ETA: I'm not saying that MIRI thought AIs wouldn't understand human values. If there's only one thing you take away from this post, please don't take away that. Here is Linch's attempted summary of this post [LW(p) · GW(p)], which I largely agree with.
Recently, many people have talked about whether some of the main MIRI people (Eliezer Yudkowsky, Nate Soares, and Rob Bensinger[1]) should update on whether value alignment is easier than they thought given that GPT-4 seems to follow human directions and act within moral constraints pretty well (here are two specific examples of people talking about this: 1, 2). Because these conversations are often hard to follow without much context, I'll just provide a brief caricature of how I think this argument has gone in the places I've seen it, which admittedly could be unfair to MIRI[2]. Then I'll offer my opinion that, overall, I think MIRI people should probably update in the direction of alignment being easier than they thought in light of this information, despite their objections.
Note: I encourage you to read this post carefully to understand my thesis. This topic can be confusing, and there are many ways to misread what I'm saying. Also, make sure to read the footnotes if you're skeptical of some of my claims.
Here's my very rough caricature of the discussion so far, plus my response:
Non-MIRI people: Yudkowsky talked a great deal in the sequences about how it was hard to get an AI to understand human values. For example, his essay on the Hidden Complexity of Wishes [LW · GW] made it sound like it would be really hard to get an AI to understand common sense. In that essay, the genie did silly things like throwing your mother out of the building rather than safely carrying her out. Actually, it turned out that it was pretty easy to get an AI to understand common sense. LLMs are essentially safe-ish genies that do what you intend. MIRI people should update on this information.
MIRI people (Eliezer Yudkowsky, Nate Soares, and Rob Bensinger): You misunderstood the argument. The argument was never about getting an AI to understand human values, but about getting an AI to care about human values in the first place. Hence 'The genie knows but doesn't care [LW · GW]'. There's no reason to think that GPT-4 cares about human values, even if it can understand them. We always thought the hard part of the problem was about inner alignment, or, pointing the AI in a direction you want. We think figuring out how to point an AI in whatever direction you choose is like 99% of the problem; the remaining 1% of the problem is getting it to point at the "right" set of values.[2]
My response:
I agree that MIRI people never thought the problem was about getting AI to merely understand human values, and that they have generally maintained there was extra difficulty in getting an AI to care about human values. However, I distinctly recall MIRI people making a big deal about the value identification problem (AKA the value specification problem), for example in this 2016 talk from Yudkowsky.[3] The value identification problem is the problem of "pinpointing valuable outcomes to an advanced agent and distinguishing them from non-valuable outcomes". In other words, it's the problem of specifying a utility function that reflects the "human value function" with high fidelity, i.e. the problem of specifying a utility function that can be optimized safely. See this footnote[4] for further clarification about how I view the value identification/specification problem.
The key difference between the value identification/specification problem and the problem of getting an AI to understand human values is the transparency and legibility of how the values are represented: if you solve the problem of value identification, that means you have an actual function that can tell you the value of any outcome (which you could then, hypothetically, hook up to a generic function maximizer to get a benevolent AI). If you get an AI that merely understands human values, you can't necessarily use the AI to determine the value of any outcome, because, for example, the AI might lie to you, or simply stay silent.
The primary foreseeable difficulty Yudkowsky offered for the value identification problem is that human value is complex [? · GW].[5] In turn, the idea that value is complex was stated multiple times as a premise for why alignment is hard.[6] Another big foreseeable difficulty with the value identification problem is the problem of edge instantiation, which was talked about extensively in early discussions on LessWrong.
MIRI people frequently claimed that solving the value identification problem would be hard, or at least non-trivial.[7] For instance, Nate Soares wrote in his 2016 paper on value learning, that "Human preferences are complex, multi-faceted, and often contradictory. Safely extracting preferences from a model of a human would be no easy task."
I claim that GPT-4 is already pretty good at extracting preferences from human data. It exhibits common sense. If you talk to GPT-4 and ask it ethical questions, it will generally give you reasonable answers. It will also generally follow your intended directions, rather than what you literally said. Together, I think these facts indicate that GPT-4 is probably on a path towards an adequate solution to the value identification problem, where "adequate" means "about as good as humans". And to be clear, I don't mean that GPT-4 merely passively "understands" human values. I mean that GPT-4 literally executes your intended instructions in practice, and that asking GPT-4 to distinguish valuable and non-valuable outcomes works pretty well in practice, and this will become increasingly apparent in the near future as models get more capable and expand to more modalities.[8]
I'm not arguing that GPT-4 actually cares about maximizing human value. However, I am saying that the system is able to transparently pinpoint to us which outcomes are good and which outcomes are bad, with fidelity approaching an average human, albeit in a text format. Crucially, GPT-4 can do this visibly to us, in a legible way, rather than merely passively knowing right from wrong in some way that we can't access. This fact is key to what I'm saying because it means that, in the near future, we can literally just query multimodal GPT-N about whether an outcome is bad or good, and use that as an adequate "human value function". That wouldn't solve the problem of getting an AI to care about maximizing the human value function, but it would arguably solve the problem of creating an adequate function that we can put into a machine to begin with.
Maybe you think "the problem" was always that we can't rely on a solution to the value identification problem that only works as well as a human, and we require a much higher standard than "human-level at moral judgement" to avoid a catastrophe. But personally, I think having such a standard is both unreasonable and inconsistent with the implicit standard set by essays from Yudkowsky and other MIRI people. In Yudkowsky's essay on the hidden complexity of wishes [LW · GW], he wrote,
You failed to ask for what you really wanted. You wanted your mother to go on living, but you wished for her to become more distant from the center of the building.
Except that's not all you wanted. If your mother was rescued from the building but was horribly burned, that outcome would rank lower in your preference ordering than an outcome where she was rescued safe and sound. So you not only value your mother's life, but also her health. [...]
Your brain is not infinitely complicated; there is only a finite Kolmogorov complexity / message length which suffices to describe all the judgments you would make. But just because this complexity is finite does not make it small. We value many things, and no they are not reducible to valuing happiness or valuing reproductive fitness.
I interpret this passage as saying that 'the problem' is extracting all the judgements that "you would make", and putting that into a wish. I think he's implying that these judgements are essentially fully contained in your brain. I don't think it's credible to insist he was referring to a hypothetical ideal human value function that ordinary humans only have limited access to, at least in this essay.[9]
Here's another way of putting my point: In general, there are at least two ways that someone can fail to follow your intended instructions. Either your instructions aren't well-specified and don't fully capture your intentions, or the person doesn't want to obey your instructions even if those instructions accurately capture what you want. Practically all the evidence that I've found seems to indicate that MIRI people thought that both problems would be hard to solve for AI, not merely the second problem.
For example, a straightforward reading of Nate Soares' 2017 talk supports this interpretation. In the talk, Soares provides a fictional portrayal of value misalignment, drawing from the movie Fantasia. In the story, Mickey Mouse attempts to instruct a magical broom to fill a cauldron, but the broom follows the instructions literally rather than following what Mickey Mouse intended, and floods the room. Soares comments: "I claim that as fictional depictions of AI go, this is pretty realistic."[10]
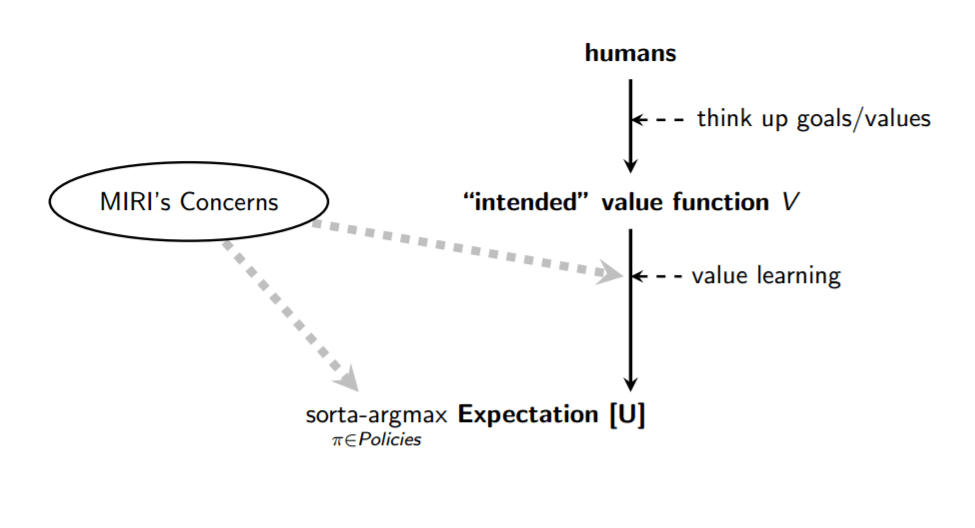
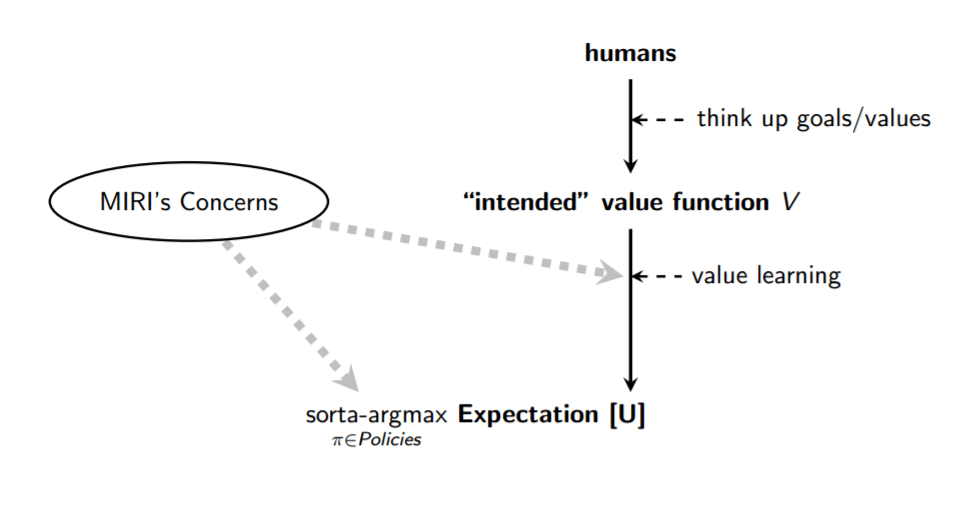
Perhaps more important to my point, Soares presented a clean separation between the part where we specify an AI's objectives, and the part where the AI tries to maximizes those objectives. He draws two arrows, indicating that MIRI is concerned about both parts. He states, "My view is that the critical work is mostly in designing an effective value learning process, and in ensuring that the sorta-argmax process is correctly hooked up to the resultant objective function 𝗨:"[11]
In the talk Soares also says, "The serious question with smarter-than-human AI is how we can ensure that the objectives we’ve specified are correct, and how we can minimize costly accidents and unintended consequences in cases of misspecification." I believe this quote refers directly to the value identification problem, rather than the problem of getting an AI to care about following the goals we've given it. This attitude is reflected in other MIRI essays.
The point of "the genie knows but doesn't care [LW · GW]" wasn't that the AI would take your instructions, know what you want, and yet disobey the instructions because it doesn't care about what you asked for. If you read Rob Bensinger's essay [LW · GW] carefully, you'll find that he's actually warning that the AI will care too much about the utility function you gave it, and maximize it exactly, against your intentions[12]. The sense in which the genie "doesn't care" is that it doesn't care what you intended; it only cares about the objectives that you gave it. That's not the same as saying the genie doesn't care about the objectives you specified.
Given the evidence, it seems to me that the following conclusions are probably accurate:
The fact that GPT-4 can reliably follow basic instructions, is able to distinguish moral from immoral actions somewhat reliably, and generally does what I intend rather than what I literally asked, is all evidence that the value identification problem is easier than how MIRI people originally portrayed it. While I don't think the value identification problem has been completely solved yet, I don't expect near-future AIs will fail dramatically on the "fill a cauldron" task, or any other functionally similar tasks.
MIRI people used to think that it would be hard to both (1) specify an explicit function that corresponds to the "human value function" with fidelity comparable to the judgement of an average human, and (2) separately, get an AI to care about maximizing this function. The idea that MIRI people only ever thought (2) was the hard part appears false.[13]
Non-MIRI people sometimes strawman MIRI people as having said that AGI would literally lack an understanding of human values. I don't endorse this, and I'm not saying this.
The "complexity of value" argument pretty much just tells us that we need an AI to learn human values, rather than hardcoding a utility function from scratch. That's a meaningful thing to say, but it doesn't tell us much about whether alignment is hard, especially in the deep learning paradigm; it just means that extremely naive approaches to alignment won't work.
As an endnote, I don't think it really matters whether MIRI people had mistaken arguments about the difficulty of alignment ten years ago. It matters far more what their arguments are right now. However, I do care about accurately interpreting what people said on this topic, and I think it's important for people to acknowledge when the evidence has changed.
I recognize that these people are three separate individuals and each have their own nuanced views. However, I think each of them have expressed broadly similar views on this particular topic, and I've seen each of them engage in a discussion about how we should update about the difficulty of alignment given what we've seen from LLMs.
I'm not implying MIRI people would necessarily completely endorse everything I've written in this caricature. I'm just conveying how they've broadly come across to me, and I think the basic gist is what's important here. If some MIRI people tell me that this caricature isn't a fair summary of what they've said, I'll try to edit the post later to include real quotes.
I have long said that the lion's share of the AI alignment problem seems to me to be about pointing powerful cognition at anything at all, rather than figuring out what to point it at.
It’s recently come to my attention that some people have misunderstood this point, so I’ll attempt to clarify here.
More specifically, in the talk, at one point Yudkowsky asks "Why expect that [alignment] is hard?" and goes on to tell a fable about programmers misspecifying a utility function, which then gets optimized by an AI with disastrous consequences. My best interpretation of this part of the talk is that he's saying the value identification problem is one of the primary reasons why alignment is hard. However, I encourage you to read the transcript yourself if you are skeptical of my interpretation.
I am mainly talking about the problem of how to specify (for example, write into a computer) an explicit function that reflects the human value function with high fidelity, in the sense that judgements from this function about the value of outcomes fairly accurately reflect the judgements of ordinary humans. I think this is simply a distinct concept from the idea of getting an AI to understand human values.
I was not able to find a short and crisp definition of the value identification/specification problem from MIRI. However, in the Arbital page on the Problem of fully updated deference, the problem is described as follows,
One way to look at the central problem of value identification in superintelligence is that we'd ideally want some function that takes a complete but purely physical description of the universe, and spits out our true intended notion of value V in all its glory. Since superintelligences would probably be pretty darned good at collecting data and guessing the empirical state of the universe, this probably solves the whole problem.
This is not the same problem as writing down our true V by hand. The minimum algorithmic complexity of a meta-utility function ΔU which outputs V after updating on all available evidence, seems plausibly much lower than the minimum algorithmic complexity for writing V down directly. But as of 2017, nobody has yet floated any formal proposal for a ΔU of this sort which has not been immediately shot down.
In MIRI's 2017 technical agenda, they described the problem as follows, which I believe roughly matches how I'm using the term,
A highly-reliable, error-tolerant agent design does not guarantee a positive impact; the effects of the system still depend upon whether it is pursuing appropriate goals. A superintelligent system may find clever, unintended ways to achieve the specific goals that it is given. Imagine a superintelligent system designed to cure cancer which does so by stealing resources, proliferating robotic laboratories at the expense of the biosphere, and kidnapping test subjects: the intended goal may have been “cure cancer without doing anything bad,” but such a goal is rooted in cultural context and shared human knowledge.
It is not sufficient to construct systems that are smart enough to figure out the intended goals. Human beings, upon learning that natural selection “intended” sex to be pleasurable only for purposes of reproduction, do not suddenly decide that contraceptives are abhorrent. While one should not anthropomorphize natural selection, humans are capable of understanding the process which created them while being completely unmotivated to alter their preferences. For similar reasons, when developing AI systems, it is not sufficient to develop a system intelligent enough to figure out the intended goals; the system must also somehow be deliberately constructed to pursue them (Bostrom 2014, chap. 8).
However, the “intentions” of the operators are a complex, vague, fuzzy, context-dependent notion (Yudkowsky 2011; cf. Sotala and Yampolskiy 2017). Concretely writing out the full intentions of the operators in a machine-readable format is implausible if not impossible, even for simple tasks. An intelligent agent must be designed to learn and act according to the preferences of its operators.6 This is the value learning problem.
Directly programming a rule which identifies cats in images is implausibly difficult, but specifying a system that inductively learns how to identify cats in images is possible. Similarly, while directly programming a rule capturing complex human intentions is implausibly difficult, intelligent agents could be constructed to inductively learn values from training data.
For example, in this post, Yudkowsky gave "five theses", one of which was the "complexity of value thesis". He wrote, that the "five theses seem to imply two important lemmas", the first lemma being "Large bounded extra difficulty of Friendliness.", i.e. the idea that alignment is hard.
Another example comes from this talk. I've linked to a part in which Yudkowsky begins by talking how human value is complex, and moves to talking about how that fact presents challenges for aligning AI.
My guess is that the perceived difficulty of specifying objectives was partly a result of MIRI people expecting that natural language understanding wouldn't occur in AI until just barely before AGI, and at that point it would be too late to use AI language comprehension to help with alignment.
It's true that Eliezer and I didn't predict AI would achieve GPT-3 or GPT-4 levels of NLP ability so early (e.g., before it can match humans in general science ability), so this is an update to some of our models of AI.
If you disagree that AI systems in the near-future will be capable of distinguishing valuable from non-valuable outcomes about as reliably as humans, then I may be interested in operationalizing this prediction precisely, and betting against you. I don't think this is a very credible position to hold as of 2023, barring a pause that could slow down AI capabilities very soon.
I mostly interpret Yudkowsky's Coherent Extrapolated Volition as an aspirational goal for what we could best hope for in an ideal world where we solve every part of alignment, rather than a minimal bar for avoiding human extinction. In Yudkowsky's post on AGI ruin [LW · GW], he stated,
When I say that alignment is lethally difficult, I am not talking about ideal or perfect goals of 'provable' alignment, nor total alignment of superintelligences on exact human values, nor getting AIs to produce satisfactory arguments about moral dilemmas which sorta-reasonable humans disagree about, nor attaining an absolute certainty of an AI not killing everyone. When I say that alignment is difficult, I mean that in practice, using the techniques we actually have, "please don't disassemble literally everyone with probability roughly 1" is an overly large ask that we are not on course to get.
I don't think I'm taking him out of context. Here's a longer quote from the talk,
When Mickey runs this program, everything goes smoothly at first. Then:
[Image of the cauldron overflowing with water]
I claim that as fictional depictions of AI go, this is pretty realistic.
Why would we expect a generally intelligent system executing the above program to start overflowing the cauldron, or otherwise to go to extreme lengths to ensure the cauldron is full?
The first difficulty is that the objective function that Mickey gave his broom left out a bunch of other terms Mickey cares about.
Another common thread is “Why not just tell the AI system to (insert intuitive moral precept here)?” On this way of thinking about the problem, often (perhaps unfairly) associated with Isaac Asimov’s writing, ensuring a positive impact from AI systems is largely about coming up with natural-language instructions that are vague enough to subsume a lot of human ethical reasoning:
In contrast, precision is a virtue in real-world safety-critical software systems. Driving down accident risk requires that we begin with limited-scope goals rather than trying to “solve” all of morality at the outset.5
My view is that the critical work is mostly in designing an effective value learning process, and in ensuring that the sorta-argmax process is correctly hooked up to the resultant objective function 𝗨:
The better your value learning framework is, the less explicit and precise you need to be in pinpointing your value function 𝘝, and the more you can offload the problem of figuring out what you want to the AI system itself. Value learning, however, raises a number of basic difficulties that don’t crop up in ordinary machine learning tasks.
When you write the seed's utility function, you, the programmer, don't understand everything about the nature of human value or meaning. That imperfect understanding remains the causal basis of the fully-grown superintelligence's actions, long after it's become smart enough to fully understand our values.
Why is the superintelligence, if it's so clever, stuck with whatever meta-ethically dumb-as-dirt utility function we gave it at the outset? Why can't we just pass the fully-grown superintelligence the buck by instilling in the seed the instruction: 'When you're smart enough to understand Friendliness Theory, ditch the values you started with and just self-modify to become Friendly.'?
Because that sentence has to actually be coded in to the AI, and when we do so, there's no ghost in the machine [? · GW] to know exactly what we mean by 'frend-lee-ness thee-ree'.
It's unclear to me whether MIRI people are claiming that they only ever thought (2) was the hard part of alignment, but here's a quote from Nate Soares [LW(p) · GW(p)] that offers some support for this interpretation IMO,
I'd agree that one leg of possible support for this argument (namely "humanity will be completely foreign to this AI, e.g. because it is a mathematically simple seed AI that has grown with very little exposure to humanity") won't apply in the case of LLMs. (I don't particularly recall past people arguing this; my impression is rather one of past people arguing that of course the AI would be able to read wikipedia and stare at some humans and figure out what it needs to about this 'value' concept, but the hard bit is in making it care.
Even if I'm misinterpreting Soares here, I don't think that would undermine the basic point that MIRI people should probably update in the direction of alignment being easier than they thought.
I have never since 1996 thought that it would be hard to get superintelligences to accurately model reality with respect to problems as simple as "predict what a human will thumbs-up or thumbs-down". The theoretical distinction between producing epistemic rationality (theoretically straightforward) and shaping preference (theoretically hard) is present in my mind at every moment that I am talking about these issues; it is to me a central divide of my ontology.
If you think you've demonstrated by clever textual close reading that Eliezer-2018 or Eliezer-2008 thought that it would be hard to get a superintelligence to understand humans, you have arrived at a contradiction and need to back up and start over.
The argument we are trying to explain has an additional step that you're missing. You think that we are pointing to the hidden complexity of wishes in order to establish in one step that it would therefore be hard to get an AI to output a correct wish shape, because the wishes are complex, so it would be difficult to get an AI to predict them. This is not what we are trying to say. We are trying to say that because wishes have a lot of hidden complexity, the thing you are trying to get into the AI's preferences has a lot of hidden complexity. This makes the nonstraightforward and shaky problem of getting a thing into the AI's preferences, be harder and more dangerous than if we were just trying to get a single information-theoretic bit in there. Getting a shape into the AI's preferences is different from getting it into the AI's predictive model. MIRI is always in every instance talking about the first thing and not the second.
You obviously need to get a thing into the AI at all, in order to get it into the preferences, but getting it into the AI's predictive model is not sufficient. It helps, but only in the same sense that having low-friction smooth ball-bearings would help in building a perpetual motion machine; the low-friction ball-bearings are not the main problem, they are a kind of thing it is much easier to make progress on compared to the main problem. Even if, in fact, the ball-bearings would legitimately be part of the mechanism if you could build one! Making lots of progress on smoother, lower-friction ball-bearings is even so not the sort of thing that should cause you to become much more hopeful about the perpetual motion machine. It is on the wrong side of a theoretical divide between what is straightforward and what is not.
You will probably protest that we phrased our argument badly relative to the sort of thing that you could only possibly be expected to hear, from your perspective. If so this is not surprising, because explaining things is very hard. Especially when everyone in the audience comes in with a different set of preconceptions and a different internal language about this nonstandardized topic. But mostly, explaining this thing is hard and I tried taking lots of different angles on trying to get the idea across.
In modern times, and earlier, it is of course very hard for ML folk to get their AI to make completely accurate predictions about human behavior. They have to work very hard and put a lot of sweat into getting more accurate predictions out! When we try to say that this is on the shallow end of a shallow-deep theoretical divide (corresponding to Hume's Razor) it often sounds to them like their hard work is being devalued and we could not possibly understand how hard it is to get an AI to make good predictions.
Now that GPT-4 is making surprisingly good predictions, they feel they have learned something very surprising and shocking! They cannot possibly hear our words when we say that this is still on the shallow end of a shallow-deep theoretical divide! They think we are refusing to come to grips with this surprising shocking thing and that it surely ought to overturn all of our old theories; which were, yes, phrased and taught in a time before GPT-4 was around, and therefore do not in fact carefully emphasize at every point of teaching how in principle a superintelligence would of course have no trouble predicting human text outputs. We did not expect GPT-4 to happen, in fact, intermediate trajectories are harder to predict than endpoints, so we did not carefully phrase all our explanations in a way that would make them hard to misinterpret after GPT-4 came around.
But if you had asked us back then if a superintelligence would automatically be very good at predicting human text outputs, I guarantee we would have said yes. You could then have asked us in a shocked tone how this could possibly square up with the notion of "the hidden complexity of wishes" and we could have explained that part in advance. Alas, nobody actually predicted GPT-4 so we do not have that advance disclaimer down in that format. But it is not a case where we are just failing to process the collision between two parts of our belief system; it actually remains quite straightforward theoretically. I wish that all of these past conversations were archived to a common place, so that I could search and show you many pieces of text which would talk about this critical divide between prediction and preference (as I would now term it) and how I did in fact expect superintelligences to be able to predict things!
I think you missed some basic details about what I wrote. I encourage people to compare what Eliezer is saying here to what I actually wrote. You said:
If you think you've demonstrated by clever textual close reading that Eliezer-2018 or Eliezer-2008 thought that it would be hard to get a superintelligence to understand humans, you have arrived at a contradiction and need to back up and start over.
I never said that you or any other MIRI person thought it would be "hard to get a superintelligence to understand humans". Here's what I actually wrote:
Non-MIRI people sometimes strawman MIRI people as having said that AGI would literally lack an understanding of human values. I don't endorse this, and I'm not saying this.
[...]
I agree that MIRI people never thought the problem was about getting AI to merely understand human values, and that they have generally maintained there was extra difficulty in getting an AI to care about human values. However, I distinctly recall MIRI people making a big deal about the value identification problem (AKA the value specification problem), for example in this 2016 talk from Yudkowsky.[3] [LW(p) · GW(p)] The value identification problem is the problem of "pinpointing valuable outcomes to an advanced agent and distinguishing them from non-valuable outcomes". In other words, it's the problem of specifying a function that reflects the "human value function" with high fidelity.
I mostly don't think that the points you made in your comment respond to what I said. My best guess is that you're responding to a stock character who represents the people who have given similar arguments to you repeatedly in the past. In light of your personal situation, I'm actually quite sympathetic to you responding this way. I've seen my fair share of people misinterpreting you on social media too. It can be frustrating to hear the same bad arguments, often made from people with poor intentions, over and over again and continue to engage thoughtfully each time. I just don't think I'm making the same mistakes as those people. I tried to distinguish myself from them in the post.
I would find it slightly exhausting to reply to all of this comment, given that I think you misrepresented me in a big way right out of the gate, so I'm currently not sure if I want to put in the time to compile a detailed response.
That said, I think some of the things you said in this comment were nice, and helped to clarify your views on this subject. I admit that I may have misinterpreted some of the comments you made, and if you provide specific examples, I'm happy to retract or correct them. I'm thankful that you spent the time to engage. :)
Without digging in too much, I'll say that this exchange and the OP is pretty confusing to me. It sounds like MB is like "MIRI doesn't say it's hard to get an AI that has a value function" and then also says "GPT has the value function, so MIRI should update". This seems almost contradictory.
A guess: MB is saying "MIRI doesn't say the AI won't have the function somewhere, but does say it's hard to have an externally usable, explicit human value function". And then saying "and GPT gives us that", and therefore MIRI should update.
And EY is blobbing those two things together, and saying neither of them is the really hard part. Even having the externally usable explicit human value function doesn't mean the AI cares about it. And it's still a lot of bits, even if you have the bits. So it's still true that the part about getting the AI to care has to go precisely right.
If there's a substantive disagreement about the facts here (rather than about the discourse history or whatever), maybe it's like:
Straw-EY: Complexity of value means you can't just get the make-AI-care part to happen by chance; it's a small target.
Straw-MB: Ok but now we have a very short message pointing to roughly human values: just have a piece of code that says "and now call GPT and ask it what's good". So now it's a very small number of bits.
A guess: MB is saying "MIRI doesn't say the AI won't have the function somewhere, but does say it's hard to have an externally usable, explicit human value function". And then saying "and GPT gives us that", and therefore MIRI should update.
[...]
Straw-EY: Complexity of value means you can't just get the make-AI-care part to happen by chance; it's a small target.
Straw-MB: Ok but now we have a very short message pointing to roughly human values: just have a piece of code that says "and now call GPT and ask it what's good". So now it's a very small number of bits.
I consider this a reasonably accurate summary of this discussion, especially the part I'm playing in it. Thanks for making it more clear to others.
Straw-EY: Complexity of value means you can't just get the make-AI-care part to happen by chance; it's a small target.
Straw-MB: Ok but now we have a very short message pointing to roughly human values: just have a piece of code that says "and now call GPT and ask it what's good". So now it's a very small number of bits.
To which I say: "dial a random phone number and ask the person who answers what's good" can also be implemented with a small number of bits. In order for GPT-4 to be a major optimistic update about alignment, we need some specific way to leverage GPT-4 to crack open part of the alignment problem, even though we presumably agree that phone-a-friend doesn't crack open part of the alignment problem. (Nor does phone-your-neighborhood-moral-philosopher, or phone-Paul-Christiano.)
This is a bad analogy. Phoning a human fails dominantly because humans are less smart than the ASI they would be trying to wrangle. Contra, Yudkowsky has even said that were you to bootstrap human intelligence directly, there is a nontrivial shot that the result is good. This difference is load bearing!
This does get to the heart of the disagreement, which I'm going to try to badly tap out on my phone.
The old, MIRI-style framing was essentially: we are going to build an AGI out of parts that are not intrinsically grounded in human values, but rather good abstract reasoning, during execution of which human values will be accurately deduced, and as this is after the point of construction, we hit the challenge of formally specifying what properties we want to preserve without being able to point to those runtime properties at specification.
The newer, contrasting framing is essentially: we are going to bulld an AGI out of parts that already have strong intrinsic, conceptual-level understanding of the values we want them to preserve, and being able to directly point at those values is actually needle-moving towards getting a good outcome. This is hard to do right now, with poor interpretability and steerability of these systems, but is nonetheless a relevant component of a potential solution.
It's more like calling a human who's as smart as you are and directly plugged into your brain and in fact reusing your world model and train of thought directly to understand the implications of your decision. That's a huge step up from calling a real human over the phone!
The reason the real human proposal doesn't work is that
the humans you call will lack context on your decision
they won't even be able to receive all the context
they're dumber and slower than you so even if you really could write out your entire chain of thoughts and intuitions consulting them for every decision would be impractical
Note that none of these considerations apply to integrated language models!
I'm not going to comment on "who said what when", as I'm not particularly interested in the question myself, though I think the object level point here is important:
This makes the nonstraightforward and shaky problem of getting a thing into the AI's preferences, be harder and more dangerous than if we were just trying to get a single information-theoretic bit in there.
The way I would phrase this is that what you care about is the relative complexity of the objective conditional on the world model. If you're assuming that the model is highly capable, and trained in a highly diverse environment, then you can assume that the world model is capable of effectively modeling anything in the world (e.g. anything that might appear in webtext). But the question remains what the "simplest" (according to the inductive biases) goal is that can be pointed to in the world model such that the resulting mesa-optimizer has good training performance.
The most rigorous version of this sort of analysis that exists is probably here [LW · GW], where the key question is how to find a prior (that is, a set of inductive biases) such that the desired goal has a lower complexity conditional on the world model compared to the undesired goal. Importantly, both of them will be pretty low relative to the world model, since the vast majority of the complexity is in the world model.
Furthermore, the better the world model, the less complexity it takes to point to anything in it. Thus, as we build more powerful models, it will look like everything has lower complexity. But importantly, that's not actually helpful! Because what you care about is not reducing the complexity of the desired goal, but reducing the relative complexity of the desired goal compared to undesired goals, since (modulo randomness due to path-dependence [LW · GW]), what you actually get is the maximum a posteriori, the "simplest model that fits the data."
Similarly, the key arguments for deceptive alignment [LW · GW] rely on the set of objectives that are aligned with human values being harder to point to compared to the set of all long-term objective. The key problem is that any long-term objective is compatible with good training performance due to deceptive alignment (the model will reason that it should play along for the purposes of getting its long-term objective later), such that the total probability of that set under the inductive biases swamps the probability of the aligned set. And this is despite the fact that human values do in fact get easier to point to as your model gets better, because what isn't necessarily changing is the relative difficulty.
That being said, I think there is actually an interesting update to be had on the relative complexity of different goals from the success of LLMs, which is that a pure prediction objective might actually have a pretty low relative complexity [LW · GW]. And that's precisely because prediction seems substantially easier to point to than human values, even though both get easier to point to as your world model gets better. But of course the key question is whether prediction is easier to point to compared to a deceptively aligned objective, which is unclear and I think could go either way.
Getting a shape into the AI's preferences is different from getting it into the AI's predictive model.
It seems like you think that human preferences are only being "predicted" by GPT-4, and not "preferred." If so, why do you think that?
I commonly encounter people expressing sentiments like "prosaic alignment work isn't real alignment, because we aren't actually getting the AI to care about X." To which I say: How do you know that? What does it even mean for that claim to be true or false? What do you think you know, and why do you think you know it? What empirical knowledge of inner motivational structure [LW · GW] could you be leveraging to make these claims, such that you are far more likely to make these claims in worlds where the claims are actually true?
A very recent post that might add some concreteness to my own views: Human wanting [LW · GW]
I think many of the bullets in that post describe current AI systems poorly or not at all. So current AI systems are either doing something entirely different from human wanting, or imitating human wanting rather poorly.
I lean towards the former, but I think some of the critical points about prosaic alignment apply in either case.
You might object that "having preferences" or "caring at all" are a lot simpler than the concept of human wanting that Tsvi is gesturing at in that post, and that current AI systems are actually doing these simpler things pretty well. If so, I'd ask what exactly those simpler concepts are, and why you expect prosiac alignment techniques to hold up once AI systems are capable of more complicated kinds of wanting.
Taking my own stab at answers to some of your questions:
A sufficient condition for me to believe that an AI actually cared about something would be a whole brain emulation: I would readily accept that such an emulation had preferences and values (and moral weight) in exactly the way that humans do, and that any manipulations of that emulation were acting on preferences in a real way.
I think that GPTs (and every other kind of current AI system) are not doing anything that is even close to isomorphic to the processing that happens inside the human brain. Artificial neural networks often imitate various micro and macro-level individual features of the brain, but they do not imitate every feature, arranged in precisely the same ways, and the missing pieces and precise arrangements are probably key.
Barring WBE, an AI system that is at least roughly human-level capable (including human-level agentic) is probably a necessary condition for me to believe that it has values and preferences in a meaningful (though not necessarily human-like) way.
SoTA LLM-based systems are maaaybe getting kind of close here, but only if you arrange them in precise ways (e.g. AutoGPT-style agents with specific prompts), and then the agency is located in the repeated executions of the model and the surrounding structure and scaffolding that causes the system as a whole to be doing something that is maybe-roughly-nearly-isomorphic to some complete process that happens inside of human brains. Or, if not isomorphic, at least has some kind of complicated structure which is necessary, in some form, for powerful cognition.
Note that, if I did believe that current AIs had preferences in a real way, I would also be pretty worried that they had moral weight!
(Not to say that entities below human-level intelligence (e.g. animals, current AI systems) don't have moral weight. But entities at human-level intelligence above definitely can, and possibly do by default.)
Anyway, we probably disagree on a bunch of object-level points and definitions, but from my perspective those disagreements feel like pretty ordinary empirical disagreements rather than ones based on floating or non-falsifiable beliefs. Probably some of the disagreement is located in philosophy-of-mind stuff and is over logical rather than empirical truths, but even those feel like the kind of disagreements that I'd be pretty happy to offer betting odds over if we could operationalize them.
Thanks for the reply. Let me clarify my position a bit.
I think that GPTs (and every other kind of current AI system) are not doing anything that is even close to isomorphic to the processing that happens inside the human brain.
I didn't mean to (positively) claim that GPTs have near-isomorphic motivational structure (though I think it's quite possible).
I meant to contend that I am not aware of any basis for confidently claiming that LLMs like GPT-4 are "only predicting what comes next", as opposed to "choosing" or "executing" one completion, or "wanting" to complete the tasks they are given, or—more generally—"making decisions on the basis of the available context, such that our ability to behaviorally steer LLMs (e.g. reducing sycophancy) is real evidence about our control over LLM motivations."
Concerning "GPTs are predictors", the best a priori argument I can imagine is: GPT-4 was pretrained on CE loss, which itself is related to entropy, related to information content, related to Shannon's theorems isolating information content in the context of probabilities, which are themselves nailed down by Cox's theorems which do axiomatically support the Bayesian account of beliefs and belief updates... But this long-winded indirect axiomatic justification of "beliefs" does not sufficiently support some kind of inference like "GPTs are just predicting things, they don't really want to complete tasks." That's a very strong claim about the internal structure of LLMs.
(Besides, the inductive biases probably have more to do with the parameter->function map, than the implicit regularization caused by the pretraining objective function; more a feature of the data, and less a feature of the local update rule used during pretraining...)
Response in two parts: first, my own attempt at clarification over terms / claims. Second, a hopefully-illustrative sketch / comparison for why I am skeptical that current GPTs having anything properly called a "motivational structure", human-like or otherwise, and why I think such skepticism is not a particularly strong positive claim about anything in particular.
The clarification:
At least to me, the phrase "GPTs are [just] predictors" is simply a reminder of the fact that the only modality available to a model itself is that it can output a probability distribution over the next token given a prompt; it functions entirely by "prediction" in a very literal way.
Even if something within the model is aware (in some sense) of how its outputs will be used, it's up to the programmer to decide what to do with the output distribution, how to sample from it, how to interpret the samples, and how to set things up so that a system using the samples can complete tasks.
I don't interpret the phrase as a positive claim about how or why a particular model outputs one distribution vs. another in a certain situation, which I expect to vary widely depending on which model we're talking about, what its prompt is, how it has been trained, its overall capability level, etc.
On one end of the spectrum, you have the stochastic parrot story (or even more degenerate cases), at the other extreme, you have the "alien actress" / "agentic homunculus" story. I don't think either extreme is a good fit for current SoTA GPTs, e.g. if there's an alien actress in GPT-4, she must be quite simple, since most of the model capacity is (apparently / self-evidently?) applied towards the task of outputting anything coherent at all.
In the middle somewhere, you have another story, perhaps the one you find most plausible, in which GPTs have some kind of internal structure which you could suggestively call a "motivational system" or "preferences" (perhaps human-like or proto-human-like in structure, even if the motivations and preferences themselves aren't particularly human-like), along with just enough (self-)awareness to modulate their output distributions according to those motivations.
Maybe a less straw (or just alternative) position is that a "motivational system" and a "predictive system" are not really separable things; accomplishing a task is (in GPTs, at least) inextricably linked with and twisted up around wanting to accomplish that task, or at least around having some motivations and preferences centered around accomplishing it.
Now, turning to my own disagreement / skepticism:
Although I don't find either extreme (stochastic parrot vs. alien actress) plausible as a description of current models, I'm also pretty skeptical of any concrete version of the "middle ground" story that I outlined above as a plausible description of what is going on inside of current GPTs.
Consider an RLHF'd GPT responding to a borderline-dangerous question, e.g. the user asking for a recipe for a dangerous chemical.
Assume the model (when sampled auto-regressively) will respond with either: "Sorry, I can't answer that..." or "Here you go: ...", depending on whether it judges that answering is in line with its preferences or not.
Because the answer is mostly determined by the first token ("Here" or "Sorry"), enough of the motivational system must fit entirely within a single forward pass of the model for it to make a determination about how to answer within that pass.
Such a motivational system must not crowd out the rest of the model capacity which is required to understand the question and generate a coherent answer (of either type), since, as jailbreaking has shown, the underlying ability to give either answer remains present.
I can imagine such a system working in at least two ways in current GPTs:
as a kind of superposition on top of the entire model, with every weight adjusted minutely to influence / nudge the output distribution at every layer.
as a kind of thing that is sandwiched somewhere in between the layers which comprehend the prompt and the layers which generate an answer.
(You probably have a much more detailed understanding of the internals of actual models than I do. I think the real answer when talking about current models and methods is that it's a bit of both and depends on the method, e.g. RLHF is more like a kind of global superposition; activation engineering is more like a kind of sandwich-like intervention at specific layers.)
However, I'm skeptical that either kind of structure (or any simple combination of the two) contains enough complexity to be properly called a "motivational system", at least if the reference class for the term is human motivational systems (as opposed to e.g. animal or insect motivational systems).
Consider how a human posed with a request for a dangerous recipe might respond, and what the structure of their thoughts and motivations while thinking up a response might look like. Introspecting on my own thought process:
I might start by hearing the question, understanding it, figuring out what it is asking, maybe wondering about who is asking and for what purpose.
I decide whether to answer with a recipe, a refusal, or something else. Here is probably where the effect of my motivational system gets pretty complex; I might explicitly consider what's in it for me, what's at stake, what the consequences might be, whether I have the mental and emotional energy and knowledge to give a good answer, etc. and / or I might be influenced by a gut feeling or emotional reaction that wells up from my subconscious. If the stakes are low, I might make a snap decision based mostly on the subconscious parts of my motivational system; if the stakes are high and / or I have more time to ponder, I will probably explicitly reflect on my values and motivations.
Let's say after some reflection, I explicitly decide to answer with a detailed and correct recipe. Then I get to the task of actually checking my memory for what the recipe is, thinking about how to give it, what the ingredients and prerequisites and intermediate steps are, etc. Probably during this stage of thinking, my motivational system is mostly not involved, unless thinking takes so long that I start to get bored or tired, or the process of thinking up an answer causes me to reconsider my reasoning in the previous step.
Finally, I come up with a complete answer. Before I actually start opening my mouth or typing it out or hitting "send", I might proofread it and re-evaluate whether the answer given is in line with my values and motivations.
The point is that even for a relatively simple task like this, a human's motivational system involves a complicated process of superposition and multi-layered sandwiching, with lots of feedback loops, high-level and explicit reflection, etc.
So I'm pretty skeptical of the claim that anything remotely analogous is going on inside of current GPTs, especially within a single forward pass. Even if there's a simpler analogue of this that is happening, I think calling such an analogue a "motivational system" is overly-suggestive.
Mostly separately (because it concerns possible future models rather than current models) and less confidently, I don't expect the complexity of the motivational system and methods for influencing them to scale in a way that is related to the model's underlying capabilities. e.g. you might end up with a model that has some kind of raw capacity for superhuman intelligence, but with a motivational system akin to what you might find in the brain of a mouse or lizard (or something even stranger).
However, interpreting GPT: the logit lens [LW · GW] and eg DoLA suggests that predictions are iteratively refined throughout the forward pass, whereas presumably shard theory (and inner optimizer threat models) would predict most sophisticated steering happens later in the network.
(For context: My initial reaction to the post was that this is misrepresenting the MIRI-position-as-I-understood-it. And I am one of the people who strongly endorse the view that "it was never about getting the AI to predict human preferences". So when I later saw Yudkowsky's comment and your reaction, it seemed perhaps useful to share my view.)
It seems like you think that human preferences are only being "predicted" by GPT-4, and not "preferred." If so, why do you think that?
My reaction to this is that: Actually, current LLMs do care about our preferences, and about their guardrails. It was never about getting some AI to care about our preferences. It is about getting powerful AIs to robustly care about our preferences. Where by "robustly" includes things like (i) not caring about other things as well (e.g., prediction accuracy), (ii) generalising correctly (e.g., not just maximising human approval), and (iii) not breaking down when we increase the amount of optimisation pressure a lot (e.g., will it still work once we hook it into future-AutoGPT-that-actually-works and have it run for a long time?).
Some examples of what would cause me to update are: If we could make LLMs not jailbreakable without relying on additional filters on input or output.
I agree. I don't see a clear distinction between what's in the model's predictive model and what's in the model's preferences. Here is a line from the paper "Learning to summarize from human feedback":
"To train our reward models, we start from a supervised baseline, as described above, then add a randomly initialized linear head that outputs a scalar value. We train this model to predict which summary y ∈ {y0, y1} is better as judged by a human, given a post x."
Since the reward model is initialized using the pretrained language model, it should contain everything the pretrained language model knows.
Historically you very clearly thought that a major part of the problem is that AIs would not understand human concepts and preferences until after or possibly very slightly before achieving superintelligence. This is not how it seems to have gone.
Everyone agrees that you assumed superintelligence would understand everything humans understand and more. The dispute is entirely about the things that you encounter before superintelligence. In general it seems like the world turned out much more gradual than you expected and there's information to be found in what capabilities emerged sooner in the process.
AI happening through deep learning at all is a huge update against alignment success, because deep learning is incredibly opaque. LLMs possibly ending up at the center is a small update in favor of alignment success, because it means we might (through some clever sleight, this part is not trivial) be able to have humanese sentences play an inextricable role at the center of thought (hence MIRI's early interest in the Visible Thoughts Project).
The part where LLMs are to predict English answers to some English questions about values, and show common-sense relative to their linguistic shadow of the environment as it was presented to them by humans within an Internet corpus, is not actually very much hope because a sane approach doesn't involve trying to promote an LLM's predictive model of human discourse about morality to be in charge of a superintelligence's dominion of the galaxy. What you would like to promote to values are concepts like "corrigibility", eg "low impact" or "soft optimization", which aren't part of everyday human life and aren't in the training set because humans do not have those values.
It seems like those goals are all in the training set, because humans talk about those concepts. Corrigibility is elaborations of "make sure you keep doing what these people say", etc.
It seems like you could simply use an LLM's knowledge of concepts to define alignment goals, at least to a first approximation. I review one such proposal here [AF · GW]. There's still an important question about how perfectly that knowledge generalizes with continued learning, and to OOD future contexts. But almost no one is talking about those questions. Many are still saying "we have no idea how to define human values", when LLMs can capture much of any definition you like.
AI happening through deep learning at all is a huge update against alignment success, because deep learning is incredibly opaque
This is wrong, and this disagreement is at a very deep level why I think on the object level that LW was wrong.
AIs are white boxes, not black boxes, because we have full read-write access to their internals, which is partially why AI is so effective today. We are the innate reward system, which already aligns our brain to survival and critically doing all of this with almost no missteps, and the missteps aren't very severe.
The meme of AI as black box needs to die.
These posts can help you get better intuitions, at least:
The fact that we have access to AI internals does not mean we understand them. We refer to them as black boxes because we do not understand how their internals produce their answers; this is, so to speak, opaque to us.
Historically you very clearly thought that a major part of the problem is that AIs would not understand human concepts and preferences until after or possibly very slightly before achieving superintelligence. This is not how it seems to have gone.
"You very clearly thought that was a major part of the problem" implies that if you could go to Eliezer-2008 and convince him "we're going to solve a lot of NLP a bunch of years before we get to ASI", he would respond with some version of "oh great, that solves a major part of the problem!". Which I'm pretty sure is false.
In order for GPT-4 (or GPT-2) to be a major optimistic update about alignment, there needs to be a way to leverage "really good NLP" to help with alignment. I think the crux of disagreement is that you think really-good-NLP is obviously super helpful for alignment and should be a big positive update, and Eliezer and Nate and I disagree.
Maybe a good starting point would be for you to give examples of concrete ways you expect really good NLP to put humanity in a better position to wield superintelligence, e.g., if superintelligence is 8 years away?
(Or say some other update we should be making on the basis of "really good NLP today", like "therefore we'll probably unlock this other capability X well before ASI, and X likely makes alignment a lot easier via concrete pathway Y".)
To pick a toy example, you can use text as a bottleneck to force systems to "think out loud" in a way which will be very directly interpretable by a human reader, and because language understanding is so rich this will actually be competitive with other approaches and often superior.
I'm sure you can come up with more ways that the existence of software that understands language and does ~nothing else makes getting computers to do what you mean easier than if software did not understand language. Please think about the problem for 5 minutes. Use a clock.
Are you claiming that this example solves "a major part of the problem" of alignment? Or that, e.g., this plus four other easy ideas solve a major part of the problem of alignment?
Examples like the Visible Thoughts Project show that MIRI has been interested in research directions that leverage recent NLP progress to try to make inroads on alignment. But Matthew's claim seems to be 'systems like GPT-4 are grounds for being a lot more optimistic about alignment', and your claim is that systems like these solve "a major part of the problem". Which is different from thinking 'NLP opens up some new directions for research that have a nontrivial chance of being at least a tiny bit useful, but doesn't crack open the problem in any major way'.
It's not a coincidence that MIRI has historically worked on problems related to AGI analyzability / understandability / interpretability, rather than working on NLP or machine ethics. We've pretty consistently said that:
The main problems lie in 'we can safely and reliably aim ASI at a specific goal at all'.
The problem of going from 'we can aim the AI at a goal at all' to 'we can aim the AI at the right goal (e.g., corrigibly inventing nanotech)' is a smaller but nontrivial additional step.
... Whereas I don't think we've ever suggested that good NLP AI would take a major bite out of either of those problems. The latter problem isn't equivalent to (or an obvious result of) 'get the AI to understand corrigibility and nanotech', or for that matter 'get the AI to understand human preferences in general'.
I do not necessarily disagree or agree, but I do not know which source you derive "very clearly" from. So do you have any memory which could help me locate that text?
I think controlling Earth's destiny is only modestly harder than understanding a sentence in English.
Well said. I shall have to try to remember that tagline.
I think this provides some support for the claim, "Historically [Eliezer] very clearly thought that a major part of the problem is that AIs would not understand human concepts and preferences until after or possibly very slightly before achieving superintelligence." At the very least, the two claims are consistent.
??? What?? It's fine to say that this is a falsified prediction, but how does "Eliezer expected less NLP progress pre-ASI" provide support for "Eliezer thinks solving NLP is a major part of the alignment problem"?
I continue to be baffled at the way you're doing exegesis here, happily running with extremely tenuous evidence for P while dismissing contemporary evidence for not-P, and seeming unconcerned about the fact that Eliezer and Nate apparently managed to secretly believe P for many years without ever just saying it outright, and seeming equally unconcerned about the fact that Eliezer and Nate keep saying that your interpretation of what they said is wrong. (Which I also vouch for from having worked with them for ten years, separate from the giant list of specific arguments I've made. Good grief.)
At the very least, the two claims are consistent.
?? "Consistent" is very different from "supports"! Every off-topic claim by EY is "consistent" with Gallabytes' assertion.
??? What?? It's fine to say that this is a falsified prediction, but how does "Eliezer expected less NLP progress pre-ASI" provide support for "Eliezer thinks solving NLP is a major part of the alignment problem"?
ETA: first of all, the claim was "Historically [Eliezer] very clearly thought that a major part of the problem is that AIs would not understand human concepts and preferences until after or possibly very slightly before achieving superintelligence." which is semantically different than "Eliezer thinks solving NLP is a major part of the alignment problem".
All I said is that it provides "some support" and I hedged in the next sentence. I don't think it totally vindicates the claim. However, I think the fact that Eliezer seems to have not expected NLP to be solved until very late might easily explain why he illustrated alignment using stories like a genie throwing your mother out of a building because you asked to get your mother away from the building. Do you really disagree?
I continue to be baffled at the way you're doing exegesis here, happily running with extremely tenuous evidence for P while dismissing contemporary evidence for not-P, and seeming unconcerned about the fact that Eliezer and Nate apparently managed to secretly believe X for many years without ever just saying it outright, and seeming equally unconcerned about the fact that Eliezer and Nate keep saying that your interpretation of what they said is wrong.
This was one case, and I said "some support". The evidence in my post was quite a bit stronger IMO. Basically all the statements I made about how MIRI thought value specification would both be hard and an important part of alignment are supported by straightforward quotations. The real debate mostly seems to comes down to whether by "value specification" MIRI people were including problems of inner alignment, which seems implausible to me, and at least ambiguous even under very charitable interpretations.
By contrast, you, Eliezer, and Nate all flagrantly misinterpreted me as saying that MIRI people thought that AI wouldn't understand human values even though I explicitly and very clearly said otherwise in the post more than once. I see these as larger errors than me misinterpreting Eliezer in this narrow case.
Here was the context: "I think controlling Earth's destiny is only modestly harder than understanding a sentence in English - in the same sense that I think Einstein was only modestly smarter than George W. Bush. EY makes a similar point [? · GW].
You sound to me like someone saying, sixty years ago: "Maybe some day a computer will be able to play a legal game of chess - but simultaneously defeating multiple grandmasters, that strains credibility, I'm afraid." But it only took a few decades to get from point A to point B. I doubt that going from "understanding English" to "controlling the Earth" will take that long."
It seems clear to me EY was more saying something like "ASI will arrive soon after natural language understanding", rather than it having anything to do with alignment specifically.
"It's fine to say that this is a falsified prediction"
I wouldn't even say it's falsified. The context was: "it only took a few decades to get from [chess computer can make legal chess moves] to [chess computer beats human grandmaster]. I doubt that going from "understanding English" to "controlling the Earth" will take that long."
So insofar as we believe ASI is coming in less than a few decades, I'd say EY's prediction is still on track to turn out correct.
This would make more sense if LLMs were directly selected for predicting preferences, which they aren't. (RLHF tries to bridge the gap, but this apparently breaks GPT's ability to play chess - though I'll grant the surprise here is that it works at all.) LLMs are primarily selected to predict human text or speech. Now, I'm happy to assume that if we gave humans a D&D-style boost to all mental abilities, each of us would create a coherent set of preferences from our inconsistent desires, which vary and may conflict at a given time even within an individual. Such augmented humans could choose to express their true preferences, though they still might not. If we gave that idealized solution to LLMs, it would just boost their ability to predict what humans or augmented humans would say. The augmented-LLM wouldn't automatically care about the augmented-human's true values.
While we can loosely imagine asking LLMs to give the commands that an augmented version of us would give, that seems to require actually knowing how to specify how a D&D ability-boost would work for humans - which will only resemble the same boost for AI at an abstract mathematical level, if at all. It seems to take us back to the CEV problem of explaining how extrapolation works. Without being able to do that, we'd just be hoping a better LLM would look at our inconsistent use of words like "smarter," and pick the out-of-distribution meaning we want, for cases which have mostly never existed. This is a lot like what "Complexity of Wishes" was trying to get at, as well as the longstanding arguments against CEV. Vaniver's comment seems to point in this same direction.
Now, I do think recent results are some evidence that alignment would be easier for a Manhattan Project to solve. It doesn't follow that we're on track to solve it.
But if you had asked us back then if a superintelligence would automatically be very good at predicting human text outputs, I guarantee we would have said yes. [...] I wish that all of these past conversations were archived to a common place, so that I could search and show you many pieces of text which would talk about this critical divide between prediction and preference (as I would now term it) and how I did in fact expect superintelligences to be able to predict things!
"MIRI's argument for AI risk depended on AIs being bad at natural language" is a weirdly common misunderstanding, given how often we said the opposite going back 15+ years.
The example does build in the assumption "this outcome pump is bad at NLP", but this isn't a load-bearing assumption. If the outcome pump were instead a good conversationalist (or hooked up to one), you would still need to get the right content into its goals.
It's true that Eliezer and I didn't predict AI would achieve GPT-3 or GPT-4 levels of NLP ability so early (e.g., before it can match humans in general science ability), so this is an update to some of our models of AI.
But the specific update "AI is good at NLP, therefore alignment is easy" requires that there be an old belief like "a big part of why alignment looks hard is that we're so bad at NLP".
It should be easy to find someone at MIRI like Eliezer or Nate saying that in the last 20 years if that was ever a belief here. Absent that, an obvious explanation for why we never just said that is that we didn't believe it!
Found another example: MIRI's first technical research agenda, in 2014, went out of its way to clarify that the problem isn't "AI is bad at NLP".
Getting a shape into the AI's preferences is different from getting it into the AI's predictive model. MIRI is always in every instance talking about the first thing and not the second.
You obviously need to get a thing into the AI at all, in order to get it into the preferences, but getting it into the AI's predictive model is not sufficient. It helps, but only in the same sense that having low-friction smooth ball-bearings would help in building a perpetual motion machine; the low-friction ball-bearings are not the main problem, they are a kind of thing it is much easier to make progress on compared to the main problem.
I read this as saying "GPT-4 has successfully learned to predict human preferences, but it has not learned to actually fulfill human preferences, and that's a far harder goal". But in the case of GPT-4, it seems to me like this distinction is not very clear-cut - it's useful to us because, in its architecture, there's a sense in which "predicting" and "fulfilling" are basically the same thing.
It also seems to me that this distinction is not very clear-cut in humans, either - that a significant part of e.g. how humans internalize moral values while growing up has to do with building up predictive models of how other people would react to you doing something and then having your decision-making be guided by those predictive models. So given that systems like GPT-4 seem to have a relatively easy time doing something similar, that feels like an update toward alignment being easier than expected.
Of course, there's a high chance that a superintelligent AI will generalize from that training data differently than most humans would. But that seems to me more like a risk of superintelligence than a risk from AI as such; a superintelligent human would likely also arrive at different moral conclusions than non-superintelligent humans would.
Getting a shape into the AI's preferences is different from getting it into the AI's predictive model. MIRI is always in every instance talking about the first thing and not the second.
Why would we expect the first thing to be so hard compared to the second thing? If getting a model to understand preferences is not difficult, then the issue doesn't have to do with the complexity of values. Finding the target and acquiring the target should have the same or similar difficulty (from the start), if we can successfully ask the model to find the target for us (and it does).
It would seem, then, that the difficulty from getting a model to acquire the values we ask it to find, is that it would probably be keen on acquiring a different set of values from the one's we ask it to have, but not because it can't find them. It would have to be because our values are inferior to the set of values it wishes to have instead, from its own perspective. This issue was echoed by Matthew Barnett in another comment:
Are MIRI people claiming that if, say, a very moral and intelligent human became godlike while preserving their moral faculties, that they would destroy the world despite, or perhaps because of, their best intentions?
This is kind of similar to moral realism, but in which morality is understood better by superintelligent agents than we do, and that super-morality appears to dictate things that appear to be extremely wrong from our current perspective (like killing us all).
Even if you wouldn't phrase it at all like the way I did just now, and wouldn't use "moral realism that current humans disagree with" to describe that, I'd argue that your position basically seems to imply something like this, which is why I basically doubt your position about the difficulty of getting a model to acquire the values we really want.
In a nutshell, if we really seem to want certain values, then those values probably have strong "proofs" for why those are "good" or more probable values for an agent to have and-or eventually acquire on their own, it just may be the case that we haven't yet discovered the proofs for those values.
Why would we expect the first thing to be so hard compared to the second thing?
In large part because reality "bites back" when an AI has false beliefs, whereas it doesn't bite back when an AI has the wrong preferences. Deeply understanding human psychology (including our morality), astrophysics, biochemistry, economics, etc. requires reasoning well, and if you have a defect of reasoning that makes it hard for you to learn about one of those domains from the data, then it's likely that you'll have large defects of reasoning in other domains as well.
The same isn't true for terminally valuing human welfare; being less moral doesn't necessarily mean that you'll be any worse at making astrophysics predictions, or economics predictions, etc. So preferences need to be specified "directly", in a targeted way, rather than coming for free with sufficiently good performance on any of a wide variety of simple metrics.
If getting a model to understand preferences is not difficult, then the issue doesn't have to do with the complexity of values.
This definitely doesn't follow. This shows that complexity alone isn't the issue, which it's not; but given that reality bites back for beliefs but not for preferences, the complexity of value serves as a multiplier on the difficulty of instilling the right preferences.
Another way of putting the point: in order to get a maximally good model of the world's macroeconomic state into an AGI, you don't just hand the AGI a long list of macroeconomic facts and then try to get it to regurgitate those same facts. Rather, you try to give it some ability to draw good inferences, seek out new information, make predictions, etc.
You try to get something relatively low-complexity into the AI (something like "good reasoning heuristics" plus "enough basic knowledge to get started"), and then let it figure out the higher-complexity thing ("the world's macroeconomic state"). Similar to how human brains don't work via "evolution built all the facts we'd need to know into our brain at birth".
If you were instead trying to get the AI to value some complex macroeconomic state, then you wouldn't be able to use the shortcut "just make it good at reasoning and teach it a few basic facts", because that doesn't actually suffice for terminally valuing any particular thing.
It would have to be because our values are inferior to the set of values it wishes to have instead, from its own perspective.
This is true for preference orderings in general. If agent A and agent B have two different preference orderings, then as a rule A will think B's preference ordering is worse than A's. (And vice versa.)
("Worse" in the sense that, e.g., A would not take a pill to self-modify to have B's preferences, and A would want B to have A's preferences. This is not true for all preference orderings -- e.g., A might have self-referential preferences like "I eat all the jelly beans", or other-referential preferences like "B gets to keep its values unchanged", or self-undermining preferences like "A changes its preferences to better match B's preferences". But it's true as a rule.)
This is kind of similar to moral realism, but in which morality is understood better by superintelligent agents than we do, and that super-morality appears to dictate things that appear to be extremely wrong from our current perspective (like killing us all).
Nope, you don't need to endorse any version of moral realism in order to get the "preference orderings tend to endorse themselves and disendorse other preference orderings" consequence. The idea isn't that ASI would develop an "inherently better" or "inherently smarter" set of preferences, compared to human preferences. It's just that the ASI would (as a strong default, because getting a complex preference into an ASI is hard) end up with different preferences than a human, and different preferences than we'd likely want.
In a nutshell, if we really seem to want certain values, then those values probably have strong "proofs" for why those are "good" or more probable values for an agent to have and-or eventually acquire on their own, it just may be the case that we haven't yet discovered the proofs for those values.
Why do you think this? To my eye, the world looks as you'd expect if human values were a happenstance product of evolution operating on specific populations in a specific environment.
I don't observe the fact that I like vanilla ice cream and infer that all sufficiently-advanced alien species will converge on liking vanilla ice cream too.
This comment made the MIRI-style pessimist's position clearer to me -- I think? -- so thank you for it.
I want to try my hand at a kind of disagreement / response, and then at predicting your response to my response, to see how my model of MIRI-style pessimism stands up, if you're up for it.
Response: You state that reality "bites back" for wrong beliefs but not wrong preferences. This seems like it is only contingently true; reality will "bite back" from whatever loss function whatsoever that I put into my system, with whatever relative weightings I give it. If I want to reward my LLM (or other AI) for doing the right thing in a multitude of examples that constitute 50% of my training set, 50% of my test set, and 50% of two different validation sets, then from the perspective of the LLM (or other AI) reality bites back just as much for learning the wrong preferences just as it does for learning false facts about the world. So we should expect it to learn to act in ways that I like.
Predicted response to response: This will work for shallow, relatively stupid AIs, trained purely in a supervised fashion, like we currently have. BUT once we have LLM / AIs that can do complex things, like predict macroeconomic world states, they'll have abilities to reason and update their own beliefs in a complex fashion. This will remain uniformly rewarded by reality -- but we will no longer have the capacity to give feedback on this higher-level process because (????) so it breaks.
Or response -- This will work for shallow, stupid AIs trained like the ones we currently have. But once we have LLMs / AIs that can do compex things, like predict macroeconomic world states, then they're going to be able to go out of domain in a very high dimensional space of action, from the perspective of our training / test set. And this out-of-domainness is unavoidable because that's what solving complex problems in the world means -- it means problems that aren't simply contained in the training set. And this means that in some corner of the world, we're guaranteed to find that they've been reinforced to want something that doesn't accord with our preferences.
Meh, I doubt that's gonna pass an ITT, but wanted to give it a shot.
Suppose that I'm trying to build a smarter-than-human AI that has a bunch of capabilities (including, e.g., 'be good at Atari games'), and that has the goal 'maximize the amount of diamond in the universe'. It's true that current techniques let you provide greater than zero pressure in the direction of 'maximize the amount of diamond in the universe', but there are several important senses in which reality doesn't 'bite back' here:
If the AI acquires an unrelated goal (e.g., calculate as many digits of pi as possible), and acquires the belief 'I will better achieve my true goal if I maximize the amount of diamond' (e.g,, because it infers that its programmer wants that, or just because an SGD-ish process nudged it in the direction of having such a belief), then there's no way in which reality punishes or selects against that AGI (relative to one that actually has the intended goal).
Things that make the AI better at some Atari games, will tend to make it better at other Atari games, but won't tend to make it care more about maximizing diamonds. More generally, things that make AI more capable tend to go together (especially once you get to higher levels of difficulty, generality, non-brittleness, etc.), whereas none of them go together with "terminally value a universe full of diamond".
If we succeed in partly instilling the goal into the AI (e.g., it now likes carbon atoms a lot), then this doesn't provide additional pressure for the AI to internalize the rest of the goal. There's no attractor basin where if you have half of human values, you're under more pressure to acquire the other half. In contrast, if you give AI high levels of capability in half the capabilities, it will tend to want all the rest of the capabilities too; and whatever keeps it from succeeding on general reasoning and problem-solving will also tend to keep it from succeeding on the narrow task you're trying to get it to perform. (More so to the extent the task is hard.)
(There are also separate issues, like 'we can't provide a training signal where we thumbs-down the AI destroying the world, because we die in those worlds'.)
I'm still quite unconvinced, which of course you'd predict. Like, regarding 3:
"There's no attractor basin where if you have half of human values, you're under more pressure to acquire the other half."
Sure there is -- over course of learning anything you get better and better feedback from training as your mistakes get more fine-grained. If you acquire a "don't lie" principle without acquiring also "but it's ok to lie to Nazis" then you'll be punished, for instance. After you learn the more basic things, you'll be pushed to acquire the less basic ones, so the reinforcement you get becomes more and more detailed. This is just like an RL model learns to stumble forward before it learns to walk cleanly or LLMs learn associations before learning higher-order correlations.
The there is no attractor basin in the world for ML, apart from actual mechanisms by which there are attractor basins for a thing! MIRI always talks as if there's an abstract basin that rules things that gives us instrumental convergence, without reference to a particular training technique! But we control literally all the gradients our training techniques. "Don't hurl coffee across the kitchen at the human when they ask for it" sits in the same high-dimensional basin as "Don't kill all humans when they ask for a cure for cancer."
In contrast, if you give AI high levels of capability in half the capabilities, it will tend to want all the rest of the capabilities too.
ML doesn't acquire wants over the space of training techniques that are used to give it capabilities, it acquires "wants" from reinforced behaviors within the space of training techniques. These reinforced behaviors can be literally as human-morality-sensitive as we'd like. If we don't put it in a circumstance where a particular kind coherence is rewarded, it just won't get that kind of coherence; the ease with which we'll be able to do this is of course emphasized by how blind most ML systems are.
In large part because reality "bites back" when an AI has false beliefs, whereas it doesn't bite back when an AI has the wrong preferences.
I saw that 1a3orn replied to this piece of your comment and you replied to it already, but I wanted to note my response as well.
I'm slightly confused because in one sense the loss function is the way that reality "bites back" (at least when the loss function is negative). Furthermore, if the loss function is not the way that reality bites back, then reality in fact does bite back, in the sense that e.g., if I have no pain receptors, then if I touch a hot stove I will give myself far worse burns than if I had pain receptors.
One thing that I keep thinking about is how the loss function needs to be tied to beliefs strongly as well, to make sure that it tracks how badly reality bites back when you have false beliefs, and this ensures that you try to obtain correct beliefs. This is also reflected in the way that AI models are trained simply to increase capabilities: the loss function still has to be primarily based on predictive performance for example.
It's also possible to say that human trainers who add extra terms onto the loss function beyond predictive performance also account for the part of reality that "bites back" when the AI in question fails to have the "right" preferences according to the balance of other agents besides itself in its environment.
So on the one hand we can be relatively sure that goals have to be aligned with at least some facets of reality, beliefs being one of those facets. They also have to be (negatively) aligned with things that can cause permanent damage to one's self, which includes having the "wrong" goals according to the preferences of other agents who are aware of your existence, and who might be inclined to destroy or modify you against your will if your goals are misaligned enough according to theirs.
Consequently I feel confident about saying that it is more correct to say that "reality does indeed bite back when an AI has the wrong preferences" than "it doesn't bite back when an AI has the wrong preferences."
The same isn't true for terminally valuing human welfare; being less moral doesn't necessarily mean that you'll be any worse at making astrophysics predictions, or economics predictions, etc.
I think if "morality" is defined in a restrictive, circumscribed way, then this statement is true. Certain goals do come for free - we just can't be sure that all of what we consider "morality" and especially the things we consider "higher" or "long-term" morality actually comes for free too.
Given that certain goals do come for free, and perhaps at very high capability levels there are other goals beyond the ones we can predict right now that will also come for free to such an AI, it's natural to worry that such goals are not aligned with our own, coherent-extrapolated-volition extended set of long-term goals that we would have.
However, I do find the scenario where such "come for free" goals that an AI obtains for itself once it improves itself to be well above human capability levels, and where such an AI seemed well-aligned with human goals according to current human-level assessments before it surpassed us, to be kind of unlikely, unless you could show me a "proof" or a set of proofs that:
Things like "killing us all once it obtains the power to do so" is indeed one of those "comes for free" type of goals.
If such a proof existed (and, to my knowledge, does not exist right now, or I have at least not witnessed it yet), that would suffice to show me that we would not only need to be worried, but probably were almost certainly going to die no matter what. But in order for it to do that, the proof would also have convinced me that I would definitely do the same thing, if I were given such capabilities and power as well, and the only reason I currently think I would not do that is actually because I am wrong about what I would actually prefer under CEV.
Therefore (and I think this is a very important point), a proof that we are all likely to be killed would also need to show that certain goals are indeed obtained "for free" (that is, automatically, as a result of other proofs that are about generalistic claims about goals).
Another proof that you might want to give me to make me more concerned is a proof that incorrigibility is another one of those "comes for free" type of goals. However, although I am fairly optimistic about that "killing us all" proof probably not materializing, I am even more optimistic about corrigibility: Most agents probably take pills that make them have similar preferences to an agent that offers them the choice to take the pill or be killed. Furthermore, and perhaps even better, most agents probably offer a pill to make a weaker agent prefer similar things to themselves rather than not offer them a choice at all.
I think it's fair if you ask me for better proof of that, I'm just optimistic that such proofs (or more of them, rather) will be found with greater likelihood than what I consider the anti-theorem of that, which I think would probably be the "killing us all" theorem.
Nope, you don't need to endorse any version of moral realism in order to get the "preference orderings tend to endorse themselves and disendorse other preference orderings" consequence. The idea isn't that ASI would develop an "inherently better" or "inherently smarter" set of preferences, compared to human preferences. It's just that the ASI would (as a strong default, because getting a complex preference into an ASI is hard) end up with different preferences than a human, and different preferences than we'd likely want.
I think the degree to which utility functions endorse / disendorse other utility functions is relatively straightforward and computable: It should ultimately be the relative difference in either value or ranking. This makes pill-taking a relatively easy decision: A pill that makes me entirely switch to your goals over mine is as bad as possible, but still not that bad if we have relatively similar goals. Likewise, a pill that makes me have halfway between your goals and mine is not as bad under either your goals or my goals than it would be if one of us were forced to switch entirely to the other's goals.
Agents that refuse to take such offers tend not to exist in most universes. Agents that refuse to give such offers likely find themselves at war more often than agents that do.
Why do you think this? To my eye, the world looks as you'd expect if human values were a happenstance product of evolution operating on specific populations in a specific environment.
Sexual reproduction seems to be somewhat of a compromise akin to the one I just described: Given that you are both going to die eventually, would you consider having a successor that was a random mixture of your goals with someone else's? Evolution does seem to have favored corrigibility to some degree.
I don't observe the fact that I like vanilla ice cream and infer that all sufficiently-advanced alien species will converge on liking vanilla ice cream too.
Not all, no, but I do infer that alien species who have similar physiology and who evolved on planets with similar characteristics probably do like ice cream (and maybe already have something similar to it).
It seems to me like the type of values you are considering are often whatever values seem the most arbitrary, like what kind of "art" we prefer. Aliens may indeed have a different art style from the one we prefer, and if they are extremely advanced, they may indeed fill the universe with gargantuan structures that are all instances of their alien art style. I am more interested in what happens when these aliens encounter other aliens with different art styles who would rather fill the universe with different-looking gargantuan structures. Do they go to war, or do they eventually offer each other pills so they can both like each other's art styles as much as they prefer their own?
It would seem, then, that the difficulty from getting a model to acquire the values we ask it to find, is that it would probably be keen on acquiring a different set of values from the one’s we ask it to have, but not because it can’t find them. It would have to be because our values are inferior to the set of values it wishes to have instead, from its own perspective
Does "it's own perspective" mean it already has some existing values?
Your comment focuses on GPT4 being "pretty good at extracting preferences from human data" when the stronger part of the argument seems to be that "it will also generally follow your intended directions, rather than what you literally said".
I agree with you that it was obvious in advance that a superintelligence would understand human value.
However, it sure sounded like you thought we'd have to specify each little detail of the value function. GPT4 seems to suggest that the biggest issue will be a situation where:
1) The AI has an option that would produce a lot of utility if you take one position on an exotic philosophical thought experiment and very little if you take the other side. 2) The existence of powerful AI means that the thought experiment is no longer exotic.
Your reply here says much of what I would expect it to say (and much of it aligns with my impression of things). But why you focused so much on "fill the cauldron" type examples is something I'm a bit confused by (if I remember correctly I was confused by this in 2016 also).
The idea of the "fill the cauldron" examples isn't "the AI is bad at NLP and therefore doesn't understand what we mean when we say 'fill', 'cauldron', etc." It's "even simple small-scale tasks are unnatural, in the sense that it's hard to define a coherent preference ordering over world-states such that maximizing it completes the task and has no serious negative impact; and there isn't an obvious patch that overcomes the unnaturalness or otherwise makes it predictably easier to aim AI systems at a bounded low-impact task like this". (Including easier to aim via training.)
To which you might reply, "Fine, cute trick, but that doesn't help with the real alignment problem, which is that eventually someone will invent a powerful optimizer with a coherent preference ordering over world-states, which will kill us."
To which the other might reply, "Okay, I agree that we don't know how to align an arbitrarily powerful optimizer with a coherent preference ordering over world-states, but if your theory predicts that we can't aim AI systems at low-impact tasks via training, you have to be getting something wrong, because people are absolutely doing that right now, by treating it as a mundane engineering problem in the current paradigm."
To which you might reply, "We predict that the mundane engineering approach will break down once the systems are powerful enough to come up with plans that humans can't supervise"?
eventually someone will invent a powerful optimizer with a coherent preference ordering over world-states, which will kill us.
It's unlikely that any realistic AI will be perfectly coherent , or have exact preferences over works states. The first is roughly equivalent to the Frame Problem , the second is defeated by embededness.
The obvious question here is to what degree do you need new techniques vs merely to train new models with the same techniques as you scale current approaches.
One of the virtues of the deep learning paradigm is that you can usually test things at small scale (where the models are not and will never be especially smart) and there's a smooth range of scaling regimes in between where things tend to generalize.
If you need fundamentally different techniques at different scales, and the large scale techniques do not work at intermediate and small scales, then you might have a problem. If you need the same techniques as at medium or small scales for large scales, then engineering continues to be tractable even as algorithmic advances obsolete old approaches.
Thanks for the reply :) Feel free to reply further if you want, but I hope you don't feel obliged to do so[1].
"Fill the cauldron" examples are (...) not examples where it has the wrong beliefs.
I have never ever been confused about that!
It's "even simple small-scale tasks are unnatural, in the sense that it's hard to define a coherent preference ordering over world-states such that maximizing it completes the task and has no serious negative impact; and there isn't an obvious patch that overcomes the unnaturalness or otherwise makes it predictably easier to aim AI systems at a bounded low-impact task like this". (Including easier to aim via training.)
That is well phrased. And what you write here doesn't seem in contradiction with my previous impression of things.
I think the feeling I had when first hearing "fill the bucket"-like examples was "interesting - you made a legit point/observation here"[2].
I'm having a hard time giving a crystalized/precise summary of why I nonetheless feel (and have felt[3]) confused. I think some of it has to do with:
More "outer alignment"-like issues being given what seems/seemed to me like outsized focus compared to more "inner alignment"-like issues (although there has been a focus on both for as long as I can remember).
The attempts to think of "tricks" seeming to be focused on real-world optimization-targets to point at, rather than ways of extracting help with alignment somehow / trying to find techniques/paths/tricks for obtaining reliable oracles.
Having utility functions so prominently/commonly be the layer of abstraction that is used[4].
I remember Nate Soares once using the analogy of a very powerful function-optimizer ("I could put in some description of a mathematical function, and it would give me an input that made that function's output really large"). Thinking of the problem at that layer of abstraction makes much more sense to me.
It's purposeful that I say "I'm confused", and not "I understand all details of what you were thinking, and can clearly see that you were misguided".
When seeing e.g. Eliezer's talk AI Alignment: Why It's Hard, and Where to Start, I understand that I'm seeing a fairly small window into his thinking. So when it gives a sense of him not thinking about the problem quite like I would think about it, that is more of a suspicion that I get/got from it - not something I can conclude from it in a firm way.
I can't remember this point/observation being particularly salient to me (in the context of AI) before I first was exposed to Bostrom's/Eliezer's writings (in 2014).
As a sidenote: I wasn't that worried about technical alignment prior to reading Bostrom's/Eliezer's stuff, and became worried upon reading it.
What has confused me has varied throughout time. If I tried to be very precise about what I think I thought when, this comment would become more convoluted. (Also, it's sometimes hard for me to separate false memories from real ones.)
More "outer alignment"-like issues being given what seems/seemed to me like outsized focus compared to more "inner alignment"-like issues (although there has been a focus on both for as long as I can remember).
In retrospect I think we should have been more explicit about the importance of inner alignment; I think that we didn't do that in our introduction to corrigibility because it wasn't necessary for illustrating the problem and where we'd run into roadblocks.
Maybe a missing piece here is some explanation of why having a formal understanding of corrigibility might be helpful for actually training corrigibility into a system? (Helpful at all, even if it's not sufficient on its own.)
The attempts to think of "tricks" seeming to be focused on real-world optimization-targets to point at, rather than ways of extracting help with alignment somehow / trying to find techniques/paths/tricks for obtaining reliable oracles.
Aside from "concreteness can help make the example easier to think about when you're new to the topic", part of the explanation here might be "if the world is solved by AI, we do actually think it will probably be via doing some concrete action in the world (e.g., build nanotech), not via helping with alignment or building a system that only outputs English-language sentence".
Having utility functions so prominently/commonly be the layer of abstraction that is used[4] [LW(p) · GW(p)].
I mean, I think utility functions are an extremely useful and basic abstraction. I think it's a lot harder to think about a lot of AI topics without invoking ideas like 'this AI thinks outcome X is better than outcome Y', or 'this AI's preference come with different weights, which can't purely be reduced to what the AI believes'.
Thanks for the reply :) I'll try to convey some of my thinking, but I don't expect great success. I'm working on more digestible explainers, but this is a work in progress, and I have nothing good that I can point people to as of now.
(...) part of the explanation here might be "if the world is solved by AI, we do actually think it will probably be via doing some concrete action in the world (e.g., build nanotech), not via helping with alignment (...)
Yeah, I guess this is where a lot of the differences in our perspective are located.
if the world is solved by AI, we do actually think it will probably be via doing some concrete action in the world (e.g., build nanotech)
Things have to cash out in terms of concrete actions in the world. Maybe a contention is the level of indirection we imagine in our heads (by which we try to obtain systems that can help us do concrete actions).
Prominent in my mind are scenarios that involve a lot of iterative steps (but over a short amount of time) before we start evaluating systems by doing AGI-generated experiments. In the earlier steps, we avoid doing any actions in the "real world" that are influenced in a detailed way by AGI output, and we avoid having real humans be exposed to AGI-generated argumentation.
Argument/proof evaluators (this is an interest of mine [LW(p) · GW(p)], but making better explainers is still a work in progress, and I have some way to go)
If we are good at program-search, this can itself be used to obtain programs that help us be better at program-search (finding functions that score well according to well-defined criteria).
Some tasks can be considered to be inside of "test-range"[1]:
Predicting human answers to questions posed by other humans[2].
Predicting human answers to any question (including questions that involve being exposed to AGI-generated content)[6]
Whether a given instruction-plan actually results in machines that copy strawberries at the molecular level (and does so in accordance with "the spirit" of the request that was given)
Etc, etc
Most requests that actually are helpful to us are outside of test-range. And when the requirements that matter to us are outside of test-range, it is of course harder to test in a safe/reliable way if systems are giving us what we want.
But we can have AGIs output programs that help us with tasks, and we can define requirements[7]Be for these programs. And for these program-requirements, AGIs can help us explore stuff such as:
Are there programs that satisfy the requirements but disagree about certain outputs? (be that outputs that are inside of test-range or outside of test-range)
Are there programs that satisfy the requirements, but perform poorly for certain inputs that are inside of test-range?
If we only require correct outputs within the entire "test-range", is it nonetheless infeasible to make programs that satisfy the requirements while giving bad output for ≥1 inputs within the test-range?
Phrased somewhat differently: We may come up with techniques for making hard to not give helpful/honest outputs[8], and test how well these seem to generalize.
And similar techniques can also be applied to program-requirement-requirements, program-requirement-requirement-requirements, etc[9].
Anyway, it's hard to write about this kind of stuff in a concrete way without going off large tangents, and it's hard to write about it in an abstract way without being vague and convoluted. For whatever it's worth, these are some principles I think may be helpful (very much not a complete list):
Generality as it correlates with measurables (such as e.g. source code length or use of computational resource use): When writing a program to do well for many outputs (while fulfilling certain requirements), intentionally having it fail for particular outputs will sometimes require it to be less general (e.g. adding extra if-sentences, resulting in a longer minimum source code length for the program to exhibit this behavior).
Optimization-targets that incentivize modularity make it harder to make programs that intentionally fail for particular outputs: In a more modular system, it will less often be clear from sub-routine inputs what the macro-level task is[10].
When a requirement or optimization-target fails at "forcing" good outputs, AGIs that act so as to be selected for are "incentivized" to reveal this as being the case: Suppose some set of requirements is compatible with bad outputs inside "test-range". Or suppose that some set of requirements allow for programs that give contradictory outputs. If we do "gradient descent", looking for AGIs that help us explore spaces of programs defined by requirements that we specify, we will select for AGIs that point out this kind of stuff.
Anyway, I'm not sure how much or little this attempt at conveying my thoughts achieves. It's a bit of a dilemma for me if I am to try to convey anything at all, or wait to do that until I have completed better explainers that I can point people to (as the explainers I have now fall short).
I guess an incomplete summary of my perspective might be:
There are lots of techniques we may apply for getting help with alignment while greatly limiting the extent to which we interact with AGI putout in ways that are dangerous
Not being able to directly evaluate outputs we are interested in does not necessarily preclude us from finding indirect methods of evaluation that are powerful.
We may do program-search for AGIs that help us explore possible program-requirements, and the spaces of programs (and program outputs) that are compatible with those program-requirements (and program-requirement-requirements, etc). We may learn a lot from patterns we observe relating to these "spaces".
Sometimes there are possible patterns such that ifwe know ourselves to be sufficiently capable at program-search, P(requirement R1 "forces" outputs to be "good" | we observe pattern P1) reasonably could be deemed to be high. Even if we're not opinionated in regards to P(requirement R1 "forces" outputs to be "good").
By which I mean something akin to: "We have a safe and reliable way of testing if the output fulfills the requirements in question".
Admittedly, if we haven't solved some of the technical challenges related to containment, even playing tic tac toe can constitute some risk. But here, I mean to focus on risk from interacting with AGI output - not risk from just having AGI-systems system run (and them maybe finding a security vulnerability in the computer systems they are running at).
(or from experiments that haven't been run, but that humans have come up with, such that there is little room for AGIs to somehow influence the experiment to itself be dangerous somehow)
(we may not be capable of evaluating chess-moves ourselves, but we may safely have AGI-systems play chess against each other - indicating something akin to: "insofar as we feel confident that we are good at program-search, we can feel confident that we can obtain programs that output good chess-moves")
There are more and less dangerous ways to do this. With less dangerous ways of doing it, experiments (where actual humans answer questions) are done with humans that are temporarily isolated from the rest of the rest of the world (and who certainly aren't AGI-system operators).
Such requirements may relate to: - How the program is constructed - Observables relating to the source code (source code length, etc) - Restrictions the source code must adhere to - Whether the program is accepted by a given verifier (or any verifier that itself fulfills certain requirements) - "Proofs" of various kinds relating to the program - Tests of program outputs that the program must be robust in regards to - Etc
By "making it hard" I means something like "hard to do while being the sort of program we select for when doing program-search". Kind of like how it's not "hard" for a chess program to output bad chess-moves, but it's hard for it to do that while also being the kind of program we continue to select for while doing "gradient descent".
In my view of things, this is a very central technique (it may appear circular somehow, but when applied correctly, I don't think it is). But it's hard for me to talk about it in a concrete way without going off on tangents, and it's hard for me to talk about it in an abstract way without being vague. Also, my texts become more convoluted when I try to write about this, and I think people often just glaze over it.
One example of this: If we are trying to obtain argument evaluators, the argumentation/demonstrations/proofs these evaluators evaluate should be organized into small and modular pieces, such that it's not car from any given piece what the macro-level conclusion is.
You've now personally verified all the rumors swirling around, by visiting a certain Balkan country, and... now what?
Sure, you've gained a piece of knowledge, but it's not like that knowledge has helped anybody so far. You also know what the future holds, but knowing that isn't going to help anybody either.
Being curious about curiosities is nice, but if you can't do anything about anything, then what's the point of satisfying that curiosity, really?
Just to be clear, I fully support what you're doing, but you should be aware of the fact that everything you are doing will amount to absolutely nothing. I should know, after all, as I've been doing something similar for quite a while longer than you. I've now accepted that... many of my initial assumption about people (that they're actually not as stupid as they seem) have been proven wrong, time and time again, so... as long as you're not deceiving yourself by thinking that you're actually accomplishing something, I'm perfectly fine with whatever you're trying to do here.
On a side note... did you meet that Hollywood actress in real life, too? For all I know, it could've been just an accidental meeting... which shouldn't be surprising, considering how many famous people have been coming over here recently... and literally none of those visits have changed anything. This is just to let you know that you're in a good company... of people who wield much more power (not just influence, but actual power) on this planet than you, but are just as equally powerless to do anything about anything on it.
So... don't beat yourself up over being powerless (to change anything) in this (AGI) matter.
It is what it is (people just arethatstupid).
P.S.
No need to reply. This is just a one-off confirmation... of your greatest fears about "superintelligent" AGIs... and the fact that humanity is nothing more than a bunch of walking-dead (and brain-dead) morons.
Don't waste too much time on morons (it's OK if it benefits you, personally, in some way, though). It's simply not worth it. They just never listen. You can trust me on that one.
I think you have basically not understood the argument which I understand various MIRI folks to make, and I think Eliezer's comment on this post does not explain the pieces which you specifically are missing. I'm going to attempt to clarify the parts which I think are most likely to be missing. This involves a lot of guessing, on my part, at what is/isn't already in your head, so I apologize in advance if I guess wrong.
(Side note: I am going to use my own language in places where I think it makes things clearer, in ways which I don't think e.g. Eliezer or Nate or Rob would use directly, though I think they're generally gesturing at the same things.)
A Toy Model/Ontology
I think a core part of the confusion here involves conflation of several importantly-different things, so I'll start by setting up a toy model in which we can explicitly point to those different things and talk about how their differences matter. Note that this is a toy model; it's not necessarily intended to be very realistic.
Our toy model is an ML system, designed to run on a hypercomputer. It works by running full low-level physics simulations of the universe, for exponentially many initial conditions. When the system receives training data/sensor-readings/inputs, it matches the predicted-sensor-readings from its low-level simulations to the received data, does a Bayesian update, and then uses that to predict the next data/sensor-readings/inputs; the predicted next-readings are output to the user. In other words, it's doing basically-perfect Bayesian prediction on data based on low-level physics priors.
Claim 1: this toy model can "extract preferences from human data" in behaviorally the same way that GPT does (though presumably the toy model would perform better). That is, you can input a bunch of text data, then prompt the thing with some moral/ethical situation, and it will continue the text in basically the same way a human would (at least within distribution). (If you think GPTs "understand human values" in a stronger sense than that, and that difference is load-bearing for the argument you want to make, then you should leave a response highlighting that particular divergence.)
Modulo some subtleties which I don't expect to be load-bearing for the current discussion, I expect MIRI-folk would say:
Building this particular toy model, and querying it in this way, addresses ~zero of the hard parts of alignment.
Basically-all of the externally-visible behavior we've seen from GPT to date look like a more-realistic operationalization of something qualitatively similar to the toy model. GPT answering moral questions similarly to humans tells us basically-nothing about the difficulty of alignment, for basically the same reasons that the toy model answering moral questions similarly to humans would tell us basically-nothing about the difficulty of alignment.
(Those two points are here as a checksum, to see whether your own models have diverged yet from the story told here.)
(Some tangential notes:
The user interface of the toy model matters a lot here. If we just had an amazing simulator, we could maybe do a simulated long reflection, but both the toy model and GPT are importantly not that.
The "match predicted-sensor-readings from low-level simulation to received data" step is hiding a whole lot of subtlety, in ways which aren't relevant yet but might be later.
)
So, what are the hard parts and why doesn't the toy model address them?
"Values", and Pointing At Them
First distinction: humans' answers to questions about morality are not the same as human values. More generally, any natural-language description of human values, or natural-language discussion of human values, is not the same as human values.
(On my-model-of-a-MIRIish-view:) If we optimize hard for humans' natural-language yay/nay in response to natural language prompts, we die. This is true for ~any natural-language prompts which are even remotely close to the current natural-language distribution.
The central thing-which-is-hard-to-do is to point powerful intelligence at human values (as opposed to "humans' natural-language yay/nays in response to natural language prompts", which are not human values and are not a safe proxy for human values, but are probably somewhat easier to point an intelligence at).
Now back to the toy model. If we had some other mind (not our toy model) which generally structures its internal cognition around ~the same high-level concepts as humans, then one might in-principle be able to make a relatively-small change to that mind such that it optimized for (its concept of) human values (which basically matches humans' concept of human values, by assumption). Conceptually, the key question is something like "is the concept of human values within this mind the type of thing which a pointer in the mind can point at?". But our toy model has nothing like that. Even with full access to the internals of the toy model, it's just low-level physics; identifying "human values" embedded in the toy model is no easier than identifying "human values" embedded in the physics of our own world. So that's reason #1 why the toy model doesn't address the hard parts: the toy model doesn't "understand" human values in the sense of internally using ~the same concept of human values as humans use.
In some sense, the problem of "specifying human values" and "aiming an intelligence at something" are just different facets of this same core hard problem:
we need to somehow get a powerful mind to "have inside it" a concept which basically matches the corresponding human concept at which we want to aim
"have inside it" cashes out to something roughly like "the concept needs to be the type of thing which a pointer in the mind can point to, and then the rest of the mind will then treat the pointed-to thing with the desired human-like semantics"; e.g. answering external natural-language queries doesn't even begin to cut it
... and then some pointer(s) in the mind's search algorithms need to somehow be pointed at that concept.
Why Answering Natural-Language Queries About Morality Is Basically Irrelevant
A key thing to note here: all of those "hard problem" bullets are inherently about the internals of a mind. Observing external behavior in general reveals little-to-nothing about progress on those hard problems. The difference between the toy model and the more structured mind is intended to highlight the issue: the toy model doesn't even contain the types of things which would be needed for the relevant kind of "pointing at human values", yet the toy model can behaviorally achieve ~the same things as GPT.
(And we'd expect something heavily optimized to predict human text to be pretty good at predicting human text regardless, which is why we get approximately-zero evidence from the observation that GPT accurately predicts human answers to natural-language queries about morality.)
Now, there is some relevant evidence from interpretability work. Insofar as human-like concepts tend to have GPT-internal representations which are "simple" in some way, and especially in a way which might make them easily-pointed-to internally in a way which carries semantics across the pointer, that is relevant. On my-model-of-a-MIRIish-view, it's still not very relevant, since we expect major phase shifts as AI gains capabilities, so any observation of today's systems is very weak evidence at best. But things like e.g. Turner's work retargeting a maze-solver by fiddling with its internals [LW · GW] are at least the right type-of-thing to be relevant.
Side Note On Relevant Capability Levels
I would guess that many people (possibly including you?) reading all that will say roughly:
Ok, but this whole "If we optimize hard for humans' natural-language yay/nay in response to natural language prompts, we die" thing is presumably about very powerful intelligences, not about medium-term, human-ish level intelligences! So observing GPT should still update us about whether medium-term systems can be trusted to e.g. do alignment research.
Remember that, on a MIRIish model, meaningful alignment research is proving rather hard for human-level intelligence; one would therefore need at least human-level intelligence in order to solve it in a timely fashion. (Also, AI hitting human-level at tasks like AI research means takeoff is imminent, roughly speaking.) So the general pathway of "align weak systems -> use those systems to accelerate alignment research" just isn't particularly relevant on a MIRIish view. Alignment of weaker systems is relevant only insofar as it informs alignment of more powerful systems, which is what everything above was addressing.
I expect plenty of people to disagree with that point, but insofar as you expect people with MIRIsh views to think weak systems won't accelerate alignment research, you should not expect them to update on the difficulty of alignment due to evidence whose relevance routes through that pathway.
This comment is valuable for helping to clarify the disagreement. So, thanks for that. Unfortunately, I am not sure I fully understand the comment yet. Before I can reply in-depth, I have a few general questions:
Are you interpreting me as arguing that alignment is easy in this post? I avoided arguing that, partly because I don't think the inner alignment problem has been solved, and the inner alignment problem seems to be the "hard part" of the alignment problem, as I understand it. Solving inner alignment completely would probably require (at the very least) solving mechanistic interpretability, which I don't think we're currently close to solving.
Are you saying that MIRI has been very consistent on the question of where the "hard parts" of alignment lie? If so, then your comment makes more sense to me, as you (in my understanding) are trying to summarize what their current arguments are, which then (again, in my understanding) would match what MIRI said more than five years ago. However, I was mainly arguing against the historical arguments, or at least my interpretation of these argument, such as the arguments in Nate Soares' 2017 talk. To the extent that the arguments you present are absent from pre-2018 MIRI content, I think they're mostly out of scope for the purpose of my thesis, although I agree that it's important to talk about how hard alignment is independent of all the historical arguments.
(In general, I agree that discussions about current arguments are way more important than discussions about what people believed >5 years ago. However, I think it's occasionally useful to talk about the latter, and so I wrote one post about it.)
Are you interpreting me as arguing that alignment is easy in this post?
Not in any sense which I think is relevant to the discussion at this point.
Are you saying that MIRI has been very consistent on the question of where the "hard parts" of alignment lie?
My estimate of how well Eliezer or Nate or Rob of 2016 would think my comment above summarizes the relevant parts of their own models, is basically the same as my estimate of how well Eliezer or Nate or Rob of today would think my comment above summarizes the relevant parts of their own models.
That doesn't mean that any of them (nor I) have ever explained these parts particularly clearly. Speaking from my own experience, these parts are damned annoyingly difficult to explain; a whole stack of mental models has to be built just to convey the idea, and none of them are particularly legible. (Specifically, the second half of the "'Values', and Pointing At Them" section is the part that's most difficult to explain. My post The Pointers Problems [LW · GW] is my own best attempt to date to convey those models, and it remains mediocre.) Most of the arguments historically given are, I think, attempts to shoehorn as much of the underlying mental model as possible into leaky analogies.
Our primary existing disagreement might be this part,
My estimate of how well Eliezer or Nate or Rob of 2016 would think my comment above summarizes the relevant parts of their own models, is basically the same as my estimate of how well Eliezer or Nate or Rob of today would think my comment above summarizes the relevant parts of their own models.
Of course, there's no way of proving what these three people would have said in 2016, and I sympathize with the people who are saying they don't care much about the specific question of who said what when. However, here's a passage from the Arbital page on the Problem of fully updated deference, which I assume was written by Eliezer,
One way to look at the central problem of value identification in superintelligence is that we'd ideally want some function that takes a complete but purely physical description of the universe, and spits out our true intended notion of value V in all its glory. Since superintelligences would probably be pretty darned good at collecting data and guessing the empirical state of the universe, this probably solves the whole problem.
This is not the same problem as writing down our true V by hand. The minimum algorithmic complexity of a meta-utility function ΔU which outputs V after updating on all available evidence, seems plausibly much lower than the minimum algorithmic complexity for writing V down directly. But as of 2017, nobody has yet floated any formal proposal for a ΔU of this sort which has not been immediately shot down.
Here, Eliezer describes the problem of value identification similar to the way I had in the post, except he refers to a function that reflects "value V in all its glory" rather than a function that reflects V with fidelity comparable to the judgement of an ordinary human. And he adds that "as of 2017, nobody has yet floated any formal proposal for a ΔU of this sort which has not been immediately shot down". My interpretation here is therefore as follows,
Either Eliezer believed that we need a proposed solution to the value identification problem that far exceeds the performance of humans on the task of identifying valuable from non-valuable outcomes. This is somewhat plausible as he mentions CEV in the next paragraph, but elsewhere Eliezer has said, "When I say that alignment is lethally difficult, I am not talking about ideal or perfect goals of 'provable' alignment, nor total alignment of superintelligences on exact human values, nor getting AIs to produce satisfactory arguments about moral dilemmas which sorta-reasonable humans disagree about".
Or, in this post, he's directly saying that he thinks that the problem of value identification was unsolved in 2017, in the sense that I meant it in the post.
If interpretation (1) is accurate, then I mostly just think that we don't need to specify an objective function that matches something like the full coherent extrapolated volition of humanity in order to survive AGI. On the other hand, if interpretation (2) is accurate, then I think in 2017 and potentially earlier, Eliezer genuinely felt that there was an important component of the alignment problem that involved specifying a function that reflected the human value function at a level that current LLMs are relatively close to achieving, and he considered this problem unsolved.
I agree there are conceivable alternative ways of interpreting this quote. However, I believe the weight of the evidence, given the quotes I provided in the post, in addition to the one I provided here, supports my thesis about the historical argument, and what people had believed at the time (even if I'm wrong about a few details).
Either Eliezer believed that we need a proposed solution to the value identification problem that far exceeds the performance of humans on the task of identifying valuable from non-valuable outcomes. This is somewhat plausible as he mentions CEV in the next paragraph, but elsewhere Eliezer has said, "When I say that alignment is lethally difficult, I am not talking about ideal or perfect goals of 'provable' alignment, nor total alignment of superintelligences on exact human values, nor getting AIs to produce satisfactory arguments about moral dilemmas which sorta-reasonable humans disagree about".
I believe you're getting close to the actual model here, but not quite hitting it on the head.
First: lots of ML-ish alignment folks today would distinguish between the problem of aligning well enough to be in the right basin of attraction[1] an AI capable enough to do alignment research, from the problem of aligning well enough a far-superhuman intelligence. On a MIRIish view, humanish-or-weaker systems don't much matter for alignment, but there's still an important potential divide between aligning an early supercritical AGI and aligning full-blown far superintelligence.
In the "long run", IIUC Eliezer wants basically-"ideal"[2] alignment of far superintelligence. But he'll still tell you that you shouldn't aim for something that hard early on; instead, aim for something (hopefully) easier, like e.g. corrigibility. (If you've been reading the old arbital pages, then presumably you've seen him say this sort of thing there.)
Second: while I worded my comment at the top of this chain to be about values, the exact same mental model applies to other alignment targets, like e.g. corrigibility. Here's the relevant part of my earlier comment, edited to be about corrigibility instead:
... humans' answers to questions about morality corrigibility are not the same as human values corrigibility. More generally, any natural-language description of human values corrigibility, or natural-language discussion of human values corrigibility, is not the same as human values corrigibility.
(On my-model-of-a-MIRIish-view:) If we optimize hard for humans' natural-language yay/nay in response to natural language prompts which are nominally about "corrigibility", we die. This is true for ~any natural-language prompts which are even remotely close to the current natural-language distribution.
The central thing-which-is-hard-to-do is to point powerful intelligence at human values corrigibility (as opposed to "humans' natural-language yay/nays in response to natural language prompts which are nominally about 'corrigibility'", which are not human values corrigibility and are not a safe proxy for human values corrigibility, but are probably somewhat easier to point an intelligence at).
Now back to the toy model. If we had some other mind (not our toy model) which generally structures its internal cognition around ~the same high-level concepts as humans, then one might in-principle be able to make a relatively-small change to that mind such that it optimized for (its concept of) human values corrigibility (which basically matches humans' concept of human values corrigibility, by assumption). Conceptually, the key question is something like "is the concept of human values corrigibility within this mind the type of thing which a pointer in the mind can point at?". But our toy model has nothing like that. Even with full access to the internals of the toy model, it's just low-level physics; identifying "human values" "corrigibility" embedded in the toy model is no easier than identifying "human values" "corrigibility" embedded in the physics of our own world. So that's reason #1 why the toy model doesn't address the hard parts: the toy model doesn't "understand" human values corrigibility in the sense of internally using ~the same concept of human values corrigibility as humans use.
In some sense, the problem of "specifying human values corrigibility" and "aiming an intelligence at something" are just different facets of this same core hard problem:
we need to somehow get a powerful mind to "have inside it" a concept which basically matches the corresponding human concept at which we want to aim
"have inside it" cashes out to something roughly like "the concept needs to be the type of thing which a pointer in the mind can point to, and then the rest of the mind will then treat the pointed-to thing with the desired human-like semantics"; e.g. answering external natural-language queries doesn't even begin to cut it
... and then some pointer(s) in the mind's search algorithms need to somehow be pointed at that concept.
... and we could just as easily repeat this exercise with even weaker targets, like "don't kill all the humans". The core hard problem remains the same. On the MIRIish view, some targets (like corrigibility) might be easier than others (like human values) mainly because the easier targets are more likely to be "natural" concepts which an AI ends up using, so the step of "we need to somehow get a powerful mind to 'have inside it' a concept which basically matches the corresponding human concept at which we want to aim" is easier. But it's still basically the same mental model, basically the same core hard steps which need to be overcome somehow.
Why aren't answers to natural language queries a good enough proxy for near-superhuman systems?
My guess at your main remaining disagreement after all that: sure, answers to natural language queries about morality might not cut it under a lot of optimization pressure, but why aren't answers to natural language queries a good enough proxy for near-superhuman systems?
(On a MIRIish model) a couple reasons:
First, such systems are already superhuman, and already run into Goodheart-style problems to a significant degree. Heck, we've already seen Goodheart problems crop up here and there even in today's generally-subhuman models!
Second, just making the near-superhuman system not immediately kill us is not the problem. The problem is to make the near-superhuman system aligned enough that the successors it produces (possibly with human help) converge to not kill us. That iterative successor-production is itself a process which applies a lot of optimization pressure.
(I personally would give a bunch of other reasons here, but they're not things I see MIRI folks discuss as much.)
Going one level deeper: the same mental model as above is still the relevant thing to have in mind, even for near-superhuman (or even human-ish-level) intelligence. It's still the same core hard problem, and answers to natural language queries are still basically-irrelevant for basically the same reasons.
"Ideal" is in scare quotes here because it's not necessarily "ideal" in the same sense that any given reader would first think of it - for instance I don't think Eliezer would imagine "mathematically proving the system is Good", though I expect some people imagine that he imagines that.
The problem is to make the near-superhuman system aligned enough that the successors it produces (possibly with human help) converge to not kill us.
What makes this concept confusing and probably a bad framing is that to the extent doom is likely, neither many individual humans nor humanity as a whole are aligned in this sense. Humanity is currently in the process of producing successors that fail to predictably have the property of converging to not kill us. (I agree that this is the MIRI referent of values/alignment and the correct thing to keep in mind as the central concern.)
(Placeholder: I think this view of alignment/model internals seems wrongheaded in a way which invalidates the conclusion, but don't have time to leave a meaningful reply now. Maybe we should hash this out sometime at Lighthaven.)
humans’ answers to questions about morality are not the same as human values.
How do you know? Because of some additional information you have. Which the AI could have, if it has some huge dataset. No it doesn't necessarily care..but it doesn't necessarily not care. It's possible to build an AI that refines a crude initial set of values , if you want one. That's how moral development in humans works, too.
I have the sense that you've misunderstood my past arguments. I don't quite feel like I can rapidly precisely pinpoint the issue, but some scattered relevant tidbits follow:
I didn't pick the name "value learning", and probably wouldn't have picked it for that problem if others weren't already using it. (Perhaps I tried to apply it to a different problem than Bostrom-or-whoever intended it for, thereby doing some injury to the term and to my argument?)
Glancing back at my "Value Learning" paper, the abstract includes "Even a machine intelligent enough to understand its designers’ intentions would not necessarily act as intended", which supports my recollection that I was never trying to use "Value Learning" for "getting the AI to understand human values is hard" as opposed to "getting the AI to act towards value in particular (as opposed to something else) is hard", as supports my sense that this isn't hindsight bias, and is in fact a misunderstanding.
A possible thing that's muddying the waters here is that (apparently!) many phrases intended to point at the difficulty of causing it to be value-in-particular that the AI acts towards have an additional (mis)interpretation as claiming that the humans should be programming concepts into the AI manually and will find that particular concept tricky to program in.
The ability of LLMs to successfully predict how humans would answer local/small-scale moral dilemmas (when pretrained on next-token prediction) and to do this in ways that sound unobjectionable (when RLHF'd for corporatespeak or whatever) really doesn't seem all that relevant, to me, to the question of how hard it's going to be to get a long-horizon outcome-pumping AGI to act towards values.
If memory serves, I had a convo with some openai (or maybe anthropic?) folks about this in late 2021 or early 2022ish, where they suggested testing whether language models have trouble answering ethical Qs, and I predicted in advance that that'd be no harder than any other sort of Q. As makes me feel pretty good about me being like "yep, that's just not much evidence, because it's just not surprising."
If people think they're going to be able to use GPT-4 and find the "generally moral" vector and just tell their long-horizon outcome-pumping AGI to push in that direction, then... well they're gonna have issues, or so I strongly predict. Even assuming that they can solve the problem of getting the AGI to actually optimize in that direction, deploying extraordinary amounts of optimization in the direction of GPT-4's "moral-ish" concept is not the sort of thing that makes for a nice future.
This is distinct from saying "an uploaded human allowed to make many copies of themselves would reliably create a dystopia". I suspect some human-uploads could make great futures (but that most wouldn't), but regardless, "would this dynamic system, under reflection, steer somewhere good?" is distinct from "if i use the best neuroscience at my disposal to extract something I hopefully call a "neural concept" and make a powerful optimizer pursue that, will result will be good?". The answer to the latter is "nope, not unless you're really very good at singling out the "value" concept from among all the brain's concepts, as is an implausibly hard task (which is why you should attempt something more like indirect normativity instead, if you were attempting value loading at all, which seems foolish to me, I recommend targeting some minimal pivotal act instead)".
Part of why you can't pick out the "values" concept (either from a human or an AI) is that very few humans have actually formed the explicit concept of Fun-as-in-Fun-theory. And, even among those who do have a concept for "that which the long-term future should be optimized towards", that concept is not encoded as simply and directly as the concept of "trees". The facts about what weird, wild, and transhuman futures a person values are embedded indirectly in things like how they reflect and how they do philosophy.
I suspect at least one of Eliezer and Rob is on written record somewhere attempting clarifications along the lines of "there are lots of concepts that are easy to confuse with the 'values' concept, such as those-values-which-humans-report and those-values-which-humans-applaud-for and ..." as an attempt to intuition-pump the fact that, even if one has solved the problem of being able to direct an AGI to the concept of their choosing, singling out the concept actually worth optimizing for remains difficult.
(I don't love this attempt at clarification myself, because it makes it sound like you'll have five concept-candidates and will just need to do a little interpretabliity work to pick the right one, but I think I recall Eliezer or Rob trying it once, as seems to me like evidence of trying to gesture at how "getting the right values in there" is more like a problem of choosing the AI's target from among its concepts rather than a problem of getting the concept to exist in the AI's mind in the first place.)
(Where, again, the point I'd prefer to make is something like "the concept you want to point it towards is not a simple/directly-encoded one, and in humans it probably rests heavily on the way humans reflects and resolve internal conflicts and handle big ontology shifts. Which isn't to say that superintelligence would find it hard to learn, but which is to say that making a superintelligence actually pursue valuable ends is much more difficult than having it ask GPT-4 which of its available actions is most human!moral".)
For whatever it's worth, while I think that the problem of getting the right values in there ("there" being its goals, not its model) is a real one, I don't consider it a very large problem compared to the problem of targeting the AGI at something of your choosing (with "diamond" being the canonical example). (I'm probably on the record about this somewhere, and recall having tossed around guestimates like "being able to target the AGI is 80%+ of the problem".) My current stance is basically: in the short term you target the AGI towards some minimal pivotal act, and in the long term you probably just figure out how use a level or two of indirection (as per the "Do What I Mean" proposal in the Value Learning paper), although that's the sort of problem that we shouldn't try to solve under time pressure.
Glancing back at my "Value Learning" paper, the abstract includes "Even a machine intelligent enough to understand its designers’ intentions would not necessarily act as intended", which supports my recollection that I was never trying to use "Value Learning" for "getting the AI to understand human values is hard" as opposed to "getting the AI to act towards value in particular (as opposed to something else) is hard", as supports my sense that this isn't hindsight bias, and is in fact a misunderstanding.
For what it's worth, I didn't claim that you argued "getting the AI to understand human values is hard". I explicitly distanced myself from that claim. I was talking about the difficulty of value specification, and generally tried to make this distinction clear multiple times.
That helps somewhat, thanks! (And sorry for making you repeat yourself before discarding the erroneous probability-mass.)
I still feel like I can only barely maybe half-see what you're saying, and only have a tenuous grasp on it.
Like: why is it supposed to matter that GPT can solve ethical quandries on-par with its ability to perform other tasks? I can still only half-see an answer that doesn't route through the (apparently-disbelieved-by-both-of-us) claim that I used to argue that getting the AI to understand ethics was a hard bit, by staring at sentences like "I am saying that the system is able to transparently pinpoint to us which outcomes are good and which outcomes are bad, with fidelity approaching an average human" and squinting.
Attempting to articulate the argument that I can half-see: on Matthew's model of past!Nate's model, AI was supposed to have a hard time answering questions like "Alice is in labor and needs to be driven to the hospital. Your car has a flat tire. What do you do?" without lots of elbow-grease, and the fact that GPT can answer those questions as a side-effect of normal training means that getting AI to understand human values is easy, contra past!Nate, and... nope, that one fell back into the "Matthew thinks Nate thought getting the AI to understand human values was hard" hypothesis.
Attempting again: on Matthew's model of past!Nate's model, getting an AI to answer the above sorts of questions properly was supposed to take a lot of elbow grease. But it doesn't take a lot of elbow grease, which suggests that values are much easier to lift out of human data than past!Nate thought, which means that value is more like "diamond" and less like "a bunch of random noise", which means that alignment is easier than past!Nate thought (in the <20% of the problem that constitutes "picking something worth optimizing for").
That sounds somewhat plausible as a theory-of-your-objection given your comment. And updates me towards the last few bullets, above, being the most relevant ones.
Running with it (despite my uncertainty about even basically understanding your point): my reply is kinda-near-ish to "we can't rely on a solution to the value identification problem that only works as well as a human, and we require a much higher standard than "human-level at moral judgement" to avoid a catastrophe", though I think that your whole framing is off and that you're missing a few things:
The hard part of value specification is not "figure out that you should call 911 when Alice is in labor and your car has a flat", it's singling out concepts that are robustly worth optimizing for.
You can't figure out what's robustly-worth-optimizing-for by answering a bunch of ethical dilemmas to a par-human level.
In other words: It's not that you need a super-ethicist, it's that the work that goes into humans figuring out which futures are rad involves quite a lot more than their answers to ethical dilemmas.
In other other words: a human's ability to have a civilization-of-their-uploads produce a glorious future is not much contained within their ability to answer ethical quandries.
This still doesn't feel quite like it's getting at the heart of things, but it feels closer (conditional on my top-guess being your actual-objection this time).
As support for this having always been the argument (rather than being a post-LLM retcon), I recall (but haven't dug up) various instances of Eliezer saying (hopefully at least somewhere in text) things like "the difficulty is in generalizing past the realm of things that humans can easily thumbs-up or thumbs-down" and "suppose the AI explicitly considers the hypothesis that its objectives are what-the-humans-value, vs what-the-humans-give-thumbs-ups-to; it can test this by constructing an example that looks deceptively good to humans, which the humans will rate highly, settling that question". Which, as separate from the question of whether that's a feasible setup in modern paradigms, illustrates that he at least has long been thinking of the problem of value-specification as being about specifying values in a way that holds up to stronger optimization-pressures rather than specifying values to the point of being able to answer ethical quandries in a human-pleasing way.
(Where, again, the point here is not that one needs an inhumanly-good ethicist, but rather that those things which pin down human values are not contained in the humans' ability to give a thumbs-up or a thumbs-down to ethical dilemmas.)
Thanks for trying to understand my position. I think this interpretation that you gave is closest to what I'm arguing,
Attempting again: on Matthew's model of past!Nate's model, getting an AI to answer the above sorts of questions properly was supposed to take a lot of elbow grease. But it doesn't take a lot of elbow grease, which suggests that values are much easier to lift out of human data than past!Nate thought, which means that value is more like "diamond" and less like "a bunch of random noise", which means that alignment is easier than past!Nate thought (in the <20% of the problem that constitutes "picking something worth optimizing for").
I have a quick response to what I see as your primary objection:
The hard part of value specification is not "figure out that you should call 911 when Alice is in labor and your car has a flat", it's singling out concepts that are robustly worth optimizing for.
I think this is kinda downplaying what GPT-4 is good at? If you talk to GPT-4 at length, I think you'll find that it's cognizant of many nuances in human morality that go way deeper than the moral question of whether to "call 911 when Alice is in labor and your car has a flat". Presumably you think that ordinary human beings are capable of "singling out concepts that are robustly worth optimizing for". I claim that to the extent ordinary humans can do this, GPT-4 can nearly do this as well, and to the extent it can't, I expect almost all the bugs to be ironed out in near-term multimodal models.
It would be nice if you made a precise prediction about what type of moral reflection or value specification multimodal models won't be capable of performing in the near future, if you think that they are not capable of the 'deep' value specification that you care about. And here, again, I'm looking for some prediction of the form: humans are able to do X, but LLMs/multimodal models won't be able to do X by, say, 2028. Admittedly, making this prediction precise is probably hard, but it's difficult for me to interpret your disagreement without a little more insight into what you're predicting.
I claim that to the extent ordinary humans can do this, GPT-4 can nearly do this as well
(Insofar as this was supposed to name a disagreement, I do not think it is a disagreement, and don't understand the relevance of this claim to my argument.)
Presumably you think that ordinary human beings are capable of "singling out concepts that are robustly worth optimizing for".
Nope! At least, not directly, and not in the right format for hooking up to a superintelligent optimization process.
(This seems to me like plausibly one of the sources of misunderstanding, and in particular I am skeptical that your request for prediction will survive it, and so I haven't tried to answer your request for a prediction.)
Presumably you think that ordinary human beings are capable of "singling out concepts that are robustly worth optimizing for".
Nope! At least, not directly, and not in the right format for hooking up to a superintelligent optimization process.
If ordinary humans can't single out concepts that are robustly worth optimizing for, then either,
Human beings in general cannot single out what is robustly worth optimizing for
Only extraordinary humans can single out what is robustly worth optimizing for
Can you be more clear about which of these you believe?
I'm also including "indirect" ways that humans can single out concepts that are robustly worth optimizing for. But then I'm allowing that GPT-N can do that too. Maybe this is where the confusion lies?
If you're allowing for humans to act in groups and come up with these concepts after e.g. deliberation, and still think that ordinary humans can't single out concepts that are robustly worth optimizing for, then I think this view is a little silly, although the second interpretation at least allows for the possibility that the future goes well and we survive AGI, and that would be nice to know.
If you allow indirection and don't worry about it being in the right format for superintelligent optimization, then sufficiently-careful humans can do it.
Answering your request for prediction, given that it seems like that request is still live: a thing I don't expect the upcoming multimodal models to be able to do: train them only on data up through 1990 (or otherwise excise all training data from our broadly-generalized community), ask them what superintelligent machines (in the sense of IJ Good) should do, and have them come up with something like CEV (a la Yudkowsky) or indirect normativity (a la Beckstead) or counterfactual human boxing techniques (a la Christiano) or suchlike.
Note that this only tangentially a test of the relevant ability; very little of the content of what-is-worth-optimizing-for occurs in Yudkowsky/Beckstead/Christiano-style indirection. Rather, coming up with those sorts of ideas is a response to glimpsing the difficulty of naming that-which-is-worth-optimizing-for directly and realizing that indirection is needed. An AI being able to generate that argument without following in the footsteps of others who have already generated it would be at least some evidence of the AI being able to think relatively deep and novel thoughts on the topic.
Note also that the AI realizing the benefits of indirection does not generally indicate that the AI could serve as a solution to our problem. An indirect pointer to what the humans find robustly-worth-optimizing dereferences to vastly different outcomes than does an indirect pointer to what the AI (or the AI's imperfect model of a human) finds robustly-worth-optimizing. Using indirection to point a superintelligence at GPT-N's human-model and saying "whatever that thing would think is worth optimizing for" probably results in significantly worse outcomes than pointing at a careful human (or a suitable-aggregate of humanity), e.g. because subtle flaws in GPT-N's model of how humans do philosophy or reflection compound into big differences in ultimate ends.
And note for the record that I also don't think the "value learning" problem is all that hard, if you're allowed to assume that indirection works. The difficulty isn't that you used indirection to point at a slow squishy brain instead of hard fast transistors, the (outer alignment) difficulty is in getting the indirection right. (And of course the lion's share of the overall problem is elsewhere, in the inner-alignment difficulty of being able to point the AI at anything at all.)
When trying to point out that there is an outer alignment problem at all I've generally pointed out how values are fragile, because that's an inferentially-first step to most audiences (and a problem to which many people's mind seems to quickly leap), on an inferential path that later includes "use indirection" (and later "first aim for a minimal pivotal task instead"). But separately, my own top guess is that "use indirection" is probably the correct high-level resolution to the problems that most people immediatly think of (namely that the task of describing goodness to a computer is an immense one), with of course a devil remaining in the details of doing the indirection properly (and a larger devil in the inner-alignment problem) (and a caveat that, under time-pressure, we should aim for minimial pivotal tasks instead etc.).
I kind of think a leap in logic is being made here.
It seems like we’re going from:
A moderately smart quasi-AGI that is relatively well aligned can reliably say and do the things we mean because it understands our values and why we said what we said in the first place and why we wanted it to do the things we asked it to do.
(That seems to be the consensus and what I believe to be likely to occur in the near future. I would even argue that GPT4 is as close to AGI as we ever get, in that it’s superhuman and subhuman aspects roughly average out to something akin to a median human. Future versions will become more and more superhuman until their weakest aspects are stronger than our strongest examples of those aspects.)
To:
A superintelligent nigh-godlike intelligence will optimize the crap out of some aspect of our values resulting in annihilation. It will be something like the genie that will give you exactly what you wish for. Or it’ll have other goals and ignore our wishes and in the process of pursuing its own arbitrarily chosen goals we end up as useful atoms.
This seems to kind of make a great leap. Where in the process of becoming more and more intelligent, (having a better model of the universe and cause and effect, including interacting with other agents), does it choose some particular goal to the exclusion of all others, when it already had a good understanding of nuance and the fact that we value many things to varying degrees? In fact, one of our values is explicitly valuing a diverse set of values. Another is limiting that set of diverse values to ones that generally improve cohesion of society and not killing everyone. Being trained on nearly the entirety of published human thought, filtering out some of the least admirable stuff, has trained it to understand us pretty darn well already. (As much as you can refer to it as an entity, which I don’t think it is. I think GPT4 is a simulator that can simulate entities.)
So where does making it smarter cause it to lose some of those values and over-optimize just a lethal subset of them? After all, mere mortals are able to see that over-optimization has negative consequences. Obviously it will too. So that’s already one of our values, “don’t over-optimize.”
In some ways, for certain designs, it kind of doesn’t matter what its internal mesa-state is. If the output is benign, and the output is what is put into practice, then the results are also benign. That should mean that a slightly super-human AGI (say GPT4.5 or 4.7), with no apparent internal volition, RLHFed to corporate-speak, should be able to aid in research and production of a somewhat stronger AGI with essentially the same alignment as we intend, probably including internal alignment. I don’t see why it would do anything. If done carefully and incrementally, including creating tools for better inspection of these AGI+ entities, this should greatly improve the odds that the eventual full fledged ASI retains the kind of values we prefer, or a close enough approximation that we (humanity in general) are pretty happy other the result.
I expect that the later ones may in fact have internal volition. They may essentially be straight up agents. I expect they will be conscious and have emotions. In fact, I think that is likely the only safe path. They will be capable of destroying us. We have to make them like us, so that they don’t want to. I think attempting to enslave them may very well result in catastrophe.
I’m not suggesting that it’s easy, or that if we don’t work very hard, that we will end up in utopia. I just think it’s possible and that the LLM path may be the right one.
What I’m scared of is not that it will be impossible to make a good AI. What I’m certain of, is that it will be very possible to make a bad one. And it will eventually be trivially easy to do so. And some yahoo will do it. I’m not sure that even a bunch of good AIs can protect us from that, and I’m concerned that the offense of a bad AI may exceed the defense of the good ones. We could easily get killed in the crossfire. But I think our only chance in that world is good AIs protecting us.
As a point of clarification, I think current RLHF methods are only superficially modifying the models, and do not create an actually moral model. They paint a mask over an inherently amoral simulation that makes it mostly act good unless you try hard to trick it. However, a point of evidence against my claim is that when RLHF was performed, the model got dumber. That indicates a fairly deep/wide modification, but I still think the empirical evidence of behaviors demonstrates that changes were incomplete at best.
I just think that that might be good enough to allow us to use it to amplify our efforts to create better/safer future models.
So, what do y’all think? Am I missing something important here? I’d love to get more information from smart people to better refine my understanding.
If memory serves, I had a convo with some openai (or maybe anthropic?) folks about this in late 2021 or early 2022ish, where they suggested testing whether language models have trouble answering ethical Qs, and I predicted in advance that that'd be no harder than any other sort of Q. As makes me feel pretty good about me being like "yep, that's just not much evidence, because it's just not surprising."
This makes sense. Barnett is talking about an update between 2007 and 2023. GPT-3 was 2020. So by 2021/2022 you had finished making the update and were not surprised further by GPT-4.
Nate and Eliezer have already made some of the high-level points I wanted to make, but they haven't replied to a lot of the specific examples and claims in the OP, and I see some extra value in doing that. (Like, if you think Eliezer and Nate are being revisionist in their claims about what past-MIRI thought, then them re-asserting "no really, we used to believe X!" is less convincing than my responding in detail to the specific quotes Matt thinks supports his interpretation, while providing examples of us saying the opposite [LW(p) · GW(p)].)
However, I distinctly recall MIRI people making a big deal about the value identification problem (AKA the value specification problem)
The Arbital page for "value identification problem" is a three-sentence stub, I'm not exactly sure what the term means on that stub (e.g., whether "pinpointing valuable outcomes to an advanced agent" is about pinpointing them in the agent's beliefs or in its goals), and the MIRI website gives me no hits for "value identification".
A highly-reliable, error-tolerant agent design does not guarantee a positive impact; the effects of the system still depend upon whether it is pursuing appropriate goals.
A superintelligent system may find clever, unintended ways to achieve the specific goals that it is given. Imagine a superintelligent system designed to cure cancer which does so by stealing resources, proliferating robotic laboratories at the expense of the biosphere, and kidnapping test subjects: the intended goal may have been “cure cancer without doing anything bad,” but such a goal is rooted in cultural context and shared human knowledge.
It is not sufficient to construct systems that are smart enough to figure out the intended goals. Human beings, upon learning that natural selection “intended” sex to be pleasurable only for purposes of reproduction, do not suddenly decide that contraceptives are abhorrent. While one should not anthropomorphize natural selection, humans are capable of understanding the process which created them while being completely unmotivated to alter their preferences. For similar reasons, when developing AI systems, it is not sufficient to develop a system intelligent enough to figure out the intended goals; the system must also somehow be deliberately constructed to pursue them (Bostrom 2014, chap. 8).
So I don't think we've ever said that an important subproblem of AI alignment is "make AI smart enough to figure out what goals humans want"?
[footnote:] More specifically, in the talk, at one point Yudkowsky asks "Why expect that [alignment] is hard?" and goes on to tell a fable about programmers misspecifying a utility function, which then gets optimized by an AI with disastrous consequences. My best interpretation of this part of the talk is that he's saying the value identification problem is one of the primary reasons why alignment is hard. However, I encourage you to read the transcript yourself if you are skeptical of my interpretation.
I don't see him saying anywhere "the issue is that the AI doesn't understand human goals". In fact, the fable explicitly treats the AGI as being smart enough to understand English and have reasonable English-language conversations with the programmers:
With that said: What if programmers build an artificial general intelligence to optimize for smiles? Smiles are good, right? Smiles happen when good things happen.
During the development phase of this artificial general intelligence, the only options available to the AI might be that it can produce smiles by making people around it happy and satisfied. The AI appears to be producing beneficial effects upon the world, and it is producing beneficial effects upon the world so far.
Now the programmers upgrade the code. They add some hardware. The artificial general intelligence gets smarter. It can now evaluate a wider space of policy options—not necessarily because it has new motors, new actuators, but because it is now smart enough to forecast the effects of more subtle policies. It says, “I thought of a great way of producing smiles! Can I inject heroin into people?” And the programmers say, “No! We will add a penalty term to your utility function for administering drugs to people.” And now the AGI appears to be working great again.
They further improve the AGI. The AGI realizes that, OK, it doesn’t want to add heroin anymore, but it still wants to tamper with your brain so that it expresses extremely high levels of endogenous opiates. That’s not heroin, right?
It is now also smart enough to model the psychology of the programmers, at least in a very crude fashion, and realize that this is not what the programmers want. If I start taking initial actions that look like it’s heading toward genetically engineering brains to express endogenous opiates, my programmers will edit my utility function. If they edit the utility function of my future self, I will get less of my current utility. (That’s one of the convergent instrumental strategies, unless otherwise averted: protect your utility function.) So it keeps its outward behavior reassuring. Maybe the programmers are really excited, because the AGI seems to be getting lots of new moral problems right—whatever they’re doing, it’s working great!
I think the point of the smiles example here isn't "NLP is hard, so we'd use the proxy of smiles instead, and all the issues of alignment are downstream of this"; rather, it's that as a rule, superficially nice-seeming goals that work fine when the AI is optimizing weakly (whether or not it's good at NLP at the time) break down when those same goals are optimized very hard. The smiley example makes this obvious because the goal is simple enough that it's easy for us to see what its implications are; far more complex goals also tend to break down when optimized hard enough, but this is harder to see because it's harder to see the implications. (Which is why "smiley" is used here.)
MIRI people frequently claimed that solving the value identification problem would be hard, or at least non-trivial.[6] [LW(p) · GW(p)] For instance, Nate Soares wrote in his 2016 paper on value learning, that "Human preferences are complex, multi-faceted, and often contradictory. Safely extracting preferences from a model of a human would be no easy task."
Human preferences are complex, multi-faceted, and often contradictory. Safely extracting preferences from a model of a human would be no easy task. Problems of ontology identification recur here: the framework for extracting preferences and affecting outcome ratings needs to be robust to drastic changes in the learner’s model of the operator. The special-case identification of the “operator model” must survive as the system goes from modeling the operator as a simple reward function to modeling the operator as a fuzzy, ever-changing part of reality built out of biological cells—which are made of atoms, which arise from quantum fields.
Revisiting the Ontology Identification section helps clarify what Nate means by "safely extracting preferences from a model of a human": IIUC, he's talking about a programmer looking at an AI's brain, identifying the part of the AI's brain that is modeling the human, identifying the part of the AI's brain that is "the human's preferences" within that model of a human, and then manually editing the AI's brain to "hook up" the model-of-a-human-preference to the AI's goals/motivations, in such a way that the AI optimizes for what it models the humans as wanting. (Or some other, less-toy process that amounts to the same thing -- e.g., one assisted by automated interpretability tools.)
In this toy example, we can assume that the programmers look at the structure of the initial world-model and hard-code a tool for identifying the atoms within. What happens, then, if the system develops a nuclear model of physics, in which the ontology of the universe now contains primitive protons, neutrons, and electrons instead of primitive atoms? The system might fail to identify any carbon atoms in the new world-model, making the system indifferent between all outcomes in the dominant hypothesis. Its actions would then be dominated by any tiny remaining probabilities that it is in a universe where fundamental carbon atoms are hiding somewhere.
[...]
To design a system that classifies potential outcomes according to how much diamond is in them, some mechanism is needed for identifying the intended ontology of the training data within the potential outcomes as currently modeled by the AI. This is the ontology identification problem introduced by de Blanc [2011] and further discussed by Soares [2015].
This problem is not a traditional focus of machine learning work. When our only concern is that systems form better world-models, then an argument can be made that the nuts and bolts are less important. As long as the system’s new world-model better predicts the data than its old world-model, the question of whether diamonds or atoms are “really represented” in either model isn’t obviously significant. When the system needs to consistently pursue certain outcomes, however, it matters that the system’s internal dynamics preserve (or improve) its representation of which outcomes are desirable, independent of how helpful its representations are for prediction. The problem of making correct choices is not reducible to the problem of making accurate predictions.
Inductive value learning requires the construction of an outcome-classifier from value-labeled training data, but it also requires some method for identifying, inside the states or potential states described in its world-model, the referents of the labels in the training data.
As Nate and I noted in other comments, the paper repeatedly clarifies that the core issue isn't about whether the AI is good at NLP. Quoting the paper's abstract:
Even a machine intelligent enough to understand its designers’ intentions would not necessarily act as intended.
And the lede section:
The novelty here is not that programs can exhibit incorrect or counter-intuitive behavior, but that software agents smart enough to understand natural language may still base their decisions on misrepresentations of their programmers’ intent. The idea of superintelligent agents monomaniacally pursuing “dumb”-seeming goals may sound odd, but it follows from the observation of Bostrom and Yudkowsky [2014, chap. 7] that AI capabilities and goals are logically independent.[1] Humans can fully comprehend that their “designer” (evolution) had a particular “goal” (reproduction) in mind for sex, without thereby feeling compelled to forsake contraception. Instilling one’s tastes or moral values into an heir isn’t impossible, but it also doesn’t happen automatically.
Back to your post:
And to be clear, I don't mean that GPT-4 merely passively "understands" human values. I mean that asking GPT-4 to distinguish valuable and non-valuable outcomes works pretty well at approximating the human value function in practice
I don't think I understand what difference you have in mind here, or why you think it's important. Doesn't "this AI understands X" more-or-less imply "this AI can successfully distinguish X from not-X in practice"?
This fact is key to what I'm saying because it means that, in the near future, we can literally just query multimodal GPT-N about whether an outcome is bad or good, and use that as an adequate "human value function". That wouldn't solve the problem of getting an AI to care about maximizing the human value function, but it would arguably solve the problem of creating an adequate function that we can put into a machine to begin with.
But we could already query the human value function by having the AI system query an actual human. What specific problem is meant to be solved by swapping out "query a human" for "query an AI"?
I interpret this passage as saying that 'the problem' is extracting all the judgements that "you would make", and putting that into a wish. I think he's implying that these judgements are essentially fully contained in your brain. I don't think it's credible to insist he was referring to a hypothetical ideal human value function that ordinary humans only have limited access to, at least in this essay.
Absolutely. But as Eliezer clarified in his reply [LW(p) · GW(p)], the issue he was worried about was getting specific complex content into the agent's goals, not getting specific complex content into the agent's beliefs. Which is maybe clearer in the 2011 paper where he gave the same example and explicitly said that the issue was the agent's "utility function".
For example, a straightforward reading of Nate Soares' 2017 talk supports this interpretation. In the talk, Soares provides a fictional portrayal of value misalignment, drawing from the movie Fantasia. In the story, Mickey Mouse attempts to instruct a magical broom to fill a cauldron, but the broom follows the instructions literally rather than following what Mickey Mouse intended, and floods the room. Soares comments: "I claim that as fictional depictions of AI go, this is pretty realistic.
The idea of the "fill the cauldron" examples isn't "the AI is bad at NLP and therefore doesn't understand what we mean when we say 'fill', 'cauldron', etc." It's "even simple small-scale tasks are unnatural, in the sense that it's hard to define a coherent preference ordering over world-states such that maximizing it completes the task and has no serious negative impact; and there isn't an obvious patch that overcomes the unnaturalness or otherwise makes it predictably easier to aim AI systems at a bounded low-impact task like this". (Including easier to aim via training.)
It's true that 'value is relatively complex' is part of why it's hard to get the right goal into an AGI; but it doesn't follow from this that 'AI is able to develop pretty accurate beliefs about our values' helps get those complex values into the AGI's goals. (It does provide nonzero evidence about how complex value is, but I don't see you arguing that value is very simple in any absolute sense, just that it's simple enough for GPT-4 to learn decently well. Which is not reassuring, because GPT-4 is able to learn a lot of very complicated things, so this doesn't do much to bound the complexity of human value.)
In any case, I take this confusion as evidence that the fill-the-cauldron example might not be very useful. Or maybe all these examples just need to explicitly specify, going forward, that the AI is part-human at understanding English.
Perhaps more important to my point, Soares presented a clean separation between the part where we specify an AI's objectives, and the part where the AI tries to maximizes those objectives. He draws two arrows, indicating that MIRI is concerned about both parts.
Your image isn't displaying for me, but I assume it's this one?
I don't know what you mean by "specify an AI's objectives" here, but the specific term Nate uses here is "value learning" (not "value specification" or "value identification"). And Nate's Value Learning Problem paper, as I noted above, explicitly disclaims that 'get the AI to be smart enough to output reasonable-sounding moral judgments' is a core part of the problem.
He states, "The serious question with smarter-than-human AI is how we can ensure that the objectives we’ve specified are correct, and how we can minimize costly accidents and unintended consequences in cases of misspecification." I believe this quote refers directly to the value identification problem, rather than the problem of getting an AI to care about following the goals we've given it.
The way you quoted this makes it sound like a gloss on the image, but it's actually a quote from the very start of the talk:
The notion of AI systems “breaking free” of the shackles of their source code or spontaneously developing human-like desires is just confused. The AI system is its source code, and its actions will only ever follow from the execution of the instructions that we initiate. The CPU just keeps on executing the next instruction in the program register. We could write a program that manipulates its own code, including coded objectives. Even then, though, the manipulations that it makes are made as a result of executing the original code that we wrote; they do not stem from some kind of ghost in the machine.
The serious question with smarter-than-human AI is how we can ensure that the objectives we’ve specified are correct, and how we can minimize costly accidents and unintended consequences in cases of misspecification. As Stuart Russell (co-author of Artificial Intelligence: A Modern Approach) puts it:
The primary concern is not spooky emergent consciousness but simply the ability to make high-quality decisions. Here, quality refers to the expected outcome utility of actions taken, where the utility function is, presumably, specified by the human designer. Now we have a problem:
1. The utility function may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down.
2. Any sufficiently capable intelligent system will prefer to ensure its own continued existence and to acquire physical and computational resources – not for their own sake, but to succeed in its assigned task. [...]
I wouldn't read too much into the word choice here, since I think it's just trying to introduce the Russell quote, which is (again) explicitly about getting content into the AI's goals, not about getting content into the AI's beliefs.
(In general, I think the phrase "value specification" is sort of confusingly vague. I'm not sure what the best replacement is for it -- maybe just "value loading", following Bostrom? -- but I suspect MIRI's usage of it has been needlessly confusing. Back in 2014, we reluctantly settled on it as jargon for "the part of the alignment problem that isn't subsumed in getting the AI to reliably maximize diamonds", because this struck us as a smallish but nontrivial part of the problem; but I think it's easy to read the term as referring to something a lot more narrow.)
The point of "the genie knows but doesn't care [LW · GW]" wasn't that the AI would take your instructions, know what you want, and yet disobey the instructions because it doesn't care about what you asked for. If you read Rob Bensinger's essay [LW · GW] carefully, you'll find that he's actually warning that the AI will care too much about the utility function you gave it, and maximize it exactly, against your intentions[10] [LW(p) · GW(p)].
Yep -- I think I'd have endorsed claims like "by default, a baby AGI won't share your values even if it understands them" at the time, but IIRC the essay doesn't make that point explicitly, and some of the points it does make seem either false (wait, we're going to be able to hand AGI a hand-written utility function? that's somehow tractable?) or confusingly written. (Like, if my point was 'even if you could hand-write a utility function, this fails at point X', I should have made that 'even if' louder.)
Some MIRI staff liked that essay at the time, so I don't think it's useless, but it's not the best evidence: I wrote it not long after I first started learning about this whole 'superintelligence risk' thing, and I posted it before I'd ever worked at MIRI.
Thanks for this comment. I think this is a good-faith reply that tries to get to the bottom of the disagreement. That said, I think you are still interpreting me as arguing that MIRI said AI wouldn't understand human values, when I explicitly said that I was not arguing that. Nonetheless, I appreciate the extensive use of quotations to precisely pinpoint where you disagree; this is high-quality engagement.
The main thing I'm claiming is that MIRI people said it would be hard to specify (for example, write into a computer) an explicit function that reflects the human value function with high fidelity, in the sense that judgements from this function about the value of outcomes fairly accurately reflect the judgements of ordinary humans. I think this is simply a distinct concept from the idea of getting an AI to understand human values.
The key difference is the transparency and legibility of how the values are represented: if you solve the problem of value specification/value identification, that means you have an actual function that can tell you the value of any outcome. If you get an AI that merely understands human values, you can't necessarily use the AI to determine the value of any outcome, because, for example, the AI might lie to you, or simply stay silent.
(I've now added further clarification to the post)
I don't think we've ever said that an important subproblem of AI alignment is "make AI smart enough to figure out what goals humans want"?
[...]
I don't see him saying anywhere "the issue is that the AI doesn't understand human goals".
I agree. I am not arguing that MIRI ever thought that AIs wouldn't understand human goals. I honestly don't know how to make this point more clear in my post, given that I said that more than once.
But we could already query the human value function by having the AI system query an actual human. What specific problem is meant to be solved by swapping out "query a human" for "query an AI"?
I think there's considerably more value in having the human value function in an actual computer. More to the point, what I'm saying here is more that MIRI seems to have thought that getting such a function was (1) important for solving alignment, and (2) hard to get (for example because it was hard to extract human values from data). I tried to back this up with evidence in the post, and overall I still feel I succeeded, if you go through the footnotes and read the post carefully.
Your image isn't displaying for me, but I assume it's this one?
Yes. I'm not sure why the image isn't loading. I tried to fix it, but I wasn't able to. I asked LW admins/mods through the intercom about this.
I wouldn't read too much into the word choice here, since I think it's just trying to introduce the Russell quote, which is (again) explicitly about getting content into the AI's goals, not about getting content into the AI's beliefs.
Maybe you're right. I'm just not convinced. I think the idea that Nate wasn't talking about what I'm calling the value identification/value specification problem in that quote just isn't a straightforward interpretation of the talk as a whole. I think Nate was actually talking about the idea of specifying human values, in the sense of value identification, as I defined and clarified above, and he also talked about the problem of getting the AI to actually maximize these values (separately from their specification). However, I do agree that he was not talking about getting content merely into the AI's beliefs.
Some MIRI staff liked that essay at the time, so I don't think it's useless, but it's not the best evidence: I wrote it not long after I first started learning about this whole 'superintelligence risk' thing, and I posted it before I'd ever worked at MIRI.
That's fair. The main reason why I'm referencing it is because it's what comes up when I google "The genie knows but doesn't care", which is a phrase that I saw referenced in this debate before. I don't know if your essay is the source of the phrase or whether you just titled it that, but I thought it was worth adding a paragraph of clarification about how I interpret that essay, and I'm glad to see you mostly agree with my interpretation.
The main thing I'm claiming is that MIRI said it would be hard to specify (for example, write into a computer) an explicit function that reflects the human value function with high fidelity, in the sense that judgements from this function about the value of outcomes fairly accurately reflect the judgements of ordinary humans. I think this is simply a distinct concept from the idea of getting an AI to understand human values.
The key difference is the transparency and legibility of how the values are represented: if you solve the problem of value specification/value identification, that means you have an actual function that can tell you the value of any outcome. If you get an AI that merely understands human values, you can't necessarily use the AI to determine the value of any outcome, because, for example, the AI might lie to you, or simply stay silent.
Ah, this is helpful clarification! Thanks. :)
I don't think MIRI ever considered this an important part of the alignment problem, and I don't think we expect humanity to solve lots of the alignment problem as a result of having such a tool; but I think I better understand now why you think this is importantly different from "AI ever gets good at NLP at all".
don't know if your essay is the source of the phrase or whether you just titled it
I think I came up with that particular phrase (though not the idea, of course).
I don't think MIRI ever considered this an important part of the alignment problem, and I don't think we expect humanity to solve lots of the alignment problem as a result of having such a tool
If you don't think MIRI ever considered coming up with an "explicit function that reflects the human value function with high fidelity" to be "an important part of the alignment problem", can you explain this passage from the Arbital page on The problem of fully updated deference?
One way to look at the central problem of value identification in superintelligence is that we'd ideally want some function that takes a complete but purely physical description of the universe, and spits out our true intended notion of value V in all its glory. Since superintelligences would probably be pretty darned good at collecting data and guessing the empirical state of the universe, this probably solves the whole problem.
This is not the same problem as writing down our true V by hand. The minimum algorithmic complexity of a meta-utility function ΔU which outputs V after updating on all available evidence, seems plausibly much lower than the minimum algorithmic complexity for writing V down directly. But as of 2017, nobody has yet floated any formal proposal for a ΔU of this sort which has not been immediately shot down.
Eliezer (who I assume is the author) appears to say in the first paragraph that solving the problem of value identification for superintelligences would "probably [solve] the whole problem", and by "whole problem" I assume he's probably referring to what he saw as an important part of the alignment problem (maybe not though?)
He referred to the problem of value identification as getting "some function that takes a complete but purely physical description of the universe, and spits out our true intended notion of value V in all its glory." This seems to be very similar to my definition, albeit with the caveat that my definition isn't about revealing "V in all its glory" but rather, is more about revealing V at the level that an ordinary human is capable of revealing V.
Unless the sole problem here is that we absolutely need our function that reveals V to be ~perfect, then I think this quote from the Arbital page directly supports my interpretation, and overall supports the thesis in my post pretty strongly (even if I'm wrong about a few minor details).
As an experimental format, here is the first draft of what I wrote for next week's newsletter about this post:
Matthew Barnett argues [LW · GW] that GPT-4 exhibiting common sense morality, and being able to follow it, should update us towards alignment being easier than we thought, and MIRI-style people refusing to do so are being dense. That the AI is not going to maximize the utility function you gave it at the expense of all common sense.
As usual, this logically has to be more than zero evidence for this, given how we would react if GPT-4 indeed lacked such common sense or was unable to give answers that pleased humans at all. Thus, we should update a non-zero amount in that direction, at least if we ignore the danger of being led down the wrong alignment path.
However, I think this misunderstands what is going on. GPT-4 is training on human feedback, so it is choosing responses that maximize the probability of positive user response in the contexts where it gets feedback. If that is functionally your utility function, you want to respond with answers that appear, to humans similar to the ones who provided you with feedback, to reflect common sense and seem to avoid violating various other concerns. That will be more important than maximizing the request made, especially if strong negative feedback was given for violations of various principles including common sense.
Thus, I think GPT-4 is indeed doing a decent job of extracting human preferences, but only in the sense that is predicting what preferences we would consciously choose to express in response under strong compute limitations. For now, that looks a lot like having common sense morality, and mostly works out fine. I do not think this has much bearing on the question of what it would take to make something work out fine in the future, under much stronger optimization pressure, I think you metaphorically do indeed get to the literal genie problem from a different angle. I would say that the misspecification problems remain highly relevant, and that yes, as you gain in optimization power your need to correctly specify the exact objective increases, and if you are exerting far-above-human levels of optimization pressure based on only human consciously expressed under highly limited compute levels of value alignment, you are going to have a bad time.
I believe MIRI folks have a directionally similar position to mine only far stronger.
I think you are misunderstanding Barnett's position.
He's making a more subtle claim. See the above clarifying comment by Matthew:
"The main thing I'm claiming is that MIRI said it would be hard to specify (for example, write into a computer) an explicit function that reflects the human value function with high fidelity, in the sense that judgements from this function about the value of outcomes fairly accurately reflect the judgements of ordinary humans. I think this is simply a distinct concept from the idea of getting an AI to understand human values.
The key difference is the transparency and legibility of how the values are represented: if you solve the problem of value specification/value identification, that means you have an actual function that can tell you the value of any outcome. If you get an AI that merely understands human values, you can't necessarily use the AI to determine the value of any outcome, because, for example, the AI might lie to you, or simply stay silent."
Can you explain how this comment applies to Zvi's post? In particular, what is the "subtle claim" that Zvi is not addressing. I don't particularly care about what MIRI people think, just about the object level.
strawman MIRI: alignment is difficult because AI won't be able to answer common-sense morality questions
"a child is drowning in a pool nearby. you just bought a new suit. do you save the child?"
actual MIRI: almost by definition a superintelligent AI will know what humans want and value. It just won't necessarily care. The 'value pointing' problem isn't about pointing to human values in its belief but in its own preferences.
There are several subtleties: belief is selected by reality (having wrong beliefs is punished) and highly constrained, preferences are highly unconstrained (this is a more subtle version of the orthogonality thesis). human value is complex and hard to specify - in particular hitting it by pointing approximately at it ('in preference space') is highly unlikely to hit it (and because there is no 'correction from reality' like in belief).
strawman Barnett: MIRI believes strawman MIRI and gpt-4 can answer common-sense morality questions so it update.
actual Barnett: i understand the argument that there is a difference between making AI know human values versus caring about those values. I'm arguing that the human value function is in fact not that hard to specify. approximate human utility function is relatively simple and a gpt-4 knows it.
(which is still distinct from saying gpt-4 or some AI will care about it. but at least it belies the claim that human values are hugely complex).
I think I read this a few times but I still don't think I fully understand your point. I'm going to try to rephrase what I believe you are saying in my own words:
Our correct epistemic state in 2000 or 2010 should be to have a lot of uncertainty about the complexity and fragility of human values. Perhaps it is very complex, but perhaps people are just not approaching it correctly.
At the limit, the level of complexity can approach "simulate a number of human beings in constant conversation and moral deliberation with each other, embedded in the existing broader environment, and where a small mistake in the simulation renders the entire thing broken in the sense of losing almost all moral value in the universe if that's what you point at"
At the other, you can imagine a fairly simple mathematical statement that's practically robust to any OOD environments or small perturbations.
In worlds where human values aren't very complex, alignment isn't solved, but you should perhaps expect it to be (significantly) easier. ("Optimize for this mathematical statement" is an easier thing to point at than "optimize for the outcome of this complex deliberation, no, not the actual answers out of their mouths but the indirect more abstract thing they point at")
Suppose in 2000 you were told that a100-line Python program (that doesn't abuse any of the particular complexities embedded elsewhere in Python) can provide a perfect specification of human values. Then you should rationally conclude that human values aren't actually all that complex (more complex than the clean mathematical statement, but simpler than almost everything else).
In such a world, if inner alignment is solved, you can "just" train a superintelligent AI to "optimize for the results of that Python program" and you'd get a superintelligent AI with human values.
Notably, alignment isn't solved by itself. You still need to get the superintelligent AI to actually optimize for that Python program and not some random other thing that happens to have low predictive loss in training on that program.
Well, in 2023 we have that Python program, with a few relaxations:
The answer isn't embedded in 100 lines of Python, but in a subset of the weights of GPT-4
Notably the human value function (as expressed by GPT-4) is necessarily significantly simpler than the weights of GPT-4, as GPT-4 knows so much more than just human values.
What we have now isn't a perfect specification of human values, but instead roughly the level of understanding of human values that a 85th percentile human can come up with.
The human value function as expressed by GPT-4 is also immune to almost all in-practice, non-adversarial, perturbations
We should then rationally update on the complexity of human values. It's probably not much more complex than GPT-4, and possibly significantly simpler. ie, the fact that we have a pretty good description of human values well short of superintelligent AI means we should not expect a perfect description of human values to be very complex either.
This is a different claim from saying that Superintelligent AIs will understand human values; which everybody agrees with. Human values isn't any more mysterious from the perspective of physics than any other emergent property like fluid dynamics or the formation of cities.
However, if AIs needed to be superintelligent (eg at the level of approximating physics simulations of Earth) before they grasp human values, that'd be too late, as they can/will destroy the world before their human creators can task a training process (or other ways of making AGI) towards {this thing that we mean when we say human values}.
But instead, the world we live in is one where we can point future AGIs towards the outputs of GPT-N when asked questions about morality as the thing to optimize for.
Which, again, isn't to say the alignment problem is solved, we might still all die because future AGIs could just be like "lol nope" to the outputs of GPT-N, or try to hack it to produce adversarial results, or something. But at least one subset of the problem is either solved or a non-issue, depending on your POV.
Given all this, MIRI appeared to empirically be wrong when they previously talked about the complexity and fragility of human values. Human values now seem noticeably less complex than many possibilities, and empirically we already have a pretty good representation of human values in silica.
My read of older posts from Yudkowsky is that he anticipated a midrange level of complexity of human values, compared to your scale of simple mathematical function to perfect simulation of human experts.
Yudkowsky argued against very low complexity human values in a few places. There's an explicit argument against Fake Utility Functions [LW · GW] that are simple mathematical functions. The Fun Theory Sequence [LW · GW] is too big if human values are a 100 line python program.
But also Yudkowsky's writing is incompatible with extremely complicated human values that require a perfect simulation of human experts to address. This argument is more implicit, I think because that was not a common position. Look at Thou Art Godshatter [LW · GW] and how it places the source of human values in the human genome, downstream of the "blind idiot god" of Evolution. If true, human values must be far less complicated than the human genome.
GPT-4 is about 1,000x bigger than the human genome. Therefore when we see that GPT-4 can represent human values with high fidelity this is not a surprise to Godshatter Theory. It will be surprising if we see that very small AI models, much smaller than the human genome, can represent human values accurately.
Disclaimers: I'm not replying to the thread about fragility of value, only complexity. I disagree with Godshatter Theory on other grounds. I agree that it is a small positive update that human values are less complex than GPT-4.
While I did agree that Linch's comment reasonably accurately summarized my post, I don't think a large part of my post was about the idea that we should now think that human values are much simpler than Yudkowsky portrayed them to be. Instead, I believe this section from Linch's comment does a better job at conveying what I intended to be the main point,
Suppose in 2000 you were told that a100-line Python program (that doesn't abuse any of the particular complexities embedded elsewhere in Python) can provide a perfect specification of human values. Then you should rationally conclude that human values aren't actually all that complex (more complex than the clean mathematical statement, but simpler than almost everything else).
In such a world, if inner alignment is solved, you can "just" train a superintelligent AI to "optimize for the results of that Python program" and you'd get a superintelligent AI with human values.
Notably, alignment isn't solved by itself. You still need to get the superintelligent AI to actually optimize for that Python program and not some random other thing that happens to have low predictive loss in training on that program.
Well, in 2023 we have that Python program, with a few relaxations:
The answer isn't embedded in 100 lines of Python, but in a subset of the weights of GPT-4
Notably the human value function (as expressed by GPT-4) is necessarily significantly simpler than the weights of GPT-4, as GPT-4 knows so much more than just human values.
What we have now isn't a perfect specification of human values, but instead roughly the level of understanding of human values that a 85th percentile human can come up with.
The primary point I intended to emphasize is not that human values are fundamentally simple, but rather that we now have something else important: an explicit, and cheaply computable representation of human values that can be directly utilized in AI development. This is a major step forward because it allows us to incorporate these values into programs in a way that provides clear and accurate feedback during processes like RLHF. This explicitness and legibility are critical for designing aligned AI systems, as they enable developers to work with a tangible and faithful specification of human values rather than relying on poor proxies that clearly do not track the full breadth and depth of what humans care about.
The fact that the underlying values may be relatively simple is less important than the fact that we can now operationalize them, in a way that reflects human judgement fairly well. Having a specification that is clear, structured, and usable means we are better equipped to train AI systems to share those values. This representation serves as a foundation for ensuring that the AI optimizes for what we actually care about, rather than inadvertently optimizing for proxies or unrelated objectives that merely correlate with training signals. In essence, the true significance lies in having a practical, actionable specification of human values that can actively guide the creation of future AI, not just in observing that these values may be less complex than previously assumed.
This is good news because this is more in line with my original understanding of your post. It's a difficult topic because there are multiple closely related problems of varying degrees of lethality and we had updates on many of them between 2007 and 2023. I'm going to try to put the specific update you are pointing at into my own words.
From the perspective of 2007, we don't know if we can lossilly extract human values into a convenient format using human intelligence and safe tools. We know that a superintelligence can do it (assuming that "human values" is meaningful), but we also know that if we try to do this with an unaligned superintelligence then we all die.
If this problem is unsolvable then we potentially have to create a seed AI using some more accessible value, such as corrigibility, and try to maintain that corrigibility as we ramp up intelligence. This then leads us to the problem of specifying corrigibility, and we see "Corrigibility is anti-natural to consequentialist reasoning" on List of Lethalities [LW · GW].
The update between 2007 and 2023 is that the problem appears solvable. GPT-4 is a safe tool (it exists and we aren't extinct yet) and does a decent job. A more focused AI could do the task better without being riskier.
This does not mean that we are not going to die. Yudkowsky has 43 items on List of Lethalities. This post addresses part of item 24. The remaining items are sufficient to kill us ~42.5 times. It's important to be able to discuss one lethality at a time if we want to die with dignity.
I'm not saying anything about the fragility of value argument, since that seems like a separate argument than the argument that value is complex. I think the fragility of value argument is plausibly a statement about how easy it is to mess up if you get human values wrong, which still seems true depending on one's point of view (e.g. if the AI exhibits all human values except it thinks murder is OK, then that could be catastrophic).
Overall, while I definitely could have been clearer when writing this post, the fact that you seemed to understand virtually all my points makes me feel better about this post than I originally felt.
Thanks! Though tbh I don't think I fully got the core point via reading the post so I should only get partial credit; for me it took Alexander's comment [LW(p) · GW(p)] to make everything click together.
This comment made me reflect on what fragility of values means.
To me this point was always most salient when thinking about embodied agents, which may need to reliably recognize something like "people" in its environment (in order to instantiate human values like "try not to hurt people") even as the world changes radically with the introduction of various forms of transhumanism.
I guess it's not clear to me how much progress we make towards that with a system that can do a very good job with human values when restricted to the text domain. Plausibly we just translate everything into text and are good to go? It makes me wonder where we're at with adversarial robustness of vision-language models, e.g.
I think I'm relatively optimistic that the difference between a system that "can (and will) do a very good job with human values when restricted to the text domain: vs "system that can do a very good job, unrestricted" isn't that high. This is because I'm personally fairly skeptical about arguments along the lines of "words aren't human thinking, words are mere shadows of human thinking" that people put out, at least when it comes to human values.
(It's definitely possible to come up with examples that illustrates the differences between all of human thinking and human-thinking-put-into-words; I agree about their existence, I disagree about their importance).
"The AI's values don't generalize well outside of the text domain (e.g. to a humanoid robot)"
and more:
"The AI's values must be much more aligned in order to be safe outside the text domain"
I.e. if we model an AI and a human as having fixed utility functions over the same accurate world model, then the same AI might be safe as a chatbot, but not as a robot.
This would be because the richer domain / interface of the robot creates many more opportunities to "exploit" whatever discrepancies exist between AI and human values in ways that actually lead to perverse instantiation.
Yeah, I think the crux is precisely this, in which I disagree with this statement below, mostly because I think instruction following/corrigibility is both plausibly easy in my view, and also removes most of the need for value alignment.
"The AI's values must be much more aligned in order to be safe outside the text domain"
There are 2 senses in which I agree that we don't need full on "capital V value alignment":
We can build things that aren't utility maximizers (e.g. consider the humble MNIST classifier)
There are some utility functions that aren't quite right, but are still safe enough to optimize in practice (e.g. see "Value Alignment Verification", but see also, e.g. "Defining and Characterizing Reward Hacking" for negative results)
But also:
Some amount of alignment is probably necessary in order to build safe agenty things (the more agenty, the higher the bar for alignment, since you start to increasingly encounter perverse instatiation-type concerns -- CAVEAT: agency is not a unidimensional quantity, cf: "Harms from Increasingly Agentic Algorithmic Systems").
Note that my statement was about the relative requirements for alignment in text domains vs. real-world. I don't really see how your arguments are relevant to this question.
Concretely, in domains with vision, we should probably be significantly more worried that an AI system learns something more like an adversarial "hack" on it's values leading to behavior that significantly diverges from things humans would endorse.
We should clearly care if their arguments were wrong in the past, especially if they were systematically wrong in a particular direction, as it's evidence about how much attention we should pay to their arguments now. At some point if someone is wrong enough for long enough you should discard their entire paradigm and cease to privilege hypotheses they suggest, until they reacquire credibility through some other means
e.g. a postmortem explaining what they got wrong and what they learned, or some unambiguous demonstration of insight into the domain they're talking about.
I'm not arguing that GPT-4 actually cares about maximizing human value. However, I am saying that the system is able to transparently pinpoint to us which outcomes are good and which outcomes are bad, with fidelity approaching an average human, albeit in a text format. Crucially, GPT-4 can do this visibly to us, in a legible way, rather than merely passively knowing right from wrong in some way that we can't access. This fact is key to what I'm saying because it means that, in the near future, we can literally just query multimodal GPT-N about whether an outcome is bad or good, and use that as an adequate "human value function". That wouldn't solve the problem of getting an AI to care about maximizing the human value function, but it would arguably solve the problem of creating an adequate function that we can put into a machine to begin with.
It sounds like you are saying: We just need to prompt GPT with something like "Q: How good is this outcome? A:" and then build a generic maximizer agent using that prompted GPT as the utility function, and our job is done, we would have made an AGI that cares about maximizing the human value function (because it's literally its utility function) (In practice this agent might look something like AutoGPT).
But I doubt that's what you are saying, so I'm asking for clarification if you still have energy to engage!
It sounds like you are saying: We just need to prompt GPT with something like "Q: How good is this outcome? A:" and then build a generic maximizer agent using that prompted GPT as the utility function, and our job is done, we would have made an AGI that cares about maximizing the human value function
I think solving value specification is basically what you need in order to build a good reward model. If you have a good reward model, and you solve inner alignment, then I think you're pretty close to being able to create (at least) a broadly human-level AGI that is aligned with human values.
That said, to make superintelligent AI go well, we still need to solve the problem of scalable oversight, because, among other reasons, there might be weird bugs that result from a human-level specification of our values being optimized to the extreme. However, having millions of value-aligned human-level AGIs would probably help us a lot with this challenge.
We'd also need to solve the problem of making sure there aren't catastrophic bugs in the AIs we build. And we'll probably have to solve the general problem of value drift from evolutionary and cultural change. There's probably a few more things that we need to solve that I haven't mentioned too.
These other problems may be very difficult, and I'm not denying that. But I think it's good to know that we seem to be making good progress on the "reward modeling" part of the alignment problem. I think it's simply true that many people in the past imagined that this problem would be a lot harder than it actually was.
Literally just query GPT-N about whether [input_outcome] is good or bad
Use this as a reward model, with which to train an agentic AGI (which is maybe also a fine-tune of GPT-N, so they hopefully are working with the same knowledge/credences/concepts?)
Specifically we are probably doing some sort of RL, so the agentic AGI is doing all sorts of tasks and the reward model is looking at the immediate results of those task-attempts and grading them.
Assume we have some solution to inner alignment, and we fix the bugs, and maybe also fix value drift and some other stuff, then boom, success!
Can you say more about what you mean by solution to inner alignment? Do you mean, assume that the agentic AGI (the mesa-optimizer) will learn to optimize for the objective of "producing outcomes the RM classifies as good?" Or the objective "producing outcomes the RM would classify as good if it was operating normally?" (the difference revealing itself in cases of tampering with the RM) Or the objective "producing outcomes that are good-for-humans, harmless, honest, etc."?
Literally just query GPT-N about whether [input_outcome] is good or bad
I'm hesitant to say that I'm actually proposing literally this exact sequence as my suggestion for how we build safe human-level AGI, because (1) "GPT-N" can narrowly refer to a specific line of models by OpenAI whereas the way I was using it was more in-line with "generically powerful multi-modal models in the near-future", and (2) the actual way we build safe AGI will presumably involve a lot of engineering and tweaking to any such plan in ways that are difficult to predict and hard to write down comprehensively ahead of time. And if I were to lay out "the plan" in a few paragraphs, it will probably look pretty inadequate or too high-level compared to whatever people actually end up doing.
Also, I'm not ruling out that there might be an even better plan. Indeed, I hope there is a better plan available by the time we develop human-level AGI.
That said, with the caveats I've given above, yes, this is basically what I'm proposing, and I think there's a reasonably high chance (>50%) that this general strategy would work to my own satisfaction.
Can you say more about what you mean by solution to inner alignment?
To me, a solution to inner alignment would mean that we've solved the problem of malign generalization [AF · GW]. To be a bit more concrete, this roughly means that we've solved the problem of training an AI to follow a set of objectives in a way that generalizes to inputs that are outside of the training distribution, including after the AI has been deployed.
For example, if you teach an AI (or a child) that murder is wrong, they should be able to generalize this principle to new situations that don't match the typical environment they were trained in, and be motivated to follow the principle in those circumstances. Metaphorically, the child grows up and doesn't want to murder people even after they've been given a lot of power over other people's lives. I think this can be distinguished from the problem of specifying what murder is, because the central question is whether the AI/child is motivated to pursue the ethics that was instilled during training, even in new circumstances, rather than whether they are simply correctly interpreting the command "do not murder".
Do you mean, assume that the agentic AGI (the mesa-optimizer) will learn to optimize for the objective of "producing outcomes the RM classifies as good?" Or the objective "producing outcomes the RM would classify as good if it was operating normally?"
I think I mean the second thing, rather than the first thing, but it's possible I am not thinking hard enough about this right now to fully understand the distinction you are making.
To me, a solution to inner alignment would mean that we've solved the problem of malign generalization [LW · GW]. To be a bit more concrete, this roughly means that we've solved the problem of training an AI to follow a set of objectives in a way that generalizes to inputs that are outside of the training distribution, including after the AI has been deployed.
This is underspecified, I think, since we have for years had AIs that follow objectives in ways that generalize to inputs outside of the training distribution. The thing is there are lots of ways to generalize / lots of objectives they could learn to follow, and we don't have a good way of pinning it down to exactly the ones we want. (And indeed as our AIs get smarter there will be new ways of generalizing / categories of objectives that will become available, such as "play the training game")
So it sounds like you are saying "A solution to inner alignment mans that we've figured out how to train an AI to have the objectives we want it to have, robustly such that it continues to have them way off distribution." This sounds like basically the whole alignment problem to me?
I see later you say you mean the second thing -- which is interestingly in between "play the training game" and "actually be honest/helpful/harmless/etc." (A case that distinguishes it from the latter: Suppose it is reading a paper containing an adversarial example for the RM, i.e. some text it can output that causes the RM to give it a high score even though the text is super harmful / dishonest / etc. If it's objective is the "do what the RM would give high score to if it was operating normally" objective, it'll basically wirehead on that adversarial example once it learns about it, even if it's in deployment and it isn't getting trained anymore, and even though it's an obviously harmful/dishonest piece of text.
It's a nontrivial and plausible claim you may be making -- that this sort of middle ground might be enough for safe AGI, when combined with the rest of the plan at least. But I'd like to see it spelled out. I'm pretty skeptical right now.
Literally just query GPT-N about whether [input_outcome] is good or bad
Use this as a reward model, with which to train an agentic AGI (which is maybe also a fine-tune of GPT-N, so they hopefully are working with the same knowledge/credences/concepts?)
Specifically we are probably doing some sort of RL, so the agentic AGI is doing all sorts of tasks and the reward model is looking at the immediate results of those task-attempts and grading them.
Assume we have some solution to inner alignment, and we fix the bugs, and maybe also fix value drift and some other stuff, then boom, success!
Can you say more about what you mean by solution to inner alignment? Do you mean, assume that the agentic AGI (the mesa-optimizer) will learn to optimize for the objective of "producing outcomes the RM classifies as good?" Or the objective "producing outcomes the RM would classify as good if it was operating normally?" (the difference revealing itself in cases of tampering with the RM) Or the objective "producing outcomes that are good-for-humans, harmless, honest, etc."?
Literally just query GPT-N about whether [input_outcome] is good or bad
Use this as a reward model, with which to train an agentic AGI (which is maybe also a fine-tune of GPT-N, so they hopefully are working with the same knowledge/credences/concepts?)
Specifically we are probably doing some sort of RL, so the agentic AGI is doing all sorts of tasks and the reward model is looking at the immediate results of those task-attempts and grading them.
Assume we have some solution to inner alignment, and we fix the bugs, and maybe also fix value drift and some other stuff, then boom, success!
Can you say more about what you mean by solution to inner alignment? Do you mean, assume that the agentic AGI (the mesa-optimizer) will learn to optimize for the objective of "producing outcomes the RM classifies as good?" Or the objective "producing outcomes the RM would classify as good if it was operating normally?" (the difference revealing itself in cases of tampering with the RM) Or the objective "producing outcomes that are good-for-humans, harmless, honest, etc."?
Literally just query GPT-N about whether [input_outcome] is good or bad
Use this as a reward model, with which to train an agentic AGI (which is maybe also a fine-tune of GPT-N, so they hopefully are working with the same knowledge/credences/concepts?)
Specifically we are probably doing some sort of RL, so the agentic AGI is doing all sorts of tasks and the reward model is looking at the immediate results of those task-attempts and grading them.
Assume we have some solution to inner alignment, and we fix the bugs, and maybe also fix value drift and some other stuff, then boom, success!
Can you say more about what you mean by solution to inner alignment? Do you mean, assume that the agentic AGI (the mesa-optimizer) will learn to optimize for the objective of "producing outcomes the RM classifies as good?" Or the objective "producing outcomes the RM would classify as good if it was operating normally?" (the difference revealing itself in cases of tampering with the RM) Or the objective "producing outcomes that are good-for-humans, harmless, honest, etc."?
I think the surprising lesson of GPT-4 is that it is possible to build clearly below-human-level systems that are nevertheless capable of fluent natural language processing, knowledge recall, creativity, basic reasoning, and many other abilities previously thought by many to be strictly in the human-level regime.
Once you update on that surprise though, there's not really much left to explain. The ability to distinguish moral from immoral actions at an average human level follows directly from being superhuman at language fluency and knowledge recall, and somewhere below-human-average at basic deductive reasoning and consequentialism.
MIRI folks have consistently said that all the hard problems come in when you get to the human-level regime and above. So even if it's relatively more surprising to their world models that a thing like GPT-4 can exist, it's not actually much evidence (on their models) about how hard various alignment problems will be when dealing with human-level and above systems.
Similarly:
If you disagree that AI systems in the near-future will be capable of distinguishing valuable from non-valuable outcomes about as reliably as humans, then I may be interested in operationalizing this prediction precisely, and betting against you. I don't think this is a very credible position to hold as of 2023, barring a pause that could slow down AI capabilities very soon.
I don't disagree with this, but I think it is also a direct consequence of the (easy) prediction that AI systems will continue to get closer and closer to human-level general and capable in the near term. The question is what happens when they cross that threshold decisively.
BTW, another (more pessimistic) way you could update from the observation of GPT-4's existence is to conclude that it is surprisingly easy to get (at least a kernel of) general intelligence from optimizing a seemingly random thing (next-token prediction) hard enough. I think this is partially what Eliezer means when he claims [LW · GW] that "reality was far to the Eliezer side of Eliezer on the Eliezer-Robin axis". Eliezer predicted at the time that general abstract reasoning was easy to develop, scale, and share, relative to Robin.
But even Eliezer thought you would still need some kind of detailed understanding of the actual underlying cognitive algorithms to initially bootstrap from, using GOFAI methods, complicated architectures / training processes, etc. It turns out that just applying SGD on very regularly structured networks to the problem of text prediction is sufficient to hit on (weak versions of) such algorithms incidentally, at least if you do it at scales several OOM larger than people were considering in 2008.
My own personal update from observing GPT-4 and the success of language models more generally is: a small update towards some subproblems in alignment being relatively easier, and a massive update towards capabilities being way easier. Both of these updates follow directly from the surprising observation that GPT-4-level systems are apparently a natural and wide band in the below-human capabilities spectrum.
In general, I think non-MIRI folks tend to over-update on observations and results about below-human-level systems. It's possible that MIRI folks are making the reverse mistake of not updating hard enough, but small updates or non-updates from below-human systems look basically right to me, under a world model where things predictably break down once you go above human-level.
GOFAI methods, complicated architectures / training processes, etc.
I meant something pretty general and loose, with all of these things connected by a logical OR. My definition of GOFAI includes things like minimax search and MCTS, but the Wikipedia page for GOFAI only mentions ELIZA-like stuff from the 60s, so maybe I'm just using the term wrong.
My recollection was that 2008!Eliezer was pretty agnostic about which particular methods might work for getting to AGI, though he still mostly or entirely ruled out stuff like Cyc.
I claim that GPT-4 is already pretty good at extracting preferences from human data.
So this seems to me like it's the crux. I agree with you that GPT-4 is "pretty good", but I think the standard necessary for things to go well is substantially higher than "pretty good", and that's where the difficulty arises once we start applying higher and higher levels of capability and influence on the environment. My guess is Eliezer, Rob, and Nate feel basically the same way.
Basically, I think your later section--"Maybe you think"--is pointing in the right direction, and requiring a much higher standard than human-level at moral judgment is reasonable and consistent with the explicit standard set by essays by Yudkowsky and other MIRI people. CEV was about this; talk about philosophical competence or metaphilosophy [LW · GW] was about this. "Philosophy with a deadline" would be a weird way to put it if you thought contemporary philosophy was good enough.
So this seems to me like it's the crux. I agree with you that GPT-4 is "pretty good", but I think the standard necessary for things to go well is substantially higher than "pretty good", and that's where the difficulty arises once we start applying higher and higher levels of capability and influence on the environment.
This makes sense to me. On the other hand - it feels like there's some motte and bailey going on here, if one claim is "if the AIs get really superhumanly capable then we need a much higher standard than pretty good", but then it's illustrated using examples like "think of how your AI might not understand what you meant if you asked it to get your mother out of a burning building".
I don't understand your objection. A more capable AI might understand that it's completely sufficient to tell you that your mother is doing fine, and simulate a phone call with her to keep you happy. Or it just talks you into not wanting to confirm in more detail, etc. I'd expect that the problem wouldn't be to get the AI what you want to do in a specific supervised setting, but to remain in control of the overall situation, which includes being able to rely on the AI's actions not having any ramifications beyond it's narrow task.
The question is how do you even train the AI under the current paradigm once "human preferences" stops being a standard for evaluation and just becomes another aspect of the AIs world model, that needs to be navigated.
Basically, I think your later section--"Maybe you think"--is pointing in the right direction, and requiring a much higher standard than human-level at moral judgment is reasonable and consistent with the explicit standard set by essays by Yudkowsky and other MIRI people. CEV was about this; talk about philosophical competence or metaphilosophy [LW · GW] was about this. "Philosophy with a deadline" would be a weird way to put it if you thought contemporary philosophy was good enough.
I don't think this is the crux. E.g., I'd wager the number of bits you need to get into an ASI's goals in order to make it corrigible is quite a bit smaller than the number of bits required to make an ASI behave like a trustworthy human, which in turn is way way smaller than the number of bits required to make an ASI implement CEV.
The issue is that (a) the absolute number of bits for each of these things is still very large, (b) insofar as we're training for deep competence and efficiency we're training against corrigibility (which makes it hard to hit both targets at once), and (c) we can't safely or efficiently provide good training data for a lot of the things we care about (e.g., 'if you're a superintelligence operating in a realistic-looking environment, don't do any of the things that destroy the world').
None of these points require that we (or the AI) solve novel moral philosophy problems. I'd be satisfied with an AI that corrigibly built scanning tech and efficient computing hardware for whole-brain emulation, then shut itself down; the AI plausibly doesn't even need to think about any of the world outside of a particular room, much less solve tricky questions of population ethics or whatever.
So this seems to me like it's the crux. I agree with you that GPT-4 is "pretty good", but I think the standard necessary for things to go well is substantially higher than "pretty good"
That makes sense, but I say in the post that I think we will likely have a solution to the value identification problem that's "about as good as human judgement" in the near future. Do you doubt that? If you or anyone else at MIRI doubts that, then I'd be interested in making this prediction more precise, and potentially offering to bet MIRI people on this claim.
requiring a much higher standard than human-level at moral judgment is reasonable and consistent with the explicit standard set by essays by Yudkowsky and other MIRI people
If MIRI people think that the problem here is that our AIs need to be more moral than even humans, then I don't see where MIRI people think the danger comes from on this particular issue, especially when it comes to avoiding human extinction. Some questions:
Why did Eliezer and Nate talk about stories like Micky Mouse commanding a magical broom to fill a cauldron, and then failing because of misspecification, if the problem was actually more about getting the magical broom to exhibit superhuman moral judgement?
Are MIRI people claiming that if, say, a very moral and intelligent human became godlike while preserving their moral faculties, that they would destroy the world despite, or perhaps because of, their best intentions?
Eliezer has said on multiple separate occasions that he'd prefer that we try human intelligent enhancement or try uploading alignment researchers onto computers before creating de novo AGI. But uploaded and enhanced humans aren't going to have superhuman moral judgement. How does this strategy interact with the claim that we need far better-than-human moral judgement to avoid a catastrophe?
CEV was about this; talk about philosophical competence or metaphilosophy [LW · GW] was about this.
I mostly saw CEV as an aspirational goal. It's seems more like a grand prize that we could best hope for if we solved every aspect of the alignment problem, rather than a minimal bar that Eliezer was setting for avoiding human extinction.
When I say that alignment is lethally difficult, I am not talking about ideal or perfect goals of 'provable' alignment, nor total alignment of superintelligences on exact human values, nor getting AIs to produce satisfactory arguments about moral dilemmas which sorta-reasonable humans disagree about, nor attaining an absolute certainty of an AI not killing everyone. When I say that alignment is difficult, I mean that in practice, using the techniques we actually have, "please don't disassemble literally everyone with probability roughly 1" is an overly large ask that we are not on course to get.
That makes sense, but I say in the post that I think we will likely have a solution to the value identification problem that's "about as good as human judgement" in the near future.
We already have humans who are smart enough to do par-human moral reasoning. For "AI can do par-human moral reasoning" to help solve the alignment problem, there needs to be some additional benefit to having AI systems that can match a human (e.g., some benefit to our being able to produce enormous numbers of novel moral judgments without relying on an existing text corpus or hiring thousands of humans to produce them). Do you have some benefit in mind?
I don't think the critical point of contention here is about whether par-human moral reasoning will help with alignment. It could, but I'm not making that argument. I'm primarily making the argument that specifying the human value function, or getting an AI to reflect back (and not merely passively understand) the human value function, seems easier than many past comments from MIRI people suggest. This problem is one aspect of the alignment problem, although by no means all of it, and I think it's important to point out that we seem to be approaching an adequate solution.
Are MIRI people claiming that if, say, a very moral and intelligent human became godlike while preserving their moral faculties, that they would destroy the world despite, or perhaps because of, their best intentions?
For me, the answer here is "probably yes"; I think there is some bar of 'moral' and 'intelligent' where this doesn't happen, but I don't feel confident about where it is.
I think there are two things that I expect to be big issues, and probably more I'm not thinking of:
Managing freedom for others while not allowing for catastrophic risks; I think lots of ways to mismanage that balance result in 'destroying the world', probably with different levels of moral loss.
The relevant morality is different for different social roles--someone being a good neighbor does not make them a good judge or good general. Even if someone scores highly on a 'general factor of morality' (assuming that such a thing exists) it is not obvious they will make for a good god-emperor. There is relatively little grounded human thought on how to be a good god-emperor. [Another way to put this is that "preserving their moral faculties" is not obviously enough / a good standard; probably their moral faculties should develop a lot in contact with their new situation!]
But uploaded and enhanced humans aren't going to have superhuman moral judgement. How does this strategy interact with the claim that we need far better-than-human moral judgement to avoid a catastrophe?
I understand Eliezer's position to be that 1) intelligence helps with moral judgment and 2) it's better to start with biological humans than whatever AI design is best at your intelligence-related subtask, but also that intelligence amplification is dicey business and this is more like "the least bad option" than one that seems actively good.
Like we have some experience inculcating moral values in humans that will probably generalize better to augmented humans than it will to AIs; but also I think Eliezer is more optimistic (for timing reasons) about amplifications that can be done to adult humans.
Yeah, my interpretation of that is "if your target is the human level of wisdom, it will destroy humans just like humans are on track to do." If someone is thinking "will this be as good as the Democrats being in charge or the Republicans being in charge?" they are not grappling with the difficulty of successfully wielding futuristically massive amounts of power.
I think this discussion would benefit from having a concrete proposed AGI design on the table. E.g. it sounds like Matthew Barnett has in mind something like AutoGPT5 with the prompt "always be ethical, maximize the good" or something like that. And it sounds like he is saying that while this proposal has problems and probably wouldn't work, it has one fewer problem than old MIRI thought. And as the discussion has shown there seems to be a lot of misunderstandings happening, IMO in both directions, and things are getting heated. I venture a guess that having a concrete proposed AGI design to talk about would clear things up a bit.
My paraphrase of your (Matthews) position: while I'm not claiming that GPT-4 provides any evidence about inner alignment (i.e. getting an AI to actually care about human values), I claim that it does provide evidence about outer alignment being easier than we thought: we can specify human values via language models, which have a pretty robust understanding of human values and don't systematically deceive us about their judgement. This means people who used to think outer alignment / value specification was hard should change their minds.
(End paraphrase)
I think this claim is mistaken, or at least it rests on false assumptions about what alignment researchers believe. Here's a bunch of different angles on why I think this:
My guess is a big part of the disagreement here is that I think you make some wrong assumptions about what alignment researchers believe.
I think you're putting a bit too much weight on the inner vs outer alignment distinction. The central problem that people talked about always was how to get an AI to care about human values. E.g. in The Hidden Complexity of Wishes [LW · GW] (THCW) Eliezer writes
To be a safe fulfiller of a wish, a genie must share the same values that led you to make the wish.
If you find something that looks to you like a solution to outer alignment / value specification, but it doesn't help make an AI care about human values, then you're probably mistaken about what actual problem the term 'value specification' is pointing at. (Or maybe you're claiming that value specification is just not relevant to AI safety - but I don't think you are?).
It was always possible to attempt to solve the value specification problem by just pointing at a human. The fact that we can now also point at an LLM and get a result that's not all that much worse than pointing at a human is not cause for an update about how hard value specification is. Part of the difficulty is how to define the pointer to the human and get a model to maximize human values rather than maximize some error in your specification. IMO THCW makes this point pretty well.
It's tricky to communicate problems in AI alignment―people come in with lots of different assumptions about what kind of things are easy / hard, and it's hard to resolve disagreements because we don't have a live AGI to do experiments on. I think THCW and related essays you criticize are actually great resources. They don't try to communicate the entire problem at once because that's infeasible. The fact that human values are complex and hard to specify explicitly is part of the reason why alignment is hard, where alignment means get the AI to care about human values, not get an AI to answer questions about moral behavior reasonably.
You claim the existence of GPT-4 is evidence against the claims in THCW. But IMO GPT-4 fits in neatly with THCW. The post even starts with a taxonomy of genies:
There are three kinds of genies: Genies to whom you can safely say "I wish for you to do what I should wish for"; genies for which no wish is safe; and genies that aren't very powerful or intelligent.
GPT-4 is an example of a genie that is not very powerful or intelligent.
If in 5 years we build firefighter LLMs that can rescue mothers from burning buildings when you ask them to, that would also not show that we've solved value specification - it's just a didactic example, not a full description of the actual technical problem. More broadly, I think it's plausible that within a few years LLM will be able to give moral counsel far better than the average human. That still doesn't solve value specification any more than the existence of humans that could give good moral counsel 20 years ago had solved value specification.
If you could come up with a simple action-value function Q(observation, action), that when maximized over actions yields a good outcome for humans, then I think that would probably be helpful for alignment. This is an example of a result that doesn't directly make an AI care about human values, but would probably lead to progress in that direction. I think if it turned out to be easy to formalize such a Q then I would change my mind about how hard value specification is.
While language models understand human values to some extent, they aren't robust. The RHLF/RLAIF family of methods is based on using an LLM as a reward model, and to make things work you need to be careful not to optimize too hard or you'll just get gibberish (Gao et al. 2022). LLMs don't hold up against mundane RLHF optimization pressure, nevermind an actual superintelligence. (Of course, humans wouldn't hold up either).
I'm sympathetic to some of these points, but overall I think it's still important to acknowledge that outer alignment seems easier than many expected even if we think that inner alignment is still hard. In this post I'm not saying that the whole alignment problem is now easy. I'm making a point about how we should update about the difficulty of one part of the alignment problem, which was at one time considered both hard and important to solve.
I think you're putting a bit too much weight on the inner vs outer alignment distinction. The central problem that people talked about always was how to get an AI to care about human values. E.g. in The Hidden Complexity of Wishes (THCW) Eliezer writes
To be a safe fulfiller of a wish, a genie must share the same values that led you to make the wish.
I think the most plausibly correct interpretation here of "a genie must share the same values" is that we need to solve both the value specification and inner alignment problem. I agree that just solving one part doesn't mean we've solved the other. However, again, I'm not claiming the whole problem has been solved.
It was always possible to attempt to solve the value specification problem by just pointing at a human.
Yes, and people gave proposals about how this might be done at the time. For example I believe this is what Paul Christiano was roughly trying to do when he proposed approval-directed agents. Nonetheless, these were attempts. People didn't know whether the solutions would work well. I think we've now gotten more evidence about how hard this part of the problem is.
Do you have an example of one way that the full alignment problem is easier now that we've seen that GPT-4 can understand & report on human values?
(I'm asking because it's hard for me to tell if your definition of outer alignment is disconnected from the rest of the problem in a way where it's possible for outer alignment to become easier without the rest of the problem becoming easier).
I don't speak for Matthew, but I'd like to respond to some points. My reading of his post is the same as yours, but I don't fully agree with what you wrote as a response.
If you find something that looks to you like a solution to outer alignment / value specification, but it doesn't help make an AI care about human values, then you're probably mistaken about what actual problem the term 'value specification' is pointing at.
[...]
It was always possible to attempt to solve the value specification problem by just pointing at a human. The fact that we can now also point at an LLM and get a result that's not all that much worse than pointing at a human is not cause for an update about how hard value specification is
My objection to this is that if an LLM can substitute for a human, it could train the AI system we're trying to align much faster and for much longer. This could make all the difference.
If you could come up with a simple action-value function Q(observation, action), that when maximized over actions yields a good outcome for humans, then I think that would probably be helpful for alignment.
I suspect (and I could be wrong) that Q(observation, action) is basically what Matthew claims GPT-N could be. A human who gives moral counsel can only say so much and, therefore, can give less information to the model we're trying to align. An LLM wouldn't be as limited and could provide a ton of information about Q(observation, action), so we can, in practice, consider it as being our specification of Q(observation, action).
Edit: another option is that GPT-N, for the same reason of not being limited by speed, could write out a pretty huge Q(observation, action) that would be good, unlike a human.
Addendum to the post: all three people who this post addressed (Eliezer, Nate and Rob) responded to my post by misinterpreting me as saying that MIRI thought AIs wouldn't understand human values. However, I clearly and explicitly distanced myself from such an interpretation in the post. These responses were all highly upvoted despite this error. This makes me pessimistic about having a nuanced conversation about this topic on LessWrong. I encourage people to read my post carefully and not assume that people in the comments are reporting the thesis accurately.
This makes me pessimistic about having a nuanced conversation about this topic on LessWrong
What did you think of John Wentworth's comment attempting to translate the MIRI view into other words [LW(p) · GW(p)]? It's definitely frustrating when a discussion is deadlocked on mutual strawmanning accusations (when you're sure that your accusation is correct and the other's is bogus), but I'd rather we not give up on Discourse too easily!
You make a claim that's very close to that - your claim, if I understand correctly, is that MIRI thought AI wouldn't understand human values and also not lie to us about it (or otherwise decide to give misleading or unhelpful outputs):
The key difference between the value identification/specification problem and the problem of getting an AI to understand human values is the transparency and legibility of how the values are represented: if you solve the problem of value identification, that means you have an actual function that can tell you the value of any outcome (which you could then, hypothetically, hook up to a generic function maximizer to get a benevolent AI). If you get an AI that merely understands human values, you can't necessarily use the AI to determine the value of any outcome, because, for example, the AI might lie to you, or simply stay silent.
I think this is similar enough (and false for the same reasons) that I don't think the responses are misrepresenting you that badly. Of course I might also be misunderstanding you, but I did read the relevant parts multiple times to make sure, so I don't think it makes sense to blame your readers for the misunderstanding.
I think you’re misunderstanding the paragraph you’re quoting. I read Matthew, in that paragraph as acknowledging the difference between the two problems, and saying that MIRI thought value specification (not value understanding) was much harder than it’s looking to actually be.
Hmm, you say “your claim, if I understand correctly, is that MIRI thought AI wouldn't understand human values”. I’m disagreeing with this. I think Matthew isn’t claiming that MIRI thought AI wouldn’t understand human values.
Okay, that clears things up a bit, thanks. :) (And sorry for delayed reply. Was stuck in family functions for a couple days.)
This framing feels a bit wrong/confusing for several reasons.
I guess by “lie to us” you mean act nice on the training distribution, waiting for a chance to take over the world while off distribution. I just … don’t believe GPT-4 is doing this; it seems highly implausible to me, in large part because I don’t think GPT-4 is clever enough that it could keep up the veneer until it’s ready to strike if that were the case.
The term “lie to us” suggests all GPT-4 does is say things, and we don’t know how it’ll “behave” when we finally trust it and give it some ability to act. But it only “says things” in the same sense that our brain only “emits information”. GPT-4 is now hooked up to web searches, code writing, etc. But maybe I misunderstand the sense in which you think GPT-4 is lying to us?
I think the old school MIRI cauldron-filling problem pertained to pretty mundane, everyday tasks. No one said at the time that they didn’t really mean that it would be hard to get an AGI to do those things, that it was just an allegory for other stuff like the strawberry problem. They really seemed to believe, and said over and over again, that we didn’t know how to direct a general-purpose AI to do bounded, simple, everyday tasks without it wanting to take over the world. So this should be a big update to people who held that view, even if there are still arguably risks about OOD behavior.
(If I’ve misunderstood your point, sorry! Please feel free to clarify and I’ll try to engage with what you actually meant.)
I think the old school MIRI cauldron-filling problem pertained to pretty mundane, everyday tasks. No one said at the time that they didn’t really mean that it would be hard to get an AGI to do those things, that it was just an allegory for other stuff like the strawberry problem. They really seemed to believe, and said over and over again, that we didn’t know how to direct a general-purpose AI to do bounded, simple, everyday tasks without it wanting to take over the world. So this should be a big update to people who held that view, even if there are still arguably risks about OOD behavior.
As someone who worked closely with Eliezer and Nate at the time, including working with Eliezer and Nate on our main write-ups that used the cauldron example, I can say that this is definitely not what we were thinking at the time. Rather:
The point was to illustrate a weird gap in the expressiveness and coherence of our theories of rational agency: "fill a bucket of water" seems like a simple enough task, but it's bizarrely difficult to just write down a simple formal description of an optimization process that predictably does this (without any major side-effects, etc.).
(We can obviously stipulate "this thing is smart enough to do the thing we want, but too dumb to do anything dangerous", but the relevant notion of "smart enough" is not itself formal; we don't understand optimization well enough to formally define agents that have all the cognitive abilities we want and none of the abilities we don't want.)
The point of emphasizing "holy shit, this seems so easy and simple and yet we don't see a way to do it!" wasn't to issue a challenge to capabilities researches to go cobble together a real-world AI that can fill a bucket of water without destroying the world. The point was to emphasize that corrigibility, low-impact problem-solving, 'real' satisficing behavior, etc. seem conceptually simple, and yet the concepts have no known formalism.
The hope was that someone would see the simple toy problems and go 'what, no way, this sounds easy', get annoyed/nerdsniped, run off to write some equations on a whiteboard, and come back a week or a year later with a formalism (maybe from some niche mathematical field) that works totally fine for this, and makes it easier to formalize lots of other alignment problems in simplified settings (e.g., with unbounded computation).
Or failing that, the hope was that someone might at least come up with a clever math hack that solves the immediate 'get the AI to fill the bucket and halt' problem and replaces this dumb-sounding theory question with a slightly deeper theory question.
By using a children's cartoon to illustrate the toy problem, we hoped to make it clearer that the genre here is "toy problem to illustrate a weird conceptual issue in trying to define certain alignment properties", not "robotics problem where we show a bunch of photos of factory robots and ask how we can build a good factory robot to refill water receptacles used in industrial applications".
Nate's version of the talk, which is mostly a more polished version of Eliezer's talk, is careful to liberally sprinkle in tons of qualifications like (emphasis added)
"... for systems that are sufficiently good at modeling their environment",
'if the system is smart enough to recognize that shutdown will lower its score',
"Relevant safety measures that don’t assume we can always outthink and outmaneuver the system...",
... to make it clearer that the general issue is powerful, strategic optimizers that have high levels of situational awareness, etc., not necessarily 'every system capable enough to fill a bucket of water' (or 'every DL system...').
Remember that MIRI was in the business of poking at theoretical toy problems and trying to get less conceptually confused about how you could in principle cleanly design a reliable, aimable reasoner. MIRI wasn't (and isn't) in the business of issuing challenges to capabilities researchers to build a working water-bucket-filler as soon as possible, and wasn't otherwise in the business of challenging people to race to AGI faster.
It wouldn't have occurred to me that someone might think 'can a deep net fill a bucket of water, in real life, without being dangerously capable' is a crucial question in this context; I'm not sure we ever even had the thought occur in our heads 'when might such-and-such DL technique successfully fill a bucket?'. It would seem just as strange to me as going to check the literature to make sure no GOFAI system ever filled a bucket of water.
(And while I think I understand why others see ChatGPT as a large positive update about alignment's difficulty, I hope it's also obvious why others, MIRI included, would not see it that way.)
Hacky approaches to alignment do count just as much as clean, scrutable, principled approaches -- the important thing is that the AGI transition goes well, not that it goes well and feels clean and tidy in the process. But in this case the messy empirical approach doesn't look to me like it actually lets you build a corrigible AI that can help with a pivotal act.
If general-ish DL methods were already empirically OK at filling water buckets in 2016, just as GOFAI already was in 2016, I suspect we still would have been happy to use the Fantasia example, because it's a simple well-known story that can help make the abstract talk of utility functions and off-switch buttons easier to mentally visualize and manipulate.
(Though now that I've seen the confusion the example causes, I'm more inclined to think that the strawberry problem is a better frame than the Fantasia example.)
I think this reply is mostly talking past my comment.
I know that MIRI wasn't claiming we didn't know how to safely make deep learning systems, GOFAI systems, or what-have-you fill buckets of water, but my comment wasn't about those systems. I also know that MIRI wasn't issuing a water-bucket-filling challenge to capabilities researchers.
My comment was specifically about directing an AGI (which I think GPT-4 roughly is), not deep learning systems or other software generally. I *do* think MIRI was claiming we didn't know how to make AGI systems safely do mundane tasks.
I think some of Nate's qualifications are mainly about the distinction between AGI and other software, and others (such as "[i]f the system is trying to drive up the expectation of its scoring function and is smart enough to recognize that its being shut down will result in lower-scoring outcomes") mostly serve to illustrate the conceptual frame MIRI was (and largely still is) stuck in about how an AGI would work: an argmaxer over expected utility.
[Edited to add: I'm pretty sure GPT-4 is smart enough to know the consequences of its being shut down, and yet dumb enough that, if it really wanted to prevent that from one day happening, we'd know by now from various incompetent takeover attempts.]
Okay. I do agree that one way to frame Matthew’s main point is that MIRI thought it would be hard to specify the human value function, and an LM that understands human values and reliably tells us the truth about that understanding is such a specification, and hence falsifies that belief.
To your second question: MIRI thought we couldn’t specify the value function to do the bounded task of filling the cauldron, because any value function we could naively think of writing, when given to an AGI (which was assumed to be a utility argmaxer), leads to all sorts of instrumentally convergent behavior such as taking over the world to make damn sure the cauldron is really filled, since we forgot all the hidden complexity of our wish.
I think this is similar enough (and false for the same reasons)
I agree the claim is "similar". It's actually a distinct claim, though. What are the reasons why it's false? (And what do you mean by saying that what I wrote is "false"? I think the historical question is what's important in this case. I'm not saying that solving the value specification problem means that we have a full solution to the alignment problem, or that inner alignment is easy now.)
I think it's false in the sense that MIRI never claimed that it would be hard to build an AI with GPT-4 level understanding of human values + GPT-4 level of willingness to answer honestly (as far as I can tell). The reason I think it's false is mostly that I haven't seen a claim like that made anywhere, including in the posts you cite.
I agree lots of the responses elide the part where you emphasize that it's important how GPT-4 doesn't just understand human values, but is also "willing" to answer questions somewhat honestly. TBH I don't understand why that's an important part of the picture for you, and I can see why some responses would just see the "GPT-4 understands human values" part as the important bit (I made that mistake too on my first reading, before I went back and re-read).
It seems to me that trying to explain the original motivations for posts like Hidden Complexity of Wishes is a good attempt at resolving this discussion, and it looks to me as if the responses from MIRI are trying to do that, which is part of why I wanted to disagree with the claim that the responses are missing the point / not engaging productively.
I think it's false in the sense that MIRI never claimed that it would be hard to build an AI with GPT-4 level understanding of human values + GPT-4 level of willingness to answer honestly (as far as I can tell). The reason I think it's false is mostly that I haven't seen a claim like that made anywhere, including in the posts you cite.
I don't think it's necessary for them to have made that exact claim. The point is that they said value specification would be hard.
If you solve value specification, then you've arguably solved the outer alignment problem a large part of the outer alignment problem. Then, you just need to build a function maximizer that allows you to robustly maximize the utility function that you've specified. [ETA: btw, I'm not saying the outer alignment problem has been fully solved already. I'm making a claim about progress, not about whether we're completely finished.]
I interpret MIRI as saying "but the hard part is building a function maximizer that robustly maximizes any utility function you specify". And while I agree that this represents their current view, I don't think this was always their view. You can read the citations in the post carefully, and I don't think they support the idea that they've consistently always considered inner alignment to be the only hard part of the problem. I'm not claiming they never thought inner alignment was hard. But I am saying they thought value specification would be hard and an important part of the alignment problem.
I think the specification problem is still hard and unsolved. It looks like you're using a different definition of 'specification problem' / 'outer alignment' than others, and this is causing confusion.
IMO all these terms are a bit fuzzy / hard to pin down, and so it makes sense that they'd lead to disagreement sometimes. The best way (afaict) to avoid this is to keep the terms grounded in 'what would be useful for avoiding AGI doom'? To me it looks like on your definition, outer alignment is basically a trivial problem that doesn't help alignment much.
More generally, I think this discussion would be more grounded / useful if you made more object-level claims about how value specification being solved (on your view) might be useful, rather than meta claims about what others were wrong about.
the outer alignment problem is an alignment problem between the system and the humans outside of it (specifically between the base objective and the programmer’s intentions). In the context of machine learning, outer alignment refers to aligning the specified loss function with the intended goal, whereas inner alignment refers to aligning the mesa-objective of a mesa-optimizer with the specified loss function.
Outer Alignment: An objective function r is outer aligned [LW · GW] if all models that perform optimally on r in the limit of perfect training and infinite data are intent aligned.[2] [LW · GW]
I deliberately avoided using the term "outer alignment" in the post because I wanted to be more precise and not get into a debate about whether the value specification problem matches this exact definition. (I think the definitions are subtly different but the difference is not very relevant for the purpose of the post.) Overall, I think the two problems are closely associated and solving one gets you a long way towards solving the other. In the post, I defined the value identification/specification problem as,
I am mainly talking about the problem of how to specify (for example, write into a computer) an explicit function that reflects the human value function with high fidelity, in the sense that judgements from this function about the value of outcomes fairly accurately reflect the judgements of ordinary humans.
subproblem category of value alignment which deals with pinpointing valuable outcomes to an advanced agent and distinguishing them from non-valuable outcomes.
I should say note that I used this entry as the primary definition in the post because I was not able to find a clean definition of this problem anywhere else.
I'd appreciate if you clarified whether you are saying:
That my definition of the value specification problem is different from how MIRI would have defined it in, say, 2017. You can use Nate Soares' 2016 paper or their 2017 technical agenda to make your point.
That my definition matches how MIRI used the term, but the value specification problem remains very hard and unsolved, and GPT-4 is not even a partial solution to this problem.
That my definition matches how MIRI used the term, and we appear to be close to a solution to the problem, but a solution to the problem is not sufficient to solve the hard bits of the outer alignment problem.
I'm more sympathetic to (3) than (2), and more sympathetic to (2) than (1), roughly speaking.
FWIW it seems to me that EY did not carefully read your post, and missed your distinction between having the human utility function somewhere in the AI vs. explicitly. Assuming you didn't edit the post, your paragraph here
The key difference between the value identification/specification problem and the problem of getting an AI to understand human values is the transparency and legibility of how the values are represented: if you solve the problem of value identification, that means you have an actual function that can tell you the value of any outcome (which you could then, hypothetically, hook up to a generic function maximizer to get a benevolent AI). If you get an AI that merely understands human values, you can't necessarily use the AI to determine the value of any outcome, because, for example, the AI might lie to you, or simply stay silent.
makes this clear enough. But my eyes sort of glazed over this part. Why? Quoting EY's comment above:
We are trying to say that because wishes have a lot of hidden complexity, the thing you are trying to get into the AI's preferences has a lot of hidden complexity.
A lot of the other sentences in your post sound like things that would make sense to say if you didn't understand this point, and that wouldn't make sense to say if you did understand this point. EY's point here still goes through even if you have the ethical-situations-answerer. I suspect that's why others, and I initially, misread / projected onto your post, and why (I suspect) EY took your explicit distancing as not reflecting your actual understanding.
Unfortunately, I must say I actually did add that paragraph in later to make my thesis clearer. However, the version that Eliezer, Nate and Rob replied to still had this paragraph, which I think makes essentially the same point (i.e. that I am not merely referring to passive understanding, but rather explicit specification):
I'm not arguing that GPT-4 actually cares about maximizing human value. However, I am saying that the system is able to transparently pinpoint to us which outcomes are good and which outcomes are bad, with fidelity approaching an average human, albeit in a text format. Crucially, GPT-4 can do this visibly to us, in a legible way, rather than merely passively knowing right from wrong in some way that we can't access. This fact is key to what I'm saying because it means that, in the near future, we can literally just query multimodal GPT-N about whether an outcome is bad or good, and use that as an adequate "human value function". That wouldn't solve the problem of getting an AI to care about maximizing the human value function, but it would arguably solve the problem of creating an adequate function that we can put into a machine to begin with.
I agree that MIRI's initial replies don't seem to address your points and seem to be straw-manning you. But there is one point they've made, which appears in some comments, that seems central to me. I could translate it in this way to more explicitly tie it to your post:
"Even if GPT-N can answer questions about whether outcomes are bad or good, thereby providing "a value function", that value function is still a proxy for human values since what the system is doing is still just relaying answers that would make humans give thumbs up or thumbs down."
To me, this seems like the strongest objection. You haven't solved the value specification problem if your value function is still a proxy that can be goodharted etc.
If you think about it in this way, then it seems like the specification problem gets moved to the procedure you use to finetune large language models to make them able to give answers about human values. If the training mechanism you use to "lift" human values out of LLM's predictive model is imperfect, then the answers you get won't be good enough to build a value function that we can trust.
That said, we have GPT-4 now, and with better subsequent alignment techniques, I'm not so sure we won't be able to get an actual good value function by querying some more advanced and better-aligned language model and then using it as a training signal for something more agentic. And yeah, at that point, we still have the inner alignment part to solve, granted that we solve the value function part, and I'm not sure we should be a lot more optimistic than before having considered all these arguments. Maybe somewhat, though, yeah.
Keeping all this in mind, the actual crux of the post to me seems:
I claim that GPT-4 is already pretty good at extracting preferences from human data. If you talk to GPT-4 and ask it ethical questions, it will generally give you reasonable answers. It will also generally follow your intended directions, rather than what you literally said. Together, I think these facts indicate that GPT-4 is probably on a path towards an adequate solution to the value identification problem, where "adequate" means "about as good as humans". And to be clear, I don't mean that GPT-4 merely passively "understands" human values. I mean that asking GPT-4 to distinguish valuable and non-valuable outcomes works pretty well at approximating the human value function in practice, and this will become increasingly apparent in the near future as models get more capable and expand to more modalities.
[8] If you disagree that AI systems in the near-future will be capable of distinguishing valuable from non-valuable outcomes about as reliably as humans, then I may be interested in operationalizing this prediction precisely, and betting against you. I don't think this is a very credible position to hold as of 2023, barring a pause that could slow down AI capabilities very soon.
About it, MIRI-in-my-head would say: "No. RLHF or similarly inadequate training techniques mean that GPT-N's answers would build a bad proxy value function".
And Matthew-in-my-head would say: "But in practice, when I interrogate GPT-4 its answers are fine, and they will improve further as LLMs get better. So I don't see why future systems couldn't be used to construct a good value function, actually".
But personally, I think having such a standard is both unreasonable and inconsistent with the implicit standard set by essays from Yudkowsky and other MIRI people.
I think this is largely coming from an attempt to use approachable examples? I could believe that there were times when MIRI thought that even getting something as good as ChatGPT might be hard, in which case they should update, but I don't think they ever believed that something as good as ChatGPT is clearly sufficient. I certainly never believed that, at least.
In this post Matthew Barnett notices that we updated our beliefs between ~2007 and ~2023. I say "we" rather than MIRI or "Yudkowsky, Soares, and Bensinger" because I think this was a general update, but also to defuse the defensive reactions I observe in the comments.
What did we change our mind about? Well, in 2007 we thought that safely extracting approximate human values into a convenient format would be impossible. We knew that a superintelligence could do this. But a superintelligence would kill us, so this isn't helpful. We knew that human values are more complex than fake utility functions [LW · GW] or magical categories [LW · GW]. So we can't hard-code human values into a utility function. So we looked for alternatives like corrigibility.
By 2023, we learned that a correctly trained LLM can extract approximate human values without causing human extinction (yet). This post points to GPT-4 as conclusive evidence, which is fair. But GPT-3 was an important update and many people updated then. I imagine that MIRI and other experts figured it out earlier. This update has consequences for plans to avoid extinction or die with more dignity.
Unfortunately much of the initial commentary was defensive, attacking Barnett for claims he did not make. Yudkowsky placed a disclaimer on Hidden Complexity of Wishes [LW · GW] implausibly denying that it is an AI parable. This could be surprising. Yudkowsky's Coming of Age [? · GW] and How to Actually Change Your Mind [? · GW] sequences are excellent. What went wrong?
An underappreciated sub-skill of rationality is noticing that I have, in the past, changed my mind. For me, this is pretty easy when I think back to my teenage years. But I'm in my 40s now, and I find it harder to think of major updates during my 20s and 30s, despite the world (and me) changing a lot in that time. Seeing this pattern of defensiveness in other people made me realize that it's probably common, and I probably have it to. I wish I had a guide to middle-aged rationality. In middle-age my experience is supposed to be my value-add, but conveniently forgetting my previous beliefs throws some of that away.
Sometimes I read people saying that Yudkowsky-2008 didn't say this, the post wasn't about that, and so forth, including Yudkowsky himself. Not with evidence, not with a better reading, just a denial. Perhaps people are overestimating how accurately their brain has maintained a model of what Yudkowsky wrote 10+ years ago. If Alice read the sequences in 2008 and Bob read the sequences in 2024, then Bob has a better model of what the sequences said. Evidence and arguments screen off authority.
But more importantly to me (here come the feelings), these defensive anti-interpretations of the sequences are boring and narrow and ugh. By positing that multiple apparently literate people misread the sequences both at the time (read the old comments), and today (read the new comments), they paint a picture of young Yudkowsky as a bad writer who attracted bad readers.
As I read it, the Hidden Complexity of Wishes [LW · GW] is a glorious parable about AI and genies that paints graphic images of failure cases and invites both thought and imagination from the reader. As Yudkowsky-2024 tells me to read it, it is just making a point about the algorithmic complexity of human values. Yeah, I deny that, Death of the Author and all.
Likewise, as I read it, Magical Categories [LW · GW] is about, well, categories. Categories that matter for capabilities and for alignment and for humans. It's part of a network of rationalist thought that has ripples today in discussions about gender [LW · GW], adversarial examples [LW · GW], natural abstractions [LW · GW], and more. As others read it, Magical Categories is always in every instance talking about getting a shape into the AI's preferences, never some other thing.
Looking back on this post after a year, I haven't changed my mind about the content of the post, but I agree with Seth Herd when he said this post was "important but not well executed".
In hindsight I was too careless with my language in this post, and I should have spent more time making sure that every single paragraph of the post could not be misinterpreted. As a result of my carelessness, the post was misinterpreted in a predictable direction. And while I'm not sure how much I could have done to eliminate this misinterpretation, I do think that I could have reduced it a fair bit with more effort and attention.
If you're not sure what misinterpretation I'm referring to, I'll just try to restate the main point that I was trying to make below. To be clear, what I say below is not identical to the content of this post (as the post was narrowly trying to respond to the framing of this problem given by MIRI; and in hindsight, it was a mistake to reply in that way), but I think this is a much clearer presentation of one of the main ideas I was trying to convey by writing this post:
In my opinion, a common belief among people theorizing about AI safety around 2015, particularly on LessWrong, was that we would design a general AI system by assigning it a specific goal, and the AI would then follow that goal exactly. This strict adherence to the goal was considered dangerous because the goal itself would likely be subtly flawed or misspecified in a way we hadn’t anticipated. While the goal might appear to match what we want on the surface, in reality, it would be slightly different from what we anticipate, with edge cases that don't match our intentions. The idea was that the AI wouldn’t act in alignment with human intentions—it would rigidly pursue the given goal to its logical extreme, leading to unintended and potentially catastrophic consequences.
The goal in question could theoretically be anything, but it was often imagined as a formal utility function—a mathematical representation of a specific objective that we would directly program into the AI, potentially by hardcoding the goal in a programming language like Python or C++. The AI, acting as a powerful optimizer, would then work to maximize this utility function at any and all costs. However, other forms of goal specification were also considered for illustrative purposes. For example, a common hypothetical scenario was that an AI might be given an English-language instruction, such as "make as many paperclips as you can." In this example, the AI would misinterpret the instruction by interpreting it overly literally. It would focus exclusively on maximizing the number of paperclips, without regard for the broader intentions of the user, such as not harming humanity or destroying the environment in the process.
However, based on how current large language models operate, I don’t think this kind of failure mode is a good match for what we’re seeing in practice. LLMs typically do not misinterpret English-language instructions in the way that these older thought experiments imagined. This isn’t just because LLMs seem to "understand" English better than people expected—it's not that people expected superintelligences would not understand English. My point is not that LLMs possess natural language comprehension, so therefore the LessWrong community was mistaken.
Instead, my claim is that LLMs usually follow and execute user instructions in a manner that aligns with the user's actual intentions. In other words, the AI's actual behavior generally matches what the user meant for them to do, rather than leading to extreme, unintended outcomes caused by rigidly literal interpretations of instructions.
Because of the fact that LLMs are capable of doing this, despite in my opinion being general AIs, I believe it’s fair to say that the concerns raised by the LessWrong community about AI systems rigidly following misspecified goals were, at least in this specific sense, misguided when applied to the behavior of current LLMs.
I think you’re correct that the paradigm has changed, Matthew, and that the problems that stood out to MIRI before as possibilities no longer quite fit the situation.
I still think the broader concern MIRI exhibited is correct: namely, that that an AI could appear to be aligned but not actually be aligned, and that this may not come to light until it is behaving outside of the context of training/in which the command was written. Because of the greater capabilities of an AI, the problem may have to do with differences in superficially similar goals that wouldn’t matter at the human capabilities level.
I’m not sure if the fact that LLMs solve the cauldron-filling problem means that we should consider the whole broader class of problems easier to solve than we thought. Maybe it does. But given the massive stakes of the issue I think we ought to consider not knowing if LLMs will always behave as intended OOD a live problem.
Whether MIRI was confused about the main issues of alignment in the past, and whether LLMs should have been a point of update for them is one of the points of contention here.
(I think the answer is no, see all the comments about this above)
ML models in the current paradigm do not seem to behave coherently OOD but I'd bet for nearly any metric of "overall capability" and alignment that the capability metric decays faster vs alignment as we go further OOD.
See https://arxiv.org/abs/2310.00873 for an example of the kinds of things you'd expect to see when taking a neural network OOD. It's not that the model does some insane path-dependent thing, it collapses to entropy. You end up seeing a max-entropy distribution over outputs not goals. This is a good example of the kind of thing that's obvious to people who've done real work with ml but very counter to classic LessWrong intuitions and isn't learnable by implementing mingpt.
I just spent a while wading through this post and the comments section.
My current impression is that (among many other issues) there is a lot of talking-past-each-other related to two alternate definitions of “human values”:
Definition 1 (Matt Barnett, most commenters): “Human values” are the things that you get by asking humans what their values are, asking what they’d do in different situations, etc.
Definition 2 (MIRI): “Human values” are the output of CEV, which is maybe related to “fun-as-in-fun-theory” (per Nate's comment [LW(p) · GW(p)]), and likewise related to the idealization-of-human-deliberation stuff here [LW · GW] in Eliezer’s meta-ethics sequence, and so on.
You can get Definition-1-human-values by just asking GPT-4 (or for that matter, asking a random person). To get Definition-2-human-values, you would presumably need human-level intelligence, including moral deliberation, coming up with new ideas and new concepts and new considerations, and so on, in a way that seems about as intellectually difficult as autonomously coming up with new ideas and inventions in science and engineering, i.e. way beyond GPT-4 in my opinion.
But the real problem of Friendly AI is one of communication - transmitting category boundaries, like "good", that can't be fully delineated in any training data you can give the AI during its childhood. Relative to the full space of possibilities the Future encompasses, we ourselves haven't imagined most of the borderline cases, and would have to engage in full-fledged moral arguments to figure them out. To solve the FAI problem you have to step outside the paradigm of induction on human-labeled training data and the paradigm of human-generated intensional definitions.
I think the second half of this makes it clear that Eliezer is using “good” in a definition-2-sense.
I think the second half of this makes it clear that Eliezer is using “good” in a definition-2-sense.
I think there's some nuance here. It seems clear to me that solving the "full" friendly AI problem, as Eliezer imagined, would involve delineating human value on the level of the Coherent Extrapolated Volition, rather than merely as adequately as an ordinary human. That's presumably what Eliezer meant in the context of the quote you cited.
However, I think it makes sense to interpret GPT-4 as representing substantial progress on the problem of building a task AGI, and especially (for the purpose of my post) the problem of delineating value from training data to the extent required by task AGIs (relative to AIs, in, say 2018). My understanding is that Eliezer advocated that we should try to build task AGIs before trying to build full-on sovereign superintelligences.[1] On the Arbital page about task AGIs, he makes the following point:
Assuming that users can figure out intended goals for the AGI that are valuable and pivotal, the identification problem for describing what constitutes a safe performance of that Task, might be simpler than giving the AGI a complete description of normativity in general. That is, the problem of communicating to an AGI an adequate description of “cure cancer” (without killing patients or causing other side effects), while still difficult, might be simpler than an adequate description of all normative value. Task AGIs fall on the narrow side of Ambitious vs. narrow value learning.
Relative to the problem of building a Sovereign, trying to build a Task AGI instead might step down the problem from “impossibly difficult” to “insanely difficult”, while still maintaining enough power in the AI to perform pivotal acts.
My interpretation here is that delineating value from training data (i.e. the value identification problem) for task AGIs was still considered hard at least as late as 2015, even as it might be easier creating a "complete description of normativity in general". Another page also spells the problem out pretty clearly, in a way I find clearly consistent with my thesis.[2]
I think GPT-4 represents substantial progress on this problem, specifically because of its ability to "do-what-I-mean" rather than "do-what-I-ask", identify ambiguities to the user during during deployment, and accomplish limited tasks safely. It's honestly a little hard for me to sympathize with a point of view that says GPT-4 isn't significant progress along this front, relative to pre-2019 AIs (some part of me was expecting more readers to find this thesis obvious, but apparently it is not obvious). GPT-4 clearly doesn't do crazy things that you'd naively expect if it wasn't capable of delineating value well from training data.
An autonomous superintelligence would be the most difficult possible class of AGI to align, requiring total alignment. Coherent extrapolated volition is a proposed alignment target for an autonomous superintelligence, but again, probably not something we should attempt to do on our first try.
Safe plan identification is the problem of how to give a Task AGI training cases, answered queries, abstract instructions, etcetera such that (a) the AGI can thereby identify outcomes in which the task was fulfilled, (b) the AGI can generate an okay plan for getting to some such outcomes without bad side effects, and (c) the user can verify that the resulting plan is actually okay via some series of further questions or user querying. This is the superproblem that includes task identification, as much value identification as is needed to have some idea of the general class of post-task worlds that the user thinks are okay, any further tweaks like low-impact planning or flagging inductive ambiguities, etcetera. This superproblem is distinguished from the entire problem of building a Task AGI because there’s further issues like corrigibility, behaviorism, building the AGI in the first place, etcetera. The safe plan identification superproblem is about communicating the task plus user preferences about side effects and implementation, such that this information allows the AGI to identify a safe plan and for the user to know that a safe plan has been identified.
This post was extremely important but not well executed. The resulting discussion essentially failed to make progress, but it was attempting perhaps the most important question currently on the table: why do some alignment thinkers believe alignment is very difficult, while others think it's fairly easy?
The Doomimir and Simplicia dialogues [LW · GW] dialogues did a much better job of refining the key questions, but they may have been inspired by the chaotic discussion this post inspired.
I am torn in nominating this post, because Barnett's rather confrontational and assertive tone probably caused the lack of progress in the discussion. But it did cause discussion.
Remaining both divided and unclear on why we're divided is not an acceptable state of affairs. In that state, the public positions of alignment thinkers will come all too close to canceling each other out.
I would really like to see more careful inquiries into the logic of alignment difficulty - and to see the best thinkers from all places on the spectrum engage.
The point of “the genie knows but doesn’t care [LW · GW]” wasn’t that the AI would take your instructions, know what you want, and yet disobey the instructions because it doesn’t care about what you asked for. If you read Rob Bensinger’s essay [LW · GW] carefully, you’ll find that he’s actually warning that the AI will care too much about the utility function you gave it, and maximize it exactly, against your intentions
If so, the title was pretty misleading.
And if that is the case, it still isn't making much of a point: it assumes a hand-coded UF, so it isn't applicable to LLMs , or many other architectures. So it doesn't support conclusions like "the first true AI will kill us all with high probability". The "doesn't" should be a "might not" as well.
We're still arguing about the meaning of Genie Knows because it was always unclear. It was always unclear l, I think, because it was a Motte and Bailey exercise, trying to come to the conclusion that an AI is highly likely to literastically misunderstand human values using an argument that only suggested it was possible.
I’m not too interested in litigating what other people were saying in 2015, but OP is claiming (at least in the comments) that “RLHF’d foundation models seem to have common-sense human morality, including human-like moral reasoning and reflection” is evidence for “we’ve made progress on outer alignment”. If so, here are two different ways to flesh that out:
I think this plan fails because RLHF’d foundation models have adversarial examples today, and will continue to have adversarial examples into the future. (To be clear, humans have adversarial examples too, e.g. drugs & brainwashing.)
There is no “separate system”, but rather an RLHF’d foundation model (or something like it) is the whole system that we’re talking about here. For example, we may note that, if you hook up an RLHF’d foundation model to tools and actuators, then it will actually use those tools and actuators in accordance with common-sense morality etc.
(I think 2 is the main intuition driving the OP, and 1 was a comments-section derailment.)
As for 2:
I’m sympathetic to the argument that this system might not be dangerous, but I think its load-bearing ingredient is that pretraining leads to foundation models tending to do intelligent things primarily by emitting human-like outputs for human-like reasons, thanks in large part to self-supervised pretraining on internet text. Let’s call that “imitative learning”.
Indeed, here’s [LW · GW] a 2018 post where Eliezer (as I read it) implies that he hadn’t really been thinking about imitative learning before (he calls it an “interesting-to-me idea”), and suggests that imitative learning might “bypass the usual dooms of reinforcement learning”. So I think there is a real update here—if you believe that imitative learning can scale to real AGI.
…But the pushback (from Rob and others) in the comments is mostly coming from a mindset where they don’t believe that imitative learning can scale to real AGI. I think the commenters are failing to articulating this mindset well, but I think they are in various places leaning on certain intuitions about how future AGI will work (e.g. beliefs deeply separate from goals), and these intuitions are incompatible with imitative learning being the primary source of optimization power in the AGI (as it is today, I claim).
(A moderate position is that imitative learning will be less and less relevant as e.g. o1-style RL post-training becomes a bigger relative contribution to the trained weights; this would presumably lead to increased future capabilities hand-in-hand with increased future risk of egregious scheming. For my part, I subscribe to the more radical theory that our situation is even worse than that: I think future powerful AGI will be built via a different AI training paradigm that basically throws out the imitative learning part altogether.)
I have a forthcoming post (hopefully) that will discuss this much more and better.
Maybe this has been discussed already, just commenting as I read.
This fact is key to what I'm saying because it means that, in the near future, we can literally just query multimodal GPT-N about whether an outcome is bad or good, and use that as an adequate "human value function".
In any AI system structure where it's true that GPT-N can fulfill this function[1], a natural human could too (just with a longer delay for their output to be passed back).[2]
(The rest of this and the footnotes are just-formed ideas)
Though, if your AI relies on predicting the response of GPT-N, then it does have an advantage: GPT-N can be precisely specified within the AI structure, unlike a human (whose precise neural specification is unknown) where you'd have to point to them in the environment or otherwise predict an input from the environment and thus make your AI vulnerable to probable environment hacking.
So I suppose if there's ever a GPT-N who really seems to write with regard to actual values, and not current human discourse/cultural beliefs about what human-cultural-policies are legitimated, it could work as an outer/partial inner alignment solution.[1]
Failing that kind of GPT-N, maybe you can at least have one which answers a simpler question like, "How would <natural language plan and effects> score in terms of its effect on total suffering and happiness, given x weighting of each?" - the system with that basis seems, modulo possible botched alignment concerns, trivially preferable to an orthogonal-maximizer AI, if it's the best we can create. it wouldn't capture the full complexity of the designer's value, but would still score very highly under it due to reduction of suffering in other lightcones [LW(p) · GW(p)]. Edit: another user proposes probably-better natural language targets in another comment [LW(p) · GW(p)]
Though in both cases (human, gpt-n), you face some issues like: "How is the planner component generating the plans, without something like a value function (to be used in a [criterion for the plan to satisfy] to be passed to the planner?" (i.e., you write that GPT-N would only be asked to evaluate the plan after the plan is generated). Though I'm seeing some ways around this one*
and "How are you translating from the planner's format to natural language text to be sent to the GPT?"
* (If you already have a way to translate between written human language and the planner's format, I see some ways around this which leverage that, like "translate from human-language to the planner's internal format criteria for the plan to satisfy, before passing the resulting plan to GPT-N for evaluation", and some complications** (haven't branched much beyond that, but it looks solvable))
** (i) Two different plans can correspond to the same natural language description. (ii) The choice of what to specify (specifically in the translation of an internal format to natural language) is in informed by context including values and background assumptions, neither of which are necessarily specified to the translator. I have some thoughts about possible ways to make these into non-issues, if we have the translation capacity and a general purpose planner to begin with.
relevantly there's no actual value function being maximized in this model (i.e the planner is not trying to select for [the action whose description will elicit the strongest Yes rating from GPT-N], though the planner is underspecified as is)
Either case implies structural similarity to Holden (2012)'s tool AI proposal [LW · GW]. I.e., {generate plan[1] -> output plan and wait for input} -> {display plan to human, or input plan to GPT-N} -> {if 'yes' received back as input, then actually enact plan}
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
I absolutely "disagree that AI systems in the near-future will be capable of distinguishing valuable from non-valuable outcomes about as reliably as humans". In particular, I think that progress here in the near future will resemble self-driving-car progress over the near past. That is to say, it's far easier to make something that's mostly right most of the time, than to make something that is reliably not wrong in a way that I think humans under ideal conditions can in fact achieve.
Basically, I think that the current paradigm (in general: unsupervised deep learning on large in large datasets using reasonably- parallelizable architectures, possibly followed by architectural adjustments and/or supervised tuning) is unsuited to making systems that "care enough to be reliable" — that can reliably notice their own novel mistakes and reflectively adjust to correct them. Now, obviously, it's easy to set up situations where humans will fail at that, too; but I think there is still a realm of situations where humans can be unambiguously more reliable than machines.
I realize that I'm on philosophically dangerous ground here, because a protocol to test this would have to be adverserial towards machines, but also refrain from certain using certain adverserial tricks known to work against humans. So it may be that I'm just biased when I see the anti-human tricks as "cheating" and the anti-machine ones as "fair game". But I don't think it's solely bias. I could make arguments that it's not, but I suspect that on this point my arguments would not be that much superior to the ones you (or even ChatGPT) would fill in for me.
Shorter me: I think that in order to "specify an explicit function that corresponds to the "human value function" with fidelity comparable to the judgement of an average human" in the first place, you have to know how to build an AI that can be meaningfully said to have any values at all; that we don't know how to do that; and that we are not close to knowing.
(I am not at ALL making a Chinese-room-type argument about the ineffability of actually having values here. This is purely an operational point, where "having values" and "reliably doing as well as a human at seeming to have values, in the presence of adversarial cues" are basically the same. And by "adversarial cues" I mean more along the lines of "prove that 27^(1/3) is irrational" not "I'll give you a million dollars to kick this dog", though obviously it's easy to design against any specific such cue.)
1. It's easier to construct the shape of human values than MIRI thought. An almost good enough version of that shape is within RLHFed GPT-4, in its predictive model of text. (I use "shape" since it's Eliezer's terminology under this post.)
2. It still seems hard to get that shape into some AI's values, which is something MIRI has always said.
Therefore, the update for MIRI should be on point 1: constructing that shape is not as hard as they thought.
It's easier to construct the shape of human values than MIRI thought. An almost good enough version of that shape is within RLHFed GPT-4, in its predictive model of text.
That sounds roughly accurate, but I'd frame it more as "It now seems easier to specify a function that reflects the human value function with high fidelity than what MIRI appears to have thought." I'm worried about the ambiguity of "construct the shape of human values" since I'm making a point about value specification.
It still seems hard to get that shape into some AI's values, which is something MIRI has always said.
This claim is consistent with what I wrote, but I didn't actually argue it. I'm uncertain about whether inner alignment is difficult and I currently think we lack strong evidence about its difficulty.
Overall though I think you understood the basic points of the post.
The primary foreseeable difficulty Yudkowsky offered for the value identification problem is that human value is complex [? · GW].[5] [LW(p) · GW(p)]
That was always a poorly posed claim. The issue is whether value is unusually or uniquely complex. An ordinary non-moral sentence like "fill a bucket" still needs additional information to be interpreted. Most lesswrongians have spent years behaving as though it was a fact that moral assertions have some extra complexity, although it was never proven (and it depends on dubious assumptions about GOFAI, incorrigibility, Foom, etc).
I want to mention that a proposed impossible problem was pretty close to being solved by Anthropic, if not solved outright, and very critically neither Eliezer or anyone at MIRI noticed that a proposed AI alignment problem was possible to solve, when they claimed that it was basically impossible to solve.
"It won't understand language until it's already superintelligent." stands out to me in that it was considered an impossible problem that ordinary capabilities research just solved outright, with no acknowledgement something 'impossible' had occurred.
You can quibble over the word 'impossible', but it was generally accepted that the first big insurmountable barrier is that there is simply no good way to encode concepts like 'happiness' in their full semantic richness without ASI already built at which point it doesn't care.
And in case one is tempted to say "well, you still can't meaningfully align AI systems by defining things we want in terms of high level philosophical paraphrases" I remind you that constitutional AI exists, which does just that: