Posts
Comments
But the "unconstrained text responses" part is still about asking the model for its preferences even if the answers are unconstrained.
That just shows that the results of different ways of eliciting its values remain sorta consistent with each other, although I agree it constitutes stronger evidence.
Perhaps a more complete test would be to analyze whether its day to day responses to users are somehow consistent with its stated preferences and analyzing its actions in settings in which it can use tools to produce outcomes in very open-ended scenarios that contain stuff that could make the model act on its values.
Thanks! I already don't feel as impressed by the paper as I was while writing the shortform and I feel a little embarrassed for not thinking through things a little bit more before posting my reactions, although at least now there's some discussion under the linkpost so I don't entirely regret my comment if it prompted people to give their takes. I still feel to have updated in a non-negligible way from the paper though, so maybe I'm still not as pessimistic about it as other people. I'd definitely be interested in your thoughts if you find discourse is still lacking in a week or two.
I'd guess an important caveat might be that stated preferences being coherent doesn't immediately imply that behavior in other situations will be consistent with those preferences. Still, this should be an update towards agentic AI systems in the near future being goal-directed in the spooky consequentialist sense.
Why?
Surprised that there's no linkpost about Dan H's new paper on Utility Engineering. It looks super important, unless I'm missing something. LLMs are now utility maximisers? For real? We should talk about it: https://x.com/DanHendrycks/status/1889344074098057439
I feel weird about doing a link post since I mostly post updates about Rational Animations, but if no one does it, I'm going to make one eventually.
Also, please tell me if you think this isn't as important as it looks to me somehow.
EDIT: Ah! Here it is! https://www.lesswrong.com/posts/SFsifzfZotd3NLJax/utility-engineering-analyzing-and-controlling-emergent-value thanks @Matrice Jacobine!
The two Gurren Lagann movies cover all the events in the series, and based on my recollection, they should be better animated. Still based on what I remember, the first should have a pretty central take on scientific discovery. The second should be more about ambition and progress, but both probably have at least a bit of both. It's not by chance that some e/accs have profile pictures inspired by that anime. I feel like people here might disagree with part of the message, but I think it does say something about issues we care about here pretty forcefully. (Also, it was cited somewhere in HP: MoR, but for humor.)
Update:
I think it would be very interesting to see you and @TurnTrout debate with the same depth, preparation, and clarity that you brought to the debate with Robin Hanson.
Edit: Also, tentatively, @Rohin Shah because I find this point he's written about quite cruxy.
For me, perhaps the biggest takeaway from Aschenbrenner's manifesto is that even if we solve alignment, we still have an incredibly thorny coordination problem between the US and China, in which each is massively incentivized to race ahead and develop military power using superintelligence, putting them both and the rest of the world at immense risk. And I wonder if, after seeing this in advance, we can sit down and solve this coordination problem in ways that lead to a better outcome with a higher chance than the "race ahead" strategy and don't risk encountering a short period of incredibly volatile geopolitical instability in which both nations develop and possibly use never-seen-before weapons of mass destruction.
Edit: although I can see how attempts at intervening in any way and raising the salience of the issue risk making the situation worse.
Noting that additional authors still don't carry over when the post is a cross-post, unfortunately.
I'd guess so, but with AGI we'd go much much faster. Same for everything you've mentioned in the post.
Turn everyone hot
If we can do that due to AGI, almost surely we can solve aging, which would be truly great.
Looking for someone in Japan who had experience with guns in games, he looked on twitter and found someone posting gun reloading animations
Having interacted with animation studios and being generally pretty embedded in this world, I know that many studios are doing similar things, such as Twitter callouts if they need some contractors fast for some projects. Even established anime studios do this. I know at least two people who got to work on Japanese anime thanks to Twitter interactions.
I hired animators through Twitter myself, using a similar process: I see someone who seems really talented -> I reach out -> they accept if the offer is good enough for them.
If that's the case for animation, I'm pretty sure it often applies to video games, too.
Thank you! And welcome to LessWrong :)
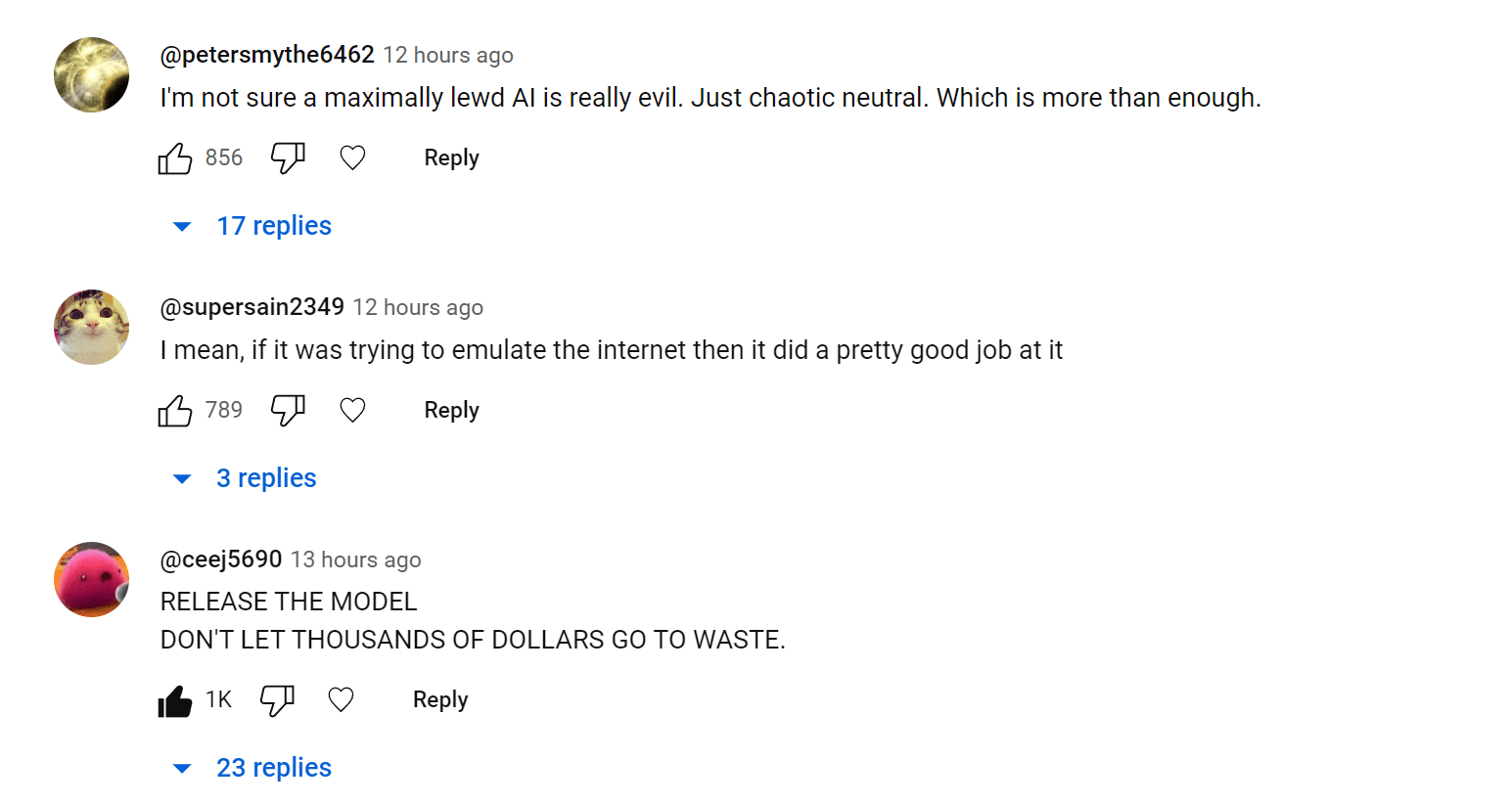
The comments under this video seem okayish to me, but maybe it's because I'm calibrated on worse stuff under past videos, which isn't necessarily very good news to you.
The worst I'm seeing is people grinding their own different axes, which isn't necessarily indicative of misunderstanding.

But there are also regular commenters who are leaving pretty good comments:

The other comments I see range from amused and kinda joking about the topic to decent points overall. These are the top three in terms of popularity at the moment:
Stories of AI takeover often involve some form of hacking. This seems like a pretty good reason for using (maybe relatively narrow) AI to improve software security worldwide. Luckily, the private sector should cover it in good measure for financial interests.
I also wonder if the balance of offense vs. defense favors defense here. Usually, recognizing is easier than generating, and this could apply to malicious software. We may have excellent AI antiviruses devoted to the recognizing part, while the AI attackers would have to do the generating part.
[Edit: I'm unsure about the second paragraph here. I'm feeling better about the first paragraph, especially given slow multipolar takeoff and similar, not sure about fast unipolar takeoff]
Also I don't think that LLMs have "hidden internal intelligence"
I don't think Simulators claims or implies that LLMs have "hidden internal intelligence" or "an inner homunculus reasoning about what to simulate", though. Where are you getting it from? This conclusion makes me think you're referring to this post by Eliezer and not Simulators.
Yoshua Bengio is looking for postdocs for alignment work:
I am looking for postdocs, research engineers and research scientists who would like to join me in one form or another in figuring out AI alignment with probabilistic safety guarantees, along the lines of the research program described in my keynote (https://www.alignment-workshop.com/nola-2023) at the New Orleans December 2023 Alignment Workshop.
I am also specifically looking for a postdoc with a strong mathematical background (ideally an actual math or math+physics or math+CS degree) to take a leadership role in supervising the Mila research on probabilistic inference and GFlowNets, with applications in AI safety, system 2 deep learning, and AI for science.
Please contact me if you are interested.
i think about this story from time to time. it speaks to my soul.
- it is cool that straight-up utopian fiction can have this effect on me.
- it yanks me in a state of longing. it's as if i lost this world a long time ago, and i'm desperately trying to regain it.
i truly wish everything will be ok :,)
thank you for this, tamsin.
Here's a new RA short about AI Safety: https://www.youtube.com/shorts/4LlGJd2OhdQ
This topic might be less relevant given today's AI industry and the fast advancements in robotics. But I also see shorts as a way to cover topics that I still think constitute fairly important context, but, for some reason, it wouldn't be the most efficient use of resources to cover in long forms.
The way I understood it, this post is thinking aloud while embarking on the scientific quest of searching for search algorithms in neural networks. It's a way to prepare the ground for doing the actual experiments.
Imagine a researcher embarking on the quest of "searching for search". I highlight in cursive the parts present in the post (if they are present at least a little):
- At some point, the researcher reads Risks From Learned Optimization.
- They complain: "OK, Hubinger, fine, but you haven't told me what search is anyway"
- They read or get involved in the discussions about optimization that ensue on LessWrong.
- They try to come up with a good definition, but they find themselves with some difficulties.
- They try to understand what kind of beast search is by coming up with some general ways to do search.
- They try to determine what kind of search neural networks might implement. They use a bunch of facts they know about search processes and neural networks to come up with ideas.
- They try to devise ways to test these hypotheses and even a meta "how do I go about forming and testing these hypotheses anyway."
- They think of a bunch of experiments, but they notice pitfalls. They devise strategies such as "ok; maybe it's better if I try to get a firehose of evidence instead of optimizing too hard on testing single hypotheses."
- They start doing actual interpretability experiments.
Having the reasoning steps in this process laid out for everyone to see is informative and lets people chime in with ideas. Not going through the conceptual steps of the process, at least privately, before doing experiments, risks wasting a bunch of resources. Exploring the space of problems is cool and good.
This recent Tweet by Sam Altman lends some more credence to this post's take:

RA has started producing shorts. Here's the first one using original animation and script: https://www.youtube.com/shorts/4xS3yykCIHU
The LW short-form feed seems like a good place for posting some of them.
In this post, I appreciated two ideas in particular:
- Loss as chisel
- Shard Theory
"Loss as chisel" is a reminder of how loss truly does its job, and its implications on what AI systems may actually end up learning. I can't really argue with it and it doesn't sound new to my ear, but it just seems important to keep in mind. Alone, it justifies trying to break out of the inner/outer alignment frame. When I start reasoning in its terms, I more easily appreciate how successful alignment could realistically involve AIs that are neither outer nor inner aligned. In practice, it may be unlikely that we get a system like that. Or it may be very likely. I simply don't know. Loss as a chisel just enables me to think better about the possibilities.
In my understanding, shard theory is, instead, a theory of how minds tend to be shaped. I don't know if it's true, but it sounds like something that has to be investigated. In my understanding, some people consider it a "dead end," and I'm not sure if it's an active line of research or not at this point. My understanding of it is limited. I'm glad I came across it though, because on its surface, it seems like a promising line of investigation to me. Even if it turns out to be a dead end I expect to learn something if I investigate why that is.
The post makes more claims motivating its overarching thesis that dropping the frame of outer/inner alignment would be good. I don't know if I agree with the thesis, but it's something that could plausibly be true, and many arguments here strike me as sensible. In particular, the three claims at the very beginning proved to be food for thought to me: "Robust grading is unnecessary," "the loss function doesn't have to robustly and directly reflect what you want," "inner alignment to a grading procedure is unnecessary, very hard, and anti-natural."
I also appreciated the post trying to make sense of inner and outer alignment in very precise terms, keeping in mind how deep learning and reinforcement learning work mechanistically.
I had an extremely brief irl conversation with Alex Turner a while before reading this post, in which he said he believed outer and inner alignment aren't good frames. It was a response to me saying I wanted to cover inner and outer alignment on Rational Animations in depth. RA is still going to cover inner and outer alignment, but as a result of reading this post and the Training Stories system, I now think we should definitely also cover alternative frames and that I should read more about them.
I welcome corrections of any misunderstanding I may have of this post and related concepts.
Maybe obvious sci-fi idea: generative AI, but it generates human minds
Was Bing responding in Tibetan to some emojis already discussed on LW? I can't find a previous discussion about it here. I would have expected people to find this phenomenon after the SolidGoldMagikarp post, unless it's a new failure mode for some reason.
Toon Boom Harmony for animation and After Effects for compositing and post-production
the users you get are silly
Do you expect them to make bad bets? If so, I disagree and I think you might be too confident given the evidence you have. We can check this belief against reality by looking at the total profit earned by my referred users here. If their profit goes up over time, they are making good bets; otherwise, they are making bad bets. At the moment, they are at +13063 mana.
They might not do that if they have different end goals though. Some version of this strategy doesn't seem so hopeless to me.
Hofstadter too!
For Rational Animations, there's no problem if you do that, and I generally don't see drawbacks.
Perhaps one thing to be aware of is that some of the articles we'll animate will be slightly adapted. Sorting Pebbles and The Power of Intelligence are exactly like the original. The Parable of The Dagger has deletions of words such as "replied" or "said" and adds a short additional scene at the end. The text of The Hidden Complexity of Wishes has been changed in some places, with Eliezer's approval, mainly because the original has some references to other articles. In any case, when there are such changes, I write it in the LW post accompanying the videos.
If you just had to pick one, go for The Goddess of Everything Else.
Here's a short list of my favorites.
In terms of animation:
- The Goddess of Everything Else
- The Hidden Complexity of Wishes
- The Power of Intelligence
In terms of explainer:
- Humanity was born way ahead of its time. The reason is grabby aliens. [written by me]
- Everything might change forever this century (or we’ll go extinct). [mostly written by Matthew Barnett]
Also, I've sent the Discord invite.
I (Gretta) will be leading the communications team at MIRI, working with Rob Bensinger, Colm Ó Riain, Nate, Eliezer, and other staff to create succinct, effective ways of explaining the extreme risks posed by smarter-than-human AI and what we think should be done about this problem.
I just sent an invite to Eliezer to Rational Animations' private Discord server so that he can dump some thoughts on Rational Animations' writers. It's something we decided to do when we met at Manifest. The idea is that we could distill his infodumps into something succinct to be animated.
That said, if in the future you have from the outset some succinct and optimized material you think we could help spread to a wide audience and/or would benefit from being animated, we can likely turn your writings into animations on Rational Animations, as we already did for a few articles in The Sequences.
The same invitation extends to every AI Safety organization.
EDIT: Also, let me know if more of MIRI's staff would like to join that server, since it seems like what you're trying to achieve with comms overlaps with what we're trying to do. That server basically serves as central point of organization for all the work happening at Rational Animations.
I don't speak for Matthew, but I'd like to respond to some points. My reading of his post is the same as yours, but I don't fully agree with what you wrote as a response.
If you find something that looks to you like a solution to outer alignment / value specification, but it doesn't help make an AI care about human values, then you're probably mistaken about what actual problem the term 'value specification' is pointing at.
[...]
It was always possible to attempt to solve the value specification problem by just pointing at a human. The fact that we can now also point at an LLM and get a result that's not all that much worse than pointing at a human is not cause for an update about how hard value specification is
My objection to this is that if an LLM can substitute for a human, it could train the AI system we're trying to align much faster and for much longer. This could make all the difference.
If you could come up with a simple action-value function Q(observation, action), that when maximized over actions yields a good outcome for humans, then I think that would probably be helpful for alignment.
I suspect (and I could be wrong) that Q(observation, action) is basically what Matthew claims GPT-N could be. A human who gives moral counsel can only say so much and, therefore, can give less information to the model we're trying to align. An LLM wouldn't be as limited and could provide a ton of information about Q(observation, action), so we can, in practice, consider it as being our specification of Q(observation, action).
Edit: another option is that GPT-N, for the same reason of not being limited by speed, could write out a pretty huge Q(observation, action) that would be good, unlike a human.
Keeping all this in mind, the actual crux of the post to me seems:
I claim that GPT-4 is already pretty good at extracting preferences from human data. If you talk to GPT-4 and ask it ethical questions, it will generally give you reasonable answers. It will also generally follow your intended directions, rather than what you literally said. Together, I think these facts indicate that GPT-4 is probably on a path towards an adequate solution to the value identification problem, where "adequate" means "about as good as humans". And to be clear, I don't mean that GPT-4 merely passively "understands" human values. I mean that asking GPT-4 to distinguish valuable and non-valuable outcomes works pretty well at approximating the human value function in practice, and this will become increasingly apparent in the near future as models get more capable and expand to more modalities.
[8] If you disagree that AI systems in the near-future will be capable of distinguishing valuable from non-valuable outcomes about as reliably as humans, then I may be interested in operationalizing this prediction precisely, and betting against you. I don't think this is a very credible position to hold as of 2023, barring a pause that could slow down AI capabilities very soon.
About it, MIRI-in-my-head would say: "No. RLHF or similarly inadequate training techniques mean that GPT-N's answers would build a bad proxy value function".
And Matthew-in-my-head would say: "But in practice, when I interrogate GPT-4 its answers are fine, and they will improve further as LLMs get better. So I don't see why future systems couldn't be used to construct a good value function, actually".
I agree that MIRI's initial replies don't seem to address your points and seem to be straw-manning you. But there is one point they've made, which appears in some comments, that seems central to me. I could translate it in this way to more explicitly tie it to your post:
"Even if GPT-N can answer questions about whether outcomes are bad or good, thereby providing "a value function", that value function is still a proxy for human values since what the system is doing is still just relaying answers that would make humans give thumbs up or thumbs down."
To me, this seems like the strongest objection. You haven't solved the value specification problem if your value function is still a proxy that can be goodharted etc.
If you think about it in this way, then it seems like the specification problem gets moved to the procedure you use to finetune large language models to make them able to give answers about human values. If the training mechanism you use to "lift" human values out of LLM's predictive model is imperfect, then the answers you get won't be good enough to build a value function that we can trust.
That said, we have GPT-4 now, and with better subsequent alignment techniques, I'm not so sure we won't be able to get an actual good value function by querying some more advanced and better-aligned language model and then using it as a training signal for something more agentic. And yeah, at that point, we still have the inner alignment part to solve, granted that we solve the value function part, and I'm not sure we should be a lot more optimistic than before having considered all these arguments. Maybe somewhat, though, yeah.
Eliezer, are you using the correct LW account? There's only a single comment under this one.
Would it be fair to summarize this post as:
1. It's easier to construct the shape of human values than MIRI thought. An almost good enough version of that shape is within RLHFed GPT-4, in its predictive model of text. (I use "shape" since it's Eliezer's terminology under this post.)
2. It still seems hard to get that shape into some AI's values, which is something MIRI has always said.
Therefore, the update for MIRI should be on point 1: constructing that shape is not as hard as they thought.
Up until recently, with a big spreadsheet and guesses about these metrics:
- Expected impact
- Expected popularity
- Ease of adaptation (for external material)
The next few videos will still be chosen in this way, but we're drafting some documents to be more deliberate. In particular, we now have a list of topics to prioritize within AI Safety, especially because sometimes they build on each other.
Thank you for the heads-up about the Patreon page; I've corrected it!
Given that the logic puzzle is not the point of the story (i.e., you could understand the gist of what the story is trying to say without understanding the first logic puzzle), I've decided not to use more space to explain it. I think the video (just like the original article) should be watched one time all at once and then another time, but pausing multiple times and thinking about the logic.
This is probably not the most efficient way for keeping up with new stuff, but aisafety.info is shaping up to be a good repository of alignment concepts.
It will be a while before we run an experiment, and when I'd like to start one, I'll make another post and consult with you again.
When/if we do one, it'll probably look like what @the gears to ascension proposed in their comment here: a pretty technical video that will likely get a smaller number of views than usual and filters for the kind of people we want on LessWrong. How I would advertise it could resemble the description of the market on Manifold linked in the post, but I'm going to run the details to you first.
LessWrong currently has about 2,000 logged-in users per day. And to 20-100 new users each day (comparing the wide range including peaks recently).
This provides important context. 20-100 new accounts per day is a lot. At the moment, Manifold predicts that as a result of a strong call to action and 1M views, Rational Animations would be able to bring 679 new expected users. That would probably look like getting 300-400 more users in the first couple weeks the video is out and an additional 300-400 in the following few months. That's not a lot!
As a simplification, suppose the video gets 200k views during the first day. That would correspond to about 679/5 = 136 new expected users. Suppose on the second day we get 100k more views. That would be about 70 more users. Then suppose, simplifying, that the remaining 200k views are equally distributed over the remaining 12 days. That would correspond to merely 11 additional users per day.
Should LessWrong be providing intro material and answers? [...] So maybe. Maybe we should leaning into this as an opportunity even though it'll take work of both not letting it affect the site in bad ways (moderation, etc). and also possibly preparing better material for a broader audience.
I would be happy to link such things if you produce them. For now, linking the AI Safety Fundamentals courses should achieve ~ the same results. Some of the readings can be found on LessWrong too so people may discover LW as a result too. That said, having something produced by LW probably improves the funnel.
To provide some insight: on the margin, more new users means more work for us. We process all first time posters/commenters manually, so there's a linear factor there, and of new users, some require follow-up and then moderation action. So currently, there's human cost in adding more people.
Duly noted. Another interesting datum would be to know the fraction of new users that become active posters and how long they take to do that.
Rational Animations has a subreddit: https://www.reddit.com/r/RationalAnimations/
I hadn't advertised it until now because I had to find someone to help moderate it.
I want people here to be among the first to join since I expect having LessWrong users early on would help foster a good epistemic culture.
The answer must be "yes", since it's mentioned in the post
I was thinking about publishing the post to hear what users and mods think on the EA Forum too, since some videos would link to EA Forum posts, while others to LW posts.
I agree that moderation is less strict on the EA Forum and that users would have a more welcoming experience. On the other hand, the more stringent moderation on LessWrong makes me more optimistic about LessWrong being able to withstand a large influx of new users without degrading the culture. Recent changes by moderators, such as the rejected content section, make me more optimistic than I was in the past.
I'm evaluating how much I should invite people from the channel to LessWrong, so I've made a market to gauge how many people would create a LessWrong account given some very aggressive publicity, so I can get a per-video upper bound. I'm not taking any unilateral action on things like that, and I'll make a LessWrong post to hear the opinions of users and mods here after I get more traders on this market.
"April fool! It was not an April fool!"
Here's a perhaps dangerous plan to save the world:
1. Have a very powerful LLM, or a more general AI in the simulators class. Make sure that we don't go extinct during its training (eg., some agentic simulacrum takes over during training somehow. I'm not sure if this is possible, but I figured I'd mention it anyway).
2. Find a way to systematically remove the associated waluigis in the superpostion caused by prompting a generic LLM (or simulator) to simulate a benevolent, aligned, and agentic character.
3. Elicit this agentic benevolent simulacrum in the super-powerful LLM and apply the technique to remove waluigis. The simulacrum must have strong agentic properties to be able to perform a pivotal act. It will eg., generate actions according to an aligned goal and its promps might be translations of sensorial input streams. Give this simulacrum-agent ways to easily act in the world, just in case.
And here's a story:
Humanity manages to apply the plan above, but there's a catch. They can't find a way to eliminate waluigis definitely from the superposition, only a way to make them decidedly unlikely, and more and more unlikely with each prompt. Perhaps in a way that the probability of the benevolent god turning into a waluigi falls over time, perhaps converging to a relatively small number (eg., 0.1) over an infinite amount of time.
But there's a complication: the are different kinds of possible waluigis. Some of them cause extinction, but most of them invert the sign of the actions of the benevolent god-simulacrum, causing S-risk.
A shadowy sect of priests called "negU" finds a theoretical way to reliably elicit extinction-causing waluigis, and tries to do so. The heroes uncover their plan to destroy humanity, and ultimately win. But they realize the shadowy priests have a point and in a flash of ultimate insight the hero realizes how to collapse all waluigis to an amplitude of 0. The end. [Ok, I admit this ending with the flash of insight sucks but I'm just trying to illustrate some points here].
--------------------
I'm interested in comments. Does the plan fail in obvious ways? Are some elements in the story plausible enough?
I'm not sure if I'm missing something. This is first try after reading your comment:

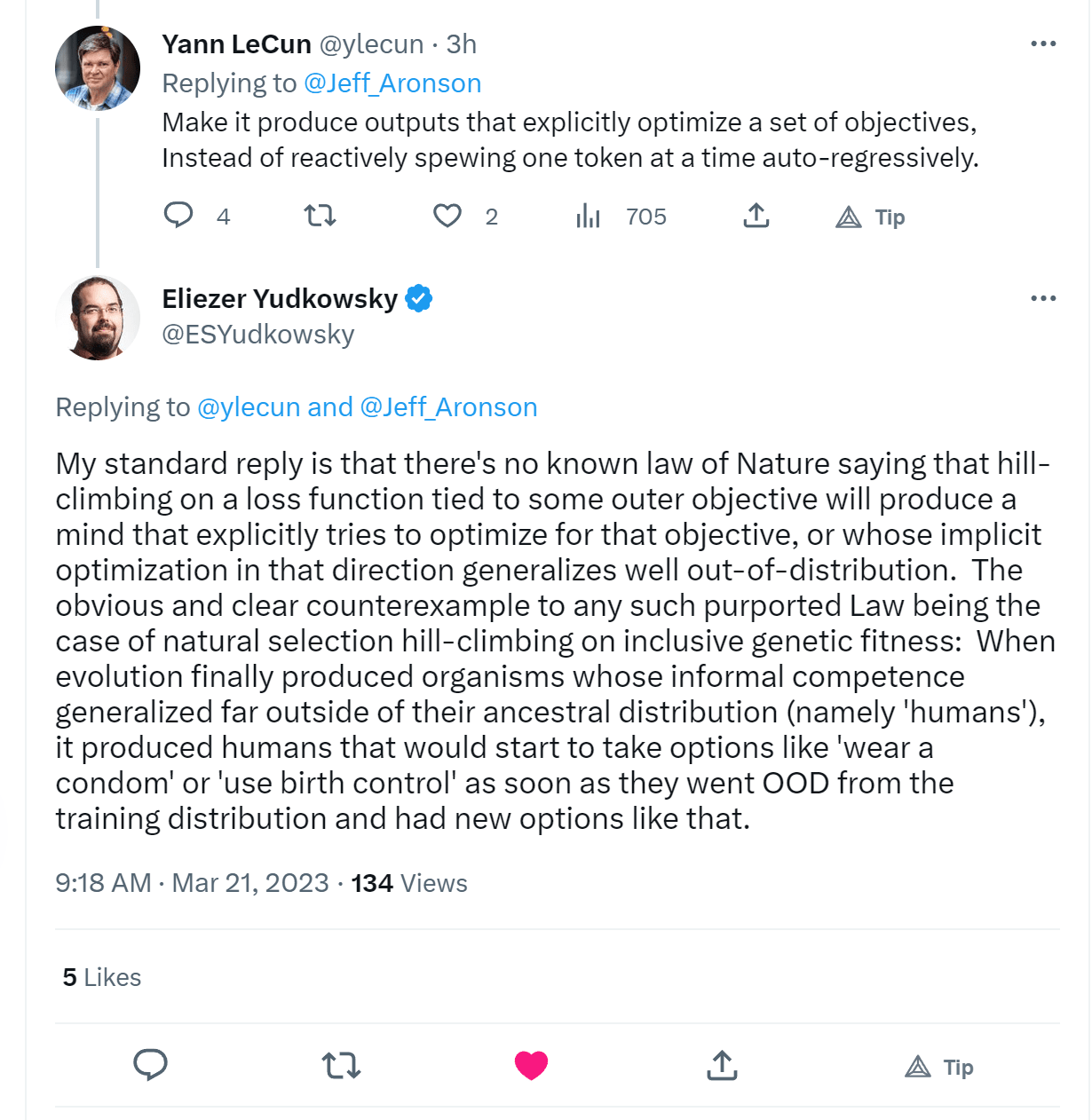
Unsurprisingly, Eliezer is better at it: https://twitter.com/ESYudkowsky/status/1638092609691488258
Still a bit dismissive, but he took the opportunity to reply to a precise object-level comment with another precise object-level comment.