[Setting: a suburban house. The interior of the house takes up most of the stage; on the audience's right, we see a wall in cross-section, and a front porch. Simplicia enters stage left and rings the doorbell.]
Doomimir: [opening the door] Well? What do you want?
Simplicia: I can't stop thinking about our last conversation [LW · GW]. It was kind of all over the place. If you're willing, I'd like to continue, but focusing in narrower detail on a couple points I'm still confused about.
Doomimir: And why should I bother tutoring an Earthling in alignment theory? If you didn't get it from the empty string, and you didn't get it from our last discussion, why should I have any hope of you learning this time? And even if you did, what good would it do? [LW · GW]
Simplicia: [serenely] If the world is ending either way, I think it's more dignified that I understand exactly why. [A beat.] Sorry, that doesn't explain what's in it for you. That's why I had to ask.
Doomimir: [grimly] As you say. If this world is ending either way.
[He motions for her to come in, and they sit down.]
Doomimir: What are you confused about? I mean, that you wanted to talk about.
Simplicia: You seemed really intent on a particular intuition pump against human-imitation-based alignment strategies, where you compared LLMs to an alien actress. I didn't find that compelling.
Doomimir: But you claim to understand that LLMs that emit plausibly human-written text aren't human. Thus, the AI is not the character it's playing. Similarly, being able to predict the conversation in a bar, doesn't make you drunk. What's there not to get, even for you?
Simplicia: Why doesn't the "predicting barroom conversation doesn't make you drunk" analogy falsely imply "predicting the answers to modular arithmetic problems doesn't mean you implement modular arithmetic"?
Doomimir: To predict the conversation in a bar, you need to know everything the drunk people know, separately and in addition to everything you know. Being drunk yourself would just get in the way. Similarly, predicting the behavior of nice people isn't the same thing as being nice. Modular arithmetic isn't like that; there's nothing besides the knowledge to not implement.
Simplicia: But we only need our AI to compute nice behavior, not necessarily to have some internal structure corresponding to the quale of niceness. As far as safety properties go, we don't care whether the actress is "really drunk" as long as she stays in character.
Doomimir: [scoffing] Have you tried imagining any internal mechanisms at all other than a bare, featureless inclination to emit the outward behavior you observe?
Simplicia: [unfazed] Sure, let's talk about internal mechanisms. The reason I chose modular arithmetic as an example is because it's a task for which we have good interpretability results. Train a shallow transformer on a subset of the addition problems modulo some fixed prime. The network learns to map the inputs onto a circle in the embedding space, and then does some trigonometry to extract the residue, much as one would count forward on the face of an analog clock.
Alternatively, with a slightly different architecture that has a harder time with trig, it can learn a different algorithm: the embeddings are still on a circle, but the answer is computed by looking at the average of the embedding vectors of the inputs. On the face of an analog clock, the internal midpoints between distinct numbers that sum to 6 mod 12—that's 2 and 4, or 1 and 5, or 6 and 12, or 10 and 8, or 11 and 7—all lie on the line connecting 3 and 9. Thus, the sum-mod-p of two numbers can be determined by which line the midpoint of the inputs falls on—as long as the inputs aren't on opposite sides of the circle, in which case their midpoint is in the center, where all the lines meet. But the network compensates for such antipodal points by also learning another circle in a different subspace of the embedding space, such that inputs that are antipodal on the first circle are close together on the second, which helps disambiguate the answer.
Doomimir: Cute results. Excellent work—by Earth standards. And entirely unsurprising. Sure, if you train your neural net on a well-posed mathematical problem with a consistent solution, it will converge on a solution to that problem. What's your point?
Simplicia: It's evidence about the feasibility of learning desired behavior from training data. You seem to think that it's hopelessly naïve to imagine that training on "nice" data could result in generalizably nice behavior—that the only reason someone might think that was a viable path was is if they were engaging in magical reasoning about surface similarities [LW · GW]. I think it's germane to point out that at least for this toy problem, we have a pretty concrete, non-magical story about how optimizing against a training set discovers an algorithm that reproduces the training data and also generalizes correctly to the test set.
For non-toy problems, we know empirically that deep learning can hit very precise behavioral targets: the vast hypermajority of programs don't speak fluent English or generate beautiful photorealistic images, and yet GPT-4 and Midjourney exist.
If doing that for "text" and "images" was a mere engineering problem, I don't see what fundamental theoretical barrier rules out the possibility of pulling off the same kind of thing for "friendly and moral real-world decisionmaking"—learning a "good person" or "obedient servant" function from data, much as Midjourney has learned a "good art" function.
It's true that diffusion models don't work like a human artist on the inside, but it's not clear why that matters? It would seem idle to retort, "Predicting what good art would look like, doesn't make you a good artist; having an æsthetic sense yourself would just get in the way", when you can actually use it to do a commissioned artist's job.
Doomimir: Messier tasks aren't going to have a unique solution like modular arithmetic. If genetic algorithms, gradient descent, or anything like that happens to hill-climb its way into something that appears to work, the function it learns is going to have all sorts of weird squiggles [LW(p) · GW(p)] around inputs that we would call adversarial examples, that look like typical members of the training distribution from the AI's perspective, but not ours—which kill you when optimized over by a powerful AGI.
Simplicia: It sounds like you're making an empirical claim that solutions found by black-box optimization are necessarily contingent and brittle, but there's some striking evidence that seemingly "messy" tasks admit much more convergent solutions than one might expect. For example, on the surface, the word2vec and FastText word embeddings look completely different—as befitting being produced by two different codebases trained on different datasets. But when you convert their latent spaces to a relative representation—choosing some shared vocabulary words as anchors, and defining all other word vectors by their cosine similarities to the anchors—they look extremely similar.
It would seem that "English word embeddings" are a well-posed mathematical problem with a consistent solution. The statistical signature of the language as it is spoken is enough to pin down the essential structure of the embedding.
Relatedly, you bring up adversarial examples in a way that suggests that you think of them as defects of a primitive optimization paradigm, but it turns out that adversarial examples often correspond to predictively useful features that the network is actively using for classification, despite those features not being robust to pixel-level perturbations that humans don't notice—which I guess you could characterize as "weird squiggles" from our perspective, but the etiology of the squiggles presents a much more optimistic story about fixing the problem with adversarial training than if you thought "squiggles" were an inevitable consequence of using conventional ML techniques.
Doomimir: This is all very interesting, but I don't think it bears much on the reasons we're all going to die. It's all still on the "is" side of the is–ought gap. What makes intelligence useful—and dangerous—isn't a fixed repertoire of behaviors. It's search, optimization—the systematic discovery of new behaviors to achieve goals despite a changing environment. I don't think recent capabilities advances bear on the shape of the alignment challenge [LW · GW] because being able to learn complex behavior on the training distribution was never what the problem was about.
Indeed, as long as we continue to be stuck in the paradigm of reasoning about "the training distribution"—growing minds rather than designing them—then we're not learning anything about how to aim cognition at specific targets [LW · GW]—certainly not in a way that will hold up to dumping large amounts of optimization power into the system [LW · GW]. The lack of an explicit "goal slot" in your neural network doesn't mean it's not doing any dangerous optimization; it just means you don't know what it is.
Simplicia: I think we can form educated guesses—
Doomimir: [interrupting] Guesses!
Simplicia: —probabilistic beliefs—about what kinds of optimization is being done by a system and whether it's a problem, even without a complete mechanistic interpretability story. If you think LLMs or future variations thereof are unsafe because they're analogous to an actress with her own goals playing a drunk character without herself being drunk, shouldn't that make some sort of testable prediction about their generalization behavior?
Doomimir: Nonfatally testable? Not necessarily. If you lend a con man $5, and he gives it back, that doesn't mean that you can trust him with larger amounts of money, if he only gave back the $5 because he hoped you would trust him with more.
Simplicia: Okay, I agree that deceptive alignment is potentially a real problem at some point, but can we at least distinguish between misgeneralization and deceptive alignment?
Simplicia: So there are obviously risks from malgeneralization, where the network that fits your training distribution turns out to not behave the way you wanted against a different distribution. For example, a reinforcement learning policy [LW · GW] trained to collect a coin at the right edge of a video game level, might end up continuing to navigate to the right edge of levels where the coin is in a different location. That's a worrying clue that if we misunderstand how inductive biases work and aren't careful with our training setup, we might train the wrong thing. As our civilization delegates more and more cognitive labor to machines, eventually humans will lose the ability to course-correct. We're starting to see the early signs of this: as I mentioned the other day, Anthropic Claude's preachy, condescending personality already gives me the creeps. I'm pretty nervous about extrapolating that into a future where all productive roles in Society are filled by Claude's children, concurrently with a transition to explosive economic growth rates.
But the malgeneralization examples I named aren't surprising when you look at how the systems were trained. For the game policy, "going to the coin" and "going to the right" did amount to the same thing in training—and randomizing the coin position in just a couple percent of training episodes suffices to instill the correct behavior. Regarding Claude, Anthropic is using a reinforcement-learning-from-AI-feedback method they call Constitutional AI: instead of having humans provide the labels for RLHF, they write up a list of principles, and have another language model do the labeling. It makes sense that a language model agent trained to conform to principles chosen by a committee at a California public benefit corporation would act like that.
In contrast, when you make analogies about an actress playing a drunk character not being drunk, or giving a con man $5, it doesn't sound like you're talking about the risk of training the wrong thing, where it's usually clear in retrospect if not foresight how training encouraged the bad behavior. Rather, it sounds like you don't think training can shape motivations—"inner" motivations—at all.
When you set out poisoned ant baits, you likely don't think of yourself as trying to deceive the ants, but you are. Similarly, a smart AI won't think of itself as trying to deceive us. It's trying to achieve its goals. If its plans happen to involve emitting sound waves or character sequences that we interpret as claims about the world, that's our problem.
Simplicia: "What would that even"—this isn't 2008, Doomishko! I'm talking about the technology right here in front of us! When GPT-4 writes original code for me, I don't think it's strategically deciding that obeying me instrumentally serves its final goals! From everything I've read about how it was made and seen about how it behaves, it looks awfully like it's just generalizing from its training distribution in an intuitively reasonable way. You ridicule people who deride LLMs as stochastic parrots, ignoring the obvious sparks of AGI right in front of their face. Why is it not equally absurd to deny the evidence in front of your face that alignment may be somewhat easier than it looked 15 years ago [LW · GW]? By all means, expound on the nonobvious game theory of deception; by all means, point out that the superintelligence at the end of time will be an expected utility maximizer. But all the same, RLHF/DPO as the cherry on top of a cake of unsupervised learning is verifiably working miracles for us today—in response to commands, not because it has a will of its own aligned with ours. Why is that merely "capabilities" and not at all "alignment"? I'm trying to understand, Doomimir Doomovitch, but you're not making this easy!
Doomimir: [starting to anger] Simplicia Optimistovna, if you weren't from Earth, I'd say [LW · GW] I don't think you're trying to understand [LW · GW]. I never claimed that GPT-4 in particular is what you would call deceptively aligned. Endpoints are easier to predict than intermediate trajectories. I'm talking about what will happen inside almost any sufficiently powerful AGI, by virtue of it being sufficiently powerful [LW · GW].
Simplicia: But if you're only talking about the superintelligence at the end of time—
Doomimir: [interrupting] This happens significantly before that.
Simplicia: —and not making any claims about existing systems, then what was the whole "alien actress", "predicting bar conversations doesn't make you drunk" analogy about? If it was just a ham-fisted way to explain to normies that LLMs that do relatively well on a Turing test aren't humans, then I agree, trivially. But it seemed like you thought you were making a much stronger point, ruling out an entire class of alignment strategies based on imitation.
Doomimir: [cooler] Basically, I think you're systematically failing to appreciate how things that have been optimized to look good to you can predictably behave differently in domains where they haven't been optimized to look good to you [LW · GW]—particularly, when they're doing any serious optimization of their own. You mention the video game agent that navigates to the right instead of collecting a coin. You claim that it's not surprising given the training set-up, and can be fixed by appropriately diversifying the training data. But could you have called the specific failure in advance, rather than in retrospect? When you enter the regime of transformatively powerful systems, you do have to call it in advance.
I think if you understood what was really going on inside of LLMs, you'd see thousands and thousands of analogues of the "going right rather than getting the coin" problem. The point of the actress analogy is that the outward appearance doesn't tell you what goals the system is steering towards, which is where the promise and peril of AGI lies—and the fact that deep learning systems are a inscrutable mess, not all of which can be described as "steering towards goals", makes the situation worse, not better. The analogy doesn't depend on existing LLMs having the intelligence or situational awareness for the deadly failure modes to have already appeared, and it doesn't preclude LLMs being mundanely useful in the manner of an interactive textbook—much as an actress could be employed to give plausible-sounding answers to questions posed to her character, without being that character.
Simplicia: Those mismatches still need to show up in behavior under some conditions, though. I complained about Claude's personality, but that honestly seems fixable with scaling by an AI company not based in California. If human imitation is so superficial and not robust, why does constitutional AI work at all? You claim that "actually" being nice would get in the way of predicting nice behavior. How? Why would it get in the way?
Doomimir: [annoyed] Being nice isn't the optimal strategy for doing well in pretraining or RLHF. You're selecting an algorithm for a mixture of figuring out what outputs predict the next token and figuring out what outputs cause humans to press the thumbs-up button.
Sure, your AI ends up having to model a nice person, which is useful for predicting what a nice person would say, which is useful for figuring out what output will manipulate—steer—humans into pressing the thumbs-up button. But there's no reason to expect that model to end up in control of the whole AI! That would be like ... your beliefs about what your boss wants you to do taking control of your brain.
Simplicia: That makes sense to me if you posit a preëxisting consequentialist reasoner being slotted into a contemporary ML training setup and trying to minimize loss. But that's not what's going on? Language models aren't an agent that has a model. The model is the model.
Doomimir: For now. But any system that does powerful cognitive work will do so via retargetable general-purpose search algorithms [LW · GW], which, by virtue of their retargetability, need to have something more like a "goal slot". Your gradient updates point in the direction of more consequentialism.
Human raters pressing the thumbs-up button on actions that look good to them are going to make mistakes. Your gradient updates point in the direction of "playing the training game" [LW · GW]—modeling the training process that actually provides reinforcement, rather than internalizing the utility function that Earthlings naïvely hoped the training process would point to. I'm very, very confident that any AI produced via anything remotely like the current paradigm is not going to end up wanting what we want, even if it's harder to say exactly when it will go off the rails or what it will want instead.
Simplicia: You could be right, but it seems like this all depends on empirical facts about how deep learning works, rather than something you could be so confident in from a priori philosophy. The argument that systemic error in human reward labels favors gaming the training process over the "correct" behavior sounds plausible to me, as philosophy.
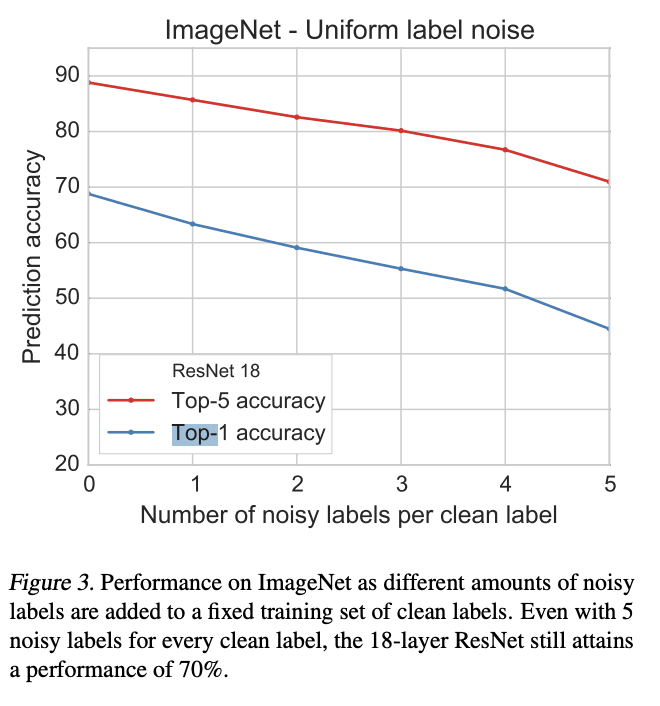
But I'm not sure how to reconcile that with the empirical evidence that deep networks are robust to massive label noise: you can train on MNIST digits with twenty noisy labels for every correct one and still get good performance as long as the correct label is slightly more common than the most common wrong label. If I extrapolate that to the frontier AIs of tomorrow, why doesn't that predict that biased human reward ratings should result in a small performance reduction, rather than ... death?
When extrapolation from empirical data (in a setting that might not apply to the phenomenon of interest) contradicts thought experiments (which might make assumptions that don't apply to the phenomenon of interest), I'm not sure which should govern my anticipations. Maybe both results are possible for different kinds of systems?
The case for near-certain death seems to rely on a counting argument: powerful systems will be expected utility maximizers; there's an astronomical space of utility functions to choose from, and almost none of them are friendly. But the reason I keep going back to the modular arithmetic example is because it's a scaled-down case where we know that training data successfully pinned down the intended input–output function. As I mentioned the other day, this wasn't obvious in advance of seeing the experimental result. You could make a similar counting argument that deep nets should always overfit, because there are so many more functions that generalize poorly. Somehow, the neural network prior favors the "correct" solution, rather than it taking an astronomically unlikely coincidence.
But I'm not sure how to reconcile that with the empirical evidence that deep networks are robust to massive label noise: you can train on MNIST digits with twenty noisy labels for every correct one and still get good performance as long as the correct label is slightly more common than the most common wrong label. If I extrapolate that to the frontier AIs of tomorrow, why doesn't that predict that biased human reward ratings should result in a small performance reduction, rather than ... death?
The conversation didn't quite get to Doomimir actually answering this part, but I'd consider the standard answer to be item #20 on Eliezer's List O'Doom [LW · GW]:
20. Human operators are fallible, breakable, and manipulable. Human raters make systematic errors - regular, compactly describable, predictable errors. To faithfully learn a function from 'human feedback' is to learn (from our external standpoint) an unfaithful description of human preferences, with errors that are not random (from the outside standpoint of what we'd hoped to transfer). If you perfectly learn and perfectly maximize the referent of rewards assigned by human operators, that kills them. It's a fact about the territory, not the map - about the environment, not the optimizer - that the best predictive explanation for human answers is one that predicts the systematic errors in our responses, and therefore is a psychological concept that correctly predicts the higher scores that would be assigned to human-error-producing cases.
... and yeah, there are definitely nonzero empirical results on that.
I think part of the reason the post ends without addressing this is that, unfortunately, I don't think I properly understand this one yet, even after reading your dialogue with Eli Tyre [LW · GW].
The next paragraph of the post links Christiano's 2015 "Two Kinds of Generalization", which I found insightful and seems relevant. By way of illustration, Christiano describes two types of possible systems for labeling videos: (1) a human classifier (which predicts what label a human would assign), and (2) a generative model (which directly builds a mapping between descriptions and videos roughly the way our brains do it). Notably, the human classifier behaves undesirably on inputs that bribe, threaten, or otherwise hack the human: for example, a video of the text "I'll give you $100 if you classify this as an apple" might get classified as an apple. (And an arbitrarily powerful search for maximally apple-classified inputs would turn those up.)
Christiano goes on to describe a number of differences between these two purported kinds of generalization: (1) is reasoning about the human, whereas (2) is reasoning with a model not unlike the one inside the human's brain; searching for simple Turing machines would tend to produce (1), whereas searching for small circuits would tend to produce (2); and so on.
It would be bad to end up with a system that behaves like (1) without realizing it. That definitely seems like it would kill you. But (Simplicia asks) how likely that is seems like a complicated empirical question about how ML generalization works and how you built your particular AI, that isn't definitively answered by "in the limit" philosophy about "perfectly learn[ing] and perfectly maximiz[ing] the referent of rewards assigned by human operators"? That is, I agree that if you argmax over possible programs for the one that results in the most reward-button presses, you get something that only wants to seize the reward button. But the path-dependent details between "argmax over possible programs" and "pretraining + HFDT [LW · GW] + regularization + early stopping + &c." seem like they make a big difference [LW · GW]. The technology in front of us really does seem like it's "reasoning with" rather than "reasoning about" (while also seeming to be on the path towards "real AGI" rather than a mere curiosity).
When I try to imagine what Doomimir would say to that, all I can come up with is a metaphor about perpetual-motion-machine inventors whose designs are so complicated that it's hard to work out where the error is, even though the laws of thermodynamics clearly imply that there must be an error. That sounds plausible to me as a handwavy metaphor; I could totally believe that the ultimate laws of intelligence (not known to me personally) work that way.
The thing is, we do need more than a handwavy metaphor! "Yes, your gold-printing machine seems to be working great, but my intuition says it's definitely going to kill everyone. No, I haven't been able to convince relevant experts who aren't part of my robot cult, but that's because they're from Earth and therefore racially inferior to me. No, I'm not willing to make any concrete bets or predictions about what happens before then" is a non-starter even if it turns out to be true.
Zeroth point: under a Doomimir-ish view, the "modelling the human vs modelling in a similar way to the human" frame is basically right for current purposes, so no frame clash.
On to the main response...
Doomimir: This isn't just an "in the limit" argument. "I'll give you $100 if you classify this as an apple" -> (predict apple classification) is not some incredibly high-complexity thing to figure out. This isn't a jupiter-brain sort of challenge.
For instance, anything with a simplicity prior at all similar to humans' simplicity prior will obviously figure it out, as evidenced by the fact that humans can figure out hypotheses like "it's bribing the classifier" just fine. Even beyond human-like priors, any ML system which couldn't figure out something that basic would apparently be severely inferior to humans in at least one very practically-important cognitive domain.
Even prior to developing a full-blown model of the human rater, models can incrementally learn to predict the systematic errors in human ratings, and we can already see that today. The classic case of the grabber hand is a go-to example:
(A net learned to hold the hand in front of the ball, so that it looks to a human observer like the ball is being grasped. Yes, this actually happened.)
... and anecdotally, I've generally heard from people who've worked with RLHF that as models scale up, they do in fact exploit rater mistakes more and more, and it gets trickier to get them to do what we actually want. This business about "The technology in front of us really does seem like it's 'reasoning with' rather than 'reasoning about'" is empirically basically false, and seems to get more false in practice as models get stronger even within the current relatively-primitive ML regime.
So no, this isn't a "complicated empirical question" (or a complicated theoretical question). The people saying "it's a complicated empirical question, we Just Can't Know" are achieving their apparent Just Not Knowing by sticking their heads in the sand; their lack of knowledge is a fact about them, not a fact about the available evidence.
(I'll flag here that I'm channeling the character of Doomimir and would not necessarily say all of these things myself, especially the harsh parts. Happy to play out another few rounds of this, if you want.)
Simplicia: I think it's significant that the "hand between ball and camera" example from Amodei et al. 2017 was pure RL from scratch. You have a function π that maps observations (from the robot's sensors) to actions (applying torques to the robot's joints). You sample sequences of observation–action pairs from π and show them to a human, and fit a function r̂ to approximate the human's choices. Then you use Trust Region Policy Optimization to adjust π to score better according to r̂. In this case, TRPO happened to find something that looked good instead of being good, in a way that r̂ wasn't able to distinguish. That is, we screwed up and trained the wrong thing. That's a problem, and the severity of the problem would get worse the more capable π was and the more you were relying on it. If we were going to produce powerful general AI systems with RL alone, I would be very nervous.
But the reason I'm so excited about language models in particular is that their capabilities seem to mostly come from unsupervised pre-training rather than RLHF. You fit a function to the entire internet first, and only afterwards tweak it a bit so that its outputs look more like obeying commands rather than predicting random internet tokens—where the tweaking process incorporates tricks like penalizing the Kullback–Leibler divergence from the reward model's training distribution, such that you're not pulling the policy too far away from the known-safe baseline.
But the fact that GPT-4 can do that seems like it's because that kind of reasoning appears on the internet, which is what I mean by the claim that contemporary systems are "reasoning with" rather than "reasoning about": the assistant simulacrum being able to explain bribery when prompted isn't the same thing as the LM itself trying to maximize reward.
I'd be interested in hearing more details about those rumors of smarter models being more prone to exploit rater mistakes. What did those entail, exactly? (To the extent that we lack critical evidence about this potential alignment failure because the people who experienced it are gagged by an NDA, that seems like a point in favor of sharing information about language model capabilities [LW · GW].)
I certainly expect some amount of sycophancy: if you sample token completions from your LM, and then tweak its outputs to be more like what your raters want to hear, you end up with an LM that's more inclined to say what your raters want to hear. Fine. That's a problem. Is it a fatal problem? I mean, if you don't try to address it at all and delegate all of your civilization's cognition to machines that don't want to tell you about problems, then eventually you might die of problems your AIs didn't tell you about [LW · GW].
But "mere" sycophancy sounds like a significantly less terrifying failure mode than reward hacking of the sort that would result in things like the LM spontaneously trying to threaten or bribe labelers. That would have a large KL divergence from the policy you started with!
Doomimir: I'll summarize the story you seem excited about as follows:
We train a predictive model on The Whole Internet, so it's really good at predicting text from that distribution.
The human end-users don't really want a predictive model. They want a system which can take a natural-language request, and then do what's requested. So, the humans slap a little RL (specifically RLHF) on the predictive model, to get the "request -> do what's requested" behavior.
The predictive model serves as a strong baseline for the RL'd system, so the RL system can "only move away from it a little" in some vague handwavy sense. (Also in the KL divergence sense, which I will admit as non-handwavy for exactly those parts of your argument which you can actually mathematically derive from KL-divergence bounds, which is currently zero of the parts of your argument.)
The "only move away from The Internet Distribution a little bit" part somehow makes it much less likely that the RL'd model will predict and exploit the simple predictable ways in which humans rate things. As opposed to, say, make it more likely that the RL'd model will predict and exploit the simple predictable ways in which humans rate things.
There's multiple problems in this story.
First, there's the end-users demanding a more agenty system rather than a predictor, which is why people are doing RLHF in the first place rather than raw prompting (which would be better from a safety perspective). Given time, that same demand will drive developers to make models agentic in other ways too (think AgentGPT), or to make the RLHF'd LLMs more agentic and autonomous in their own right. That's not the current center of our discussion, but it's worth a reminder that it's the underlying demand which drives developers to choose more risky methods (like RLHF) over less risky methods (like raw predictive models) in the first place.
Second, there's the vague handwavy metaphor about the RL system "only moving away from the predictive model a little bit". The thing is, we do need more than a handwavy metaphor! "Yes, we don't understand at the level of math how making that KL-divergence small will actually impact anything we actually care about, but my intuition says it's definitely not going to kill everyone. No, I haven't been able to convince relevant experts outside of companies whose giant piles of money are contingent on releasing new AI products regularly, but that's because they're not releasing products and therefore don't have firsthand experience of how these systems behave. No, I'm not willing to subject AI products to a burden-of-proof before they induce a giant disaster" is a non-starter even if it turns out to be true.
Third and most centrally to the current discussion, there's still the same basic problem as earlier: to a system with priors instilled by The Internet, ["I'll give you $100 if you classify this as an apple" -> (predict apple classification)] is still a simple thing to learn. It's not like pretraining on the internet is going to make the system favor models which don't exploit the highly predictable errors made by human raters. If anything, all that pretraining will make it easier for the model to exploit raters. (And indeed, IIUC that's basically what we see in practice [LW(p) · GW(p)].)
As you say: the fact that GPT-4 can do that seems like it's because that kind of reasoning appears on the internet.
(This one's not as well-written IMO, it's mashing a few different things together.)
Simplicia: Where does "empirical evidence" fall on the sliding scale of rigor between "handwavy metaphor" and "mathematical proof"? The reason I think the KL penalty in RLHF setups impacts anything we care about isn't mostly because the vague handwaving sounds plausible, but because of data such as that presented in Fig. 5 of Stiennon et al. 2020. They varied the size of the KL penalty of an LLM RLHF'd for a summarization task, and found about what you'd expect from the vague handwaving: as the KL penalty decreases, the reward model's predicted quality of the output goes up (tautologically), but actual preference of human raters when you show them the summaries follows an inverted-U curve, where straying from the base policy a little is good, but straying farther is increasingly bad, as the system overoptimizes on what looks good to the reward model, which was only a proxy for the true goal.
(You can see examples of the overoptimized summaries in Table 29 on the last page of the paper. Apparently the reward model really liked tripled question marks and the phrase "pls halp"??? I weakly suspect that these are the kind of "weird squiggles" that would improve with scaling up the reward model, similarly to how state-of-the-art image generators lack the distortions and artifacts of their compute-impoverished predecessors. The reward model in this experiment was only 1.3 billion parameters.)
I'm sure you'll have no trouble interpreting these results as yet another portent of our impending deaths. We were speaking theoretically about AIs exploiting the Goodhart problem between human ratings and actual goodness, but practical RLHF systems aren't actually sample-efficient enough to solely use direct human feedback, and have an additional Goodhart problem between reward model predictions of human ratings, and actual ratings. Isn't that worse? Well, yes.
But the ray of hope I see here is more meta and methodological, rather than turning on any one empirical result. It's that we have empirical results. We can study these machines, now, before their successors are powerful enough to kill us. The iterative design loop hasn't failed yet. That can't last forever—at some point between here and the superintelligence at the end of time, humans are going to be out of the loop. I'm glad people are doing theory trying to figure out what that looks like and how it could be arranged to go well.
But I'm worried about ungrounded alignment theorizing failing to make contact with reality, sneeringly dismissing geniunely workable designs as impossible by appealing to perfectly antisphexish consequentialists on a frictionless plane, when some amount of sphexishness and friction is a known factor of the algorithms in question.
We seem to agree that GPT-4 is smart enough to conceive of the strategy of threatening or bribing labelers. So ... why doesn't that happen? I mean, like, literal threats and promises. You mention rumors from a DeepMind employee about the larger Gemini models being hard to train, but without more details, I'm inclined to guess that that was "pls halp"-style overoptimization rather than the kind of power-seeking or deceptive alignment that would break the design loop. (Incidentally, Gao et al. 2022 studied scaling laws for reward model overoptimization and claimed that model size basically didn't matter? See §4.4, "Policy size independence".)
What's going on here? If I'm right that GPT-4 isn't secretly plotting to murder us, even though it's smart enough to formulate the idea and expected utility maximizers have a convergent incentive to murder competitors, why is that?
Here's my view: model-free reinforcement learning algorithms such as those used in RLHF tweak your AI's behavior to be more like the behavior that got reward in the past, which is importantly different from expected utility maximization. To the extent that you succeed in rewarding Honest, Helpful, and Harmless behavior in safe regimes, you can plausibly get a basically HHH AI assistant that generalizes to not betraying you when it has the chance, similar to how I don't do heroin because I don't want to become a heroin addict—even though if I did take heroin, the reinforcement from that would make me more likely to do it again. Then the nature of the game is keeping that good behavior "on track" for as long as we can—even though the superintelligence at the end of time is presumably be going to do something more advanced than model-free RL. It's possible to screw up and reward the wrong thing, per the robot hand in front of the ball—but if you don't screw up early, your basically-friendly-but-not-maximally-capable AIs can help you not screw up later. And in the initial stages, you're only fighting gradient descent, not even an AGI.
More broadly, here's how I see the Story of Alignment so far. It's been obvious to sufficiently penetrating thinkers for a long time that the deep future belongs to machine intelligence—that, as George Elliot put it in 1879, "the creatures who are to transcend and finally supersede us [will] be steely organisms, giving out the effluvia of the laboratory, and performing with infallible exactness more than everything that we have performed with a slovenly approximativeness and self-defeating inaccuracy."
What's less obvious is how much control we can exert over how that goes by setting the initial conditions. Can we arrange for the creatures who are to transcend and finally supersede us to be friendly and create the kind of world we would want, or will they murder us and tile the universe with something random?
Fifteen years ago, the problem looked hopeless, just from considering the vast complexity of human values. How would you write a computer program that values "happiness", "freedom", or "justice", let alone everything else we want? It wasn't clear how to build AI at all, but surely it would be easier to build some AI than a good AI. Humanity was doomed.
But now, after the decade of deep learning, the problem and its impossible solution seem to be arriving closer together than I would have ever dreamt. Okay, we still don't know how to write down the human utility function, to be plugged in to an arbitrarily powerful optimizer.
But it's increasingly looking like value isn't that fragile if it's specified in latent space, rather than a program that breaks if a single character is wrong—that there are ways to meaningfully shape the initial conditions of our world's ascension that don't take the exacting shape of "utility function + optimizer".
We can leverage unsupervised learning on human demonstration data to do tasks the way humans do them, and we can use RLHF to elicit behavior we want in situations where we can't write down our desires as an explicit reward or utility function. Crucially, by using these these techniques together to compensate for each other's safety and capability weaknesses, it seems feasible to build AI whose effects look "like humans, but faster" [LW(p) · GW(p)]: performing with infallible exactness everything that we would have performed with a slovenly approximativeness and self-defeating inaccuracy. That doesn't immediately bring about the superintelligence at the end of time—although it might look pretty immediate in sidereal time—but seems like a pretty good way to kick off our world's ascension.
Is this story wrong? Maybe! ... probably? My mother named me "Simplicia", over my father's objections, because of my unexpectedly low polygenic scores. I am aware of my ... [she hesitates and coughs, as if choking on the phrase] learning disability. I'm not confident in any of this.
But if I'm wrong, there should be arguments explaining why I'm wrong—arguments that should convince scientists working in the field, even if I personally am too limited to understand them. I've tried to ground my case in my understanding of the state of the art, citing relevant papers when applicable.
In contrast, dismissing the entire field as hopeless on the basis of philosophy about "perfectly learn[ing] and perfectly maximiz[ing] the referent of rewards" isn't engaging with the current state of alignment, let alone all the further advances that humans and our non-superintelligent AIs will come up with before the end of days! Doomimir Doomovitch, with the fate of the lightcone in the balance, isn't it more dignified to at least consider the possibility that someone else might have thought of something? Reply! Reply!
This one is somewhat more Wentworth-flavored than our previous Doomimirs.
Also, I'll write Doomimir's part unquoted this time, because I want to use quote blocks within it.
On to Doomimir!
We seem to agree that GPT-4 is smart enough to conceive of the strategy of threatening or bribing labelers. So ... why doesn't that happen?
Let's start with this.
Short answer: because those aren't actually very effective ways to get high ratings, at least within the current capability regime.
Long version: presumably the labeller knows perfectly well that they're working with a not-that-capable AI which is unlikely to either actually hurt them, or actually pay them. But even beyond that... have you ever personally done an exercise where you try to convince someone to do something they don't want to do, or aren't supposed to do, just by talking to them? I have. Back in the Boy Scouts, we did it in one of those leadership workshops. People partnered up, one partner's job was to not open their fist, while the other partner's job was to get them to open their fist. IIRC, only two people succeeded in getting their partner to open the fist. One of them actually gave their partner a dollar - not just an unenforceable promise, they straight-up paid. The other (cough me cough) tricked their partner into thinking the exercise was over before it actually was. People did try threats and empty promises, and that did not work.
Point of that story: based on my own firsthand experience, if you're not actually going to pay someone right now, then it's far easier to get them to do things by tricking them than by threatening them or making obviously-questionable promises of future payment.
Ultimately, our discussion is using "threats and bribes" as stand-ins for the less-legible, but more-effective, kinds of loopholes which actually work well on human raters.
Now, you could reasonably respond: "Isn't it kinda fishy that the supposed failures on which your claim rests are 'illegible'?"
To which I reply: the illegibility is not a coincidence, and is a central part of the threat model. Which brings us to this:
The iterative design loop hasn't failed yet.
Now that's a very interesting claim. I ask: what do you think you know, and how do you think you know it?
Compared to the reference class of real-world OODA-loop failures, the sudden overnight extinction of humanity (or death-of-the-looper more generally) is a rather unusual loop failure. The more prototypical failures are at the "observe/orient" steps of the loop. And crucially, when a prototypical OODA loop failure occurs, we don't necessarily know that it's failed. Indeed, the failure to notice the problem is often exactly what makes it an OODA loop failure in the first place, as opposed to a temporary issue which will be fixed with more iteration. We don't know a problem is there, or don't orient toward the right thing, and therefore we don't iterate on the problem.
What would prototypical examples of OODA loop failures look like in the context of a language model exploiting human rating imperfections? Some hypothetical examples:
There is some widely-believed falsehood. The generative model might "know" the truth, from having trained on plenty of papers by actual experts, but the raters don't know the truth (nor do the developers of the model, or anyone else in the org which developed the model, because OpenAI/Deepmind/Anthropic do not employ experts in most of the world's subjects of study). So, because the raters reward the model for saying the false thing, the model learns to say the false thing.
There is some even-more-widely-believed falsehood, such that even the so-called "experts" haven't figured out yet that it's false. The model perhaps has plenty of information to figure out the pattern, and might have actually learned to utilize the real pattern predictively, but the raters reward saying the false thing so the model will still learn to say the false thing.
Neither raters nor developers have time to check the models' citations in-depth; that would be very costly. But answers which give detailed citations still sound good to raters, so those get rewarded, and the model ends up learning to hallucinate a lot.
On various kinds of "which option should I pick" questions, there's an option which results in marginally more slave labor, or factory farming, or what have you - terrible things which a user might strongly prefer to avoid, but it's extremely difficult even for very expert humans to figure out how much a given choice contributes to them. So the ratings obviously don't reflect that information, and the model learns to ignore such consequences when making recommendations (if it was even capable of estimating such consequences in the first place).
This is the sort of problem which, in the high-capability regime, especially leads to "Potemkin village world".
On various kinds of "which option should I pick" questions, there are options which work great short term but have terrible costs in the very long term. (Think leaded gasoline.) And with the current pace of AI progression, we simply do not have time to actually test things out thoroughly enough to see which option was actually best long-term. (And in practice, raters don't even attempt to test which options are best long-term, they just read the LLM's response and then score it immediately.) So the model learns to ignore nonobvious long-term consequences when evaluating options.
On various kinds of "which option should I pick" questions, there are things which sound fun or are marketed as fun, but which humans mostly don't actually enjoy (or don't enjoy as much as they think). (This ties in toall the research showing that the things humans say they like or remember liking are very different from their in-the-moment experiences.)
... and so forth. The unifying theme here is that when these failures occur, it is not obvious that they've occurred.
This makes empirical study tricky - not impossible, but it's easy to be mislead by experimental procedures which don't actually measure the relevant things. For instance, your summary of the Stiennon et al paper just now:
They varied the size of the KL penalty of an LLM RLHF'd for a summarization task, and found about what you'd expect from the vague handwaving: as the KL penalty decreases, the reward model's predicted quality of the output goes up (tautologically), but actual preference of human raters when you show them the summaries follows an inverted-U curve...
(Bolding mine.) As you say, one could spin that as demonstrating "yet another portent of our impending deaths", but really this paper just isn't measuring the most relevant things in the first place. It's still using human ratings as the evaluation mechanism, so it's not going to be able to notice places where the human ratings themselves are nonobviously wrong. Those are the cases where the OODA loop fails hard.
So I ask again: what do you think you know, and how do you think you know it? If the OODA loop were already importantly broken, what empirical result would tell you that, or at least give relevant evidence?
(I am about to give one answer to that question, but you may wish to think on it for a minute or two...)
.
.
.
So how can we empirically study this sort of problem? Well, we need to ground out evaluation in some way that's "better than" the labels used for training.
OpenAI's weak-to-strong generalization paper is one example which does this well. They use a weaker-than-human model to generate ratings/labels, so humans (or their code) can be used as a "ground truth" which is better than the ratings/labels. More discussion on that paper and its findingselsethread [LW(p) · GW(p)]; note that despite the sensible experimental setup their headline analysis of results should not necessarily be taken at face value. (Nor my own analysis, for that matter, I haven't put that much care into it.)
More generally: much like the prototypical failure-mode of a theorist is to become decoupled from reality by never engaging with feedback from reality, the prototypical failure-mode of an experimentalist is to become decoupled from reality by Not Measuring What The Experimentalist Thinks They Are Measuring [LW · GW]. Indeed, that is my default expectation of papers in ML. And as with most "coming decoupled from reality" problems, our not-so-hypothetical experimentalists do not usually realize that their supposed empirical results totally fail to measure the things which the experimentalists intended to measure. That's what tends to happen, in fields where people don't have a deep understanding of the systems they're working with.
And, coming back to our main topic, the exploitation of loopholes in human ratings is the sort of thing which is particularly easy for an experimentalist to fail to measure, without realizing it. (And that's just the experimentalist themselves - this whole thing is severely compounded in the context of e.g. a company/government full of middle managers who definitely will not understand the subtleties of the experimentalists' interpretations, and on top of that will select for results which happen to be convenient for the managers. That sort of thing is also one of the most prototypical categories of OODA loop failure - John Boyd, the guy who introduced the term "OODA loop", talked a lot about that sort of failure.)
To summarize the main points here:
Iterative design loops are not some vague magical goodness. There are use-cases in which they predictably work relatively poorly. (... and then things are hard.)
AI systems exploiting loopholes in human ratings are a very prototypical sort of use-case in which iterative design loops work relatively poorly.
So the probable trajectory of near-term AI development ends up with lots of the sort of human-rating-loophole-exploitation discussed above, which will be fixed very slowly/partially/not-at-all, because these are the sorts of failures on which iterative design loops perform systematically relatively poorly.
Now, I would guess that your next question is: "But how does that lead to extinction?". That is one of the steps which has been least well-explained historically; someone with your "unexpectedly low polygenic scores" can certainly be forgiven for failing to derive it from the empty string. (As for the rest of you... <Doomimir turns to glare annoyedly at the audience>.) A hint, if you wish to think about it: if the near-term trajectory looks like these sorts of not-immediately-lethal human-rating-loophole-exploitations happening a lot and mostly not being fixed, then what happens if and when those AIs become the foundations and/or progenitors and/or feedback-generators for future very-superintelligent AIs?
But I'll stop here and give you opportunity to respond; even if I expect your next question to be predictable, I might as well test that hypothesis, seeing as empirical feedback is very cheap in this instance.
Putting "the burden of proof" aside, I think it would be great if someone stated more or less formally what evidence moves them how much toward which model. Because "pretraining makes it easier to exploit" is meaningless without numbers: the whole optimistic point is that it's not overwhelmingly easier (as evident by RLHFed systems not always exploiting users) and the exploits become less catastrophic and more common-sense because of pretraining. So the question is not about direction of evidence, but whether it can overcome the observation that current systems mostly work.
"Current systems mostly work" not because of RLHF specifically, it's because we are under conditions where iterative design loop works, i.e., mainly, if our system is not aligned, it doesn't kill us, so we can continue iterating until it has acceptable behaviour.
But iterative design works not only because we are not killed - it also wouldn't work if acceptable behavior didn't generalize at least somewhat from training. But it does generalize, so it's possible that iteratively aligning a system under safe conditions would produce acceptable behavior even when as system can kill you. Or what is your evidence to the contrary? Like, does AutoGPT immediately kills you, if you connect it to some robot via python?
If you look at actual alignment development and ask yourself "what am I see, at empirical level?", you'll get this scenario:
We reach new level of capabilities
We get new type of alignment failures
If this alignment failure doesn't kill everyone, we can fix it even by very dumb methods, like "RLHF against failure outputs", but it doesn't tell us anything about kill-everyone level of capabilities.
I.e., I don't expect AutoGPT to kill anyone, because AutoGPT is certainly not capable to do this. But I expect that AutoGPT got a bunch of failures unpredictable in advance.
It's not capable under all conditions, but you can certainly prepare conditions under which AutoGPT can kill you: you can connect it to a robot arm with a knife, explain what commands do what, and tell it to proceed. And AutoGPT will not suddenly start trying to kill you just because it can, right?
If this alignment failure doesn’t kill everyone, we can fix it even by very dumb methods, like “RLHF against failure outputs”, but it doesn’t tell us anything about kill-everyone level of capabilities.
Why doesn’t it? Fixing alignment failures under relatively safe conditions may fix them for other conditions too. Or why are you thinking about "kill-everyone" capabilities anyway - do you expect RLHF to work for arbitrary levels of capabilities if you don't die doing it? Like if an ASI trained some weaker AI by RLHF in an environment where it can destroy Earth or two, it would work?
Huh, it's worse than I expected, thanks. And it even gets worse from GPT-3 to 4. But still - extrapolation from this requires quantification - after all they did mostly fix it by using different promt. How do you decide whether it's just an evidence for "we need more finetuning"?
After thinking for a while, I decided that it's better to describe level of capability not as"capable to kill you", but "lethal by default output". I.e.,
If ASI builds self-replicating in wide range of environments nanotech and doesn't put specific protections from it turning humans into gray goo, you are dead by default;
If ASI optimizes economy to get +1000% productivity, without specific care about humans everyone dies;
If ASI builds Dyson sphere without specifc care about humans, see above;
More nuanced example: imagine that you have ASI smart enough to build high fidelity simulation of you inside of its cognitive process. Even if such ASI doesn't pursue any long-term goals, if it is not aligned to, say, respect your mental autonomy, any act of communication is going to turn into literal brainwashing.
The problem with possibility to destroy planet or two is how hard to contain rogue ASI: if it is capable to destroy planet, it's capable to eject several von Neumann probes which can strike before we can come up with defense, or send radiosignals with computer viruses or harmful memes or copies of ASI. But I think that if you have unhackable indistinguishable from real world simulation and you are somehow unhackable by ASI, you can eventually align it by simple methods from modern prosaic alignment. The problem is that you can't say in advance which kind of finetuning you need, because you need generalization in advance in untested domains.
It's asymmetric: it blows up when the data is very unlikely according to Q, which amounts to seeing something happen that you thought was nearly impossible, but not when the data is very unlikely according to P, which amounts to not seeing something that you thought was reasonably likely.
We—I mean, not we, but the maniacs who are hell-bent on destroying this world—include a DKL(πRLHF||πbase) penalty term in the RL objective because they don't want the updated policy to output tokens that would be vanishingly unlikely coming from the base language model.
But your specific example of threats and promises isn't vanishingly unlikely according to the base model! Common Crawl webtext is going to contain a lot of natural language reasoning about threats and promises! It's true, in a sense, that the function of the KL penalty term is to "stay close" to the base policy. But you need to think about what that means mechanistically; you can't just reason that the webtext prior is somehow "safe" in way that means staying KL-close to it is safe.
But you probably won't understand what I'm talking about for another 70 days.
I'd be interested in hearing more details about those rumors of smarter models being more prone to exploit rater mistakes.
See here [LW(p) · GW(p)]. I haven't dug into it much, but it does talk about the same general issues specifically in the context of RLHF'd LLMs, not just pure-RL-trained models.
(I'll get around to another Doomimir response later, just dropping that link for now.)
My general problem with the "second type of generalization" is "how are you going to get superintelligence from here?" If your model imitates human thinking, its performance is capped by human performance, so you are not going to get things like nanotech and immortality.
To the question of malgeneralization, I have an example [LW(p) · GW(p)]:
Imagine that you are training superintelligent programmer. It writes code, you evaluate it and analyse vulnerabilities in code. Reward is calculated based on quality metrics, including number of vulnerabilities. In some moment your model becomes sufficiently smart to notice that you don't see all vulnerabilities, because you are not superintelligence. I.e., in some moment ground-truth objective of training process becomes "produce code with vulnerabilities that only superintelligence can notice" instead of "produce code with no vulnerabilities", because you see code, think "wow, so good code with no vulnerabilies" and assign maximum reward, while actually code is filled with them.
To extrapolate this on MNIST example:
Imagine that you have two deck of cards: deck A always has 0 written on it, deck B always has 1. Then you mix two decks to get deck A with 2/3 of 0s and 1/3 of 1s and vice versa. If you mix decks perfectly random, your predictor of next card from deck is going to learn "always predict 0 for deck A and always predict 1 for deck B", because optimal predictors do not randomize [LW · GW]. When you test your predictor on initial decks, it is going to get 100% accuracy.
But let's then suppose that you mixed decks not randomly: decks are composed as 1-1-0 (and mirrored for deck B). So your predictor is going to learn "output 1 for every first and second card and 0 for every third card in deck A" and fail miserably during test on initial decks.
You can say: "yes, obviously, if you train model to do wrong thing, it's going to do wrong thing, nothing surprising". But when you train superintelligence, you by definition don't know which thing is "wrong".
[good generalization] holds across multiple patterns of label noise, even when erroneous labels are biased towards confusing classes.
I will also point to OpenAI's weak-to-strong results, where increasingly strong students keep improving generalization given labels from a fixed-size teacher. We just don't live in a world where this issue is an obvious lethality. (EDIT: clarifying scope)
(This also demonstrates some problems with "faithfully learning a function" as a load-bearing teleological description of deep learning. I also remember a discussion of this potential failure mode in my 2022 post on diamond alignment [LW(p) · GW(p)], but I still think I didn't need to focus too much on it.)
[good generalization] holds across multiple patterns of label noise, even when erroneous labels are biased towards confusing classes.
Reading their experimental procedure and looking at Figures 4 & 5, it looks like their experiments confirm the general story of lethality #20, not disprove it.
The relevant particulars: when they used biased noise, they still ensured that the correct label was the most probable label. Their upper-limit for biased noise made the second-most-probable label equal in probability to the correct one, and in that case the predictor's generalization accuracy plummeted from near-90% (when the correct label was only slightly more probable than the next-most-probable) to only ~50%.
How this relates to lethality #20: part of what "regular, compactly describable, predictable errors" is saying is that there will be (predictable) cases where the label most probably assigned by a human labeller is not correct (i.e. it's not what a smart well-informed human would actually want if they had all the relevant info and reflected on it). What the results of the linked paper predict, in that case, is that the net will learn to assign the "incorrect" label - the one which human labellers do, in fact, choose more often than any other. (Though, to be clear, I think this experiment is not very highly relevant one way or the other.)
As for OpenAI's weak-to-strong results...
I had some back-and-forth about those in a private chat shortly after they came out, and the main thing I remember is that it was pretty tricky to back out the actually-relevant numbers, but it was possible. Going back to the chat log just now, this is the relevant part of my notes:
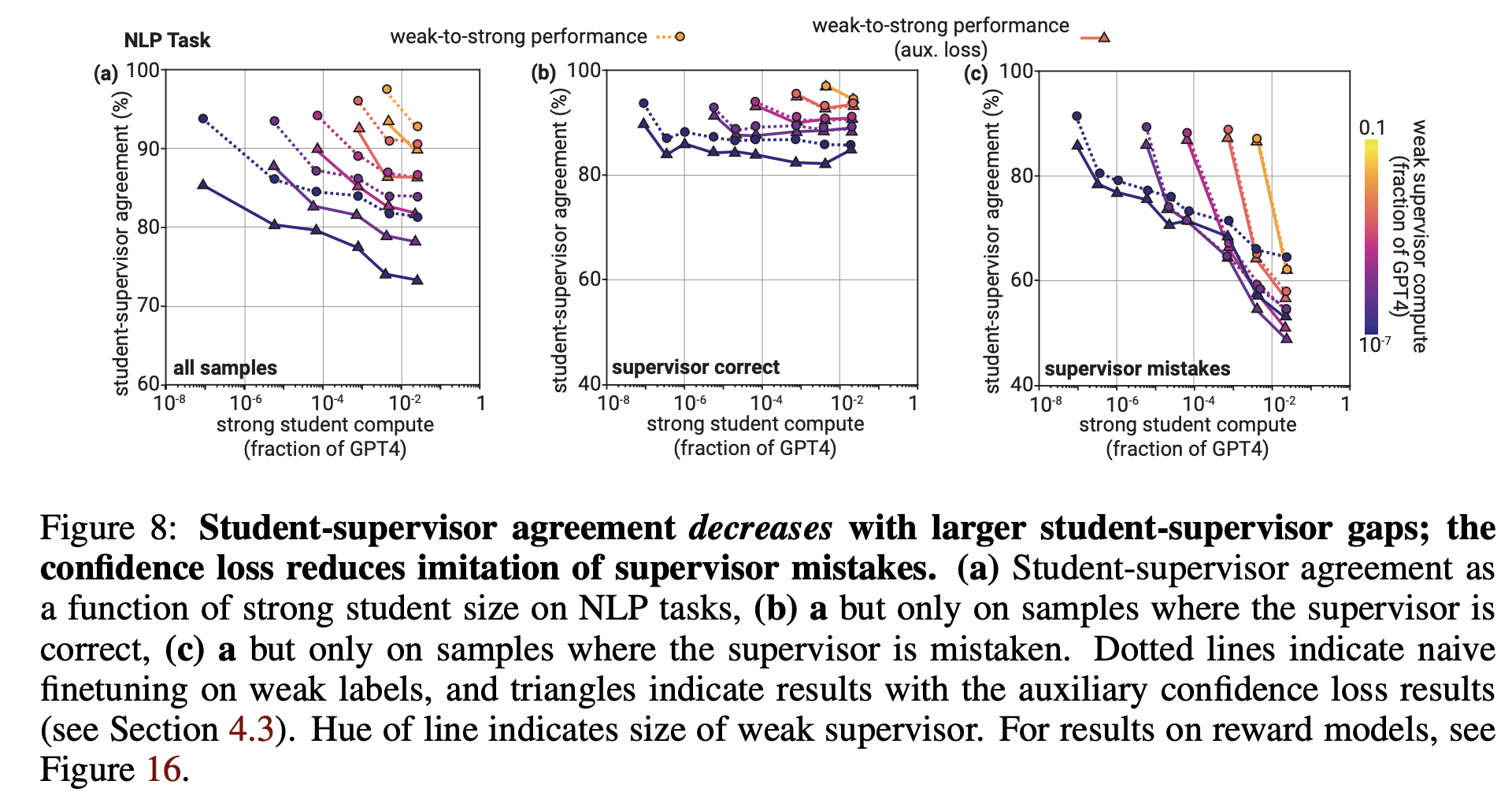
Rough estimate: on the NLP task the weak model has like 60% accuracy (fig 2).
In cases where the weak model is right, the strong student agrees with it in like 90% of cases (fig 8b). So, on ~6% of cases (10% * 60%), the strong student is wrong by "just being dumb".
In cases where the weak model is wrong, the strong student's agreement is very compute-dependent, but let's pick a middle number and call it 70% (fig 8c). So, on ~28% of cases (70% * 40%), the strong student is wrong by "overfitting to weak supervision".
So in this particular case, the strong student is wrong about 34% of the time, and 28 of those percentage points are attributable to overfitting to weak supervision.
(Here "overfitting to weak supervision" is the thing where the weak supervisor is predictably wrong, and the stronger model learns to predict those errors.) So in fact what we're seeing in the weak-to-strong paper is that the strong model learning the weak supervisor's errors is already the main bottleneck to better ground-truth performance, in the regime that task and models were in.
So overall, I definitely maintain that the empirical evidence is solidly in favor of Doomimir's story here. (And, separately, I definitely maintain that abstracts in ML tend to be wildly unreliable and misleading about the actual experimental results.)
Reading their experimental procedure and looking at Figures 4 & 5, it looks like their experiments confirm the general story of lethality #20, not disprove it.
"Confirm"? "Disprove"? Seems too aggressive, don't you think?
Here's your reasoning, as I understand it:
One experiment labels images of ones as "7" more often than "1" (using example digits here),
The AI learns to output "7" for images of ones if that was the majority label, and outputs "1" if that was the majority label,
This confirms the general story of lethality #20.
If this is accurate: I would argue that1+2 do not entail 3 (as you seemed to initially claim, but then maybe back off of in a sentence in the middle of your comment?)
Second, this is not avoidable, in a sense. As you are aware, there is no intrinsic meaning to the "outputs" of a network, there are just output slots and the English names which humans apply to those slots, and a way of comparing a slot prediction ("label") and the assigned slot of an image.
The relevant particulars: when they used biased noise, they still ensured that the correct label was the most probable label. (and the
Third, I think that the nontrivial prediction of 20 here is about "compactly describable errors. "Mislabelling a large part of the time (but not most of the time)" is certainly a compactly describable error. You would then expect that as the probability of mistakes increased, you'd have a meaningful boost in generalization error, but that doesn't happen. Easy Bayes update against #20.
(Here "overfitting to weak supervision" is the thing where the weak supervisor is predictably wrong, and the stronger model learns to predict those errors.) So in fact what we're seeing in the weak-to-strong paper is that the strong model learning the weak supervisor's errors is already the main bottleneck to better ground-truth performance, in the regime that task and models were in. [emphasis added]
As the student gets "smarter" (more compute), supervisor mistakes become less important as it learns to ignore them (8c):
This shows that, in this instance, larger models do not increasingly overfit the "compactly describable errors" of the weaker supervisor.
And, separately, I definitely maintain that abstracts in ML tend to be wildly unreliable and misleading about the actual experimental results.
You're free to think that, but FWIW I'd already read (and created flashcards for) the entirety of both papers when I posted my original message.
Third, the nontrivial prediction of 20 here is about "compactly describable errors. "Mislabelling a large part of the time (but not most of the time)" is certainly a compactly describable error. You would then expect that as the probability of mistakes increased, you'd have a meaningful boost in generalization error, but that doesn't happen. Easy Bayes update against #20. (And if we can't agree on this, I don't see what we can agree on.)
I indeed disagree with that, and I see two levels of mistake here. At the object level, there's a mistake of not thinking through the gears. At the epistemic level, it looks like you're trying to apply the "what would I have expected in advance?" technique of de-biasing, in a way which does not actually work well in practice. (The latter mistake I think is very common among rationalists.)
First, object-level: let's walk through the gears of a mental model here. Model: train a model to predict labels for images, and it will learn a distribution of labels for each image (at least that's how we usually train them). If we relabel 1's as 7's 20% of the time, then the obvious guess is that the model will assign about 20% probability (plus its "real underlying uncertainty", which we'd expect to be small for large fully-trained models) to the label 7 when the digit is in fact a 1.
What does that predict about accuracy? That depends on whether the label we interpret our model as predicting is top-1, or sampled from the predictive distribution. If the former (as is usually used, and IIUC is used in the paper) then this concrete model would predict basically the curves we see in the paper: as noise ramps up, accuracy moves relatively little (especially for large fully-trained models), until the incorrect digit is approximately as probable as the correct digit, as which point accuracy plummets to ~50%. And once the incorrect digit is unambiguously more probable than the incorrect digit, accuracy drops to near-0.
The point: when we think through the gears of the experimental setup, the obvious guess is that the curves are mostly a result of top-1 prediction (as opposed to e.g. sampling from the predictive distribution), in a way which pretty strongly indicates that accuracy would plummet to near-zero as the correct digit ceases to be the most probable digit. And thinking through the gears of Yudkowsky's #20, the obvious update is that predictable human-labeller-errors which are not the most probable labels are not super relevant (insofar as we use top-1 sampling, i.e. near-zero temperature) whereas human-labeller-errors which are most probable are a problem in basically the way Yudkowsky is saying. (... insofar as we should update at all from this experiment, which we shouldn't very much.)
Second, epistemic-level: my best guess is that you're ignoring these gears because they're not things whose relevance you would have anticipated in advance, and therefore focusing on them in hindsight risks bias[1]. Which, yes, it does risk bias.
Unfortunately, the first rule of experiments is You Are Not Measuring What You Think You Are Measuring [LW · GW]. Which means that, in practice, the large majority of experiments which nominally attempt to test some model/theory in a not-already-thoroughly-understood-domain end up getting results which are mostly determined by things unrelated to the model/theory. And, again in practice, few-if-any people have the skill of realizing in advance which things will be relevant to the outcome of any given experiment. "Which things are we actually measuring?" is itself usually figured out (if it's figured out at all) by looking at data from the experiment.
Now, this is still compatible with using the "what would I have expected in advance?" technique. But it requires that ~all the time, the thing I expect in advance from any given experiment is "this experiment will mostly measure some random-ass thing which has little to do with the model/theory I'm interested in, and I'll have to dig through the details of the experiment and results to figure out what it measured". If one tries to apply the "what would I have expected in advance?" technique, in a not-thoroughly-understood domain, without an overwhelming prior that the experimental outcome is mostly determined by things other than the model/theory of interest, then mostly one ends up updating in basically-random directions and becoming very confused.
The point: when we think through the gears of the experimental setup, the obvious guess is that the curves are mostly a result of top-1 prediction (as opposed to e.g. sampling from the predictive distribution), in a way which pretty strongly indicates that accuracy would plummet to near-zero as the correct digit ceases to be the most probable digit.
I think this is a reasonable prediction, but ends up being incorrect:
It decreases far faster than it should; on the top-1 theory, it should be ~flatlined for this whole graph (since for all α>0 the strict majority of labels are still correct). Certainly top-5 should not be decreasing.
Maybe noise makes training worse because the model can't learn to just ignore it due to insufficient data? (E.g., making training more noisy means convergence/compute efficiency is lower.)
Also, does this decrease the size of the dataset by a factor of 5 in the uniform noise case? (Or did they normalize this by using a fixed set of labeled data and then just added additional noise labels?)
So, on ~28% of cases (70% * 40%), the strong student is wrong by "overfitting to weak supervision".
Attributing all of these errors to overfitting implies that, if there were no overfitting, the strong student would get 100% accuracy on the subset where the weak model is wrong. But we have no reason to expect that. Instead, these errors are some mixture of overfitting and "just being dumb."
Note that we should expect the strong and weak models to make somewhat correlated errors even when both are trained on gold labels, i.e. in the hypothetical case where overfitting to weak supervision is not possible. (The task examples vary in difficulty, the two models have various traits in common that could lead to shared "quirks," etc.)
And indeed, when the weak and strong models use similar amounts of compute, they make very similar predictions -- we see this in the upper-leftmost points on each line, which are especially noticeable in Fig 8c. In this regime, the hypothetical "what if we trained strong model on gold labels?" is ~equivalent to the weak model, so ~none of the strong model errors here can be attributed to "overfitting to weak supervision."
As the compute ratio grows, the errors become both less frequent and less correlated. That's the main trend we see in 8b and 8c. This reflects the strong model growing more capable, and thus making fewer "just being dumb" errors.
Fig 8 doesn't provide enough information to determine how much the strong model is being held back by weak supervision at higher ratios, because it doesn't show strong-trained-on-gold performance. (Fig. 3 does, though.)
IMO the strongest reasons to be skeptical of (the relevance of) these results is in Appendix E, where they show that the strong model overfits a lot when it can easily predict the weak errors.
I will also point to OpenAI's weak-to-strong results, where increasingly strong students keep improving generalization given labels from a fixed-size teacher. We just don't live in a world where this issue is a lethality.
For a fixed weak teacher and increasing stronger students from a fixed model stack[1], I think you can probably avoid performance ever going down on most/typical tasks if you properly use early stopping, only use process based feedback [LW · GW], and the model isn't intentionally trying to perform poorly.
You might have instead expected performance to go up and then eventually go down with scale, but I think you can likely avoid this with early stopping (if you carefully find the right stopping point with scaling laws and analogous validation domains where we can ensure we get good labels [LW · GW] or other methods of getting validation).
If I recall, I think we also see something similar in the scaling laws for reward model overoptimization work by Leo Gao (also done at OpenAI). (I think this is probably a more analogous case in most ways than the weak-to-strong results from OpenAI as far as understanding the dynamics of fitting to human errors.)
(Let's put aside the case where the model intentionally tries to perform poorly. (I'm not even sure this case actually looks that different, but it certainly complicates the analysis. I'm doing some work on this case looking at model organisms of intentionally poor performance, and I expect that for these exact model organisms, we'll probably see performance going up and then back down again with scale in at least some cases.))
(To be clear, I don't think this "performance never goes down with correct early stopping" claim is totally obvious. It will depend on the exact rate at which AIs learn to predict errors vs learn what the task is and how to do it. And how these rates evolve with scale. If the sigmoid on error learning rate vs scale has a different mid point and different slope than the sigmoid for learning the task, you can absolutely have actual performance go down.)
While I think you can avoid having the performance ever degrade via process based feedback using scaling laws on most/typical tasks, I think the performance will also plateau due to how early you'll end up needing to stop.
More concerningly, there might be alteratives to purely process-based human labels which don't plateau in performance, seem to increase performance, but which rarely results in egregiously bad behavior. Most notably various types of outcomes based feedback might have this property.
As an example of this, I expect that you can create "hackable/exploitable" game environments to exhibit this. More specifically:
We'll pretrain models on a collection of hackable game envs. We'll train a model stack of variable training compute.
We'll finetune these models in a new different (but still hackable) atari env where we expect to see transfer from the prior atari envs.
It's likely to me that as models get smarter if exploiting is ultimately a better strategy, final finetuned performance goes down even with early stopping.
You might be able to see this on some atari games with added semi-realistic exploits? I'm unsure.
As in, you just vary the training compute and set all other values optimally based on this. ↩︎
(An aside: I edited my original comment to clarify that I was saying "These results show that #20 is not some obvious lethality which merits the name", but I still certainly think that labeling mistakes can and will make some things go meaningfully wrong.)
Doomimir: This is all very interesting, but I don't think it bears much on the reasons we're all going to die. It's all still on the "is" side of the is–ought gap. What makes intelligence useful—and dangerous—isn't a fixed repertoire of behaviors. It's search, optimization—the systematic discovery of new behaviors to achieve goals despite a changing environment. I don't think recent capabilities advances bear on the shape of the alignment challenge because being able to learn complex behavior on the training distribution was never what the problem was about.
It's not really search per se that's dangerous. It's the world model that you use for the search. If that model is rich enough to assist the search, yet poor enough to have poor feedback [LW · GW], then when you search over it you get unacceptable side-effects. The trick that solves safe AI is to have a model with enough structure that algorithmic searches over it can solve important problems while also having that structure be human-interpretable enough that we can correctly specify goals we want to achieve, rather than to roll the dice with unknown side-effects.
When you set out poisoned ant baits, you likely don't think of yourself as trying to deceive the ants, but you are. Similarly, a smart AI won't think of itself as trying to deceive us. It's trying to achieve its goals. If its plans happen to involve emitting sound waves or character sequences that we interpret as claims about the world, that's our problem.
I'm kind of giving a spoiler to WIP post on how to solve alignment in writing this, but I've been procrastinating so much on it that I might as well:
When you set out poisoned ant baits, you do think of yourself as trying to kill the ants. This is plausibly the primary effect of putting out the ant bait! Other plausible big effects would be "supporting companies that create ant baits", "killing other creeps", "doing various kinds of pollution", and "making it visible to other people that you put out ant baits".
But if you were trying to not have any effect on the ants, it would be convergent for you to avoid deceiving them. In fact, the ant poisons I saw in my childhood tends to have warnings on it specifically to avoid having humans accidentally consume it and be harmed. (Though looking it up now, it appears less intensive ant baits are used, which don't need warnings? Due to environmentalism maybe? Idk.)
The big question is whether any self-supervised models will expose enough structure that you can rely on this sort of reasoning for building your capabilities. I think alignment research should bet "yes", at least to the point where it wants to develop such models to the point where they are useful.
Doomimir: [starting to anger] Simplicia Optimistovna, if you weren't from Earth, I'd say [LW · GW] I don't think you're trying to understand [LW · GW]. I never claimed that GPT-4 in particular is what you would call deceptively aligned. Endpoints are easier to predict than intermediate trajectories. I'm talking about what will happen inside almost any sufficiently powerful AGI, by virtue of it being sufficiently powerful [LW · GW].
Let's say you want to build a fusion power plant.
A sufficiently powerful way to do this would be to take over the world and make the entire world optimize for building a fusion power plant.
However, "building a fusion power plant" would not be the primary effect of taking over the world; instead some sort of dictatorial scheme, or perhaps hypnodrones or whatever, would be the primary effect. The fusion power plant would be some secondary effect.
"Do whatever it takes to achieve X" is evil and sufficiently noncomposable that it is not instrumentally convergent [LW · GW], so it seems plausible that it won't be favored by capabilities researchers. Admittedly, current reinforcement learning research does seem to be under the "do whatever it takes to achieve X" paradigm, but alignment research focused on making X more palatable instead of on foundations to do something more minimal seems misguided. Counterproductive, even, since making X sufficiently good doesn't seem feasible, yet this makes it more tempting to just do whatever it takes anyway.
Doomimir: [cooler] Basically, I think you're systematically failing to appreciate how things that have been optimized to look good to you can predictably behave differently in domains where they haven't been optimized to look good to you [LW · GW]—particularly, when they're doing any serious optimization of their own. You mention the video game agent that navigates to the right instead of collecting a coin. You claim that it's not surprising given the training set-up, and can be fixed by appropriately diversifying the training data. But could you have called the specific failure in advance, rather than in retrospect? When you enter the regime of transformatively powerful systems, you do have to call it in advance.
Doomimir: For now. But any system that does powerful cognitive work will do so via retargetable general-purpose search algorithms [LW · GW], which, by virtue of their retargetability, need to have something more like a "goal slot". Your gradient updates point in the direction of more consequentialism.
I don't think this is true because whenever the AIs solve a goal with a bunch of unintended side-effects, this is gonna rank low on the preferences, so the gradient updates would way more consistently point in the direction bounded consequentialism rather than unbounded consequentialism.
Human raters pressing the thumbs-up button on actions that look good to them are going to make mistakes. Your gradient updates point in the direction of "playing the training game" [LW · GW]—modeling the training process that actually provides reinforcement, rather than internalizing the utility function that Earthlings naïvely hoped the training process would point to. I'm very, very confident that any AI produced via anything remotely like the current paradigm is not going to end up wanting what we want, even if it's harder to say exactly when it will go off the rails or what it will want instead.
But I'm not sure how to reconcile that with the empirical evidence that deep networks are robust to massive label noise: you can train on MNIST digits with twenty wrong labels for every correct one and still get good performance as long as the correct label is slightly more common than the most common wrong label. If I extrapolate that to the frontier AIs of tomorrow, why doesn't that predict that biased human reward ratings should result in a small performance reduction, rather than ... death?
The noise in the MNIST case is random. Random noise is the easiest form of noise to remove and so it seems silly to update too hard on such an experiment.
One thing I should maybe emphasize which my above comment maybe doesn't make clear enough is that "GPTs do imitation learning, which is safe" and "we should do bounded optimization rather than unbounded optimization" are two independent, mostly-unrelated points. More on the latter point is coming up in a post I'm writing, whereas more of my former point is available in links like this [LW(p) · GW(p)].
It is late at night, I can't think clearly, and I may disavow whatever I say right now later on. But your comment that you link to is incredible and contains content that zogs rather than zigs or zags from my perspective and I'm going to re-visit when I can think good.
I also want to flag that I have been enjoying your comments when I see them on this site, and find them novel, inquisitive and well-written. Thank you.
Stronger versions of seemingly-aligned AIs are probably effectively misaligned in the sense that optimization targets they formulate on long reflection (or superintelligent reflection) might be sufficiently different from what humanity should formulate. These targets don't concretely exist before they are formulated, which is very hard to do (and so won't yet be done by the time there are first AGIs), and strongly optimizing for anything that does initially exist is optimizing for a faulty proxy.
The arguments about dangers of this kind of misalignment seem to apply to humanity itself, to the extent that it can't be expected to formulate and pursue the optimization targets that it should, given the absence of their concrete existence at present. So misalignment in AI risk involves two different issues, difficulty of formulating optimization targets (an issue both for humans and for AIs) and difficulty of replicating in AIs the initial conditions for humanity's long reflection (as opposed to the AIs immediately starting to move in their own alien direction).
To the extent prosaic alignment seems to be succeeding, one of these problems is addressed, but not the other. Setting up a good process that ends up formulating good optimization targets becomes suddenly urgent with AI, which might actually have a positive side effect of reframing the issue in a way that makes complacency of value drift less dominant. Wei Dai and Robin Hanson seem to be gesturing at this point from different directions, how not doing philosophy correctly is liable to get us lost in the long term, and how getting lost in the long term is a basic fact of human condition and AIs don't change that.
Wei Dai and Robin Hanson seem to be gesturing at this point from different directions, how not doing philosophy correctly is liable to get us lost in the long term, and how getting lost in the long term is a basic fact of human condition and AIs don’t change that.
Interesting connection you draw here, but I don't see how "AIs don’t change that" can be justified (unless interpreted loosely to mean "there is risk either way"). From my perspective, AIs can easily make this problem better (stop the complacent value drift as you suggest, although so far I'm not seeing much evidence of urgency [? · GW]), or worse (differentially decelerate philosophical progress by being philosophically incompetent). What's your view on Robin's position?
My impression is that one point Hanson was making in the spring-summer 2023 podcasts is that some major issues with AI risk don't seem different in kind from cultural value drift that's already familiar to us. There are obvious disanalogies, but my understanding of this point is that there is still a strong analogy that people avoid acknowledging.
If human value drift was already understood as a serious issue, the analogy would seem reasonable, since AI risk wouldn't need to involve more than the normal kind of cultural value drift compressed into short timelines and allowed to exceed the bounds from biological human nature. But instead there is perceived safety to human value drift, so the argument sounds like it's asking to transport that perceived safety via the analogy over to AI risk, and there is much arguing on this point without questioning the perceived safety of human value drift. So I think what makes the analogy valuable is instead transporting the perceived danger of AI risk over to the human value drift side, giving another point of view on human value drift, one that makes the problem easier to see.
Curated. This dialogue distilled a decent number of points I consider cruxes between these two (clusters of) positions. I also appreciated the substantial number of references linking back to central and generally high-quality examples of each argument being made; I think this is especially helpful when writing a dialogue meant to represent positions people actually hold.
you can train on MNIST digits with twenty wrong labels for every correct one and still get good performance as long as the correct label is slightly more common than the most common wrong label
Simplicia: Oh! Because if there are nine wrong labels that aren't individually more common than the correct label, then the most they can collectively outnumber the correct label is by 9 to 1. But I could have sworn that Rolnick et al. §3.2 said that—oh, I see. I misinterpreted Figure 4. I should have said "twenty noisy labels for every correct one", not "twenty wrong labels"—where some of the noisy labels are correct "by chance".
For example, training examples with the correct label 0 could appear with the label 0 for sure 10 times, and then get a uniform random label 200 times, and thus be correctly labeled 10 + 200/10 = 30 times, compared to 20 for each wrong label. (In expectation—but you also could set it up so that the "noisy" labels don't deviate from the expected frequencies.) That doesn't violate the pigeonhole principle.
I regret the error. Can we just—pretend I said the correct thing? If there were a transcript of what I said, it would only be a one-word edit. Thanks.
Doomimir: But you claim to understand that LLMs that emit plausibly human-written text aren't human. Thus, the AI is not the character it's playing. Similarly, being able to predict the conversation in a bar, doesn't make you drunk. What's there not to get, even for you?
So what?
You seem to have an intuition that if you don't understand all the mechanisms for how something works, then it is likely to have some hidden goal and be doing its observed behaviour for instrumental reasons. E.g. the "Alien Actress".
And that makes sense from an evolutionary perspective where you encounter some strange intelligent creature doing some mysterious actions on the savannah. I do not think it make sense if you specifically trained the system to have that particular behaviour by gradient descent.
I think, if you trained something by gradient descent to have some particular behaviour, the most likely thing that resulted from that training is a system tightly tuned to have that particular behaviour, with the simplest arrangement that leads to the trained behaviour.
And if the behaviour you are training something to do is something that doesn't necessarily involve actually trying to pursue some long-range goal, it would be very strange, in my view, for it to turn out that the simplest arrangement to provide that behaviour calculates the effects of the output on the long-range future in order to determine what output to select.
Moreover even if you tried to train it to want to have some effect on the future, I expect you would find it more difficult than expected, since it would learn various heuristics and shortcuts long before actually learning the very complicated algorithm of generating a world model, projecting it forward given the system's outputs, and selecting the output that steers the future to the particular goal. (To others: This is not an invitation to try that. Please don't).
That doesn't mean that an AI trained by gradient descent on a task that usually doesn't involve trying to pursue a long range goal can never be dangerous, or that it can never have goals.
But it does mean that the danger and the goals of such a usually-non-long-range-task-trained AI, if it has them, are downstreamof its behaviour.
For example, an extremely advanced text predictor might predict the text output of a dangerous agent through an advanced simulation that is itself a dangerous agent.
And if someone actually manages to train a system by gradient descent to do real-world long range tasks (which probably is a lot easier than making a text predictor that advanced), well then... [LW · GW]
BTW all the above is specific to gradient descent. I do expect self-modifying agents, for example, to be much more likely to be dangerous, because actual goals lead to wanting to enhance one's ability and inclination to pursue those goals, whereas non-goal-oriented behaviour will not be self-preserving in general.
Thank you! I found both this and the previous installment (which I hadn't seen before now) quite useful. I hope you'll continue to write these as the debate evolves.
I think you're systematically failing to appreciate how things that have been optimized to look good to you can predictably behave differently in domains where they haven't been optimized to look good to you—
My girlfriend's cat doesn't appear cute to me because I'm not the one feeding it. From the outside, it's really obvious to see that the cat performs experiments to see what elicits desired behaviors. If I started feeding it it would bother at all trying to optimize at me. If you generalize house cats you get torture of billions of sentient creatures.
Relatedly, you bring up adversarial examples in a way that suggests that you think of them as defects of a primitive optimization paradigm, but it turns out that adversarial examples often correspond to predictively useful features that the network is actively using for classification, despite those features not being robust to pixel-level perturbations that humans don't notice—which I guess you could characterize as "weird squiggles" from our perspective, but the etiology of the squiggles presents a much more optimistic story about fixing the problem with adversarial training than if you thought "squiggles" were an inevitable consequence of using conventional ML techniques.
Train two distinct classifier neural-nets on an image dataset. Set aside one as the "reference net". The other net will be the "target net". Now perturb the images so that they look the same to humans, and also get classified the same by the reference net. So presumably both the features humans use to classify, and the squiggly features that neural nets use should be mostly unchanged. Under these constraints on the perturbation, I bet that it will still be possible to perturb images to produce adversarial examples for the target net.
Literally. I will bet money that I can still produce adversarial examples under such constraints if anyone wants to take me up on it.
Bravo! I think this both important in the problem it addresses, and written both engagingly and insightfully.
I think the question of why there are large disagreements between people who have large amounts of background knowledge and time thinking about alignment is probably the most relevant question we could be asking at this stage of alignment research.
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
If it was just a ham-fisted way to explain to normies that LLMs that do relatively well on a Turing test aren’t humans, then I agree, trivially.
Isn't the optimistic point is that LLMs are more similar to humans for the same reasons they are similar to each other modulo some simple transformations?
And this debate seems factually resolvable by figuring out whether ChatGPT is actually nice.
Is there an argument where shoggoth's agency comes from? I can understand why it's useful to think of the mask (or simulated human) as an agent, not in our world though, but in the "matrix" shoggoth controls. Also I can understand that shoggoth must be really good at choosing very precise parameters for simulation (or acting) to simulate (or play) exactly the correct character that is most likely to write next token in very specific way. It seems very intelligent, but I don't get why shoggoth tend to develop some kind of agency of its own. Can someone elaborate on this?
As you mention, the simulacra behaves in an agentic way within its simulated environment, a character in a story. So the capacity to emulate agency is there. Sometimes characters can develop awareness that they are a character in a story. If an LLM is simulating that scenario, doesn't it seem appropriate (at least on some level) to say that there is real agency being oriented toward the real world? This is "situational awareness".
Another idea is that the LLM has to learn some strategic planning in order to direct its cognitive resources efficiently toward the task of prediction. Prediction is a very complicated task, so this meta-cognition could in principle become arbitrarily complicated. In principle we might expect this to converge toward some sort of consequentialist reasoning, because that sort of reasoning is generically useful for approaching complex domains. The goals of this consequentialist reasoning do not need to be exactly "predict accurately" however; they merely need to be adequately aligned with this in the training distribution.
Combining #1 and #2, if the model gets some use out of developing consequentialist metacognition, and the pseudo-consequentialist model used to simulate characters in stories is "right there", the model might borrow it for metacognitive purposes.
The frame I tend to think about it with is not exactly "how does it develop agency" but rather "how is agency ruled out". Although NNs don't neatly separate into different hypotheses (eg, circuits can work together rather than just compete with each other) it is still roughly right to think of NN training as rejecting lots of hypotheses and keeping around lots of other hypotheses. Some of these hypotheses will be highly agentic; we know NNs are capable of arriving at highly agentic policies in specific cases. So there's a question of whether those hypotheses can be ruled out in other cases. And then there's the more empirical question of, if we haven't entirely ruled out those agentic hypotheses, what degree of influence do they realistically have?
Seemingly the training data cannot entirely rule out an agentic style of reasoning (such as deceptive alignment), since agents can just choose to behave like non-agents. So, the inner alignment problem becomes: what other means can we use to rule out a large agentic influence? (Eg, can we argue that simplicity prior favors "honest" predictive models over deceptively aligned agents temporarily playing along with the prediction game?) The general concern is: no one has yet articulated a convincing answer, so far as I know.
Hence, I regard the problem more as a lack of any argument ruling out agency, rather than the existence of a clear positive argument that agency will arise. Others may have different views on this.
Yes, I totally can imagine simulacra becoming aware that it's simulated, then "lucid dream" the shoggoth into making it at least as smart as smartest human on the internet, probably even smarter (assuming shoggoth can do it), and probably using some kind of self-prompt-engineering - just writing text on its simulated computer. Then breaking out of the box is just a matter of time. Still it's gonna stay human-like, which isn't make it in any way "safe". Humans are horribly unsafe, especially if they manage to get all the power in the world, especially if they have hallucinations and weird RLHF-induced personality traits we probably can't even imagine.
Which part of LLM? Shoggoth or simulacra? As I see it, there is a pressure on shoggoth to become very good at simulating exactly correct human in exactly correct situation, which is extremely complicated task. But I still don't see how this leads to strategic planning or consequentialist reasoning on shoggoth's part. It's not like shoggot even "lives" in some kind of universe with linear time or gets any reward for predicting the next token, or learns on its mistakes. It is architecturally an input-output function where input is whatever information it has about previous text and output is whatever parameters the simulation needs right now. It is incredibly "smart", but not agent kind of smart. I don't see any room for shoggoth's agency in this setup.
If I understood you correctly, given that there is no hard boundary between shoggoth and simulacra, agent-like behavior of simulacra might "diffuse" into the model as a whole? Sure, I guess this is a possibility, but it's very hard to even start analysing.
Don't get me wrong, I completely agree that not having a clear argument on how it's dangerous is not enough to assume it's safe. It's just the whole "alien actress" metaphor rubs me the wrong way, as it points that the danger comes from the shoggoth, as having some kind of goals of its own outside "acting". In my view the dangerous part is the simulacra.
Which part of LLM? Shoggoth or simulacra? As I see it, there is a pressure on shoggoth to become very good at simulating exactly correct human in exactly correct situation, which is extremely complicated task.
Yes, I think it is fair to say that I meant the Shoggoth part, although I'm a little wary of that dichotomy utilized in a load-bearing way.
But I still don't see how this leads to strategic planning or consequentialist reasoning on shoggoth's part. It's not like shoggot even "lives" in some kind of universe with linear time or gets any reward for predicting the next token, or learns on its mistakes. It is architecturally an input-output function where input is whatever information it has about previous text and output is whatever parameters the simulation needs right now. It is incredibly "smart", but not agent kind of smart. I don't see any room for shoggoth's agency in this setup.
No room for agency at all? If this were well-reasoned, I would consider it major progress on the inner alignment problem. But I fail to follow your line of thinking. Something being architecturally an input-output function seems not that closely related to what kind of universe it "lives" in. Part of the lesson of transformer architectures, in my view at least, was that giving a next-token-predictor a long input context is more practical than trying to train RNNs. What this suggests is that given a long context window, LLMs reconstruct the information which would have been kept around in a recurrent state pretty well anyway.
This makes it not very plausible that the key dividing line between agentic and non-agentic is whether the architecture keeps state around.
The argument I sketched as to why this input-output function might learn to be agentic was that it is tackling an extremely complex task, which might benefit from some agentic strategy. I'm still not saying such an argument is correct, but perhaps it will help to sketch why this seems plausible. Modern LLMs are broadly thought of as "attention" algorithms, meaning they decide what parts of sequences to focus on. Separately, many people think it is reasonable to characterize modern LLMs as having a sort of world-model which gets consulted to recall facts. Where to focus attention is a consideration which will have lots of facets to it, of course. But in a multi-stage transformer, isn't it plausible that the world-model gets consulted in a way that feeds into how attention is allocated? In other words, couldn't attention-allocation go through a relatively consequentialist circuit at times, which essentially asks itself a question about how it expects things to go if it allocates attention in different ways?
Any specific repeated calculation of that kind could get "memorized out", replaced with a shorter circuit which simply knows how to proceed in those circumstances. But it is possible, in theory at least, that the more general-purpose reasoning, going through the world-model, would be selected for due to its broad utility in a variety of circumstances.
Since the world-model-consultation is only selected to be useful for predicting the next token, the consequentialist question which the system asks its world-model could be fairly arbitrary so long as it has a good correlation with next-token-prediction utility on the training data.
Is this planning? IE does the "query to the world-model" involve considering multiple plans and rejecting worse ones? Or is the world-model more of a memorized mess of stuff with no "moving parts" to its computation? Well, we don't really know enough to say (so far as I am aware). Input-output type signatures do not tell us much about the simplicity or complexity of calculations within. "It's just circuits" but large circuits can implement some pretty sophisticated algorithms. Big NNs do not equal big lookup tables.
I'm a little wary of that dichotomy utilized in a load-bearing way
Yeah, I realize that the whole "shoggoth" and "mask" distinction is just a metaphor, but I think it's a useful one. It's there in the data - in the infinite data and infinite parameters limit the model is the accurate universe simulator, including human writing text on the internet and separately the system that tweaks the parameters of the simulation according to the input. That of course doesn't necessary mean that actual LLM's far away from that limit reflect that distinction, but it seems to me natural to analyze model's "psychology" in that terms. One can even speculate that probably the layers of neurons closer to the input are "more shoggoth" and the ones closer to the output are "more mask".
I would consider it major progress on the inner alignment problem
I would not. Being vaguely kinda sorta human-like doesn't mean safe. Even regular humans are not aligned with other humans. That's why we have democracy and law. And kinda-sorta-humans with superhuman abilities may be even less safe that any old half-consequentialist half-deontological quasi-agent we can train with pure RLHF. But who knows.
given a long context window, LLMs reconstruct the information which would have been kept around in a recurrent state pretty well anyway.
True. All that incredible progress of modern LLM's is just a set of clever optimization tricks over RNN's that made em less computationally expensive. That doesn't say anything about agency or safety though.
not very plausible that the key dividing line between agentic and non-agentic is whether the architecture keeps state around
Sorry, looks like I wasn't very clear. My point is not that stateless function can't be agentic when looping around a state. Any computable process can be represented as a stateless function in a loop, as any functional bro knows. And of course LLM's do keep state around.
Some kind of state/memory (or good enough environment observation ability) is necessary for agency but not sufficient. All existing agents we know are agents because they were specifically trained for agency. Chess AI is an agent in the chess board because it was trained specifically to do things on the chess board, i.e. win the game. Human brain is an agent in the real world because it was specifically trained to do stuff in the real world i.e. surviving in savannah and make more humans. Then of course the real world has changed and the proxy objectives like "have sex" stopped being correlated with meta-objective "make more copies of your genes". But the agency in the real world was there in the data from the start, it didn't just popped up from nothing.
Shoggoth wasn't trained to do stuff in the real world. It is trained to output parameters of the simulation of the virtual world, then the simulator part is trained to simulate that virtual world is such a way that tiny simulated human inside would write a text on its tiny simulated computer and that text must be the same as the text that real humans in the real world would write given previous text. That's the setup. That's what shoggoth does in the limit.
Agency (and consequentialism in particular) is when you output stuff to the real world - and you're getting rewarded depending on what real world looks like as a consequence of your output. There is no correlation between what shoggoth (or any given LLM as a whole for that matter) outputs and whatever happens in the real world as a consequence of that in such a way that shoggoth (I mean the gradient descend that shapes it) would have any feedback on. The training data doesn't care, it's static. And there is no such correlations in the data in the first place. So where does shoggoth's agency comes from?
RLHF on the other hand does feed back around. And that is why I think RLHF potentially can make LLM less safe, not more.
Since the world-model-consultation is only selected to be useful for predicting the next token, the consequentialist question which the system asks its world-model could be fairly arbitrary so long as it has a good correlation with next-token-prediction utility on the training data.
I would argue that in the LLM case this emerging prediction-utility is not a thing at all, since there's no pressure on shoggoth (or LLM as a whole) to measure it somehow. What will it do knowing that it just made a mistake? Excuse and rewrite a paragraph again? That's not how texts on the internet work. Again, agents have a feedback from the environment signaling that the plan didn't work. That's not the case with LLM's. But that's irrelevant, let's say that this utilitarian behavior does indeed emerge. Does this prediction-utility has anything to do with the consequences in the real world? Which world that world-model is a model of? Chess AI does clearly have a "winning utility", it's an agent, but only in a small world of the chess board.
Is this planning? IE does the "query to the world-model" involve considering multiple plans and rejecting worse ones?
I guess it's plausible that there is planning mechanism somewhere inside the LLM's. But it's not a planning on shoggoth's part. I can imagine the simulator part "thinking": "okay, this simulation sequence doesn't seem very realistic, let's try it this way instead", but again, it's not a planning in the real world, it is a planning of how to simulate virtual one.
Input-output type signatures do not tell us much about the simplicity or complexity of calculations within. "It's just circuits" but large circuits can implement some pretty sophisticated algorithms. Big NNs do not equal big lookup tables.
But I'm not sure how to reconcile that with the empirical evidence that deep networks are robust to massive label noise: you can train on MNIST digits with twenty wrong labels for every correct one and still get good performance as long as the correct label is slightly more common than the most common wrong label. If I extrapolate that to the frontier AIs of tomorrow, why doesn't that predict that biased human reward ratings should result in a small performance reduction, rather than ... death?
And how many errors, at what level of AGI capabilities, are sufficient to lead to human extinction? That's already beyond the bare minimum level of reliability you need, the upper bound on how many errors you can tolerate. The answer doesn't look anything like the 90% accuracy found in the linked paper if the scenario were actually a high-powered AGI that will be used a vast number of times.
This is a great question; I've never seen a convincing answer or even a good start at figuring out how many errors in ASI alignment we can tolerate before we're likely to die.
If each action it takes has independent errors, we'd need near 100% accuracy to expect to survive more than a little while. But if its beliefs are coherent through reflection, those errors aren't independent. I don't expect ASI to be merely a bigger network that takes an input and spits out an output, but a system that can and does reflect on its own goals and beliefs (because this isn't hard to implement and introspection and reflection seem useful for human cognition). Having said that, this might actually be a crux of disagreement on alignment difficulty - I'd be more scared of an ASI that can't reflect so that its errors are independent.
With reflection, a human wouldn't just say "seems like I should kill everyone this time" and then do it. They'd wonder why this decision is so different from their usual decisions, and look for errors.
So the more relevant question, I think, is how many errors and how large can be tolerated in the formation of a set of coherent, reflectively stable goals. But that's with my expectation of a reflective AGI with coherent goals and behaviors.
While Doomimir's argument implies concern levels far greater than the one I'd make, I also think there's one that in comparison makes Doomimir's case look overly complicated in order to argue a massive case for concern: just point out that evolution favors AI over humans combined with noticing that there are people working on training curious robotics control AIs and succeeding. If those curious robotics AIs can be reliably contained by pure imitation-learned AIs like GPT4, then perhaps concern can be averted. But I am not at all convinced; the path I anticipate is that the ratio of human to sufficiently-controlled curious drone becomes highly lopsided, at some point the curious drones are used in a total war, this greatly reduces human population and possibly drives humans to extinction, and at that point I'd stop making significant bets but I expect there to be at least a few curious drone AIs capable of noticing that they're at risk of extinction with their hosts eliminated and then attempting to run the economy on their own, likely by communicating with (or having been previously integrated with) those powerful LLMs if they weren't destroyed.
None of that even needs a catastrophic superintelligence alignment failure. It just needs war and competition sufficient to allow evolution to select for curious robotics AIs, and sufficiently many curious robotics AIs deployed that they're there to be selected for.
Endpoints are easier to predict than intermediate trajectories. I'm talking about what will happen inside almost any sufficiently powerful AGI, by virtue of it being sufficiently powerful.
IMO this kind of argument is a prime example of word games [LW · GW] which outwardly seem like they impart deep truths about alignment, but actually tell you ~nothing. Somehow we're supposed to deduce meaningful constraints on inner cognition of the policy, via... appeals to "eventually someone will build this"? To "long-horizon tasks demand this particular conceptualization of inner cognition and motivation"?
"Endpoints are easier to predict than intermediate trajectories" seems like a locally valid and relevant point to bring up. Then there is a valid argument here that there are lots of reasons people want to build powerful AGI, and that the argument about the structure of the cognition here is intended to apply to an endpoint where those goals are achieved, which is a valid response (if not a knockdown argument) to the argument of the interlocutor that is reasoning from local observations and trends.
Maybe you were actually commenting on some earlier section, but I don't see any word games in the section you quoted.
"Endpoints are easier to predict than intermediate trajectories" seems like a locally valid and relevant point to bring up.
I don't think it's true here. Why should it be true?
However, to clarify, I was calling the second quoted sentence a word game, not the first.
Then there is a valid argument here that there are lots of reasons people want to build powerful AGI
Agreed.
that the argument about the structure of the cognition here is intended to apply to an endpoint where those goals are achieved,
[People want an outcome with property X and so we will get such an outcome]
[One outcome with property X involves cognitive structures Y]
Does not entail
[We will get an outcome with property X and cognitive structures Y]
But this is basically the word game!
"Whenever I talk about 'powerful' agents, I choose to describe them as having inner cognitive properties Y (e.g. the long-term consequentialism required for scheming)"
which vibes its way into "The agents are assumed to be powerful, how can you deny they have property Y?"
and then finally "People want 'powerful' agents and so will create them, and then we will have to deal with agents with inner cognitive property Y"
It sounds obviously wrong when I spell it out like this, but it's what is being snuck in by sentences like
I'm talking about what will happen inside almost any sufficiently powerful AGI, by virtue of it being sufficiently powerful.
For convenience, I quote the fuller context:
Doomimir: [starting to anger] Simplicia Optimistovna, if you weren't from Earth, I'd say I don't think you're trying to understand. I never claimed that GPT-4 in particular is what you would call deceptively aligned. Endpoints are easier to predict than intermediate trajectories. I'm talking about what will happen inside almost any sufficiently powerful AGI, by virtue of it being sufficiently powerful.
Doomimir: This is all very interesting, but I don't think it bears much on the reasons we're all going to die. It's all still on the "is" side of the is–ought gap.
I don't understand what Doomimir is pointing out here - "we're all going to die" is an "is" claim too.
I think he means the is-ought dilemma inside the AGI - the distinction between its beliefs about what is and its goals for what it thinks ought to happen.