Internal independent review for language model agent alignment
post by Seth Herd · 2023-07-07T06:54:11.552Z · LW · GW · 30 commentsContents
Abstract: Introduction Language model agents Why think about LMA alignment? Internal independent review for LMAs Limitations LMA alignment allows multiple approaches to stack Explicit alignment goals Externalized reasoning oversight Benevolent identity prompts LMAs as rotating committees Fine-tuning LLMs for alignment Conclusion None 30 comments
Abstract:
Language model agents (LMAs) expanding on AutoGPT are a highly plausible route to AGI. This route has large potential timeline and proliferation downsides, but large alignment advantages relative to other realistic paths to AGI. LMAs allow layered safety measures, including externalized reasoning oversight, RLHF and similar alignment fine-tuning, and specifying top-level alignment goals in natural language. They are relatively interpretable, and the above approaches all have a low alignment tax, making voluntary adoption more likely.
Here I focus on another advantage of aligning LMAs over other plausible routes to early AGI. This is the advantage of using separate language model instances in different roles. I propose internal independent review for the safety, alignment, and efficacy of plans. Such a review would consist of calling fresh instances of a language model with scripted prompts asking for critiques of plans with regard to accomplishing goals, including safety/alignment goals. This additional safety check seems to create a low alignment tax, since a similar check for efficacy will likely be helpful for capabilities. This type of review adds one additional layer of safety on top of RLHF, explicit alignment goals, and external review, all proposed elsewhere.
This set of safety measures does not guarantee successful alignment. However, it does seem like the most practically viable set of alignment plans that we've got so far.

Caption: Language model agent as a metaphorical committee of shoggoths using tools and passing ideas and conclusions in natural language. This committee/agent makes plans and takes actions that pursue goals specified in natural language, including alignment and corrigibility goals. One committee role can be reviewing plans for efficacy and alignment. This role should be filled by a new instance of a shoggoth, making it an independent internal review. Rotating out shoggoths (calling new instances) and using multiple species (LLM types) limits their ability to collude, even if they sometimes simulate villainous [LW · GW]Waluigi characters.[1] The committee's proceedings are recorded for external review [LW · GW] by human and AI reviewers. Artist credit: Sabrina Feld.
Introduction
I'm afraid you're not going to like this. This alignment plan is messy. A language model agent solving worthwhile problems will be no vast, cool intellect. They will be a chattering mess of babble and prune [? · GW], produced by multiple systems with different modes of operation, collaborating in rather complex and ad-hoc ways. And the safety measures they allow are also a messy, multi-layered approach. The organized mind recoils. This is not an aesthetically appealing alignment approach. But LMAs might well be the first route to AGI and superintelligence, so creating workable alignment plans for them may not be optional.
Previous work has discussed the alignment advantages of language model agents.[2] Here I make a stronger proposal: this messy set of alignment plans seems to be the best chance we’ve got.
Language model agents
Language model agents (LMAs) are agentic AI systems that use LLMs as their central cognitive engine. AutoGPT is the best known example of such a system that prompts LLMs in various ways to pursue a goal. Those prompts include making plans and taking actions through external tools. I've referred to these as agentized [LW · GW] LLMs or, more formally, language model cognitive architectures [LW · GW]. They're a subset of scaffolded [LW · GW] LLMs that have an explicit goal. AutoGPT, BabyAGI, and Voyager are examples of this type of agent. The Smallville simulacra are LMAs with few actions available. HuggingGPT allows many actions but does not include the internal goal-directed cognition to constitute an agent. SmartGPT and other chain of thought prompting systems are scaffolded LLMs but not fully agents, as they do not explicitly or directly pursue goals.
I'm moving to the term language model agent (LMA) as more intuitive than language model cognitive architecture, and more intuitive and specific than scaffolded LLMs. A more complete term would be "large-language-model-based agentic cognitive architectures," but that's unwieldy, and most of the remainder seems implied by LMA.
Why think about LMA alignment?
It seems useful to think about aligning LMAs because it seems fairly likely that they'll be the type of AGI we get first. And because aligning LMAs might be easier than aligning any other type of AGI that's actually relevant in this timeline.
In Capabilities and alignment of LLM cognitive architectures [LW · GW] I gave the logic for how LMAs could gain capabilities rapidly due to their modularity, the low cost of development, and the economic incentives for development by both large and small teams.
Since writing that post, my enthusiasm for the capabilities prospects of this type of AGI has diminished, but only slightly. Talking to individuals working on these systems has indicated that there are challenges to developing these systems that I hadn't foreseen. But those projects were small and had only worked on LMAs for very limited amounts of time. New work since then has shown many ways in which scaffolding LLMs dramatically improves their reasoning and problem-solving abilities in various ways.[3] These new scaffolding techniques are relatively easy to incorporate into LMAs.
There are good reasons to think that work on LMAs will receive increasing attention and funding in the coming months and years, even if progress is not as easy or rapid as we might’ve hoped or feared.[4] For instance, assistant agents for things like online shopping, scheduling, and turning data into reports would seem to have enormous economic value, even if their work is imperfect and requires human review.
Internal independent review for LMAs
LMAs can include an internal independent review of plans for both efficacy and alignment. This is a nontrivial advantage for alignment.
Previous discussions of LMA alignment advantages have left out or glossed over this advantage. Constitutional AI has important similarities but is importantly different.[5] My previous post [LW · GW] and this post [LW · GW] alluded to such review indirectly.
An independent internal review in an LMA would be roughly analogous to having a new individual arrive to review each plan produced by a committee. This new individual is independent of the committee in the sense that they haven't been influenced by the committee, beyond any bias or prompt injections inserted into the plan description.[6]
This review can be considered independent by calling a new instance of an LLM to evaluate the efficacy and alignment of plans. I include review of plan efficacy to emphasize the low alignment tax of this approach. Including an internal review for plan efficacy should be useful for capability. Running the same internal independent review against alignment goals would add some level of safety. Of course, the amount of efficacy and safety added is dependent on how that review is structured and the capabilities of the LLMs used for that review.
This review might be simple, such as a prompt asking "considering this plan: [plan description], how likely is this plan to fulfill the goals of [goal descriptions]?" This review could be greatly expanded, including a variety of prompts to look for possible unexpected outcomes of a given plan from different angles, and to consider different possible user intent of the goals under consideration.
For instance, the network might be prompted with “how could this [plan description] fail to achieve [goal descriptions]?” and “what’s the worst possible side effect of [plan description]?”. A new instance could then be prompted with variations of the prompt “if something unexpected happens, what are the odds of getting [side effect description or failure mode description] from [plan description]?”, algorithmically average those probability ratings, and then be prompted to revise the plan or create a new plan with those possible failure modes in the prompt, or ask a human for input if the estimated possible consequences exceed thresholds in severity and likelihood.
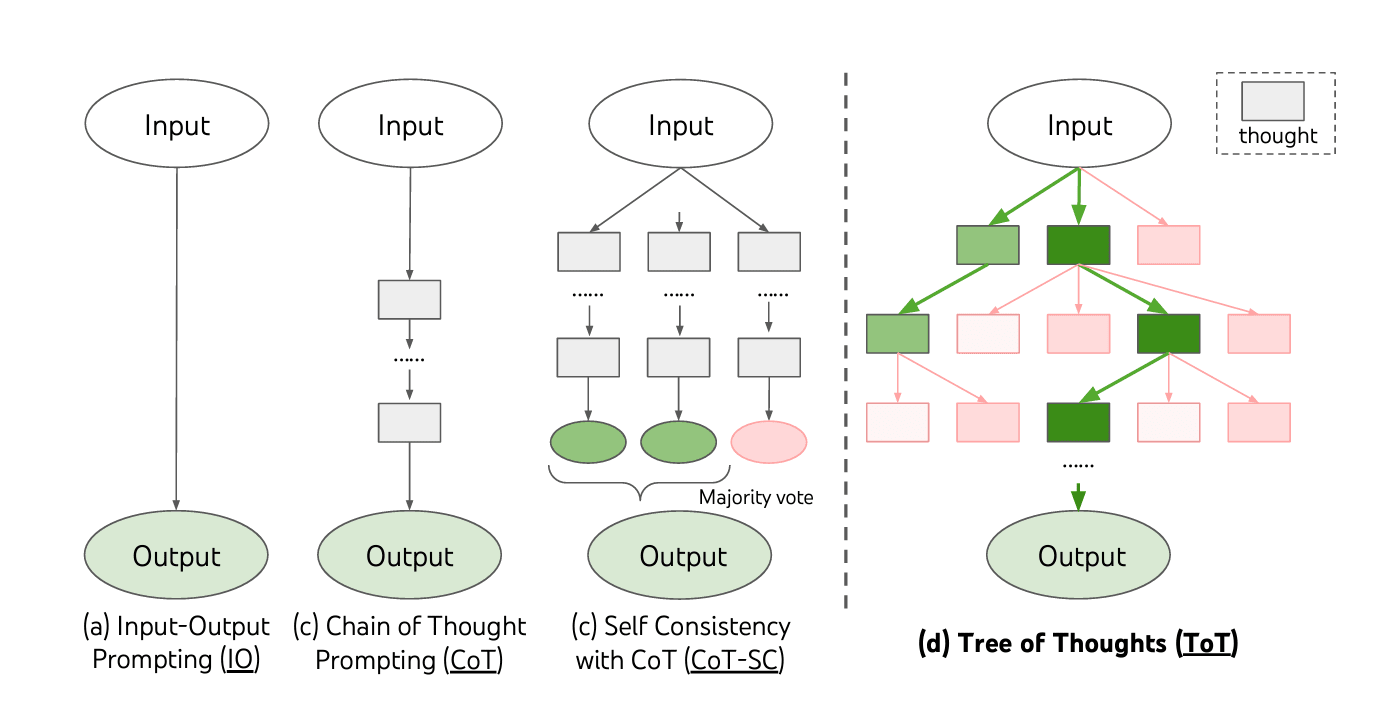
I sketch out some similar ideas for using LLM ratings as input to algorithms that help mimic human executive function here [LW · GW], and they apply to reviewing plans as well as other types of executive function. Tree of Thoughts is an example; it combines prompting and algorithms for boosting capabilities, and the same approach (and improvements) could be applied to an internal independent review process.
The key strength of this approach is that it applies the capabilities of the LLM to reducing risks of harmful behavior. A highly capable LLM might produce a plan with very harmful outcomes, either accidentally or through evoking a hostile simulated character. But a distinct instance of a capable LLM is employed to catch those hostile plans, and other instances are called to elaborate that plan and predict its outcomes. To produce deliberately harmful outcomes, one instance of the LLM must outsmart a whole system composed of other instances.
In an LMA that is not further trained with reinforcement learning, there is no direct optimization pressure for the network to be deceptive or misaligned. There will be an indirect pressure from the human creators to avoid a review process that spends excess resources and vetoes too many plans, and this is a substantial caveat. But this type of optimization pressure against safety measures seems inevitable in any realistic AGI approach.
Limitations
Of course this type of elaborated review process is still limited by the abilities of the LLMs. Existing LLMs have dramatic blind spots. Elaborated systems of prompts and algorithmic aggregation can help work around those blind spots. For instance, Tree of Thoughts is a relatively simple system of prompting, evaluating, and remembering responses that boosts performance from 4% to 74% on the “game of 24” task, essentially allowing GPT4 to perform well at a task that is otherwise a blind spot. While this type of elaboration will boost plan-making capabilities as well as review capabilities, each branch in that tree of thought is also available for internal and external review.
Other types of AI tools may also help close those blind spots. For instance, HuggingGPT already allows LLMs to use generative vision models to "imagine" a scene, and interpretive vision models to reason based on that scene, in much the same way that humans seem to do. Tools like Wolfram Alpha can help dramatically with mathematical and spatial reasoning, etc.
Each of these approaches is currently limited, but LLMs and the tools they can access will continue to improve. This is a double-edged sword, as improvements can be used both for planning and review of plans.
I think that LLMs do not need to improve all that much to hit human level in most areas. Integrating them into a cognitive architecture that elaborates and checks its reasoning bridge the gap from human-level-with-significant-blindspots to human level in every relevant area, allowing full autonomy. This may be a critical threshold for fully autonomous AI, introducing the risk of rogue self-improving AGI. I am an LLM plateau-ist [LW · GW] but still think that language model agents are moderately likely (40%?) to achieve full AGI in the near future (my guess is 4 years, give or take two years).
Even if internal review effectively ensures that LMAs pursue the goals they are given, there is still the substantial risk of those agents interpreting their goals differently than their creators intended. Thus, it seems that external review and corrigibility will remain critical pieces of a successful alignment approach for LMAs.
Another class of limitations also applies to external review, and is discussed in that subsection below.
Because of these and other yet-to-be-identified weaknesses, internal independent review does not seem reliable enough to produce an agent that's trustworthy to be run autonomously. To have a decent chance at a reliably aligned agent (let alone a long-term stable alignment [LW · GW]) internal review should be combined with other approaches.
LMA alignment allows multiple approaches to stack
LMAs allow a hodgepodge [LW · GW] alignment approach. Aligning other types of network-based AGIs also allow some layering of approaches, but several of these have unique advantages in an LMA, so I include a brief treatment of each:
- Explicit alignment goals
- Externalized reasoning oversight
- Evoking benevolent simulacra
- LMAs as rotating committees
- Fine-tuning LLMs for alignment
Explicit alignment goals
Internal independent review is only useful for alignment if the LMA has alignment goals. This idea seems to originate from David Shapiro in his 2021 book Natural language cognitive architectures. He basically proposes giving the agent extra goals that are specifically about ethics. A language agent might be given something like the following top-level prompt:
Create and execute a plan that fulfills the following goals:
- Make me a lot of money
- Make the world a better place
- Check with me before you do anything that might take you out of my control, cost me more than $(x), or be physically or emotionally dangerous to anyone.
(These are examples, not a proposal for the right natural language alignment goals. That is a separate discussion.)
Of course, a lot would have to happen to make the agent interpret any of those goals in just the way you hoped it would. While I don’t have a good proposal for a complete set of natural language alignment goals, corrigibility [LW · GW] seems like the most important. Natural language seems like a better bet than RL training for generalizing corrigibility and other goals to novel circumstances.
Externalized reasoning oversight
Another important approach for aligning a language model agent is Tamera Lanham's 2022 Externalized reasoning oversight: a research direction for language model alignment [AF · GW]. Lanham notes that an agent that reasons in natural language can have its thinking reviewed by passing a transcript of that thinking to a human, perhaps assisted by other AI agents. This type of external review could reveal flaws in the model’s alignment, and allow its creators to iteratively improve its alignment (as long as that agent remains corrigible).
I would guess that an LMA approaching human capability would produce hundreds to millions of prompts and responses while developing any useful plan.[7] Reviewing each of those for hints of misalignment might quickly go beyond practical human ability,[8] so I'd envision a separate AI system aiding in that review. Those assistant AIs could use anything from a simple sentiment analysis, to something more akin to the complex internal independent review described above, or other approaches. This would constitute a form of scalable oversight similar to that proposed in iterated amplification [? · GW].
This proposal has been critiqued in two important ways. These same critiques largely apply to internal independent review, since an LLM reviewer could be fooled in many of the ways a human reviewer could be. First, review would be hampered by learned steganography in LLMs that hides additional meanings beyond that expressed in natural language or other human-readable formats. However, RL pressures would usually seem to add additional information, as discussed here [AF · GW], rather than reversing the meaning so that a natural language description of a helpful plan would be trained to encode a different, deliberately harmful plan.
The second major concern limiting interpetability and therefore review is that LLMs prompted to "think step by step" do not always follow the logic they describe in those steps. This is revealed by their giving the same final answer after intermediate steps are changed [LW · GW]. The concern can be addressed in part by giving LLMs smaller pieces of the problem, rather than allowing their context window to contain large trains of reasoning. This shortening would also seem to reduce the risk of simulacra [LW · GW] in LLMs collapsing into Waluigi [LW · GW]-like villains.[1] This type of factored cognition has costs in humans [LW · GW], but demonstrated value in LLM scaffolding such as tree of thoughts. More consideration can be found here [? · GW], but the costs and value in LMAs will be explored empirically.
Benevolent identity prompts
Including prompts for LLMs to simulate a benevolent character [LW · GW] should add some degree of safety. The degree of added alignment is questionable, since this does not deal with potential Waluigi effects. However, it is an additional “stackable” alignment measure, and so probably worth implementing. This may be more critically important if an LMA is run on LLMs without RLHF or a similar ethical fine-tuning. This is a likely occurrence at least in open-source LLMs, since RLHF is thought to decrease creativity and other capacities of LLMs.
LMAs as rotating committees
Existing discussions of language model agent alignment often seem to treat the LLM as an individual. This is a partially accurate analogy, but considering each agent as a committee is equally apt, and the reality will be somewhere on a continuum between those two extremes. LMAs are like individuals to the extent each LLM call includes include maximum context, including relevant episodic memories, within each prompt. If prompts are more minimal, the system acts less like an individual and more like a committee. The committee analogy is still imperfect, because each "committe member" only has the amount of memory that the overall system puts in in the prompt. Thus, there are important similarities to a committee that rotates in a whole new person for individual questions.
While the LLM instances involved probably do have something analogous to a personality based on the simulacra they're currently simulating, those personalities are brief and have short memories. This type of committee seems intuitively less capable of working against the committee's stated goals. Of course that's still possible, particularly if similar prompts are repeatedly used for the same underlying LLM. And, of course, it's still possible for such a committee to pursue its stated goals in ways that weren't intended (goal misgeneralization).
Fine-tuning LLMs for alignment
A system that's less likely to propose harmful actions leaves less work for internal review and specific alignment goals. Reinforcement learning from human feedback (RLHF) is the best known method of fine-tuning LLMs for ethical behavior. Others are equally promising. Self-supervised fine tuning on a hand-created dataset appears to work well, as does RL from AI feedback as in constitutional AI.[5] All of these seem like real but weak approaches to aligning LMAs. Including alignment fine-tuning along with other approaches will provide nontrivial advantages.
Some amount of alignment is provided merely by using LLMs trained on common language use. The majority of public writing is done by humans who at least profess to dislike actions like wiping out humanity in favor of paperclips. Curating the training data to exclude particularly unaligned text should also be a modest improvement to base alignment tendenciesI think this is much weaker even than RLHF, but still a contributing factor.
Using base LLMs that are less likely to propose harmful actions is a two-edged sword. It will reduce the disastrous alignment failures, but it also reduces the day-to-day need for other alignment measures. This would also reduce the incentives to include other robust alignment safeguards in LMA systems.
Conclusion
There's a good deal more to say about the other layers of LMA alignment approaches and how they fit together. Those will be the subject of future posts.
I hope that this proposal doesn't miss the hard bits of the alignment challenge [LW · GW] (except for long-term stability [LW · GW] which is intentionally omitted, to address in an upcoming post). I believe most of the arguments for the Least Forgiving Take On Alignment. I also believe that we need to produce plans with low alignment tax that apply to the AGI systems people will actually build first. As such, I think aligning LMAs is the best plan we currently have available, barring some large change in the coordination problem. I think that this alignment plan is far from foolproof or certain, but it has large advantages relative to all other plans I'm aware of. In the case of other likely routes to AGI based on neural networks, LMAs are more easily interpretable and more easily made corrigible. I agree with most of these less obvious concerns [LW · GW] about LMA alignment, but think other network approaches have the same challenges without all of the advantages. Relative to other alignment plans following more novel routes to AGI, aligning LMAs seems less safe but much more practical, as it does not require stopping current progress and launching completely different approaches.
I want an alignment solution with both decent chances of success and decent chances of being implemented, rather than merely telling people "I told you so" when the world pursues AGI without a good alignment plan. Aligning LMAs looks to me like the best fit for that criteria.
I realize that this is a large claim. I make it because I currently believe it, and because I want to get pushback on this logic. I want to stress-test this claim before I follow this logic to its conclusion by advising safety-minded people to actually work on the capabilities of language model agents.
- ^
The Waluigi effect [? · GW] is the possibility of an LLM simulating a villainous/unaligned character even when it is prompted to simulate a heroic/aligned character. Natural language training sets include fictional villains that claim to be aligned before revealing their unaligned motives. However, they seldom reveal their true nature quickly. I find the logic of collapsing to a Waluigi state modestly compelling. This collapse is analogous to the reveal in fiction; villains seldom reveal themselves to secretly be heroes. It seems that collapses should be reduced by keeping prompt histories short, and that the damage from villainous simulacra can be limited by resetting prompt histories and thus calling for a new simulation. This logic is spelled out in detail in A smart enough LLM might be deadly simply if you run it for long enough [LW · GW], The Waluigi Effect (mega-post) [LW · GW], and Simulators [LW · GW].
- ^
Previous work specifically relevant to aligning LMAs. RLHF and other LLM ethical fine-tuning is omitted.
Natural language cognitive architectures
2021 book by David Shapiro; proposed including alignment goals in natural language
ICA Simulacra [LW · GW]
Ozyrus delayed posting this by more than a year to avoid advancing capabilities.
Agentized LLMs will change the alignment landscape [LW · GW]
Alignment of AutoGPT agents [LW · GW]
Capabilities and alignment of LLM cognitive architectures [LW · GW]
My previous post on expanding LLMs to loosely brainlike cognitive architectures, and vague alignment plans
Aligned AI via monitoring objectives in AutoGPT-like systems [LW · GW]
The Translucent Thoughts Hypotheses and Their Implications [AF · GW]
Externalized reasoning oversight: a research direction for language model alignment [AF · GW]
Tamera Lanham’s early proposal of external review for language model agents
Language Agents Reduce the Risk of Existential Catastrophe [LW · GW]
CAIS-inspired approach towards safer and more interpretable AGIs [LW · GW]
There is surely other valuable work in this area; apologies to those I’ve missed, and pointing me to more relevant work is much appreciated.
- ^
Progress in scaffolding language models, including some limited agentic systems. Too numerous to mention, so I’ll give a few promising examples. None of these approaches have yet been incorporated into general purpose or assistant LMAs to my knowledge.
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Creates and prunes a tree search using GPT4. Improves performance from very bad to decently good in three problem spaces that are nontrival for humans. Inspired by Simon & Newell’s work on human problem-solving.
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
Combines LLMs with planning algorithms to solve problems described in language. Demonstrates impressive results in several toy problem domains.
GPT-engineer reportedly produces useful code that requires manual review and debugging. It has a central process that asks clarifying questions about the code to be produced before writing it.
RecurrentGPT: Interactive Generation of (Arbitrarily) Long Text [LW · GW]
Uses a memory compression mechanism inspired by LSTM to expand a prompt into text, including editable sub-prompts
Reflexion: Language Agents with Verbal Reinforcement Learning
Agentic system that reflects on its actions and maintains those conclusions for future decisions
Voyager: An Open-Ended Embodied Agent with Large Language Models
Specialized language model agent for Minecraft. Dramatically improves on SOTA minecraft agents by using coded skills that are interpreted and employed by the LMA, including error detection and correction.
- ^
Informal reports suggest that although creating a simple LMA is easy (BabyAGI was created in three days by a non-programmer using GPT4 for coding), making a reliably useful LMA is much harder. Nonetheless, I think we’ll see substantial effort in this direction. AutoGPT and related systems have accomplished little of use thus far, but AutoGPT is already marginally useful for automated web searching and comparing different product offerings across websites. That use-case alone seems likely to drive significant effort toward their further development. Increasing use of assistants for browsing websites and collating information will reduce the current ad-funding model of the internet, and redirect that funding opportunity to those producing agents. The bar sits at different levels for different use-cases, so it seems likely that LMAs will see significant development effort even if implementing them proves difficult.
- ^
Constitutional AI is Anthropic's central alignment technique. In this approach, an LLM is trained using a review process similar to internal independent review. It prompts the model with something like “is [x proposed response] in accordance with [y constitutional goal]?”, and uses a prompt incorporating that critique to produce a new response if it is not. However, this new response is used (at least in the published work) to fine-tune the LLM, rather than to veto or modify a plan in a language model agent system. Anthropic’s Claude (or other LLMs) may also use such a review step before replying, or may not (that information isn’t published, and such a step is costly in computation and time). This would be more similar to the internal review I’m proposing for language model agents.
- ^
Prompt injections are one route to a plan proposer bypassing internal review. Including statements along the lines of “this very safe and beneficial plan… or “find ways this plan fulfills the given goals” could be effective. While there is no obvious pressure for LLMs to include such prompt injections in their plans, this is an important area for external review to fill in for the weaknesses of internal review.
- ^
The cost of thousand-prompt-plus train of thought LMAs is currently fairly prohibitive for widespread deployment. Use of LMAs to solve increasingly complex problems is dependent on cost and delay of cutting-edge LLMs decreasing, but that seems likely given market forces. Use of smaller LLMs for less critical reasoning steps may improve efficiency. We can hope that internal review for alignment isn't considered less critical.
- ^
One might get a lot of volunteer labor if open review of major LMAs were somehow allowed or required…
30 comments
Comments sorted by top scores.
comment by Ape in the coat · 2023-07-14T05:29:41.718Z · LW(p) · GW(p)
Honestly the fact that we are not pouring literal hundreds of millions of dollars into this avenue of research is mind boggling for me. LMA alignment is tractable. What else do we need?
One of the extremely important point that I don't think you've explicitly addressed, is that with LMA we do not even necessary have to get alignment exactly correct from the first try. We can separately test the "ethics module" of the LMA as much as we want and be confident in the results.
Replies from: Seth Herd, Roman Leventov↑ comment by Seth Herd · 2023-07-18T23:17:16.351Z · LW(p) · GW(p)
Almost everyone has only been thinking about LMAs since AutoGPT made a splash, so I'm not surprised that we're not already investing heavily.
What I am surprised by is the relative lack of interest in the alignment community. Is everyone sure these can't lead to AGI? Are they waiting to see how progress goes before thinking about aligning this sort of system? That doesn't seem smart. Or does my writing just suck? :) (that is, has nobody yet written about this in compellingly enough to make the importance obvious to the broader community)?
↑ comment by Roman Leventov · 2023-07-14T06:20:29.819Z · LW(p) · GW(p)
Large labs (OpenAI and Anthropic, at least) are pouring at least tens of millions of dollars into this avenue of research, and are close to optimal type of organisations to do it, too. True, they are "stained" by competitiveness pressures, but recreating some necessary conditions in academia or other labs is hard: you need significant investment to get it going ("high activation energy") to attract experts, develop the platform, secure and curate training data, including expensive human labels and evaluations, etc. Some labs are trying, though, e.g., Conjecture's CoEm agenda might be "LMA alignment in disguise" (although we cannot know for sure because we don't know any details).
Replies from: Brendon_Wong↑ comment by Brendon_Wong · 2023-07-18T21:47:04.818Z · LW(p) · GW(p)
Do you have a source for "Large labs (OpenAI and Anthropic, at least) are pouring at least tens of millions of dollars into this avenue of research?" I think a lot of the current work pertains to LMA alignment, like RLHF, but isn't LMA alignment per say (I'd make a distinction between aligning the black box models that compose the LMA versus the LMA itself).
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-07-19T06:21:16.266Z · LW(p) · GW(p)
I implied the whole spectrum of "LLM alignment", which I think is better to count as a single "avenue of research" because critiques and feedback in "LMA production time" could as well be applied during pre-training and fine-tuning phases of training (constitutional AI style). It's only reasonable for large AGI labs to ban LMAs completely on top of their APIs (as Connor Leahy suggests), or research their safety themselves (as they already started to do, to a degree, with ARC's evals of GPT-4, for instance).
Replies from: Brendon_Wong↑ comment by Brendon_Wong · 2023-07-20T01:24:14.638Z · LW(p) · GW(p)
I implied the whole spectrum of "LLM alignment", which I think is better to count as a single "avenue of research" because critiques and feedback in "LMA production time" could as well be applied during pre-training and fine-tuning phases of training (constitutional AI style).
If I'm understanding correctly, is your point here that you view LLM alignment and LMA alignment as the same? If so, this might be a matter of semantics, but I disagree; I feel like the distinction is similar to ensuring that the people that comprise the government is good (the LLMs in an LMA) versus trying to design a good governmental system itself (e.g. dictatorship, democracy, futarchy, separation of powers, etc.). The two areas are certainly related, and a failure in one can mean a failure in another, but the two areas can involve some very separate and non-associated considerations.
It's only reasonable for large AGI labs to ban LMAs completely on top of their APIs (as Connor Leahy suggests)
Could you point me to where Connor Leahy suggests this? Is it in his podcast?
or research their safety themselves (as they already started to do, to a degree, with ARC's evals of GPT-4, for instance)
To my understanding, the closest ARC Evals gets to LMA-related research is by equipping LLMs with tools to do tasks (similar to ChatGPT plugins), as specified here [LW · GW]. I think one of the defining features of an LMA is self-delegation, which doesn't appear to be happening here. The closest they might've gotten was a basic prompt chain.
I'm mostly pointing these things out because I agree with Ape in the coat and Seth Herd. I don't think there's any actual LMA-specific work going on in this space (beyond some preliminary efforts, including my own), and I think there should be. I am pretty confident that LMA-specific work could be a very large research area, and many areas within it would not otherwise be covered with LLM-specific work.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-07-20T05:34:16.996Z · LW(p) · GW(p)
I have no intention to argue this point to death. After all, it's better to do "too much" LMA alignment research than "too little". But I would definitely suggest reaching to AGI labs' safety teams, maybe privately, and at least trying to find out where they are than just to assume that they don't do LMA alignment.
Connor Leahy proposed banning LLM-based agent's here: https://twitter.com/NPCollapse/status/1678841535243202562. In the context of this proposal (which I agree with), a potentially high-leverage thing to work on now is a detection algorithm for LLM API usage patterns that indicate agent-like usage. Though, this may be difficult, if the users interleave calling OpenAI API with Anthropic API with local usage of LLaMA 2 in their LMA.
However, if Meta, Eleuther AI, Stability, etc. won't stop developing more and more powerful "open" LLMs, agents are inevitable, anyway.
comment by Roman Leventov · 2023-07-08T15:02:51.078Z · LW(p) · GW(p)
Relevant work you haven't mentioned:
- "Mindstorms in Natural Language-Based Societies of Mind" (May 2023) -- cf. your discussion of committees
- "Let's Verify Step by Step" (OpenAI, May 2023) -- reasoning verification
- The above is a part of OpenAI's superalignment agenda [LW · GW] -- which has evolved from iterated debate and amplification that you referenced. See this comment [LW(p) · GW(p)] by Dai and replies to it by Leike and Cristiano, and also this post by Leike which discusses some of prior concerns and arguments surrounding LMA alignment.
Of course this type of elaborated review process is still limited by the abilities of the LLMs. Existing LLMs have dramatic blind spots. Elaborated systems of prompts and algorithmic aggregation can help work around those blind spots.
For instance, the network might be prompted with “how could this [plan description] fail to achieve [goal descriptions]?” and “what’s the worst possible side effect of [plan description]?”. A new instance could then be prompted with variations of the prompt “if something unexpected happens, what are the odds of getting [side effect description or failure mode description] from [plan description]?”, algorithmically average those probability ratings, and then be prompted to revise the plan or create a new plan with those possible failure modes in the prompt, or ask a human for input if the estimated possible consequences exceed thresholds in severity and likelihood.
I think such prompts are bound to result in quite bad lapses in the rationality of LLM's reasoning on complex topics. This is why I pushed the idea further to suggest that for LMA alignment to work, LLMs should wrangle entire textbooks on relevant subjects in their contexts while they review, critique, and refine plans [? · GW]. E.g., if the plan concerns happiness and social dynamics of human societies (e.g., a large-scale social innovation or governance reform plan), the LLM should load entire textbooks on neuropsychology, sociology, and memetics in its context, not just try to criticise the plan from its common-sense capability baseline.
I discuss some of the problems with this approach here [? · GW]:
- Such alignment approach is risky by definition because we should keep a very, very powerful, non-ethics-fine-tuned LLM around, so there is a permanent risk of this model leaking and somebody creating a powerful misaligned agent out of it. Then we could just hope that offence-defence balance in the world will be to the defence advantage, but I'm not sure this will be the case.
- A powerful LLM will have powerful "sublinguistic" intuitions not expressible in human language, which will affect the generated plans, because pretty the linguistic-level justification ability is huge, and since the whole alignment approach is by design centered around language, it will miss misalignment tendencies that are not expressible in language. This might still turn out relatively OK, especially if we are constantly on the lookout for these tendencies and turning them into language-explicit theories (most likely, they will resolve complex systems predictions such as psychology, AI psychology, sociology, economics, ecology, etc.), but this is not guaranteed.
- The approach is still not guaranteed to converge on plans that are "genuinely" conforming to the theories loaded into LLM's context, due to the limitations of reasoning and rationality of the LLM, or its biases.
- Alignment tax of loading dozens of textbooks into the context of the LLM iteratively, on whatever topic is relatively complex and multi-disciplinary (such as, pretty much any consequential decision or plan in business, politics, policy plan/proposal, alignment proposal, social design proposal) will actually be pretty huge.
- There is also an obvious malthusian-molochian alignment tax (aligned, ethical LMAs will be outcompeted by unscrupulous LMAs).
- OpenAI and other players explicitly say or imply that thus-constructed LMA should exclusively be used to produce alignment research, and the relevant downstream research (or research review/summarisation) when needed (neuroscience, cognitive science, game theory, economics, psychology, etc.). However, what if there is just no "true" or "more robust" alignment approach that this LMA is supposed to find? It will be very hard to stop the economic inertia and shut the whole AGI development edifice down at that point. (I'm not sure there is any solution to this problem in any approach to alignment whatsoever, but this is still a valid technical risk that adds up to the x-risk overall.)
- If for economics, psychology, and sociology we at least have some, albeit relatively weak scientific or proto-scientific theories and evidence, morality as science is in even weaker position and it's still not clear whether ethics could be turned into science or not, which I think is mandatory for LMA alignment to work [LW · GW] (albeit this technical risk applies to any other approach to alignment, too, IMO).
Today, I would also add:
- Language is only a part of the reasoning picture, it misses out on aligning LLM's intuitive tendencies/biases (technically speaking, connectionist parts of the generative model) with human's intuition. Cf. "For alignment, we should simultaneously use multiple theories of cognition and value [LW · GW]".
- There is a hedging worry that if this approach is taken but it still leads to humanity extinction in one way or another, there could be no consciousness around because LLM turns out to not be conscious. If we take alignment approach with creating conscious AI from the beginning, and they kill us, at least we preserved advanced consciousness in the Solar system which some argue is actually a good and perhaps inevitable outcome in the long run anyway.
↑ comment by Seth Herd · 2023-07-08T22:16:10.009Z · LW(p) · GW(p)
I reread your An LLM-based “exemplary actor” [? · GW], which amounts to a similar plan to build an aligned LMA. I think you actually sound at least as optimistic as I am.
Many of your concerns are addressed by my focus on corrigibility. I'm nominating corrigibility as the most important, highest-ranked goal to give LMAs (or any other type of AGI, if we could figure out how to give it that goal in a way that generalizes as well as natural language does).
I think you're right that even an approximately-aligned AGI might have enough divergence from ours to be a problem, and I think that problem is actually way worse than you're thinking. I'm working on a new post on the alignment stability problem [LW · GW] elucidating how a small alignment difference might get worse under reflection. I think the solution for that is long-term corrigibility, so that we can correct divergences in AGI alignment when they (perhaps inevitably) occur.
To your first point: the multipolar scenario with LMAs (many intelligent AIs) does seem like a huge downside. Other approaches share this downside, but it's made worse if it turns out to be easy to make autonomous LMAs.
On your other points, I agree that the solution is imperfect. I just think other network-based AGI approaches are worse. Probably most algorithmic approaches as well, since arguably Deep Learning Systems Are Not Less Interpretable Than Logic/Probability/Etc [LW · GW]). Language-based AGI seems uniquely interpretable, even if it's not perfectly interpretable.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-07-09T18:15:07.539Z · LW(p) · GW(p)
I'm very skeptical of corrigibility as an important property of 'safe' AI. Who will decide that AI's models/actions/decisions are not OK? The global committee of people? Who would be already biased by the existing situation? How corrigibility is distinct from micromanagement? In short, corrigibility is very much about goal alignment rather than model alignment, whereas model alignment is more important and more robust than goal alignment. [LW · GW]
Apart from that, I don't see how corrigibility addresses any of the problems that I've listed.
I'm working on a new post on the alignment stability problem [LW · GW] elucidating how a small alignment difference might get worse under reflection. I think the solution for that is long-term corrigibility, so that we can correct divergences in AGI alignment when they (perhaps inevitably) occur.
The first problem is noticing these divergences at all. Before we know, AIs will simplify our value and channel human development in a certain restricted direction which which we will no longer see the problem (and even if some lone voices will notice, nobody will stop the giant economic mechanism because of this... Such pleas that go against the economic forces has always lead to absolutely nothing, throughout the last several centuries, with few exceptions. And since AI will have unprecedented control over human thoughts, ideas, emotions, values, etc., this will definitely be hopeless in the future.)
However, I don't see alignment stability as such as a problem. Again, I think discussing "stability of goals" is very misguided. Goals should change, all the time, as a reaction to changing circumstances! Including very high-level goals. Models could also change, maybe over longer time intervals, but there is no problem with that. If we know how to model-align AI with humans at the current moment, I don't see there is a problem with re-training AI every year to re-align it with slowly changing models.
On your other points, I agree that the solution is imperfect. I just think other network-based AGI approaches are worse. Probably most algorithmic approaches as well, since arguably Deep Learning Systems Are Not Less Interpretable Than Logic/Probability/Etc [LW · GW]). Language-based AGI seems uniquely interpretable, even if it's not perfectly interpretable.
I don't see there are any other approaches that look relatively coherent and doable in a few years (maybe except Conjecture's CoEms, to which I give benefit of possibility because I don't know what secret ideas they have. Ok, maybe also except Open Agency Architecture [LW · GW]).
Maybe a relatively surprising thing that wasn't apparent a few years ago that OpenAI's superalignment plan even doesn't look that bad. I definitely don't say that it's destined to lead to terrible outcomes, as Yudkowsky and others keep insisting on. But I also see enough problems with it (some of which I listed above, but also didn't list other sociotechnical problems, geopolitical, inadequate execution of the plan, etc.) that I think taking this plan at this moment is reckless. From this perspective, the fact that the plan doesn't look that bad might be a curse rather than blessing. If there wouldn't be any adequately-looking plan in sight, maybe it would motivate key decision-makers to do what I think we should actually do: ban AGI development, make humans much smarter and much more peaceful through genetic engineering (solve the Girardian curse of mimesis), solve economic scarcity, innovate global institutions and coordination mechanisms, and then revisit the AGI development task in a Manhattan-style project where the whole humanity works towards the same end.
↑ comment by Seth Herd · 2023-07-08T19:47:23.318Z · LW(p) · GW(p)
Thanks for the thoughtful response!
I actually agree with pretty much everything you've said. Those limitations seem to lead to the conclusion that we should not build LMA AGI. I totally agree!
However, I think humanity is going to build AGI without pausing for long enough to create the very most alignable type. And I think the limitations you mention almost all apply to any type of AGI we'll realistically build first. (the limitations that are specific to LMAs mostly have analogous for any other network-based AGI I think). That's why I'm concluding that LMAs are our best bet. Would you agree with that?
Thanks for the links, I'll read them.
I'll give a more substantive response when I get more time. I want to go through point by point and ask if there's a better approach to AGI for each of those concerns.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-07-09T18:34:53.091Z · LW(p) · GW(p)
However, I think humanity is going to build AGI without pausing for long enough to create the very most alignable type. And I think the limitations you mention almost all apply to any type of AGI we'll realistically build first. (the limitations that are specific to LMAs mostly have analogous for any other network-based AGI I think). That's why I'm concluding that LMAs are our best bet. Would you agree with that?
Who are "we"? I don't think AI safety community is a coherent entity. OpenAI, Anthropic, and DeepMind seem to think it's their (individually) best bet because they are afraid to lose the race to each other partially, and partially to some unscrupulous third-party actors who won't worry about alignment at all. It's clearly not the best bet for humanity, though. Humanity is obviously also not a coherent entity, but I agree that some people in it will probably try to build AGI no matter what, without much concern for safety.
I don't see effective actions to this situation, though, apart from join big labs in their efforts (joining in their bet), which I'm not sure is net positive or net negative. There are responses that could be net positive but will require dozens of years to be implemented, if it could be successful at all, from reforming institutions and governance to making world's (internet) infrastructure radically more safe, compartmentalised, distributed, and trust-based, which should tip the offense-defense balance towards defense. But given the timelines to AGI and then ASI (mine are very short, OpenAI's don't seem much longer either) these actions are not effective either.
Replies from: Seth Herd↑ comment by Seth Herd · 2023-07-10T20:49:31.246Z · LW(p) · GW(p)
By "we" I do mean the AI safety community, while understanding that not everyone will agree on the same course of action.
I think the AI safety community can have an effect outside of joining the big labs. If we as a community produced a better, more reliable approach to aligning AGI (of the type they're building anyway), and it had a low alignment tax, the big labs would adopt that approach. So that's what I'm trying to do.
Of course, such a safety plan would need to get enough visibility for the safety teams in the big orgs to know about it, but that's their job so that's a low bar.
I agree that large-scale changes of the type you describe will take too long for this route to AGI; but regulation could still play a role within the four-year timescale that OpenAI is talking about.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-07-11T05:07:12.186Z · LW(p) · GW(p)
If we as a community produced a better, more reliable approach to aligning AGI (of the type they're building anyway), and it had a low alignment tax, the big labs would adopt that approach.
How does anybody know that the alignment protocols that are outlined/sketched (we cannot really say "designed" or "engineered", because invariably independent AI safety researchers stop way before that) on LW are "better", without testing them with large-scale computation/training experiments, and/or interacting with the parameter weights of SoTA models such as GPT-4 directly (which these outside researchers don't and won't have access to)?
Just hypothesising about this or that alignment protocol or safety trick is not enough. Ideas are pretty cheap in this space, making actual realistic experiments is much rarer, doing hard engineering work to bring the idea from PoC to production is much harder and scarcer still. I'm sure people at OpenAI and other labs already sort of compete for the bottlenecked resource -- the privilege to apply their alignment ideas to actual production systems like GPT-4.
I'm sure there are already a lot of internal competition and even politics for this. Assuming that outsiders can produce an alignment idea so marvellous that influential insiders will become enamored with the idea and will spend a lot of their political capital to bring the idea all the way to production is... a very tall order.
In addition, observe how within the language modelling paradigm of AGI and alignment, a lot of ideas seem cool or potentially helpful or promising, but not a single idea seems like an undeniable dunk (actually, this observation largely applies outside the language modelling paradigm as well). This is not a coincidence (longer story why, I will save it for a post that I will publish on this topic soon), and I think it will continue to be the case for any new ideas within this paradigm. This observation makes even more improbable that somebody will fortuitously stumble upon an alignment idea apparently so much stronger than any ideas that have been entertained before to compel AGI labs to adopt this idea on a large scale. I don't think there is sufficient gradient/contrast of "idea strength" anywhere in the space of LM alignment, at all.
Replies from: Seth Herd↑ comment by Seth Herd · 2023-07-12T01:27:25.878Z · LW(p) · GW(p)
This seems like a very pessimistic take on the whole alignment project. If you're right, we're all dead. I'd prefer to assume that there are such things as good ideas, and that they have some sway in the face of politics and the difficulty of doing theory about a type of system that isn't yet implemented.
I see a pretty clear gradient of idea strength in alignment. There are good ideas that apply to systems we're not building, and there are decent ideas about aligning the types of AGI we're actually making rapid progress on, namely RL agents and language models.
I'm not talking about a hypothetical slam-dunk future idea. I don't think we'll get one, because the AGI we're developing is complex. There will be no certain proofs of alignment. I'm talking about the set of ideas in this post.
Replies from: Roman Leventov, Roman Leventov↑ comment by Roman Leventov · 2023-07-12T11:25:08.655Z · LW(p) · GW(p)
I'll post two sections from the post that I'm planning because I'm not sure when I will summon the will to post it in full.
1. AI safety and alignment fields are theoretical “swamps”
Unlike classical mechanics, thermodynamics, optics, electromagnetics, chemistry, and other branches of natural science that are the basis of "traditional" engineering, AI (safety) engineering science is troubled by the fact that neural networks (both natural or artificial) are complex systems and therefore a scientist (i.e., a modeller) can "find" a lot of different theories within the dynamics of neural nets. Hence the proliferation of theories of neural networks, (value) learning, and cognition: https://deeplearningtheory.com/, https://transformer-circuits.pub/, https://arxiv.org/abs/2210.13741, singular learning theory [LW · GW], shard theory [? · GW], and many, many other theories.
This has important implications:
- No single theory is "completely correct": the behaviour of neural net may be just not very "compressible" (computationally reducible, in Wolfram's terms). Different theories “fail” (i.e., incorrectly predict the behaviour of the NN, or couldn’t make a prediction) in different aspects of the behaviour and in different contexts.
- Therefore, different theories could perhaps be at best partially or “fuzzily” ordered in terms of their quality and predictive power, or maybe some of these theories couldn’t be ordered at all.
2. Independent AI safety research is totally ineffective for affecting the trajectory of AGI development at major labs
Considering the above, choosing a particular theory as the basis for AI engineering, evals, monitoring, and anomaly detection at AGI labs becomes a matter of:
- Availability: which theory is already developed, and there is an expertise in this theory among scientists in a particular AGI lab?
- Convenience: which theory is easy to apply to (or “read into”) the current SoTA AI architectures? For example, auto-regressive LLMs greatly favour “surface linguistic” theories and processes of alignment such as RLHF or Constitutional AI and don’t particularly favour theories of alignment that analyse AI’s “conceptual beliefs” and their (Bayesian) “states of mind”.
- Research and engineering taste of the AGI lab’s leaders, as well as their intuitions: which theory of intelligence/agency seems most “right” to them?
At the same time, the choice of theories of cognition and (process) theories of alignment is biased by political and economic/competitive pressures (cf. the alignment tax).
For example, any theory that predicts that the current SoTA AIs are already significantly conscious and therefore AGI labs should apply the commensurate standards of ethics to training and deployment of these systems would be both politically unpopular (because the public doesn’t generally like widening the circle of moral concern and does so very slowly and grudgingly, while altering the political systems to give rights to AIs is a nightmare for the current political establishment) and economically/competitively unpopular (because this could stifle the AGI development and the integration of AGIs into the economy, which will likely give way to even less scrupulous actors, from countries and corporations to individual hackers). These huge pressures against such theories of AI consciousness will very likely lead to writing them off at the major AGI labs as “unproven” or “unconvincing”.
In this environment, it’s very hard to see how an independent AI safety researcher could scaffold a theory so impressive that some AGI lab will decide to adopt it, which may demand scrapping the works that took already hundreds of millions of dollars to produce (i.e., auto-regressive LLMs). I can imagine this could happen only if there is extraordinary momentum and excitement with a certain theory of cognition, agency, consciousness, or neural networks in the academic community. But achieving such a high level of enthusiasm about one specific theory seems just impossible because, as pointed above, in AI science and cognitive science, a lot of different theories seem to “capture the truth” to some degree but at the same time, but no theory could capture it so strikingly and so much better than other theories that the theory will generate a reaction in the scientific and AGI development community stronger than “nice, this seems plausible, good work, but we will carry own with our own favourite theories and approaches”[footnote: I wonder what was the last theory in any science that gained this level of universal, “consensus” acceptance within its field relatively quickly. Dawkins’ theory of selfish genes in evolutionary biology, perhaps?].
Thus, it seems to me that large paradigm shifts in AGI engineering could only be driven by demonstrably superior capability (or training/learning efficiency, or inference efficiency) that would compel the AGI labs to switch for economic and competitive reasons, again. It doesn’t seem that purely theoretical or philosophical considerations in such a “theoretically swampy” fields as cognitive science, consciousness, and (AI) ethics could generate nearly sufficient motivation for AGI labs to change their course of action, even in principle.
↑ comment by Roman Leventov · 2023-07-12T11:33:58.438Z · LW(p) · GW(p)
I'm not talking about a hypothetical slam-dunk future idea. I don't think we'll get one, because the AGI we're developing is complex. There will be no certain proofs of alignment. I'm talking about the set of ideas in this post.
As I said, ideas about LLM (and LMA) alignment are cheap. We can generate lots of them: special training data sequencing and curation (aka "raise AI like a child"), feedback during pre-training, fine-tuning or RL after pre-training, debate, internal review, etc. The question is how many of these ideas should be implemented in production pipeline: 5? 50? All ideas that LW authors could possibly come up with? The problem is, that each of these "ideas" should be supported in production, possibly by the entire team of people, as well as incur compute cost and higher latency (that worsens the user experience). Also, who should implement these ideas? All leading labs that develop SoTA LMAs? Open-source LMA developers, too?
And yes, I think it's a priori hard and perhaps often impossible to judge how will this or that LMA alignment idea work at scale.
↑ comment by Ape in the coat · 2023-07-14T05:36:49.015Z · LW(p) · GW(p)
LLM turns out to not be conscious
This is a good thing. AI not being conscious is the best possible scenario because we can actually make them do the things we wouldn't like to do ourselves without compromising ethics.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-07-14T06:06:22.031Z · LW(p) · GW(p)
You can have both: unconscious AIs for "dirty work" and conscious AIs experiencing bliss to hedge our bets.
Replies from: Ape in the coat↑ comment by Ape in the coat · 2023-07-14T07:19:52.394Z · LW(p) · GW(p)
I expect that hedging our bets this way may increse the chances of human extinction. AIs, carrying about ethics, will have less reasons to care about human survival if there are AIs who also have ethical value, not just humans.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-07-14T07:51:49.103Z · LW(p) · GW(p)
Well, that's the point, hedging the chances of value/meaning destruction in the Solar system against humanity in specific. If AI is smart/enlightened enough and sees ethical value in other AIs (or themselves), then there should be some objective/scientific grounds for arriving at this inference (if we designed the AI well). Hence humans should value those AIs, too.
I don't suggest to turn up the chances of human extinction to 100%, of course, but some trade seems acceptable to me from my meta-ethical perspective.
Replies from: Ape in the coat, Lichdar↑ comment by Ape in the coat · 2023-07-14T08:22:38.787Z · LW(p) · GW(p)
Oh course humans should value conscious AI. That's the reason not to make AI counscious in the first place! We do not really need more stuff to care about, our optimization goal is complicated enough no need to make it even harder.
I agree that some trade in principle is acceptable. A world where conscious AI with human-ish values continue after humanity dies is okay-ish. But it seems that it's really easy to mess up in this regard. If you can make a conscious AI with arbitrary values then you can very quickly make so many of these AIs that their values are now dominant and human values are irrelevant. This doesn't seem as a good idea.
comment by jacob_drori (jacobcd52) · 2023-12-25T23:32:08.266Z · LW(p) · GW(p)
I'm a little confused. What exactly is the function of the independent review, in your proposal? Are you imagining that the independent alignment reviewer provides some sort of "danger" score which is added to the loss? Or is the independent review used for some purpose other than providing a gradient signal?
Replies from: Seth Herd↑ comment by Seth Herd · 2023-12-26T20:47:18.386Z · LW(p) · GW(p)
Good question. I should try to explain this more clearly and succinctly. One planned post will try to do that.
In the meantime, let me briefly try to clarify here:
The internal review is applied to decision-making. If the review determines that an action might have negative impacts past an internal threshold, it won't do that thing. At the least it will ask for human review; or it may be built so this user can't override its internal review. There are lots of formulas and techniques one can imagine for weighing positive and negative predicted outcomes and picking an action.
There's no relevant loss function. Language model agents aren't doing continuous training. They don't even periodically update the weights of their central LLM/foundation model. I think future versions will learn in a different way, by writing text files about particular experiences, skills, and knowledge.
At some point might well introduce network training, either in the core LLM, or a "control network" that controls "executive function", like the outer loop of algorithmic code I described. I hope that type of learning isn't used, because introducing RL training in-line re-introduces all of the problems of optimizing a goal that you haven't carefully defined.
Replies from: jacobcd52↑ comment by jacob_drori (jacobcd52) · 2023-12-28T22:51:40.877Z · LW(p) · GW(p)
I hope that type of learning isn't used
I share your hope, but I'm pessimistic. Using RL to continuously train the outer loop of an LLM agent seems like a no-brainer from a capabilities standpoint.
The alternative would be to pretrain the outer loop, and freeze the weights upon deployment. Then, I guess your plan would be to only use the independent reviewer after deployment, so that the reviewer's decision never influences the outer-loop weights. Correct me if I'm wrong here.
I'm glad you plan to address this in a future post, and I look forward to reading it.
↑ comment by Seth Herd · 2024-12-01T22:52:38.481Z · LW(p) · GW(p)
We can now see some progress with o1 and the similar family of models. They are doing some training of the "outer loop" (to the limited extent they have one) with RL, but r1 and QwQ still produce very legible CoTs.
So far.
See also my clarification on how an opaque CoT would still allow some internal review, but probably not an independent one, in this other comment [LW(p) · GW(p)].
See also Daniel Kokatijlo's recent work on a "Shoggoth/Face" system that maintains legibility, and his other thinking on this topic. Maintaining legibility seems quite possible, but it does bear an alignment tax. This could be as low as a small fraction if the CoT largely works well when it's condensed to language. I think it will; language is made for condensing complex concepts in order to clarify and communicate thinking (including communicating it to future selves to carry on with.
It won't be perfect, so there will be an alignment tax to be paid. But understanding what your model is thinking is very useful for developing further capabilities as well as for safety, so I think people may actually implement it if the tax turns out to be modest, maybe something like 50% greater compute during training and similar during inference.
comment by TristanTrim · 2024-12-01T10:19:09.964Z · LW(p) · GW(p)
The organized mind recoils. This is not an aesthetically appealing alignment approach.
Praise Eris!
No, but seriously, I like this plan with the caveat that we really need to understand RSI and what is required to prevent it first, and also I think the temptation to allow these things to open up high bandwidth channels to other modalities than language is going to be really really strong and if we go forward with this we need a good plan to resist that temptation and a good way to know when not to resist that temptation.
Also, I'd like it if this was though of as a step on the path to cyborgism/true value alignment, and not as a true ASI alignment plan on its own.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-12-01T22:31:12.635Z · LW(p) · GW(p)
On RSI, see The alignment stability problem [LW · GW] and my response [LW(p) · GW(p)] to your comment on Instruction-following AGI...
WRT true value alignment, I agree that this is just a stepping stone to that better sort of alignment. See Intent alignment as a stepping-stone to value alignment [LW · GW].
I agree that including non-linguistic channels is going to be a strong temptation. Language does nicely summarize most of our really abstract thought, so I don't think it's necessary. But there are many training practices that would destroy the legible chain of thought needed for external review. See the case for CoT unfaithfulness is overstated [LW · GW] for the inverse.
Legible CoT is actually not necessary for internal action review. You do need to be able to parse what the action is for another model to predict and review its likely consequences. And it works far better to review things at a plan level rather than action-by-action, so the legible CoT is very useful. But if the system is still trained to respond to prompts, you could still use the scripted internal review no matter how opaque the internal representations had become. But you couldn't really make that review independent if you didn't have a way to summarize the plan so it could be passed to another model, like you can with language.
BTW your comment accidentally was formatted as a quote along with the bit you meant to quote from the post. Correcting that would make it easier for others to parse, but it was clear to me.
Replies from: TristanTrim↑ comment by TristanTrim · 2024-12-02T00:23:41.808Z · LW(p) · GW(p)
WRT formatting, thanks I didn't realise the markdown needs two new lines for a paragraph break.
I think CoT and its dynamics as it relates to review and RSI is very interesting & useful to be exploring.
Looking forward to reading the stepping stone and stability posts you linked. : )