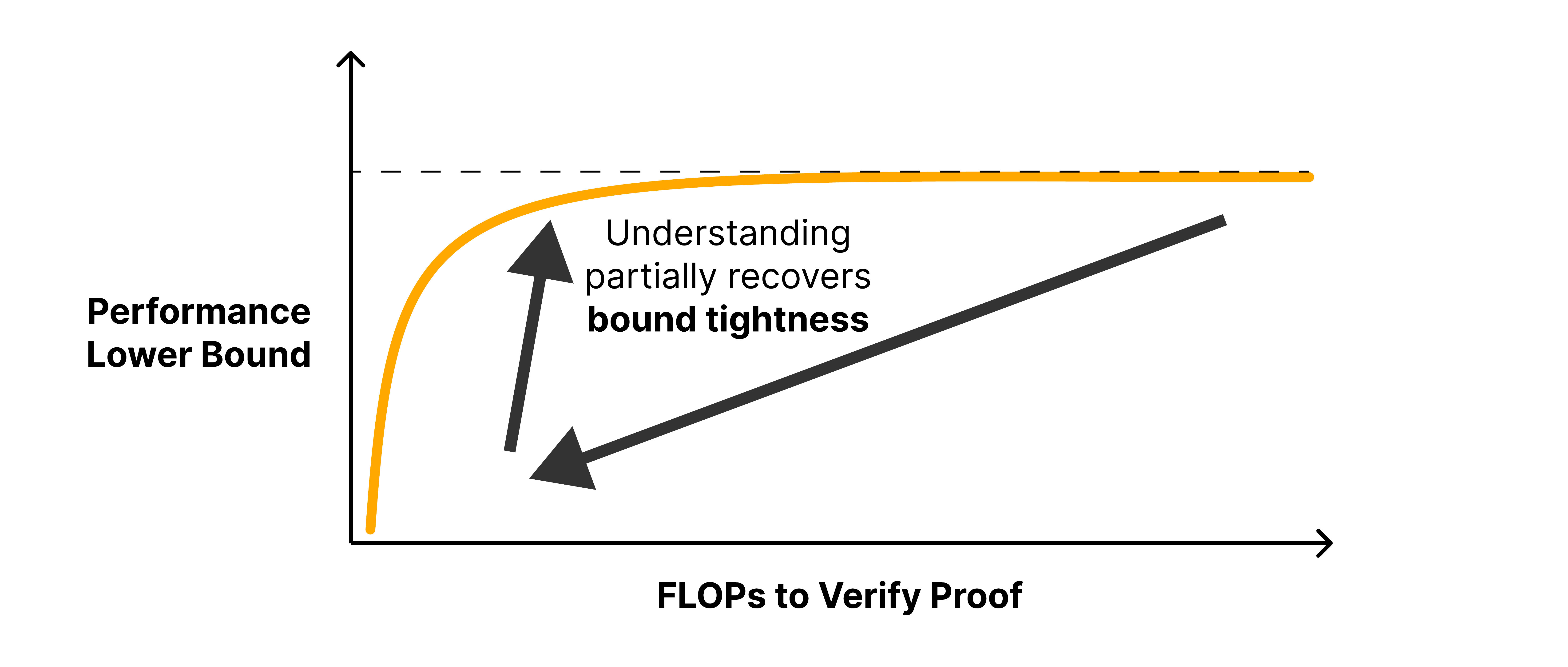
Proofs on a toy model
In our paper, we prototype the proofs approach on small transformers trained on a Max-of- task. We construct three classes of proof strategies, which each use an increasing amount of model understanding and correspondingly are cheaper to check.
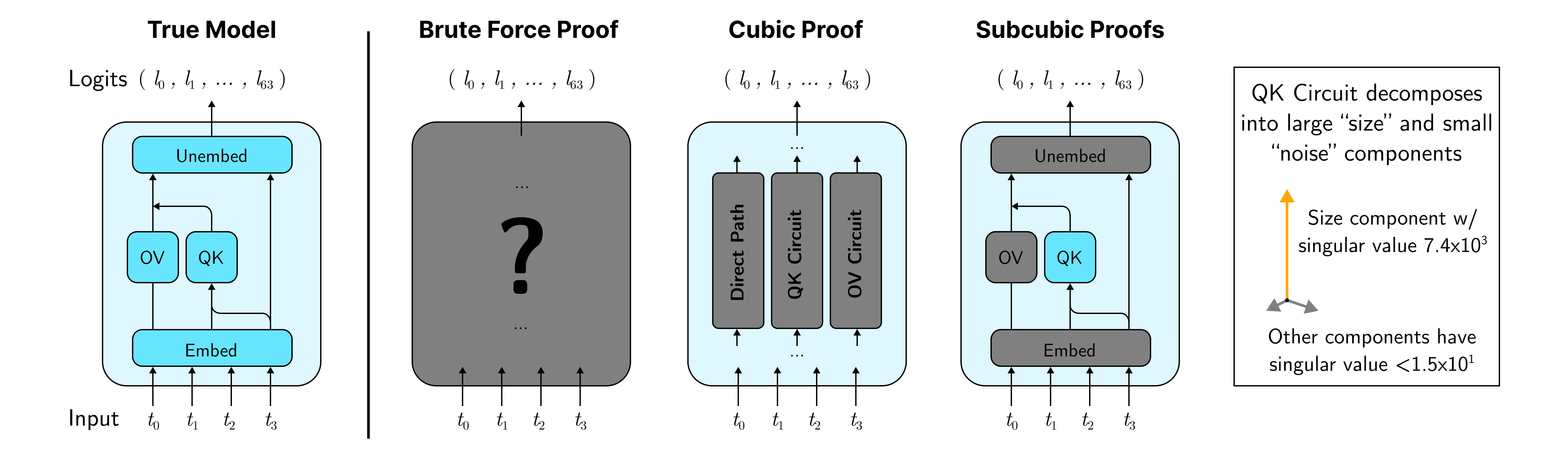
The first is the brute force proof, which uses no mechanistic understanding and treats each possible input as its own case.
The second class of proof strategies breaks models into paths (i.e. circuits), and groups the inputs by their max token, the largest non-max token, and the final query token. Besides the path decomposition, these strategies use both the fact that our models generate the correct output by paying attention to the max token in a sequence. The amount of attention paid to a given max token is primarily determined by the identity of the max token together with the largest non-max token and the final query token.
The third class of proof strategies examines each path independently, and groups the inputs for each path by two of the three types of tokens mentioned previously. To get cheaper proxies for model behavior, strategies in this class use knowledge that we might associate with traditional “mech interp”, such as the fact that the QK circuit is approximately rank one, with the principal component measuring the size of the key token.
We then qualitatively and quantitatively examine the connection between mechanistic understanding and proof length/bound tightness:
Table 1: We report the proof complexity, normalized accuracy bound, and estimated flops required (Equation 2), as well as unexplained dimensonality (Section 5). We round the FLOP and unexplained dimension counts to the closest power of 2, and report the mean/standard deviation of the bound averaged across all 151 models. As we include more aspects of the mechanistic interpretation (reflected by a lower number of unexplained dimensions), we get more compact proofs (in terms of both asymptotic complexity and FLOPs), albeit with worse bounds. For space reasons, we use , , and .
Description of Proof Complexity Cost Bound Est. FLOPs Unexplained Dimensions Brute force 0.9992 ± 0.0015 Cubic 0.9845 ± 0.0041 Sub-cubic 0.832 ± 0.011 (without mean+diff) 0.758 ± 0.039 Low-rank QK 0.806 ± 0.013 (SVD only) 0.643 ± 0.044 Low-rank EU 0.662 ± 0.061 (SVD only) Low-rank QK&EU 0.627 ± 0.060 (SVD only) Quadratic QK 0.407 ± 0.032 Quadratic QK&EU 0.303 ± 0.036
Reasoning about error in compressing the weights
As we impose tighter demands on proof length, there is a steep drop-off in tightness of bound. This is perhaps even more apparent visually:

The fundamental issue seems to be that our compression is lossy and worst-case error bounds in compression add up quickly. Going from to in the skip connection EU costs us about 15%. Going from to in the QK attention circuit EQKE costs us about 30%–40% in our best worst-case accuracy bound.
Focusing on the QK circuit, we claim that the EQKE is approximately rank one:
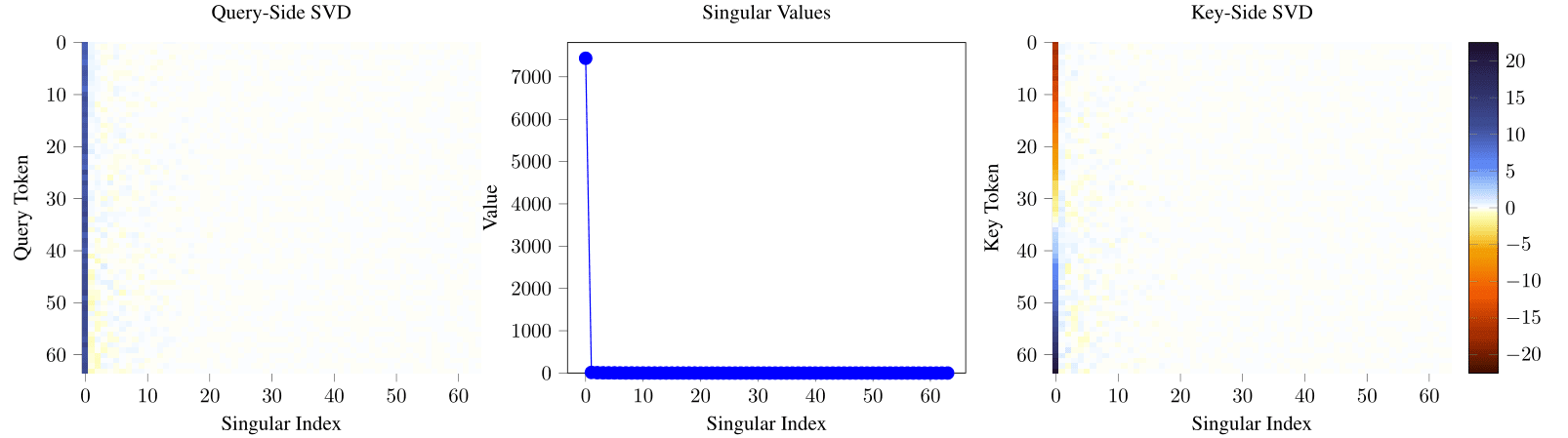
One way to cheaply check this without multiplying out EQKE (which would take time) is to factor out the principal components of each of the component matrices. Although the residuals for each of the four component matrices (after removing the first two principal components) are both small and seem to be noise, proving that there's no structure that causes the noise to interact constructively when we multiply the matrices and “blow up” is hard.
In general, it's often hard to prove an absence of structure, and we believe that this will be a key limitation on scaling proofs, even with a high degree of mechanistic understanding.
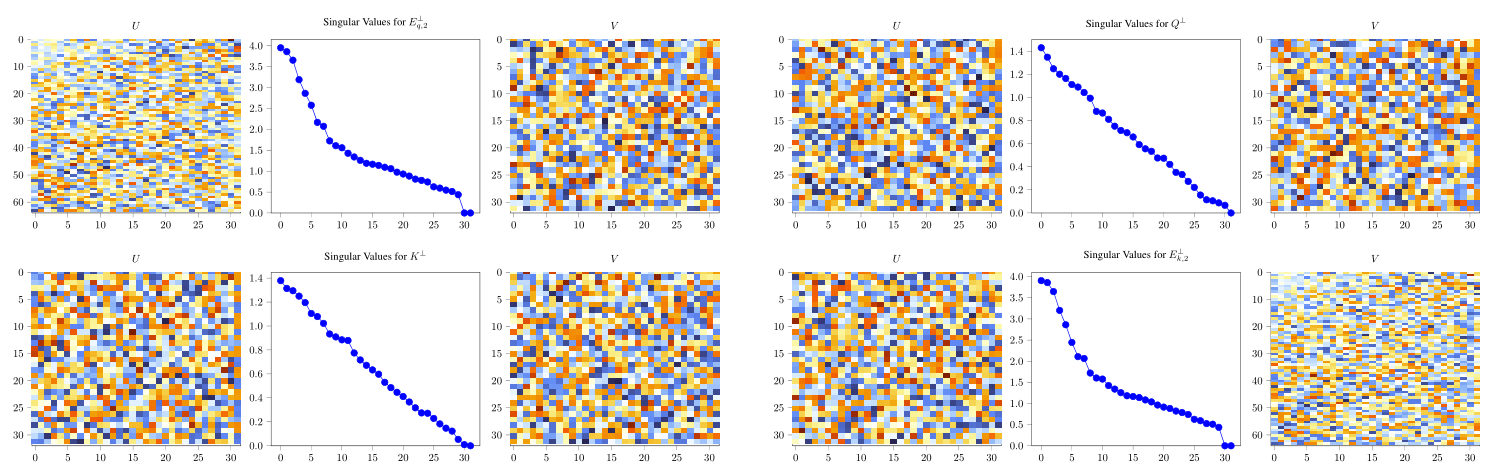
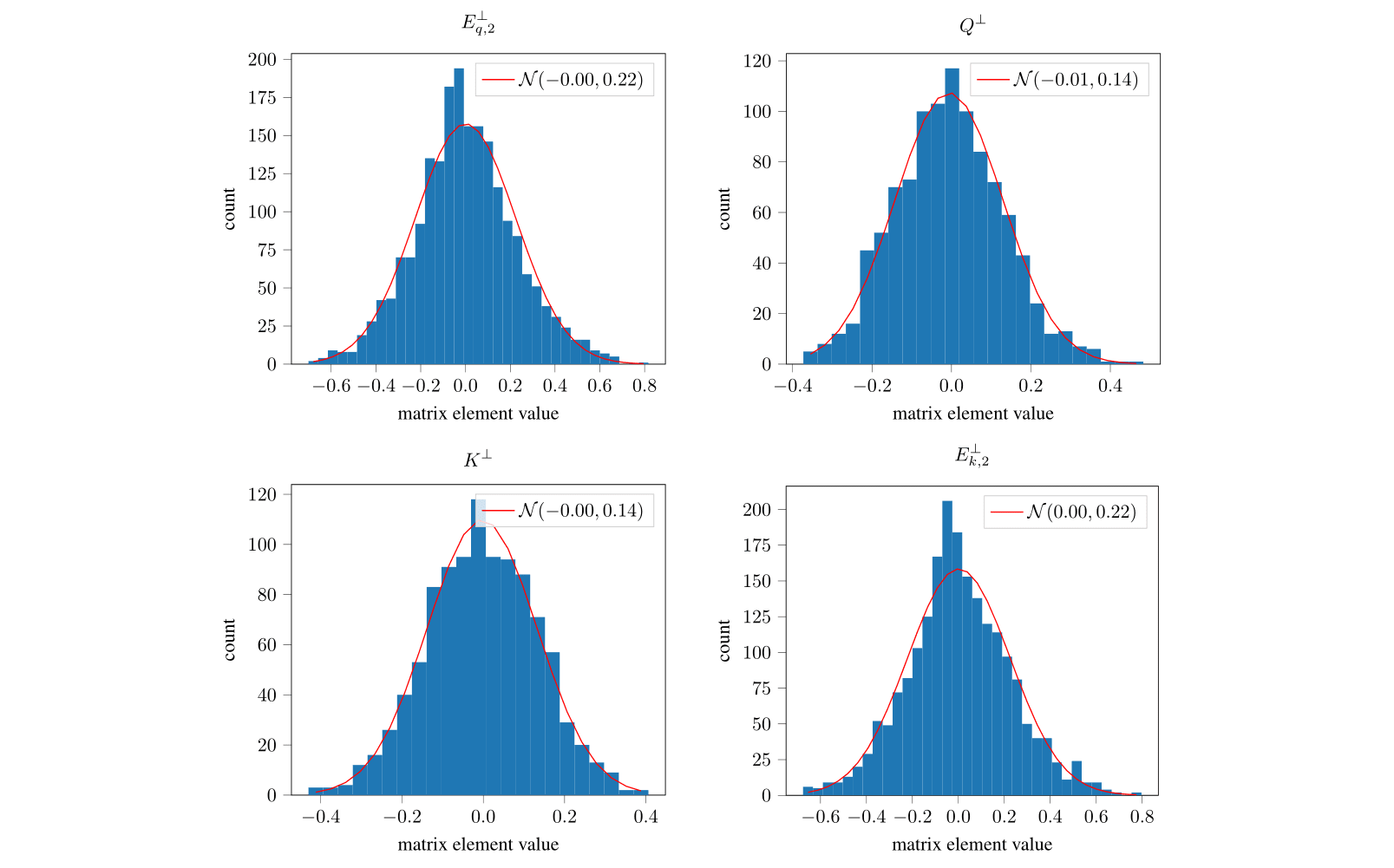

See our paper for more details.
Our takeaways
We think that there are two main takeaways from our work:
- Mechanistic interpretability as compression: we think that the proofs frame highlights the fact that the purpose of mech interp is not to explain individual model components in isolation, but instead to compress the behavior of the entire model across a full data distribution, either to achieve useful safety guarantees directly, or in ways that are useful for downstream tasks[1] such as mechanistic anomaly detection, scalable oversight, or adversarial training.
- Structureless noise as a serious challenge to scaling proofs: For any behavior, asserting that the unexplained parts of the model are always unimportant will likely be infeasibly expensive. Since it seems likely that we'll need to relax our guarantees from worst case bounds to average case bounds, we're excited about ARC Theory's work on heuristic arguments. We're also excited to see work on other approaches to relaxing the guarantees, such as getting probabilistic bounds on unstructured noise via clever sampling methods. Finally, it's possible that if we can explain the central behavior of a model on all parts of the input distribution, then we can directly finetune the model against our explanation to remove unstructured noise – we'd also be excited for work in this vein.
The work on this project was done by @Jason Gross [AF · GW], @rajashree [AF · GW], @Thomas Kwa [AF · GW], @Euan Ong [AF · GW], Chun Hei Yip, Alex Gibson, Soufiane Noubir, and @LawrenceC [AF · GW]. The paper write-up was done by @LawrenceC [AF · GW], @rajashree [AF · GW], and @Jason Gross [AF · GW]; @Adrià Garriga-alonso [AF · GW] assisted in writing up this blog post.
Citation Info
To reference this work, please cite our paper:
@misc{gross2024compact,
author = {Jason Gross and Rajashree Agrawal and Thomas Kwa and Euan Ong and Chun Hei Yip and Alex Gibson and Soufiane Noubir and Lawrence Chan},
title = {Compact Proofs of Model Performance via Mechanistic Interpretability},
year = {2024},
month = {June},
doi = {10.48550/arxiv.2406.11779},
eprint = {2406.11779},
url = {https://arxiv.org/abs/2406.11779},
eprinttype = {arXiv},
}- ^
We think that our work serves as an example of how to leverage a downstream task to pick a metric for evaluating mechanistic interpretations. Specifically, formally proving that an explanation captures why the model has a particular behavior can be thought of as a pessimal ablation of the parts the explanation claims are unimportant.[2] That is, if we can replace the unimportant parts of the model with their worst possible values (relative to our performance metric) while maintaining performance, this provides a proof that our model implements the same behavior as in our explanation.
- ^
Compare to the zero, mean, or resample ablation, where we replace the unimportant parts of the model with zeros, their mean values, or randomly sampled values from other data points.
4 comments
Comments sorted by top scores.
comment by RogerDearnaley (roger-d-1) · 2024-06-25T04:01:28.443Z · LW(p) · GW(p)
Although the residuals for each of the four component matrices (after removing the first two principal components) are both small and seem to be noise, proving that there's no structure that causes the noise to interact constructively when we multiply the matrices and “blow up” is hard.
Have you tried replacing what you believe is noise with actual random noise, with similar statistical properties, and then testing the performance of the resulting model? You may not be able to prove the original model is safe, but you can produce a model that has had all potential structure that you hypothesize is just noise replaced, where you know the noise hypothesis is true.
Replies from: jason-gross↑ comment by Jason Gross (jason-gross) · 2024-06-25T23:25:52.720Z · LW(p) · GW(p)
I believe what you describe is effectively Casual Scrubbing [AF · GW]. Edit: Note that it is not exactly the same as causal scrubbing, which picks looks at the activations for another input sampled at random.
On our particular model, doing this replacement shows us that the noise bound in our particular model is actually about 4 standard deviations worse than random, probably because the training procedure (sequences chosen uniformly at random) means we care a lot more about large possible maxes than small ones. (See Appendix H.1.2 for some very sparse details.)
On other toy models we've looked at (modular addition in particular, writeup forthcoming), we have (very) preliminary evidence suggesting that randomizing the noise has a steep drop-off in bound-tightness (as a function of how compact a proof the noise term comes from) in a very similar fashion to what we see with proofs. There seems to be a pretty narrow band of hypotheses for which the noise is structureless but we can't prove it. This is supported by a handful [AF(p) · GW(p)] of comments [AF(p) · GW(p)] about how causal scrubbing indicates that many existing mech interp hypotheses in fact don't capture enough of the behavior.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2024-07-06T04:09:16.340Z · LW(p) · GW(p)
That sounds very promising, especially that in some cases you can demonstrate that it really is just noise, and in others it seems more like it's behavior you don't yet understand so looks like noise. and replacing it with noise degrades performance — that sounds like a very useful diagnostic.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2025-01-20T23:22:26.948Z · LW(p) · GW(p)
Another variant would be, rather than replacing what you believe is structureless noise with actual structureless noise as an intervention, to simply always run the model with an additional noise term added to each neuron, or to the residual stream between each layer, or whatever, both during training and inference. (combined with a weight decay or a loss term on activation amplitudes, this soft-limits the information capacity of any specific path through the neural net). This then forces any real mechanisms in the model to operate above this background noise level: so then, once you understand how the background noise level is propagated through the model, it becomes clear that any unexplained noise below that level is in fact structureless, since any structure will be washed out by the injected noise, whereas any unexplained noise level above that, while it could still be structureless, seems more likely to be unexplained structure.
(Note that this architectural change also gives the model a new non-linearity to use: in the presence of a fixed noise term, changes in activation norm near the noise level have non-linear effects.)
Quantizing model weights during training also has a somewhat similar effect, but is likely harder to analyze, since now the information capacity limit is per weight, not per data path.