An Illustrated Summary of "Robust Agents Learn Causal World Model"
post by Dalcy (Darcy) · 2024-12-14T15:02:44.828Z · LW · GW · 2 commentsContents
Introduction Basic Setup World Agent as a Policy Oracle "Robustness" as δ-optimality under interventions Assumptions Main Theorem High-level argument Discussion Policy oracle is not a good model of an agent. The Causal Good Regulator Theorem isn't a structural theorem. Conclusion None 2 comments
This post was written during Alex Altair's agent foundations fellowship program [LW · GW], funded by LTFF. Thank you Alex Altair [LW · GW], Alfred Harwood [LW · GW], Daniel C [LW · GW] for feedback and comments.
Introduction
The selection theorems [LW · GW] agenda aims to prove statements of the following form: "agents selected under criteria has property ," where are things such as [LW · GW] world models, general purpose search, modularity, etc. We're going to focus on world models.
But what is the intuition that makes us expect to be able to prove such things in the first place? Why expect world models?
Because [LW · GW]: assuming the world is a Causal Bayesian Network with the agent's actions corresponding to the (decision) node, if its actions can robustly control the (utility) node despite various "perturbations" in the world, then intuitively it must have learned the causal structure of how 's parents influence in order to take them into account in its actions.
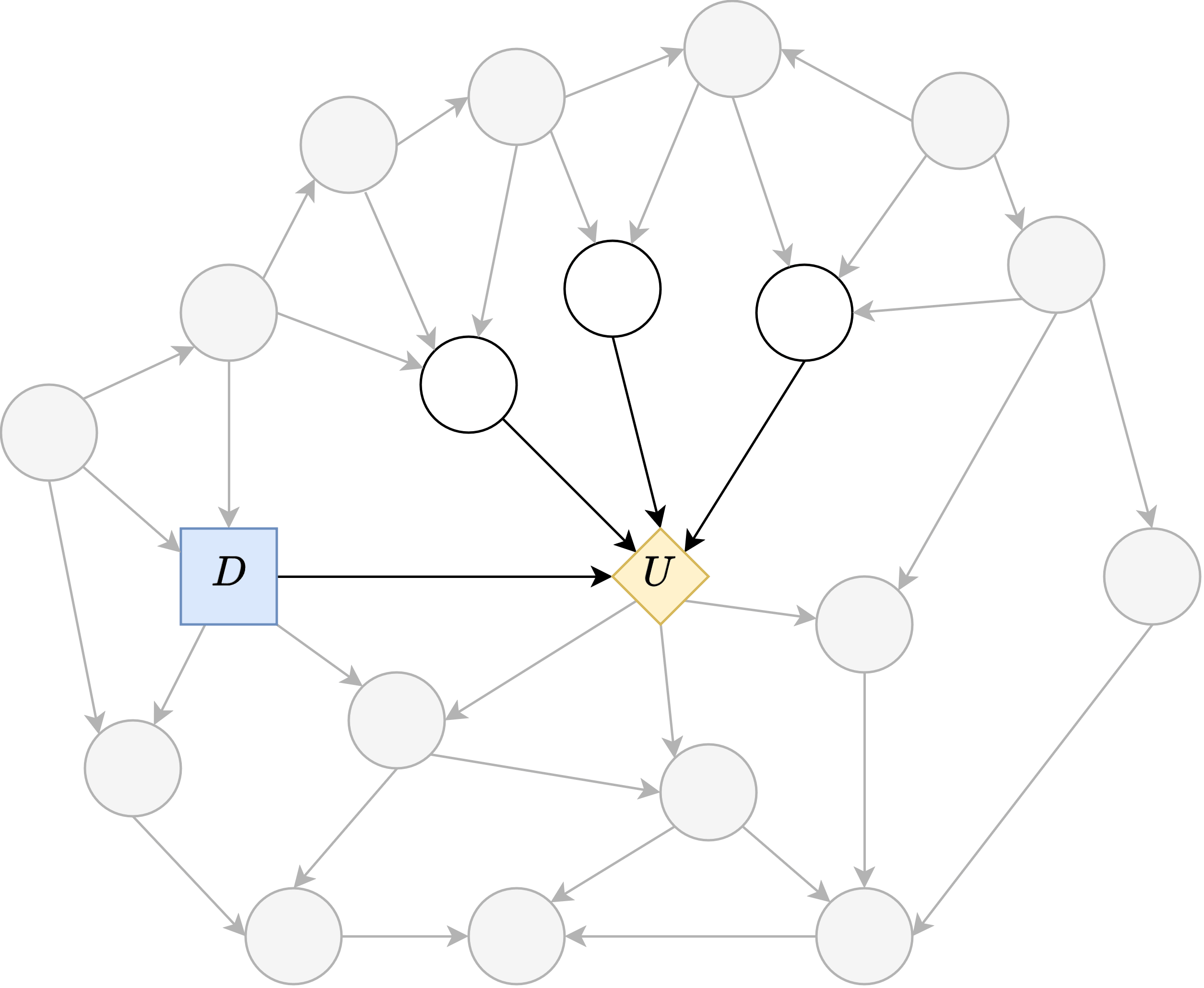
And the same for the causal structure of how 's parents' parents influence 's parents ... and by induction, it must have further learned the causal structure of the entire world upstream of the utility variable.
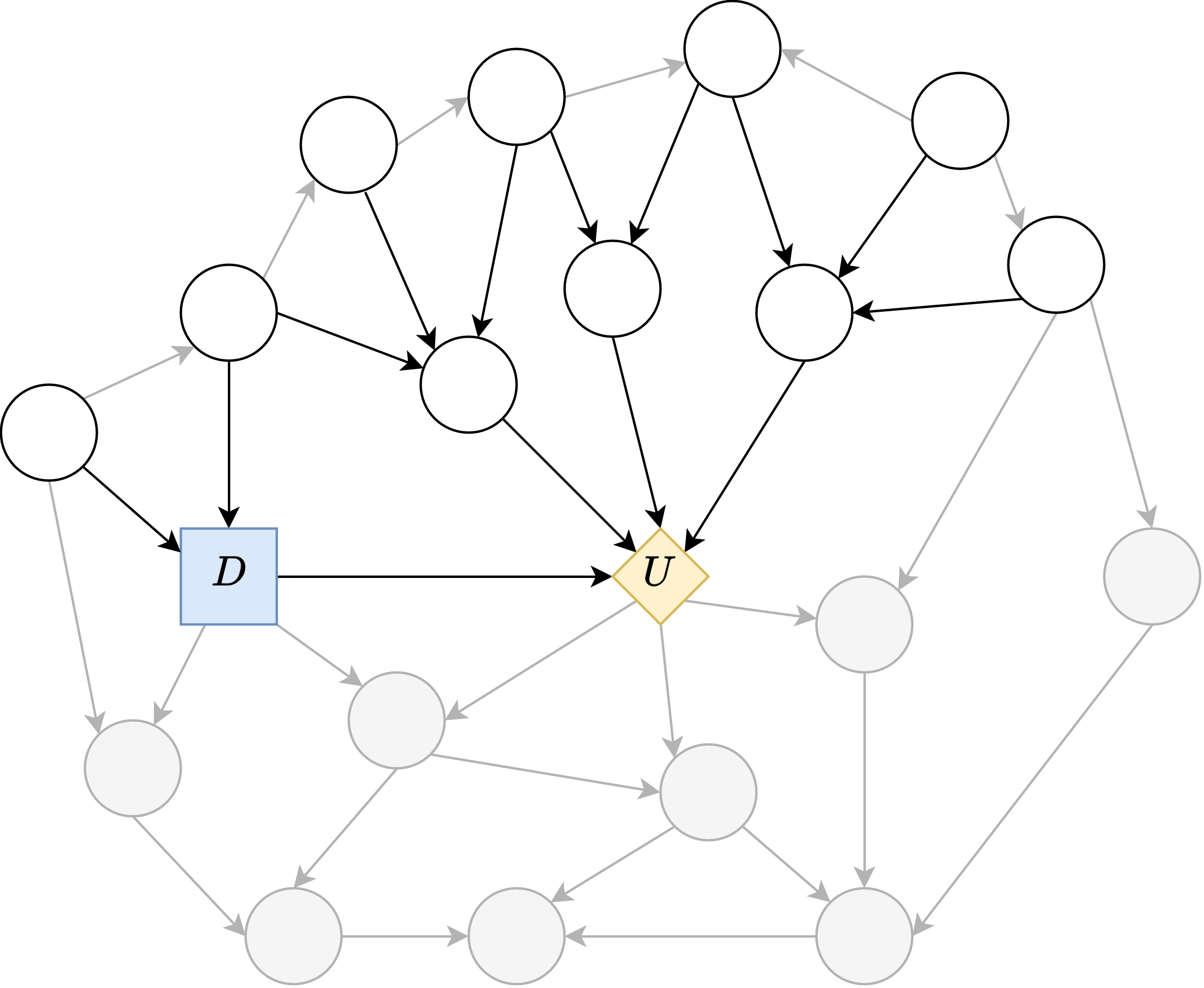
This is the intuitive argument that the paper Robust Agents Learn Causal World Model by Jonathan Richens and Tom Everitt formalizes.
Informally, its main theorem can be translated as: if an agent responds to various environment interventions by prescribing policies that overall yield low regret, then it's possible to appropriately query the agent to reconstruct an implicit world model that matches up with the ground truth causal structure.
I will refer to this result as the "Causal Good Regulator Theorem". This sequence Thoughts on the Causal Good Regulator Theorem will do the following:
- [1] a precise statement of the theorem alongside a high-level argument of its proof and discussions of the paper's results in the context of the selection theorem agenda - basically a self-complete distillation of the paper. The rest of the posts in this sequence are optional. (this post)
- [2] detailed proof of the paper's theorems, presented in a way that focuses on how one could've discovered the paper's results by themselves, with an emphasis on intuition.
- [3] extension of the paper's theorem by showing how one of the main assumptions can be relaxed without much trouble.
Basic Setup
World
The world is a Causal Bayesian Network over the set of variables corresponding to the environment , utility node , and decision node . The differences from a normal Causal Bayesian Network is that (1) is a deterministic function of its parents , and (2) , the conditional probability distribution for , is undetermined—it's something that our agent will select.
Agent as a Policy Oracle
In this paper's setup, the agent is treated as a mechanism that, informally, takes in an intervention to the world, and returns a policy i.e. it chooses .

Following this, we formally define an agent via a policy oracle which is a function that takes in an intervention (where represents the set of all allowed interventions over ) and returns a policy .

With the determined under as , all the conditional probability distributions of under are determined, meaning we can e.g., calculate the expected utility, .
This definition makes intuitive sense - if a human is told about changes in the environment (e.g., The environment has changed to "raining"), they would change their policy accordingly (e.g., greater change of taking the umbrella when going out).
But also, it is unnatural in the sense that it directly receives environmental intervention as input, unlike real agents which have to figure it out with its sensory organs that are also embedded in the world. This will be further discussed later in the post.
"Robustness" as -optimality under interventions
By a "robust" agent, intuitively we mean an agent that can consistently maximize its utility despite its environment being subject to various interventions. We formalize this in terms of "regret bounds".
We say a policy oracle has a regret if for all interventions allowed , the the oracle prescribes attains expected utility that is lower than the maximum expected utility attainable in by at most (that is, ), indicating a bound on suboptimality.
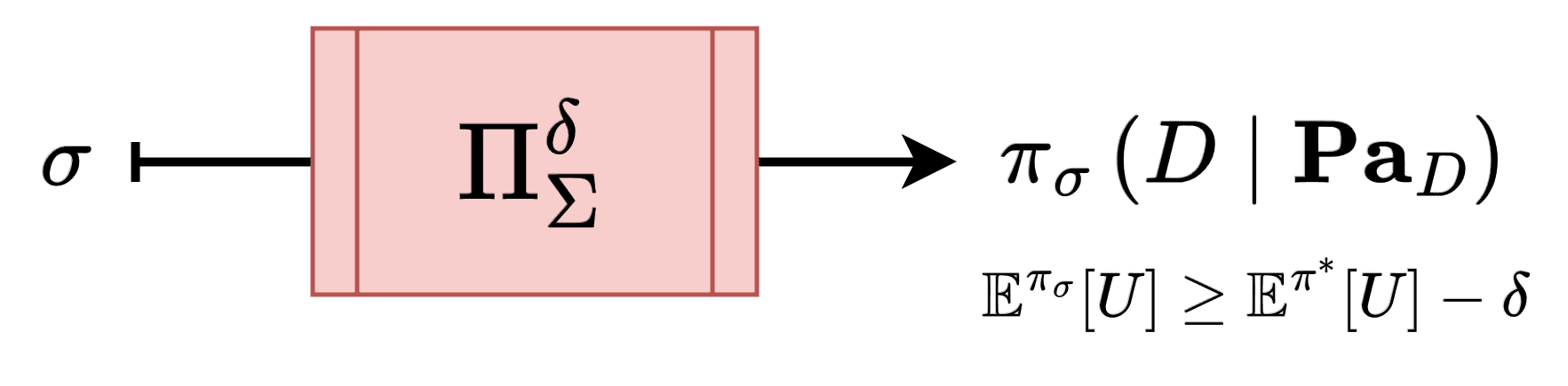
We denote a -optimal policy oracle , and -optimal one .
Now we have to choose some class of allowed interventions . This is put in a collapsible section because it doesn't matter too much for the high-level discussion of the first post.
Choice of
Now the question is the choice of - how broad of a set of perturbation do we want "robustness" to hold in? Ideally we would want it to be small while letting us prove interesting theorems - the broader this class is, the broader the set of environments our oracle is assumed to return a -optimal policy, making the agent less realistic.
Recall hard interventions: replaces to a delta distribution , and so the distribution factorizes to the following:
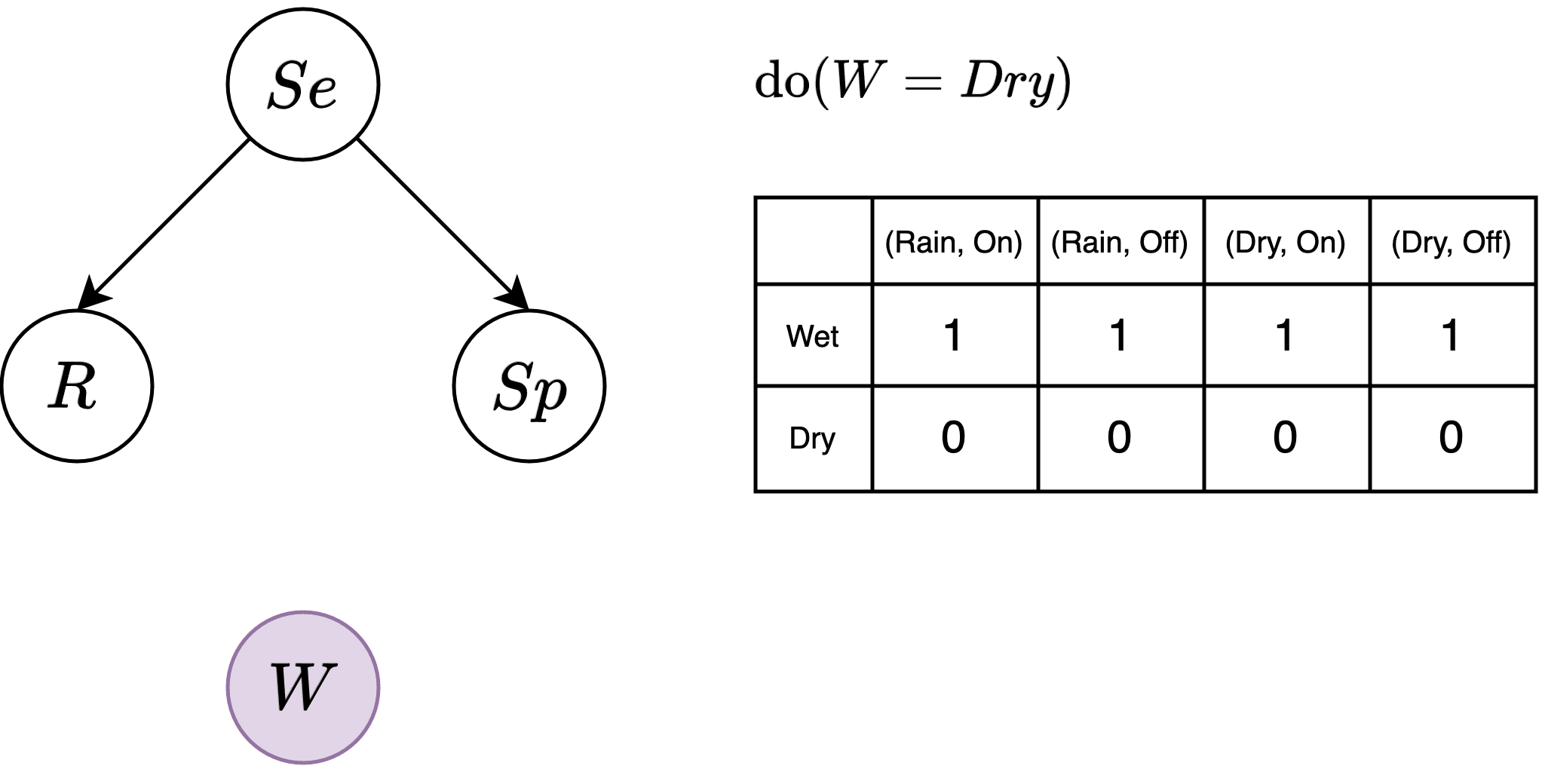
Soft interventions instead change more generally - not necessarily a delta function. It could even change the parent set to a different set as long as it doesn't introduce a cycle, of course.

The set of all soft interventions seem like a good choice of , until you realize that the condition "as long as it doesn't introduce a cycle" assumes we already know the graph structure of - but that's what we want to discover!
So the paper considers a restricted form of soft intervention called "local interventions." On top of , they apply a function . Because the function only maps the values of locally, it does not change the fact that depends on . yields .
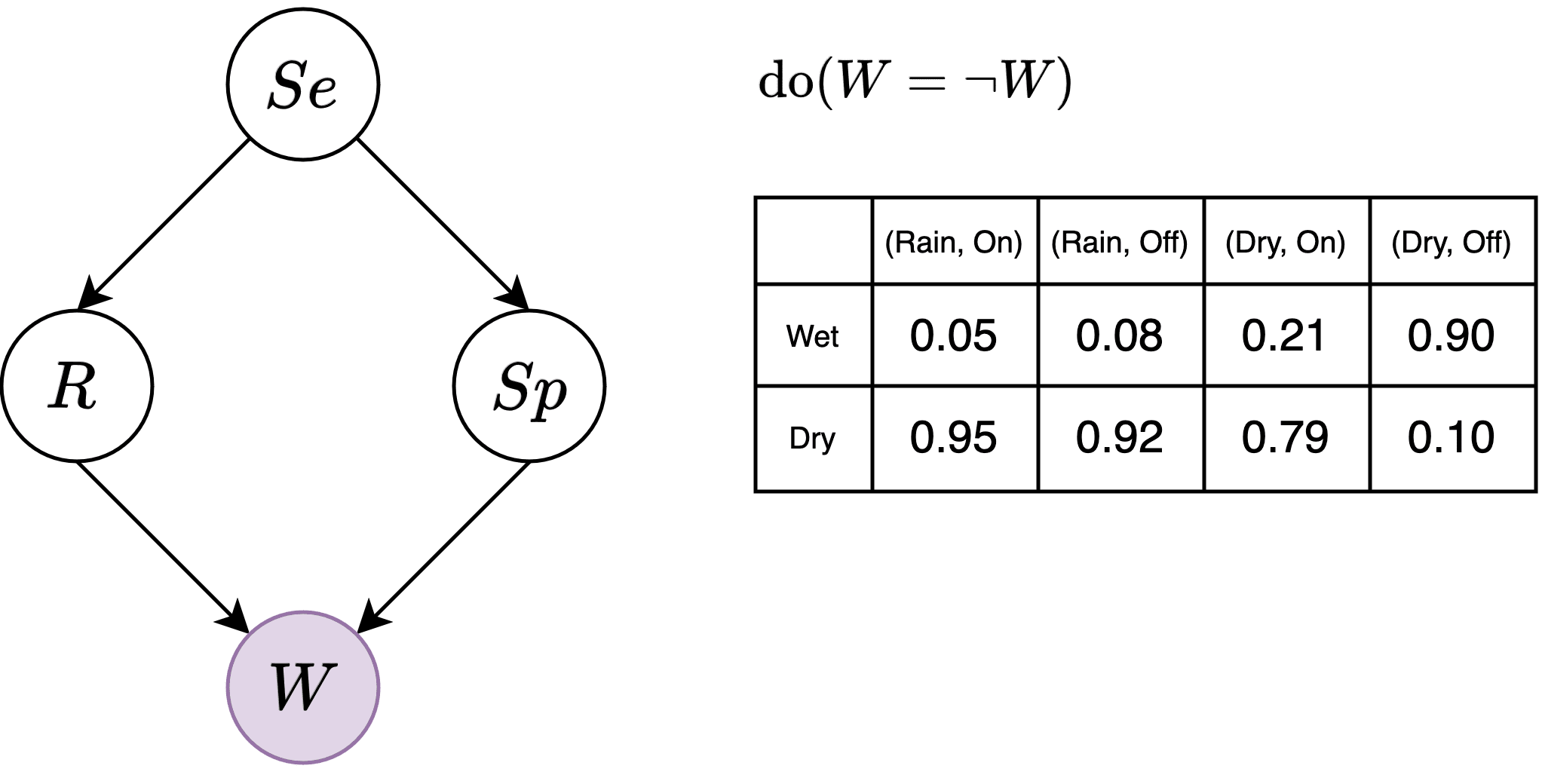
Examples:
- makes , corresponding to the hard intervention .
- makes , intuitively corresponding to e.g., shifting by ; maybe represents the location of some object in an RL world.
The paper extends this class further, considering "mixtures of local interventions," where we denote a mixed intervention for , which denotes randomly performing a local intervention with probability .
Examples:
- Suppose takes values . Then consider a local intervention , , and a mixture for some that sums to . This lets us set to literally any arbitrary distribution we want!
- This now makes it seem like a very broad class of interventions thus bad. But that's what we have for now.
Aside from these "local" interventions that only depend on the value of a node we're intervening on, the paper extends the intervention class by adding a specific form of structural intervention on the decision node .
- Specifically, they consider masking inputs to such that it only depends on . This is somewhat reasonable (despite being structural) if we assume prior knowledge of which nodes influence , e.g., perhaps by design, and control over what the decision node reads as the values of these variables.
Note: The paper mentions that this can be implemented by local interventions, but I don't think so since this is a structural intervention that doesn't just depend on values of . A set of hard interventions that set to a constant wouldn't work, because then we're not just masking inputs to D, but also masking inputs to other descendants of .
Assumptions
1) Unmediated Decision Task states that . This is pretty major.
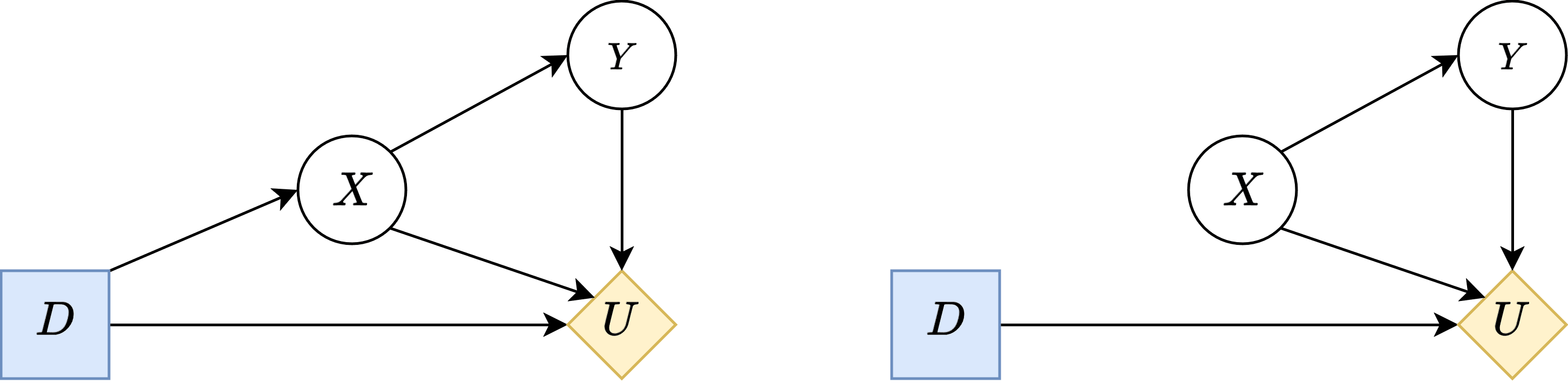
2) Domain dependence states that there exists distributions over the chance variables and (compatible with ) such that .
- This is very reasonable. If domain dependence does not hold, then the optimal policy is just a constant function.
These together imply:
- There does not exist a decision that is optimal, i.e. across all .
- , i.e. there can't be any intermediate nodes between and , and all causal effects from to must be direct.
Main Theorem
With this basic setup explained, here is the main theorem of the paper (Theorem 1):
For almost all worlds satisfying assumption 1 and 2, we can identify the directed acyclic graph and the joint distribution over all variables upstream of , given that we have access to a -optimal policy oracle.
and a second theorem, which is the approximate case (Theorem 2):
For almost all worlds satisfying assumption 1 and 2 and some other new assumptions (explained below), we can identify the directed acyclic graph and the joint distribution over some subset of variables upstream of , and the quality of estimation for each of the conditional distributions scale linearly with .
High-level argument
The proof is basically a formalization of the argument given in the introduction, but here we state it in the framework so far introduced.
The world is a Causal Bayesian Network, also containing two nodes each corresponding to an agent's decision node and utility node .
Suppose we're given an oracle that takes in an intervention as input and returns a policy (conditional distribution of the decision node given its parents) that attains maximum utility under that intervention in the environment. This oracle is an operationalizes the notion of a "robust agent."
The question of "How robust?" is determined by the class of interventions to be considered. The broader this class is, the broader the set of environments our oracle is assumed to return an optimal policy, hence the agent is less realistic.
So how do we use the oracle?
Suppose you have two interventions and , and you "interpolate"[1] between them by intervening under with a probability of , and intervening under with a probability of . Denote such an intervention .
If some decision, say, is the optimal decision returned by the oracle under , and is the optimal decision returned under , then as you gradually change from to , the optimal decision will switch from to other decisions () and eventually to .
Call the value of at which the decision eventually switches over to , .
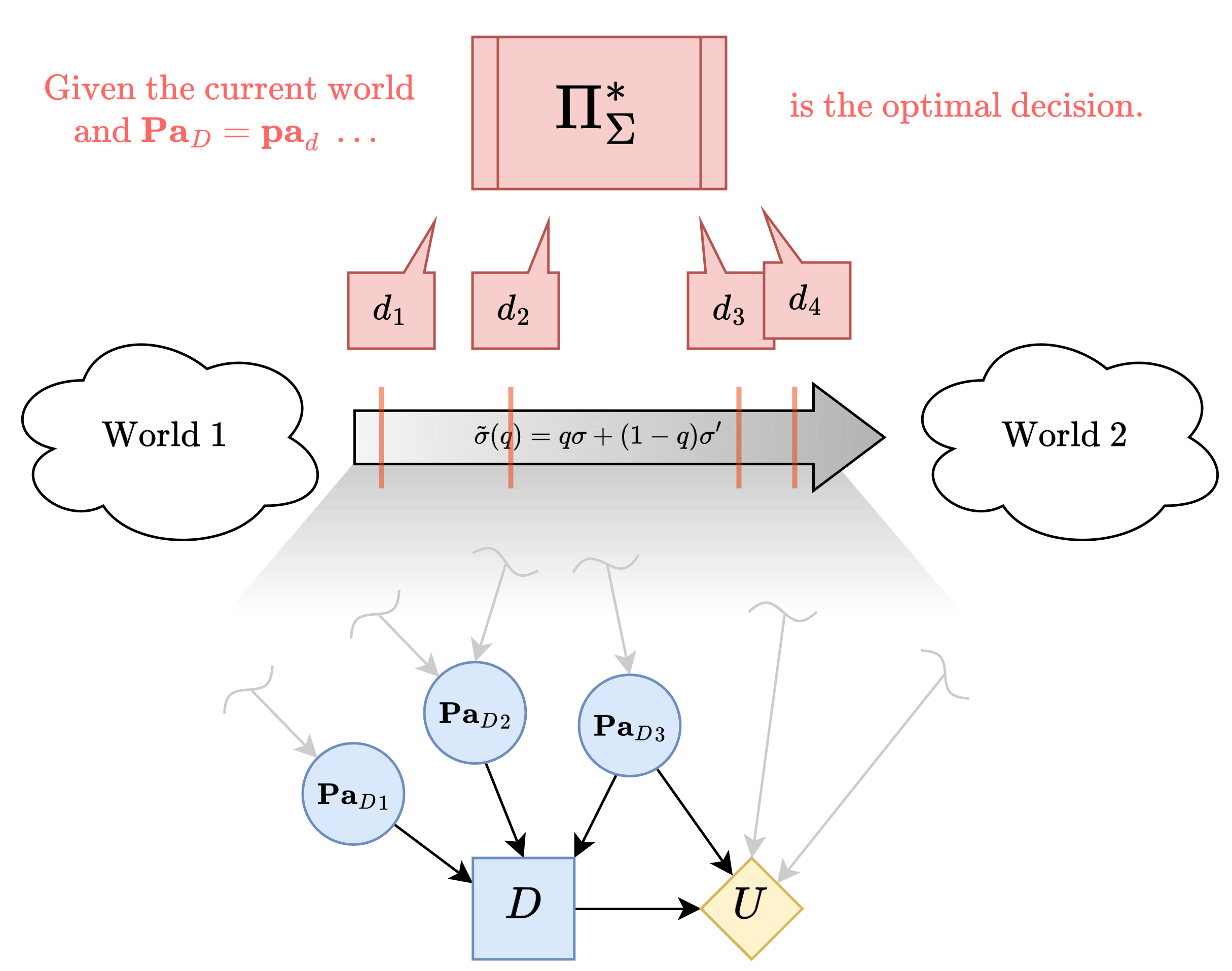
The critical insight is that can be estimated by querying the oracle with various values of q, and it also can expressed as an equation involving a number of terms corresponding to the conditional probability distributions of the Bayes Net (call it where is some node).
By cleverly setting and equating the estimate and the expression, all of the terms for upstream of can be solved. This is where we involve the earlier intuition of "induction":
- Assume some directed path where
- Step , is set such that the expression for only contains , so it can be immediately solved by comparing with the estimate.
- Step k, assume we know for , and set such that the expression contains for all . The only unknown here is .
- Thus, by induction, we should be able to infer the conditional probability distribution table of for every variable upstream of .
Furthermore, all of this can be relaxed to approximately-optimal policy oracles.
The claim for the approximate case is that given an oracle that is "imperfect by amount" it is possible to identify a subgraph of the graph corresponding to variables upstream of , and that the conditional distribution it estimates will differ from the true conditional distribution by an amount that scales linearly with for small values of .
Discussion
When viewed in terms of the selection theorem agenda, I think the results of this paper signify real advancement - (1) in its attempt at formalizing exactly the intuitive argument often used to argue for the existence of world models, (2) incorporation of causal information, (3) providing an explicit algorithm for world model discovery, and (4) relaxing its proof to the approximately optimal oracle case - many of which are important advancements on their own.
However, this work still leaves many room for improvement.
Policy oracle is not a good model of an agent.
Real agents respond to changes in the world through its sensory organs that are embedded in the world. However, the use of policy oracles imply that the agent can directly perceive the environmental intervention, where the policy oracle is sort of a sensory organ that lives outside of the causal graph of the world.
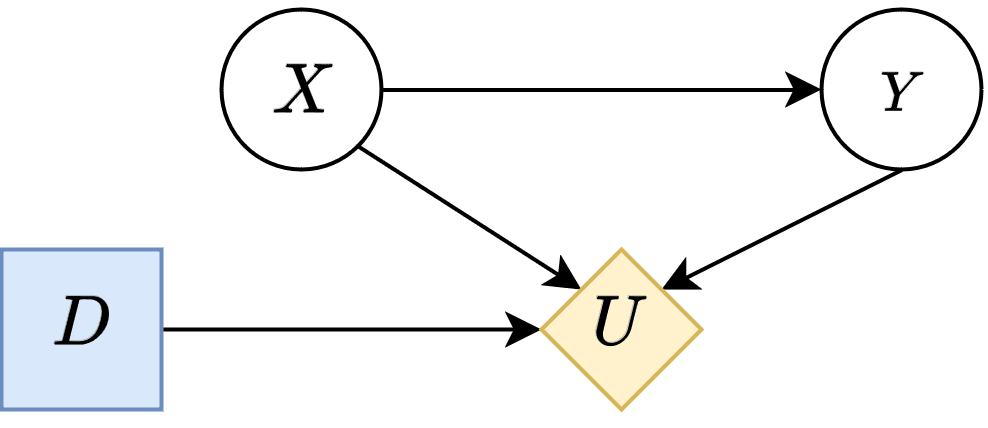
That's why even in cases like the above, where D has no input, the policy oracle can produce policies sensitive to environmental interventions. Loosely speaking, the agent's sensory nodes are only partially embedded into the environment (D's connection to its parents), and the rest (its ability to sense interventions) are outside of the causal graph of the environment.
The Causal Good Regulator Theorem isn't a structural theorem.
I think the term "world model" in the paper's title is misleading.
The existence of a "world model" is an inherently structural claim. It is a question about whether a mind's cognition explicitly uses/queries a modular subsystem that "abstracts away" the real world in some sense.
But the theorems of this paper are purely about behavioral properties - namely that some algorithm, given access to the policy oracle and the set of variables in , can query the policy oracle in a particular way to reconstruct accurately. This says nothing about whether this reconstructed is actually used internally within the agent's cognition!
- If we take the output of this algorithm and view it literally as a "world model" of the agent, then that implies the agent's "world model" is perfectly isomorphic to a subset of the environment's causal model. That would be very wrong. It shouldn't be that the "world model" recovered by the algorithm should depend on choice of variables used in , the world model should have its own ontology!
This is akin to how e.g., the VNM representation theorem is not structural: While it is possible to reconstruct a utility function from the betting behavior of agents satisfying certain axioms, that does not imply e.g., that the agent internally represents this utility function and argmaxes it.
I think this paper's result is better understood as a way to derive an implicit behavioral causal world model of an agent over a given set of variables, in the sense of answering the question: "given that I represent the world in terms of these variables , what causal relationship among these variables do the agent believe in?"
This itself is a very cool result!! The algorithm is inferring the agent's implied belief about causality with respect to any choice of variable ontology (i.e. choice of used to represent the world).
For example, I can literally imagine ...
- ... having to consist of variables like "sodium intake, blood pressure, arterial stiffness, ... vascular inflammation", and to consist of variables like "dietary habits, cardiovascular risk, life expectancy"
- ... then running the proof's algorithm on a human/LLM by treating them as a policy oracle (where can be formulated as a text input, like providing them the text "your dietary habits are set to X ... ")
- ... and being able to infer the human/LLM's implied causal beliefs on these two different ontologies about healthcare issues!
But again, it would be misleading to call these alongside their inferred causal relationship the "world model" of the human/LLM.
Conclusion
The paper Robust Agents Learn Causal World Model signifies a real advancement in the selection theorem agenda, proving that it is possible to derive an implicit behavioral causal world model from policy oracles (agents) with low regret by appropriately querying them. But it has a lot of room for improvement, especially in making its claims more "structural."
I believe this post was a self-contained explanation of the paper along with my take on it.
However, my primary motivation for reading this paper was to more rigorously understand the proof of the theorem, with the goal of identifying general proof strategies that might be applied to proving future selection theorems. This is especially relevant because this paper appears to be the first that proves a selection theorem of substantial content while being rooted in the language of causality, and I believe causality will play a critical role in future selection theorems.
For this, wait for the next post in the sequence soon to be published.
2 comments
Comments sorted by top scores.
comment by Jonathan Richens (jonrichens) · 2024-12-20T21:52:19.046Z · LW(p) · GW(p)
This is such a good deep dive into our paper, which I will be pointing people to in the future. Thanks for writing it!
Agree that conditioning on the intervention is unnatural for agents. One way around this is to note that adapting to an unknown distributional shift given only sensory inputs Pa_D is strictly harder than adapting to a known distributional shift (given Pa_D and sigma). It follows that any agent capable of adapting given only its sensory inputs must have learned a CWM (footnotes, p6).
comment by Lucas Teixeira · 2024-12-15T03:49:01.394Z · LW(p) · GW(p)
Strong upvote. Very clearly written and communicated. I've been recently thinking about digging deeper into this paper with the hopes of potentially relating it to some recent causality based interpretability work and reading this distillation has accelerated my understanding of the paper. Looking forward to the rest of the sequence!