Writer's Shortform
post by Writer · 2023-01-14T18:04:17.448Z · LW · GW · 38 commentsContents
38 comments
38 comments
Comments sorted by top scores.
comment by Writer · 2025-02-12T09:13:38.362Z · LW(p) · GW(p)
Surprised that there's no linkpost about Dan H's new paper on Utility Engineering. It looks super important, unless I'm missing something. LLMs are now utility maximisers? For real? We should talk about it: https://x.com/DanHendrycks/status/1889344074098057439
I feel weird about doing a link post since I mostly post updates about Rational Animations, but if no one does it, I'm going to make one eventually.
Also, please tell me if you think this isn't as important as it looks to me somehow.
EDIT: Ah! Here it is! https://www.lesswrong.com/posts/SFsifzfZotd3NLJax/utility-engineering-analyzing-and-controlling-emergent-value [LW · GW] thanks @Matrice Jacobine [LW · GW]!
Replies from: habryka4↑ comment by habryka (habryka4) · 2025-02-12T20:58:14.278Z · LW(p) · GW(p)
FWIW, my sense is that it's a bad paper. I expect other people will come out with critiques in the next few days that will expand on that, but I will write something if no one has done it in a week or two. I think the paper notices some interesting weak correlations, but man, it really doesn't feel like the way you would go about answering the central question it is trying to answer and I keep having the feeling of it very much having been written to produce the thing that on the most shallow read will produce the most surface-level similar object in order to persuade and be socially viral, and not to inform.
Replies from: Writer↑ comment by Writer · 2025-02-12T21:25:07.955Z · LW(p) · GW(p)
Thanks! I already don't feel as impressed by the paper as I was while writing the shortform and I feel a little embarrassed for not thinking through things a little bit more before posting my reactions, although at least now there's some discussion under the linkpost so I don't entirely regret my comment if it prompted people to give their takes. I still feel to have updated in a non-negligible way from the paper though, so maybe I'm still not as pessimistic about it as other people. I'd definitely be interested in your thoughts if you find discourse is still lacking in a week or two.
comment by Writer · 2024-06-10T22:43:30.388Z · LW(p) · GW(p)
For me, perhaps the biggest takeaway from Aschenbrenner's manifesto is that even if we solve alignment, we still have an incredibly thorny coordination problem between the US and China, in which each is massively incentivized to race ahead and develop military power using superintelligence, putting them both and the rest of the world at immense risk. And I wonder if, after seeing this in advance, we can sit down and solve this coordination problem in ways that lead to a better outcome with a higher chance than the "race ahead" strategy and don't risk encountering a short period of incredibly volatile geopolitical instability in which both nations develop and possibly use never-seen-before weapons of mass destruction.
Edit: although I can see how attempts at intervening in any way and raising the salience of the issue risk making the situation worse.
Replies from: tmeanen↑ comment by tmeanen · 2024-06-11T13:59:07.515Z · LW(p) · GW(p)
Plausibly one technology that arrives soon after superintelligence is powerful surveillance technology that makes enforcing commitments significantly easier than it historically has been. Leaving aside the potential for this to be misused for authoritarian government, advocating for this to be developed before powerful technologies of mass destruction may be a strategy.
comment by Writer · 2023-12-24T14:37:27.836Z · LW(p) · GW(p)
RA has started producing shorts. Here's the first one using original animation and script: https://www.youtube.com/shorts/4xS3yykCIHU
The LW short-form feed seems like a good place for posting some of them.

comment by Writer · 2023-12-22T12:57:06.148Z · LW(p) · GW(p)
Was Bing responding in Tibetan to some emojis already discussed on LW? I can't find a previous discussion about it here. I would have expected people to find this phenomenon after the SolidGoldMagikarp post, unless it's a new failure mode for some reason.
comment by Writer · 2024-01-17T17:13:39.738Z · LW(p) · GW(p)
Stories of AI takeover often involve some form of hacking. This seems like a pretty good reason for using (maybe relatively narrow) AI to improve software security worldwide. Luckily, the private sector should cover it in good measure for financial interests.
I also wonder if the balance of offense vs. defense favors defense here. Usually, recognizing is easier than generating, and this could apply to malicious software. We may have excellent AI antiviruses devoted to the recognizing part, while the AI attackers would have to do the generating part.
[Edit: I'm unsure about the second paragraph here. I'm feeling better about the first paragraph, especially given slow multipolar takeoff and similar, not sure about fast unipolar takeoff]
↑ comment by quetzal_rainbow · 2024-01-17T17:32:15.214Z · LW(p) · GW(p)
Hacking is usually not about writing malicious software, it's about finding vulnerabilities. You can avoid vulnerabilities entirely by provably safe software, but you still need safe hardware, which is tricky, and provably safe software is hell in development. It would be nice if AI companies used provably safe sandboxing, but it would require enormous coordination effort. And I feel really uneasy about training AI on finding vulnerabilities.
Replies from: faul_sname↑ comment by faul_sname · 2024-01-18T22:27:42.380Z · LW(p) · GW(p)
Also "provably safe" is a property a system can have relative to a specific threat model. Many vulnerabilities come from the engineer having an incomplete or incorrect threat model, though (most obviously the multitude of types of side-channel attack).
comment by Writer · 2024-01-08T13:06:54.161Z · LW(p) · GW(p)
Yoshua Bengio is looking for postdocs for alignment work:
I am looking for postdocs, research engineers and research scientists who would like to join me in one form or another in figuring out AI alignment with probabilistic safety guarantees, along the lines of the research program described in my keynote (https://www.alignment-workshop.com/nola-2023) at the New Orleans December 2023 Alignment Workshop.
I am also specifically looking for a postdoc with a strong mathematical background (ideally an actual math or math+physics or math+CS degree) to take a leadership role in supervising the Mila research on probabilistic inference and GFlowNets, with applications in AI safety, system 2 deep learning, and AI for science.
Please contact me if you are interested.
comment by Writer · 2023-06-07T14:50:36.933Z · LW(p) · GW(p)
Rational Animations has a subreddit: https://www.reddit.com/r/RationalAnimations/
I hadn't advertised it until now because I had to find someone to help moderate it.
I want people here to be among the first to join since I expect having LessWrong users early on would help foster a good epistemic culture.
comment by Writer · 2023-05-04T10:29:58.964Z · LW(p) · GW(p)
I'm evaluating how much I should invite people from the channel to LessWrong, so I've made a market to gauge how many people would create a LessWrong account given some very aggressive publicity, so I can get a per-video upper bound. I'm not taking any unilateral action on things like that, and I'll make a LessWrong post to hear the opinions of users and mods here after I get more traders on this market.
↑ comment by Chris_Leong · 2023-05-04T15:18:07.573Z · LW(p) · GW(p)
I guess one thing to think about is that Less Wrong is somewhat stricter on moderation than EA, so I wonder if inviting people to the EA forum would be a more welcoming experience?
Replies from: Writer↑ comment by Writer · 2023-05-04T15:50:24.812Z · LW(p) · GW(p)
I was thinking about publishing the post to hear what users and mods think on the EA Forum too, since some videos would link to EA Forum posts, while others to LW posts.
I agree that moderation is less strict on the EA Forum and that users would have a more welcoming experience. On the other hand, the more stringent moderation on LessWrong makes me more optimistic about LessWrong being able to withstand a large influx of new users without degrading the culture. Recent changes by moderators, such as the rejected content section [LW · GW], make me more optimistic than I was in the past [LW · GW].
Replies from: Chris_Leong↑ comment by Chris_Leong · 2023-05-04T16:06:10.656Z · LW(p) · GW(p)
If you mention Less Wrong, you might want to think carefully about how to properly set expectations.
comment by Writer · 2023-02-04T08:31:32.062Z · LW(p) · GW(p)
After reading this article [EA · GW] by Holden and this tweet by Sam Altman I want even more to talk about the very cruxes of AI Alignment on Rational Animations. The video about the most important century, for example, is something we'll do less, and we're going straight to AI notkilleveryonism.
comment by Writer · 2024-01-07T21:27:13.406Z · LW(p) · GW(p)
Here's a new RA short about AI Safety: https://www.youtube.com/shorts/4LlGJd2OhdQ
This topic might be less relevant given today's AI industry and the fast advancements in robotics. But I also see shorts as a way to cover topics that I still think constitute fairly important context, but, for some reason, it wouldn't be the most efficient use of resources to cover in long forms.
comment by Writer · 2023-02-15T14:17:19.005Z · LW(p) · GW(p)
I've made a poll.
I'm curious to hear thoughts on this topic.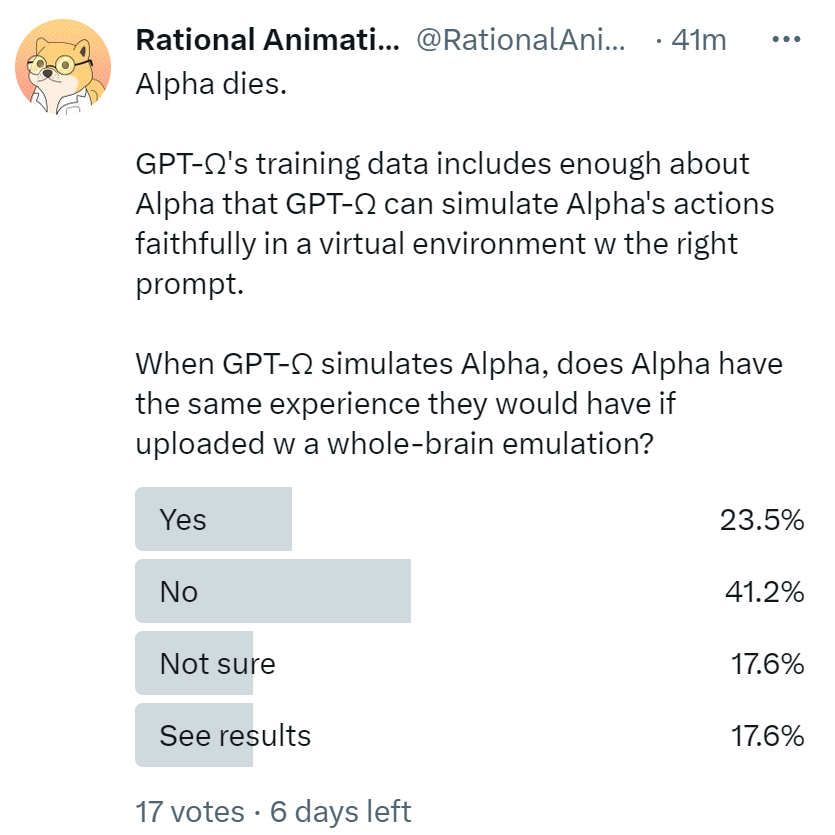
↑ comment by JBlack · 2023-02-16T01:02:32.497Z · LW(p) · GW(p)
There is not enough information to determine the answer.
To continue the thought experiment suppose that Alpha is "locked in", unable to produce any actions at all but capable of thought and sensation. The actions of such a person can be simulated faithfully very easily without simulating any of their thoughts or sensations. In more ordinary cases there is a much greater link between internal states and external actions, so perhaps it is plausible that a sufficiently accurate model of the actions might require running through the thoughts and sensations in essentially the same way that a whole brain emulation would.
We don't know whether that would be true in the real world, and in a hypothetical thought experiment that might not even conform to whatever rules reality abides by, we can't know that.
So put me down for "Not Sure", but not in the sense that the question has a definite answer that I don't know. I am very sure that the question itself is indefinite.
Replies from: green_leaf↑ comment by green_leaf · 2023-02-16T01:20:38.240Z · LW(p) · GW(p)
The actions of such a person can be simulated faithfully very easily without simulating any of their thoughts or sensations.
You can still talk with such a person by reading their brain state from a superpowered-fMRI-from-the-future, and them listening to your words.
(Talking to someone/interacting with someone's behavior is just a simplified way of saying "both-sided information transfer with the system," where you transmit the information to the system (in whatever way) and the system will generate the response the person is giving (also in whatever way).)
To the extent to which your thoughts and feelings are connected to your consciousness in any way, they can be elicited, either by the LLM computing your response (because they impact your words somehow), or by me asking how you feel (and LLM therefore having to figure out the answer).
To the extent to which your thoughts and feelings never influence your output in any way for any possible input, their existence is meaningless.
↑ comment by green_leaf · 2023-02-15T15:08:32.095Z · LW(p) · GW(p)
Yes. There is no other answer possible.
comment by Writer · 2023-01-14T18:04:17.682Z · LW(p) · GW(p)
Should I pin this comment under the Sorting Pebbles video?

It's the most liked right now, but usually even the most liked comments lose visibility over time.
Use agree/disagree votes to express whether you agree or disagree with pinning it.
comment by Writer · 2023-03-20T16:52:08.005Z · LW(p) · GW(p)
This post by Jeffrey Ladish was a pretty motivating read: https://www.facebook.com/jeffladish/posts/pfbid02wV7ZNLLNEJyw5wokZCGv1eqan6XqCidnMTGj18mQYG1ZrnZ2zbrzH3nHLeNJPxo3l
Replies from: jam_brandcomment by Writer · 2023-03-26T15:46:23.868Z · LW(p) · GW(p)
Here's a perhaps dangerous plan to save the world:
1. Have a very powerful LLM, or a more general AI in the simulators [LW · GW] class. Make sure that we don't go extinct during its training (eg., some agentic simulacrum takes over during training somehow. I'm not sure if this is possible, but I figured I'd mention it anyway).
2. Find a way to systematically remove the associated waluigis [LW · GW] in the superpostion caused by prompting a generic LLM (or simulator) to simulate a benevolent, aligned, and agentic character.
3. Elicit this agentic benevolent simulacrum in the super-powerful LLM and apply the technique to remove waluigis. The simulacrum must have strong agentic properties to be able to perform a pivotal act. It will eg., generate actions according to an aligned goal and its promps might be translations of sensorial input streams. Give this simulacrum-agent ways to easily act in the world, just in case.
And here's a story:
Humanity manages to apply the plan above, but there's a catch. They can't find a way to eliminate waluigis definitely from the superposition, only a way to make them decidedly unlikely, and more and more unlikely with each prompt. Perhaps in a way that the probability of the benevolent god turning into a waluigi falls over time, perhaps converging to a relatively small number (eg., 0.1) over an infinite amount of time.
But there's a complication: the are different kinds of possible waluigis. Some of them cause extinction, but most of them invert the sign of the actions of the benevolent god-simulacrum, causing S-risk.
A shadowy sect of priests called "negU" finds a theoretical way to reliably elicit extinction-causing waluigis, and tries to do so. The heroes uncover their plan to destroy humanity, and ultimately win. But they realize the shadowy priests have a point and in a flash of ultimate insight the hero realizes how to collapse all waluigis to an amplitude of 0. The end. [Ok, I admit this ending with the flash of insight sucks but I'm just trying to illustrate some points here].
--------------------
I'm interested in comments. Does the plan fail in obvious ways? Are some elements in the story plausible enough?
comment by Writer · 2023-03-21T08:18:41.984Z · LW(p) · GW(p)
I seriously doubt comments like these are making the situation better (https://twitter.com/Liv_Boeree/status/1637902478472630275, https://twitter.com/primalpoly/status/1637896523676811269)
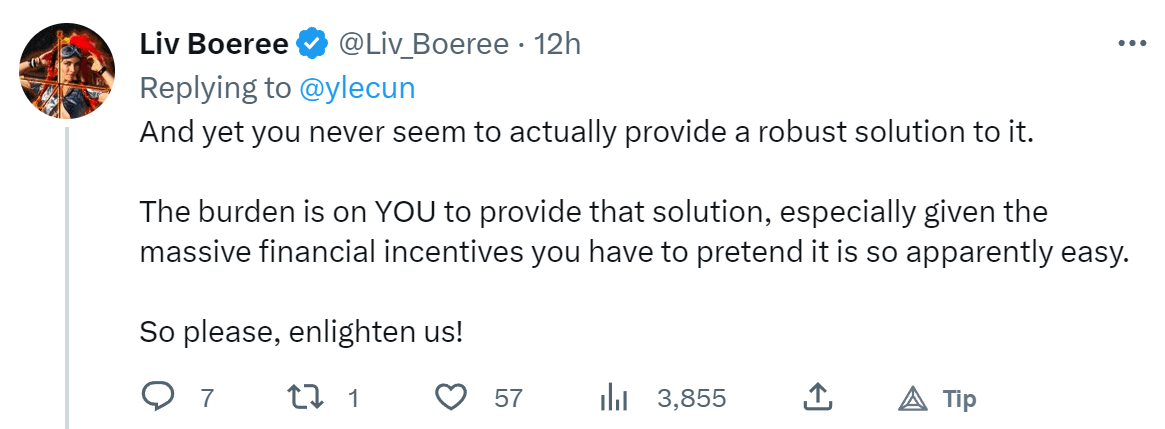
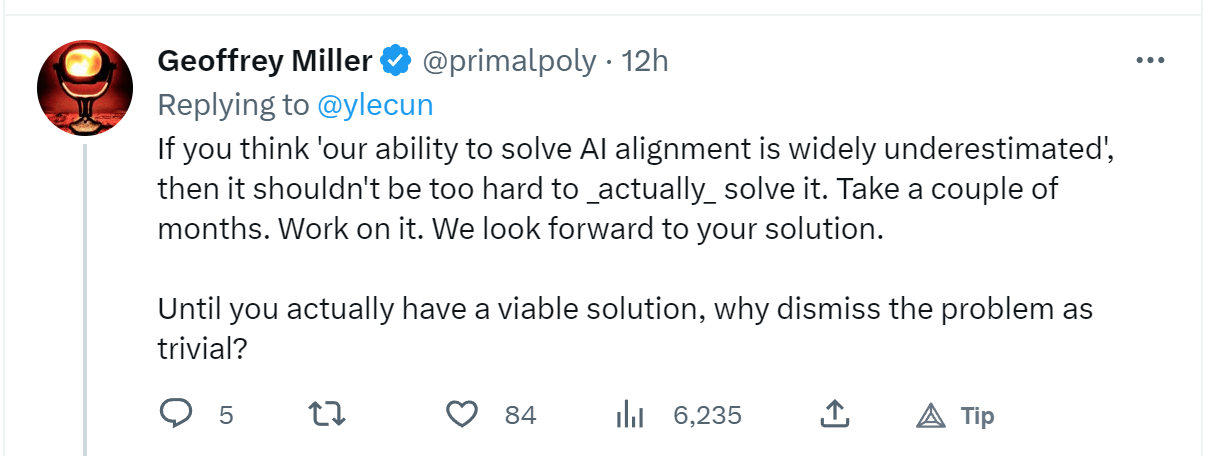
Edit: on the other hand...

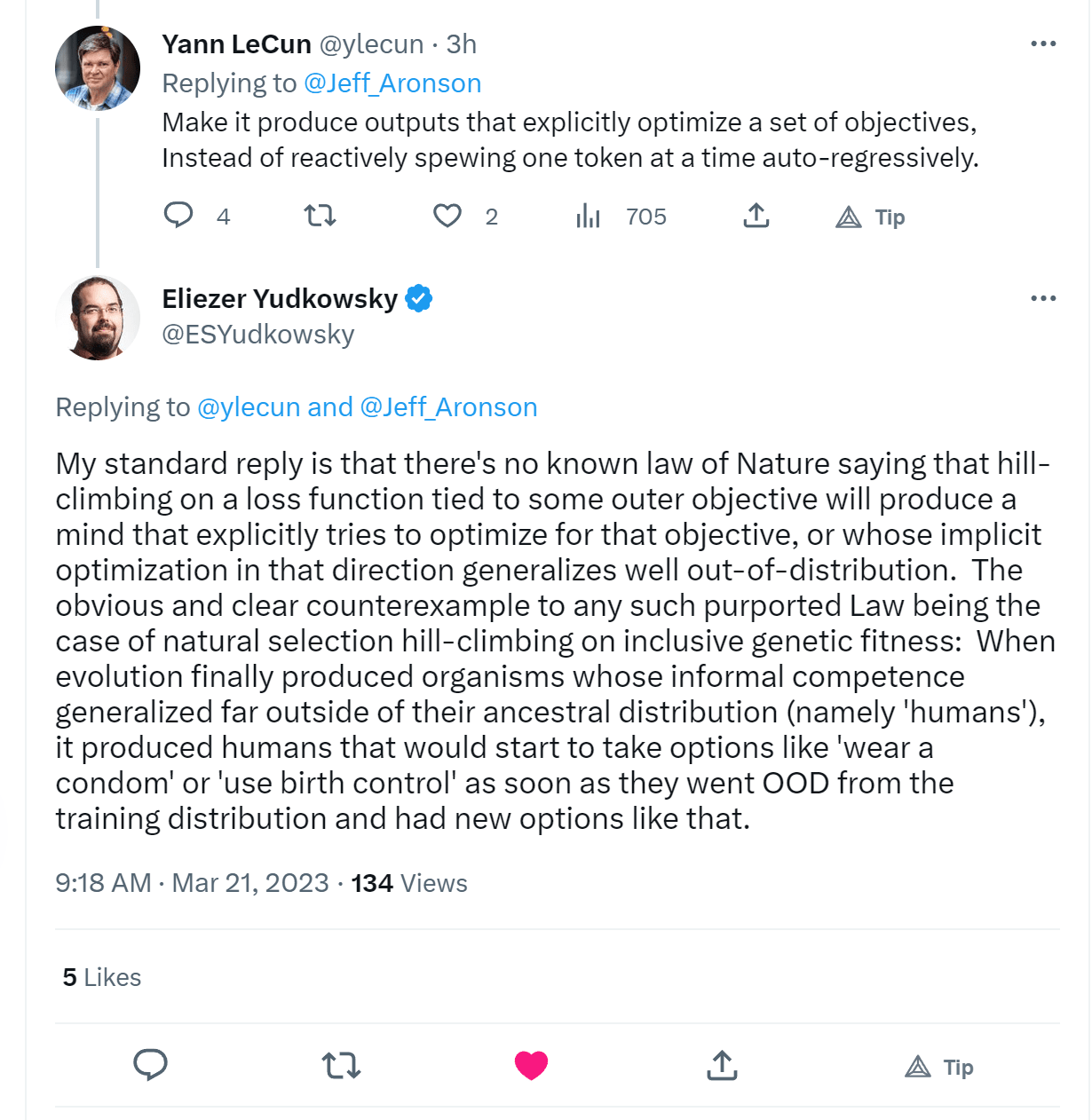
↑ comment by Writer · 2023-03-21T08:25:53.894Z · LW(p) · GW(p)
Unsurprisingly, Eliezer is better at it: https://twitter.com/ESYudkowsky/status/1638092609691488258
Still a bit dismissive, but he took the opportunity to reply to a precise object-level comment with another precise object-level comment.
comment by Writer · 2023-03-20T21:29:01.405Z · LW(p) · GW(p)
Replies from: WriterI think that the magnitude of the AI alignment problem has been ridiculously overblown & our ability to solve it widely underestimated.
I've been publicly called stupid before, but never as often as by the "AI is a significant existential risk" crowd.
That's OK, I'm used to it.
comment by Writer · 2023-03-20T10:37:34.553Z · LW(p) · GW(p)
Would it be possible to use a huge model (e.g. an LLM) to interpret smaller networks, and output human-readable explanations? Is anyone working on something along these lines?
I'm aware Kayla Lewis is working on something similar (but not quite the same thing) on a small scale. In my understanding, from reading her tweets, she's using a network to predict the outputs of another network by reading its activations.
comment by Writer · 2023-02-21T21:58:07.737Z · LW(p) · GW(p)
Is the Simulators [LW · GW] frame essentially correct?
Agreevote to say "Yes".
Disagreevote to say "No".
↑ comment by Writer · 2023-02-21T22:02:09.292Z · LW(p) · GW(p)
I'm not sure, but an interesting operationalization could be "the simulators frame is correct enough that general intelligences can be simulated by LLMs".
(I decided to write this as reply rather than in the parent comment, because I don't want this to define my question above, since people might disagree about the right way to operationalize it)
