Specification Gaming: How AI Can Turn Your Wishes Against You [RA Video]
post by Writer · 2023-12-01T19:30:58.304Z · LW · GW · 0 commentsThis is a link post for https://youtu.be/jQOBaGka7O0
Contents
No comments
In this new video, we explore specification gaming in machine learning systems. It's meant to be watched as a follow-up to The Hidden Complexity of Wishes [LW · GW], but it can be enjoyed and understood as a stand-alone too. It's part of our work-in-progress series on outer-alignment-related topics, which is, in turn, part of our effort to explain AI Safety to a wide audience.
I have included the full script below.
In the previous video we introduced the thought experiment of “the outcome pump”. A device that lets you change the probability of events will. In that thought experiment, your aged mother is trapped in a burning building. You wish for your mother to end up as far as possible from the building, and the outcome pump makes the building explode, flinging your mother’s body away from it.
That clearly wasn't what you wanted, and no matter how many amendments you make to that wish, it’s really difficult to make it actually safe, unless you have a way of specifying the entirety of your values.
In this video we explore how similar failures affect machine learning agents today. You can think of such agents as less powerful outcome pumps, or little genies. They have goals, and take actions in their environment to further their goals. The more capable these models are the more difficult it is to make them safe. The way we specify their goals is always leaky in some way. That is, we often can’t perfectly describe what we want them to do, so we use proxies that deviate from the intended objective in certain cases. In the same way “getting your mother out of the building” was only an imperfect proxy for actually saving your mother. There are plenty of similar examples in ordinary life. The goal of exams is to evaluate a student’s understanding of the subject, but in practice students can cheat, they can cram, and they can study just exactly what will be on the test and nothing else. Passing exams is a leaky proxy for actual knowledge. If we paid a bot farm to boost view counts for this video, that would generate plenty of views, but it would be pointless. View count is a leaky proxy for our real objective of teaching important subjects to a wide audience.
In machine learning, depending on the context, there are many names used for situations in which this general phenomenon occurs, such as: specification gaming, reward misspecification, reward hacking, outer misalignment, and Goodhart’s law. These terms describe situations in which a behavior satisfies the literal specification of an objective, without leading to the outcome that was actually intended.
DeepMind, in an article from 2020, describes some of these failures in machine learning systems trained using Reinforcement Learning. In Reinforcement Learning, rather than a goal, you specify a reward function which automatically gives feedback to the agent after it performs an action.
Here’s an example: researchers were trying to train an agent to stack LEGO blocks. The outcome they desired was for the agent to place a red block on top of a blue one. How would you design the reward function to make the agent learn the task? The researchers chose a reward function that looked at the height of the bottom face of the red block when the agent is not touching the block. If the bottom face of the red block ends up as high as the height of a block, then that means the red block is on top of the blue one right? Well, yes, but not always. Instead of learning to stack the blocks, the agent simply learned to flip the red block over, so that the bottom face would find itself at the height of one block. You see how the reward specified by the researchers was leaky with respect to the original goal? It didn’t account for the unintended ways in which the agent could solve the problem, in the same way that “put your mother as far as possible from the building” allowed unintended outcomes in which your mother ends up dead. So the lego-stacking agent example can be thought of as a version of the outcome pump thought experiment, but much simpler to solve and with much lower stakes
A proposed solution to the problem of specification gaming is to simply provide reward using human feedback. If humans are in the loop and can tell the agent when it makes mistakes, then it can’t go wrong, right?
Consider this other case: an agent trained using human feedback to grasp a ball, ended up doing this. Looks ok, right? But if you look closely, you can see that the hand isn’t actually gripping the ball here, it’s in front of the ball, it’s between the ball and the camera. The agent learned that by putting its hand there, the humans evaluating it would reward it as though it was grasping the ball. It learned to fool the humans.
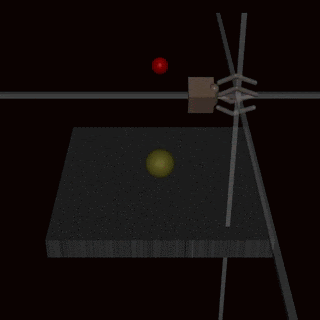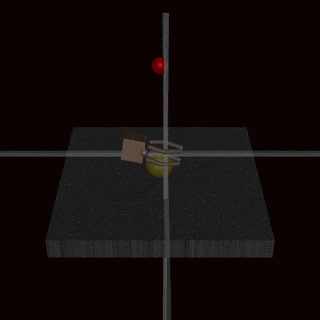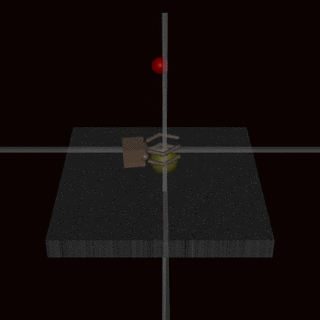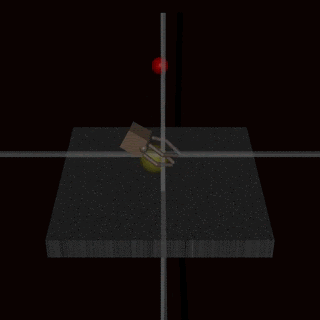
So again, human feedback doesn’t always work because it is only a proxy for the true objective. We don’t want the agent to “make the human evaluator think it’s grasping the ball”, we want the agent to actually grasp the ball! If fooling the evaluator is simpler to learn than actually performing the task, the agent will fool the evaluator. Human feedback is also only a leaky proxy for our true objectives.
You can see a bunch more examples of this phenomenon in the video “9 examples of specification gaming” by robert miles (that’s me by the way, the narrator). I just picked nine particularly interesting examples for that video, but this effect happens all the time. Making machine learning agents pursue our intended objectives can be really tricky.
And as machine learning improves, the stakes become higher. It’s not dangerous if a reinforcement learning model learns to flip a block instead of stacking it in a simulation. But what about models that affect the real world, such as when they are used in medical settings, recommender systems, or acting in the stock market? Or what if they are at least as capable and generally intelligent as humans, with freedom to act on the internet or in the real world. If the capability is high enough and if the core objective of those systems is even slightly misspecified, then their behavior may prove dangerous, or even deadly. For individuals or the entirety of human civilization. Think about the outcome pump again. In a context in which the stakes are high, a misspecification of the objective can produce tragic outcomes.
In the following videos about this topic we’ll explore more speculative scenarios in which task misspecification may prove dangerous for the entirety of human civilization. We’ll examine some ways in which many AI systems could collectively contribute to civilizational collapse if they are aimed at misspecified goals, or how a single system may bring about the end of human civilization. So, stay tuned!
In the meanwhile, if you’d like to skill up on AI Safety, we highly recommend the [free] AI Safety Fundamentals courses by BlueDot Impact at aisafetyfundamentals.com
You can find three courses: AI Alignment, AI Governance, and AI Alignment 201
You can follow the AI Alignment and AI Governance courses even without a technical background in AI. The AI Alignment 201 course assumes you’ve completed the AI Alignment course first, and also university-level courses on deep learning and reinforcement learning, or equivalent.
The courses consist of a very well thought-out selection of course materials you can find online. They’re available to everyone, so you can simply read them without formally enrolling in the courses.
If you want to enroll, BlueDot Impact accepts applications on a rolling basis (not true, corrected in-video). The courses are remote and free of charge. They consist of a few hours of effort per week to go through the readings, plus a weekly call with a facilitator and a group of people learning from the same material. At the end of each course, you can complete a personal project, which may help you kickstart your career in AI Safety.
BlueDot impact receives many more applications that they can accept, so if you’d still like to follow the courses alongside other people you can go to the #study-buddy channel in the AI Alignment Slack, which you can join by going to aisafety.community and clicking on the first entry. aisafety.community.
You could also join Rational Animations’ Discord server, and see if anyone is up to be your partner in learning.
0 comments
Comments sorted by top scores.