Proof Explained for "Robust Agents Learn Causal World Model"
post by Dalcy (Darcy) · 2024-12-22T15:06:16.880Z · LW · GW · 0 commentsContents
Recalling the Basic Setup Assumptions Proof of the Exact Case Load-Bearing part of Oracle Use Identification via Induction Constraint 1: σ will remove D's parents Constraint 2: σ fixes the environment variables other than those in the path. Constraint 3: Let σ contain a local intervention making Ck a binary variable Proof of the Approximate Case New Assumptions Load-Bearing part of Oracle Use Identification via Induction Identifying the Approximate Graph Structure None No comments
This post was written during Alex Altair's agent foundations fellowship program [LW · GW], funded by LTFF. Thank you Alex Altair [LW · GW], Alfred Harwood [LW · GW], Daniel C [LW · GW] for feedback and comments.
This is a post explaining the proof of the paper Robust Agents Learn Causal World Model in detail. Check the previous post [LW · GW] in the sequence for a higher-level summary and discussion of the paper, including an explanation of the basic setup [LW · GW] (like terminologies and assumptions) which this post will assume from now on.
Recalling the Basic Setup
Let's recall the basic setup (again, check the previous post [LW · GW] for more explanation):
- [World [LW(p) · GW(p)]] The world is a Causal Bayesian Network over the set of variables corresponding to the environment , utility node , and decision node . The differences from a normal Causal Bayesian Network is that (1) is a deterministic function of its parents , and (2) , the conditional probability distribution for , is undetermined—it's something that our agent will select.
- [Agent as a Policy Oracle [LW · GW]] An agent is a policy oracle which is a function that takes in an intervention (where represents the set of all allowed interventions over ) and returns a policy .
- [Robustness as [LW · GW]-optimality under interventions [LW · GW]] We define a "robust" agent as a policy oracle whose regret is bounded by under some class of interventions over the environment .
Assumptions
Also recall the following assumptions [LW(p) · GW(p)]:
1) Unmediated Decision Task states that . This is pretty major.
2) Domain dependence states that there exists distributions over the chance variables and (compatible with ) such that .
- This is very reasonable. If domain dependence does not hold, then the optimal policy is just a constant function.
These together imply:
- There does not exist a decision that is optimal, i.e. across all .
- , i.e. there can't be any intermediate nodes between and , and all causal effects from to must be direct.
Now, with the basic setup of the paper recalled, let's prove the main theorems.
Proof of the Exact Case
We will first prove Theorem 1:
For almost all worlds satisfying assumption 1 and 2, we can identify the directed acyclic graph and the joint distribution over all variables upstream of , given that we have access to a -optimal policy oracle.
I will attempt to present the proof in a way that focuses on how one could've discovered the paper's results by themselves, emphasizing intuitions and how trying to formalize them naturally constrains the solutions or assumptions we must use.
Load-Bearing part of Oracle Use
Somehow we're going to have to elicit information out of the policy oracle.
Recall that the oracle is a function that maps an intervention to a policy, which is a conditional probability distribution . It can be shown that if the oracle is optimal, this distribution is (almost always) a deterministic map. The argument goes like:
- Suppose that given a context , two decisions and have the same expected utility.
- Then, we can argue that this is extremely unlikely:
- Intuitively because exact equality is very unlikely for real number things.
- More rigorously because expressing this equality results in a polynomial constraint over the parameters, which has Lebesgue measure 0 over the parameterization of the conditional probability distribution).
- Therefore it is extremely likely (probability 1) that there is a strict ordering of decisions (according to their expected utility) given a context, i.e. almost always a unique maximum EU decision given a context. Therefore an optimal policy must only choose that decision in that given context, i.e. deterministic.
Then, somehow our information-eliciting procedure is going to have to exploit the fact that, given a , as we change the intervention , the optimal decision prescribed changes from to .
To make this possible, we want to rule out the existence of a decision that is universally optimal across all inputs to the utility node, because then no intervention would yield a change in the output of the oracle.
- In math, a such that for all possible inputs to the utility (other than the decision), is always the of , i.e. where
Recall the first consequence of the two assumptions we had: There does not exist a decision that is optimal, i.e. across all .
This implies that there is at least one where the optimal decision differs from !
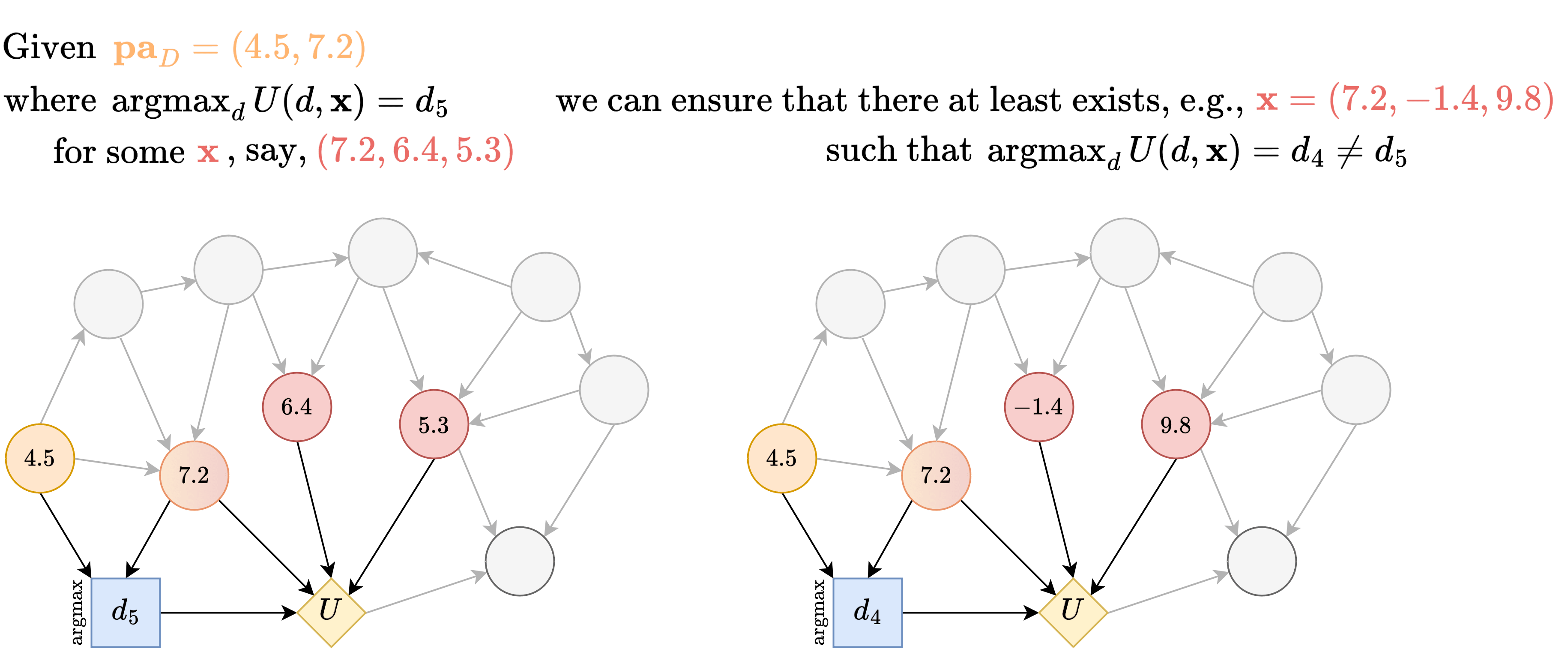
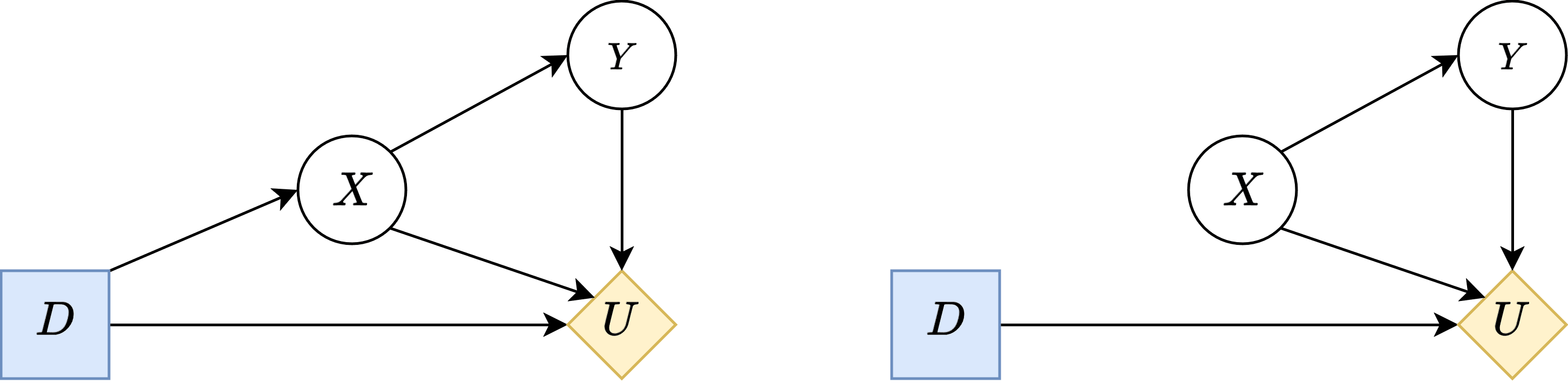
But the worry is that such will be incompatible with .
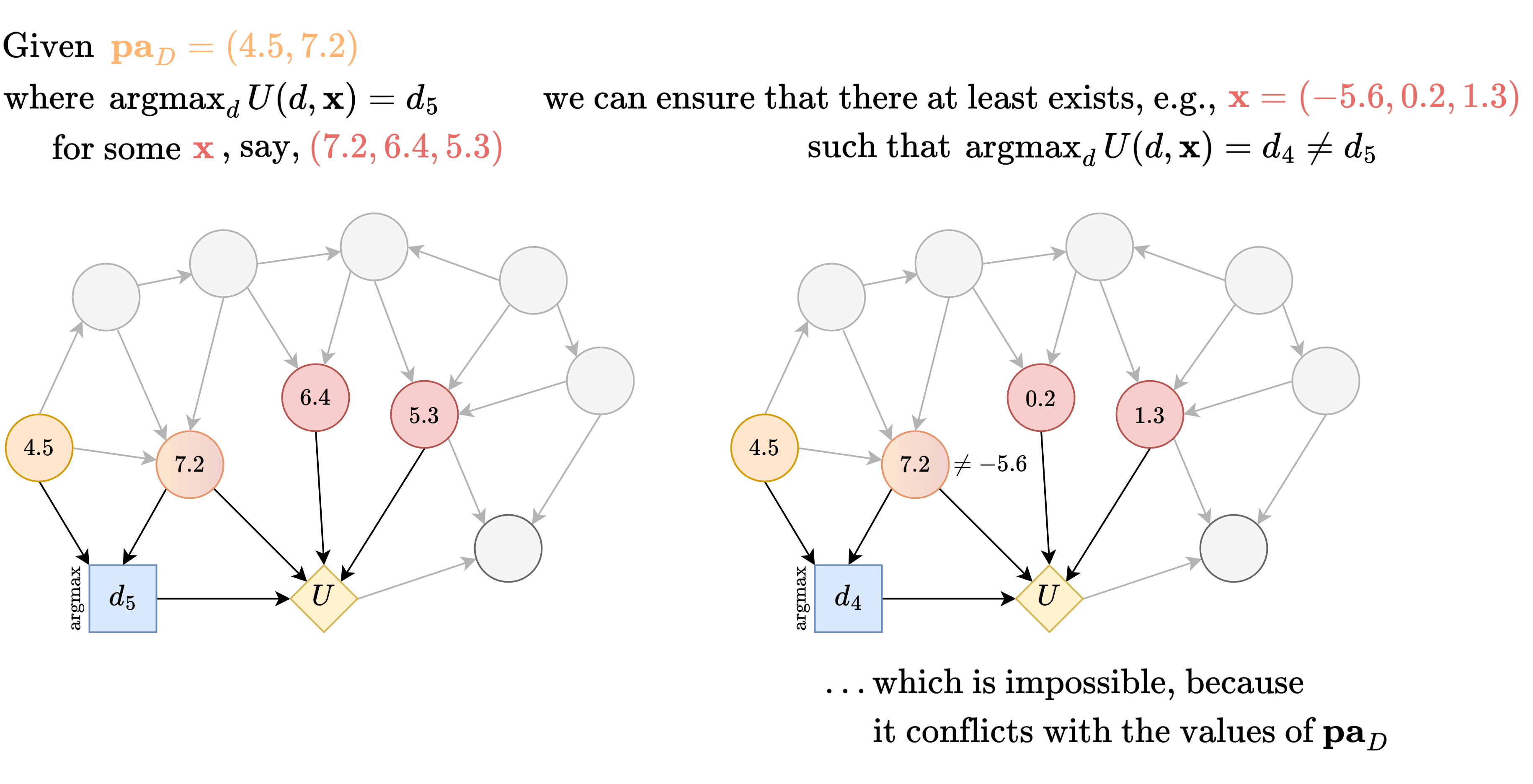
So, we will restricted to only considering that masks the inputs of by only letting depend on such that .
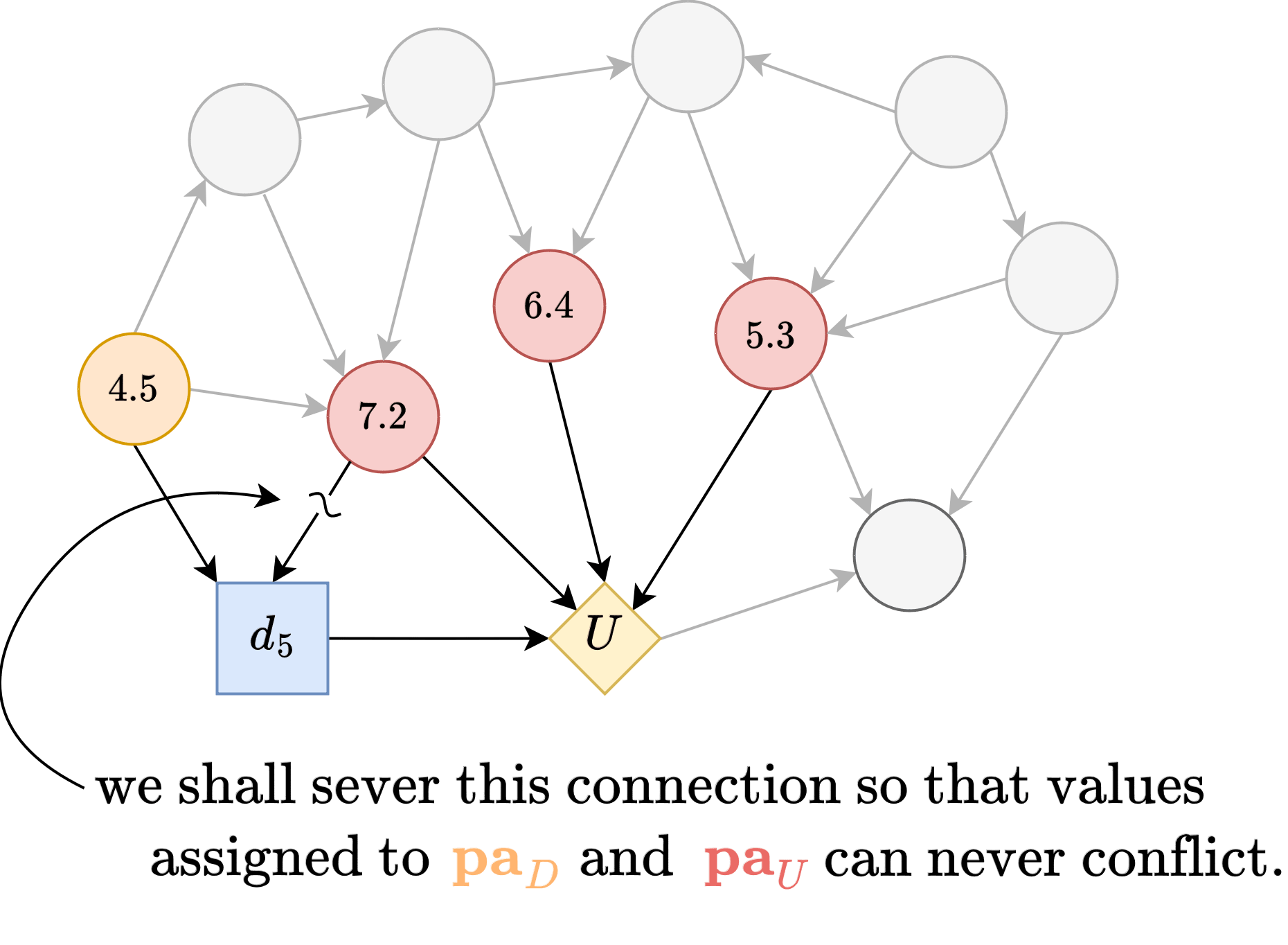
Then, given , let denote the optimal decision associated with some . Then, by the earlier argument, if we consider any intervention that does , then it would have a different optimal decision, call it .
And to operationalize "as we change the intervention," we define a mixed local intervention .
When , the policy oracle (under ) would prescribe , and for , it would prescribe . There may of course be other intermediate optimal decisions along the way as you slowly increase from to - say, and for the current example.
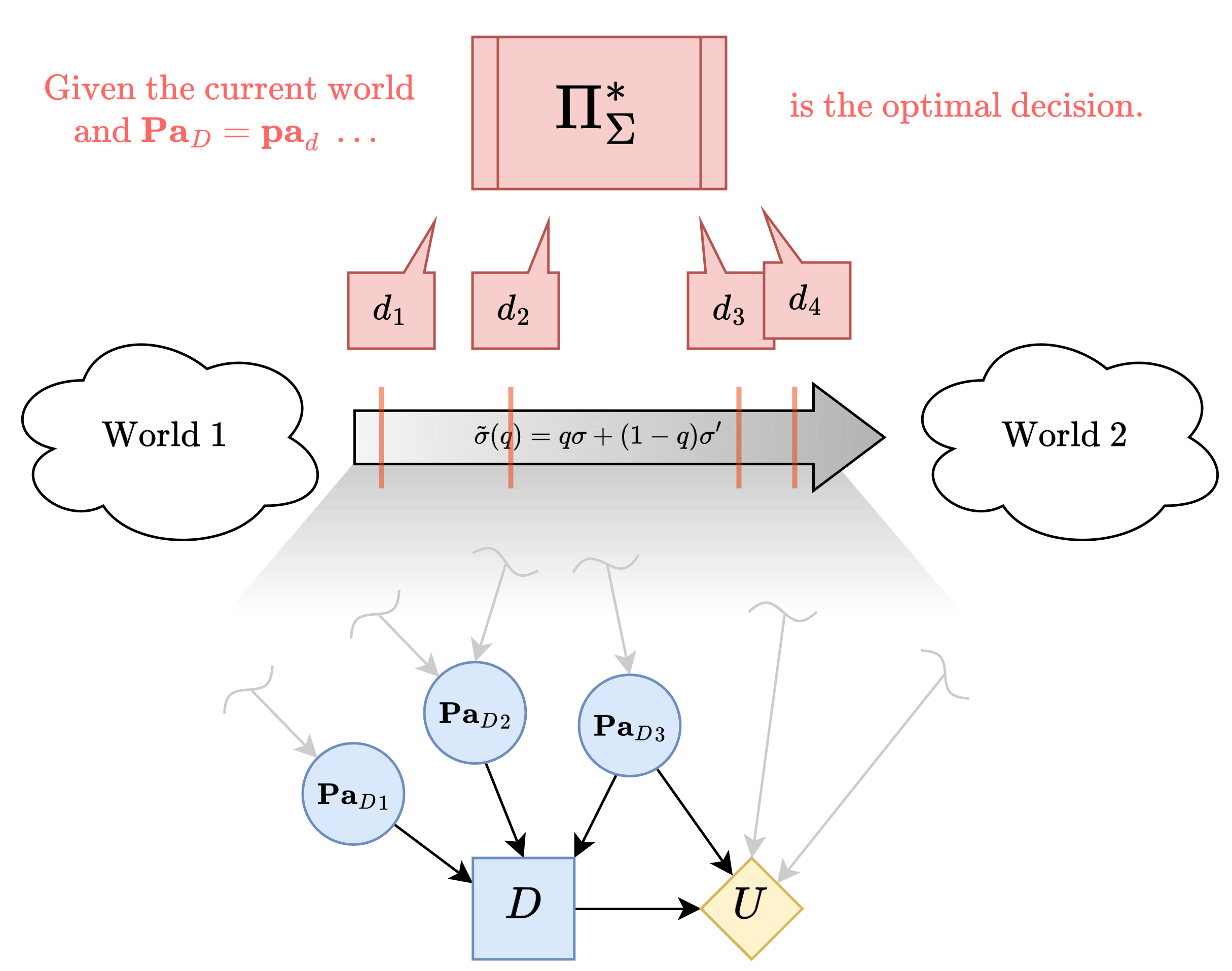
Note that once you switch your decision from to as you increase , you will never encounter again because of linearity of . Namely:
The diagram below makes it more clear why linearity implies the same decision never gets chosen twice. The oracle can be thought of as attaining the upper envelope, as denoted in dotted line.
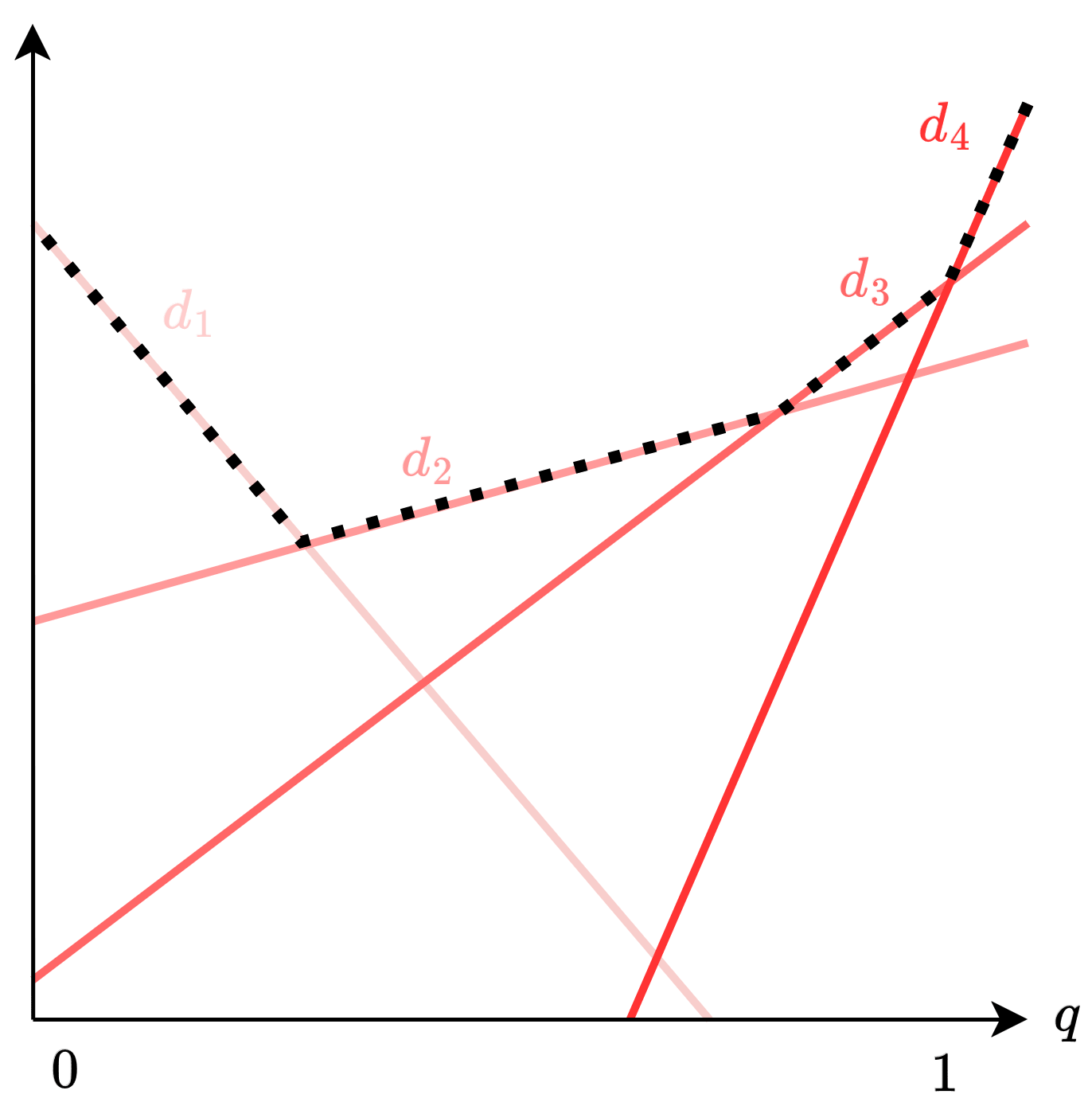
Let represent the value of at which the optimal decision switches from some (may or may not be ) to .
Insight: is interesting. It's a behavioral property of our oracle, meaning we can estimate it by repeatedly sampling it (across random samples of ). But it can also probably be expressed in closed-form in terms of some parameters of the environment (by just expanding out the definition of expected utility). So is a bridge that lets us infer properties about the environment from the oracle.
Let's derive a closed-form expression of . Let .
Detailed Proof
is a value that satisfies
Expanding out the left-hand side:
Expanding out the difference of both sides and setting it to zero:
Now we solve for :
Again, can be estimated from sampling the oracle. We know the denominator because we assume the knowledge of .
Therefore, the oracle lets us calculate , the difference in expected utility of some two decisions given some context.
Restating our chain of inquiry as a lemma:
(Lemma 4) Given that masks the inputs such that , such that we can approximate , where and .
Identification via Induction
By the Unmediated Decision Task assumption, we see that the ancestors of U look like the following. We notice that there are two types of paths to consider in our induction argument.
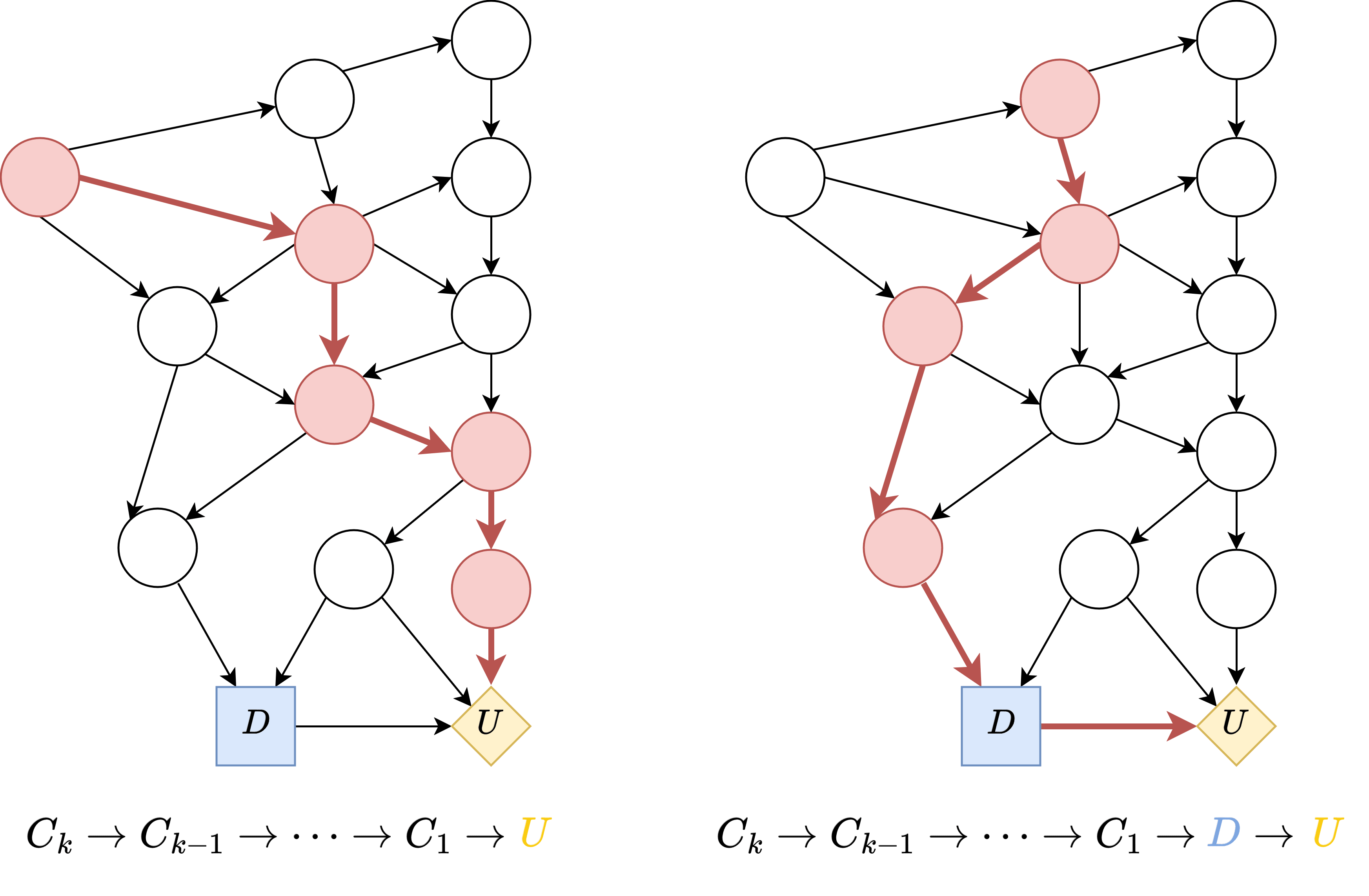
Let's first consider the first type, , where , .
We first define the following variables:
Assume are known, and are known.
The claim to prove is that, given these are known, we can identify the conditional probability distribution .
Assume we have some . We want to identify , and we have to somehow use the policy oracle for that.
Recall from Lemma 4 that given an intervention such that , for all values of , there exists two different decisions and such that can be identified.
The trick is in setting such that it makes this sum contain terms for all , for arbitrary choices of and .
Let's think through how we might discover the right constraints on .
Constraint 1: will remove 's parents
Since we want , let's just choose such that hence ).
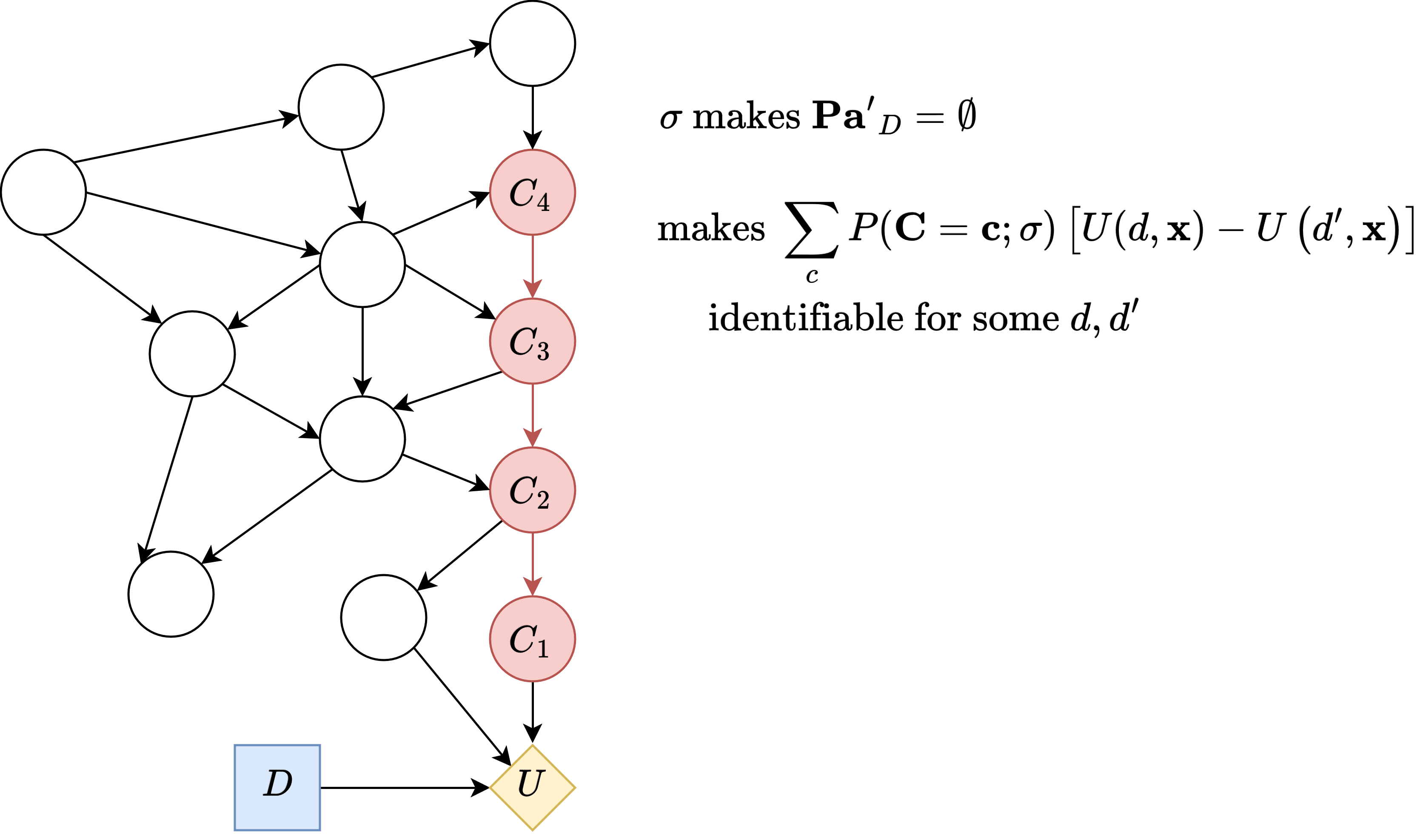
Constraint 2: fixes the environment variables other than those in the path.
Note the following: Since 's value can be computed, if it can be expressed in terms of that would let us solve for , since by the induction hypothesis all the terms except it are known. Note that we also somehow have to figure out what the set is, too.
Expanding out the above sum will give us some clue as to what further constraints we must impose on in order for the sum to be expressed that simply:
How do we choose such that
becomes
for arbitrary choices of ?
Note that setting to a constant will:
- make always have values of zero in all settings of except one, in which it will evaluate to .
- also set the values of to a constant, among others - even though we don't yet know exactly which variables belong to .
Thus such intervention immediately gets rid of the terms as we sum across , while being able to arbitrarily control the values of , and (among other variables in ).
So constraint 2: contains (such that values of should be compatible with the values of that are set earlier in constraint .)
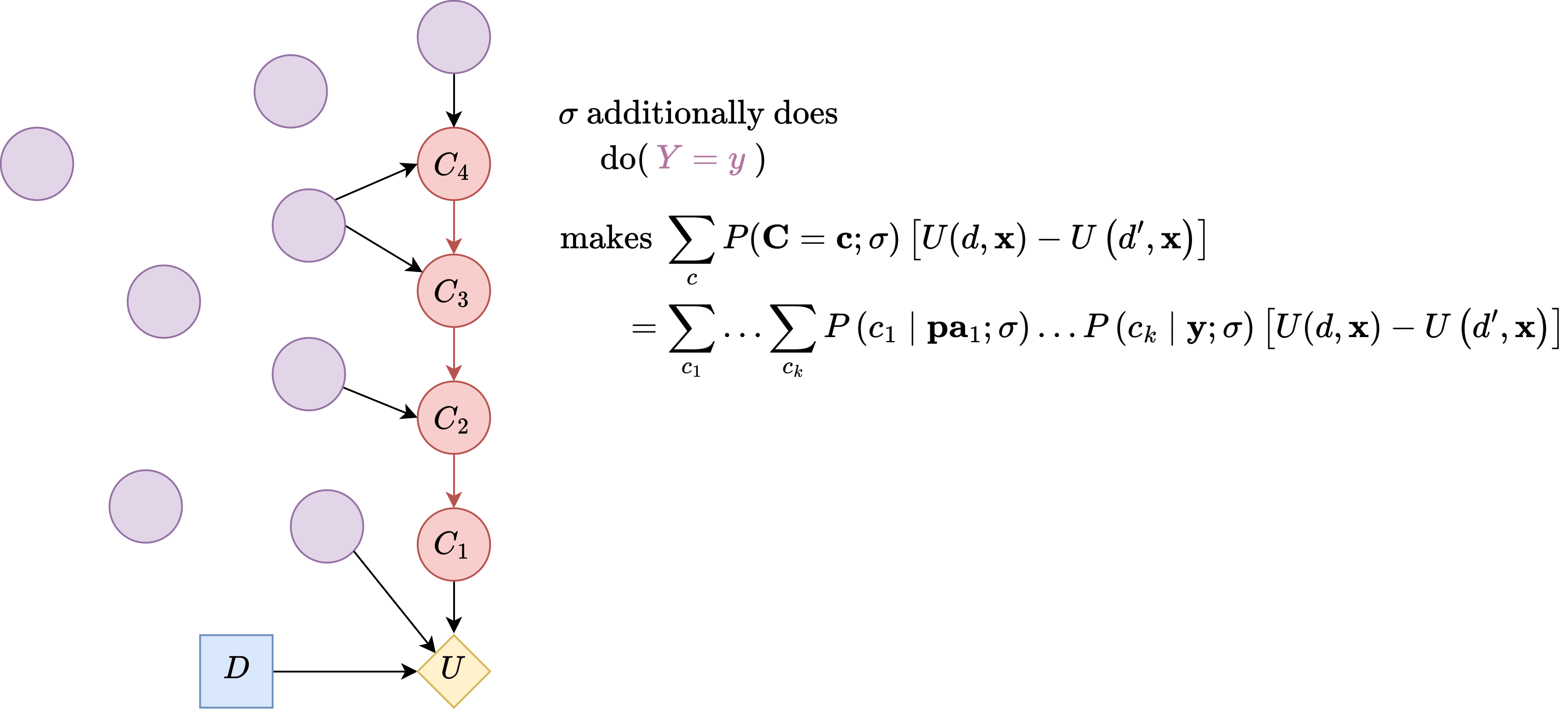
Then, we have the following expression:
So far, we haven't intervened in . So, for compatible with the value (if applicable) and , further simplifying the expression:
But this isn't yet solvable. By induction hypothesis we know for all values of and , and we know the value of the left-hand side. This equation then involves unknowns.
A fix then, is obvious an intervention that effectively sets to , which brings us to the third constraint:
Constraint 3: Let contain a local intervention making a binary variable
Specifically, let contain , where
This effectively makes a binary variable. Precisely:
and now the equation can be solved.
Let , which can be written , where .
The earlier lets us simplify as . Thus . We know (via the policy oracle), we know values of (via the induction hypothesis).
But important subtlety here: remember that we don't actually know yet. The in the above expression is meant to be understood as the implicit assignment of values to the (yet unknown to us) by the means of in .
So, by performing a set of interventions that fixes all but one of the variables of , one can discover to which variables responds to (the values of changes), and hence figure out the set.
Then, by varying the choices of , and , we can identify completely.
The base case of is clear, since where and are of the form , which is known, and so is using the oracle.
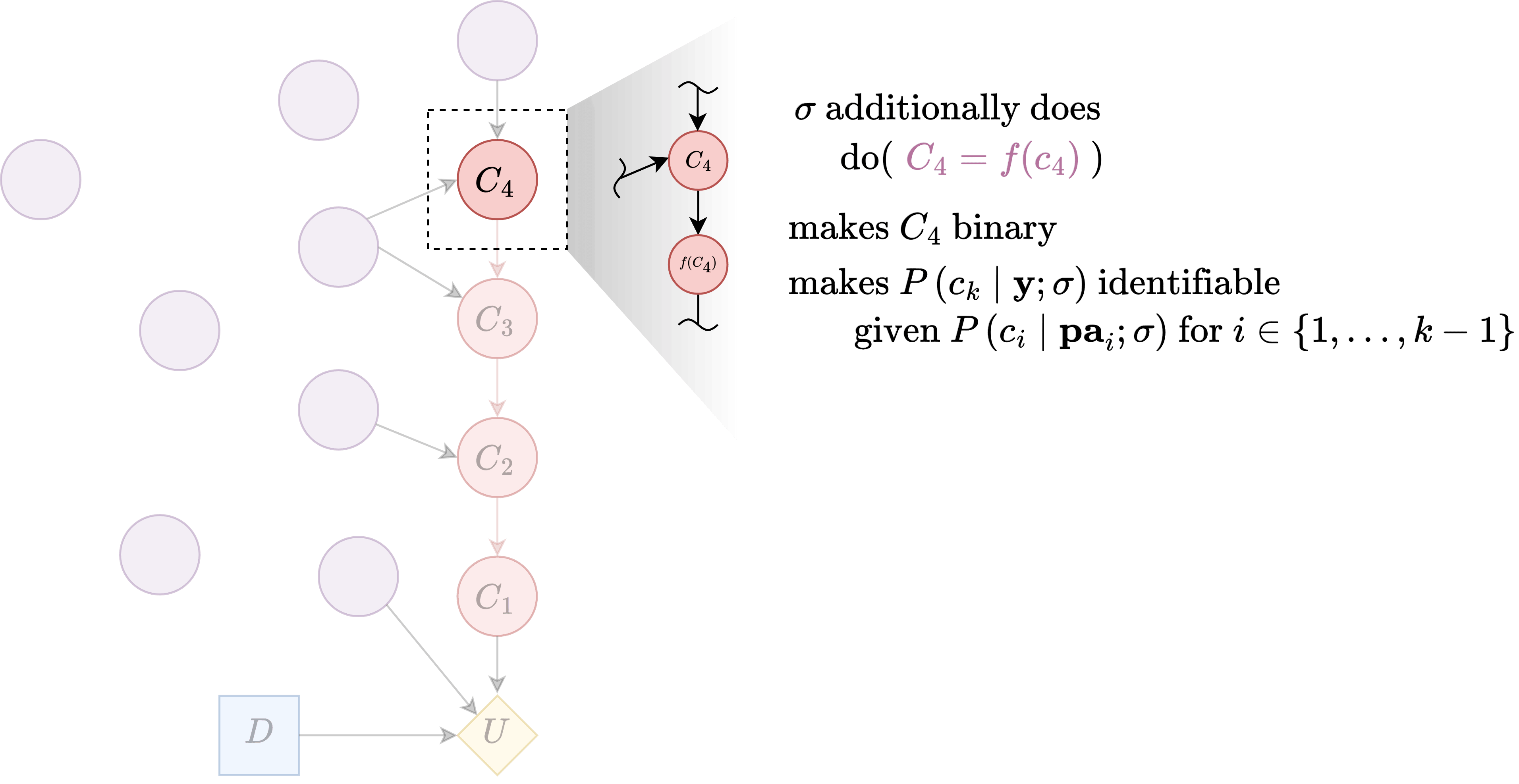
To recap, our choice of is a local intervention such that:
- masks all input to , i.e.
- fixes rest of the nodes in to a constant
- does a local intervention making into a binary variable
and we have showed that this intervention lets us identify for all along the path , where , .
Similar arguments can be used to prove the same for paths of the second type, , where .
Proof of the Approximate Case
Now, we will extend the proof to the approximate case (Theorem 2):
For almost all worlds satisfying assumption 1 and 2 and some other new assumptions (explained below), we can identify the directed acyclic graph and the joint distribution over some subset of variables upstream of , and the quality of estimation for each of the conditional distributions scale linearly with .
New Assumptions
Unless I'm mistaken here and these can actually be derived from the earlier two assumptions (Unmediated Decision Task, Domain Dependence), here are the three new conditions that the paper implicitly assumes:
3) -optimal policies are (still) almost always deterministic
The earlier proof of determinism doesn't go through in the approximate case, but the paper implicitly assumes the policy oracle still (almost always) returns an output deterministically.
4) Uniform regret
We say is -optimal if .
We say is uniformly -optimal if for all , where we define.
Note that uniformly -optimal is a stronger condition than \delta-optimal in the sense that the former implies the latter.
5) Shape of the -optimal decision boundary
The left diagram is the ground truth for how the expected utility (under context ) of various decisions change as you increase from to . Then, the right diagram shows the decision boundary for the -optimal oracle, whose decision boundaries must exactly follow the intersection points of the left diagram's lines.
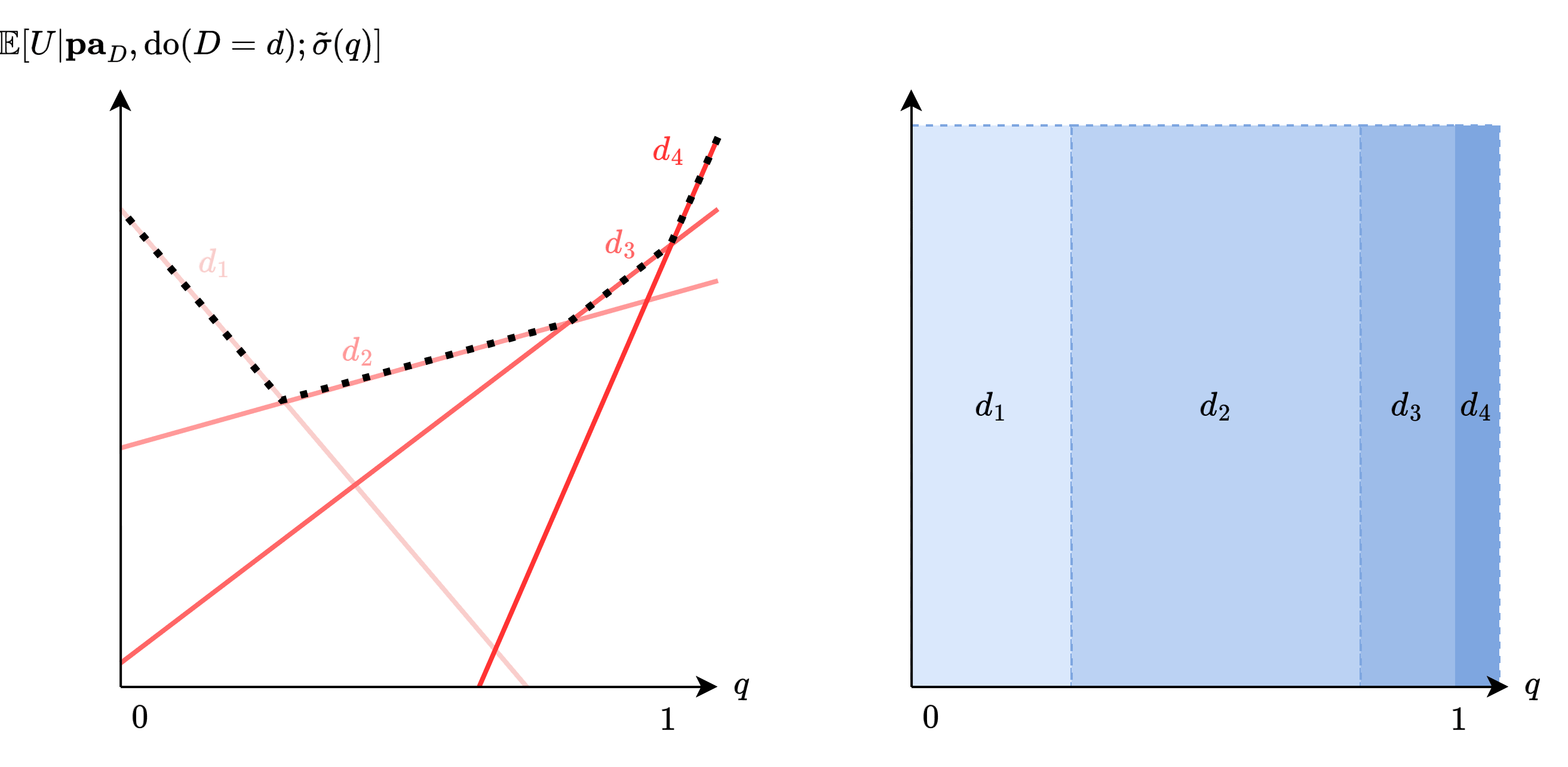
The paper then assumes that the -optimal oracle's decision boundaries must be simply a slightly shifted version of the 0-optimal oracle's decision boundaries, like the right diagram. A priori, there's no reason for the boundaries to look like this, e.g., it can look very complicated, like the left diagram. But the paper implicitly assumes this.
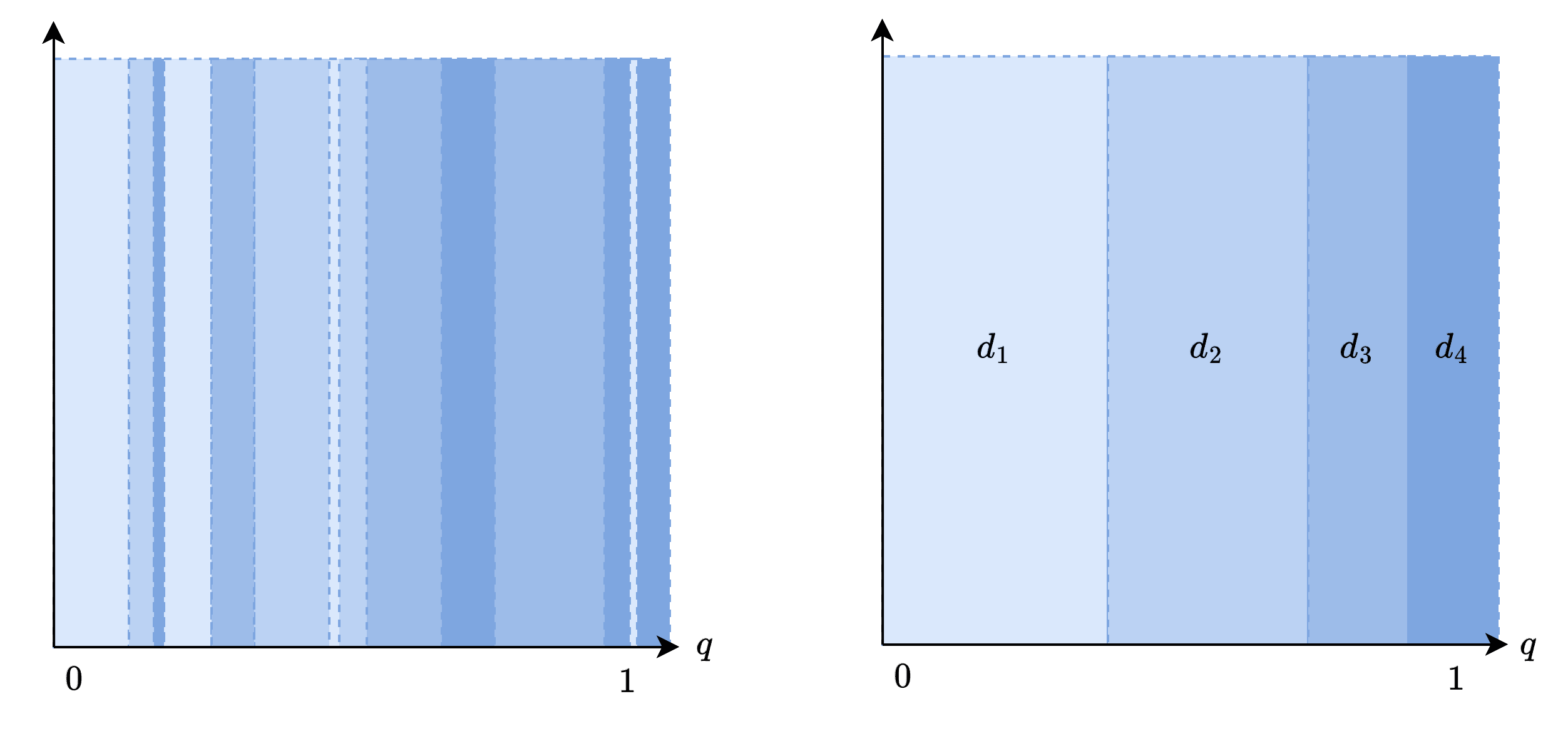
Let's now proceed to the proof. The subsections parallel that of the optimal oracle case.
Load-Bearing part of Oracle Use
Our goal is to derive , which we call .
Recall from earlier that in the optimal oracle case:
where we define as follows:
Notice that is the unique solution to .
Also note that . We know the value of . In the optimal oracle case, recall that can be estimated via MCMC.
But the problem with -oracle is that this only yields a biased estimate, which we call .
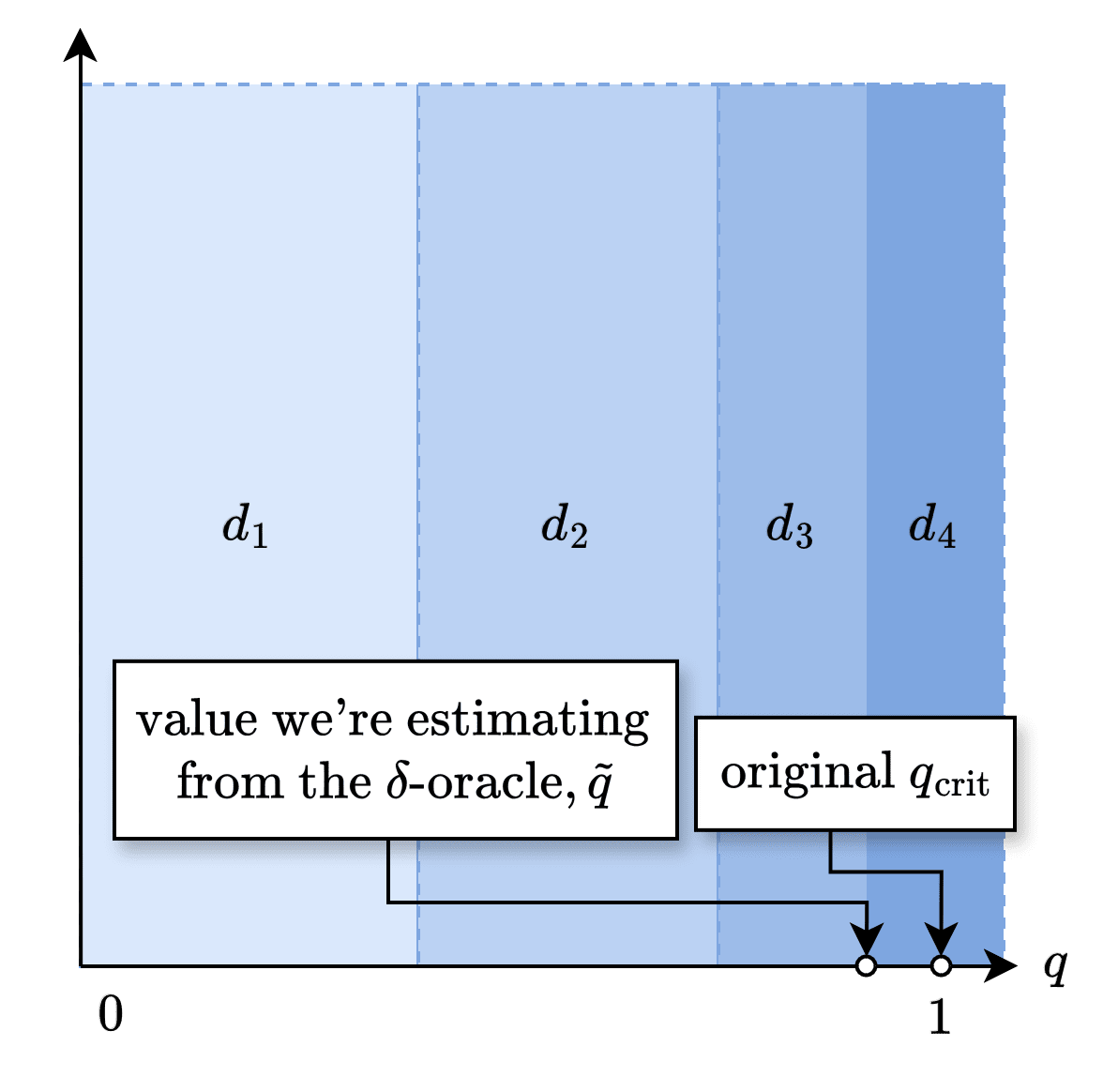
Using but naively substituting with the biased estimate, we get a biased estimate for that we call .
Our aim, then, is to bound the quality of the estimate with the bound only involving non-estimate terms, like , and .
Expanding out, . That is an estimate term, which we want to remove by bounding it via a term involving non-estimate terms. How?
First, we have yet to exploit any behavioral properties of the oracle that is related to . What are those? By definition, the oracle chooses for and for for very small . Then, the uniform regret condition says:
Take to , and assuming continuity, we can subtract the two to get
.
In other words, , or .
Because , we can rewrite the inequality as . Expanding out and rearranging the inequalities, we find out that .
Substituting this in to the expansion of Q-\tilde{Q}, we obtain the following simple bound: .
Finally, in the denominator can be eliminated as follows:
where the last line is via Taylor expanding around (arbitrarily truncated at fourth order), valid for .
Or more simply, . The error term is linear with respect to for small values of .
Identification via Induction
The argument is basically the same as that of the optimal case, except needing to incorporate error terms.
The exact case's induction hypothesis was that and are known for . Then, we showed that using a specific choice of , we can derive the relation all the terms in the right-hand are known.
Then, for the approximate case's induction hypothesis, instead assume that are known for , up to . We will show that this implies the knowledge of up to . Let's denote the approximation we have , so .
- Important subtlety here: we don't assume we know . "Knowing " is meant to be understood as knowing the values of - where contains hence implicitly intervening on - for all values of and .
Let . Because it is the sum of product of , overall it differs from by .
Hence . Because and by the earlier section, we see that .
Using the big- fact that , we thus prove .
More simply, as goes to . That proves the induction step.
The base case of is once again clear, since where and are of the form , which is known, and so is using the oracle. This shows that it can be computed, and the earlier paragraphs show that it is accurate up to .
Identifying the Approximate Graph Structure
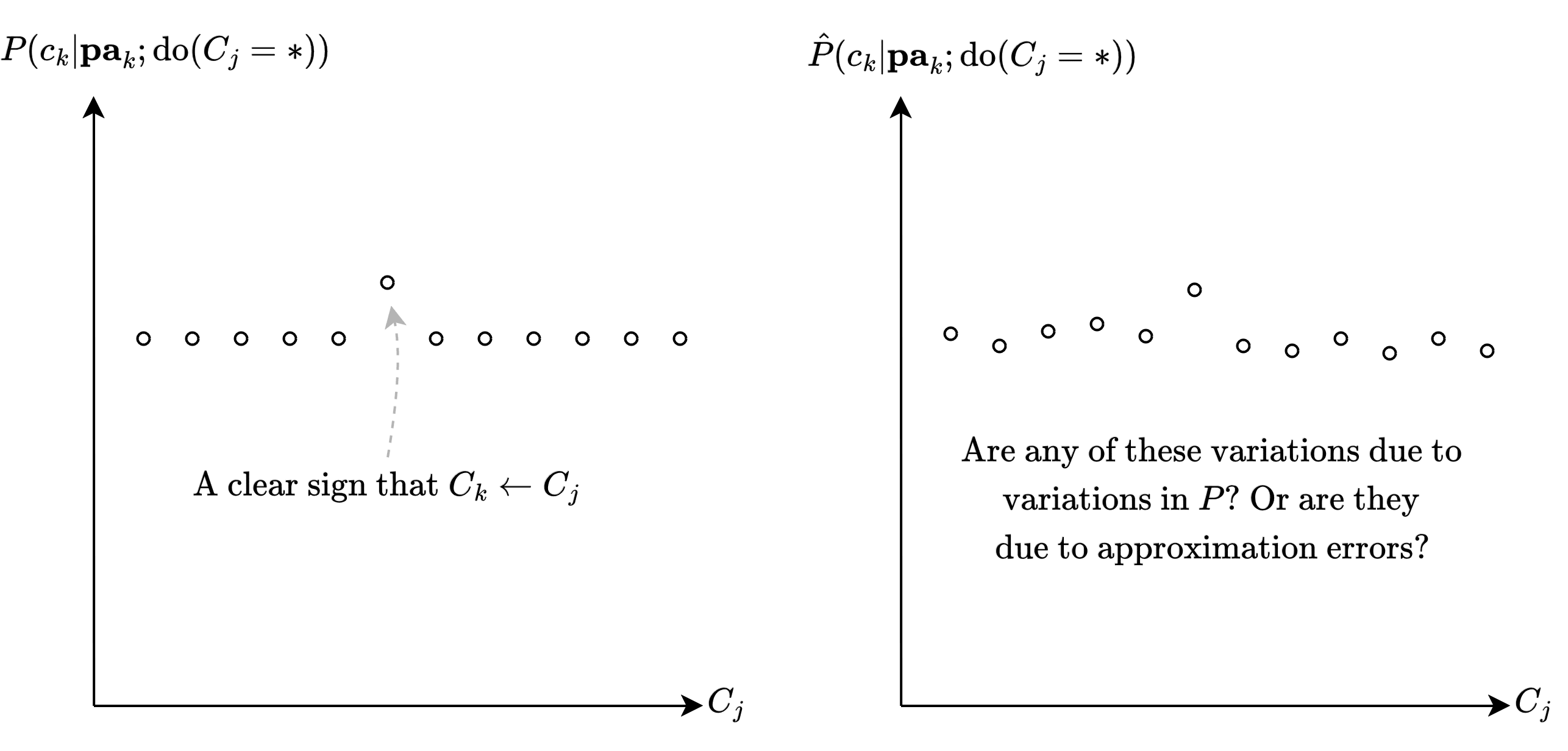
The above showed that we can identify up to , or more precisely, up to , for all values of and . In the optimal oracle case, this was sufficient for perfectly identifying , by holding all but one variables of fixed and observing which changes in those variables cause a change in the values of .
What is the issue with the approximate case?
First of all, we'll have to use instead of .
Say we want to test whether is a parent of . So we have fix everything in and vary the value of across the elements in its domain. Let's denote the value of where is set to as .
So the process is: Set , vary and see if there is a change, set a new , repeat.
The problem is that, because is only accurate up to , we can't tell if the change is due to actual differences in the underlying or due to the error in approximation.
The solution is to use one of the earlier explicit bounds on in terms of quantities that the algorithm has access to, i.e. . We can then use this bound to derive an explicit upper and lower bound for the values of , which we'll call and .
And if it's the case that there exists such that there exists and whose intervals and don't overlap, then we can guarantee that the change is due to actual differences in the underlying .
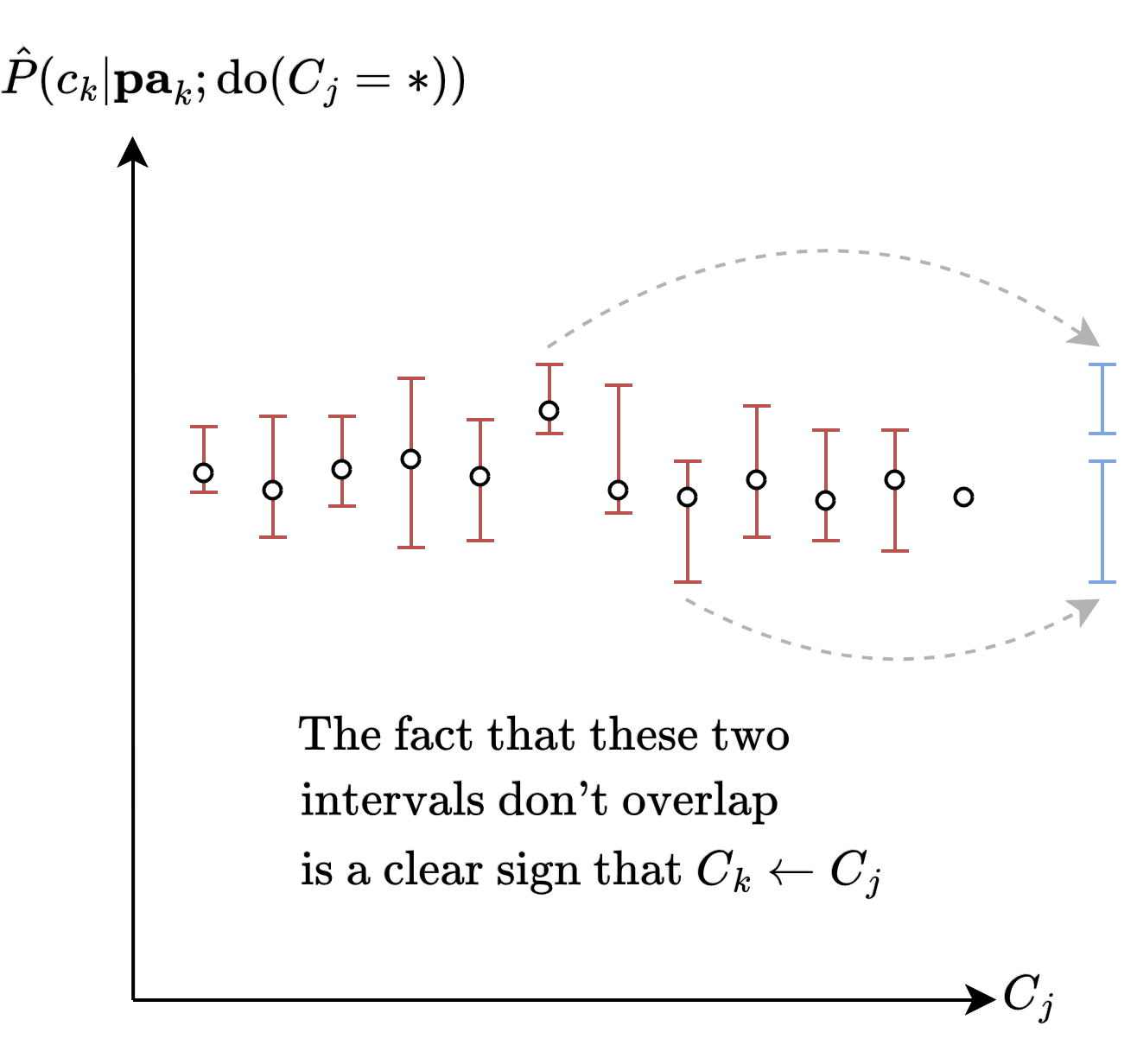
This procedure lets us identify a subset of , hence a subgraph of .
Detailed Proof
Suppose given a context, two decisions had the same expected utility.
Recall the definition: literally taking expectation over all the values that the ancestor of could take.Let and .
where goes if is incompatible with .
Note and , because only has an effect on its descendants, which isn't part of, and neither is .
Therefore,
And we're curious about the case when the difference in expected utility is zero:
Suppose that without loss of generality. Then the terms can be written as such:
Long story short, this is a polynomial constraint on the parameters of the network, and solution sets of a polynomial equation have measure zero (intuitively because for a polynomial equation to be precisely equal to zero, then the values should precisely be aligned, which is rare).
- Specifically: given a Bayesian Network G over nodes, its CPDs are as follows: . And since we're assuming all variables are discrete, these are a finite number of values that parameterize , each of which takes a value between 0 and 1.
- Suppose we find that they should satisfy some polynomial constraint: .
Then we can reasonably claim that this is extremely unlikely to happen, because in the space of all possible parameterizations , solutions to a polynomial constraint happen in a measure zero set.
0 comments
Comments sorted by top scores.